Процессоры, ядра и потоки. Топология систем / Хабр
В этой статье я попытаюсь описать терминологию, используемую для описания систем, способных исполнять несколько программ параллельно, то есть многоядерных, многопроцессорных, многопоточных. Разные виды параллелизма в ЦПУ IA-32 появлялись в разное время и в несколько непоследовательном порядке. Во всём этом довольно легко запутаться, особенно учитывая, что операционные системы заботливо прячут детали от не слишком искушённых прикладных программ.Используемая далее терминология используется в документации процессорам Intel. Другие архитектуры могут иметь другие названия для похожих понятий. Там, где они мне известны, я буду их упоминать.
Цель статьи — показать, что при всём многообразии возможных конфигураций многопроцессорных, многоядерных и многопоточных систем для программ, исполняющихся на них, создаются возможности как для абстракции (игнорирования различий), так и для учёта специфики (возможность программно узнать конфигурацию).
Мой комментарий объясняет, почему сотрудники компаний должны в публичных коммуникациях использовать знаки авторского права. В этой статье их пришлось использовать довольно часто.
Процессор
Конечно же, самый древний, чаще всего используемый и неоднозначный термин — это «процессор».В современном мире процессор — это то (package), что мы покупаем в красивой Retail коробке или не очень красивом OEM-пакетике. Неделимая сущность, вставляемая в разъём (socket) на материнской плате. Даже если никакого разъёма нет и снять его нельзя, то есть если он намертво припаян, это один чип.
Мобильные системы (телефоны, планшеты, ноутбуки) и большинство десктопов имеют один процессор. Рабочие станции и сервера иногда могут похвастаться двумя или больше процессорами на одной материнской плате.
Поддержка нескольких центральных процессоров в одной системе требует многочисленных изменений в её дизайне. Как минимум, необходимо обеспечить их физическое подключение (предусмотреть несколько сокетов на материнской плате), решить вопросы идентификации процессоров (см.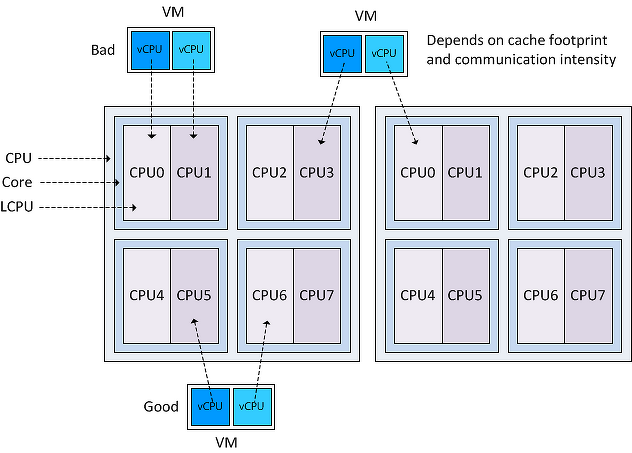
Если процессоров несколько, то каждый из них имеет собственный разъём на плате. У каждого из них при этом имеются полные независимые копии всех ресурсов, таких как регистры, исполняющие устройства, кэши. Делят они общую память — RAM. Память может подключаться к ним различными и довольно нетривиальными способами, но это отдельная история, выходящая за рамки этой статьи.
Ядро
Исторически многоядерность в Intel IA-32 появилась позже Intel® HyperThreading, однако в логической иерархии она идёт следующей.Казалось бы, если в системе больше процессоров, то выше её производительность (на задачах, способных задействовать все ресурсы). Однако, если стоимость коммуникаций между ними слишком велика, то весь выигрыш от параллелизма убивается длительными задержками на передачу общих данных. Именно это наблюдается в многопроцессорных системах — как физически, так и логически они находятся очень далеко друг от друга. Для эффективной коммуникации в таких условиях приходится придумывать специализированные шины, такие как Intel® QuickPath Interconnect. Энергопотребление, размеры и цена конечного решения, конечно, от всего этого не понижаются.
Первые многоядерные процессоры IA-32 от Intel были представлены в 2005 году. С тех пор среднее число ядер в серверных, десктопных, а ныне и мобильных платформах неуклонно растёт.
В отличие от двух одноядерных процессоров в одной системе, разделяющих только память, два ядра могут иметь также общие кэши и другие ресурсы, отвечающие за взаимодействие с памятью. Чаще всего кэши первого уровня остаются приватными (у каждого ядра свой), тогда как второй и третий уровень может быть как общим, так и раздельным. Такая организация системы позволяет сократить задержки доставки данных между соседними ядрами, особенно если они работают над общей задачей.
Микроснимок четырёхядерного процессора Intel с кодовым именем Nehalem. Выделены отдельные ядра, общий кэш третьего уровня, а также линки QPI к другим процессорам и общий контроллер памяти.
Выделены отдельные ядра, общий кэш третьего уровня, а также линки QPI к другим процессорам и общий контроллер памяти.Гиперпоток
До примерно 2002 года единственный способ получить систему IA-32, способную параллельно исполнять две или более программы, состоял в использовании именно многопроцессорных систем. В Intel® Pentium® 4, а также линейке Xeon с кодовым именем Foster (Netburst) была представлена новая технология — гипертреды или гиперпотоки, — Intel® HyperThreading (далее HT).Ничто не ново под луной. HT — это частный случай того, что в литературе именуется одновременной многопоточностью (simultaneous multithreading, SMT). В отличие от «настоящих» ядер, являющихся полными и независимыми копиями, в случае HT в одном процессоре дублируется лишь часть внутренних узлов, в первую очередь отвечающих за хранение архитектурного состояния — регистры. Исполнительные же узлы, ответственные за организацию и обработку данных, остаются в единственном числе, и в любой момент времени используются максимум одним из потоков.
Я не буду пытаться объяснить все плюсы и минусы дизайнов с SMT вообще и с HT в частности. Интересующийся читатель может найти довольно подробное обсуждение технологии во многих источниках, и, конечно же, в Википедии. Однако отмечу следующий важный момент, объясняющий текущие ограничения на число гиперпотоков в реальной продукции.
Ограничения потоков
В каких случаях наличие «нечестной» многоядерности в виде HT оправдано? Если один поток приложения не в состоянии загрузить все исполняющие узлы внутри ядра, то их можно «одолжить» другому потоку. Это типично для приложений, имеющих «узкое место» не в вычислениях, а при доступе к данным, то есть часто генерирующих промахи кэша и вынужденных ожидать доставку данных из памяти. В это время ядро без HT будет вынуждено простаивать. Наличие же HT позволяет быстро переключить свободные исполняющие узлы к другому архитектурному состоянию (т. к. оно как раз дублируется) и исполнять его инструкции. Это — частный случай приёма под названием latency hiding, когда одна длительная операция, в течение которой полезные ресурсы простаивают, маскируется параллельным выполнением других задач. Если приложение уже имеет высокую степень утилизации ресурсов ядра, наличие гиперпотоков не позволит получить ускорение — здесь нужны «честные» ядра.
