PowerToys Служебная программа Text Extractor для Windows
Twitter LinkedIn Facebook Адрес электронной почты- Статья
Text Extractor позволяет копировать текст из любого места на экране, в том числе из изображений или видео.
Способ активации
После нажатия сочетания клавиш для активации (по умолчанию: ⊞ Win+Shift+T) на экране появится наложение. Нажмите и удерживайте основную кнопку мыши и перетащите ее, чтобы активировать выбранное. Текст будет сохранен в буфере обмена.
Отключение
Режим записи деактивируется сразу после распознавания текста в выбранной области и его копирования в буфер обмена. Вы можете выйти из режима захвата, нажав клавишу ESC в любой момент.
Настройка при попытке захвата
Удерживая нажатой клавишу SHIFT, вы измените изменение размера области захвата на перемещение области захвата. После выпуска shift вы сможете снова изменить размер.
Важно!
- Полученный текст может быть несовершенным, поэтому необходимо быстро провести проверку выходных данных.
- Это средство использует OCR (оптическое распознавание символов) для чтения текста на экране.

- Используемый по умолчанию язык будет основан на Windows параметрах клавиатуры системы > (языковые пакеты OCR доступны для установки).

Параметры
В меню «Настройки» можно настроить следующие параметры:
| Параметр | Описание |
|---|---|
| Сочетание клавиш для активации | Настраиваемая команда клавиатуры для включения или отключения этого модуля. |
| Предпочитаемый язык | Язык, используемый для OCR. |
Поддерживаемые языки
Text Extractor распознает только языки, на которых установлен языковой пакет OCR.
Список можно получить с помощью PowerShell, выполнив следующие команды:
[Windows.Media.Ocr.OcrEngine, Windows.Foundation, ContentType = WindowsRuntime]
[Windows.Media.Ocr.OcrEngine]::AvailableRecognizerLanguages
Запрос языковых пакетов OCR
Чтобы вернуть список языковых пакетов поддержки, откройте PowerShell от имени администратора (щелкните правой кнопкой мыши, а затем выберите «Запуск от имени администратора») и введите следующую команду:
Get-WindowsCapability -Online | Where-Object { $_. Name -Like 'Language.OCR*' }
 Name -Like 'Language.OCR*' }
Name -Like 'Language.OCR*' }
Пример выходных данных:
Name : Language.OCR~~~el-GR~0.0.1.0 State : NotPresent Name : Language.OCR~~~en-GB~0.0.1.0 State : NotPresent Name : Language.OCR~~~en-US~0.0.1.0 State : Installed Name : Language.OCR~~~es-ES~0.0.1.0 State : NotPresent Name : Language.OCR~~~es-MX~0.0.1.0 State : NotPresent
Язык и расположение сокращены, поэтому «en-US» будет «english-США» и «en-GB» будет «English-Great Britain». Если язык недоступен в выходных данных, он не поддерживается OCR.
Установка языкового пакета OCR
Следующие команды устанавливают пакет OCR для en-US:
$Capability = Get-WindowsCapability -Online | Where-Object { $_.Name -Like 'Language.OCR*en-US*' }
$Capability | Add-WindowsCapability -Online
Удаление языкового пакета OCR
Следующие команды удаляют пакет OCR для en-US:
$Capability = Get-WindowsCapability -Online | Where-Object { $_.Name -Like 'Language.OCR*en-US*' }
$Capability | Remove-WindowsCapability -Online
Устранение неполадок
В этом разделе перечислены возможные ошибки и решения.
«Не установлены возможные языки OCR».
Это сообщение отображается, если нет доступных языков для распознавания.
