Что такое XML
Язык XML предназначен для хранения и передачи данных. HTML же предназначен для отображения данных.
Прежде чем продолжить, убедитесь, что вы обладаете базовыми знаниями в HTML. Если вы не знаете что такое HTML, то разобраться в этом вам поможет учебник HTML для начинающих. Итак,
Что такое XML?
- XML — аббревиатура от англ. eXtensible Markup Language (пер. расширяемый язык разметки).
- XML – язык разметки, который напоминает HTML.
- XML предназначен для передачи данных, а не для их отображения.
- Теги XML не предопределены. Вы должны сами определять нужные теги.
- XML описан таким образом, чтобы быть самоопределяемым.
Разница между XML и HTML
XML не является заменой HTML. Они предназначены для решения разных задач: XML решает задачу хранения и транспортировки данных, фокусируясь на том, что такое эти самые данные, HTML же решает задачу отображения данных, фокусируясь на том, как эти данные выглядят. Таким образом, HTML заботится об отображении информации, а XML о транспортировке информации.
Таким образом, HTML заботится об отображении информации, а XML о транспортировке информации.
XML ничего не делает
Возможно вам будет несколько странным это узнать, но XML ничего не делает. Он был создан для структурирования, хранения и передачи информации.
Следующий пример представляет некую заметку от Джени к Тови, сохраненную в формате XML:
<?xml version="1.0" encoding="UTF-8"?>
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Напоминание</heading>
<body>Не забудь обо мне в эти выходные!</body>
</note>
Приведенная запись вполне самоописательна. Здесь есть информация об отправителе и получателе. Также присутствуют данные заголовка и само сообщение. И при всем при этом этот документ XML не делает ничего. Это просто информация, обернутая в теги. Кто-то должен написать программу, которая будет отсылать, получать и отображать эти данные.
В XML вы изобретаете свои собственные теги
Теги в вышеприведенном примере (например, <to> и <from>) не определяются никакими стандартами XML. Эти теги были «изобретены» автором этого XML документа.
Эти теги были «изобретены» автором этого XML документа.
Все потому, что в языке XML нет предопределенных тегов.
Так, в HTML все используемые теги предопределены. HTML документы могут использовать только те теги, которые определяются в стандартах HTML (<p>, <li> и т. д.).
XML позволяет автору определять свои языковые теги и свою структуру документа.
XML – это не замена HTML
XML – это дополнение HTML.
Важно понять, что XML не является заменой HTML. В большинстве веб-приложениях XML используется для транспортировки данных, а HTML для форматирования и отображения данных.
XML – это программно- и аппаратно-независимый инструмент для транспортировки информации.
XML – везде
В настоящее время XML также важен для сети, как когда-то был важен HTML для рождения современного Интернета. XML – это общий инструмент передачи данных между всеми видами приложений.
Как используется XML Вверх Учебник XML для начинающихУстройство XML документа
Устройство XML документаЦель лабораторной работы:
- Познакомиться с языком разметки данных XML.

- Изучить правила построения HTML документов
Теоретические сведения
Устройство XML документа
Синтаксически в XML, по сравнению с HTML, нет ничего нового. Это такой же текст, размеченный тэгами, но с той лишь разницей, что в HTML существует ограниченный набор тэгов, которые можно использовать в документах, в то время, как XML позволяет создавать и использовать любую разметку, которая может понадобиться для разметки данных.
Несомненным достоинством XML является и то, что это достаточно простой язык. Основных конструкций в XML мало, но, несмотря на это, с их помощью можно создавать разметку документов практически любой сложности.
Для демонстрации структуры XML документа лучше обратиться к какому нибуть примеру. Рассмотрим следующий XML документ:
Текст текст … элемент> Текст текст текст текст текст… элемент> … корневой_элемент>Рассмотрим данный пример подробно.
Первая строка документа определяет его как XML документ, построенный в соответствии с первой версией языка ( version=»1. 0″).
В этой же конструкции можно указать и кодировку, в которой создан документ:
0″).
В этой же конструкции можно указать и кодировку, в которой создан документ:
xml version="1.0" encoding="Windows-1251" ?>. Кодировкой по умолчанию для XML является unicode. Далее находится открывающий тэг корневого (главного) элемента <корневой_элемент>, содержащий элемент <элемент>, который, в свою очередь, содержит элемент <еще_элемент атрибут=»значение» /> с атрибутом атрибут. Как видно из примера, правила записи элементов, атрибутов и их значений в XML ничем не отличаются от правил записи элементов атрибутов и их значений в HTML (также есть открывающие и закрывающие тэги элементов, элементы с содержимым и без и т.д.), только набор элементов несколько расширен, благодаря чему мы и можем «нагрузить» разметку семантикой.
Ниже приводятся несколько правил построения XML документа. Итак:
- любой XML документ должен начинаться строкой <?xml version=»1.0″ ?>
- любой XML документ должен иметь единственный (не более, не менее!) корневой элемент; например, в
HTML для этих целей использовался элемент <html>, в примере
выше — это <корневой_элемент>.
- кодировкой по умолчанию для символов XML документа является Unicode кодировка UTF-8, поэтому XML файлы должны быть сохранены в соответствующей кодировкой или в 1-й строке документа должна быть задана кодировка документа, например encoding=»Windows-1251″ (при работе только с латиницей это никак себя не проявляет, так как кодировка этих символов в ASCII совпадает с UTF-8).
- правила записи большинства конструкций языка совпадает с правилами XHTML, изучавшемся вами ранее (более подробно речь об основных конструкциях языка пойдет далее в уроке).
XML документ представляет собой обыкновенный текстовый файл с расширением .xml. Единственная особенность их заключается в том, что для символов файла рекомендуется использовать кодировку Unicode.
Основные конструкции XML
Помимо элементов, атрибутов и текста, документы могут содержать и другие конструкции,
такие как комментарии, инструкции по обработке и секции символьных данных. Эти базовые составляющие используются для того, чтобы чтобы гибко, но в четком соответствии со стандартами,
размечать документы любой сложности. Рассмотрим эти конструкции поподробнее.
Эти базовые составляющие используются для того, чтобы чтобы гибко, но в четком соответствии со стандартами,
размечать документы любой сложности. Рассмотрим эти конструкции поподробнее.
Элемент
Тэги в XML документе не просто размечают текст — они выделяют объект, называемый элементом. Элементы являются основными структурными единицами XML — именно они иерархически организуют информацию, содержащуюся в документе. Элементы могут быть пустыми, т.е. не содержать ни данных, ни других конструкций, или непустыми — включать в себя текст, другие элементы и т. п.
Пустой элемент имеет следующий вид:
<элемент атрибут="значение" атрибут="значение" ... />Примерами таких элементов в знакомом HTML являются: <br />, <img src=»images/picture.gif» /> и др.
Непустые элементы имеют вид:
<элемент атрибут="значение" атрибут="значение" ...>
. ..
Содержимое элемента
...
</элемент>  ..
Содержимое элемента
...
</элемент>
..
Содержимое элемента
...
</элемент> В HTML таких элементов большинство: <body> … </body>, <p> … </p> — в этих элементах может располагаться как текст, так и другие элементы (таблицы, рисунки…).
Необходимо помнить об обной очень важной особенности XML: имена в XML — регистро-зависимы, то есть <Sample-element />, <SAMPLE-ELEMENT /> и <sample-element /> — совершенно разные элементы.