к. оно как раз дублируется) и исполнять его инструкции. Это — частный случай приёма под названием latency hiding, когда одна длительная операция, в течение которой полезные ресурсы простаивают, маскируется параллельным выполнением других задач. Если приложение уже имеет высокую степень утилизации ресурсов ядра, наличие гиперпотоков не позволит получить ускорение — здесь нужны «честные» ядра.Типичные сценарии работы десктопных и серверных приложений, рассчитанных на машинные архитектуры общего назначения, имеют потенциал к параллелизму, реализуемому с помощью HT. Однако этот потенциал быстро «расходуется». Возможно, по этой причине почти на всех процессорах IA-32 число аппаратных гиперпотоков не превышает двух. На типичных сценариях выигрыш от использования трёх и более гиперпотоков был бы невелик, а вот проигрыш в размере кристалла, его энергопотреблении и стоимости значителен.
Другая ситуация наблюдается на типичных задачах, выполняемых на видеоускорителях. Поэтому для этих архитектур характерно использование техники SMT с бóльшим числом потоков. Так как сопроцессоры Intel® Xeon Phi (представленные в 2010 году) идеологически и генеалогически довольно близки к видеокартам, на них может быть четыре гиперпотока на каждом ядре — уникальная для IA-32 конфигурация.
Так как сопроцессоры Intel® Xeon Phi (представленные в 2010 году) идеологически и генеалогически довольно близки к видеокартам, на них может быть четыре гиперпотока на каждом ядре — уникальная для IA-32 конфигурация.
Логический процессор
Из трёх описанных «уровней» параллелизма (процессоры, ядра, гиперпотоки) в конкретной системе могут отсутствовать некоторые или даже все. На это влияют настройки BIOS (многоядерность и многопоточность отключаются независимо), особенности микроархитектуры (например, HT отсутствовал в Intel® Core™ Duo, но был возвращён с выпуском Nehalem) и события при работе системы (многопроцессорные сервера могут выключать отказавшие процессоры в случае обнаружения неисправностей и продолжать «лететь» на оставшихся). Каким образом этот многоуровневый зоопарк параллелизма виден операционной системе и, в конечном счёте, прикладным приложениям?Далее для удобства обозначим количества процессоров, ядер и потоков в некоторой системе тройкой (x, y, z), где x — это число процессоров, y — число ядер в каждом процессоре, а z — число гиперпотоков в каждом ядре.
Чаще всего операционная система прячет от конечных приложений особенности физической топологии системы, на которой она запущена. Например, три следующие топологии: (2, 1, 1), (1, 2, 1) и (1, 1, 2) — ОС будет представлять в виде двух логических процессоров, хотя первая из них имеет два процессора, вторая — два ядра, а третья — всего лишь два потока.
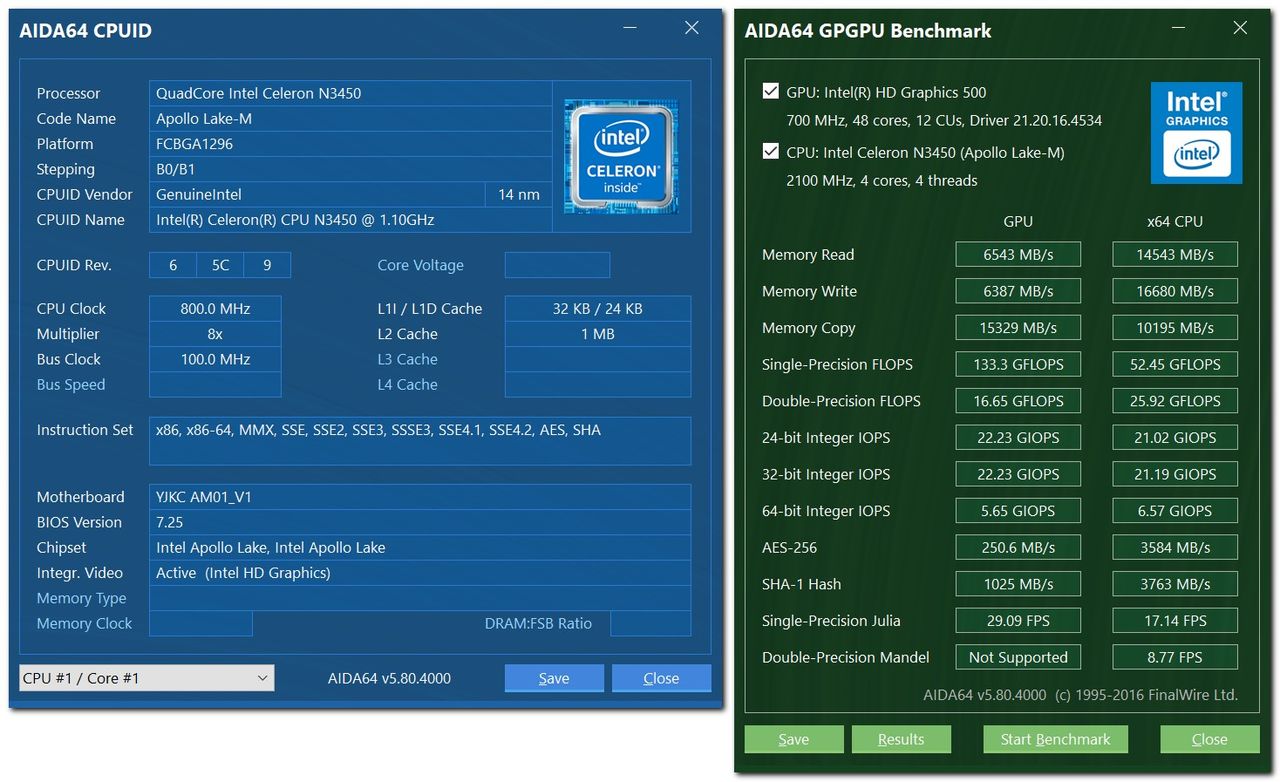
Windows Task Manager показывает 8 логических процессоров; но сколько это в процессорах, ядрах и гиперпотоках?
Linux top показывает 4 логических процессора.
