XML (eXtensible Markup Language) — Что это, зачем нужен формат «ХМЛ» и какие преимущества у этого расширения
Технический текст всегда строгий и упорядоченный, поскольку в нём важно правильно выстроить иерархию. Чтобы задать в нём логическую структуру, обязательно нужно знать, что такое XML. Этот формат особенно актуален в Java-разработке, а также при тестировании API.
Формат XML: что это за программа
Чтобы разобраться, зачем нужен XML формат, что это такое, рассмотрим стандартную ситуацию.
В организации создается внушительный объем документов для общего доступа. Сотрудники их корректируют, в том числе исправляют ошибки, делают уточнения, меняют местами абзацы. Руководители отделов контролируют этот процесс и тоже могут вносить комментарии. Обычно для подобной совместной работы используется MS Word, а чтобы применить функцию, в меню нужно выбрать «отслеживание изменений».
Корректное название таких пометок в текстовом документе – разметка. Чтобы её сделать, нужны специальные элементы для определения структуры – теги.
Чтобы её сделать, нужны специальные элементы для определения структуры – теги.
Набор таких тегов – это язык разметки. Наиболее известным и востребованным из них является XML, что расшифровывается как eXtensible Markup Language (расширяемый язык разметки).
Таким образом, можно сказать про xml формат, что это метаязык, на котором создаётся разметка данных, а также описание её языков.
Цели и задачи XML
Протокол XML помогает разработчикам наладить уникальную разметку, адаптировав её под конкретный проект или задачу. Благодаря таким возможностям его и называют расширенным.
Однако стоит помнить про расширение xml, что это не сам код, а язык описания данных. А чтобы с этими данными можно было работать, в том числе передавать, принимать или обрабатывать, необходимо писать сам код уже на языке программирования.
Используется XML для различных задач.
- Представление иерархии, когда один элемент подчиняется другому. Наглядным примером является организационная структура предприятия.

- Разметка текста по смыслу. То есть пользователь может выделить основные и дополнительные моменты, добавить пояснения или комментарии.
- Хранение типовых данных. Это может быть бухгалтерская информация, программные настройки, скрипты и т.д.
- Разметка веб-страниц по смыслу.
- Разметка текста для машинного обучения.
- Хранение результатов работы программ.

Преимущества XML
У XML есть 3 ключевых достоинства.
- Доступность. Он понятен не только для устройств, таких как компьютеры, смартфоны или планшеты, но и для человека. Документы в таком разрешении свободно могут читать и корректировать люди без профильных знаний, обращаясь к привычным инструментам редактирования.
- Совместимость. Поскольку данные записаны в текстовом формате, для их передачи не требуется конвертация. Кроме того, для внесения данных или разметки допустимо использование разных систем, пользователь может работать на любой платформе или операционной системе.
- Универсальность. ХMЛ формат нужен, чтобы структурировать, менять, запрашивать информацию. При этом он доступен в API и коде.

В HTML тоже хранятся данные в тегах. Но они отвечают за представление информации в структурированном виде, то есть можно настроить расположение заголовков, отступы абзацев и т.д. XML-теги на этом фоне более сложные, поскольку задают смысл информации. Поэтому HTML не может заменить XML. При этом XML-данные допустимо представлять в HTML-тегах.
Существуют и другие метаязыки. Но у них довольно узкая специализация, то есть они предназначены для конкретных задач.
Файл XML: что это такое и из чего он состоит
Файл XML представляет собой текстовый документ, в котором присутствуют теги для описания структуры и других его функций. Теги пишут в угловых скобках, причём их всегда два – один открывает запись, другим она заканчивается.
<первый тег> ставят перед элементом, для которого требуется разметка.
</второй тег> — закрывает разметку и располагается после элемента.Теги бывают вложенными. Это значит, что внутри одного тега находится другой. Например, они могут выглядеть так.
<message>
<warning>
Обязательно к изучению!
</warning>
</message>
В свою очередь, вложенные теги дополняют другие вложенности. Такая сложная структура называется «дерево тегов».
У тегов есть атрибуты, то есть уточняющие сведения. В данном примере для тега «PLAYER» атрибутами являются «TEAM», «TRAINER» и «RESULT».
Примеры использования XML
Первой записью в документе XML часто указывают сведения о кодировке и версии XML. Называется она «prolog» и выглядит так.
<?xml version="3.0" encoding="UTF-8"?>
Кроме того, расширение XML помогает создать новую версия сайта, не переделывая предыдущую. Например, мы запустили интернет-магазин. Сначала продавали исключительно чай оптом, но позже решили расширять ассортимент и добавить раздел с кофе.
<data>
<owner first="CHAI" last="OPTOM"/>
</owner>
<name="KOFE" last="OPTOM"/>
</data>
Для различных задач в некоторых ситуациях может использоваться общий элемент, это называется пространство имен и префиксы.
# xmlns:<name>=<«uri»>
В данном случае «name» — имя элемента, а «uri» — URL, определяющий пространство имен.
Префиксы актуальны, если возник конфликт двух версий. Например, компания занимается продажей автомобилей, но в каталоге появились игрушечные модели. Чтобы отличать реальный транспорт от детских машинок, достаточно ввести два префикса «real» и «toy».
Однако, чтобы эти префиксы работали, им необходимо задать уникальное имя в namespace. Сделать это можно через URI, в том числе подставив ссылку на описание функций или назначение пространства имен.
Как открыть файл XML
Самый простой способ посмотреть информацию – открыть файл через браузер. Нажмите на него правой кнопкой мыши, затем плавно перейдите на «открыть» и выберете подходящий браузер.
Таблицы открываются через Excel. Запустите программу и нажмите сочетание клавиш «CTRL+O». Укажите путь к файлу, то есть папку на компьютере, в которой он расположен. Также можно просто перетащить файл из нужной папки, удерживая левую кнопку мыши.