Легко заметить, что документ, состоящий из вложенных друг в друга элементов, подобен дереву: родительский элемент является корнем, дочерние элементы — ветками, а если они не содержат ничего более — листьями:
…Графически этот пример выглядит следующим образом:
В данном случае <library> является корнем, <book> и </publisher> — ветви, а <title>, <author>, <name> и <homepage> — листья
Внимание: в XML требуется тщательно следить
за правильностью вложения элементов друг в друга — элементы, раньше открытые,
должны быть позже закрыты.
Атрибут
В элементах можно использовать атрибуты с присвоенными им значениями. Атрибут задается следующим образом:
атрибут = "значение" В отличие от HTML в XML атрибуты всегда должны иметь значение! Значение атрибута заключается в двойные или одинарные кавычки. При необходимости, можно использовать одинарные кавычки внутри двойных и наоборот.
<company name = 'Акционерное Общество "Витязь"' ... />
...
<book author = "О'Генри" ... /> Имена в XML регистро-зависимые. Это относится не только к элементам, но и к атрибутам.
Символьные данные: секция CDATA
Секция CDATA выделяет часть документа, внутри которых текст не должен восприниматься как разметка. CDATA означает буквально «character data» — символьные данные. Вот пример секции CDATA:
<![CDATA[
содержимое
]]> Внутри секции CDATA могут располагаться любые символы, даже < и & — они не будут
восприниматься анализатором как управляющие. Единственная последовательность,
которая не должна присутствовать в CDATA, это «]]>»
— окончание символьных данных.
Единственная последовательность,
которая не должна присутствовать в CDATA, это «]]>»
— окончание символьных данных.
Комментарии
XML документ может содержать комментарии, записываемые следующим образом:
<!-- Это комментарий -->
...
<!--
комментарии
могут охватывать
несколько строк
--> Текст комментария может состоять из любых символов, кроме двух «-» подряд («—«).
Задание на лабораторную работу
Создать XML документ, содержащий информацию о какой-либо предметной области. Название предметной области согласовать с преподавателем. Для оформления XML документа использовать знания и пользоваться правилами, указаными в теоретических сведениях. Проверить документ на действительность.
The Apache Software Foundation создала набор ПО,
представляющего собой парсеры и другое обеспечение для работы с XML.
Одним из таких известных парсеров является Xerces.
Он существует в виде отдельного ПО, реализованного на С++ или Java. Чтобы не ограничивать Вас в выборе инструментальной среды и ОС, будем использовать Java реализацию ввиду ее кроссплатформенности и простоты использования.
Чтобы не ограничивать Вас в выборе инструментальной среды и ОС, будем использовать Java реализацию ввиду ее кроссплатформенности и простоты использования.
Замечание. Для запуска Java приложения необходимо, чтобы на компьютере была установлена Java машина от Sun. Желательно с Java SDK.
Проверить действительность My.XML можно командой
java sax.counter my.xmlПри необходимости нужно явно указать путь к архивам Xerces ключом -classpath
java -classpath "PATH\XercesImpl.jar;PATH\XercesSamples.jar" sax.Counter my.xml(замените PATH на свой путь к местоположению архивов)
Сам Xerces можно скачать отсюда или с официального сайта.
Основы XML — разметка и структура XML документов
В данной статье мы начинаем изучение языка XML и подробно рассмотрим такие моменты, как разметка и структура XML-документа. Данная информация есть базовой в изучении XML, поэтому рекомендую тщательно проработать этот материал, чтобы не оставалось никаких вопросов. От этого зависит ваш успех в будущем и скорость изучения как самого XML, так и XSLT, который мы будем изучать сразу после освоения XML.
От этого зависит ваш успех в будущем и скорость изучения как самого XML, так и XSLT, который мы будем изучать сразу после освоения XML.
Итак, XML (eXtensible Markup Language) – это язык для текстового выражения информации в стандартном виде. Сам по себе он не имеет операторов и не выполняет никаких вычислений. Таким образом, XML – это метаязык, главной задачей которого есть описание новых языков документа.
Чтобы лучше понять суть вышесказанного, давайте перейдем непосредственно к примерам и первым делом рассмотрим разметку XML-документов.
Разметка XML документов
Разметка XML-документа практически ничем не отличается от разметки обычного HTML-документа (Как создать HTML страницу. HTML теги и атрибуты. Работа с текстом, списками и изображениями в HTML). Одним из преимуществ XML являет то, что он позволяет создавать неограниченное количество тегов. Таким образом, каждый тег имеет свою семантику, то есть несет определенный смысл. Для наглядности давайте рассмотрим XML-документ со списком книг.
<books>
<book>
<author>Автор 1</author>
<name>Название 1</name>
<price>Цена 1</price>
</book>
<book>
<author>Автор 2</author>
<name>Название 2</name>
<price>Цена 2</price>
</book>
<book>
<author>Автор 3</author>
<name>Название 3</name>
<price>Цена 3</price>
</book>
</books>Как видно с примера выше, все очень банально и просто. При этом XML-документ несет куда более подробную информацию по сравнению с обычным HTML-документом. В нашем примере очень просто понять, что тег <author> отвечает за автора книги, тег <name> — за название, тег <price> — за цену и т.д. Таким образом, каждый тег имеет свой смысл.
Одной из самых важных особенностей XML-документов является то, что их можно легко обрабатывать программно. Например, обработав пример вышеприведенного текста, можно с легкостью получить нужную информацию по книгам, вывести цены на книги по их названиям и т.д. При этом полностью сохраняется возможность визуального представления документа. Для этого достаточно лишь определить, как будет выглядеть тот или иной элемент.
Например, обработав пример вышеприведенного текста, можно с легкостью получить нужную информацию по книгам, вывести цены на книги по их названиям и т.д. При этом полностью сохраняется возможность визуального представления документа. Для этого достаточно лишь определить, как будет выглядеть тот или иной элемент.
Таким образом, XML позволяет отделять данные от их представления и создавать в текстовом виде документы со структурой, указанной явным образом. Если быть точным, то только лишь за счет расширения количества тегов мы сделали следующее:
- Явным образом выделили в XML-документе структуру, что в свою очередь сделало возможным дальнейшую программную обработку документа, например, при помощи технологии XSLT, которую мы будем изучать чуть позже. При этом одной из главных особенностей является то, что данный документ по прежнему остается понятным обычному человеку.
- Отделили данные в XML-документе от того, каким образом они должны быть представлены визуально. Это в свою очередь дало широкие возможности для публикации данных на разных носителях, например, на бумаге или в сети интернет.

Подводя итог вышесказанному, можно сделать вывод, что синтаксически в XML практически нет ничего нового по сравнению с HTML. XML является таким же текстом, размеченным тегами. Единственная разница лишь в том, что XML позволяет создавать любую разметку, которая может понадобиться для описания документа, при том как в HTML существует лишь ограниченный набор тегов, которые можно использовать.
Одним словом, XML является очень простым языком с небольшим набором основных конструкций, но в то же время он предоставляет неограниченные возможности для описания данных. Таким образом, каждый разработчик как бы сам изобретает свой собственный язык, который ограничивается лишь фантазией самого разработчика.
Структура XML документов
Для того чтобы представить структуру XML документов давайте рассмотрим самый простой пример документа XML.