Это довольно удобно для создателей прикладных приложений — им не приходится иметь дело с зачастую несущественными для них особенностями аппаратуры.
Программное определение топологии
Конечно, абстрагирование топологии в единственное число логических процессоров в ряде случаев создаёт достаточно оснований для путаницы и недоразумений (в жарких Интернет-спорах). Вычислительные приложения, желающие выжать из железа максимум производительности, требуют детального контроля над тем, где будут размещены их потоки: поближе друг к другу на соседних гиперпотоках или же наоборот, подальше на разных процессорах. Скорость коммуникаций между логическими процессорами в составе одного ядра или процессора значительно выше, чем скорость передачи данных между процессорами. Возможность неоднородности в организации оперативной памяти также усложняет картину.
Информация о топологии системы в целом, а также положении каждого логического процессора в IA-32 доступна с помощью инструкции CPUID. С момента появления первых многопроцессорных систем схема идентификации логических процессоров несколько раз расширялась. К настоящему моменту её части содержатся в листах 1, 4 и 11 CPUID. Какой из листов следует смотреть, можно определить из следующей блок-схемы, взятой из статьи [2]:
Я не буду здесь утомлять всеми подробностями отдельных частей этого алгоритма. Если возникнет интерес, то этому можно посвятить следующую часть этой статьи. Отошлю интересующегося читателя к [2], в которой этот вопрос разбирается максимально подробно. Здесь же я сначала кратко опишу, что такое APIC и как он связан с топологией. Затем рассмотрим работу с листом 0xB (одиннадцать в десятичном счислении), который на настоящий момент является последним словом в «апикостроении».
APIC ID
Local APIC (advanced programmable interrupt controller) — это устройство (ныне входящее в состав процессора), отвечающее за работу с прерываниями, приходящими к конкретному логическому процессору.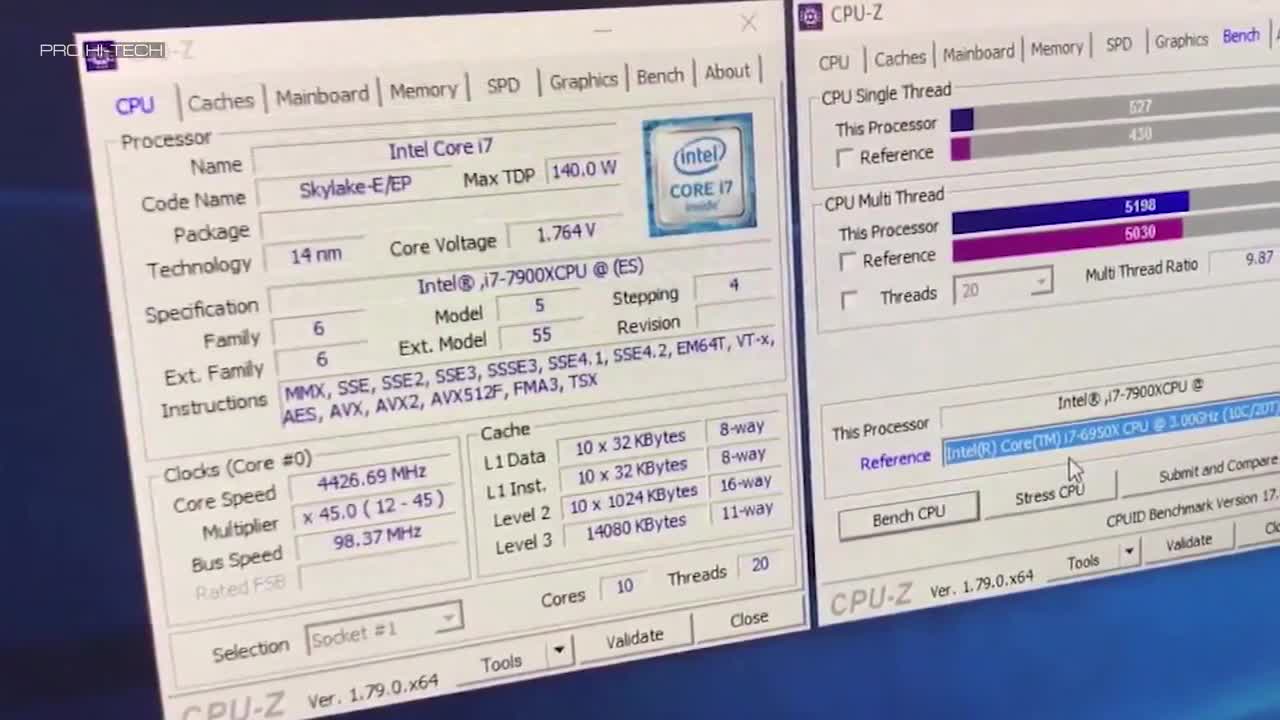 Свой собственный APIC есть у каждого логического процессора. И каждый из них в системе должен иметь уникальное значение APIC ID. Это число используется контроллерами прерываний для адресации при доставке сообщений, а всеми остальными (например, операционной системой) — для идентификации логических процессоров. Спецификация на этот контроллер прерываний эволюционировала, пройдя от микросхемы Intel 8259 PIC через Dual PIC, APIC иxAPIC кx2APIC.
Свой собственный APIC есть у каждого логического процессора. И каждый из них в системе должен иметь уникальное значение APIC ID. Это число используется контроллерами прерываний для адресации при доставке сообщений, а всеми остальными (например, операционной системой) — для идентификации логических процессоров. Спецификация на этот контроллер прерываний эволюционировала, пройдя от микросхемы Intel 8259 PIC через Dual PIC, APIC иxAPIC кx2APIC.В настоящий момент ширина числа, хранящегося в APIC ID, достигла полных 32 бит, хотя в прошлом оно было ограничено 16, а ещё раньше — только 8 битами. Нынче остатки старых дней раскиданы по всему CPUID, однако в CPUID.0xB.EDX[31:0] возвращаются все 32 бита APIC ID. На каждом логическом процессоре, независимо исполняющем инструкцию CPUID, возвращаться будет своё значение.
Выяснение родственных связей
Значение APIC ID само по себе ничего не говорит о топологии. Чтобы узнать, какие два логических процессора находятся внутри одного физического (т. е. являются «братьями» гипертредами), какие два — внутри одного процессора, а какие оказались и вовсе в разных процессорах, надо сравнить их значения APIC ID. В зависимости от степени родства некоторые их биты будут совпадать. Эта информация содержится в подлистьях CPUID.0xB, которые кодируются с помощью операнда в ECX. Каждый из них описывает положение битового поля одного из уровней топологии в EAX[5:0] (точнее, число бит, которые нужно сдвинуть в APIC ID вправо, чтобы убрать нижние уровни топологии), а также тип этого уровня — гиперпоток, ядро или процессор, — в ECX[15:8].
