4 программы для скачивания сайтов
4 программы для скачивания сайтов
Эти четыре программы помогут вам загрузить практически любой сайт к себе на компьютер. Очень полезно, если вы боитесь потерять доступ к любимым статьям, книгам, инструкциям и всему остальному, что могут удалить или заблокировать.
HTTrack позволяет пользователям загружать сайт из интернета на жесткий диск. Программа работает путем копирования содержимого всего сайта, а затем загружает все каталоги, HTML, изображения и другие файлы с сервера сайта на ваш компьютер.
При просмотре скопированного сайта HTTrack поддерживает исходную структуру ссылок сайта. Это позволяет пользователям просматривать его в обычном браузере. Кроме того, пользователи могут нажимать на ссылки и просматривать сайт точно так же, как если бы они смотрели его онлайн.
Если вы твердо придерживаетесь экосистемы Apple и имеете доступ только к Mac, вам нужно попробовать SiteSucker. Программа, получившая такое название, копирует все файлы веб-сайта на жесткий диск. Пользователи могут начать этот процесс всего за несколько кликов, что делает его одним из самых простых в использовании инструментов. Кроме того, SiteSucker довольно быстро копирует и сохраняет содержимое сайта. Однако помните, что фактическая скорость загрузки будет зависеть от пользователя.
К сожалению, SiteSucker не лишен недостатков. Во-первых, SiteSucker — платное приложение. На момент написания этой статьи SiteSucker стоит $4.99 в App Store. Кроме того, SiteSucker загружает каждый файл на сайте, который может быть найден. Это означает большую загрузку с большим количеством потенциально бесполезных файлов.
Cyotek WebCopy — инструмент, позволяющий пользователям копировать полные версии сайтов или только те части, которые им нужны. К сожалению, приложение WebCopy доступно только для Windows, но зато оно является бесплатным. Использовать WebCopy достаточно просто. Откройте программу, введите целевой URL-адрес и все.
Кроме того, WebCopy имеет большое количество фильтров и опций, позволяющих пользователям скачивать только те части сайта, которые им действительно нужны. Эти фильтры могут пропускать такие вещи, как изображения, рекламу, видео и многое другое, что может существенно повлиять на общий размер загрузки.
Этот граббер с открытым исходным кодом существует уже давно, и на это есть веские причины. GetLeft — это небольшая утилита, позволяющая загружать различные компоненты сайта, включая HTML и изображения.
GetLeft очень удобен для пользователя, что и объясняет его долговечность. Для начала просто запустите программу и введите URL-адрес сайта, затем GetLeft автоматически анализирует веб-сайт и предоставит вам разбивку страниц, перечисляя подстраницы и ссылки. Затем вы можете вручную выбрать, какие части сайта вы хотите загрузить, установив соответствующий флажок.
После того, как вы продиктовали, какие части сайта вы хотите зазрузить, нажмите на кнопку. GetLeft загрузит сайт в выбранную вами папку. К сожалению, GetLeft не обновлялся какое-то время.
Спасибо, что читаете! Подписывайтесь на мой канал в Telegram и Яндекс.Дзен. Только там последние обновления блога и новости мира информационных технологий.
Также, читайте меня в социальных сетях: Facebook, Twitter, VK, OK.
Респект за пост! Спасибо за работу!
Хотите больше постов? Новости технологий? Обзоры гаджетов? Для всего этого, а также для продвижения сайта, развития, покупки нового дизайна и оплаты хостинга, мне необходима помощь от вас, читатели. Подробнее о донатах читайте на специальной странице.
На данный момент есть возможность поддержать меня через Яндекс Деньги:
Через WebMoney:
И PayPal. Спасибо! Все собранные средства будут пущены на развитие сайта. Поддержка проекта является подарком владельцу сайта.
levashove.ru
Программы для скачивания сайта целиком

В интернете хранится множество полезной информации, к которой необходим практически постоянный доступ для некоторых пользователей. Но не всегда есть возможность подключиться к сети и зайти на нужный ресурс, а копировать содержание через такую функцию в браузере или перемещать данные в текстовый редактор не всегда удобно и конструкция сайта теряется. В таком случае на помощь приходит специализированный софт, который предназначен для локального хранения копий определенных веб-страниц.
Teleport Pro
Данная программа оснащена только самым необходимым набором функций. В интерфейсе нет ничего лишнего, а само главное окно разделено на отдельные части. Создавать можно любое количество проектов, ограничиваясь только вместительностью жесткого диска. Мастер создания проектов поможет правильно настроить все параметры для скорейшего скачивания всех необходимых документов.
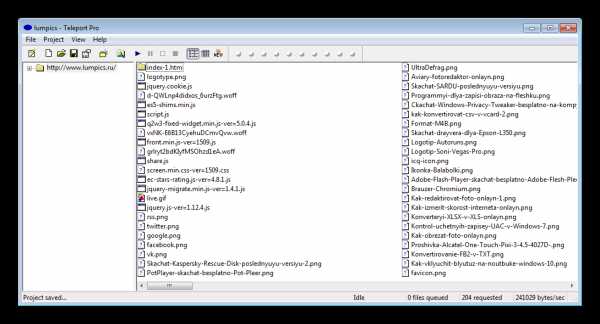
Teleport Pro распространяется платно и не имеет встроенного русского языка, но он может пригодится только при работе в мастере проекта, с остальным можно разобраться даже без знания английского.
Скачать Teleport Pro
Local Website Archive
У этого представителя уже имеется несколько приятных дополнений в виде встроенного браузера, который позволяет работать в двух режимах, просматривая онлайн страницы или сохраненные копии сайтов. Еще присутствует функция печати веб-страниц. Они не искажаются и практически не изменяются в размере, поэтому на выходе пользователь получает почти идентичную текстовую копию. Радует возможность помещения проекта в архив.
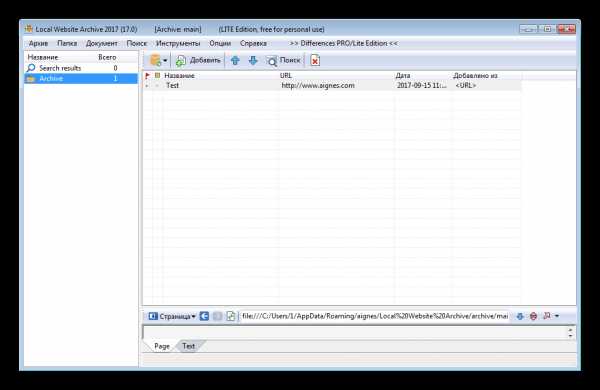
Остальное все очень схоже с другими подобными программами. Во время скачивания пользователь может мониторить состояние файлов, скорость загрузки и отслеживать ошибки, если они имеются.
Скачать Local Website Archive
Website Extractor отличается от других участников обзора тем, что разработчики подошли немного по-новому к составлению главного окна и распределению функций по разделам. Все необходимое находится в одном окне и отображается одновременно. Выбранный файл сразу же можно открыть в браузере в одном из предложенных режимов. Мастер создания проектов отсутствует, нужно просто вставить ссылки в выведенную строку, а при необходимости дополнительных настроек, открыть новое окно на панели инструментов.
