ТОП-3 лучших программы для бенчмарка процессора и видеокарты
Решили купить себе новый процессор или немного подразогнать свою старенькую (или не очень) видеокарту? Тогда вам обязательно нужно обзавестись парой-тройкой полезных программок, при помощи которых можно провести качественный бенчмарк этого железа. В сегодняшней статье мы расскажем вам о трех лучших бенчмарк-программах для ЦП и ГП.
Содержание
- ТОП-3 лучших бенчмарк-программы для ЦП
- CineBench
- RealBench
- CPU-Z
- ТОП-3 лучших бенчмарк-программы для ГП
- FutureMark Suite
- MSI Afterburner
- GPU-Z
ТОП-3 лучших бенчмарк-программы для ЦП
CineBench
CineBench является самым популярным бенчмарком не только среди обычных пользователей, но и ПК-энтузиастов. В чем суть тестирования? Программа заставит ваш процессор заниматься рендером изображения чрезвычайно высокого качества.
Чем быстрее с данной задачей справится ваш ЦП, тем выше будут его баллы по окончания тестирования. Полученные баллы затем сравниваются с баллами модели вашего процессора, находящихся в базе данных программы, а также с другими моделями ЦП. Так вы поймете, в полную ли силу работает вашего железо и все ли с ним в порядке.
Полученные баллы затем сравниваются с баллами модели вашего процессора, находящихся в базе данных программы, а также с другими моделями ЦП. Так вы поймете, в полную ли силу работает вашего железо и все ли с ним в порядке.
RealBench
RealBench — это довольно интересная программка, а все потому, что она была разработана силами команды Republic of Gamers (ROG), особого бренда компании ASUS. Учитывая, что ROG занимается созданием множества игровых компьютеров, можете быть уверены, что этой бенчмарк-программе стоит довериться.
Бенчмарк RealBench проводится при помощи четырех отдельных теста: редактирование изображения, кодирование H.264-видео, работа с OpenCL и тяжелый мультитаскинг. После окончания тестирований вы можете загрузить полученные результаты и сравнить их с результатами других пользователей.
CPU-Z
CPU-Z — удобный инструмент для проведения общего бенчмарка ЦП. Утилита предоставляет пользователю довольно массивный перечень информации касательно аппаратного обеспечения, особенно по процессору.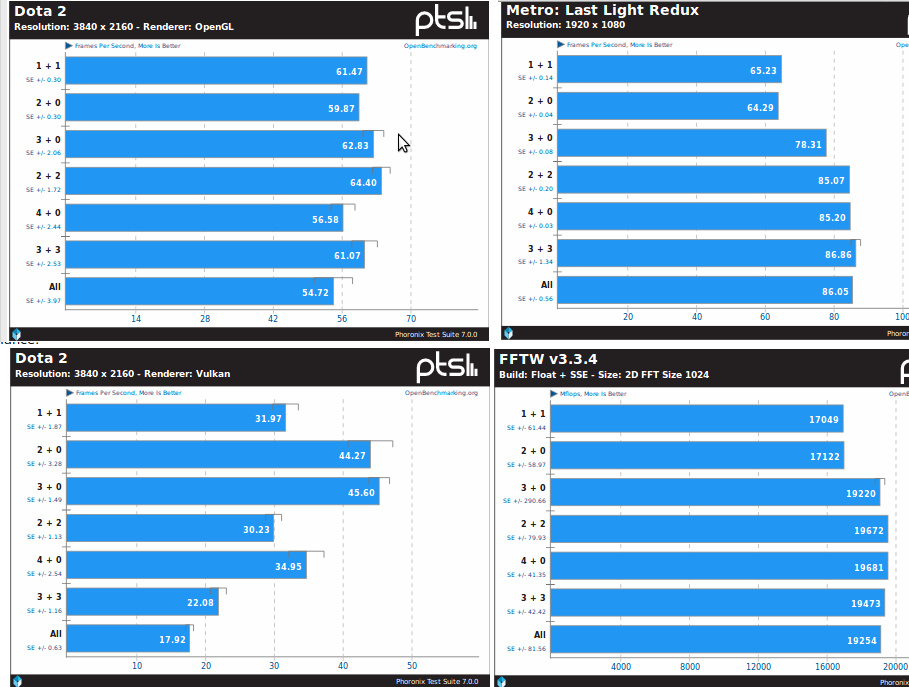 ЦП, материнская плата, оперативная память, видеокарта — тут вы сможете найти практически все необходимые сведения. И знаете что? CPU-Z — это абсолютно бесплатная утилита.
ЦП, материнская плата, оперативная память, видеокарта — тут вы сможете найти практически все необходимые сведения. И знаете что? CPU-Z — это абсолютно бесплатная утилита.
ТОП-3 лучших бенчмарк-программы для ГП
FutureMark Suite
FutureMark Suite — бенчмарк-программа для графических ускорителей действительно «крупного калибра». Верно, она является частью дорогостоящего 3DMark, тем не менее непосредственно сам FutureMark полностью бесплатен. Разумеется, без 3DMark вы лишаетесь множества крутых функций, но для бенчмарка видеокарты хватит и того, что есть. Внимание! FutureMark Suite включает в себя бенчмарки на DirectX 12, что важно для многих современных компьютеров.
MSI Afterburner
MSI Afterburner — самым популярный выбор среди геймеров, которые хотят не только провести бенчмарк своей видеокарты, но и немного подразогнать ее. Программа далеко не новая — ее успели проверить на деле миллионы пользователей по всему миру! И не переживайте о том, что у вас видеокарта не от MSI: утилита является универсальной и подходит под ГП всех производителей.
GPU-Z
GPU-Z — двоюродный брат CPU-Z. Удивительно, но GPU-Z был разработан совершенно иными разработчиками, несмотря на визуальное сходство. Название видеокарты, технологический процесс, количество транзисторов, разрядность шины и многое другое — вот что вам будет доступно в GPU-Z.