е. являются «братьями» гипертредами), какие два — внутри одного процессора, а какие оказались и вовсе в разных процессорах, надо сравнить их значения APIC ID. В зависимости от степени родства некоторые их биты будут совпадать. Эта информация содержится в подлистьях CPUID.0xB, которые кодируются с помощью операнда в ECX. Каждый из них описывает положение битового поля одного из уровней топологии в EAX[5:0] (точнее, число бит, которые нужно сдвинуть в APIC ID вправо, чтобы убрать нижние уровни топологии), а также тип этого уровня — гиперпоток, ядро или процессор, — в ECX[15:8].У логических процессоров, находящихся внутри одного ядра, будут совпадать все биты APIC ID, кроме принадлежащих полю SMT. Для логических процессоров, находящихся в одном процессоре, — все биты, кроме полей Core и SMT. Поскольку число подлистов у CPUID.0xB может расти, данная схема позволит поддержать описание топологий и с бóльшим числом уровней, если в будущем возникнет необходимость. Более того, можно будет ввести промежуточные уровни между уже существующими.
Важное следствие из организации данной схемы заключается в том, что в наборе всех APIC ID всех логических процессоров системы могут быть «дыры», т.е. они не будут идти последовательно. Например, во многоядерном процессоре с выключенным HT все APIC ID могут оказаться чётными, так как младший бит, отвечающий за кодирование номера гиперпотока, будет всегда нулевым.
Отмечу, что CPUID.0xB — не единственный источник информации о логических процессорах, доступный операционной системе. Список всех процессоров, доступный ей, вместе с их значениями APIC ID, кодируется в таблице MADT ACPI [3, 4].
Операционные системы и топология
Операционные системы предоставляют информацию о топологии логических процессоров приложениям с помощью своих собственных интерфейсов.В Linux информация о топологии содержится в псевдофайле /proc/cpuinfo, а также выводе команды dmidecode. В примере ниже я фильтрую содержимое cpuinfo на некоторой четырёхядерной системе без HT, оставляя только записи, относящиеся к топологии:
ggg@shadowbox:~$ cat /proc/cpuinfo |grep 'processor\|physical\ id\|siblings\|core\|cores\|apicid' processor : 0 physical id : 0 siblings : 4 core id : 0 cpu cores : 2 apicid : 0 initial apicid : 0 processor : 1 physical id : 0 siblings : 4 core id : 0 cpu cores : 2 apicid : 1 initial apicid : 1 processor : 2 physical id : 0 siblings : 4 core id : 1 cpu cores : 2 apicid : 2 initial apicid : 2 processor : 3 physical id : 0 siblings : 4 core id : 1 cpu cores : 2 apicid : 3 initial apicid : 3
В FreeBSD топология сообщается через механизм sysctl в переменной kern. sched.topology_spec в виде XML:
sched.topology_spec в виде XML:
user@host:~$ sysctl kern.sched.topology_spec
kern.sched.topology_spec: <groups>
<group level="1" cache-level="0">
<cpu count="8" mask="0xff">0, 1, 2, 3, 4, 5, 6, 7</cpu>
<children>
<group level="2" cache-level="2">
<cpu count="8" mask="0xff">0, 1, 2, 3, 4, 5, 6, 7</cpu>
<children>
<group level="3" cache-level="1">
<cpu count="2" mask="0x3">0, 1</cpu>
<flags><flag name="THREAD">THREAD group</flag><flag name="SMT">SMT group</flag></flags>
</group>
<group level="3" cache-level="1">
<cpu count="2" mask="0xc">2, 3</cpu>
<flags><flag name="THREAD">THREAD group</flag><flag name="SMT">SMT group</flag></flags>
</group>
<group level="3" cache-level="1">
<cpu count="2" mask="0x30">4, 5</cpu>
<flags><flag name="THREAD">THREAD group</flag><flag name="SMT">SMT group</flag></flags>
</group>
<group level="3" cache-level="1">
<cpu count="2" mask="0xc0">6, 7</cpu>
<flags><flag name="THREAD">THREAD group</flag><flag name="SMT">SMT group</flag></flags>
</group>
</children>
</group>
</children>
</group>
</groups>
В MS Windows 8 сведения о топологии можно увидеть в диспетчере задач Task Manager.
Также их предоставляет консольная утилита Sysinternals Coreinfo и API вызов GetLogicalProcessorInformation.
Полная картина
Проиллюстрирую ещё раз отношения между понятиями «процессор», «ядро», «гиперпоток» и «логический процессор» на нескольких примерах.Система (2, 2, 2)
Система (2, 4, 1)
Система (4, 1, 1)
Прочие вопросы
В этот раздел я вынес некоторые курьёзы, возникающие из-за многоуровневой организации логических процессоров.Кэши
Как я уже упоминал, кэши в процессоре тоже образуют иерархию, и она довольно сильно связано с топологией ядер, однако не определяется ей однозначно. Для определения того, какие кэши для каких логических процессоров общие, а какие нет, используется вывод CPUID.4 и её подлистов.Лицензирование
Некоторые программные продукты поставляются числом лицензий, определяемых количеством процессоров в системе, на которой они будут использоваться. Другие — числом ядер в системе. Наконец, для определения числа лицензий число процессоров может умножаться на дробный «core factor», зависящий от типа процессора!
Другие — числом ядер в системе. Наконец, для определения числа лицензий число процессоров может умножаться на дробный «core factor», зависящий от типа процессора!Виртуализация
Системы виртуализации, способные моделировать многоядерные системы, могут назначить виртуальным процессорам внутри машины произвольную топологию, не совпадающую с конфигурацией реальной аппаратуры. Так, внутри хозяйской системы (1, 2, 2) некоторые известные системы виртуализации по умолчанию выносят все логические процессоры на верхний уровень, т.е. создают конфигурацию (4, 1, 1). В сочетании с особенностями лицензирования, зависящими от топологии, это может порождать забавные эффекты.Спасибо за внимание!
