настройки и требования BIOS для…
Технология Intel® Hyper-Threading (Intel® HT) обеспечивает два вычислительных потока для каждого физического ядра. Приложения с большим количеством потоков могут выполнять больше работы параллельно, выполняя задачи быстрее.
Отображение физических и логических процессоров на экране публикации
Физический подразумевается, когда количество процессоров указано на экране BIOS POST. Количество процессоров должно указывать на количество логических процессоров только в том случае, если оно указано явным образом. В системе BIOS должно распознаться два логических процессора, но только один физический процессор. Intel® настольные ПК/серверные платы, поддерживающие технологию Hyper-Threading, будут отображать только один физический процессор во время тестирования системы.
Опции настройки BIOS для процессоров с технологией Hyper-Threading
Для настройки Intel® настольные ПК/серверные платы — главное меню программы BIOS Setup.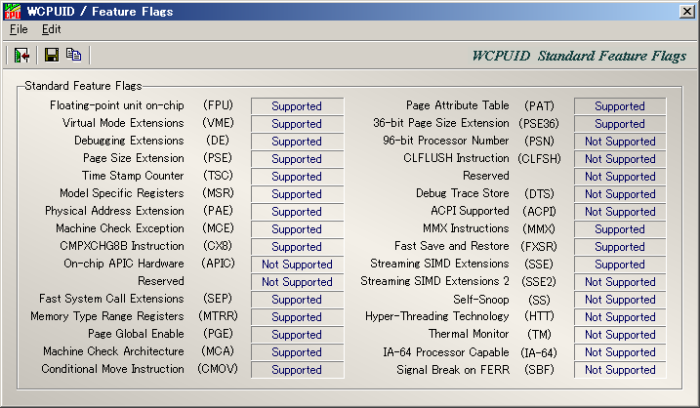
- Находится в том же окне меню, которое имеет тип процессора, тактовую частоту процессора, тактовую частоту системной шины и другие связанные с ними поля процессора.
- Текст варианта установки
- Это поле называется технологией Hyper-Threading.
- Установка параметров настройки
- Значения параметров установки включены и отключены.
- Текст справки о параметрах установки
Опции настройки BIOS для системных плат Intel® для настольных ПК
Если процессор Intel® без технологии Hyper-Threading не обнаружен:
- Опция настройки технологии Hyper-Threading неактивна (или удалена)
- Значение параметра «технология Hyper-Threading» принудительно отключено
Если процессор Intel® с технологией Hyper-Threading обнаружен:
- Отображается опция настройки технологии Hyper-Threading
- Потребитель в программе BIOS Setup может изменить режим настройки технологии Hyper-Threading
Технология Intel Hyper-Threading — что это и как работает
Впервые технология Hyper-Threading (HT, гиперпоточность) появилась 15 лет назад — в 2002 году, в процессорах Pentium 4 и Xeon, и с тех пор то появлялась в процессорах Intel (в линейке Core i, некоторых Atom, в последнее время еще и в Pentium), то исчезала (ее поддержки не было в линейках Core 2 Duo и Quad). И за это время она обросла мифическими свойствами — дескать ее наличие чуть ли не удваивает производительность процессора, превращая слабые i3 в мощные i5. При этом другие говорят что HT — обычная маркетинговая уловка, и толку от нее мало. Правда как обычно по середине — местами толк от нее есть, но двухкртаного прироста ждать точно не стоит.
И за это время она обросла мифическими свойствами — дескать ее наличие чуть ли не удваивает производительность процессора, превращая слабые i3 в мощные i5. При этом другие говорят что HT — обычная маркетинговая уловка, и толку от нее мало. Правда как обычно по середине — местами толк от нее есть, но двухкртаного прироста ждать точно не стоит.
Начнем с определения, данного на сайте Intel:
Технология Intel® Hyper-Threading (Intel® HT) обеспечивает более эффективное использование ресурсов процессора, позволяя выполнять несколько потоков на каждом ядре. В отношении производительности эта технология повышает пропускную способность процессоров, улучшая общее быстродействие многопоточных приложений.
В общем понятно то, что ничего не понятно — одни общие фразы, однако вкраце технологию они описывают — HT позволяет одному физическому ядру обрабатывать одновременно несколько (обычно два) логических потока. Но как? Процессор, поддерживающий гиперпоточность:
- может хранить информацию сразу о нескольких выполняющихся потоках;
- содержит по одному набору регистров (то есть блоков быстрой памяти внутри процессора) и по одному контроллеру прерываний (то есть встроенному блоку процессора, отвечающему за возможность последовательной обработки запросов о наступлении какого-либо события, требующего немедленного внимания, от разных устройств) на каждый логический процессор.


Допустим перед процессором стоят две задачи. Если процессор имеет одно ядро, то он будет выполнять их последовательно, если два — то параллельно на двух ядрах, и время выполнения обеих задач будет равно времени, затраченному на более тяжелую задачу. Но что если процессор одноядерный, но поддерживает гиперпоточность? Как видно на картинке выше при выполнении одной задачи процессор не занят на 100% — какие-то блоки процессора банально не нужны в данной задаче, где-то ошибается модуль предсказания переходов (который нужен для предсказания, будет ли выполнен условный переход в программе), где-то происходит ошибка обращения к кэшу — в общем и целом при выполнении задачи процессор редко бывает занят больше, чем на 70%. А технология HT как раз «подпихивает» незанятым блокам процессора вторую задачу, и получается что одновременно на одном ядре обрабатываются две задачи. Однако удвоения производительности не происходит по понятным причинам — очень часто получается так, что двум задачам нужен один и тот же вычислительный блок в процессоре, и тогда мы видим простой: пока одна задача обрабатывается, выполнение второй на это время просто останавливается (синие квадраты — первая задача, зеленые — вторая, красные — обращение задач к одному и тому же блоку в процессоре):

Плюсы и минусы технологии
С учетом того, что кристалл процессора с поддержкой HT физчески больше кристалла процессора без HT в среднем на 5% (именно столько занимают дополнительные блоки регистров и контроллеры прерываний), а поддержка HT позволяет нагрузить процессор на 90-95%, то в сравнении с 70% без HT мы получаем, что прирост в лучшем случае будет 20-30% — цифра достаточно большая.
Однако не все так хорошо: бывает, что прироста производительности от HT нет вообще, и даже бывает так, что HT ухудшает производительность процессора. Это бывает по многим причинам:
- Нехватка кэш-памяти. К примеру в современных четырехядерных i5 находится 6 мб кэша L3 — по 1.5 мб на ядро. В четырехядерных i7 с HT кэша уже 8 мб, но так как логических ядер 8, то мы получаем уже только 1 мб на ядро — при вычислениях некоторым программам этого объема может не хватать, что приводит к падению производительности.
- Отсутствие оптимизации ПО. Самая основная проблема — программы считают логические ядра физическими, из-за чего при параллельном выполнении задач на одном ядре часто возникают задержки из-за обращения задач к одному и тому же вычислительному блоку, что в итоге сводит сводит прирост производительности от HT на нет.
- Зависимость данных. Вытекает из предыдущего пункта — для выполнения одной задачи требуется результат другой, а она еще не выполнена. И опять же мы получаем простой, снижение загрузки на процессор и небольшой прирост от HT.

Таких много, ибо для вычислений HT это манна небесная — тепловыделение практически не растет, процессор особо больше не становится, а при правильной оптимизации можно получить прирост до 30%. Поэтому ее поддержку быстро внедрили в те программы, где легко можно сделать распараллеливание нагрузки — в архиваторы (WinRar), программы для 2D/3D моделирования (3ds Max, Maya), программы для обрабокти фото и видео (Sony Vegas, Photoshop, Corel Draw). Программы, плохо работающие с гиперпоточностью
Традиционно это большинство игр — их обычно бывает трудно грамотно распараллелить, поэтому зачастую четырех физических ядер на высоких частотах (i5 K-серии) более чем хватает для игр, распараллелить которые под 8 логических ядер в i7 оказывается непосильной задачей.
 Однако стоит учитывать и то, что есть фоновые процессы, и если процессор не поддерживает HT, то их обработка ложится на физические ядра, что может замедлить игру. Тут i7 с HT оказывается в выигрыше — все фоновые задачи традиционно имеют пониженный приоритет, поэтому при одновременной работе на одном физическом ядре игры и фоновой задаче игра будет получать повышенный приоритет, и при этом фоновая задача не будет «отвлекать» занятые игрой ядра — именно поэтому для стриминга или записи игр лучше брать i7 с гиперпоточностью.
Однако стоит учитывать и то, что есть фоновые процессы, и если процессор не поддерживает HT, то их обработка ложится на физические ядра, что может замедлить игру. Тут i7 с HT оказывается в выигрыше — все фоновые задачи традиционно имеют пониженный приоритет, поэтому при одновременной работе на одном физическом ядре игры и фоновой задаче игра будет получать повышенный приоритет, и при этом фоновая задача не будет «отвлекать» занятые игрой ядра — именно поэтому для стриминга или записи игр лучше брать i7 с гиперпоточностью.Пожалуй тут остается только один вопрос — так имеет ли смысл брать процессоры с HT или нет? Если вы любите держать одновременно открытыми пяток программ и при этом играть в игры, или же занимаетесь обработкой фото, видео или моделированием — да, разумеется стоит брать. А если вы привыкли перед запуском тяжелой программы закрывать все другие, и не балуетесь обработкой или моделированием, то процессор с HT вам ни к чему.
Технологии многопоточности процессоров: принцип работы и сферы применения | Процессоры | Блог
Физические ядра, логические ядра, технологии многопоточности — все это разрабатывалось инженерами для увеличения производительности компьютерного железа, требования к которому постоянно растут. Программы и игры требуют все больше ресурсов. Как же производители процессоров увеличивают мощность своих детищ? Процессор является «сердцем» компьютера и выполняет вычисления, необходимые для работы софта. Модели CPU отличаются между собой даже в рамках одного семейства. Например, Intel Core i7 отличается от i5 технологией многопоточности под названием «Hyper-Threading», о которой далее пойдет речь (Core i3, i9, и некоторые Pentium также обладают данной технологией).
Программы и игры требуют все больше ресурсов. Как же производители процессоров увеличивают мощность своих детищ? Процессор является «сердцем» компьютера и выполняет вычисления, необходимые для работы софта. Модели CPU отличаются между собой даже в рамках одного семейства. Например, Intel Core i7 отличается от i5 технологией многопоточности под названием «Hyper-Threading», о которой далее пойдет речь (Core i3, i9, и некоторые Pentium также обладают данной технологией).
Принцип работы процессорных ядер и многопоточности
В современных операционных системах одновременно работает множество процессов.