Если пакет OCR поддерживается и установлен, но по-прежнему недоступен, а системный диск X: отличается от «C:», скопируйте X:/Windows/OCR папку в C:/Windows/OCR , чтобы устранить проблему.
iPad의 Numbers에서 스프레드시트 저장 및 이름 지정하기
Numbers
iPad용 Numbers 사용 설명서
- 환영합니다
- Numbers 개요
- 이미지, 차트 및 다른 대상체 개요
- 스프레드시트 생성하기
- 스프레드시트 열기
- 의도치 않은 편집 방지하기
- 템플릿 개인 맞춤화하기
- 시트 사용하기
- 변경사항 실행 취소 또는 실행 복귀하기
- 스프레드시트 저장하기
- 스프레드시트 찾기
- 스프레드시트 삭제하기
- 스프레드시트 프린트하기
- 시트 배경 변경하기
- 앱 간에 텍스트와 대상체 복사하기
- 도구 막대 사용자화하기
- 터치스크린 기본 사항
- Numbers에서 Apple Pencil 사용하기
- VoiceOver를 사용하여 스프레드시트 생성하기
- VoiceOver를 사용하여 공식 생성 및 셀 자동 채우기
- 표 추가 또는 삭제하기
- 셀, 행, 열 선택하기
- 행과 열 추가 또는 제거하기
- 행과 열 이동하기
- 행과 열 크기 조절하기
- 셀 병합 또는 병합 해제하기
- 표 텍스트 모양 변경하기
- 표 제목 보기, 가리기 또는 편집하기
- 표 격자 색상 변경하기
- 표 스타일 사용하기
- 표 크기 조절, 이동 또는 잠그기
- 표에 텍스트 추가하기
- 서식을 사용하여 데이터 입력하기
- 셀에 대상체 추가하기
- 주식 정보 추가하기
- 날짜, 시간 또는 기간 추가하기
- 셀 자동 채우기
- 셀 내용 복사, 이동 또는 삭제하기
- 표 스냅샷 생성하기
- 날짜, 통화 등의 포맷 지정하기
- 체크상자 및 기타 제어기를 셀에 추가하기
- 양방향 텍스트의 표 포맷 지정하기
- 텍스트를 줄바꿈하여 셀에 맞추기
- 셀 하이라이트하기
- 표에서 데이터를 알파벳 순으로 정렬하기
- 데이터 필터링하기
- 카테고리 개요
- 카테고리 추가, 편집 또는 삭제하기
- 카테고리 그룹 변경하기
- 계산을 추가하여 그룹 데이터 요약하기
- 피벗 테이블 개요
- 피벗 테이블 생성하기
- 피벗 테이블 데이터 추가 및 정렬하기
- 피벗 테이블 데이터 정렬, 그룹화 등의 방식 변경하기
- 피벗 테이블 새로고침하기
- 피벗 테이블 값에 대한 원본 데이터 보기
- 합계, 평균 등을 빠르게 계산하기
- 공식 키보드 사용하기
- 표 셀의 데이터를 사용하여 값 계산하기
- 공식 복사하여 붙여넣기
- 공식 및 함수 도움말 사용하기
- 데이터를 선택하여 차트 작성하기
- 세로형 막대, 가로형 막대, 꺾은선, 영역, 원형, 도넛 및 레이더 차트 추가하기
- 분산형 및 거품 차트 추가하기
- 대화식 차트
- 차트 삭제하기
- 차트 유형 변경하기
- 차트 데이터 수정하기
- 차트 이동 및 크기 조절하기
- 데이터 시리즈 모양 변경하기
