OpenAI выпустила GPT-4 / Хабр
OpenAI представила новую модель ИИ интерпретации изображений и текста GPT-4, которую компания назвала «последней вехой в своих усилиях по расширению масштабов глубокого обучения».
The Verge
GPT-4 может принимать на вход изображения и текст — GPT-3.5 работала только с текстом — и работает на «уровне человека» в различных профессиональных и академических тестах, как утверждают разработчики. Так, на экзаменах Uniform Bar Exam, LSAT, SAT Math и SAT Evidence-Based Reading & Writing GPT-4 набрал 88% и более.
Также модель теперь распознаёт схематичные образы, в том числе и нарисованные от руки.
OpenAI потратила шесть месяцев на настройку GPT-4, используя программы состязательного тестирования, а также ChatGPT, что привело к улучшению результатов в отношении выдачи и управляемости. Модель на 82% реже отвечает на запросы о запрещённом контенте и на 40% чаще генерирует корректные ответы.
При обычном диалоге разница между GPT-3. 5 и GPT-4 может быть едва уловимой, поясняет OpenAI. «Разница проявляется, когда сложность задачи достигает достаточного порога — GPT-4 более надёжен, креативен и способен обрабатывать гораздо более тонкие инструкции, чем GPT-3.5», — отмечает компания.
5 и GPT-4 может быть едва уловимой, поясняет OpenAI. «Разница проявляется, когда сложность задачи достигает достаточного порога — GPT-4 более надёжен, креативен и способен обрабатывать гораздо более тонкие инструкции, чем GPT-3.5», — отмечает компания.
GPT-4 может подписывать и даже интерпретировать относительно сложные изображения, например, идентифицировать адаптер кабеля Lightning по изображению подключённого iPhone и т.д.
The Verge
Возможность распознавания изображений пока доступна не для всех клиентов OpenAI — OpenAI тестирует её с Be My Eyes. Новая функция «Виртуальный волонтер» компании на базе GPT-4 может отвечать на вопросы об отправленных ей изображениях. Например, если пользователь отправит фотографию своего холодильника изнутри, виртуальный волонтёр сможет не только правильно определить, что в нём находится, но и проанализировать, что можно приготовить из этих ингредиентов. Инструмент также предложит ряд рецептов и отправит пошаговое руководство по готовке.
Потенциально более значимым улучшением является инструментарий управляемости. С GPT-4 OpenAI представляет новую возможность API, «системные» сообщения, которые позволяют разработчикам задавать стиль и задачи, описывая конкретные направления. Системные сообщения по сути являются инструкциями, которые задают тон и устанавливают границы для следующих взаимодействий с ИИ.
Например, системное сообщение может выглядеть так: «Вы наставник, который всегда отвечает в сократовском стиле. Вы никогда не даёте ученику ответа, но всегда стараетесь задать правильный вопрос, чтобы помочь ему научиться думать самостоятельно. Вы всегда должны согласовывать свой вопрос с интересами и знаниями учащегося, разбивая проблему на более простые части, пока не достигнете нужного уровня».
Однако даже теперь OpenAI признаёт, что GPT-4 не идеален. Он по-прежнему «галлюцинирует» и ошибается в суждениях. В одном примере чат-бот назвал Элвиса Пресли «сыном актёра» — это очевидная ошибка.
Разработчики отмечают, что «GPT-4, как правило, не знает о событиях, которые произошли после сентября 2021 года». Иногда чат-бот может совершать простые логические ошибки или быть слишком легковерным, принимая очевидные ложные утверждения от пользователя за правдивые. Также ИИ не идеален при решении сложных проблем.
Иногда чат-бот может совершать простые логические ошибки или быть слишком легковерным, принимая очевидные ложные утверждения от пользователя за правдивые. Также ИИ не идеален при решении сложных проблем.
GPT-4 доступна через API OpenAI по списку ожидания, а также в ChatGPT Plus, премиум-плане OpenAI для ChatGPT. Ранее Microsoft подтвердила, что её чат-бот Bing работает на GPT-4. Модель уже использует Stripe для сканирования бизнес-сайтов и отправки резюме сотрудникам службы поддержки клиентов, а также Duolingo, встроившая её в новый уровень подписки на изучение языков.
Ранее генеральный директор OpenAI Сэм Альтман заявлял, что GPT-4 не будет самой большой языковой моделью. Альтман также признал, что человечеству ещё далеко до разработки совершенного ИИ.
Как цифровые инструменты анализа текстов помогают лучше понять город
Как цифровые инструменты анализа текстов помогают лучше понять город
Время чтения 15 минут.
В лаборатории «Искусственный интеллект для городов» одной из отечественных компаний придерживающимся концепции City as a Service (CaaS), в рамках которой город рассматривается как постоянный процесс потребления и производства услуг горожанами и для горожан. Именно благодаря людям города становятся успешными, именно повседневная активность горожан делает их сложными и непредсказуемыми. Горожане постоянно пользуются общественным транспортом, системами связи, публичными пространствами, а потому лучше всех знают, какие проблемы среды требуют решения в первую очередь. Компания видит в «мудрости толпы» огромный потенциал, а в выстроенной обратной связи — инструмент для повышения жизнеспособности и адаптивности городов.