Нагрузка от операционной системы на процессор идет по так называемому конвейеру, на который «выкладываются» нужные задачи для ядра. В качестве примера возьмем одно ядро процессора на частоте 4 ГГц с одним ALU (арифметико-логическое устройство) и одним FPU (математический сопроцеесор). Частота в 4 ГГц означает, что ядро исполняет 4 миллиарда тактов в секунду. К ядру по конвейеру поступают задачи, требующие исполнительной мощности, на которые тратится процессорное время.
К ядру по конвейеру поступают задачи, требующие исполнительной мощности, на которые тратится процессорное время.
Часто происходят случаи, когда для выполнения необходимой операции процессору приходится ждать данные из кеша более низкой скорости (L3 кеш), или же оперативной памяти. Данная ситуация называется кэш-промах. Это происходит, когда в кэше ядра не была найдена запрошенная информация и приходится обращаться к более медленной памяти. Также существуют и другие причины, заставляющие прерывать выполнение операции ядром, что негативно сказывается на производительности.
Данный конвейер можно представить, как настоящую сборочную линию на заводе — рабочий (ядро) выполняет работу, поступающую к нему на ленту. И если необходимо взять нужный инструмент, работник отходит, оставляя конвейер простаивать без работы. То есть, исполняемая задача прерывается. Инструментом, за которым пошел рабочий, в данном случае является информация из оперативной памяти или же L3 кэша. Поскольку L1 и L2 кэш намного быстрее, чем любая другая память в компьютере, работа с вычислениями теряет в скорости.
На конвейере с одним потоком не могут выполняться одновременно несколько процессов. Ядро постоянно прерывает выполнение одной операции для другой, более приоритетной. Если появятся две одинаково приоритетные задачи, одна из них обязательно будет остановлена, ведь ядро не сможет работать над ними одновременно. И чем больше поступает задач одновременно, тем больше прерываний происходит.
Способы увеличения производительности процессоров
Разгон
При увеличении частоты ядра повышается количество исполняемых операций за секунду. Казалось бы, с возрастанием производительности процессора проблемы должны исчезнуть. Но все не так просто, как хотелось бы думать. Прирост от увеличения частоты ЦП нелинейный. Множество процессов все еще делят одно ядро между собой и обращаются к памяти. Кроме того, не решается проблема с кэш-промахами и прерываниями операций, поскольку объем кэша от разгона не изменяется. Разгон — не самый лучший способ решения проблемы нехватки потоков. В пример можно привести всю ту же сборочную линию: рабочий увеличивает темп работы, но по-прежнему не умеет собирать два и более заказа одновременно.
В пример можно привести всю ту же сборочную линию: рабочий увеличивает темп работы, но по-прежнему не умеет собирать два и более заказа одновременно.
Увеличение количества потоков на ядро
В процессорах Intel данная технология носит название Hyper-Threading, а в процессорах от Amd — SMT. Производители добавляют еще один регистр для работы со вторым конвейером. Пока один поток простаивает, ожидая нужные данные, свободная вычислительная мощность может быть использована вторым потоком. На кристалл же добавлен еще один контроллер прерываний и набор регистров.
Появляется возможность избавиться от последствий прерывания операций и сокращения времени простоя процессорной мощности. Благодаря чему ядро с двумя потоками выполняет больше работы за одинаковый отрезок времени, нежели в случае с однопотоком. На примере с рабочим: у конвейера появляется вторая сборочная линия, на которую выкладываются заказы. Пока производство на первой ленте простаивает в ожидании нужных инструментов, рабочий приступает к работе на второй ленте, сокращая время перерыва.
Стоит учитывать, что логический поток это не второе ядро, как может показаться с первого взгляда. Это лишь дополнительная «линия производства», чтобы более эффективно использовать доступную мощность. Из минусов технологии Hyper-Threading или SMT можно выделить увеличение тепловыделения, недостаток кэша (кэш на два потока по-прежнему общий), и проблемы с оптимизацией некоторых программ или игр, не способных отличать настоящее ядро от логического потока.
Именно по этой причине процессоры серии i7 «горячее» и имеют больше кэша по сравнению с i5. Использование технологии многопоточности может принести примерно до 30 % прироста производительности. Все это применимо как к Intel Hyper-Threading, так и к AMD SMT, поскольку технологии во многом схожи. Может возникнуть вопрос: «Если можно добавить второй поток, то почему бы не добавить третий и четвертый?» Это реализуемо, но не имеет смысла, поскольку кэш одного ядра достаточно мал для большего количества потоков и прироста производительности практически не будет.
Увеличение количества ядер
Это самый действенный способ решения проблемы, поскольку каждый конвейер теперь располагает своим FPU, ALU и кэшем, который не придется делить с другим потоком. Разные процессы используют разные ядра, из-за чего реже происходят кэш-промахи и конфликты приоритетных задач. Способ, разумеется, несет в себе некоторые издержки для производителей: дороговизна разработки и производства, увеличение тепловыделения и размера кристалла, и, как результат, повышается итоговая стоимость процессора.
Сферы применения многопоточных процессоров
С развитием компьютерных технологий перечень программ, использующих многопоточность, неуклонно растет. Это дает огромный простор разработчикам для создания нового софта и игр. Например, сейчас каждый современный triple-A проект оптимизирован для многопоточных процессоров, что позволяет наслаждаться игрой, получая высокий уровень fps на многоядерном CPU.
Еще больше распространены многоядерные системы в среде разработчиков. Программы для 3D-моделирования, монтажа видео и создания музыки требуют параллельного выполнения большого количества задач, с чем хорошо справляются системы с Hyper-Threading или SMT. В операционных системах мощность одного потока может тратиться на фоновые задачи (Skype, браузер, мессенджер), в то время как остальные задействуются для тяжелой игры или программы.
Программы для 3D-моделирования, монтажа видео и создания музыки требуют параллельного выполнения большого количества задач, с чем хорошо справляются системы с Hyper-Threading или SMT. В операционных системах мощность одного потока может тратиться на фоновые задачи (Skype, браузер, мессенджер), в то время как остальные задействуются для тяжелой игры или программы.
Но далеко не всегда увеличение количества потоков означает увеличение общей производительности. Почему же SMT процессоры порой уступают немногопоточным собратьям? Дело в программной поддержке. Иногда плохо оптимизированные программы не могут отличать логический поток от настоящего ядра, из-за чего на одно ядро может попасть две тяжелых задачи и замедлить работу. Тем не менее, подобные технологии имеют огромный потенциал, главное — грамотно реализовать его на программном уровне.
Еще раз о Hyper Threading
«…И мы горды и враг наш горд
Рука, забудь о лени. Посмотрим,
кто у чьих ботфорт в конце
концов склонит свои колени…»
© х/ф «Д’артаньян и три мушкетера»
Некоторое время назад автор позволил себе «слегка поворчать» по поводу новой парадигмы от Intel Hyper Threading. К чести корпорации Intel, недоумение автора не осталось ею незамеченной. А посему автору предложили помощь в выяснении (как деликатно дали оценку менеджеры корпорации) «настоящей» ситуации с технологией Hyper Threading. Ну что же желание выяснить истину можно только похвалить. Не так ли, уважаемый читатель? По крайней мере, именно так звучит одна из прописных истин: правда это хорошо. Что ж, будем стараться действовать в соответствии с данной фразой. Тем более, что действительно появилось некоторое количество новых сведений.
К чести корпорации Intel, недоумение автора не осталось ею незамеченной. А посему автору предложили помощь в выяснении (как деликатно дали оценку менеджеры корпорации) «настоящей» ситуации с технологией Hyper Threading. Ну что же желание выяснить истину можно только похвалить. Не так ли, уважаемый читатель? По крайней мере, именно так звучит одна из прописных истин: правда это хорошо. Что ж, будем стараться действовать в соответствии с данной фразой. Тем более, что действительно появилось некоторое количество новых сведений.
Для начала сформулируем, что же именно мы знаем про технологию Hyper Threading:
1. Данная технология предназначена для увеличения эффективности работы процессора. Дело в том, что, по оценкам Intel, большую часть времени работает всего 30% (кстати, достаточно спорная цифра подробности ее вычисления неизвестны) всех исполнительных устройств в процессоре. Согласитесь, это достаточно обидно. И то, что возникла идея каким-то образом «догрузить» остальные 70% выглядит вполне логично (тем более что сам по себе процессор Pentium 4, в котором и внедрят эту технологию, отнюдь не страдает от избыточной производительности на мегагерц).
2. Суть технологии Hyper Threading состоит в том, что во время исполнения одной «нити» программы простаивающие исполнительные устройства могут заняться исполнением другой «нити» программы (или «нити» другой программы). Или, например, исполняя одну последовательность команд, ожидать данных из памяти для исполнения другой последовательности.
3. Естественно, выполняя различные «нити», процессор должен каким-либо образом отличать, какие команды к какой «нити» относятся. Значит, есть какой-то механизм (некая метка), благодаря которой процессор отличает, к какой «нити» относятся команды.
4. Ясно также, что, учитывая небольшое количество регистров общего назначения в архитектуре х86 (всего 8), у каждой нити свой набор регистров. Впрочем, это уже давно не новость данное ограничение архитектуры уже довольно давно обходится при помощи «переименования регистров». Другими словами, физических регистров намного больше, чем логических.
5. Также известно, что в случае, когда несколько «нитей» претендуют на одни и те же ресурсы, либо одна из «нитей» ждет данных во избежание падения производительности программисту необходимо вставлять специальную команду «pause». Естественно, это потребует очередной перекомпиляции программ.
6. Также понятно, что возможны ситуации, когда попытки одновременного исполнения нескольких «нитей» приведут к падению производительности. Например, из-за того, что размер кэша L2 не бесконечный, а активные «нити» будут пытаться загрузить кэш возможна ситуация, когда такая «борьба за кэш» приведет к постоянной очистке и перезагрузке данных в кэше второго уровня.
7. Intel утверждает, что при оптимизации программ под данную технологию выигрыш будет составлять до 30%. (Вернее, Intel утверждает, что на сегодняшних серверных приложениях и сегодняшних системах измеренный выигрыш до 30%) Гм…. Это более чем достаточный стимул для оптимизации.
 Так что эту идею автор вынужден признать вполне здравой.
Так что эту идею автор вынужден признать вполне здравой. В процессоре Pentium III их 40. Наверняка это число для Pentium 4 больше у автора есть ничем не обоснованное (кроме соображений «симметрии» 🙂 мнение, что их порядка сотни. Никаких достоверных сведений об их количестве найти не удалось. По неподтвержденным пока данным, их 256. По другим данным другое число. В общем, полная неопределенность…. Кстати, позиция Intel по этому поводу совершенно непонятна 🙁 автору непонятно, чем вызвана подобная секретность.
В процессоре Pentium III их 40. Наверняка это число для Pentium 4 больше у автора есть ничем не обоснованное (кроме соображений «симметрии» 🙂 мнение, что их порядка сотни. Никаких достоверных сведений об их количестве найти не удалось. По неподтвержденным пока данным, их 256. По другим данным другое число. В общем, полная неопределенность…. Кстати, позиция Intel по этому поводу совершенно непонятна 🙁 автору непонятно, чем вызвана подобная секретность.
