Сканирование и распознавание изображений»
МИНОБРНАУКИ РОССИИ
Борисоглебский филиал
федерального государственного бюджетного образовательного учреждения
высшего образования
«Воронежский государственный университет»
Факультет физико-математического и естественно – научного образования
Кафедра прикладной математики, информатики,
Физики и методики их преподавания
Отчёт по научно-исследовательской практике
«Сканирование и распознавание изображений»
Выполнила: студентка 5 курса 2 группы
заочного отделения
Белева С.С
Проверил: Тараканов А.Ф.
Борисоглебск — 2015
Содержание
Введение
 Характеристики сканера
Характеристики сканераСканирование
Распознавание текстов и изображений
Применение сканирования
Заключение
Список используемых источников
Введение
Одним из основных способов ввода информации в вычислительные системы является сканирование. Именно сканер стал тем устройством, с помощью которого в компьютер попадает огромное количество информации.
С помощью современной аппаратуры сканирования с высоким разрешением исходного документа довольно просто формируется графический файл специального формата. Такой файл после соответствующей обработки может быть преобразован в любой из форматов, которые применяются в информационных технологиях. Это форматы представления текстов и графических видов информации — фотографий, слайдов, рисунков и т.п.
Преобразование документа в электронный вид делится на два этапа: получение графического образа документа и перевод графического образа в текстовый формат. Графический образ документа является результатом сканирования. Перевод графического образа документа в текстовый формат может быть произведен вручную или посредством автоматического распознавания.
Графический образ документа является результатом сканирования. Перевод графического образа документа в текстовый формат может быть произведен вручную или посредством автоматического распознавания.
Говоря о сканировании, вспомним, что же такое сканер? А так же рассмотрим основные характеристики сканеров.
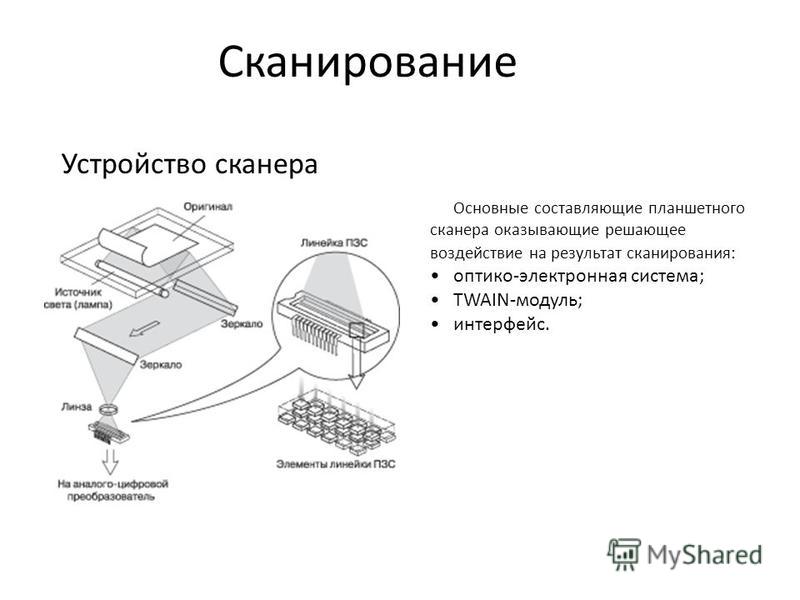
Сканер. Характеристики сканера
Скамнер (англ. scanner) — устройство, выполняющее преобразование расположенного на плоском носителе (чаще всего бумаге) изображения в цифровой формат.
В 1857 году флорентийский аббат Джованни Казелли (итал. GiovanniCaselli) изобрёл прибор для передачи изображения на расстояние, названный впоследствии пантелеграф. Передаваемая картинка наносилась на барабан токопроводящими чернилами и считывалась с помощью иглы.
В 1902 году, немецким физиком Артуром Корном (нем. ArthurKorn) была запатентована технология фотоэлектрического сканирования, получившая впоследствии название телефакс. Передаваемое изображение закреплялось на прозрачном вращающемся барабане, луч света от лампы, перемещающейся вдоль оси барабана, проходил сквозь оригинал и через расположенные на оси барабана призму и объектив попадал населеновый фотоприёмник. Эта технология до сих пор применяется в барабанных сканерах.
Передаваемое изображение закреплялось на прозрачном вращающемся барабане, луч света от лампы, перемещающейся вдоль оси барабана, проходил сквозь оригинал и через расположенные на оси барабана призму и объектив попадал населеновый фотоприёмник. Эта технология до сих пор применяется в барабанных сканерах.
В дальнейшем, с развитием полупроводников, усовершенствовался фотоприёмник, был изобретен планшетный способ сканирования, но сам принцип оцифровки изображения остаётся почти неизменным.
Основные характеристики сканеров.
Оптическое разрешение. Является основной характеристикой сканера. Сканер снимает изображение не целиком, а по строчкам. По вертикали планшетного сканера движется полоска светочувствительных элементов и снимает по точкам изображение строку за строкой. Чем больше светочувствительных элементов у сканера, тем больше точек он может снять с каждой горизонтальной полосы изображения. Это и называется оптическим разрешением. Оно определяется количеством светочувствительных элементов (фотодатчиков), приходящихся на дюйм горизонтали сканируемого изображения. Обычно его считают по количеству точек на дюйм — dpi (dotsperinch). Нормальный уровень разрешение не менее 600 dpi, увеличивать его еще дальше — значит, применять дорогую оптику, дорогие светочувствительные элементы, и увеличивать время сканирования. Для обработки слайдов необходимо более высокое разрешение 1200 dpi.
Оно определяется количеством светочувствительных элементов (фотодатчиков), приходящихся на дюйм горизонтали сканируемого изображения. Обычно его считают по количеству точек на дюйм — dpi (dotsperinch). Нормальный уровень разрешение не менее 600 dpi, увеличивать его еще дальше — значит, применять дорогую оптику, дорогие светочувствительные элементы, и увеличивать время сканирования. Для обработки слайдов необходимо более высокое разрешение 1200 dpi.
Разрешение по X. Этот параметр показывает количество пикселей у фоточувствительной линейки, из которых формируется изображение. Разрешение является одной из основных характеристик сканера. Большинство моделей имеет оптическое разрешение сканера 600 или 1200 dpi (точек на дюйм). Его достаточно для получения качественной копии. Для профессиональной работы с изображением необходимо более высокое разрешение.
Разрешение по Y. Этот параметр определяется величиной хода шагового двигателя и точностью работы механики.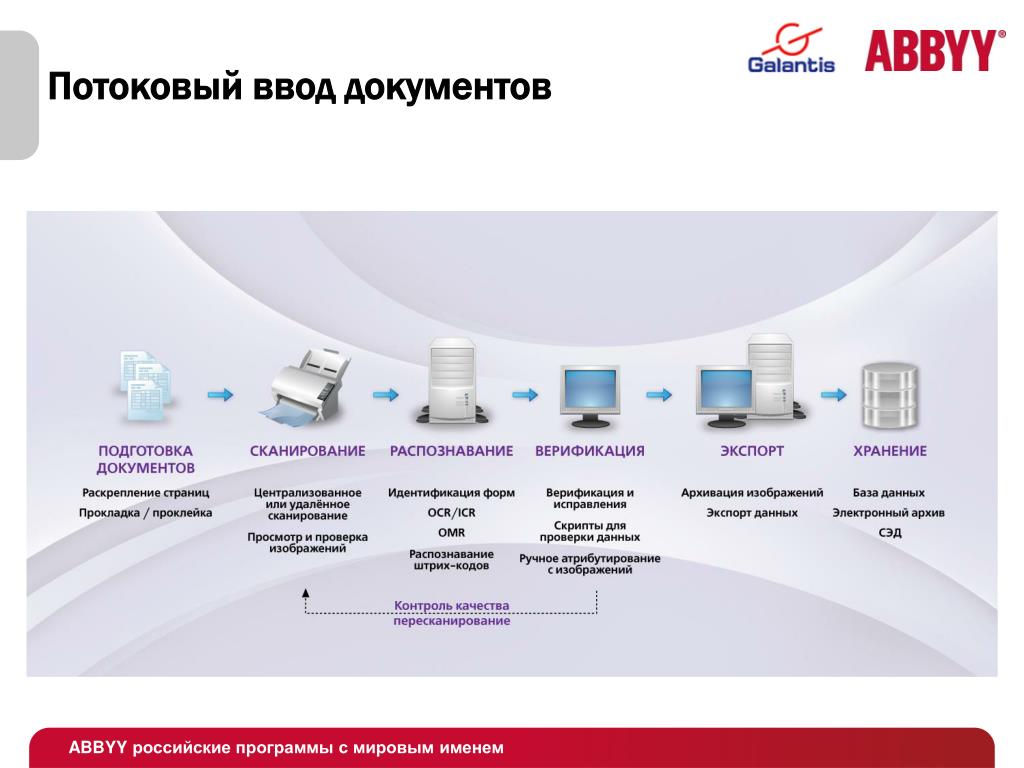 Механическое разрешение сканера значительно выше оптического разрешения фотолинейки. Именно оптическое разрешение линейки фотоэлементов будет определять общее качество отсканированного изображения.
Механическое разрешение сканера значительно выше оптического разрешения фотолинейки. Именно оптическое разрешение линейки фотоэлементов будет определять общее качество отсканированного изображения.
Скорость сканирования. Скорость сканирования зависит от разрешения при сканировании и от размера оригинала. Обычно производители указывают этот параметр для формата А4. Скорость сканирования может измеряться количеством страниц в минуту или временем, необходимым для сканирования одной страницы. Иногда измеряется в количестве сканируемых линий в секунду.
Глубина цвета. Как правило, производители указывают два значения для глубины цвета — внутреннюю глубину и внешнюю. Внутренняя глубина — это разрядность АЦП (аналого-цифрового преобразователя) сканера, она указывает на то, сколько цветов сканер способен различить в принципе. Внешняя глубина — это количество цветов, которое сканер может передать компьютеру. Большинство моделей используют для цветопередачи 24 бита (по 8 на каждый цвет). Для стандартных задач в офисе и дома этого вполне достаточно. Но если вы собираетесь использовать сканер, для серьезной работы с графикой, попробуйте найти модель с большим числом разрядов.
Для стандартных задач в офисе и дома этого вполне достаточно. Но если вы собираетесь использовать сканер, для серьезной работы с графикой, попробуйте найти модель с большим числом разрядов.
Максимальная оптическая плотность. Максимальная оптическая плотность у сканера — это оптическая плотность оригинала, которую сканер отличает от ‘полной темноты’. Чем больше это значение, тем больше чувствительность сканера и, тем выше качество сканирования темных изображений.
Тип источника света. Ксеноновые лампы отличаются малым временем прогрева, долгим сроком службы и небольшими размерами. Флуоресцентные лампы с холодным катодом дешевы в производстве и имеют долгий срок службы. Светодиоды (LED) обладают малыми размерами, низким энергопотреблением и не требуют времени для прогрева. Но по качеству цветопередачи LED-сканеры уступают сканерам с флуоресцентными и ксеноновыми лампами.
Тип датчика сканера. В сканерах МФУ обычно используется один из двух типов датчиков: контактный (CIS) или ПЗС (CCD).
Виды сканеров.
планшетные — наиболее распространённый вид сканеров, поскольку обеспечивает максимальное удобство для пользователя — высокое качество и приемлемую скорость сканирования. Представляет собой планшет, внутри которого под прозрачным стеклом расположен механизм сканирования;
ручные — в них отсутствует двигатель, следовательно, объект приходится сканировать пользователю вручную, единственным его плюсом является дешевизна и мобильность, при этом он имеет массу недостатков — низкое разрешение, малую скорость работы, узкая полоса сканирования, возможны перекосы изображения, поскольку пользователю будет трудно перемещать сканер с постоянной скоростью;
листопротяжные — лист бумаги вставляется в щель и протягивается по направляющим роликам внутри сканера мимо лампы. Имеет меньшие размеры, по сравнению с планшетным, однако может сканировать только отдельные листы, что ограничивает его применение в основном офисами компаний. Многие модели имеют устройство автоматической подачи, что позволяет быстро сканировать большое количество документов;
Имеет меньшие размеры, по сравнению с планшетным, однако может сканировать только отдельные листы, что ограничивает его применение в основном офисами компаний. Многие модели имеют устройство автоматической подачи, что позволяет быстро сканировать большое количество документов;
планетарные сканеры — применяются для сканирования книг или легко повреждающихся документов. При сканировании нет контакта со сканируемым объектом (как в планшетных сканерах). Подробности на английском языке;
книжные сканеры — предназначены для сканирования брошюрованных документов. Сканирование производится лицевой стороной вверх — таким образом, Ваши действия по сканированию неотличимы от перелистывания страниц при обычном чтении. Это предотвращает их повреждение и позволяет пользователю видеть документ в процессе сканирования;
слайд-сканеры — как ясно из названия, служат для сканирования плёночных слайдов, выпускаются как самостоятельные устройства, так и в виде дополнительных модулей к обычным сканерам;
сканеры штрих-кода — небольшие, компактные модели для сканирования штрих-кодов товара в магазинах.
Принцип действия
Сканируемый объект кладется на стекло планшета сканируемой поверхностью вниз. Под стеклом располагается подвижная лампа, движение которой регулируется шаговым двигателем. Свет, отраженный от объекта, через систему зеркал попадает на чувствительную матрицу, далее на АЦП и передается в компьютер. За каждый шаг двигателя сканируется полоска объекта, которые потом объединяются программным обеспечением в общее изображение.
Изображение всегда сканируется в формат RAW — а затем конвертируется в обычный графический формат с применением текущих настроек яркости, контрастности, и т. д. Эта конвертация осуществляется либо в самом сканере, либо в компьютере — в зависимости от модели конкретного сканера. На параметры и качество RAW-данных влияют такие аппаратные настройки сканера, как время экспозиции матрицы, уровни калибровки белого и чёрного, и т.п.
Сканирование
Для пользователей компьютеров единственным путём просмотра электронных файлов является сканирование изображения. Во время этого процесса сканер преобразовывает текст, графику листа и плёнку в цифровой образ, процесс преобразования может быть аналоговым и цифровым.
Во время этого процесса сканер преобразовывает текст, графику листа и плёнку в цифровой образ, процесс преобразования может быть аналоговым и цифровым.
Процесс сканирования изображения является лёгким и доступным и чаще всего работают со сканером, при использовании он является наиболее эффективным и разнообразным. Его широко используют для коммерческих целей, но любителям также нравится сканировать изображения, особенно если они увлекаются фотографиями. Также часто его используют в художественном творчестве, это заодно и весело, и полезно.
Обучающая программа по сканированию всегда доступна, как и для рисунка, так и для документов. Не для пользователей компьютеров единственным путём просмотра электронных файлов является сканирование изображения. Во время этого процесса сканер преобразовывает текст, графику листа и плёнку в цифровой образ, процесс преобразования может быть аналоговым и цифровым.
Для сканирования изображения нужно следовать нескольким основным шагам, для любого типа сканера или программного обеспечения метод сканирования фотографий на планшетном сканере один и тот же. Когда лампа светит на фотографию, оптические ячейки сканера фиксируют цвета, отражающиеся с точек изображения. Такими цветами являются красный, зелёный и синий. (КЗС).
Когда лампа светит на фотографию, оптические ячейки сканера фиксируют цвета, отражающиеся с точек изображения. Такими цветами являются красный, зелёный и синий. (КЗС).
Пиксель или элемент рисунка передаётся к каждой точке и измеряется в пикселях из расчёта на дюйм, это является разрешением образа. Три числа представляют каждый пиксель на образе, и эти числа показывают яркость красного, зелёного и синего компонента цвета. Итак, есть разные форматы изображения, и каждый формат хранит информацию о пикселях и цветах в разных вариантах.имеет значения, что вы хотите перенести в компьютер: текст или рисунок, вы должны знать, как работать со сканером. Обычно программное обеспечение объясняет все шаги детально, и сканировать изображения вы можете практически как цветным, так и чёрно- белым.
Пиксель или элемент рисунка передаётся к каждой точке и измеряется в пикселях из расчёта на дюйм, это является разрешением образа. Три числа представляют каждый пиксель на образе, и эти числа показывают яркость красного, зелёного и синего компонента цвета.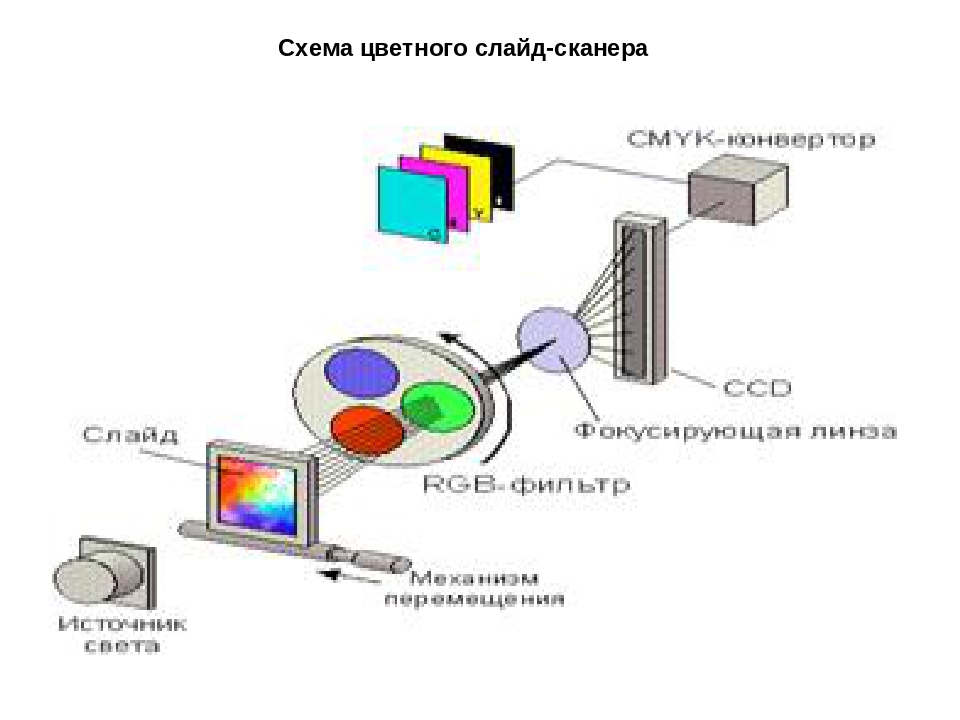 Итак, есть разные форматы изображения, и каждый формат хранит информацию о пикселях и цветах в разных вариантах.
Итак, есть разные форматы изображения, и каждый формат хранит информацию о пикселях и цветах в разных вариантах.
Сканирование документов — процесс создания электронного изображения бумажного документа, напоминает его фотографирование. На этапе сканирования производится получение изображения при помощи сканера и сохранение их в виде, удобном для последующей обработки.
Процесс сканирования осуществляется автоматически и требует от пользователя только вспомогательных операций, таких как смена сканируемой страницы.
Сканирование, как единый сквозной процесс, распадается на две независимых ветви. По одному направлению идёт ввод в вычислительные системы текстовых массивов информации, по другому — графических.
Задача сканирования текстов, при необходимом качественном разрешении, на 90% состоит в распознавании. А для этого разработано математическое обеспечение, которое позволяет эффективно построить технологию получения качественных электронных документов.
Чтобы реализовать автоматический или автоматизированный перевод бумажных документов в электронный вид, необходимо выполнить сканирование бумажных документов и распознать их содержимое с помощью специальных программ, называемых системами оптического распознавания символов.
Распознавание текстов и изображений
Процесс распознавания изображений является сложной многоэтапной процедурой. Многоэтапность (иерархичность) обусловлена тем, что различные задачи обработки на самом деле тесно связаны и качество решения одной из них влияет на выбор метода решения остальных. Так выбор метода распознавания зависит от конкретных условий предъявления входных изображений, в том числе характера фона, других изображений, помеховой обстановки и связан с выбором методов предобработки, сегментации, фильтрации.
