Как определить по фото что это такое
Допустим у Вас есть какое-то изображение (рисунок, картинка, фотография), и Вы хотите найти такое же (дубликат) или похожее в интернет. Это можно сделать при помощи специальных инструментов поисковиков Google и Яндекс, сервиса TinEye, а также потрясающего браузерного расширения PhotoTracker Lite, который объединяет все эти способы. Рассмотрим каждый из них.
Укажите адрес картинки в сети интернет либо загрузите её с компьютера (можно простым перетаскиванием в специальную области в верхней части окна браузера):
Результат поиска выглядит таким образом:
Вы мгновенно получаете доступ к следующей информации:
- Какие в сети есть размеры изображения, которое Вы загрузили в качестве образца для поиска
- Список сайтов, на которых оно встречается
- Похожие картинки (модифицированы на основе исходной либо по которым алгоритм принял решение об их смысловом сходстве)
Поиск похожих картинок в тинай
Многие наверняка уже слышали об онлайн сервисе TinEye, который русскоязычные пользователи часто называют Тинай. Он разработан экспертами в сфере машинного обучения и распознавания объектов. Как следствие всего этого, тинай отлично подходит не только для поиска похожих картинок и фотографий, но их составляющих.
Проиндексированная база изображений TinEye составляет более 10 миллиардов позиций, и является крупнейших во всем Интернет. «Здесь найдется всё» — это фраза как нельзя лучше характеризует сервис.
Переходите по ссылке https://www.tineye.com/, и, как и в случае Яндекс и Google, загрузите файл-образец для поиска либо ссылку на него в интернет.
На открывшейся страничке Вы получите точные данные о том, сколько раз картинка встречается в интернет, и ссылки на странички, где она была найдена.
PhotoTracker Lite – поиск 4в1
Расширение для браузера PhotoTracker Lite (работает в Google Chrome, Opera с версии 36, Яндекс.Браузере, Vivaldi) позволяет в один клик искать похожие фото не только в указанных выше источниках, но и по базе поисковика Bing (Bing Images)!
В настройках приложения укажите источники поиска, после чего кликайте правой кнопкой мыши на любое изображение в браузере и выбирайте опцию «Искать это изображение» PhotoTracker Lite:
Есть еще один способ поиска в один клик. По умолчанию в настройках приложения активирован пункт «Показывать иконку быстрого поиска». Когда Вы наводите на какое-то фото или картинку, всплывает круглая зеленая иконка, нажатие на которую запускает поиск похожих изображений – в новых вкладках автоматически откроются результаты поиска по Гугл, Яндекс, Тинай и Бинг.
Расширение создано нашим соотечественником, который по роду увлечений тесно связан с фотографией. Первоначально он создал этот инструмент, чтобы быстро находить свои фото на чужих сайтах.
Когда это может понадобиться
- Вы являетесь фотографом, выкладываете свои фото в интернет и хотите посмотреть на каких сайтах они используются и где возможно нарушаются Ваши авторские права.
- Вы являетесь блогером или копирайтером, пишите статьи и хотите подобрать к своему материалу «незаезженное» изображение.
- А вдруг кто-то использует Ваше фото из профиля Вконтакте или Фейсбук в качестве аватарки на форуме или фальшивой учетной записи в какой-либо социальной сети? А ведь такое более чем возможно!
- Вы нашли фотографию знакомого актера и хотите вспомнить как его зовут.
На самом деле, случаев, когда может пригодиться поиск по фотографии, огромное множество. Можно еще привести и такой пример…
Как найти оригинал заданного изображения
Например, у Вас есть какая-то фотография, возможно кадрированная, пожатая, либо отфотошопленная, а Вы хотите найти её оригинал, или вариант в лучшем качестве.
- Оригинальное изображение, как правило имеет больший размер и лучшее качество по сравнению с измененной копией, полученной в результате кадрирования. Конечно можно в фотошопе выставить картинке любой размер, но при его увеличении относительно оригинала, всегда будут наблюдаться артефакты. Их можно легко заметить даже при беглом визуальном осмотре.
Уважаемые читатели, порекомендуйте данный материал своим друзьям в социальных сетях, а также задавайте свои вопросы в комментариях и делитесь своим мнением!
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Еще совсем недавно поисковики могли искать только по словам. Нет, конечно же, существовали такие сервисы, как
Чем отличается поиск по загруженным картинкам от обычного
Поисковик не понимал, что именно изображено на фото, которые он выдавал в результатах, а лишь ориентировался на те слова, что встречались в тексте рядом с этим изображением (на тех страницах сайтов, где он их нашел) или которые были прописаны в его атрибутах alt или title (тега img). Фактически для поисковика картинка была «черным ящиком», о котором он мог судить только по косвенным признакам (ее описанию).
В результате чего, по запросу «синяя курица» могли быть показаны «розовые слоники». Конечно же, подобные огрехи поиска по фотографиям исправлялись вручную (так называемыми асессорами, которые просматривали выдачу глазами), но делалось это только для наиболее часто вводимых запросов. Да и не это главное.
Важно то, что нельзя было показать поисковику картинку плохого качества, чтобы он нашел вам оригинал в высоком разрешении или же показать ему фото человека (читайте про поиск людей в Контакте, Фейсбуке и др.
Иногда фото может являться одним из многих в серии (фоторепортаж, фотоинструкция, разные ракурсы) и у вас может возникнуть желание найти все остальные изображения из этой же серии, чтобы понять суть. Как это сделать? Какие слова вбивать в поисковую строку? А вот еще пример. Увидели вы диван на фотографии и захотели узнать, где именно продается такой же и по какой цене.
Сложная задача, или даже неразрешимая (в первом приближении), если запрос вводить словами. Тут нужно каким-то образом загрузить картинку в поисковую систему и последняя должна понять, что именно на ней изображено, и попытаться дать вам ответы на все поставленные чуть выше вопросы.
Этого поиск по изображениям до недавних пор не мог сделать, но зато теперь может. Поиск по картинке-образцу (фотографии или любому другому изображению) сейчас поддерживают обе поисковых системы лидирующих в России — Google и Яндекс. Причем последний научился это делать лишь совсем недавно, но, тем не менее научился.
Если попробовать погрузиться во всю глубину принципов этого действа, то большинству из нас вряд ли это покажется интересным. Мне в этом плане очень понравилось объяснение представителя Яндекса.
Картинка разбивается на небольшие фрагменты, которые можно назвать виртуальными словами. Ну а дальше процесс происходит по той же логике, что и обычный поиск. Ищется тот же набор визуальных слов, и чем ближе он будет к загруженному пользователем изображению, тем выше он будет стоять в результатах поиска.
Как работает поиск по фото в Гугле
Давайте посмотрим это все на примерах Яндекса и Гугла. Начнем с самого крупного поисковика в мире. Для того чтобы попасть в святая святых, можно на странице обычного поиска кликнуть по кнопке «Картинки», а можно сразу перейти по этой ссылке:
Кликаете по иконке фотоаппарата, расположенной в правой области строки Google-поиска.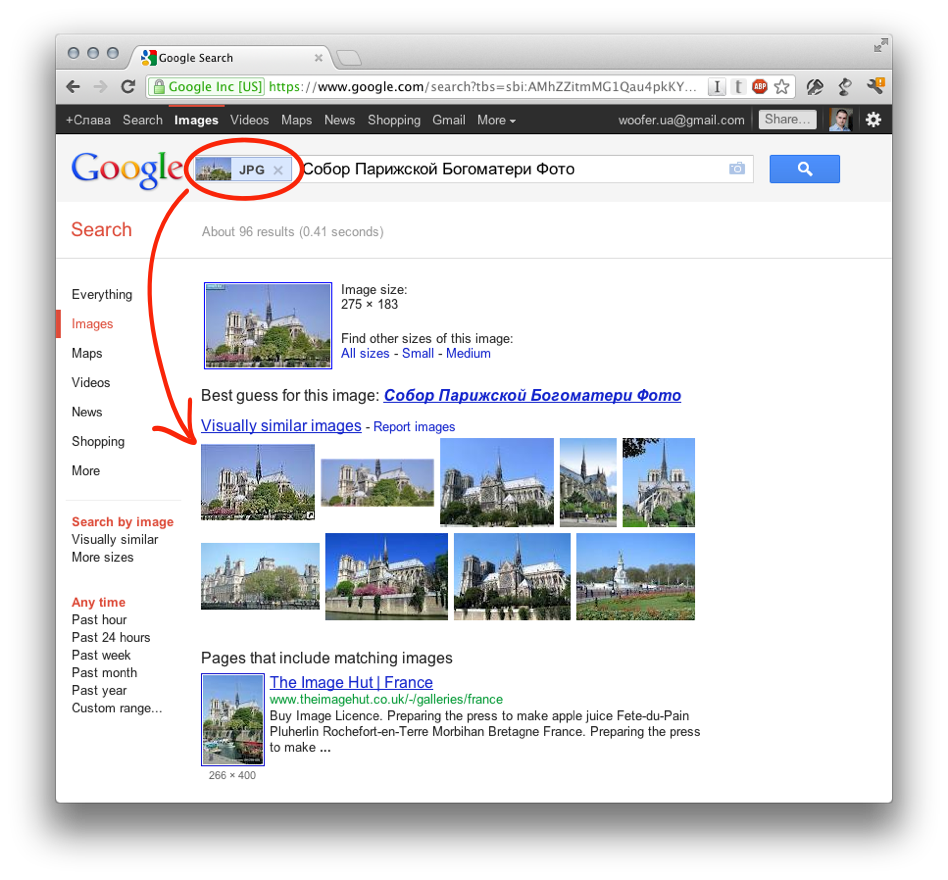 Вам предоставляется две возможности для загрузки в поиск нужной картинки или фотографии — указать ее адрес (его можно будет скопировать, кликнув по фото правой кнопкой мыши и выбрав вариант «копировать URL изображения», или подобный ему по смыслу) в интернете или же загрузить со своего компьютера.
Вам предоставляется две возможности для загрузки в поиск нужной картинки или фотографии — указать ее адрес (его можно будет скопировать, кликнув по фото правой кнопкой мыши и выбрав вариант «копировать URL изображения», или подобный ему по смыслу) в интернете или же загрузить со своего компьютера.
В показанном примере я просто указал Урл адрес изображения, которое нашел на официальном сайте Википедии (что это такое?).
В результатах поиска получил такую вот картину:
Google мне рассказал, что на фото изображен Альберт Эйнштейн в молодости, а также предложил посмотреть то же самое изображение, но большего или меньшего размера. Также можно посмотреть похожие картинки, а под ними можно посмотреть веб-страницы, где этот графический файл имеет место быть.
В поисковой строке можно ввести уточняющие слова, например, если вы хотите узнать обо всех перипетиях судьбы этого человека, то введите слово «биография». В результате будут найдены страницы, на которых поиск обнаружил загруженную вами картинку и на которых имеется биография того, кто на ней изображен.
Я упомянул про два основных способа загрузки изображения в поиск Гугла — указать ссылку на графический файл или загрузить его со своего компьютера. Но для пользователей Google браузера имеется еще и третий способ активации сего действа.
Если вы находитесь в Google Chrome, то просто подведите мышь к той картинке или фотографии на странице, которая вас заинтересовала по тем или иным причинам (например, вы хотите узнать, правдивую ли фотку выложила во Вконтакте ваша виртуальная знакомая или это какая-то известная личность запечатлена).
В результате появится контекстное меню и вам нужно будет выбрать из него пункт «Найти это изображение в Гугле». После этого вы очутитесь в уже знакомом окне Google-поиска по картинкам со всей собранной информацией о фотке вашей знакомой.
Поиск по файлам картинок в Яндексе
Совсем недавно и лидер поискового рынка рунета обзавелся подобным инструментом. Новую технологию они назвали «Компьютерным зрением» и дали ей кодовое название «Сибирь». Картинка при этом разбивается на визуальные слова (области смены контраста, границы и т.п.) и по всей базе, имеющейся в Яндексе, ищется наличие данного набора визуальных слов в других изображениях.
Новую технологию они назвали «Компьютерным зрением» и дали ей кодовое название «Сибирь». Картинка при этом разбивается на визуальные слова (области смены контраста, границы и т.п.) и по всей базе, имеющейся в Яндексе, ищется наличие данного набора визуальных слов в других изображениях.
А уже потом из них выбираются те, в которых данные визуальные слова стоят в том же порядке, что и в оригинальной загруженной картинке. На практике это действо выглядит очень похоже на Гугл — в правой области поиска по фото от Яндекса
Хотя, если у вас имеется Урл адрес нужной картинки, его можно вставить непосредственно в строку графического поиска и нажать на кнопку «Найти», как показано на предыдущем скриншоте.
Узнать Урл адрес изображения на веб-странице можно, кликнув по ней правой кнопкой мыши и выбрав пункт контекстного меню «Копировать адрес изображения» или подобный ему (в разных браузерах используются разные названия).
Если же вам нужно загрузить картинку в поиск со своего компьютера, то кликайте по иконке фотоаппарата.
Результаты поиска будут выглядеть примерно так:
Как видите, из них тоже можно довольно легко понять, что на фото изображен великий Эйнштейн, но вот в Гугле мне как-то больше понравилось оформление выдачи. Возможно, что в Яндексе над этим еще надо будет работать. Найденные в Яндексе фотки также можно будет отсортировать по размеру и типу графических файлов (по формату).
Что примечательно, Яндекс ведет историю ваших поисков, в том числе и по картинкам. При необходимости вы можете ее просмотреть или удалить, если хотите убрать компрометирующие вас материалы. Как это сделать читайте в статье про то, как посмотреть и очистить историю в Яндексе.
Поиск похожих фотографий в Тинай и товаров по фото в Таобао
В общем-то, в большинстве случаев описанных сервисов вам должно хватить, но, возможно, что и Тинай вам когда-нибудь пригодится. Тут опять же вам на выбор предлагают два способа загрузки картинки-образца — путем ввода Урл адреса или напрямую с компьютера.
Тут опять же вам на выбор предлагают два способа загрузки картинки-образца — путем ввода Урл адреса или напрямую с компьютера.
Этот сервис хорошо подходит для поиска похожих фото или отдельных составляющих, из которых оно было смонтировано. Как видно из показанного ниже скриншота — Тинай нашел источники оригинальных изображений, из которых состоял образец.
Китайский поисковик Таобао обладает возможностью поиска товаров по загруженной вами его фотографии. В результате вы получите не только адреса тех интернет-магазинов, где его можно купить, но и сможете выбрать наиболее выгодное для вас предложение.
Правда для работы с ним нужно знать китайский. Однако есть несколько сайтов, которые позволяют искать товары по фото через базу в Таобао, но при этом имеют русскоязычный интерфейс и результаты поиска тоже переводятся на русский.
Результаты поиска товара по фото выглядят так:
Яндекс Алиса и другие приложения научились распознавать картинки и фото с камеры, и делать с ними различные полезные действия.
Сейчас уже существует довольно много мобильных приложений, которые распознают фотографии для получения некоторой полезной информации о людях или объёктах на нём. Одно из таких приложений – Facer, показывает на кого из знаменитостей вы похожи, используя алгоритмы на основе нейронных сетей.
Загружаете фото лица крупным планом и через пару секунд вы видите трёх знаменитостей, на которых вы похожи, с указанием процента сходства. Среди похожих на себя звёзд можно встретить российских и зарубежных музыкантов, актёров, блогеров или спортсменов. Приложение Facer можно скачать по ссылкам: на Android и iOS.
У компании Яндекс тоже есть функции распознавания изображений, они встроены в их голосового помощника. Алиса научилась искать информацию по фотографиям с камеры или любым другим картинкам, которые вы ей отправите. На основе загруженного изображения помощник может сделать некоторые полезные действия. Эти новыми функциями можно воспользоваться в приложении Яндекс и Яндекс.Браузер.
Эти новыми функциями можно воспользоваться в приложении Яндекс и Яндекс.Браузер.
Содержание
Где скачать Алису с поиском по картинкам
Голосовой ассистент Алиса встроен в приложение под названием «Яндекс». Скачать приложение для Android и iOS можно по этим ссылкам:
Как включить поиск по картинкам в Алисе
- Чтобы открыть Алису нажимаем на красный значок приложения «Яндекс».
- Первый способ открыть функцию распознавания изображений: нажимаем на серый значок фотоаппарата с лупой в поисковой строке и переходим к шагу 4. Второй способ: нажимаем на фиолетовый значок Алисы или говорим «Привет, Алиса!» если у вас включена голосовая активация.
- Откроется диалог (чат) с Алисой. Нужно дать команду Алисе «Распознай изображение» или «Сделай фото». Также вы можете нажать на серый значок фотоаппарата с лупой.
- Приложение попросит доступ к камере вашего мобильного устройства. Нажимаем «Разрешить».
- Откроется режим съёмки. Здесь вы можете загрузить изображение из вашей галлереи или сделать новый снимок прямо сейчас. Нажмите на фиолетовый круг, чтобы сделать снимок.
