Как распознать текст с помощью ABBYY FineReader: пошаговая инструкция
[contents]
В этот раз расскажу как превращать бумажные документы в электронный вид формата PDF, а также, как бумажный документ перекинуть в компьютер с целью изменить текст. Итак начнем.
У меня на руках бумажный документ.
СКАНИРОВАНИЕ в PDF
Задача: перекинуть в компьютер (перевести в электронный вид) этот документ. Притом нужно сделать именно в таком виде чтобы нельзя было его в будущем изменить (грубо говоря надо сделать фото документа). Потом этот электронный документ нужно переслать по почте на электронный адрес. Притом клиент просит именно в формате pdf.
По этапам:
1) пропускаю документ через сканер
2) сохраняю полученный отпечаток в формате pdf на свой компьютер
3) пересылаю полученный файл по почте
В своей работе я использую для решения такой задачи 2 программы:
Foxit Phantom или ABBYY FineReader. Для понятности прикладываю скриншоты:
В Foxit Phantom при включенном сканере необходимо в главном меню выбрать ФАЙЛ-СОЗДАТЬ PDF-СО СКАНЕРА…
 Выбираем место, пишем название файла и сохраняем.
Выбираем место, пишем название файла и сохраняем.В ABBYY FineReader в панели инструментов есть огромные кнопки. Одна из них называется СКАНИРОВАТЬ в PDF. Её и используем.
Если же надо отсканировать многостраничный документ то, по этапам:
1) Нажимаем кнопку под номером 1 СКАНИРОВАНИЕ
Получаем отсканированный документ
Также сканируем ещё одну страницу (нажимаем ещё раз кнопку под номером 1 СКАНИРОВАНИЕ).
2) Сохраняем в PDF
В итоге получаем готовый многостраничный документ в виде файла в формате PDF.
Теперь данный файл можно отправлять по электронной почте.
РАСПОЗНАВАНИЕ ТЕКСТА
Задача: перевести бумажный документ в электронный вид (в компьютер)
По этапам:
1) Сканирование (кнопка 1 СКАНИРОВАНИЕ)
2) Распознавание (кнопка 2 РАСПОЗНАТЬ ВСЕ)
Распознавание нужно понимать как процесс перевода фотографии (картинки) в текст (буквы, цифры, знаки). Если Вы сфотографировали текстовую страницу, то после распознавания 99% текста с бумаги превратиться в текст электронный. Электронный текст уже можно на компьютере менять (редактировать) так, как Вам захочется.
Если Вы сфотографировали текстовую страницу, то после распознавания 99% текста с бумаги превратиться в текст электронный. Электронный текст уже можно на компьютере менять (редактировать) так, как Вам захочется.
3) Сохранение в текстовый редактор (кнопка 4 Сохранить)
Советую выбирать ПЕРЕДАТЬ ВСЕ СТРАНИЦЫ В—MICROSOFT WORD
Получаем
Хотелось бы указать на важные моменты при процедуре РАСПОЗНАВАНИЯ. Есть нюансы при работе.
Сразу после распознавания советую поглядеть на результат. Особенно на блоки, которые создает программа FineReader.
Это области выделенные в прямоугольные рамки. Рамки эти разного цвета. Если красного цвета-то этот блок распознался как КАРТИНКА. Если черного цвета — то ТЕКСТ. Блоки бывают разного типа. Тип блока можно узнать щелкнув на блоке ПРАВОЙ клавишей мыши и выбрав ИЗМЕНИТЬ ТИП БЛОКА.
Маленькая хитрость: можно выделить произвольную область и пометить любым типом блок. Например выделим ту часть текста, которая плохо распознается, при помощи левой клавиши мыши (нажимает, удерживаем и тянем, рамка меняет размер).
В итоге документ в Word-е будет иметь блок текста и блок картинка. Блок картинка будет иметь абсолютно неизменный вид. Данный способ я использую при сохранении печатей, нестандартных шрифтов, картинок, фотографий.
ЗЫ: Знания и умения работать с PDF, сканировать и распознавать документы очень часто выручают в офисной работе. Знание — экономит Ваше время!
Не пропусти самое интересное!
Подписывайтесь на нас в Facebook и Вконтакте!
Сканеры. Сканирование и распознавание текста — Студопедия
Еще одним устройством, предназначенным для работы с текстовым документом, является сканер. Сканер служит для считывания текстовой или графической (рисунок, фотография) информации с оригинала и ввод её в компьютер.
Принцип действия сканера состоит в следующем. Лампа холодного свечения (как в копировальных аппаратах) создает световой поток, который отражается от оригинала и считывается датчиком. Считанная и оцифрованная информация посылается в компьютер.
Основные характеристики сканеров определяется разрешением, с которым возможна оцифровка оригинала, и глубиной воспринимаемого цвета. Стандартным разрешением для офисного сканера можно считать 300-600 точек на дюйм. Это так называемое оптическое разрешение, т.е. разрешение, которое способен дать непосредственно датчик сканера. Существуют программы, которые путем интерполяции увеличивают разрешение. Такое программное разрешение не сильно влияет на качество получаемого изображения и используется только для определенных случаев работы с графикой. Глубина цвета определяется битностью информации о цвете в одной точке. Если сказано в характеристике сканера, что глубина его цветопередачи 30 бит, то это означает следующее: в одной точке хранится информация о 2
После оцифровки текста он представляется в виде изображения и необходимо провести его распознание. Для этого применяются несколько программ распознавания оптических образов. С русским текстом могут работать программы FineReader и Cunie.
С русским текстом могут работать программы FineReader и Cunie.
Таким образом, при работе с текстом будет следующая последовательность действий: помещение оригинала на стекло сканера, запуск программы сканирования, получение изображения, распознавание текста из изображения, помещение распознанного текста в текстовой редактор и его редактирование, если это необходимо.
Если необходимо отсканировать рисунок, то изображение помещается на стекло сканера, сканируется и записывается в графическом файле или обрабатывается в графическом редакторе.
При отсутствии факсового аппарата, но при наличии факс-модемной платы в компьютере возможна посылка факсовых сообщений, используя возможности сканера как считывающего
Глава 8 Сканирование, распознавание и конвертирование с помощью ABBYY FineReader
Глава 8
Сканирование, распознавание и конвертирование с помощью ABBYY FineReader
В процессе написания работы вам наверняка будут встречаться тексты или рисунки из книг и журнальных статей, которые вам захочется поместить в свой документ. Если вы планируете использовать фрагмент, то его можно набрать повторно. Однако если вам нужны несколько страниц, гораздо лучше прибегнуть к другим способам работы с печатным текстом. Если у вас или у кого-то из ваших друзей есть сканер, можно сканировать нужный фрагмент, а затем вставить его в документ.
Если вы планируете использовать фрагмент, то его можно набрать повторно. Однако если вам нужны несколько страниц, гораздо лучше прибегнуть к другим способам работы с печатным текстом. Если у вас или у кого-то из ваших друзей есть сканер, можно сканировать нужный фрагмент, а затем вставить его в документ.
Процесс преобразования текста из бумажного вида в электронный состоит из нескольких частей. Первый этап – это сканирование документа. Однако если превращение бумажной картинки в электронную завершается на этапе сканирования, то превращение текста в электронный на этом этапе только начинается. В результате сканирования и фотографии, и текста будет получен графический файл.
Если вы захотите изменить полученный текст либо использовать только его часть, сделать это будет очень сложно. Дело в том, что графический файл представляет собой набор точек разных цветов, а текстовый файл – это набор символов. Чтобы в процессе сканирования получить текстовый документ, состоящий из символов, графический файл необходимо каким-то образом преобразовать в текстовый. Сделать это можно с помощью специальных приложений, называемых OCR-программами (OCR расшифровывается как Optical Character Recognition – оптическое распознавание символов).
Сделать это можно с помощью специальных приложений, называемых OCR-программами (OCR расшифровывается как Optical Character Recognition – оптическое распознавание символов).