<?xml version="1.0" encoding="utf-8"?>
<pricelist>
<book>
<title>Книга 1</title>
<author>Автор 1</author>
<price>Цена 1</price>
</book>
<book>
<title>Книга 2</title>
<author>Автор 2</author>
<price>Цена 2</price>
</book>
<book>
<title>Книга 3</title>
<author>Автор 3</author>
<price>Цена 3</price>
</book>
</pricelist>Итак, мы видим, что данный пример практически ничем не отличается от предыдущего за исключением немного изменившихся тегов и нескольких атрибутов.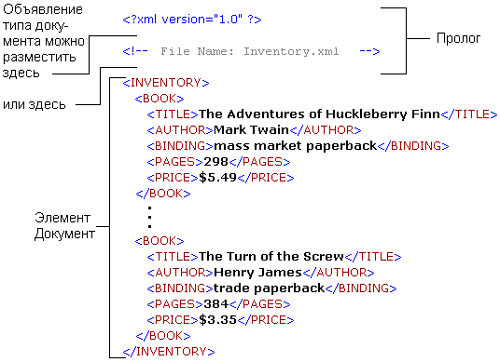 Главное отличие здесь заключается в первой строчке, которая определяет файл как XML документ, построенный в соответствии с первой версией языка. Более подробно об этом мы поговорим в следующих статьях рубрики «Уроки XML и XSLT».
Главное отличие здесь заключается в первой строчке, которая определяет файл как XML документ, построенный в соответствии с первой версией языка. Более подробно об этом мы поговорим в следующих статьях рубрики «Уроки XML и XSLT».
На данный момент нам важнее всего понять, что это очень простой язык, который очень похож на обычный HTML. В примере выше мы видим, что XML тоже имеет теги, которые могут быть вложенными, то есть содержать внутри себя другие теги. При этом теги в XML не просто ограничивают часть текста, а формируют отдельный элемент. Исходя из этого, то, что выделено тегами, в XML принято называть элементами.
Стоит также заметить, что в XML есть также атрибуты, комментарии и множество других элементов и конструкций. К сожалению одной статьи недостаточно для того чтобы обо всем подробно написать, поэтому будут написаны отдельные статьи по каждой теме. Если вы не хотите их пропустить, то рекомендую подписаться на новостную рассылку любым удобным для вас способом в пункте «Подписка» либо воспользоваться формой ниже.
На этом все. Удачи вам и успехов в изучении основ XML.
Обнаружили ошибку? Выделите ее и нажмите Ctrl+Enter
Структура и правила создания XML-документа.
Структура и правила создания XML-документа. Структура документаПростейший XML- документ может выглядеть так, как это показано в
Примере 1
Пример 1
<?xml version="1.0"?> <list_of_items> <item><first/>Первый</item> <item>Второй <sub_item>подпункт 1</sub_item></item> <item>Третий</item> <item><last/>Последний</item> </list_of_items>
Обратите внимание на то, что этот документ очень похож на обычную
HTML-страницу. Также, как и в HTML, инструкции, заключенные в угловые
скобки называются тэгами и служат для разметки основного текста документа. В XML существуют открывающие, закрывающие и пустые тэги (в HTML понятие
пустого тэга тоже существует, но специального его обозначения не
требуется).
В XML существуют открывающие, закрывающие и пустые тэги (в HTML понятие
пустого тэга тоже существует, но специального его обозначения не
требуется).
Тело документа XML состоит из элементов разметки (markup) и непосредственно содержимого документа — данных (content). XML — тэги предназначены для определения элементов документа, их атрибутов и других конструкций языка. Более подробно о типах применяемой в документах разметки мы поговорим чуть позже.
Любой XML-документ должен всегда начинаться с инструкции , внутри которой также можно задавать номер версии языка, номер кодовой страницы и другие параметры, необходимые программе-анализатору в процессе разбора документа.
Правила создания XML- документа
В общем случае XML- документы должны удовлетворять следующим требованиям:
- В заголовке документа помещается объявление XML, в котором указывается язык разметки документа, номер его версии и дополнительная информация
- Каждый открывающий тэг, определяющий некоторую область данных в
документе обязательно должен иметь своего закрывающего «напарника»,
т. е., в отличие от HTML, нельзя опускать закрывающие тэги
- В XML учитывается регистр символов
- Все значения атрибутов, используемых в определении тэгов, должны быть заключены в кавычки
- Вложенность тэгов в XML строго контролируется, поэтому необходимо следить за порядком следования открывающих и закрывающих тэгов
- Вся информация, располагающаяся между начальным и конечными тэгами, рассматривается в XML как данные и поэтому учитываются все символы форматирования ( т.е. пробелы, переводы строк, табуляции не игнорируются, как в HTML)
 е., в отличие от HTML, нельзя опускать закрывающие тэги
е., в отличие от HTML, нельзя опускать закрывающие тэги
Если XML- документ не нарушает приведенные правила, то он называется формально-правильным и все анализаторы, предназначенные для разбора XML- документов, смогут работать с ним корректно.
Однако кроме проверки на формальное соответствие грамматике языка, в
документе могут присутствовать средства контроля над содержанием
документа, за соблюдением правил, определяющих необходимые соотношений
между элементами и формирующих структуру документа. Например, следующий
текст, являясь вполне правильным XML- документом, будет абсолютно
бессмысленным:
Например, следующий
текст, являясь вполне правильным XML- документом, будет абсолютно
бессмысленным:
<country><title>Russia</title><city><title>Novosibirsk</country> </title></city>
Для того, чтобы обеспечить проверку корректности XML- документов, необходимо использовать анализаторы, производящие такую проверку и называемые верифицирующими.
На сегодняшний день существует два способа контроля правильности XML-
документа: DTD — определения (Document Type Definition) и схемы данных
(Semantic Schema). Более подробно об использовании DTD и схемах будет
описано в следующих разделах. В отличии от SGML, определение DTD- правил в
XML не является необходимостью, и это обстоятельство позволяет нам
создавать любые XML- документы, не ломая пока голову над весьма непростым
синтаксисом DTD.
Конструкции языка
Содержимое XML- документа представляет собой набор элементов, секций CDATA, директив анализатора, комментариев, спецсимволов, текстовых данных. Рассмотрим каждый из них подробней.
Элементы данных
Элемент — это структурная единица XML- документа. Заключая слово rose в в тэги , мы определяем непустой элемент, называемый , содержимым которого является rose. В общем случае в качестве содержимого элементов могут выступать как просто какой-то текст, так и другие, вложенные, элементы документа, секции CDATA, инструкции по обработке, комментарии, — т.е. практически любые части XML- документа.