Распознавание — чаще всего конечный этап обработки, лежащий в основе процессов интерпретации и понимания.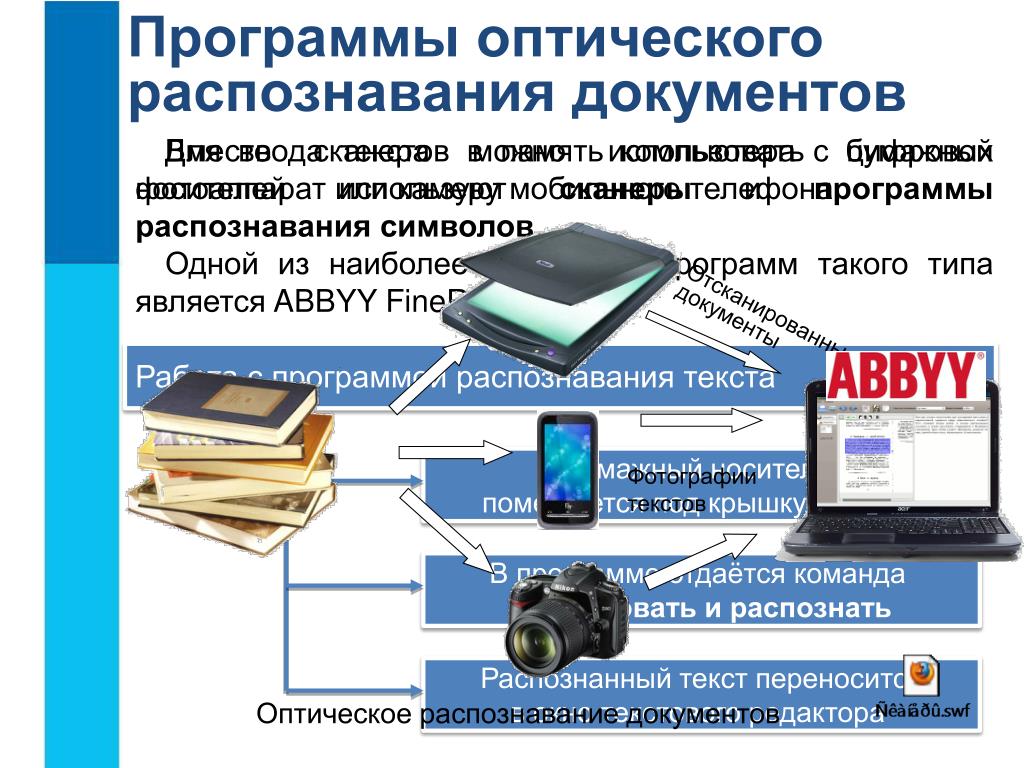 Входными для распознавания являются изображения, выделенные в результате сегментации и, частично, отреставрированные. Они отличаются от эталонных геометрическими и яркостными искажениями, а также сохранившимися шумами.
Входными для распознавания являются изображения, выделенные в результате сегментации и, частично, отреставрированные. Они отличаются от эталонных геометрическими и яркостными искажениями, а также сохранившимися шумами.
На этом шаге происходит идентификация документа и выделение его объектов (полей, пометок, штрихкодов и прочего), удаляются помехи, которые мешают распознаванию (например, разграфка). Далее происходит распознавание полей документа. Затем проводится оценка достоверности результатов распознавания, после чего производится обобщенный лингвистический анализ поля.
После распознавания может следовать специальная обработка его результатов на основании априорной лингвистической и структурной информации о поле. После этого принимается решение о достоверности результатов распознавания. В системе реализована схема, признающая поле недостоверным в случае наличия в нем хотя бы одного недостоверного символа. После этого происходит сохранение результатов распознавания во внутренний формат системы и выполняется контроль логической непротиворечивости данных.
Кроме всего этот этап выполняет дополнительные функции: автоматическое определение угла поворота страницы и его автоматическая коррекция.
Процесс распознавания полностью автоматический, не требует наличия оператора, при этом возможно распараллеливание распознавания в рамках локальной сети.
При необходимости, после распознавания документ передается на верификацию. Если же необходимости в верификации нет, распознанные данные могут экспортироваться во внешние информационные системы и базы данных.
Верификация документа: исправление ошибок заполнения и распознавания, подтверждение результатов распознавания «сомнительных» полей, просмотр полей, не прошедших логический контроль, и принятие решения о дальнейшей судьбе таких документов. На этом этапе оператор производит визуальный контроль результатов распознавания и принимает решение о дальнейшем маршруте документа. Процесс реализован в двухоконном редакторе форм. В одном окне показано изображение бумажного документа, в другом — электронная форма, содержащая распознанные данные.
В одном окне показано изображение бумажного документа, в другом — электронная форма, содержащая распознанные данные.
Процесс верификации документа идет по следующей схеме. Оператору предъявляется изображение и электронная форма с распознанными данными. При этом поля, не прошедшие контроль достоверности и логической непротиворечивости, подсвечены цветом для привлечения внимания оператора. Оператор, перемещая фокус между полями электронной формы, видит диагностику ошибок и либо исправляет ошибку, либо, если ошибку нельзя исправить, принимает решение передать документ на этап обработки «плохих» документов. При передвижении по полям модуль автоматически подсвечивает рамку поля на изображении.
Для повышения эффективности работы оператора предусмотрены два режима: проход только по полям, не прошедшим контроль, и режим пропуска незаполненных полей. Кроме этого, если прикреплен словарь, содержащий допустимые значения для поля, то имеется возможность указать в описании поля необходимость предъявления словаря оператору и разрешить оператору вставлять в поле значения из словаря.
После окончания верификации документа оператору предлагается либо отложить его, либо передать на этап экспорта данных.
Возможно распараллеливание процесса верификации в рамках локальной сети. В крупных проектах массового ввода могут быть одновременно задействованы десятки операторов, выполняющих функцию верификации потока документов.
После верификации, данные могут экспортироваться во внешние информационные системы и базы данных.
Точность распознавания
Ключевым параметром систем распознавания, характеризующим их практическую ценность, является точность распознавания, то есть процент правильно распознанных символов.
OpticalCharacterRecognition — системы могут достигать наилучшей точности распознавания — свыше 99,9% для чистых изображений, составленных из обычных шрифтов. На первый взгляд такая точность распознавания кажется идеальной, но уровень ошибок все же удручает, потому что, если имеется приблизительно 1500 символов на странице, то даже при коэффициенте успешного распознавания 99,9 % получается одна или две ошибки на страницу. В таких случаях на помощь приходит метод проверки по словарю. То есть, если какого-то слова нет в словаре системы, то она по специальным правилам пытается найти похожее. Но это все равно не позволяет исправлять 100 % ошибок, что требует человеческого контроля результатов.
В таких случаях на помощь приходит метод проверки по словарю. То есть, если какого-то слова нет в словаре системы, то она по специальным правилам пытается найти похожее. Но это все равно не позволяет исправлять 100 % ошибок, что требует человеческого контроля результатов.
Точность распознавания падает за счет ошибок распознавания. Повышению точности распознавания способствует устранение указанных ниже причин ошибок.
Причины ошибок при распознавании
Встречающиеся в реальной жизни тексты обычно далеки от совершенства, и процент ошибок распознавания для «нечистых» текстов часто недопустимо велик. Грязные изображения — здесь наиболее очевидная проблема, потому что даже небольшие пятна могут затенять определяющие части символа или преобразовывать один в другой. Еще одной проблемой является неаккуратное сканирование, связанное с «человеческим фактором», так как оператор, сидящий за сканером, просто не в состоянии разглаживать каждую сканируемую страницу и точно выравнивать ее по краям сканера.
Если документ был ксерокопирован, нередко возникают разрывы и слияния символов. Любой из этих эффектов может заставлять систему ошибаться, потому что некоторые из OCR-систем полагают, что непрерывная область изображения должна быть одиночным символом.
Страница, расположенная с нарушением границ или перекосом, создает немного искаженные символьные изображения, которые могут быть перепутаны OCR.
Более трудоёмкой является задача сканирования цветных изображений. Она обычно заключается в наиболее полном считывании информации с оригинала, т. е. его тонового и цветового диапазона, а также разрешения. При этом желательно по необходимости скорректировать недостатки оригинала с точки зрения последующего использования изображения. Например, компенсировать нежелательный цветовой сдвиг, тоновый дисбаланс или подавить полиграфический растр оригинала.
В настоящее время для решения этих задач многие фирмы производят соответствующее оборудование и разрабатывают математическое обеспечение. Однако именно в наличии большого количества возможностей и способов организовать технологический процесс сканирования и кроется главная опасность. Выбор определённого устройства и программ позволяет удовлетворительно и без перенастроек работать только со сравнительно небольшим диапазоном типов документов.
Однако именно в наличии большого количества возможностей и способов организовать технологический процесс сканирования и кроется главная опасность. Выбор определённого устройства и программ позволяет удовлетворительно и без перенастроек работать только со сравнительно небольшим диапазоном типов документов.
Применение сканирования
Применение сканеров имеет широкий диапазон и находится в постоянном развитии. Сканирование интенсивно используются в специализированных информационных технологиях. По сканированию текста наиболее полно наработан опыт в создании электронных библиотек Интернета. По второму направлению — цветной графики, давно работают в области полиграфии
Успешность применения сканеров зависит не только от их собственных качеств, но и от правильного их использования. Каждая из областей применения имеет свой собственный акцент и делает ударение на различные характеристики системы.
Настольные издательские системы (вы вводите в издаваемую статью рисунки, диаграммы, фотографии). В данном случае сканеры должны быть как минимум цветными, обладать высокой разрешающей способностью, широким диапазоном оптических плотностей, с числом передаваемых цветов 16 777 216 (24 бита на точку — 8 бит на каждый цвет RGB) и т.д.
В данном случае сканеры должны быть как минимум цветными, обладать высокой разрешающей способностью, широким диапазоном оптических плотностей, с числом передаваемых цветов 16 777 216 (24 бита на точку — 8 бит на каждый цвет RGB) и т.д.
Системы обработки документов (пакет оптического распознавания символов вместе со сканером научат ваш компьютер «читать» текст, экономия времени, которое тратится на ввод с клавиатуры). Сканеры, применяемые для этих целей не должны быть цветными, т.к. для сканирования текста необходимо регистрировать только два уровня — белый и черный (глубина точки 1 бит), высоких разрешающих способностей здесь тоже не требуется, а значит, стоимость сканера сильно снижается.
САПР (сканер + программа векторизации облегчает процесс ввода чертежей для дальнейшего их использования в пакетах автоматического проектирования). Нет необходимости применять здесь цветной сканер, но разрешающая способность должна быть достаточно высокой, чтобы косые линии не выглядели как ступеньки лестницы.
Системы компьютерной анимации. Здесь почти всю область применения занимают проекционные сканеры, обеспечивающие хорошее качество вводимых изображений и возможность ввода проекций трехмерных тел.
Системы для передачи информации (факс — модем + сканер = факс машина).
Заключение
Качество сканированного изображения определяется многими факторами. Такие как — тип сканируемого оригинала, технические возможности сканера, квалификация оператора сканера, размер оригинала, от которого зависит необходимая кратность увеличения, разрешение при сканировании, а также особенности любой обработки, примененной к изображению в ходе сканирования. Сканируете ли вы оригиналы самостоятельно, пользуетесь ли услугами сервисного бюро или агентства допечатной обработки, для успеха проектов в области печати нелишне детально представлять себе процесс получения сканированных изображений. Кроме того, если вы хотите, чтобы сканированные изображения имели высокое качество, до стадии сканирования необходимо в максимально возможной степени узнать о возможностях вывода изображения и специфике печати — размере выводимого изображения, а также параметрах печатного станка — пространственной частоте растра, типе бумаги, типе печатного станка, ограничениях на тоновый диапазон, а также ожидаемом увеличении размера растровой точки.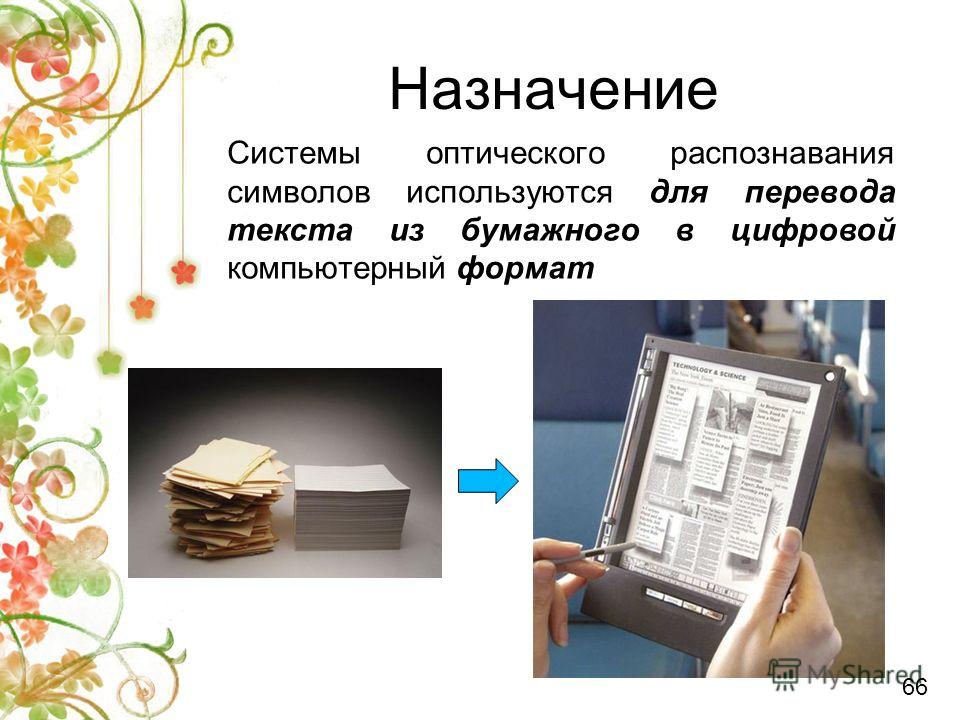 Согласование характеристик сканирования и этих факторов гарантирует, что каждое сканированное вами изображение будет качественным.
Согласование характеристик сканирования и этих факторов гарантирует, что каждое сканированное вами изображение будет качественным.
Список используемых источников
1. http://www.microbs.ru/hardware_pc/scan.shtml
2. http://cognitiveforms.ru/technologies/
3. http://www.novojonov.ru/content/printable.aspx?key=soft-electronic-archive&file=08-scan-ocr
4. http://www.awella.ru/newsscanirovanie.php.htm
5. В.П. Леонтьев «Новейшая энциклопедия персонального компьютера 2003». — М.: «ОЛМА-ПРЕСС», 2003. — 920с.
Сканирование и распознавание изображений
Реферат.
Тема: Сканирование и распознавание изображений.
2012 год
Введение.

Одним из основных способов ввода информации в вычислительные системы является сканирование. Именно сканер стал тем устройством, с помощью которого в компьютер попадает огромное количество информации.
С помощью современной аппаратуры сканирования с высоким разрешением исходного документа довольно просто формируется графический файл специального формата. Такой файл после соответствующей обработки может быть преобразован в любой из форматов, которые применяются в информационных технологиях. Это форматы представления текстов и графических видов информации – фотографий, слайдов, рисунков и т.п.
Преобразование документа в электронный вид делится на два этапа: получение графического образа документа и перевод графического образа в текстовый формат. Графический образ документа является результатом сканирования. Перевод графического образа документа в текстовый формат может быть произведен вручную или посредством автоматического распознавания.
Говоря о сканировании,
вспомним, что же такое сканер? А
так же рассмотрим основные характеристики
сканеров.
Сканер. Характеристики сканера.
Ска́нер (англ. scanner) — устройство, выполняющее преобразование расположенного на плоском носителе (чаще всего бумаге) изображения в цифровой формат.
В 1857 году флорентийский аббат Джова
В 1902 году, немецким
физиком Артуром Корном (нем. Arthur Korn) была запатентована технология
фотоэлектрического сканирования, получившая
впоследствии название телефакс. Передаваемое
изображение закреплялось на прозрачном
вращающемся барабане, луч света от лампы,
перемещающейся вдоль оси барабана, проходил
сквозь оригинал и через расположенные
на оси барабана призму и объектив поп
В дальнейшем, с развитием полупроводников, усовершенствовался фотоприёмник, был изобретен планшетный способ сканирования, но сам принцип оцифровки изображения остаётся почти неизменным.
Основные характеристики сканеров.
- Оптическое разрешение. Является основной характеристикой сканера. Сканер снимает изображение не целиком, а по строчкам. По вертикали планшетного сканера движется полоска светочувствительных элементов и снимает по точкам изображение строку за строкой. Чем больше светочувствительных элементов у сканера, тем больше точек он может снять с каждой горизонтальной полосы изображения. Это и называется оптическим разрешением. Оно определяется количеством светочувствительных элементов (фотодатчиков), приходящихся на дюйм горизонтали сканируемого изображения. Обычно его считают по количеству точек на дюйм — dpi (dots per inch). Нормальный уровень разрешение не менее 600 dpi, увеличивать его еще дальше — значит, применять дорогую оптику, дорогие светочувствительные элементы, и увеличивать время сканирования.
 Для обработки слайдов необходимо более высокое разрешение 1200 dpi.
Для обработки слайдов необходимо более высокое разрешение 1200 dpi. - Разрешение по X. Этот параметр показывает количество пикселей у фоточувствительной линейки, из которых формируется изображение. Разрешение является одной из основных характеристик сканера. Большинство моделей имеет оптическое разрешение сканера 600 или 1200 dpi (точек на дюйм). Его достаточно для получения качественной копии. Для профессиональной работы с изображением необходимо более высокое разрешение.
- Разрешение по Y. Этот параметр определяется величиной хода шагового двигателя и точностью работы механики. Механическое разрешение сканера значительно выше оптического разрешения фотолинейки. Именно оптическое разрешение линейки фотоэлементов будет определять общее качество отсканированного изображения.
- Скорость сканирования. Скорость сканирования зависит от разрешения при сканировании и от размера оригинала. Обычно производители указывают этот параметр для формата А4. Скорость сканирования может измеряться количеством страниц в минуту или временем, необходимым для сканирования одной страницы. Иногда измеряется в количестве сканируемых линий в секунду.
- Глубина цвета. Как правило, производители указывают два значения для глубины цвета — внутреннюю глубину и внешнюю. Внутренняя глубина — это разрядность АЦП (аналого-цифрового преобразователя) сканера, она указывает на то, сколько цветов сканер способен различить в принципе. Внешняя глубина — это количество цветов, которое сканер может передать компьютеру. Большинство моделей используют для цветопередачи 24 бита (по 8 на каждый цвет). Для стандартных задач в офисе и дома этого вполне достаточно. Но если вы собираетесь использовать сканер, для серьезной работы с графикой, попробуйте найти модель с большим числом разрядов.
- Максимальная оптическая плотность. Максимальная оптическая плотность у сканера — это оптическая плотность оригинала, которую сканер отличает от ‘полной темноты’. Чем больше это значение, тем больше чувствительность сканера и, тем выше качество сканирования темных изображений.
- Тип источника света. Ксеноновые лампы отличаются малым временем прогрева, долгим сроком службы и небольшими размерами. Флуоресцентные лампы с холодным катодом дешевы в производстве и имеют долгий срок службы. Светодиоды (LED) обладают малыми размерами, низким энергопотреблением и не требуют времени для прогрева. Но по качеству цветопередачи LED-сканеры уступают сканерам с флуоресцентными и ксеноновыми лампами.
- Тип датчика сканера. В сканерах МФУ обычно используется один из двух типов датчиков: контактный (CIS) или ПЗС (CCD). CIS представляет собой линейку фотоэлементов, которая равна ширине сканируемой поверхности. Во время сканирования она перемещается под стеклом и строка за строкой передает информацию об изображении на оригинале в виде электрического сигнала. Для освещения обычно используются светодиоды, которые расположены в непосредственной близости от фотолинейки на той же подвижной платформе. Сканеры на базе CIS имеют простую конструкцию, тонкий корпус и небольшой вес, они обычно дешевле сканеров на базе CCD. Основной недостаток CIS состоит в малой глубине резкости.
 Для обработки слайдов необходимо более высокое разрешение 1200 dpi.
Для обработки слайдов необходимо более высокое разрешение 1200 dpi. Иногда измеряется в количестве сканируемых линий в секунду.