Современные OCR-системы умеют распознавать печатный, а в некоторых случаях и рукописный текст на многих языках, могут сохранять полученный результат в удобном формате (например, в формате Word), исправлять погрешности сканирования, а также отделять текст от изображения. Наиболее популярными на сегодняшний день OCR-системами являются FineReader (http:// www.abbyy.com) и Cunei Form (http://www.cognitive.ru).
Системы распознавания текстов у опытных пользователей компьютеров ассоциируются в первую очередь с названием FineReader. Действительно, продукт фирмы ABBYY Software удобен, обеспечивает высокое качество распознавания, «понимает» около 200 языков и умеет различать даже листинги программ, написанные на некоторых языках программирования (например, Basic, C/C++, Java, Pascal).
В этой главе детально рассмотрим, как можно превратить бумажный текст в электронный с помощью программы FineReader (рис.
Рис. 8.1. Окно программы FineReader
Процесс сканирования в FineReader осуществляется двумя способами. Вы можете воспользоваться услугами Мастера Scan&Read, с помощью которого пройдете все четыре этапа преобразования документа бумажного вида в электронный (сканирование, распознавание, проверка и сохранение). Второй вариант – вручную пройти все эти шаги, выбирая соответствующие пункты меню либо используя кнопки панели инструментов.
После запуска FineReader и выбора режима работы программы (с помощью мастера или вручную) необходимо установить в сканер печатный документ. Для запуска процесса сканирования нажмите кнопку Сканировать либо выполните команду Файл ? Сканировать изображение.
После выбора способа сканирования откроется окно, в котором можно выполнить предварительный просмотр и установить необходимые параметры (рис. 8.2). Это окно для разных типов сканера имеет разный вид, но все же основные его параметры одинаковы. Расскажу о наиболее общих параметрах сканирования на примере использования сканера Mustek 1200 UB Plus.
Рис. 8.2. Настройка параметров сканирования
Обратите внимание на то, как вы размещаете источник в сканере. Постарайтесь добиться, чтобы книга или журнал лежали как можно ровнее, ведь если текст расположить неровно, он будет распознан неправильно и вам придется вручную исправлять много ошибок.
После того как вы указали параметры сканирования, можно выполнить предварительный просмотр страницы. Для этого необходимо нажать кнопку Preview (Предварительный просмотр). На этом этапе вы сможете увидеть, верно ли установлена страница в сканер, захватывает ли область сканирования весь текст или какая-то его часть остается за пределами. Затем вы можете поправить страницу в сканирующем устройстве, только потом не забудьте повторно предварительно ее просмотреть.
В левой части окна сканирования размещены вкладки и поля для настройки параметров. В списке Scan Mode (Режим сканирования) можно выбрать режим сканирования. Существует три варианта: цветной режим (Color (24 bit)), в оттенках серого (Gray) или сканирование текста (Lineart). Если вы собираетесь сканировать фотографии или изображение, советую выбрать первый или второй режим. Третий вариант идеально подходит для сканирования текста. Безусловно, вы можете задать цветной режим и при сканировании книги, но следует знать, что в этом случае результирующий файл будет занимать гораздо больше места, чем при сканировании в других режимах.
Если вы собираетесь сканировать фотографии или изображение, советую выбрать первый или второй режим. Третий вариант идеально подходит для сканирования текста. Безусловно, вы можете задать цветной режим и при сканировании книги, но следует знать, что в этом случае результирующий файл будет занимать гораздо больше места, чем при сканировании в других режимах.
В списке Scan Size (Размер сканирования) вы можете установить размер окна сканирования. По умолчанию предлагается значение Custom (Обычный), то есть совпадающий с размером листа в сканере. Однако, чтобы ускорить процедуру сканирования, особенно для тех документов, которые сравнительно невелики, вы можете выбрать другие значения этого параметра, например А4 (размер стандартного листа бумаги), В5 или Letter (Письмо).
Следующий параметр – Resolution (Разрешение) – очень важен для результата сканирования. Разрешение измеряется в dpi (dots per inch, точек на дюйм). Эта величина характеризует, насколько качественным будет результат сканирования – полученное изображение. Чем выше разрешение, тем лучше будет выглядеть картинка. В то же время большие значения этого параметра говорят также о том, что полученный графический файл будет очень большой. Поэтому разрешение нужно выбирать рационально.
Чем выше разрешение, тем лучше будет выглядеть картинка. В то же время большие значения этого параметра говорят также о том, что полученный графический файл будет очень большой. Поэтому разрешение нужно выбирать рационально.
В параметрах сканирования можно выбрать различные значения dpi – от самого маленького (50) до огромного (19200). Существуют некоторые правила выбора dpi, руководствуясь которыми, вы получите наиболее оптимальный результат. Для сканирования текстов со средним размером шрифта установите 300 dpi. Для текстов, набранных мелким шрифтом (менее 9 пт), лучше использовать 400–600 dpi. Картинки, отсканированные с разрешением меньше 600 dpi, могут получиться недостаточно четкими.
Собственно, это разрешение подойдет для черно-белых изображений. Если вы хотите получить качественный цветной рисунок, в этом случае величину разрешения стоит увеличить хотя бы до 900 dpi.
Область Output (Вывод) позволяет настроить параметры вывода сканирования, то есть параметры отображения результата сканирования на листе бумаги.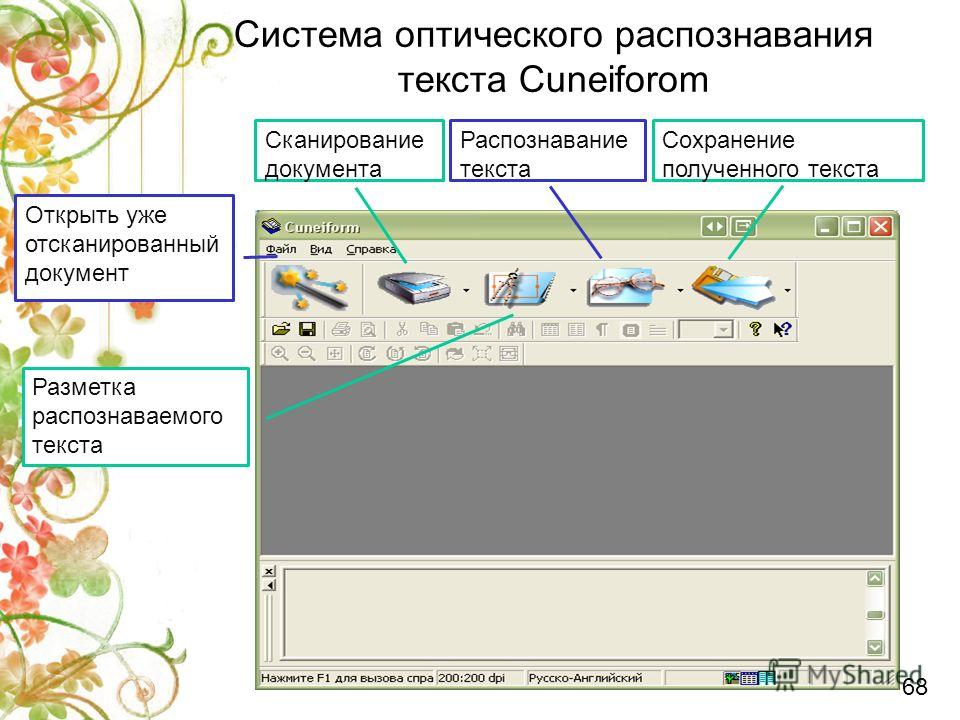 Например, в поле Scaling (Масштабирование) указывают масштаб готового документа. Изменить установленное по умолчанию значение вы можете двумя способами: ввести вручную необходимую величину в поле Scaling (Масштабирование) или переместить бегунок рядом с ним.
Например, в поле Scaling (Масштабирование) указывают масштаб готового документа. Изменить установленное по умолчанию значение вы можете двумя способами: ввести вручную необходимую величину в поле Scaling (Масштабирование) или переместить бегунок рядом с ним.