Ну и, понятное дело, у программы есть своя функция бенчмарка. Более того, GPU-Z способен создавать резервную копию BIOS видеокарты, что будет полезно для всех пользователей, которые любят копаться в настройках своего ГП. Как все другие утилиты в списке, GPU-Z универсален и подходит для видеокарт от NVIDIA, AMD и Intel.
Компьютеры
Новости Benchmark — Shazoo
Cohen
27Судя по новым тестам, RTX 4090 на 60% быстрее RTX 3090 Ti
Независимые тесты RTX 4090 уже в процессе и согласно первым оценкам, производительность нового флагмана Nvidia примерно на 60% превосходит RTX 3090 Ti.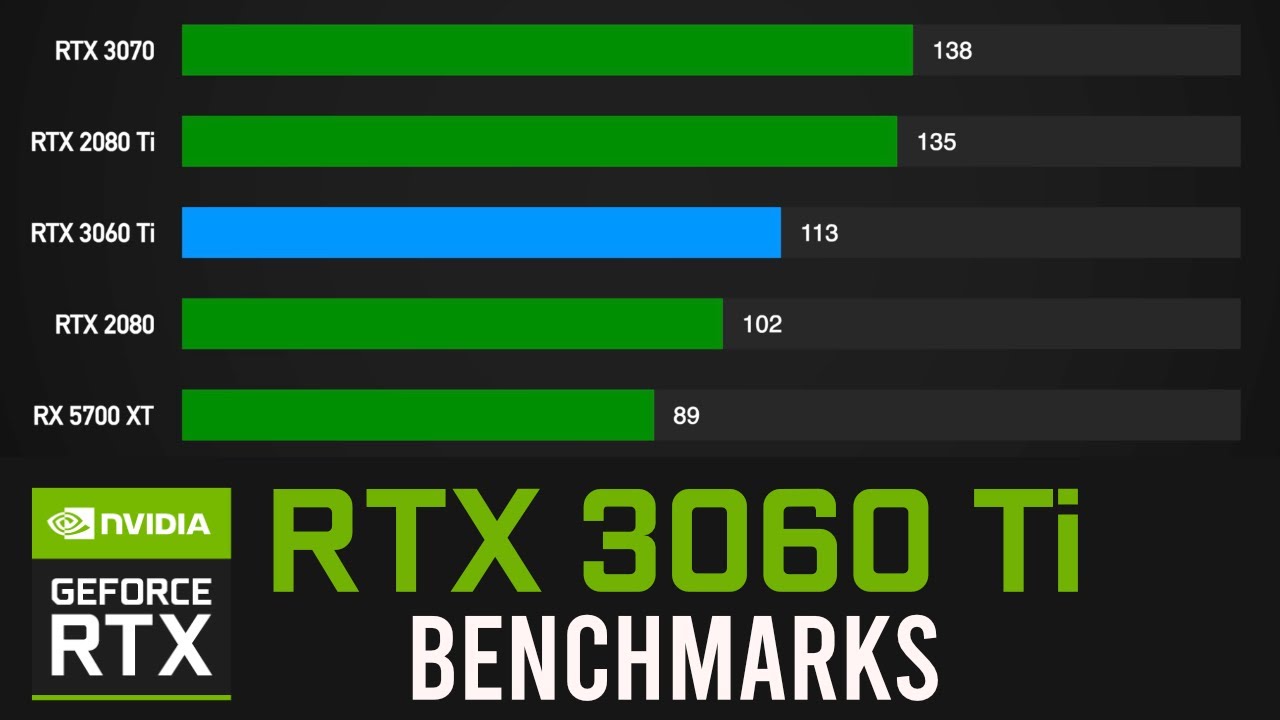 Сравнение с обычной RTX 3090 показывает результаты даже выше. Однако насколько это скажется…
Сравнение с обычной RTX 3090 показывает результаты даже выше. Однако насколько это скажется…
cyber_samovar
2Компания Basemark выпустила первый в мире кросс-платформенный бенчмарк для трассировки лучей
Вчера финская компания Basemark сообщила о выходе первого в мире кросс-платформенного бесплатного бенчмарка для трассировки лучей, который получил название Relic of Life. Программа поддерживает Windows 10/11, Linux, macOS, Android и iOS. Из поддерживаемых API на…
carduckx7
29Слух: Названы лучшие бюджетные процессоры для игровых ПК
На китайской платформе Bilibili пользователь опубликовал скриншоты результатов бенчмарков процессоров Intel Core i3-12300 и Core i3-12100. Ни один из них ещё официально не подтвержден Intel. Несмотря на это, результаты тестов действительно впечатляют. Процессоры якобы тестировали…
Ни один из них ещё официально не подтвержден Intel. Несмотря на это, результаты тестов действительно впечатляют. Процессоры якобы тестировали…
cyber_samovar
10520-30 FPS на высоких настройках в Cyberpunk 2077 — первые тесты Steam Deck
Сайт Tom’s Hardware со ссылкой на китайского энтузиаста, который получил девкит Steam Deck, опубликовал первые тесты портативного PC от Valve в некоторых играх. Результаты действительно отличные, особенно в таком монстре, как Cyberpunk 2077. На высоких…
Cohen
22Интерфейс GeForce Experience может снижать частоту кадров в играх, например Cyberpunk 2077
Интерфейс GeForce Experience — довольно полезная штука, особенно для тех, кто занимается записью игрового процесса или любит наблюдать за производительностью.
scavenz
11Новый процессор Ryzen 7 3800XT засветился в тесте Ashes of Singularity
Согласно слухам, на следующей неделе AMD представит новые процессоры серии Matisse Refresh. В линейку свежих чипов войдут три модели, одна из которых засветилась в игровом тесте Ashes of Singularity. Речь идет о Ryzen 7 3800XT….
scavenz
21Crytek выпустила неоново-нуарный бенчмарк на CryEngine
В марте Crytek объявила, что к концу текущего года CryEngine обзаведется трассировкой лучей на любых видеокартах.