Ну что же, некоторые особенности мы сформулировали. Теперь давайте попробуем обдумать некоторые следствия (по возможности опираясь на известные нам сведения). Что же можно сказать? Ну, во-первых, необходимо тщательнее разобраться, что же именно нам предлагают. Так ли «бесплатен» этот сыр? Для начала разберемся, как именно будет происходить «одновременная» обработка нескольких «нитей». Кстати, что подразумевает корпорация Intel под словом «нить»?
У автора сложилось впечатление (возможно, ошибочное), что в данном случае имеется ввиду программный фрагмент, который мультизадачная операционная система назначает на исполнение одному из процессоров мультипроцессорной аппаратной системы. «Постойте!» заявит внимательный читатель «это же одно из определений! Что тут нового?». А ничего в данном вопросе автор на оригинальность не претендует. Разобраться бы, что «наоригинальничала» Intel :-). Ну что же примем в качестве рабочей гипотезы.
«Постойте!» заявит внимательный читатель «это же одно из определений! Что тут нового?». А ничего в данном вопросе автор на оригинальность не претендует. Разобраться бы, что «наоригинальничала» Intel :-). Ну что же примем в качестве рабочей гипотезы.
Далее исполняется некоторая нить. Тем временем декодер команд (кстати, полностью асинхронный и не входящий в пресловутые 20 стадий Net Burst) осуществляет выборку и дешифрацию (со всеми взаимозависимостями) в микроинструкции. Здесь надо пояснить, что автор подразумевает под словом «асинхронный» дело в том, что результат «разваливания» х86 команд в микроинструкции происходит в блоке дешифрации. Каждая команда х86 может быть декодирована в одну, две, или более микроинструкций. При этом на стадии обработки выясняются взаимозависимости, доставляются необходимые данные по системной шине. Соответственно, скорость работы этого блока часто будет зависеть от скорости доступа данных из памяти и в худшем случае определяется именно ею. Было бы логично «отвязать» его от того конвейера, в котором, собственно, и происходит выполнение микроопераций. Это было сделано путем помещения блока дешифрации перед trace cache. Чего мы этим добиваемся? А добиваемся мы при помощи такой «перестановки блоков» местами простой вещи если в trace cache есть микроинструкции для исполнения процессор работает более эффективно. Естественно, этот блок работает на частоте процессора в отличие от Rapid Engine. Кстати, у автора сложилось впечатление, что данный декодер представляет собой нечто вроде конвейера длиной до 10–15 стадий. Таким образом, от выборки данных из кэша до получения результата проходит, по всей видимости, порядка 30 35 стадий (включая конвейер Net Burst, см. Microdesign Resources August2000 Microprocessor report Volume14 Archive8, page12).
Было бы логично «отвязать» его от того конвейера, в котором, собственно, и происходит выполнение микроопераций. Это было сделано путем помещения блока дешифрации перед trace cache. Чего мы этим добиваемся? А добиваемся мы при помощи такой «перестановки блоков» местами простой вещи если в trace cache есть микроинструкции для исполнения процессор работает более эффективно. Естественно, этот блок работает на частоте процессора в отличие от Rapid Engine. Кстати, у автора сложилось впечатление, что данный декодер представляет собой нечто вроде конвейера длиной до 10–15 стадий. Таким образом, от выборки данных из кэша до получения результата проходит, по всей видимости, порядка 30 35 стадий (включая конвейер Net Burst, см. Microdesign Resources August2000 Microprocessor report Volume14 Archive8, page12).
Полученный набор микроинструкций вместе со всеми взаимозависимостями накапливается в trace cache в том самом, который приблизительно 12 000 микроопераций. По приблизительным оценкам источник такой оценки строение микроинструкции P6; дело в том, что принципиально длина инструкций вряд ли кардинально поменялась (считая длину микроинструкции вместе со служебными полями порядка 100 бит) размер trace cache получается от 96 КБ до 120 КБ!!! Однако! На фоне этого кэш данных размером 8 КБ выглядит как-то несимметрично :-)… и бледно. Конечно, при увеличении размера увеличиваются задержки доступа (к примеру, при увеличении до 32КБ задержки вместо двух тактов составят 4). Но неужели так важна скорость доступа в этот самый кэш данных, что увеличение задержки на 2 такта (на фоне общей длины всего конвейера) делает такое увеличение объема невыгодным? Или дело просто в нежелании увеличивать размер кристалла? Но тогда при переходе на 0.13 мкм первым делом стоило увеличить именно этот кэш (а не кэш второго уровня). Сомневающимся в данном тезисе стоило бы припомнить переход с Pentium на Pentium MMX благодаря увеличению кэша первого уровня вдвое практически все программы получали 10 15% прироста производительности.
По приблизительным оценкам источник такой оценки строение микроинструкции P6; дело в том, что принципиально длина инструкций вряд ли кардинально поменялась (считая длину микроинструкции вместе со служебными полями порядка 100 бит) размер trace cache получается от 96 КБ до 120 КБ!!! Однако! На фоне этого кэш данных размером 8 КБ выглядит как-то несимметрично :-)… и бледно. Конечно, при увеличении размера увеличиваются задержки доступа (к примеру, при увеличении до 32КБ задержки вместо двух тактов составят 4). Но неужели так важна скорость доступа в этот самый кэш данных, что увеличение задержки на 2 такта (на фоне общей длины всего конвейера) делает такое увеличение объема невыгодным? Или дело просто в нежелании увеличивать размер кристалла? Но тогда при переходе на 0.13 мкм первым делом стоило увеличить именно этот кэш (а не кэш второго уровня). Сомневающимся в данном тезисе стоило бы припомнить переход с Pentium на Pentium MMX благодаря увеличению кэша первого уровня вдвое практически все программы получали 10 15% прироста производительности. Что же говорить об увеличении вчетверо (особенно учитывая, что скорости процессоров выросли до 2ГГц, а коэффициент умножения с 2.5 до 20)? По неподтвержденным данным, в следующей модификации ядра Pentium4 (Prescott) кэш первого уровня таки увеличат до 16 или 32 КБ. Также увеличится кэш второго уровня. Впрочем, на сегодняшний момент все это не более чем слухи. Откровенно говоря, слегка непонятная ситуация. Хотя оговоримся автор вполне допускает, что подобной идее мешает некая конкретная причина. Как пример подойдут некие требования по геометрии расположения блоков или банальная нехватка свободного места вблизи конвейера (ясно ведь, что необходимо расположить кэш данных поближе к ALU).
Что же говорить об увеличении вчетверо (особенно учитывая, что скорости процессоров выросли до 2ГГц, а коэффициент умножения с 2.5 до 20)? По неподтвержденным данным, в следующей модификации ядра Pentium4 (Prescott) кэш первого уровня таки увеличат до 16 или 32 КБ. Также увеличится кэш второго уровня. Впрочем, на сегодняшний момент все это не более чем слухи. Откровенно говоря, слегка непонятная ситуация. Хотя оговоримся автор вполне допускает, что подобной идее мешает некая конкретная причина. Как пример подойдут некие требования по геометрии расположения блоков или банальная нехватка свободного места вблизи конвейера (ясно ведь, что необходимо расположить кэш данных поближе к ALU).
Не отвлекаясь, смотрим на процесс дальше. Конвейер работает пусть нынешние команды задействуют ALU. Ясно, что FPU, SSE, SSE2 и прочие при этом простаивают. Не тут-то было вступает в действие Hyper Threading. Заметив, что готовы микроинструкции вместе с данными для новой нити, блок переименования регистров выделяет новой нити порцию физических регистров. Кстати, возможны два варианта блок физических регистров общий для всех нитей, или же отдельный для каждого. Судя по тому, что в презентации Hyper Threading от Intel в качестве блоков, которые надо изменять, блок переименования регистров не указан выбран первый вариант. Это хорошо или плохо? С точки зрения технологов явно хорошо, ибо экономит транзисторы. С точки зрения программистов пока неясно. Если количество физических регистров действительно 128, то при любом разумном количестве нитей ситуации «нехватка регистров» возникнуть не может. Затем они (микроинструкции) отправляются в планировщик, который, собственно, направляет их на исполнительное устройство (если оно не занято) или «в очередь», если данное исполнительное устройство сейчас недоступно. Таким образом, в идеале достигается более эффективное спользование имеющихся исполнительных устройств. В это время сам процессор с точки зрения ОС выглядит как два «логических» процессора.
Кстати, возможны два варианта блок физических регистров общий для всех нитей, или же отдельный для каждого. Судя по тому, что в презентации Hyper Threading от Intel в качестве блоков, которые надо изменять, блок переименования регистров не указан выбран первый вариант. Это хорошо или плохо? С точки зрения технологов явно хорошо, ибо экономит транзисторы. С точки зрения программистов пока неясно. Если количество физических регистров действительно 128, то при любом разумном количестве нитей ситуации «нехватка регистров» возникнуть не может. Затем они (микроинструкции) отправляются в планировщик, который, собственно, направляет их на исполнительное устройство (если оно не занято) или «в очередь», если данное исполнительное устройство сейчас недоступно. Таким образом, в идеале достигается более эффективное спользование имеющихся исполнительных устройств. В это время сам процессор с точки зрения ОС выглядит как два «логических» процессора. Гм… Неужели все так безоблачно? Давайте присмотримся к ситуации: часть оборудования (как-то кэши, Rapid Engine, модуль предсказания переходов) являются общими для обоих процессоров. Кстати, точность предсказания переходов от этого, скорее всего, слегка пострадает. Особенно, если исполняемые одновременно нити не связаны друг с другом. А часть (например, MIS [Microcode Instruction Sequencer] планировщик последовательности микрокоманд подобие ПЗУ, содержащее набор заранее запрограммированных последовательностей обычных операций и RAT [Register Alias Table] таблица переименования [псевдонимов] регистров) блоков должна отличать различные нити, запущенные на «разных» процессорах. Попутно (из общности кэша) следует, что, если две нити являются «жадными» к кэшу (то есть увеличение кэша дает большой эффект), то применение Hyper Threading способно даже снизить скорость. Это происходит потому, что на сегодняшний момент реализован «конкурентный» механизм борьбы за кэш «активная» в данный момент нить вытесняет «неактивную».