Любой непустой элемент должен состоять из начального, конечного тэгов и данных, между ними заключенных. Например, следующие фрагменты будут являться элементами:
<flower>rose</flower> <city>Novosibirsk</city>а эти — нет:
<rose> <flower> rose
Набором всех элементов, содержащихся в документе, задается его
структура и определяются все иерархическое соотношения. Плоская модель
данных превращается с использованием элементов в сложную иерархическую
систему со множеством возможных связей между элементами. Например, в
следующем примере мы описываем месторасположение Новосибирских
университетов (указываем, что Новосибирский Университет расположен в
городе Новосибирске, который, в свою очередь, находится в России),
используя для этого вложенность элементов XML :
Плоская модель
данных превращается с использованием элементов в сложную иерархическую
систему со множеством возможных связей между элементами. Например, в
следующем примере мы описываем месторасположение Новосибирских
университетов (указываем, что Новосибирский Университет расположен в
городе Новосибирске, который, в свою очередь, находится в России),
используя для этого вложенность элементов XML :
<country> <cities-list> <city> <title>Новосибирск</title> <universities-list> <university> <title>Сибирский Государственный Университет Телекоммуникаций и Информатики</title> <address URL="www.neic.nsk.su"/> </university> <university> <title>Новосибирский Государственный Университет</title> <address URL="www.nsu.ru"/> </university> </universities-list> </city> <city> <title>Москва</title> <universities-list> <university> <title>Московский Государственный Университет</title> <address URL="www.
 msu.ru"/>
</university>
</universities-list>
</city>
</cities-list>
</country>
msu.ru"/>
</university>
</universities-list>
</city>
</cities-list>
</country>
Производя в последствии поиск в этом документе, программа клиента будет опираться на информацию, заложенную в его структуру — используя элементы документа. Т.е. если, например, требуется найти нужный университет в нужном городе, используя приведенный фрагмент документа, то необходимо будет просмотреть содержимое конкретного элемента <university>, находящегося внутри конкретного элемента <city>. Поиск при этом, естественно, будет гораздо более эффективен, чем нахождение нужной последовательности по всему документу.
В XML документе, как правило, определяется хотя бы один элемент, называемый корневым и с него программы-анализаторы начинают просмотр документа. В приведенном примере этим элементом является <country>
В некоторых случаях тэги могут изменять и уточнять семантику тех или
иных фрагментов документа, по разному определяя одну и ту же информацию и
тем самым предоставляя приложению-анализатору этого документа сведения о
контексте использования описываемых данных. Например, прочитав фрагмент
<river>Lena</river> мы можем догадаться, что речь в этой части
документа идет о реке, а вот во фрагменте <name>Lena</name> —
о имени.
Например, прочитав фрагмент
<river>Lena</river> мы можем догадаться, что речь в этой части
документа идет о реке, а вот во фрагменте <name>Lena</name> —
о имени.
В случае, если элемент не имеет содержимого, т.е. нет данных, которые он должен определять, он называется пустым. Примером пустых элементов в HTML могут служить такие тэги HTML, как <br>, <hr>, <img>;. Необходимо только помнить, что начальный и конечные тэги пустого элемента как бы объединяется в один, и надо обязательно ставить косую черту перед закрывающей угловой скобкой (например, <empty/>;)
Комментарии
Комментариями является любая область данных, заключенная между
последовательностями символов Комментарии пропускаются
анализатором и поэтому при разборе структуры документа в качестве значащей
информации не рассматриваются.
Атрибуты
Если при определении элементов необходимо задать какие-либо параметры, уточняющие его характеристики, то имеется возможность использовать атрибуты эдлемента. Атрибут — это пара «название» = «значение», которую надо задавать при определении элемента в начальном тэге. Пример:
<color RGB="true">#ff08ff</color> <color RGB="false">white</color>или
<author id=0>Ivan Petrov</autho>Примером использования атрибутов в HTML является описание элемента <font>:
<font color="white" name="Arial">Black</font>
Cпециальные символы
Для того, чтобы включить в документ символ, используемый для
определения каких-либо конструкций языка (например, символ угловой скобки)
и не вызвать при этом ошибок в процессе разбора такого документа, нужно
использовать его специальный символьный либо числовой идентификатор. Например, < , > » или $(десятичная форма записи), 
(шестнадцатеричная) и т.д. Строковые обозначения спецсиволов могут
определяться в XML документе при помощи компонентов (entity).
Например, < , > » или $(десятичная форма записи), 
(шестнадцатеричная) и т.д. Строковые обозначения спецсиволов могут
определяться в XML документе при помощи компонентов (entity).
Директивы анализатора
Инструкции, предназначенные для анализаторов языка, описываются в XML документе при помощи специальных тэгов — и ?>;. Программа клиента использует эти инструкции для управления процессом разбора документа. Наиболее часто инструкции используются при определении типа документа (например, Xml version=»1.0″?>) или создании пространства имен.
CDATA
Чтобы задать область документа, которую при разборе анализатор будет
рассматривать как простой текст, игнорируя любые инструкции и специальные
символы, но, в отличии от комментариев, иметь возможность использовать их
в приложении, необходимо использовать тэги . Внутри этого
блока можно помещать любую информацию, которая может понадобится
программе- клиенту для выполнения каких-либо действий (в область CDATA,
можно помещать, например, инструкции JavaScript). Естественно, надо
следить за тем, чтобы в области, ограниченной этими тэгами не было
последовательности символов ]].
Внутри этого
блока можно помещать любую информацию, которая может понадобится
программе- клиенту для выполнения каких-либо действий (в область CDATA,
можно помещать, например, инструкции JavaScript). Естественно, надо
следить за тем, чтобы в области, ограниченной этими тэгами не было
последовательности символов ]].
C# и .NET | Работа с XML
XML-документы
Последнее обновление: 14.10.2019
На сегодняшний день XML является одним из распространенных стандартов документов, который позволяет в удобной форме сохранять сложные по структуре данные. Поэтому разработчики платформы .NET включили в фреймворк широкие возможности для работы с XML.
Прежде чем перейти непосредственно к работе с XML-файлами, сначала рассмотрим, что представляет собой xml-документ и как он может хранить объекты, используемые в программе на c#.
Например, у нас есть следующий класс:
class User
{
public string Name { get; set; }
public int Age { get; set; }
public string Company { get; set; }
}
В программе на C# мы можем создать список объектов класса User:
User user1 = new User { Name = "Bill Gates", Age = 48, Company = "Microsoft" };
User user2 = new User { Name = "Larry Page", Age = 42, Company = "Google" };
List<User> users = new List<User> { user1, user2 };
Чтобы сохранить список в формате xml мы могли бы использовать следующий xml-файл:
<?xml version="1.0" encoding="utf-8" ?>
<users>
<user name="Bill Gates">
<company>Microsoft</company>
<age>48</age>
</user>
<user name="Larry Page">
<company>Google</company>
<age>48</age>
</user>
</users>
XML-документ объявляет строка <?xml version="1.. Она задает версию (1.0) и кодировку (utf-8) xml. Далее идет
собственно содержимое документа. 0" encoding="utf-8" ?>
0" encoding="utf-8" ?>
XML-документ должен иметь один единственный корневой элемент, внутрь которого помещаются все остальные элементы. В данном случае таким элементом является
элемент <users>. Внутри корневого элемента <users> задан набор элементов <user>. Вне корневого элемента
мы не можем разместить элементы user.
Каждый элемент определяется с помощью открывающего и закрывающего тегов, например, <user> и </user>, внутри которых
помещается значение или содержимое элементов. Также элемент может иметь сокращенное объявление: <user /> — в конце элемента помещается слеш.
Элемент может иметь вложенные элементы и атрибуты. В данном случае каждый элемент user имеет два вложенных элемента company и
age и атрибут name.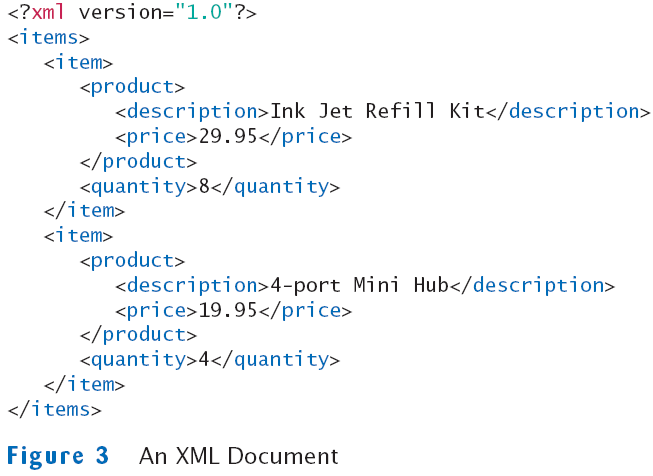
Атрибуты определяются в теле элемента и имеют следующую форму: название="значение". Например, <user name="Bill Gates">,
в данном случае атрибут называется name и имеет значение Bill Gates
Внутри простых элементов помещается их значение. Например, <company>Google</company> — элемент company имеет значение
Google.
