Что такое XML / Хабр
Если вы тестируете API, то должны знать про два основных формата передачи данных:- XML — используется в SOAP (всегда) и REST-запросах (реже);
- JSON — используется в REST-запросах.
Сегодня я расскажу вам про XML.
XML, в переводе с англ eXtensible Markup Language — расширяемый язык разметки. Используется для хранения и передачи данных. Так что увидеть его можно не только в API, но и в коде.
Этот формат рекомендован Консорциумом Всемирной паутины (W3C), поэтому он часто используется для передачи данных по API. В SOAP API это вообще единственно возможный формат входных и выходных данных!
См также:
Что такое API — общее знакомство с API
Введение в SOAP и REST: что это и с чем едят — видео про разницу между SOAP и REST.
Так что давайте разберемся, как он выглядит, как его читать, и как ломать! Да-да, а куда же без этого? Надо ведь выяснить, как отреагирует система на кривой формат присланных данных.

Содержание
Как устроен XML
Возьмем пример из документации подсказок Дадаты по ФИО:
<req>
<query>Виктор Иван</query>
<count>7</count>
</req>И разберемся, что означает эта запись.
Теги
В XML каждый элемент должен быть заключен в теги. Тег — это некий текст, обернутый в угловые скобки:
<tag>Текст внутри угловых скобок — название тега.
Тега всегда два:
- Открывающий — текст внутри угловых скобок
<tag> - Закрывающий — тот же текст (это важно!), но добавляется символ «/»
</tag>
Ой, ну ладно, подловили! Не всегда. Бывают еще пустые элементы, у них один тег и открывающий, и закрывающий одновременно. Но об этом чуть позже!
С помощью тегов мы показываем системе «вот тут начинается элемент, а вот тут заканчивается». Это как дорожные знаки:
— На въезде в город написано его название: Москва
— На выезде написано то же самое название, но перечеркнутое: Москва*
* Пример с дорожными знаками я когда-то давно прочитала в статье Яндекса, только ссылку уже не помню. А пример отличный!
А пример отличный!
Корневой элемент
В любом XML-документе есть корневой элемент. Это тег, с которого документ начинается, и которым заканчивается. В случае REST API документ — это запрос, который отправляет система. Или ответ, который она получает.
Чтобы обозначить этот запрос, нам нужен корневой элемент. В подсказках корневой элемент — «req».
Он мог бы называться по другому:
<main><sugg>
Да как угодно. Он показывает начало и конец нашего запроса, не более того. А вот внутри уже идет тело документа — сам запрос. Те параметры, которые мы передаем внешней системе. Разумеется, они тоже будут в тегах, но уже в обычных, а не корневых.
Значение элемента
Значение элемента хранится между открывающим и закрывающим тегами. Это может быть число, строка, или даже вложенные теги!
Вот у нас есть тег «query». Он обозначает запрос, который мы отправляем в подсказки.
Внутри — значение запроса.
Это как если бы мы вбили строку «Виктор Иван» в GUI (графическом интерфейсе пользователя):
Пользователю лишняя обвязка не нужна, ему нужна красивая формочка. А вот системе надо как-то передать, что «пользователь ввел именно это». Как показать ей, где начинается и заканчивается переданное значение? Для этого и используются теги.
Система видит тег «query» и понимает, что внутри него «строка, по которой нужно вернуть подсказки».
Параметр count = 7 обозначает, сколько подсказок вернуть в ответе. Если тыкать подсказки на демо-форме Дадаты, нам вернется 7 подсказок. Это потому, что туда вшито как раз значение count = 7. А вот если обратиться к документации метода, count можно выбрать от 1 до 20.
Откройте консоль разработчика через f12, вкладку Network, и посмотрите, какой запрос отправляется на сервер. Там будет значение count = 7.См также:
Что тестировщику надо знать про панель разработчика — подробнее о том, как использовать консоль.
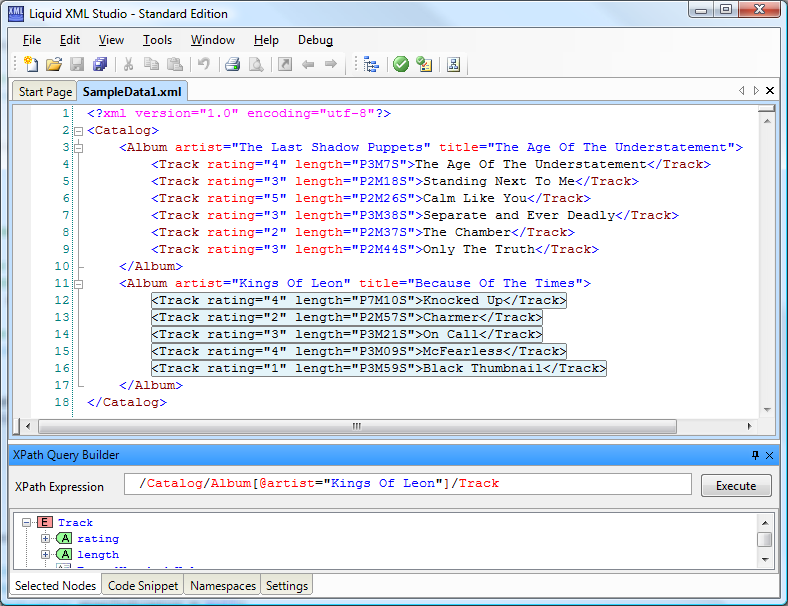
Обратите внимание:
- Виктор Иван — строка
- 7 — число
Но оба значения идут без кавычек. В XML нам нет нужды брать строковое значение в кавычки (а вот в JSON это сделать придется).
Атрибуты элемента
название_атрибута = «значение атрибута»Например:
<query attr1=“value 1”>Виктор Иван</query>
<query attr1=“value 1” attr2=“value 2”>Виктор Иван</query>Зачем это нужно? Из атрибутов принимающая API-запрос система понимает, что такое ей вообще пришло.
Например, мы делаем поиск по системе, ищем клиентов с именем Олег. Отправляем простой запрос:
<query>Олег</query>А в ответ получаем целую пачку Олегов! С разными датами рождения, номерами телефонов и другими данными.
 Допустим, что один из результатов поиска выглядит так:
Допустим, что один из результатов поиска выглядит так:<party type="PHYSICAL" sourceSystem="AL" rawId="2">
<field name=“name">Олег </field>
<field name="birthdate">02.01.1980</field>
<attribute type="PHONE" rawId="AL.2.PH.1">
<field name="type">MOBILE</field>
<field name="number">+7 916 1234567</field>
</attribute>
</party>Давайте разберем эту запись. У нас есть основной элемент party.
У него есть 3 атрибута:
- type = «PHYSICAL» — тип возвращаемых данных. Нужен, если система умеет работать с разными типами: ФЛ, ЮЛ, ИП. Тогда благодаря этому атрибуту мы понимаем, с чем именно имеем дело и какие поля у нас будут внутри. А они будут отличаться! У физика это может быть ФИО, дата рождения ИНН, а у юр лица — название компании, ОГРН и КПП
- sourceSystem = «AL» — исходная система. Возможно, нас интересуют только физ лица из одной системы, будем делать отсев по этому атрибуту.

- rawId = «2» — идентификатор в исходной системе. Он нужен, если мы шлем запрос на обновление клиента, а не на поиск. Как понять, кого обновлять? По связке sourceSystem + rawId!

Внутри party есть элементы field.
У элементов field есть атрибут name. Значение атрибута — название поля: имя, дата рождения, тип или номер телефона. Так мы понимаем, что скрывается под конкретным field.
Это удобно с точки зрения поддержки, когда у вас коробочный продукт и 10+ заказчиков. У каждого заказчика будет свой набор полей: у кого-то в системе есть ИНН, у кого-то нету, одному важна дата рождения, другому нет, и т.д.
Но, несмотря на разницу моделей, у всех заказчиков будет одна XSD-схема (которая описывает запрос и ответ):
— есть элемент party;
— у него есть элементы field;
— у каждого элемента field есть атрибут name, в котором хранится название поля.
А вот конкретные названия полей уже можно не описывать в XSD. Их уже «смотрите в ТЗ». Конечно, когда заказчик один или вы делаете ПО для себя или «вообще для всех», удобнее использовать именованные поля — то есть «говорящие» теги. Какие плюшки у этого подхода:
Их уже «смотрите в ТЗ». Конечно, когда заказчик один или вы делаете ПО для себя или «вообще для всех», удобнее использовать именованные поля — то есть «говорящие» теги. Какие плюшки у этого подхода:
— При чтении XSD сразу видны реальные поля. ТЗ может устареть, а код будет актуален.
— Запрос легко дернуть вручную в SOAP Ui — он сразу создаст все нужные поля, нужно только значениями заполнить. Это удобно тестировщику + заказчик иногда так тестирует, ему тоже хорошо.
В общем, любой подход имеет право на существование. Надо смотреть по проекту, что будет удобнее именно вам. У меня в примере неговорящие названия элементов — все как один будут field
Помимо элементов field в party есть элемент attribute. Не путайте xml-нотацию и бизнес-прочтение:
- с точки зрения бизнеса это атрибут физ лица, отсюда и название элемента — attribute.
- с точки зрения xml — это элемент (не атрибут!), просто его назвали attribute. XML все равно (почти), как вы будете называть элементы, так что это допустимо.
 XML все равно (почти), как вы будете называть элементы, так что это допустимо.
XML все равно (почти), как вы будете называть элементы, так что это допустимо.У элемента attribute есть атрибуты:
- type = «PHONE» — тип атрибута. Они ведь разные могут быть: телефон, адрес, емейл…
- rawId = «AL.2.PH.1» — идентификатор в исходной системе. Он нужен для обновления. Ведь у одного клиента может быть несколько телефонов, как без ID понять, какой именно обновляется?
Такая вот XML-ка получилась. Причем упрощенная. В реальных системах, где хранятся физ лица, данных сильно больше: штук 20 полей самого физ лица, несколько адресов, телефонов, емейл-адресов…
Но прочитать даже огромную XML не составит труда, если вы знаете, что где. И если она отформатирована — вложенные элементы сдвинуты вправо, остальные на одном уровне. Без форматирования будет тяжеловато…
А так всё просто — у нас есть элементы, заключенные в теги. Внутри тегов — название элемента. Если после названия идет что-то через пробел: это атрибуты элемента.
XML пролог
Иногда вверху XML документа можно увидеть что-то похожее:
<?xml version="1.0" encoding="UTF-8"?>Эта строка называется XML прологом. Она показывает версию XML, который используется в документе, а также кодировку. Пролог необязателен, если его нет — это ок. Но если он есть, то это должна быть первая строка XML документа.
XSD-схема
XSD (XML Schema Definition) — это описание вашего XML. Как он должен выглядеть, что в нем должно быть? Это ТЗ, написанное на языке машины — ведь схему мы пишем… Тоже в формате XML! Получается XML, который описывает другой XML.
Фишка в том, что проверку по схеме можно делегировать машине. И разработчику даже не надо расписывать каждую проверку. Достаточно сказать «вот схема, проверяй по ней».
Если мы создаем SOAP-метод, то указываем в схеме:
- какие поля будут в запросе;
- какие поля будут в ответе;
- какие типы данных у каждого поля;
- какие поля обязательны для заполнения, а какие нет;
- есть ли у поля значение по умолчанию, и какое оно;
- есть ли у поля ограничение по длине;
- есть ли у поля другие параметры;
- какая у запроса структура по вложенности элементов;
- . ..
 ..
..Теперь, когда к нам приходит какой-то запрос, он сперва проверяется на корректность по схеме. Если запрос правильный, запускаем метод, отрабатываем бизнес-логику. А она может быть сложной и ресурсоемкой! Например, сделать выборку из многомиллионной базы. Или провести с десяток проверок по разным таблицам базы данных…
Поэтому зачем запускать сложную процедуру, если запрос заведом «плохой»? И выдавать ошибку через 5 минут, а не сразу? Валидация по схеме помогает быстро отсеять явно невалидные запросы, не нагружая систему.
Более того, похожую защиту ставят и некоторые программы-клиенты для отправки запросов. Например, SOAP Ui умеет проверять ваш запрос на well formed xml, и он просто не отправит его на сервер, если вы облажались. Экономит время на передачу данных, молодец!
А простому пользователю вашего SOAP API схема помогает понять, как составить запрос. Кто такой «простой пользователь»?
- Разработчик системы, использующей ваше API — ему надо прописать в коде, что именно отправлять из его системы в вашу.
- Тестировщик, которому надо это самое API проверить — ему надо понимать, как формируется запрос.

Да-да, в идеале у нас есть подробное ТЗ, где всё хорошо описано. Но увы и ах, такое есть не всегда. Иногда ТЗ просто нет, а иногда оно устарело. А вот схема не устареет, потому что обновляется при обновлении кода. И она как раз помогает понять, как запрос должен выглядеть.
Итого, как используется схема при разработке SOAP API:
- Наш разработчик пишет XSD-схему для API запроса: нужно передать элемент такой-то, у которого будут такие-то дочерние, с такими-то типами данных. Эти обязательные, те нет.
- Разработчик системы-заказчика, которая интегрируется с нашей, читает эту схему и строит свои запросы по ней.
- Система-заказчик отправляет запросы нам.
- Наша система проверяет запросы по XSD — если что-то не так, сразу отлуп.
- Если по XSD запрос проверку прошел — включаем бизнес-логику!
А теперь давайте посмотрим, как схема может выглядеть! Возьмем для примера метод doRegister в Users.
 Чтобы отправить запрос, мы должны передать email, name и password. Есть куча способов написать запрос правильно и неправильно:
Чтобы отправить запрос, мы должны передать email, name и password. Есть куча способов написать запрос правильно и неправильно:Попробуем написать для него схему. В запросе должны быть 3 элемента (email, name, password) с типом «string» (строка). Пишем:
<xs:element name="doRegister ">
<xs:complexType>
<xs:sequence>
<xs:element name="email" type="xs:string"/>
<xs:element name="name" type="xs:string"/>
<xs:element name="password" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>А в WSDl сервиса она записана еще проще:
<message name="doRegisterRequest">
<part name="email" type="xsd:string"/>
<part name="name" type="xsd:string"/>
<part name="password" type="xsd:string"/>
</message>Конечно, в схеме могут быть не только строковые элементы. Это могут быть числа, даты, boolean-значения и даже какие-то свои типы:
<xsd:complexType name="Test">
<xsd:sequence>
<xsd:element name="value" type="xsd:string"/>
<xsd:element name="include" type="xsd:boolean" minOccurs="0" default="true"/>
<xsd:element name="count" type="xsd:int" minOccurs="0" length="20"/>
<xsd:element name="user" type="USER" minOccurs="0"/>
</xsd:sequence>
</xsd:complexType>А еще в схеме можно ссылаться на другую схему, что упрощает написание кода — можно переиспользовать схемы для разных задач.
См также:
XSD — умный XML — полезная статья с хабра
Язык определения схем XSD — тут удобные таблички со значениями, которые можно использовать
Язык описания схем XSD (XML-Schema)
Пример XML схемы в учебнике
Официальный сайт w3.org
Практика: составляем свой запрос
Ок, теперь мы знаем, как «прочитать» запрос для API-метода в формате XML. Но как его составить по ТЗ? Давайте попробуем. Смотрим в документацию. И вот почему я даю пример из Дадаты — там классная документация!
Что, если я хочу, чтобы мне вернуть только женские ФИО, начинающиеся на «Ан»? Берем наш исходный пример:
<req>
<query>Виктор Иван</query>
<count>7</count>
</req>В первую очередь меняем сам запрос. Теперь это уже не «Виктор Иван», а «Ан»:
<req>
<query>Ан</query>
<count>7</count>
</req>Далее смотрим в ТЗ. Как вернуть только женские подсказки? Есть специальный параметр — gender.
 Название параметра — это название тегов. А внутри уже ставим пол. «Женский» по английски будет FEMALE, в документации также. Итого получили:
Название параметра — это название тегов. А внутри уже ставим пол. «Женский» по английски будет FEMALE, в документации также. Итого получили:<req>
<query>Ан</query>
<count>7</count>
<gender>FEMALE</gender>
</req>Ненужное можно удалить. Если нас не волнует количество подсказок, параметр count выкидываем. Ведь, согласно документации, он необязательный. Получили запрос:
<req>
<query>Ан</query>
<gender>FEMALE</gender>
</req>Вот и все! Взяли за основу пример, поменяли одно значение, один параметр добавили, один удалили. Не так уж и сложно. Особенно, когда есть подробное ТЗ и пример )))
Попробуй сам!
Напишите запрос для метода MagicSearch в Users. Мы хотим найти всех Ивановых по полному совпадению, на которых висят актуальные задачи.
Well Formed XML
Разработчик сам решает, какой XML будет считаться правильным, а какой нет. Но есть общие правила, которые нельзя нарушать. XML должен быть well formed, то есть синтаксически корректный.
Но есть общие правила, которые нельзя нарушать. XML должен быть well formed, то есть синтаксически корректный.
Чтобы проверить XML на синтаксис, можно использовать любой XML Validator (так и гуглите). Я рекомендую сайт w3schools. Там есть сам валидатор + описание типичных ошибок с примерами.
В готовый валидатор вы просто вставляете свой XML (например, запрос для сервера) и смотрите, всё ли с ним хорошо. Но можете проверить его и сами. Пройдитесь по правилам синтаксиса и посмотрите, следует ли им ваш запрос.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.
Давайте пройдемся по каждому правилу и обсудим, как нам применять их в тестировании. То есть как правильно «ломать» запрос, проверяя его на well-formed xml. Зачем это нужно? Посмотреть на фидбек от системы.![]() Сможете ли вы по тексту ошибки понять, где именно облажались?
Сможете ли вы по тексту ошибки понять, где именно облажались?
См также:
Сообщения об ошибках — тоже документация, тестируйте их! — зачем тестировать сообщения об ошибках
1. Есть корневой элемент
Нельзя просто положить рядышком 2 XML и полагать, что «система сама разберется, что это два запроса, а не один». Не разберется. Потому что не должна.
И если у вас будет лежать несколько тегов подряд без общего родителя — это плохой xml, не well formed. Всегда должен быть корневой элемент:
Что мы делаем для тестирования этого условия? Правильно, удаляем из нашего запроса корневые теги!
2. У каждого элемента есть закрывающийся тег
Тут все просто — если тег где-то открылся, он должен где-то закрыться. Хотите сломать? Удалите закрывающийся тег любого элемента.
Но тут стоит заметить, что тег может быть один. Если элемент пустой, мы можем обойтись одним тегом, закрыв его в конце:
<name/>Это тоже самое, что передать в нем пустое значение
<name></name>Аналогично сервер может вернуть нам пустое значение тега.
 Можно попробовать послать пустые поля в Users в методе FullUpdateUser. И в запросе это допустимо (я отправила пустым поле name1), и в ответе SOAP Ui нам именно так и отрисовывает пустые поля.
Можно попробовать послать пустые поля в Users в методе FullUpdateUser. И в запросе это допустимо (я отправила пустым поле name1), и в ответе SOAP Ui нам именно так и отрисовывает пустые поля.Итого — если есть открывающийся тег, должен быть закрывающийся. Либо это будет один тег со слешом в конце.
Для тестирования удаляем в запросе любой закрывающийся тег.
3. Теги регистрозависимы
Как написали открывающий — также пишем и закрывающий. ТОЧНО ТАК ЖЕ! А не так, как захотелось.
А вот для тестирования меняем регистр одной из частей. Такой XML будет невалидным
4. Правильная вложенность элементов
Элементы могут идти друг за другом
Один элемент может быть вложен в другой
Но накладываться друг на друга элементы НЕ могут!
5. Атрибуты оформлены в кавычках
Даже если вы считаете атрибут числом, он будет в кавычках:
<query attr1=“123”>Виктор Иван</query>
<query attr1=“атрибутик” attr2=“123” >Виктор Иван</query>Для тестирования пробуем передать его без кавычек:
<query attr1=123>Виктор Иван</query>Итого
XML (eXtensible Markup Language) используется для хранения и передачи данных.
Передача данных — это запросы и ответы в API-методах. Если вы отправляете SOAP-запрос, вы априори работаете именно с этим форматом. Потому что SOAP передает данные только в XML. Если вы используете REST, то там возможны варианты — или XML, или JSON.Хранение данных — это когда XML встречается внутри кода. Его легко понимает как машина, так и человек. В формате XML можно описывать какие-то правила, которые будут применяться к данным, или что-то еще.
Вот пример использования XML в коде open-source проекта folks. Я не знаю, что именно делает JacksonJsonProvider, но могу «прочитать» этот код — есть функционал, который мы будем использовать (featuresToEnable), и есть тот, что нам не нужен(featuresToDisable).
Формат XML подчиняется стандартам. Синтаксически некорректный запрос даже на сервер не уйдет, его еще клиент порежет. Сначала проверка на well formed, потом уже бизнес-логика.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.