Текстовый документ можно открыть с помощью любого программного продукта, поддерживающего XML-разрешение. Это может быть MS Word, блокнот и т.д.
Часто файлы находятся на сайте, скачивать их необязательно. Для их просмотра существуют специализированные сервисы, такие как codebeautify.org, XMLGrid и другие.
Заключение
XML помогает делать в документах разметку, то есть структурировать его, делать удобным для восприятия. Это единственный универсальный формат, который подходит для разнообразных целей и задач. Кроме того, он доступен для многих типов устройств, совместим со множеством клиентских платформ и операционными системами. И хотя для создания тегов в XML-файлов необходима подготовка и минимальный набор профильных знаний, открыть и прочитать документы может любой человек.
И хотя для создания тегов в XML-файлов необходима подготовка и минимальный набор профильных знаний, открыть и прочитать документы может любой человек.
Что такое XML / Хабр
Если вы тестируете API, то должны знать про два основных формата передачи данных:
- XML — используется в SOAP (всегда) и REST-запросах (реже);
- JSON — используется в REST-запросах.
Сегодня я расскажу вам про XML.
XML, в переводе с англ eXtensible Markup Language — расширяемый язык разметки. Используется для хранения и передачи данных. Так что увидеть его можно не только в API, но и в коде.
Этот формат рекомендован Консорциумом Всемирной паутины (W3C), поэтому он часто используется для передачи данных по API. В SOAP API это вообще единственно возможный формат входных и выходных данных!
См также:
Что такое API — общее знакомство с API
Что такое JSON — второй популярный формат
Введение в SOAP и REST: что это и с чем едят — видео про разницу между SOAP и REST.

Так что давайте разберемся, как он выглядит, как его читать, и как ломать! Да-да, а куда же без этого? Надо ведь выяснить, как отреагирует система на кривой формат присланных данных.
Содержание
- Как устроен XML
- Теги
- Корневой элемент
- Значение элемента
- Атрибуты элемента
- XML пролог
- XSD-схема
- Практика: составляем свой запрос
- 1. Есть корневой элемент
- 2. У каждого элемента есть закрывающийся тег
- 3. Теги регистрозависимы
- 4. Правильная вложенность элементов
- 5. Атрибуты оформлены в кавычках
- Итого
Как устроен XML
Возьмем пример из документации подсказок Дадаты по ФИО:
<req> <query>Виктор Иван</query> <count>7</count> </req>
И разберемся, что означает эта запись.
Теги
В XML каждый элемент должен быть заключен в теги. Тег — это некий текст, обернутый в угловые скобки:
<tag>
Текст внутри угловых скобок — название тега.
Тега всегда два:
- Открывающий — текст внутри угловых скобок
<tag>
- Закрывающий — тот же текст (это важно!), но добавляется символ «/»
</tag>
Ой, ну ладно, подловили! Не всегда. Бывают еще пустые элементы, у них один тег и открывающий, и закрывающий одновременно. Но об этом чуть позже!
С помощью тегов мы показываем системе «вот тут начинается элемент, а вот тут заканчивается». Это как дорожные знаки:
— На въезде в город написано его название: Москва
— На выезде написано то же самое название, но перечеркнутое: Москва*
* Пример с дорожными знаками я когда-то давно прочитала в статье Яндекса, только ссылку уже не помню.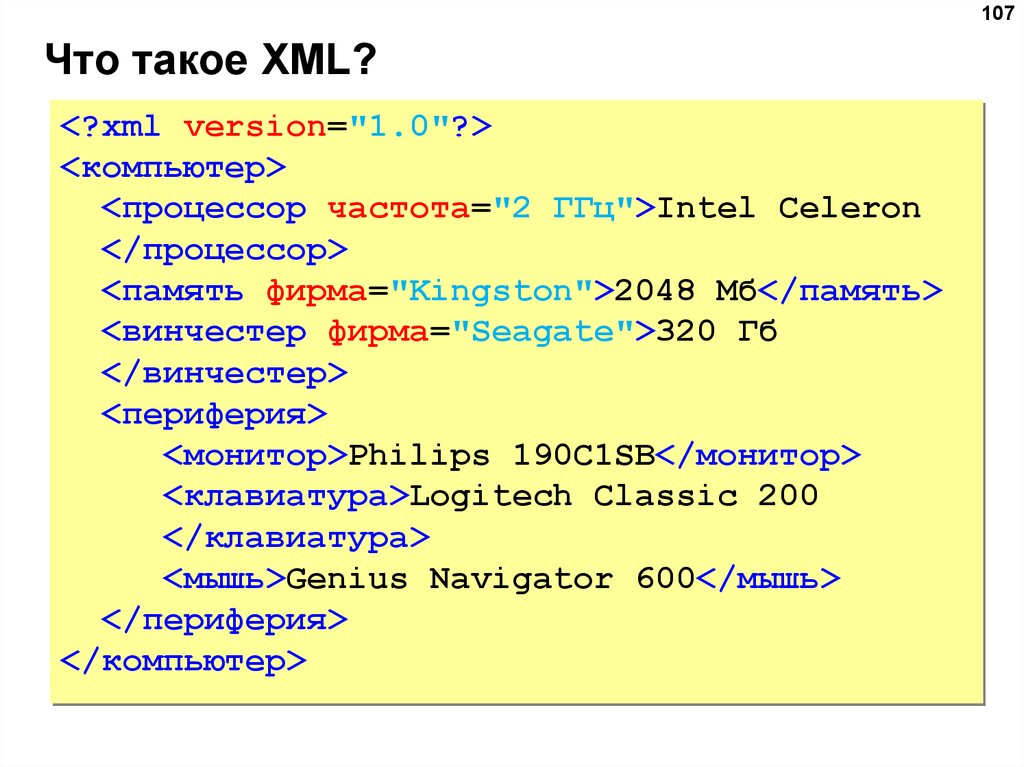 А пример отличный!