Названия элементов являются регистрозависимыми, поэтому <company> и <COMPANY> будут представлять разные элементы.
Таким образом, весь список Users из кода C# сопоставляется с корневым элементом <users>, каждый объект User — с элементом <user>,
а каждое свойство объекта User — с атрибутом или вложенным элементом элемента <user>
Что использовать для свойств — вложенные элементы или атрибуты? Это вопрос предпочтений — мы можем использовать как атрибуты, так и вложенные элементы. Так, в предыдущем примере вполне можно использовать вместо атрибута вложенный элемент:
Так, в предыдущем примере вполне можно использовать вместо атрибута вложенный элемент:
<?xml version="1.0" encoding="utf-8" ?>
<users>
<user>
<name>Bill Gates</name>
<company>Microsoft</company>
<age>48</age>
</user>
<user>
<name>Larry Page</name>
<company>Google</company>
<age>48</age>
</user>
</users>
Теперь рассмотрим основные подходы для работы с XML, которые имеются в C#.
Что такое XML / Хабр
Если вы тестируете API, то должны знать про два основных формата передачи данных:
- XML — используется в SOAP (всегда) и REST-запросах (реже);
- JSON — используется в REST-запросах.
Сегодня я расскажу вам про XML.
XML, в переводе с англ eXtensible Markup Language — расширяемый язык разметки. Используется для хранения и передачи данных. Так что увидеть его можно не только в API, но и в коде.
Используется для хранения и передачи данных. Так что увидеть его можно не только в API, но и в коде.
Этот формат рекомендован Консорциумом Всемирной паутины (W3C), поэтому он часто используется для передачи данных по API. В SOAP API это вообще единственно возможный формат входных и выходных данных!
См также:
Что такое API — общее знакомство с API
Что такое JSON — второй популярный формат
Введение в SOAP и REST: что это и с чем едят — видео про разницу между SOAP и REST.
Так что давайте разберемся, как он выглядит, как его читать, и как ломать! Да-да, а куда же без этого? Надо ведь выяснить, как отреагирует система на кривой формат присланных данных.
Содержание
Как устроен XML
Возьмем пример из документации подсказок Дадаты по ФИО:
<req>
<query>Виктор Иван</query>
<count>7</count>
</req> И разберемся, что означает эта запись.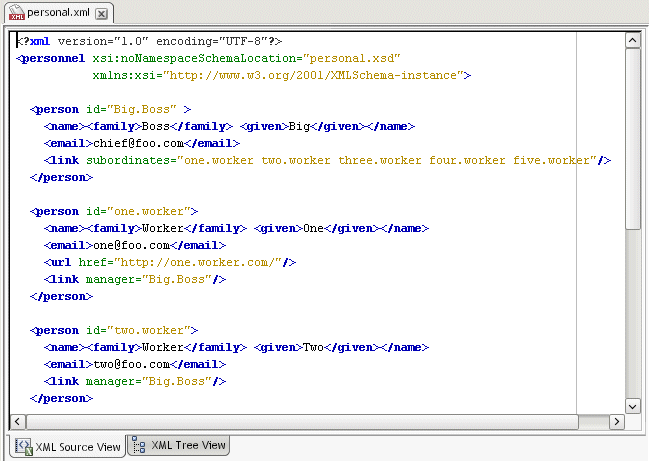
Теги
В XML каждый элемент должен быть заключен в теги. Тег — это некий текст, обернутый в угловые скобки:
<tag>Текст внутри угловых скобок — название тега.
Тега всегда два:
- Открывающий — текст внутри угловых скобок
<tag> - Закрывающий — тот же текст (это важно!), но добавляется символ «/»
</tag>
Ой, ну ладно, подловили! Не всегда. Бывают еще пустые элементы, у них один тег и открывающий, и закрывающий одновременно. Но об этом чуть позже!
С помощью тегов мы показываем системе «вот тут начинается элемент, а вот тут заканчивается». Это как дорожные знаки:
— На въезде в город написано его название: Москва
— На выезде написано то же самое название, но перечеркнутое: Москва*
* Пример с дорожными знаками я когда-то давно прочитала в статье Яндекса, только ссылку уже не помню. А пример отличный!
Корневой элемент
В любом XML-документе есть корневой элемент. Это тег, с которого документ начинается, и которым заканчивается. В случае REST API документ — это запрос, который отправляет система. Или ответ, который она получает.
Это тег, с которого документ начинается, и которым заканчивается. В случае REST API документ — это запрос, который отправляет система. Или ответ, который она получает.
Чтобы обозначить этот запрос, нам нужен корневой элемент. В подсказках корневой элемент — «req».
Он мог бы называться по другому:
<main><sugg>Да как угодно. Он показывает начало и конец нашего запроса, не более того. А вот внутри уже идет тело документа — сам запрос. Те параметры, которые мы передаем внешней системе. Разумеется, они тоже будут в тегах, но уже в обычных, а не корневых.
Значение элемента
Значение элемента хранится между открывающим и закрывающим тегами. Это может быть число, строка, или даже вложенные теги!
Вот у нас есть тег «query». Он обозначает запрос, который мы отправляем в подсказки.
Внутри — значение запроса.
Это как если бы мы вбили строку «Виктор Иван» в GUI (графическом интерфейсе пользователя):
Пользователю лишняя обвязка не нужна, ему нужна красивая формочка. А вот системе надо как-то передать, что «пользователь ввел именно это». Как показать ей, где начинается и заканчивается переданное значение? Для этого и используются теги.
А вот системе надо как-то передать, что «пользователь ввел именно это». Как показать ей, где начинается и заканчивается переданное значение? Для этого и используются теги.
Система видит тег «query» и понимает, что внутри него «строка, по которой нужно вернуть подсказки».
Параметр count = 7 обозначает, сколько подсказок вернуть в ответе. Если тыкать подсказки на демо-форме Дадаты, нам вернется 7 подсказок. Это потому, что туда вшито как раз значение count = 7. А вот если обратиться к документации метода, count можно выбрать от 1 до 20.
Откройте консоль разработчика через f12, вкладку Network, и посмотрите, какой запрос отправляется на сервер. Там будет значение count = 7.См также:
Что тестировщику надо знать про панель разработчика — подробнее о том, как использовать консоль.
Обратите внимание:
- Виктор Иван — строка
- 7 — число
Но оба значения идут
без кавычек. В XML нам нет нужды брать строковое значение в кавычки (а вот в JSON это сделать придется).
В XML нам нет нужды брать строковое значение в кавычки (а вот в JSON это сделать придется).