Если вы тестировщик, то при тестировании запросов в формате XML обязательно попробуйте нарушить каждое правило! Да, система должна уметь обрабатывать такие ошибки и возвращать адекватное сообщение об ошибке. Но далеко не всегда она это делает.
А если система публичная и возвращает пустой ответ на некорректный запрос — это плохо. Потому что разработчик другой системы налажает в запросе, а по пустому ответу даже не поймет, где именно. И будет приставать к поддержке: «Что же у меня не так?», кидая информацию по кусочкам и в виде скринов исходного кода. Оно вам надо? Нет? Тогда убедитесь, что система выдает понятное сообщение об ошибке!
См также:
Что такое XML
Учебник по XML
Изучаем XML. Эрик Рэй (книга по XML)
Заметки о XML и XLST
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
А полезные видео — на моем youtube-канале
XML— это очень просто… | XML | Статьи | Программирование Realcoding.Net
В последнее время аббревиатура «XML» все чаще встречается в
статьях, книгах и разговорах профессионалов (и дилетантов). Многое уже было
сказано, и многое еще будет сказано об этой универсальной технологии. Основная
цель данной статьи состоит в том, чтобы ввести читателя в мир расширяемого языка
разметки и показать некоторые средства, используемые для представления знаний
посредством XML-технологий и последующей визуализации этих знаний. Я не
собираюсь утомлять читателя пространными описаниями стандартов на документы XML,
рекомендуемых консорциумом W3C (зайдите в гости к консорциуму, проживающему по
адресу http://www.w3.org; здесь расположена вся
официальная документация). О некоторых стандартах и их реализации мы поговорим в
следующих статьях, а сейчас наша основная задача — понять, из-за чего,
собственно говоря, начался весь этот шум вокруг XML.
Прежде всего, необходимо отметить, что высказывания вроде «XML позволит решить все проблемы электронной коммерции» или «XML скоро полностью вытеснит HTML» являются в корне неверными и показывают неведение их авторов относительно роли XML в электронном бизнесе и месте расширяемого языка разметки в сфере интернет-технологий. По мнению ведущих экспертов, XML можно использовать как дополнение к HTML. Вероятно, в будущем XML будет применяться для описания данных, тогда как прерогативой HTML останется форматирование и презентация этих данных.
Судя по наметившимся тенденциям, в будущем XML будет служить
связующим звеном между различными платформами и приложениями. Что же касается
применения XML в бизнесе, то наилучшей областью для этого специалисты считают B2B (business-to-business). Уже сейчас многие компании, специализирующиеся в
электронной коммерции, активно применяют расширяемый язык разметки для улучшения
взаимодействия с партнерами.
Что же такое XML? Если речь идет о формальном определении, я бы предложил следующее: XML — это универсальный, не зависящий от платформы язык разметки, который можно использовать для представления иерархических данных и унификации передаваемой информации. Сама аббревиатура расшифровывается как Extensible Markup Language, что в переводе означает «расширяемый язык разметки». Как и HTML (Hypertext Markup Language), XML является потомком SGML (Standard General Markup Language) — «дедушки» языков разметки, который в течение многих лет используется в издательском деле. Иногда говорят, что XML — это не язык, а скорее метаязык, с помощью которого можно определять другие языки. Действительно, путем создания новых тэгов и определения новых структур с помощью этих тэгов мы фактически создаем новые языки с их собственным синтаксисом и семантикой.
Предвижу давно напрашивающийся вопрос: чем же был плох HTML?
Последние версии этого языка в сочетании с каскадными таблицами стилей (CSS)
позволяют создавать очень красивые web-сайты и обладают практически
неограниченными возможностями форматирования гипертекстовых документов. Зачем же
нам морочить голову, изобретать и добавлять новые тэги, когда и стандартных
элементов (плюс возможности стилевых таблиц) хватает даже для самого
причудливого оформления Web-страницы? Дело в том, что XML в его «чистом» виде
слабо связан с форматированием документов. Альфа и омега этого языка —
возможность семантически и синтаксически корректно описывать сложные
структурированные данные. Правильно же представленные данные легче обрабатывать,
передавать и представлять пользователю.
Зачем же
нам морочить голову, изобретать и добавлять новые тэги, когда и стандартных
элементов (плюс возможности стилевых таблиц) хватает даже для самого
причудливого оформления Web-страницы? Дело в том, что XML в его «чистом» виде
слабо связан с форматированием документов. Альфа и омега этого языка —
возможность семантически и синтаксически корректно описывать сложные
структурированные данные. Правильно же представленные данные легче обрабатывать,
передавать и представлять пользователю.
Представим себе, что нам необходимо описать некоторые данные о человеке, например, его имя и возраст. Следующий фрагмент HTML-документа выполняет эту задачу:
Теперь попробуем сделать то же самое с помощью XML:
Этот тривиальный пример хорошо демонстрирует различия в
представлении данных с помощью HTML и XML. Действительно, то, что относилось к
тексту в HTML-представлении (слова «Name» и «Age»), относится к структуре в
XML-документе (тэги <name> и <age>). Таким образом, XML позволяет лучше
структурировать хранимую и передаваемую информацию. Если в традиционном HTML
понятия «представление» и «визуализация» часто смешиваются, то при работе с XML
мы четко разделяем эти понятия. Все, что относится к описанию предметной
области, делается средствами XML, а то, что относится к визуализации, мы
оставляем специальным программам и стилевым таблицам.
Таким образом, XML позволяет лучше
структурировать хранимую и передаваемую информацию. Если в традиционном HTML
понятия «представление» и «визуализация» часто смешиваются, то при работе с XML
мы четко разделяем эти понятия. Все, что относится к описанию предметной
области, делается средствами XML, а то, что относится к визуализации, мы
оставляем специальным программам и стилевым таблицам.
Синтаксис прост, но строг…
Рассмотрим следующий простой документ XML:
<?xml version=»1.0″?> <people> <person> <name> <first_name>Ivan</first_name> <second_name>Ivanovich</second_name> <surname>Ivanov</surname> </name> <age>8</age> <hobby>football</hobby> </person> <person> <name> <first_name>Pyotr</first_name> <second_name>Petrovich</second_name> <surname>Petrov</surname> </name> <age>25</age> <hobby>chess</hobby> </person> <person> <name> <first_name>Nikolay</first_name> <second_name>Nikolayevich</second_name> <surname>Nikolayev</surname> </name> <age>45</age> <hobby>swimming</hobby> </person> </people>
Первая строка:
является декларацией используемой версии языка. В данном случае
это версия 1.0. Не пропускайте эту строку в ваших документах!
В данном случае
это версия 1.0. Не пропускайте эту строку в ваших документах!
Вторая строка
описывает корневой элемент документа (the root element). Составитель как бы предупреждает: «этот документ содержит информацию о людях».
Элементы, представленные тэгами <person> и </person> являются дочерними узлами (child nodes) корневого узла <people>. Слово «class» представляет собой имя атрибута, значение которого равно children. Узлы <name>, <age> и <hobby> являются потомками (descendants) узла <people> и дочерними узлами для <person>. Наконец, тэги <first_name>, <second_name> и <surname> — это «дети» для <name>, «внуки» для <person> и «правнуки» для <people>.
Последняя строка
определяет конец корневого элемента.
Отметим некоторые особенности синтаксиса XML.
В отличие от HTML, все элементы XML должны иметь закрывающий тэг (closing tag). В HTML следующая запись допустима:
В XML опускать закрывающие тэги нельзя. Для данного примера представление текста в формате XML могло бы выглядеть так:
<p>Это мой первый параграф</p> <p>Это мой второй параграф</p>
Впрочем, вместо <p> мы могли бы использовать другой тэг, например, отсутствующий в HTML тэг <prgrph>, благо XML позволяет нам изобретать наши собственные тэги. Заметим, что первая, «декларативная» строка документа не содержит закрывающего тэга. Это не ошибка. Дело в том, что декларации не являются элементами XML и не имеют закрывающих тэгов.
В отличие от HTML, тэги XML чувствительны к регистру (case
sensitive). Если в HTML строки символов <IMG>, <img> и <Img> представляют собой
один и тот же тэг, то в XML эти тэги не эквивалентны. Примеры:
Примеры:
<Letter>Это неправильная запись!</letter> <letter>Это правильная запись</letter>
В HTML иногда можно нарушить правила вложения тэгов без тяжелых последствий (в виде сообщения об ошибке). В XML это невозможно. Например, код
в HTML допускается. В XML такая запись ошибочна. Правильный код выглядел бы так:
В отличие от HTML, все документы XML должны иметь корневой элемент. Все остальные элементы являются «потомками» корневого. При этом строгие правила вложения не должны нарушаться.
В отличие от HTML, XML сохраняет пробелы. Строка
в HTML будет показана так:
В XML все пробелы будут сохранены.
В HTML значения атрибутов элементов часто могут не заключаться в
кавычки. В XML все значения атрибутов непременно должны быть заключены в
кавычки. Нарушение этого правила обязательно приведет к ошибке. Если в нашем
примере третью строку изменить следующим образом:
Если в нашем
примере третью строку изменить следующим образом:
синтаксис XML будет нарушен.
«Хорошие» и «плохие» документы
Документы XML, удовлетворяющие всем требованиям синтаксиса, называют правильными (well-formed). С этой точки зрения построенный нами документ с корневым элементом <people> является правильным. Я надеюсь, что на вашем компьютере заблаговременно был установлен Microsoft Internet Explorer 5.0. Если так, то мы можем проверить «правильность» нашего документа прямо сейчас. Сохраните текст документа в файле myFirstXML.xml и откройте этот файл в Internet Explorer. Если вы правильно скопировали текст, получится нечто вроде этого (рис. 1).
Если бы мы допустили какую-нибудь синтаксическую ошибку, например, забыли закрыть какой-нибудь тэг, программа-анализатор сообщила бы нам об этом через окно Internet Explorer.
Следует отметить, что я перечислил лишь основные правила
синтаксиса XML, акцентируя внимание читателя на их отличии от правил построения
документов HTML. Кроме правильных документов различают также действительные (valid) документы, которые удовлетворяют специальным определениям типа
документа (Document Type Definition, DTD). Определение типа документа
представляет собой описание логической структуры, в соответствии с которой
строится документ. DTD определяет части документа и указывает, какие элементы и
в каком порядке в них могут размещаться. Определение типа документа — это, по
сути дела, набор правил, который передается специальной программе-анализатору (parser)
для обработки документа и определения его соответствия правилам построения.
Кроме правильных документов различают также действительные (valid) документы, которые удовлетворяют специальным определениям типа
документа (Document Type Definition, DTD). Определение типа документа
представляет собой описание логической структуры, в соответствии с которой
строится документ. DTD определяет части документа и указывает, какие элементы и
в каком порядке в них могут размещаться. Определение типа документа — это, по
сути дела, набор правил, который передается специальной программе-анализатору (parser)
для обработки документа и определения его соответствия правилам построения.
Детальные определения типа документа не являются обязательными (хотя рекомендуются) для построения XML-документов. В настоящее время разрабатываются новые, быть может, более эффективные средства задания структуры документа (например, так называемые схемы). Обсуждение деталей DTD выходит за рамки данной статьи. Хочу лишь отметить, что первая строка рассмотренного нами ранее документа
является частью DTD (в рассмотренном примере DTD содержит лишь
одну эту строку).
Презентация документа
Я чувствую, что читатель устал от теоретических рассуждений и ждет конкретных указаний, которые помогли бы ему воочию оценить работу XML. Я уже писал, что XML прежде всего используется для представления, а не для визуализации данных. Тем не менее, существуют изящные методы визуализации документов XML. Попробуем визуализировать рассмотренный ранее документ с помощью каскадных таблиц стилей (CSS), о которых вы, вероятно, уже слышали.
Визуализация документов XML с помощью CSS по сути ничем не отличается от визуализации документов HTML. Требуется лишь связать нужный документ с нужной таблицей стилей. Что может быть проще?
Создайте файл myFirstXML.css в той же папке, что и myFirstXML.xml и занесите в него следующие определения стилей:
person {display: block; color: blue; margin-bottom: 30pt}
name {display: block; color: brown}
age, hobby {display: block}
person. children {background-color: yellow}
children {background-color: yellow}
Здесь display: block означает, что данный элемент нужно представлять в виде отдельного блока в окне браузера, color определяет цвет переднего плана, margin-bottom: 30pt здесь означает, что от каждого элемента <person> следует отступить на 30 пунктов вниз перед показом следующего элемента. Наконец, элементы <person> со значением атрибута class, равным children, следует подсветить желтым цветом.
Не забудьте сохранить файл.
Добавьте в ранее созданный файл myFirstXML.xml строку
после строки
с целью декларировать связь документа XML со стилевой таблицей CSS.
Опять сохраните файл.
Откройте файл myFirstXML.xml в окне Internet Explorer.
Нет, не все так просто…
Таблицы CSS, позволяющие визуализировать XML-документы, все же
не решают всех проблем. В настоящее время имеются гораздо более мощные средства
для трансформации и презентации документов XML, позволяющие не только
произвольным образом форматировать документ XML, но и изменять его структуру,
осуществлять поиск и сортировку в документе и выполнять другие интересные и
полезные операции. Для расширения таких возможностей был разработан специальный
расширяемый язык стилей (XSL). У читателя может возникнуть вопрос:
«Если я хочу связывать документ XML с различными стилевыми таблицами, должен ли
я каждый раз менять строку документа, декларирующего его связь со стилевой
таблицей, или это можно делать динамически, используя скрипты или языки
программирования?» Конечно, можно! Впрочем, об этом в следующий раз…
Для расширения таких возможностей был разработан специальный
расширяемый язык стилей (XSL). У читателя может возникнуть вопрос:
«Если я хочу связывать документ XML с различными стилевыми таблицами, должен ли
я каждый раз менять строку документа, декларирующего его связь со стилевой
таблицей, или это можно делать динамически, используя скрипты или языки
программирования?» Конечно, можно! Впрочем, об этом в следующий раз…
Десять правил XML, которые нужно знать
Как правильно использовать XML
Джек Херрингтон
Опубликовано 26.03.2012
Часто используемые сокращения
- CDATA: Character Data (символьные данные)
- DOM: Document Object Model (объектная модель документа)
- E4X: ECMAScript for XML (ECMAScript для XML)
- IDE: Integrated Development Environment (интегрированная среда разработки)
- W3C: World Wide Web Consortium (консорциум WWW)
- XML: Extensible Markup Language (расширяемый язык разметки)
- XSLT: Extensible Stylesheet Language Transformations (расширяемый язык преобразований таблиц стилей)
В настоящее время XML воспринимается как нечто само собой разумеющееся. Он повсюду! Но если посмотреть со стороны, то можно увидеть, что это мощная технология. Есть интегрированные среды разработки, которые помогают строить XML-деревья. Есть целый ряд технологий проверки корректности XML-кода. Есть XSLT – специальный язык преобразования XML. Поддержка XML встроена даже непосредственно в синтаксис некоторых языков (как, например, E4X в ActionScript).
Он повсюду! Но если посмотреть со стороны, то можно увидеть, что это мощная технология. Есть интегрированные среды разработки, которые помогают строить XML-деревья. Есть целый ряд технологий проверки корректности XML-кода. Есть XSLT – специальный язык преобразования XML. Поддержка XML встроена даже непосредственно в синтаксис некоторых языков (как, например, E4X в ActionScript).
Но у XML есть и обратная сторона. Его можно использовать неправильно. Его можно использовать плохо. Он может быть чрезмерно сложным. Он может быть недоопределенным. С ним может быть трудно работать. Что нужно сделать для более эффективного использования этой мощной технологии? В своей статье я дам 10 советов, которые помогут ответить на этот вопрос.
Не используйте XML в качестве имени файла или корневого тега
Много раз я видел XML-код, хранящийся в файлах с расширением .xml. Это бессмысленно. Такое расширение не скажет мне ничего, чего бы я не знал, просто выполнив команду cat. Как только я увижу теги, я сразу пойму, что это XML. Вместо этого расширения используйте расширение, имеющее смысл для пользователя. Также можно использовать уникальное расширение, чтобы при поиске Google возвращал ссылки на документацию или на примеры вашего формата XML-файла.
Вместо этого расширения используйте расширение, имеющее смысл для пользователя. Также можно использовать уникальное расширение, чтобы при поиске Google возвращал ссылки на документацию или на примеры вашего формата XML-файла.
Еще одной проблемой в некоторых XML-документах является использование корневого тега <xml>. Это опять-таки ни о чем не говорит. Что находится в этом файле? Если это список контактов, корневым узлом должен быть тег <contacts>. XML должен быть читабельным, поэтому используйте имена тегов и атрибутов, имеющие отношение к бизнес-задаче, над которой работаете. Если корневым узлом является <contacts>, я предполагаю увидеть теги <contact>, а затем теги <name>, <first>, <middle>, <last> и т.д.
Не переопределяйте обобщенные или специфичные для языка конструкции
Я понимаю, что XML – это формат для сохранения данных. В своем большинстве языки предоставляют способ сохранения структур данных в XML. Хорошо, если вы уверены, что только написанные на том же языке процессы будут когда-либо читать или писать ваш XML-код. Такое, однако, встречается редко. Если ваше приложение пишет что-то в файл, вполне вероятно, что в какой-то момент времени его прочтет пользователь или какое-нибудь приложение на другом языке.
В своем большинстве языки предоставляют способ сохранения структур данных в XML. Хорошо, если вы уверены, что только написанные на том же языке процессы будут когда-либо читать или писать ваш XML-код. Такое, однако, встречается редко. Если ваше приложение пишет что-то в файл, вполне вероятно, что в какой-то момент времени его прочтет пользователь или какое-нибудь приложение на другом языке.
Этим я хочу сказать, что специфичные для языка конструкции нужно хранить вне XML. Как часто вы встречали <data type="NSDate">07-18-2010</data>? Что такое NSDate? Ага, это имя класса для работы с датами на прикладной платформе. Что произойдет при смене платформы или языка? Потребуется преобразование тегов NSDate во что-то другое, что используется на новой платформе.
Храните специфику языка вне XML и используйте простые теги, скажем <date>...<date>. Такой тег легко понимаем, читабелен и не зависит от конкретного языка или интегрированной среды.
Еще одно важное правило – избегайте использования в XML излишних обобщений. Взгляните на следующий пример (листинг 1):
Листинг 1. Обобщенное дерево узлов
<nodes>
<node type="user">
<node type="first">jack</node>
</node>
</nodes>Что это означает? Я понял, что это список пользователей. Но человеку трудно это читать и редактировать. Еще хуже то, что этот XML-код очень трудно использовать в средствах, подобных XSLT, или проверять его корректность при помощи схемы. В листинге 2 показано, что на самом деле означает приведенный выше XML-код.
Листинг 2. Более эффективное дерево узлов
<users>
<user>
<first>jack</first>
</user>
</users>Разве так не лучше? Код говорит то, что означает, и означает то, что говорит. Его легче читать и анализировать. Его легче проверять и преобразовывать при помощи XSLT.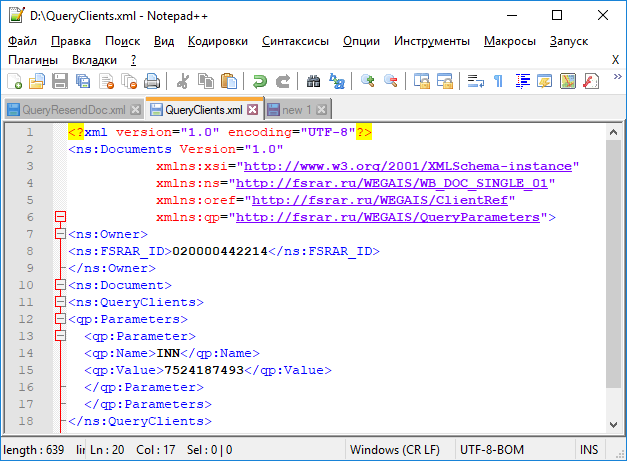 Он даже меньше по размеру.
Он даже меньше по размеру.
Не делайте файлы слишком большими
Знаю, что вы скажете: «Дисковая память стоит дешево. За десять центов я куплю еще один терабайт». Это верно. Вы действительно можете создавать гигабайтные XML-файлы. Но программирование – это постоянные компромиссы. Приходится менять дисковое пространство на время или память на время. А при работе с огромным XML-файлом вы получаете худшие стороны и того, и другого. Файл занимает много места на диске, а на его анализ и проверку уходит много времени. Кроме того, большой файл исключает использование DOM-анализатора, поскольку построение дерева требует бесконечного времени и огромного количества памяти.
Какова же альтернатива? Можно создать несколько файлов. Один выступает в качестве индекса, а другие содержат большие ресурсы, которые, возможно, будут нужны не всем пользователям этого XML. Другой вариант– вынос всех больших фрагментов CDATA из XML-файла и помещение их в свои собственные файлы с собственными форматами. Если вы хотите хранить все данные вместе, запакуйте все файлы в новый файл с новым расширением. Любой популярный язык программирования имеет модули, облегчающие быструю упаковку и распаковку файлов.
Если вы хотите хранить все данные вместе, запакуйте все файлы в новый файл с новым расширением. Любой популярный язык программирования имеет модули, облегчающие быструю упаковку и распаковку файлов.
Не используйте пространства имен, если в этом нет острой необходимости
Пространства имен (namespace) – это мощная составляющая XML-лексикона. Они облегчают реализацию расширяемых форматов файлов. Вы можете определить базовый набор тегов для всех потребностей вашего приложения, а затем разрешить пользователям добавлять свои собственные данные в свое собственное пространство имен в файле, не затрагивая ваше дерево объектов.
Однако пространства имен очень затрудняют синтаксический анализ и управление данными. Они сбивают с толку расширения языков программирования, такие как E4X. Они затрудняют использование XML в XSLT. Наконец, они делают XML-файлы намного более трудными для чтения.
Поэтому используйте пространства имен XML, только если это действительно необходимо. Не используйте их просто потому, что «XML позволяет это делать». XML прекрасно работает и без пространств имен.
XML прекрасно работает и без пространств имен.
Не используйте специальные символы
Все мои советы направлены на поддержание чистоты, простоты и легкости восприятия вашего XML-кода. В этом смысле даже спецификация XML позволяет многое, что совсем необязательно использовать. Например, в названиях элементов и атрибутов можно использовать тире. Но это очень затрудняет использование такого XML-кода в расширениях языка, например в E4X. Вопрос в том, стоит ли?
Я рекомендую избегать использования любых специальных символов в названиях элементов и атрибутов.
Используйте XML Schema
Синтаксический анализ XML является непростой задачей. Для точного анализа необходимо проделать большую работу по защите кода от возможного отсутствия и некорректного использования тегов или атрибутов. Это дополнительная работа по написанию кода, дополнительная сложность, а также затенение реальной бизнес-логики, являющейся вашей главной заботой. Как избежать этого? Проверяйте XML перед его использованием. Для этого можно использовать несколько стандартов. Можно указать Document Type Definition (DTD) или XML Schema (ссылки на информацию о DTD и XML Schema приведены в разделе Ресурсы). Лично я нахожу XML Schema намного более простой в работе, но если вы новичок в этом деле, попробуйте различные системы проверки корректности.
Для этого можно использовать несколько стандартов. Можно указать Document Type Definition (DTD) или XML Schema (ссылки на информацию о DTD и XML Schema приведены в разделе Ресурсы). Лично я нахожу XML Schema намного более простой в работе, но если вы новичок в этом деле, попробуйте различные системы проверки корректности.
Большим преимуществом является то, что после проверки корректности XML в нем можно быть уверенным. Возможно, это не нужно для внутренних XML-файлов вашего приложения. Но это очень полезно, если XML генерируется другим приложением или пишется вручную.
Нумеруйте версии
Очень легко упустить из виду тот факт, что XML, хранящийся в файлах, эквивалентен формату файла. Первое, что должен содержать файл любого формата, – это номер версии. Его достаточно легко добавить: <customers version="1">...</customers>. Код, выполняющий чтение файла, должен проверить, что номер версии не больше его текущей версии, и сгенерировать исключительную ситуацию, если это не так. Это гарантирует, что любые последующие версии кода не будут конфликтовать с более старыми версиями при использовании новых тегов. Конечно же, вы должны обеспечить поддержку всех старых версий файлов при дальнейшей разработке своего приложения.
Это гарантирует, что любые последующие версии кода не будут конфликтовать с более старыми версиями при использовании новых тегов. Конечно же, вы должны обеспечить поддержку всех старых версий файлов при дальнейшей разработке своего приложения.
Сочетайте узлы и атрибуты
Инженеры довольно ленивый народ. Я могу это утверждать, поскольку сам такой. Не спорьте, все мы такие. Если интегрированная среда разработки предложит выполнить экспорт XML вместо нас, мы наверняка согласимся. Но обычно интегрированная среда создает очень плохой XML-код. Вероятно, вы уже встречались с чем-то похожим на листинг 3:
Листинг 3. Список пользователей
<users>
<user>
<id>1</id>
<first>jack</first>
</user>
</users>Должен ли <id> быть тегом? Я утверждаю, что он должен быть атрибутом. Код становится более коротким и осмысленным, появляется возможность искать пользователя по идентификатору при помощи простого XPath-выражения (/users/user[@id=1]).
Чтобы код был читабелен, несомненно лучше использовать атрибуты, как показано в листинге 4.
Листинг 4. Более удобный список пользователей
<users>
<user>
<first>jack</first>
</user>
</users>Понятно, что интегрированная среда сгенерировала листинг 3, потому что всегда безопаснее использовать узлы. Но атрибуты позволяют идентифицировать важные элементы в DOM-дереве, поэтому следует использовать их.
Используйте CDATA, но не злоупотребляйте этим
XML налагает множество ограничений на использование определенных символов: кавычек, амперсандов, знаков «меньше» и «больше» и т.д. Однако на практике эти символы используются очень часто. Поэтому приходится либо преобразовывать все в безопасный для XML формат, либо помещать большие фрагменты текста, кода или еще чего-нибудь в блоки CDATA. Мне кажется, что разработчики избегают использования CDATA, поскольку думают, что это затруднит синтаксический анализ. Но разделы
Но разделы CDATA анализировать не труднее, чем что-либо другое – большинство DOM-анализаторов обрабатывает их самостоятельно, поэтому вам даже не нужно думать об этом.
Еще одной важной причиной использования CDATA является сохранение точного форматирования данных. Например, при экспорте Wiki-страницы вы наверняка захотите в точности сохранить позиции таких символов как возврат каретки и перевод строки, поскольку они играют особую роль в Wiki-формате.
Почему же не использовать разделы CDATA постоянно? Потому что они очень затрудняют чтение документа. Это особенно неприятно, когда в них нет необходимости. Итак, используйте их и поощряйте их использование пользователями ваших XML-файлов в тех ситуациях, когда данные, по вашему мнению, будут содержать специальные символы и когда нужно сохранить первоначальное форматирование. Но не используйте CDATA в прочих ситуациях.
Храните необязательные данные в отдельной области
До сих пор я рассказывал об XML-документах с жестким форматом. Я даже рекомендовал использовать технологию проверки корректности, (например, XML Schema), гарантирующую жесткую структуру. Тому есть веская причина: структурированные данные легче анализировать. А если нужна определенная гибкость? Я рекомендую размещать необязательные данные в отдельном блоке в своем собственном узле. Взгляните, например, на листинг 5.
Я даже рекомендовал использовать технологию проверки корректности, (например, XML Schema), гарантирующую жесткую структуру. Тому есть веская причина: структурированные данные легче анализировать. А если нужна определенная гибкость? Я рекомендую размещать необязательные данные в отдельном блоке в своем собственном узле. Взгляните, например, на листинг 5.
Листинг 5. Неупорядоченная запись о пользователе
<users>
<user>
<first>jack</first>
<middle>d</middle>
<last>herrington</last>
<runningpace>8:00</runningpace>
</user>
</users>Эта запись содержит все ожидаемые данные о пользователе. Я согласен с first, middle, last, но зачем здесь runningpace? Это необходимо? Будете ли у вас много таких полей? Будут ли они расширяемыми? Если ответ на все эти вопросы утвердителен, я порекомендовал бы сделать так (см. листинг 6):
Листинг 6.
 Хорошо структурированная запись о пользователе
Хорошо структурированная запись о пользователе<users>
<user>
<first>jack</first>
<middle>d</middle>
<last>herrington</last>
<userdata>
<field name="runningpace">8:00</field>
</userdata>
</user>
</users>При таком подходе вы можете иметь сколько угодно полей, не загромождая пространство имен родительского элемента <user>. Вы даже можете проверить корректность этого документа, а также обратиться к определенному полю при помощи XPath-выражения (//user/userdata/field[@name=’runningpace’).
Заключение
Обдумайте то, что я сказал. Я порекомендовал пять вещей, которые стоит делать, и пять вещей, которых следует избегать. Не все мои советы применимы в любых обстоятельствах. Иногда XML – это только формат хранения данных, передаваемых по сети и живущих всего несколько миллисекунд. В этом случае ни о чем заботиться не стоит. Но при использовании XML в качестве формата файлов вам следует прислушаться к моим советам и применить представленные здесь рекомендации.
В этом случае ни о чем заботиться не стоит. Но при использовании XML в качестве формата файлов вам следует прислушаться к моим советам и применить представленные здесь рекомендации.
Ресурсы для скачивания
Похожие темы
- Оригинал статьи: Five XML dos and five don’ts that you need to know (EN).
- Эксперты по языку скорее всего захотят познакомиться со спецификацией W3C XML Specification. Станьте экспертом по языку и узнайте подробнее об XML — простом, очень гибком текстовом формате, предназначенном для публикации электронных документов и играющем важную роль в обмене данными в Web и повсюду.
- Document Type Definition (DTD) в Википедии: информация о DTD — наборе объявлений разметки, определяющих тип документа для семейства языков разметки SGML (SGML, XML, HTML).
- XML Schema в Википедии: краткое описание типа XML-документа, ограничивающееся структурой и содержимым документов данного типа.
- Спецификация W3C XSLT: информация о замечательном способе преобразования XML в разнообразные форматы.
- Спецификация W3C XPath: очень полезное средство, которое можно использовать для быстрого и удобного поиска узлов даже в самом сложном XML-документе.
- Разработка XML при помощи Eclipse: использование возможностей XML в Eclipse (Павел Лешек (Pawel Leszek), developerWorks, апрель 2003 года): информация об Eclipse и его расширениях для редактирования XML (EN).
- Расширение E4X для Actionscript (ECMAScript): отличный способ интегрировать XML непосредственно в логику вашего приложения. Это расширение настолько полезно, что де-факто становится открытым стандартом хранения в языке (Википедия).
- Другие статьи данного автора (Джек Херрингтон (Jack Herrington), developerWorks, с марта 2005 года по настоящее время): статьи об Ajax, JSON, PHP, XML и других технологиях.
- Сертификация IBM по XML: информация о получении сертификата IBM-Certified Developer по XML и смежным технологиям.