А пример отличный!
Корневой элемент
В любом XML-документе есть корневой элемент. Это тег, с которого документ начинается, и которым заканчивается. В случае REST API документ — это запрос, который отправляет система. Или ответ, который она получает.
Чтобы обозначить этот запрос, нам нужен корневой элемент. В подсказках корневой элемент — «req».
Он мог бы называться по другому:
<main>
<sugg>
Да как угодно. Он показывает начало и конец нашего запроса, не более того. А вот внутри уже идет тело документа — сам запрос. Те параметры, которые мы передаем внешней системе. Разумеется, они тоже будут в тегах, но уже в обычных, а не корневых.
Значение элемента
Значение элемента хранится между открывающим и закрывающим тегами. Это может быть число, строка, или даже вложенные теги!
Вот у нас есть тег «query». Он обозначает запрос, который мы отправляем в подсказки.
Он обозначает запрос, который мы отправляем в подсказки.
Внутри — значение запроса.
Это как если бы мы вбили строку «Виктор Иван» в GUI (графическом интерфейсе пользователя):
Пользователю лишняя обвязка не нужна, ему нужна красивая формочка. А вот системе надо как-то передать, что «пользователь ввел именно это». Как показать ей, где начинается и заканчивается переданное значение? Для этого и используются теги.
Система видит тег «query» и понимает, что внутри него «строка, по которой нужно вернуть подсказки».
Параметр count = 7 обозначает, сколько подсказок вернуть в ответе. Если тыкать подсказки на демо-форме Дадаты, нам вернется 7 подсказок. Это потому, что туда вшито как раз значение count = 7. А вот если обратиться к документации метода, count можно выбрать от 1 до 20.
Откройте консоль разработчика через f12, вкладку Network, и посмотрите, какой запрос отправляется на сервер. Там будет значение count = 7.См также:
Что тестировщику надо знать про панель разработчика — подробнее о том, как использовать консоль.

Обратите внимание:
- Виктор Иван — строка
- 7 — число
Но оба значения идут
безкавычек. В XML нам нет нужды брать строковое значение в кавычки (а вот в JSON это сделать придется).
Атрибуты элемента
У элемента могут быть атрибуты — один или несколько. Их мы указываем внутри отрывающегося тега после названия тега через пробел в виде
название_атрибута = «значение атрибута»
Например:
<query attr1=“value 1”>Виктор Иван</query> <query attr1=“value 1” attr2=“value 2”>Виктор Иван</query>
Зачем это нужно? Из атрибутов принимающая API-запрос система понимает, что такое ей вообще пришло.
Например, мы делаем поиск по системе, ищем клиентов с именем Олег. Отправляем простой запрос:
<query>Олег</query>
А в ответ получаем целую пачку Олегов! С разными датами рождения, номерами телефонов и другими данными. Допустим, что один из результатов поиска выглядит так:
<party type="PHYSICAL" sourceSystem="AL" rawId="2">
<field name=“name">Олег </field>
<field name="birthdate">02.01.1980</field>
<attribute type="PHONE" rawId="AL.2.PH.1">
<field name="type">MOBILE</field>
<field name="number">+7 916 1234567</field>
</attribute>
</party>Давайте разберем эту запись. У нас есть основной элемент party.
У него есть 3 атрибута:
- type = «PHYSICAL» — тип возвращаемых данных. Нужен, если система умеет работать с разными типами: ФЛ, ЮЛ, ИП. Тогда благодаря этому атрибуту мы понимаем, с чем именно имеем дело и какие поля у нас будут внутри. А они будут отличаться! У физика это может быть ФИО, дата рождения ИНН, а у юр лица — название компании, ОГРН и КПП
- sourceSystem = «AL» — исходная система. Возможно, нас интересуют только физ лица из одной системы, будем делать отсев по этому атрибуту.
- rawId = «2» — идентификатор в исходной системе. Он нужен, если мы шлем запрос на обновление клиента, а не на поиск. Как понять, кого обновлять? По связке sourceSystem + rawId!
 Тогда благодаря этому атрибуту мы понимаем, с чем именно имеем дело и какие поля у нас будут внутри. А они будут отличаться! У физика это может быть ФИО, дата рождения ИНН, а у юр лица — название компании, ОГРН и КПП
Тогда благодаря этому атрибуту мы понимаем, с чем именно имеем дело и какие поля у нас будут внутри. А они будут отличаться! У физика это может быть ФИО, дата рождения ИНН, а у юр лица — название компании, ОГРН и КППВнутри party есть элементы field.
У элементов field есть атрибут name. Значение атрибута — название поля: имя, дата рождения, тип или номер телефона. Так мы понимаем, что скрывается под конкретным field.