Именно благодаря людям города становятся успешными, именно повседневная активность горожан делает их сложными и непредсказуемыми. Горожане постоянно пользуются общественным транспортом, системами связи, публичными пространствами, а потому лучше всех знают, какие проблемы среды требуют решения в первую очередь. Компания видит в «мудрости толпы» огромный потенциал, а в выстроенной обратной связи — инструмент для повышения жизнеспособности и адаптивности городов.
Современных исследователей-урбанистов интересует, что люди думают о местах, в которых живут, и как их отношения с городской средой меняются во времени? С какими сложностями они сталкиваются ежедневно, и с чем связаны эти сложности? Какие объекты городской среды наиболее часто упоминаются в связи с той или иной проблемой, и где они расположены?
Чтобы дать ответ на эти вопросы в масштабах города, необходимо обработать массив текстовой информации с помощью специального программного обеспечения.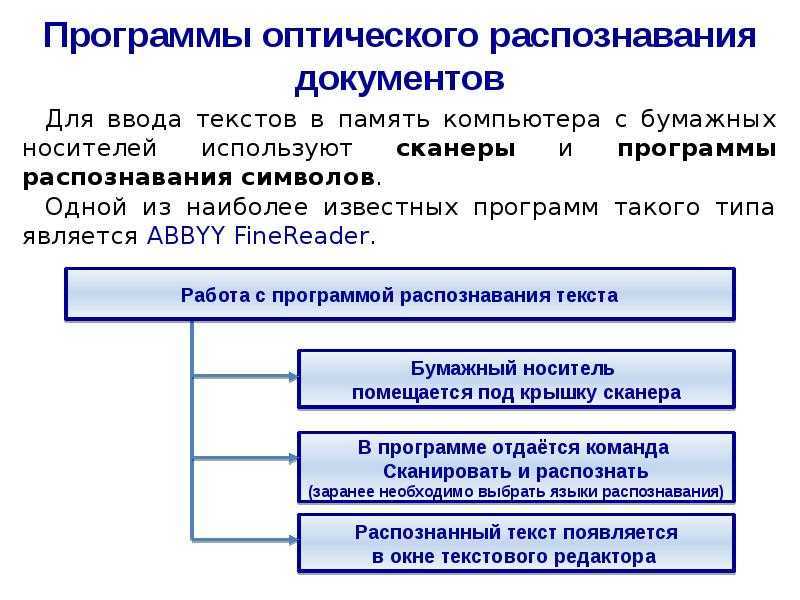 Сложность этой работы заключается в природе созданных человеком языков. Когда мы общаемся, мы вкладываем в нашу речь значительный объем смыслов и нюансов, опыта и контекста. И в то же время язык — это крайне ограниченный по своей природе носитель. Поэтому язык многозначен, емок и изменчив, но для человека, как правило, не составляет труда его декодировать, в то время как компьютеры умеют работать лишь с числами, хотя и очень быстро.
Сложность этой работы заключается в природе созданных человеком языков. Когда мы общаемся, мы вкладываем в нашу речь значительный объем смыслов и нюансов, опыта и контекста. И в то же время язык — это крайне ограниченный по своей природе носитель. Поэтому язык многозначен, емок и изменчив, но для человека, как правило, не составляет труда его декодировать, в то время как компьютеры умеют работать лишь с числами, хотя и очень быстро.
Первостепенная задача заключается в том, чтобы представить тексты о городе в численном виде — таким образом, чтобы потери информации были минимальны, а математические свойства создаваемых объектов отражали семантические особенности текстов-праобразов. Существует ряд способов осуществить такой перевод. В частности, для этого используются нейросетевые модели, которые обучаются на коллокациях слов – их совместном употреблении в больших корпусах новостей, записей в блогах, художественной литературе. Этот подход основан на дистрибутивной гипотезе в лингвистике, суть которой еще в 1957 г. изложил англичанин Джон Руперт Фёрс: «Слово узнаешь по его окружению».
изложил англичанин Джон Руперт Фёрс: «Слово узнаешь по его окружению».
После векторизации текстов может быть использован целый набор инструментов — например, создать модель для автоматической классификации текстов, в частности, определения их эмоциональной окраски. Такой анализ интересно наблюдать в привязке к пространству, чтобы увидеть, какие места в городе вызывают наибольшее недовольство жителей и требуют особого внимания. Существуют и другие применения такого подхода к анализу текстов — например, исследователи из Future Cities Lab в Сингапуре ищут по всему городу локации, где люди чаще всего обсуждают искусство, и получают неожиданные инсайты.