Атрибуты элемента
У элемента могут быть атрибуты — один или несколько. Их мы указываем внутри отрывающегося тега после названия тега через пробел в виде
название_атрибута = «значение атрибута»Например:
<query attr1=“value 1”>Виктор Иван</query>
<query attr1=“value 1” attr2=“value 2”>Виктор Иван</query>Зачем это нужно? Из атрибутов принимающая API-запрос система понимает, что такое ей вообще пришло.
Например, мы делаем поиск по системе, ищем клиентов с именем Олег. Отправляем простой запрос:
<query>Олег</query>А в ответ получаем целую пачку Олегов! С разными датами рождения, номерами телефонов и другими данными. Допустим, что один из результатов поиска выглядит так:
<party type="PHYSICAL" sourceSystem="AL" rawId="2">
<field name=“name">Олег </field>
<field name="birthdate">02. 01.1980</field>
<attribute type="PHONE" rawId="AL.2.PH.1">
<field name="type">MOBILE</field>
<field name="number">+7 916 1234567</field>
</attribute>
</party> 01.1980</field>
<attribute type="PHONE" rawId="AL.2.PH.1">
<field name="type">MOBILE</field>
<field name="number">+7 916 1234567</field>
</attribute>
</party>
01.1980</field>
<attribute type="PHONE" rawId="AL.2.PH.1">
<field name="type">MOBILE</field>
<field name="number">+7 916 1234567</field>
</attribute>
</party>Давайте разберем эту запись. У нас есть основной элемент
party.
У него есть 3 атрибута:
- type = «PHYSICAL» — тип возвращаемых данных. Нужен, если система умеет работать с разными типами: ФЛ, ЮЛ, ИП. Тогда благодаря этому атрибуту мы понимаем, с чем именно имеем дело и какие поля у нас будут внутри. А они будут отличаться! У физика это может быть ФИО, дата рождения ИНН, а у юр лица — название компании, ОГРН и КПП
- sourceSystem = «AL» — исходная система. Возможно, нас интересуют только физ лица из одной системы, будем делать отсев по этому атрибуту.
- rawId = «2» — идентификатор в исходной системе. Он нужен, если мы шлем запрос на обновление клиента, а не на поиск. Как понять, кого обновлять? По связке sourceSystem + rawId!
 Как понять, кого обновлять? По связке sourceSystem + rawId!
Как понять, кого обновлять? По связке sourceSystem + rawId!Внутри party есть элементы field.
У элементов field есть атрибут name. Значение атрибута — название поля: имя, дата рождения, тип или номер телефона. Так мы понимаем, что скрывается под конкретным field.
Это удобно с точки зрения поддержки, когда у вас коробочный продукт и 10+ заказчиков. У каждого заказчика будет свой набор полей: у кого-то в системе есть ИНН, у кого-то нету, одному важна дата рождения, другому нет, и т.д.
Но, несмотря на разницу моделей, у всех заказчиков будет одна XSD-схема (которая описывает запрос и ответ):
— есть элемент party;
— у него есть элементы field;
— у каждого элемента field есть атрибут name, в котором хранится название поля.
А вот конкретные названия полей уже можно не описывать в XSD. Их уже «смотрите в ТЗ». Конечно, когда заказчик один или вы делаете ПО для себя или «вообще для всех», удобнее использовать именованные поля — то есть «говорящие» теги.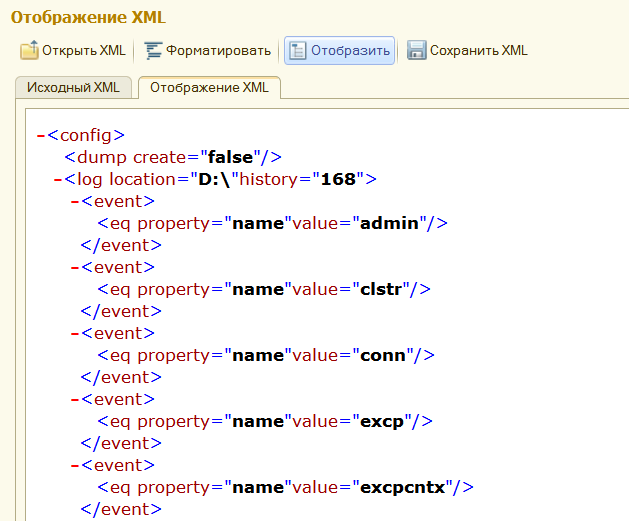 Какие плюшки у этого подхода:
Какие плюшки у этого подхода:
— При чтении XSD сразу видны реальные поля. ТЗ может устареть, а код будет актуален.
— Запрос легко дернуть вручную в SOAP Ui — он сразу создаст все нужные поля, нужно только значениями заполнить. Это удобно тестировщику + заказчик иногда так тестирует, ему тоже хорошо.
В общем, любой подход имеет право на существование. Надо смотреть по проекту, что будет удобнее именно вам. У меня в примере неговорящие названия элементов — все как один будут field. А вот по атрибутам уже можно понять, что это такое.
Помимо элементов field в party есть элемент attribute. Не путайте xml-нотацию и бизнес-прочтение:
- с точки зрения бизнеса это атрибут физ лица, отсюда и название элемента — attribute.
- с точки зрения xml — это элемент (не атрибут!), просто его назвали attribute. XML все равно (почти), как вы будете называть элементы, так что это допустимо.
У элемента attribute есть атрибуты:
- type = «PHONE» — тип атрибута. Они ведь разные могут быть: телефон, адрес, емейл…
- rawId = «AL.2.PH.1» — идентификатор в исходной системе. Он нужен для обновления. Ведь у одного клиента может быть несколько телефонов, как без ID понять, какой именно обновляется?
 Они ведь разные могут быть: телефон, адрес, емейл…
Они ведь разные могут быть: телефон, адрес, емейл…Такая вот XML-ка получилась. Причем упрощенная. В реальных системах, где хранятся физ лица, данных сильно больше: штук 20 полей самого физ лица, несколько адресов, телефонов, емейл-адресов…
Но прочитать даже огромную XML не составит труда, если вы знаете, что где. И если она отформатирована — вложенные элементы сдвинуты вправо, остальные на одном уровне. Без форматирования будет тяжеловато…
А так всё просто — у нас есть элементы, заключенные в теги. Внутри тегов — название элемента. Если после названия идет что-то через пробел: это атрибуты элемента.
XML пролог
Иногда вверху XML документа можно увидеть что-то похожее:
<?xml version="1.0" encoding="UTF-8"?> Эта строка называется XML прологом. Она показывает версию XML, который используется в документе, а также кодировку. Пролог необязателен, если его нет — это ок. Но если он есть, то это должна быть первая строка XML документа.
Она показывает версию XML, который используется в документе, а также кодировку. Пролог необязателен, если его нет — это ок. Но если он есть, то это должна быть первая строка XML документа.
UTF-8 — кодировка XML документов по умолчанию.
XSD-схема
XSD
(
XML
Schema
Definition) — это описание вашего XML. Как он должен выглядеть, что в нем должно быть? Это ТЗ, написанное на языке машины — ведь схему мы пишем… Тоже в формате XML! Получается XML, который описывает другой XML.
Фишка в том, что проверку по схеме можно делегировать машине. И разработчику даже не надо расписывать каждую проверку. Достаточно сказать «вот схема, проверяй по ней».
Если мы создаем SOAP-метод, то указываем в схеме:
- какие поля будут в запросе;
- какие поля будут в ответе;
- какие типы данных у каждого поля;
- какие поля обязательны для заполнения, а какие нет;
- есть ли у поля значение по умолчанию, и какое оно;
- есть ли у поля ограничение по длине;
- есть ли у поля другие параметры;
- какая у запроса структура по вложенности элементов;
- . ..