В полях Width (Ширина) и Height (Высота) можно указать размеры полученного изображения – ширину и высоту соответственно. Список рядом позволяет задать единицы измерения: Inches (Дюймы), СМ (Сантиметры) или Pixels (точки). Обратите внимание: в области Image Size (Размер изображения) указано, каков будет размер полученного изображения в килобайтах.
В этом же окне вы можете сохранить настройки в INI-файле, для этого предназначена кнопка Save (Сохранить). Если у вас раньше были сохранены настройки, открыть их можно с помощью кнопки Load (Загрузить).
Возможно, в некоторых случаях вам нужно будет отсканировать не всю страницу, а только часть. Для этого выделите нужную область сканирования. Воспользуйтесь кнопкой Cropping Tool (Обрезка), после чего измените размеры прямоугольника таким образом, чтобы был выделен только нужный вам фрагмент.
После того как вы убедились, что страница расположена верно и все параметры установлены, можно начинать процедуру сканирования. Для этого нажмите кнопку Scan (Сканировать) (рис. 8.3).
При работе с рисунками после сканирования следует сохранить изображение в графическом формате. Для этого выполните команду Файл ? Сохранить пакет как и укажите имя и тип сохраняемого файла.
Создав графический файл, вы всегда сможете обработать его в графическом редакторе, например в Paint или Photoshop: обрезать лишние блоки, добавить надписи, подкорректировать рисунок.
Если вы имеете дело с текстом, следующим этапом вашей работы будет распознавание. Задача распознавания состоит в том, чтобы превратить отсканированное изображение в текст, сохранив при этом оформление страницы.
Рис. 8.3. Результат сканирования
Примечание
Если при сканировании вы сохранили результат в виде графического файла, его можно открыть для последующей обработки, выполнив команду Файл ? Открыть PDF-изображение.
По умолчанию в окне программы FineReader отображаются одновременно два окна – Изображение и Текст. Вы можете управлять отображением этих окон на экране с помощью специальных кнопок панели инструментов FineReader: кнопка Показывать оба окна означает исходное состояние размещения окон, можно нажать кнопку Показывать окно Изображение или Показывать окно Текст и представить таким образом только одно из окон. Кроме этого, в полях Масштаб каждого из окна можно задать масштаб исходного изображения. Дополнительные настройки внешнего вида окна доступны в меню Вид.
Если ваша страница содержит только сплошной текст, вы можете смело переходить сразу к распознаванию. Однако если на странице есть изображения, схемы или таблицы, перед запуском процедуры распознавания следует провести анализ макета страницы (сегментирование). Анализ макета страницы позволяет разбить страницу на блоки, указав тем самым, какие именно участки полученного изображения следует распознать, а какие можно будет проигнорировать.
Анализ макета страницы можно проводить автоматически или вручную. Автоматическое сегментирование FineReader осуществляет, если сразу после сканирования запустить процесс распознавания. Для этого вам нужно нажать кнопку Распознать на панели инструментов. Вручную выделять блоки есть смысл, если вы хотите распознать не весь отсканированный документ, а лишь его часть, либо в результате автоматического сегментирования блоки были выделены неверно.
Для анализа макета страницы необходимо выполнить команду Процесс ? Распознать ? Анализ макета страницы. FineReader произведет автоматическое разбиение страницы на блоки (рис. 8.4). Для выделения или редактирования блока следует воспользоваться командой Изображение ? Изменить тип блока и в появившемся меню выбрать нужный тип. Например, если у вас в тексте встречаются иллюстрации, пометьте их с помощью типа блока Картинка – выбрав пункт меню, вам следует выделить в окне Изображение нужный фрагмент. Точно так же помечаются текст и таблица.
Рис. 8.4. Анализ макета страницы означает выделение на ней блоков разного типа
При обработке изображения, полученного в результате сканирования, FineReader выделяет блоки нескольких типов. Блок Зона распознавания используется для распознавания и автоматического анализа. В результате обработки он будет разделен на блоки других типов. Для корректного распознавания таблицы существует специальный блок Таблица, для распознавания текста – Текст, для изображений используются Картинка и Штрих-код.
Следующим этапом обработки изображения является установка параметров сканирования – вы должны задать язык распознавания, тип печати, ориентацию текста. Язык распознавания устанавливается на панели Стандартная, причем FineReader умеет распознавать не только одноязычный, но и многоязычный текст, например содержащий элементы на русском и английском. Этот параметр очень важен, и если в вашем тексте встречаются английские термины, обязательно выберите пункт Русский и английский, иначе большинство английских слов будут распознаны неверно.
Тип печати обычно определяется автоматически. Однако в некоторых случаях, особенно для текстов, напечатанных в черновом варианте или на матричном принтере, тип печати необходимо устанавливать вручную. Для этого выполните команду Сервис ? Опции, перейдите на вкладку Общие и нажмите кнопку Дополнительные опции. В появившемся окне (рис. 8.5) выберите нужное значение с помощью переключателя Тип печати. По умолчанию здесь установлен переключатель Авто, но вы можете выбрать другой – например, Пишущая машинка или Матричный принтер.
Рис. 8.5. Настройка параметров распознавания текста
После установки параметров можно начинать распознавание.
Результат распознавания будет отображаться в окне Текст, встроенном редакторе программы FineReader.
Примечание
Иногда программа по умолчанию неверно распознает блоки с вертикальным текстом. Для изменения ориентации текста щелкните правой кнопкой мыши на блоке с вертикальным текстом, выберите пункт Свойства и в открывшемся окне укажите нужный вариант в списке Направление текста. После этого еще раз распознайте этот блок.
После этого еще раз распознайте этот блок.
Для проверки текста нажмите кнопку Проверить. На экране отобразится окно Проверка (рис. 8.6). В верхней его части система будет по очереди выделять найденные ошибки. Вы можете исправлять их непосредственно в этом окне. После исправления не забудьте нажать кнопку Подтвердить. В некоторых случаях программа FineReader будет предлагать варианты замены слова с ошибкой. Используя предложенные варианты исправления текста либо задав изменения вручную, можно исправить неверно распознанные слова.
Рис. 8.6. После распознавания текст необходимо проверить
Во время проверки текста вы можете добавлять исправленные слова в словарь. Это позволит повысить качество распознавания, так как при распознавании система сверяется со словарем, в котором может не быть некоторых слов, особенно терминов или сокращений.
После завершения проверки закройте окно. Все исправления будут сохранены в распознанном тексте документа.
Получив готовый текст, вы можете его отформатировать – для этого предназначена панель инструментов Форматирование. На ней размещены инструменты для изменения шрифта и способа выравнивания текста.
На ней размещены инструменты для изменения шрифта и способа выравнивания текста.
После распознавания и исправления результаты работы можно сохранить в отдельном файле, скопировать в буфер обмена либо передать во внешнее приложение.
Один из способов сохранения результатов работы в FineReader – использование мастера сохранения результатов. Для его запуска нажмите кнопку Сохранить.
В окне мастера предлагается выбрать приложение для передачи текста либо одну из возможностей: Сохранить страницы, Отправить страницы по электронной почте, Копировать в буфер обмена (рис. 8.7). В этом же окне можно задать параметры сохранения оформления распознанного текста и возможность сохранения картинок.
Рис. 8.7. Мастер сохранения результатов
Выбрав пункт Microsoft Word, вы таким образом отобразите распознанный текст в окне текстового редактора Word.
После этого можно продолжить работу с документом.
Программа FineReader завоевывает все больше поклонников, так как ее возможности позволяют превратить текст или изображения даже самого плохого качества в электронный документ с наименьшими потерями. После освоения основных функций программы вам не составит большого труда преобразовать в электронный вид десятки бумажных страниц.
После освоения основных функций программы вам не составит большого труда преобразовать в электронный вид десятки бумажных страниц.
Данный текст является ознакомительным фрагментом.