Структура и правила создания XML-документа.
Структура и правила создания XML-документа. Структура документаПростейший XML- документ может выглядеть так, как это показано в
Примере 1
Пример 1
<?xml version="1.0"?> <list_of_items> <item><first/>Первый</item> <item>Второй <sub_item>подпункт 1</sub_item></item> <item>Третий</item> <item><last/>Последний</item> </list_of_items>
Обратите внимание на то, что этот документ очень похож на обычную
HTML-страницу. Также, как и в HTML, инструкции, заключенные в угловые
скобки называются тэгами и служат для разметки основного текста документа.
В XML существуют открывающие, закрывающие и пустые тэги (в HTML понятие
пустого тэга тоже существует, но специального его обозначения не
требуется).
Тело документа XML состоит из элементов разметки (markup) и непосредственно содержимого документа — данных (content). XML — тэги предназначены для определения элементов документа, их атрибутов и других конструкций языка. Более подробно о типах применяемой в документах разметки мы поговорим чуть позже.
Любой XML-документ должен всегда начинаться с инструкции , внутри которой также можно задавать номер версии языка, номер кодовой страницы и другие параметры, необходимые программе-анализатору в процессе разбора документа.
Правила создания XML- документа
В общем случае XML- документы должны удовлетворять следующим требованиям:
- В заголовке документа помещается объявление XML, в котором указывается язык разметки документа, номер его версии и дополнительная информация
- Каждый открывающий тэг, определяющий некоторую область данных в
документе обязательно должен иметь своего закрывающего «напарника»,
т. е., в отличие от HTML, нельзя опускать закрывающие тэги
- В XML учитывается регистр символов
- Все значения атрибутов, используемых в определении тэгов, должны быть заключены в кавычки
- Вложенность тэгов в XML строго контролируется, поэтому необходимо следить за порядком следования открывающих и закрывающих тэгов
- Вся информация, располагающаяся между начальным и конечными тэгами, рассматривается в XML как данные и поэтому учитываются все символы форматирования ( т.е. пробелы, переводы строк, табуляции не игнорируются, как в HTML)
 е., в отличие от HTML, нельзя опускать закрывающие тэги
е., в отличие от HTML, нельзя опускать закрывающие тэги
Если XML- документ не нарушает приведенные правила, то он называется формально-правильным и все анализаторы, предназначенные для разбора XML- документов, смогут работать с ним корректно.
Однако кроме проверки на формальное соответствие грамматике языка, в
документе могут присутствовать средства контроля над содержанием
документа, за соблюдением правил, определяющих необходимые соотношений
между элементами и формирующих структуру документа. Например, следующий
текст, являясь вполне правильным XML- документом, будет абсолютно
бессмысленным:
Например, следующий
текст, являясь вполне правильным XML- документом, будет абсолютно
бессмысленным:
<country><title>Russia</title><city><title>Novosibirsk</country> </title></city>
Для того, чтобы обеспечить проверку корректности XML- документов, необходимо использовать анализаторы, производящие такую проверку и называемые верифицирующими.
На сегодняшний день существует два способа контроля правильности XML-
документа: DTD — определения (Document Type Definition) и схемы данных
(Semantic Schema). Более подробно об использовании DTD и схемах будет
описано в следующих разделах. В отличии от SGML, определение DTD- правил в
XML не является необходимостью, и это обстоятельство позволяет нам
создавать любые XML- документы, не ломая пока голову над весьма непростым
синтаксисом DTD.
Конструкции языка
Содержимое XML- документа представляет собой набор элементов, секций CDATA, директив анализатора, комментариев, спецсимволов, текстовых данных. Рассмотрим каждый из них подробней.
Элементы данных
Элемент — это структурная единица XML- документа. Заключая слово rose в в тэги , мы определяем непустой элемент, называемый , содержимым которого является rose. В общем случае в качестве содержимого элементов могут выступать как просто какой-то текст, так и другие, вложенные, элементы документа, секции CDATA, инструкции по обработке, комментарии, — т.е. практически любые части XML- документа.
Любой непустой элемент должен состоять из начального, конечного тэгов и данных, между ними заключенных. Например, следующие фрагменты будут являться элементами:
<flower>rose</flower> <city>Novosibirsk</city>а эти — нет:
<rose> <flower> rose
Набором всех элементов, содержащихся в документе, задается его
структура и определяются все иерархическое соотношения. Плоская модель
данных превращается с использованием элементов в сложную иерархическую
систему со множеством возможных связей между элементами. Например, в
следующем примере мы описываем месторасположение Новосибирских
университетов (указываем, что Новосибирский Университет расположен в
городе Новосибирске, который, в свою очередь, находится в России),
используя для этого вложенность элементов XML :
Плоская модель
данных превращается с использованием элементов в сложную иерархическую
систему со множеством возможных связей между элементами. Например, в
следующем примере мы описываем месторасположение Новосибирских
университетов (указываем, что Новосибирский Университет расположен в
городе Новосибирске, который, в свою очередь, находится в России),
используя для этого вложенность элементов XML :
<country> <cities-list> <city> <title>Новосибирск</title> <universities-list> <university> <title>Сибирский Государственный Университет Телекоммуникаций и Информатики</title> <address URL="www.neic.nsk.su"/> </university> <university> <title>Новосибирский Государственный Университет</title> <address URL="www.nsu.ru"/> </university> </universities-list> </city> <city> <title>Москва</title> <universities-list> <university> <title>Московский Государственный Университет</title> <address URL="www.
 msu.ru"/>
</university>
</universities-list>
</city>
</cities-list>
</country>
msu.ru"/>
</university>
</universities-list>
</city>
</cities-list>
</country>
Производя в последствии поиск в этом документе, программа клиента будет опираться на информацию, заложенную в его структуру — используя элементы документа. Т.е. если, например, требуется найти нужный университет в нужном городе, используя приведенный фрагмент документа, то необходимо будет просмотреть содержимое конкретного элемента <university>, находящегося внутри конкретного элемента <city>. Поиск при этом, естественно, будет гораздо более эффективен, чем нахождение нужной последовательности по всему документу.
В XML документе, как правило, определяется хотя бы один элемент, называемый корневым и с него программы-анализаторы начинают просмотр документа. В приведенном примере этим элементом является <country>
В некоторых случаях тэги могут изменять и уточнять семантику тех или
иных фрагментов документа, по разному определяя одну и ту же информацию и
тем самым предоставляя приложению-анализатору этого документа сведения о
контексте использования описываемых данных. Например, прочитав фрагмент
<river>Lena</river> мы можем догадаться, что речь в этой части
документа идет о реке, а вот во фрагменте <name>Lena</name> —
о имени.
Например, прочитав фрагмент
<river>Lena</river> мы можем догадаться, что речь в этой части
документа идет о реке, а вот во фрагменте <name>Lena</name> —
о имени.
В случае, если элемент не имеет содержимого, т.е. нет данных, которые он должен определять, он называется пустым. Примером пустых элементов в HTML могут служить такие тэги HTML, как <br>, <hr>, <img>;. Необходимо только помнить, что начальный и конечные тэги пустого элемента как бы объединяется в один, и надо обязательно ставить косую черту перед закрывающей угловой скобкой (например, <empty/>;)
Комментарии
Комментариями является любая область данных, заключенная между
последовательностями символов Комментарии пропускаются
анализатором и поэтому при разборе структуры документа в качестве значащей
информации не рассматриваются.
Атрибуты
Если при определении элементов необходимо задать какие-либо параметры, уточняющие его характеристики, то имеется возможность использовать атрибуты эдлемента. Атрибут — это пара «название» = «значение», которую надо задавать при определении элемента в начальном тэге. Пример:
<color RGB="true">#ff08ff</color> <color RGB="false">white</color>или
<author id=0>Ivan Petrov</autho>Примером использования атрибутов в HTML является описание элемента <font>:
<font color="white" name="Arial">Black</font>
Cпециальные символы
Для того, чтобы включить в документ символ, используемый для
определения каких-либо конструкций языка (например, символ угловой скобки)
и не вызвать при этом ошибок в процессе разбора такого документа, нужно
использовать его специальный символьный либо числовой идентификатор. Например, < , > » или $(десятичная форма записи), 
(шестнадцатеричная) и т.д. Строковые обозначения спецсиволов могут
определяться в XML документе при помощи компонентов (entity).
Например, < , > » или $(десятичная форма записи), 
(шестнадцатеричная) и т.д. Строковые обозначения спецсиволов могут
определяться в XML документе при помощи компонентов (entity).
Директивы анализатора
Инструкции, предназначенные для анализаторов языка, описываются в XML документе при помощи специальных тэгов — и ?>;. Программа клиента использует эти инструкции для управления процессом разбора документа. Наиболее часто инструкции используются при определении типа документа (например, Xml version=»1.0″?>) или создании пространства имен.
CDATA
Чтобы задать область документа, которую при разборе анализатор будет
рассматривать как простой текст, игнорируя любые инструкции и специальные
символы, но, в отличии от комментариев, иметь возможность использовать их
в приложении, необходимо использовать тэги . Внутри этого
блока можно помещать любую информацию, которая может понадобится
программе- клиенту для выполнения каких-либо действий (в область CDATA,
можно помещать, например, инструкции JavaScript). Естественно, надо
следить за тем, чтобы в области, ограниченной этими тэгами не было
последовательности символов ]].
Внутри этого
блока можно помещать любую информацию, которая может понадобится
программе- клиенту для выполнения каких-либо действий (в область CDATA,
можно помещать, например, инструкции JavaScript). Естественно, надо
следить за тем, чтобы в области, ограниченной этими тэгами не было
последовательности символов ]].
AndroidManifest.xml — что это и зачем он нужен?
18.01.2009
Когда вы создаете новое приложение, в корне вашего проекта автоматически создается файл AndroidManifest.xml. AndroidManifest.xml — это необходимый файл в любом проекте. Он определяет глобальные значения для вашего пакета, в нем вы описываете, что находится внутри вашего приложения — деятельности, сервисы и тд. Вы так же определяете, как все эти элементы взаимодействуют с Андроид. Например, какие виды данных может перехватывать ваша программа. Должна ли она отображаться в главном меню вашего телефона и тд.
Одна из важных частей манифеста — это фильтры намерений (intent filters). Эти фильтры описывают где и когда ваша деятельность (activity) может быть запущена. Когда деятельность (activity) или операционная система хочет совершить некие действия, напрммер, отрыть веб страницу или окно выбора контакта, оно создает объект намерений. Этот объект может содержать несколько дескрипторов описывающих, что именно вы хотите сделать, какие данные вам нужны для этого и какого типа, а так же дополнительную информацию. Android сравнивает информацию в объекте намериний (Intent object) с фильтрами намерений которые были представлены всеми программами установленными у вас, и находит приложение наиболее для этого подходящее.
Кроме того, объявляя в вашем приложении деятельности, провайдеры содержимого, сервисы, нарения и фильтры намерений, вы так же можете указать огранияения и инструменты (управление безопасностью и тестирование).
Простой пример AndroidManifest.xml:
<?xml version="1. |
 0" encoding="utf-8"?>
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.my_domain.app.helloactivity">
<application android:label="@string/app_name">
<activity android:name=".HelloActivity">
<intent-filter>
<action android:name="android.intent.action.MAIN"/>
<category android:name="android.intent.category.LAUNCHER"/>
</intent-filter>
</activity>
</application>
</manifest>
0" encoding="utf-8"?>
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.my_domain.app.helloactivity">
<application android:label="@string/app_name">
<activity android:name=".HelloActivity">
<intent-filter>
<action android:name="android.intent.action.MAIN"/>
<category android:name="android.intent.category.LAUNCHER"/>
</intent-filter>
</activity>
</application>
</manifest>Несколько особенностей:
- Каждый файл AndroidManifest.xml (как и большинство дляругих xml файлов в Android) включает описание пространства имен
xmlns:android="http://schemas.android.com/apk/res/android", в качестве своего первого элемента.
- Большинство манифестов включает одиночный элемент
<application>, который определяет уровень и свойства компонент приложения доступных из пакета.
- Любой пакет может быть представлен пользователю как самостоятельная программа, доступной из главноего меню телефона. Для этого нужно что бы в прокете была хотя бы одна деятельность, которая поддерживает действие MAIN и категорию LAUNCHER показанную в примере выше.