Литература
- Intel Corporation. Intel® 64 and IA-32 Architectures Software Developer’s Manual. Volumes 1–3, 2014. www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html
- Shih Kuo. Intel® 64 Architecture Processor Topology Enumeration, 2012 — software.
 intel.com/en-us/articles/intel-64-architecture-processor-topology-enumeration
intel.com/en-us/articles/intel-64-architecture-processor-topology-enumeration - OSDevWiki. MADT. wiki.osdev.org/MADT
- OSDevWiki. Detecting CPU Topology. wiki.osdev.org/Detecting_CPU_Topology_%2880×86%29
 intel.com/en-us/articles/intel-64-architecture-processor-topology-enumeration
intel.com/en-us/articles/intel-64-architecture-processor-topology-enumerationбудут интегрированы «основные возможности ИИ»
Главная / ПК и компоненты / Новости
Новости
Похоже, визуальный процессор Meteor Lake почти официально выпущен.
Марк Хачман
Старший редактор, PCWorld 28 сентября 2022 г. 3:30 по тихоокеанскому времени
Image: Intel
Руководители Intel во вторник подтвердили, что компания приложит согласованные усилия, чтобы внедрить возможности искусственного интеллекта в ПК с помощью своих ядер следующего поколения под кодовым названием Meteor Lake.
Исполнительный директор Intel Пэт Гелсингер и сотрудник Intel Раджшри Чабуксвар подтвердили, что в Meteor Lake появятся возможности искусственного интеллекта, который, вероятно, будет называться чипом Core 14-го поколения. Intel официально представила версию своего процессора Core 13-го поколения (Raptor Lake) для настольных ПК на этой неделе на конференции Intel Innovation в Сан-Хосе.
Intel официально представила версию своего процессора Core 13-го поколения (Raptor Lake) для настольных ПК на этой неделе на конференции Intel Innovation в Сан-Хосе.
ИИ оказался мощной возможностью для бизнеса внутри предприятия, и, по-видимому, в большинстве анонсов корпоративных чипов подчеркивалась их способность делать логические выводы. Аппаратное обеспечение ИИ может помочь в обучении алгоритмов визуальному распознаванию, прогностическим возможностям и многому другому. А в смартфонах искусственный интеллект используется для фильтрации фонового звука и помогает различать передний план фотографии во время фотосъемки.
Однако на ПК его эффекты менее заметны. Он также может отфильтровывать фоновый шум при использовании Alexa или собственного приложения Cortana для Windows — что, к сожалению, потребители редко делают. Такие приложения, как Photoshop, должны иметь возможность использовать возможности искусственного интеллекта с точки зрения редактирования фотографий. А недавнее обновление Windows 11 2022 года включает в себя некоторые интеллектуальные эффекты, которые помогут выделить вас во время видеозвонков, как в Teams.
Тем не менее, ИИ не так важен, как, скажем, производительность, время автономной работы или любые другие возможности. Однако похоже, что это может измениться.
Когда Гелсингера спросили, что делает Intel, чтобы сделать искусственный интеллект привлекательным для ПК, он в шутку ответил: «Пока не могу вам сказать, потому что мы еще не запустили Meteor Lake».
Гелсингер, тем не менее, продолжил описание того, что, по его мнению, может достичь Метеорное озеро. «Одна из вещей, которые мы привнесем, — это то, что я бы сказал, — это основные возможности ИИ», — сказал он. «Я сижу в Zoom или Teams [звонок]. Хочу ли я иметь синхронный перевод или контекстуализацию этого звонка? Да. Хочу ли я иметь камеры, которые следят за говорящим и улучшают изображение? Да.»
Гелсингер сравнил это с первыми днями процессоров X86, когда в чипах не было модуля с плавающей запятой для математических вычислений — отдаленного концептуального предка сегодняшних графических процессоров. «Люди скажут, что для этого нам действительно не нужны числа с плавающей запятой», — сказал он. «И то, что он только что стал стандартом… Что ж, ИИ будет таким, стандартным и поставляемым на каждую из наших платформ».
«Люди скажут, что для этого нам действительно не нужны числа с плавающей запятой», — сказал он. «И то, что он только что стал стандартом… Что ж, ИИ будет таким, стандартным и поставляемым на каждую из наших платформ».
Разница, по словам Гелсингера, заключалась в том, что потребительский ИИ, скорее всего, будет оптимизирован для потребительских ПК иначе, чем в центре обработки данных.
Раджшри Чабуксвар из Intel представил этот слайд, в котором обсуждались улучшения искусственного интеллекта, которые появятся в Meteor Lake.Марк Хачман / IDG
В ходе презентации во вторник днем Чабуксвар из Intel сказал, что Intel планирует «скоро появится новый механизм ускорения искусственного интеллекта». «Этот движок будет сосредоточен на предоставлении потрясающих возможностей на основе ИИ, которые обеспечат отличную систему, а также отзывчивость приложений», — сказала она.
Чабуксвар подтвердила PCWorld после своей презентации, что она говорила о Метеорном озере.
Чабуксвар также сообщила, что новый ИИ-ускоритель будет поддерживаться Microsoft, правда, в каком качестве она не сказала.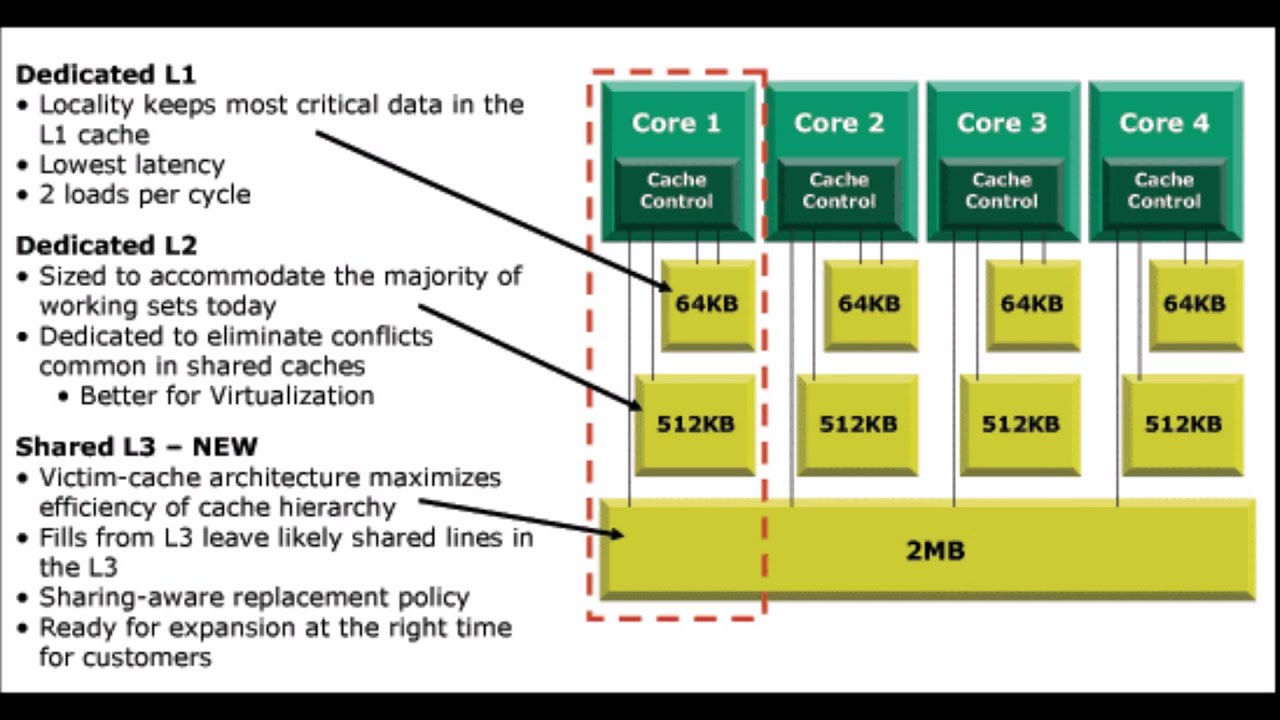 Однако в презентации Intel, очевидно, сделанной во время своего технологического тура в Израиле, Sweclockers сфотографировал одобрение от Microsoft Вивека Прадипа, который руководит командой компьютерного зрения в Microsoft Applied Sciences. Однако блок AI, по-видимому, будет известен как VPU с кодовым названием «Movidus».