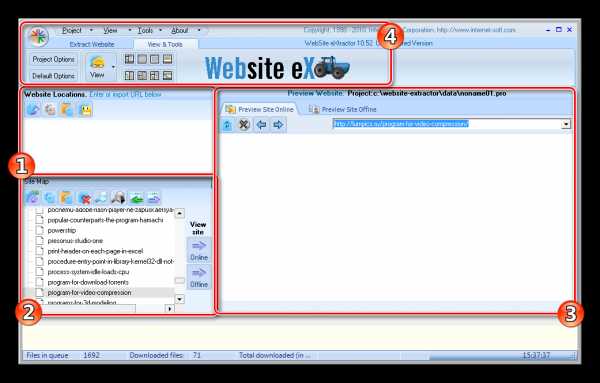
Опытным пользователям понравится широкий набор различных настроек проекта, начиная от фильтрации файлов и лимитов уровней ссылок, и заканчивая редактированием прокси-сервера и доменов.
Скачать Website Extractor
Web Copier
Ничем не примечательная программа для сохранения копий сайтов на компьютере. В наличии стандартный функционал: встроенный браузер, мастер создания проектов и подробная настройка. Единственное, что можно отметить – поиск файлов. Пригодится для тех, кто потерял место, где была сохранена веб-страница.
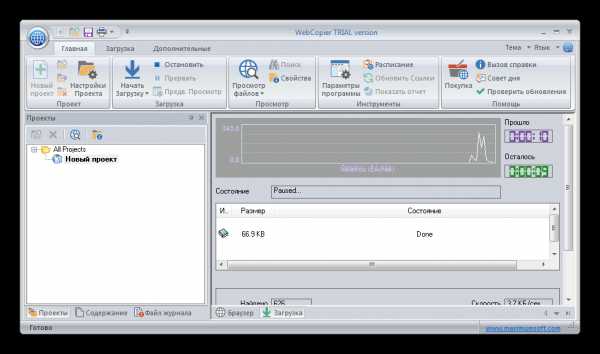
Для ознакомления есть бесплатная пробная версия, которая не ограничена в функционале, лучше опробовать ее перед тем, как покупать полную версию на официальном сайте разработчиков.
Скачать Web Copier
WebTransporter
В WebTransporter хочется отметить ее абсолютно бесплатное распространение, что редкость для подобного софта. В ней присутствует встроенный браузер, поддержка скачивания нескольких проектов одновременно, настройка соединения и ограничения по объему загруженной информации или размерам файлов.
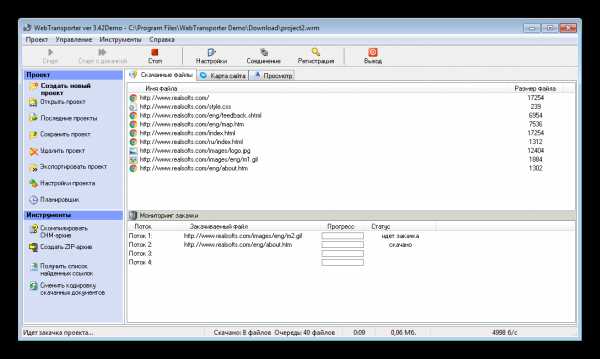
Скачивание происходит в несколько потоков, настройка которых осуществляется в специальном окне. Мониторить состояние загрузки можно на главном окне в отведенном размере, где отображается информация о каждом потоке отдельно.
Скачать WebTransporter
WebZIP
Интерфейс данного представителя выполнен довольно непродуманно, поскольку новые окна не открываются отдельно, а отображаются в главном. Единственное, что спасает – редактирование их размера под себя. Однако данное решение может понравиться некоторым пользователям. Программа отображает скачанные страницы отдельным списком, и доступен их просмотр сразу же во встроенном браузере, который ограничен автоматическим открытием только двух вкладок.

Подходит WebZIP для тех, кто собирается скачивать большие проекты и будет открывать их одним файлом, а не каждую страницу отдельно через HTML документ. Такой просмотр сайтов позволяет выполнять оффлайн браузер.
Скачать WebZIP
HTTrack Website Copier
Просто хорошая программа, в которой присутствует мастер создания проектов, фильтрация файлов и дополнительные настройки для продвинутых пользователей. Файлы не скачиваются сразу, а первоначально проводится сканирование всех типов документов, что есть на странице. Это позволяет изучить их еще даже до сохранения на компьютере.

Отслеживать подробные данные о состоянии скачивания можно в главном окне программы, где отображено количество файлов, скорость загрузки, ошибки и обновления. Доступно открытие папки сохранения сайта через специальный раздел в программе, где отображены все элементы.
Скачать HTTrack Website Copier
Список программ еще можно продолжать, но здесь приведены основные представители, которые отлично справляются со своей задачей. Почти все отличаются некоторым набором функций, но одновременно и похожи друг на друга. Если вы выбрали для себя подходящий софт, то не спешите его покупать, протестируйте сначала пробную версию, чтобы точно сформировать мнение о данной программе.
Мы рады, что смогли помочь Вам в решении проблемы.Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
ДА НЕТlumpics.ru
Как скопировать сайт целиком и бесплатно
Для того чтобы разобраться, какое копирование вам подойдет лучше всего, в первую очередь, вам стоит определиться с целями и задачами. Возможно, вам подойдет простое копирование с помощью браузера, а, возможно, потребуется помощь специалиста. Давайте вкратце пройдемся по основным способам копирования сайта и сделаем правильный вывод.
Требуется скачать содержимое страниц сайта?
И так, если вам достаточно просто скопировать содержимое страниц сайта себе на компьютер или флешку, то вам подойдет банальное сохранение страниц через браузер. Это будет самый простой, быстрый и бесплатный способ копирования. Само собой, этот вариант не гарантирует, что копия сайта будет работать также исправно, как и сайт-оригинал, но материалы сайта к себе на локальный компьютер у вас получиться сохранить.
Необходимо скопировать сайт с минимальными изменениями?
Если же вам нужно иметь точную копию сайта и при этом у вас есть небольшие навыки программирования или знания основ верстки сайтов, то использование программ и сервисов, скорее всего, будет наилучшим для вас решением. С помощью программы или онлайн-сервиса вы сможете бесплатно создать копию сайта, а дальше внести все необходимые изменения и переделать сайт под себя. Скорее всего, ваших знаний и нескольких дней чтения советов с форумов будет достаточно, чтобы удалить ненужный код, отредактировать текст и изображения.
Стоит задача сделать рабочую копию сайта?
Если же вы планируете скопировать сайт целиком и переделать его под себя, при этом вы не являетесь разработчиком сайтов, и знаний верстки у вас нет, то ни один из выше описанных способов вам не подойдет. В вашем случае, рекомендуется сразу обратиться к специалисту, который все сделает за вас и сэкономит ваше драгоценное время. Найти разработчика, который скопирует и настроит функционал сайта, вы сможете либо по объявлению, либо на фрилансе, либо воспользовавшись сервисами предоставляющие услуги по копированию сайтов.
Стоит понимать, что обращаясь к специалисту, сделать копию сайта бесплатно у вас вряд ли получится, но вот договориться и скопировать сайт недорого вы сможете. Главное, не старайтесь искать исполнителя, который скопирует сайт очень дешево. Не гонитесь за низкими ценами, так как это чаще всего влияет на качество проделанной специалистом работы. Ищите надежного специалиста, который сможет помочь вам и в будущем и не исчезнет после того как получит деньги от вас.