Детальное описание структуры файла AndroidManifest.xml file.
- <manifest>
- Корневой элемент, содержащий полное описание вашего пакета. В него могут включаться следующие элементы:
- <uses-permission>
- описывает права необходимые для того что бы ваша программа работала корректно. То есть, если вы в своей программе хотите использовать доступ к данным GPS, то в этой секции вы должны явно это указать, например так: <uses-permission android:name=”android.permission.ACCESS_GPS” /> Манифест может вообще не содержать этот элемент.
- <permission>
- В этой секции описываются права, которые должны запросить другие приложения для доступа к вашему. Манифест может вообще не содержать этот элемент.
- <instrumentation>
- Описывает код компонентов инструментария доступный для тестирования функционала этого или другого приложения. Манифест может вообще не содержать этот элемент.
- <application>
- Корневой элемент содержащий описание компонент уровня приложения доступных в пакете. Этот элемент может содержать глобальные и/или значения по умолчанию, такие как иконка программы, название, тема оформления, необходимые права доступа и тд. Манифест может вообще не содержать этот элемент. Под ним также могут располагаться ноль или более других описаний:
- <activity>
- Деятельность это основной компонент приложения взаимодействующий с пользователем. Первое окно которое видят пользователи при запуске программы, это и есть деятельность, и большинство других окон будут реализованы как отдельные деятелньости описанные тэгом <activity>.
Замечание: Каждая деятельность должна иметь собственный тэг <activity> в файле манифеста. Если деятельность не описана в манифесте, то вы не сможете ее запускать. Ваше приложение вызовет ошибку.Для поддержки позднего поиска вашей деятельности, вы можете включить один или более <intent-filter> элементов для описания действий, которые деятельность поддерживает.
- <intent-filter>
- Описывается определенный тип значений намерений, которые компоненты подерживают в качестве фильтров намерений. В дополнение, различные типы значений могут быть указаны под этим элементом. Аттрибутымогут быть указаны для получения уникального названия, иконки или другой информации для действия которое было описано.
- <action>
- Действие намерений, которое компонент поддерживает.
- <category>
- Категория намерений которое компонент поддерживает.
- <data>
- Указываются поддерживаемые типы: Intent data MIME type, Intent data URI scheme, Intent data URI authority или Intent data URI path.
Вы так же можете ассоциировать один или более компонентов <meta-data> со своей деятельностью, что бы другие клиенты могли получить для поиска дополнительной информации о ней:
- <meta-data>
- Добавляет описание мета информации к вашей деятельности, клиенты которой могут получить ее через ComponentInfo.metaData.
- <receiver>
- Широковещательный приемник (BroadcastReceiver) позволяет приложению узнавать о изменениях с данными или действиями которые случились, даже если программа не запущена. Так же как и <activity>, вы можете указать один или более <intent-filter> или значения <meta-data>, которые получатель поддерживает.
- <service>
- Сервис это компонент который может быть запущен в фоне на произвольное количество времени. Так же как и в теге <activity>, опционально вы можете указать один или более <intent-filter> или <meta-data> элементов, которые поддерживает сервис.
- <provider>
- Провайдер содержимого (ContentProvider) это компонент который управлет доступом к данным вашей программы, предоставляя его другим приложениям. Вы так же можете указать один или более элементов <meta-data>.
Автор: vovkab
 Манифест может вообще не содержать этот элемент.
Манифест может вообще не содержать этот элемент. Если деятельность не описана в манифесте, то вы не сможете ее запускать. Ваше приложение вызовет ошибку.
Если деятельность не описана в манифесте, то вы не сможете ее запускать. Ваше приложение вызовет ошибку.
как его создать и отредактировать
XML-фид — это структурированный файл для хранения информации об услугах либо товарах, позволяющий импортировать данные для рекламных кампаний в удобном формате. Файлы такого формата создают для работы с Google Merchant Center, Яндекс.Директом, Яндекс.Недвижимостью, email-рассылок с описанием товаров и других инструментов интернет-маркетинга.
Для чего используют XML-фид
XML-фид представляет собой файл с кодом на языке XML, ссылку на который используют в различных сервисах. С помощью XML-фида осуществляется импорт товаров из интернет-магазинов и услуг агентств недвижимости, туроператоров, строительных фирм и прочих компаний.
Варианты использования XML-фидов
Импорт товаров в онлайн-площадки сравнения предложений различных интернет-магазинов, например hotline.ua, Яндекс.Маркет, Google Покупки:
Создание email-рассылок, содержащих описание, ссылки и изображения товаров:
Применение в рекламных кампаниях Яндекс.Директ: использование фидов Яндекс.Маркета, Яндекс.Недвижимости и XML-фида Авто.ру.
Как XML-фид создать
Для создания XML-фида используются теги, в которых прописывают название продукта и его характеристики, например, цену, размер, добавляют ссылку на изображение.
Основные XML-теги зависят от спецификации, которая используется в выбранном сервисе, наиболее распространенные варианты:
- <availability>Наличие товара</availability>;
- <link>Ссылка на товар</link>;
- <title>Название товара или услуги</title>;
- <price>Цена товара</price>;
- <description>Описание</description>;
- <brand>Производитель</brand> и пр.