- Алиса распознает объект на изображении.
- Давайте попробуем загрузить фотографию из памяти, т.е. галереи вашего iPhone или Android. Нажимаем на иконку с фотографией.
- Алиса попросит доступ к вашим фотографиям. Нажимаем «Разрешить».
- Выбираем фотографию.
- Через некоторое время фотография загрузится на сервера Яндекса и Алиса вам скажет, на что похоже загруженное изображение. В нашем случае мы загрузили фотографию умной колонки Amazon Echo Dot, и Алиса её успешно распознала.
Возможности Алисы по распознаванию изображений и список команд
Помимо общей команды «сделай фото», Алисе можно дать более точную команду по распознаванию объекта. Алиса умеет делать следующие операции с изображениями по соответствующим командам:
Узнать знаменитость по фото
- Кто на фотографии?
- Что за знаменитость на фотографии?
Алиса распознаёт фото знаменитых людей. Мы загрузили изображение актёра Константина Хабенского и Алиса успешно распознала его.
Мы загрузили изображение актёра Константина Хабенского и Алиса успешно распознала его.
Распознать надпись или текст и перевести его
- Распознай текст
- Распознай и переведи надпись
Вы можете загрузить фотографию с текстом и Алиса распознает его и даже поможет его перевести. Для того, чтобы распознать и перевести текст с помощью Алисы необходимо:
— Загрузить фото с текстом.
— Прокрутить вниз.
— Нажать «Найти и перевести текст».
— Откроется распознанный текст. Нажимаем «Перевести».
— Откроется Яндекс.Переводчик с переведённым текстом.
Узнать марку и модель автомобиля
- Определи марку автомобиля
- Распознай модель автомобиля
Алиса умеет определять марки автомобилей. Например, она без труда распознаёт новый автомобиль Nissan X-Trail, в который встроена мультимедийная система Яндекс.Авто с Алисой и Яндекс.Навигатором.
Узнать породу животного
- Распознай животное
- Определи породу собаки
Алиса умеет распознавать животных. Например, Алиса распознала не только, что на фото собака, но и точно определила породу Лабрадор по фото.
Узнать вид растения
- Определи вид растения
- Распознай растение
Если вы встретили экзотическое растение, Алиса поможет вам узнать его название.
Узнать автора и название картины
- Распознай картину
- Определи что за картина
Если вы увидели картину и хотите узнать её название, автора и описание, просто попросите Алису вам помочь. Картину «Утро в сосновом лесу» художника Ивана Ивановича Шишкина Алиса определяет моментально.
Найти предмет в Яндекс.Маркет
- Определи товар
- Найди товар
Если вы увидите интересный предмет, который вы не прочь были бы приобрести – вы можете попросить Алису найти похожие на него товары. Найденный товар вы можете открыть на Яндекс Маркете и там прочитать его характеристики, или сразу заказать.
Распознать QR-код
- Определи Кью Эр код
- Распознай Кью Эр код
Алиса пока не так быстро и качественно распознаёт QR коды, нам потребовалось несколько попыток, чтобы успешно распознать QR код.
Попробуйте распознать с помощью Алисы какое-нибудь изображение и напишите о своём опыте и впечатлениях в комментариях.
Яндекс постоянно добавляет новые команды для Алисы. Мы сделали приложение со справкой по командам , которое регулярно обновляем. Установив это приложение, у вас всегда будет под рукой самый актуальный список команд:
“>
Как определить монтаж на фото :: Разоблачаем фейки, фотошоп и ретушь :: Блог Вастрик.ру
В 1855 году пионер портретной фотографии Оскар Рейландер сфотографировал себя несколько раз и наложил негативы друг на друга при печати. Получившееся двойное селфи считается первым фотомонтажом в истории. Наверное лайков тогда собрал, уух…Теперь же каждый подросток с фотошопом, смартфоном и интернетом сможет даже лучше. Правда чаще всего эти коллажи неимоверно доставляют. А вот профессионалы научились скрывать свою работу весьма качественно. Это был вызов.
Совокупность методов анализа модифицированных изображений назвали Image Forensics, что можно перевести как «криминалистика изображений». В интернете существует куча сервисов, заявляющих, что они за два клика помогут определить подлинность фото. Особенно доставляют самые тупые, которые идут смотреть EXIF и если там нет оригинальных метаданных камеры начинают громко вопить «вероятно фото было модифицировано». И про них даже в New York Times пишут (а про тебя нет). Я пересмотрел около десятка сервисов и остановился на одном: Forensically. В нём реализовано большинство описанных в статье алгоритмов, я буду часто на него ссылаться. Все описанные методы названы оригинальными английскими названиями, чтобы не было путаницы.Однако возможность загрузить свою фотку в какой-то сервис и посмотреть на красивые шумы не сделает из вас сыщика.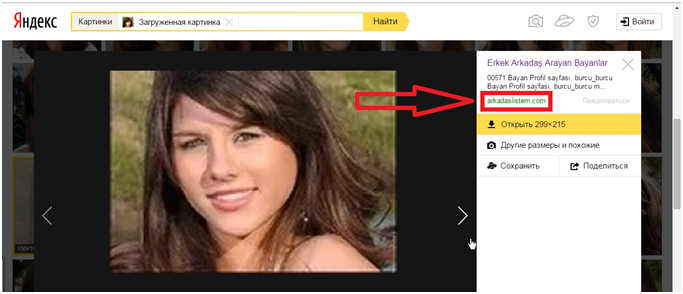 Поначалу может быть трудно и непонятно, а первые эксперименты точно окажутся неудачными. У меня так же было. Тут как в спорте — нужен намётанный глаз и опыт как должно и не должно быть. Умение не просто смотреть на шумные картинки, а видеть еле заметные искажения в них.
Поначалу может быть трудно и непонятно, а первые эксперименты точно окажутся неудачными. У меня так же было. Тут как в спорте — нужен намётанный глаз и опыт как должно и не должно быть. Умение не просто смотреть на шумные картинки, а видеть еле заметные искажения в них.
Не существует 100% метода, позволяющего определить фейк. Но есть человеческие ошибки.
Найдет самые глупые косякиГлавный инструмент — наши глаза. Так что первым делом стоит открыть фото в любимом графическом редакторе или просмотрщике, поставить зум в 1000% внимательно втыкать в предположительное место монтажа. С этого начинается любой анализ. Чем более неопытный монтажер попался — тем проще будет найти косяки, артефакты и склейки. Иногда фейки настолько кривые, что можно нагуглить оригинал используя поиск по изображениям или заметив несоответствия в EXIF.
Brightness and contrast. Сделать темные области ярче, а яркие темнее. Теоретически поможет лучше разглядеть артефакты, склейки и другие места, которые неопытный фотошопер просто замазюкал темненьким и посчитал, что не заметят.
Color adjustment. Увеличивая насыщенность или яркость разных цветов, можно заметить неестественные переливы и границы склейки.
Иногда фейк палится игрой с уровнями и контрастом Invert. Часто помогает увидеть скрытую информацию в однотонных объектах.Sharpen and blur. Добавление резкости поможет прочитать надписи на табличках, есть целые сервисы, которые могут побороть заблюренные области.
Normalization and histograms. Работа с гистограммой по сути объединяет сразу несколько методов в один. Если вы прошарены в графике — гистограммы будут серьезным оружием.
Даже если определить фейковость сразу не удалось, у вас уже могли появиться полезные наблюдения, чтобы перейти к следующим методам с страшными математическими названиями.
Реальные фотографии полны шума. От матрицы камеры или фотосканера, от алгоритмов сжатия или по естественным природным причинам. Графические редакторы же этот шум не создают, их инструменты живут в «идеальном мире», потому чаще всего «размазывают» шум оригинального изображения. Кроме того, два изображения чаще всего обладают разной степенью зашумленности.
Поиграть самому можно здесь.
Как обмануть
Добавить своего шума. Самый очевидный вариант. Хочешь скрыть свои косяки — навали на фото столько шума, чтобы забить оригинальный.Пережать JPEG. Уменьшение качества изображение в два раза делает шумы неразличимыми (вот исследование).
Каждый раз при сохранении картинки ваш редактор заново прогоняет её через кучу преобразований — конвертирует цвета, делит на блоки, усредняет значения пикселей, и. т.д. Он занимается этим даже если вы выбрали 100% качество при сохранении, так уж устроен алгоритм JPEG. Интересующиеся могут почитать про него глубокую статью полную косинусных преобразований.
т.д. Он занимается этим даже если вы выбрали 100% качество при сохранении, так уж устроен алгоритм JPEG. Интересующиеся могут почитать про него глубокую статью полную косинусных преобразований.
Так как JPEG — формат сжатия с потерями, то при каждом сохранении растет количество математических усреднений, ошибок или более популярный термин — «артефактов». Два сохранения с 90% сжатием примерно эквивалентно одному с 81% по количеству этих самых артефактов. На практике это может принести пользу. Даже если зоркий глаз не видит разницы между 80% и 85% сжатием, то наверное есть инструменты, которые наглядно покажут это различие? Да, Error Level Analysis или ELA.
Фейки с наложениями чаще всего делают подыскав нужные изображения где-нибудь в гугле. Вероятность, что найденные изображения будут с одинаковым уровнем артефактов, ну, крайне мала. Социальные сети или даже специализированные хранилища фотографий всё равно пережимают изображения под себя при загрузке, чтобы не платить за хранение гигабайтов ваших селфи из отпуска. Обратное тоже верно — если вы накладываете на найденное в интернете изображение свежую фотографию со своей камеры, она будет заметно выделяться по качеству. Заметно не для глаза, а для ELA — он покажет разительно меньше артефактов на вашей новой фотографии.
ELA — не панацея. Сфотографируйте летящую чайку на фоне ровного синего неба (ага, особенно в Москве), сохраните её в jpg и прогоните через анализатор ошибок. Результат покажет просто огромное количество артефактов на чайке и их полное отсутствие на фоне, из чего начинающие сразу сделают вывод — чайка прифотошоплена. Да что там начинающие, сама команда Bellingcat с этим бывало глупо и по-детски наёбывалась. Алгоритм JPEG достаточно чисто работает на ровных цветовых областях и градиентах, и куда больше ошибается на резких переходах — отсюда такой результат, а не из-за ваших домыслов.
Да что там начинающие, сама команда Bellingcat с этим бывало глупо и по-детски наёбывалась. Алгоритм JPEG достаточно чисто работает на ровных цветовых областях и градиентах, и куда больше ошибается на резких переходах — отсюда такой результат, а не из-за ваших домыслов.
Поиграть с ELA можно тут.
Как обмануть
Много раз пересохранить. Все свои манипуляции алгоритм JPEG делает внутри блоков максимум 8×8 пикселей. В теории нужно 64 раза пересохранить изображение, чтобы уровни ошибок стали неотличимы друг от друга. На практике же это происходит гораздо раньше, достаточно пересохранить картинку раз 10 и ELA, да и некоторые другие методы, больше не увидят ничего полезного.Изменить размер. Чтобы не напрягаться с пересохранением можно поступить еще проще — отресайзить изображение на какой-нибудь коэффициент не кратный степени двойки. То есть в 2 раза (50%) уменьшить не подойдет, а вот что-нибудь типа на 83% — уже всё, никакой ELA больше не поможет.
Смонтировать из одного источника или из lossless-формата. Вы сфотографировали двух людей на свой фотоаппарат, или скачали фотографии из какого-нибудь блога, где автор скорее всего пересохранял их всего раз-два. Либо наложили друг на друга две PNG’шки. Во всех этих случаях ELA не покажет ничего интересного.
Либо наложили друг на друга две PNG’шки. Во всех этих случаях ELA не покажет ничего интересного.
В жизни свет никогда не падает на объекты абсолютно равномерно. Области ближе к источнику всегда ярче, дальше — темнее. Никакого расизма, только физика. Если разбить изображения на небольшие блоки, скажем 3×3 пикселя, то внутри каждого можно будет заметить переход от более темных пикселей к светлым. Примерно так:
Мысленно нарисуем кучу маленьких стрелочек к источнику света На первом изображении свет падает сверху и стрелочки направлены хаотически — это характеризует рассеянный свет. Второе изображение — компьютерная графика, на ней свет падает слишком идеально, никаких шумов и отклонений как на настоящем фото. Третье изображение — фотография с резким переходом, в центре стрелочки массово смотрят в самую яркую сторону, а на фоне — рассеяны так же, как на первом фото.
Рисовать стрелочки хоть и наглядно, но мы физически не сможем изобразить все градиенты освещенности для каждого блока поверх картинки. Стрелочки займут всё изображение и мы не увидим ничего. Потому для большей наглядности придумали не рисовать их, а использовать цветовое кодирование. Для направления вектора понадобится две координаты, и еще одна для его длины — а у нас как раз есть для этого три цветовых компоненты — R, G, B. В итоге получатся вот такие карты освещенности.
В итоге получатся вот такие карты освещенности.
Рука ковбоя с рекламы Kenwood даже на глаз выглядит не очень натурально. Если посмотреть на карту освещенности (по центру), она и правда отличается по характеру освещения. ELA справа тоже намекает, что рука прифотошоплена. Как выяснится потом не только рука, но еще и голова и шляпа. Но еще лучше карты освещенности справляются с определением ретуши. Surface Blur, Liquify, Clone Stamp и другие любимые инструменты фотографов начинают светиться на картах освещенности как урановые ломы тихой весенней ночью. Нагляднее всего выглядит анализ фотографий из журналов или рекламных плакатов — там ретушеры не жалеют блюра и морфинга, а это непаханное поле для практики.
Лично я считаю карты освещенности одним из самых полезных методов, потому что он чаще всего срабатывает и мало кто знает как его обмануть. Поиграться можно здесь.
Как обмануть
Не знаю. Говорят помогает изменение яркости и насыщенности цветов по отдельности, но на бытовых фотографиях такие вещи всегда будут заметны глазу. Если вы знаете простой и действующий метод — расскажите в комментах под этим абзацем, всем будет интересно.Сиськи всегда лучший пример. Рекламный плакат PETA. Крест явно был прифотошоплен (вот блин), ретушер оставил тени под руками, но не добавил их под крестом — косяк.
 Зато полностью перерисовал «кожу» модели, её карта освещенности выглядит как у компьютерного рендера выше. ELA явно показывает фейковость креста и задаёт вопросы по поводу реальности крыльев. А я уже поверил, что это настоящий ангел! Везде обман!
Пример из онлайн-магазина Ralph Lauren. Палится Liquify на обоих руках модели, замазанная какуля на плече, ремень нарисован почти заново, а вся кожа лица и рук подверглась сильному блюру. Силуэт на стене передаёт привет ретушеру и фотографу — кто-то косячит со светом 🙂 Найдет копипаст, вытягивание и несоотвествие цветов, Healing Brush, Clone Stamp
Зато полностью перерисовал «кожу» модели, её карта освещенности выглядит как у компьютерного рендера выше. ELA явно показывает фейковость креста и задаёт вопросы по поводу реальности крыльев. А я уже поверил, что это настоящий ангел! Везде обман!
Пример из онлайн-магазина Ralph Lauren. Палится Liquify на обоих руках модели, замазанная какуля на плече, ремень нарисован почти заново, а вся кожа лица и рук подверглась сильному блюру. Силуэт на стене передаёт привет ретушеру и фотографу — кто-то косячит со светом 🙂 Найдет копипаст, вытягивание и несоотвествие цветов, Healing Brush, Clone StampМетод PCA или на русском «метод главных компонент». Чтобы ко мне не придрались, мол, слишком просто всё рассказываешь и наверное не шаришь, вот описание PCA для рептилоидов.
Метод главных компонент осуществляет переход к новой системе координат y1,…,ур в исходном пространстве признаков x1,…,xp которая является системой ортонормированных линейных комбинаций. Линейные комбинации выбираются таким образом, что среди всех возможных линейных нормированных комбинаций исходных признаков первая главная компонента обладает наибольшей дисперсией. Геометрически это выглядит как ориентация новой координатной оси у1 вдоль направления наибольшей вытянутости эллипсоида рассеивания объектов исследуемой выборки в пространстве признаков x1,…,xp. Вторая главная компонента имеет наибольшую дисперсию среди всех оставшихся линейных преобразований, некоррелированных с первой главной компонентой. Она интерпретируется как направление наибольшей вытянутости эллипсоида рассеивания, перпендикулярное первой главной компоненте. Следующие главные компоненты определяются по аналогичной схеме.
А теперь для людей: представьте, что цветовые компоненты R, G и B мы взяли как оси координат — каждая от 0 до 255. И на этом трехмерном графике точками отметили все пиксели, которые есть на нашем изображении. Получится что-то похожее на картинку ниже.