CryptoNick
25Анализ производительности Call of Duty: Modern Warfare — хорошая работа
Издание DSOG провело анализ производительности Call of Duty: Modern Warfare. Согласно Infinity Ward, игра использует новый движок и поддерживает DirectX 12. Для этого тестов были использован Intel i9 9900K с 16 ГБ памяти DDR4 на…
Cohen
3D Mark поддерживает бенчмарк PCIe 4.0 — как это выглядит
UL Benchmarks объявила, что тестирование работы PCIe 4. 0 теперь доступно в рамках бенчмарк-программы 3D Mark. По словам разработчиков, 3DMark PCI Express включает тест, замеряющий пропускную способность вашего GPU при работе через интерфейс PCI Expreess. Четвертая…
0 теперь доступно в рамках бенчмарк-программы 3D Mark. По словам разработчиков, 3DMark PCI Express включает тест, замеряющий пропускную способность вашего GPU при работе через интерфейс PCI Expreess. Четвертая…
Cohen
45Официальные тесты AMD Radeon VII в 25 играх
AMD поделилась первым официальным бенчмарком видеокарты Radeon VII, представленной на CES 2019. Компания сравнила производительность нового флагмана с RX Vega 64 в 25 играх и результат в целом соответствует тому, что можно ожидать от GPU. …
Cohen
9Бенчмарк Port Royal с трассировкой лучей появился в 3D Mark
Futuremark выпустила новую версию своего инструмента для тестирования трассировки лучей на PC — 3D Mark Port Royal Raytracing Benchmark. К сожалению, Port Royal пока доступна только в продвинутой и профессиональной версии 3D Mark, то есть…
К сожалению, Port Royal пока доступна только в продвинутой и профессиональной версии 3D Mark, то есть…
Cohen
33Официальные тесты видеокарт RTX 2080 Ti и RTX 2080 в 12 играх
Nvidia опубликовала собственные графики производительности новых видеокарт GeForce RTX 2080 Ti и RTX 2080 в сравнении с предыдущим флагманом. Причем не простые, а все были проведены в современных играх с 4K разрешением и максимальными настройками…
Cohen
518K-скриншоты Final Fantasy XV с PC-версии
Осторожно, эта подборка скриншотов в 8K-разрешении весит очень много. Если вы на сайте с мобильного устройства и с ограничением трафика, то смотрите кадры только после подключения к Wi-Fi! Все это вы можете увидеть и сами. ..
..
Cohen
59Первый официальный бенчмарк Xbox One X от Microsoft
Eurogamer, который в апреле представил технические характеристики Xbox One X — самой мощной игровой консоли, способной выводить игры в нативном 4K (ряд тайтлов с апскейлом). Сегодня Eurogamer опубликовал официальные бенчмарки Xbox One X, сделанные Microsoft…
TOMCREO
174Тесты процессоров AMD Ryzen — AMD снова в игре
Последняя архитектура процессоров от AMD была не слишком удачной, да и в целом дела у AMD шли не важно. При отсутствие конкуренции на рынке процессоров Intel почти полностью захватил рынок, но теперь возможно все изменится. …
…
Как сравнить свою видеокарту в 2022 году | Сайед Заиди | Predict
Как сравнить вашу видеокарту в 2022 году | Сайед Заиди | Предсказать | MediumPhoto by Caspar Camille Rubin на UnsplashУзнайте больше о производительности вашего графического процессора, выполнив тестовый тест вашей видеокарты в 2022 году. 22
После тщательно обдумав свои варианты, вы, наконец, остановились на графической карте и хотите узнать, как она работает. Хорошее понимание того, как тест вашей видеокарты имеет решающее значение для компьютерных геймеров, и как любой…
Автор Syed Zaidi
227 Последователи
· Писатель для
Студент | Писатель на полставки | Top Writer — GPU
Еще от Syed Zaidi и Predict
Syed Zaidi
in
Что делать, если вы теряете деньги в криптовалюте?
Несколько советов, как минимизировать потери от обвала рынка криптовалют.
·3 минуты чтения·22 мая 2021 г.
Рейд Эллиот
в
Этот плагин ChatGPT действительно новаторский
A Deep-D ive on Wolfram, ИИ для принятия решений и общества «черных ящиков»
·12 минут чтения·6 апреля
в
НАСА предупреждает о выходе из-под контроля сверхмассивной черной дыры
НАСА обнаружило сверхмассивную черную дыру, мчащуюся между галактиками. Открытие было сделано с помощью телескопа Хаббл, выпущенного на…
3 минуты чтения·10 апреля
Сайед Заиди
в
Почему «Интерстеллар» считается лучшим научно-фантастическим фильмом всех времен?
Узнайте больше об Interstellar, его истории и причинах его успеха.
·3 мин чтения·3 октября 2022 г.
Просмотреть все от Syed Zaidi
Рекомендовано Medium
The PyCoach
в
Вы используете чат GPT неправильно! Вот как быть впереди 99% пользователей ChatGPT
Освойте ChatGPT, изучив технику быстрого доступа.

·7 мин чтения·17 марта
Дэвид Уотсон
Да пребудет с вами прибыль: нетрадиционная деловая мудрость от неожиданного гуру
Уроки Мастера Йоды для успеха в бизнесе 9 0042
·Чтение 5 мин·4 дней назад
Александр Нгуен
в
Почему я продолжаю отказывать кандидатам во время собеседований в Google…
Они не соответствуют планке.
·4 минуты чтения·13 апреля
Линда Кэролл
в
Я спросил ChatGPT, как заработать 1000 долларов в Интернете. Это было весело.