Полезный совет перед копированием сайта
И так, мы разобрались и выяснили, что для того чтобы копия сайта отображалась и работала, так же корректно как и оригинал, потребуются хоть какие-то знания разработчика. Если вы не хотите тратить время на это или не чувствуете в себе силы справиться с этой задачей, и все-таки решили обратиться к специалисту, то рекомендуем вам составить правильное техническое задание и прописать все нюансы. Это однозначно поможет вам добиться лучшего результата, а программисту позволит быстрее понять, что от него требуется.
sitecopy.pro
программа для загрузки файлов и скачивания сайта целиком.
У Вас в браузере заблокирован JavaScript. Разрешите JavaScript для работы сайта!
Скачать WGet для Windows можно здесьПришедшая из мира Linux, свободно распространяемая утилита Wget позволяет скачивать как отдельные файлы из интернета, так и сайты целиком, следуя по ссылкам на веб-страницах.
Чтобы получить подсказку по параметрам WGet наберите команду man wget в Linux или wget.exe —help в Windows.
Допустим, мы хотим создать полную копию сайта www.site.com на своем диске. Для этого открываем командную строку (Wget — утилита консольная) и пишем такую команду:
wget.exe -r -l10 -k -p -E -nc http://www.site.comWGET рекурсивно (параметр -r) обойдет каталоги и подкаталоги на удалённом сервере включая css-стили(-k) с максимальной глубиной рекурсии равной десяти (-l), а затем заменить в загруженных HTML-документах абсолютные ссылки на относительные (-k) и расширения на html(-E) для последующего локального просмотра скачанного сайта. При повторном скачивании не будут лица и перезаписываться повторы(-nc). К сожалению внутренние стили и картинки указанные в стилях не скачиваются
Если предполагается загрузка с сайта какого-либо одного каталога (со всеми вложенными в него папками), то логичнее будет включить в командную строку параметр -np. Он не позволит утилите при поиске файлов подниматься по иерархии каталогов выше указанной директории:
wget.exe -r -l10 -k http://www.site.com -np
Если загрузка данных была случайно прервана, то для возобновления закачки с места останова, необходимо в команду добавить ключ -с:
wget.exe -r -l10 -k http://www.site.com -c
По умолчанию всё скаченное сохраняется в рабочей директории утилиты. Определить другое месторасположение копируемых файлов поможет параметр -P:
wget.exe -r -l10 -k http://www.site.com -P c:\internet\files
Наконец, если сетевые настройки вашей сети предполагают использование прокси-сервера, то его настройки необходимо сообщить программе. См. Конфигурирование WGET
wget -m -k -nv -np -p --user-agent="Mozilla/5.0 (compatible; Konqueror/3.0.0/10; Linux)" АДРЕС_САЙТА
Загрузка всех URL, указанных в файле FILE:
wget -i FILE
Скачивание файла в указанный каталог (-P):
wget -P /path/for/save ftp://ftp.example.org/some_file.iso
Использование имени пользователя и пароля на FTP/HTTP (вариант 1):
wget ftp://login:[email protected]/some_file.iso
Использование имени пользователя и пароля на FTP/HTTP (вариант 2):
wget --user=login --password=password ftp://ftp.example.org/some_file.iso
Скачивание в фоновом режиме (-b):
wget -b ftp://ftp.example.org/some_file.iso
Продолжить (-c continue) загрузку ранее не полностью загруженного файла:
wget -c http://example.org/file.iso
Скачать страницу с глубиной следования 10, записывая протокол в файл log:
wget -r -l 10 http://example.org/ -o log
Скачать содержимое каталога http://example.org/~luzer/my-archive/ и всех его подкаталогов, при этом не поднимаясь по иерархии каталогов выше:
wget -r --no-parent http://example.org/~luzer/my-archive/
Для того, чтобы во всех скачанных страницах ссылки преобразовывались в относительные для локального просмотра, необходимо использовать ключ -k:
wget -r -l 10 -k http://example.org/
Также поддерживается идентификация на сервере:
wget --save-cookies cookies.txt --post-data 'user=foo&password=bar' http://example.org/auth.php
Скопировать весь сайт целиком:
wget -r -l0 -k http://example.org/
Например, не загружать zip-архивы:
wget -r -R «*.zip» http://freeware.ru
Залогиниться и скачать файлик ключа
@echo off wget --save-cookies cookies.txt --post-data "login=ТВОЙЛОГИН&password=ТВОЙПАРОЛЬ" http://beta.drweb.com/files/ -O- wget --load-cookies cookies.txt "http://beta.drweb.com/files/?p=win%%2Fdrweb32-betatesting.key&t=f" -O drweb32-betatesting.key
Внимание! Регистр параметров WGet различен!
Базовые ключи запуска
-V
—version
Отображает версию Wget.
-h
—help
Выводит помощь с описанием всех ключей командной строки Wget.
-b
—background
Переход в фоновый режим сразу после запуска. Если выходной файл не задан -o, выход перенаправляется в wget-log.
-e command
—execute command
Выполнить command, как если бы она была частью файла .wgetrc.
Команда, запущенная таким образом, будет выполнена после команд в .wgetrc, получая приоритет над ними.
Для задания более чем одной команды wgetrc используйте несколько ключей -e.
Протоколирование и ключи входного файла
-o logfile
—output-file=logfile
Протоколировать все сообщения в logfile. Обычно сообщения выводятся в standard error.
-a logfile
—append-output=logfile
Дописывать в logfile. То же, что -o, только logfile не перезаписывается, а дописывается.
Если logfile не существует, будет создан новый файл.
-d
—debug
Включает вывод отладочной информации, т.е. различной информации, полезной для разработчиков Wget при некорректной работе.
Системный администратор мог выбрать сборку Wget без поддержки отладки, в этом случае -d работать не будет.
Помните, что сборка с поддержкой отладки всегда безопасна — Wget не будет выводить отладочной информации,
пока она явно не затребована через -d.
-q
—quiet
Выключает вывод Wget.
-v
—verbose
Включает подробный вывод со всей возможной информацией. Задано по умолчанию.
-nv
—non-verbose
Неподробный вывод — отключает подробности, но не замолкает совсем (используйте -q для этого),
отображаются сообщения об ошибках и основная информация.
-i file
—input-file=file
Читать URL из входного файла file, в этом случае URL не обязательно указывать в командной строке.
Если адреса URL указаны в командной строке и во входном файле, первыми будут запрошены адреса из командной строки.
Файл не должен (но может) быть документом HTML — достаточно последовательного списка адресов URL.
Однако, при указании —force-html входной файл будет считаться html.
В этом случае могут возникнуть проблемы с относительными ссылками,
которые можно решить указанием <base href=»url»> внутри входного файла или —base=url в командной строке.
-F
—force-html
При чтении списка адресов из файла устанавливает формат файла как HTML.
Это позволяет организовать закачку по относительным ссылкам в локальном HTML-файле при указании <base href=»url»>
внутри входного файла или —base=url в командной строке.
-B URL
—base=URL
Используется совместно c -F для добавления URL к началу относительных ссылок во входном файле, заданном через -i.
Ключи скачивания
—bind-address=ADDRESS
При открытии клиентских TCP/IP соединений bind() на ADDRESS локальной машины. ADDRESS может указываться в виде имени хоста или IP-адреса.
Этот ключ может быть полезен, если машине выделено несколько адресов IP.
-t number
—tries=number
Устанавливает количество попыток в number. Задание 0 или inf соответствует бесконечному числу попыток. По умолчанию равно 20,
за исключением критических ошибок типа «в соединении отказано» или «файл не найден» (404), при которых попытки не возобновляются.
