Программа для сканирования и распознавания текста
Для максимально эффективного использования устройства необходима программа распознавания текста. Профессиональные потоковые сканеры компании успешно работают с различными распространенными программными продуктами. Программа для оцифровки текста может быть приобретена как в комплекте с устройством, так и отдельно от него. На данный момент компании поставляет два варианта ПО, которое отвечает всем необходимым характеристикам и обеспечивает наилучшую производительность и эффективность эксплуатации устройства. Правильно подобранная программа для сканирования и распознавания позволит использовать возможности сканера на максимум.
Рекомендованное программное обеспечение для сканирования и распознавания информации
DpuScan – программа для сканирования и распознавания текста. Современное мощное ПО, предполагающее пакетную обработку информации. Продукт содержит все необходимые для настройки аппарата функции, а также специальные возможности: улучшение качества изображений, конвертация цветовой гаммы, распознавание текста, работа со штрих-кодами и патч-кодами, массовая сортировка документов.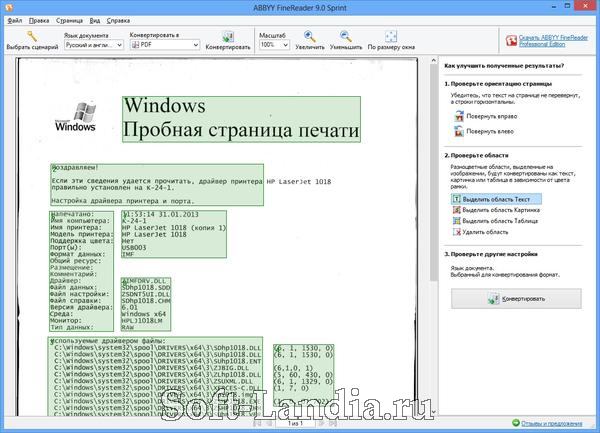
При одновременной работе большого количества станций, возможно, понадобится сервер централизованного управлениями лицензиями, профилями и библиотеками. Это решение позволяет не привязывать программное обеспечение к локальному компьютеру одного сотрудника и использовать программу для распознования текста на любой машине. Помимо прочего, решение также позволяет добавлять новые лицензии, осуществлять контроль доступа и ведение статистики, настройку и хранение профилей. Программа для распознания текста и серверное приложение оптимально расходуют ресурсы компьютера.
Другое специальное решение для проектной оцифровки документов – продукт LIMB. Эта программа распознавания текста представляет собой наиболее полное и профессиональное решение, содержащее в себе огромный набор различных инструментов.
Аналоги программных продуктов
Для работы с профессиональными сканерами может быть использована и другая программа распознания текста. В частности – наиболее распространенные и известные продукты от компании ABBYY (FineReader, FlexiCapture, FormReader, ScanStation, Recognition Server), распространенное за рубежом ПО от CROSSCAP и программа Kofax Capture.
Запросить цены
Программы для распознавания текста
Зачем нужны программы распознавания текста.
Программы распознавания текста позволяют работать с отсканированными изображениями. С их помощью выполняется редактирование информации, исправление ошибок, сохранение данных в нужном формате и т.д.
Как работает сканер.
Чтобы лучше понять ценность упомянутых программ разберемся с тем, как работает сканер. Механизм устройства помещен в корпус, верхняя часть которого представлена стеклом. Внутри находится яркая лампа и зеркала. Именно они отвечают за «фотографирование» источника для сканирования. При этом шрифт и изображения считываются в виде цветных, серых или черно-белых точек (в зависимости от модели устройства). А за распознавание текста и картинок отвечает драйвер сканера.
Именно они отвечают за «фотографирование» источника для сканирования. При этом шрифт и изображения считываются в виде цветных, серых или черно-белых точек (в зависимости от модели устройства). А за распознавание текста и картинок отвечает драйвер сканера.
Полученное изображение является своеобразной фотографией исходного источника, будь то разворот книги, лист формата A4 или справка. Программы для распознавания текста позволяют расширить возможности пользователя, редактировать текст, исправлять ошибки.
Для наглядности рассмотрим пример. Допустим, вам нужно вставить большой кусок текста из книги в дипломную работу. Чтобы не тратить время на перепечатывание с листа, страницы можно отсканировать. Однако этого недостаточно, поскольку вы получите файлы-картинки, которые не подойдут для использования в Microsoft Word. С помощью программ для распознавания текста пользователь отредактирует полученное изображение и сможет вставить информацию в текстовый редактор.
Возможности современных программ для распознавания текста.
Если предстоит сканирование листов с четко прописанными буквами, читабельным, ярким шрифтом, то с такой задачей справится любой сканер. Куда хуже обстоит дело, если речь идет о таких носителях информации, как старые, потрепанные листы бумаги или пожелтевшие газеты. Не каждый драйвер сможет идентифицировать подобный текст, а потому возможности специальной программы придутся как нельзя кстати. С их помощью утраченные области шрифта легко восстановить, дописав на клавиатуре в рамках редактора.
Отдельные программы предоставляют даже такие эксклюзивные возможности, как правка рукописного текста. Правда, для этого нужно, чтобы разрешение картинки было не меньше 300 точек на дюйм. Кроме того, буквы в строке должны быть примерно одной высоты, одного наклона и написаны как можно аккуратнее.
Функцию распознавания рукописного текста поддерживают такие программы, как ABBYY FineReader, CuneiForm (бесплатная утилита), MyScript Stylus, SimpleOCR и другие. Помимо русских символов они идентифицируют буквы, написанные на иностранном языке. Кроме того, программы распознают таблицы и рисунки, перенося их в компьютер для последующего редактирования.
Помимо русских символов они идентифицируют буквы, написанные на иностранном языке. Кроме того, программы распознают таблицы и рисунки, перенося их в компьютер для последующего редактирования.
Таким образом, ни один современный пользователь ПК, имеющий сканер, не обойдется без программы распознавания текста
. Выбор платных и бесплатных утилит позволит выбрать то, что отвечает именно вашим запросам с точки зрения функциональности.Текст — Распознавание
Freemore OCR September 01, 2020Freemore OCR — бесплатная и простая в использовании программа, которая позволяет быстро и легко извлекать текст из изображений и PDF документов, с последующим их сохранением в виде текстового (TXT) или Word файла…
get_app15 007 | Бесплатная |
Lingvanex Translator 1.1.132.0Мощный инструмент для перевода текста для больших документов на 127 языков. Присутствует возможность переводить голос и любые аудиофайлы, имеется функция преобразования речи в текст, можно переводить текст с фотографий, сохранять переводы в закладки и пр….
Присутствует возможность переводить голос и любые аудиофайлы, имеется функция преобразования речи в текст, можно переводить текст с фотографий, сохранять переводы в закладки и пр….
get_app581 | Условно-бесплатная |
ABBYY FineReader 15.0 / 10.0get_app1 821 452 | Демо версия |
NAPS2 6.1.2NAPS2 (Not Another PDF Scanner 2) — очень удобная оболочка для сканирования документов и сохранения их в формат PDF или в виде графического изображения…
get_app30 333 | Бесплатная |
HippoScan 1.5.6HippoScan (ранее ScanTool) — программа, которая пригодится тем пользователям, кто часто делает электронные копии бумажных документов. ..
..
get_app36 320 | Бесплатная |
Scanitto Pro 3.19 Scanitto Pro — быстрая и не перегруженная массой ненужных функций программа для сканирования. Поддерживает точную настройку параметров сканирования, копирование документов и сохранение документов в PDF и TIFF файлы…get_app26 551 | Условно-бесплатная |
AfterScan 6.3AfterScan — Если Вы занимаетесь сканированием и распознаванием текстов, имеете дело с поточным редактированием набранных текстов, собираете свою собственную электронную библиотеку или просто хотите привести в порядок мемуары, то эта программа для Вас. Про…
get_app28 982 | Условно-бесплатная |
ABBYY Screenshot Reader 11.0.250ABBYY Screenshot Reader — простая и удобная программа для создания снимков любой области экрана с возможностью автоматического распознавания текста на полученых изображениях.
get_app57 687 | Условно-бесплатная |
Polyglot 3000 3.79Полиглот 3000 — автоматический определитель языка, который предназначен для быстрого и корректного определения того на каком языке написан введённый Вами текст…
get_app25 044 | Бесплатная |
KyrSpell 2.3KyrSpell — Орфографический модуль проверки орфографии киргизского языка и расстановки переноса в приложениях Microsoft Office и других приложениях…
get_app3 124 | Бесплатная |
CuneiForm 12CuneiForm — удобное в эксплуатации приложение, которое предназначено для распознавания текста и конвертации бумажных документов и графических файлов в редактируемый текст. Используются алгоритмы оптического распознавания (OCR) и словарная проверка…
get_app131 044 | Бесплатная |
Spell Checker 2. 1.0.115
1.0.115Spell Checker — Программа для проверки орфографии введенного с клавиатуры текста. Spell Checker работает как отдельная надстройка системы и совместима с любым программным обеспечением…
get_app14 377 | Бесплатная |
Система оптического распознавания текстов — БИОРГ
Все чаще встречаются ситуации, когда человек сталкивается с задачей перевода рукописей или напечатанных на бумаге текстов на цифровые носители.