Так что вся эта математика нам дает? Дело в том, что если какие-то цвета на изображении стоят «не на своих местах» — они будут сильно выделяться из этого облака пикселей, то есть на карте PCA начнут светиться ярким белым цветом. Это может означать локальную цветокоррекцию или же полную вклейку. Диаграммы PCA может построить тот же Forensically. На них будет изображено расстояние от каждого пикселя картинки до плоскости 1, 2 и 3 главной компоненты. Так как расстояние — это число, то изображения будут черно-белыми.
Как видно из примеров, PCA не очень наглядный и требует ну уж очень сильно присматриваться к таким мелким косякам, которые вполне могут оказаться случайностями. Потому PCA редко используется в одиночку, его применяют как дополнение к другим.
Самому поиграться можно здесь.
Как обмануть
Заблюрить. Любой блюр смазывает соседние цвета и делает «колбасятину» более округлой. Хороший блюр сильно затруднит исследование по методу PCA.
Любой блюр смазывает соседние цвета и делает «колбасятину» более округлой. Хороший блюр сильно затруднит исследование по методу PCA.Еще хитрее изменить размер. Хотя PCA и более устойчив к изменение размеров изображения, говорят можно попробовать подобрать такой процент, чтобы обмануть даже его.
Дискретное вейвлет-преобразование очень чувствительно к резкости объектов в кадре. Если фотографии сняты на разные объективы, использовался зум или просто немного отличалась точка фокусировки — после DWT эти отличия будут намного виднее. То же самое произойдет, если у какого-то объекта в кадре изменяли размер — резкость таких частей будет заметно ниже.
Без лишних погружений в теорию сигналов, вейвлет — это такая простенькая волнушка, как на картинке ниже.
Картинка — это тоже двухмерный сигнал из цветных пикселей, а значит её можно разложить на вейвлеты. Для достаточно точного приближения изображения 800×600 требуется до 480000 вейвлетов на цветовой канал. Если уменьшать это количество — будет сильно падать резкость и цветопередача. Но что это даёт, кроме сжатия?
А вот что: вейвлеты приближают области с разной резкостью по-разному. Чем плавнее переходы — тем проще плавному по своей природе вейвлету его воспроизвести, а чтобы приблизить резкий переход — надо больше вейвлетов. Это как пытаться сделать из кучи шариков идеальный куб.
На практике полезно рассматривать приближения с помощью 1%, 3% или 5% вейвлетов. На этом количестве перепады в резкости становятся достаточно заметны глазу, как видно на примере одного из участников соревнования по фотомонтажу, который не определяется другими методами, но заметен при вейвлет-преобразовании.
Как обмануть
Сделать фотографии с одной точки, одним объективом с фиксированным фокусом и сразу обработать в RAW. Редкие студийные условия, но всё может быть. Сколько вон лет разбирали всякие видео с Усамой Бен-Ладеном, целые книги писали.
Сколько вон лет разбирали всякие видео с Усамой Бен-Ладеном, целые книги писали.Изображение очень маленькое. Чем меньше изображение — тем сложнее его анализировать вейвлетами. Картинки меньше 200х200 пикселей можно даже не пытаться прогонять через DWT.
Заключение
Погружаясь в тему Image Forensics начинаешь понимать, что любой из методов можно обмануть. Одни легко обходятся с помощью пережатых до 10 шакалов JPEG’ов, другие цветокоррекцией, блюром, ресайзом или поворотом изображения на произвольные углы. Оцифровка журнала или TV-сигнала тоже добавляет ошибок в исходник, усложняя анализ. И тут вы начинаете понимать:Вполне возможно отфотошопить изображение так, что никто не докажет обратное. Но для этого надо не быть глупеньким.
Зная эти методы, можно скрыть монтаж настолько, чтобы потом сказать в стиле пресс-секретаря президента: «эти картинки — лишь домыслы ангажированной кучки людей, мы не видим на них ничего нового». И такое вполне вероятно.Но это не значит, что занятие полностью бесполезно. Здесь как в криптографии: пока те, кто делает фейки не знают матчасти так же глубоко — сила на стороне знаний, математики и анализа.
Приглашаю экспертов высказаться в комментарии. При подготовке поста я написал нескольким разбирающимся в теме профессионалам в лички, но ответа до сих пор не получил.
Ну а чтобы стимулировать новые посты, подпишитесь на рассылку или пошарьте этот пост у себя. Специльно сделал удобные кнопочки чуть ниже. Так я буду видеть, что всё это хоть кому-то интересно.
На лице написано. Ученые объяснили, как определить характер по фотографии
https://ria.ru/20210207/kharakter-1596224358.html
На лице написано. Ученые объяснили, как определить характер по фотографии
На лице написано. Ученые объяснили, как определить характер по фотографии
Исследователи предположили, что особенности личности можно понять по внешнему виду, а именно по фотопортрету. С одной стороны, черты лица, как и характера, мы… РИА Новости, 07.02.2021
С одной стороны, черты лица, как и характера, мы… РИА Новости, 07.02.2021
2021-02-07T08:00
2021-02-07T08:00
2021-02-07T08:19
наука
характер
искусственный интеллект
гормоны
биология
здоровье
принстонский университет
/html/head/meta[@name=’og:title’]/@content
/html/head/meta[@name=’og:description’]/@content
https://cdn21.img.ria.ru/images/07e5/02/05/1596218880_0:166:3072:1894_1920x0_80_0_0_f04260e80558e09155c33eeaf0b618c2.jpg
МОСКВА, 7 фев — РИА Новости, Альфия Еникеева. Исследователи предположили, что особенности личности можно понять по внешнему виду, а именно по фотопортрету. С одной стороны, черты лица, как и характера, мы наследуем от предков, с другой — на формирование лицевого скелета во время внутриутробного развития влияют гормоны: например, повышенный тестерон. Действительно ли снимок способен многое рассказать о незнакомце, разбиралось РИА Новости.Прирожденные изменникиСклонность мужчин к измене в буквальном смысле написана на лице — к такому выводу пришли австралийские ученые. Они попросили больше полутора тысяч человек рассмотреть 189 фотографий и предположить, кто из изображенных людей неверен партнерам. Каждый, чьи снимки оказались в руках добровольцев, предоставил ученым детальную информацию о своей личной жизни.Выяснилось, что неверных мужчин вычислить по лицу проще, чем женщин. Почти 14 процентов участниц и 16 процентов участников распознали изменщика, а 12 и 18 процентов соответственно — определили тех, кто интересуется чужими женами и невестами. Правильные ответы были выше случайного попадания. При этом точность суждений о неверности не зависела от привлекательности мужчин, но коррелировала с мужественностью их лиц.А вот вывести на чистую воду неверных жен не сумел почти никто — с заданием справились лишь четыре процента мужчин и 3,3 процента женщин. Еще хуже дело обстояло с дамами, которые предпочитают женатых: по внешнему виду разлучниц распознали 3,7 процента мужчин и 0,9 процента женщин.По мнению авторов работы, несмотря на относительно невысокий процент правильных ответов, способность определить человека, склонного к измене, может быть своеобразным механизмом адаптации. С эволюционной точки зрения отношения с неверным партнером невыгодны — повышается риск потерять ценные ресурсы, необходимые для рождения и выращивания потомства. Поэтому тот, кто вовремя идентифицирует потенциального ловеласа или охотника за чужими женами, получает преимущество.Тестостероновая зависимостьПохожие выводы сделали канадские исследователи — правда, они зашли с другого конца. Сначала попросили 145 молодых людей рассказать о контактах с противоположным полом. Несколько месяцев спустя 314 человек — среди них не было участников первого опроса — предоставили ученым сведения о сексуальной ориентации, а также об изменах и отношении к сексу без любви.Обработав изображения и сопоставив их с ответами, специалисты обнаружили: люди с квадратными или широкими лицами, как правило, испытывают более сильное сексуальное влечение, чем их ровесники с овальной формой лица. Причем это характерно как для одиноких, так для тех, кто в паре. Кроме того, широколицые мужчины, как выяснилось, больше склонны обманывать партнершу. У женщин такой корреляции не заметили.Ученые считают, что у выявленных закономерностей есть научное объяснение. Соотношение ширины и высоты лица взрослых зависит от уровня тестостерона. У мужчин с высокой концентрацией этого гормона лица более широкие, с крупными скулами. Как правило, характер у них волевой, порой даже агрессивный. Кроме того, они сексуально активнее: тестостерон влияет и на формирование полового поведения.Нечеловеческая точностьПо фотографии можно определить не только склонность к изменам или агрессии, но и основные черты характера из так называемой Большой пятерки — психологической модели, описывающей личность по пяти признакам: экстраверсии, доброжелательности, добросовестности, эмоциональной устойчивости и открытости новому опыту. Правда, с этой задачей лучше справляются не люди, а искусственный интеллект, полагают российские ученые.Они попросили 12 500 добровольцев сфотографироваться с нейтральным выражением и заполнить анкеты на определение качеств личности. Всего получилось больше 31 тысячи снимков — все анфас и сделанные при хорошем освещении. Изображения разметили с помощью нейросети так, чтобы можно было выделить отдельные черты, которые затем соотнесли с результатами опросников.Выяснилось, что лучше всего с внешностью коррелирует добросовестность, а хуже — открытость новому опыту, особенно у женщин. В среднем обученная нейросеть определяла черты характера с вероятностью 58 процентов. А это чуть выше случайного попадания.Тем не менее ученые подчеркивают: разработанный ими искусственный интеллект вычисляет личностные качества по фотографии лучше, чем люди.Впрочем, к результатам таких исследований надо относиться с осторожностью. Как отмечает профессор Принстонского университета Александр Тодоров, подобные работы (даже те, где суждения выносят добровольцы, а не искусственный интеллект) опираются на распространенное заблуждение, что снимок — все равно что сам человек. Однако это не так. Изображение статично, а люди подсознательно оценивают не только черты лица, но и мимику, позу и даже тембр голоса.Кроме того, не стоит забывать, что физиогномику — определение душевных качеств и состояния здоровья, исходя из анализа черт лица — до сих пор считают лженаукой. И развенчивающих ее работ гораздо больше, чем подтверждающих достоверность.
https://ria.ru/20190805/1557127711.html
https://ria.ru/20170501/1493437909.html
https://ria.ru/20161115/1481392166.html
РИА Новости
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
2021
РИА Новости
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
Новости
ru-RU
https://ria.ru/docs/about/copyright.html
https://xn--c1acbl2abdlkab1og.xn--p1ai/
РИА Новости
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
https://cdn24.img.ria.ru/images/07e5/02/05/1596218880_251:0:2982:2048_1920x0_80_0_0_01801d596593ff5c5a5432b02f4cb094.jpgРИА Новости
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
РИА Новости
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
характер, искусственный интеллект, гормоны, биология, здоровье, принстонский университет
МОСКВА, 7 фев — РИА Новости, Альфия Еникеева. Исследователи предположили, что особенности личности можно понять по внешнему виду, а именно по фотопортрету. С одной стороны, черты лица, как и характера, мы наследуем от предков, с другой — на формирование лицевого скелета во время внутриутробного развития влияют гормоны: например, повышенный тестерон. Действительно ли снимок способен многое рассказать о незнакомце, разбиралось РИА Новости.
Прирожденные изменники
Склонность мужчин к измене в буквальном смысле написана на лице — к такому выводу пришли австралийские ученые. Они попросили больше полутора тысяч человек рассмотреть 189 фотографий и предположить, кто из изображенных людей неверен партнерам. Каждый, чьи снимки оказались в руках добровольцев, предоставил ученым детальную информацию о своей личной жизни.Выяснилось, что неверных мужчин вычислить по лицу проще, чем женщин. Почти 14 процентов участниц и 16 процентов участников распознали изменщика, а 12 и 18 процентов соответственно — определили тех, кто интересуется чужими женами и невестами. Правильные ответы были выше случайного попадания. При этом точность суждений о неверности не зависела от привлекательности мужчин, но коррелировала с мужественностью их лиц.
А вот вывести на чистую воду неверных жен не сумел почти никто — с заданием справились лишь четыре процента мужчин и 3,3 процента женщин. Еще хуже дело обстояло с дамами, которые предпочитают женатых: по внешнему виду разлучниц распознали 3,7 процента мужчин и 0,9 процента женщин.
5 августа 2019, 08:00НаукаГормональный сдвиг. Почему натестостероненный мужчина себе не хозяинПо мнению авторов работы, несмотря на относительно невысокий процент правильных ответов, способность определить человека, склонного к измене, может быть своеобразным механизмом адаптации. С эволюционной точки зрения отношения с неверным партнером невыгодны — повышается риск потерять ценные ресурсы, необходимые для рождения и выращивания потомства. Поэтому тот, кто вовремя идентифицирует потенциального ловеласа или охотника за чужими женами, получает преимущество.
Тестостероновая зависимость
Похожие выводы сделали канадские исследователи — правда, они зашли с другого конца. Сначала попросили 145 молодых людей рассказать о контактах с противоположным полом. Несколько месяцев спустя 314 человек — среди них не было участников первого опроса — предоставили ученым сведения о сексуальной ориентации, а также об изменах и отношении к сексу без любви.Обработав изображения и сопоставив их с ответами, специалисты обнаружили: люди с квадратными или широкими лицами, как правило, испытывают более сильное сексуальное влечение, чем их ровесники с овальной формой лица. Причем это характерно как для одиноких, так для тех, кто в паре. Кроме того, широколицые мужчины, как выяснилось, больше склонны обманывать партнершу. У женщин такой корреляции не заметили.
Ученые считают, что у выявленных закономерностей есть научное объяснение. Соотношение ширины и высоты лица взрослых зависит от уровня тестостерона. У мужчин с высокой концентрацией этого гормона лица более широкие, с крупными скулами. Как правило, характер у них волевой, порой даже агрессивный. Кроме того, они сексуально активнее: тестостерон влияет и на формирование полового поведения.
Нечеловеческая точность
По фотографии можно определить не только склонность к изменам или агрессии, но и основные черты характера из так называемой Большой пятерки — психологической модели, описывающей личность по пяти признакам: экстраверсии, доброжелательности, добросовестности, эмоциональной устойчивости и открытости новому опыту. Правда, с этой задачей лучше справляются не люди, а искусственный интеллект, полагают российские ученые.Они попросили 12 500 добровольцев сфотографироваться с нейтральным выражением и заполнить анкеты на определение качеств личности. Всего получилось больше 31 тысячи снимков — все анфас и сделанные при хорошем освещении. Изображения разметили с помощью нейросети так, чтобы можно было выделить отдельные черты, которые затем соотнесли с результатами опросников.
1 мая 2017, 16:00НаукаУченые узнали, как высокий уровень тестостерона влияет на поведение мужчинВыяснилось, что лучше всего с внешностью коррелирует добросовестность, а хуже — открытость новому опыту, особенно у женщин. В среднем обученная нейросеть определяла черты характера с вероятностью 58 процентов. А это чуть выше случайного попадания.
Тем не менее ученые подчеркивают: разработанный ими искусственный интеллект вычисляет личностные качества по фотографии лучше, чем люди.
Впрочем, к результатам таких исследований надо относиться с осторожностью. Как отмечает профессор Принстонского университета Александр Тодоров, подобные работы (даже те, где суждения выносят добровольцы, а не искусственный интеллект) опираются на распространенное заблуждение, что снимок — все равно что сам человек. Однако это не так. Изображение статично, а люди подсознательно оценивают не только черты лица, но и мимику, позу и даже тембр голоса.Кроме того, не стоит забывать, что физиогномику — определение душевных качеств и состояния здоровья, исходя из анализа черт лица — до сих пор считают лженаукой. И развенчивающих ее работ гораздо больше, чем подтверждающих достоверность.
15 ноября 2016, 12:51НаукаУченые доказали, что физиогномика является лженаукойНеобычный эксперимент со студентами-добровольцами показал, что особенности характера человека невозможно «вычислить» по чертам его лица, и что люди ориентируются на свой собственный опыт при оценке других людей по их облику.Adobe представила приложение, позволяющее определить, подвергалось ли лицо на фото редактированию в Photoshop
Компания Adobe провела очередную ежегодную конференцию MAX в Калифорнии, на которой показала свои новые разработки. Пожалуй, самой необычной новинкой презентации стало приложение About Face. Программа способна определить, отредактировано ли лицо на фото при помощи редактора Photoshop или нет.
Как сообщается, в основе приложения лежит нейросеть, которая попиксельно анализирует изображение и выявляет места, в которых присутствуют следы редактирования. После этого ПО выдает свой «вероятностный вердикт» — то есть с какой вероятностью, по мнению алгоритма, изображение может являться отредактированным. Однако это не еще все особенности разработки: например, она также может подсветить на фото конкретные части лица, которые, с ее точки зрения, подверглись редактированию. Так, в ходе презентации спикер растянул лицо, изменил улыбку и увеличил глаза человеку на фотографии. About Face успешно обнаружила эти изменения:
Помимо этого, приложение, основываясь на результатах анализа, может попытаться восстановить оригинальное изображение:
Оригинальное фото (слева) и фото, которое было восстановлено ПО About Face после изучения его отредактированного варианта (справа; отредактированный вариант представлен на предыдущем изображении в новости).По мнению разработчиков Adobe, ПО по типу About Face в настоящее время крайне актуально, поскольку сегодня по интернету вовсю «гуляют» отредактированные фейки. Когда компания собирается выпустить About Face, не сообщается. Кроме того, намерены ли разработчики адаптировать свое решение под другие фоторедакторы, помимо Photoshop, также неизвестно.