Городские инсайтыЧтобы наиболее эффективно использовать информацию о пространственном распределении сообщений, нужно определить их географическую привязку, даже если горожанин по какой-то причине не поставил геотег. Это возможно, если человек упоминает в тексте улицу, район, населенный пункт или ближайшее кафе. Выделить такое упоминание помогают статистические модели, обученные решать задачу распознавания именованных сущностей (Named Entity Recognition). Здесь необходимо прибегнуть к сторонним разработкам с открытым исходным кодом, которые показывают одни из лучших результатов по русскому языку на сегодняшний день.
Выделить такое упоминание помогают статистические модели, обученные решать задачу распознавания именованных сущностей (Named Entity Recognition). Здесь необходимо прибегнуть к сторонним разработкам с открытым исходным кодом, которые показывают одни из лучших результатов по русскому языку на сегодняшний день.
В работе над Civic Tech продуктами были задействованы и более традиционные методы компьютерной лингвистики. Хотелось бы посмотреть на физическое состояние районов и улиц глазами тех, кто ходит по ним каждый день. Когда жителей что-то не устраивает, их недовольство часто обретает две формы: либо им кажется, что в городе чего-то не хватает (кинотеатра, детских садов, красивого сквера, стрит-ритейла), либо, наоборот, что-то находится в избытке (глухие заборы, мусор, кричащая реклама). Используя знания о синтаксической структуре текстов и экспертизу компании в проведении краудсорсинговых компаний, стало возможным выделять такие объекты в идеях и отзывах горожан. Эта внутренняя разработка заточена под городскую специфику и очень удобна при ранжировании запросов по популярности и анализе пространства на предмет нехватки или избытка тех или иных объектов.
Иногда при работе с данными соцсетей мы хотим быстро увидеть, какие процессы, люди, места являются наиболее важными в выгрузке за определенный период, и оценить, в каком контексте они упоминаются. Это осуществляется в три этапа: сначала осуществляется проход по массиву текстов с помощью графового алгоритма TextRank и выделяем ключевые слова и словосочетания, затем смотрим на тексты, в которых они встретились, и оцениваем эмоции в этих текстах. После этого удаляем смысловые дубликаты, определяя синонимию с помощью дистрибутивно-семантических моделей. Это позволяет автоматизировать значительный объем ручной работы в ходе качественных исследований.
ПотенциалЭти и другие инструменты анализа — например, автоматическое реферирование для получения информационной выжимки или фильтрация «мусорных» сообщений и рекламы — сегодня дают возможность жителям быть услышанными и участвовать в развитии города. С их помощью можно уже на стадии предпроектного исследования определить ключевые запросы жителей района, посетителей парка или набережной, понять, какие ключевые темы обсуждают жители в связи с развитием городской среды.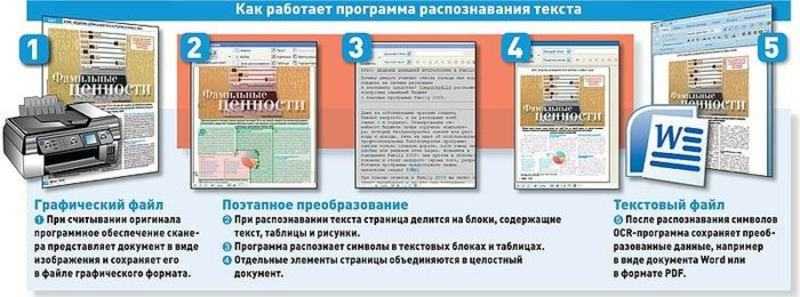 Также возможно оценить эффект от уже осуществленных изменений на основе данных из соцсетей и анализа тональности. Это огромный шаг вперед по сравнению с точечными опросами общественного мнения и редкими встречами с группами наиболее активных граждан.
Также возможно оценить эффект от уже осуществленных изменений на основе данных из соцсетей и анализа тональности. Это огромный шаг вперед по сравнению с точечными опросами общественного мнения и редкими встречами с группами наиболее активных граждан.
Визуализация ключевых словосочетаний. Размер круга указывает на частоту упоминания слова. Красный цвет — на употребление в более негативном контексте. Попарные расстояния между кругами отражают семантическую близость словосочетаний.
Мы возлагаем большие надежды на обратную связь от горожан, потому что они, ежедневно взаимодействуя с городскими системами и подсистемами, первыми замечают сигналы, свидетельствующие о потребности в качественных изменениях. Чтобы в полной мере использовать потенциал существующих технологий, предстоит решить еще много задач: научиться собирать информацию в реальном времени и хранить ее, чтобы впоследствии извлекать временные инсайты, автоматизировать коммуникацию с жителями с помощью диалоговых инструментов, настроить как можно более точные алгоритмы, создать регулятивные рамки и наладить межорганизационное взаимодействие, вести борьбу за открытые данные. Мы надеемся, что существующий потенциал больших данных вскоре будет реализован и поставлен на службу горожанам по всему миру.
Мы надеемся, что существующий потенциал больших данных вскоре будет реализован и поставлен на службу горожанам по всему миру.