 ..
..Теперь, когда к нам приходит какой-то запрос, он сперва проверяется на корректность по схеме. Если запрос правильный, запускаем метод, отрабатываем бизнес-логику. А она может быть сложной и ресурсоемкой! Например, сделать выборку из многомиллионной базы. Или провести с десяток проверок по разным таблицам базы данных…
Поэтому зачем запускать сложную процедуру, если запрос заведом «плохой»? И выдавать ошибку через 5 минут, а не сразу? Валидация по схеме помогает быстро отсеять явно невалидные запросы, не нагружая систему.
Более того, похожую защиту ставят и некоторые программы-клиенты для отправки запросов. Например, SOAP Ui умеет проверять ваш запрос на well formed xml, и он просто не отправит его на сервер, если вы облажались. Экономит время на передачу данных, молодец!
А простому пользователю вашего SOAP API схема помогает понять, как составить запрос. Кто такой «простой пользователь»?
- Разработчик системы, использующей ваше API — ему надо прописать в коде, что именно отправлять из его системы в вашу.
- Тестировщик, которому надо это самое API проверить — ему надо понимать, как формируется запрос.

Да-да, в идеале у нас есть подробное ТЗ, где всё хорошо описано. Но увы и ах, такое есть не всегда. Иногда ТЗ просто нет, а иногда оно устарело. А вот схема не устареет, потому что обновляется при обновлении кода. И она как раз помогает понять, как запрос должен выглядеть.
Итого, как используется схема при разработке SOAP API:
- Наш разработчик пишет XSD-схему для API запроса: нужно передать элемент такой-то, у которого будут такие-то дочерние, с такими-то типами данных. Эти обязательные, те нет.
- Разработчик системы-заказчика, которая интегрируется с нашей, читает эту схему и строит свои запросы по ней.
- Система-заказчик отправляет запросы нам.
- Наша система проверяет запросы по XSD — если что-то не так, сразу отлуп.
- Если по XSD запрос проверку прошел — включаем бизнес-логику!
А теперь давайте посмотрим, как схема может выглядеть! Возьмем для примера метод
doRegister в Users. Чтобы отправить запрос, мы должны передать email, name и password. Есть куча способов написать запрос правильно и неправильно:
Чтобы отправить запрос, мы должны передать email, name и password. Есть куча способов написать запрос правильно и неправильно:
Попробуем написать для него схему. В запросе должны быть 3 элемента (
email, name, password) с типом
«string»(строка). Пишем:
<xs:element name="doRegister ">
<xs:complexType>
<xs:sequence>
<xs:element name="email" type="xs:string"/>
<xs:element name="name" type="xs:string"/>
<xs:element name="password" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>А в
WSDl сервисаона записана еще проще:
<message name="doRegisterRequest">
<part name="email" type="xsd:string"/>
<part name="name" type="xsd:string"/>
<part name="password" type="xsd:string"/>
</message>Конечно, в схеме могут быть не только строковые элементы. Это могут быть числа, даты, boolean-значения и даже какие-то свои типы:
<xsd:complexType name="Test">
<xsd:sequence>
<xsd:element name="value" type="xsd:string"/>
<xsd:element name="include" type="xsd:boolean" minOccurs="0" default="true"/>
<xsd:element name="count" type="xsd:int" minOccurs="0" length="20"/>
<xsd:element name="user" type="USER" minOccurs="0"/>
</xsd:sequence>
</xsd:complexType> А еще в схеме можно ссылаться на другую схему, что упрощает написание кода — можно переиспользовать схемы для разных задач.
См также:
XSD — умный XML — полезная статья с хабра
Язык определения схем XSD — тут удобные таблички со значениями, которые можно использовать
Язык описания схем XSD (XML-Schema)
Пример XML схемы в учебнике
Официальный сайт w3.org
Практика: составляем свой запрос
Ок, теперь мы знаем, как «прочитать» запрос для API-метода в формате XML. Но как его составить по ТЗ? Давайте попробуем. Смотрим в документацию. И вот почему я даю пример из Дадаты — там классная
документация!
Что, если я хочу, чтобы мне вернуть только женские ФИО, начинающиеся на «Ан»? Берем наш исходный пример:
<req>
<query>Виктор Иван</query>
<count>7</count>
</req>В первую очередь меняем сам запрос. Теперь это уже не «Виктор Иван», а «Ан»:
<req>
<query>Ан</query>
<count>7</count>
</req>Далее смотрим в ТЗ. Как вернуть только женские подсказки? Есть специальный параметр —
gender. Название параметра — это название тегов. А внутри уже ставим пол. «Женский» по английски будет
Название параметра — это название тегов. А внутри уже ставим пол. «Женский» по английски будет
, в документации также. Итого получили:
<req>
<query>Ан</query>
<count>7</count>
<gender>FEMALE</gender>
</req>Ненужное можно удалить. Если нас не волнует количество подсказок, параметр count выкидываем. Ведь, согласно документации, он необязательный. Получили запрос:
<req>
<query>Ан</query>
<gender>FEMALE</gender>
</req>Вот и все! Взяли за основу пример, поменяли одно значение, один параметр добавили, один удалили. Не так уж и сложно. Особенно, когда есть подробное ТЗ и пример )))
Попробуй сам!
Напишите запрос для метода MagicSearch в Users. Мы хотим найти всех Ивановых по полному совпадению, на которых висят актуальные задачи.
Well Formed XML
Разработчик сам решает, какой XML будет считаться правильным, а какой нет. Но есть общие правила, которые нельзя нарушать. XML должен быть well formed, то есть синтаксически корректный.
Но есть общие правила, которые нельзя нарушать. XML должен быть well formed, то есть синтаксически корректный.
Чтобы проверить XML на синтаксис, можно использовать любой XML Validator (так и гуглите). Я рекомендую сайт w3schools. Там есть сам валидатор + описание типичных ошибок с примерами.
В готовый валидатор вы просто вставляете свой XML (например, запрос для сервера) и смотрите, всё ли с ним хорошо. Но можете проверить его и сами. Пройдитесь по правилам синтаксиса и посмотрите, следует ли им ваш запрос.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.
Давайте пройдемся по каждому правилу и обсудим, как нам применять их в тестировании. То есть как правильно «ломать» запрос, проверяя его на well-formed xml. Зачем это нужно? Посмотреть на фидбек от системы. Сможете ли вы по тексту ошибки понять, где именно облажались?
Сможете ли вы по тексту ошибки понять, где именно облажались?
См также:
Сообщения об ошибках — тоже документация, тестируйте их! — зачем тестировать сообщения об ошибках
1. Есть корневой элемент
Нельзя просто положить рядышком 2 XML и полагать, что «система сама разберется, что это два запроса, а не один». Не разберется. Потому что не должна.
И если у вас будет лежать несколько тегов подряд без общего родителя — это плохой xml, не well formed. Всегда должен быть корневой элемент:
Что мы делаем для тестирования этого условия? Правильно, удаляем из нашего запроса корневые теги!
2. У каждого элемента есть закрывающийся тег
Тут все просто — если тег где-то открылся, он должен где-то закрыться. Хотите сломать? Удалите закрывающийся тег любого элемента.