Заглянуть в коллективный разум может быть очень полезно, но это также может быть настолько глупо, что даже смешно
· чтение за 6 минут·24 марта
Макс Хильсдорф
в
Аудио GPT — Взгляд в будущее создания музыки
Исследовательская работа проанализирована и объяснена
·10 минут чтения·6 дней назад
Джинджер Лю. М.Ф.А.
М.Ф.А.
в
Создание версии меня с искусственным интеллектом
Как я использовал искусственный интеллект для синтеза речи и создатель цифрового человека с искусственным интеллектом 5
Статус
Карьера
Преобразование текста в речь
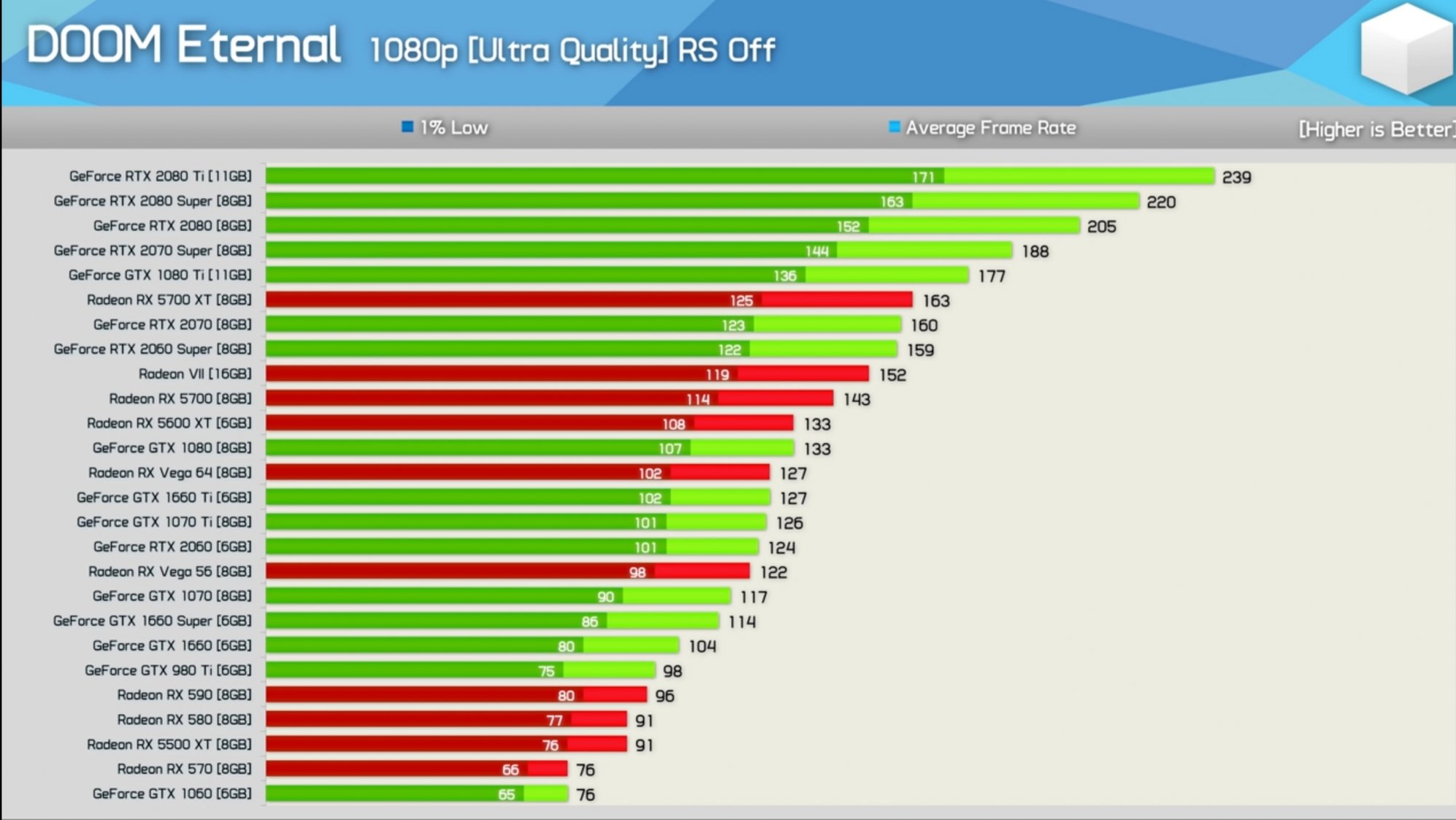
Тесты GPU для глубокого обучения 2021
Хотя мы протестировали лишь небольшую часть всех доступных графических процессоров, мы думаем, что рассмотрели все графические процессоры, которые в настоящее время лучше всего подходят для обучения и разработки в области глубокого обучения благодаря своим вычислительным возможностям и возможностям памяти. и их совместимость с текущими платформами глубокого обучения.
GTX 1080TI
Классический графический процессор NVIDIA для глубокого обучения, выпущенный только в 2017 году, с 11 ГБ памяти DDR5 и 3584 ядрами CUDA был разработан для вычислительных рабочих нагрузок. Он уже давно снят с производства и был просто добавлен в качестве ориентира.
RTX 2080TI
RTX 2080 TI была выпущена в четвертом квартале 2018 года. Она оснащена 5342 ядрами CUDA, организованными в виде 544 тензорных ядер NVIDIA Turing смешанной точности, обеспечивающих 107 тензорных терафлопс производительности ИИ и 11 ГБ сверхбыстрого G DDR6 Память. Производство этого графического процессора было прекращено в сентябре 2020 года, и сейчас он практически недоступен.
Titan RTX
Titan RTX основан на самой большой версии архитектуры Turing™. Titan RTX обеспечивает производительность 130 тензорных терафлопов благодаря 576 тензорным ядрам и 24 ГБ сверхбыстрой памяти GDDR6.