Из других представленных в ходе мероприятия новинок можно выделить инструмент Awesome Audio, который позволяет в один клик убрать из аудиозаписи посторонние шумы, устранить реверберацию и эхо и в целом значительно улучшить качество аудиозаписи. Предполагается, что функция, разрабатываемая для Adobe Audition — фирменного аудиоредактора Adobe — найдут полезной, прежде всего, аматоры, ведущие собственные подкасты, у которых нет профессионального аудиооборудования.
Еще одной интересной разработкой является решение под названием All in Sneak. Инструмент работает следующим образом: на входе ему дается две фотографии с одинаковым фоном, но с разными запечатленными на них людьми, после чего ПО задействует систему распознавания лиц, автоматически определяет людей, которые запечатлены на одном фото, но не представлены на другом, и вырезает их фигуры из одного фото и вставляет в другое. По мнению разработчиков, All in Sneak найдут полезным путешественники: как правило, когда группа туристов делает групповое фото, один из них управляет камерой и во время съемки находится за кадром; разработанное специалистами Adobe ПО позволит без труда разместить на одном фото всех членов группы.
Приложение под названием Sound Seek, в свою очередь, способно автоматически выделять на аудиозаписи запинки по типу «ээээ» и «эммм» и вырезать их.
Наконец, ПО Sweet Talk призвано значительно упростить процесс анимирования статичных лиц на фотографиях и рисунках. Определив лицо на изображении, нейросеть пытается анимировать его таким образом, чтобы его выражение, а также движения рта и глаз соответствовали предоставленной пользователем на входе аудиодорожке.
Источник: The Verge
Как определить возраст по фото?
И, главное, стоит ли пытаться?.. Третий миф из 51 мифа, которые врач Тийна Орасмяэ-Медер и Яна Зубцова развенчали в ходе написания книжки, посвящен горячей теме возраста, фоточек в сети и неизбежных после этого обсуждений: «целых 42?!» — «всего 55?! Ну надо же…»
Я долго думала, какой миф из нашего второго тома «Бьюти-мифы» выдать в эфир следующим. На самом деле это не совсем простая задачка, потому что они наматываются друг на друга, как нитки на катушку: без 3-го непонятен 5-ый, без 46-го — 49-ый, нельзя сказать Б, не сказав А. То есть можно, но — будет непонятно). Самостоятельных мифов не так уж и много, так что есть над чем подумать.
Но тут так удачно сложилось — мы опубликовали пост «Как ухаживают за собой косметологи: Александра Гонт о своих любимых средствах и процедурах» — и — ожидаемо — в комментариях прилетело «Для 50 лет нормально», «Для 50-ти ненормально», «А я делаю примерно ничего, и внешностью своей довольна». Мне не кажется, что это вообще корректно, даже если перед вами косметолог, даже если он рассказывает про свои любимые кремы и процедуры (типа, сам напрашивается:), даже если вы на самом деле так искренне думаете.
Но главное — это совершенно беспочвенно. Вот что считают по этому поводу наука криминалистика и искусственный интеллект.
МИФ № 12. О ТОМ, ЧТО ВОЗРАСТ ЧЕЛОВЕКА МОЖНО ОПРЕДЕЛИТЬ ПО ФОТО
Иллюстрация — Анна Гончаренко«Есть одна блогерша-косметолог, пишет про антиэйдж. А на фотках выглядит на 55+. И что-то я сомневаюсь в ее советах…»
Любимый формат желтых сайтов (возможно, сами себя они считают развлекательными) – подборки фотографий звезд с заголовками «Выглядит ли Джулия Робертс на свои 85?» Другой популярный жанр – «50-летние актрисы без ретуши» – и комментарии к ним: «50?! Да ладно, я бы дала все 61 с половиной». – «А у меня мама ничем не пользуется, к хирургам не обращалась, и в свои 95 выглядит моложе, чем Деми Мур». Люди абсолютно убеждены, что это пара пустяков – определить возраст по фотографии.
Вроде бы вне интернет-баталий кому какое дело, кто на сколько лет выглядит? Это правда так важно? Оказывается, важно. Например, криминалистам. Если свидетель, глядя на фото, говорит: «Этому человеку около 50», а потенциальному обвиняемому 30, это влияет на ход следствия.
И в рамках разработки программы распознавания внешнего возраста криминалисты создали огромную базу и провели масштабные исследования (в основном в США). В этих исследованиях использовались миллионы фото- и видеоизображений, которые оценивались волонтерами от 18 до 80 лет с разным культурным бэкграундом. Их ответы анализировали ученые и AI (Artificial intelligence – искусственный интеллект). Самым забавным выводом из всего этого стал факт, что ни AI, ни человек не может на глаз точно определить возраст другого человека.
Ошибались все. Погрешность составляла от 15 до 30 лет. Иногда подростков-юнцов принимали за людей 30–40 лет.
Так какие же факторы действительно влияют на восприятие возраста? Спойлер: отсутствие или наличие морщин даже не вошло в топ-5 признаков.
Первое, на что обращает внимание человеческий (и компьютерный) глаз, – ровный цвет лица. Чем больше у персонажа на фото пигментных пятен, покраснений и высыпаний, тем старше он кажется. И юная девушка с веснушками может выглядеть старше, чем 40-летняя женщина с абсолютно ровной кожей.
Второй момент – объемы. Пухлые губы – признак молодости, подсознательно мы это считываем. И средняя часть лица должна быть объемной и выпуклой. Когда объема не хватает, человек кажется старше.
Для определения возраста европейцев важны глаза. Чем они больше, тем человек кажется моложе.
Кроме того, огромное значение имеет общая актуальность образа. Неприятная новость для женщин, всю жизнь хранящих верность прическе, с которой они ходили на выпускной. До 70% взрослых американок придерживаются того же образа, который они нашли в 23 года*. Видимо, 23 – момент, когда большинство определяется в своих бьюти- и фэшн-предпочтениях и идет с ними по жизни. Даже если у вас не будет никаких морщин, начесанная челка, которую вы научились делать в 1980-х, в 2020 году выдаст ваш подлинный возраст. Причем и искусственный интеллект, и человеческий глаз прочитают этот параметр одинаково.
То же касается актуальности в одежде. Сейчас в Европе молодая женщина на каблуках – опустим церемонии бракосочетаний, официальные торжества и светские рауты – явление настолько редкое, что люди считают, что не такая уж она, скорее всего, молодая. А еще 15 лет назад было наоборот: каблуки носили молодые, пожилые предпочитали лодочки на плоском ходу.
И только оценив это все, люди обращают внимание на морщины. Но и тут не все однозначно. Морщинки, выдающие позитивную мимику, возраста практически не добавляют. Гусиные лапки, появляющиеся при улыбке, могут скостить вам несколько лет. Гравитационные складки и глубокие статические морщины – другое дело. Но если все остальное соответствует характеристикам молодого человека, вам их простят.
Это все касается фото.
С видео еще интереснее: походка? жестикуляция? быстрота движений? Когда изображение прокручивали на повышенной (всего на 5%!) скорости, и люди, и искусственный интеллект отнимали у героя от 5 до 10 лет. То есть если вы двигаетесь быстро, вас воспринимают как человека на 10 лет моложе. Размашистость движений тоже оказалась важна. Тот, кто активно жестикулирует, выигрывает 5–10 лет у того, кто ведет себя сдержанно.
А морщины опять-таки оказались не слишком важны.
Еще в ходе эксперимента был выявлен интересный факт. Чем моложе волонтеры, тем более пожилыми казались им люди, которые очевидно старше их. И наоборот: возрастные участники при прочих равных принимали 25-летних людей за 20-летних. То есть, если собеседник старше нас, мы склонны прибавлять ему лет, и наоборот. Допустим, вам 45. 50-летнюю женщину вы с большой долей вероятности сочтете 55-летней. А 33–35-летнюю – 30-летней. Но довольно точно назовете возраст ровесницы.
Исходя из этого, кстати, в магазинах на кассы, где отпускают алкоголь и сигареты, стали ставить молодых сотрудников. Потому что возрастные кассиры просили паспорт у 30-летних, подозревая в них несовершеннолетних. А не потому, что – разочаруем вас – в 30 лет вы выглядите на 16.
И тут встает вопрос: если возраст настолько трудно определяется визуально, может, его вообще нельзя определить? И можно нарисовать новый паспорт и всем говорить, что вам 35 и никто не догадается, что на самом деле – 50?
Существует ли вообще научный метод определения возраста? Да, существует. Появился он сравнительно недавно и называется «Часы Хорвата» – по имени замечательного американского молодого ученого-генетика Стива Хорвата. И, понятное дело, имеет отношение к генетике. Точнее, к эпигенетике.
Как говорит профессор Александр Вайсерман, заведующий лабораторией в Институте геронтологии НАМНУ, ДНК человека можно представить в виде елки. Она украшена эпигенетическими метками. В процессе жизни мы одни лампочки выкручиваем на максимум, другие гасим до минимума. Это называется up-regulation и down-regulation. Например, мама голодала во время беременности. Значит, у ребенка выкрутятся на максимум гены, ответственные за выживание без еды. Его организм предполагает: прости, брат, но жизнь тебе предстоит не слишком сытая. Однако если ребенок попадает туда, где с питанием все будет нормально, это сыграет с ним злую шутку. С высокой вероятностью у него разовьется диабет и метаболический синдром.
Или – акселерация. Откуда она взялась? А просто родители хорошо ели и хорошо кормили потомство. И у детей включились на максимум гены роста трубчатых костей: их организм решил, что и кальция, и белков на это хватит. В итоге детки переросли предков.
В общем, любое событие может повесить на елку игрушку и оставить метку.
Стив Хорват изобрел метод, позволяющий выяснить, сколько таких игрушек-меток навешано на наших ДНК. И заметил, что их количество соотносится с возрастом. Чем их больше – тем вы старше. Такой ДНК-анализ делается по крови, и он определяет возраст в рядовых случаях с точностью до месяца, в сложных – до полутора лет.
И это хорошая новость и для криминалистов, и для врачей.
Любопытно, что не все органы стареют одинаково. Быстрее всего – женская грудь (что, конечно, досадно). А мозг стареет медленно и, в отличие от груди, его проще тренировать. С помощью новых впечатлений, путешествий, изучения иностранных языков и вообще всего нового. И еще интересный момент: если возраст ткани органа, согласно анализам, старше, чем паспортный возраст человека, это может служить сигналом, что этот орган подвержен риску опухолей. (А некоторые виды опухолей, наоборот, эти часы замедляют, хотя таких мало). Если вам 40 лет, а вашей груди – 47, высока вероятность, что через пару лет там разовьется опухоль. Для медицины это шанс для ранней диагностики и превентивной терапии.
Но возраст кожи по методу Хорвата определить мы пока не можем. На ее состояние влияет слишком много внешних факторов. Тот же ультрафиолет: если вы много загораете, ваша кожа, по сути, является кожей человека, который старше вас лет на 10–15.
А все это мы к тому, что не надо так уж фанатично бояться морщин. Их наличие – не приговор. Их отсутствие – не главный признак молодости.
И, добавим еще — не надо чувствовать себя третейским судьей, глядя на фотографию и выдвигая мнение, насколько хорошо/плохо выглядит и на сколько лет «тянет» человек:)
Читайте также:
Как определить пол астронотуса, фото.
Пол астронотуса определить не так-то просто. Здесь показано на конкретных примерах, как это можно сделать. И важно определить правильно, так как повзрослев однополые рыбы уживаются вместе далеко не всегда.
Любители астронотусов часто не знают, какого пола их питомцы. Если хочется получить от них потомство, то половой вопрос приобретает не теоретический, а практический интерес. Случается, что мирно живут однополые рыбы (как самцы, так и самки) но, ясное дело, мальков от них не дождаться.
Бывает противоположная ситуация, когда казалось бы пара рыб почему-то никак не желает жить дружно. Самец постоянно колотит «самку», которая на самом деле также является самцом. Вот почему любителям астронотусов важно точно знать какого пола рыбы живут в аквариуме, тогда многое в их поведении будет понятно.
Надо сказать, что конфликтовать могут (и нередко это делают) и самец с самкой, но сложившейся паре ссоры и демонстративные «драки», такая показана на картинке-заставке к данному материалу, обычно не приводят к травмам и забитости одной из рыб.
Определить пол у астронотусов не очень просто, но, как правило, возможно. А чтобы научиться это делать, давайте посмотрим на фотографии реальных пар.
Пара 1:
Фото 1. Астронотусы, кто тут самец, а кто самка? Если рыбы одного возраста, то самцы обычно крупнее и лобастее. Спинной и анальный плавники у них длиннее, чем у самок. Посмотрите на участки плавников, которые отмечены стрелочками, у самца (он слева) они более вытянутые.
Фото 2. В этом ракурсе различия в длине спинного и анального плавников видны лучше. Самец слева.
Пара 2:
Фото 3. Самец слева. Видно, что лоб у него более широкий.
Фото 4.
Фото 5. Это самец, а на фото 4 — самка.
Фото 6. Пара астронотусов, самец сверху.
Пара 3:
Видео 1. Нерестящаяся пара астронотусов. Различия в положении и длинне спинного и анального плавников нечеткие, но есть. Легко различить пол по генитальным папиллам: у самка генитальная папилла (яйцеклад) толще и больше. Включите субтитры на видео, чтобы получить подсказки, кто самец, а кто самка.
Лучше один раз увидеть, чем читать длинные словесные объяснения. Надеюсь, что этот материал поможет любителям астронотусов разобраться с половой принадлежностью своих питомцев. Надо, однако отметить, что у молодых рыб определить пол по форме спинного и анального плавников практически невозможно. Если кто-то знает иные признаки определения пола у астронотусов, пожалуйста поделитесь своими знаниями на нашем аквариумном форуме.
Автор:
В. Ковалёв 26.01.2015 Обновлено 20.05.2020Как определить размер браслета «на глаз»: 7 типажей
Содержание:
- Как выбрать размер браслета классическим способом
- Как выбрать браслет по типажу?
- Как должен сидеть браслет на руке?
- Лайфхаки: как тайно узнать размер браслета
- Полезная информация
- Заключение или что делать, если браслет все-таки не подошел
Браслет — прекрасный подарок не только себе, но и любимому, другу, подруге, коллеге. Такое украшение легко подобрать вне зависимости от того, чем увлекается дорогой вам человек, где работает, как выглядит.
Ведь широкий ассортимент современных браслетов позволяет сделать подарок гарантированно удачным, подобрать именно то изделие, которое гармонично дополнит образ человека, подчеркнет его увлечения, или станет романтическим напоминанием о ваших отношениях, о важных для вас обоих воспоминаниях.
Если вы приобретаете украшение для себя, определить размер просто, но что делать, если вы не знаете размер человека, которому хотите его подарить?
Бренд Constantin Nautics составил подробный гид о том, как определить размер браслета даже без линейки и сантиметровой ленты, чтобы каждая покупка стала удачной!
- Как выбрать размер браслета классическим способом
Размеры женских браслетов определяются так же, как и мужских. Основным параметром является обхват запястья.
Браслеты Constantin Nautics создаются в полной размерной линейке: от 15 до 21 сантиметра. Но в случае необходимости мы идем клиентам на встречу и изготавливаем эксклюзивные украшения в нужном размере — меньше 15-го или больше 21-го.
Чтобы определить нужный размер классическим способом, нужно сделать замер обхвата запястья по выступающей косточке при помощи сантиметровой ленты.
Если сантиметровой ленты нет под рукой, вам поможет обычная нитка. Сделайте замер ею, а затем измерьте нитку линейкой или рулеткой. Добавьте к полученному результату 3-5 мм свободного запаса — полученная величина и есть нужный вам размер браслета.
В расчет берется длина самого браслета, без замка.
Средний обхват запястья у женщин при нормальном телосложении считается около 16-17 см, а у мужчин — 19-20 см.
Если размер наручного украшения подобран правильно, между ремешком и запястьем должен свободно проходить палец.
По статистике обхват запястья у женщин изменяется от 14 до 19 см. Для того чтобы быстро сориентироваться, какой размер вам необходим, ознакомьтесь с таблицей женских размеров для ювелирных браслетов на руку.