Гм… Неужели все так безоблачно? Давайте присмотримся к ситуации: часть оборудования (как-то кэши, Rapid Engine, модуль предсказания переходов) являются общими для обоих процессоров. Кстати, точность предсказания переходов от этого, скорее всего, слегка пострадает. Особенно, если исполняемые одновременно нити не связаны друг с другом. А часть (например, MIS [Microcode Instruction Sequencer] планировщик последовательности микрокоманд подобие ПЗУ, содержащее набор заранее запрограммированных последовательностей обычных операций и RAT [Register Alias Table] таблица переименования [псевдонимов] регистров) блоков должна отличать различные нити, запущенные на «разных» процессорах. Попутно (из общности кэша) следует, что, если две нити являются «жадными» к кэшу (то есть увеличение кэша дает большой эффект), то применение Hyper Threading способно даже снизить скорость. Это происходит потому, что на сегодняшний момент реализован «конкурентный» механизм борьбы за кэш «активная» в данный момент нить вытесняет «неактивную». Впрочем, механизм кэширования, по-видимому, может измениться. Также понятно, что скорость (по крайней мере, на текущий момент) будет снижаться в тех приложениях, в которых она снижалась и в честном SMP. Как пример SPEC ViewPerf обычно на однопроцессорных системах показывает более высокие результаты. А посему наверняка на системе с Hyper Threading результаты будут меньше, чем без нее. Собственно, результаты практического тестирования Hyper Threading можно посмотреть по этому адресу.
Впрочем, механизм кэширования, по-видимому, может измениться. Также понятно, что скорость (по крайней мере, на текущий момент) будет снижаться в тех приложениях, в которых она снижалась и в честном SMP. Как пример SPEC ViewPerf обычно на однопроцессорных системах показывает более высокие результаты. А посему наверняка на системе с Hyper Threading результаты будут меньше, чем без нее. Собственно, результаты практического тестирования Hyper Threading можно посмотреть по этому адресу.
Кстати, в интернет проскакивала информация о том, что ALU в Pentium 4 16 разрядные. Сначала автор относился к подобной информации весьма скептически дескать, чего завистники удумали :-). А потом публикация подобной информации в Micro Design Report заставила таки задуматься а вдруг правда? И, хотя информация об этом к теме статьи прямого отношения не имеет — трудно удержаться :-). Насколько автору «хватило понимания», суть в том, что ALU действительно 16-разрядный. Подчеркиваю только ALU. К разрядности самого процессора это отношения не имеет. Таким образом, за полтакта (это называется тик, tick) ALU (удвоенной частоты, как Вы помните) вычисляет только 16 разрядов. Вторые 16 вычисляются за следующие полтакта. Отсюда, кстати, легко понятна необходимость сделать ALU вдвое быстрее это необходимо для своевременного «перемалывания» данных. Таким образом, полных 32 разряда вычисляются за полный такт. На самом деле, по-видимому, необходимы 2 такта из-за необходимости «склеивать» и «расклеивать» разряды но этот вопрос необходимо уточнить. Собственно, раскопки (про которые можно написать отдельную поэму) дали следующее: каждое ALU поделено на 2 16-разрядные половинки. Первые полтакта первая половинка обрабатывает 16 разрядов двух чисел и формируют биты переносов для вторых половинок. Вторая половинка в это время заканчивает обработку предыдущих чисел. Второй тик первая половинка ALU обрабатывает 16 разрядов от следующей пары чисел и формирует их переносы. Вторая половинка обрабатывает старшие 16 разрядов первой пары чисел и получает готовый 32-разрядный результат. Задержка получения 1 результата 1 такт, но потом каждые полтакта вылезает по 1 32-разрядному результату. Достаточно остроумно и эффективно. Почему же была выбрана именно такая модель ALU? По видимому, подобной организацией Intel убивает несколько «зайцев»:
К разрядности самого процессора это отношения не имеет. Таким образом, за полтакта (это называется тик, tick) ALU (удвоенной частоты, как Вы помните) вычисляет только 16 разрядов. Вторые 16 вычисляются за следующие полтакта. Отсюда, кстати, легко понятна необходимость сделать ALU вдвое быстрее это необходимо для своевременного «перемалывания» данных. Таким образом, полных 32 разряда вычисляются за полный такт. На самом деле, по-видимому, необходимы 2 такта из-за необходимости «склеивать» и «расклеивать» разряды но этот вопрос необходимо уточнить. Собственно, раскопки (про которые можно написать отдельную поэму) дали следующее: каждое ALU поделено на 2 16-разрядные половинки. Первые полтакта первая половинка обрабатывает 16 разрядов двух чисел и формируют биты переносов для вторых половинок. Вторая половинка в это время заканчивает обработку предыдущих чисел. Второй тик первая половинка ALU обрабатывает 16 разрядов от следующей пары чисел и формирует их переносы. Вторая половинка обрабатывает старшие 16 разрядов первой пары чисел и получает готовый 32-разрядный результат. Задержка получения 1 результата 1 такт, но потом каждые полтакта вылезает по 1 32-разрядному результату. Достаточно остроумно и эффективно. Почему же была выбрана именно такая модель ALU? По видимому, подобной организацией Intel убивает несколько «зайцев»:
1. Ясно, что конвейер «шириной» 16 разрядов разгонять легче, чем шириной 32 разряда просто по причине наличия перекрестных помех и Ко
2. По-видимому, Интел счел операции целочисленного вычисления достаточно часто встречающимися, чтобы ускорять именно ALU, а не, скажем, FPU. Вероятно, при вычислении результатов целочисленных операций используются либо таблицы, либо схемы «с накоплением переноса». Для сравнения, одна 32-битная таблица это 2E32 адресов, т.е. 4гигабайта. Две 16-разрядные таблицы это 2х64кб или 128 килобайт почувствуйте разницу! Да и накопление переносов в двух 16-разрядных порциях происходит быстрее, чем в одной 32-разрядной.
3. Экономит транзисторы и… тепло. Ведь ни для кого не секрет, что все эти архитектурные ухищрения греются. По видимому, это была достаточно большая (а, возможно, и главная) проблема чего стоит, к примеру, Thermal Monitor как технология! Ведь необходимости в подобной технологии как таковой не очень много то есть, конечно, приятно, что она есть. Но давайте говорить честно простой блокировки хватило бы для достаточной надежности. Раз такая сложная технология была предусмотрена значит, всерьез рассматривался вариант, когда подобные изменения частоты на ходу были одним из штатных режимов работы. А, может, основным? Ведь не зря ходили слухи, что Pentium 4 задумывался с гораздо большим количеством исполнительных устройств. Тогда проблема тепла должна была стать просто основной. Вернее, по тем же слухам, тепловыделение должно было составить до 150 Вт. А тогда очень логично принять меры к тому, чтобы процессор работал «в полную силу» только в таких системах, где обеспечено нормальное охлаждение. Тем более, что большинство корпусов «китайского» происхождения продуманностью конструкции с точки зрения охлаждения отнюдь не блещут. Гм…. Далековато забрались 🙂
Но все это теоретизирования. Есть ли сегодня процессоры, в которых применяется эта технология? Есть. Это Xeon (Prestonia) и XeonMP. Причем, интересно, что XeonМР от Xeon отличается поддержкой до 4 процессоров (чипсеты типа IBM Summit поддерживают до 16 процессоров, методика приблизительно такая же, как и в чипсете ProFusion) и наличием кэша третьего уровня объемом 512 КБ и 1 МБ, интегрированного в ядро. Кстати, а почему интегрировали кэш именно третьего уровня? Почему не увеличен кэш первого уровня? Должна же быть какая-то разумная причина…. Почему не увеличили кэш второго уровня? Возможно, причина в том, что Advanced Transfer Cache нуждается в относительно небольших задержках. А увеличение объема кэша приводит к увеличению задержек. Посему кэш третьего уровня для ядра и кэша второго уровня вообще «представляется» как шина. Просто шина :-). Так что прогресс налицо сделано все, чтобы данные подавались в ядро как можно быстрее (а, попутно, поменьше загружалась шина памяти).
Ну что же получается, никаких особо узких мест и нет? Что же автор, так и не сможет «поворчать»? Один процессор — а ОС видит два. Хорошо! Два процессора а ОС видит 4! Кррасота! Стоп! А какая это ОС у нас работает с 4-мя процессорами? Операционные системы от Микрософт, которые понимают больше двух процессоров, стоят совсем других денег. Например, 2000 Professional, XP Professional, NT4.0 понимают только два процессора. А, учитывая, что пока что данная технология предназначается на рынок рабочих станций (и серверов) и есть только в соответствующих процессорах — получается просто чертовски обидно. На сегодня мы можем использовать процессора с такой технологией, только купив двухпроцессорную плату и поставив один процессор. Чем дальше, тем «страньше», как говаривала Алиса в стране чудес…. То есть, человек, жаждущий использовать данную технологию, просто вынужден покупать версии Server и Advanced Server нынешних операционных систем. Ох, и дороговат выходит «бесплатный» процессор…. Стоит добавить, пожалуй, что в настоящий момент Intel активно «общается» с Microsoft, пытаясь привязать политику лицензирования к физическому процессору. По крайней мере, согласно документу, новые операционные системы от Microsoft будут лицензироваться по физическим процессорам. По крайней мере, WindowsXP лицензируется именно по количеству физических процессоров.
Естественно, всегда можно обратиться к операционным системам других производителей. Да только будем откровенными это не очень хороший выход из текущей ситуации…. Так что можно понять колебания Интел, которая довольно долго думала использовать эту технологию, или нет.
Ну что же не забываем достаточно важный вывод: применение Hyper Threading способно привести как к выигрышу, так и к проигрышу в производительности. Ну а поскольку проигрыш нами уже обсужден попробуем понять, что же необходимо для выигрыша: а для выигрыша необходимо, чтобы об этой технологии знали:
- BIOS материнской платы
- Операционная система (!!!)
- Собственно, само приложение
Вот на этом моменте позвольте остановиться поподробнее дело в том, что за BIOS дело не станет. Операционную систему мы обсудили чуть ранее. А вот в те нити, которые, например, ожидают данных из памяти придется вводить специальную команду pause, чтобы не замедлять работу процессора; ведь при отсутствии данных нить способна блокировать те или иные исполнительные устройства. А чтобы вставить эту команду, приложения придется перекомпилировать это не есть хорошо, но, с легкой руки Intel, к этому в последнее время все стали привыкать :-). Таким образом, основной (по мнению автора) недостаток технологии Hyper Threading это необходимость очередной компиляции. Основное преимущество такого подхода — подобная перекомпиляция попутно (и, скорее всего, более заметно 🙂 подымет производительность в «честных» двухпроцессорных системах а это можно только приветствовать. Кстати, уже есть экспериментальные данные, которые подтверждают, что в большинстве случаев программы, оптимизированные под SMP, выигрывают от Hyper Threading от 15% до 18%. Это весьма неплохо. Кстати, там же можно увидеть, в каких случаях Hyper Threading приводит к падению производительности.
И напоследок давайте попробуем пофантазировать, что же может измениться (улучшиться) в дальнейшем развитии этой идеи. Достаточно очевидно, что развитие данной технологии будет прямо связано с развитием ядра Pentium 4. Таким образом, представим себе потенциальные изменения в ядре. Что там у нас дальше по плану? 0.09 микронная технология, более известная как 90нм…. Автор склонен считать (на сегодняшний момент), что развитие данного семейства процессоров пойдет сразу по нескольким направлениям:
- Благодаря более «тонкому» техпроцессу частота процессора станет еще выше.