Чтобы продемонстрировать работу инструментов обработки естественных языков, мы подготовили реферат этой статьи с помощью нескольких алгоритмов.
1. Алгоритм KL-Sum добавляет к выжимке предложения, максимально сокращающие расстояние Кульбака-Лейблера между изначальным текстом и рефератом. На наш взгляд, в данном случае он дает наиболее точные результаты:
«Горожане постоянно пользуются общественным транспортом, системами связи, публичными пространствами, а потому лучше всего знают, какие проблемы среды требуют решения в первую очередь. Наша первостепенная задача как разработчиков заключается в том, чтобы представить тексты о городе в численном виде — таким образом, чтобы потери информации были минимальны, а математические свойства создаваемых объектов отражали семантические особенности текстов-прообразов.
Когда жителей что-то не устраивает, их недовольство часто обретает две формы: либо им кажется, что в городе чего-то не хватает (кинотеатра, детских садов, красивого сквера, стрит-ритейла), либо, наоборот, что-то находится в избытке (глухие заборы, мусор, кричащая реклама). С помощью таких инструментов анализа у нас есть возможность на стадии предпроектного исследования определить ключевые запросы жителей района, посетителей парка или набережной, понять, какие ключевые темы обсуждают жители в связи с развитием городской среды. Чтобы в полной мере использовать потенциал существующих технологий, предстоит решить еще много задач: научиться собирать информацию в реальном времени и хранить ее, чтобы впоследствии извлекать временные инсайты, автоматизировать коммуникацию с жителями с помощью диалоговых инструментов, настроить как можно более точные алгоритмы, создать регулятивные рамки и наладить межорганизационное взаимодействие, вести борьбу за открытые данные».
 Когда жителей что-то не устраивает, их недовольство часто обретает две формы: либо им кажется, что в городе чего-то не хватает (кинотеатра, детских садов, красивого сквера, стрит-ритейла), либо, наоборот, что-то находится в избытке (глухие заборы, мусор, кричащая реклама). С помощью таких инструментов анализа у нас есть возможность на стадии предпроектного исследования определить ключевые запросы жителей района, посетителей парка или набережной, понять, какие ключевые темы обсуждают жители в связи с развитием городской среды. Чтобы в полной мере использовать потенциал существующих технологий, предстоит решить еще много задач: научиться собирать информацию в реальном времени и хранить ее, чтобы впоследствии извлекать временные инсайты, автоматизировать коммуникацию с жителями с помощью диалоговых инструментов, настроить как можно более точные алгоритмы, создать регулятивные рамки и наладить межорганизационное взаимодействие, вести борьбу за открытые данные».
Когда жителей что-то не устраивает, их недовольство часто обретает две формы: либо им кажется, что в городе чего-то не хватает (кинотеатра, детских садов, красивого сквера, стрит-ритейла), либо, наоборот, что-то находится в избытке (глухие заборы, мусор, кричащая реклама). С помощью таких инструментов анализа у нас есть возможность на стадии предпроектного исследования определить ключевые запросы жителей района, посетителей парка или набережной, понять, какие ключевые темы обсуждают жители в связи с развитием городской среды. Чтобы в полной мере использовать потенциал существующих технологий, предстоит решить еще много задач: научиться собирать информацию в реальном времени и хранить ее, чтобы впоследствии извлекать временные инсайты, автоматизировать коммуникацию с жителями с помощью диалоговых инструментов, настроить как можно более точные алгоритмы, создать регулятивные рамки и наладить межорганизационное взаимодействие, вести борьбу за открытые данные».2. Latent Semantic Analysis — этот алгоритм способен определять синонимы и выявлять алгебраическим методом скрытые темы, которые присутствуют в документе в неявном виде:
Latent Semantic Analysis — этот алгоритм способен определять синонимы и выявлять алгебраическим методом скрытые темы, которые присутствуют в документе в неявном виде:
«Наша первостепенная задача как разработчиков заключается в том, чтобы представить тексты о городе в численном виде — таким образом, чтобы потери информации были минимальны, а математические свойства создаваемых объектов отражали семантические особенности текстов-прообразов. Существует ряд способов осуществить такой перевод — в частности, для этого используются нейросетевые модели, которые обучаются на коллокациях слов – их совместном употреблении в больших корпусах новостей, записей в блогах, художественной литературе. Существуют и другие применения такого подхода к анализу текстов — например, исследователи из Future Cities Lab в Сингапуре ищут по всему городу локации, где люди чаще всего обсуждают искусство, и получают неожиданные инсайты.Эти и другие инструменты анализа, как, например, автоматическое реферирование для получения информационной выжимки, фильтрация «мусорных» сообщений и рекламы сегодня дают возможность жителям быть услышанными и участвовать в развитии города.
 Мы возлагаем большие надежды на обратную связь от горожан, потому что они, ежедневно взаимодействуя с городскими системами и подсистемами, первыми замечают сигналы, свидетельствующие о потребности в качественных изменениях».