Quadro RTX 6000
Quadro RTX 6000 — это серверная версия популярного Titan RTX с улучшенной вентиляцией нескольких графических процессоров, дополнительными возможностями виртуализации и памятью ECC. Он питается от того же Turing ™ в качестве ядра Titan RTX с 576 тензорными ядрами, обеспечивающими производительность 130 тензорных терафлопов и 24 ГБ сверхбыстрой памяти GDDR6 ECC.
Quadro RTX 8000
Quadro RTX 8000 — старший брат RTX 6000. С тем же процессором GPU, но с удвоенной памятью GPU: 48 ГБ GDDR6 ECC. Фактически, в настоящее время это графический процессор с самой большой доступной памятью графического процессора, который лучше всего подходит для самых требовательных к памяти задач.
RTX 3080
Одна из первых моделей графических процессоров на базе архитектуры NVIDIA Ampere™ с улучшенными ядрами RT и Tensor и новыми потоковыми мультипроцессорами. RTX 3080 оснащен 10 ГБ сверхбыстрой памяти GDDR6X и 8704 ядрами CUDA.
RTX 3080 Ti
Старший брат RTX 3080 с 12 ГБ сверхбыстрой памяти GDDR6X и 10240 ядрами CUDA.
RTX 3090
GeForce RTX™ 3090 относится к классу TITAN поколения графических процессоров NVIDIA Ampere™. Он оснащен 10496 ядрами CUDA, 328 тензорными ядрами третьего поколения и новыми потоковыми мультипроцессорами. Как и Titan RTX, он имеет 24 ГБ памяти GDDR6X.
NVIDIA RTX A6000
NVIDIA RTX A6000 — это обновленная версия Quadro RTX 6000 на базе Ampere. Она оснащена тем же процессором GPU (GA-102), что и RTX 309.0, но со всеми включенными ядрами процессора. Что приводит к 10752 ядрам CUDA и 336 тензорным ядрам третьего поколения. Кроме того, у него вдвое больше памяти графического процессора по сравнению с RTX 3090: 48 ГБ GDDR6 ECC.
Tesla V100
Обладая 640 тензорными ядрами, Tesla V100 стал первым в мире графическим процессором, преодолевшим барьер производительности глубокого обучения в 100 терафлопс (TFLOPS), включая 16 ГБ памяти HBM2 с максимальной пропускной способностью. Он основан на графическом процессоре Volta, который доступен только для серии профессиональных графических процессоров NVIDIA.
NVIDIA A100
Nvidia A100 — флагман поколения процессоров Nvidia Ampere. Благодаря 6912 ядрам CUDA, 432 тензорным ядрам третьего поколения и 40 ГБ памяти HBM2 с максимальной пропускной способностью. Один A100 преодолевает барьер производительности Peta TOPS.
Один A100 преодолевает барьер производительности Peta TOPS.
Получение максимальной производительности от Tensorflow
Были предприняты некоторые меры, чтобы получить максимальную производительность от Tensorflow для сравнительного анализа.
Размер пакета
Одним из наиболее важных параметров оптимизации рабочей нагрузки для каждого типа графического процессора является использование оптимального размера пакета. Размер пакета указывает, сколько параллельных размножений сети выполняется, результаты каждого размножения усредняются по пакету, а затем результат применяется для корректировки весов сети. лучший размер пакета с точки зрения производительности напрямую связан с объемом доступной памяти графического процессора .
Больший размер пакета повысит параллелизм и улучшит использование ядер графического процессора. Но размер пакета не должен превышать доступную память графического процессора , так как в этом случае должны сработать механизмы подкачки памяти и снизить производительность, иначе приложение просто аварийно завершает работу с исключением «недостаточно памяти».
Большой размер партии в некоторой степени не оказывает отрицательного влияния на результаты обучения, напротив, большой размер партии может иметь положительный эффект для получения более обобщенных результатов. Примером может служить BigGAN, где для достижения наилучших результатов предлагается размер пакета до 2048. Еще одна интересная информация о влиянии размера партии на результаты обучения была опубликована OpenAI.
Tensorflow XLA
Функция производительности Tensorflow, которая была объявлена стабильной некоторое время назад, но по-прежнему отключена по умолчанию, — это XLA (ускоренная линейная алгебра). Он выполняет оптимизацию графа сети, динамически компилируя части сети в определенные ядра, оптимизированные для конкретного устройства. Это может иметь выигрыш в производительности от 10% до 30% по сравнению со статически созданными ядрами Tensorflow для разных типов слоев.
Эту функцию можно включить с помощью простой опции или флага среды, и она напрямую влияет на производительность выполнения. Как включить XLA в своих проектах читайте здесь.
Как включить XLA в своих проектах читайте здесь.
Обучение с плавающей запятой 16 бит / смешанной точности
Что касается заданий логического вывода, то для повышения производительности предоставляется более низкая точность с плавающей запятой и еще более низкое 8- или 4-битное целочисленное разрешение. В большинстве ситуаций обучения 16-битная точность с плавающей запятой также может применяться для задач обучения с незначительной потерей точности обучения и может значительно ускорить выполнение заданий обучения. Применение 16-битной точности с плавающей запятой не так уж тривиально, поскольку модель должна быть настроена для ее использования. Поскольку не все этапы вычислений должны выполняться с более низкой битовой точностью, смешивание различных битовых разрешений для вычислений называется «смешанной точностью».
Полный потенциал обучения смешанной точности будет лучше изучен с помощью Tensor Flow 2.X и, вероятно, станет тенденцией развития для повышения производительности платформы глубокого обучения.
Мы предоставляем тесты для 32-битной и 16-битной точности с плавающей запятой в качестве эталона для демонстрации потенциала.