Однако в презентации Intel, очевидно, сделанной во время своего технологического тура в Израиле, Sweclockers сфотографировал одобрение от Microsoft Вивека Прадипа, который руководит командой компьютерного зрения в Microsoft Applied Sciences. Однако блок AI, по-видимому, будет известен как VPU с кодовым названием «Movidus».
«Microsoft считает, что нейронные процессоры, такие как Intel VPU, представляют собой переломный момент в вычислительной технике и станут ключом к предоставлению совершенно нового диапазона восхитительных возможностей пользователям Windows на их ПК», — как сообщается, Прадип написал, добавив, что Microsoft « тесно сотрудничает с Intel в области VPU.
Слухи и утечки разного рода, связанные с блокировкой ИИ в Meteor Lake следующего поколения, циркулировали в течение большей части года, с обновлением драйвера, по-видимому, подтверждающим движок ИИ, за которым последовала более подробная утечка следующего поколения. сама архитектура.
Интересно, что Intel не будет первой, кто попытается популяризировать ИИ на ПК. Intel попыталась популяризировать ИИ с помощью своего ядра 10-го поколения Ice Lake, за которым последовали усилия Qualcomm с процессорами Snapdragon. Однако ни то, ни другое не увенчалось успехом.
Intel попыталась популяризировать ИИ с помощью своего ядра 10-го поколения Ice Lake, за которым последовали усилия Qualcomm с процессорами Snapdragon. Однако ни то, ни другое не увенчалось успехом.
Автор: Марк Хачман, старший редактор
В качестве старшего редактора PCWorld Марк, среди прочего, занимается новостями Microsoft и технологиями чипов. Ранее он писал для PCMag, BYTE, Slashdot, eWEEK и ReadWrite.
Архитектура, плюсы и минусы и специальные варианты использования
Что такое графический процессор (GPU)?
Графический процессор (GPU) — это компьютерный процессор, выполняющий быстрые вычисления для рендеринга изображений и графики. Графические процессоры используют параллельную обработку для ускорения своей работы. Они делят задачи на более мелкие части и распределяют их между несколькими процессорными ядрами (до сотен ядер), работающих в одном графическом процессоре.
Графические процессоры традиционно отвечали за рендеринг 2D- и 3D-изображений, видео и анимации, но сегодня их можно использовать в более широком диапазоне, включая глубокое обучение и анализ больших данных.
До появления графических процессоров центральные процессоры (ЦП) выполняли вычисления, необходимые для рендеринга графики. Однако процессоры неэффективны для многих вычислительных приложений. Графические процессоры разгружают графическую обработку и массовые параллельные задачи с центральных процессоров, чтобы обеспечить более высокую производительность для специализированных вычислительных задач.
Что такое центральный процессор (ЦП)?
ЦП — это процессор, состоящий из логических вентилей, которые обрабатывают низкоуровневые инструкции в компьютерной системе. Процессоры считались мозгом интегральной схемы персонального компьютера. ЦП выполняют основные логические, арифметические операции и операции ввода-вывода, а также распределяют команды между другими компонентами и подсистемами, работающими на компьютере.
Современные ЦП обычно являются многоядерными, что означает наличие двух или более процессоров в интегральной схеме.
Использование нескольких ядер в одном процессоре снижает энергопотребление, повышает производительность и обеспечивает эффективную параллельную обработку нескольких задач.
Это часть нашей серии статей о мульти-GPU.
В этой статье:
- ЦП и ГП: архитектура
- ЦП и ГП: плюсы и минусы
- ЦП и ГП для машинного обучения и глубокого обучения
- Использование ЦП и ГП s Вместе для HPC
- Виртуализация графического процессора с помощью Run.AI
ЦП и ГП: архитектура
Ниже описаны компоненты ЦП и ГП соответственно.
Архитектура ЦП
ЦП могут быстро последовательно обрабатывать данные благодаря множеству тяжелых ядер и высокой тактовой частоте. Они подходят для выполнения разнообразных задач и могут переключаться между различными задачами с минимальной задержкой. Скорость процессоров может создавать впечатление параллелизма, но они могут обрабатывать только одну задачу за раз.
На следующей концептуальной схеме показаны основные компоненты ЦП.
Хотя дизайн каждого ЦП может отличаться, основными компонентами ЦП являются:
- Блок управления (CU) — блок управления извлекает инструкции, декодирует и выполняет их. Он также отправляет управляющие сигналы для управления аппаратным обеспечением и направляет данные по процессорной системе.
- Часы — помогает координировать компоненты компьютера. Часы производят регулярные электрические импульсы для синхронизации компонентов. Частота импульсов, измеряемая в герцах (Гц), называется тактовой частотой. Более высокие частоты позволяют обрабатывать больше инструкций в течение заданного периода времени.
- Арифметико-логическое устройство (АЛУ) — это устройство выполняет вычисления. Он принимает логические и арифметические решения и служит шлюзом для передачи данных из основной памяти во вторичную память.