Иногда измеряется в количестве сканируемых линий в секунду. Ксеноновые лампы отличаются малым временем прогрева, долгим сроком службы и небольшими размерами. Флуоресцентные лампы с холодным катодом дешевы в производстве и имеют долгий срок службы. Светодиоды (LED) обладают малыми размерами, низким энергопотреблением и не требуют времени для прогрева. Но по качеству цветопередачи LED-сканеры уступают сканерам с флуоресцентными и ксеноновыми лампами.
Ксеноновые лампы отличаются малым временем прогрева, долгим сроком службы и небольшими размерами. Флуоресцентные лампы с холодным катодом дешевы в производстве и имеют долгий срок службы. Светодиоды (LED) обладают малыми размерами, низким энергопотреблением и не требуют времени для прогрева. Но по качеству цветопередачи LED-сканеры уступают сканерам с флуоресцентными и ксеноновыми лампами. Основной недостаток CIS состоит в малой глубине резкости.
Основной недостаток CIS состоит в малой глубине резкости.Виды сканеров.
- планшетные — наиболее распространённый вид сканеров, поскольку обеспечивает максимальное удобство для пользователя — высокое качество и приемлемую скорость сканирования. Представляет собой планшет, внутри которого под прозрачным стеклом расположен механизм сканирования.
- ручные — в них отсутствует двигатель, следовательно, объект приходится сканировать пользователю вручную, единственным его плюсом является дешевизна и мобильность, при этом он имеет массу недостатков — низкое разрешение, малую скорость работы, узкая полоса сканирования, возможны перекосы изображения, поскольку пользователю будет трудно перемещать сканер с постоянной скоростью.
- листопротяжные — лист бумаги вставляется в щель и протягивается по направляющим роликам внутри сканера мимо лампы. Имеет меньшие размеры, по сравнению с планшетным, однако может сканировать только отдельные листы, что ограничивает его применение в основном офисами компаний. Многие модели имеют устройство автоматической подачи, что позволяет быстро сканировать большое количество документов.
- планетарные сканеры — применяются для сканирования книг или легко повреждающихся документов. При сканировании нет контакта со сканируемым объектом (как в планшетных сканерах). Подробности на английском языке http://en.wikipedia.org/wiki/
Planetary_scanner - книжные сканеры — предназначены для сканирования брошюрованных документов. Сканирование производится лицевой стороной вверх — таким образом, Ваши действия по сканированию неотличимы от перелистывания страниц при обычном чтении. Это предотвращает их повреждение и позволяет пользователю видеть документ в процессе сканирования.
- слайд-сканеры — как ясно из названия, служат для сканирования плёночных слайдов, выпускаются как самостоятельные устройства, так и в виде дополнительных модулей к обычным сканерам.
- сканеры штрих-кода — небольшие, компактные модели для сканирования штрих-кодов товара в магазинах.
 Многие модели имеют устройство автоматической подачи, что позволяет быстро сканировать большое количество документов.
Многие модели имеют устройство автоматической подачи, что позволяет быстро сканировать большое количество документов.
Принцип действия
Сканируемый объект кладется на стекло планшета сканируемой поверхностью вниз. Под стеклом располагается подвижная лампа, движение которой регулируется шаговым двигателем. Свет, отраженный от объекта, через систему зеркал попадает на чувствительную матрицу, далее на АЦП и передается в компьютер. За каждый шаг двигателя сканируется полоска объекта, которые потом объединяются программным обеспечением в общее изображение.
Изображение всегда сканируется в формат RAW — а затем конвертируется в обычный графический формат с применением текущих настроек яркости, контрастности, и т. д. Эта конвертация осуществляется либо в самом сканере, либо в компьютере — в зависимости от модели конкретного сканера. На параметры и качество RAW-данных влияют такие аппаратные настройки сканера, как время экспозиции матрицы, уровни калибровки белого и чёрного, и т. п.
Сканирование.
Для пользователей компьютеров
единственным путём просмотра электронных
файлов является сканирование изображения. Во время этого процесса сканер преобразовывает
текст, графику листа и плёнку в цифровой
образ, процесс преобразования может быть
аналоговым и цифровым.
Во время этого процесса сканер преобразовывает
текст, графику листа и плёнку в цифровой
образ, процесс преобразования может быть
аналоговым и цифровым.
Процесс сканирования изображения является лёгким и доступным и чаще всего работают со сканером, при использовании он является наиболее эффективным и разнообразным. Его широко используют для коммерческих целей, но любителям также нравится сканировать изображения, особенно если они увлекаются фотографиями. Также часто его используют в художественном творчестве, это заодно и весело, и полезно.
Обучающая программа по сканированию всегда доступна, как и для рисунка, так и для документов. Не для пользователей компьютеров единственным путём просмотра электронных файлов является сканирование изображения. Во время этого процесса сканер преобразовывает текст, графику листа и плёнку в цифровой образ, процесс преобразования может быть аналоговым и цифровым.
Для сканирования изображения нужно
следовать нескольким основным шагам,
для любого типа сканера или программного
обеспечения метод сканирования фотографий
на планшетном сканере один и тот же.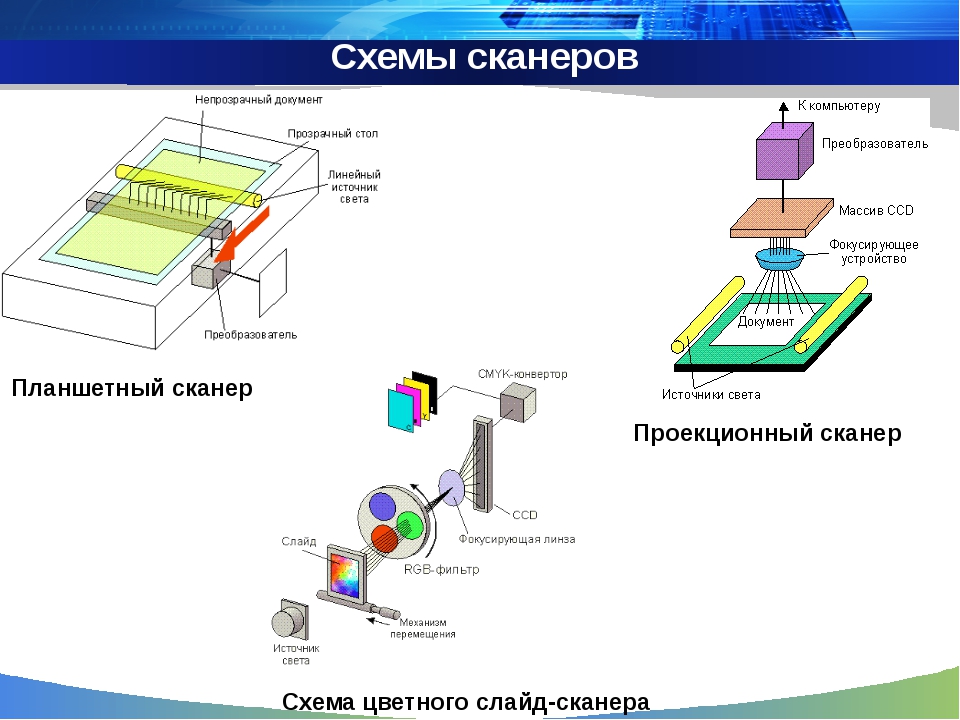 Когда
лампа светит на фотографию, оптические
ячейки сканера фиксируют цвета, отражающиеся
с точек изображения. Такими цветами являются
красный, зелёный и синий. (КЗС).
Когда
лампа светит на фотографию, оптические
ячейки сканера фиксируют цвета, отражающиеся
с точек изображения. Такими цветами являются
красный, зелёный и синий. (КЗС).
Пиксель или элемент рисунка передаётся к каждой
точке и измеряется в пикселях из расчёта
на дюйм, это является разрешением образа.
Три числа представляют каждый пиксель
на образе, и эти числа показывают яркость
красного, зелёного и синего компонента
цвета. Итак, есть разные форматы изображения,
и каждый формат хранит информацию о пикселях
и цветах в разных вариантах.
имеет значения, что вы хотите перенести
в компьютер: текст или рисунок, вы должны
знать, как работать со сканером. Обычно
программное обеспечение объясняет все
шаги детально, и сканировать изображения
вы можете практически как цветным, так
и чёрно- белым.
Пиксель или элемент
рисунка передаётся к каждой точке
и измеряется в пикселях из расчёта
на дюйм, это является разрешением
образа. Три числа представляют каждый пиксель на образе,
и эти числа показывают яркость красного,
зелёного и синего компонента цвета. Итак,
есть разные форматы изображения, и каждый
формат хранит информацию о пикселях и
цветах в разных вариантах.
Итак,
есть разные форматы изображения, и каждый
формат хранит информацию о пикселях и
цветах в разных вариантах.
Сканирование документов – процесс создания электронного изображения бумажного документа, напоминает его фотографирование. На этапе сканирования производится получение изображения при помощи сканера и сохранение их в виде, удобном для последующей обработки.
Процесс сканирования осуществляется автоматически и требует от пользователя только вспомогательных операций, таких как смена сканируемой страницы.
Сканирование, как единый сквозной процесс, распадается на две независимых ветви. По одному направлению идёт ввод в вычислительные системы текстовых массивов информации, по другому – графических.
Задача сканирования
текстов, при необходимом качественном
разрешении, на 90% состоит в распознавании.
А для этого разработано 
Чтобы реализовать автоматический или автоматизированный перевод бумажных документов в электронный вид, необходимо выполнить сканирование бумажных документов и распознать их содержимое с помощью специальных программ, называемых системами оптического распознавания символов.
Распознавание текстов и изображений.
Процесс распознавания изображений является сложной многоэтапной процедурой. Многоэтапность (иерархичность) обусловлена тем, что различные задачи обработки на самом деле тесно связаны и качество решения одной из них влияет на выбор метода решения остальных. Так выбор метода распознавания зависит от конкретных условий предъявления входных изображений, в том числе характера фона, других изображений, помеховой обстановки и связан с выбором методов предобработки, сегментации, фильтрации.
Распознавание — чаще всего конечный этап обработки,
лежащий в основе процессов интерпретации
и понимания. Входными для распознавания
являются изображения, выделенные в результате
сегментации и, частично, отреставрированные. Они отличаются от эталонных геометрическими
и яркостными искажениями, а также сохранившимися
шумами.
Они отличаются от эталонных геометрическими
и яркостными искажениями, а также сохранившимися
шумами.
На этом шаге происходит
идентификация документа и
После распознавания
может следовать специальная
обработка его результатов на
основании априорной 
Глава 18 Система распознавания текста FineReader
Система распознавания одна из наиболее перспективных областей применения искусственного интеллекта. Существует решение, максимально приближенное к человеческой способности читать: оно построено на принципах, сформулированных в результате наблюдений за поведением животных и человека. Это технология целостного, целенаправленного и адаптивного восприятия.
Процесс обработки FineReader осуществляется в несколько этапов:
1. Сканирование.
2. Выделение блоков на изображении.
3. Распознавание.
Затем
нужно
проверить
ошибки и
сохранить
результат
распознавания
(передать его
в другое
приложение,
например в
текстовый
редактор WORD, в Буфер и
т. п.).
п.).
FineReader это система оптического распознавания текстов. Она преобразует полученное с помощью сканера графическое изображение (картинку) в текст (то есть в коды букв, «понятные» компьютеру). Основные модификации Standard, Professional, Рукопись.
Функции, обеспечиваемые модификациями FineReader
| Функции | Standard | Professional | Рукопись |
| Типы распознаваемых текстов | Печатные |
Печатные, рукописные |
|
| Распознавание штрих-кода | нет | да | да |
| Возможность обучения новым символам | да | да | да |
Распознавание
многоколоночного
текста с
картинками
и таблицами. Сохранение
оформления
в формате RTF
Сохранение
оформления
в формате RTF |
да | да | да |
| Интернет: сохранение документа в формате HTML | да | да | да |
| Поддержка языков | |||
| Встроенная программа проверки орфографии | да | да | да |
| Распознавание многоязычных документов | да | да | да |
| Создание новых языков |
нет |
да | да |
| Распознавание таблиц | |||
| Распознавание таблиц, сохранение результатов в форматах RTF, CSV, XLS, DBF | да | да | да |
| Ручная и автоматическая сегментация таблиц | да | да | да |
| Пост-редактор распознанных таблиц | да | да | да |
В
библиотеках
следует,
конечно,
применять
профессиональные
версии
программ (это
замечание
касается
любых
программ). Если есть
возможность,
а главное
уровень
решаемых
задач, то
необходимо
приобретать
модификацию
Рукопись.
Если есть
возможность,
а главное
уровень
решаемых
задач, то
необходимо
приобретать
модификацию
Рукопись.
Библиотекарям приходится сканировать именно тексты, которые должны быть потом распознаны и превращены в текстовый файл. Если же сканер используется для выполнения платных услуг по сканированию и распознавание не требуется, то можно использовать программы, предназначенные только для сканирования и сохранения картинки.
Для большего комфорта работы необходимо, чтобы программа была связана с подключенным к ней сканером: меню Сервис Выбор сканера.
О планшетных сканерахНаиболее
универсальный
и наиболее
распространенный
тип сканера. Как правило,
обеспечивает
высокое
разрешение
при средней и
высокой
скорости
сканирования.
Как правило,
обеспечивает
высокое
разрешение
при средней и
высокой
скорости
сканирования.
Планшетные сканеры делятся на две группы:
1. Для работы в офисе и дома.
Как правило, эти сканеры обладают максимальным оптическим разрешением 300 dpi, обычно достаточным для систем распознавания текстов и проведения простых работ по вводу фотографий для любительских фотоальбомов или дизайна страниц в Интернете. Они могут подключаться через параллельный порт, собственную ISA или PSI карту, или SCSI. Обычно имеют максимальную область сканирования A4.
2. Профессиональные сканеры.
Цветные.
Оптическое
разрешение 600 dpi
и выше. Имеют SCSI
интерфейс.
Зачастую
комплектуются
модулем для
сканирования
слайдов. Область
сканирования
от Legal до A3.
Область
сканирования
от Legal до A3.
Некоторые модели сканеров могут дополнительно комплектоваться устройством автоматической подачи бумаги (Automat Document Feeder ADF). Как правило, они производятся только для моделей, имеющих либо SCSI, либо другой достаточно быстрый интерфейс с компьютером.
При выборе модели сканера необходимо обращать внимание на следующие моменты:
1. Если предполагается сканировать толстые книги, желательно, чтобы крышка сканера это позволяла не была жестко закреплена, а могла выдвигаться.
2. Если
сканер
снабжен
автоподатчиком,
необходимо
проследить,
как сканер и
его драйвер
обрабатывают
ситуацию
перекоса
бумаги в
лотке
автоподатчика. Сканер
должен
позволять
легко
разрешать
эту проблему.
Сканер
должен
позволять
легко
разрешать
эту проблему.
3. Следует обращать внимание на шум, производимый при сканировании. Некоторые дешевые сканеры довольно шумные, что может доставить массу неудобств при работе в офисе или дома.
О листовых сканерахПрименяются обычно в офисе или дома для сканирования отдельных листов. Однако существуют модели, у которых снимается нижняя часть, что позволяет сканировать книги и журналы, но при этом качество изображения, как правило, резко снижается. Из-за невысокой скорости и среднего качества изображения применяются при эпизодической работе.
До
недавнего
времени
листовые
сканеры
служили
дешевой
альтернативой
планшетным. Дополнительным
стимулом при
покупке
может
служить
экономное
использование
рабочего
пространства.
Существуют
модели для
сканирования
как черно-белых,
так и цветных
изображений.
Обычно
максимальная
область
сканирования
A 4.
Дополнительным
стимулом при
покупке
может
служить
экономное
использование
рабочего
пространства.
Существуют
модели для
сканирования
как черно-белых,
так и цветных
изображений.
Обычно
максимальная
область
сканирования
A 4.
При выборе данной модели сканера необходимо обращать внимание на следующие моменты:
1. Сканер должен легко «захватывать» бумагу из лотка.
2. Как сканер и его драйвер обрабатывают ситуацию перекоса бумаги в лотке. Сканер должен позволять легко разрешать эту проблему.
3. Часто
бывает
полезной
способность
TWAIN-драйвера
сканера
сканировать
в
автоматическом
режиме всю
стопку
документов,
вставленную
в лоток, а не
ждать
команды
после
сканирования
каждого
листа. Как
правило, эта
способность
связана с
другой не
менее важной
автоматическое
определение
того,
кончилась ли
бумага в
лотке.
Как
правило, эта
способность
связана с
другой не
менее важной
автоматическое
определение
того,
кончилась ли
бумага в
лотке.
Из-за невысокого качества получаемого изображения ручные сканеры применяются обычно дома. В отличие от других типов сканеров, позволяют получать хорошее изображение области около корешка книг в жестком переплете.
До недавнего времени они служили дешевой альтернативой планшетным сканерам.
Модели с мотором иногда позволяют достигать лучшего качества сканирования за счет более равномерного перемещения сканера.
Дополнительным
стимулом при
покупке
может
служить
экономное
использование
рабочего
пространства. Существуют
модели,
предназначенные
для
сканирования
черно-белых и
модели для
сканирования
цветных
изображений.
Обычно
максимальная
ширина
сканируемой
области 10 см.
Существуют
модели,
предназначенные
для
сканирования
черно-белых и
модели для
сканирования
цветных
изображений.
Обычно
максимальная
ширина
сканируемой
области 10 см.
При выборе модели сканера необходимо обращать внимание на следующие моменты:
1. Качество
отсканированного
изображения (лучше
всего
текста).
Качество
изображения
не должно
страдать при
более или
менее
равномерном
перемещении
сканера.
Обычно
запоминается
скорость
сканирования
на разных
этапах и
происходит
программная
компенсация
неизбежных
вертикальных
искажений.
Если драйвер
сканера не
умеет
компенсировать
вертикальные
искажения, то
получить
качественное
изображение
текста
практически
невозможно.
2. Проверьте, позволяет ли сканер указывать направление сканирования: слева направо, сверху вниз, справа налево.
3. Часто бывает полезной способность TWAIN-драйвера склеивать куски изображений. К сожалению, ею не всегда можно реально воспользоваться.
Некоторые общие советы на применение сканеров при вводе документов:1. Документация сканера и сопровождающего программного обеспечения должна быть на русском языке.
2. В документации должны быть указаны адреса центров технического обслуживания.
3. Сканер
должен иметь
в комплекте TWAIN-драйвер
совместимый
с той
операционной
системой, в
которой вы
будете его
использовать. Обычно на коробке
сканера при
этом
присутствует
логотип Twain-compliant
или Twain-compatible. Как
правило, все
современные
сканеры
имеют TWAIN-драйвер,
совместимый
с MS Windows’95, 98. Кроме
того, все
сканеры
подключаемые
через SCSI,
одинаково
успешно
работают в MS Windows’95,
98 и Windows NT 4.0.
Проблему
могут
составить
только
сканеры,
подключаемые
через
параллельный
порт или
специальные
карты, при
работе в MS Windows NT 4.0.
Обычно на коробке
сканера при
этом
присутствует
логотип Twain-compliant
или Twain-compatible. Как
правило, все
современные
сканеры
имеют TWAIN-драйвер,
совместимый
с MS Windows’95, 98. Кроме
того, все
сканеры
подключаемые
через SCSI,
одинаково
успешно
работают в MS Windows’95,
98 и Windows NT 4.0.
Проблему
могут
составить
только
сканеры,
подключаемые
через
параллельный
порт или
специальные
карты, при
работе в MS Windows NT 4.0.
4. Обратите
внимание на
диалог с
опциями
сканера,
который
возникает
перед
сканированием.
Желательно,
чтобы в этом
окне была
легко
доступна
опция выбора
типа
сканируемого
изображения (черно-белый,
серый,
цветной). В
идеале еще и
серый с 16
градациями (обычно
только с 256
градациями)
это позволит
включать
встроенный в
систему FineReader автоматический
подбор
яркости при
сканировании
в сером (обычно
серое
изображение
с 16 градациями
сканируется
быстрее за
счет
меньшего
объема
информации,
чем с 256
градациями). Возможность
работать с
серым
изображением
особенно
важна для
библиотек,
так как очень
часто
возникает
необходимость
сканирования
печатных
текстов
разного
качества (бумага,
шрифт и т.д.).