В XML-feed добавляют сведения о всех необходимых товарах, и сохраняют файл в корневом каталоге сайта на хостинг-провайдере. В рекламном сервисе указывается ссылка на созданный XML-фид, после чего считываются данные о товарах и добавляются на веб-площадку. Эта технология позволяет автоматически обновлять сведения о товарах на всех партнерских рекламных площадках при изменении цен и характеристик продуктов, а также обновлении ассортимента интернет-магазина.
Как создать XML-feed Google
XML-feed создается для добавления товаров в Google Merchant Center:
При этом доступны следующие форматы XML:
Рассмотрим более подробно создание XML-фидов в форматах RSS 2.0 и Atom 1.0.
{«0»:{«lid»:»1573230077755″,»ls»:»10″,»loff»:»»,»li_type»:»em»,»li_name»:»email»,»li_ph»:»Email»,»li_req»:»y»,»li_nm»:»email»},»1″:{«lid»:»1596820612019″,»ls»:»20″,»loff»:»»,»li_type»:»hd»,»li_name»:»country_code»,»li_nm»:»country_code»}}
Истории бизнеса и полезные фишки
Пример создания фида в формате RSS 2.
 0
0- Создайте файл, имя которого будет совпадать с названием фида, зарегистрированного в аккаунте, с расширением .xml.
- Добавьте в файл указание версии XML и пространства имен Google Merchant Center:
<?xml version="1.0"?><rss version="2.0" xmlns:g="http://base.google.com/ns/1.0">- Поместите все дальнейшие сведения о товарах внутри тега <channel> </channel>.
- Заполните предопределенные атрибуты данными о фиде:
<title>Интернет-магазин бамперов</title><link>https://www.super-bamper.ua</link><description>Качественные бампера с бесплатной доставкой</description>- Информацию о каждом отдельном товаре помещайте в тег <item> </item>.
- Добавьте атрибуты с названием, ценой, идентификатором, описанием, состоянием и доступностью товара. Укажите ссылки на товар и его изображение:
<title>Бампер на ВАЗ 2106</title><link>https://www. super-bamper.ua/bamper-2106.html</link><description>Заводской передний бампер на ВАЗ 2106</description><g:price>1000 UAH</g:price><g:id>V-2106-179543</g:id><g:condition>new</g:condition><g:availability>in_stock</g:availability><g:image_link>https://www.super-bamper.ua/images/bamper-2106.jpg</g:image_link> super-bamper.ua/bamper-2106.html</link><description>Заводской передний бампер на ВАЗ 2106</description><g:price>1000 UAH</g:price><g:id>V-2106-179543</g:id><g:condition>new</g:condition><g:availability>in_stock</g:availability><g:image_link>https://www.super-bamper.ua/images/bamper-2106.jpg</g:image_link>
super-bamper.ua/bamper-2106.html</link><description>Заводской передний бампер на ВАЗ 2106</description><g:price>1000 UAH</g:price><g:id>V-2106-179543</g:id><g:condition>new</g:condition><g:availability>in_stock</g:availability><g:image_link>https://www.super-bamper.ua/images/bamper-2106.jpg</g:image_link>При заполнении сведений обратите внимание на следующие нюансы:
- для отличия атрибутов из пространства имен Merchant Center необходимо добавлять к стандартным тегам префикс «g:», иначе атрибуты не будут отображаться;
- описание товара не должно превышать 5000 символов;
- идентификатор товара (id) должен быть уникальным;
- состояние (condition) нужно обязательно указывать для бывших в употреблении (used) и восстановленных (refurbished) товаров. Для новых (new) изделий этот атрибут не обязателен;
- доступность товара (availability) принимает такие значения: in_stock (в наличии), out_of_stock (нет в наличии), preorder (предзаказ).

- Укажите дополнительные атрибуты, характеризующие продукцию, — это положительно повлияет на количество отображений в товарных объявлениях. Доступны следующие атрибуты:
<g:shipping><g:country>UA</g:country><g:service>Бесплатная доставка</g:service><g:price>0 UAH</g:price></g:shipping>- производитель:
<g:brand>ВАЗ</g:brand><g:color>White</g:color>Допускается указание нескольких цветов для многоцветных изделий, например, значение Red/White/Black для описания красного товара с белыми и черными элементами.
Итоговый файл должен иметь такой вид:
- После добавления всех товаров закройте теги:
</channel></rss>- Добавьте созданный XML-фид в корневой каталог собственного сайта, чтобы в дальнейшем он был доступен по адресу название-сайта. ru/имя-фида.xml.
 ru/имя-фида.xml.
ru/имя-фида.xml.Пример создания фида в формате Atom 1.0
Создание XML-фида в данном формате сходно с описанным выше примером в RSS 2.0, однако есть ряд отличий:
- После создания XML-файла и указания версии XML пропишите название формата и пространство имен таким образом:
<feed xmlns="http://www.w3.org/2005/Atom"xmlns:g="http://base.google.com/ns/1.0">- Пропишите название фида, ссылку на сайт и дату обновления:
<title>XML-feed for Google</title><link href="https://www.oboi.com" rel="self" type="text/html" /><updated>2019-09-20T17:00:05Z</updated>- В этой спецификации сведения о каждом товаре прописываются внутри тега <entry>. Добавьте данный тег и пропишите 5 предопределенных атрибутов. В данном формате вместо тега <description> (описание) используется <summary>, а также добавляются элементы <id> (идентификатор) и <updated> (дата обновления):
<title>Виниловые обои с маками</title><id>OV-04589</id><link href="https://www. oboi.com/vinilovye-oboi-s-makami.html" /><summary>Качественные моющиеся обои немецкого производства.</summary><updated>2019-09-18T15:15:08Z</updated> oboi.com/vinilovye-oboi-s-makami.html" /><summary>Качественные моющиеся обои немецкого производства.</summary><updated>2019-09-18T15:15:08Z</updated>
oboi.com/vinilovye-oboi-s-makami.html" /><summary>Качественные моющиеся обои немецкого производства.</summary><updated>2019-09-18T15:15:08Z</updated>- Заполните атрибуты из пространства имен Google Merchant Center:
<g:image_link>https://www.oboi.com/pictures/vinilovye-oboi-s-makami.png</g:image_link> <g:price>150 UAH</g:price> <g:condition>new</g:condition> - В этой спецификации использование дополнительных атрибутов в описании товара также приветствуется. Для некоторых товаров должны использоваться атрибуты цвета, размера, материала, возрастной категории, производителя и прочие.
- Добавьте закрывающие теги:
</entry></feed>Итоговый файл в данной спецификации выглядит так:
Создание XML-фида Google с помощью онлайн-генератора
Ручное создание фида, описанное в предыдущем разделе, подойдет для небольшого количества товаров. Если необходимо создать фид с сотнями или тысячами товаров, необходимо использовать онлайн-генератор либо самостоятельно прописать код на PHP, подключающийся к базе данных и добавляющий необходимые теги и значения в файл.
Если необходимо создать фид с сотнями или тысячами товаров, необходимо использовать онлайн-генератор либо самостоятельно прописать код на PHP, подключающийся к базе данных и добавляющий необходимые теги и значения в файл.
При отсутствии навыков программирования оптимальным вариантом будет онлайн-генератор обновляемого XML-фида, например:
Обновляемый фид для Google Merchant Center и Ads
Woocommerce Google Feed Manager
Модуль ManyFeed для OpenCart
Как создать XML-фид Яндекс
В рекламе Яндекса предлагается использовать несколько форматов фидов в зависимости от типа товаров и услуг:
- фид Яндекс.Маркета для розничной торговли;
- фид Авто.ру для продажи автомобилей;
- фид Яндекс.Недвижимости для риелторских агентств, продающих жилую недвижимость.
Создание фида для динамических объявлений в Яндекс.Маркете
- Создайте фид в формате YML — Yandex Market Language.
- Пропишите версию XML и корневой элемент документа, содержащий дату генерации фида:
<?xml version="1. 0" encoding="UTF-8"?><yml_catalog date="2019-09-20 16:03"> 0" encoding="UTF-8"?><yml_catalog date="2019-09-20 16:03">
0" encoding="UTF-8"?><yml_catalog date="2019-09-20 16:03">- Внесите информацию о названии магазина и ссылку на сайт:
<shop><name>Jeans</name><url>https://www.jeans.com.ua</url>- Для добавления всех необходимых предложений интернет-магазина откройте тег <offers>, поместите информацию о каждом товаре внутри тегов <offer> </offer>.
- Добавьте в каждое товарное предложение идентификатор, название, ссылки на товар и его изображение, цену и код валюты:
<offer available="true"><url>https://www.jeans.com.ua/blue-jeans-for-kids.html</url><price>470</price><picture>https://www.jeans.com.ua/images/blue-jeans-for-kids.JPG</picture><name>Детские джинсы голубого цвета</name><description>Турецкие летние джинсы для мальчиков от 2 до 4 лет</description></offer>- Дополните информацию о товарах с помощью таких элементов как <model> (модель), <vendor> (производитель), <delivery> (возможность доставки) и прочими доступными тегами.
- Закройте теги с товарными предложениями и корневой элемент:

</offers> </shop></yml_catalog>В результате должен получится фид подобного вида:
Создание фида для продажи легковых автомобилей
- Создайте XML-файл, добавьте его версию, откройте теги <data> и <cars> для добавления информации об автомобилях:
<?xml version="1.0"?><data><cars>- Информация о каждом автомобиле вносится в тег <car></car>. Добавьте один из вариантов идентификаторов автомобилей — <unique_id> либо <vin>. Также укажите цену, валюту, ссылку на товар и его изображение:
<car><url>https://www.auto.ru/1784445</url><images>https://images.auto.ru/bmw.jpg</images><price>150000</price><currency>UAH</currency><vin>XWBCA41ZXDK259205</vin></car>- Для дополнительных сведений об автомобиле используются теги <color> (цвет), <mark_id> (марка машины), <body_type> (тип кузова) и другие элементы.
- После добавления информации обо всех автомобилях закройте теги:

</cars></data> На выходе получается фид такого вида:
Создание фида для продажи жилой недвижимости
- Создайте данный фид, используя формат YRL, — Yandex Realty Language.
- Все предложения добавьте внутри тега <offers>, сведения о каждом объекте недвижимости помещайте внутри элемента <offer></offer>.
- Заполните обязательные элементы: <internal-id> (идентификатор),<name> (название объекта недвижимости), <type> продажа</type>,<location> (местоположение объекта), <locality-element> (название населенного пункта, <url> (ссылка на предложение) и другие необходимые атрибуты.
- Закройте тег с предложениями недвижимости: </offers>
Пример готового фида YRL:
Как проверить фид в формате XML
1.
 Проверка фидов Google
Проверка фидов GoogleФиды Google проверяют при загрузке в Merchant Center. Зайдите в пункт меню «Products» («Товары»), затем выберите «Feeds» («Фиды»). Нажмите знак плюса:
Затем выберите страну, язык, укажите название фида и способ загрузки:
Загрузите XML-файл в тестовом режиме и нажмите «Continue»:
Проверка занимает несколько минут, после ее прохождения отобразится, есть ли ошибки в фиде.
2. Проверка фидов Яндекс
Для проверки фидов в формате XML используют Яндекс XML-валидатор. Выберите нужный формат и тип добавления фида — непосредственно в сервис, в виде ссылки или файла, затем нажмите «Проверить»:
Данный фид успешно прошел валидацию.
Запомнить
- XML-фиды используют для быстрого добавления и обновления данных о большом количестве товаров и услуг на различные рекламные сервисы и маркетплейсы.
- Создание фида должно происходить в соответствии с выбранной спецификацией, указанной в требованиях поисковой системы или рекламной площадки.
- Создать фид можно как в ручном режиме, так и с помощью онлайн-генераторов. При наличии навыков программирования XML-фиды пишут на PHP, осуществляя автоматическое чтение сведений о товарах из базы данных интернет-магазинов.
- Созданные фиды нужно проверить с помощью онлайн-валидаторов, при наличии ошибок их необходимо отредактировать.

Что такое XML и JSON. Их особенности.
Помимо HTML, картинок и видео на сайте необходимо передавать и отображать различную информацию.
Сейчас я говорю про массивы данных, про сложную иерархическую структуру.
Для передачи информации как в интеграции, так и для сайтов используются определенныей форматы данных.
JSON и XML используются для получения и отправки данных с веб-сервера.
JSON (англ. JavaScript Object Notation) — простой формат обмена данными, основанный на языке программирования JavaScript. Использует человекочитаемый текст для передачи объектов данных.
Пример синтаксиса:
«employees»:[
{«firstName»:«Lev», «lastName»:«Tolstoy»},
{«firstName»:«Anna», «lastName»:«Karenina»},
{«firstName»:«Aleksey», «lastName»:«Vronsky»},
]
Синтаксические правила JSON
- Данные указываются в парах имя / значение, разделяемые двоеточием «firstName»:«Lev»
- Данные разделяются запятыми «firstName»:«Anna», «lastName»:
«Karenina» - Фигурные скобки удерживают объекты {«firstName»:«Lev»,«lastName»:«Tolstoy»},
- Квадратные скобки содержат массивы
Преимущества JSON
- Меньше слов больше дела
XML требует открытия и закрытия тегов, а JSON использует пары имя / значение, четко обозначенные «{«и»}» для объектов, «[«и»]» для массивов, «,» (запятую) для разделения пары и «:»(двоеточие) для отделения имени от значения. - Размер имеет значение
При одинаковом объеме информации JSON почти всегда значительно меньше, что приводит к более быстрой передаче и обработке. - Близость к javascript
JSON является подмножеством JavaScript, поэтому код для его анализа и упаковки вполне естественно вписывается в код JavaScript.

XML
XML — язык разметки, который определяет набор правил для кодирования документов в формате, который читается человеком и читается машиной. Но чем больше информации (вложений, комментариев, вариантов тегов и т.д.) в xml, тем сложнее ее читать человеку.
XML хранит данные в текстовом формате. Это обеспечивает независимый от программного и аппаратного обеспечения способ хранения, транспортировки и обмена данными. XML также облегчает расширение или обновление до новых операционных систем, новых приложений или новых браузеров без потери данных.
Пример синтаксиса:
Синтаксис XML
- Весь XML документ должен иметь корневой элемент.
- Все теги должны быть закрыты (либо самозакрывающийся тег).
- Все теги должны быть правильно вложены.
- Имена тегов чувствительны к регистру.
- Имена тегов не могут содержать пробелы.
- Значения атрибута должны появляться в кавычках («»).
- Атрибуты не могут иметь вложения (в отличие от тегов).
- Пробел сохраняется.