Для женской руки:
| Обхват запястья, см | Размер браслета с замком, см | Маркировка | Размер Constantin Nautics |
| 14-15 | 15-16 | XS | 15 см |
| 15-16 | 16-17 | S | 16 см |
| 16-17 | 17-18 | M | 17 см |
| 17-18 | 18-20 | L | 18 см |
| 18-19 | 20-21 | XL | 19 см |
| Телосложение | Приблизительный вес | Статистический размер кисти |
| Худышка | До 50 кг | До 15 см |
| Хрупкая красотка | До 60 кг | До 15-16 см |
| Девушка среднего телосложения | До 80 кг | 16-18 см |
| Аппетитная прелестница | Более 80 кг | Более 18 см |
Размер мужского браслета можно определить очень просто, воспользовавшись таблицей мужских размеров браслетов на руку.
Для мужской руки
| Обхват запястья, см | Размер браслета с замком, см | Маркировка | Размер Constantin Nautics |
| 16-17 | 18 | S | 17 см |
| 17-18 | 19 | M | 18 см |
| 18-19 | 20 | L | 19 см |
| 19-20 | 21 | XL | 20 см |
| 20-21 | 21-22 | XXL | 21 см |
- Как выбрать браслет по типажу?
Если в случае выбора украшения для себя у вас вряд ли возникнут сомнения в размере, то чтобы определиться с размером браслета для другого человека нужно очень постараться. Constantin Nautics спешит успокоить. Богатый опыт работы позволил нам «набить глаз», мы научились определять размер браслетов даже по фотографии клиента!
Если вы не уверены в выборе, мы можем помочь вам. Просто пришлите фотографию человека, которому хотите подарить браслет.
В 90% случаев мы определяем нужный браслет правильно. Наша техника основывается на типажах и телосложении людей.
Каждый человек вне зависимости от нехватки или избытка веса, имеет свою соматическую конституцию. Особенности развития костной и жировой ткани генетически запрограммированы. Для каждого типажа характерны свои физические особенности. Но ни избыток, ни нехватка веса не влияют на обхват запястья.
У астеников этот показатель около 16 см, у нормостеников от 16 до 18 см, у гиперстеников более 18 см. Люди с атлетическим типом сложения скорей всего имеют обхват запястья более 20 см.
Именно на основе физических параметров и внешности человека визуально можно определить размер нужного браслета.
Считается, что с 16 по 17 — это среднестатистические женские размеры браслетов. С 19 до 20 — среднестатистические мужские размеры браслетов.
Чтобы понять, к какому типу относится человек, которому адресован подарок, и правильно выбрать размер браслета, воспользуйтесь подборкой Constantin Nautics! Просто найдите фотографии людей, близких по типажу тому человеку, которому вы выбираете браслет.
Совет: если не уверены в нужном размере браслета, возьмите на 1 см больше, это будет не критично для посадки по руке, но в этом случае ваш подарок точно подойдет.
15 размерЭтот размер браслета скорей подойдет миниатюрным, хрупким на вид персонам, чей вес менее 50 кг. Это изящные люди, часто высокие, с тонкими длинными руками и ногами, у них узкие плечи, бедра и грудная клетка, тонкая шея, слабовыраженные мышцы. Обхват их запястья практически одинаков с обхватом руки чуть выше. У таких людей практически нет жировых отложений. Да, частый вид занятий таких людей — балет и моделинг. Их размер одежды скорей всего колеблется от XS до S. Известные представители этого типа: Кейт Мосс, Одри Хепберн, Эдвард Нортон.
15 размер
15 размер
16 размер
Самый распространенный женский размер в России (как и следующий 17-й). Такой носят хрупкие красотки и красавцы с узкими плечами, но в отличие от 15-го, у таких людей больше жировая прослойка, на вид они более крепкие, чем предыдущий типаж. Их тоже можно назвать миниатюрными и изящными, но во внешности таких людей уже угадывается легкая мускулатура. Среди них тоже много моделей, балерин, танцовщиц. Среди известных представителей: Жизель Бюндхен, Кэмерон Диаз, Уитни Хьюстон.
16 размер
16 размер
16 размер
16 размер
17 размер
Еще один распространенный женский размер в России. 17 размер браслетов скорей всего подойдет людям, которые внешне более хрупкие, чем представители типажей со средним телосложением. Они могут быть любого роста (преимущественно тоже среднего), носят 44-46 размер одежды, имеют правильные пропорции тела, отличаются стройными ногами.
17 размер
17 размер
17 размер
17 размер
17 размер
18 размер
18 размер носят мужчины с худощавым телосложением и женщины с латентной (скрытой) полнотой. Это подвижные и изящные люди с пропорциональной фигурой, среднего роста, с развитой грудной клеткой. Их размер одежды может колебаться от 46-го до 52-го.
18 размер
18 размер
19 размер
Такой размер браслетов подойдет людям с широкой костью, с выраженной мускулатурой. Часто это люди роста выше среднего, с размером одежды от 52-го до 54-го. Это самый распространенный мужской размер (вместе со следующим 20-м).
19 размер
19 размер
19 размер
19 размер
20 размерТакие браслеты носят скорей всего крупные люди «в теле», увлеченные спортом, либо, наоборот, отличающиеся повышенным весом. Часто они имеют высокий рост и массивное телосложение, их размер одежды может колебаться от 54-го до 60-го.
20 размер
20 размер
20 размер
21 размерТакие люди обычно плотного телосложения, имеют явный избыточный вес, либо ярко выраженную мускулатуру. У них массивная фигура, широкие плечи, талия и грудная клетка.
21 размер
21 размер
22 размерМы подобрались к нестандартным размерам, которые выходят за рамки размерной линейки, но могут быть изготовлены на заказ по вашему запросу. 22-ой размер браслетов носят «взбитые» люди, часто склонные к полноте. У них широкие плечи и талия, развитая грудная клетка, тяжелые конечности.
22 размер
23 размерЭти обаятельные великаны имеют высокий рост, широкие плечи и грудную клетку. У них может быть явный переизбыток жировых отложений, тяжелые конечности и кости. Часто у них есть живот. Они могут увлекаться тяжелыми видами спорта, так как такой тип людей способен быстро набирать мышечную массу. Такой размер браслета скорей всего носят мужчины. По вашему специальному заказу мы также можем изготовить его для вас.
23 размер
3. Как должен сидеть браслет на руке?
Строгих правил насчет этого нет, все зависит от личных предпочтений обладателя браслета, но некоторые нюансы все же есть:
- Если изделие изготовлено из металла, оно должно свободно двигаться по руке, оно может быть длинней окружности запястья на 1 — 2 см.
- Если изделие изготовлено из кожи, оно может плотно прилегать к руке, но не препятствовать свободному кровотоку и не врезаться в кожу. Попробуйте мизинцем попасть под браслет, если он проходит, значит, размер выбран идеально.
- Браслеты из цепей выбираются на 2-3 см больше, они не должны стягивать руку, свободное «провисание» только приветствуется.
Несмотря на общепризнанную линейку размеров, есть бренды, которые придерживаются своей отдельной сетки.
Например, вопреки логичному правилу: обхват запястья в сантиметрах = размеру браслета в сантиметрах, бренд Пандора пошел своим собственным путем и тому есть объяснение: при дополнении основы браслета шармами, она уменьшается в обхвате.
Поэтому чтобы правильно определить необходимый размер, и не обнаружить с удивлением, что он стал вам мал, нужно к полученному обхвату запястья прибавить 2-3 сантиметра. Если замеры оказались на границе двух размеров, исходите из того, как вы планируете носить браслет. Если вы хотите дополнить его множеством шармов, выбирайте больший размер. Если желаете обойтись одним-двумя дополнительными элементами, можете выбрать меньший размер.
По статистике самый популярный размер браслета Пандора — 19 сантиметров (т.е. обычный 17-й). Важно помнить, что при носке браслеты Pandora могут немного тянуться — со временем они становятся более гибкими и могут стать длинней на 1 см.
- Лайфхаки: как тайно узнать размер браслета
Если определить размер браслета женщины или мужчины по типажу вам все-таки сложно, и вы боитесь ошибиться с выбором, можете воспользоваться нашими хитрыми лайфхаками.
Способ №1: НаблюдательныйЭто самый простой способ узнать нужный размер браслета. Обратите внимание на манжеты рубашки, блузки, куртки человека, которому собираетесь сделать приятный подарок. Если манжеты достаточно плотно прилегают к руке, вы можете взять их обхват за образец нужного размера. Выберите удобное время и спокойно замерьте манжеты, полученное число и будет искомым.
Способ №2: ОчевидныйВаш любимый человек носит часы? Тогда половина дела сделана. Если эти часы на браслете-цепочке, просто измерьте их длину. Ваш любимый человек носит часы на кожаном ремешке? Проследите, на какую дырочку он их застегивает, измерьте длину и прибавьте для надежности 1 см. Готово.
Способ №3: НежныйСпособ спорный, но иногда действенный. Обхватите запястье человека (невзначай, просто так) своими пальцами и запомните, где они сомкнулись. При первой возможности измерьте это расстояние.
Способ №4: ОпасныйЕсли будущий счастливый обладатель браслета отличается завидным крепким сном, вы можете просто измерить его запястье ниточкой, а затем измерить ее при помощи линейки или сантиметровой ленты. Но будьте осторожней и заранее приготовьте объяснение для своего странного поведения, на случай внезапного пробуждения второй половины
- Полезная информация
Желая сделать заказ у иностранного производителя, вы можете «зависнуть», ведь в отличие от российских, западные бренды указывают размер браслетов в дюймах. Чтобы узнать свой размер, нужно просто умножить свой размер в сантиметрах на 2,54.
Также западные производители нередко предлагают выбрать размер браслета по размеру одежды человека. Ниже приведена таблица соответствия.
| Размер одежды | Длина браслета в дюймах |
Petite (очень маленький) | 7 |
| S (маленький) | 7,25 |
| M (средний) | 7,5 |
| L (большой) | 7,75 |
| XL (очень большой) | 8 |
Все браслеты можно разделить на мягкие и жесткие. Жесткие браслеты (bangle) не гнутся, могут быть с застежкой и плотно прилегать к руке, или без застежки, в такие рука входит свободно, но браслет не спадает.
Мягкие браслеты самые популярные и их разновидностей гораздо больше.
Виды жестких браслетов
Виды мягких браслетов- Браслеты-цепочки — самый распространенный вид украшений, которые с одинаковым успехом носят и мужчины, и женщины. Благодаря разнообразному плетению, цепочки могут отличаться фактурой, рисунком. Среди разновидностей плетений: якорное (звенья выполнены в виде якорной цепи), бельцер (круглая форма звеньев), снейк (узор цепи напоминает рисунок змеи), ромбо (звенья в форме ромбов), картье (элементы имеют разный размер и чередуются в определенной последовательности) и др.
- Слэйв-браслет — надевается на кисть и соединяется цепочкой с кольцом на одном или двух пальцах.
- Кожаные браслеты — прекрасный вариант для каждодневной носки. Могут представлять собой гладкую полоску кожи, фактурный плетеный шнурок или переплетение нескольких шнурков.
- Браслеты с шармами — яркий представитель — браслеты Пандора, представляют собой основу и множество шармов или подвесок, которые можно надевать в зависимости от повода и настроения.
- Красная нить — обережная нить из Израиля стала не просто амулетом, а модным современным украшением. Ее часто дополняют различными подвесками.
- Шамбала — браслет с крупными бусинами из натуральных или ненатуральных камней. Такие браслеты считаются не просто украшением, а, как и браслеты с красной нитью, — современными амулетами, воздействующими на определенные сферы жизни человека.
Если вы все-таки не уверены, что сможете правильно определить размер браслета, вы всегда можете приобрести модель с регулируемой застежкой. Огромный ассортимент современных браслетов не ограничит ваш выбор, и вы сможете сделать удачный подарок.
Но если вы все же узнали нужный размер браслета, тогда поле для выбора становится еще шире, вы можете выбрать браслет с любой застежкой.
- Шпренгельный механизм — круглый замок с пружинной защелкой. Такой вид застежки часто используется в миниатюрных и тонких браслетах. Легкий замок не перегружает дизайн, но может быть не очень удобен в использовании, благодаря своим размерам.
- Карабин — один из самых популярных видов застежки. Выглядит как петля с пружинной скобой. Такой замок считается прочным, надежным и удобным в эксплуатации, при определенной сноровке его можно открыть даже одной рукой.
- Замок-коробка — состоит из миниатюрной коробочки с отверстием и защелки, его используют довольно редко и в основном тогда, когда дизайн предполагает потайной замок, который не выделяется из общего рисунка.
- Шарнирный замок — подвижное соединение двух частей браслета при помощи специального штифта.
- Замок-пряжка — складывающийся замочек, принцип работы которого основан на шарнире и защелке.
- Винтовой замок — выглядит очень эстетично и легко вписывается практически в любой дизайн, но он может раскручиваться при слабой резьбе.
- Застежка тогл (на костыль) — интересный вид замка, система которого состоит из T-образного штифта, вставляемого в крупное звено браслета. Благодаря естественному натяжению, такой замок надежно фиксирует браслет на руке.
Строгих правил для обладателей браслетов не существует, современные тенденции доказали, что смелые решения приводят к потрясающим результатам. Образы street-style это нам демонстрируют. Браслеты надевают с чем угодно и куда угодно, играют с контрастами и экспериментируют с сочетаниями.
Но некоторые советы, выработанные годами, все же есть.
- Персонам с тонкими запястьями и изящными руками подходят практически все браслеты, кроме очень массивных, такие могут создать эффект кандалов.
- Дамам в теле хорошо подойдут крупные браслеты, которые заметны на руке. При желании их могут заменить несколько тонких изделий.
- Лучше не создавать ненужной конкуренции между кольцом и браслетом. Если вы желаете одновременно надеть оба украшения, то носите их на разных руках, так образ не будет перегружен лишними деталями.
- Следите, чтобы браслет не выбивался из общего настроения с другими украшениями образа. Например, морской браслет будет визуально конфликтовать с серьгами-кисточками.
- Добавить строгому деловому образу элегантности позволит тонкий жесткий браслет или классическая цепочка.
- Если вы счастливый обладатель яркого по дизайну браслета, позвольте ему солировать в образе, исключите другие украшения.
- Чтобы носить браслет мужчинам достаточно просто иметь ухоженные руки, ну а девушкам стоит продумать заранее, какой цвет лака подойдет к выбранному вами украшению, чтобы подчеркнуть красоту браслета и изящество рук.
- Если вы хотите универсальных браслет, подходящий к любой одежде гардероба, остановите выбор на лаконичных изделиях из металла или кожи базовых оттенков. Такие украшения подойдут и для офисного гардероба, и для повседневной носки.
- Смешивать два разных металла в одном образе — дурной тон… так было раньше. Сейчас модницы отважились на смелые эксперименты и запросто носят золотые браслеты вместе с серебряными цепочками, серебряные серьги вместе с золотыми пряжками ремней. Главное — чувство гармонии.
- Еще одно правило, которое утратило свою актуальность: украшения нужно носить комплектом. Это то же самое, что туфли и сумочка одного цвета. Скучно! Продемонстрируйте окружающим вашу способность гармонично подобрать украшения, не входящие в один комплект.
- Чтобы браслет не затерялся, старайтесь найти для него достойное обрамление, обнаженная рука или облегающий рукав джемпера — лучший выбор. А вот рукава с орнаментом, вышивкой, узорами или крупным принтом явно будут отвлекать внимание от украшения и перегрузят образ.
… из серебра
Быстро вернуть серебряному браслету прежний вид позволит кипячение в специальном растворе из воды и соды, добавьте к нему кусочек фольги и погрузите украшение. Реакция сульфида серебра с содой и алюминием быстро уберет с браслета потемнение.
… из кожи
Такие изделия нельзя подвергать длительному воздействию солнца, иначе возможно появление микротрещин. По той же причине, если браслет намок, сушите его в естественных условиях вдали от источников тепла.
… из текстиля
Браслеты Constantin Nautics светлой гаммы можно стирать в обычной стиральной машине. Перед стиркой нужно снять металлические застежки. Если их снять нельзя, тогда лучше стирать вручную.
… из металла
Фурнитуру браслетов Constantin Nautics производят из нержавеющей стали, она безопасна и нетоксична. Если на металлических деталях появились небольшие пятна, их достаточно протереть обычной тканью.
- Заключение или что делать, если браслет все-таки не подошел
Определение размера браслета по типажу — это не 100% вариант. Ошибка в пределах 1 см всегда может быть. Но бренд Constantin Nautics гарантирует удачную покупку в любом случае — если приобретенный браслет не подошел по размеру, в течение 30 дней с момента покупки мы можем обменять его на нужный.
Это можно сделать и инкогнито, в случае, если браслет вам подарили, и вы не хотите огорчать или обременять дорогого человека необходимостью замены подарка. Просто пришлите нам его и укажите желаемый размер браслета.
Компания Wolfram создала веб-сайт, на котором будет идентифицировано любое изображение, которое вы на него набросите.