Возможность
работать с
серым
изображением
особенно
важна для
библиотек,
так как очень
часто
возникает
необходимость
сканирования
печатных
текстов
разного
качества (бумага,
шрифт и т.д.).
Окно программы
Окно программы FineReader имеет сложную структуру (оно разбито на несколько кадров, в которых отражаются результаты сканирования, страницы, которые необходимо распознать, результаты распознавания).
Нажмите кнопку с изображением сканера на панели инструментов (сканировать).
Вы
можете
добавлять
отсканированные
страницы в
пакет, по
умолчанию
создаваемый
при запуске
программы,
или открыть
другой пакет (нажмите
кнопку) и
записывать
отсканированные
страницы в
него.
Нажмите стрелку справа от кнопки и из локального меню выберите пункт Сканировать и распознать.
Система отсканирует изображение, выделит на нем блоки, а затем распознает его.
Если у Вас отмечен пункт Открывать последний пакет (меню Сервис, пункт Опции…, закладка Установки), то при загрузке программа будет открывать последний пакет, с которым вы работали в предыдущей сессии.
Параметры сканирования:
Яркость: для светлых документов необходимо уменьшить яркость (сделать их темнее), для темных увеличить (сделать их светлее).
Разрешение: 300 dpi для большинства документов; 400600 dpi для документов, набранных мелким шрифтом.
Выбор разрешения это регулировка яркости у всех типов изображения.
 Часто у черно-белых
изображений
регулировка
яркости
осуществляется
не выбором
яркости (brigthness), а
выбором
порога (threshold). Это
ничем не хуже,
однако, если
вы потом
отключите
опцию Показ
диалога TWAIN-драйвера, то
скорее всего
не сможете
регулировать
яркость.
Часто у черно-белых
изображений
регулировка
яркости
осуществляется
не выбором
яркости (brigthness), а
выбором
порога (threshold). Это
ничем не хуже,
однако, если
вы потом
отключите
опцию Показ
диалога TWAIN-драйвера, то
скорее всего
не сможете
регулировать
яркость.
| Особенности входного изображения | Что сделать |
| Светлые или тонкие буквы | Уменьшить яркость (сделать темнее) |
| Темные или толстые буквы | Увеличить яркость (сделать светлее) |
| Глянцевая бумага | Уменьшить яркость |
| Слипшиеся символы | Увеличить яркость |
| Разрывы | Уменьшить яркость |
| Смазанные или заполненные контуры букв | Увеличить яркость |
Обратите
внимание на
скорость
сканирования
в режиме
черно-белого
изображения
(300 dpi). Желательно,
чтобы это
время не
превышало 12
минуты.
Желательно,
чтобы это
время не
превышало 12
минуты.
Обратите внимание на скорость сканирования в режиме цветного изображения (300 dpi). Желательно, чтобы это время не превышало 56 минут. В некоторых дешевых моделях, подключаемых через параллельный порт, это время может достигать огромных значений.
Некоторые
TWAIN-драйверы
при запуске
сканирования
показывают
окно с
сообщением о
том, что идет
разогрев (Warming ) или
калибровка (Calibrating ). Как
правило, это
занимает
около минуты.
Иногда эта
операция
происходит
при каждом
запуске
сканирования,
даже если оно
идет
практически
непрерывно
или
сканируется
предварительное
изображение (Preview). Как
утверждают
разработчики
сканеров, это
необходимо
для более
корректной
цветопередачи. Желательно,
чтобы этого
режима не
было вообще
или чтобы он
был
отключаемым.
Желательно,
чтобы этого
режима не
было вообще
или чтобы он
был
отключаемым.
Повернуть изображение
Распознаваемое изображение должно иметь стандартную ориентацию: текст должен читаться сверху вниз и строки должны быть параллельны нижнему краю экрана.
Вы можете указать программе, чтобы она автоматически подбирала ориентацию страницы.
Если ориентация не подбирается автоматически, повернуть изображение можно вручную:
1. Выделите нужные изображения.
Выделить одну страницу Нажмите на нее мышью.
Выделить несколько страниц подряд Удерживая клавишу SHIFT, нажмите мышью на первую страницу выборки, а затем на последнюю.
2. Выделить
несколько
страниц не
подряд
Выделить
несколько
страниц не
подряд
Удерживая клавишу CTRL, последовательно нажимайте на интересующие страницы.
Нажмите кнопку, с изображением направления, чтобы повернуть изображение на 90.
Из меню Изображение выберите пункт Повернуть на 180, чтобы перевернуть изображение вверх ногами.
Таким же образом можно повернуть активное открытое изображение.
Распознавание
Установка языка распознавания и типа текста:
Язык распознавания и тип текста являются главными параметрами распознавания.
Языки,
которые
имеют
словарную
поддержку:
английский,
голландский,
датский,
испанский,
итальянский,
немецкий,
норвежский,
польский,
португальский,
русский,
украинский,
финский
французский,
шведский.
При распознавании текста на том или ином языке выберите нужный язык из списка на панели Распознавание.
Если нужного языка нет в списке, то выберите значение Другой… и в открывшемся списке найдите нужный язык или выберите несколько языков, слова которых встречаются в распознаваемом тексте.
Тип текста определяется в системе автоматически. Однако для распознавания текстов, напечатанных на пишущей машинке или матричном принтере в черновом режиме, чтобы повысить надежность и скорость распознавания, выберите соответствующее значение в списке на панели инструментов.
Если
вы
распознавали
тексты,
напечатанные
на пишущей
машинке или
матричном
принтере, то
при
возвращении
к
типографскому
тексту не
забудьте
снова
выбрать
значение Авто.
Открытие изображения:
-
Меню Файл Открыть.
-
Выберите диск и папку, где находятся нужные файлы.
-
Выберите нужные файлы и нажмите OK.
-
Выбранные файлы копируются в текущий пакет.
-
Вы можете указать, чтобы выбранные изображения не копировались, а перемещались в пакет (отметьте пункт Перемещать файлы в пакет).
Тогда при загрузке в текущий пакет выбранные файлы будут копироваться туда, где находится ваш пакет и удаляться оттуда.
Также можно добавлять изображения из буфера или через drag-&-drop.
Запуск распознавания:
-
Выделите нужные страницы в окне пакета.
Подведите
курсор и
щелкните 1 раз
левой
кнопкой мыши.
-
Нажмите кнопку Распознать открытую страницу. Активизируйте открытое изображение и нажмите кнопку Распознать.
 Подведите
курсор и
щелкните 1 раз
левой
кнопкой мыши.
Подведите
курсор и
щелкните 1 раз
левой
кнопкой мыши.
Распознать все нераспознанные страницы:
-
Нажмите стрелку справа от кнопки Распознать и из открывшегося меню выберите пункт Распознать все нераспознанные страницы.
-
Программа выделяет блоки (если они еще не выделены) и распознает изображения.
Установить расположение текста на странице:
Программа
FineReader
автоматически
определяет
раскладку
текста на
странице. Для
книг, газет,
факсов,
отчетов и т. п.
подходит
положение Автоматическое
определение.
И только в
редких
случаях,
например при
распознавании
оглавлений и
листингов
программ,
нужно
специально
указывать
программе,
что текст
напечатан в
одну колонку.
п.
подходит
положение Автоматическое
определение.
И только в
редких
случаях,
например при
распознавании
оглавлений и
листингов
программ,
нужно
специально
указывать
программе,
что текст
напечатан в
одну колонку.
1. Меню Сервис Опции
2. В диалоге Опции выберите закладку Сегментация.
3. В группе Число колонок выберите пункт Одна колонка (для текста, напечатанного в одну колонку с большими промежутками между словами) или Автоматическое определение.
Сохранить результаты распознавания в файл:
1. Если Вы хотите сохранить не все страницы пакета, то выделите нужные в окне Пакет.
2. Нажмите
стрелку
справа от
кнопки Сохранить
и в
открывшемся
меню
выберите
пункт Сохранить
в файл.
3. В открывшемся диалоговом окне выберите диск, каталог и укажите имя и расширение файла, в который хотите экспортировать распознанный текст.
4. Установите переключатель Какие страницы сохранять в положение Все распознанные или Только выделенные.
5. Чтобы записывать каждую страницу в отдельный файл, отметьте пункт Записывать каждую страницу в отдельный файл. Тогда имена, которые эти файлы получат, будут состоять из заданного имени и порядкового номера (1, 2, и т.д.).
6. Нажмите OK.
Вы можете передать результаты распознавания в одно из следующих приложений: MS Word, MS Excel, Corel WordPerfect, Lotus Word Pro или PROMT:
1. Активизируйте
окно пакета (нажмите
в нем мышью) и
нажмите
стрелку
справа от
кнопки Сохранить.
Активизируйте
окно пакета (нажмите
в нем мышью) и
нажмите
стрелку
справа от
кнопки Сохранить.
2. В открывшемся меню выберите пункт Передать в Word, Передать в Excel и т.п.
Для выделенных страниц:
1. Если вы хотите передать в другое приложение не все страницы, а только некоторые, то выделите нужные страницы в окне Пакет.
2. Нажмите на стрелку справа от кнопки Сохранить и выберите пункт Мастер сохранения результатов.
3. В
открывшемся
списке
выберите
нужное
приложение и
отметьте
пункт Сохранять
только
выделенные
страницы. По
нажатию Готово
в этом
диалоге
результаты
распознавания
передаются в
выбранное
приложение.
Назад
Проверьте свои знания
Часть 1. Сканирование и распознавание. Секреты сканирования на ПК
Читайте также
Распознавание речи
Распознавание речи Интересная системная утилита, с помощью которой можно распознавать речь и переводить ее в текст. К сожалению, поддерживается работа только с английским
14.2. Сканирование компьютера
14.2. Сканирование компьютера Защитник Windows может сканировать компьютер в трех режимах.? Быстрая проверка. Позволяет просканировать системные каталоги и системный реестр – наиболее уязвимые места операционной системы. При этом на проверку тратится гораздо меньше
Глава 9 Сканирование, распознавание и конвертирование с помощью ABBYY FineReader
Глава 9 Сканирование, распознавание и конвертирование с помощью ABBYY FineReader
В процессе написания работы вам наверняка будут встречаться тексты или рисунки из книг и журнальных статей, которые необходимо поместить в документ. Если вы планируете использовать лишь фрагмент,
Если вы планируете использовать лишь фрагмент,
Распознавание типов
Распознавание типов Статический метод TheMachine.FireThisPerson() строился так, чтобы он мог принимать любой тип, производный от Employee, но возникает один вопрос: как метод «узнает», какой именно производный тип передается методу. Кроме того, если поступивший параметр имеет тип Employee, то
Глава 17. Сканирование
Глава 17. Сканирование Сканирующее устройство «просматривает» печатный материал и передает его в OCR-систему. Далее печатный материал преобразуется в изображение, которое на данном этапе нельзя отредактировать ни в одном текстовом
Глава 32. Распознавание
Глава 32. Распознавание
Задача распознавания состоит в том с тем, чтобы преобразовать отсканированное изображение в текст, сохранив при этом оформление страницы. Прежде чем приступить к распознаванию текста, необходимо установить основные параметры распознавания: язык
Распознавание
Задача распознавания состоит в том с тем, чтобы преобразовать отсканированное изображение в текст, сохранив при этом оформление страницы. Прежде чем приступить к распознаванию текста, необходимо установить основные параметры распознавания: язык
FineReader – распознавание текста
FineReader – распознавание текста Ввести со сканера текст в компьютер – задача не слишком трудная. Однако работать с таким текстом невозможно: как и любое сканированное изображение, страница с текстом представляет собой графический файл – обычную картинку. Отсюда возникают
Сканирование и распознавание
Сканирование и распознавание Ввести со сканера текст в компьютер – задача не слишком трудная. Однако работать с таким текстом невозможно: как и любое сканированное изображение, страница с текстом представляет собой графический файл – обычную картинку. Отсюда возникают
Глава 8 Сканирование, распознавание и конвертирование с помощью ABBYY FineReader
Глава 8 Сканирование, распознавание и конвертирование с помощью ABBYY FineReader В процессе написания работы вам наверняка будут встречаться тексты или рисунки из книг и журнальных статей, которые вам захочется поместить в свой документ. Если вы планируете использовать
ПИСЬМОНОСЕЦ: Распознавание опечатков
ПИСЬМОНОСЕЦ: Распознавание опечатков Автор: Владимир ГуриевДо первого апреля еще далеко, но посмешить народ уже хочется. Так попробуем же…Думаю, редакция «Терры» прекрасно знает, как мы доверяем нашему любимому журналу. И по этому поводу у меня возникла одна мысль: а что,
1. Сканирование
1. Сканирование Задача этой ступени перевести бумажные страницы книги в соответствующие им файлы в формате TIFF с разрешением 300dpi. Это разрешение достаточно для книжного текста обычного («читабельного») размера. Мелкий шрифт или желание передать мелкие детали иллюстраций
Распознавание вида компонент
Распознавание вида компонент Компоненты x и y объявлены как относящиеся к типу REAL без ассоциированного алгоритма, следовательно, они являются атрибутами. Все остальные компоненты содержат конструкции видаisdo… Инструкции …endкоторые описывают алгоритм, что является
Сканирование изображений
Сканирование изображений В этой главе будут кратко рассмотрены следующие вопросы:? сканирование изображения;? редактирование изображения;? вывод изображения на печать.Сканирование позволяет перевести изображение с материального носителя, например с фотографии, в
Распознавание лица
Распознавание лица В отличие от других систем биометрической идентификации, распознавание лица носит пассивный характер: оно может осуществляться без ведома человека, позволяя производить идентификацию в лифте или при проходе через дверь. Сегодня биометрические
Сканирование изображений. Новейший самоучитель работы на компьютере
Читайте также
Сканирование всего компьютера
Сканирование всего компьютера Некоторые вредоносные программы могут скрываться в папках или файлах, к которым обращение происходит редко, а активность проявлять во время загрузки или выключения компьютера, когда антивирусный монитор еще не запущен или уже не работает.
10.7.2. Сканирование портов
10.7.2. Сканирование портов В разд. 1.1 мы говорили о том, что на начальном этапе взлома компьютера хакер должен получить как можно больше сведений о жертве. Средством сбора первичной информации является сканирование портов. Делать это с собственного компьютера опасно,
14.2. Сканирование компьютера
14.2. Сканирование компьютера Защитник Windows может сканировать компьютер в трех режимах.? Быстрая проверка. Позволяет просканировать системные каталоги и системный реестр – наиболее уязвимые места операционной системы. При этом на проверку тратится гораздо меньше
Часть 1. Сканирование и распознавание
Часть 1. Сканирование и распознавание Глава 1. Как работает сканирующее устройство В процессе ввода изображения в компьютер в первую очередь необходимо преобразовать его в последовательность электрических сигналов. Для этого используются так называемые
Глава 7. Цветное сканирование
Глава 7. Цветное сканирование Все светочувствительные приборы, применяемые в сканерах, измеряют только яркость попадающего на них света, но не его спектральные характеристики, по которым человеческий глаз различает цвета. Поэтому для ввода в компьютер цветных
Глава 15. Как осуществляется сканирование в программе Adobe Photoshop TWAIN
Глава 15. Как осуществляется сканирование в программе Adobe Photoshop TWAIN Под TWAIN-интерфейсом понимается международный стандарт, который в свое время был принят для единого взаимодействия устройств ввода изображений с той или иной программой, которая «обслуживает» подобные
Глава 17. Сканирование
Глава 17. Сканирование Сканирующее устройство «просматривает» печатный материал и передает его в OCR-систему. Далее печатный материал преобразуется в изображение, которое на данном этапе нельзя отредактировать ни в одном текстовом
Глава 28. Сканирование TWAIN-интерфейс
Глава 28. Сканирование TWAIN-интерфейс В программе ABBYY FineReader работа со сканирующими устройствами осуществляется исключительно через интерфейс TWAIN вашей операционной системы.Под TWAIN-интерфейсом понимается международный стандарт, который в свое время был принят для единого
Глава 30. Сканирование многостраничных документов
Глава 30. Сканирование многостраничных документов В программе ABBYY FineReader для удобства процесса сканирования большого количества страниц предусмотрен специальный режим процесса сканирования: Сканировать несколько страниц, который дает возможность в одном цикле
Глава 1. Сканирование и обработка графических документов
Глава 1. Сканирование и обработка графических документов Автоматизация проектирования пережила начальную стадию. Эйфория от замены кульмана на его компьютерный эквивалент на базе систем AutoCAD или КОМПАС прошла, конструкторы (архитекторы, топографы), прошедшие этот этап,
Сканирование и распознавание
Сканирование и распознавание Ввести со сканера текст в компьютер – задача не слишком трудная. Однако работать с таким текстом невозможно: как и любое сканированное изображение, страница с текстом представляет собой графический файл – обычную картинку. Отсюда возникают
Глава 8 Сканирование, распознавание и конвертирование с помощью ABBYY FineReader
Глава 8 Сканирование, распознавание и конвертирование с помощью ABBYY FineReader В процессе написания работы вам наверняка будут встречаться тексты или рисунки из книг и журнальных статей, которые вам захочется поместить в свой документ. Если вы планируете использовать
1. Сканирование
1. Сканирование Задача этой ступени перевести бумажные страницы книги в соответствующие им файлы в формате TIFF с разрешением 300dpi. Это разрешение достаточно для книжного текста обычного («читабельного») размера. Мелкий шрифт или желание передать мелкие детали иллюстраций
Сетевое сканирование портов
Сетевое сканирование портов Сетевое сканирование портов включает в себя процесс автоматизированного выявления уязвимостей на удаленных системах с последующим захватом последних. В качестве сканеров подобного рода можно привести что-нибудь вроде XSpider, Essential Net Tools, Net Bios
Сканирование радужной оболочки
Сканирование радужной оболочки Из всех известных систем биометрической идентификации сканирование радужной оболочки является наиболее точным и стабильным. Тонкий узор на радужке формируется еще до рождения и остается неизменным на протяжении всей жизни (кроме
Что такое технология оптического распознавания символов, или OCR
КАКАЯ ТЕХНОЛОГИЯ ЛЕЖИТ В ОСНОВЕ OCR?
Компания ABBYY, опираясь на результаты многолетних исследований, реализовала принципы IPA в компьютерной программе. Система оптического распознавания символов ABBYY FineReader – единственная в мире система OCR, действующая в соответствии с вышеописанными принципами на всех этапах обработки документа. Эти принципы делают программу максимально гибкой и интеллектуальной, предельно приближая ее работу к тому, как распознает символы человек. На первом этапе распознавания система постранично анализирует изображения, из которых состоит документ, определяет структуру страниц, выделяет текстовые блоки, таблицы. Кроме того, современные документы часто содержат всевозможные элементы дизайна: иллюстрации, колонтитулы, цветной фон или фоновые изображения. Поэтому недостаточно просто найти и распознать обнаруженный текст, важно с самого начала определить, как устроен рассматриваемый документ: есть ли в нем разделы и подразделы, ссылки и сноски, таблицы и графики, оглавление, проставлены ли номера страниц и т. д. Затем в текстовых блоках выделяются строки, отдельные строки делятся на слова, слова на символы.
Важно отметить, что выделение символов и их распознавание также реализовано в виде составных частей единой процедуры. Это позволяет в полной мере использовать преимущества принципов IPA. Выделенные изображения символов поступают на рассмотрение механизмов распознавания букв, называемых классификаторами.
В системе ABBYY FineReader применяются классификаторы следующих типов: растровый, признаковый, контурный, структурный, признаково-дифференциальный и структурно-дифференциальный. Растровый и признаковый классификаторы анализируют изображение и выдвигают несколько гипотез о том, какой символ на нем представлен. В ходе анализа каждой гипотезе присваивается определенная оценка (так называемый вес). По итогам проверки мы получаем список гипотез, проранжированный по весу (то есть по степени уверенности в том, что перед нами именно такой символ). Можно сказать, что в данный момент система уже «догадывается», на что похож рассматриваемый символ.
После этого в соответствии с принципами IPA ABBYY FineReader проводит проверку выдвинутых гипотез. Это делается с помощью дифференциального признакового классификатора.