Продолжение на ЛитРесУслуга сканирования и распознавания текста на заказ СПб
Часто возникает потребность внести изменения в документы, полученные со сканера, или в оригинал, сохраненный как графический файл с расширениями jpg, tif, png, pdf и другими, делающими редактирование невозможным. «Копицентр» в Санкт-Петербурге выполняет сканирование для последующей работы с файлами с помощью установленного специального программного обеспечения.
Профессионалы полиграфии производят распознавание сканированного текста с картинок, изображений, фотографий, а также при необходимости выполняют дальнейшую обработку. При этом оригиналы для расшифровки допускаются в электронном виде или напечатанные на бумажных носителях.
При этом оригиналы для расшифровки допускаются в электронном виде или напечатанные на бумажных носителях.
Распознавание русского текста со сканера
Для приведения в электронный вид книг, журналов, пособий и иных машинописных записей распознавание русского текста со сканера требует намного меньше времени, чем перенабор вручную. Отсканированные страницы предварительно сохраняют как графические файлы или передаются в обработку сразу.
Распознавание русского и английского текстов или копирование происходят намного быстрее, если расшить бумажный носитель и пропустить листы через автоподатчик сканера. Сшитые страницы сканируются вручную, что дороже и занимает больше времени.
Распознавание отсканированного текста и текста с фото изображений
Текстовый файл получают путем распознавания с отсканированного и сохраненного в любом расширении изображения.
Сегодня с помощью фотоаппарата и камеры в мобильнике легко сохранить нужную информацию, к примеру, на стендах. Но часто требуется только текст, а не фотоизображение. В наших копицентрах распознают отсканированный текст с фотографий, картинок, сделанных цифровыми фотоаппаратами и камерами мобильных телефонов.
Но часто требуется только текст, а не фотоизображение. В наших копицентрах распознают отсканированный текст с фотографий, картинок, сделанных цифровыми фотоаппаратами и камерами мобильных телефонов.
При этом возможно удаление лишних элементов, а также последующее редактирование. Полученные текстовые файлы с желаемым расширением оператор копицентра записывает на выбранный носитель или отправляет на указанный электронный адрес заказчику.
Бесплатный OCR API
Получите бесплатный ключ API OCR
Зарегистрируйтесь здесь, чтобы получить бесплатный ключ API OCR. OCR API обеспечивает простой способ анализа изображений и многостраничных PDF-документов (PDF OCR)
и получение результатов извлеченного текста, возвращенного в формате JSON. У OCR API есть три уровня / уровня.
Бесплатный план OCR API имеет ограничение скорости 500 запросов в течение одного дня на IP-адрес , чтобы предотвратить случайную рассылку спама.
Для еще более быстрого реагирования и гарантированного 100% времени безотказной работы доступны планы PRO.
PRO OCR API работает на физически иных серверах, чем наша бесплатная служба OCR API.
Вы получите URL-адреса глобальных конечных точек PRO и свой ключ API в приветственном письме сразу после
вы зарегистрировались для учетной записи PRO или PRO PDF.PRO OCR API также можно приобрести как локально устанавливаемую локальную программу OCR.
| План API | Бесплатно | ПРО | PRO PDF | Предприятие |
|---|---|---|---|---|
| Стоимость | Бесплатно | 30 долларов в месяц | 60 $ / мес. | 299 $ + / месяц |
| Зарегистрироваться и получить ключ API | Зарегистрируйтесь для бесплатно API-ключ | Купить PROAPI Key | Купить PRO PDFAPI Key | Связаться с отделом продаж |
| Запросов / месяц | 25 000 | 300 000 | 300 000 | Custom |
| Дополнительные преобразования * | н / д | 10 долларов США / 100 000 | 20 долларов США / 100 000 | Включено |
| Ограничение размера файла | 1 МБ | 5 МБ | 100 МБ + | 100 МБ + |
| Ограничение страницы PDF | 3 | 3 | 999+ | 999+ |
| Создание PDF с возможностью поиска | Да (с водяным знаком) | Есть | Есть | Есть |
| Скорость | Быстро | Быстрее (больше серверов, меньше нагрузка) | Самый быстрый (собственный сервер) | |
| Ограничение скорости ** | 500 звонков / ДЕНЬ | 600 звонков / 1 мин | 600 звонков / 1 мин | Custom |
| Соглашение об уровне обслуживания (SLA) | н / д | 100% время безотказной работы или возврат денег (выделенные резервные серверы в США / ЕС / Азии) | Пользовательское местоположение | |
* Дополнительные преобразования: мы автоматически взимаем , а не за дополнительные преобразования. Вместо этого, если вы достигнете предела, мы свяжемся с вами, и вы сможете решить, хотите ли вы платить за дополнительные преобразования или остановиться на текущий расчетный период.
Вместо этого, если вы достигнете предела, мы свяжемся с вами, и вы сможете решить, хотите ли вы платить за дополнительные преобразования или остановиться на текущий расчетный период.
** Ограничение скорости составляет на IP-адрес . Для тарифных планов PRO мы можем изменить ограничение скорости по умолчанию на без дополнительных затрат .
Пример: если вы используете ключ PRO API в приложении для мобильного телефона, каждый пользователь (= каждый уникальный IP-адрес) имеет ограничение скорости.
60 преобразований OCR в течение одной минуты.Таким образом, разные пользователи не могут блокировать друг друга.
Этого должно быть достаточно для большинства случаев использования, но если вам нужен более высокий лимит, просто сообщите нам
и мы увеличим вашу ставку.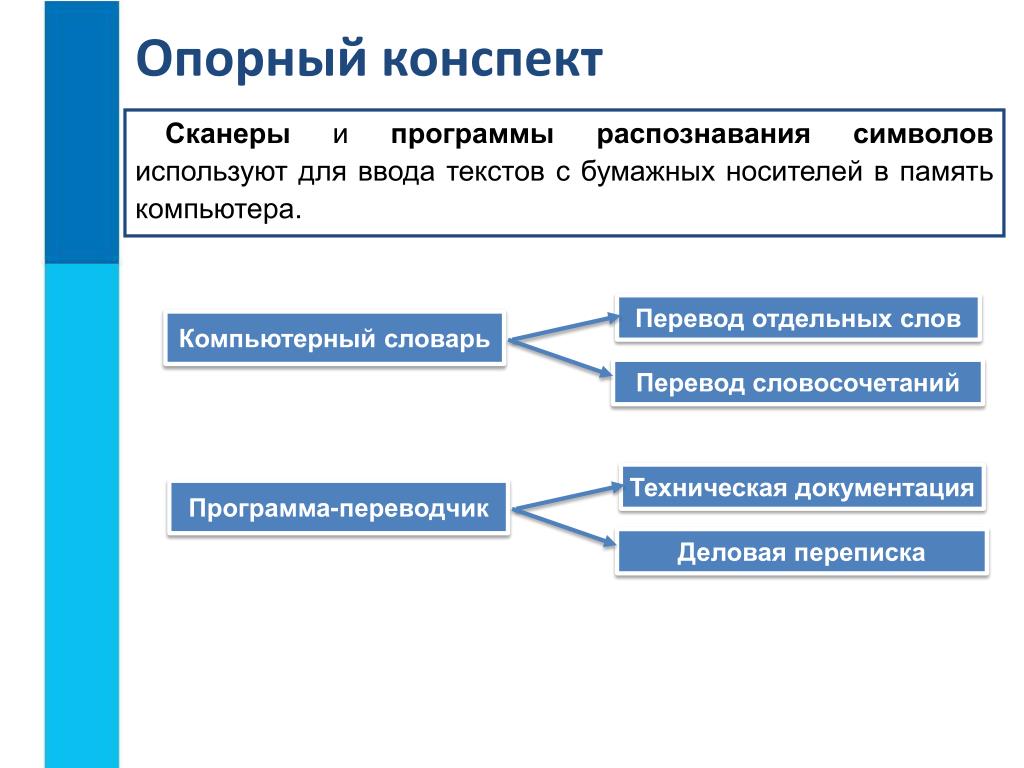 Дополнительную информацию об API см. На странице часто задаваемых вопросов по OCR API.