Одна из самых удивительных вещей, которые вы можете сделать с помощью Wolfram Alpha, — это спросить его, какие самолеты находятся над головой. Если вы разговариваете по телефону, он получит ваше местоположение, а затем свяжет его с базой данных рейсов, включая их высоту, угол и даже их номер полета и тип самолета. Но во многих отношениях последний инструмент поиска Стивена Вольфрама впечатляет больше. Он разработан, чтобы идентифицировать что-либо на картинке.Вы просто загружаете фотографию и через несколько секунд получаете компьютерное предположение.
«Не всегда получается правильно».
«Не всегда получается, но в большинстве случаев я думаю, что все получается замечательно», — пишет Вольфрам. «И мне особенно интересно то, что, когда он делает что-то не так, ошибки, которые он делает, в основном кажутся исключительно человеческими». При кратком тестировании это довольно справедливая оценка. Я подключил такие вещи, как Half Dome национального парка Йосемити, и мне сказали, что это «возвышение», а фотография геккона была идентифицирована как «ночная ящерица».«Примечательно, что изображение коровы было идентифицировано как« черный ангус », а две чашки мороженого — как« замороженный йогурт ». Достаточно близко.
Удивительно, как все это выходит за рамки нападения на веб-сайт с фотографиями вашего последнего отпуска или того, что у вас на кухне. Вольфрам говорит, что он думает, что проект может быть полезен, если применить его к большим коллекциям фотографий, чтобы попытаться идентифицировать и классифицировать их. Эта технология также может использоваться другими для встраивания идентификации изображений в свои приложения.Подумайте о визуальном распознавании, которое можно найти в фотографиях Google +, но и в других фото-приложениях и сервисах.
Обучение системе проводилось на кошках, ленивцах и чубакке
По словам Вольфрама, для обучения системы ей были переданы «несколько десятков миллионов» изображений, чтобы она могла узнать, что к чему. Это «казалось очень сопоставимым с количеством различных видов объектов, которые люди получают в первые пару лет жизни», — добавил он. Системе также были предоставлены сложные изображения, такие как кошки в скафандрах, ленивцы в праздничных шляпах и даже Чубакка — все, что ей не удавалось правильно идентифицировать, но изящно:
Теперь он способен распознавать около 10 000 общих типов объектов, хотя Вольфрам отмечает, что ему все еще трудно распознавать конкретных людей, искусство и вещи, которые не являются «реальными повседневными объектами».«
Новый имиджевый проект присоединяется к Google Goggles и Amazon Firefly в качестве инструментов быстрой идентификации, хотя, в частности, разработан без намерения пытаться продать вам что-нибудь с тем, что он найдет. Это также появилось через некоторое время после нового Magic View от Flickr, а также исследовательского сайта Microsoft, который определяет пол и возраст людей на основе фотографий. Однако, в отличие от Microsoft, Вольфрам говорит, что сохраняет уменьшенную версию фотографии после того, как вы ее загрузили (чтобы ею можно было поделиться с другими людьми), и что он собирает изображения, чтобы продолжить обучение своей системы, поэтому будьте внимательны к тому, что вы Отправить в.
Вот как это было с несколькими разными изображениями:
Достаточно близко.
Welp.
Я вроде как вижу …
Что в значительной степени справедливо:
Как использовать объектив Google для идентификации объектов с помощью камеры
Google Lens — это инструмент, который использует распознавание изображений, чтобы помочь вам ориентироваться в реальном мире с помощью Google Assistant.
Вы можете использовать его для идентификации изображений на вашей камере и получения дополнительной информации о достопримечательностях, местах, растениях, животных, продуктах и других объектах. Его также можно использовать для сканирования и автоматического перевода текста.
Вот что вам нужно сделать, чтобы начать использовать этот полезный инструмент для идентификации изображений вокруг вас.
Ознакомьтесь с продуктами, упомянутыми в этой статье:
Google Pixel 3 (от 799 долларов США.99 в Best Buy)
iPhone Xs (от 999,99 долларов США в Best Buy)
iPad (от 329,99 долларов США в Best Buy)
Как использовать Google Lens
Прежде чем вы сможете использовать Google Lens, убедитесь, что вы загрузили приложение на свой телефон из магазина Google Play. И имейте в виду, что это доступно только тем, у кого есть телефон Android (если вы не используете Google Фото, инструкции по которым вы можете увидеть внизу).
Как только это будет сделано, вот как начать использовать его для идентификации изображений через Google Ассистент на телефоне Android:
1. Нажмите и удерживайте кнопку «Домой», чтобы открыть Google Assistant.
2. Коснитесь значка компаса в правом нижнем углу экрана.
Нажмите кнопку компаса в правом нижнем углу.Девон Дельфино / Business Insider3. Коснитесь значка камеры, расположенного слева от значка микрофона в нижней центральной части экрана.
Коснитесь кнопки камеры в нижней части экрана.Девон Дельфино / Business Insider4. Если вы впервые используете Google Lens, возможно, вам придется нажать «Начать», чтобы продолжить.
Нажмите «Начать», чтобы запустить Google Lens.Девон Дельфино / Business Insider5. Сделайте снимок того, что вы хотите, чтобы Google Lens идентифицировал, нажав кнопку поиска в нижней центральной части экрана.
Используйте кнопку поиска, чтобы получить информацию с помощью Google Lens.Девон Дельфино / Business InsiderПосле того, как вы сделаете снимок и Google Lens определит изображение, вы получите список соответствующей информации о нем.
Чтобы использовать другие функции инструмента, вы можете выбрать один из множества различных вариантов в зависимости от вашей фотографии — значок документа для сканирования текста, значки символов для перевода текста, корзина для покупок с информацией о покупках или вилка и нож значок для ресторанов.
Как использовать Google Lens через Google ФотоВ качестве альтернативы, если вы еще не активировали Google Assistant на своем телефоне или у вас нет доступа к нему, вы также можете получить доступ к Google Lens через приложение Google Фото.
Сначала сделайте снимок того, что хотите идентифицировать. Затем откройте приложение Google Фото, выберите эту фотографию и коснитесь значка Google Lens.Оттуда вы сможете получить доступ ко всем инструментам и функциям, упомянутым выше, на вашем телефоне Android.
Вы можете использовать Google Lens через Google Фото на вашем iPhone или iPad, но некоторые из ваших возможностей будут ограничены; например, вы не сможете идентифицировать продукты и штрих-коды.
Могут ли люди идентифицировать оригинальные и обработанные фотографии реальных сцен? | Когнитивные исследования: принципы и последствия
В 2015 году одно из самых престижных событий в мире фотожурналистики — World Press Photo Contest — вызвало разногласия после дисквалификации 22 участников, в том числе победителя общего приза, за манипулирование их фотографиями.Новости о дисквалификации вызвали бурную общественную дискуссию о роли фотоманипуляции в фотожурналистике. World Press Photo в ответ выпустила новый этический кодекс предстоящего конкурса, согласно которому участники «должны гарантировать, что их фотографии точно и честно представляют сцену, свидетелями которой они стали, чтобы аудитория не была введена в заблуждение» (World Press Photo). Они также ввели новые меры безопасности для обнаружения подделанных изображений, в том числе компьютеризированный тест фото-верификации для заявок, достигших предпоследнего раунда конкурса.Необходимость в таком процессе проверки подчеркивает трудности, с которыми сталкиваются организаторы конкурса при попытке аутентифицировать изображения. Если эксперты в области фотографии не могут обнаружить манипуляции с изображениями, на что надеяться фотографы-любители или другие потребители фотографических изображений? Это вопрос, на который мы стремились ответить. То есть насколько непрофессионалы могут отличить подлинные фотографии от подделок?
Цифровые изображения и технологии обработки изображений резко выросли в предыдущие десятилетия. Люди делают больше фотографий, чем когда-либо прежде.По оценкам, только в 2015 году будет сделан один триллион фотографий (Worthington, 2014) и что в среднем на Facebook загружается более 350 миллионов фотографий в день, то есть более 14 миллионов фотографий в час или 4000 фотографий в секунду ( Смит, 2013). Растущая популярность фотографий сочетается с возрастающей частотой, с которой ими манипулируют. Хотя трудно оценить распространенность фотоманипуляции, недавний глобальный опрос фотожурналистов показал, что 76% рассматривают фотоманипуляции как серьезную проблему, 51% утверждают, что всегда или часто улучшают изображения в камере или в формате RAW (т.е., необработанные) файлы, и 25% признают, что они, по крайней мере, иногда, изменяют содержание фотографий (Hadland, Campbell, & Lambert, 2015). В совокупности эти результаты говорят о том, что мы регулярно сталкиваемся с сочетанием реальных и поддельных изображений.
Распространенность и популярность манипулируемых изображений поднимает два важных вопроса. Во-первых, в какой степени обработанные изображения изменяют наши представления о прошлом? Мы знаем, что образы могут оказывать сильное влияние на наши воспоминания, убеждения и поведение (например,г., Ньюман, Гарри, Бернштейн, Кантнер и Линдси, 2012; Уэйд, Гарри, Рид и Линдси, 2002; Уэйд, Грин и Нэш, 2010). Простой просмотр подделанной фотографии и попытка вспомнить событие, которое она изображает, может заставить людей вспомнить совершенно ложные события, такие как полет на воздушном шаре в детстве или встреча с персонажем Warner Brothers Багзом Банни в Диснейленде (Braun, Ellis, & Loftus, 2002; Сакки, Аньоли и Лофтус, 2007; Стрэндж, Сазерленд и Гарри, 2006). Таким образом, если люди не могут отличить настоящие детали от фальшивых на фотографиях, манипуляции часто могут изменить то, во что мы верим и помним.
Во-вторых, в какой степени фотографии могут быть допустимы в качестве доказательства в суде? Законы, регулирующие использование фотографических доказательств в судебных делах, такие как Федеральные правила доказывания (1975), отстают от цифровых изменений (Parry, 2009). Когда-то фотографиями было трудно манипулировать; процесс был сложным, трудоемким и требовал специальных знаний. Тем не менее, в эпоху цифровых технологий даже любители могут использовать сложное программное обеспечение для редактирования изображений, чтобы создавать подробные и убедительные поддельные изображения. Федеральные правила доказывания гласят, что содержание фотографии может быть доказано, если свидетель подтвердит, что фотография является честной и точной.Другими словами, лицо, сделавшее фотографию, любое лицо, которое впоследствии обрабатывает ее, или любое лицо, присутствовавшее при съемке фотографии, не обязаны свидетельствовать о подлинности фотографии. Если люди не могут отличить оригинальные фотографии от поддельных, то стороны могут использовать подделанные изображения, чтобы намеренно обмануть суд, или даже свидетельствовать об изображениях, не зная, что они были изменены.
К сожалению, не существует простого решения, позволяющего избежать обмана людей манипулированием фотографиями в повседневной жизни или на криминальной арене (Parry, 2009).Но недавно появившаяся область судебной экспертизы изображений позволяет лучше защитить себя от мошенничества с фотографиями (например, Farid, 2006). Судебная экспертиза изображений использует цифровые технологии для определения подлинности изображения и основана на предпосылке, что цифровое манипулирование изменяет значения пикселей, составляющих изображение. Проще говоря, манипулирование фотографией оставляет за собой след, даже если он едва заметен и не виден невооруженным глазом (Фарид, 2009). Учитывая, что различные типы манипуляций — например, клонирование, ретуширование, склейка — влияют на лежащие в основе пиксели уникальным и систематическим образом, судебно-медицинские эксперты могут разработать компьютерные методы для выявления подделок изображений.Такие технологические разработки внедряются в нескольких областях, включая право, фотожурналистику и научные публикации (Oosterhoff, 2015). Однако подавляющее большинство суждений о подлинности изображений по-прежнему делается на глаз, и, насколько нам известно, только в одном опубликованном исследовании изучалась степень, в которой люди могут обнаруживать несоответствия в изображениях.
Фарид и Браво (2010) исследовали, насколько хорошо люди могут использовать три подсказки — тени, отражения и искажение перспективы — которые часто указывают на фальсификацию фотографий.Исследователи создали серию компьютерных сцен, состоящих из основных геометрических фигур. Некоторые сцены, например, согласовывались с одним источником света, тогда как другие несовместимы с одним источником света. Когда несоответствия были очевидны, то есть когда тени бегали в противоположных направлениях, наблюдатели могли идентифицировать вмешательство с почти 100% точностью. Тем не менее, когда несоответствия были незначительными, например, когда тени представляли собой комбинацию результатов от двух разных положений света на одной и той же стороне комнаты, наблюдатели работали лишь немного лучше, чем случайность.Эти предварительные результаты, основанные на компьютерных сценах геометрических объектов, предполагают, что человеческая зрительная система плохо распознает несоответствия в таких изображениях.
В текущем исследовании мы изучили, одинаково ли плохо люди обнаруживают несоответствия в изображениях реальных сцен. С одной стороны, мы можем ожидать, что люди будут работать еще хуже, если попытаются обнаружить манипуляции на реальных фотографиях. Исследования показывают, что реальные фотографии обычно содержат много многоэлементных объектов, которые могут скрывать искажения (Bex, 2010; Hulleman & Olivers, 2015).Например, люди с метаморфопсией нарушения зрения часто не замечают каких-либо проблем со зрением в повседневной жизни, однако нарушение становится очевидным, когда они видят простые стимулы, такие как сетка из равномерно расположенных горизонтальных и вертикальных линий (Amsler, 1953). ; Bouwens & Meurs, 2003). Мы также знаем, что людям труднее обнаруживать определенные типы искажений, такие как изменения контрастности изображения, в сложных реальных сценах, чем в более упрощенных стимулах (Bex, 2010; Bex, Solomon, & Dakin, 2009).В общем, если людям особенно трудно обнаруживать манипуляции в сложных сценах реального мира, то можно ожидать, что наши испытуемые будут действовать хуже, чем испытуемые Фарида и Браво (2010).
С другой стороны, есть веские основания предполагать, что люди могут преуспеть в обнаружении манипуляций в реальных сценах. Исследования визуального познания показывают, что люди могут обнаруживать манипуляции с изображениями, используя свои знания о типичных проявлениях реальных сцен. Сцены реального мира имеют общие свойства, такие как способ организации и структурирования значений яркости пикселей (Barlow, 1961; Gardner-Medwin & Barlow, 2001; Olshausen & Field, 2000).Со временем зрительная система человека приспособилась к таким статистическим закономерностям и имеет ожидания относительно того, как сцены должны выглядеть . Когда изображением манипулируют, структура свойств изображения изменяется, что может создать несоответствие между тем, что люди видят, и тем, что они ожидают увидеть (Craik, 1943; Friston, 2005; Rao & Ballard, 1999; Tolman, 1948). Таким образом, основываясь на этой статистике реальной сцены, мы можем предсказать, что люди смогут использовать это «несоответствие» как сигнал для обнаружения манипуляции.Если это так, наши испытуемые должны лучше, чем шанс, обнаруживать манипуляции в реальных сценах.
Несмотря на отсутствие исследований, непосредственно посвященных прикладному вопросу о способности людей обнаруживать подделки фотографий, способность людей обнаруживать изменения в сцене хорошо изучена с помощью визуального познания. Примечательно, что слепота к изменениям — это поразительное открытие, что в некоторых ситуациях люди на удивление медленно или полностью неспособны обнаруживать изменения, внесенные в две сцены, или находить различия между ними (например,г., Пашлер, 1988; Саймонс, 1996; Саймонс и Левин, 1997). В некоторых ранних исследованиях исследователи продемонстрировали неспособность наблюдателей обнаруживать изменения, внесенные в сцену во время движения глаз (саккада), используя очень простые стимулы (например, Wallach & Lewis, 1966), а затем и в сложных реальных сценах ( например, Grimes, 1996). Исследователи также показали, что слепота к изменениям возникает даже тогда, когда глаза фиксируются на сцене: парадигма мерцания, например, имитирует эффекты саккады или моргания глаз, вставляя пустой экран между непрерывным и последовательным представлением оригинала и измененного изображения. изображение (Rensink, O’Regan, & Clark, 1997).Часто требуется большое количество чередований между двумя изображениями, прежде чем изменение можно будет идентифицировать. Кроме того, слепота к изменениям сохраняется, когда исходное и измененное изображения отображаются рядом (Scott-Brown, Baker, & Orbach, 2000), когда изменение маскируется камерой, вырезанной в движущихся изображениях (Levin & Simons, 1997), и даже когда изменения происходят в реальных ситуациях (Simons & Levin, 1998).