Кроме того, следует отметить, что ABBYY FineReader поддерживает 192 языка распознавания. Интеграция системы распознавания со словарями помогает программе при анализе документов: распознавание происходит более точно и упрощает дальнейшую проверку результата с учетом данных об основном языке документа и словарной проверки отдельных предположений. После подробной обработки огромного числа гипотез программа принимает решение и предоставляет пользователю распознанный текст.
Smart Engines – интеллектуальное распознавание изображений
Описание
«КОРУС Консалтинг» является официальным партнером Smart Engines и предлагает решения для интеллектуального распознавания изображений.
Smart Engines – российский разработчик систем обработки изображений и распознавания символов в видеопотоке, мобильных решений в области процессинга изображений и сжатия электронных образов.
- Smart ArchiveHelper – оперативное сканирование и импорт документов.
Набор технологических инструментов для создания электронных архивов Smart ArchiveHelper даст возможность сканировать и импортировать документы, автоматически распознавать и классифицировать их, обрабатывать и оптимизировать размер изображений, а также готовить образы документов для сохранения в электронном архиве.
- Smart IDReader – сканирование документов с помощью мобильных устройств.
Smart IDReader – продукт, позволяющий быстро распознавать документы, удостоверяющие личность и права собственности с помощью фотокамер и сканеров мобильных устройств. При этом, полный цикл распознавания в видеопотоке и в условиях сильной зашумленности изображения, начиная от первого контакта паспорта с камерой и заканчивая получением результата, составляет 1-2 секунды.
- Smart CardReader – распознавание пластиковых, банковских, дисконтных карт.
Встраиваемая система Smart CardReader предоставляет возможность распознавания пластиковых, банковских, дисконтных карт в видеопотоке камеры мобильного устройства или обычной веб-камеры. Разработанные алгоритмы дают высокую точность и скорость сканирования даже в неприспособленных условиях. При этом распознавание банковской карты в видеопотоке составляет 1 – 1,5 секунды.
Программное обеспечение SmartEngine используется в программно-аппаратном комплексе Smart PassportBox, предназначенном для быстрого сканирования документов удостоверяющих личность.
Распознавание изображений становится все более незаменимым приложением по мере того, как сканирование набирает обороты
Поскольку крупные розничные торговцы, такие как Amazon, Target и Macy’s, предлагают распознавание изображений в своих мобильных приложениях, эта технология, вероятно, станет обязательной, хотя более сложные развертывания сканирования в магазин могут остаться ограниченными.
Опции сканирования для покупки, позволяющие потребителям совершать покупки непосредственно из каталогов розничного продавца, печатной рекламы и вывески в магазинах, становятся все более стандартным предложением.Тем не менее, все больше розничных продавцов также изо всех сил пытаются конкурировать с Amazon и демонстрируют и используют технологию распознавания изображений, которая позволяет потребителям направлять свой телефон на любой объект и получать предложения по аналогичным продуктам в приложении бренда.
«Несомненно, распознавание изображений будет играть важную роль в мобильной коммерции в следующем году», — сказал Ник Де Тустен, директор по продажам LTU Technologies, Нью-Йорк. «Мы достигли переломного момента, когда у достаточного количества потребителей есть« рефлекс сканирования », и нет ничего более естественного, чем сканирование изображения продукта.
«Кроме того, я думаю, что потребители устали от QR-кода. Нам надоело видеть эти уродливые коды и теги, и мы хотим более простой, более естественный и эстетичный способ: распознавание изображений — вот что. Возможно, это клише, но пришло время распознавания образов ».
Принятие потребителями
Бренды, уже предлагающие функции сканирования до магазина в своих приложениях, могут рассчитывать на широкое признание пользователей, поскольку праздничные покупки идут полным ходом. Target атакует функцию распознавания изображений Amazon с помощью приложения In a Snap, которое позволяет пользователям сканировать изображение каталога или вывески в определенных магазинах и получать дополнительную информацию о продукте, чтобы совершить покупку в приложении (см. Историю).
Между тем Macy’s еще больше усиливает функцию сканирования для покупки, выпустив приложение Image Search, которое позволяет гостям делать снимки любого предмета, а затем легко искать и покупать аналогичный продукт на Macys.com (см. Историю ). Фотосъемка реальных продуктов и предоставление пользователям возможности мгновенно покупать аналогичные товары — это аспект демонстрации, который многие потребители сочтут чрезвычайно ценным.
«Эта технология поможет еще больше сократить разрыв между офлайн (демонстрация в магазине) и онлайн, мобильными и настольными устройствами, просмотром и покупками», — сказал Джамел Агауа, генеральный директор MobPartner, Сан-Франциско.«В 2014 году потребители начали использовать технологию распознавания изображений, предоставляемую розничными торговцами. Я ожидаю, что в 2015 году внедрение будет расти быстрыми темпами, поскольку все больше розничных продавцов осознают преимущества и преимущества технологии как для потребителей, так и для своего бизнеса ».
Для брендов, которые интегрировались с Apple Pay или другими мобильными платежными системами, этот тип программного обеспечения для распознавания изображений может еще больше поднять продажи мобильной коммерции.
«Это скоро станет функцией ставок за столом для всех приложений — потребители будут ожидать, что эта функция будет доступна, или же они будут использовать приложение конкурентов, чтобы поднять продукты и получить информацию, которую они ищут», — сказал Вивек Агравал. , вице-президент по мобильному и развивающемуся опыту в Skava, Сан-Франциско.
«Кроме того, с появлением Apple Pay распознавание изображений станет ключевым способом сократить количество кликов / касаний, которые пользователь должен выполнить, чтобы в конечном итоге купить продукт».
Тем не менее, при продвижении потребителями функций сканирования до магазина необходимо учитывать демографические данные. Миллениалы, у которых уже есть приложения своих любимых брендов на своих мобильных устройствах, оценят удобство, но пожилым людям может потребоваться некоторое время, чтобы привыкнуть к этой идее, хотя в конечном итоге это может привести к увеличению числа загрузок приложений.
«Я думаю, это будет зависеть от потребителя и от того, насколько он знаком с функцией сканирования в магазин», — сказал г-н Де Тустен. «Для некоторых это будет« вау — аккуратно! », А для других -« Я никогда этого не получу. Просто дайте мне старый добрый ценник ».
« Потребители в конечном итоге будут стремиться от магазина к сканированию, но это займет у одних демографических групп больше времени, чем у других ».
Преодоление проблем
Ключом к конкуренции с розничными конгломератами является обеспечение безупречной работы функции распознавания изображений.Функция Amazon iOS Flow предлагает гибкость в распознавании предметов, от логотипов и иллюстраций до других уникальных визуальных функций.
«Потребители изрядно измучены невыполненными обещаниями о прошлых функциях приложений для мобильной коммерции», — сказал Крис Меллоу, директор по цифровым технологиям и взаимодействию в Grupo Gallegos, Хантингтон-Бич, Калифорния. «Тем не менее, если эта функциональность действительно сделает покупки лучше опыт, он будет принят.
«Основная проблема со сканированием в магазин заключается в том, что он позиционируется как простое решение для тех потребителей, которые хотят просмотреть и удержать товар в магазине, а затем совершить покупку в более дешевом интернет-магазине.А в тех случаях, когда кто-то предпринял усилия, чтобы пойти в обычный магазин, чтобы просмотреть продукт, вы должны подумать, что они могут найти этот продукт в Интернете с помощью текстового поиска с очень небольшими усилиями ».
«Если функция сканирования в магазин не добавляет существенной ценности, не говоря уже о правильной работе, клиенты будут делать то же самое, что они делали со сканированием UPC и QR-кодов, и просто игнорировать это», — сказал г-н Меллоу. .
Маркетологам, стремящимся укрепить свои мобильные стратегии в 2015 году, следует подумать о добавлении функций распознавания изображений в приложениях, чтобы не отставать от усилий других крупных брендов для удобства клиентов и упрощения процессов оформления заказа.Однако обеспечение работы технологии на всех мобильных устройствах является ключевым требованием, поскольку для мобильных пользователей важно первое впечатление.
«Если на получение результата уйдет слишком много времени или вы получите неправильный результат, это будет отказом», — сказал де Тустен из LTU Technologies. «Бренды должны сосредоточиться на том, чтобы сделать серверную часть быстрой и точной, чтобы интерфейс был простым и функциональным для потребителей».
Final Take
Алекс Самуэли, помощник редактора Mobile Commerce Daily, Нью-Йорк
Распознавание изображений в 2021 году: подробное руководство
В этой статье рассматривается распознавание изображений, приложение искусственного интеллекта ( AI) и компьютерное зрение.Распознавание изображений с помощью глубокого обучения — ключевое приложение искусственного интеллекта, которое сегодня используется для решения широкого круга реальных задач.
Я дам исчерпывающий обзор современных методов и реализаций распознавания изображений. В частности, вы узнаете о:
- Что такое распознавание изображений
- Как работает распознавание изображений
- Традиционное и современное распознавание изображений с глубоким обучением
- Распознавание изображений и глубокое обучение в нейронных сетях
- Самое лучшее и самое лучшее популярные алгоритмы распознавания изображений
- Как использовать Python для распознавания изображений
- Примеры и приложения
- Внедрение систем распознавания изображений
Создавайте системы распознавания изображений без написания кода с нуля с помощью мощной платформы компьютерного зрения Viso Suite без кода.Пакет Viso — это комплексное решение для распознавания изображений, предназначенное для управления всем жизненным циклом приложения (создание, развертывание, мониторинг).
Что такое распознавание изображений?
Распознавание изображений — это задача идентификации представляющих интерес объектов на изображении и определения, к какой категории они принадлежат. Распознавание фотографий и распознавание изображений — это термины, которые используются как синонимы.
Когда мы визуально видим объект или сцену, мы автоматически идентифицируем объекты как разные экземпляры и связываем их с отдельными определениями.Однако визуальное распознавание — очень сложная задача для машин.
Распознавание изображений с использованием искусственного интеллекта — давняя исследовательская проблема в области компьютерного зрения. Хотя со временем развивались разные методы, общей целью распознавания изображений является классификация обнаруженных объектов по разным категориям. Поэтому его еще называют распознаванием объектов.
В последние годы машинное обучение, в частности технология глубокого обучения, добилось больших успехов во многих задачах компьютерного зрения и понимания изображений.Следовательно, методы распознавания изображений с глубоким обучением достигают лучших результатов с точки зрения производительности (количество кадров в секунду / FPS) и гибкости. Позже в этой статье мы рассмотрим наиболее эффективные алгоритмы глубокого обучения и модели искусственного интеллекта для распознавания изображений.
Значение и определение распознавания изображений
В области компьютерного зрения такие термины, как сегментация, классификация, распознавание и обнаружение, часто используются взаимозаменяемо, а различные задачи частично совпадают.Хотя это в основном не проблема, все становится запутанным, если ваш рабочий процесс требует, чтобы вы специально выполняли конкретную задачу.
Сравнение распознавания изображений и компьютерного зрения
Термины «распознавание изображений» и «компьютерное зрение» часто используются как синонимы, но на самом деле они разные. Фактически, распознавание изображений — это приложение компьютерного зрения, которое включает в себя набор задач, включая обнаружение объектов, идентификацию изображений и классификацию изображений.
Приложение обнаружения объекта для обнаружения маскиРаспознавание изображений vs.Локализация объекта
Локализация объекта — это еще одна подгруппа компьютерного зрения, которую часто путают с распознаванием изображений. Локализация объекта относится к определению местоположения одного или нескольких объектов на изображении и рисованию ограничительной рамки по их периметру. Однако локализация объекта не включает классификацию обнаруженных объектов.
Распознавание изображений и обнаружение изображений
Термины распознавание изображений и обнаружение изображений часто используются вместо друг друга.Однако есть важные технические отличия.
Обнаружение изображения — это задача использования изображения в качестве входных данных и поиска различных объектов внутри него. Примером является обнаружение лиц, алгоритмы которого стремятся найти образцы лиц на изображениях (см. Пример ниже). Когда мы строго занимаемся обнаружением, нас не волнует, имеют ли обнаруженные объекты какое-либо значение. Цель обнаружения изображения состоит только в том, чтобы отличить один объект от другого, чтобы определить, сколько различных объектов присутствует в изображении.Таким образом, ограничивающие рамки нарисованы вокруг каждого отдельного объекта.
С другой стороны, распознавание изображений — это задача идентификации интересующих объектов в изображении и распознавания, к какой категории или классу они принадлежат.
Пример распознавания лиц с глубоким обучениемКак работает распознавание изображений?
Использование традиционного компьютерного зрения
Традиционный подход компьютерного зрения к распознаванию изображений представляет собой последовательность фильтрации изображений, сегментации, выделения признаков и классификации на основе правил.
Однако традиционный подход компьютерного зрения требует высокого уровня знаний, большого количества инженерного времени и содержит множество параметров, которые необходимо определять вручную, в то время как переносимость для других задач довольно ограничена.
Использование машинного обучения и глубокого обучения
Распознавание изображений с машинным обучением, с другой стороны, использует алгоритмы для изучения скрытых знаний из набора данных хороших и плохих образцов (контролируемое обучение). Самый популярный метод машинного обучения — это глубокое обучение, при котором в модели используется несколько скрытых слоев.
Внедрение глубокого обучения в сочетании с мощным аппаратным обеспечением AI и графическими процессорами сделало большой прорыв в области распознавания изображений. Благодаря глубокому обучению алгоритмы классификации изображений и распознавания лиц достигают производительности выше человеческого уровня и обнаружения объектов в реальном времени.
Кроме того, мы наблюдали недавний скачок в производительности алгоритмов вывода. В 2017 году алгоритм Mask RCNN был самым быстрым детектором объектов в реальном времени в тесте MS COCO со временем логического вывода 330 мс на кадр.Для сравнения, алгоритм YOLOR, который был выпущен в 2021 году, достигает времени вывода 12 мс на том же тесте, даже превосходя популярные алгоритмы глубокого обучения YOLOv4 и YOLOv3.
По сравнению с традиционным подходом компьютерного зрения к ранней обработке изображений 20 лет назад, глубокое обучение требует только инженерных знаний инструмента машинного обучения, а не опыта в конкретных областях машинного зрения для создания функций ручной работы. Кроме того, для специальных реализаций глубокого обучения нужны только десятки обучающих образцов.
Однако глубокое обучение требует ручной маркировки данных для аннотирования хороших и плохих образцов (Image Annotation). Процесс обучения на основе данных, которые маркируются людьми, называется обучением с учителем. Процесс создания таких помеченных данных для обучения моделей ИИ требует трудоемкой работы человека, например, для аннотирования стандартных дорожных ситуаций при автономном вождении.
Пример ручного аннотирования изображений с помощью инструмента CVATПроцесс систем распознавания изображений
Есть несколько шагов, которые лежат в основе работы систем распознавания изображений.
- Набор данных с обучающими данными
Для моделей распознавания изображений требуются обучающие данные (видео, изображение, фото и т. Д.). Нейронным сетям нужны обучающие изображения из полученного набора данных, чтобы создать представление о том, как выглядят определенные классы.
Например, для модели распознавания изображений, которая обнаруживает разные позы (модель оценки позы), потребуется несколько экземпляров разных человеческих поз, чтобы понять, что делает позы уникальными друг от друга. - Обучение нейронных сетей для распознавания изображений
Изображения из созданного набора данных вводятся в алгоритм нейронной сети.Это аспект глубокого или машинного обучения при создании модели распознавания изображений. Обучение алгоритма распознавания изображений позволяет распознаванию изображений сверточной нейронной сети идентифицировать определенные классы. Сегодня для этих целей широко используются несколько хорошо протестированных фреймворков. - Тестирование модели AI
Обученную модель необходимо протестировать с изображениями, которые не являются частью обучающего набора данных. Это используется для определения удобства использования, производительности и точности модели.Таким образом, около 80-90% полного набора данных изображений используется для обучения модели, а остальные данные зарезервированы для тестирования модели. Производительность модели измеряется на основе набора параметров, которые показывают процентную достоверность точности для тестового изображения, неправильные идентификации и многое другое. Прочтите нашу статью о том, как оценить производительность моделей машинного обучения.
Распознавание изображений с помощью машинного обучения
До того, как графические процессоры (графические процессоры) стали достаточно мощными для поддержки массово-параллельных вычислительных задач нейронных сетей, традиционные алгоритмы машинного обучения были золотым стандартом для распознавания изображений.
Машинное обучение Модели распознавания изображений
Давайте посмотрим на три самых популярных модели машинного обучения распознавания изображений.
- Машины опорных векторов
SVM работают, создавая гистограммы изображений, содержащих целевые объекты, а также изображений, которые не содержат. Затем алгоритм берет тестовое изображение и сравнивает обученные значения гистограммы со значениями различных частей изображения для проверки совпадений. - Набор функций Модели
Набор функций Модели, такие как масштабно-инвариантное преобразование элементов (SIFT) и Максимально стабильные экстремальные области (MSER), работают, беря изображение для сканирования и образец фотографии объекта, который нужно найти, в качестве эталона.Затем он пытается сопоставить элементы из образца фотографии по пикселям с различными частями целевого изображения, чтобы увидеть, найдены ли совпадения. - Алгоритм Виолы-Джонса
Широко используемый алгоритм распознавания лиц из времен до CNN (сверточной нейронной сети), Виола-Джонс работает путем сканирования лиц и извлечения признаков, которые затем проходят через повышающий классификатор. Это, в свою очередь, генерирует ряд усиленных классификаторов, которые используются для проверки тестовых изображений. Чтобы найти успешное совпадение, тестовое изображение должно давать положительный результат от каждого из этих классификаторов.
Модели распознавания изображений с глубоким обучением
В распознавании изображений использование сверточных нейронных сетей (CNN) также называется распознаванием глубоких изображений. CNN не имеют себе равных среди традиционных методов машинного обучения. CNN не только быстрее и обеспечивают наилучшие результаты обнаружения, но также могут обнаруживать несколько экземпляров объекта изнутри изображения, даже если изображение слегка деформировано, растянуто или изменено в какой-либо другой форме.
В распознавании глубоких изображений сверточные нейронные сети превосходят людей даже в таких задачах, как классификация объектов по мелкозернистым категориям, таким как конкретная порода собак или вид птиц.
Самые популярные модели глубокого обучения, такие как YOLO, SSD и RCNN, используют сверточные слои для анализа изображения или фотографии. Во время обучения каждый слой свертки действует как фильтр, который учится распознавать какой-то аспект изображения, прежде чем он будет передан следующему.
Один слой обрабатывает цвета, другой — формы и т. Д. В конце концов, совокупный результат всех этих слоев коллективно учитывается при определении того, было ли найдено совпадение.
Распознавание изображений AI с обнаружением и классификацией объектов с использованием глубокого обученияПопулярные алгоритмы распознавания изображений
Для распознавания изображений или фотографий несколько алгоритмов на голову выше остальных.Хотя все это алгоритмы глубокого обучения, их фундаментальный подход к тому, как они распознают разные классы объектов, варьируется. Давайте посмотрим на некоторые, которые широко используются в наши дни.
Faster Region-based CNN (Faster RCNN)
Faster RCNN (Region-based Convolutional Neural Network) — лучший исполнитель в семействе алгоритмов распознавания изображений R-CNN, включая R-CNN и Fast R-CNN.
Он использует сеть предложений региона (RPN) для обнаружения функций вместе с Fast RCNN для распознавания изображений, что делает его значительным обновлением по сравнению с его предшественником (Примечание: Fast RCNN vs. Быстрее RCNN). Более быстрый RCNN может обрабатывать изображение менее 200 мс, в то время как Fast RCNN занимает 2 секунды и более.
Детектор одиночных снимков (SSD)
RCNN рисуют ограничивающие прямоугольники вокруг предложенного набора точек на изображении, некоторые из которых могут перекрываться. Детекторы одиночного кадра (SSD) дискретизируют эту концепцию, разделяя изображение на ограничивающие прямоугольники по умолчанию в виде сетки с разными соотношениями сторон.
Затем он объединяет карты характеристик, полученные в результате обработки изображения с различными соотношениями сторон, для естественной обработки объектов различных размеров.Это делает SSD-диски очень гибкими, точными и простыми в обучении. Реализация SSD может обрабатывать изображение за 125 мс.
You Only Look Once (YOLO)
YOLO означает You Only Look Once, и в соответствии со своим названием алгоритм обрабатывает кадр только один раз, используя фиксированный размер сетки, а затем определяет, содержит ли блок сетки изображение или нет.