-O file
—output-document=file
Документы сохраняются не в соответствующие файлы, а конкатенируются в файл с именем file.
Если file уже существует, то он будет перезаписан. Если в качестве file задано -, документы будут выведены в стандартный вывод (отменяя -k).
Помните, что комбинация с -k нормально определена только для скачивания одного документа.
-nc
—no-clobber
Если файл скачивается более одного раза в один и тот же каталог, то поведение Wget определяется несколькими ключами, включая -nc.
В некоторых случаях локальный файл будет затёрт или перезаписан при повторном скачивании, в других — сохранён.
При запуске Wget без -N, -nc или -r скачивание того же файла в тот же каталог приводит к тому, что исходная копия файла сохраняется,
а новая копия записывается с именем file.1. Если файл скачивается вновь, то третья копия будет названа file.2 и т.д.
Если указан ключ -nc, такое поведение подавляется, Wget откажется скачивать новые копии файла.
Таким образом, «no-clobber» неверное употребление термина в данном режиме — предотвращается не затирание файлов
(цифровые суффиксы уже предотвращали затирание), а создание множественных копий.
При запуске Wget с ключом -r, но без -N или -nc, перезакачка файла приводит к перезаписыванию на место старого.
Добавление -nc предотвращает такое поведение, сохраняя исходные версии файлов и игнорируя любые новые версии на сервере.
При запуске Wget с ключом -N, с или без -r, решение о скачивании новой версии файла зависит от локальной
и удалённой временных отметок и размера файла. -nc не может быть указан вместе с -N.
При указании -nc файлы с расширениями .html и .htm будут загружаться с локального диска и обрабатываться так,
как если бы они были скачаны из сети.
-c
—continue
Продолжение закачки частично скачанного файла. Это полезно при необходимости завершить закачку,
начатую другим процессом Wget или другой программой. Например:
wget -c ftp://htmlweb.ru/ls-lR.Z
Если в текущем каталоге имеется файл ls-lR.Z, то Wget будет считать его первой частью удалённого файла и запросит сервер о продолжении закачки с отступом от начала, равному длине локального файла.
Нет необходимости указывать этот ключ, чтобы текущий процесс Wget продолжил закачку при пи потере связи на полпути. Это изначальное поведение. -c влияет только на закачки, начатые до текущего процесса Wget, если локальные файлы уже существуют.
Без -c предыдущий пример сохранит удалённый файл в ls-lR.Z.1, оставив ls-lR.Z без изменения.
Начиная с версии Wget 1.7, при использовании -c с непустым файлом, Wget откажется начинать закачку сначала, если сервер не поддерживает закачку, т.к. это привело бы к потере скачанных данных. Удалите файл, если вы хотите начать закачку заново.
Также начиная с версии Wget 1.7, при использовании -c для файла равной длины файлу на сервере Wget откажется скачивать и выведет поясняющее сообщение. То же происходит, если удалённый файл меньше локального (возможно, он был изменён на сервере с момента предыдущей попытки) — т.к. «продолжение» в данном случае бессмысленно, скачивание не производится.
С другой стороны, при использовании -c локальный файл будет считаться недокачанным, если длина удалённого файла больше длины локального. В этом случае (длина(удалённая) — длина(локальная)) байт будет скачано и приклеено в конец локального файла. Это ожидаемое поведение в некоторых случаях: например, можно использовать -c для скачивания новой порции собранных данных или лог-файла.
Однако, если файл на сервере был изменён, а не просто дописан, то вы получите испорченный файл. Wget не обладает механизмами проверки, является ли локальный файл начальной частью удалённого файла. Следует быть особенно внимательным при использовании -c совместно с -r, т.к. каждый файл будет считаться недокачанным.
Испорченный файл также можно получить при использовании -c с кривым HTTP прокси, который добавляет строку тима «закачка прервана». В будущих версиях возможно добавление ключа «откат» для исправления таких случаев.
Ключ -c можно использовать только с FTP и HTTP серверами, которые поддерживают заголовок Range.
—progress=type
Выбор типа индикатора хода закачки. Возможные значения: «dot» и «bar».
Индикатор типа «bar» используется по умолчанию. Он отображает ASCII полосу хода загрузки (т.н. «термометр»).
Если вывод не в TTY, то по умолчанию используется индикатор типа «dot».
Для переключения в режим «dot» укажите —progress=dot. Ход закачки отслеживается и выводится на экран в виде точек,
где каждая точка представляет фиксированный размер скачанных данных.
При точечной закачке можно изменить стиль вывода, указав dot:style. Различные стили определяют различное значение для одной точки.
По умолчанию одна точка представляет 1K, 10 точек образуют кластер, 50 точек в строке.
Стиль binary является более «компьютер»-ориентированным — 8K на точку, 16 точек на кластер и 48 точек на строку (384K в строке).
Стиль mega наиболее подходит для скачивания очень больших файлов — каждой точке соответствует 64K, 8 точек на кластер и 48 точек в строке
(строка соответствует 3M).
Стиль по умолчанию можно задать через .wgetrc. Эта установка может быть переопределена в командной строке.
Исключением является приоритет «dot» над «bar», если вывод не в TTY. Для непременного использования bar укажите —progress=bar:force.
-N
—timestamping
Включает использование временных отметок.
-S
—server-response
Вывод заголовков HTTP серверов и ответов FTP серверов.
—spider
При запуске с этим ключом Wget ведёт себя как сетевой паук, он не скачивает страницы, а лишь проверяет их наличие.
Например, с помощью Wget можно проверить закладки:
wget --spider --force-html -i bookmarks.html
Эта функция требует большой доработки, чтобы Wget достиг функциональности реальных сетевых пауков.
-T seconds
—timeout=seconds
Устанавливает сетевое время ожидания в seconds секунд. Эквивалентно одновременному указанию —dns-timeout,
—connect-timeout и —read-timeout.
Когда Wget соединяется или читает с удалённого хоста, он проверяет время ожидания и прерывает операцию при его истечении.
Это предотвращает возникновение аномалий, таких как повисшее чтение или бесконечные попытки соединения.
Единственное время ожидания, установленное по умолчанию, — это время ожидания чтения в 900 секунд.
Установка времени ожидания в 0 отменяет проверки.
Если вы не знаете точно, что вы делаете, лучше не устанавливать никаких значений для ключей времени ожидания.
—dns-timeout=seconds
Устанавливает время ожидания для запросов DNS в seconds секунд. Незавершённые в указанное время запросы DNS будут неуспешны.
По умолчанию никакое время ожидания для запросов DNS не устанавливается, кроме значений, определённых системными библиотеками.
—connect-timeout=seconds
Устанавливает время ожидания соединения в seconds секунд. TCP соединения, требующие большего времени на установку, будут отменены.
По умолчанию никакое время ожидания соединения не устанавливается, кроме значений, определённых системными библиотеками.
—read-timeout=seconds
Устанавливает время ожидания чтения (и записи) в seconds секунд. Чтение, требующее большего времени, будет неуспешным.
Значение по умолчанию равно 900 секунд.
—limit-rate=amount
Устанавливает ограничение скорости скачивания в amount байт в секунду. Значение может быть выражено в байтах,
килобайтах с суффиксом k или мегабайтах с суффиксом m. Например, —limit-rate=20k установит ограничение скорости скачивания в 20KB/s.
Такое ограничение полезно, если по какой-либо причине вы не хотите, чтобы Wget не утилизировал всю доступную полосу пропускания.