- Будем надеяться, что кэш данных увеличат. Хотя бы до 32КБ.
- Сделают «честное», 32 разрядное ALU. Это должно поднять производительность.
- Увеличат скорость системной шины (впрочем, это уже в ближайших планах).
- Сделают двухканальную DDR память (опять же, ждать осталось относительно недолго).
- Возможно, введут аналог технологии х86-64, если данная технология (усилиями AMD) приживется. При этом автор изо всех сил надеется, что этот аналог будет совместимым с х86-64. Хватит уже плодить несовместимых друг с другом расширений…. Опять же, небезынтересным для нас будет интервью Джерри Сандерса, в котором тот заявил, что AMD и Intel в прошлом году договорились о кросс-лицензировании на все, кроме системной шины Pentium4. Значит ли это, что Intel встроит х86-64 в следующее ядро Pentium4 (Prescott), а AMD встроит в свои процессора Hyper Threading? Вопрос интересный….
- Возможно, будет увеличено количество исполнительных устройств. Правда, как и предыдущий, это достаточно спорный пункт, поскольку требует практически полного перепроектирования ядра а это долгий и трудоемкий процесс.
Интересно, будет ли развиваться идея Hyper Threading? Дело в том, что в количественном отношении ей развиваться особо некуда понятно, что два физических процессора лучше трех логических. Да и позиционировать будет нелегко…. Интересно, что Hyper Threading может пригодиться и при интегрировании двух (или более) процессоров на кристалл. Ну а под качественными изменениями автор имеет ввиду, что наличие такой технологии в обычных десктопах приведет к тому, что фактически большинство пользователей будут работать на [почти] двухпроцессорных машинах что очень хорошо. Хорошо потому, что подобные машины работают не в пример «плавнее» и «отзывчивее» на действия пользователя даже под большой нагрузкой. Сие, с точки зрения автора, есть весьма хорошо.
Вместо послесловия
Автор должен признаться, что в течение работы над статьей его отношение к Hyper Threading неоднократно менялось. По мере того, как собиралась и обрабатывалась информация отношение становилось то в целом положительным, то наоборот :-). На сегодняшний момент можно написать следующее:
есть только два способа повышать производительность повышать частоту, и повышать производительность за такт. И, если вся архитектура Pentium4 рассчитана на первый путь, то Hyper Threading как раз второй. Уже с этой точки зрения ее можно только приветствовать. Так же Hyper Threading несет несколько интересных следствий, как-то: изменение парадигмы программирования, привнесение многопроцессорности в массы, увеличение производительности процессоров. Однако, на этом пути есть несколько «больших кочек», на которых важно не «застрять»: отсутствие нормальной поддержки со стороны операционных систем и, самое главное, необходимость перекомпиляции (а в некоторых случаях и смены алгоритма) приложений, чтобы они в полной мере смогли воспользоваться преимуществами Hyper Threading. К тому же, наличие Hyper Threading сделало бы возможной действительно параллельную работу операционной системы и приложений а не «кусками» по очереди, как сейчас. Конечно, при условии, что хватит свободных исполнительных устройств.
Автор хотел подчеркнуть бы свою признательность Максиму Леню (aka C.A.R.C.A.S.S.) и Илье Вайцману (aka Stranger_NN) за неоднократную и неоценимую помощь при написании статьи.
Также хотелось бы сказать спасибо всем участникам форума, которые неоднократно высказывали ценные замечания.
Еще раз о Hyper-Threading / Хабр
Было время, когда понадобилось оценить производительность памяти в контексте технологии Hyper-threading. Мы пришли к выводу, что ее влияние не всегда позитивно. Когда появился квант свободного времени, возникло желание продолжить исследования и рассмотреть происходящие процессы с точностью до машинных тактов и битов, используя программное обеспечение собственной разработки.Исследуемая платформа
Объект экспериментов – ноутбук ASUS N750JK c процессором Intel Core i7-4700HQ. Тактовая частота 2.4GHz, повышаемая в режиме Intel Turbo Boost до 3.4GHz. Установлено 16 гигабайт оперативной памяти DDR3-1600 (PC3-12800), работающей в двухканальном режиме. Операционная система – Microsoft Windows 8.1 64 бита.
Рис.1 Конфигурация исследуемой платформы.
Процессор исследуемой платформы содержит 4 ядра, что при включении технологии Hyper-Threading обеспечивает аппаратную поддержку 8 потоков или логических процессоров. Эту информацию Firmware платформы передает операционной системе посредством ACPI-таблицы MADT (Multiple APIC Description Table). Поскольку платформа содержит только один контроллер оперативной памяти, таблица SRAT (System Resource Affinity Table), декларирующая приближенность процессорных ядер к контроллерам памяти, отсутствует. Очевидно, исследуемый ноутбук не является NUMA-платформой, но операционная система, в целях унификации, рассматривает его как NUMA-систему с одним доменом, о чем говорит строка NUMA Nodes = 1. Факт, принципиальный для наших экспериментов – кэш память данных первого уровня имеет размер 32 килобайта на каждое из четырех ядер. Два логических процессора, разделяющие одно ядро, используют кэш-память первого и второго уровней совместно.
Исследуемая операция
Исследовать будем зависимость скорости чтения блока данных от его размера. Для этого выберем наиболее производительный метод, а именно чтение 256-битных операндов посредством AVX-инструкции VMOVAPD. На графиках по оси X отложен размер блока, по оси Y – скорость чтения. В окрестности точки X, соответствующей размеру кэш-памяти первого уровня, ожидаем увидеть точку перегиба, поскольку производительность должна упасть после того, как обрабатываемый блок выйдет за пределы кэш-памяти. В нашем тесте, в случае многопоточной обработки, каждый из 16 инициируемых потоков, работает с отдельным диапазоном адресов. Для управления технологией Hyper-Threading в рамках приложения, в каждом из потоков используется API-функция SetThreadAffinityMask, задающая маску, в которой каждому логическому процессору соответствует один бит. Единичное значение бита разрешает использовать заданный процессор заданным потоком, нулевое значение – запрещает. Для 8 логических процессоров исследуемой платформы, маска 11111111b разрешает использовать все процессоры (Hyper-Threading включен), маска 01010101b разрешает использовать по одному логическому процессору в каждом ядре (Hyper-Threading выключен).
MBPS (Megabytes per Second) – скорость чтения блока в мегабайтах в секунду;
CPI (Clocks per Instruction) – количество тактов на инструкцию;
TSC (Time Stamp Counter) – счетчик процессорных тактов.
Примечание.Тактовая частота регистра TSC может не соответствовать тактовой частоте процессора при работе в режиме Turbo Boost. Это необходимо учитывать при интерпретации результатов.
В правой части графиков визуализируется шестнадцатеричный дамп инструкций, составляющих тело цикла целевой операции, выполняемой в каждом из программных потоков, или первые 128 байт этого кода.
Опыт №1. Один поток
Рис.2 Чтение одним потоком
Максимальная скорость 213563 мегабайт в секунду. Точка перегиба имеет место при размере блока около 32 килобайт.
Опыт №2. 16 потоков на 4 процессора, Hyper-Threading выключен
Рис.3 Чтение шестнадцатью потоками. Количество используемых логических процессоров равно четырем
Hyper-Threading выключен. Максимальная скорость 797598 мегабайт в секунду. Точка перегиба имеет место при размере блока около 32 килобайт. Как и ожидалось, по сравнению с чтением одним потоком, скорость выросла приблизительно в 4 раза, по количеству работающих ядер.
Опыт №3. 16 потоков на 8 процессоров, Hyper-Threading включен
Рис.4 Чтение шестнадцатью потоками. Количество используемых логических процессоров равно восьми
Hyper-Threading включен. Максимальная скорость 800722 мегабайт в секунду, в результате включения Hyper-Threading почти не выросла. Большой минус – точка перегиба имеет место при размере блока около 16 килобайт. Включение Hyper-Threading немного увеличило максимальную скорость, но падение скорости теперь наступает при вдвое меньшем размере блока – около 16 килобайт, поэтому существенно упала средняя скорость. Это не удивительно, каждое ядро имеет собственную кэш-память первого уровня, в то время, как логические процессоры одного ядра, используют ее совместно.
Выводы
Исследованная операция достаточно хорошо масштабируется на многоядерном процессоре. Причины – каждое из ядер содержит собственную кэш-память первого и второго уровней, размер целевого блока сопоставим с размером кэш-памяти, и каждый из потоков работает со своим диапазоном адресов. В академических целях мы создали такие условия в синтетическом тесте, понимая, что реальные приложения обычно далеки от идеальной оптимизации. А вот включение Hyper-Threading, даже в этих условиях дало негативный эффект, при небольшой прибавке пиковой скорости, имеет место существенный проигрыш в скорости обработки блоков, размер которых находится в диапазоне от 16 до 32 килобайт.
Про Intel Hyper-Threading и производительность виртуальных машин / Хабр
Всегда относился к Intel Hyper-Threading как к маркетинговому продукту. Но недавно я взглянул на эту технологию под другим углом.Настал момент, когда лицензия vSphere Standart позволила создавать и запускать виртуальные машины с количеством виртуальных процессоров равных 8. О том, чем это грозит в случае установленного процессора с 4-мя физическими ядрами и поддержкой Hyper-Threading, читайте дальше.
Думаю, данный материал нужно рассматривать как продолжение моих попыток ускорить работу терминального сервера, про это я писал тут.
Про Hyper-Threading
Принцип действия Hyper-Threading основывается на том, что в каждый момент времени только часть ресурсов процессора используется при выполнении программного кода. Неиспользуемые ресурсы также можно загрузить работой — например, задействовать для параллельного выполнения еще одного приложения либо другого потока этого же приложения.
Следуя слогану Intel «Чем больше задач, тем выше эффективность работы», чтобы увидеть результат я буду запускать в разных сессиях на терминальном сервере просмотр фильмов. Чем больше я смогу запустить фильмов, тем лучше; снижение нагрузки на процессор также приветствуется.
На VM, подготовленную для тестирования, установлена ОС ws2008 R2 Standart. На момент тестирования были установлены все обновления. Для воспроизведения роликов установлен кодек и плеер DIVX.
Тестовый стенд собран из сервера HP ML350 G6 c процессором Intel Xeon E5620 1шт.
E5620 Specifications
Launch Date Q1’10
of Cores 4
of Threads 8
Base Frequency 2.4 GHz
Начну с результатов ESXi
На сервер установлена версия ESXi сервера 5.1-1483097.
Про логику работы ESXi + Hyperthreading на Хабре опубликован интересный материал «Оптимизация работы виртуальной инфраструктуры на базе VMWare vSphere», рекомендую к ознакомлению.
Несколько экспериментов с размерами vcpu, технология intel HT активна, воспроизводился тестовый ролик с качеством 480p.