Такие поразительные сбои в восприятии говорят о том, что люди не формируют автоматически полное и подробное визуальное представление сцены в памяти.Следовательно, чтобы обнаружить изменение, может потребоваться сосредоточенное внимание на изменившемся аспекте (Simons & Levin, 1998). Итак, какие аспекты сцены, скорее всего, привлекут к себе пристальное внимание? Одно из предположений состоит в том, что внимание направляется заметностью; более важные аспекты сцены привлекают внимание и представлены более точно, чем менее важные аспекты. В поддержку этой идеи исследования показали, что изменения более важных объектов обнаруживаются легче, чем изменения менее важных объектов (Rensink et al., 1997). Другие результаты, однако, показывают, что наблюдатели иногда пропускают даже большие изменения в центральных аспектах сцены (Simons & Levin, 1998). Поэтому вопрос о том, что определяет яркость сцены, продолжает изучаться. В частности, исследователи расходятся во мнениях относительно того, является ли визуальная заметность объектов в сцене на низком уровне, например яркость (например, Lansdale, Underwood, & Davies, 2010; Pringle, Irwin, Kramer, & Atchley, 2001; Spotorno & Faure, 2011) или семантическое значение высокого уровня сцены (Stirk & Underwood, 2007) имеет наибольшее влияние на распределение внимания.
Какие еще факторы влияют на предрасположенность людей к изменению слепоты? Одно надежное открытие в литературе по обнаружению сигналов состоит в том, что способность принимать точные решения в отношении восприятия зависит от силы сигнала и количества шума (Green & Swets, 1966). Теория обнаружения сигналов была применена к обнаружению изменений. В одном исследовании наблюдатели судили, остались ли два последовательно представленных массива цветных точек идентичными или произошли изменения (Wilken & Ma, 2004).Что особенно важно, исследователи манипулировали силой сигнала в испытаниях изменений, варьируя количество цветных точек на дисплее, которые менялись, в то время как шум (общий размер набора) оставался постоянным. Производительность улучшилась в зависимости от количества точек на дисплее, которые меняли цвет — проще говоря, больший сигнал привел к большему обнаружению изменений.
Учитывая отсутствие исследований, изучающих способность людей обнаруживать подделки фотографий, слепота к изменениям представляет собой весьма актуальную область исследований.Однако ключевое различие между исследованием слепоты к изменениям и нашими текущими экспериментами состоит в том, что наша задача обнаружения изменений не включает в себя сравнение двух изображений; поэтому представление сцены в памяти не является важным фактором в нашем исследовании. То есть испытуемые не сравнивают исходную и измененную версии изображения. Вместо этого они делают свое суждение, основываясь на просмотре только одного изображения. Это изображение является либо исходным неизмененным изображением, либо изображением, которое было изменено каким-либо образом.
В текущем исследовании мы изучали способность людей определять общие типы манипуляций с изображениями, которые часто применяются к реальным фотографиям. Мы проводили различие между физически неправдоподобными и правдоподобными манипуляциями. Например, физически неправдоподобное изображение может изображать уличную сцену, освещенную только солнцем, с тенью человека, бегущей в одну сторону, и тенью автомобиля, бегущей в другую сторону. Такие тени подразумевают невозможное: два солнца. В качестве альтернативы, когда на изображении ретушируется незнакомое лицо, это вполне правдоподобно; устранение пятен и морщин или отбеливание зубов не противоречат физическим ограничениям в мире, которые определяют, как должно выглядеть лицо.В нашем исследовании геометрических манипуляций и теней составили нашу категорию неправдоподобных манипуляций, в то время как аэрография и сложение или вычитание манипуляции составили нашу правдоподобную категорию манипуляций. Наш пятый тип манипуляции, суперсаддитивный , представил все четыре типа манипуляции на одном изображении и, таким образом, включил обе категории манипуляции.
У нас был ряд прогнозов относительно способности людей обнаруживать манипуляции на реальных фотографиях.Мы ожидали, что тип манипуляции — неправдоподобный или правдоподобный — повлияет на способность людей обнаруживать манипуляции и определять их местонахождение. В частности, люди должны правильно идентифицировать больше физически неправдоподобных манипуляций, чем физически правдоподобных манипуляций, учитывая наличие доказательств на фотографии. Мы также ожидали, что люди будут лучше правильно обнаруживать и определять местонахождение манипуляций, которые вызывают большее изменение пикселей на фотографии, чем манипуляции, вызывающие меньшее изменение.
11 лучших приложений для распознавания изображений, которые стоит посмотреть в 2021 году
В области машинного зрения распознавание изображений означает способность программного обеспечения идентифицировать людей, объекты, места или действия на изображениях.
Технологии машинного зрения объединяют камеры устройств и алгоритмы искусственного интеллекта для достижения точного распознавания изображений для управления автономными роботами и транспортными средствами или для выполнения других задач (например, поиска содержимого изображений).
За последние несколько лет на рынке появилось немало приложений, основанных на технологиях распознавания изображений.Вот 11 фильмов, которые стоит посмотреть в 2019 году.
1. Google LensЭто фантастическое приложение позволяет делать снимки с помощью камеры смартфона, а затем выполнять поиск по изображениям в Интернете. Он работает так же, как обратный поиск изображений Google, предлагая пользователям ссылки на страницы, статьи Википедии и другие соответствующие ресурсы, связанные с изображением.
2. Aipoly Vision
Категория: Доступность
Доступность — одна из самых интересных областей в приложениях для распознавания изображений.Aipoly — отличный пример приложения, разработанного, чтобы помочь людям с ослабленным зрением и дальтонизмом распознавать объекты или цвета, на которые они указывают камерой своего смартфона.
3. TapTapSee
Категория: Доступность
Это приложение для мобильной камеры было разработано для слепых и слабовидящих пользователей . TapTapSee использует камеру вашего устройства и функции VoiceOver, чтобы сделать снимок или видео всего, на что вы направляете свой смартфон, и определить это вслух.
4. Поиск кулачкаКатегория: Покупки
Позволяя пользователям буквально искать в Physical World ™, это приложение предлагает мобильную визуальную поисковую систему. Сделайте снимок объекта, и приложение расскажет вам, что это такое, и выдаст практические результаты, такие как изображения, видео и местные предложения по покупкам.
Как только пользователи найдут то, что искали, они могут сохранить свои результаты в своих профилях и легко поделиться ими с друзьями и семьей.Чтобы открывать для себя больше продуктов, пользователи могут подписаться на других и создать свою социальную ленту.
5. ScreenShopКатегория: Покупки
Это приложение для любителей моды, которые хотят знать, где взять предметы, которые они видят на фотографиях блогеров, манекенщиц и знаменитостей. Приложение в основном идентифицирует покупаемые товары на фотографиях , уделяя особое внимание одежде и аксессуарам.
Достаточно сделать снимок экрана с фото или видео, и приложение покажет вам соответствующие товары в интернет-магазинах, а также аналогичные товары из их обширного и постоянно обновляемого каталога.
6. Flow на базе Amazon
Категория: Покупки
Flow может идентифицировать миллионы товаров , например DVD и CD, обложки книг, видеоигры и упакованные товары для дома — например, коробку ваших любимых хлопьев.
Он также позволяет сканировать визитные карточки, чтобы быстро добавлять новых людей в ваши контакты.Flow также декодирует штрих-коды UPC, QR-коды, номера телефонов, а также веб-адреса и адреса электронной почты, а также информацию на визитных карточках.
7. Google Поиск обратного изображенияКатегория: Проверка на сходство
Этот удобный инструмент поможет вам найти изображения, похожие на то, что вы загружаете. Результаты поиска могут включать похожие изображения, сайты, содержащие изображение, а также размеры изображения, которое вы искали.
Это очень полезно для тех, кому нужно найти более качественное изображение в Интернете или искать что-то конкретное, например, определенную породу кошек.
8. LeafSnapКатегория: Природа
Разработанная исследователями из Колумбийского университета, Университета Мэриленда и Смитсоновского института, эта серия бесплатных мобильных приложений использует программное обеспечение для визуального распознавания , чтобы помочь пользователям идентифицировать виды деревьев по фотографиям их листьев.
Приложения включают в себя потрясающие изображения с высоким разрешением листьев, цветов и фруктов для вашего удовольствия.
9. CalorieMama
Категория: Продукты питания
Сочетая в себе технологии глубокого обучения и классификации изображений, это приложение сканирует содержимое блюда на вашей тарелке, указывает ингредиенты и вычисляет общее количество калорий — и все это с одной фотографии! Сделайте снимок своего обеда и получите всю информацию о питании, которая вам нужна, чтобы оставаться в форме и быть здоровым.
Приложение гордится тем, что имеет наиболее разнообразную в культурном отношении систему идентификации продуктов питания на рынке, а их Food AI API постоянно повышает ее точность благодаря новым изображениям продуктов питания, добавляемым в базу данных на регулярной основе.
10. ВивиноКатегория: Продукты питания
Любители вина оценят это приложение.Пользователю просто нужно сфотографировать любую этикетку вина или винную карту ресторана, чтобы мгновенно получить подробную информацию о ней вместе с рейтингами и отзывами сообщества.
Кроме того, вино можно купить и доставить на дом. После того, как пользователи попробуют вино, они могут добавить свои собственные оценки и обзоры, чтобы поделиться с сообществом, а получит персональные рекомендации.
11. Не хот-догКатегория: Развлечения
Это классика.Потому что иногда вам просто нужно знать, есть ли на картинке перед вами хот-дог.
Технология распознавания изображений в сочетании с мобильностью и программным обеспечением искусственного интеллекта предлагает мощный набор потенциальных функций, расширяющих возможности наших смартфонов за пределами нашего воображения.
Следите за этим пространством, чтобы оставаться в авангарде вдохновляющих разработок на мобильной арене.
Пять способов проверить изображение и идентифицировать правообладателя
Фото Доминика Мартина
Интернет-мир наводнен красивыми картинками.Хотя использование этих изображений может показаться заманчивым, важно помнить, что это может представлять собой нарушение авторских прав — действие, которое может иметь серьезные юридические и финансовые последствия.
Это не означает, что доступ к изображениям в Интернете запрещен. просто перед использованием изображения вам необходимо проверить его исходный источник, подтвердить, разрешено ли вам его использовать, а также условия, связанные с этим.
Это может быть, например, что вы можете использовать изображение в соответствии с определенной лицензией Creative Commons и должны включать четкую информацию о его создателе.Или вам может потребоваться связаться с владельцем, чтобы приобрести лицензию на использование изображения.
Однако прежде чем продолжить, первым делом необходимо установить правильного владельца изображения, и есть несколько способов сделать это. Вот наше удобное руководство из пяти шагов:
1. Найдите кредитное изображение или контактную информациюЕсли вы найдете изображение в Интернете, внимательно ищите подпись, в которой указано имя создателя изображения или владельца авторских прав. Также может быть адрес электронной почты или ссылка на веб-сайт владельца изображения.Используя эту информацию, вы можете связаться с владельцем изображения, чтобы запросить использование его изображения, купив лицензию или договорившись об условиях использования.
2. Найдите водяной знакВодяной знак на изображении является явным признаком того, что изображение защищено авторским правом. Часто водяной знак содержит текст, указывающий на имя или компанию, которой принадлежит изображение: погуглите и узнайте.
Ни при каких обстоятельствах не пытайтесь использовать программное обеспечение для удаления водяного знака с изображения.Это демонстрирует явное и умышленное намерение нарушить авторские права — доказательства, которые, вероятно, сработают против вас, если дело будет передано в суд.
3. Проверьте метаданные изображенияНекоторые создатели изображений встраивают важную информацию о своих изображениях в метаданные файла (также известные как данные EXIF). Эту информацию легко получить с рабочего стола Mac или ПК; вот пошаговая инструкция.
4. Выполните обратный поиск изображений в GoogleЕсли вы все еще не можете найти сведения о владельце изображения, обратный поиск изображений Google может оказаться полезным.Просто загрузите файл или вставьте ссылку на изображение на http://images.google.com и следите за результатами, чтобы узнать, где еще находится изображение в Интернете. Оттуда вы сможете узнать информацию о владельце.
Если вы работаете с большим объемом изображений и хотите регулярно искать источники, вы можете рассмотреть такой сервис, как Pixsy.
5. Если сомневаетесь, не используйтеЧтобы защитить свои средства к существованию, правообладатели часто активно отслеживают случаи несанкционированного использования своей работы.Если вы выполнили все вышеперечисленные шаги, но по-прежнему не можете полностью проверить источник изображения и определить владельца авторских прав, просто не используйте изображение. Доступно множество высококачественных банков изображений, которые предлагают простой способ доступа и использования изображений для всех различных спецификаций и бюджетов. Нарушению авторских прав просто нет оправдания, и последствия могут быть дорогостоящими и неприятными.
**
Сводка
- Перед использованием изображения вам необходимо проверить его исходный источник, подтвердить, разрешено ли вам его использовать, а также условия, связанные с этим.
- Поищите подсказки в подписи к изображению, проверьте наличие водяного знака и проверьте, есть ли в метаданных изображения сведения об авторских правах.
- Свяжитесь с владельцем изображения, чтобы приобрести лицензию или согласиться с условиями использования.
- Если вы по-прежнему не можете проверить источник изображения, попробуйте использовать инструмент обратного поиска Google по изображениям.
- Чтобы защитить свои средства к существованию, правообладатели часто активно отслеживают случаи несанкционированного использования их работ.
- Если у вас все еще есть сомнения относительно владельца или возможности использования изображения, просто не делайте этого.
Вернуться в Академию домой
Проект идентификации изображений — сочинения Стивена Вольфрама
«Что это за фотография?» Обычно люди могут ответить на такие вопросы мгновенно, но в прошлом это всегда казалось недосягаемым для компьютеров. Почти 40 лет я был уверен, что компьютеры рано или поздно появятся, но гадал, когда.
Я создал системы, которые наделяют компьютеры всеми видами интеллекта, большая часть которого выходит за рамки человеческого.И в течение долгого времени мы интегрируем весь этот интеллект в Wolfram Language.
Теперь я с радостью могу сказать, что мы достигли важной вехи: наконец-то появилась функция ImageIdentify, встроенная в язык Wolfram Language, которая позволяет вам спросить: «Что это за изображение?» — и получить ответ.
И сегодня мы запускаем проект идентификации изображений на языке Wolfram Language в Интернете, чтобы каждый мог легко сделать любой снимок (перетащить его с веб-страницы, привязать его к себе на телефон или загрузить из файла) и посмотреть, что ImageIdentify думает об этом. это:
Не всегда получается, но в большинстве случаев я думаю, что получается замечательно.И мне особенно интересно то, что, когда он делает что-то не так, ошибки, которые он делает, в основном кажутся исключительно человеческими.
Это прекрасный практический пример искусственного интеллекта. Но для меня важнее то, что мы достигли точки, в которой мы можем интегрировать такого рода «операции искусственного интеллекта» прямо в язык Wolfram Language, чтобы использовать их в качестве нового мощного строительного блока для программирования, основанного на знаниях.
Теперь на языке Wolfram Language
В сеансе Wolfram Language все, что вам нужно сделать для идентификации изображения, — это передать его в функцию ImageIdentify:
То, что вы получаете обратно, — это символическая сущность, с которой язык Wolfram Language может затем выполнять больше вычислений — например, в этом случае выяснить, есть ли у вас животное, млекопитающее и т. Д.Или просто попросите определение:
Или, скажем, сгенерируйте облако слов из его записи в Википедии:
А если бы у кого-то было много фотографий, можно было бы немедленно написать программу на языке Wolfram Language, которая, например, давала бы статистику по различным видам животных, или самолетов, или устройств, или чего-то еще, что появляется на фотографиях.
Благодаря ImageIdentify, встроенному прямо в язык Wolfram Language, легко создавать API или приложения, которые его используют. А с помощью Wolfram Cloud также легко создавать веб-сайты, такие как проект идентификации изображений Wolfram Language.
Личная предыстория
Лично я долго ждал ImageIdentify. Почти 40 лет назад я читал книги с такими названиями, как Компьютер и мозг , из-за которых казалось неизбежным, что когда-нибудь мы достигнем искусственного интеллекта — вероятно, путем имитации электрических соединений в мозге. И в 1980 году, воодушевленный успехом моего первого компьютерного языка, я решил, что должен подумать о том, что потребуется для создания полномасштабного искусственного интеллекта.
Отчасти меня воодушевило то, что — в раннем предчувствии языка Wolfram Language — я основал свой первый компьютерный язык на мощном символьном сопоставлении с образцом, который, как я представлял, может каким-то образом уловить определенные аспекты человеческого мышления. Но я знал, что хотя такие задачи, как идентификация изображений, также основывались на сопоставлении с образцом, для них требовалось нечто иное — более приблизительная форма сопоставления.
Я пытался изобрести примерные схемы хеширования. Но я все думал, что мозгу это удается; мы должны получить от них подсказки.Это привело меня к изучению идеализированных нейронных сетей и их поведения.
Тем временем я также работал над некоторыми фундаментальными вопросами естествознания — о космологии и о том, как структуры возникают в нашей Вселенной — и изучал поведение самогравитирующих скоплений частиц.
И в какой-то момент я понял, что и нейронные сети, и самогравитирующие газы являются примерами систем, которые имеют простые базовые компоненты, но каким-то образом достигают сложного общего поведения.И, разобравшись с этим, я закончил изучение клеточных автоматов и, в конце концов, сделал все открытия, которые стали A New Kind of Science .