Дополнительную информацию об API см. На странице часто задаваемых вопросов по OCR API.
Вы можете проверить производительность и время безотказной работы API на странице статуса API.
Теперь пора начать: ниже вы найдете пример кода для вызова API из Postman, AutoHotKey (AHK), cURL,
C #, ASP.СЕТЬ, Дельфи,
iOS, Java (приложение для Android),
Node.JS NPM, Python, C ++ / QT,
Рубин,
и Javascript. (Если у вас есть примеры кода для других языков, сообщите нам, и мы добавим их в этот список).
Более быстрое распознавание текста с тарифами PRO
В наших планах OCR PRO мы используем избыточные высокопроизводительные конечные точки API в регионах США, ЕС и Азии.Мы гарантируем 100% безотказную работу или возврат денег. Наши размещенные планы PRO OCR:
Помимо подключения к нашим серверам PRO OCR, вы также можете напрямую купить наше программное обеспечение OCR и разместить его у себя. Этот вариант описан в следующем абзаце ниже.
верхнийOCR.space Локальный автономный сервер OCR
| OCR.space Local — Enterprise Image и PDF OCR |
|---|
| OCR.space — это мощное серверное программное обеспечение OCR для автоматического ввода документов и преобразования PDF.
С OCR.space Local вы можете установить и разместить наш популярный OCR API и программное обеспечение для создания PDF с возможностью поиска на вашем собственном ПК и / или в вашем центре обработки данных.Полностью поддерживается установка в виртуализированных и облачных средах, таких как Amazon AWS AMI или Microsoft Azure.
Технически локальный сервер OCR идентичен нашему популярному онлайн-сервису OCR API. Переход с облака на локальную среду или наоборот
не требует изменения кода. Локальная версия имеет те же функции, параметры API и такое же качество OCR, что и OCR.план космоса ПРО PDF, но работает на 100% локально и в автономном режиме — он никогда не подключается к Интернету. |
| OCR.пространство доступно как размещенное решение (подписка) или как устанавливаемое программное обеспечение (единовременный платеж). |
| Для получения дополнительной информации и заказа локальных лицензий OCR.space обратитесь в отдел продаж. |
Конечная точка бесплатного OCR API (POST)
Бесплатный OCR APIhttps: // api.ocr.space/parse/image API поддерживает https: // (SSL) и обычные http: // соединения.
«GET» Конечная точка API OCR
Использование OCR API никогда не было таким простым …
Помимо полнофункционального OCR API «POST» по адресу / parse / image , мы предоставляем дополнительную конечную точку OCR API.
на / parse / ImageUrl для запросов GET.Хотя он и не так универсален, как POST API,
Это простой в использовании. Все, что вам нужно для вызова API, находится внутри URL-адреса.
Пример (просто щелкните ссылку, чтобы запустить OCR) :
https://api.ocr.space/parse/imageurl?apikey=helloworld&url=http://i.imgur.com/fwxooMv.png
Язык распознавания текста по умолчанию — английский. Чтобы использовать другой язык, добавьте к URL-адресу и язык .Вы также можете запросить координаты слова x / y с помощью isOverlayRequired :
https://api.ocr.space/parse/imageurl?apikey=helloworld&url=http://i.imgur.com/s1JZUnd.gif&language=chs&isOverlayRequired= правда
Важное ограничение конечной точки GET api заключается в том, что он позволяет отправлять изображения и PDF-файлы только с помощью метода URL , как только
Запросы HTTP POST могут предоставлять серверу дополнительные данные в теле сообщения.GET-запросы включают все
необходимые данные в URL. Таким образом, по замыслу GET api не может поддерживать загрузку файлов (параметр file )
или строки BASE64 ( base64image ).
GET API прост и быстр в использовании. Просто обратите внимание, что URL-адрес с ключом api может храниться в истории вашего браузера. Но это , а не , проблема безопасности, потому что даже если кто-то получит доступ к вашему личному ключу API, он или она не может получить доступ к какой-либо информации о вас или документах, включенных в OCR, потому что мы вообще не храним такую информацию.В худшем случае кто-то использует все ваши бесплатные преобразования. Если это может быть проблемой для вашего приложения, просто продолжайте использовать POST-версию API с полным SSL-шифрованием или переключитесь на PRO OCR API, который предоставляет дополнительные возможности.
верхнийВ таблице ниже перечислены все возможные параметры API.В качестве дополнительной документации мы опубликовали образец коллекции вызовов API, которую вы можете загрузить в Postman. И последнее но не в последнюю очередь: наша бесплатная онлайн-форма ocr на первой странице — это не что иное, как POST-вызов бесплатной конечной точки OCR API, и ее также можно использовать для тестирования.
| Ключ | Значение | Описание |
|---|---|---|
апики | API-ключ (отправляем в шапке) | Получите бесплатный ключ API |
url или файл или base64Image | url : URL-адрес удаленного файла изображения (убедитесь, что он имеет правильный тип содержимого) файл : файл многокомпонентного закодированного изображения с именем файла base64Image : изображение или PDF в виде строки в кодировке Base64 | Вы можете использовать три метода для загрузки входного изображения или PDF.Мы рекомендуем метод URL-адреса для файлов размером> 10 МБ для более быстрой загрузки. |
язык | [Необязательно] Арабский = ара Болгарский = бул Китайский (упрощенный) = chs Китайский (традиционный) = cht Хорватский = hrv Чешский = чешских крон Датский = дан Голландский = dut Английский = англ. Финский = фин Французский = fre Немецкий = ger Греческий = gre Венгерский = гунн Корейский = крон Итальянский = ita Японский = иен Польский = pol Португальский = по Русский = рус Словенский = slv Испанский = spa Шведский = swe Турецкий = тур | Язык, используемый для OCR.Если язык не указан, по умолчанию используется английский eng . ВАЖНО: Код языка всегда состоит из |
isOverlayRequired | [Необязательно] Логическое значение | По умолчанию = False Если true, возвращает координаты ограничивающих рамок для каждого слова.Если false, текст OCR возвращается только как текстовый блок (это уменьшает ответ JSON). Данные наложения можно использовать, например, для отображения текста поверх изображения. |
тип файла | [Необязательно] Строковое значение: PDF, GIF, PNG, JPG, TIF, BMP | Заменяет автоматическое определение типа файла на основе типа содержимого.Поддерживаемые форматы файлов изображений: png, jpg (jpeg), gif, tif (tiff) и bmp. Для документа ocr api поддерживает формат Adobe PDF. Поддерживаются многостраничные файлы TIFF. |
обнаружение | [необязательно] истина / ложь | Если установлено значение true, api правильно автоповорачивает изображение и устанавливает TextOrientation параметр
в ответе JSON.Если изображение повернуто на , а не на , тогда TextOrientation = 0, в противном случае это степень поворота, например. г. «270». |
isCreateSearchablePdf | [Необязательно] Логическое значение | По умолчанию = Ложь Если верно, API генерирует PDF с возможностью поиска. Этот параметр автоматически устанавливает isOverlayRequired = true. |
isSearchablePdfHideTextLayer | [Необязательно] Логическое значение | По умолчанию = Ложь . Если true, текстовый слой скрыт (не виден) |
масштаб | [необязательно] истина / ложь | Если установлено значение true, api выполняет внутреннее масштабирование.Это может значительно улучшить результат распознавания текста, особенно для сканирование PDF с низким разрешением. Обратите внимание, что в демонстрации на первой странице используется scale = true, но API по умолчанию использует scale = false. Также это Сообщение на форуме OCR. |
isTable | [необязательно] истина / ложь | Если установлено значение true, логика OCR гарантирует, что результат анализа текста всегда возвращается построчно.Этот переключатель рекомендуется для OCR таблиц, OCR чеков, обработка счетов и все другие типы входные документы, имеющие табличную структуру. |
OCRE Двигатель | [Необязательно] 1 или 2 | Двигатель 1 по умолчанию.См. Разделы OCR Engines. |
Совет: при обслуживании изображений из корзины Amazon AWS S3, облачного хранилища Google или аналогичных служб для использования с параметром «URL» убедитесь, что ссылка на файл имеет правильный тип содержимого.