Как видно из результатов, при использовании 8 потоков на терминальном сервере удалось запустить еще одну копию фильма и получить средний прирост в 20%. А вот разница между виртуальными процессорами и виртуальными ядрами в случае одного физического процессором незаметна.
Нагрузку я фиксировал с VM, если фиксировать с хоста — цифры будут другими, по какой-то причине хост сервер фиксирует отличный от VM результат. Вот как это выглядит при работе реальных пользователей:
В следующих тестах я буду выключать HT в биосе и воспроизводить ролики с качеством 480р, 720р и 1080р.
Результаты Hyper-V 2012
На сервер установлена ОС ws2012 R2 Standart и установлены все обновления на момент тестирования.
Тестовая VM портировалась с платформы VMware на платформу Microsoft.
Показания производительности снимались с хоста:
Результаты Hyper-V 2008
На сервер установлена ОС ws2008 R2 Standart и установлены все обновления на момент тестирования.
Показания производительности снимались с хоста, однако платформа Hyper-V 2008 с активным HT не позволила создать VM с 8 vcpu, в связи с чем получены странные результаты.
После того как, я не смог запустить VM в конфигурации 8 vcpu решил проверить работу Hyper-V 2008 в связке с VDI. Были созданы несколько VM с ОС Windows 7 x86, все обновления установлены.
Результаты для 4 vcpu per VM:
Результаты для 2 vcpu per VM:
Конфигурация с 2 vcpu per VM показала результат лучше, очень заметно для ролика 1080р.
Результаты физического сервера ws2008 R2
Эти данные будут использоваться как эталонные:
Сравнения всех платформ
Для сравнения буду использовать результаты, полученные для видео 480р:
Можно сделать следующие выводы:
Использование HT дает результат, который можно заметить в много поточных задачах. Пользу HT в задачах более «узких» нужно проверять.
В проведенных тестах явного лидера между платформами нет. А обладателям лицензий ws2008, которые используются для Hyper-V, стоит задуматься про апдейт, если есть необходимость использовать большие VM.
Получить результат максимально приближенный к ФС позволит инфраструктура VDI.
Думаю, данный результат обеспечил кодек RemoteFX 8.
Решено: какова связь между «аппаратной нитью» и «гиперпоточностью»?
Когда мы разделяем слова, это может сбивать с толку, не так ли? Документация TBB неверна, спасибо, что указали на это.
Мы решили НЕ называть аппаратные потоки на текущем сопроцессоре Intel Xeon Phi (ранее известный под кодовым названием Knights Corner) именем «гиперпотоки». Важнее всего знать, что для достижения максимальной производительности обычно требуется больше потоков Knights Corner на ядро, чем при использовании гиперпоточности.Это согласуется с «высоко параллельной» оптимизацией сопроцессора Intel Xeon Phi. Разница в этих аппаратных методах потоковой передачи поучительна, поэтому я постараюсь дать объяснение, которое имеет смысл.
Независимо от того, о каком устройстве Intel мы говорим, ядро обработки будет иметь один или несколько «аппаратных потоков» на каждое ядро. Мы используем «аппаратные потоки» как очень общий термин, который относится к многопоточности, достигаемой в основном за счет дублирования состояния потока и совместного использования большей части всего остального в ядре обработки.Многопоточность достигается за счет дублирования почти всего, всего «ядра» — вот что такое многоядерные и многоядерные конструкции. Процессоры и сопроцессор могут иметь как «аппаратные потоки», так и множество ядер. «Гиперпоточность» — это очень специфическая форма реализации «аппаратного потока», которая встречается только в динамических (так называемых неупорядоченных) механизмах выполнения.
Это подчеркивает разницу в микроархитектуре Knights Corner и микроархитектуре процессора Intel Xeon. Микроархитектура Knights Corner использует выполнение «по порядку», поэтому аппаратные потоки выполняют относительно простой циклический перебор для питания каналов двойного исполнения микроархитектуры.В этой конструкции вы можете выполнять две векторные инструкции (SIMD) параллельно, но они должны поступать из разных потоков. Вот почему мы советуем программистам использовать как минимум два потока на ядро на сопроцессорах Intel Xeon Phi. Если вы этого не сделаете, производительность с плавающей запятой (FP) достигнет пика примерно на половине возможного. Для большинства программистов это просто вопрос того, чтобы OpenMP или TBB использовали не менее 122 потоков на 61-ядерном устройстве. Многие из нас имеют обыкновение ограничивать интенсивный код FP потоками = ядрами на машинах с гиперпоточностью.Это связано с тем, что на гиперпоточных машинах мы находим микроархитектуру с механизмом выполнения вне очереди. В этих конструкциях полный потенциал FP может быть реализован с помощью одного потока. Дополнительные потоки на любом устройстве будут оказывать большее давление на кеши и требовать большей пропускной способности памяти. Если ваш алгоритм уже достигает пикового использования FP, дополнительные потоки бесполезны, если они не помогают с сокрытием задержки. По большей части механизмы выполнения вне очереди заботятся о сокрытии задержки, чего не может выполнить упорядоченный дизайн.Следовательно, при использовании гиперпоточности на процессоре Intel Xeon вы можете достичь максимальной производительности с потоками = ядрами. Благодаря дизайну упорядоченного выполнения в микроархитектуре Knights Corner для достижения пика необходимы как минимум два потока, а скрытие задержки часто усиливается еще большим количеством потоков. Многие алгоритмы считают, что три потока на ядро - их золотая середина, в то время как другие предпочитают два или четыре.
При обучении программированию для сопроцессора Intel Xeon Phi мы обнаружили, что было полезно говорить об этом различии в основном для того, чтобы побудить всех нас поэкспериментировать с тем, сколько потоков на ядро лучше всего обслуживает наши приложения.Используя OpenMP или TBB, это так же просто, как установить другой параметр или переменную среды и запустить несколько раз для сравнения. Никаких изменений в программе нельзя избежать.
Если мы привыкли всегда запускать потоки = ядра на гиперпотоковой машине, то полезно знать, что Knights Corner не использует гиперпотоки, и мы должны использовать как минимум два потока на ядро (почти всегда), чтобы получить лучшую производительность.
Тем не менее, сегодня гиперпоточность намного более продвинута, чем десять лет назад.Если в последнее время мы не решались тестировать производительность наших приложений с гиперпоточностью, нам следует подумать о проведении некоторых тестов производительности. Если вы удивлены, насколько лучше с Hyper-Threading, чем раньше, пожалуйста, не говорите нашим маркетологам … или они захотят называть их «Hyper-Thread PRO» или что-то еще, что я скажу чтобы объяснить в будущем блоге. 😉
Надеюсь, это все проясняет.
Спасибо, что указали на нашу ошибку в документах TBB — я постараюсь их исправить.
Посмотреть решение в исходном сообщении
404: Страница не найдена
WhatIs.com Ищите тысячи технических определений Просмотреть определения :- А
- B
- C
- D
- E
- F
- G
- H
- I
- Дж
- К
- L
- M
- N
- O
- P
- Q
- R
- S
- т
- U
- В
- Вт
- X
- Y
- Z
- #
- Сеть Techtarget
- Технический ускоритель
- Что такое.com
- Просмотреть определения
По теме
Выберите категорию
- AppDev
- Программное обеспечение для бизнеса
- Компьютерные науки
- Потребительские технологии
- Дата-центр
- ИТ-менеджмент
- Сеть
- Безопасность
- Хранение и данные Mgmt
- Agile, Scrum, XP
- Яблоко
- DevOps
- Интернет-приложения
- Java
- Linux
- Microsoft
- Открытый исходный код
- Операционные системы
- Программирование
- Программные приложения
- Разработка программного обеспечения
- Веб-сервисы, SOA
- Amazon Web Services (AWS)
- Google — Android
- Microsoft — Windows
- Открытый исходный код
- Оракул
- Salesforce
- SAP
Что такое Hyper-Threading? [Разъяснение технологии]
Если вы недавно задумывались о покупке процессора Intel или компьютера с установленным процессором Intel, возможно, вы слышали термин «Hyper-Threading», появившийся у ваших барабанных перепонок.Вы, вероятно, не знакомы с этим термином, если не будете в курсе мельчайших деталей компьютерного оборудования.
Однако понимание Hyper-Threading важно, потому что это основная функция некоторых процессоров Intel.Как и большинство основных функций процессора, его могут изменить продавцы, с которыми вы встретитесь. Сотрудник магазина Fry ‘сказал мне, что Hyper-Threading фактически удваивает количество ядер процессора. Хотя в каком-то смысле это правда, в основном это преувеличение.
Что такое ЦП и для чего он нужен?Аббревиатуры в вычислительной технике сбивают с толку.Что вообще такое процессор? А мне нужен четырехъядерный или двухъядерный процессор? А как насчет AMD или Intel? Мы здесь, чтобы помочь объяснить разницу!
Давайте посмотрим, что на самом деле означает Hyper-Threading .
Краткая история Hyper-Threading
В зависимости от того, когда вы в последний раз покупали компьютер, вы можете вспомнить Hyper-Threading как функцию, которую Intel представила, а затем прекратила.Понятно, что это может вызвать кислый привкус во рту — зачем Intel прекратить его выпуск, если это не проблема?
Правда не такая мрачная.Hyper-Threading какое-то время была доступна на некоторых процессорах Intel Pentium 4 и Intel Xeon. Он был прекращен не потому, что сама функция была плохой, а потому, что процессор, который ее использовал, оказался ошибочным по другим причинам. Архитектура Pentium 4 стала для Intel незначительной катастрофой, потому что она не смогла развиваться в том направлении, на которое рассчитывала Intel (Intel хотела иметь процессоры Pentium 4 с тактовой частотой до 10 ГГц). В результате Intel вернулась к разработке процессоров на основе генеалогического дерева Pentium Pro.
Hyper-Threading исчез, но не забыт.В конце концов Intel нашла время и ресурсы, чтобы интегрировать его в другую новую архитектуру процессора — Nehalem. Это архитектура, которая является основой всех современных процессоров Intel Core i3, i5 и i7.
Nice Threads, Мужчина
Несмотря на все достижения, которые мы сделали в мире процессоров, у них все еще есть одно серьезное ограничение — отдельное ядро процессора может выполнять только одну инструкцию за раз.Скажем, например, что у вас одновременно открыты MS Office, Firefox и Skype. Вы чувствуете, что выполняете несколько задач одновременно, но с точки зрения процессора это не так. Ядро процессора, выполняющее данные, связанные с этими программами, выполняет по одной инструкции за раз, но, поскольку это происходит очень быстро, вы не замечаете никакой задержки.
Но там — это задержка.Эта задержка связана с тем, как данные из каждой программы поступают в процессор. Каждый поток данных — или поток, поступающий в процессор, должен планироваться и выполняться ядром индивидуально. Однако гиперпоточность позволяет каждому ядру процессора планировать и назначать ресурсы сразу двум потокам.