- 범례, 격자선 및 기타 표시 추가하기
- 차트 텍스트 및 레이블 모양 변경하기
- 차트 테두리 및 배경 추가하기
- 차트 스타일 사용하기
- 텍스트를 선택하고 삽입점 놓기
- 텍스트 추가하기
- 텍스트 복사하여 붙여넣기
- 다른 언어로 스프레드시트 포맷 지정하기
- 발음 안내 사용하기
- 양방향 텍스트 사용하기
- 세로 텍스트 사용하기
- 텍스트 모양 변경하기
- 텍스트 스타일 사용하기
- 텍스트 대문자 변경하기
- 단락의 첫 문자 장식 추가하기
- 합자
- 문자 위 첨자 또는 아래 첨자로 만들기
- 자동으로 분수 포맷 지정하기
- 대시 및 따옴표 포맷 지정하기
- 중국어, 일본어 또는 한국어 텍스트 포맷 지정하기
- 탭 중단 지점 설정하기
- 텍스트 정렬하기
- 텍스트를 열로 포맷 지정하기
- 줄 간격 조절하기
- 목록 포맷 지정하기
- 방정식 추가 및 편집하기
- 링크 추가하기
- 이미지 추가하기
- 이미지 갤러리 추가하기
- 이미지 편집하기
- 도형 추가 및 편집하기
- 도형 조합 또는 분리하기
- 도형 라이브러리에 도형 저장하기
- 도형 안에 텍스트 추가 및 정렬하기
- 선 및 화살표 추가하기
- 그림 추가 및 편집하기
- 비디오 및 오디오 추가하기
- 비디오 및 오디오 기록하기
- 비디오 및 오디오 편집하기
- 동영상 포맷 설정하기
- 대상체 위치 지정 및 정렬하기
- 정렬 안내선 사용하기
- 텍스트 상자 또는 도형 안에 대상체 배치하기
- 대상체 레이어화, 그룹화 및 잠그기
- 대상체 투명도 변경하기
- 색상이나 이미지로 대상체 채우기
- 대상체 또는 시트에 테두리 추가하기
- 설명 또는 제목 추가하기
- 반사 또는 그림자 추가하기
- 대상체 스타일 사용하기
- 대상체 크기 조절, 회전 및 뒤집기
- 단어 검색하기
- 텍스트 찾기 및 대치하기
- 자동으로 텍스트 대치하기
- 맞춤법 검사하기
- 주석의 저자 이름 설정하기
- 텍스트 하이라이트하기
- 주석 추가 및 프린트하기
- 스프레드시트 보내기
- 공동 작업 개요
- 다른 사람을 초대하여 공동 작업하기
- 공유 스프레드시트에서 공동 작업하기
- 공유 스프레드시트에서 최신 활동 보기
- 공유 스프레드시트의 설정 변경하기
- 스프레드시트 공유 중단하기
- 공유 폴더 및 공동 작업
- Box를 사용하여 공동 작업하기
- Numbers와 함께 iCloud 사용하기
- Excel 또는 텍스트 파일 가져오기
- Excel 또는 다른 파일 포맷으로 내보내기
- 이전 버전의 스프레드시트 복원하기
- 스프레드시트 이동하기
- 스프레드시트 암호로 보호하기
- 사용자 설정 템플릿 생성 및 관리하기
- AirDrop으로 스프레드시트 전송하기
- Handoff를 사용하여 스프레드시트 전송하기
- Finder를 통해 스프레드시트 전송하기
- 키보드 단축키
- 키보드 단축키 기호
- 저작권
Numbers는 작업할 때 스프레드시트를 자동으로 저장하고 기본 이름을 지정합니다.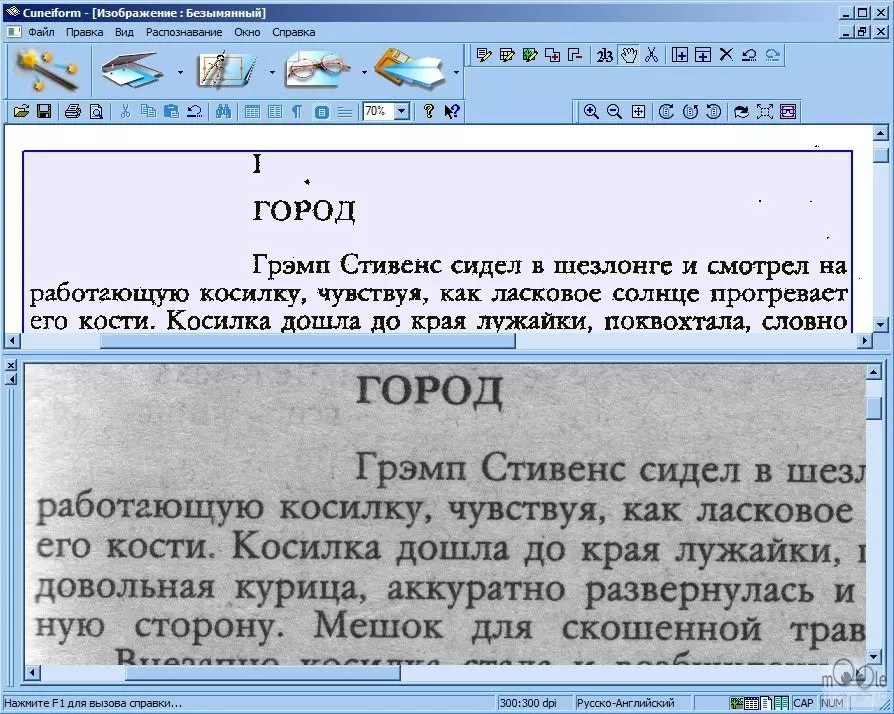 언제든지 스프레드시트의 이름을 변경하거나 다른 이름으로 복제본을 생성할 수 있습니다.