Тест глубокого обучения
Модель визуального распознавания ResNet50 в версии 1.0 используется для нашего теста. Как классическая сеть глубокого обучения с ее сложной 50-уровневой архитектурой с различными сверточными и остаточными слоями, она по-прежнему является хорошей сетью для сравнения достижимой производительности глубокого обучения. Поскольку он используется во многих бенчмарках, доступна близкая к оптимальной реализация, обеспечивающая максимальную производительность графического процессора и показывающая пределы производительности устройств.
Среда тестирования
Мы использовали наш сервер AIME A4000 для тестирования. Это продуманная среда для запуска нескольких высокопроизводительных графических процессоров, обеспечивающая оптимальное охлаждение и возможность запуска каждого графического процессора в слоте PCIe 4. 0 x16, напрямую подключенном к ЦП.
0 x16, напрямую подключенном к ЦП.
Поколение NVIDIA Ampere обладает преимуществами интерфейса PCIe 4.0, который удваивает скорость передачи данных до 31,5 ГБ/с между ЦП и между графическими процессорами.
Возможность подключения оказывает заметное влияние на производительность глубокого обучения, особенно в конфигурациях с несколькими графическими процессорами.
Кроме того, AIME A4000 обеспечивает сложное охлаждение, необходимое для достижения и поддержания максимальной производительности.
Технические характеристики для воспроизведения наших тестов:
- AIME A4000, Epyc 7402 (24 ядра), 128 ГБ ECC RAM
- Ubuntu 20.04
- Версия драйвера NVIDIA 455.45 90 301 CUDA 11.1.74
- CUDNN 8.0.5
- Tensorflow 1.15.4
Сценарии Python, использованные для теста, доступны на Github по адресу: Tensorflow 1.x Benchmark
Результатом наших измерений является среднее изображение в секунду, которое можно обучить при выполнении 100 пакетов с заданным размером пакета.
Поколение NVIDIA Ampere явно лидирует, а A100 рассекретила все остальные модели.
При обучении с плавающей запятой 16-битной точности ускорители вычислений A100 и V100 увеличивают свое преимущество. Но также RTX 3090 может более чем удвоить производительность по сравнению с 32-битными вычислениями с плавающей запятой.
Ускорение графического процессора по сравнению с центральным процессором увеличивается здесь до 167-кратной скорости 32-ядерного процессора, что делает вычисления на графическом процессоре не только возможными, но и обязательными для высокопроизводительных задач глубокого обучения.
Производительность обучения глубокому обучению с несколькими графическими процессорами
Следующий уровень производительности глубокого обучения заключается в распределении рабочих и обучающих нагрузок между несколькими графическими процессорами. AIME A4000 поддерживает до 4 графических процессоров любого типа.
Глубокое обучение хорошо масштабирует на нескольких графических процессорах. Метод выбора для масштабирования нескольких GPU как минимум в 90% случаев — разнести батч по графическим процессорам. Таким образом, эффективный размер пакета представляет собой сумму размера пакета каждого используемого графического процессора.
Метод выбора для масштабирования нескольких GPU как минимум в 90% случаев — разнести батч по графическим процессорам. Таким образом, эффективный размер пакета представляет собой сумму размера пакета каждого используемого графического процессора.
Таким образом, каждый GPU вычисляет свой пакет для обратного распространения для применяемых входных данных среза пакета. Затем результаты каждого графического процессора обмениваются и усредняются, а веса модели корректируются соответствующим образом и должны распределяться обратно на все графические процессоры.
Что касается обмена данными, то для сбора результатов партии и корректировки весов перед запуском следующей партии приходится пик обмена данными. Пока графические процессоры работают над пакетом, обмен данными между графическими процессорами не происходит или не происходит вообще.
В этом стандартном решении для масштабирования нескольких графических процессоров необходимо убедиться, что все графические процессоры работают с одинаковой скоростью, иначе самый медленный графический процессор будет узким местом , которого должны ждать все графические процессоры! Поэтому смешивание разных типов графических процессоров бесполезно .
С AIME A4000 достигнут хороший коэффициент масштабирования 0,88, поэтому каждый дополнительный GPU добавляет около 88% своей возможной производительности к общей производительности
Производительность обучения в перспективе
Чтобы получить более четкое представление о том, как измерение количества изображений в секунду преобразуется во время обработки и ожидания при обучении таких сетей, мы рассмотрим реальный пример использования обучения такой сети с большим набором данных.
