Как привести выписку ЕГРН в читаемый вид, используя python / Хабр
Тернист и труден путь человека, столкнувшегося с ФГИС ЕГРН Росреестра. Его ждут бесконечные ожидания загрузки браузера, ключи, капчи, интервалы между запросами в 5 минут. За что ему такие страдания? Он же уже внес свои кровные, когда решился работать с данной системой и заказывать свои выписки. Но нет — получение выписки из ЕГРН, это как раздевание репчатого лука. Последний шаг, который поджидает страдальца — скачанная, вожделенная выписка представлена zip архивом, в котором, гм, еще один архив и файл sig. А уже внутри лежит сам файл выписки. Но прочитать его тоже непросто — он в xml. И чтобы все срослось, необходимо, оказывается загружать этот xml вместе с sig на специальную страницу Росреестра. А там, там еще капча ждет. И так с каждой выпиской! Вот эту последнюю боль будем сегодня побеждать, используя python.Задача:
- распаковать все zip в папке,
- загрузить по спец. ссылке в Росреестр,
- скачать, наконец!, человекочитаемый вид выписки.


После импорта модулей python:
import os import zipfile import webbrowser,time from selenium import webdriver from selenium.common.exceptions import NoSuchElementException from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.action_chains import ActionChainsРаспакуем все zip архивы и удалим их, чтобы они не путались с содержимым:
zipFiles = []
sigFiles = []
for filename in os.listdir('.'):
if filename.endswith('.zip'):
zipfile.ZipFile(filename, 'r').extractall()
os.remove(filename)
Получились zip архивы и sig файлы к ним, которые далее будут загружаться на сайт Росреестра:Переходим к основному циклу программы по всем файлам в директории (в моем случае «С:/2»):
for filename in zipFiles:
act = browser.find_element_by_id('sig_file')
act.send_keys('C:\\2\\'+str(filename)+'. sig')
act = browser.find_element_by_id('xml_file')
#распаковываем zip файл
zip_ref = zipfile.ZipFile(filename, 'r').extractall()
#берем xml из распакованного
for f in os.listdir('.'):
if f.endswith('.xml'):
print(f)
#вводим xml файл на сайте
act.send_keys('C:\\2\\'+str(f))
act = browser.find_element_by_css_selector('input.brdg1111')
act.click()
i = str(input("Введите каптчу: "))
for b in i:
act.send_keys(b)
time.sleep (0.1)
#act.submit()
act = browser.find_element_by_css_selector('.terminal-button-bright')
act.click()
time.sleep (5)
try:
act = browser.find_element_by_link_text('Показать в человекочитаемом формате')
act.click()
После успешной загрузки страницы портала Росреестра rosreestr.gov.ru/wps/portal/cc_vizualisation, программа найдет в директории zip архив, достанет оттуда xml файл выписки и вставит в нужное поле на сайте. То же самое программа сделает с файлом sig, прилагаемым к xml: sig')
act = browser.find_element_by_id('xml_file')
#распаковываем zip файл
zip_ref = zipfile.ZipFile(filename, 'r').extractall()
#берем xml из распакованного
for f in os.listdir('.'):
if f.endswith('.xml'):
print(f)
#вводим xml файл на сайте
act.send_keys('C:\\2\\'+str(f))
act = browser.find_element_by_css_selector('input.brdg1111')
act.click()
i = str(input("Введите каптчу: "))
for b in i:
act.send_keys(b)
time.sleep (0.1)
#act.submit()
act = browser.find_element_by_css_selector('.terminal-button-bright')
act.click()
time.sleep (5)
try:
act = browser.find_element_by_link_text('Показать в человекочитаемом формате')
act.click()
sig')
act = browser.find_element_by_id('xml_file')
#распаковываем zip файл
zip_ref = zipfile.ZipFile(filename, 'r').extractall()
#берем xml из распакованного
for f in os.listdir('.'):
if f.endswith('.xml'):
print(f)
#вводим xml файл на сайте
act.send_keys('C:\\2\\'+str(f))
act = browser.find_element_by_css_selector('input.brdg1111')
act.click()
i = str(input("Введите каптчу: "))
for b in i:
act.send_keys(b)
time.sleep (0.1)
#act.submit()
act = browser.find_element_by_css_selector('.terminal-button-bright')
act.click()
time.sleep (5)
try:
act = browser.find_element_by_link_text('Показать в человекочитаемом формате')
act.click()
Далее программа будет ждать ввода капчи:
После ввода пользователем капчи, она отправит ее на сайт и нажмет на ссылку скачивания уже «нормальной» выписки из ЕГРН:
Откроется окно, в котором будет готовая выписка, сохранить которую можно в html либо, нажав в Chrome CTRL+P, — в pdf.