Это делают и огромные корпорации, где архивы ценных бумаг нужно для надежности перевести в электронный вид, и маленькие, но стремительно развивающиеся компании, которые не желают отставать от современных тенденций.
И это логично, ведь в эпоху информационных технологий все процессы сводятся к обеспечению максимального комфорта и автоматизации, это касается и ведения документооборота. На замену монотонному многочасовому труду, когда приходилось вручную перепечатывать километры информации приходят технологии оптического распознавания текста (OCR).
Что это означает
OCR или Optical Character Recognition – это система оптического распознавания символов, с помощью которой происходит преобразование изображений, к примеру фотографий печатного текста, файлов в PDF-формате, а также отсканированных документов, в текстовые форматы с возможностью их дальнейшего редактирования и наличием в них поиска.
Как результат – можно справиться с различными задачами. Например, если на почту пришел договор, а его необходимо отредактировать или есть бумажная версия документа, статьи, рукописного заявления и т.д., которое легко можно отсканировать. Но что делать дальше?
Используя различные программы по распознаванию текста, появляется возможность быстрого, а главное качественного их преобразования в редактируемые форматы, к примеру, doc или docx. Прибегая к такого рода услугам следует обращать внимание на многие факторы, которые могут сыграть ключевую роль при выборе компании, которая производит оптическое распознавание.
Что вы получите, обратившись в Биорг
Только высококачественную и квалифицированную помощь в оцифровке необходимых бумаг. Компания «Биорг» зарекомендовала себя как лидер в сфере сканирования и распознания документов. Работая с нами, клиенты получают весь спектр необходимых услуг, а также приятные бонусы:
- в работу принимаются бумаги с различной степенью тяжести распознавания текста, в том числе старые, ветхие или измятые;
- большой объем выполняемой работы – от 10 тысяч листов до 10 млн;
- возможность контролировать все этапы процесса, благодаря предоставлению отчетности;
- достоверность и сохранность данных – финансовая гарантия соответствия исходной и конечной информации;
- предварительная обработка и подготовка документов, а также сортировка цифрового варианта;
- работа с разными форматами: PDF, JPEG, RTF, TIFF, а также предоставление результата на различных электронных носителях;
Среди предоставляемых услуг стоит выделить:
- Сканирование, сортировка и обработка документовСистема дает возможность качественно и быстро обрабатывать заполненные от руки бумаги, такие как: бланки, анкеты, купоны маркетинговых акций и клубных программ, заявления, листы с опросами и бумаги с любыми личными данными.
 Результатом преобразования большого объема документов служит база данных с содержащимися документами и архив с полным объемом обработанных данных, в том числе с изображениями и базой. Подробнее об обработке анкет.
Результатом преобразования большого объема документов служит база данных с содержащимися документами и архив с полным объемом обработанных данных, в том числе с изображениями и базой. Подробнее об обработке анкет. - Архивная обработка документовПроцедура, в которой нуждаются многие компании и предприятия, ведь большие архивы в бумажном виде рано или поздно придется привести к цифровому формату. Среди вышеупомянутых документов могут быть: картотеки, книги, чертежи и графики, бухгалтерская и кадровая документация, а также архивные фонды и т.п. Подробнее об услуге обработки архивов.
- ПО БисканЭто уникальное комплексное программное обеспечение, которое использует систему оптического распознавания текста любого уровня сложности – от анкет или брошюр до рукописей и изображений. Подробнее о Бискане.
 Результатом преобразования большого объема документов служит база данных с содержащимися документами и архив с полным объемом обработанных данных, в том числе с изображениями и базой. Подробнее об обработке анкет.
Результатом преобразования большого объема документов служит база данных с содержащимися документами и архив с полным объемом обработанных данных, в том числе с изображениями и базой. Подробнее об обработке анкет.Какие трудности возникают при оцифровке
Системы оптического распознавания документов несовершенны и имеют ряд проблем. Самыми частыми становятся следующие:
- Различные формы начертаний символов, это зависит от того, какой шрифт использовался в исходном документе.
- Искажение символа, которое может быть вызвано влиянием световых эффектов – теней, отражений, бликов. Часто при некачественной фотографии или плохо отсканированном документе происходит искажение наклона или мелких элементов символа.
- Проблема масштабирования символов связана с изменением размера исходного символа в результате сканирования или фотографии.

Для решения вышеупомянутых проблем OCR должна уметь выделять текстовые поля, в них – строки, а уже затем – конкретные символы, оставаясь при этом не чувствительной к их размеру, шрифту и прочим параметрам печати или почерка. Но компания «Биорг» использует в работе методы по улучшению распознавания, которые призваны свести к минимуму подобные погрешности.
Процедура работы системы оптического распознавания
Изначально необходимо получить изображение исходного документа в цифровом формате. Это может быть фотография или отсканированный документ.
OCR должна определить, какая структура характерна тексту: наличие абзацев, таблиц, колонок, изображений и т. д. Затем происходит разделение части текстовой области на отдельные символы.
д. Затем происходит разделение части текстовой области на отдельные символы.
В зависимости от качества исходного текста используются растровые или векторные методы распознания текста, при которых исходное изображение символа сравнивается с хранящимся в памяти растровым или векторным символом соответственно.
Результатом будет считаться символ, который в наибольшей степени совпадает с изображением из памяти устройства. Для каждого конкретного документа система распознания подбирает отдельный набор изображений для сравнивания. В случае анализа фотографии, перед основной процедурой необходимо также обработать фото на предмет устранения бликов от вспышки, плохой яркости, недостаточного контраста и прочих дефектов изображения.
При применении ПО Бискан используются технологии, точно распознающие даже устаревшие или нечеткие изображения и документы. Точность гарантирована и достигает 99.9% – не более 1 ошибки на 10 000 символов. А как приятное дополнение – это простота использования и удобный интерфейс, пользоваться которым можно без каких-либо дополнительных умений.
Оставьте заявку
Программа для сканирования и распознавания текста, актуальный список
Главная страница » Софт / ПрограммыВ наше время появились очень удобные программы, с помощью которых легко и быстро напечатанный текст можно отредактировать, путем сканирования и вывода на экрана в документе Word. Больше не нужно перепечатывать в ручную и тратить на это несколько часов, теперь всё стало намного проще.
Вашему вниманию предоставляют знаменитую и удобную в своем использовании хорошую программу под названием Optical Character Recognition, что в переводе означает Оптическое распознавание символов. Данные программы созданы для перевода некоторого изображения, рисунков и любых предоставленных документов в текст который после можно отредактировать в любых известных текстовых редакторах. Эти программы очень экономят время и предоставляют большой выигрыш в скорости набора, ко всему этому количество ошибок сводится к минимуму. Так что эти программы сохраняют все возможные иллюстрации, что тоже не мало важно.
Далее мы расскажем Вам о некоторых программах с помощью которых вы сможете совершить подобные процедуры, так называемые программы-помощники. Они распознают как русский текст, так и украинский, и английский. Зачастую программа автоматически определяет язык документа, но пожеланию эту настройку можно выполнить и в ручную.
Программы для сканирования и распознавания текста
И та, первой мы рассмотрим программу OCR CuneiForm. Эта программа является бесплатной. С лёгкостью сканирует и распознает текст, эта программа русского разработчика Cognitive Technologies.
С самого начала программа OCR CuneiForm рассматривалась как некий коммерческий продукт, но начиная уже с 2007 года со средины зимы компания начала распространять данную программу бесплатно.
Данная программа оптического распознавания символов зачастую идет в комплекте с некоторыми, выборочными моделями знаменитых фирм сканеров таких как: Canon, Oki, HP и другие. Самое интересное что, данные этой программы пользуются так же большим спросом у потребителей программы Corel Draw, это некая программа для обработки изображений.