Например, набор данных ImageNet 2017 состоит из 1 431 167 изображений. Для однократной обработки каждого изображения набора данных, так называемой 1 эпохи обучения, в ResNet50 потребуется около:
| Конфигурация | поплавок 32 обучение | поплавок 16 тренировочный |
|---|---|---|
| Процессор (32 ядра) | 27 часов | 27 часов |
| Один RTX 2080 TI | 69 минут | 29 минут |
| Один RTX 3080 | 53 минуты | 22 минуты |
| Один RTX 3080 TI | 45 минут | 21 минута |
| Один RTX 3090 | 41 минута | 18 минут |
| Один RTX A6000 | 41 минута | 16 минут |
| Одиночный NVIDIA A100 | 23 минуты | 8,5 минут |
| 4 x RTX 2080TI | 19 минут | 8 минут |
| 4 х Тесла V100 | 15 минут | 4,5 минуты |
| 4 x RTX 3090 | 11,5 минут | 5 минут |
| 4 x NVIDIA A100 | 6,5 минут | 3 минуты |
Обычно требуется не менее 50 периодов обучения, чтобы можно было получить результат для оценки после:
| Конфигурация | поплавок 32 тренировочный | поплавок 16 тренировочный |
|---|---|---|
| Процессор (32 ядра) | 55 дней | 55 дней |
| Один RTX 2080 TI | 57 часов | 24 часа |
| Один RTX 3080 | 44 часа | 18 часов |
| Один RTX 3080 TI | 38 часов | 17 часов |
| Один RTX 3090 | 34 часа | 14,5 часов |
| Один RTX A6000 | 34 часа | 14,5 часов |
| Одиночный NVIDIA A100 | 19 часов | 8 часов |
| 4 x RTX 2080TI | 16 часов | 6,5 часов |
| 4 х Тесла V100 | 12 часов | 4 часа |
| 4 x RTX 3090 | 9,5 часов | 4 часа |
| 4 x NVIDIA A100 | 5,5 часов | 2,5 часа |
Это показывает, что правильная настройка может изменить продолжительность задачи обучения с недель до одного дня или даже нескольких часов.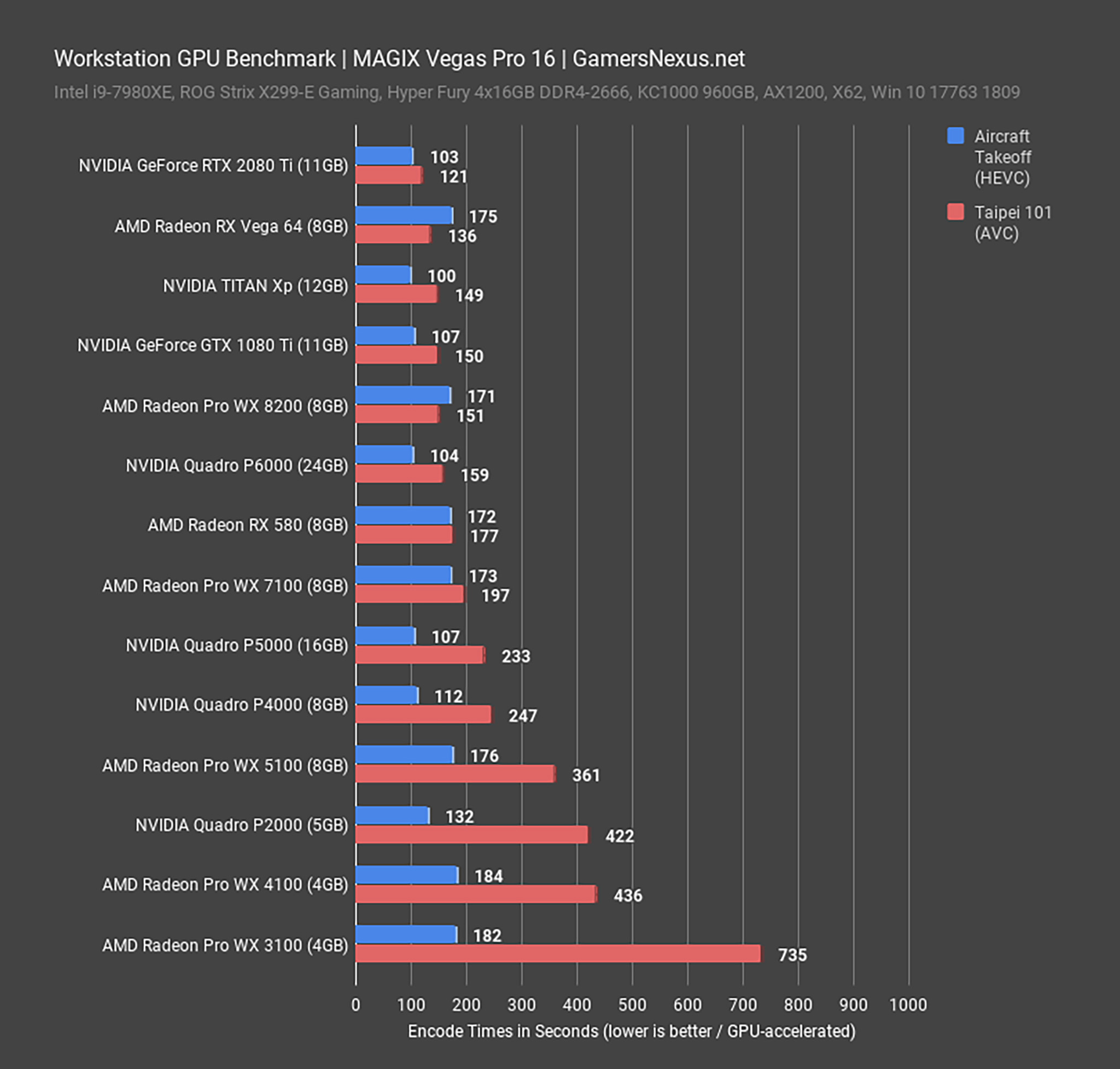 В большинстве случаев, вероятно, желательно время тренировки, позволяющее проводить тренировку в течение ночи, чтобы получить результаты на следующее утро.
В большинстве случаев, вероятно, желательно время тренировки, позволяющее проводить тренировку в течение ночи, чтобы получить результаты на следующее утро.
Выводы
Смешанная точность может ускорить тренировку более чем в 2 раза
Особенность, на которую стоит обратить внимание в отношении производительности, — это переключение тренировки с точности с плавающей запятой 32 на тренировку со смешанной точностью. Получение повышения производительности путем настройки программного обеспечения в зависимости от ваших ограничений, вероятно, может быть очень эффективным шагом для удвоения производительности.
Масштабирование с использованием нескольких графических процессоров более чем осуществимо
Масштабирование производительности глубокого обучения с использованием нескольких графических процессоров хорошо масштабируется как минимум до 4 графических процессоров: 2 графических процессора часто могут превзойти следующий более мощный графический процессор с точки зрения цены и производительности.
Это верно, например, при сравнении 2 x RTX 3090 с NVIDIA A100.
Лучший графический процессор для глубокого обучения?
Как и в большинстве случаев, на вопрос нет однозначного ответа. Производительность, безусловно, является наиболее важным аспектом графического процессора, используемого для задач глубокого обучения, но не единственным.