Осталось добавить авторазгадывание капчи и автоскачивание человекочитаемых выписок. Но это ведь самое простое здесь, не так ли?
Код программы — здесь.
|
|

как декодировать данные xml в удобочитаемый формат
спросил
Изменено 7 лет, 1 месяц назад
Просмотрено 1к раз
У меня есть несколько XML-файлов, которые использовались как файлы личных данных в астрологическом приложении.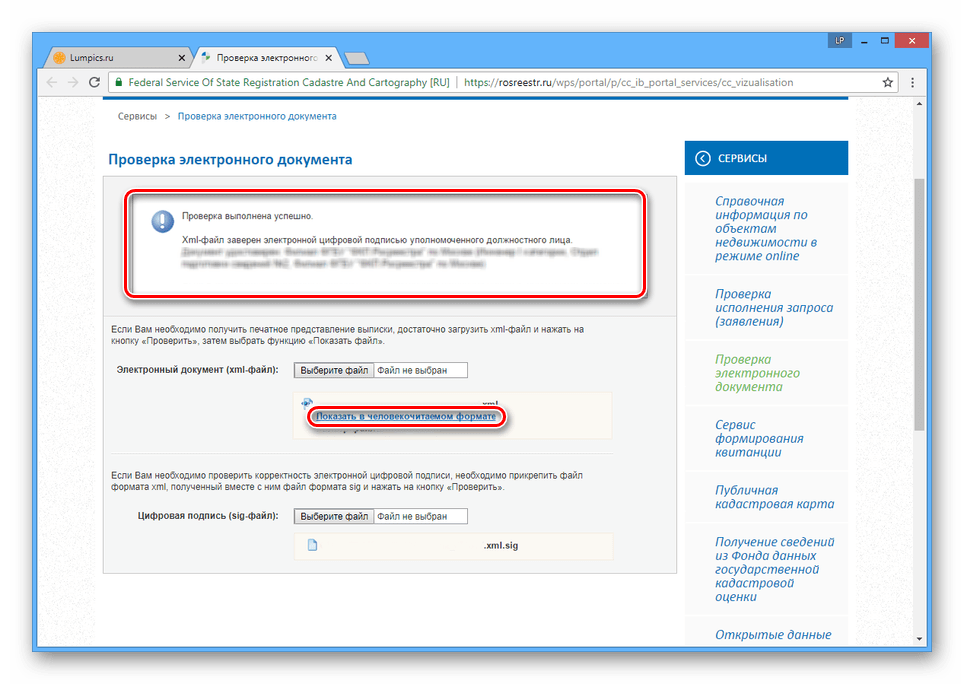
Приложение больше не существует, но мне все еще нужны данные. Открывая xml у меня есть следующее:
<Дата Рождения>2442260.7083333
или
<Дата Рождения>2436617.0375000
в данном случае реальная дата 17.02.1959. 12:54 (12:54 — время рождения).
или
<Дата Рождения>2446904.4652778
в данном случае реальная дата 18.04.1987. 23:10 (23:10 — время рождения).
Есть ли способ расшифровать это и получить дату/время в читаемом формате?
5Метод кодирования действительно основан на днях (целая часть) и долях дней (десятичная часть), но эпоха примерно 6611 лет назад.
Самый простой способ расшифровать эти даты/время — использовать Excel с поправкой на эпоху (нулевую точку). Корректировка составляет -2415019 дней.
Таким образом, если подставить формулу
= 2436617,0375-2415019
в ячейке и формате даты/времени вы получите
17.