Wget реализует ограничение через sleep на необходимое время после сетевого чтения, которое заняло меньше времени,
чем указанное в ограничении. В итоге такая стратегия приводит к замедлению скорости TCP передачи приблизительно до указанного ограничения.
Однако, для установления баланса требуется определённое время, поэтому не удивляйтесь, если ограничение будет плохо работать
для небольших файлов.
-w seconds
—wait=seconds
Ждать указанное количество seconds секунд между закачками. Использование этой функции рекомендуется для снижения нагрузки на сервер
уменьшением частоты запросов. Вместо секунд время может быть указано в минутах с суффиксом m, в часах с суффиксом h или днях с суффиксом d.
Указание большого значения полезно, если сеть или хост назначения недоступны, так чтобы Wget ждал достаточное время для исправления
неполадок сети до следующей попытки.
—waitretry=seconds
Если вы не хотите, чтобы Wget ждал между различными закачками, а только между попытками для сорванных закачек,
можно использовать этот ключ. Wget будет линейно наращивать паузу, ожидая 1 секунду после первого сбоя для данного файла,
2 секунды после второго сбоя и так далее до максимального значения seconds.
Таким образом, значение 10 заставит Wget ждать до (1 + 2 + … + 10) = 55 секунд на файл.
Этот ключ включён по умолчанию в глобальном файле wgetrc.
—random-wait
Некоторые веб-сайты могут анализировать логи для идентификации качалок, таких как Wget,
изучая статистические похожести в паузах между запросами. Данный ключ устанавливает случайные паузы в диапазоне от 0 до 2 * wait секунд,
где значение wait указывается ключом —wait. Это позволяет исключить Wget из такого анализа.
В недавней статье на тему разработки популярных пользовательских платформ был представлен код,
позволяющий проводить такой анализ на лету. Автор предлагал блокирование подсетей класса C для
блокирования программ автоматического скачивания, несмотря на возможную смену адреса, назначенного DHCP.
На создание ключа —random-wait подвигла эта больная рекомендация блокировать множество невиновных пользователей по вине одного.
-Y on/off
—proxy=on/off
Включает или выключает поддержку прокси. Если соответствующая переменная окружения установлена, то поддержка прокси включена по умолчанию.
-Q quota
—quota=quota
Устанавливает квоту для автоматических скачиваний. Значение указывается в байтах (по умолчанию),
килобайтах (с суффиксом k) или мегабайтах (с суффиксом m).
Квота не влияет на скачивание одного файла. Так если указать wget -Q10k ftp://htmlweb.ru/ls-lR.gz,
файл ls-lR.gz будет скачан целиком. То же происходит при указании нескольких URL в командной строке.
Квота имеет значение при рекурсивном скачивании или при указании адресов во входном файле.
Т.о. можно спокойно указать wget -Q2m -i sites — закачка будет прервана при достижении квоты.
Установка значений 0 или inf отменяет ограничения.
—dns-cache=off
Отключает кеширование запросов DNS. Обычно Wget запоминает адреса, запрошенные в DNS,
так что не приходится постоянно запрашивать DNS сервер об одном и том же (обычно небольшом) наборе адресов.
Этот кэш существует только в памяти. Новый процесс Wget будет запрашивать DNS снова.
Однако, в некоторых случаях кеширование адресов не желательно даже на короткий период запуска такого приложения как Wget.
Например, секоторые серверы HTTP имеют динамически выделяемые адреса IP, которые изменяются время от времени.
Их записи DNS обновляются при каждом изменении. Если закачка Wget с такого хоста прерывается из-за смены адреса IP,
Wget повторяет попытку скачивания, но (из-за кеширования DNS) пытается соединиться по старому адресу.
При отключенном кешировании DNS Wget будет производить DNS-запросы при каждом соединении и, таким образом,
получать всякий раз правильный динамический адрес.
Если вам не понятно приведённое выше описание, данный ключ вам, скорее всего, не понадобится.
—restrict-file-names=mode
Устанавливает, какие наборы символов могут использоваться при создании локального имени файла из адреса удалённого URL.
Символы, запрещённые с помощью этого ключа, экранируются, т.е. заменяются на %HH, где HH — шестнадцатиричный код соответствующего символа.
По умолчанию Wget экранирует символы, которые не богут быть частью имени файла в вашей операционной системе,
а также управляющие символы, как правило непечатные. Этот ключ полезен для смены умолчания,
если вы сохраняете файл на неродном разделе или хотите отменить экранирование управляющих символов.
Когда mode установлен в «unix», Wget экранирует символ / и управляющие символы в диапазонах 0-31 и 128-159. Это умолчание для Ос типа Unix.
Когда mode установлен в «windows», Wget экранирует символы \, |, /, :, ?, «, *, и управляющие символы в диапазонах 0-31 и 128-159.
Дополнительно Wget в Windows режиме использует + вместо : для разделения хоста и порта в локальных именах файлов и @ вместо ?
для отделения запросной части имени файла от остального. Таким образом, адрес URL, сохраняемый в Unix режиме как
www.htmlweb.ru:4300/search.pl?input=blah, в режиме Windows будет сохранён как www.htmlweb.ru+4300/search.pl@input=blah.
Этот режим используется по умолчанию в Windows.
Если к mode добавить, nocontrol, например, unix,nocontrol, экранирование управляющих символов отключается.
Можно использовать —restrict-file-names=nocontrol для отключения экранирования управляющих символов без влияния
на выбор ОС-зависимого режима экранирования служебных символов.
Ключи каталогов
-nd
—no-directories
Не создавать структуру каталогов при рекурсивном скачивании. С этим ключом все файлы сохраняются в текущий каталог
без затирания (если имя встречается больше одного раза, имена получат суффикс .n).
-x
—force-directories
Обратное -nd — создаёт структуру каталогов, даже если она не создавалась бы в противном случае.
Например, wget -x http://htmlweb.ru/robots.txt сохранит файл в htmlweb.ru/robots.txt.
-nH
—no-host-directories
Отключает создание хост-каталога. По умолчания запуск Wget -r http://htmlweb.ru/ создаст структуру каталогов,
начиная с htmlweb.ru/. Данный ключ отменяет такое поведение.
—protocol-directories
Использовать название протокола как компонент каталога для локальный файлов.
Например, с этим ключом wget -r http://host сохранит в http/host/… вместо host/….
—cut-dirs=number
Игнорировать number уровней вложенности каталогов. Это полезный ключ для чёткого управления каталогом для
сохранения рекурсивно скачанного содержимого.
Например, требуется скачать каталог ftp://htmlweb.ru/pub/xxx/. При скачивании с -r локальная копия будет сохранена
в ftp.htmlweb.ru/pub/xxx/. Если ключ -nH может убрать ftp.htmlweb.ru/ часть, остаётся ненужная pub/xemacs.
Здесь на помощь приходит —cut-dirs; он заставляет Wget закрывать глаза на number удалённых подкаталогов.
Ниже приведены несколько рабочих примеров —cut-dirs.
No options -> ftp.htmlweb.ru/pub/xxx/ -nH -> pub/xxx/ -nH --cut-dirs=1 -> xxx/ -nH --cut-dirs=2 -> . --cut-dirs=1 -> ftp.htmlweb.ru/xxx/
Если вам нужно лишь избавиться от структуры каталогов, то этот ключ может быть заменён комбинацией -nd и -P. Однако, в отличии от -nd, —cut-dirs не теряет подкаталоги — например, с -nH —cut-dirs=1, подкаталог beta/ будет сохранён как xxx/beta, как и ожидается.