Мы возлагаем большие надежды на обратную связь от горожан, потому что они, ежедневно взаимодействуя с городскими системами и подсистемами, первыми замечают сигналы, свидетельствующие о потребности в качественных изменениях».3. Метод TextRank был разработан под влиянием алгоритма PageRank, использовавшегося создателями поисковой системы Google для ранжирования выдачи страниц по поисковому запросу. Он строит связи между предложениями и выявляет, какие из них связаны с наиболее важными словами или темами:
«Какие объекты городской среды наиболее часто упоминаются в связи с той или иной проблемой и в каком регионе? Иногда при работе с данными соцсетей мы хотим быстро увидеть, какие процессы, люди, места являются наиболее важными в выгрузке за определенный период, и оценить, в каком контексте они упоминаются. Это осуществляется в три этапа: сначала мы проходим по массиву текстов с помощью графового алгоритма TextRank и выделяем ключевые слова и словосочетания, затем смотрим на тексты, в которых они встретились, и оцениваем эмоции в этих текстах.
 С помощью таких инструментов анализа у нас есть возможность на стадии предпроектного исследования определить ключевые запросы жителей района, посетителей парка или набережной, понять, какие ключевые темы обсуждают жители в связи с развитием городской среды. Чтобы в полной мере использовать потенциал существующих технологий, предстоит решить еще много задач: научиться собирать информацию в реальном времени и хранить ее, чтобы впоследствии извлекать временные инсайты, автоматизировать коммуникацию с жителями с помощью диалоговых инструментов, настроить как можно более точные алгоритмы, создать регулятивные рамки и наладить межорганизационное взаимодействие, вести борьбу за открытые данные».
С помощью таких инструментов анализа у нас есть возможность на стадии предпроектного исследования определить ключевые запросы жителей района, посетителей парка или набережной, понять, какие ключевые темы обсуждают жители в связи с развитием городской среды. Чтобы в полной мере использовать потенциал существующих технологий, предстоит решить еще много задач: научиться собирать информацию в реальном времени и хранить ее, чтобы впоследствии извлекать временные инсайты, автоматизировать коммуникацию с жителями с помощью диалоговых инструментов, настроить как можно более точные алгоритмы, создать регулятивные рамки и наладить межорганизационное взаимодействие, вести борьбу за открытые данные».4. Алгоритм Reduction осуществляет графовую суммаризацию, где важность предложения определяется суммой весов ребер, связывающих его с другими предложениями. Вес ребра вычисляется так же, как в алгоритме TextRank:
«Какие объекты городской среды наиболее часто упоминаются в связи с той или иной проблемой и в каком регионе? Такой анализ интересно наблюдать в привязке к пространству, чтобы увидеть, какие места в городе вызывают наибольшее недовольство жителей и требуют особого внимания.
 Эти и другие инструменты анализа, как, например, автоматическое реферирование для получения информационной выжимки, фильтрация «мусорных» сообщений и рекламы сегодня дают возможность жителям быть услышанными и участвовать в развитии города. С помощью таких инструментов анализа у нас есть возможность на стадии предпроектного исследования определить ключевые запросы жителей района, посетителей парка или набережной, понять, какие ключевые темы обсуждают жители в связи с развитием городской среды. Чтобы в полной мере использовать потенциал существующих технологий, предстоит решить еще много задач: научиться собирать информацию в реальном времени и хранить ее, чтобы впоследствии извлекать временные инсайты, автоматизировать коммуникацию с жителями с помощью диалоговых инструментов, настроить как можно более точные алгоритмы, создать регулятивные рамки и наладить межорганизационное взаимодействие, вести борьбу за открытые данные».
Эти и другие инструменты анализа, как, например, автоматическое реферирование для получения информационной выжимки, фильтрация «мусорных» сообщений и рекламы сегодня дают возможность жителям быть услышанными и участвовать в развитии города. С помощью таких инструментов анализа у нас есть возможность на стадии предпроектного исследования определить ключевые запросы жителей района, посетителей парка или набережной, понять, какие ключевые темы обсуждают жители в связи с развитием городской среды. Чтобы в полной мере использовать потенциал существующих технологий, предстоит решить еще много задач: научиться собирать информацию в реальном времени и хранить ее, чтобы впоследствии извлекать временные инсайты, автоматизировать коммуникацию с жителями с помощью диалоговых инструментов, настроить как можно более точные алгоритмы, создать регулятивные рамки и наладить межорганизационное взаимодействие, вести борьбу за открытые данные».5. Luhn является наиболее простым алгоритмом. Он наиболее широко известен и основан на предположении, что наиболее важные предложения — те, которые содержат наиболее важные слова. Важные слова — те, которые чаще встречаются в тексте, но при этом не входят в список стоп-слов (слова вроде «ты», «я», «он», «но» и так далее):
Он наиболее широко известен и основан на предположении, что наиболее важные предложения — те, которые содержат наиболее важные слова. Важные слова — те, которые чаще встречаются в тексте, но при этом не входят в список стоп-слов (слова вроде «ты», «я», «он», «но» и так далее):
«Сложность этой работы заключается в природе созданных человеком языков. После векторизации текстов может быть использован целый набором инструментов — например, создать модель для автоматической классификации текстов, в частности, определения их эмоциональной окраски. Такой анализ интересно наблюдать в привязке к пространству, чтобы увидеть, какие места в городе вызывают наибольшее недовольство жителей и требуют особого внимания. Это позволяет автоматизировать значительный объем ручной работы в ходе качественных исследований. С помощью таких инструментов анализа у нас есть возможность на стадии предпроектного исследования определить ключевые запросы жителей района, посетителей парка или набережной, понять, какие ключевые темы обсуждают жители в связи с развитием городской среды».