언제든지 스프레드시트의 이름을 변경하거나 다른 이름으로 복제본을 생성할 수 있습니다.
스프레드시트 이름 변경하기
이름을 변경할 스프레드시트를 여십시오.
도구 막대에서 을 탭한 다음, 이름 변경을 탭하십시오.
새로운 이름을 입력하고 완료를 탭하십시오.
현재 이름을 빠르게 삭제하려면 텍스트 필드에서 을 탭하십시오.
스프레드시트의 복사본 저장하기
Numbers를 열고 스프레드시트가 이미 열려 있는 경우, 왼쪽 상단 모서리의 스프레드시트를 탭하면 사용자의 모든 스프레드시트가 나타납니다.
스프레드시트 축소판을 길게 터치하고 손가락을 들어올린 다음 복제를 탭하십시오.
이름 뒤에 숫자가 붙은 복제본이 나타납니다.
복사하려는 스프레드시트가 보이지 않는 경우 검색해 보거나 화면 하단에서 둘러보기 또는 최근 항목을 탭하십시오. iPad의 Numbers에서 스프레드시트 찾기를 참조하십시오.
추가 정보iPad의 Numbers에서 스프레드시트 보내기iPad에서 Numbers 스프레드시트 이동하기iPad의 Numbers에서 이전 버전의 스프레드시트 복원하기iPad의 Numbers와 함께 iCloud 사용하기
Максимальное количество символов: 250
Не указывайте в комментарии личную информацию.Максимальное количество символов: 250.
Благодарим вас за отзыв.
Чтение текста с изображения с помощью одной строки кода Python | Дарио Радечич
Опубликовано в·
Чтение: 5 мин.·
28 октября 2019 г.Работа с изображениями — нетривиальная задача. Вам, как человеку, легко посмотреть на что-то и сразу понять, на что вы смотрите. Но компьютеры так не работают.
Фото Ленина Эстрады на UnsplashНепосильные для вас задачи, вроде сложной арифметики, да и вообще математики, это то, что компьютер пережевывает, не вспотев. Но вот соответствует полной противоположности — тривиальные для вас задачи, например распознавание кошки или собаки на изображении, очень сложны для компьютера. В каком-то смысле мы идеальная пара. По крайней мере, сейчас.
В то время как классификация изображений и задачи, требующие некоторого уровня компьютерного зрения, могут потребовать хорошего кода и глубокого понимания, чтение текста с несколько хорошо отформатированного изображения оказывается в Python однострочным — и может быть применено ко многим реальным проблемам.
И в сегодняшнем посте я хочу доказать это утверждение. Придется кое-что установить, но это не займет много времени. Вот библиотеки, которые вам понадобятся:
- OpenCV
- PyTesseract
Я не хочу больше продлевать эту вступительную часть, так почему бы нам не перейти к хорошему прямо сейчас.
Теперь эта библиотека будет использоваться только для загрузки изображений, вам на самом деле не нужно иметь четкое представление о ней заранее (хотя это может быть полезно, вы поймете почему).
Согласно официальной документации:
OpenCV (Библиотека компьютерного зрения с открытым исходным кодом) — это библиотека программного обеспечения для компьютерного зрения и машинного обучения с открытым исходным кодом. OpenCV был создан, чтобы обеспечить общую инфраструктуру для приложений компьютерного зрения и ускорить использование машинного восприятия в коммерческих продуктах. Будучи продуктом с лицензией BSD, OpenCV позволяет компаниям легко использовать и модифицировать код.
 [1]
[1]В двух словах, вы можете использовать OpenCV для выполнения любых преобразований изображений , это довольно простая библиотека.
Если он еще не установлен, в терминале будет всего одна строка:
pip install opencv-python
Вот и все. До этого момента было легко, но скоро все изменится.