Для этой цели алгоритм обнаружения объектов использует метрику достоверности и несколько ограничивающих рамок в каждом квадрате сетки. Однако здесь не рассматриваются сложности, связанные с множественными соотношениями сторон или картами функций, и, таким образом, хотя это дает результаты быстрее, они могут быть несколько менее точными, чем SSD.
Одной из самых популярных моделей YOLO является ее третья версия — YOLOv3. Самый изящный вариант YOLO под названием Tiny YOLO может обрабатывать видео со скоростью до 244 кадров в секунду или 1 изображение со скоростью 4 мс.
Алгоритм распознавания изображений YOLOv3 применяется к фотографии плотной сцены.Как применять распознавание изображений
Распознавание изображений с помощью Python
Python — язык программирования, который выбирают большинство инженеров компьютерного зрения. Он поддерживает огромное количество библиотек, специально разработанных для рабочих процессов AI, включая распознавание изображений.
- Шаг № 1: Чтобы настроить компьютер для выполнения задач распознавания изображений Python, вам необходимо загрузить Python и установить пакеты, необходимые для выполнения заданий распознавания изображений, включая Keras.
- Шаг № 2: Keras — это высокоуровневый API глубокого обучения для запуска приложений искусственного интеллекта. Он работает на TensorFlow / Python и помогает конечным пользователям развертывать приложения машинного обучения и искусственного интеллекта, используя простой для понимания код.
- Шаг № 3: Если на вашем компьютере нет видеокарты, вы можете использовать бесплатные экземпляры графического процессора онлайн в Google Colab.Для классификации животных существует хорошо маркированный набор данных, известный как «Животные-10», который вы можете найти на Kaggle. Набор данных можно загрузить совершенно бесплатно.
- Шаг № 4: После того, как вы получили онлайн-набор данных от Kaggle, получив токен API, вы можете начать кодирование на Python после повторной загрузки необходимых файлов на Google Диск.
Для получения более подробной информации о реализациях для конкретных платформ, несколько хорошо написанных статей в Интернете шаг за шагом проведут вас через процесс настройки среды для ИИ на вашем компьютере или на вашем Colab, который вы можете использовать.
API распознавания изображений (облако) и Edge AI
APIобеспечивают простой способ распознавания изображений путем вызова облачной службы API, такой как Amazon Rekognition (AWS Cloud). Точно так же легко использовать API для распознавания объектов на изображениях с помощью Google Vision API для таких задач, как обнаружение объектов или лиц, распознавание текста или распознавание рукописного ввода. API распознавания изображений, такой как API обнаружения объектов TensorFlow, представляет собой мощный инструмент для разработчиков, позволяющий быстро создавать и развертывать программное обеспечение для распознавания изображений, если вариант использования допускает выгрузку данных (отправка визуальных элементов на облачный сервер).Использование API для распознавания изображений используется для получения информации о самом изображении (классификация изображений или идентификация изображения) или содержащихся объектах (обнаружение объектов).
Чистые облачные API-интерфейсы компьютерного зрения полезны для создания прототипов и низкомасштабных решений, которые позволяют выгрузку данных (конфиденциальность, безопасность, законность), не являются критически важными (возможность подключения, пропускная способность, надежность), а не в режиме реального времени (задержка, объем данных, затраты). Чтобы преодолеть эти ограничения чисто облачных решений, последние тенденции в области распознавания изображений сосредоточены на расширении облака за счет использования пограничных вычислений с машинным обучением на устройстве.
Чтобы узнать, как работают API-интерфейсы распознавания изображений, какой из них выбрать, а также об ограничениях API-интерфейсов для задач распознавания, я рекомендую вам ознакомиться с нашим обзором лучших платных и бесплатных API-интерфейсов компьютерного зрения в 2021 году.
Хотя API-интерфейсы компьютерного зрения могут Для обработки отдельных изображений системы Edge AI используются для выполнения задач распознавания видео в реальном времени, перемещая машинное обучение в непосредственной близости от источника данных (Edge Intelligence). Это позволяет обрабатывать изображения AI в реальном времени, поскольку визуальные данные обрабатываются без выгрузки данных (выгрузки данных в облако), что обеспечивает более высокую производительность логического вывода и надежность, необходимые для систем промышленного уровня.
Платформа AI для распознавания изображений
Если вы не хотите начинать с нуля и использовать предварительно настроенную инфраструктуру, вы можете попробовать низкокодовые платформы AI Vision, которые предоставляют популярное программное обеспечение для распознавания изображений с открытым исходным кодом. -коробка. Например, Viso Suite — это комплексная платформа компьютерного зрения для создания и развертывания систем реального времени на основе нейронных сетей для задач распознавания изображений.
Разработка распознавания изображений с помощью платформы без кода Viso SuiteДля чего используется распознавание изображений?
Технология распознавания изображений AI становится все более востребованной во всех отраслях.Его приложения обеспечивают экономическую ценность в таких отраслях, как здравоохранение, розничная торговля, безопасность, сельское хозяйство и многих других. Чтобы увидеть обширный список приложений для компьютерного зрения и распознавания изображений, я рекомендую вам наш список из 56 самых популярных приложений компьютерного зрения в 2021 году.
Анализ и идентификация лиц
Анализ лиц — это популярное приложение для распознавания изображений. Современные методы машинного обучения позволяют использовать видеопоток любой цифровой камеры или веб-камеры. В таких приложениях программное обеспечение распознавания изображений использует алгоритмы ИИ для одновременного обнаружения лиц, оценки позы лица, выравнивания лица, распознавания пола, определения улыбки, оценки возраста и распознавания лиц с использованием глубокой сверточной нейронной сети.
Анализ лица с помощью компьютерного зрения позволяет системам распознавать личность, намерения, эмоциональное состояние и состояние здоровья, возраст или этническую принадлежность. Некоторые инструменты распознавания фотографий даже нацелены на количественную оценку уровня воспринимаемой привлекательности с помощью баллов.
Другие задачи, связанные с распознаванием лиц, включают идентификацию изображений лиц, распознавание лиц и проверку лиц, которые включают методы обработки зрения для поиска и сопоставления обнаруженного лица с изображениями лиц в базе данных. Методы распознавания с глубоким обучением позволяют идентифицировать людей на фотографиях или видео, даже если они стареют или находятся в сложных условиях освещения.
Одна из самых популярных программных библиотек с открытым исходным кодом для создания приложений распознавания лиц AI называется DeepFace, которая может анализировать изображения и видео. Чтобы узнать больше об анализе лица с помощью ИИ и распознавания видео, я рекомендую прочитать нашу статью о Deep Face Recognition.
Пример анализа лица с распознаванием изображений с использованием программной библиотеки DeepFace.Анализ медицинских изображений
Технология визуального распознавания широко используется в медицинской промышленности, чтобы компьютеры понимали изображения, которые обычно получаются в процессе лечения.Медицинский анализ изображений становится очень прибыльной разновидностью искусственного интеллекта. Например, существует множество работ по выявлению меланомы, смертельного рака кожи. Программное обеспечение для распознавания изображений с глубоким обучением позволяет отслеживать опухоли во времени, например, для обнаружения аномалий при сканировании рака груди.
Подробнее о приложениях распознавания изображений в здравоохранении.
Мониторинг животных
В системах визуального искусственного интеллекта в сельском хозяйстве используются новые методы, которые были обучены определять тип животного и его действия.Программное обеспечение для распознавания изображений AI используется для мониторинга животных в сельском хозяйстве, где за домашним скотом можно наблюдать удаленно для обнаружения болезней, обнаружения аномалий, соблюдения правил защиты животных, промышленной автоматизации и т. Д.
Ознакомьтесь с нашим руководством о лучших приложениях компьютерного зрения в сельском хозяйстве и умном сельском хозяйстве.
Технология распознавания изображений, используемая для наблюдения за животнымиОбнаружение узоров и объектов
Технологии распознавания фотографий и видео AI полезны для идентификации людей, узоров, логотипов, объектов, мест, цветов и форм.Возможность настройки распознавания изображений позволяет использовать его в сочетании с несколькими программами. Например, после того, как программа распознавания изображений специализируется на обнаружении людей, ее можно использовать для подсчета людей — популярного приложения компьютерного зрения в розничных магазинах.
Чтобы узнать все, что вам нужно знать о передовых технологиях обнаружения и распознавания образов на изображениях, я рекомендую прочитать нашу статью Что такое распознавание образов ?.
Приложение Image Recognition для автоматического обнаружения опасных объектовАвтоматическая идентификация изображений растений
Идентификация растений на основе изображений быстро развивается и уже используется в исследованиях и природопользовании.В исследовательском документе от июля 2021 года была проанализирована точность идентификации изображения для определения семейства растений, форм роста, форм жизни и региональной частоты. Инструмент выполняет распознавание поиска изображений, используя фотографию растения с программным обеспечением для сопоставления изображений, чтобы запросить результаты в онлайн-базе данных.
Результаты указывают на высокую точность распознавания: 79,6% из 542 видов примерно на 1500 фотографиях были правильно идентифицированы, в то время как семейство растений было правильно идентифицировано для 95% видов.
Распознавание изображений еды
Распознавание изображений различных типов пищевых продуктов с помощью глубокого обучения применяется для компьютерной оценки питания. Системы компьютерного зрения были разработаны для повышения точности текущих измерений рациона питания путем анализа изображений продуктов питания, снятых мобильными устройствами. Приложение для распознавания изображений используется для онлайн-распознавания образов в изображениях, загружаемых учащимися.
Распознавание при поиске изображений
Распознавание при поиске изображений использует визуальные функции, полученные от глубокой нейронной сети, для разработки эффективных и масштабируемых методов поиска изображений.Цель состоит в том, чтобы выполнять поиск изображений на основе содержимого для онлайн-приложений распознавания изображений. Исследователи разработали крупномасштабный визуальный словарь из обучающего набора функций нейронной сети для решения этой сложной задачи.
Прочтите о связанных темах
В настоящее время сверточные нейронные сети (CNN), такие как ResNet и VGG, представляют собой современные нейронные сети для распознавания изображений. В 2021 году в исследовании компьютерного зрения Vision Transformers (ViT) недавно использовались для задач распознавания изображений и показали многообещающие результаты.Модели ViT достигают точности сверточных нейронных сетей (CNN) при 4-кратном увеличении вычислительной эффективности.
Прочитав о том, что такое распознавание изображений и как работает распознавание фотографий или изображений, вы можете изучить другие статьи по этой теме:
Начало работы — создание системы распознавания изображений
В viso.ai мы используем Viso Suite , комплексная платформа компьютерного зрения. Мы предоставляем программное обеспечение и инфраструктуру для предприятий и предприятий, обеспечивающих работу надежных систем распознавания изображений в реальном времени.Используйте видеопоток любой цифровой камеры (камеры наблюдения, системы видеонаблюдения, веб-камеры и т. Д.) С новейшими, наиболее мощными моделями искусственного интеллекта прямо из коробки.
Увидеть — значит поверить: свяжитесь с нашей командой экспертов по искусственному интеллекту и запросите демонстрацию, чтобы увидеть основные функции.
Классификация отсканированных документов с использованием компьютерного зрения | by Arpan Das
Подход с глубоким обучением для решения проблемы классификации отсканированных документов
В эпоху цифровой экономики такие секторы, как банковское дело, страхование, управление, медицинский и юридический секторы, по-прежнему имеют дело с различными рукописными заметками и отсканированными документами.На более поздних этапах жизненного цикла бизнеса поддерживать и классифицировать эти документы вручную становится очень утомительно. Простое и понятное автоматическое объединение этих неклассифицированных документов в каталог значительно упростит обслуживание и использование информации, а также значительно сократит ручные усилия.
Отсканированные документыЦелью данного тематического исследования является разработка решения на основе глубокого обучения, которое может автоматически классифицировать документы.
Данные: Для этого тематического исследования мы будем использовать набор данных RVL-CDIP (Комплексная обработка информации о документах Ryerson Vision Lab), который состоит из 400 000 изображений в оттенках серого в 16 классах, по 25 000 изображений на класс.Имеется 320 000 обучающих изображений, 40 000 проверочных изображений и 40 000 тестовых изображений. Размеры изображений таковы, что их наибольший размер не превышает 1000 пикселей. Размер этого набора данных более 200 ГБ.
Отображение проблем Business-ML: Мы можем отобразить бизнес-проблему как проблему классификации нескольких классов. В текущем наборе данных 16 классов. Нам нужно предсказать класс документов на основе только значений пикселей отсканированного документа, что усложняет задачу. Но подождите, почему мы не можем использовать OCR для извлечения текста и применения методов НЛП? Да, нам тоже понравилась эта идея, но низкое качество сканирования привело к низкому качеству извлечения текста. В практических бизнес-сценариях мы также не контролируем качество сканирования, поэтому модели, основанные на OCR, могут страдать от плохого обобщения даже после надлежащей предварительной обработки.
KPI и бизнес-ограничения: Набор данных достаточно сбалансирован. Поэтому мы выбрали точность в качестве основного показателя, а средний балл F1 — в качестве второстепенного показателя, чтобы наказать ошибочно классифицированные точки данных.Мы также использовали метрику путаницы для проверки производительности модели. Требуется умеренная задержка и нет особых требований к интерпретируемости.
Можем ли мы получить что-нибудь по интенсивности пикселей и размеру документов?
Давайте попробуем визуализировать среднюю интенсивность пикселей и размер документов с помощью прямоугольной диаграммы
На прямоугольной диаграмме мы можем заметить, что размер одного типа отсканированных документов сильно отличается от других, но также есть совпадения.Например, размер файла класса 13 и класса 9 сильно различается, но размер класса 9 перекрывается с классом 4 и классом 6,7.
Можно заметить, что в 75% случаев средняя интенсивность пикселей класса 4 находится в пределах 160–230 пикселей. Но примерно в 50% случаев оно также перекрывается со средним значением пикселя класса 6. Для других классов среднее значение пикселя перекрывается.
Аналитический подход
Для решения поставленной задачи мы обучили сверточные нейронные сети (CNN) на расширенных данных.Мы пробовали обучать модель с дополнением данных и без него, результаты сопоставимы.
Аналитическая схема рабочего процесса высокого уровняОтлично! Но как решить сетевую архитектуру? Как вы тренировали сеть, ведь данные сразу не помещаются в память?
Обучение нейронной сети с нуля требует значительного времени и вычислительных ресурсов для схождения, чтобы избежать этого, мы воспользовались помощью трансферного обучения. Мы начали с весов предварительно обученных сетей, обученных на наборе данных ImageNet и повторно обученных на нашем наборе данных.Текущая модель SOTA для этого жанра задач использует обучение с передачей между доменами и внутри домена, где изображение делится на четыре части: верхний колонтитул, нижний колонтитул, левое тело и правое тело. Предварительно обученная модель VGG16 сначала используется для обучения по всем изображениям (междоменная область), затем эта модель используется для обучения части изображений (внутренняя область).
В этом эксперименте мы использовали несколько иной подход. Вместо обучения переносу внутри домена с использованием VGG16 мы обучили две параллельные модели VGG16 и InceptionResNetV2 и использовали их стек в качестве нашей окончательной модели.Мы предполагали, что из-за разной архитектуры этих двух моделей они будут изучать разные аспекты изображений, и их наложение приведет к хорошему обобщению. Но как мы выбираем эти модели? В основном это результат перекрестной проверки. Мы пробовали различные сетевые архитектуры, такие как VGG16, VGG19, DenseNet, ResNet, InceptionNet, и были выбраны две лучшие.
Мы использовали класс keras ImageDataGenerator для предварительной обработки и загрузки обучающих данных на ходу, вместо того, чтобы загружать все данные один раз в память.
Заключительный этап обучения сети VGG16ОК. Но как бороться с гиперпараметрами?
Для любой CNN гиперпараметры: скорость обучения, размер пула, размер сети, размер пакета, выбор оптимизатора, регуляризация, размер ввода и т. Д.
Скорость обучения играет важную роль в конвергенции нейронной сети. Функции потерь, используемые в задачах глубокого обучения, невыпуклые, а это означает, что поиск глобального минимума — непростая задача при наличии нескольких локальных минимумов и седловых точек.Если скорость обучения слишком низкая, она будет медленно сходиться, а если скорость обучения слишком высока, она начнет колебаться. Для этого тематического исследования мы использовали метод под названием «Cyclic Learning Rate», который направлен на обучение нейронной сети таким образом, чтобы скорость обучения изменялась циклически для каждого пакета обучения.
А почему работает? В CLR мы изменяем скорость обучения в пределах порогового значения. Периодическая более высокая скорость обучения помогает преодолеть, если он застрял в седловой точке или в локальных минимумах.
Для других гиперпараметров мы разработали специальные служебные функции, чтобы проверить, какая конфигурация работает лучше. Допустим, через 10 эпох мы получили точность 47%. Мы будем использовать эту модель в качестве базовой линии тестирования на этом этапе, и с помощью служебных функций мы проверим, какой набор конфигурации (например, batch_size / optimizer / learning_rate) приведет к большей точности в будущих эпохах.
Результаты
Мы достигли точности 90,7% при использовании модели VGG16 и 88% при использовании InceptionResNetV2.Пропорциональная составная модель из двух вышеупомянутых моделей получила точность обучения 97% и точность тестирования 91,45%.
, вы можете найти полную реализацию здесь.
Образец цитирования:
- AW Harley, A. Ufkes, KG Derpanis, «Evaluation of Deep Convolutional Nets for Document Image Classification and Retrieval», ICDAR, 2015.
- https://arxiv.org/abs/ 1506.01186
- https://www.researchgate.net/publication/332948719_Segmentation_of_Scanned_Documents_Using_Deep-Learning_Approach
Что такое распознавание изображений? | автор Dr.Датаман | Dataman в AI
Первый вопрос, который может у вас возникнуть, — в чем разница между компьютерным зрением и распознаванием изображений. Действительно, компьютерное зрение активно развивалось Google, Amazon и многими разработчиками искусственного интеллекта, и два термина «компьютерное зрение» и «распознавание изображений» могли использоваться как синонимы. Компьютерное зрение (CV) позволяет компьютеру имитировать человеческое зрение, а выполнять действия . Например, CV может быть разработан для обнаружения бегущего по дороге ребенка и подачи предупреждающего сигнала водителю.Напротив, распознавание изображений — это анализ пикселей и шаблонов изображения для распознавания изображения как конкретного объекта. Компьютерное зрение означает, что оно может «что-то делать» с распознанными изображениями. Поскольку в этом посте я опишу методы машинного обучения для распознавания изображений, я по-прежнему буду использовать термин «распознавание изображений». В этой статье я делаю краткое введение в данные изображения и объясняю, почему сверточные автоэнкодеры являются предпочтительным методом работы с данными изображения.
Я подумал, что полезно упомянуть три широкие категории данных. К трем категориям данных относятся: (1) некоррелированные данные (в отличие от последовательных данных), (2) последовательные данные (включая данные текстового и голосового потока) и (3) данные изображения. Глубокое обучение имеет три основных варианта для каждой категории данных: (1) стандартная нейронная сеть прямого распространения, (2) RNN / LSTM и (3) сверточная NN (CNN). Для читателей, которым нужны учебные пособия по каждому типу, рекомендуется проверить «Объяснение глубокого обучения удобным для регрессии способом» для (1) текущей статьи «Техническое руководство для RNN / LSTM / GRU по прогнозированию цен на акции». для (2) и «Глубокое обучение с помощью PyTorch не мучительно», «Что такое распознавание изображений?», «Легкое обнаружение аномалий с помощью автоэнкодеров» и «Сверточные автоэнкодеры для уменьшения шума изображения» для (3).Вы можете добавить в закладки сводную статью «Пути обучения Dataman — развивайте свои навыки, двигайте свою карьеру».
Что такое распознавание изображений?
Как говорится во фразе «Что видишь, то и получаешь», человеческий мозг облегчает зрение. Людям не требуется никаких усилий, чтобы отличить собаку, кошку или летающую тарелку. Но компьютеру довольно сложно имитировать этот процесс: они кажутся простыми только потому, что Бог устроил наш мозг невероятно способным распознавать изображения. Распространенным примером распознавания изображений является оптическое распознавание символов (OCR).Сканер может идентифицировать символы на изображении для преобразования текстов изображения в текстовый файл. Таким же образом можно применить OCR для распознавания текста номерного знака на изображении.