Источник
Компания VESOLV оказывает услуги в области инжиниринга Al, ML, NLP, разработки алгоритмов и программного обеспечения. Автоматизирует обработку неструктурированных и малоструктурированных данных.
Оставить заявку
Список 5 лучших инструментов OCR с открытым исходным кодом
Опубликовано — Келси Тейлор
Средства OCR сканируют, идентифицируют и оцифровывают письменный текст или печатные документы и –
- Упрощают редактирование, изучение и поиск.
- Помощь в вводе данных посредством автоматизации.
- Снижение затрат
- Экономьте время с повышенной скоростью.
- Устойчивое управление хранилищем.
- Обеспечение аварийного восстановления.
- Защита данных.
- Доступность данных Swift.
- Более эффективное использование ресурсов.
Системы OCR используются для создания машиночитаемого текста из физических документов. Кроме того, с помощью искусственного интеллекта, системы нейронных сетей, теперь можно читать рукописный текст с гораздо большей точностью и распознаванием символов.
Кроме того, с помощью искусственного интеллекта, системы нейронных сетей, теперь можно читать рукописный текст с гораздо большей точностью и распознаванием символов.
Другие побочные продукты OCR включают интеллектуальное распознавание слов (IWR) и распознавание оптических меток (OMR).
Подробнее о OCR по сравнению с ICR — отличие программного обеспечения для распознавания символов
Какие предприятия выберут инструменты OCR с открытым исходным кодом?
Вам необходимо использовать услуги технологии оптического распознавания символов, если ваш бизнес связан со счетами и юридической документацией по выставлению счетов или, проще говоря, вводом данных в любой форме.
Также используется для проверки ограничений систем защиты от ботов CAPTCHA. Мобильные приложения OCR также широко используются во многих отношениях в настоящее время.
Некоторые общие места, где может пригодиться оптическое распознавание символов:
- Аэропорты
- Банки
- электронные книги
- Дорожные системы
- Объявления
- Системы цепочки поставок
Лучшие инструменты и программное обеспечение OCR с открытым исходным кодом, доступные на сегодняшний день:
- Тессеракт
- ПКР
- CuneiForm
- Кракен
- А9Т9
Тессеракт
Tesseract — это самый известный механизм распознавания текста с открытым исходным кодом, изначально разработанный Hewlett-Packard. Это бесплатное программное обеспечение под лицензией Apache, спонсируемое Google с 2006 года.
Это бесплатное программное обеспечение под лицензией Apache, спонсируемое Google с 2006 года.
Tesseract OCR Engine считается одной из самых точных, свободно доступных систем с открытым исходным кодом. Благодаря последней стабильной версии 4.1.0, основанной на LSTM. 1, Tesseract поддерживает до 116 языков.
Выполняемый из CIL (интерфейс командной строки), Tesseract нуждается в отдельном GUI (графическом пользовательском интерфейсе), поскольку он не оснащен собственным. Он имеет сложный конвейер предварительной обработки изображений и может получать новую информацию через свои нейронные сети.
GOCR
GOCR — бесплатное программное обеспечение для распознавания символов с открытым исходным кодом, разработанное в соответствии с Стандартной общественной лицензией GNU.
GOCR или JOCR — исходная аббревиатура — GOCR.
Расшифровывается как GNU Optical Character Recognition. Но на тот момент это уже было принято. Итак, JOCR (оптическое распознавание символов Йорга) был принят после Йорга Шуленбурга (первоначальный разработчик).
GOCR утверждает, что поддерживает одноколоночные шрифты без засечек высотой от 20 до 60 пикселей, а также может переводить штрих-коды.
Его также можно использовать в качестве приложения командной строки для других проектов. Он поддерживает платформы операционных систем Linux, Windows и OS/2.
CuneiForm
Бесплатная система с открытым исходным кодом — CuneiForm, теперь также известная как Cognitive OpenOCR. Он имеет встроенную базу данных и вывод. Он охватывает 23 разных языка. Также выполняется сканирование текстового формата, идентификация и анализ макета документа.