-P prefix
—directory-prefix=prefix
Устанавливает корневой каталог в prefix. Корневой каталог — это каталог, куда будут сохранены все файлы и подкаталоги,
т.е. вершина скачиваемого дерева. По умолчанию . (текущий каталог).
Ключи HTTP
-E
—html-extension
Данный ключ добавляет к имени локального файла расширение .html, если скачиваемый URL имеет тип application/xhtml+xml или text/html,
а его окончание не соответствует регулярному выражению \.[Hh][Tt][Mm][Ll]?. Это полезно, например, при зеркалировании сайтов,
использующих .asp страницы, когда вы хотите, чтобы зеркало работало на обычном сервере Apache.
Также полезно при скачивании динамически-генерируемого содержимого. URL типа http://site.com/article.cgi?25
будет сохранён как article.cgi?25.html.
Сохраняемые таким образом страницы будут скачиваться и перезаписываться при каждом последующем зеркалировании,
т.к. Wget не может сопоставить локальный файл X.html удалённому адресу URL X
(он ещё не знает, что URL возвращает ответ типа text/html или application/xhtml+xml).
Для предотвращения перезакачивания используйте ключи -k и -K, так чтобы оригинальная версия сохранялась как X.orig.
—http-user=user
—http-passwd=password
Указывает имя пользователя user и пароль password для доступа к HTTP серверу. В зависимости от типа запроса Wget закодирует их,
используя обычную (незащищённую) или дайджест схему авторизации.
Другой способ указания имени пользователя и пароля — в самом URL. Любой из способов раскрывает ваш пароль каждому,
кто запустит ps. Во избежание раскрытия паролей, храните их в файлах .wgetrc или .netrc и убедитесь в недоступности
этих файлов для чтения другими пользователями с помощью chmod. Особо важные пароли не рекомендуется хранить даже в этих файлах.
Вписывайте пароли в файлы, а затем удаляйте сразу после запуска Wget.
—no-cache
Отключает кеширование на стороне сервера. В этой ситуации Wget посылает удалённому серверу соответствующую директиву
(Pragma: no-cache) для получения обновлённой, а не кешированной версии файла. Это особенно полезно для стирания устаревших
документов на прокси серверах.
Кеширование разрешено по умолчанию.
—no-cookies
Отключает использование cookies. Cookies являются механизмом поддержки состояния сервера.
Сервер посылает клиенту cookie с помощью заголовка Set-Cookie, клиент включает эту cookie во все последующие запросы.
Т.к. cookies позволяют владельцам серверов отслеживать посетителей и обмениваться этой информацией между сайтами,
некоторые считают их нарушением конфиденциальности. По умолчанию cookies используются;
однако сохранение cookies по умолчанию не производится.
—load-cookies file
Загрузка cookies из файла file до первого запроса HTTP. file — текстовый файл в формате,
изначально использовавшемся для файла cookies.txt Netscape.
Обычно эта опция требуется для зеркалирования сайтов, требующих авторизации для части или всего содержания.
Авторизация обычно производится с выдачей сервером HTTP cookie после получения и проверки регистрационной информации.
В дальнейшем cookie посылается обозревателем при просмотре этой части сайта и обеспечивает идентификацию.
Зеркалирование такого сайта требует от Wget подачи таких же cookies, что и обозреватель.
Это достигается через —load-cookies — просто укажите Wget расположение вашего cookies.txt, и он отправит идентичные обозревателю cookies.
Разные обозреватели хранят файлы cookie в разных местах:
Netscape 4.x. ~/.netscape/cookies.txt.
Mozilla and Netscape 6.x. Файл cookie в Mozilla тоже называется cookies.txt, располагается где-то внутри ~/.mozilla в директории вашего профиля.
Полный путь обычно выглядит как ~/.mozilla/default/some-weird-string/cookies.txt.
Internet Explorer. Файл cookie для Wget может быть получен через меню File, Import and Export, Export Cookies.
Протестировано на Internet Explorer 5; работа с более ранними версиями не гарантируется.
Other browsers. Если вы используете другой обозреватель, —load-cookies будет работать только в том случае,
если формат файла будет соответствовать формату Netscape, т.е. то, что ожидает Wget.
Если вы не можете использовать —load-cookies, может быть другая альтернатива.
Если обозреватель имеет «cookie manager», то вы можете просмотреть cookies, необходимые для зеркалирования.
Запишите имя и значение cookie, и вручную укажите их Wget в обход «официальной» поддержки:
wget --cookies=off --header "Cookie: name=value"
—save-cookies file
Сохранение cookies в file перед выходом. Эта опция не сохраняет истекшие cookies и cookies
без определённого времени истечения (так называемые «сессионные cookies»).
См. также —keep-session-cookies.
—keep-session-cookies
При указании —save-cookies сохраняет сессионные cookies. Обычно сессионные cookies не сохраняются,
т.к подразумевается, что они будут забыты после закрытия обозревателя. Их сохранение полезно для сайтов,
требующих авторизации для доступа к страницам. При использовании этой опции разные процессы Wget для сайта будут выглядеть
как один обозреватель.
Т.к. обычно формат файла cookie file не содержит сессионных cookies, Wget отмечает их временной отметкой истечения 0.
—load-cookies воспринимает их как сессионные cookies, но это может вызвать проблемы у других обозревателей
Загруженные таким образом cookies интерпретируются как сессионные cookies, то есть для их сохранения с
—save-cookies необходимо снова указывать —keep-session-cookies.
—ignore-length
К сожалению, некоторые серверы HTTP (CGI программы, если точнее) посылают некорректный заголовок Content-Length,
что сводит Wget с ума, т.к. он думает, что документ был скачан не полностью.
Этот синдром можно заметить, если Wget снова и снова пытается скачать один и тот же документ,
каждый раз указывая обрыв связи на том же байте.
С этим ключом Wget игнорирует заголовок Content-Length, как будто его никогда не было.
—header=additional-header
Укажите дополнительный заголовок additional-header для передачи HTTP серверу. Заголовки должны содержать «:»
после одного или более непустых символов и недолжны содержать перевода строки.
Вы можете указать несколько дополнительных заголовков, используя ключ —header многократно.
wget --header='Accept-Charset: iso-8859-2' --header='Accept-Language: hr' http://aaa.hr/
Указание в качестве заголовка пустой строки очищает все ранее указанные пользовательские заголовки.
—proxy-user=user
—proxy-passwd=password
Указывает имя пользователя user и пароль password для авторизации на прокси сервере. Wget кодирует их, использую базовую схему авторизации.
Здесь действуют те же соображения безопасности, что и для ключа —http-passwd.
—referer=url
Включает в запрос заголовок `Referer: url’. Полезен, если при выдаче документа сервер считает, что общается с интерактивным обозревателем,
и проверяет, чтобы поле Referer содержало страницу, указывающую на запрашиваемый документ.
—save-headers
Сохраняет заголовки ответа HTTP в файл непосредственно перед содержанием, в качестве разделителя используется пустая строка.
-U agent-string
—user-agent=agent-string
Идентифицируется как обозреватель agent-string для сервера HTTP.
HTTP протокол допускает идентификацию клиентов, используя поле заголовка User-Agent. Это позволяет различать программное обеспечение,
обычно для статистики или отслеживания нарушений протокола. Wget обычно идентифицируется как Wget/version, где version — текущая версия Wget.