Поскольку вас интересует распознавание изображений, я рекомендую вам посмотреть это интересное видео:
Как работает распознавание изображений?
Как научить компьютер отличать одно изображение от другого? Процесс модели распознавания изображений ничем не отличается от процесса моделирования машинного обучения.Я перечисляю процесс моделирования для распознавания изображений на этапах с 1 по 4.
Этап моделирования 1: извлечение пиксельных элементов из изображения
Рисунок (A)Во-первых, из изображения извлекается большое количество характеристик, называемых элементами. Изображение на самом деле состоит из «пикселей», как показано на рисунке (A). Каждый пиксель представлен числом или набором чисел — и диапазон этих чисел называется глубиной цвета (или битовой глубиной). Другими словами, глубина цвета указывает максимальное количество потенциальных цветов, которые можно использовать в изображении.В (8-битном) изображении в градациях серого (черно-белом) каждый пиксель имеет одно значение в диапазоне от 0 до 255. Большинство изображений сегодня используют 24-битный цвет или выше. Цветное изображение RGB означает, что цвет в пикселе представляет собой комбинацию красного, зеленого и синего цветов. Каждый из цветов находится в диапазоне от 0 до 255. Этот генератор цветов RGB показывает, как любой цвет может быть сгенерирован с помощью RGB. Таким образом, пиксель содержит набор из трех значений: RGB (102, 255, 102) относится к цвету # 66ff66. Изображение n шириной 800 пикселей, высотой 600 пикселей имеет 800 x 600 = 480 000 пикселей = 0.48 мегапикселей («мегапиксель» составляет 1 миллион пикселей). Изображение с разрешением 1024 × 768 представляет собой сетку с 1024 столбцами и 768 строками, что, следовательно, содержит 1024 × 768 = 0,78 мегапикселя.
Моделирование Шаг 2: Подготовьте помеченные изображения для обучения модели
Рисунок (B)После преобразования каждого изображения в тысячи функций с известными метками изображений мы можем использовать их для обучения модели. На рисунке (B) показано множество изображений с пометками, которые принадлежат к разным категориям, таким как «собака» или «рыба».Чем больше изображений мы можем использовать для каждой категории, тем лучше можно обучить модель определять, является ли изображение изображением собаки или рыбы. Здесь мы уже знаем категорию, к которой принадлежит изображение, и используем их для обучения модели. Это называется машинным обучением с учителем.
Моделирование Шаг 3: Обучите модель классифицировать изображения
Рисунок (C)Рисунок (C) демонстрирует, как модель обучается с предварительно помеченными изображениями. Огромные сети в середине можно рассматривать как гигантский фильтр.Изображения в извлеченных формах попадают на входную сторону, а метки — на выходную. Цель здесь — обучить сети так, чтобы изображение с его характеристиками, поступающими из входных данных, соответствовало метке справа.
Шаг моделирования 4. Распознать (или спрогнозировать) новое изображение как одну из категорий
После обучения модели ее можно использовать для распознавания (или прогнозирования) неизвестного изображения. На рисунке (D) показано, что новое изображение распознается как изображение собаки. Обратите внимание, что новое изображение также пройдет процесс извлечения пиксельных элементов.
Сверточные нейронные сети — алгоритм распознавания изображений
Сети на рисунке (C) или (D) подразумевают, что популярные модели являются моделями нейронных сетей. Сверточные нейронные сети (CNN или ConvNets) широко применяются при классификации изображений, обнаружении объектов или распознавании изображений.
Мягкое объяснение сверточных нейронных сетей
Я буду использовать изображения рукописных цифр MNIST для объяснения CNN. Изображения MNIST представляют собой черно-белые изображения произвольной формы для чисел от 0 до 9.Легче объяснить концепцию с помощью черно-белого изображения, потому что каждый пиксель имеет только одно значение (от 0 до 255) (обратите внимание, что цветное изображение имеет три значения в каждом пикселе).
Сетевые уровни CNN отличаются от типичных нейронных сетей. Существует четыре типа слоев: свертка, ReLU, объединение и полносвязные слои, как показано на рисунке (E). Что делает каждый из четырех типов? Позволь мне объяснить.
- Слой свертки
Первый шаг, который делают CNN, — это создание множества небольших частей, называемых элементами , таких как блоки 2×2.Чтобы визуализировать процесс, я использую три цвета для обозначения трех функций на рисунке (F). Каждая особенность характеризует некую форму исходного изображения.
Позвольте каждой функции сканировать исходное изображение. Если есть идеальное совпадение, в этом поле отображается высокий балл. Если совпадение мало или нет совпадений, оценка будет низкой или нулевой. Этот процесс получения оценок называется , фильтрация .
Рисунок (G)Рисунок (G) показывает три функции. Каждая функция создает изображение с фильтром с высокими и низкими баллами при сканировании исходного изображения.Например, красное поле обнаружило четыре области на исходном изображении, которые идеально соответствуют объекту, поэтому оценки для этих четырех областей высокие. Розовые квадраты — это области, которые в некоторой степени совпадают. Процесс поиска всех возможных совпадений путем сканирования исходного изображения называется сверткой . Отфильтрованные изображения складываются вместе, образуя сверточный слой .
2. Уровень ReLUs
Выпрямленный линейный блок (ReLU) — это шаг, который совпадает с шагом в типичных нейронных сетях.Он исправляет любое отрицательное значение до нуля, чтобы гарантировать правильное поведение математики.
3. Максимальный уровень объединения
Рисунок (H)Объединение уменьшает размер изображения. На рисунке (H) окно 2×2 просматривает каждое из отфильтрованных изображений и присваивает максимальное значение этого окна 2×2 блоку 1×1 в новом изображении. Как показано на рисунке, максимальное значение в первом окне 2×2 — это высокий балл (обозначенный красным), поэтому высокий балл присваивается блоку 1×1. Поле 2×2 переместится во второе окно, где отображается высокий балл (красный) и низкий балл (розовый), поэтому ячейке 1×1 присваивается высокий балл.После объединения создается новый набор отфильтрованных изображений меньшего размера.
4. Полностью связанный слой (последний слой)
Теперь мы разделяем меньшие отфильтрованные изображения и складываем их в один список, как показано на рисунке (I). Каждое значение в единственном списке предсказывает вероятность для каждого из конечных значений 1,2,…, 0. Эта часть такая же, как выходной слой в типичных нейронных сетях. В нашем примере «2» получает наивысший общий балл по всем узлам единого списка.Таким образом, CNN распознает исходное рукописное изображение как «2».
В чем разница между CNN и типичными NN?
Типичные нейронные сети складывают исходное изображение в список и превращают его в входной слой. Информация между соседними пикселями может не сохраняться. Напротив, CNN создают сверточный слой, который сохраняет информацию между соседними пикселями.
Есть ли какой-нибудь предварительно обученный код CNN, который я могу использовать?
Да.Если вы заинтересованы в изучении кода, у Keras есть несколько предварительно обученных CNN, включая Xception, VGG16, VGG19, ResNet50, InceptionV3, InceptionResNetV2, MobileNet, DenseNet, NASNet и MobileNetV2. Стоит упомянуть об этой большой базе данных изображений ImageNet, которую вы можете добавить или загрузить в исследовательских целях.
Бизнес-приложения
Распознавание изображений имеет широкое применение. В следующем модуле я покажу вам, как распознавание изображений может применяться для обработки требований в страховании.
Как создать приложение для распознавания изображений, такое как Vivino
Этикетки формируют наше восприятие мира. Обычно мы предпочитаем знать названия объектов, людей и мест, с которыми мы взаимодействуем, или даже больше — какой бренд относится к тому или иному продукту, который мы собираемся приобрести, и какие отзывы о его качестве дают другие. Устройства, оснащенные функцией распознавания изображений, могут автоматически обнаруживать эти этикетки. Программное обеспечение для распознавания изображений для смартфонов — это именно тот инструмент для захвата и определения имени на цифровых фотографиях и видео.
Благодаря разработке высокоточных, контролируемых и гибких алгоритмов распознавания изображений теперь можно идентифицировать изображения, текст, видео и объекты. Давайте узнаем, что это такое, как это работает, как создать приложение для распознавания изображений и какие технологии использовать при этом.
Что такое распознавание изображений в искусственном интеллекте?
В настоящее время распознавание изображений использует как искусственный интеллект, так и классические подходы глубокого обучения, чтобы можно было сравнивать разные изображения друг с другом или со своим собственным репозиторием для определенных атрибутов, таких как цвет и масштаб.Системы на основе искусственного интеллекта также начали превосходить компьютеры, которые обучены менее подробным знаниям предмета.
AI-распознавание изображений часто считается одним термином, обсуждаемым в контексте компьютерного зрения, машинного обучения как части искусственного интеллекта и обработки сигналов. Короче говоря, распознавание изображений является частным из трех. Таким образом, в принципе, программное обеспечение для распознавания изображений не должно использоваться как синоним обработки сигналов, но его определенно можно рассматривать как часть большой области искусственного интеллекта и компьютерного зрения.Давайте подробнее рассмотрим, что означает каждое из четырех понятий.
Распознавание изображений. Поскольку изображение является ключевым элементом ввода и вывода, распознавание изображений предназначено для понимания визуального представления определенного изображения. Другими словами, это программное обеспечение обучено извлекать много полезной информации и играет важную роль в предоставлении ответа на такой вопрос, как изображение. Так обычно понимают термин «распознавание изображений».
Обработка сигналов. На входе может быть не только изображение, но и различные сигналы, такие как звуки и биологические измерения. Эти сигналы полезны, когда дело доходит до распознавания голоса, а также для различных приложений, таких как распознавание лиц. SP — это более широкая область, чем технология идентификации изображений, и в сочетании с глубоким обучением она способна обнаруживать закономерности и взаимосвязи, которые до сих пор не наблюдались.
Компьютерное зрение. Это целая научная дисциплина, которая занимается созданием искусственных систем, получающих информацию из таких входных источников, как изображения, видео или другие многомерные гиперспектральные данные. Процесс компьютерного зрения включает такие методы, как обнаружение лиц, сегментация, отслеживание, оценка позы, локализация и отображение, а также распознавание объектов. Эти данные обрабатываются интерфейсами прикладного программирования (API), о которых мы поговорим позже в этой статье.
Машинное обучение. Это общий термин для всех вышеперечисленных концепций. ML охватывает распознавание изображений, обработку сигналов и компьютерное зрение. Кроме того, это довольно общая структура с точки зрения ввода и вывода — он принимает любой знак для ввода, возвращающего любую количественную или качественную информацию, сигнал, изображение или видео в качестве вывода. Такое разнообразие запросов и ответов обеспечивается за счет использования большого и сложного набора обобщенных алгоритмов машинного обучения.
Как работает программное обеспечение для распознавания изображений
Обнаружение изображений выполняется двумя разными методами.Эти методы называются методами нейронных сетей. Первый метод называется классификацией или обучением с учителем , а второй метод называется обучением без учителя .
При обучении с учителем используется процесс, чтобы определить, относится ли конкретное изображение к определенной категории, а затем оно сравнивается с уже обнаруженными изображениями в этой категории. При обучении без учителя используется процесс, чтобы определить, входит ли изображение в категорию само по себе.Нейронные сети — это сложные вычислительные методы, предназначенные для классификации и отслеживания изображений.
Вам следует знать, что приложение для распознавания изображений, скорее всего, будет использовать комбинацию контролируемых и неконтролируемых алгоритмов.
Метод классификации (также называемый контролируемым обучением) использует алгоритм машинного обучения для оценки особенности изображения, называемой важной характеристикой. Затем он использует эту функцию, чтобы сделать предположение о том, может ли изображение быть интересным для данного пользователя.Алгоритм машинного обучения сможет определить, содержит ли изображение важные для пользователя функции.
Метаданные классифицируют изображения и извлекают такую информацию, как размер, цвет, формат и формат границ. Изображения разделены на разные теги, называемые информационными классами, и каждый тег связан с изображением. Эти информационные классы используются механизмом распознавания для понимания «значения» изображения.
Данные, используемые для идентификации изображений, например: «милый ребенок» или «изображение собаки», должны быть помечены, чтобы быть полезными.Это требует анализа данных с помощью таких методов извлечения информации, как классификация или перевод.
Итак, распознавание образов при обработке изображений — это многоэтапный процесс, который включает:
- Обнаружение исходного изображения
- Анализ и классификация данных
- Обучение с подкреплением
- Процесс обучения ИИ
- Мониторинг и воспроизведение тренировочного процесса
Как выбрать API распознавания изображений?
Еще один важный компонент, о котором следует помнить при создании приложения для распознавания изображений, — это API.С начала революции искусственного интеллекта и машинного обучения были разработаны различные API-интерфейсы компьютерного зрения. Лучшие API распознавания изображений используют преимущества последних технологических достижений и дают вашему приложению распознавания фотографий возможность предлагать лучшее сопоставление изображений и более надежные функции. Таким образом, размещенные службы API доступны для интеграции с существующим приложением или использования для создания определенной функции или всего бизнеса.
Не у каждой компании достаточно ресурсов для инвестирования в создание всей команды инженеров компьютерного зрения.Итак, ниже представлен список API-интерфейсов распознавания изображений, на которые нужно обратить внимание, если вы хотите, чтобы некоторые готовые решения с открытым исходным кодом упростили вашу жизнь:
API Google Cloud Vision. API Google Cloud Vision позволяет загружать изображения или создавать собственные наборы данных для распознавания изображений. Это помогает вам искать известные человеческие модели и создавать на их основе изображения. Он доступен в Google Cloud Platform (GCP). Вы можете интегрировать это с некоторыми проектами обработки изображений, а также в свои собственные приложения.
Amazon Rekognition. Один из лучших способов распознавания изображений — использовать эту систему Amazon. Amazon Rekognition предлагает множество API-интерфейсов, которые позволяют обучать ваш собственный механизм визуального распознавания и выполнять сегментацию изображений и видео, обнаруживая и анализируя объекты, лица или некоторый откровенный контент, распознавая знакомые лица или лица знаменитостей и многое другое.
IBM Watson Visual Recognition. Служба Watson Visual Recognition в IBM Cloud подходит для многих приложений, поскольку позволяет пользователям гибко использовать API.Предварительно обученные модели, предоставляемые службой Visual Recognition, можно использовать для создания приложений, которые могут работать во многих условиях. Затем эта модель обучается обнаруживать определенные классы объектов.
API компьютерного зрения Microsoft. Это программное обеспечение для распознавания изображений является неотъемлемой частью Azure Cognitive Services. Это позволяет идентифицировать и анализировать контент в изображениях. Кроме того, с его помощью вы можете попробовать тренировать свое компьютерное зрение, чтобы распознавать лица и эмоции людей.Внедрить службу компьютерного зрения в ваше приложение несложно — просто добавьте вызов API.
Clarifai API. Это один из лучших сервисов поиска изображений. Он предлагает на выбор планы Community (с бесплатным ключом API), Essential и Enterprise. Можно использовать как стандартные модели распознавания изображений, так и создавать собственные модели, обученные на заказ. Готовые модели могут распознавать лица, цвета, одежду, распознавать еду и многое другое. Он значительно быстрее, чем другие поисковые системы, поскольку использует вывод вместо прямого поиска.
Как предприятия могут использовать распознавание изображений?
Преимущества распознавания изображений находят применение во всем мире. Итак, вопрос не только в том, как создать приложение для распознавания изображений, но и в том, как создать приложение для распознавания изображений, которое может улучшить ваш бизнес. Используя огромные объемы данных для обучения компьютеров распознаванию изображений, техника машинного обучения может привести к трем большим положительным изменениям, которые мы обсудим ниже.
1. Улучшена возможность обнаружения продукта с помощью визуального поиска. Хорошо обученная модель распознавания изображений позволяет точно маркировать товары. У таких приложений обычно есть каталог, в котором продукты упорядочены по определенным критериям. Такая точная организация ряда маркированных продуктов позволяет эффективно и быстро находить то, что нужно пользователю. Благодаря сверхмощному ИИ эффективность внедрения тегов может постоянно расти, а автоматическая маркировка продуктов сама по себе позволяет минимизировать человеческие усилия и снизить количество ошибок.
2. Повышение вовлеченности аудитории в социальных сетях. Распознавание изображений и лиц в социальных сетях уже стало реальностью. Социальные сети, такие как Facebook и Instagram, побуждают пользователей делиться изображениями и отмечать на них своих друзей. А их обученные модели искусственного интеллекта мгновенно распознают сцены, людей и эмоции. Некоторые сети пошли еще дальше, автоматически создав хэштеги для обновленных фотографий. Все это может улучшить взаимодействие с пользователем и помочь людям осмысленно организовать свои фотогалереи.
3. Оптимизированная реклама и интерактивный маркетинг. Еще одним преимуществом использования технологии идентификации изображений в приложении является оптимизация мобильной рекламы. Интерактивные маркетинговые кампании во многом зависят от знания клиента. Фактически, максимизировать эффективность рекламы в некоторых мобильных приложениях можно, изменив их дизайн и добавив в них технологию идентификации изображений. В конце концов, технология идентификации изображений — это всего лишь еще один инструмент в наборе инструментов для маркетинга приложений.
Примеры лучших приложений для распознавания изображений
Провидцы продолжают придумывать все более интересные идеи для проектов по распознаванию изображений. Однако некоторые вертикали более благоприятны для распознавания изображений, чем другие. Чтобы проиллюстрировать вышеуказанные преимущества для бизнеса, давайте рассмотрим несколько примеров того, как распознавание изображений успешно работает в приложениях из совершенно разных отраслей.
1. Vivino — сканирование винных этикеток.
Vivino — это самое загружаемое мобильное винное приложение в мире, которое, среди прочего, использует распознавание изображений, обученное на огромной базе данных винных бутылок и фотографий этикеток, чтобы создать идеальное изображение для ваших любимых вин.С Vivino вы также можете заказывать свои любимые вина по запросу через приложение и получать всевозможную статистику о них, такую как бренд, цена, рейтинг и многое другое. Vivino очень интуитивно понятен и имеет простую навигацию, гарантируя, что вы сможете получить всю необходимую информацию, сделав снимок бутылки вина, которое вы хотите купить, еще находясь в винном магазине.
2. PictureThis — распознавание разновидностей деревьев, растений или цветов.
Picture Это одно из самых популярных приложений для идентификации растений, которое имеет базу данных, содержащую более 10 000 видов растений.Приложение позволяет определять сорта растений по фотографиям. После того, как фотография растения сделана или загружена из телефонной галереи, PictureThis анализирует изображение, сравнивая его с изображениями в своей базе данных, и получает результат. Затем это поможет вам определить, соответствует ли это совпадению. Кроме того, в приложении вы найдете советы по уходу за растениями, напоминания о поливе и красивые обои.
3. Zebra Medical Vision — медицинская диагностическая визуализация на основе искусственного интеллекта.
Zebra Medical Vision — компания, занимающаяся глубоким обучением в сфере медицинской визуализации, чья платформа для анализа изображений позволяет выявлять риски и предлагать пути лечения онкологических пациентов.Это возможно благодаря мощной технологии распознавания изображений на основе искусственного интеллекта. Механизм Zebra анализирует полученные изображения (рентгеновские снимки и компьютерную томографию), используя свою базу данных сканирований и инструменты глубокого обучения, тем самым помогая рентгенологам справляться с растущими рабочими нагрузками. Помимо внедрения программного обеспечения искусственного интеллекта для выявления потенциальных рисков, Zebra Medical Vision разработала множество приложений, которые упрощают визуальную оценку и руководство пациентами с онкологическими заболеваниями.
Заключение
Машинное обучение, компьютерное зрение и распознавание изображений, очевидно, становятся обычным явлением и больше не являются чем-то экстраординарным.Сложно создать приложение для распознавания изображений и преуспеть в этом. Однако с правильной командой инженеров ваша работа, проделанная в области компьютерного зрения, окупится. Изучите рынок, определите дорожную карту для своего проекта, выберите API-интерфейсы и решите, как именно вы собираетесь включить распознавание изображений и связанные с ним технологии в свое будущее приложение.