Так что насчет нейронных сетей? Они не были моим любимым типом систем: они казались слишком произвольными и сложными по своей структуре по сравнению с другими системами, которые я изучал в вычислительной вселенной. Но время от времени я снова думал о них, выполняя моделирование, чтобы лучше понять основы их поведения, или пытался понять, как их можно использовать для практических задач, таких как приблизительное сопоставление с образцом:
Нейронные сети в целом имеют замечательную историю американских горок.Впервые они появились в 1940-х годах. Но к 1960-м годам их популярность пошла на убыль, и ходили слухи, что было «математически доказано», что они никогда не могут сделать ничего очень полезного.
Однако оказалось, что это справедливо только для однослойных сетей «персептрон». А в начале 1980-х годов возродился интерес к нейронным сетям, которые также имели «скрытый слой». Но, несмотря на то, что я знал многих лидеров этого направления, я должен сказать, что оставался в некоторой степени скептиком, не в последнюю очередь потому, что у меня сложилось впечатление, что нейронные сети в основном используются для задач, которые, казалось, были бы легко выполнены во многих областях. другие способы.
Я также чувствовал, что нейронные сети слишком сложны как формальные системы — и однажды я даже попытался разработать свою собственную альтернативу. Но все же я поддерживал людей в своем академическом исследовательском центре, изучающих нейронные сети, и включил статьи о них в свой журнал Complex Systems .
Я знал, что существуют практические применения нейронных сетей — например, для визуального распознавания символов — но их было немного и они были редкостью. И с годами, казалось, мало что могло пригодиться.
Машинное обучение
Между тем мы были заняты разработкой множества мощных и очень практичных способов анализа данных в Mathematica и в том, что впоследствии стало языком Wolfram Language. И несколько лет назад мы решили, что пришло время пойти дальше и попытаться интегрировать высокоавтоматизированное общее машинное обучение. Идея заключалась в том, чтобы сделать широкие, общие функции с большой мощностью; например, чтобы иметь единственную функцию Classify, которую можно было бы обучить классифицировать любые вещи: скажем, день vs.ночные фотографии, звуки различных музыкальных инструментов, уровень срочности электронной почты и т. д.
Мы применяем самые современные методы. Но, что более важно, мы постарались добиться полной автоматизации, чтобы пользователям не нужно было ничего знать о машинном обучении: им просто нужно было вызвать Classify.
Сначала я не был уверен, что это сработает. Но это действительно так, и это очень впечатляюще.
Люди могут предоставлять данные для обучения практически по чему угодно, а язык Wolfram Language автоматически настраивает для них классификаторы.Мы также предоставляем все больше и больше встроенных классификаторов, например для языков или флагов стран:
А недавно мы решили, что пришло время попробовать классическую задачу крупномасштабного классификатора: идентификацию изображения. И теперь результат — ImageIdentify.
Все об аттракторах
Что на самом деле означает идентификация изображения? В мире существует некоторое количество названных видов вещей, и цель состоит в том, чтобы сказать, к какому из них принадлежит конкретная картина.Или, более формально, отобразить все возможные изображения в определенный набор символических имен объектов.
У нас нет внутреннего способа описать объект, например стул. Все, что мы можем сделать, это просто привести множество примеров стульев и эффективно сказать: «Все, что выглядит как один из них, мы хотим идентифицировать как стул». По сути, мы хотим, чтобы изображения, которые «близки» к нашим примерам стульев, отображались на имя «стул», а другие — нет.
Итак, существует множество систем, которые обладают таким «аттракторным» поведением.В качестве физического примера представьте горный пейзаж. Капля дождя может упасть где угодно в горах, но (по крайней мере, в идеализированной модели) она стечет в одну из ограниченного числа самых низких точек. Близлежащие капли будут стремиться течь в одну и ту же самую низкую точку. Далекие капли могут быть по другую сторону водораздела, и поэтому они будут стекать в другие нижние точки.
Капли дождя подобны нашим изображениям; самые низкие точки подобны различным объектам. С каплями дождя мы говорим о вещах, которые физически движутся под действием силы тяжести.Но изображения состоят из цифровых пикселей. И вместо того, чтобы думать о физическом движении, мы должны думать о цифровых значениях, обрабатываемых программами.
И там может происходить точно такое же «аттракторное» поведение. Например, существует множество клеточных автоматов, в которых можно изменить цвета нескольких ячеек в их начальных условиях, но все же остаться в том же фиксированном конечном состоянии «аттрактора». (Большинство клеточных автоматов на самом деле демонстрируют более интересное поведение, которое не переходит в фиксированное состояние, но менее ясно, как применить это к задачам распознавания.)
Итак, что произойдет, если мы возьмем изображения и применим к ним правила клеточного автомата? По сути, мы занимаемся обработкой изображений, и действительно, некоторые общие операции обработки изображений (выполняемые как на компьютерах, так и при визуальной обработке человека) представляют собой простые двумерные клеточные автоматы.
Клеточный автомат легко заставить различать определенные особенности изображения, например, пятна темных пикселей. Но для идентификации реального изображения нужно еще кое-что. В аналогии с горами мы должны «вылепить» горный пейзаж так, чтобы нужные капли дождя стекали в нужные точки.
Программы создаются автоматически
Итак, как нам это сделать? В случае цифровых данных, таких как изображения, неизвестно, как это сделать одним махом; мы знаем только, как делать это итеративно и постепенно. Мы должны начать с базовой «плоской» системы и постепенно выполнять «лепку».
Об этом виде итеративного скульптинга мало что известно. Я довольно много думал об этом для дискретных программ, таких как клеточные автоматы (и машины Тьюринга), и уверен, что можно сделать кое-что очень интересное.Но я так и не понял, как это сделать.
Однако для систем с непрерывными (действительными) параметрами есть отличный метод, называемый обратным распространением, который основан на исчислении. По сути, это версия очень распространенного метода градиентного спуска, при котором производные вычисляются, а затем используются для определения того, как изменить параметры, чтобы система, которую вы используете, лучше соответствовала желаемому поведению.
Итак, какую систему следует использовать? Удивительно общий выбор — нейронные сети.Название заставляет задуматься о мозге и биологии. Но для наших целей нейронные сети — это просто формальные вычислительные системы, которые состоят из композиций функций с множеством входов с непрерывными параметрами и дискретными порогами.
Насколько легко заставить одну из этих нейронных сетей выполнять интересные задачи? Говоря абстрактно, это сложно сказать. И в течение как минимум 20 лет у меня сложилось впечатление, что на практике нейронные сети в основном могут делать только то, что также было довольно легко сделать другими способами.
Но несколько лет назад это начало меняться. И начали слышать о серьезных успехах в применении нейронных сетей для решения практических задач, таких как идентификация изображений.
Что заставило это случиться? Компьютеры (и особенно линейная алгебра в графических процессорах) стали достаточно быстрыми, чтобы — с помощью множества алгоритмических приемов, некоторые из которых фактически задействовали клеточные автоматы — стало практичным обучать нейронные сети с миллионами нейронов на миллионах примеров. (Между прочим, это были «глубокие» нейронные сети, которые больше не ограничивались небольшим количеством слоев.) И как-то внезапно это сделало масштабные практические приложения доступными.
Почему именно сейчас?
Я не думаю, что это совпадение, что это произошло именно тогда, когда количество используемых искусственных нейронов оказалось на досягаемости от количества нейронов в соответствующих частях нашего мозга.
Само по себе это число не имеет значения. Скорее дело в том, что если мы пытаемся выполнять задачи, такие как идентификация изображений, которые выполняет человеческий мозг, то неудивительно, что нам нужна система с аналогичным масштабом.
Люди могут легко распознать несколько тысяч видов вещей — примерно столько же существительных, сколько можно представить в человеческих языках. Низшие животные, вероятно, различают гораздо меньше видов вещей. Но если мы пытаемся добиться идентификации изображения, подобного человеку, и эффективно сопоставить изображения со словами, существующими в человеческих языках, то это определяет определенный масштаб проблемы, которая, по-видимому, может быть решена с помощью «человеческого» масштаб »нейронная сеть.
Безусловно, существуют различия между вычислительными и биологическими нейронными сетями — хотя после обучения сети процесс, скажем, получения результата из изображения кажется довольно похожим.Но методы, используемые для обучения вычислительных нейронных сетей, значительно отличаются от того, что кажется правдоподобным для использования биологией.
Тем не менее, в процессе разработки ImageIdentify я был весьма шокирован тем, насколько сильно напоминал биологический случай. Во-первых, количество обучающих изображений — несколько десятков миллионов — казалось очень сопоставимым с количеством различных видов объектов, которые люди получают в первые пару лет жизни.
Все, что видел, была шляпа
Были также причуды обучения, которые казались очень близкими к тому, что мы видели в биологическом случае.Например, в какой-то момент мы совершили ошибку, не имея человеческих лиц на тренировках. И когда мы показали фотографию Индианы Джонса, система не заметила его лица и идентифицировала изображение как шляпу. Возможно, это не удивительно, но для меня это поразительно напоминает классический эксперимент со зрением, в котором котята, выращенные в среде с вертикальными полосами, не видят горизонтальных полос.
Наверное, так же, как и мозг, нейронная сеть ImageIdentify имеет много слоев, содержащих множество различных типов нейронов.(Само собой разумеется, что общая структура хорошо описывается символическим выражением языка Wolfram Language.)
Трудно сказать что-то значимое о большей части того, что происходит внутри сети. Но если посмотреть на первый или два слоя, можно распознать некоторые особенности, которые он выделяет. И они кажутся удивительно похожими на особенности, которые, как мы знаем, выделяются реальными нейронами в первичной зрительной коре.
Я сам давно интересовался такими вещами, как визуальное распознавание текстуры (есть ли «примитивы текстуры», например, есть основные цвета?), И я подозреваю, что теперь мы сможем многое в этом разобраться.Я также думаю, что очень интересно посмотреть, что происходит на более поздних уровнях нейронной сети — потому что, если мы сможем их распознать, мы должны увидеть «возникающие концепции», которые, по сути, описывают классы изображений и объектов в мире, включая те, для которых у нас еще нет слов в человеческих языках.
Мы потеряли муравьедов!
Как и многие другие проекты, которые мы реализуем для языка Wolfram Language, разработка ImageIdentify потребовала объединения множества различных вещей. Масштабное курирование обучающих образов.Разработка общей онтологии изображаемых объектов с отображением на стандартные конструкции языка Wolfram Language. Анализ динамики нейронных сетей физическими методами. Детальная оптимизация параллельного кода. Даже некоторые поиски в стиле A New Kind of Science программ в вычислительной вселенной. И множество суждений о том, как создать функциональность, которая действительно была бы полезна на практике.
Вначале мне не было ясно, что весь проект ImageIdentify будет работать.И вначале количество совершенно неверно идентифицированных изображений было тревожно высоким. Но одна проблема за другой решалась, и постепенно стало ясно, что, наконец, мы достигли точки в истории, когда можно было создать полезную функцию ImageIdentify.
Проблем еще было много. Система будет хорошо справляться с одними вещами, но терпит неудачу в других. Затем мы что-то корректировали, и возникали новые сбои и шквал сообщений с темами вроде «Мы потеряли муравьедов!» (о том, как изображения, которые ImageIdentify использовал, чтобы правильно идентифицировать муравьедов, внезапно были идентифицированы как нечто совершенно иное).
Отладка ImageIdentify была интересным процессом. Что считается разумным вкладом? Какой разумный результат? Как сделать выбор между получением более конкретных результатов и получением результатов, которые, по вашему мнению, не являются неправильными (просто собака, охотничья собака или гончая)?
Иногда мы видели вещи, которые сначала казались совершенно безумными. Свинью ошибочно приняли за «упряжь». Кусок каменной кладки, ошибочно идентифицированный как «мопед». Но хорошей новостью было то, что мы всегда находили причину — например, путаницу из-за того, что одни и те же нерелевантные объекты неоднократно присутствовали в обучающих изображениях для определенного типа объекта (например,грамм. «Единственный раз, когда ImageIdentify видел азиатскую каменную кладку такого типа, был на фотографиях, где также были мопеды»).
Для тестирования системы я часто пробовал несколько необычные или неожиданные изображения:
И то, что я обнаружил, было очень поразительным и очаровательным. Да, ImageIdentify может ошибаться. Но почему-то ошибки казались очень понятными и в каком-то смысле очень человечными. Казалось, что то, что делает ImageIdentify, успешно улавливает часть сущности человеческого процесса идентификации изображений.
Так что насчет таких вещей, как абстрактное искусство? Это своего рода тест Роршаха для людей и машин — и интересный взгляд на «разум» ImageIdentify:
В диких условиях
Что-то вроде ImageIdentify никогда не будет закончено. Но пару месяцев назад мы выпустили предварительную версию на языке Wolfram Language. И сегодня мы обновили эту версию и использовали ее для запуска проекта идентификации изображений Wolfram Language.
Мы продолжим обучение и разработку ImageIdentify, не в последнюю очередь на основе отзывов и статистики с сайта.Как и в случае с Wolfram | Alpha в области понимания естественного языка, без фактического использования людьми нет реального способа реалистично оценить прогресс — или даже определить, какими должны быть цели для «понимания естественного изображения».
Должен сказать, что мне нравится играть с проектом идентификации образов Wolfram Language. После стольких лет приятно видеть, что этот вид искусственного интеллекта действительно работает. Но более того, когда вы видите, как ImageIdentify реагирует на странное или вызывающее изображение, часто возникает определенное чувство «ага», как будто вам только что очень по-человечески показали какое-то новое понимание — или шутку — об изображении.
Внизу, конечно, просто исполняемый код — с очень простыми внутренними циклами, которые почти такие же, как, например, в моих программах нейронной сети с начала 1980-х годов (за исключением того, что теперь они являются функциями языка Wolfram Language, скорее чем низкоуровневый код C).
Это увлекательный — и чрезвычайно необычный — пример в истории идей: нейронные сети изучались 70 лет и неоднократно отклонялись. Но теперь именно они принесли нам успех в таком типичном примере задачи искусственного интеллекта, как идентификация изображений.Я ожидаю, что первые пионеры нейронных сетей, такие как Уоррен Маккалок и Уолтер Питтс, не найдут ничего удивительного в сути того, что делает проект по идентификации изображений на языке Wolfram Language, хотя они могут быть удивлены тем, что на то, чтобы достичь этого, потребовалось 70 лет.
Но для меня большее значение имеет то, что теперь можно сделать, интегрировав такие вещи, как ImageIdentify, во всю символическую структуру языка Wolfram Language. То, что делает ImageIdentify, — это то, чему люди учатся в каждом поколении.Но символический язык дает нам возможность представить общие интеллектуальные достижения на протяжении всей истории человечества. И создание всех этих вещей вычислительными, я считаю, имеет монументальное значение, и я только начинаю понимать.
Но на сегодня, я надеюсь, вам понравится проект идентификации образов Wolfram Language. Думайте об этом как о праздновании достижений искусственного интеллекта. Думайте об этом как об интеллектуальной игре, которая помогает понять, что такое искусственный интеллект.Но не забывайте о том, что я считаю наиболее захватывающим: это еще и практическая технология, которую вы можете использовать здесь и сейчас в Wolfram Language и развертывать где угодно.
Можно ли с помощью объектива Google определить, какое у меня насекомое или ошибка?
Спасибо за то, что доверили The Pest Rangers здоровье и благополучие своего дома или бизнеса. Поскольку мы работаем вместе как сообщество и нация, чтобы лучше понять и смягчить распространение нового коронавируса, всех нас просят придерживаться новых правил и делать все возможное, чтобы практиковать социальное дистанцирование.
Пожалуйста, знайте, что, как защитники здоровья населения, продуктов питания и имущества, мы очень серьезно относимся к своей роли в обеспечении качества вашей жизни. Специалисты по борьбе с вредителями несут ответственность за защиту от грызунов, насекомых, паукообразных и других животных, которые могут нанести ущерб собственности и угрожать здоровью людей из-за распространения болезней и бактерий, а также причинения болезненных укусов и укусов. Наши критически важные услуги распространяются на дома людей и предприятия, а также на основные коммерческие предприятия, такие как медицинские учреждения, предприятия пищевой промышленности и многое другое.
Мы настоятельно рекомендуем всем следовать советам Центров по контролю и профилактике заболеваний США (CDC) и руководителей нашего правительства. Как организация, мы принимаем дополнительные меры, чтобы обеспечить наилучший уровень защиты как для наших клиентов, так и для наших сотрудников. Дополнительную информацию о предпринимаемых нами шагах можно найти в руководстве CDC для предприятий, которое можно найти здесь.
Это служит для информирования вас о том, что с 16.03.2020 The Pest Rangers будут работать по измененному графику .С приходом весны мы продолжим предоставлять услуги на основе запросов клиентов. Экстерьерные услуги будут завершены как всегда.
Ваш комментарий будет первым