Это удобно с точки зрения поддержки, когда у вас коробочный продукт и 10+ заказчиков. У каждого заказчика будет свой набор полей: у кого-то в системе есть ИНН, у кого-то нету, одному важна дата рождения, другому нет, и т.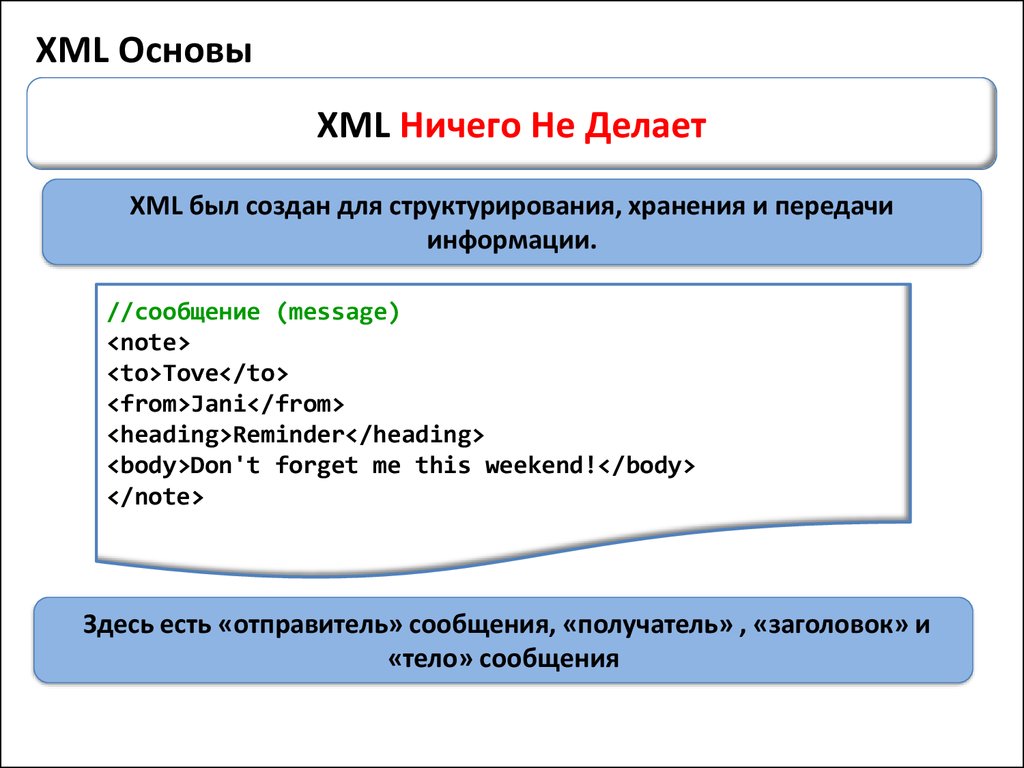 д.
д.
Но, несмотря на разницу моделей, у всех заказчиков будет одна XSD-схема (которая описывает запрос и ответ):
— есть элемент party;
— у него есть элементы field;
— у каждого элемента field есть атрибут name, в котором хранится название поля.
А вот конкретные названия полей уже можно не описывать в XSD. Их уже «смотрите в ТЗ». Конечно, когда заказчик один или вы делаете ПО для себя или «вообще для всех», удобнее использовать именованные поля — то есть «говорящие» теги. Какие плюшки у этого подхода:
— При чтении XSD сразу видны реальные поля. ТЗ может устареть, а код будет актуален.
— Запрос легко дернуть вручную в SOAP Ui — он сразу создаст все нужные поля, нужно только значениями заполнить. Это удобно тестировщику + заказчик иногда так тестирует, ему тоже хорошо.
В общем, любой подход имеет право на существование. Надо смотреть по проекту, что будет удобнее именно вам. У меня в примере неговорящие названия элементов — все как один будут field. А вот по атрибутам уже можно понять, что это такое.
А вот по атрибутам уже можно понять, что это такое.
Помимо элементов field в party есть элемент attribute. Не путайте xml-нотацию и бизнес-прочтение:
- с точки зрения бизнеса это атрибут физ лица, отсюда и название элемента — attribute.
- с точки зрения xml — это элемент (не атрибут!), просто его назвали attribute. XML все равно (почти), как вы будете называть элементы, так что это допустимо.
У элемента attribute есть атрибуты:
- type = «PHONE» — тип атрибута. Они ведь разные могут быть: телефон, адрес, емейл…
- rawId = «AL.2.PH.1» — идентификатор в исходной системе. Он нужен для обновления. Ведь у одного клиента может быть несколько телефонов, как без ID понять, какой именно обновляется?
Такая вот XML-ка получилась. Причем упрощенная. В реальных системах, где хранятся физ лица, данных сильно больше: штук 20 полей самого физ лица, несколько адресов, телефонов, емейл-адресов…
Но прочитать даже огромную XML не составит труда, если вы знаете, что где. И если она отформатирована — вложенные элементы сдвинуты вправо, остальные на одном уровне. Без форматирования будет тяжеловато…
И если она отформатирована — вложенные элементы сдвинуты вправо, остальные на одном уровне. Без форматирования будет тяжеловато…
А так всё просто — у нас есть элементы, заключенные в теги. Внутри тегов — название элемента. Если после названия идет что-то через пробел: это атрибуты элемента.
XML пролог
Иногда вверху XML документа можно увидеть что-то похожее:
<?xml version="1.0" encoding="UTF-8"?>
Эта строка называется XML прологом. Она показывает версию XML, который используется в документе, а также кодировку. Пролог необязателен, если его нет — это ок. Но если он есть, то это должна быть первая строка XML документа.
UTF-8 — кодировка XML документов по умолчанию.
XSD-схема
XSD (XML Schema Definition) — это описание вашего XML. Как он должен выглядеть, что в нем должно быть? Это ТЗ, написанное на языке машины — ведь схему мы пишем… Тоже в формате XML! Получается XML, который описывает другой XML.
Фишка в том, что проверку по схеме можно делегировать машине. И разработчику даже не надо расписывать каждую проверку. Достаточно сказать «вот схема, проверяй по ней».
Если мы создаем SOAP-метод, то указываем в схеме:
- какие поля будут в запросе;
- какие поля будут в ответе;
- какие типы данных у каждого поля;
- какие поля обязательны для заполнения, а какие нет;
- есть ли у поля значение по умолчанию, и какое оно;
- есть ли у поля ограничение по длине;
- есть ли у поля другие параметры;
- какая у запроса структура по вложенности элементов;
- …
Теперь, когда к нам приходит какой-то запрос, он сперва проверяется на корректность по схеме. Если запрос правильный, запускаем метод, отрабатываем бизнес-логику. А она может быть сложной и ресурсоемкой! Например, сделать выборку из многомиллионной базы. Или провести с десяток проверок по разным таблицам базы данных…
Поэтому зачем запускать сложную процедуру, если запрос заведом «плохой»? И выдавать ошибку через 5 минут, а не сразу? Валидация по схеме помогает быстро отсеять явно невалидные запросы, не нагружая систему.