Преимущества:
- Поддержка метаданных
Одним из самых больших преимуществ XML является то, что мы можем помещать метаданные в теги в форме атрибутов. В JSON атрибуты будут добавлены как другие поля-члены в представлении данных, которые НЕ могут быть желательны. - Визуализация браузера
Большинство браузеров отображают XML в удобочитаемой и организованной форме. Древовидная структура XML в браузере позволяет пользователям естественным образом сворачивать отдельные элементы дерева. Эта функция будет особенно полезна при отладке. - Поддержка смешанного контента
Хорошим вариантом использования XML является возможность передачи смешанного контента в пределах одной и той же полезной нагрузки данных. Этот смешанный контент четко различается по разным тегам.
 Этот смешанный контент четко различается по разным тегам.
Этот смешанный контент четко различается по разным тегам.Для наглядности представим сходства и различия XML и JSON в виде таблицы.
Что такое XML-файл и как его открыть?
В современном мире многие профессии требуют хотя бы некоторого владения компьютерами и технологиями. XML обычно используется на рабочем месте по разным причинам. Понимание того, что такое XML и как использовать файлы XML, может помочь вам ориентироваться в технологически продвинутом рабочем месте. В этой статье мы обсудим файлы XML, их преимущества, распространенное использование XML и способы открытия файла XML.
Что такое XML-файл?
Файл XML — это файл с расширяемым языком разметки, который используется для структурирования данных для хранения и транспортировки.В XML-файле есть как теги, так и текст. Теги обеспечивают структуру данных. Текст в файле, который вы хотите сохранить, окружен этими тегами, которые соответствуют определенным правилам синтаксиса. По своей сути XML-файл представляет собой стандартный текстовый файл, в котором используются настраиваемые теги для описания структуры документа и того, как его следует хранить и транспортировать.
По своей сути XML-файл представляет собой стандартный текстовый файл, в котором используются настраиваемые теги для описания структуры документа и того, как его следует хранить и транспортировать.
Например, версии Microsoft Office 2007 и более поздние используют XML для структуры документа. Итак, когда вы сохраняете документ в Word, Excel или PowerPoint, вы получите заголовок документа с буквой «X» в конце.«X» означает XML. Для документа Word заголовок будет представлен с «.DOCX» в конце.
XML — это язык разметки, что означает, что это компьютерный язык, использующий теги для описания компонентов в файле. Этот язык разметки XML содержит реальные слова вместо синтаксиса программирования. Самые популярные языки разметки — HTML и XML. Возможно, вы уже знакомы с HTML, но XML имеет несколько ключевых отличий, например:
- Цель: В HTML или языке разметки гипертекста информация отображается, а в XML эта информация передается.Обычно для кодирования веб-страниц используется HTML. С другой стороны, XML — это язык описания данных, который используется для хранения данных.
- Возможность настройки: HTML использует заранее выбранный диапазон символов разметки или шорткодов, которые описывают представление содержимого веб-страницы. И наоборот, XML является расширяемым и позволяет пользователям настраивать и создавать свои собственные символы разметки. Таким образом, с помощью XML пользователи получают полный контроль и могут создавать неограниченный набор символов для описания своего содержимого.
 С другой стороны, XML — это язык описания данных, который используется для хранения данных.
С другой стороны, XML — это язык описания данных, который используется для хранения данных.Преимущества XML
Использование файлов XML выгодно по многим причинам, в том числе:
- Читаемость: Для аналитика данных данные должны быть легко доступны и читаемы. XML-файлы легко понять, потому что они используют человеческий язык с реальными словами вместо компьютерного языка. Например, имена тегов XML четко определяют и объясняют данные. Каждый тег размещен перед своими данными, поэтому информация аккуратна и организована. Кроме того, поскольку обмен данными осуществляется с помощью языка разметки XML, компьютеры легко обрабатывают файлы XML.
- Совместимость: файлы XML совместимы с Java и полностью переносимы, что означает, что вы можете получать доступ и передавать данные в любое время и из любого места. Все, что вам нужно, это приложения, которые могут обрабатывать XML, а затем вы можете хранить и передавать свои данные.
- Настройка: XML как расширяемый язык разметки позволяет пользователям создавать свои собственные теги или использовать теги, созданные другими пользователями.Если вы используете теги от других пользователей, вам необходимо убедиться, что теги используют естественный язык вашего домена и обладают необходимыми функциями. Пользователи могут создавать неограниченное количество тегов в XML.
 Кроме того, поскольку обмен данными осуществляется с помощью языка разметки XML, компьютеры легко обрабатывают файлы XML.
Кроме того, поскольку обмен данными осуществляется с помощью языка разметки XML, компьютеры легко обрабатывают файлы XML.Распространенное использование XML
XML имеет множество применений в широком диапазоне веб-страниц и приложений. Некоторые распространенные варианты использования XML включают:
Некоторые распространенные варианты использования XML включают:
- Веб-публикация: С помощью XML пользователи могут создавать и настраивать интерактивные веб-страницы.После того, как данные сохранены в XML, вы можете управлять содержимым для разных пользователей или нескольких устройств. Вам нужно будет убедиться, что вы проверяете обработку таблиц стилей на этом пути. Может быть полезно использовать расширяемый процессор преобразования языка таблиц стилей, который позволит вам преобразовывать XML-файл в другие макеты, такие как HTML для веб-страниц. В бизнесе использование XML таким образом будет задачей веб-разработчика.
- Веб-задачи: XML можно использовать для веб-поиска и автоматизации задач.Таким образом, XML проверяет информацию в файле, что упрощает получение лучших результатов при выполнении веб-поиска. Например, если пользователь выполняет поиск в Интернете автора по имени Джим Грин, используя HTML, на странице результатов поиска могут отображаться другие вхождения слова «зеленый», кроме автора. Но если вы используете XML, веб-поиск будет ограничен необходимой вам информацией, то есть информацией, найденной в теге.
- Общие приложения: Все виды приложений могут извлечь выгоду из XML, поскольку он предлагает упрощенный метод доступа к информации.Этот простой процесс позволяет как приложениям, так и устройствам использовать, хранить, передавать и отображать данные. Например, на рабочем месте архитекторы данных и программисты ежедневно используют XML.
 Но если вы используете XML, веб-поиск будет ограничен необходимой вам информацией, то есть информацией, найденной в теге.
Но если вы используете XML, веб-поиск будет ограничен необходимой вам информацией, то есть информацией, найденной в теге.Как открыть файл XML
Работа с файлами XML относительно проста даже для новичка. Существует несколько различных методов открытия XML-файла: открыть файл и отредактировать его в текстовом редакторе или открыть и просмотреть файл в веб-браузере.
Шаги для открытия XML-файла с помощью текстового редактора включают:
- Щелкните правой кнопкой мыши XML-файл, который вы хотите открыть.
- Укажите на « Открыть с помощью » в контекстном меню.
- Щелкните опцию « Блокнот ».

Текстовые редакторы «Блокнот» и «Блокнот ++» — хорошие варианты для открытия файлов XML. Однако в Блокноте вы можете открыть файл XML, но форматирование может стать хаотичным и запутанным. В этом случае может быть лучше использовать Notepad ++, поскольку он остается верным исходному форматированию файла.
Шаги по открытию XML-файла для просмотра в веб-браузере:
- Откройте веб-браузер по умолчанию.
- Дважды щелкните файл XML, и он должен открыться в вашем браузере.
- Если он не открывается, щелкните файл правой кнопкой мыши, чтобы найти список опций для его открытия в других программах.
- Теперь вы сможете выбрать свой веб-браузер из списка программ.
В современном технологически развитом обществе важно понимать, как использовать файлы XML на рабочем месте. Использование XML дает много преимуществ, и, к счастью, работа с файлами XML — простой процесс.У пользователей есть несколько различных вариантов открытия и просмотра файлов XML в зависимости от ваших технологических предпочтений.
Объяснение XML
Что такое XML?
XML означает расширяемый язык разметки. Язык разметки — это набор кодов или тегов, описывающих текст в цифровом документе. Самый известный язык разметки — это язык разметки гипертекста (HTML), который используется для форматирования веб-страниц. XML, более гибкий двоюродный брат HTML, позволяет вести сложный бизнес через Интернет.
Каковы преимущества XML перед HTML?
В то время как HTML сообщает приложению браузера, как должен выглядеть документ, XML описывает содержимое документа. Другими словами, XML заботится о том, как организована информация, а не о том, как она отображается. (Форматирование XML выполняется с помощью отдельных таблиц стилей.)
Для иллюстрации рассмотрим следующие теги HTML: команда
сигнализирует абзац, а слово переводится в слово .HTML-теги исправлены; каждый разработчик сайта использует одни и те же теги для выполнения одних и тех же действий. XML, напротив, позволяет создавать собственные теги для обозначения значения или использования данных. Итак, если вы используете XML для описания продаваемого виджета, ваши теги могут выглядеть так:
100 $ »SKU =« 555432 »дилер =« Widgets Incorporated »>.
= «Superwidget»>
XML, напротив, позволяет создавать собственные теги для обозначения значения или использования данных. Итак, если вы используете XML для описания продаваемого виджета, ваши теги могут выглядеть так:
100 $ »SKU =« 555432 »дилер =« Widgets Incorporated »>.
= «Superwidget»>
XML дает множество преимуществ. Он позволяет передавать данные между корпоративными базами данных и веб-сайтами без потери важной описательной информации.Он позволяет автоматически настраивать представление данных, а не отображать одну и ту же страницу для всех желающих. И это делает поиск более эффективным, потому что поисковые системы могут сортировать по точным тегам, а не по длинным страницам текста.
Каковы бизнес-приложения XML?
Поскольку XML обеспечивает сложное кодирование данных на веб-сайтах, он помогает компаниям интегрировать свои информационные потоки. Создав единый набор тегов XML для всех корпоративных данных, можно легко обмениваться информацией между веб-сайтами, базами данных и другими внутренними системами. Но революционная сила XML заключается в поддержке транзакций между предприятиями. Когда компания продает товар или услугу другой компании, необходимо обмениваться большим объемом информации — о ценах, сроках, спецификациях, графиках поставок и так далее. Универсальная природа HTML делает такой обмен через Интернет затруднительным, если не невозможным. С помощью XML вся необходимая информация может быть передана в электронном виде, что позволяет закрывать сложные сделки без вмешательства человека.Вот почему веб-рынки B2B, например, управляемые Ariba и Commerce One, уже используют XML для автоматического сопоставления покупателей и продавцов. В недалеком будущем о вашей компании можно будет судить по содержимому ее тегов XML.
Но революционная сила XML заключается в поддержке транзакций между предприятиями. Когда компания продает товар или услугу другой компании, необходимо обмениваться большим объемом информации — о ценах, сроках, спецификациях, графиках поставок и так далее. Универсальная природа HTML делает такой обмен через Интернет затруднительным, если не невозможным. С помощью XML вся необходимая информация может быть передана в электронном виде, что позволяет закрывать сложные сделки без вмешательства человека.Вот почему веб-рынки B2B, например, управляемые Ariba и Commerce One, уже используют XML для автоматического сопоставления покупателей и продавцов. В недалеком будущем о вашей компании можно будет судить по содержимому ее тегов XML.
Но если отдельные компании создают свои собственные теги, как они будут делиться информацией друг с другом?
Это риск гибкости. Без стандартизированного синтаксиса одна компания может создавать уникальные теги, неузнаваемые для ее поставщиков и покупателей. Чтобы уменьшить эту опасность, многие словари XML создаются в таких областях, как финансы, математика, химия и электронная коммерция. Эти словари, встроенные в XML, стандартизируют определения тегов. На Уолл-стрит, например, JP Morgan и PricewaterhouseCoopers недавно предложили FpML, словарь, который стандартизировал бы теги XML для обмена иностранной валюты и других финансовых транзакций. Аналогичные усилия предпринимаются и в других отраслях.
Чтобы уменьшить эту опасность, многие словари XML создаются в таких областях, как финансы, математика, химия и электронная коммерция. Эти словари, встроенные в XML, стандартизируют определения тегов. На Уолл-стрит, например, JP Morgan и PricewaterhouseCoopers недавно предложили FpML, словарь, который стандартизировал бы теги XML для обмена иностранной валюты и других финансовых транзакций. Аналогичные усилия предпринимаются и в других отраслях.
XML — XML: Extensible Markup Language
XML (Extensible Markup Language) — это язык разметки, похожий на HTML, но без предопределенных тегов для использования.Вместо этого вы определяете свои собственные теги, разработанные специально для ваших нужд. Это эффективный способ хранения данных в формате, который можно хранить, искать и совместно использовать. Что наиболее важно, поскольку основной формат XML стандартизован, если вы делитесь или передаете XML между системами или платформами, локально или через Интернет, получатель по-прежнему может анализировать данные благодаря стандартизированному синтаксису XML.
Существует множество языков, основанных на XML, включая XHTML, MathML, SVG, XUL, XBL, RSS и RDF.Вы также можете определить свои собственные.
Эта часть статьи находится в процессе написания …
Полная структура языков XML и XML, основанных на тегах.
Декларация XML
XML — декларация не является тегом. Он используется для передачи метаданных документа.
Атрибуты:
- версия:
- В этом документе использована версия XML.
- кодировка:
- Используемая кодировка в этом документе.
Правила правильного проектирования
Чтобы XML-документ был правильным, должны выполняться следующие условия:
- Документ должен быть правильно оформлен.
- Документ должен соответствовать всем правилам синтаксиса XML.
- Документ должен соответствовать семантическим правилам, которые обычно устанавливаются в схеме XML или DTD ( Document Type Definition). .
 .
.Пример
<сообщение>
<предупреждение>
Привет мир
Теперь давайте посмотрим на исправленную версию того же документа:
<сообщение>
<предупреждение>
Привет мир
Документ, содержащий неопределенный тег, недействителен. Например, если мы никогда не определяли тег , приведенный выше документ не будет действительным.
Большинство браузеров предлагают отладчик, который может определять плохо сформированные XML-документы.
Как и HTML, XML предлагает методы (называемые объектами) для ссылки на некоторые специальные зарезервированные символы (например, знак «больше», используемый для тегов).Вам следует знать пять из этих персонажей:
| Организация | Персонаж | Описание |
|---|---|---|
| & lt; | < | Знак меньше |
| & gt; | > | Знак больше |
| & amp; | и | Амперсанд |
| & quot; | « | Одна двойная кавычка |
| ‘ | ‘ | Один апостроф (или одинарная кавычка) |
Несмотря на то, что заявлено всего 5 сущностей, можно добавить больше с помощью определения типа документа. Например, чтобы создать новый
Например, чтобы создать новый & warning; , вы можете это сделать:
]> <сообщение> & предупреждение;
Вы также можете использовать числовые ссылки на символы для указания специальных символов; например, & # xA9; это символ «©».
XML обычно используется в описательных целях, но есть способы отображения данных XML.Если вы не определите конкретный способ визуализации XML, необработанный XML будет отображаться в браузере.
Одним из способов стилизации вывода XML является указание CSS для применения к документу с помощью инструкции обработки xml-stylesheet .
Существует также еще один более мощный способ отображения XML: Extensible Stylesheet Language Transformations (XSLT), который можно использовать для преобразования XML в другие языки, такие как HTML. Это делает XML невероятно универсальным.
Это делает XML невероятно универсальным.
Эта статья, очевидно, представляет собой лишь очень краткое введение в то, что такое XML, с несколькими небольшими примерами и ссылками для начала. Для получения дополнительных сведений об XML вам следует поискать в Интернете более подробные статьи.
Изучение языка разметки гипертекста (HTML) поможет вам лучше понять XML.
Статья «Использование XML», приведенная выше, является отличным источником информации для преобразования и создания вашего собственного языка.
Разница между XML и HTML
- Подробности
Что такое XML?
XML — это язык разметки, предназначенный для хранения данных. Это обычно используется или передача данных. Это чувствительно к регистру. XML предлагает вам определить элементы разметки и создать собственный язык разметки. Базовая единица XML известна как элемент. Расширение XML-файла — .xml
Базовая единица XML известна как элемент. Расширение XML-файла — .xml
Из этого туториала Вы узнаете
Что такое HTML?
HTML — это язык разметки, который помогает создавать и проектировать веб-контент.Он имеет множество тегов и атрибутов для определения макета и структуры веб-документа. Он предназначен для отображения данных в форматированном виде. Документ HTML имеет расширение .htm или .html.
Редактировать HTML-код можно в любом базовом редакторе кода, даже в блокноте. Отредактированный код можно выполнить в любом браузере. Браузеры отображают используемые теги и представляют контент, который вы хотите отобразить, с примененным форматированием или без него.
КЛЮЧЕВАЯ РАЗНИЦА
- XML — это сокращение от языка расширяемой разметки, тогда как HTML — это язык гипертекстовой разметки.
- XML в основном ориентирован на передачу данных, в то время как HTML ориентирован на представление данных.
- XML — это контент, тогда как HTML — формат.
- XML чувствителен к регистру, а HTML — без учета регистра.
- XML обеспечивает поддержку пространств имен, а HTML не обеспечивает поддержку пространств имен.
- XML является строгим для закрывающего тега, в то время как HTML не является строгим.
- Теги XML являются расширяемыми, тогда как HTML имеет ограниченное количество тегов.
- Теги XML не определены заранее, тогда как в HTML есть предопределенные теги.