Так что это сильно зависит от ваших требований. Вот наши оценки наиболее перспективных графических процессоров для глубокого обучения:
RTX 3080 TI
Он обеспечивает наибольшую отдачу от затраченных средств. Если вы ищете экономичное решение, установка с несколькими графическими процессорами может занять лидирующие позиции в высшей лиге, при этом затраты на приобретение будут ниже, чем у одного самого высокопроизводительного графического процессора.
Обладая 12 ГБ памяти графического процессора, он имеет явное преимущество перед RTX 3080 без TI и является подходящей заменой RTX 2080 TI. Но с ростом и увеличением требований к размерам моделей глубокого обучения память объемом 12 ГБ, вероятно, также станет узким местом RTX 3080 TI.
RTX 3090
В настоящее время RTX 3090 является реальным шагом вперед по сравнению с RTX 2080 TI. Благодаря своей сложной памяти объемом 24 ГБ и явному увеличению производительности по сравнению с RTX 2080 TI он устанавливает предел для этого поколения графических процессоров для глубокого обучения.
Установка с двумя RTX 3090 может превзойти установку с четырьмя RTX 2080 TI по времени цикла глубокого обучения, с меньшим энергопотреблением и более низкой ценой.
NVIDIA A100
Если требуется максимальная производительность независимо от цены и максимальная плотность производительности, NVIDIA A100 — лучший выбор: она обеспечивает максимальную вычислительную производительность во всех категориях.
Производительность A100 значительно улучшена по сравнению с Tesla V100, что делает соотношение цены и качества более приемлемым.
Кроме того, более низкое энергопотребление в 250 Вт по сравнению с 700 Вт в конфигурации с двумя RTX 3090 при сопоставимой производительности достигает диапазона, при котором при постоянной полной нагрузке разница в затратах на электроэнергию может стать фактором, который следует учитывать.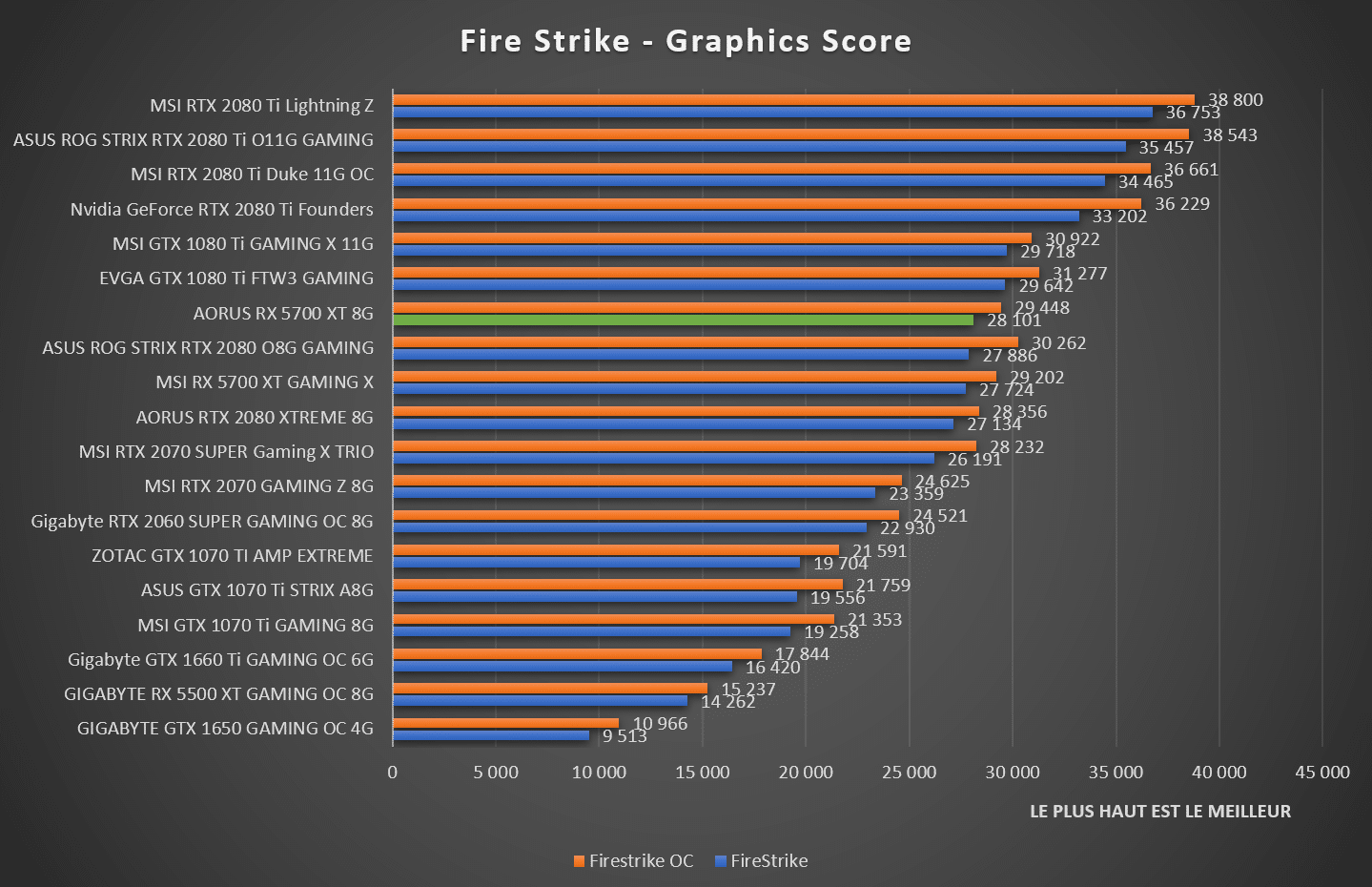
Ваш комментарий будет первым