Что это за библиотека? Ну, согласно Википедии:
Tesseract — это движок оптического распознавания символов для различных операционных систем. Это бесплатное программное обеспечение, выпущенное под лицензией Apache версии 2.0, а разработка спонсируется Google с 2006 года.[2]
Я уверен, что сейчас доступны более сложные библиотеки, но я обнаружил, что эта работает очень хорошо. По моему собственному опыту, эта библиотека должна уметь читать текст с любого изображения, при условии, что шрифт не какой-то бык***, который даже вы не умеете читать.
Если он не может прочитать ваше изображение, потратьте больше времени на эксперименты с OpenCV, применяя различные фильтры, чтобы выделить текст.
Теперь установка немного затруднительна. Если вы используете Linux, все сводится к паре sudo-apt get команды:
sudo apt-get update
sudo apt-get install tesseract-ocr
sudo apt-get install libtesseract-dev
Я работаю в Windows, поэтому процесс немного сложнее скучный.
Во-первых, откройте ЭТОТ URL-адрес и загрузите 32-битную или 64-битную программу установки:
Установка сама по себе проста, сводится к нажатию Next пару раз. И да, вам также нужно сделать установку pip :
pip install pytesseract
Это все? Нет. Вам все еще нужно сообщить Python, где установлен Tesseract. На машинах с Linux мне не нужно было этого делать, но в Windows это необходимо. По умолчанию он установлен в Program Files .
Если вы все сделали правильно, выполнение этой ячейки не должно выдавать ошибки:
Все хорошо? Вы можете продолжать.
Чтение текста с изображения — довольно сложная задача для компьютера. Вдумайтесь, компьютер не знает, что такое буква, он работает только с цифрами. То, что происходит за капотом, может сначала показаться черным ящиком, но я призываю вас продолжить расследование, если это вас интересует.
Я не утверждаю, что PyTesseract всегда будет работать идеально, но я нашел его достаточно хорошим даже для некоторых сложных изображений. Но не прямо из коробки. Некоторые манипуляции с изображением необходимы, чтобы выделить текст.
Знаю, это сложная тема. Возьмите его один день за один раз. Однажды это станет для вас второй натурой.
Извлечение текста из изображения — конвертер изображений в текст (бесплатно)
реклама
Извлечь текст
реклама
реклама
Преобразователь изображения в текст позволяет извлекать текст из изображения одним щелчком мыши.
Он сканирует изображение с помощью новейшей технологии OCR и извлекает каждый фрагмент текста, написанный на изображении.
Как преобразовать изображение в текст?
Чтобы извлечь текст из изображения с помощью этого онлайн-конвертера, выполните следующие действия:
- Перетащите или загрузите файл из системы.
- Или вставьте URL-адрес определенного изображения.
- Нажмите кнопку Извлечь текст .
Преобразователь будет использовать новейшую технологию оптического распознавания символов и сгенерирует извлеченный текстовый отчет за считанные секунды.
Что такое технология OCR?
OCR — это технология оптического распознавания символов, используемая для преобразования любого изображения, содержащего рукописный или печатный читаемый текст.
После того как файл будет обработан онлайн-системой OCR, извлеченный текст можно редактировать с помощью программного обеспечения для обработки текстов, такого как MS Word.
Зачем использовать этот конвертер изображений в текст?
Этот конвертер изображения в текст идеально подходит для сканирования и извлечения нужного читаемого текста из изображения.
Кроме того, он предоставляет следующие лучшие функции для простого получения необходимого текста из любого изображения:
Без регистрации
Для использования этого конвертера изображений в текст не требуется регистрация или процесс установки.
Совершенно бесплатно и извлекает текст из изображений за доли секунды.
Загрузка изображений
Эта функция позволяет загружать изображения в форматах PNG, JPEG, BMP и JPG. Пользователи также могут без каких-либо препятствий перетаскивать изображения из своих систем.
Извлечение текста по URL-адресу
Извлечение читаемого текста из изображений по URL-адресу позволяет получить желаемый текст из любого изображения в Интернете.
Отчет о точном извлеченном тексте
Если вы загружаете изображение в конвертер как:
Он сканирует все изображение, извлекает читаемый текст и создает отчет о точном тексте как:
Копировать данные результата
Эта функция позволяет копировать текст с изображения в режиме реального времени.
Ваш комментарий будет первым