Особенности XML
Google Trends Сравнение HTML и XML- Теги XML не определены заранее. Вам необходимо определить свои собственные теги.
- XML был разработан для передачи данных, а не для отображения этих данных.
- Разметка XML легко понять человеку.
- Хорошо структурированный формат легко читается и записывается из программ.
- XML — это расширяемый язык разметки, такой как HTML.
Особенности HTML
Вопросы о переполнении стека HTML и XML- Это простой язык, поддерживающий создание веб-страниц.
- Достаточно богатый, чтобы обеспечить поддержку встраивания мультимедиа в документы
- Достаточно гибкий, чтобы поддерживать гипертекстовые ссылки

Пример XML
<адрес>Кришна Рунгта 9898613050 Этот адрес электронной почты защищен от спам-ботов. У вас должен быть включен JavaScript для просмотра. 27 сентября 1985 г.
Пример HTML
Заголовок страницы Первый заголовок Первый абзац.
XML против HTML
| Параметр | XML | HTML |
| Тип языка | XML — это структура для определения языков разметки. | HTML — это предопределенный язык разметки. |
| Тип языка | С учетом регистра | Без учета регистра |
| Структурные детали | Предусмотрено | Не предусмотрено.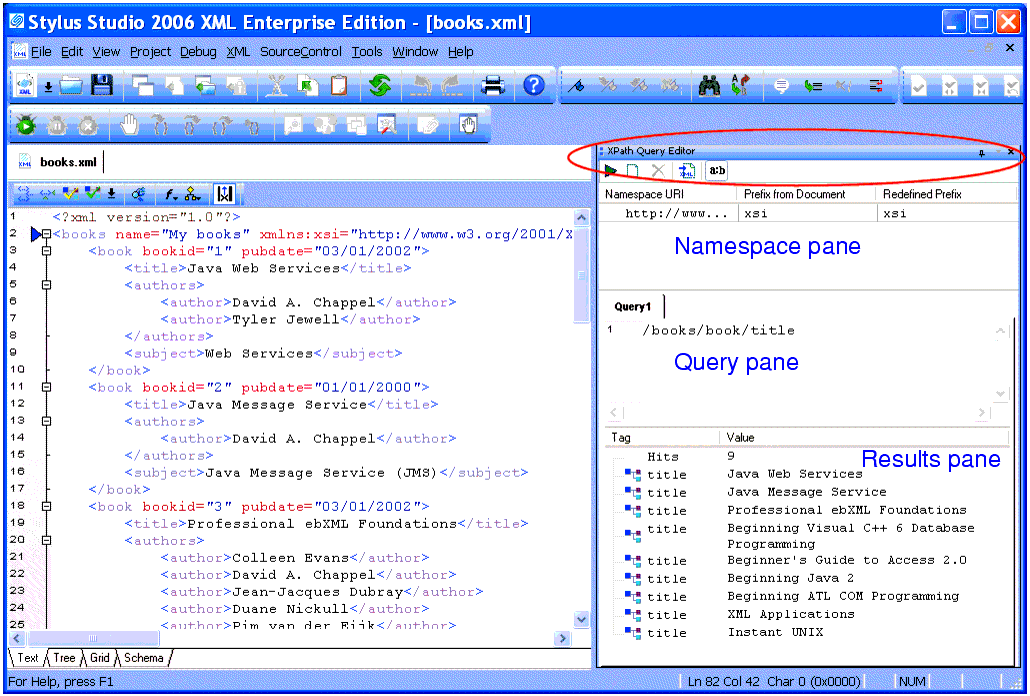 |
| Цель | Передача данных | Представление данных |
| Ошибки кодирования | Ошибки кодирования не допускаются. | Мелкие ошибки игнорируются. |
| Пробелы | В коде можно использовать пробелы. | В коде нельзя использовать пробелы. |
| Вложение | Должно быть выполнено надлежащим образом. | Не влияет на код. |
| Управляемый | XML — управляемый контент | HTML — управляемый формат |
| Конец тегов | Закрывающий тег важен в правильно сформированном XML-документе. | Закрывающий тег требуется не всегда. Тег требует эквивалентного тега, но тегу не требуется тег |
| Кавычки | Кавычки, необходимые для значений атрибутов XML. | Для значений атрибутов кавычки не требуются. |
| Поддержка объекта | Объекты должны выражаться соглашениями. В основном с использованием атрибутов и элементов. В основном с использованием атрибутов и элементов. | Предлагает поддержку собственных объектов |
| Поддержка NULL | Необходимо использовать xsi: nil для элементов в документе экземпляра XML, а также необходимо импортировать соответствующее пространство имен. | Исходно распознает нулевое значение. |
| Пространства имен | XML обеспечивает поддержку пространств имен. Это поможет вам избежать конфликта имен при объединении с другими документами. | Не поддерживает концепцию пространств имен. Коллизий при именовании можно избежать либо с помощью префикса в имени члена объекта, либо путем вложения объектов. |
| Решения о форматировании | Требуются более значительные усилия для сопоставления типов приложений с элементами и атрибутами XML. | Обеспечивает прямое сопоставление данных приложения. |
| Размер | Документы обычно имеют большой размер, особенно если при форматировании используется элементный подход. | Синтаксис очень короткий и дает форматированный текст. |
| Анализ в Javascript | Требуется реализация XML DOM и код приложения для преобразования текста обратно в объекты JavaScript. | Дополнительный код приложения для анализа текста не требуется. Для этой цели вы можете использовать функцию eval JavaScript. |
| Кривая обучения | Очень сложно, так как вам нужно изучить такие технологии, как XPath, XML Schema, DOM и т. Д. | HTML — это простой стек технологий, знакомый разработчикам. |
Преимущества использования XML
Вот значительные преимущества использования XML:
- Делает документы переносимыми между системами и приложениями. С помощью XML вы можете быстро обмениваться данными между разными платформами.
- XML отделяет данные от HTML
- XML упрощает процесс смены платформы
Преимущества использования HTML
Ниже приведены преимущества использования языка HTML:
- Интерфейсы браузера документов HTML просты в создании
- Он работает во всей системе который в остальном не имеет отношения.
- HTML легко понять, потому что он имеет очень простой синтаксис.
- Вы можете использовать множество тегов для создания веб-страницы.
- Позволяет использовать различные цвета, объекты и макеты

Недостатки использования XML
Вот несколько недостатков использования XML:
- Для XML требуется приложение обработки
- Синтаксис XML очень похож на другие альтернативы «текстовые» форматы передачи данных, которые иногда сбивают с толку.
- Нет внутренней поддержки типов данных.
- Синтаксис XML избыточен.
- Не позволяет пользователю создавать свои теги.
Недостатки использования HTML
Вот несколько недостатков использования HTML:
- HTML не имеет проверки синтаксиса и структуры
- HTML не подходит для обмена данными
- HTML не учитывает контекст
- HTML не позволяет Мы используем для описания информационного содержания или семантики документа
- HTML не является объектно-ориентированным, поэтому это не расширяемый и очень нестабильный язык.
- Хранение данных и обмен данными невозможны с использованием HTML.

История версий HTML и XML
| Версия | Год |
| HTML | 1991 |
| HTML 2.0 | 1995 |
| HTML 3,2 902 HTML 4.01 | 1999 |
| XHTML | 2000 |
| HTML5 | 2014 |
История XML
| Версия | Год 10 | 1998 |
| XML 1.1 | 2004 |
Что такое RSS
Что такое RSS
18 декабря 2002 г.
Марк Пилигрим
RSS — это формат для распространения новостей и контента новостных сайтов, включая
главный
новостные сайты, такие как Wired, сайты сообществ, ориентированные на новости, такие как Slashdot, и личные блоги. Но это не только для новостей. Практически все, что можно разбить на отдельные
Предметы
может быть распространен через RSS: страница «последних изменений» вики, журнал изменений CVS
чекины,
даже история пересмотра книги. Как только информация о каждом элементе будет в формате RSS,
ан
Программа с поддержкой RSS может проверять ленту на наличие изменений и реагировать на изменения соответствующим образом.
путь.
Но это не только для новостей. Практически все, что можно разбить на отдельные
Предметы
может быть распространен через RSS: страница «последних изменений» вики, журнал изменений CVS
чекины,
даже история пересмотра книги. Как только информация о каждом элементе будет в формате RSS,
ан
Программа с поддержкой RSS может проверять ленту на наличие изменений и реагировать на изменения соответствующим образом.
путь.
RSS-программ, называемых агрегаторами новостей, популярны в сообществе веб-блоггеров.
Много
веб-журналы делают контент доступным в RSS. Агрегатор новостей поможет вам не отставать от
все твои
любимые блоги, проверяя их RSS-каналы и отображая новые записи из каждого из
их.
Краткая история
Но программисты будьте осторожны.Название «RSS» — это обобщающий термин для формата, охватывающего несколько
разные версии как минимум двух разных (но параллельных) форматов. Оригинал
RSS,
версия 0.90, была разработана Netscape как формат для создания порталов заголовков
к
основные новостные сайты. Это считалось слишком сложным для своих целей; более простая версия,
0,91,
был предложен и впоследствии отклонен, когда Netscape потеряла интерес к созданию порталов.
бизнес.Но 0.91 был приобретен другим поставщиком, UserLand Software, который намеревался
использовать
это как основа его продуктов для ведения веб-журналов и другого программного обеспечения для записи в Интернете.
Тем временем, третья, некоммерческая группа отделилась и разработала новый формат на основе то, что они воспринимали как исходные руководящие принципы RSS 0.90 (до того, как он получил упрощенный в 0.91). Этот формат, основанный на RDF, называется RSS 1.0. Но UserLand был не участвовал в разработке этого нового формата, и, как сторонник упрощения 0.90, он не было счастлив, когда был объявлен RSS 1.0. Вместо того, чтобы принимать RSS 1.0, UserLand продолжил улучшаться ветка 0.9x, через версии 0.92, 0.93, 0.94 и, наконец, 2.0.
Какой бардак.
Так что мне использовать?
Это 7 — сосчитайте, 7! — разные форматы, все называемые «RSS». Как кодировщик RSS-осведомлен
программы, вам нужно быть достаточно либеральными, чтобы обрабатывать все варианты. Но как
содержание
производитель, который хочет сделать ваш контент доступным через синдикацию, какой формат должен
ты
выбирать?
Как кодировщик RSS-осведомлен
программы, вам нужно быть достаточно либеральными, чтобы обрабатывать все варианты. Но как
содержание
производитель, который хочет сделать ваш контент доступным через синдикацию, какой формат должен
ты
выбирать?
| Версия | Владелец | Плюсы | Статус | Рекомендация |
|---|---|---|---|---|
| 0.90 | Netscape | Устарело с версией 1. 0 0 | Не использовать | |
| 0,91 | UserLand | Офигительный простой | Официально устарело на 2.0, но все еще довольно популярны | Используется для базового распространения. Простой способ перехода на 2.0, если вам нужно больше гибкость |
| 0,92, 0,93, 0,94 | UserLand | Допускает более обширные метаданные, чем 0.91 | Устарело с версией 2. 0 0 | Используйте 2.0 вместо |
| 1,0 | RSS-DEV Рабочая группа | На основе RDF, расширяемость с помощью модулей, не контролируемых одним поставщиком | Стабильное ядро, разработка активных модулей | Используйте для приложений на основе RDF или если вам нужны расширенные модули, специфичные для RDF |
| 2.0 | UserLand | Расширяемость с помощью модулей, простой путь миграции из ветки 0.9x | Стабильное ядро, разработка активных модулей | Использование для универсальной синдикации с большим количеством метаданных |
Как выглядит RSS?
Представьте, что вы хотите написать программу, которая читает RSS-каналы, чтобы вы могли публиковать
заголовки
на своем сайте, создайте собственный портал или отечественный агрегатор новостей или что-то еще. Что
делает
RSS-канал похож? Это зависит от того, о какой версии RSS вы говорите. Вот
а
образец RSS-канала 0.91 (адаптированный из XML.com
Новостная лента):
Что
делает
RSS-канал похож? Это зависит от того, о какой версии RSS вы говорите. Вот
а
образец RSS-канала 0.91 (адаптированный из XML.com
Новостная лента):
http: //www.xml.ru /
http: //www.xml. com / pub / a / 2002/12/04 / normalizing.html

http://www.xml.com/pub/a/2002/12/04/som.html
http: // www.xml.com/pub/a/2002/12/04/svg.html
Просто, правда? Канал состоит из канала, у которого есть заголовок, ссылка, описание и
(необязательно) язык, за которым следует ряд элементов, каждый из которых имеет заголовок, ссылку,
и
описание.
Теперь посмотрите версию RSS 1.0 той же информации:
xmlns = "http://purl.org/rss/1.0/ "
xmlns: dc =" http://purl.org/dc/elements/1.1/ "
>
http: // www.xml.com/
< предмет
rdf: about = "http://www. xml.com/pub/a/2002/12/04/normalizing.html">
xml.com/pub/a/2002/12/04/normalizing.html">
http: / /www.xml.com/pub/a/2002/12/04/normalizing.html
http: //www.xml.com/pub/a/2002/12/04/som.html
 NET Schema Object Model для программного управления W3C XML
Схемы.
NET Schema Object Model для программного управления W3C XML
Схемы.
http: / / www.xml.com/pub/a/2002/12/04/svg.html
Чуть более подробный.Люди, знакомые с RDF, узнают в нем XML
сериализация документа RDF; остальной мир хотя бы признает, что
мы
синдицирование, по сути, той же информации. Фактически, мы включаем немного больше
информация: авторы и даты публикации на уровне элементов, которые RSS 0.91 не поддерживает.
Несмотря на то, что RSS 1.0 является RDF / XML, структурно он похож на предыдущие версии RSS. — достаточно похоже, чтобы мы могли просто рассматривать его как XML и писать одну функцию для извлечения информация из RSS 0.91 или RSS 1.0. Однако есть некоторые важные различия, о которых наш код должен будет знать:
Корневой элемент —
rdf: RDFвместоrss. Нам либо понадобится для обработки обоих явным образом или просто игнорировать имя корневого элемента в целом и слепо искать внутри него полезную информацию.RSS 1.0 широко использует пространства имен. Пространство имен RSS 1.0
http://purl.org/rss/1.0/, и он определен как пространство имен по умолчанию. В feed также используетhttp://www.w3.org/1999/02/22-rdf-syntax-ns#для Специфичные для RDF элементы (которые мы просто проигнорируем для наших целей) иhttp: // изн.org / dc / elements / 1.1 /(Dublin Core) для дополнительных метаданные авторов статей и дат публикации.Здесь можно пойти двумя путями: если у нас нет XML-синтаксического анализатора, учитывающего пространство имен, мы может слепо предположить, что фид использует стандартные префиксы и пространство имен по умолчанию и найдите в них элементы
itemиdc: creator. Это действительно сработает в большом количестве реальных случаев; большинство RSS-каналов используют
то
пространство имен по умолчанию и те же префиксы для общих модулей, таких как Dublin Core. Эта
это
ужасный взлом. Нет гарантии, что в фиде не будет использоваться другой префикс.
для
пространство имен (которое было бы совершенно корректным XML и RDF).Если или когда это произойдет, мы
скучать
Это.Если в нашем распоряжении есть XML-синтаксический анализатор, поддерживающий пространство имен, мы можем создать более элегантное решение, которое обрабатывает каналы RSS 0.91 и 1.0. Мы можем искать предметы в нет пространство имен; если это не удается, мы можем искать элементы в RSS 1.
0 пространство имен. (Не показаны,
но каналы RSS 0.90 также используют пространство имен, но не то же самое, что и RSS 1.0. И что
мы
действительно нужен список пространств имен для поиска.)Менее очевидны, но все же важны, элементы
item— это за пределами каналэлемент.(В RSS 0.91 элементыitemбыли внутри каналаНаконец, вы заметите, что есть дополнительный элемент
itemsвнутриканал. Это полезно только для парсеров RDF, и мы проигнорируем его.
и предположим, что порядок элементов в RSS-канале определяется их порядком.
из
элементы item.