Эта замечательная программа OCR CuneiForm очень быстро и надежно к тому же и качественно распознает любой выбранный текст, потому что в базе программы заложено около 20 разных языков, которые эта программа может распознать. Так же она с лёгкостью справится с распознанием смешанного языка в документе.
Следующей программой для рассмотрения будет ABBYY Finereader. Это очень популярная на рынке программа для распознавания всех текстов. Создатель – российская известная компания ABBYY.
Данная программа очень популярна во многих регионах, она является одной из самых практичных и удобных программ, а также очень проста в своем использовании. Она имеет дополнительную функцию сохранения и оформления документов. Она представлена тремя разными пакетами, которые имеют разницу в своем интерфейсе, а также отличаются некоторыми возможностями, стоимостью и типом лицензии. И так нашему вниманию предоставлены следующие пакеты распознавания:
— Home Edition;
— Professional Edition;
— Corporate Edition.
Пакет Home Edition в основном предназначен исключительно для домашнего простого использования, он очень легкий в своем использовании. Очень удобное использования для тех, кто в основном хочет получить точную копию страницы с какой-либо книги, какого-либо журнала или других источников. Для дальнейшего редактирования в офисных программах. Интерфейс данной программы очень прост, все процедуры можно проделать с помощью нажатия всего лишь одной кнопочки, что очень удобно, легко и быстро.
Такой пакет распознавания разных символов как, Professional Edition и Corporate Edition, созданы для профессионального использования. В их дополнительных функциях присутствуют распознавание PDF файлов, а также в программы встроенный редактор текста и существуют программы которые проверяют орфографию. Версия Corporate более уникальна, её в основном используют в офисах, где налажена сетевая связь сканеров и других многофункциональных устройств. С помощью этой программы, редактировать и использовать полученные данные после сканирования могут сразу несколько пользователей.
Возможности данных OCR намного шире, чем у предыдущей. В программе заложено около 180 языков, для распознавания, 38 из которых эта программа может проверить на орфографию. Уже версия Professional может распознать иврит, японский и китайский языки. Так же Finereader имеет возможность открывать все графические файлы различных форматов.
В предпоследней версии ABBYY Finereader 9.0 есть такая возможность распознавать разные изображения, которые были сделаны на цифровой фотоаппарат.
Программа ABBYY Finereader не является бесплатной, но она заслуживает своей цены.
Перейдем к рассмотрению следующей не менее интересной программы OmniPage – это программа для сканирования и распознания текстовых документов от компании Nuance Communications.
Главным плюсом этой программы является скорость. Она очень быстро и одновременно качественно распознает любые документы. В своей базе данных имеет около 120 языком с разными алфавитами, такими как: латинский, кириллица, и другие. Эта программа, также, как и ABBYY Finereader может распознавать изображения, полученные с цифровой фотокамеры.
Еще одним значительным плюсом этой программы, является возможность осуществлять работу с несколькими документами одновременно. Есть возможность, открывать, редактировать, распознавать и сохранять некоторое количество документов одновременно, что очень удобно.
Программа OmniPage имеет три версии, которые на данный момент выпускаются, это – Standard, Professional, Enterprise. Версия Professional очень удобна тем, что имеет возможность любой документ сохранить в PDF. Это очень удобно.
Ознакомится более подробно с данной программой вы можете на сайте www.nuance.com
Также нашему вниманию представлена еще одна программа Readiris производитель – компания I.R.I.S.
Точно также как и выше предоставленные программы, данная программа создана для распознавания текста. Очень удобна в использовании, если требуется распознать таблицу либо иллюстрацию.
Существует две версии данного продукта – это Pro и Corporate . Данные программы распознают, как ближневосточные языки, так и восточные. В своей базе программа имеет 120 языков включая и русский. Версия Pro уступает Corporate в работе с PDF файлами.
В своей базе программа имеет 120 языков включая и русский. Версия Pro уступает Corporate в работе с PDF файлами.
Вконтакте
Одноклассники
Google+
Распознавание текста в документообороте
Данный модуль предназначен для распознавания текста при сканировании из карточки документа, поставляется только с коммерческими версиями СЭД. Для его работы в составе системы FossDoc используется стороннее программное обеспечение Tesseract, которое распространяется его разработчиками свободно по открытой лицензии. Для использования данного модуля требуется, чтобы он был включен в серверную лицензию FossDoc.
Далее будет рассмотрено:
- Распознавание текста
- Дополнительные настройки модуля
Распознавание текста
Команды для распознавания текста находятся в меню кнопки Сканирование карточки документа. Для распознавания можно сначала отсканировать некоторый документ (или приложить уже отсканированный документ на закладку файлы)
Для распознавания можно сначала отсканировать некоторый документ (или приложить уже отсканированный документ на закладку файлы)
Допустим вы получили тем или иным образом некоторые отсканированные документы. Нажмите Сканирование/Распознать и выберите файлы, для которых необходимо распознать текст:
Если вы установите галочку «Сохранить в один файл», система объединит тексты из выбранных файлов в один файл. В результате будет создан файл в двух форматах — PDF и TXT. По умолчанию название файлов — «Document»:
Аналогичным образом вы можете выбрать пункт Сканировать и распознать, чтобы сразу выполнить сканирование и распознавание отсканированного текста. После сканирования появится диалог:
Выберите Завершить и распознать и нажмите ОК. Документ с распознанным текстом будет создан. Установите галочку Сохранить в один файл для объединения нескольких документов в один.
Дополнительные настройки модуля
Система по умолчанию настроена на распознавание текста на 3 языках: украинский, английский и русский. Если вы уверены, что для вашей работы требуется только один язык для распознавания, можете выбрать в настройках только его, — это несколько сократит время работы программы распознавания. Для того, чтобы выбрать один язык, перейдите в программе администрирования в Библиотеки документов/Сервер на закладку Библиотека сервера, нажмите «Настройка«:
Выберите нужный язык и нажмите ОК.
В чем смысл сканирования и распознавания текста
Решились на создание электронного архива? Тогда вам будет полезно узнать, каким образом выполняется оцифровка бумажных документов. В ней выделим две составляющие – сканирование и индексирование.
Суть процесса сканирования заключается в создании цифрового изображения текста (скана) в редактируемом формате PDF. Затем наступает очередь индексирование от сканированных страниц, для возможности поиска информации. Текст можно или распознать и максимально автоматизировать процесс или делать опись ручками.
Затем наступает очередь индексирование от сканированных страниц, для возможности поиска информации. Текст можно или распознать и максимально автоматизировать процесс или делать опись ручками.
Сканирование
Сначала установим параметры этого процесса. Один из них — DPI-качество, или разрешение изображения. Чем выше установленный показатель, тем более четкой получится картинка и тем меньше ошибок придется исправлять впоследствии.
Теперь выберем режим. Текстовые черно-белые документы сканируют в режиме черно-белого сканирования, страницы с цветными схемами и фотографиями – в цветном режиме, сканирование в оттенках серого применяется для страниц с изображениями, когда цветность копии не имеет значения.
Индексирование с помощью распознавания
От сканированный документ распознается с помощью специальной программы. При распознавании многостраничного документа программа воспроизводит его исходную структуру, что в дальнейшем позволяет обойтись без форматирования. В процессе распознавания могут возникать ошибки – тогда область с ошибкой выделяется и редактируется и верифицируются.
В процессе распознавания могут возникать ошибки – тогда область с ошибкой выделяется и редактируется и верифицируются.
Сохранение результатов
На финальном этапе еще раз проверяем текст на наличие возможных дефектов распознавания. Это можно сделать автоматически из режима проверки или просмотреть документ самостоятельно, без участия программы. И последнее, сохраняем документ по-прежнему в формате PDF или конвертируем его в другой формат.
Работа завершена. Мы получили точную копию оригинала, теперь документ будет храниться, не занимая места на полке стеллажа, без риска кражи, порчи или потери.
Программное обеспечение для сканирования и считывания— SNOW
Программное обеспечение для сканирования и чтения начинается с использования сканера для сканирования бумажных документов в компьютер. Затем программа переведет изображение в цифровой текст, чтобы его можно было читать и редактировать. Этот процесс преобразования изображения текста, такого как отсканированный бумажный документ или электронный файл PDF, в редактируемый компьютером текст называется оптическим распознаванием символов (OCR).