Представьте себе рабочего на конвейере.К ней приходят два типа виджетов, и ей нужно делать разные вещи с каждым виджетом. Однако иногда происходит задержка из-за того, что конвейерная лента слишком медленная или из-за того, что неправильный виджет был отправлен в неправильное время. Hyper-Threading похож на добавление еще одной конвейерной ленты, поэтому теперь есть одна, предназначенная для каждого типа виджета. Работник по-прежнему один, но теперь виджеты можно доставлять к ней быстрее и эффективнее, поэтому она ждет работы реже.
Не то же самое, что удвоение ядер
Если вы загрузите двухъядерный процессор с Hyper-Threading и откроете диспетчер задач Windows, вы увидите четыре графика.Именно здесь и проявляется большая часть недоразумений, связанных с удвоением количества ядер Hyper-Threading. Я даже разговаривал с одним беднягой, который думал, что купил восьмиядерный процессор, потому что увидел восемь графиков в диспетчере задач Windows. Это то, что ему сказал торговый представитель, поэтому, когда он пошел домой и увидел восемь графиков, его зацепило. Видеть было верой.
В Windows отображаются два графика для каждого ядра процессора Hyper-Threading, поскольку Windows определяет два логических процессора для каждого ядра.Термин «логический процессор» звучит причудливо, но логический процессор по определению — это процессор, который не существует физически. Windows может отправлять потоки каждому логическому процессору, но фактическое выполнение по-прежнему выполняет только одно ядро, поэтому одно ядро с Hyper-Threading резко отличается от двух отдельных физических ядер.
Преимущество Hyper-Threading
Хорошо, хватит технической болтовни.Теперь давайте приступим к самому важному — как Hyper-Threading повлияет на производительность компьютера, о создании или покупке.
Что касается повседневных задач, таких как просмотр веб-страниц, электронная почта и обработка текстов, Hyper-Threading не окажет большого влияния.Да, Hyper-Threading теоретически лучше справляется с многозадачностью. Однако современные процессоры настолько быстры, что базовые программы редко ограничиваются скоростью вашего процессора. Способ кодирования программ также может быть ограничением. Иногда вы можете обнаружить, что у вас открыто множество программ, но только одно из ядер вашего процессора активно используется. Это потому, что программы по какой-либо причине не разделяют свою работу между различными доступными ядрами.
Однако, когда вы пытаетесь выполнить тяжелую работу, Hyper-Threading может быть более полезной.Скорее всего, выиграют программы 3D-рендеринга, мощные приложения для перекодирования аудио / видео и научные приложения, созданные для максимальной многопоточной производительности. Но вы также можете получить повышение производительности при кодировании аудиофайлов в iTunes, воспроизведении 3D-игр и архивировании / разархивировании папок. Повышение производительности может составлять до 30%, хотя также будут ситуации, когда Hyper-Threading вообще не обеспечивает повышения.
Заключение
Как показывает показатель увеличения производительности , только до 30%, Hyper-Threading составляет , а не , как удвоение количества ядер в процессоре.Если торговый представитель когда-либо скажет вам это, будьте осторожны, потому что он либо невежественен, либо счастлив солгать вам, если думает, что это поможет продвинуть оборудование.
С учетом сказанного, Hyper-Threading — отличная функция, и она того стоит.Это особенно хорошо, если вам нравится часто редактировать медиафайлы или вы используете свой компьютер в качестве рабочей станции для профессиональных программ, таких как Photoshop или Maya.
7 подземных торрент-сайтов для получения контента без цензурыВам нужны специализированные поисковые системы, чтобы найти легальные торренты, закрытые дома, публичные записи и даже НЛО.Войдите в даркнет.
Об авторе Мэтт Смит (Опубликовано 571 статья)Мэтью Смит — писатель-фрилансер, живущий в Портленде, штат Орегон. Он также пишет и редактирует для Digital Trends.
Больше От Мэтта СмитаПодпишитесь на нашу рассылку новостей
Подпишитесь на нашу рассылку, чтобы получать технические советы, обзоры, бесплатные электронные книги и эксклюзивные предложения!
Еще один шаг…!
Подтвердите свой адрес электронной почты в только что отправленном вам электронном письме.
Hyper-Threading и все, что вам нужно знать
Каким бы быстрым ни был ваш компьютер, он всегда может быть быстрее. Если вас не устраивают результаты обработки вашего компьютера, возможно, пришло время гиперпоточить ядра вашего центрального процессора (ЦП). Гиперпоточность может быть отличным способом повысить скорость обработки вашего ПК без необходимости серьезной модернизации оборудования.
Однако у гиперпоточности есть некоторые недостатки, поэтому следует действовать с осторожностью.Продолжайте читать, чтобы узнать все о гиперпоточности, чтобы узнать, подходит ли это решение для вашего ПК или не стоит ваших усилий.Что такое гиперпоточность?
Прежде чем вы сможете понять, что такое гиперпоточность, вам сначала нужно познакомиться с тем, как центральный процессор (ЦП) работает и обрабатывает информацию. ЦП декодирует информацию, выполняет математические алгоритмы и считывает строки нулей и единиц, которые составляют код в его наиболее примитивной форме.
Когда вы запускаете приложение, код этой программы берется с жесткого диска и сохраняется в оперативной памяти (RAM) перед загрузкой в CPU.Затем ЦП считывает инструкции из ОЗУ для выполнения поставленной задачи. Когда технологические компании называют свои ЦП «двухъядерными», это означает, что в ЦП есть 2 ядра (отдельные процессорные блоки).
Intel® указывает количество ядер, которые они используют с i3, i5, i7 и т. Д. Это немного вводит в заблуждение, учитывая, что процессор Intel i7 Core не имеет 7 ядер; он идет с четырьмя. Есть несколько экстремальных процессоров Intel i7 Core, которые могут иметь 6 или 8 ядер. Вы всегда можете вернуться к описанию продукта, если не знаете, сколько ядер в вашем ЦП.
Не уходя слишком далеко от гиперпоточности, важно сначала понять, как ядра обрабатывают данные в ЦП. Когда данные отправляются из ОЗУ в ЦП, они разделяются и направляются в разные ядра.
Представьте себе железнодорожную станцию: такие программы, как Microsoft Word и Excel, представляют собой грузовые перевозки поездов, движущихся через станцию, но на вокзале (ядре) есть только один набор путей. «Грузы», или программные инструкции, идут последовательно по рельсам.Все просто, правда?
Так как же работает гиперпоточность? Когда вы выполняете гиперпоточность своих ядер, вы, по сути, создаете две дорожки в депо. Вместо того, чтобы перемещаться по одному пути, они будут разделяться и обрабатываться в депо, что сокращает время, в течение которого они перемещаются. Вместо того, чтобы загружать по одной программе в ядро, гиперпоточность позволяет загружать сразу несколько программ. По сути, каждое ядро становится двумя процессорами вместо одного .
Основная цель гиперпоточности — увеличить количество независимых инструкций на «дорожках», ведущих к ядру.Эта способность является результатом суперскалярной архитектуры или параллельных вычислений, в которых ЦП управляет несколькими конвейерами команд для выполнения нескольких инструкций в одно и то же время.
Теперь, когда вы понимаете, как работает гиперпоточность, преимущества и потенциальное увеличение скорости, которое она может дать вашему ПК, довольно очевидны.
Повысит ли гиперпоточность производительность моего компьютера?
Согласно Intel [1], гиперпоточность ваших ядер может привести к увеличению производительности и скорости на 30% при сравнении двух идентичных ПК с одним гиперпоточным процессором.В исследовании, опубликованном на Forbes, гиперпоточность процессора AMD® (Ryzen 5 1600) показала увеличение общей производительности обработки на 17% [2].
Несмотря на эти результаты, гиперпоточность ваших ядер не всегда является оптимальным решением. Будут задачи, в которых скорость вашего процессора не увеличивается, несмотря на гиперпоточность. Частично это связано с тем, что не все приложения и строки данных могут эффективно загружаться в многопоточное ядро.
В эксперименте, проведенном bit-tech.net, гиперпоточный Intel i7 Core сравнивался с однопоточным Intel i7 Core после прохождения нескольких различных тестов [3]. Когда дело дошло до редактирования изображений, многозадачности и энергопотребления, гиперпоточный аналог оказался хуже, чем однопоточный. Тем не менее, он показал такие же или лучшие результаты, когда дело дошло до кодирования видео Handbrake, общего пользовательского теста ПК и игры в популярную игру Crysis .
Гиперпоточность ядер в вашем ЦП повышает производительность и скорость в каждом конкретном случае в зависимости от того, какие задачи совместимы с гиперпоточным ядром.Если вы хотите повысить общую производительность своего ПК, использование гиперпоточности может стать шагом в правильном направлении.
Как включить гиперпоточность
Прежде чем вы сможете использовать гиперпоточность для своих ядер, вам необходимо выяснить, позволяет ли это ваш процессор. Некоторые ядра ЦП по умолчанию являются гиперпоточными, и от вас ничего не требуется.
Чтобы включить гиперпоточность, вам сначала нужно войти в настройки BIOS вашей системы. Для тех, кто не знаком, BIOS расшифровывается как Basic Input / Output System.BIOS запускается, когда вы включаете компьютер, соединяя различные компоненты, такие как жесткий диск, ЦП и клавиатуру, в дополнение к управлению потоком данных.
Когда вы узнаете, что ваш ЦП совместим с гиперпоточностью, и научитесь входить в настройки BIOS вашей системы, выберите подходящий хост для вашей системы. Должна быть вкладка конфигурации или меню для выбора. Выберите «Процессор» и нажмите «Свойства». Должно появиться диалоговое окно, в котором вы можете включить или отключить гиперпоточность.
Некоторые производители и поставщики могут обозначить эту опцию как «Логический процессор» или «Включить гиперпоточность». Процесс зависит от производителя. Например, включение гиперпоточности для процессора AMD будет иметь несколько иной набор слов, чем включение гиперпоточности для процессора Intel.
Резюме; один раз в BIOS выберите:
- Процессор
- Свойства
- Логический процессор / Включить гиперпоточность
Убедитесь, что ваш ЦП совместим с гиперпоточностью, прежде чем тратить время на выполнение инструкций.Если вы используете гиперпоточность своего ядра и вам не нравятся результаты, отключение этого параметра происходит в том же порядке. Перейдите в BIOS и отключите эту опцию.
Подходит ли гиперпоточность для игр?
Подходит ли гиперпоточность для игр, зависит от имеющегося у вас количества ядер. Большинство продвинутых игр требуют 2 или 4 ядра для лучшей производительности. Узнайте о лучших процессорах для игр и о лучших способах разгона улучшить игры.Игра
Если вы когда-либо пробовали играть в игры с интенсивной графикой на процессоре Intel i3 Core, то, вероятно, вы знаете, сколько проблем возникает из-за ограниченного количества ядер.Отставание и ореолы — лишь малая часть списка проблем, вызванных недостаточной вычислительной мощностью.