 02.59 00:54
02.59 00:54
Для другого значения формула
= 2446904,4652778-2415019
дает дату
18.04.87 11:10
, поэтому я подозреваю, что значение 23:10, которое вы указали, является опечаткой.
Обратите внимание, что вычисление даты эпохи (когда в прошлом была нулевая точка) бессмысленно, так как в то время не использовались современные календари. Вы можете экстраполировать, но вам придется выбрать календарь (юлианский против григорианского или что-то еще), и что бы вы ни придумали (около 4595 г. до н.э.), оно ни для чего не будет полезным.
Вот скриншот образца рабочего листа Excel
Первый столбец — ваши значения, второй — значение, скорректированное с учетом смещения эпохи, а третий — второй столбец, отформатированный как дата/время.
Excel использует 31.12.1899 00:00 в качестве своей эпохи; то есть нулевое значение отображается в Excel как 01/0/1900 (что само по себе странно), а значение 1 дает 1/1/1900 . Если вы хотите выполнить преобразование в коде, вы можете использовать эти знания, чтобы настроить смещение для любой библиотеки программирования, которую вы используете.
Если вы хотите выполнить преобразование в коде, вы можете использовать эти знания, чтобы настроить смещение для любой библиотеки программирования, которую вы используете.
На самом деле это не вопрос XML, а вопрос интерпретации странного (и, вероятно, недокументированного) представления даты. Дробная часть числа — 17/24, что указывает на то, что оно, вероятно, означает 17:00 данной даты. Однако, когда мы интерпретируем часть перед запятой как номер дня, она будет основана на дате около 6687 лет назад. Кажется, это не имеет особого смысла…
4Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя электронную почту и парольОпубликовать как гость
Электронная почтаТребуется, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
Пишите легко читаемый XML на Python
спросил
Изменено 8 лет, 2 месяца назад
Просмотрено 3к раз
Есть ли способ, кроме создания собственного метода для написания XML с использованием python, который легко читается? xMLFile.write(xmlDom.toxml()) создает правильный xml, но читать их довольно сложно. Я попробовал toprettyxml, но, похоже, он мало что делает. например вот что я считаю удобочитаемым xml:
<мой корень>
Сводка решений из приведенных ниже ответов:
1) Если вам просто нужно время от времени читать его для отладки, то вместо форматирования xml во время записи используйте xmllint или редактор xml для его чтения. Или
Или
2) Используйте библиотеку типа Beautiful Soup. Или
3) Напишите свой собственный метод
- python
- xml
печать lxml.etree.tostring(root_node, pretty_print=True)
Если вы используете elementalTree, этот код будет работать.
XMLtext= ET.tostringlist(root)
Выходная Строка = ''
уровень=-1
для t в XMLtext:
если t[0]=='<':
уровень=уровень+1
если т[0:2]=='':
t="\n"+" "*уровень+t
if t[-2:]=='/>' или t[level*4+1:level*4+3]=='':
т=т+'\п'
ВыводСтр=ВыводСтр+т
f = открыть ("test.xml", "w")
f.write(OutputStr)
е.закрыть()
К сожалению, удобочитаемость XML для человека не была целью разработки. Наоборот, BeautifulStoneSoup пытается усовершенствовать XML. Это не здорово, но это лучше, чем ничего.
Это не здорово, но это лучше, чем ничего.
Напишите собственный метод форматирования XML-документа. Например, это создаст формат вашей примерной строки XML:
rep={" ":" \n",
"/>":"\n/>"}
outStr=xmlDom.toxml()
для k в репе:
outStr=outStr.replace(k, rep[k])
Я думаю, что лучший способ сделать это с использованием батарей, включенных в Python, приведен в этом ответе: https://stackoverflow.com/a/1206856.
импорт xml.dom.minidom xml = xml.dom.minidom.parse(xml_fname) # или xml.dom.minidom.parseString(xml_string) pretty_xml_as_string = xml.toprettyxml()
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя электронную почту и парольОпубликовать как гость
Электронная почтаТребуется, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
Ваш комментарий будет первым