Преимущества использования программного обеспечения OCR заключаются в том, что оно экономит время и усилия пользователя при создании и редактировании документов.Это позволит экспортировать преобразованный текст и использовать его с различными приложениями для обработки текстов, макетов страниц и электронных таблиц.
Лица, у которых есть проблемы с печатью, могут испытывать трудности с чтением бумажной информации из-за дислексии, нарушения зрения или различий в обучении, а физические различия могут означать, что обращение с печатным словом и его чтение могут быть препятствием, и им может быть полезно сканирование материала в компьютер. Это может помочь при чтении книг, почты, журналов, отчетов и других публикаций.
Использование программного обеспечения для сканирования и чтения может улучшить доступ к документам, а также может увеличить время выполнения задачи. Там, где это возможно, получить доступную в электронном виде копию материала часто проще, чем попросить учащегося, учителя, родителя или другого ресурса просканировать материал (например, запросить исходный текстовый формат распечатанного раздаточного материала). Учителя могут предоставлять документы, используя программное обеспечение для обработки текстов вместо формата PDF, а сотрудники службы поддержки учащихся должны попытаться получить доступные форматы книги у своих местных поставщиков альтернативных форматов.
Учителя могут предоставлять документы, используя программное обеспечение для обработки текстов вместо формата PDF, а сотрудники службы поддержки учащихся должны попытаться получить доступные форматы книги у своих местных поставщиков альтернативных форматов.
Лица с ослабленным зрением или слепотой могут воспользоваться программой оптического распознавания текста, которая включает следующие функции:
- Встроенная функция преобразования текста в речь
- Возможность изменять размер, тип и цвет шрифта
- Возможность смены фона и цвета выделения
- Обеспечьте дополнительный интервал между символами, словами или строками
- Для пользователей Брайля: возможность отправлять файлы на устройства для создания заметок или использовать вместе с обновляемым дисплеем Брайля.
Чтобы учесть различия в обучении, при покупке программного обеспечения OCR важно учитывать следующие особенности:
- Встроенная функция преобразования текста в речь
- Выделение слова, предложения или абзаца за раз с использованием контрастных цветов
- Отображать на экране только одно слово, чтобы лучше усвоить материал.
- Словарь, тезаурус, омофоны и слогификация
- Проверка орфографии, Предсказание
- Инструменты исследования, такие как выделение, закладки, сноски, текстовые заметки и голосовые заметки
Приложения и устройства OCR (например,грамм. Ручки OCR) обеспечивают портативность или позволяют людям с небольшим опытом работы с компьютером или без него использовать его с легкостью. Обязательно подумайте о том, требуется ли по-прежнему компьютерное программное обеспечение, поскольку портативные варианты могут быть более подходящими в качестве быстрого решения в пути, но преобразование более длинных чтений в цифровой текст может быть лучше для более длинных документов.
Хотите узнать больше о программах для сканирования и чтения? Ottawa Network for Education создала видеоролики для учащихся, которые заинтересованы в изучении или начале использования технологий для чтения, письма и других занятий в школе.Чтобы узнать больше о программах для сканирования и чтения, посетите веб-сайт Оттавской образовательной сети и посмотрите видео под названием «Слух значит верить. AT для поддержки чтения »и« Инструменты для чтения ».
Вопросы, которые следует задать при выборе программного обеспечения для сканирования и чтенияФункции и настройка
- Поддерживает ли он функции, для которых вы хотите его использовать? (например, оптическое распознавание символов для сканирования распечатанных документов или недоступных PDF-файлов и т. д.)
- Требуются ли большие объемы чтения? Какова точность программного обеспечения при преобразовании больших объемов текста? Рассмотрим услуги или подход к высокоскоростному сканированию. Наличие учебников, которые уже доступны для программ преобразования текста в речь или чтения с экрана, может сэкономить время вместо того, чтобы школа сканировала и добавляла правильную разметку / теги в документы.
- Может ли программа управлять многоколоночным текстом?
- Есть ли текстовое представление и можно ли его настроить (например,г., размер, цвет, стиль шрифта; межстрочный и словарный интервалы, поля; маскировка; отображение одного слова и т. д.)
- Существуют ли дополнительные функции или настраиваемые параметры, которые соответствуют потребностям ваших пользователей? (например, предсказание слов при написании документов, увеличение просмотра текста на странице, настройка размера меню или количества отображаемых элементов). Различные программные приложения имеют функции, которые могут поддерживать разные потребности (например, полное управление с клавиатуры для полностью слепого ученика по сравнению с интерфейсом на основе значков для учащегося без потери зрения и различий в обучении).
- Нужен ли пользователю доступ к нескольким компьютерным системам? Если да, рассмотрите варианты (например, программное обеспечение на USB-ключе, программное обеспечение с несколькими установками на лицензию, онлайн или встроенные опции и т. Д.)
- Требуется ли портативность? Рассмотрим решение для сканирования и чтения, которое представляет собой портативное устройство (например, носимые устройства, специальный планшет, перо) или приложение на телефоне или планшете.
Совместимость
- У вас уже есть повседневное программное обеспечение с функцией распознавания текста — обязательно проверьте, насколько хорошо эта функция работает для ваших целей.
- Совместимо ли оно с вашим компьютером или операционной системой устройства?
- Это панель инструментов, которая считывается в других программных приложениях, или она считывается только в рамках своей собственной программы (или их комбинации)? Если это панель инструментов, какие приложения она поддерживает? (например, совместимость с какими интернет-браузерами)
- Какие форматы файлов он может читать? (например, PDF, DOCX, Daisy, TXT, HTML и т. д.) Можете ли вы экспортировать информацию в разные форматы файлов?
- Нужно ли работать с другой техникой (например, с.g., распознавание голоса для тех, кто испытывает трудности с использованием клавиатуры) и можно ли запрограммировать или настроить другие технологии для совместной работы?
- Совместим ли сканер с программным обеспечением для сканирования и чтения?
- Может ли он выводиться на обновляемый дисплей Брайля или печатать на устройстве для тиснения Брайля?
Удобство использования
- Какова кривая обучения различным функциям программного обеспечения? Некоторое программное обеспечение может показаться простым, но использование функций может быть не таким интуитивным, как кажется.
- Есть ли у него удобный интерфейс (например, меню, панель инструментов, панель управления)? Насколько сложна структура меню или панели инструментов? Насколько легко изменить настройки?
- Имеет ли пользователь базовые навыки работы с компьютером? Рассмотрим сканер или устройство со встроенным программным обеспечением для оптического распознавания текста для людей, практически не имеющих опыта работы с компьютером. Подумайте, нужно ли ему подключаться к монитору или телевизору для отображения текста, есть ли у него место для хранения или можно сохранять на USB-ключ, является ли он портативным, имеет удобную панель управления или кнопки, время автономной работы и т. Д.
Речевой вывод
- Можно настроить голос? (например, речь, высота звука, громкость, многословность или какой речевой отклик вы хотите услышать)?
- Какие голоса и синтезаторы доступны? На каком они языке? Можно ли скачать / купить и установить дополнительные голоса?
- Можно ли изменять размер блоков чтения? (например, чтение по абзацу, чтение по предложению)
- Будет ли речевая обратная связь мешать окружающей среде? Нужны наушники?
- Может ли он преобразовывать текст в аудиофайлы, такие как.wav или .mp3 для последующего прослушивания?
Опора
- Какие типы встроенных обучающих программ доступны? Какие еще виды поддержки доступны для пользователей?
- Есть ли пробный период или демонстрационная копия для тестирования программного обеспечения?
- Как вы получите поддержку, если она вам понадобится? (например, техник в школе, местный продавец, по телефону, по электронной почте, через удаленный доступ и т. д.)
- Сколько стоят обновления? Можно ли приобрести какое-либо соглашение об управлении программным обеспечением или пакет обновления?
- Какая модель оплаты? (е.г., покупка, оплата по факту использования)
Ссылки предназначены только для информационных целей. SNOW не поддерживает любое из следующего программного и аппаратного обеспечения.