Более того, похожую защиту ставят и некоторые программы-клиенты для отправки запросов. Например, SOAP Ui умеет проверять ваш запрос на well formed xml, и он просто не отправит его на сервер, если вы облажались. Экономит время на передачу данных, молодец!
А простому пользователю вашего SOAP API схема помогает понять, как составить запрос. Кто такой «простой пользователь»?
- Разработчик системы, использующей ваше API — ему надо прописать в коде, что именно отправлять из его системы в вашу.
- Тестировщик, которому надо это самое API проверить — ему надо понимать, как формируется запрос.
Да-да, в идеале у нас есть подробное ТЗ, где всё хорошо описано. Но увы и ах, такое есть не всегда. Иногда ТЗ просто нет, а иногда оно устарело. А вот схема не устареет, потому что обновляется при обновлении кода. И она как раз помогает понять, как запрос должен выглядеть.
Итого, как используется схема при разработке SOAP API:
- Наш разработчик пишет XSD-схему для API запроса: нужно передать элемент такой-то, у которого будут такие-то дочерние, с такими-то типами данных. Эти обязательные, те нет.
- Разработчик системы-заказчика, которая интегрируется с нашей, читает эту схему и строит свои запросы по ней.
- Система-заказчик отправляет запросы нам.
- Наша система проверяет запросы по XSD — если что-то не так, сразу отлуп.
- Если по XSD запрос проверку прошел — включаем бизнес-логику!
 Эти обязательные, те нет.
Эти обязательные, те нет.А теперь давайте посмотрим, как схема может выглядеть! Возьмем для примера метод doRegister в Users. Чтобы отправить запрос, мы должны передать email, name и password. Есть куча способов написать запрос правильно и неправильно:
Попробуем написать для него схему. В запросе должны быть 3 элемента (email, name, password) с типом «string» (строка). Пишем:
<xs:element name="doRegister ">
<xs:complexType>
<xs:sequence>
<xs:element name="email" type="xs:string"/>
<xs:element name="name" type="xs:string"/>
<xs:element name="password" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>А в WSDl сервиса она записана еще проще:
<message name="doRegisterRequest"> <part name="email" type="xsd:string"/> <part name="name" type="xsd:string"/> <part name="password" type="xsd:string"/> </message>
Конечно, в схеме могут быть не только строковые элементы. Это могут быть числа, даты, boolean-значения и даже какие-то свои типы:
Это могут быть числа, даты, boolean-значения и даже какие-то свои типы:
<xsd:complexType name="Test">
<xsd:sequence>
<xsd:element name="value" type="xsd:string"/>
<xsd:element name="include" type="xsd:boolean" minOccurs="0" default="true"/>
<xsd:element name="count" type="xsd:int" minOccurs="0" length="20"/>
<xsd:element name="user" type="USER" minOccurs="0"/>
</xsd:sequence>
</xsd:complexType>А еще в схеме можно ссылаться на другую схему, что упрощает написание кода — можно переиспользовать схемы для разных задач.
См также:
XSD — умный XML — полезная статья с хабра
Язык определения схем XSD — тут удобные таблички со значениями, которые можно использовать
Язык описания схем XSD (XML-Schema)
Пример XML схемы в учебнике
Официальный сайт w3.org
Практика: составляем свой запрос
Ок, теперь мы знаем, как «прочитать» запрос для API-метода в формате XML. Но как его составить по ТЗ? Давайте попробуем. Смотрим в документацию. И вот почему я даю пример из Дадаты — там классная документация!
Но как его составить по ТЗ? Давайте попробуем. Смотрим в документацию. И вот почему я даю пример из Дадаты — там классная документация!
Что, если я хочу, чтобы мне вернулись только женские ФИО, начинающиеся на «Ан»? Берем наш исходный пример:
<req> <query>Виктор Иван</query> <count>7</count> </req>
В первую очередь меняем сам запрос. Теперь это уже не «Виктор Иван», а «Ан»:
<req> <query>Ан</query> <count>7</count> </req>
Далее смотрим в ТЗ. Как вернуть только женские подсказки? Есть специальный параметр — gender. Название параметра — это название тегов. А внутри уже ставим пол. «Женский» по английски будет FEMALE, в документации также. Итого получили:
<req> <query>Ан</query> <count>7</count> <gender>FEMALE</gender> </req>
Ненужное можно удалить. Если нас не волнует количество подсказок, параметр count выкидываем. Ведь, согласно документации, он необязательный. Получили запрос:
Если нас не волнует количество подсказок, параметр count выкидываем. Ведь, согласно документации, он необязательный. Получили запрос:
<req> <query>Ан</query> <gender>FEMALE</gender> </req>
Вот и все! Взяли за основу пример, поменяли одно значение, один параметр добавили, один удалили. Не так уж и сложно. Особенно, когда есть подробное ТЗ и пример )))
Попробуй сам!
Напишите запрос для метода MagicSearch в Users. Мы хотим найти всех Ивановых по полному совпадению, на которых висят актуальные задачи.
Well Formed XML
Разработчик сам решает, какой XML будет считаться правильным, а какой нет. Но есть общие правила, которые нельзя нарушать. XML должен быть well formed, то есть синтаксически корректный.
Чтобы проверить XML на синтаксис, можно использовать любой XML Validator (так и гуглите). Я рекомендую сайт w3schools. Там есть сам валидатор + описание типичных ошибок с примерами.