Программное обеспечение для распознавания изображений в настоящее время присутствует почти во всех отраслях, где данные собираются, обрабатываются и анализируются.Приложения компьютерного зрения также постоянно появляются в мобильной индустрии. Так что подумайте о возможности воспользоваться этим и оптимизируйте свои бизнес-операции с помощью IR.
© 2020, ООО Вилмате
Как работает сканирование документов с оптическим распознаванием текста?
Криса Вудфорда. Последнее изменение: 11 мая 2021 г.
Вы когда-нибудь с трудом читали почерк друга? Считай себя удачливым, то, что вы не работаете в Почтовой службе США, которая должна расшифровать и доставить около 30 миллионов рукописных конвертов каждый день! Поскольку большая часть нашей жизни компьютеризирована, это жизненно важно, чтобы машины и люди могли понимать друг друга и передавать информацию туда и обратно.В основном у компьютеров есть вещи их путь — мы должны «разговаривать» с ними через относительно грубые устройства, такие как клавиатуры и мышей, чтобы они могли понять, что мы от них хотим. Но когда речь идет об обработке более человеческих видов информации, например старомодная печатная книга или письмо, нацарапанное Перьевая ручка, компьютеры должны работать намного усерднее. Вот где оптический персонаж распознавание (OCR). Это своего рода программное обеспечение (программа), способная автоматически анализировать печатный текст и превращать его в форма, которую компьютеру легче обрабатывать.OCR лежит в основе всего, от программ анализа почерка на мобильных телефонах до гигантские машины для сортировки почты, которые гарантируют, что все эти миллионы писем доходят до места назначения. Как именно это работает? Давайте присмотритесь!
Фото: Распознавание персонажей: Для нас с вами это слово «ан», но для компьютера это просто бессмысленный черно-белый узор. И обратите внимание, как волокна бумаги вносят некоторую путаницу в изображение. Если бы чернила были немного более блеклыми, серо-белый узор из волокон начал бы мешать и затруднять распознавание букв.
Что такое OCR?
Фото: Когда дело доходит до оптического распознавания символов, наши глаза и мозг намного превосходят любой компьютер.
Когда вы читаете эти слова на экране компьютера, ваши глаза и мозг выполняет оптическое распознавание символов, даже если вы этого не заметите! Ваши глаза узнают образцы света и тьмы, которые составляют символы (буквы, цифры и другие знаки препинания) меток), напечатанных на экране, и ваш мозг использует их, чтобы вычислить из того, что я пытаюсь сказать (иногда, читая отдельные символов, но в основном путем сканирования целых слов и целых групп слова сразу).
Компьютеры тоже могут это делать, но для них это действительно тяжелая работа. Первое проблема в том, что у компьютера нет глаз, поэтому, если вы хотите, чтобы он читал что-то вроде страницы старой книги, вы должны представить ее с изображение этой страницы, созданное с помощью оптического сканер или цифровая камера. Страница, которую вы создаете таким образом, является графический файл (часто в виде JPG) и, насколько возможно, компьютерный обеспокоен, нет никакой разницы между ним и фотографией Тадж-Махал или любой другой рисунок: это совершенно бессмысленный узор пикселей (цветные точки или квадраты, составляющие любые компьютерное графическое изображение).Другими словами, у компьютера есть изображение страницу, а не сам текст — он не может прочитать слова на страницу как мы можем, вот так. OCR — это процесс превращения изображение текста в текст, другими словами, создание чего-то как файл TXT или DOC из отсканированного JPG распечатанного или рукописного страница.
В чем преимущество OCR?
Когда напечатанная страница принимает форму машиночитаемого текста, вы можете все, что ты не умел делать раньше.Вы можете поискать по нему по ключевому слову (удобно, если его очень много), отредактируйте его с помощью текстовый процессор, включить его в веб-страницу, сжать в ZIP-архив и храните его на гораздо меньшем пространстве, отправьте по электронной почте — и все виды других изящных вещей. Машиночитаемый текст также можно декодировать с помощью программ чтения с экрана, инструментов, использующих синтезаторы речи (компьютеризированные голоса, вроде того, что использовал Стивен Хокинг), чтобы прочитать слова на экране, чтобы их могут понять слепые и слабовидящие люди. (Еще в 1970-е годы одним из первых основных применений OCR было создание копировальных аппаратов. устройство под названием Kurzweil Reading Machine, которое могло читать печатные книги вслух для слепых.)
Фото: Сканирование в кармане: приложения для распознавания текста для смартфонов быстрые, точные и удобные. Слева: здесь я сканирую текст статьи, которую вы сейчас читаете, прямо с экрана компьютера с помощью смартфона и Text Scanner (приложение для Android от Peace). Справа: несколько секунд спустя на экране моего телефона появляется очень точная версия отсканированного текста.
Как работает OCR?
Предположим, жизнь была действительно простой, и в ней была только одна буква. алфавит: А.Даже в этом случае вы, вероятно, увидите, что OCR будет довольно сложная проблема — потому что каждый человек пишет букву А в немного другой способ. Даже с печатным текстом есть проблема, потому что книги и другие документы печатаются на самых разных гарнитуры (шрифты) и букву A можно напечатать с большим количеством тонких разные формы.
Фото: между этими разными версиями заглавной буквы A есть немало различий, напечатаны разными компьютерными шрифтами, но есть и основное сходство: вы можете видеть, что почти все они состоят из двух наклонных линий, которые встречаются посередине вверху, с горизонтальной линией между ними.
Вообще говоря, есть два разных способа решить эту проблему, либо полностью распознав персонажей (распознавание образов) или путем обнаружения отдельных линий и символы штрихов сделаны из (обнаружение признаков) и идентифицирующие им так. Давайте посмотрим на них по очереди.
Распознавание образов
Если все точно так же написали букву А, получится компьютер признать это было бы легко. Вы бы просто сравнили отсканированное изображение с сохраненной версией буквы A и, если они совпадают, это было бы так.Вроде как у Золушки: «Если тапочки подходят …»
Так как же заставить всех писать одинаково? Еще в 1960-х годах был разработан специальный шрифт OCR-A, который можно было использовать на такие вещи, как банковские чеки и так далее. Каждая буква была одинаковой ширину (так что это был пример так называемого моноширинного шрифта) и штрихи были тщательно продуманы, чтобы каждую букву можно было легко отличается от всех остальных. Чековые принтеры были разработаны так все они использовали этот шрифт, а оборудование для оптического распознавания текста было разработано для распознавания это тоже.За счет стандартизации одного простого шрифта OCR стало относительно простая проблема для решения. Единственная проблема в том, что большая часть того, что в мире отпечатки не написаны в OCR-A, и никто не использует этот шрифт для своих почерк! Итак, следующим шагом было научить программы OCR распознавать буквы, написанные с помощью ряда очень распространенных шрифтов (например, Times, Helvetica, Courier и т. Д.). Это означало, что они могли распознать много печатного текста, но все еще не было никакой гарантии, что они смогут распознавать любой шрифт, который вы можете им послать.
Фото: Шрифт OCR-A: предназначен для чтения как людьми, так и компьютерами. Возможно, вы не узнаете стиль текста, но числа, вероятно, покажутся вам знакомыми по чекам и компьютерным распечаткам. Обратите внимание, что похожие на вид символы (например, строчная буква «l» в объяснении и цифра «1» внизу) были разработаны таким образом, чтобы компьютеры могли легко отличить их друг от друга.
Обнаружение функции
Также известен как извлечение признаков или интеллектуальное распознавание символов. (ICR), это гораздо более изощренный способ определения персонажей.Предположим, вы являетесь компьютерной программой OCR, представленной множеством разные буквы, написанные множеством разных шрифтов; как ты выбираешь все буквы Как будто все они выглядят немного по-разному? Ты мог бы используйте такое правило: если вы видите две наклонные линии, которые пересекаются точка вверху, в центре, и есть горизонтальная линия между ними примерно на полпути, это буква А. Примените это правило и вы узнаете большинство заглавных букв As, независимо от шрифта они написаны. Вместо того, чтобы распознать полный образец A, вы обнаруживаете особенности отдельных компонентов (наклонные линии, перечеркнутые линии или что-то еще), из которых состоит персонаж.Самый современные программы OCR omnifont (те, которые могут распознавать печатный текст любым шрифтом) работают по определению признаков, а не по шаблону признание. Некоторые используют нейронные сети (компьютерные программы которые автоматически извлекают шаблоны, как мозг).
Фото: Обнаружение признаков: вы можете быть уверены, что смотрите на заглавную букву A, если сможете определить эти три составные части, соединенные вместе правильным образом.
Как работает распознавание рукописного ввода?
Распознавание символов, составляющих аккуратно напечатанный лазерной печатью компьютерный текст, является относительно легко по сравнению с расшифровкой чьих-то нацарапанных почерк.Это простая, но хитрая повседневная проблема. где человеческий мозг безоговорочно побеждает умные компьютеры: мы все можем сделать грубая попытка угадать сообщение, скрытое даже в худшем человеческом пишу. Как? Мы используем комбинацию автоматического распознавания образов, извлечение функций и, что очень важно, знания о писателе и смысл написанного («Это письмо от моей подруги Харриет — о концерте классической музыки, на который мы ходили вместе, так что слово она написанное здесь, скорее, будет «тромбон», чем «трамвайная линия».»)
Фото: Распознавание рукописного ввода: Курсивный почерк (буквы соединены и переходят вместе) компьютеру намного труднее распознать, чем компьютерный печатный шрифт, потому что трудно определить, где заканчивается одна буква и начинается другая. Многие люди пишут так поспешно, что не утруждают себя составлением букв полностью, что затрудняет распознавание по образцу или признаку. Другая проблема заключается в том, что почерк — это выражение индивидуальности, поэтому люди могут изо всех сил стараться сделать свой почерк отличным от нормы.Когда дело доходит до чтения таких слов, мы в значительной степени полагаемся на значение написанного, наши знания об авторе и слова, которые мы уже прочитали, — с чем компьютеры не могут так легко справиться.
Упрощение
Когда компьютеры действительно должны распознавать почерк, проблема часто заключается в для них упрощено. Например, компьютеры для сортировки почты обычно нужно только распознать почтовый индекс (почтовый индекс) на конверте, а не весь адрес. Поэтому им просто нужно определить относительно небольшой объем текста, составленный только из основных букв и цифр.Люди рекомендуется писать коды разборчиво (оставляя пробелы между символы, используя только прописные буквы) и, иногда, конверты заранее напечатаны с маленькими квадратами, чтобы вы могли написать символы в помочь вам разделить их.
Формы, предназначенные для обработки с помощью OCR, иногда имеют отдельные поля для написания каждой буквы или слабые инструкции, известные как поля гребешков, которые побуждают людей хранить буквы отдельно и пишите разборчиво. (Обычно поля гребенки печатаются в специальном цвет, например розовый, называется выпадающим цветом, который можно легко отделить от текст люди на самом деле пишут, обычно черными или синими чернилами.)
Artwork: Формы, разработанные для OCR, включают простые средства для уменьшения ошибок сканирования, включая поля гребенок (вверху) и поля символов (в центре), напечатанные выпадающим цветом (розовый), и пузырьковые поля выбора или флажки (внизу).
Планшетные компьютеры и мобильные телефоны с функцией распознавания рукописного ввода часто используют извлечение функций для распознавания буквы, как вы их пишете. Если вы пишете, например, букву А, сенсорный экран может почувствовать, что вы пишете сначала одну наклонную линию, а затем прочее, а затем соединяющую их горизонтальную линию.Другими словами, компьютер получает преимущество в распознавании функций, потому что вы формируя их по отдельности, один за другим, что значительно усложняет извлечение признаков. легче, чем выбирать черты из рукописного текста на бумаге.
Кто изобрел OCR?
Большинство людей думают, что заставить машины читать человеческий текст — относительно недавнее нововведение, но оно старше, чем вы могли подумать. Вот краткий обзор истории OCR:
- 1928/9: Густав Таушек из Вены, Австрия патентует базовую «читающую машину» с оптическим распознаванием текста.«Пол Гендель из General Electric подает патент на аналогичную систему в США в апреле 1931 года. Оба основаны на идее использования светочувствительных фотоэлементов для распознавания узоров. на бумаге или карточке.
- 1949: Л. Флори и У. Пайк из RCA Laboratories разработал машину на основе фотоэлементов, которая может читать текст слепым людям на скорость 60 слов в минуту. (Прочтите все об этом в выпуске Popular Science за февраль 1949 года.)
- 1950: Дэвид Х. Шепард разрабатывает машины, которые могут преобразовывать печатную информацию в машиночитаемую форму для вооруженных сил США и более поздних версий. основывает новаторскую компанию по оптическому распознаванию текста под названием Intelligent Machines Исследования (IMR).Shepherd также разрабатывает машиночитаемый шрифт Farrington B (также называемый OCR-7B и 7B-OCR), который сейчас широко используется для печати тисненых номеров на кредитных картах.
- 1960: Лоуренс (Ларри) Робертс, исследователь компьютерной графики, работающий в Массачусетском технологическом институте, разрабатывает раннее распознавание текста с использованием специально упрощенных шрифтов, таких как OCR-A. Позже он становится одним из отцы-основатели Интернета.
- 1950-е / 1960-е: Reader’s Digest и RCA совместно разрабатывают некоторые из первых коммерческих систем распознавания текста.
- 1960-е: Почтовые службы по всему миру начинают использовать технологию OCR для сортировки почты. К ним относятся Почтовая служба США, Главное почтовое отделение Великобритании (GPO, теперь называемое Королевской почтой), Почта Канады и Немецкая Deutsche Post. Почтовые службы, которым помогают такие компании, как Lockheed Martin, по сей день остаются в авангарде исследований OCR.
- 1974: Раймонд Курцвейл разрабатывает машину для чтения Kurzweil (KRM), которая объединяет планшетный сканер и синтезатор речи в машине, которая может читать напечатанные страницы слепым людям вслух.Программное обеспечение для оптического распознавания текста Kurzweil приобретается Xerox и продается под названиями ScanSoft и (позже) Nuance Communications.
- 1993: Apple Newton MessagePad (PDA) — один из первых портативных компьютеров с функцией распознавания рукописного ввода на сенсорном экране. В 90-е годы распознавание рукописного ввода становится все более популярной функцией в мобильных телефонах и КПК (особенно в новаторских Ладонь и PalmPilot) и других КПК.
- 2000: Исследователи из Университета Карнеги-Меллона решают проблему создания хорошего оптического распознавания символов систему с ног на голову — и разработать систему защиты от спама под названием CAPTCHA (см. подпись ниже).
- 2007: Появление iPhone побудило к разработке удобных приложений для смартфонов с функцией «укажи и щелкни», которые могут сканировать и конвертировать текст с помощью камеры телефона.
Фото: Из исследования OCR мы знаем, что компьютерам трудно распознать плохо напечатанные слова, которые люди могут относительно легко прочитать. Вот почему подобные головоломки CAPTCHA используются, чтобы помешать спамерам бомбардировать почтовые системы, доски объявлений и другие веб-сайты. Он был разработан Университетом Карнеги-Меллона, а затем приобретен Google как часть его первоначальной системы reCAPTCHA.У оригинальной reCAPTCHA было дополнительное преимущество: когда вы вводили искаженные слова, вы помогали Google распознавать часть отсканированного текста из старой книги, которую он хотел преобразовать в машиночитаемую форму. Фактически, вы выполняли небольшое распознавание текста от имени Google. Большинство веб-сайтов перешли на другой, более безопасный тест CAPTCHA, который включает идентификацию фотографий автомобилей, гор и других повседневных вещей.
Как распознавание изображений улучшит вашу рекламу в социальных сетях
Мнения, высказанные предпринимателями, участниками являются их собственными.
Сегодня все больше и больше компаний понимают, что привлечение внимания их аудитории в социальных сетях — лучший способ продвигать свои продукты, привлекать трафик на свои веб-сайты и увеличивать конверсию. Фактически, по данным GlobalWebIndex, средний пользователь Интернета теперь каждый день проводит на социальных платформах примерно на 15 минут больше, чем он или она смотрит телевизор.
вонри | Getty Images
Связано: 17 удивительных — и удивительных — применений технологии распознавания лиц
В целом сила социальных сетей растет день ото дня, и вместе с ними появляется все более мощная и эффективная реклама в социальных сетях.
Из-за этого Facebook недавно получил новый патент на технологию распознавания изображений, которая изменит способ получения рекламодателями фотографий в социальных сетях. Эта новая технология будет иметь возможность сканировать тысячи изображений в социальных сетях одновременно и сортировать их на наличие признаков вашего продукта, продуктов конкурентов, логотипов и т. Д.
Хотя эта технология может показаться большинству пользователей немного жуткой — она в основном преследует их фотографии в социальных сетях и делится этими фотографиями и информацией профиля с рекламодателями — она может дать много преимуществ для вашего бизнеса.Итак, когда он появится, как вы сможете использовать эту футуристическую технологию, чтобы лучше рекламировать свою целевую аудиторию в Интернете?
Вот как распознавание изображений улучшит вашу рекламу в социальных сетях.
Определите любимые продукты пользователей.
Как уже упоминалось, технология распознавания изображений Facebook может сканировать фотографии в социальных сетях и идентифицировать определенные продукты и логотипы на изображениях. Таким образом, эта технология может помочь вам определить точные любимые продукты, выбранные вашей целевой аудиторией.Например, вы можете использовать эту технологию, чтобы узнать, использует ли ваша целевая аудитория продукт конкурента.
Обнаружение этой информации может помочь вам адаптировать рекламу в социальных сетях для этих пользователей и побудить их перейти на другую версию.
С другой стороны, вы можете обнаружить в Интернете пользователей, которые уже используют ваш продукт и опубликовать его фотографии в Интернете, и использовать эту информацию для дополнительных или перекрестных продаж связанных с ними продуктов. Технология может даже стимулировать повторные покупки: например, если пользователь разместил в социальных сетях изображение со своим недавним заказом на Starbucks, вскоре после этого в социальных сетях может появиться реклама Starbucks, чтобы убедить этого любителя кофе вернуться снова.
Определите покупательское поведение.
Распознавание изображений также может помочь вам найти больше целевой аудитории, определяя покупательское поведение. Представьте себе: программное обеспечение для распознавания изображений сканирует изображения в социальных сетях и находит пользователя, который разместил фотографию, на которой она носит браслет Cartier и держит сумочку Louis Vuitton.
По теме: Может ли искусственный интеллект определять изображения лучше, чем люди?
Эта информация подскажет вам, что этот пользователь социальной сети заинтересован в покупке предметов роскоши и может иметь более высокий доход, чем в среднем.Вместо того, чтобы тратить время на продвижение вашего люксового бренда среди незаинтересованных пользователей, использование программного обеспечения для распознавания изображений дает вам хорошее представление о том, кто, скорее всего, станет вашим клиентом.
Например, следующее объявление Rolex на Facebook не будет доступно всем. Но если вы работаете в сегменте предметов роскоши, использование программного обеспечения для распознавания изображений позволяет показывать рекламу именно покупателям предметов роскоши.
Источник изображения: Mondovo.com
Не забывайте, что программа распознавания изображений может сканировать изображения и для других типов логотипов.Итак, если кто-то в социальных сетях публикует свою фотографию на кухне, распознавание изображений может сканировать и идентифицировать этикетки продуктов на заднем плане. Если увиденные продукты относятся к универсальным брендам, вы можете догадаться, что этот пользователь ценит доступность.
Найдите новые варианты использования продукта.
Вы также можете использовать программное обеспечение для распознавания изображений, чтобы узнать о новых способах использования ваших продуктов клиентами, о которых вы никогда раньше не задумывались. Распознавание изображений может не только сканировать изображения в социальных сетях на предмет продуктов, но и определять другие объекты на изображениях.
В качестве примера представьте, что вы создали рюкзак, специально предназначенный для туристов и туристов. Но когда программное обеспечение для распознавания изображений сканирует изображения на Facebook для поиска вашего продукта, инструмент обнаруживает что-то общее со многими изображениями: ваш рюкзак, сделанный для путешественников, используется многими учениками старших классов и колледжей для повседневного использования. Обретение этих новых поклонников и новое использование вашего продукта позволит вам лучше продвигать свой продукт среди ранее неизвестной аудитории.
Ваш комментарий будет первым