ABBYY — ABBYY Fine Reader (Windows и Mac)
Adobe — Acrobat (Windows и Mac)
Creaceed — Prizmo (Mac)
Expervision — TypeReader (Windows)
И.R.I.S. — ReadIRIS (Windows и Mac)
Nuance — OmniPage (Windows)
Prime Recognition — PrimeOCR (Windows)
Газировка — PDF Anywhere
Vividata — Магазин OCR (Linux и UNIX)
Производители программного обеспечения для оптического распознавания текста с функциями преобразования текста в речьПрограммное обеспечение Claro — Claro Read Plus (Windows и Mac)
Freedom Scientific — Открытая книга (Windows), WYNN Wizard (Windows)
Образовательные системы Kurzweil — Kurzweil 1000 (Windows), Kurzweil 3000 (Windows и Mac)
Nuance — Omni Page Standard (Windows), Omni Page Professional (Windows), Omni Page Pro X (Mac), Omni Page Enterprise (Windows)
Premiere Assistive Technology — Scan and Read Pro доступен отдельно или в составе следующих пакетов: Literacy Productivity Pack (Windows и Mac), Premier To Go (Windows)
Text Help Systems Ltd.- Чтение и запись (Windows, Mac, iOS, Android, Google)
Производители программного обеспечения для оптического распознавания текста с альтернативными сканирующими устройствамиC Technologies — C Pen (Windows)
Freedom Scientific — SARA CE (устройство для сканирования и чтения), продукты ABIsee: Zoom-Ex (Windows), ZoomTwix (Windows), Eye Pal (Windows), Eye Pal SOLO и SOLO LV, Eye-Pal Ace и Ace Plus
Optelec — ClearReader
WizCom Technologies — перо для чтения, Quicktionary
** Также проверьте производителей систем видеонаблюдения, так как многие из них имеют опцию оптического распознавания текста
Производители программного обеспечения OCR для нелатинского языкаABBYY — ABBYY FineReader (Windows)
И.R.I.S. — ReadIRIS для Windows (Windows), ReadIRIS для Mac (Mac)
NewSoft — BizCard, Presto! DanChing (Windows)
Бесплатное / открытое ПО OCR / проектыFreeOCR от Tesseract (Windows)
GOCR по общественной лицензии GNU (Linux / Mac / Windows)
Microsoft Office Document Imaging (Windows)
Ocrad — это движок OCR с открытым исходным кодом, который работает с программой сканирования Kooka и KDE (GNU / Linux и UNIX)
SimpleOCR от Simple Software (Windows)
TopOCR от TopSoft, Inc.(Windows)
WebOCR от Expervision (Windows)
** Обратите внимание, что ряд основных продуктов (например, OneNote) поддерживает функции распознавания текста.
Как это соотносится с законодательством AODA Программное обеспечение для сканирования и чтенияотносится к следующим разделам Интегрированных стандартов доступности Закона о доступности для жителей Онтарио с ограниченными возможностями (AODA), в частности к некоторым из следующих разделов Стандартов информации и коммуникации:
Значение AODA- Программное обеспечение для сканирования и чтения позволяет пользователям сканировать печатный документ, который можно преобразовать в один или несколько форматов файлов, таких как электронный текст, шрифт Брайля или аудио, предоставляя альтернативные средства доступа к информации и образовательным ресурсам.
- Люди взаимодействуют, учатся и общаются по-разному. Возможности обучения расширяются, когда предоставляются гибкие способы использования учебных материалов. Для обмена знаниями важно учитывать, как люди общаются. Альтернативные форматы учитывают различные способы обмена информацией.
- Закон AODA устанавливает, что образовательные учреждения и их сотрудники знают, как создавать доступные или готовые к конвертации версии учебников и печатных материалов, а также уметь взаимодействовать и общаться с людьми с ограниченными возможностями, которые могут использовать альтернативные форматы и устройства.
Чтобы узнать, как этот раздел соотносится с основными принципами правил обслуживания клиентов AODA, посетите страницу AODA на SNOW.
Чтобы узнать о способах внедрения инноваций, разработки и дизайна для обеспечения доступности, посетите веб-сайт Исследовательского центра инклюзивного дизайна (IDRC) Университета OCAD и веб-сайт проекта льдиной IDRC.
7 лучших программ оптического распознавания текста для Windows 10 [Руководство на 2021 год]
Soda PDF предлагает широкий спектр решений для вашего офисного пакета, а также мощный инструмент распознавания текста, который поможет вам оцифровать ваши документы.
Преобразовать документы в цифровой текст без повторного набора довольно просто. Просто сделайте снимки своих физических документов с помощью мобильного телефона, загрузите их в Soda PDF и конвертируйте их в редактируемый PDF за считанные секунды.
Очень гибкий, этот инструмент позволяет настраивать инструмент распознавания текста в соответствии с вашими потребностями. Благодаря как автоматическому, так и ручному сканированию вы полностью контролируете передачу текста.
Необходимо одновременно сканировать несколько изображений или документов? Функция пакетного сканирования OCR помогает распознавать текст из нескольких изображений или документов, сокращая время преобразования.
Инструмент OCR включен в PRO-версию Soda PDF, которая предлагает наилучшее соотношение цены и качества для всех ваших нужд редактирования PDF.
Soda PDF включает ряд других инструментов, которые помогут вам редактировать PDF-файлы проще и быстрее:
- Полнофункциональные возможности редактирования
- Простое создание и преобразование PDF
- Объединение и сжатие файлов
- Заполнение форм, опросы и электронные подписи
Если вы не уверены, подходит ли вам Soda PDF, доступна бесплатная пробная версия, которая позволяет изучить все его функции.Гибкая система ценообразования позволяет выбрать наиболее подходящий тарифный план.
Soda PDF
Превратите любое изображение в текст за секунды с помощью Soda PDF!Readiris — последняя версия этого высокопроизводительного программного обеспечения для распознавания текста. Он поставляется с новым интерфейсом, новым механизмом распознавания и более быстрым управлением документами.
Вы можете легко конвертировать во множество различных форматов, включая аудиофайлы благодаря его вербальному распознаванию.
Readiris — одно из тех чрезвычайно мощных программ оптического распознавания текста, которые требуют меньше усилий для начала работы.Хотя это платная программа, вы получаете то, за что платите.
Readiris поддерживает большинство форматов файлов и обладает другими привлекательными функциями, упрощающими процесс преобразования.
Например, изображения могут быть получены с подключенных устройств, таких как сканеры, и приложение также позволяет настраивать параметры обработки, такие как настройки DPI.
После завершения обработки Readiris определяет текстовые разделы или зоны и позволяет извлекать тексты либо из определенной зоны, либо из всего файла.
Readiris имеет редкую функцию облачного сохранения, которая позволяет пользователям сохранять извлеченный текст в различных облачных хранилищах, таких как Google Drive, OneDrive, Dropbox и другие.
Он также имеет множество функций редактирования и обработки текста, позволяя пользователям даже сканировать штрих-коды.
Readiris
Конвертируйте аудиоформаты и создавайте редактируемые файлы из отсканированных документов. Получите лучшее предложение прямо сейчас!сканов могут быть доступны для поиска — Как оцифровать ваши источники (DIY)
сканов могут быть доступны для поиска — Как оцифровать ваши источники (DIY) — Библиотечные руководства в Университете Тулейна Перейти к основному содержаниюПохоже, вы используете Internet Explorer 11 или старше.Этот веб-сайт лучше всего работает с современными браузерами, такими как последние версии Chrome, Firefox, Safari и Edge. Если вы продолжите работу в этом браузере, вы можете увидеть неожиданные результаты.
Сделайте PDF-файлы доступными для поиска с помощью OCR
OCR (оптическое распознавание символов) — это технология, которая позволяет преобразовывать различные типы текстовых документов, например отсканированные бумажные документы, файлы PDF или изображения, снятые цифровой камерой, в редактируемые данные с возможностью поиска.
Почему это полезно?
Когда OCR преобразует отсканированное изображение в цифровой текст, оно становится текстовым файлом с возможностью поиска, что значительно упрощает навигацию.
Вы можете быстро найти номер страницы любимой цитаты или, например, найти все случаи использования определенного ключевого слова в большом документе.
Вы также можете копировать, вставлять и редактировать фрагменты текста в документе.
Документы можно преобразовать в цифровой текст с помощью программного обеспечения оптического распознавания текста, такого как Adobe Acrobat Pro DC .
Лучшие практики и ограничения
Рекомендации по настройке сканирования для OCR:
- Для точности обычно рекомендуется разрешение 300 dpi. Если размер шрифта меньше 10 пунктов, рекомендуется 400 точек на дюйм.
- Оттенки серого рекомендуется по сравнению с Ч / Б, потому что они сохранят больше деталей.Если в вашем документе есть цветные изображения, вам следует сканировать в цветном режиме.
- PDF, TIFF и PNG рекомендуются для несжатых форматов файлов. JPEG будет терять качество при каждом редактировании и сохранении.