Гиперпоточность Intel i5 и гиперпоточность i3 могут быть чрезвычайно полезны для игр, учитывая, что эти процессоры изначально не обладают огромной мощностью. Играя в такие игры, как Crysis , вы заметите резкое улучшение и конкурентное преимущество. Гиперпоточность Intel i7 может быть чрезмерной. Если вы не играете в несколько игр одновременно или не запускаете несколько приложений в фоновом режиме, вам, вероятно, не понадобится такая дополнительная мощность.
Потоковая передача
При потоковой передаче игры гиперпоточность ядер может быть чрезвычайно выгодной. Когда вам нужно запустить игру поверх нескольких приложений, необходимых для записи и загрузки видео, суперскалярная архитектура обеспечит бесперебойную работу вашей системы.
Если вы ведете потоковую передачу на новейшем процессоре Intel i7 Core, вы, вероятно, не заметите большой разницы. Продвинутые процессоры невероятно быстрые как есть. Однако процессоры с 2 или 4 ядрами могут не дать вам достаточно энергии для игры, даже после гиперпоточности.
Лучшие процессоры для гиперпоточности
Большинство игр класса AAA ориентированы на процессоры с 4 или более ядрами. Если ваша цель — игры, выбирайте AMD Ryzen, Intel i5 или лучше.
Intel i5-8400, который вы можете найти в игровом настольном ПК HP OMEN 870, — отличное место для начала, если у вас ограниченный бюджет. Этот процессор с 6 ядрами и 6 потоками имеет базовую тактовую частоту 3,8 ГГц и тактовую частоту в режиме турбо 4,0 ГГц. Хотя этот процессор не поддерживает разгон, он должен обеспечивать более чем достаточную мощность для игр с максимальными настройками.Intel i7-8700K имеет 6 ядер и 12 потоков, на которых вы можете запускать множество фоновых задач, пока играете. Вы можете найти этот процессор в игровом настольном ПК HP Pavilion. AMD Ryzen 7 2700 в том же ценовом диапазоне, что и Intel i7-8700K, предлагает 8 ядер, 16 потоков и возможности разгона. Компания AMD, о которой часто забывают, производит невероятные процессоры для компьютеров, ноутбуков и специализированных игровых ПК. Если вы заинтересованы в создании игрового ПК с нуля или в покупке готовой системы, вам следует серьезно подумать о процессоре AMD для продвинутых игр.AMD Ryzen 3 2200G — чрезвычайно доступный процессор, учитывая, сколько от него можно получить. Четыре ядра, базовая частота 3,5 ГГц, а также возможности разгона позволяют расширить возможности вашего ПК. Игровой настольный компьютер HP OMEN 875 Obelisk может похвастаться тремя процессорами AMD Ryzen на выбор, чтобы оформить вашу покупку.Если вы действительно хотите сделать все возможное и построить суперкомпьютер, Intel Core i9 7900X находится в особой лиге. Хотя цена определенно отражает его передовые компоненты, его производительность трудно превзойти.С 10 ядрами и 20 потоками вы можете рассчитывать на одновременное выполнение множества задач.
Подходит ли гиперпоточность для игр VR?
VR-игры съедают массу вашей вычислительной мощности, и вам будет гораздо лучше, если вы обновите свой процессор, чем пытаетесь перегрузить существующий. Самые популярные VR-игры используют огромные объемы данных, и без высокопроизводительной видеокарты вы не сможете ими пользоваться. Если вы купите ПК с продвинутой видеокартой, подходящей для иммерсивных VR-игр, ваш процессор, вероятно, оборудован поддерживать.Обязательно выберите систему, которая работает на высокой скорости, или подготовьтесь к созданию собственной системы, если VR-игры являются главным приоритетом. В противном случае вам, возможно, придется изо всех сил пытаться разогнать процессор или гиперпоточность ядер, чтобы погрузиться в безумие виртуальной реальности.Вокруг AMD Zen ходит много разговоров о возможностях виртуальной реальности. Такие компании, как Intel и AMD, в настоящее время готовятся к будущему игр, чтобы доставить невероятные впечатления, как никогда раньше.
Резюме
При том, что оборудование для игровых ПК продолжает улучшаться, у вас может возникнуть соблазн отложить крупную покупку, но лучшие игры AAA заставят вас потратиться на мощность процессора, чтобы получить максимальную отдачу от игра.Если вы планируете использовать гиперпоточность для ядер в вашем процессоре, убедитесь, что это того стоит и что ваш процессор на это способен. Hyper-threading — это относительно простое обновление ПК, которое легко включить. Если он вам не подходит, вы можете просто зайти в BIOS и снова выключить его.
Вы можете многое приобрести и не так много потерять, почему бы не попробовать?
Об авторе : Шон Уэйли является автором статьи HP® Tech Takes .Шон — специалист по созданию контента со степенью литературы в SDSU. Он обладает обширными познаниями в области компьютерного оборудования и программирования.Что такое технология Hyper-Threading? | Блог GearBest
Технология Hyper-threading заключается в том, что ЦП одновременно выполняет несколько программ для совместного использования ресурсов ЦП. Теоретически необходимо выполнять два потока одновременно с двумя ЦП, а процессор P4 должен добавить дополнительный логический указатель ЦП (блок логической обработки.В результате площадь кристалла нового поколения P4 HT на 5% больше, чем у предыдущего P4. Остальные, такие как ALU (блок целочисленных операций), FPU (блок операций с плавающей запятой) и кэш L2 (двухуровневый кеш), остаются прежними, и эти части являются общими.
Несмотря на то, что с помощью технологии Hyper-Threading можно выполнять два потока одновременно, это не похоже на два реальных процессора, каждый процессор имеет независимые ресурсы. Когда оба потока нуждаются в ресурсе одновременно, один из них временно останавливается и отказывается от ресурса до тех пор, пока он не станет свободным.Следовательно, производительность гиперпоточности не равна производительности двух процессоров.
Гиперпоточность и улучшение производительности
Вообще говоря, многие люди думают, что использование технологии гиперпоточности может значительно улучшить производительность системы, но так ли это на самом деле? Не забывайте о необходимых условиях для реализации технологии Hyper-Threading, о которых мы говорили ранее, что является предпосылкой эффективности технологии Hyper-Threading.Помимо поддержки операционной системы, также требуется поддержка программного обеспечения. С этого момента мы можем видеть, что с точки зрения текущей ситуации с программным обеспечением, программное обеспечение, поддерживающее двухпроцессорную технологию, в конце концов, все еще находится в небольшом количестве. Для большинства программного обеспечения из-за различных принципов проектирования мы не можем получить прямую выгоду от технологии Hyper-Threading. Поскольку технология Hyper-Threading обрабатывает команды параллельно на уровне потоков и динамически выделяет процессоры и другие ресурсы в соответствии с потоками.Основная идея этой технологии — & amp; ldquo; parallelism (Parallelism) », то есть для повышения параллелизма выполнения команд и эффективности каждого тактового сигнала. Это требует, чтобы программное обеспечение было многопоточным в дизайне и улучшало возможности параллельной обработки. В настоящее время приложения на ПК практически не используются оптимизирован для этого, и использование технологии Hyper-Threading не смогло добиться значительного улучшения производительности. Неизбежность появления
Повышение производительности процессора
Необходимо повысить производительность процессора.Хотя верно то, что увеличение тактовой частоты и емкости кэш-памяти ЦП может улучшить производительность ЦП, технически сложно повысить производительность ЦП. Фактически, по многим причинам в приложении исполнительный блок ЦП используется не полностью. Если ЦП не может правильно читать данные (узкое место шины / памяти), использование его исполнительного модуля значительно снизится. Кроме того, в большинстве текущих потоков выполнения отсутствует поддержка ILP (параллелизм на уровне инструкций, одновременное выполнение нескольких инструкций).Все это привело к тому, что текущая производительность центрального процессора не полностью воспроизведена. Поэтому Intel принимает другую идею для повышения производительности ЦП, чтобы ЦП мог выполнять несколько потоков одновременно, что может сделать ЦП более эффективным, то есть так называемую «гиперпоточность» (Hyper-Threading, именуемую как HT «). Технология Hyper-threading использует специальные аппаратные инструкции для моделирования двух логических ядер в двух физических микросхемах, чтобы один процессор мог использовать параллельные вычисления на уровне потоков, которые совместимы с многопоточными операционными системами и программным обеспечением, что снижает время простоя ЦП и повышает эффективность работы ЦП.
Использование гиперпоточности по времени позволяет приложениям использовать разные части микросхемы одновременно. Хотя однопоточный чип может обрабатывать тысячи инструкций в секунду, он может работать только с одной инструкцией одновременно. Технология гиперпоточности может заставить чип выполнять многопоточную обработку одновременно, так что производительность чипа может быть улучшена.
Технология Hyperthreading
Hyperthreading Intel P4 имеет два рабочих режима: однозадачный режим (однозадачный режим и многозадачный режим (многозадачный режим).Если программа не поддерживает многопроцессорность (многопроцессорные задания), система остановит работу одного из логических ЦП и сконцентрирует ресурсы на одном логическом ЦП, так что производительность однопоточной программы не будет снижена из-за один из логических ЦП простаивает, но остановленный логический ЦП все еще ожидает работы. Он занимает определенное количество ресурсов, поэтому, когда ЦП с Hyper-Threading запускает программный режим Single Task Mode, он не сможет достичь производительности ЦП без Hyper-Threading, но разрыв в производительности не будет слишком большим.Другими словами, при запуске однопоточного программного обеспечения технология гиперпоточности даже снизит производительность системы, особенно когда многопоточная операционная система запускает однопоточное программное обеспечение.
Следует отметить, что ЦП с технологией гиперпоточности нуждается в поддержке набора микросхем и программного обеспечения, чтобы в полной мере использовать преимущества этой технологии. Такие операционные системы, как: Microsoft Windows XP, Microsoft Windows 2003 и более поздние версии ядра Linux 2.4.x также поддерживают технологию гиперпоточности.
● Более 300 000 товаров ● 20 различных категорий ● 15 местных складов ● Несколько ведущих брендов | ● Глобальные способы оплаты: Visa American, Master ExpressCard ● Принимаются PayPal, Western Union и банковский перевод. ● Boleto Bancario через Ebanx (для Бразилии) | ||
● Незарегистрированная авиапочта ● Зарегистрированная авиапочта ● Линия приоритета доставка | ● 45-дневная гарантия возврата денег ● 365-дневная гарантия бесплатного ремонта ● 7-дневная гарантия Dead on Arrival (DOA) |
многопоточность — Hyper-threading, Multi-threading, Multi -обработка и многозадачность — Теория
Переполнение стека- Около
- Продукты
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимайте технических специалистов и создавайте свой бренд работодателя
- Реклама Обратитесь к разработчикам и технологам со всего мира
- О компании
Ваш комментарий будет первым