Но тут стоит заметить, что тег может быть один. Если элемент пустой, мы можем обойтись одним тегом, закрыв его в конце:
<name/>Это тоже самое, что передать в нем пустое значение
<name></name> Аналогично сервер может вернуть нам пустое значение тега. Можно попробовать послать пустые поля в Users в методе
Можно попробовать послать пустые поля в Users в методе
. И в запросе это допустимо (я отправила пустым поле
name1), и в ответе SOAP Ui нам именно так и отрисовывает пустые поля.
Итого — если есть открывающийся тег, должен быть закрывающийся. Либо это будет один тег со слешом в конце.
Для тестирования удаляем в запросе любой закрывающийся тег.
3. Теги регистрозависимы
Как написали открывающий — также пишем и закрывающий. ТОЧНО ТАК ЖЕ! А не так, как захотелось.
А вот для тестирования меняем регистр одной из частей. Такой XML будет невалидным
4. Правильная вложенность элементов
Элементы могут идти друг за другом
Один элемент может быть вложен в другой
Но накладываться друг на друга элементы НЕ могут!
5. Атрибуты оформлены в кавычках
Даже если вы считаете атрибут числом, он будет в кавычках:
<query attr1=“123”>Виктор Иван</query>
<query attr1=“атрибутик” attr2=“123” >Виктор Иван</query>Для тестирования пробуем передать его без кавычек:
<query attr1=123>Виктор Иван</query>Итого
XML (eXtensible Markup Language) используется для хранения и передачи данных.
Передача данных — это запросы и ответы в API-методах. Если вы отправляете SOAP-запрос, вы априори работаете именно с этим форматом. Потому что SOAP передает данные только в XML. Если вы используете REST, то там возможны варианты — или XML, или JSON.Хранение данных — это когда XML встречается внутри кода. Его легко понимает как машина, так и человек. В формате XML можно описывать какие-то правила, которые будут применяться к данным, или что-то еще.
Вот пример использования XML в коде open-source проекта folks. Я не знаю, что именно делает JacksonJsonProvider, но могу «прочитать» этот код — есть функционал, который мы будем использовать (featuresToEnable), и есть тот, что нам не нужен(featuresToDisable).
Формат XML подчиняется стандартам. Синтаксически некорректный запрос даже на сервер не уйдет, его еще клиент порежет. Сначала проверка на well formed, потом уже бизнес-логика.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.
Если вы тестировщик, то при тестировании запросов в формате XML обязательно попробуйте нарушить каждое правило! Да, система должна уметь обрабатывать такие ошибки и возвращать адекватное сообщение об ошибке. Но далеко не всегда она это делает.
А если система публичная и возвращает пустой ответ на некорректный запрос — это плохо. Потому что разработчик другой системы налажает в запросе, а по пустому ответу даже не поймет, где именно. И будет приставать к поддержке: «Что же у меня не так?», кидая информацию по кусочкам и в виде скринов исходного кода. Оно вам надо? Нет? Тогда убедитесь, что система выдает понятное сообщение об ошибке!
См также:
Что такое XML
Учебник по XML
Изучаем XML. Эрик Рэй (книга по XML)
Заметки о XML и XLST
Что такое JSON — второй популярный формат
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
Документ XML
Приветствую, уважаемые посетители блога okITgo.ru! Продолжаем рассматривать язык XML. В данной статье подробнее остановимся на строении документа расширяемого языка разметки. XML документы формируют древовидную структуру, которая начинается в “корне” и разветвляется до “листьев”.
Пример XML документа
XML документы описывают сами себя и используют простой синтаксис:
| <?xml version=”1.0″ encoding=”UTF-8″?> <note> <to>Петя</to> <from>Марина</from> <heading>Напоминание</heading> <body>Не забудь купить молока!</body> </note> |
Первая строка – это XML объявление. Она определяет версию XML (1.0) и используемую кодировку
(UTF-8 – Юникод).
Следующая строка описывает корневой элемент документа xml, в данном случае мы указываем, что этот документ является запиской (англ. note):
Следующие 4 строки описывают 4 дочерних элемента корня (to, from, heading и body):
| <to>Петя</to> <from>Марина</from> <heading>Напоминание</heading> <body>Не забудь купить молока!</body> |
И наконец последняя строчка определяет конец корневого элемента:
Из структуры документа приведенного примера легко предположить, что этот XML документ содержит записку от Марины к Пете.
Данный пример хорошо иллюстрирует тот факт, что XML является самодокументированным языком, т.е. описывающим самого себя.
XML Документы Формируют Древовидную Структуру
XML документы должны содержать корневой элемент. Этот элемент является “родительским” для всех остальных элементов.
Элементы в документе XML составляют дерево документа. Это дерево начинается с корня и разветвляется, заканчиваясь листьями.
Все элементы могут иметь внутри себя другие элементы, называемые дочерними:
| <отец> <сын 1> <сын 2>…..</сын 2> </сын 1> </корень> |
Термины отец, сын, брат используются для описания взаимоотношений между элементами. Родительские элементы имеют дочерние. Дочерние элементы на одном и том же уровне иерархии называются братьями (или сестрами).
Все элементы могут иметь текстовое содержимое и атрибуты (прямо как в HTML).
Пример:
Изображение выше представляет собой одну книгу, описанную в XML документе ниже:
| <bookstore> <book category=”NOVEL”> <title lang=”en”>Банка червей</title> <author>Джеймс Хэдли Чейз</author> <year>1992</year> <price>30.00</price> </book> <book category=”CHILDREN”> <title lang=”en”>Книга джунглей</title> <author>Редьярд Киплинг</author> <year>1998</year> <price>29.99</price> </book> <book category=”WEB”> <title lang=”en”>Изучаем XML</title> <author>Эрик Рей</author> <year>2003</year> <price>39.95</price> </book> </bookstore> |
Корневым элементом в примере является <bookstore> – книжный магазин. Все элементы <book> в документе содержатся внутри <bookstore>. Элемент <book> имеет 4 дочерних элемента: <title> (заголовок),< author> (автор), <year> (год издания), <price> (цена).
Введение в XML
XML — это программно-аппаратно-независимый инструмент для хранения и транспортировка данных.
Что такое XML?
- XML означает расширяемый язык разметки
- XML — это язык разметки, очень похожий на HTML .
- XML был разработан для хранения и передачи данных
- XML был разработан, чтобы быть информативным
- XML — это рекомендация W3C
XML ничего не делает
Может быть, это немного сложно понять, но XML ничего не делает.
Это записка Туве от Яни, хранящаяся как XML:
<Примечание>
XML, приведенный выше, довольно информативен:
- Имеется информация об отправителе.
- Имеет информацию о приемнике
- Имеет товарную позицию
- Имеет тело сообщения.
Но все же приведенный выше XML ничего не делает. XML — это просто информация, заключенная в теги.
Кто-то должен написать программу для отправки, получения, хранить, или отображать:
Примечание
Кому: Тове
От: Яни
Напоминание
Не забывай меня в эти выходные!
Разница между XML и HTML
XML и HTML были разработаны для разных целей:
- XML был разработан для передачи данных — с акцентом на то, что такое данные
- HTML был разработан для отображения данных с упором на то, как данные выглядят
- Теги XML не определены заранее, в отличие от тегов HTML
XML не использует предопределенные теги
В языке XML нет предопределенных тегов.
Теги в приведенном выше примере (например,
HTML работает с предопределенными тегами, такими как
,

Ваш комментарий будет первым