- Средняя яркость 50% подходит для большинства сканированных изображений. Слишком высокая или низкая яркость может отрицательно повлиять на точность.
- Прямолинейность начального сканирования может повлиять на качество распознавания текста. Перекошенные страницы могут привести к неточному распознаванию.
Некоторые ограничения OCR:
- OCR может не преобразовывать символы с очень большим или очень маленьким размером шрифта.
- OCR лучше всего работает с печатными документами хорошего качества. Рукописные документы не могут быть легко прочитаны программой оптического распознавания текста.
- Язык: тексты, опубликованные до 1850 года, могут быть несовместимы с программным обеспечением OCR.
- Шум — крапинки, полосы, водяные знаки, штампы и другие знаки, не являющиеся частью текста, могут мешать распознаванию текста. Это могут быть изображения с рукописными заметками, текстом в кружке и другими примечаниями, которые иногда делаются для документа до сканирования.
Это произведение находится под лицензией Creative Commons Attribution-NonCommercial 4.0 Международная лицензия.
OCR не распознает текст в Adobe Acrobat Professional | Small Business
Оптическое распознавание символов предоставляет почти автоматизированные средства оцифровки текста со отсканированных страниц, устраняя необходимость их повторного набора. Adobe Acrobat Professional включает в себя возможности оптического распознавания текста, которые позволяют сохранять отсканированные результаты непосредственно в форматах Rich Text Format или в форматах файлов Microsoft Word DOC и DOCX. Если вы открываете документ в Acrobat Professional, но программа отказывается распознавать текст, четко видимый на странице, проверьте исходный файл на предмет некоторых распространенных проблем, которые могут вызвать проблемы с распознаванием текста.
Живой текст
Возможно, наименее очевидная причина сбоев оптического распознавания текста в Acrobat Professional — это попытка оцифровывать страницу, которая уже содержит живой текст. Если вам абсолютно необходимо запустить OCR для текста, который вы можете скопировать в буфер обмена и вставить в текстовый редактор или экспортировать из Acrobat непосредственно в текстовый формат, вы должны сначала преобразовать живой текст вашего файла в пиксели. В противном случае вы увидите сообщение об ошибке, сообщающее об ошибке распознавания.
Перекошенный или размытый источник
Отсканированные изображения с низким разрешением менее 150 пикселей на дюйм обеспечивают плохой исходный материал для возможностей OCR Acrobat Professional, а также для других программ OCR.Точно так же, если ваши сканы получаются искаженными, вероятность получения хороших результатов снижается. Исправление проблем с низким разрешением обычно требует повторного сканирования источника при более высоком значении ppi, предпочтительно 300 ppi. Если вы сканируете распечатанные страницы на графическом сканере без устройства подачи документов, найдите время, чтобы правильно расположить бумагу на стекле сканера, или откройте сканы в программе, которая может помочь вам выровнять их, например Adobe Photoshop.
Оригинал низкого качества
Хотя сканирование с высоким разрешением улучшает результаты оптического распознавания текста, обеспечивая Acrobat Professional более качественным исходным материалом, старая поговорка «мусор на входе, мусор на выходе» применяется, когда ваш оригинал низкого качества.Сканирование отправленных по факсу материалов и распечаток с принтера для создания микрофильмов или микрофиш может привести к худшим результатам распознавания текста. Если такие источники, как эти, являются вашей единственной формой ввода, запланируйте потратить время, необходимое для исправления вывода OCR, или перепечатайте текст, если он короткий.
Формы и графика
Программа оптического распознавания текста лучше всего работает, когда вы представляете ее с четкими непрерывными полосами текста в полностраничных столбцах. Если исходный материал включает текст в рамке, такой как формат формы, или большое количество графического материала, качество распознавания текста может снизиться, поскольку программное обеспечение изо всех сил пытается отличить текст от нетекстового материала.В крайних случаях вы можете сделать фотокопию формы и очистить некоторые ее поля и строки, прежде чем пытаться отсканировать и распознать ее содержимое.
Ссылки
Биография писателя
Элизабет Мотт писала с 1983 года. Мотт имеет большой опыт написания рекламных текстов для всего, от кухонной техники и финансовых услуг до образования и туризма. Она имеет степень бакалавра искусств и магистра искусств по английскому языку в Университете штата Индиана.
PDF7: выполнение оптического распознавания текста в отсканированном документе PDF для получения фактического текста
Цель этого метода — гарантировать, что визуально отображаемый текст представлен таким образом, что его можно воспринимать без его визуальное представление, мешающее его читабельности.
Документ, состоящий из отсканированных изображений текста, изначально недоступен потому что содержание документа — изображения, а не текст, доступный для поиска. Вспомогательные технологии не могут читать или извлекать слова; пользователи не могут выделять, редактировать, изменять размер или перекомпоновку текста, а также они не могут изменять текст и фон цвета; и авторы не могут управлять PDF-файлом для обеспечения доступности.
По этим причинам авторам следует использовать фактический текст, а не изображения. текста, используя инструмент разработки, такой как Microsoft Word или Oracle Open Office для создания и преобразования содержимого в PDF.
Если авторы не имеют доступа к исходному файлу и инструменту разработки, отсканированные изображения текста можно преобразовать в PDF с помощью оптических символов распознавание (OCR). Затем Adobe Acrobat Pro можно использовать для создания доступных текст.
Этот пример показан с Adobe Acrobat Pro. Существуют и другие программные инструменты, выполняющие аналогичные функции. См. Список других программных инструментов в PDF Authoring Tools, которые обеспечивают поддержку специальных возможностей.
В этом примере используется простое сканированное изображение текста на одной странице.Для обеспечения что фактический текст хранится в документе, выполните следующие действия:
Отсканируйте документ с максимально возможным разрешением для улучшения производительность OCR.
Загрузите отсканированный документ в Acrobat Acrobat Pro. Выберите Документ> OCR. Распознавание текста> Распознать текст с помощью OCR …
В следующем диалоговом окне выберите переключатель Все страницы в разделе Страницы (или Текущая страница, если вы конвертируете только одну страницу), а затем выберите ОК.
В списке «Настройки» выберите «Изменить». В следующем диалоговом окне выберите Форматированный текст и графика в раскрывающемся списке «Стиль вывода PDF». Это важно для обеспечения доступности.
В зависимости от разрешения и четкости текста OCR преобразует изображения слов и символов в фактический текст. Напишите что Acrobat Pro не распознает, указан как «подозреваемый в распознавании текста» или текстовый элемент, который, как подозревает Acrobat, был распознан неправильно.
Чтобы исправить подозреваемых, выберите «Документ»> «Распознавание текста с оптическим распознаванием текста»> «Найти». Первый подозреваемый OCR. Acrobat Pro представляет каждого подозреваемого по одному, которые можно исправить с помощью инструментов коррекции Acrobat Pro.
Запустите Advanced> Accessibility> Add Tags to Document
Test for accessibility: Advanced> Accessibility> Full Проверить …
Примечание: В качестве альтернативы вы можете использовать Документ> OCR Распознавание текста> Найти всех подозреваемых OCR для отображения всех подозреваемых OCR в то же время для более быстрого редактирования.
На следующем изображении показан отсканированный одностраничный документ в Adobe Acrobat. Pro.
На следующем изображении показано преобразованное содержимое после добавления тегов в документ. Возможно, потребуется использовать TouchUp Reading Инструмент заказа и панель тегов, чтобы правильно пометить контент для предполагаемого итоговый документ. Для этого примера изображение спирального переплета книги был отмечен при преобразовании. Использовался инструмент TouchUp Reading Order. , чтобы скрыть изображение как фоновое (декоративное) (см. PDF4: Скрытие декоративных изображений с помощью тега Artifact в документах PDF ).Рецепт заголовки были помечены как заголовки первого уровня.
Примечание. Acrobat Pro может автоматически добавлять теги при запуске файла. через OCR.
Этот пример показан в действии на рабочем примере генерации фактического текста и результата выполнения OCR.
Ресурсы предназначены только для информационных целей, без какой-либо поддержки.
Процедура
Для каждой страницы, преобразованной в текст с помощью OCR, убедитесь, что результат PDF-файл был преобразован правильно одним из следующих способов:
Прочтите PDF-документ с помощью программы чтения с экрана или инструмента, который читает вслух, прислушиваясь к тому, что весь текст читается правильно и в правильном порядке чтения.
Сохраните документ как текст и убедитесь, что преобразованный текст является полным и в правильном порядке чтения.