Однако, некоторые сайты проводят политику адаптации вывода для обозревателя на основании поля User-Agent.
В принципе это не плохая идея, но некоторые серверы отказывают в доступе клиентам кроме Mozilla и Microsoft Internet Explorer.
Этот ключ позволяет изменить значение User-Agent, выдаваемое Wget. Использование этого ключа не рекомендуется,
если вы не уверены в том, что вы делаете.
—post-data=string
—post-file=file
Использует метод POST для всех запросов HTTP и отправляет указанные данные в запросе. —post-data отправляет в качестве данных строку string,
а —post-file — содержимое файла file. В остальном они работают одинаково.
Пожалуйста, имейте в виду, что Wget должен изначально знать длину запроса POST. Аргументом ключа —post-file должен быть обычный файл;
указание FIFO в виде /dev/stdin работать не будет. Не совсем понятно, как можно обойти это ограничение в HTTP/1.0.
Хотя HTTP/1.1 вводит порционную передачу, для которой не требуется изначальное знание длины, клиент не может её использовать,
если не уверен, что общается с HTTP/1.1 сервером. А он не может этого знать, пока не получит ответ, который, в свою очередь,
приходит на полноценный запрос. Проблема яйца и курицы.
Note: если Wget получает перенаправление в ответ на запрос POST, он не отправит данные POST на URL перенаправления.
Часто URL адреса, обрабатывающие POST, выдают перенаправление на обычную страницу (хотя технически это запрещено),
которая не хочет принимать POST. Пока не ясно, является ли такое поведение оптимальным; если это не будет работать, то будет изменено.
Пример ниже демонстрирует, как авторизоваться на сервере, используя POST, и затем скачать желаемые страницы,
доступные только для авторизованных пользователей:
wget --save-cookies cookies.txt --post-data 'user=foo&password=bar' http://htmlweb.ru/auth.php
wget --load-cookies cookies.txt -p http://server.com/interesting/article.php
Конфигурирование WGET
Основные настроки, которые необходимо писать каждый раз, можно указать в конфигурационном файле программы. Для этого зайдите в рабочую директорию Wget, найдите там файл sample.wgetrc, переименуйте его в .wgetrc и редакторе пропишите необходимые конфигурационные параметры.
user-agent = "Mozilla/5.0" tries = 5 количество попыток скачать wait = 0 не делать паузы continue = on нужно докачивать dir_prefix = ~/Downloads/ куда складывать скачаное use_proxy=on - использовать прокси http_proxy - характеристики вашего прокси-сервера.
Как под Windows заставить WGET читать настройки из wgetrc файла:
- Задать переменную окружения WGETRC, указав в ней полный путь к файлу.
- Задать переменную HOME, в которой указать путь к домашней папке пользователя (c:\Documents and settings\jonh). Тогда wget будет искать файл «wgetrc» в этой папке.
- Кроме этого можно создать файл wget.ini в той же папке, где находится wget.exe, и задать там дополнительные параметры командной строки wget.
Полезную информацию по WGET можно почерпнуть здесь:
htmlweb.ru
Онлайн сервис скачивания сайтов. Перенос существующего сайта на CMS.
Восстановить с субдоменами
Оптимизировать HTML-код
Оптимизировать картинки
Сжать JS
Сжать CSS
Вычистить счетчики и аналитику
Вычистить рекламу
Удалить внешние ссылки, сохранив анкоры
Удалить внешние ссылки вместе с анкорами
Удалить кликабельные контакты
Удалить внешние iframes альфа
Сделать внутренние ссылки относительными рекомендуем
Сделать сайт без www. (обновляются все внутренние ссылки) рекомендуем
Сделать сайт с www. (обновляются все внутренние ссылки)
Сохранить перенаправления
ru.archivarix.com
Программы для загрузки сайтов на жесткий диск / Программное обеспечение
Обращаясь по любому поводу к нескончаемым ресурсам всемирной паутины, порой, мы даже не замечаем, насколько стали интернет-зависимыми. Нужно написать реферат – материалы берутся из Сети, возникла необходимость посоветоваться со знающим человеком в каком-либо вопросе – ответ на свой вопрос отыскивается на тематическом форуме, просто одолевает скука – в распоряжении есть онлайновые библиотеки, а также файловые архивы с играми, музыкой, видео и т.д. При этом, «зависимых» людей, которые были бы полностью довольны скоростью соединения с интернетом, крайне мало. Переход на более быстрый тип соединения помогает ощутить свободу, но лишь в первое время. Единственное средство не ждать загрузки с сервером – закачать любимый сайт на жесткий диск целиком. В этом случае время, потраченное на открытие файлов, будет определяться только скоростью работы винчестера. Если сайт содержит тысячу страниц, то сохранять их по одной в обычном браузере очень неудобно. Эта задача решается специальными утилитами, чьи возможности сохранения гораздо шире, чем у Firefox, Opera и других программ для веб-серфинга.Teleport Pro 1.43
Это программа из тех, про которые говорят: «проверено временем». Не претендуя на первое место по обилию редко используемых функций, она стабильно и качественно выполняет свою работу – загружает из сети сайты. Простой интерфейс Teleport Pro обманчив – программа достаточно гибкая в настройке и возможностей у нее достаточно, чтобы перенести на жесткий диск практически любой сайт. Настройка программы производится с помощью специального мастера, который позволяет указать глубину загрузки и определить типы файлов, которые нужно скачать. Важно также указать, что вы хотите получить на выходе: копию сайта с возможностью переходить с одной страницы на другую (в этом случае ссылки будут заменены на относительные) или же перенос сайта на жесткий диск с сохранением структуры и ссылок. Кроме выкачки сайта на жесткий диск, Teleport Pro может помочь решить несколько других задач, например, составить список всех страниц, на которые ссылается сайт, выполнить на сайте поиск файлов определенного типа или страниц, в тексте которых имеются ключевые слова. Сохранение страниц сайта может производиться с возможностью просмотра всех ссылок в режиме оффлайн или с сохранением внутренней структуры ссылок на страницы сайта. Для файлов, которые должны игнорироваться при загрузке проекта, в окне параметров программы нужно указать маски, согласно которым будут отсеиваться ненужные ссылки. Если требуется выполнить несколько проектов один за другим, можно использовать планировщик заданий Sсheduler, который позволяет загрузить несколько интернет-ресурсов, согласно составленному расписанию. Он представлен в виде отдельной утилиты, которую можно найти в папке, куда установлена Teleport Pro. После выполнения составленного проекта или через указанное время (например, через четыре часа после запуска) программа может автоматически завершить свою работу. Программа стоит $40. Скачать триал-версию можно отсюда.Offline Explorer Pro 4.6