Не должно
быть «Content-Type: application / x-www-form-urlencoded» (который, кажется, используется по умолчанию для AWS), но image / png или аналогичный для изображений.Для PDF-документов убедитесь, что тип содержимого не «image / pdf» , а application / pdf . Вы можете проверить тип содержимого ваших ссылок, например, с помощью
это средство проверки типов содержимого MIME (внешняя служба, а не наша). OCR API использует тип контента для автоматического определения нужного файла. Но если у вас неправильный тип содержимого и вы не можете его изменить (например,потому что вы не контролируете облачное хранилище), без проблем:
В этом случае вы можете перезаписать автоматическое определение типа файла, добавив
параметр filetype = и напрямую сообщает API, какой тип документа вы отправляете (PNG, JPG, GIF, PDF).
Новое: если вам нужно определить состояние флажков, свяжитесь с нами по поводу функций оптического распознавания меток (OMR) (бета).
верхнийВыберите лучший механизм распознавания текста
OCR API предлагает два разных механизма OCR с разной логикой обработки. Мы рекомендуем вам попробовать оба и затем используйте тот движок, который дает лучший результат распознавания текста. Вы можете использовать оба механизма OCR с нашим бесплатный онлайн-сервис OCR на главной странице и с параметром OCREngine = 1/2 в вашем вызове API.
Особенности OCR Engine 1:
- — поддерживает больше языков (включая азиатские языки, такие как китайский, японский и корейский)
- — Быстрее
- — Поддерживает изображения большего размера
- — Поддержка многостраничного сканирования TIFF
- — Параметр: OCREngine = 1
Особенности модуля OCR 2:
- — Только западные латинские символы (английский, немецкий, французский ,…)
- — Автоопределение языка. Не имеет значения, какой язык OCR вы выберете, если он использует латинские символы
- — Обычно лучше при распознавании текста одним числом и буквенно-цифровом распознавании текста (например, SUDOKO, Точечная матрица OCR, МСЗ OCR, …)
- — Обычно лучше распознавать специальные символы, такие как @ + -…
- — Обычно лучше с повернутым текстом (Форум: обнаружение спама в изображениях)
- — Максимальный размер изображения: ширина 5000 пикселей и высота 5000 пикселей
- — Параметр: OCREngine = 2
Корпоративная поддержка: Оба механизма OCR доступны для автономного использования, а также для самостоятельного размещения в качестве локального OCR!
Возвращенный ответ JSON с результатом OCR идентичен для обоих движков! При необходимости можно переключаться между обоими двигателями.Функции, не упомянутые в этом сравнении движка OCR, одинаковы для обоих движков, например PDF OCR, определение ориентации и поддержка сканирования чеков. Если у вас есть какие-либо вопросы об использовании Engine 1 или 2, задайте их на нашем форуме OCR API.
верхнийAPI возвращает результаты в формате JSON.Результат обычно содержит ExitCode, Подробная информация об ошибке (если произошла) и несколько проанализированных результатов для страниц изображений / PDF. Пожалуйста, проверьте ниже ответ, возвращаемый веб-API, и определение различных параметров. На рисунке ниже показаны успешные и ошибочные ответы.
{
"ParsedResults": [
{
"TextOverlay": {
«Строки»: [
{
«Слова»: [
{
"WordText": "Слово 1",
«Левый»: 106,
«Верх»: 91,
«Высота»: 9,
«Ширина»: 11
},
{
"WordText": "Слово 2",
«Левый»: 121,
«Верх»: 90,
«Высота»: 13,
«Ширина»: 51
}
..
.
Больше слов
],
«MaxHeight»: 13,
«MinTop»: 90
},
.
.
.
.
Больше строк
],
"HasOverlay": правда,
«Сообщение»: null
},
"FileParseExitCode": "1",
"ParsedText": "Это образец результата анализа",
"ErrorMessage": ноль,
"ErrorDetails": null
},
{
"TextOverlay": null,
«FileParseExitCode»: -10,
"ParsedText": ноль,
"Сообщение об ошибке" : "... сообщение об ошибке (если есть) ",
"ErrorDetails": "... подробное сообщение об ошибке (если есть)"
}
.
.
.
],
"OCRExitCode": "2",
"IsErroredOnProcessing": ложь,
"ErrorMessage": ноль,
"ErrorDetails": null
"SearchablePDFURL": "https: // ....." (если запрошено, иначе null)
"ProcessingTimeInMilliseconds": "3000"
}
| Ключ | Значение | Описание |
|---|---|---|
Результаты анализа | OCR результаты | Результаты OCR для изображения или для каждой страницы PDF.Для PDF: каждая страница имеет собственный результат распознавания текста и сообщение об ошибке (если есть) |
OCRExitCode | Целое число | Код выхода показывает, было ли OCR выполнено успешно, частично или с ошибкой |
IsErroredOnProcessing | верно / неверно | Если возникает ошибка при разборе страниц изображения / PDF |
Сообщение об ошибке | Текст | Сообщение об ошибке возникла при разборе образа |
Сведения об ошибке | Текст | Подробное сообщение об ошибке |
Доступный для поискаPDFURL | Ссылка | См. PDF-файл с возможностью поиска |
| РЕЗУЛЬТАТ РАЗБОРА ИЗОБРАЖЕНИЯ / СТРАНИЦЫ | ||
FileParseExitCode | Код выхода для каждого проанализированного результата | Код выхода, возвращенный механизмом синтаксического анализа 0: Файл не найден 1: Успешно -10: Ошибка синтаксического анализа модуля OCR -20: Тайм-аут -30: Ошибка проверки - 99: Неизвестная ошибка |
ParsedText | Разобранный текст | Проанализированный текст изображения |
TextOverlay | Наложение данных для текста на изображении / pdf | Только если для isOverlayRequired установлено значение True |
линий | Массив строк в наложенном тексте | Содержит массив всех строк.Каждая строка будет содержать массив слов |
слов | Массив слов в строке | Содержит слова с конкретными деталями слова, такими как текст и позиция |
WordText | Текст слова | Содержит текст конкретного слова |
Левый | Расстояние слова слева (в пикселях (px)) | Содержит расстояние (в пикселях) слова от левого края изображения. |
Верх | Расстояние слова сверху (в пикселях) | Содержит расстояние (в пикселях) слова от верхнего края изображения. |
Высота | Высота слова | Содержит высоту (в пикселях) слова |
Ширина | Ширина слова | Содержит ширину (в пикселях) слова |
MaxHeight | Максимальная высота строки | Содержит высоту (в пикселях) линии |
MinTop | Минимальное расстояние линии от верхнего края изображения | Содержит расстояние (в пикселях) линии от верхнего края в исходном размере изображения |
HasOverlay | Оверлей присутствует или нет | Истина / Ложь в зависимости от того, присутствует ли оверлей для проанализированного результата или нет |
Сообщение об ошибке | Текст | Сообщение об ошибке, возвращаемое механизмом анализа |
Сведения об ошибке | Текст | Подробное сообщение об ошибке, возвращаемое механизмом синтаксического анализа для целей отладки |
Вы можете создавать PDF-файлы с возможностью поиска (иногда также называемые Sandwich PDF-файлы) непосредственно через API.PDF-файл возвращается как ссылка для скачивания
в ответе API JSON форма "SearchablePDFURL": "..." .
Ссылка для скачивания действительна в течение одного часа, по истечении этого времени документ удаляется с наших серверов OCR.
Переключатель isCreateSearchablePdf = true запускает создание PDF-файла с возможностью поиска. По умолчанию,
добавленный текстовый слой виден — это идеальный вариант для тестирования результата, так как вы можете сравнить результат OCR непосредственно со сканированным изображением.Добавляя isSearchablePdfHideTextLayer = true , вы делаете текстовый слой невидимым.