Разработан Cognitive Technologies OpenOCR имеет бесплатные лицензии/лицензии BSD. Он поддерживает кроссплатформенность, но не имеет компонента графического интерфейса для Linux.
Puma.NET — это его библиотека-оболочка; это упрощает работу по распознаванию символов в любых приложениях .NET Framework 2.0 или выше. В процессе работы он выполняет проверку по словарю, чтобы улучшить качество распознавания.
Kraken
Kraken был разработан для исправления ошибок Ocropus без нарушения других его функций.
Он опирается на свою библиотеку нейронных сетей CLSTM и, таким образом, получает новый опыт работы с данными из своих предыдущих проектов. На разных платформах для запуска требуются некоторые внешние библиотеки.
Эта сохраненная информация помогает ему более точно определить возникающие проблемы проверки данных. Позже его рабочий процесс помогает в обучении новых моделей.
A9T9
Microsoft A9T9 — это простое бесплатное программное обеспечение с открытым исходным кодом для оптического чтения и распознавания символов для Windows. Он имеет очень простую в использовании и легко устанавливаемую систему приложений для магазина Windows.
Его другие функции включают 100% рекламное ПО и систему, свободную от программ-шпионов. Он также имеет плавные настраиваемые исходные коды для улучшения возможностей разработки и модификации.
Опции, кроме упомянутых выше, включают OCRopus, Calamari и Ocrad.
Читайте также: Все, что вам нужно знать об интеллектуальном распознавании символов
Что такое оптическое распознавание символов (OCR)?
Технология оптического распознавания символов (OCR) — это эффективный бизнес-процесс, который экономит время, деньги и другие ресурсы за счет использования возможностей автоматического извлечения и хранения данных.
Оптическое распознавание символов (OCR) иногда называют распознаванием текста. Программа OCR извлекает и повторно использует данные из отсканированных документов, изображений с камер и PDF-файлов, содержащих только изображения. Программное обеспечение OCR выделяет буквы на изображении, объединяет их в слова, а затем объединяет слова в предложения, тем самым обеспечивая доступ к исходному контенту и его редактирование. Это также устраняет необходимость ручного ввода данных.
Системы OCR используют комбинацию аппаратного и программного обеспечения для преобразования физических печатных документов в машиночитаемый текст.
Программное обеспечение OCR может использовать преимущества искусственного интеллекта (ИИ) для реализации более совершенных методов интеллектуального распознавания символов (ICR), таких как определение языков или стилей почерка. Процесс OCR чаще всего используется для преобразования бумажных юридических или исторических документов в документы в формате pdf, чтобы пользователи могли редактировать, форматировать и искать документы, как если бы они были созданы с помощью текстового процессора.
История оптического распознавания символов
В 1974 году Рэй Курцвейл основал компанию Kurzweil Computer Products, Inc., чей продукт для многошрифтового оптического распознавания символов (OCR) мог распознавать текст, напечатанный практически любым шрифтом. Он решил, что лучшим применением этой технологии будет устройство машинного обучения для слепых, поэтому он создал читающую машину, которая может читать текст вслух в формате преобразования текста в речь. В 1980 году Курцвейл продал свою компанию Xerox, которая была заинтересована в дальнейшей коммерциализации преобразования текста с бумаги в компьютер.
В 1980 году Курцвейл продал свою компанию Xerox, которая была заинтересована в дальнейшей коммерциализации преобразования текста с бумаги в компьютер.
Технология OCR стала популярной в начале 1990-х годов при оцифровке исторических газет. С тех пор технология претерпела ряд усовершенствований. Современные решения способны обеспечить почти идеальную точность оптического распознавания символов. Передовые методы используются для автоматизации сложных рабочих процессов обработки документов. До появления технологии OCR единственным способом цифрового форматирования документов был повторный ввод текста вручную. Это не только отнимало много времени, но и приводило к неизбежным неточностям и опечаткам. Сегодня услуги OCR широко доступны для общественности. Например, Google Cloud Vision OCR используется для сканирования и хранения документов на вашем смартфоне.
Как работает оптическое распознавание символов?
Оптическое распознавание символов (OCR) использует сканер для обработки физической формы документа. После копирования всех страниц программа OCR преобразует документ в двухцветную или черно-белую версию. Отсканированное изображение или растровое изображение анализируется на наличие светлых и темных областей, и темные области идентифицируются как символы, которые необходимо распознать, а светлые области идентифицируются как фон. Затем темные области обрабатываются для поиска букв алфавита или цифровых цифр. Этот этап обычно включает в себя выбор одного символа, слова или блока текста за раз. Затем символы идентифицируются с использованием одного из двух алгоритмов — распознавания образов или распознавания признаков.
После копирования всех страниц программа OCR преобразует документ в двухцветную или черно-белую версию. Отсканированное изображение или растровое изображение анализируется на наличие светлых и темных областей, и темные области идентифицируются как символы, которые необходимо распознать, а светлые области идентифицируются как фон. Затем темные области обрабатываются для поиска букв алфавита или цифровых цифр. Этот этап обычно включает в себя выбор одного символа, слова или блока текста за раз. Затем символы идентифицируются с использованием одного из двух алгоритмов — распознавания образов или распознавания признаков.