- Регистры — регистр содержит небольшой объем высокоскоростной памяти внутри процессора. В регистрах хранятся данные, необходимые для обработки, в том числе декодируемая инструкция, адрес следующей инструкции и результаты вычислений. Разные процессоры содержат разное количество и типы регистров. Однако большинство процессоров, вероятно, включают в себя программный счетчик, регистр адреса памяти (MAR), регистр данных памяти (MDR), регистр текущих инструкций (CIR) и аккумулятор (ACC).
- Кэши — это небольшая встроенная в процессор оперативная память, которая может временно хранить данные и повторно используемые инструкции. Кэши обеспечивают высокоскоростную обработку, потому что данные более доступны для процессора, чем внешняя оперативная память.
- Шины — это быстрые внутренние соединения, которые отправляют данные и сигналы от процессора к другим компонентам. Существует три типа шин: адресная шина для передачи компонентов адресов памяти, таких как устройства ввода/вывода и первичная память; шина данных для передачи фактических данных; и шина управления для передачи сигналов управления и тактовых импульсов.
 Он также отправляет управляющие сигналы для управления аппаратным обеспечением и направляет данные по процессорной системе.
Он также отправляет управляющие сигналы для управления аппаратным обеспечением и направляет данные по процессорной системе. Однако большинство процессоров, вероятно, включают в себя программный счетчик, регистр адреса памяти (MAR), регистр данных памяти (MDR), регистр текущих инструкций (CIR) и аккумулятор (ACC).
Однако большинство процессоров, вероятно, включают в себя программный счетчик, регистр адреса памяти (MAR), регистр данных памяти (MDR), регистр текущих инструкций (CIR) и аккумулятор (ACC).Архитектура графического процессора
На высоком уровне архитектура графического процессора ориентирована на то, чтобы ядра выполняли максимально возможное количество операций, а не на быстрый доступ памяти к кэш-памяти процессора, как в ЦП. Ниже приведена диаграмма, показывающая типичную архитектуру графического процессора NVIDIA. Мы обсудим его как распространенный пример современной архитектуры графического процессора.
Ниже приведена диаграмма, показывающая типичную архитектуру графического процессора NVIDIA. Мы обсудим его как распространенный пример современной архитектуры графического процессора.
Источник: ResearchGate
Графический процессор NVIDIA состоит из трех основных компонентов:
- Кластеры процессоров (ПК) — GPU состоит из нескольких кластеров потоковых мультипроцессоров.
- Потоковые мультипроцессоры (SM) — каждый SM имеет несколько процессорных ядер и кэш-память уровня 1, которая позволяет ему распределять инструкции по своим ядрам.
- Кэш уровня 2 — это общий кеш, который соединяет SM вместе. Каждый SM использует кэш уровня 2 для извлечения данных из глобальной памяти.
- DRAM — это глобальная память графического процессора, обычно основанная на таких технологиях, как GDDR-5 или GDDR-6. Он содержит инструкции, которые должны быть обработаны всеми SM.
Задержка памяти не является критическим фактором в этом типе конструкции графического процессора. Основная проблема заключается в том, чтобы убедиться, что у графического процессора достаточно вычислений, чтобы все ядра были заняты.
Архитектура CUDA
NVIDIA разработала широко используемую унифицированную архитектуру вычислительных устройств (CUDA). CUDA предоставляет API, который позволяет разработчикам использовать ресурсы графического процессора, не требуя специальных знаний об аппаратном обеспечении графического процессора.
Графический процессор NVIDIA выделяет память в соответствии с определенной иерархией CUDA. Разработчики CUDA могут оптимизировать использование памяти напрямую через API. Вот основные компоненты графического процессора, которые сопоставляются с конструкциями CUDA, которыми разработчики могут управлять непосредственно из своих программ:
- Регистры — память, выделенная отдельным ядрам CUDA, управляемая как «потоки» в модели CUDA. Данные в регистрах могут обрабатываться быстрее, чем на любом другом уровне архитектуры. С этого момента каждый компонент обрабатывает данные все медленнее.
- Постоянная память — встроенная память, доступная для СМ.
- Кэш L1 — встроенная память, разделяемая между ядрами, управляемая в рамках CUDA как «блоки CUDA». Кэш L1 управляется аппаратно и, таким образом, обеспечивает быструю передачу данных.
- Кэш L2 — память, совместно используемая всеми блоками CUDA на нескольких SM. Кэш хранит как глобальную, так и локальную память.
- Глобальная память — разрешает доступ к DRAM устройства. Это самый медленный элемент для доступа к программе CUDA.
 Данные в регистрах могут обрабатываться быстрее, чем на любом другом уровне архитектуры. С этого момента каждый компонент обрабатывает данные все медленнее.
Данные в регистрах могут обрабатываться быстрее, чем на любом другом уровне архитектуры. С этого момента каждый компонент обрабатывает данные все медленнее.Сравнение ЦП и ГП: плюсы и минусы
Преимущества и ограничения ЦП
ЦП имеют несколько явных преимуществ для современных вычислительных задач:
- Гибкость — ЦП — это процессор общего назначения, который может выполнять множество задач и выполнять многозадачность между несколькими действиями.
- Быстрее во многих контекстах — ЦП быстрее, чем ГП, при выполнении таких операций, как обработка данных в ОЗУ, операции ввода-вывода и администрирование операционной системы.
- Точность — ЦП могут выполнять математические операции среднего уровня с более высокой точностью, чем графические процессоры, что важно для многих вариантов использования.
- Кэш-память — ЦП имеют большой объем локальной кэш-памяти, что позволяет им обрабатывать большие наборы линейных инструкций.
- Аппаратная совместимость — ЦП совместимы со всеми типами материнских плат и конструкций систем, тогда как для графических процессоров требуется специализированная аппаратная поддержка.

ЦП имеют следующие недостатки по сравнению с ГП:
- Параллельная обработка — ЦП менее приспособлены к задачам, требующим миллионов одинаковых операций, из-за их ограниченного параллелизма.
- Замедленная разработка — ЦП — это очень зрелая технология, которая уже достигла пределов своего развития, в то время как у графических процессоров гораздо больше возможностей для совершенствования.
- Совместимость — несколько типов процессоров, включая процессоры x86 и ARM, и программное обеспечение может быть совместимо не со всеми типами.

Преимущества и ограничения GPU
К уникальным преимуществам GPU относятся:
- Высокая пропускная способность данных не имеет себе равных среди процессоров.
- Массивный параллелизм — GPU имеет сотни ядер, что позволяет ему выполнять массовые параллельные вычисления, такие как умножение матриц.