В готовый валидатор вы просто вставляете свой XML (например, запрос для сервера) и смотрите, всё ли с ним хорошо. Но можете проверить его и сами. Пройдитесь по правилам синтаксиса и посмотрите, следует ли им ваш запрос.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.
Давайте пройдемся по каждому правилу и обсудим, как нам применять их в тестировании. То есть как правильно «ломать» запрос, проверяя его на well-formed xml. Зачем это нужно? Посмотреть на фидбек от системы. Сможете ли вы по тексту ошибки понять, где именно облажались?
См также:
Сообщения об ошибках — тоже документация, тестируйте их! — зачем тестировать сообщения об ошибках
1. Есть корневой элемент
Нельзя просто положить рядышком 2 XML и полагать, что «система сама разберется, что это два запроса, а не один». Не разберется. Потому что не должна.
Не разберется. Потому что не должна.
И если у вас будет лежать несколько тегов подряд без общего родителя — это плохой xml, не well formed. Всегда должен быть корневой элемент:
Что мы делаем для тестирования этого условия? Правильно, удаляем из нашего запроса корневые теги!
2. У каждого элемента есть закрывающийся тег
Тут все просто — если тег где-то открылся, он должен где-то закрыться. Хотите сломать? Удалите закрывающийся тег любого элемента.
Но тут стоит заметить, что тег может быть один. Если элемент пустой, мы можем обойтись одним тегом, закрыв его в конце:
<name/>
Это тоже самое, что передать в нем пустое значение
<name></name>
Аналогично сервер может вернуть нам пустое значение тега. Можно попробовать послать пустые поля в Users в методе FullUpdateUser. И в запросе это допустимо (я отправила пустым поле name1), и в ответе SOAP Ui нам именно так и отрисовывает пустые поля.
И в запросе это допустимо (я отправила пустым поле name1), и в ответе SOAP Ui нам именно так и отрисовывает пустые поля.
Итого — если есть открывающийся тег, должен быть закрывающийся. Либо это будет один тег со слешом в конце.
Для тестирования удаляем в запросе любой закрывающийся тег.
3. Теги регистрозависимы
Как написали открывающий — также пишем и закрывающий. ТОЧНО ТАК ЖЕ! А не так, как захотелось.
А вот для тестирования меняем регистр одной из частей. Такой XML будет невалидным
4. Правильная вложенность элементов
Элементы могут идти друг за другом
Один элемент может быть вложен в другой
Но накладываться друг на друга элементы НЕ могут!
5. Атрибуты оформлены в кавычках
Даже если вы считаете атрибут числом, он будет в кавычках:
<query attr1=“123”>Виктор Иван</query> <query attr1=“атрибутик” attr2=“123” >Виктор Иван</query>
Для тестирования пробуем передать его без кавычек:
<query attr1=123>Виктор Иван</query>
Итого
XML (eXtensible Markup Language) используется для хранения и передачи данных.
Передача данных — это запросы и ответы в API-методах. Если вы отправляете SOAP-запрос, вы априори работаете именно с этим форматом. Потому что SOAP передает данные только в XML. Если вы используете REST, то там возможны варианты — или XML, или JSON.Хранение данных — это когда XML встречается внутри кода. Его легко понимает как машина, так и человек. В формате XML можно описывать какие-то правила, которые будут применяться к данным, или что-то еще.
Вот пример использования XML в коде open-source проекта folks. Я не знаю, что именно делает JacksonJsonProvider, но могу «прочитать» этот код — есть функционал, который мы будем использовать (featuresToEnable), и есть тот, что нам не нужен(featuresToDisable).
Формат XML подчиняется стандартам. Синтаксически некорректный запрос даже на сервер не уйдет, его еще клиент порежет. Сначала проверка на well formed, потом уже бизнес-логика.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.

Если вы тестировщик, то при тестировании запросов в формате XML обязательно попробуйте нарушить каждое правило! Да, система должна уметь обрабатывать такие ошибки и возвращать адекватное сообщение об ошибке. Но далеко не всегда она это делает.
А если система публичная и возвращает пустой ответ на некорректный запрос — это плохо. Потому что разработчик другой системы налажает в запросе, а по пустому ответу даже не поймет, где именно. И будет приставать к поддержке: «Что же у меня не так?», кидая информацию по кусочкам и в виде скринов исходного кода. Оно вам надо? Нет? Тогда убедитесь, что система выдает понятное сообщение об ошибке!
См также:
Что такое XML
Учебник по XML
Изучаем XML. Эрик Рэй (книга по XML)
Заметки о XML и XLST
Что такое JSON — второй популярный формат
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
А полезные видео — на моем youtube-канале
Формат файла XML | Подробное объяснение формата XML-файла с примерами
Формат XML-файла является инструментом и определяется как средство обмена информацией, описывает данные и содержит метаданные. Этот инструмент преобразует XML-файл в другие форматы, такие как PDF или любые другие приложения с несколькими уровнями отступов, чтобы придать XML-файлам элегантность. Файл XML имеет формальную структуру и используется для файлов данных; при этом XML-файлы нельзя хранить в плоском файле. Формат файла играет роль в определении стандартного блока, соответствующего потребностям пользователя. В XML мы могли бы определить пользовательский элемент разметки и следовать определенным правилам, но не поддерживать и обрабатывать XML-документы с ошибками.