Создание PDF-файла с возможностью поиска на основе результата распознавания текста требует дополнительного времени обработки, поэтому вам следует активировать только это
функция, если вам нужен результат OCR в формате PDF.
ПРИМЕЧАНИЕ. Вы должны использовать и параметров, isCreateSearchablePdf = true и isSearchablePdfHideTextLayer = false или true , в противном случае сгенерированный PDF-файл не содержит текстового слоя.
При использовании с уровнем бесплатного OCR API созданный PDF-файл содержит водяной знак «Создано OCR.space» в правом нижнем углу. С PRO OCR API водяной знак не добавляется в PDF.
верхнийСамый быстрый способ протестировать OCR API — выполнить вызов GET — просто скопируйте URL-адрес в свой веб-браузер.
Тестовый API с приложением Postman
Начало работы: воспользуйтесь бесплатным Приложение Postman для Windows, Mac и Linux чтобы протестировать OCR API и поиграть с различными параметрами.
Совет: Если у вас установлен Postman, вы можете нажать кнопку «Выполнить в Postman» выше, чтобы импортировать набор из шести тестовых вызовов API в Postman .В примерах используется ключ api «helloworld», и они готовы к запуску без каких-либо дополнительных изменений.(a) Предоставление изображения / PDF для распознавания текста через URL-адрес
На скриншотах ниже показаны настройки отправки изображения / PDF-файла по URL-адресу. Обратите внимание, что кодировка установлена на multipart / form-data .
Во всех случаях (загрузка файла через URL, файл или base64) ключ API (пароль) отправляется в заголовке:
(b) Загрузите изображение / PDF-файл для распознавания текста с вашего сервера / ПК
То же приложение Postman, но на этот раз мы используем настройку «Файл» для загрузки изображения или PDF.
(c) Отправить изображение как строку Base64
То же приложение Postman, но на этот раз мы используем параметр «Base64Image» для отправки изображения в виде строки.
Совет: убедитесь, что после вставки строки base64 в Postman нет лишней «новой строки».Если есть, API будет (по праву) вернуть «Недействительное изображение base64». ошибка.
Тестовая строка BASE64
Ссылки открывают текстовый файл в браузере: Image Base64 String, TIFF Base64 String, PDF как строка Base64. Вы можете копировать и вставьте содержимое этих текстовых файлов непосредственно в поле «base64image» Postman или в любой другой тестовый код.
Важно: строка base64 должна начинаться с типа содержимого документа. Например, используйте data: image / jpeg; base64, здесь строка данных , данные: изображение / png; base64, строка данных здесь или для документов PDF данные: приложение / pdf; base64, строка данных здесь . Большинство онлайн-сервисов преобразования изображений в base64 не
добавьте этот заголовок, они просто предоставляют строку необработанных данных.Таким образом, вы должны добавить его вручную, когда используете такие строки для тестирования.
Командная строка cURL
(a) Предоставление изображения / PDF для распознавания текста через URL-адрес
curl https://api.ocr.space/Parse/Image -H "apikey: helloworld" --data "isOverlayRequired = true & url = http: //dl.a9t9.com/blog/ocr-online/screenshot.jpg&language = eng "
curl — это инструмент командной строки и библиотека с открытым исходным кодом для передачи данных с синтаксисом URL.Библиотека libcurl переносима. Он строится и работает одинаково практически на любой платформе (Windows, Mac, Linux, …).
(b) Загрузите изображение / PDF-файл для распознавания текста с вашего сервера / ПК
curl -H "apikey: helloworld" --form "[email protected]" --form "language = eng" --form "isOverlayRequired = true" https://api.ocr.space/Parse/Image
Примечание: @ скриншот.jpg предполагает, что изображение с именем «screenshot.jpg» находится в том же каталоге, что и cURL.exe. Обратите внимание, что для isOverlay требуется (по умолчанию: no), а параметры language (по умолчанию: eng) необязательны.
(c) Отправить изображение в виде строки в формате Base64
curl -H "apikey: helloworld" --form "base64Image = data: image / jpeg; base64, / 9j / AAQSk [здесь длинная строка]" --form "language = eng" --form "isOverlayRequired = false" https: // api.ocr.space/parse/image
Строка base64 в этом примере усечена. Вы можете скачать полную командную строку как командный файл Windows с GitHub.
У нас есть несколько тестовых строк base64, доступных для загрузки.
верхнийC # (проект Visual Studio)
Существует готовый пример проекта Visual Studio C # для с помощью OCR API из C # на GitHub.
Тестовое приложение позволяет быстро загружать и тестировать любое изображение с помощью OCR API.
В качестве реального примера взгляните на популярный инструмент повышения производительности «ShareX»:
ShareX использует OCR.space PRO API, и доступен полный исходный код C #.
верхнийiOS: Objective-C и Swift
Предоставленные пользователем фрагменты кода для Цель-C и Swift — хорошая отправная точка для приложений iPhone с функциями распознавания текста.
верхнийAndroid: Java
Используете Android? Взгляните на этот образец приложения для Android
который использует бесплатный OCR API. В
Ява
app показывает, как вызвать API с помощью HttpsURLConnection от пользователя «bsuhas». И тут
это другое, отличное от пользователя «Globalizer» репо Java.Спасибо обоим за предоставленный фрагмент кода.
Веб-приложение PHP OCR API Demo
Для PHP у нас есть полное, готовое к запуску демонстрационное веб-приложение, которое позволяет пользователю выбрать документ, а затем загрузить его. изображение или PDF-документ в OCR API.
Вы найдете
полный исходный код на Github
.
Питон
Вот пример того, как получить доступ к API из Python с помощью команды requests.post .
Полный исходный код можно найти на GitHub (спасибо пользователю «Zaargh» за предоставленный фрагмент кода).Еще одна оболочка Python для нашего OCR SDK доступна от пользователя GitHub a4fr (спасибо всем за создание фрагментов кода).
верхнийAutoHotKey (AHK)
AHK — популярный рекордер макросов для Windows. Для проектов автоматизации Windows, требующих
распознавать текст на изображениях, вы можете подключиться к OCR API с CreateFormData (PostData, ContentType, oForm) .Это сообщение на форуме AHK содержит подробности.
C ++ / QT
Используете C ++? Jhiroka из UCLA поделился с нами этим примером: пример приложения C ++ / QT OCR API.
Если вы используете библиотеку C ++ Casablanca для вызова HTTP POST, обратите внимание, что вам нужно URL-адрес кодировать данные изображения поверх кодировки Base64.Библиотека C ++ Casablanca, похоже, не делает это автоматически (в отличие от Postman), поэтому используйте функцию web :: uri :: encode_data_string для кодирования данных файла после кодирования запроса Base64.
Перейти
Пользователь Маттео создал репозиторий Github с модулем Go для OCR API.
верхнийРубин
Используете Ruby? Suyesh поделился с нами этим Ruby gem (библиотекой): OCR API Ruby gem.
Perl
Используете Perl? Затем взгляните на этого пользователя OCR API, отправленного Perl OCR.космический модуль.
Powershell
У нас есть фрагмент кода OCR Powershell. Это включает скачивание созданный сэндвич PDF.
верхнийJavascript
Расширение Chrome
Расширение Copyfish для Chrome, Edge и Firefox с открытым исходным кодом использует наш OCR API.Вы можете найти его исходный код Javascript здесь. Сюда входит код, показывающий, как обрабатывать возвращенные данные наложения текста. Обратите внимание, что расширение Copyfish использует версию PRO OCR API.
Проверьте это: вы можете установить расширение Copyfish OCR в Хром, Край, и Fire Fox.