- Подходит для специализированных вариантов использования — GPU могут обеспечить значительное ускорение для специализированных задач, таких как глубокое обучение, анализ больших данных, секвенирование генома и т. д.
 д.
д. К недостаткам GPU по сравнению с CPU относятся:
- Многозадачность — GPU могут выполнять одну задачу в большом масштабе, но не могут выполнять вычислительные задачи общего назначения.
- Стоимость — Отдельные GPU в настоящее время намного дороже, чем CPU. Специализированные крупномасштабные системы GPU могут стоить сотни тысяч долларов.
- Сложность обработки. Сложность — GPU может испытывать трудности с обработкой плохо структурированных задач. Они не могут эффективно обрабатывать логику ветвления, последовательные операции или другие сложные шаблоны программирования.
ЦП и ГП для машинного обучения и глубокого обучения
ЦП и ГП предлагают явные преимущества для проектов искусственного интеллекта (ИИ) и больше подходят для конкретных случаев использования.
Примеры использования ЦП
ЦП является главным в компьютерной системе и может планировать тактовую частоту ядер и системных компонентов. Процессоры могут быстро выполнять сложные математические вычисления, если они обрабатывают одну задачу за раз. Производительность ЦП начинает замедляться при одновременном выполнении нескольких задач.
Процессоры могут быстро выполнять сложные математические вычисления, если они обрабатывают одну задачу за раз. Производительность ЦП начинает замедляться при одновременном выполнении нескольких задач.
ЦП имеют узкие, специализированные варианты использования для рабочих нагрузок ИИ. ЦП могут хорошо подходить для обработки задач с интенсивным использованием алгоритмов, которые не поддерживают параллельную обработку. Примеры включают:
- Алгоритмы логического вывода и машинного обучения (МО) в реальном времени, которые плохо распараллеливаются
- Рекуррентные нейронные сети, основанные на последовательных данных
- Рекомендательные системы логического вывода и обучения с высокими требованиями к памяти для встраивания слоев использование крупномасштабных выборок данных, таких как 3D-данные, для логического вывода и обучения
ЦП полезны для задач, требующих последовательных алгоритмов или выполнения сложных статистических вычислений. Такие задачи не распространены в современных приложениях ИИ, учитывая, что большинство компаний предпочитают эффективность и скорость графических процессоров специализации центральных процессоров. Тем не менее, некоторые специалисты по данным предпочитают разрабатывать алгоритмы ИИ по-другому, полагаясь на последовательную обработку или логику, а не на статистические вычисления.
Такие задачи не распространены в современных приложениях ИИ, учитывая, что большинство компаний предпочитают эффективность и скорость графических процессоров специализации центральных процессоров. Тем не менее, некоторые специалисты по данным предпочитают разрабатывать алгоритмы ИИ по-другому, полагаясь на последовательную обработку или логику, а не на статистические вычисления.
Примеры использования графических процессоров
Графические процессоры лучше всего подходят для параллельной обработки и в большинстве случаев являются предпочтительным вариантом для обучения моделей ИИ. Обучение ИИ обычно включает в себя обработку в основном идентичных одновременных операций с несколькими выборками данных. Наборы обучающих данных продолжают расти, требуя все более массивного параллелизма для обеспечения эффективного выполнения задач.
Предприятия обычно предпочитают графические процессоры, поскольку для большинства приложений ИИ требуется параллельная обработка нескольких вычислений. Примеры включают:
Примеры включают:
- Нейронные сети
- Ускоренный ИИ и операции глубокого обучения с массовым параллельным вводом данных
- Традиционные алгоритмы логического вывода и обучения ИИ
Графические процессоры обеспечивают чистую вычислительную мощность, необходимую для обработки практически идентичных или неструктурированных данных. За последние 30 лет графические процессоры эволюционировали и перешли от персональных компьютеров к рабочим станциям, серверам и центрам обработки данных. Графические процессоры, вероятно, продолжат доминировать в приложениях, работающих в центрах обработки данных или в облаке.
Сопутствующее содержимое: Прочтите наше руководство по ГП для глубокого обучения
Совместное использование ЦП и ГП для высокопроизводительных вычислений
Высокопроизводительные вычисления (HPC) — это набор технологий, обеспечивающих крупномасштабные массовые параллельные вычисления. Традиционно системы высокопроизводительных вычислений основывались на процессорах, но современные системы высокопроизводительных вычислений все чаще используют графические процессоры. Серверы HPC обычно объединяют несколько ЦП и ГП в одной системе.
Традиционно системы высокопроизводительных вычислений основывались на процессорах, но современные системы высокопроизводительных вычислений все чаще используют графические процессоры. Серверы HPC обычно объединяют несколько ЦП и ГП в одной системе.
Системы высокопроизводительных вычислений, сочетающие ЦП и ГП, используют специально оптимизированную шину PCIe. Шаблон проектирования, называемый «двойной корневой конфигурацией», обеспечивает эффективный доступ к памяти для большого количества процессоров. В двойном корневом сервере есть два основных процессора с отдельной зоной памяти для каждого процессора. Шина PCIe разделена между двумя процессорами, и примерно половина слотов PCIe, которые обычно используются для графических процессоров, назначены каждому процессору.
В этой архитектуре существует три типа быстрых каналов передачи данных:
- Соединение между графическими процессорами — соединение NVlink обеспечивает быструю связь между графическими процессорами со скоростью передачи данных до 300 ГБ/с. Это позволяет программистам работать с несколькими графическими процессорами, как если бы они были одним большим графическим процессором.
- Межкорневое соединение — быстрое соединение, такое как Ultra Path Interconnect (UPI) в системах Intel, позволяет процессорам, принадлежащим каждому из двух процессоров, взаимодействовать с другой частью платы PCIe.
- Сетевое соединение — быстрый сетевой интерфейс, обычно использующий infiniband.
 Это позволяет программистам работать с несколькими графическими процессорами, как если бы они были одним большим графическим процессором.
Это позволяет программистам работать с несколькими графическими процессорами, как если бы они были одним большим графическим процессором. Конструкция PCIe с двумя корнями обеспечивает оптимальное использование памяти ЦП и памяти графического процессора, поддерживая приложения, требующие как массовых параллельных, так и последовательных вычислительных операций.
Связанное содержимое: Прочтите наши руководства по:
- Кластер GPU
- Кластер HPC (скоро)
GPU Virtual изация с помощью Run:AI
Run:AI автоматизирует управление ресурсами и координацию рабочих нагрузок для инфраструктуры машинного обучения.
Ваш комментарий будет первым