Подробно объясните формат файла XML
Как правило, формат файла — это стандартный способ хранения файла в определенном формате. Файл XML представляет собой обычный текстовый документ, и для их идентификации он хранится с расширением файла . xml. Формат файла XML может быть прочитан человеком или машиной и предназначен для передачи данных через Интернет и может обрабатывать сотни записей в расчетах. Большинство языков программирования используют XML-библиотеки, которые выполняют синтаксический анализ. Процесс преобразования XML-файлов в другие необходимые форматы называется преобразованием с понижением частоты. XML используется в качестве формата для других языков описания, таких как RSS, формат DOCX, XSL, Microsoft dotnet. Этот XML-файл можно открыть непосредственно в текстовом редакторе notepad++. Существует множество файловых организаций для обработки типов файлов; нам нужно несколько разговоров между ними. XML — это просто организация, необходимая для данных и веб-страниц. Затем, чтобы иногда просмотреть файл, можно дважды щелкнуть браузер (средство просмотра файла по умолчанию). Формат файла XML содержит три категории.
xml. Формат файла XML может быть прочитан человеком или машиной и предназначен для передачи данных через Интернет и может обрабатывать сотни записей в расчетах. Большинство языков программирования используют XML-библиотеки, которые выполняют синтаксический анализ. Процесс преобразования XML-файлов в другие необходимые форматы называется преобразованием с понижением частоты. XML используется в качестве формата для других языков описания, таких как RSS, формат DOCX, XSL, Microsoft dotnet. Этот XML-файл можно открыть непосредственно в текстовом редакторе notepad++. Существует множество файловых организаций для обработки типов файлов; нам нужно несколько разговоров между ними. XML — это просто организация, необходимая для данных и веб-страниц. Затем, чтобы иногда просмотреть файл, можно дважды щелкнуть браузер (средство просмотра файла по умолчанию). Формат файла XML содержит три категории.
- Первый раздел с идентификатором документа
- Содержание документа
- Метаданные с полями и аспектами.
Компонент структуры просто представлен элементом, связанным с атрибутами. Раздел одной структуры документа выполняет различные стили. Идентификация документа включает корневой элемент, который является основной частью XML-документа. Разработчикам необходимо преобразовать двоичные файлы в формат XML. Новый формат файлов описан ниже и называется офисными открытыми форматами. Здесь мы создаем открытый документ и предоставляем реализацию для указанного формата. Основная цель заключается в том, что формат должен быть принят всеми официальными документами, такими как электронные таблицы, а презентация также позволяет вернуть право собственности пользователям. Он указан как
- Спецификация формата файла XML
- Формат файла DTD
Код XML представлен как
<офис:документ>
Этот тип документа имеет вложенные документы с такими характеристиками, как класс и версия.
Тело документа задается как
С полями и данными, связанными со стилями и формами
…// структуры стилей, включая семейство, автоматические и родительские стили
В формах
Простой пример формата XML приведен ниже
ИМЯ ГРУППЫ =” ” NAME=”DOCNAME “
Для многостраничных разделов ОПЦИИ DAP применимы в XML. Различные форматы файлов использовались для формирования этой древовидной структуры для встраивания файлов XHTML, SVG.
Различные форматы файлов использовались для формирования этой древовидной структуры для встраивания файлов XHTML, SVG.
Общий формат файла XML для тегов и данных приведен ниже.
Следующие сообщения определяются как
XML, являющийся хранилищем данных жизненно важную роль в связи с базой данных, особенно в небольшом наборе приложений. Простой характер XML позволяет формату файла расширять сериализуемое содержимое объекта. Например, Manifold записывает свою информацию в файл .xml, пока экспортирует свои рисунки и изображения. Этот формат файла содержит всю информацию в метаданных.
// Теги описания
Примечание.
Расширяемую таблицу стилей можно использовать, если XML использует разные форматы при импорте файла.
Примеры
В этом разделе рассказывается, как структурировать XML-файл и разрешить его выполнение в формате XML, доступном в Интернете.
Пример №1
<Компания>Redmi
<год>2016
Объяснение:
Простой файл XML в различных форматах файлов создается в Online Formatter; поэтому выходные данные отображаются в виде структуры двоичного дерева.
Выход:
Пример #2
Использование Excel — простой импорт в таблицы
Объяснение:
Над кодом фрагмент объясняет учетные данные для банковских операций. В этом примере формат файла импортируется в лист Excel. Первый снимок показывает, как импортировать файлы XML через Excel (внешний источник). Далее Snapshot показывает, как XML-данные хранятся в удобной таблице.
В этом примере формат файла импортируется в лист Excel. Первый снимок показывает, как импортировать файлы XML через Excel (внешний источник). Далее Snapshot показывает, как XML-данные хранятся в удобной таблице.
Выход:
Пример № 3
Формат файла XML для значений датчиков
Мера. «?>
<Мин>36
 01e-06
01e-06
Объяснение:
Приведенный выше код создает научные параметры, используемые в механических расчетах. Результат показан.
Выходные данные:
Пример №4
<Больница>
<Сектор>
<Пациент>Эми Сэлвин
Объяснение:
Приведенный выше код управления больницей импортирован в таблицу Excel с помощью XML . XML хорошо используется в формате структур данных, особенно в веб-сервисах.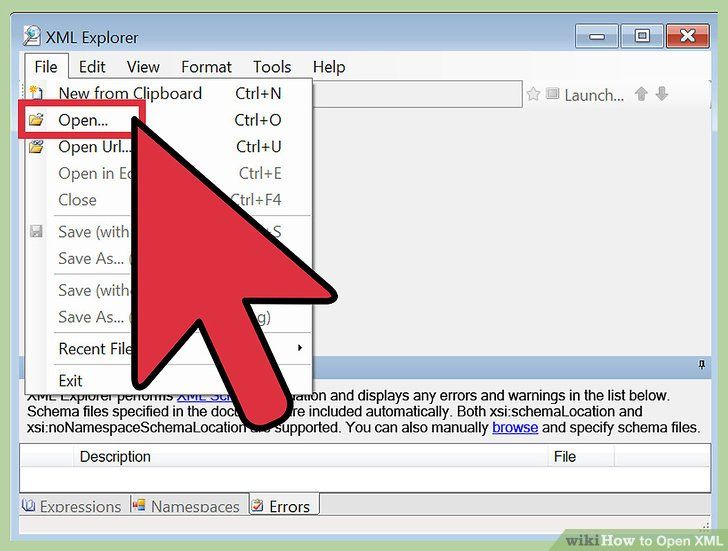
Вывод:
Заключение
Таким образом, любой разработчик приложений должен знать о форматах файлов, чтобы использовать их в реальной жизни. В новейших технологиях многим разработчикам требуется несколько профессиональных рабочих мест, в таком случае файлы XML помогают управлять технически развитым рабочим местом. Таким образом, форматы файлов XML очень просты в обращении и имеют структуру, помогающую преобразовывать и преобразовывать в различные форматы файлов. На рынке доступно несколько пакетов XML-инструментов для импорта и экспорта XML-файлов в различных приложениях.