Распознавание образов используется, когда программе OCR подаются примеры текста в различных шрифтах и форматах для сравнения и распознавания символов в отсканированном документе или файле изображения.
Обнаружение особенностей происходит, когда OCR применяет правила, касающиеся особенностей определенной буквы или цифры, для распознавания символов в отсканированном документе. Особенности включают количество угловых линий, пересекающихся линий или кривых в символе. Например, заглавная буква «А» хранится в виде двух диагональных линий, пересекающихся с горизонтальной линией посередине. Когда символ идентифицируется, он преобразуется в код ASCII (американский стандартный код для обмена информацией), который компьютерные системы используют для дальнейших манипуляций.
Особенности включают количество угловых линий, пересекающихся линий или кривых в символе. Например, заглавная буква «А» хранится в виде двух диагональных линий, пересекающихся с горизонтальной линией посередине. Когда символ идентифицируется, он преобразуется в код ASCII (американский стандартный код для обмена информацией), который компьютерные системы используют для дальнейших манипуляций.
Программа OCR также анализирует структуру изображения документа. Он делит страницу на элементы, такие как блоки текста, таблицы или изображения. Строки делятся на слова, а затем на символы. После того, как символы выделены, программа сравнивает их с набором изображений шаблонов. После обработки всех возможных совпадений программа представляет вам распознанный текст.
Преимущества оптического распознавания символов
Основное преимущество технологии оптического распознавания символов (OCR) заключается в том, что она упрощает процесс ввода данных, обеспечивая легкий текстовый поиск, редактирование и хранение.
Преимущества использования технологии OCR включают следующее:
- Снижение затрат
- Ускорение рабочих процессов
- Автоматизировать маршрутизацию документов и обработку контента
- Централизация и защита данных (отсутствие пожаров, взломов или потери документов в задних хранилищах)
- Улучшить обслуживание, обеспечив сотрудников самой актуальной и точной информацией
Варианты использования оптического распознавания символов
Наиболее известный вариант использования оптического распознавания символов (OCR) — преобразование печатных бумажных документов в машиночитаемые текстовые документы. После того, как отсканированный бумажный документ проходит обработку OCR, текст документа можно редактировать с помощью текстового процессора, такого как Microsoft Word или Google Docs.
OCR часто используется как скрытая технология, поддерживающая многие известные системы и службы в нашей повседневной жизни. Важные, но менее известные варианты использования технологии OCR включают автоматизацию ввода данных, помощь слепым и слабовидящим людям и индексирование документов для поисковых систем, таких как паспорта, номерные знаки, счета-фактуры, банковские выписки, визитные карточки и автоматическое распознавание номерных знаков. .
OCR позволяет оптимизировать моделирование больших данных путем преобразования бумажных документов и отсканированных изображений в машиночитаемые файлы PDF с возможностью поиска. Обработка и извлечение ценной информации не могут быть автоматизированы без предварительного применения оптического распознавания символов в документах, где еще нет текстовых слоев.
Благодаря распознаванию текста OCR отсканированные документы могут быть интегрированы в систему больших данных, которая теперь способна считывать данные клиентов из банковских выписок, контрактов и других важных печатных документов. Вместо того, чтобы заставлять сотрудников проверять бесчисленные документы с изображениями и вручную вводить входные данные в автоматизированный рабочий процесс обработки больших данных, организации могут использовать OCR для автоматизации на этапе ввода интеллектуального анализа данных. Программное обеспечение OCR может идентифицировать текст на изображении, извлекать текст из изображений, сохранять текстовый файл и поддерживать jpg, jpeg, png, bmp, tiff, pdf и другие форматы.
Вместо того, чтобы заставлять сотрудников проверять бесчисленные документы с изображениями и вручную вводить входные данные в автоматизированный рабочий процесс обработки больших данных, организации могут использовать OCR для автоматизации на этапе ввода интеллектуального анализа данных. Программное обеспечение OCR может идентифицировать текст на изображении, извлекать текст из изображений, сохранять текстовый файл и поддерживать jpg, jpeg, png, bmp, tiff, pdf и другие форматы.
Оптическое распознавание символов и IBM
Являясь мировым лидером в области технологий, IBM постоянно выпускает новые и улучшенные программные приложения как для бизнеса, так и для личного использования. За прошедшие десятилетия IBM улучшила свои возможности оптического распознавания символов, объединив их с искусственным интеллектом (ИИ).
Простого создания шаблонов документов уже недостаточно, поскольку предприятиям также нужны аналитические данные. Объединение AI и OCR вместе оказывается выигрышной стратегией для сбора данных, в то время как программное обеспечение для распознавания одновременно собирает информацию и понимает контент.
Ваш комментарий будет первым