Offline Explorer – это одна из самых мощных программ для загрузки Интернет-контента. Помимо своего основного предназначения — копирования сайтов целиком – Offline Explorer Pro имеет массу других назначений. Например, ее очень удобно использовать для сохранения на жесткий диск потокового видео и флеш-файлов. Поддерживается и загрузка видеофайлов с сайта YouTube. Также программа может автоматически загрузить все графические файлы из интернет-галереи и утилиты из файлового архива сайта. Все загруженные файлы можно тут же просматривать во встроенном браузере. Поскольку программа имеет большое количество настроек, параметры, определяющие характер загрузки, могут быть сохранены в виде так называемых пользовательских шаблонов, которые затем можно использовать повторно. Такие предварительные настройки могут включать, например, фильтры для типов скачиваемых файлов, ограничение на размер, определение их расположения, данные для автоматической авторизации и многое другое. Интересной особенностью программы является то, что для каждого из типов загружаемых файлов можно устанавливать свои правила. Так, например, проект можно сконфигурировать таким образом, чтобы файлы rar скачивались с любого сайта, а рисунки и звуковые файлы – только из исходной папки. Кроме этого, загрузку можно ограничивать по протоколу и ключевым словам. В отличие от аналогичных программ, Offline Explorer анализирует не только видимый текст, но и HTML-теги, отыскивая в них ключевые слова. Если вход на сайт защищен паролем, программа может приостановить выполнение проекта или самостоятельно заполнить поля для ввода пароля и логина. Интеграция Offline Explorer с такими популярными программами как Firefox и Opera, позволяет выполнять загрузку новой ссылки или всех ссылок, которые имеются на данной странице, прямо из окна контекстного меню браузера. Кроме этого, есть возможность импорта избранных ссылок с последующей загрузкой некоторых из них. Наконец, стоит сказать, что Offline Explorer выпускается в трех версиях: Offline Explorer, Offline Explorer Pro и Offline Explorer Enterprise. Первая версия является базовой и содержит только основные параметры. В ней отсутствуют такие возможности, как перетаскивание ссылок из браузера, организация проектов при помощи вложенных папок, сохранение страниц и файлов, загрузка по протоколу HTTPS и некоторые другие. Две другие версии программы незначительно различаются между собой максимальным количеством загруженных ссылок (в Offline Explorer Enterprise их может быть до 100 млн. в одном проекте, а в Offline Explorer Pro – до трех миллионов) и поддержкой OLE-автоматизации, благодаря которой можно управлять программой из других приложений. В целом можно сказать, что Offline Explorer Enterprise предназначена для крупных компаний, поэтому большинству пользователей будет достаточно возможностей Offline Explorer Pro, стоимость которой $70. Скачать Offline Explorer можно отсюда.WinHTTrack Website Copier 3.40-2
Основная причина, по которой эта программа попала в наш обзор – бесплатный статус. Оффлайн-браузеры – это достаточно удобные, но в то же время достаточно дорогие программы, поэтому программа, которая предлагает скачивать сайты бесплатно, не может не привлечь внимание. Работа с WinHTTrack Website Copier организована в виде мастера. Нужно указать название проекта, начальные ссылки, с которых должна производиться загрузка (можно сразу несколько), а также определить параметры выкачки сайта. Программа имеет русский интерфейс, но лучше использовать английскую версию, так как из-за проблем с кодировкой некоторые названия параметров отображаются некорректно. Среди интересных возможностей WinHTTrack Website Copier – определение максимальной глубины выкачки отдельно для страниц с того же сервера, на котором находится исходная страница, и для страниц, которые расположены на внешних серверах. Благодаря этому можно предотвратить ситуацию, когда программа начнет целиком скачивать сайт, на который имеет ссылка с исходной страницы, но который вас совершенно не интересует. Еще одна удобная особенность программы – возможность следить за процессом загрузки страниц. Выкачка сайта может выполняться в несколько потоков (их количество можно задать в настройках проекта). Когда она начинается, вы можете видеть адрес каждой страницы, которая загружается, а также ползунок, отображающий ход выкачки. Рядом с этими данными для каждой страницы есть кнопка «Пропустить». Таким образом, если вы увидите, что WinHTTrack Website Copier тянет ненужный и большой файл, вы тут же сможете остановить это задание. Загрузка проекта при этом прекращена не будет. В WinHTTrack Website Copier нет встроенной программы для просмотра веб-страниц, как, например, в Offline Explorer, поэтому выкаченные сайты нужно просматривать во внешнем браузере, с которым вы обычно работаете в интернете. Просто найдите команду «Просмотр сайтов» в меню «Файл», и программа сгенерирует HTML-страничку с перечнем всех проектов, которые загружались с ее помощью. Страница будет открыта в браузере, который используется в системе по умолчанию, после чего можно будет выбрать один из проектов и начать оффлайн-просмотр сайта. Скачать WinHTTrack Website Copier можно отсюда.Выводы
К хорошему человек привыкает быстро, поэтому уже через неделю работы на быстром канале, вновь появляется дискомфорт от необходимости ждать момента, когда файлы будут скачаны на жесткий диск. При увеличении пропускной способности сети, естественно растет желание воспользоваться дополнительными сервисами – посмотреть трейлер нового фильма, пройтись по онлайновым телевизионным каналам в поисках свежих новостей, просмотреть видеоблог и так далее. Конечно, использование оффлайн-браузеров не решит в полной мере проблему нехватки «интернет-мощностей», однако сделает ее менее ощутимой, позволив комфортно искать информацию. Teleport Pro давно заслужила доверие многих тысяч пользователей, благодаря гибким настройкам и корректной обработке сайтов, Offline Explorer отличается более дружественным интерфейсом и поддержкой большего количества типов файлов. Что же касается WinHTTrack Website Copier, то, как уже было сказано выше, эта программа интересна, прежде всего, своим бесплатным статусом.Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
3dnews.ru
Скопировать сайт онлайн. Бесплатно.
clonesite.ru — сервис, с помощью которого можно полностью скачать сайт на компьютер онлайн и бесплатно.
Как работает сервис
1. Вставьте
ссылку
2. Нажмите
«Cкопировать»
3. Дождитесь
начала скачивания
4. Файлы загружены
на компьютер
Если сервис не работает или результат не подходит
К сожалению, не все сайты можно сохранить вышеописанным методом. Для некоторых случаев требуется особый подход.
Напишите комментарий в форму ниже: адрес сайта который вы пытались скопировать и прочие детали. Мы постараемся, по возможности, выяснить в чем дело и напишем ответ. Вы можете воспользоваться альтернативными методами.
Что внутри
В основе сервиса лежит wget — полезная и простая программа Linux. На серверной стороне она выглядит как «wget -k -p -Q10M http://site.com»:
- Параметр -p означает, что все ресурсы, на которые есть ссылки в документе (картинки, css, js) будут будут сохранены вместе с главным документом.
- Параметр -k укажет программе преобразовать все ссылки на ресурсы, чтобы их можно было использовать на компьютере.
- Параметр -Q10M, задает ограничение в 10 мегабайт на размер всего скачиваемого сайта (это сделано в целях безопасности).
Как использовать скачанные файлы
Если ссылка введена правильно, загрузка сайта начнется автоматически, спустя некоторое время. На ваш компьютер будет сохранен архив с файлами. После распаковки найдите в папке index.html и откройте в браузере. Если загрузка прошла успешно и все файлы корректно отобразились, вы увидите сохраненную копию сайта (лендинга).
Что не будет сохранено в архиве
Серверные ресурсы, такие как скрипты php, обработчики форм, базы данных, и прочий back-end, хранящийся на серверной стороне никаким образом не может быть получен обычным пользователем. Доступ к этим файлам может получить только владелец сайта (хостинга).
Как сделать рабочими формы на сайте
В процессе заполнения
Три причины поделиться проектом
- Сервис бесплатный
- Нет необходимости делать репосты
- Нет регистрации
Пожалуйста, поддержите проект, поделитесь с друзьями. Или оставьте комментарий в форму ниже.
clonesite.ru
Ваш комментарий будет первым