Используйте инструмент, способный отображать преобразованный контент чтобы открыть документ PDF и убедиться, что весь текст был преобразован и находится в правильном порядке чтения.
Используйте инструмент, который предоставляет доступ к документу через специальные возможности. API и убедитесь, что весь текст был преобразован и находится в правильном порядок чтения.
Ожидаемые результаты
Если это достаточный метод для критерия успеха, то неудача этой процедуры тестирования не обязательно означает, что критерий успеха не был удовлетворен каким-либо другим способом, только то, что этот метод не был успешным реализованы и не могут использоваться для подтверждения соответствия.
Программное обеспечение для ScanSnap | Справка ScanSnap
В этом разделе объясняются функции каждого программного обеспечения и способы его установки.Используйте программное обеспечение, чтобы указать настройки сканирования для сканирования документов с помощью ScanSnap или для управления, поиска, редактирования и использования записей данных содержимого, созданных из документов, которые вы отсканировали.
Окна
- ScanSnap Home
Этот драйвер сканера требуется для сканирования документов с помощью ScanSnap. Кроме того, это настольное приложение для более эффективного редактирования, управления и использования записей данных контента. Отсканированные изображения можно сохранить на компьютер в виде файлов PDF или JPEG.
Кроме того, файлы, отличные от изображений, созданные путем сканирования документов с помощью ScanSnap, могут быть импортированы в ScanSnap Home в качестве записей данных содержимого.
Загрузите ScanSnap Home отсюда, а затем установите его.
- Онлайн-обновление ScanSnap
Это приложение, которое проверяет последние обновления и доступные программы на сервере загрузки и устанавливает их.
Проверка последних обновлений и проверка доступных программ выполняется автоматически и регулярно на сервере загрузки, и появляется уведомление, если они доступны.
ScanSnap Online Update устанавливается вместе со ScanSnap Home.
- ABBYY FineReader для ScanSnap
Это приложение может выполнять распознавание текста на отсканированных изображениях с помощью OCR (оптического распознавания символов) для преобразования данных изображения в файлы Word, Excel или PowerPoint, которые можно редактировать.
Установите ABBYY FineReader для ScanSnap из ScanSnap Online Update после установки ScanSnap Home.
Отобразите Главное окно ScanSnap Home и выберите [Справка] в меню → [Онлайн-обновление] → [Проверить наличие обновлений], чтобы запустить ScanSnap Online Update.
- Пакет OCR
Пакет OCR — это набор языков, которые можно использовать для распознавания текста.Установив OCR Pack, вы можете добавить дополнительные языки для распознавания текста.
Список языков, включенных в пакет OCR, см. В пакете OCR (Windows).
- Kofax Power PDF Standard Kofax Power PDF Standard или Nuance Power PDF Standard Nuance Power PDF Standard
Это приложение для создания, редактирования, управления и использования электронных документов в формате PDF.
Чтобы установить Kofax Power PDF Standard, перейдите по URL-адресу, который напечатан в лицензионном сертификате, поставляемом с ScanSnap, и загрузите установщик с веб-сайта.
Чтобы установить Kofax Power PDF Standard или Nuance Power PDF Standard, перейдите по URL-адресу, который напечатан в лицензионном сертификате, поставляемом с ScanSnap, и загрузите установщик с веб-сайта.
Чтобы установить Nuance Power PDF Standard, перейдите по URL-адресу, указанному в лицензионном сертификате, поставляемом со ScanSnap, и загрузите установщик с веб-сайта.
Подробнее об установке программного обеспечения см. Здесь.
Порядок работы см. В справке приложения.
Mac OS
- ScanSnap Home
Этот драйвер сканера требуется для сканирования документов с помощью ScanSnap.Кроме того, это настольное приложение для более эффективного редактирования, управления и использования записей данных контента. Отсканированные изображения можно сохранить на компьютер в виде файлов PDF или JPEG.
Кроме того, файлы, отличные от изображений, созданные путем сканирования документов с помощью ScanSnap, могут быть импортированы в ScanSnap Home в качестве записей данных содержимого.
Загрузите ScanSnap Home отсюда, а затем установите его.
- Онлайн-обновление ScanSnap
Это приложение, которое проверяет последние обновления и доступные программы на сервере загрузки и устанавливает их.
Проверка последних обновлений и проверка доступных программ выполняется автоматически и регулярно на сервере загрузки, и появляется уведомление, если они доступны.
ScanSnap Online Update устанавливается вместе со ScanSnap Home.
- ABBYY FineReader для ScanSnap
Это приложение может выполнять распознавание текста на отсканированных изображениях с помощью OCR (оптического распознавания символов) для преобразования данных изображения в файлы Word, Excel или PowerPoint, которые можно редактировать.
Установите ABBYY FineReader для ScanSnap из ScanSnap Online Update после установки ScanSnap Home.
Отобразите Главное окно ScanSnap Home и выберите [Справка] в строке меню → [Онлайн-обновление] → [Проверить наличие обновлений], чтобы запустить ScanSnap Online Update.
- Kofax Power PDF Standard для MacKofax Power PDF Standard для Mac или Nuance Power PDF Standard для MacNuance Power PDF Standard для Mac
Это приложение для создания, редактирования, управления и использования электронных документов в формате PDF.
Чтобы установить Kofax Power PDF Standard для Mac, перейдите по URL-адресу, который напечатан в лицензионном сертификате, поставляемом с ScanSnap, и загрузите установщик с веб-сайта.
Чтобы установить Kofax Power PDF Standard для Mac или Nuance Power PDF Standard для Mac, перейдите по URL-адресу, который напечатан в лицензионном сертификате, поставляемом с ScanSnap, и загрузите установщик с веб-сайта.
Чтобы установить Nuance Power PDF Standard для Mac, перейдите по URL-адресу, который напечатан в лицензионном сертификате, поставляемом с ScanSnap, и загрузите установщик с веб-сайта.
Подробнее об установке программного обеспечения см. Здесь.
Порядок работы см. В справке приложения.
Top 5 OCR (оптическое распознавание символов) API и программное обеспечение
Что такое OCR?
OCR — Оптическое распознавание символов — полезная функция машинного зрения.OCR позволяет распознавать и извлекать текст из изображений для дальнейшей обработки / сохранения. Это очень полезно для обработки сканированных изображений / изображений текста — например, при работе со счетами, отсканированными формами и вывесками.
Мы рассмотрели несколько API для распознавания текста, оценив их на основе:
- Точность — мы перепробовали их все с изображением ниже, чтобы убедиться, что они четко распознают текст.
- Цена — мы указываем цену за вызов различных API.
- Специальные возможности — некоторые из рассмотренных нами API обладают особыми возможностями, что делает их более подходящими для конкретных задач, таких как сканирование счетов / распознавание логотипов.
Мы использовали следующее изображение, чтобы опробовать API, поскольку оно содержит много текста в разных стилях и размерах, а также некоторую графику, которая может сбить с толку API.
Посмотреть список лучших OCR API
Лучшие OCR API
1. Microsoft Computer Vision
Microsoft Computer Vision API — это полный набор инструментов компьютерного зрения, охватывающий такие возможности, как создание интеллектуальных эскизов изображений , распознавание знаменитостей на изображениях и описание содержания изображений с помощью ИИ.
Точность
Microsoft API предлагает две конечные точки OCR: OCR из файла изображения и OCR из URL-адреса изображения. Обе конечные точки работают одинаково с разными источниками.
Распознавание текста работает хорошо и возвращает текст, разделенный на области текста. В каждой области есть строки, и в каждой строке есть слова, которые содержат фактический текст. Разделение удобно для понимания структуры содержимого изображения, хотя, если вам нужен текст в виде одной большой строки и вас не волнует позиционирование, потребуется дополнительный код.
Цена
Уровень бесплатного пользования API Microsoft предоставит вам 5000 запросов в месяц. У API есть 3 платных плана:
- 19,90 долларов -> 15 000 запросов в месяц
- 74,90 долларов США -> 70 000 запросов в месяц
- 199,90 долларов США -> 200 000 запросов в месяц
По теме: Как использовать API компьютерного зрения с Python
2. SemaMediaData
Этот API представляет собой выделенную платформу OCR с единственной функцией — Image OCR.У него также есть «родственный» API — Video OCR, который оптимизирован для извлечения текста из видео (подробнее об этом позже).