Рекомендуемые статьи
Это руководство по формату файлов XML. Здесь мы подробно обсудим объяснение формата файла XML, а также примеры и результаты. Вы также можете ознакомиться со следующими статьями, чтобы узнать больше:
- Сопоставление XML
- PHP XML Reader
- объект C# в XML
- Проверка XML
XML-файлы: MedlinePlus
Чтобы использовать функции обмена на этой странице, включите JavaScript.
MedlinePlus создает наборы данных XML, которые вы можете скачать и использовать. Если у вас есть вопросы о XML-файлах MedlinePlus, свяжитесь с нами. Дополнительные источники данных MedlinePlus в формате XML см. на странице веб-службы. Если вы ищете данные от MedlinePlus Genetics, см. Файлы данных и API MedlinePlus Genetics.
Если вы используете данные из XML-файлов MedlinePlus или создаете интерфейс, использующий эти файлы, укажите, что информация взята из МедлайнПлюс.gov. Дополнительные указания см. на странице API NLM.
Темы о здоровье
MedlinePlus ежедневно (со вторника по субботу) публикует три типа XML-файлов по темам здравоохранения:
- MedlinePlus Health Topic XML
- MedlinePlus Сжатый раздел о здоровье XML
- MedlinePlus Health Тематическая группа XML
Шесть самых последних файлов и соответствующие им DTD связаны внизу этого раздела.
XML-файлы темы здравоохранения MedlinePlus содержат записи для всех английских и
Испанские темы здоровья. Каждая запись темы здоровья включает элементы данных
связанные с этой темой. Эти связанные данные включают в себя:
Каждая запись темы здоровья включает элементы данных
связанные с этой темой. Эти связанные данные включают в себя:
- основные метаданные (название темы здравоохранения, URL-адрес, язык, дата создания и идентификатор), Словарь
- (MeSH, «также называемые» термины и см. ссылки),
- полное резюме, членство в группе
- ,
- темы, связанные со здоровьем,
- эквивалентных английских или испанских тем,
- связанный контент на других языках,
- первичный институт NIH и
- все записи сайта (ссылки), назначенные странице темы здоровья, включая их имена, URL-адреса, организации, назначения категорий и стандартные описания.
Эти XML-файлы позволяют загружать и использовать практически весь текст и ссылки, которые появляются на тематических страницах MedlinePlus, посвященных вопросам здоровья. Для получения полной информации обо всех элементах и атрибутах в XML-файле темы здравоохранения MedlinePlus см. описание XML-файла MedlinePlus.
описание XML-файла MedlinePlus.
Сжатый XML-файл темы здоровья MedlinePlus содержит ту же информацию, что и XML-файл темы здоровья MedlinePlus, но для упрощения загрузки он публикуется в виде ZIP-файла.
XML-файлы тематической группы MedlinePlus о здоровье содержат информацию обо всех тематических группах на английском и испанском языках.
Файлы, созданные 15 апреля 2023 г.
MedlinePlus Health Topic XML (28622 K) (DTD, 5 K)
Файлы, созданные 14 апреля 2023 г.
MedlinePlus Health Topic XML (28623 K) (DTD, 5 K)
MedlinePlus Сжатый XML-файл темы Health (4388 K)
MedlinePlus Health Topic Group XML (11 K) (DTD, 3 K)
Файлы, созданные 13 апреля 2023 г.
MedlinePlus Health Topic XML (28621 K) (DTD, 5 K) K)
MedlinePlus Health Topic Group XML (11 K) (DTD, 3 K)
Файлы, созданные 12 апреля 2023 г.
MedlinePlus Health Topic XML (28621 K) (DTD, 5 K) (4389 КБ)
XML тематической группы MedlinePlus Health (11 КБ) (DTD, 3 КБ)
Файлы, созданные 11 апреля 2023 г.

MedlinePlus Health Topic XML (28622 K) (DTD, 5 K) K)
Файлы, созданные 8 апреля 2023 г.
MedlinePlus Health Topic XML (28624 K) (DTD, 5 K) , 3 K)
Определения медицинских терминов
Эти файлы содержат определения медицинских терминов на английском языке. Файлы содержат
- условия здоровья
- определений
- Источники NIH для определений
Эти файлы обновляются нечасто.
Определения медицинских терминов: Фитнес XML (7 КБ)
Определения медицинских терминов: Общее здоровье XML (5 КБ)
Определения медицинских терминов: Минералы XML (9 КБ)
Определения медицинских терминов: Питание XML (14 КБ)
Определения медицинских терминов: витамины XML (9 КБ)
Определение схемы XML (XSD, 2 КБ)
Словарь медицинских услуг
Этот файл содержит информацию обо всех Условиях предоставления местных услуг, используемых для веб-сайта Go Local. Файл содержит
- условия обслуживания
- определения и см.

Ваш комментарий будет первым