верхнийNPM / Node.js
Последняя версия оболочки OCR API Node.JS принадлежит пользователю DavideViolante . Он позволяет указать конечные точки OCR Space API (бесплатно и PRO). Старые оболочки Node.JS: Пользователь Dennis.K опубликовал пакет NPM для OCR API и Anthony Luzquiños выпустил обновленный пакет NPM для OCR API.
верхнийJQuery
Это пример JQuery, показывающий, как сделать запрос к api с помощью AJAX и получить результаты изображения для обработки.
верхний
- // Готовим данные формы
- var formData = new FormData ();
- форма Данные.append ("файл", fileToUpload);
- formData.append ("URL", "URL-адрес-изображения-или-PDF-файла");
- formData.append ("язык", "англ");
- formData.append ("apikey", "Ваш-API-ключ-здесь");
- formData.append ("isOverlayRequired", True);
- // Асинхронно отправить запрос на анализ OCR
- jQuery.ajax ({
- url: https://api.ocr.space/parse/image,
- data: formData,
- dataType: 'json',
- cache: false,
- contentType: false,
- processData: false,
- type: 'POST',
- success: function (ocrParsedResult) {
- // Получить проанализированные результаты, код выхода и сообщение об ошибке и подробности
- var parsedResults = ocrParsedResult ["ParsedResults"];
- var ocrExitCode = ocrParsedResult ["OCRExitCode"];
- var isErroredOnProcessing = "ocrParsedResult50";
- var errorDetails = ocrParsedResult ["ErrorDetails"];
- var processingTimeInMilliseconds = ocrParsedResult ["ProcessingTimeInMilliseconds"];
- // Если мы получили проанализированные результаты, затем переберите результаты, чтобы что-то сделать
- if (parsedResults! = Null) {
- // Цикл через проанализированные результаты
- $.each (parsedResults, function (index, value) {
- var exitCode = value ["FileParseExitCode"];
- var parsedText = value ["ParsedText"];
- var errorMessage = value ["ParsedTextFileName
- "];
var errorDetails = значение ["ErrorDetails"];- var textOverlay = значение ["TextOverlay"];
- var pageText = '';
- переключатель (+ exitCode) {
- case 1:
- pageText = parsedText;
- перерыв;
- case 0:
- case -10:
- case -20:
- case -30:
- case -99:
- default:
- pageText + = "Error:" + errorMessage;
- перерыв;
- }
- $.каждый (textOverlay ["Lines"], функция (индекс, значение) {
- ..........................
- .. ........................
- ........................ ..
- ПЕРЕХОДИТЕ ПО СТРОКАМ И ПОЛУЧИТЕ СЛОВА ДЛЯ ОТОБРАЖЕНИЯ НАД НАЛОЖЕНИЕМ ИЗОБРАЖЕНИЯ
- ..........................
- ..........................
- ...................... ....
- });
- ..........................
- ..........................
- ..........................
- ВАШ КОД ЗДЕСЬ
- ........ ..................
- ..........................
- .. ........................
- });
- }
- }
- });
OCR Text Scanner 2.1.3 Android APK’sını indir
OCR-Text Scanner — это приложение для распознавания символов на изображении с высокой (99% +) точностью.
Превратит ваш мобильный телефон в сканер текста и переводчик.
Обеспечена поддержка 92 языков (африкаанс, албанский, арабский, азербайджанский, баскский, белорусский, бенгальский, болгарский, бирманский, каталонский, китайский (упрощенный), китайский (традиционный), хорватский, чешский, датский, голландский, английский, эстонский, Финский, французский, галисийский, немецкий, греческий, гуджарати, иврит, хинди, венгерский, исландский, индонезийский, итальянский, японский, каннада, кхмерский, корейский, латышский, литовский, македонский, малайский, малаялам, мальтийский, маратхи, непальский, норвежский, Панджаби, персидский (фарси), польский, португальский, румынский, русский, санскрит, сербский (латиница), словацкий, словенский, испанский, суахили, шведский, тагальский, тамильский, телугу, тайский, турецкий, украинский, урду, вьетнамский и др.)
Особенности сканера текста:
• Извлечь текст на изображении
• Перевести текст на более чем 100+ языков
• Копировать — текст на экране
• Обрезать и улучшить изображение перед распознаванием текста.
• Редактировать и отправлять результат распознавания текста.
• История сканирования.
• Распознавать текст с изображения поддерживает 92 языка.
• Извлекает номер телефона, адрес электронной почты, URL.
Ссылка на демонстрацию видео:
https://www.youtube.com/watch?v=5GC6kvuDGb0
Пожалуйста, отправьте письмо, если вы обнаружите какие-либо ошибки, проблемы или вам нужна какая-либо функция.
Примечание. Рукописный текст не работает.
OCR-Metin Tarayıcı, bir görüntüdeki karakterleri yüksek (% 99 +) hassasiyetle tanıyan bir uygulamadır.
Cep telefonunuzu metin tarayıcıya ve tercümana çevirir.
92 dilde destek verdi (Африкаанс, Арнавуча, Арапча, Азери, Башка, Беларусьса, Бенгалия, Бенгалия, Бирманья, Каталанка, Синце (Базитлештирилмиш), Синце (Геленекселесел), Хырчекач, Эстенгизеек, Данчаек, Фесеек, Эстенгизеек, Данчеек , Fransızca, Galiçyaca, Almanca, Yunanca, Guceratça, İbranice, Hintçe, Macarca, İzlandaca, Endonezyaca, Italyanca, Japonca, Kannada, Khmer, Korece, Letonca, Litvanca, Makedonçepalthami, Makedonçepalthami, Makedonçepalthami, Malayca, , Farsça (Фарса), Lehçe, Portekizce, Romence, Rusça, Sanskritçe, Sırpça (Latince), Slovakça, Slovence, İspanyolca, Svahili, İsveççe, Tagalogca, Tamilce, Telugu Dili, Tayçaçeca, daarın )
Metin Tarayıcı Özellikleri:
• Resmin Üzerine Metin ıkarma
• Metni 100’den fazla dile çevirin
• Kopyala — Ekrandaki Metin
• OCR’den önce görüntüyrtirıırtir.
• OCR sonucunu düzenleyin ve paylaşın.
• Tarama geçmişi.
• Resimdeki metni tanımak 92 dili desteklemektedir.
• Телефонный номер, электронная почта, URL’yi çıkarır.
Видео демонстрации bağlantısı:
https://www.youtube.com/watch?v=5GC6kvuDGb0
Herhangi bir hata, sorun veya özellik bulmak için lütfen posta gönderin.
Not: El yazısı metin çalışmaz.
Text Scanner MOD APK [OCR] v7.1.2 (Премиум)
Это самая высокая точность распознавания текста в мире.
Вы можете преобразовывать изображения в текст. Наслаждайтесь!
Скачать сканер текста [OCR] MOD APK
Это лучший сканер текста [OCR]!
Самая высокая скорость и высокое качество
во всех приложениях Android!
Вы можете преобразовать изображение в текст.
Когда вы получаете доступ к URL-адресу или номеру телефона, указанному в журналах или брошюрах,
действительно сложно ввести URL-адрес или номер телефона с клавиатуры.
Так что используйте сканер текста [OCR]!
Поскольку он автоматически распознает символы с изображения,
позволяет получить доступ к URL-адресу или номеру телефона немедленно!
Когда вы записываете заметку, написанную на доске или белой доске,
очень сложно записать ее с клавиатуры.
Но вы можете сделать это очень легко с помощью сканера текста [OCR]!
Возможна немедленная запись содержимого!
[Особенности сканера текста [OCR]]
● Самая высокая скорость чтения в мире
● Высокая точность чтения в мире
● Поддержка фотографий вашего альбома
● Поддержка более 50 языков
● Поддержка рукописного ввода
● Распознаваемый текст, возможно выполнение следующая операция
— Доступ по URL
— Телефонный звонок
— Копирование в буфер обмена
— Отправить электронное письмо
— Сохранить на Google Диск
— Сохранить в Google Keep
— Поделиться в Google+
— Поделиться в Google Hangouts
— и т.
Ваш комментарий будет первым