SemaMedia API также требует ручной настройки языка для каждого запроса (с помощью параметра lang). В сценариях, где язык известен, это должно повысить точность, поскольку позволяет API сравнивать распознанные слова со словарем (при использовании параметра df = True).
Точность
API очень хорошо обработал предоставленное изображение.Он возвращает массив результатов, каждая область текста с позицией на изображении, а также текстовый результат.
Специальные возможности
Платформа SemaMedia также поддерживает видео OCR с Video OCR API. Согласно документам, OCR видео — это каскад анализа, который включает в себя сегментацию видео (жесткую вырезку), обнаружение / распознавание видеотекста и распознавание именованных объектов из видеотекста (NER — это бесплатная надстройка). Результат анализа этого метода обеспечивает автоматический поиск и индексирование видео, а также поиск видео по содержанию в видеоархивах.Подробный пример можно найти на нашем демонстрационном сайте.
Цена
Уровень бесплатного пользования API SemaMedia дает вам 100 запросов в месяц. У API 3 платных плана:
- 50,00 долларов -> 2200 запросов в месяц
- 200,00 долларов США -> 13 500 запросов в месяц
- 500,00 долларов США -> 40 000 запросов в месяц
3. Taggun
Taggun API — это уникальный OCR API, предназначенный непосредственно для сканирования счетов-фактур и квитанций.Это может быть полезно, поскольку API не только распознает текст на изображении, но также распознает структуру счета и возвращает проанализированные данные, такие как totalAmount , taxAmoumt , merchantName и т. Д.…
Accuracy
Вызывая конечную точку обработки простых квитанций, API возвращает оценку точности для каждого возвращенного фрагмента информации. Иногда это будет 0, и информация будет отсутствовать. Однако когда информация есть, она обычно точна.
Метка по точности метки может использоваться, чтобы запрашивать у пользователей поля, которые не распознаются должным образом в отсканированном счете.
Цена
Taggun API имеет бесплатный план, который включает 50 запросов в месяц, и платный план стоимостью 90 долларов, который включает 1000 ежемесячных запросов.
4. Cloudmersive
Cloudmersive OCR API — отличный инструмент для простого извлечения текста из изображений. Он имеет только одну конечную точку — изображение в текст, и возвращает весь текст изображения в виде одной строки, а не по регионам.Это может быть полезно при расшифровке большого куска текста (из книги / статьи), и нужен только сам текст.
Точность
API был довольно точным и успешно транскрибировал большинство слов в документе.
Цена
На уровне бесплатного пользования Cloudmersive API вы получите 50 000 запросов в месяц. У API есть 3 платных плана:
- 19,99 долларов -> 100 000 запросов в месяц
- 49,99 долларов -> 250 000 запросов в месяц
- 99 долларов.90 -> 500 000 запросов в месяц
5. Google Cloud Vision
Google Cloud Vision API — это комплексная платформа машинного зрения с возможностями, выходящими за рамки OCR, такими как распознавание лиц, маркировка изображений и обнаружение ориентиров (определение естественного / рукотворный ориентир в изображениях).
Точность
Используя конечную точку / detectText с предоставленным изображением, API хорошо идентифицировал текст. Ответ содержит поле textAnnotation , которое содержит различные сегменты слова в изображении с их текстом и расположением.Это может быть очень удобно для выделения определенных слов на изображении (например, выделения названий брендов / слов из списка).
API также возвращает поле fullTextAnnotation , которое содержит весь текст изображения в виде одной строки, а также обнаруженный язык документа.
Цена
API включает 1000 бесплатных вызовов API в месяц и взимает 1,5 доллара США за каждую последующую 1000 запросов (по состоянию на апрель 2018 г.).
Специальные функции
API Google Cloud Vision также имеет связанную с OCR конечную точку / detectLogos.Учитывая изображение, содержащее логотипы брендов, эта конечная точка может идентифицировать бренды, которым они принадлежат. Во время нашего тестирования эта конечная точка легко идентифицировала логотипы ведущих брендов.
Сводка: Лучшие API-интерфейсы OCR
| OCR API | Автоопределение языка | Текст по регионам | 10 Текстовая аннотация 3 (все текстовые аннотации) | Запросы на уровне бесплатного пользования | Приблиз.цена за звонок | |||||
|---|---|---|---|---|---|---|---|---|---|---|
Google Cloud Vision | Да | Да | 03039 | |||||||
Sema Media Data | Нет | Да | Нет | 340 90 | ||||||
Taggun | Да | Нет | Да (счета-фактуры) | 9402 | Cloudmersive | Да | Нет | Да | 50,000 | $0002 |
Microsoft Computer Vision | Да | Да | Нет | | Допустим, вам поручили оцифровывать ежемесячные счета от поставщиков. Вы можете пойти по старинке и вводить их вручную, исправляя орфографические ошибки.Вы также можете использовать сканер или популярное программное обеспечение для оптического распознавания символов, чтобы преобразовать всю информацию в счетах в цифровые файлы. Хотя все параметры, упомянутые выше, выполнимы, только оптическое распознавание символов (OCR) гарантирует эффективность, точность и внимание к деталям. Однако, прежде чем мы засыпаем вас более подробной информацией, давайте перейдем к сути и расскажем, что такое OCR и где оно используется. Что такое OCR?OCR — это аббревиатура от оптического распознавания символов, технологии, которая позволяет электронным или механическим способом преобразовывать тексты в печатных, рукописных, печатных, отсканированных и графических документах в машиночитаемый цифровой формат данных.Технология распознает и извлекает символы, такие как буквы, цифры и знаки препинания, из текстов изображений, а также печатных и письменных документов и преобразует их в электронный формат, который легко читается программами и компьютерами. Ранние версии OCR обучались с изображениями каждого символа, и они могли работать только с одним шрифтом за раз. Однако сегодня можно найти передовые системы, которые могут обеспечить высокую точность распознавания. Кроме того, современные системы могут работать с разными шрифтами на ходу и предоставлять результаты в виде множества входных цифровых файловых форматов. Однако технология OCR не учитывает характер документа или элемента, содержащего символы. Он только ищет в элементе тексты, которые необходимо преобразовать. Тем, кто хочет узнать как природу предмета, так и его персонажей, необходимо объединить различные технологии. Как работает OCRОптическое распознавание символов позволяет преобразовывать символы в три основных этапа; предварительная обработка изображений, распознавание символов и постобработка. Предварительная обработка изображенияЭтот шаг включает в себя ряд процессов, которые предназначены для улучшения четкости изображения для лучшего и успешного распознавания. Основная цель предварительной обработки — подавить искажения и улучшить важные функции сканируемого документа или изображения. Распознавание символовЭтот шаг включает два основных алгоритма OCR, которые позволяют использовать устройство для обнаружения только намеченных частей или форм оцифрованного изображения.Если входные данные слишком велики, будет обработана только их небольшая часть. Этот шаг гарантирует, что важные части документа или изображения сохранены, а повторяющиеся части отсортированы — это гарантирует лучшую производительность, когда дело доходит до распознавания текста. ПостобработкаПостобработка шаг, направленный на исправление ошибок и обеспечение повышенной точности OCR. Точность можно повысить за счет использования словаря — списка допустимых слов, чисел или кодов.Таким образом, алгоритм может вернуться только к списку требуемых чисел, слов и кодов. Этот шаг может также включать другие методы, направленные на повышение точности. К ним относятся такие вещи, как использование стандартных цветов и бизнес-правил. Для чего используется OCR?С момента своего создания оптическое распознавание символов применялось в различных областях, от банковского дела до истории. И теперь, когда технология претерпела колоссальный прогресс, вы обнаружите это сегодня в нескольких областях.К ним относятся:
Как и многие другие технологии, большинство компаний ищут способы интегрировать OCR в свои приложения и системы. И один из лучших способов сделать это — использовать API. В настоящее время существует несколько API-интерфейсов OCR, которые люди могут использовать для распознавания различных символов из огромного массива изображений и документов. Вместо того, чтобы тратить целое состояние на устройства OCR, частные лица и предприятия могут воспользоваться API-интерфейсами OCR, которые также могут помочь извлекать печатный или рукописный текст из изображений. Посмотреть список лучших OCR API Статьи по темеFAQЧто такое OCR API?OCR — оптическое распознавание символов — полезная функция машинного зрения. OCR позволяет распознавать и извлекать текст из изображений для дальнейшей обработки / сохранения. Это очень полезно для обработки сканированных изображений / изображений текста — например, при работе со счетами, отсканированными формами и вывесками. |
Ваш комментарий будет первым