 Это действительно сработает в большом количестве реальных случаев; большинство RSS-каналов используют
то
пространство имен по умолчанию и те же префиксы для общих модулей, таких как Dublin Core. Эта
это
ужасный взлом. Нет гарантии, что в фиде не будет использоваться другой префикс.
для
пространство имен (которое было бы совершенно корректным XML и RDF).Если или когда это произойдет, мы
скучать
Это.
Это действительно сработает в большом количестве реальных случаев; большинство RSS-каналов используют
то
пространство имен по умолчанию и те же префиксы для общих модулей, таких как Dublin Core. Эта
это
ужасный взлом. Нет гарантии, что в фиде не будет использоваться другой префикс.
для
пространство имен (которое было бы совершенно корректным XML и RDF).Если или когда это произойдет, мы
скучать
Это. 0 пространство имен. (Не показаны,
но каналы RSS 0.90 также используют пространство имен, но не то же самое, что и RSS 1.0. И что
мы
действительно нужен список пространств имен для поиска.)
0 пространство имен. (Не показаны,
но каналы RSS 0.90 также используют пространство имен, но не то же самое, что и RSS 1.0. И что
мы
действительно нужен список пространств имен для поиска.) Это полезно только для парсеров RDF, и мы проигнорируем его.
и предположим, что порядок элементов в RSS-канале определяется их порядком.
из
элементы
Это полезно только для парсеров RDF, и мы проигнорируем его.
и предположим, что порядок элементов в RSS-канале определяется их порядком.
из
элементы А как насчет RSS 2.0? К счастью, как только мы написали код для обработки RSS 0.91 и 1.0, RSS 2.0 — это проще простого. Вот версия той же ленты RSS 2.0:
http: //www.xml.com/
http://www. xml.com/pub/a/ 2002/12/04 / normalizing.html
http://www.xml.com/pub/a/2002/12/04/som.html
 12.2002
12.2002
http://www.xml.com/pub/a/2002/12/04/svg.html
Как показывает этот пример, RSS 2.0 использует пространства имен, такие как RSS 1.0, но это не RDF. подобно
RSS
0.91, пространство имен по умолчанию отсутствует, и элементы возвращаются в канал .Если
наш код достаточно либерален, чтобы учесть различия между RSS 0.91 и 1.0, RSS
2. 0
не должно иметь дополнительных морщин.
0
не должно иметь дополнительных морщин.
Как я могу читать RSS?
Теперь давайте приступим к чтению этих примеров RSS-каналов из Python. Первый вещь нам нужно будет загрузить несколько RSS-каналов.В Python это просто; большинство дистрибутивов поставляются как с библиотекой поиска URL, так и с анализатором XML. (Примечание для пользователей Mac OS X 10.2: ваш копия Python не поставляется с анализатором XML; вам нужно сначала установить PyXML.)
из xml.dom import minidom
import urllib
def load (rssURL):
return
минидом.синтаксический анализ (urllib.urlopen (rssURL))
Принимает URL-адрес RSS-канала и возвращает проанализированное представление DOM,
как родной
Объекты Python.
Следующий бит — сложная часть. Чтобы компенсировать различия в форматах RSS,
хорошо
нужна функция, которая ищет определенные элементы в любом количестве пространств имен.Python
Библиотека XML включает getElementsByTagNameNS , который принимает пространство имен и тег
name, поэтому мы будем использовать это, чтобы сделать наш код достаточно общим для обработки RSS 0.9x / 2.0 (который
не имеет
пространство имен по умолчанию), RSS 1.0 и даже RSS 0.90. Эта функция найдет всех элементов
с заданным именем в любом месте узла. Это хорошая вещь; это означает, что мы можем
поиск
для элемента элемента в корневом узле и всегда находить их, независимо от того, являются ли они
внутри или снаружи канала элемент .
DEFAULT_NAMESPACES = \
(Нет, # RSS 0.91, 0.92, 0.93, 0.94, 2.0
'http://purl.org/rss/1.0/', # RSS 1.0
'http://my.netscape.com/ rdf / simple / 0.9 / '# RSS 0.90
)
def getElementsByTagName (node, tagName, possibleNamespaces = DEFAULT_NAMESPACES):
для пространства имен в возможных пространствах имен:
дочерних элементов =
node.getElementsByTagNameNS (пространство имен, tagName)
, если
len (children): return children
return []
Наконец, нам нужны две служебные функции, чтобы облегчить нашу жизнь.Во-первых, наши getElementsByTagName Функция вернет список элементов, но большая часть
раз мы знаем, что будет только один. Изделие имеет только один заголовок , одна ссылка , одна описание и т. Д. Хорошо
определить первую функцию
Д. Хорошо
определить первую функцию , которая возвращает первый элемент заданного имени (опять же,
поиск в нескольких разных пространствах имен).Во-вторых, библиотеки Python XML
отлично в
разбор XML-документа на узлы, но не очень полезен при возврате данных
все вместе
очередной раз. Мы определим функцию textOf , которая возвращает весь текст
конкретный элемент XML.
def first (node, tagName, possibleNamespaces = DEFAULT_NAMESPACES):
children = getElementsByTagName (node, tagName, possibleNamespaces)
return len (children) and children [0] or None
def textOf (node):
return node and «».присоединиться ([child.data для ребенка в
node.childNodes]) или «»
Вот и все. Фактический синтаксический анализ прост. Возьмем URL в командной строке, скачиваем
Это,
проанализируйте его, получите список элементов, а затем получите полезную информацию по каждому элементу:
Фактический синтаксический анализ прост. Возьмем URL в командной строке, скачиваем
Это,
проанализируйте его, получите список элементов, а затем получите полезную информацию по каждому элементу:
DUBLIN_CORE = ('http: // изн.org / dc / elements / 1.1 / ',)
if __name__ ==’ __main__ ‘:
import sys
rssDocument
= load (sys.argv [1])
для элемента в getElementsByTagName (rssDocument,
‘item’):
print ‘title:’, textOf (first (item, ‘title’))
print ‘link:’, textOf (first (item, ‘link’))
print ‘description:’, textOf ( first (item, ‘description’))
print ‘date:’, textOf (first (item, ‘date’, DUBLIN_CORE))
print ‘author:’, textOf (first (item, ‘creator’, DUBLIN_CORE))
Распечатать
Запускаем его с нашим образцом RSS 0. 91 подача
печатает только заголовок, ссылку и описание (поскольку в фиде не было других
информация о датах или авторах):
91 подача
печатает только заголовок, ссылку и описание (поскольку в фиде не было других
информация о датах или авторах):
$ питон rss1.py
http://www.xml.com/2002/12/18/examples/rss091.xml.txt
заголовок: Нормализация XML, часть 2
ссылка:
http://www.xml.com/pub/a/2002/12/04/normalizing.html
описание: В этой секунде и
последний взгляд на применение методов реляционной нормализации к данным W3C XML Schema
моделирования, Уилл Провост обсуждает, когда не следует нормализовать, масштабы уникальности и
то
четвертая и пятая нормальные формы.
дата:
автор:
название: Ссылка на объектную модель схемы .NET
:
http://www. xml.com/pub/a/2002/12/04/som.html
xml.com/pub/a/2002/12/04/som.html
описание: Priya Lakshminarayanan
подробно описывает использование объектной модели схемы .NET для программного управления.
XML-схем W3C.
дата:
автор:
название: Прошлое и многообещающее будущее SVG
ссылка:
http://www.xml.com/pub/a/2002/12/04/svg.html Описание
: в столбце SVG этого месяца
Антуан Квинт оглядывается на путь SVG через 2002 год и с нетерпением ждет 2003 года.
дата:
автор:
И для образца RSS 1.0, и для образца RSS 2.0 мы также получаем даты и
авторов по каждому шт. . Мы повторно используем наш собственный getElementsByTagName функцию, но передать пространство имен Dublin Core и соответствующее имя тега. Мы могли бы
повторное использование
та же функция для извлечения информации из любого из основных модулей RSS. (Там
площадь
несколько расширенных модулей, специфичных для RSS 1.0, для которых потребуется полный анализатор RDF, но
они есть
не широко используется в общедоступных RSS-каналах.)
(Там
площадь
несколько расширенных модулей, специфичных для RSS 1.0, для которых потребуется полный анализатор RDF, но
они есть
не широко используется в общедоступных RSS-каналах.)
Вот результат для нашего образца RSS 1.0 подача:
$ питон rss1.py
http: // www.xml.com/2002/12/18/examples/rss10.xml.txt
заголовок: Нормализация XML, часть 2
ссылка:
http://www.xml.com/pub/a/2002/12/04/normalizing.html Описание
: в эту секунду и
последний взгляд на применение методов реляционной нормализации к данным W3C XML Schema
моделирования, Уилл Провост обсуждает, когда не следует нормализовать, масштабы уникальности и
то
четвертая и пятая нормальные формы.
дата: 2002-12-04
автор: Уилл Провост
название: Ссылка на объектную модель схемы .NET
:
http://www.xml.com/pub/a/2002/12/04/som.html
описание: Прия Лакшминараянан
подробно описывает использование объектной модели схемы .NET для программного управления.
XML-схем W3C.
дата: 04.12.2002
автор: Прия Лакшминараянан
название: Прошлое и многообещающее будущее SVG
ссылка:
http: // www.xml.com/pub/a/2002/12/04/svg.html
описание: в столбце SVG этого месяца
Антуан Квинт оглядывается на путь SVG через 2002 год и с нетерпением ждет 2003 года.
дата: 2002-12-04
автор: Антуан Квинт
Работает с нашим образцом RSS 2.0 дает те же результаты.
Этот метод обрабатывает около 90% RSS-каналов; остальные плохо сформированы
в
множество интересных способов, в основном вызванных созданием инструментов публикации, не поддерживающих XML
поступает из шаблонов и не соблюдает основные правила правильного формата XML. В следующем месяце
хорошо
решить сложную проблему обработки RSS-каналов, которые почти, но не совсем
правильно сформированный XML.
В следующем месяце
хорошо
решить сложную проблему обработки RSS-каналов, которые почти, но не совсем
правильно сформированный XML.
Что такое XML-файл? (И как открыть один)
Что нужно знать
- XML-файл — это файл расширяемого языка разметки.
- Откройте его с помощью онлайн-средства просмотра XML, кода Visual Studio или Notepad ++.
- Конвертируйте в JSON, CSV, HTML и другие файлы с помощью тех же программ.
В этой статье описывается, что такое файлы XML и где они используются, какие программы могут их открывать и как преобразовать один в другой текстовый формат, такой как JSON, PDF или CSV.
Что такое XML-файл?
Файл XML — это файл расширяемого языка разметки. Это простые текстовые файлы, которые сами по себе ничего не делают, кроме описания транспортировки, структуры и хранения данных.
RSS-канал — один из распространенных примеров файлов на основе XML.
Некоторые XML-файлы вместо этого являются файлами Cinelerra Video Project, используемыми в программе редактирования видео Cinelerra. Файл содержит параметры, связанные с проектом, такие как список последних изменений, внесенных в проект, а также пути к расположению файлов мультимедиа.
Lifewire / Miguel CoХотя они кажутся связанными, потому что их расширения файлов схожи, файлы XLM не совпадают с файлами XML.
Как открыть файл XML
Многие программы открывают файлы XML, включая Online XML Viewer от Code Beautify и некоторые веб-браузеры.Некоторые популярные программы также редактируют файлы XML.
Некоторые известные бесплатные редакторы XML включают Notepad ++ и XML Notepad 2007. EditiX и Adobe Dreamweaver — пара других популярных редакторов XML, но их можно использовать бесплатно только в том случае, если вам удастся получить пробную версию. Популярный редактор Microsoft Visual Studio Code обрабатывает XML-файлы как чемпион.
Популярный редактор Microsoft Visual Studio Code обрабатывает XML-файлы как чемпион.
То, что XML-файл можно легко открыть и просмотреть, не означает, что он будет делать что-нибудь . Многие программы разных типов используют XML как способ хранения своих данных стандартным способом, но на самом деле , использующее XML-файл для определенной цели, требует, чтобы вы знали, для чего этот конкретный XML-файл хранит данные.
Например, формат XML используется для файлов MusicXML, формата нот на основе XML. Вы, конечно, можете открыть один из этих XML-файлов в любом текстовом редакторе, чтобы увидеть, какие данные там есть, но на самом деле это полезно только в такой программе, как Finale NotePad.
Поскольку XML-файлы являются текстовыми файлами, любой текстовый редактор, включая встроенный в Windows инструмент «Блокнот», сможет правильно отображать и редактировать содержимое XML-файла. Вышеупомянутые специализированные редакторы XML лучше подходят для редактирования файлов XML, поскольку они понимают структуру файла. Стандартный текстовый редактор не так прост в использовании для редактирования файлов XML.
Стандартный текстовый редактор не так прост в использовании для редактирования файлов XML.
Однако, если вы хотите пойти по этому пути, посмотрите наш список лучших бесплатных текстовых редакторов для некоторых из наших фаворитов.
Файлы Cinelerra Video Project, которые используют расширение файла XML, можно открывать с помощью программного обеспечения Cinelerra для Linux. Раньше программа была разделена на две части: Heroine Virtual и Community Version, но теперь они объединены в одну.
Если вы по-прежнему не можете открыть файл, убедитесь, что вы не путаете его с файлом, имеющим только то же имя расширения, например, файл XMP, XMF или ML.
Как преобразовать файл XML
Лучшее решение для преобразования файла XML в другой формат — использовать один из уже упомянутых редакторов. Программа, создающая XML-файл, более чем вероятно сможет сохранить тот же файл в другом формате.
Например, простой текстовый редактор, который может открывать текстовый документ, такой как XML, обычно может сохранить файл в другом текстовом формате, таком как TXT. Однако вы ничего не получите от этого переключателя, кроме изменения расширения файла.
Однако вы ничего не получите от этого переключателя, кроме изменения расширения файла.
Если вы ищете быстрое решение, вы можете попробовать онлайн-конвертер XML в JSON от Code Beautify. Этот инструмент позволяет конвертировать XML в JSON, вставляя XML-код на веб-сайт, а затем загружая файл .JSON на свой компьютер. Вы также можете найти на своем компьютере файл XML или загрузить его по URL-адресу.
Конечно, конвертер XML в JSON полезен только в том случае, если это то, что вам нужно. Вот несколько других бесплатных онлайн-конвертеров XML, которые могут быть вам более полезны:
Вот несколько бесплатных конвертеров, которые конвертируют в XML вместо из XML:
Обычно вы не можете изменить расширение файла (например, расширение файла XML) на то, которое распознает ваш компьютер, и ожидать, что только что переименованный файл можно будет использовать.Фактическое преобразование формата файла с использованием одного из описанных выше методов должно выполняться в большинстве случаев. Однако, поскольку XML основан на тексте, переименование расширения может быть полезным в некоторых ситуациях.
Однако, поскольку XML основан на тексте, переименование расширения может быть полезным в некоторых ситуациях.
Дополнительная информация о файлах XML
Файлы XML отформатированы с помощью тегов, как и файлы других языков разметки, например файлы HTML. Вы можете увидеть образец файла XML на веб-сайте Microsoft.
Начиная с Microsoft Office 2007, Microsoft использует форматы на основе XML для Word, Excel и PowerPoint, ориентированные на соответствующие форматы файлов:.DOCX, .XLSX и .PPTX. Microsoft предлагает подробное объяснение преимуществ использования этих типов файлов на основе XML.
Некоторые другие типы файлов на основе XML включают файлы EDS, XSPF, FDX, SEARCH-MS, CMBL, APPLICATION и DAE.
W3Schools имеет лотов и информации о файлах XML, если вы хотите подробно изучить, как с ними работать.
Спасибо, что сообщили нам!
Расскажите, почему!
Другой Недостаточно деталей Трудно понятьHTML против XML — GeeksforGeeks
HTML против XML
HTML: HTML ( Hyper Text Markup Language ) используется для создания веб-страниц и веб-приложений. Это язык разметки. С помощью HTML мы можем создать нашу собственную статическую страницу. Он используется для отображения данных, а не для переноса данных. HTML — это комбинация гипертекста и языка разметки. Гипертекст определяет связь между веб-страницами. Язык разметки используется для определения текстового документа внутри тега, который определяет структуру веб-страниц. Этот язык используется для аннотирования (создания заметок для компьютера) текста, чтобы машина могла его понять и соответствующим образом манипулировать текстом.
Это язык разметки. С помощью HTML мы можем создать нашу собственную статическую страницу. Он используется для отображения данных, а не для переноса данных. HTML — это комбинация гипертекста и языка разметки. Гипертекст определяет связь между веб-страницами. Язык разметки используется для определения текстового документа внутри тега, который определяет структуру веб-страниц. Этот язык используется для аннотирования (создания заметок для компьютера) текста, чтобы машина могла его понять и соответствующим образом манипулировать текстом.
Пример:
|
Выход:
XML: XML ( eXtensible Markup Language ) также используется для создания веб-страниц и веб-приложений. Он динамический, потому что он используется для передачи данных, а не для отображения данных. Цели разработки XML сосредоточены на простоте, универсальности и удобстве использования в Интернете. Это текстовый формат данных с сильной поддержкой Unicode для разных человеческих языков. Хотя дизайн XML ориентирован на документы, этот язык широко используется для представления произвольных структур данных, например, используемых в веб-сервисах.
Он динамический, потому что он используется для передачи данных, а не для отображения данных. Цели разработки XML сосредоточены на простоте, универсальности и удобстве использования в Интернете. Это текстовый формат данных с сильной поддержкой Unicode для разных человеческих языков. Хотя дизайн XML ориентирован на документы, этот язык широко используется для представления произвольных структур данных, например, используемых в веб-сервисах.
Пример:
|
Выход:
G4G Geeksforgeeks 2345456767
Разница между HTML и XML: Между HTML и XML есть много различий. Эти важные отличия приведены ниже:
Эти важные отличия приведены ниже:
| HTML | XML |
|---|---|
| HTML означает Hyper Text Markup Language. | XML означает расширяемый язык разметки . |
| HTML статичен. | XML является динамическим. |
| HTML - это язык разметки. | XML предоставляет основу для определения языков разметки. |
| HTML может игнорировать мелкие ошибки. | XML не допускает ошибок. |
| HTML не чувствителен к регистру. | XML чувствителен к регистру. |
| HTML-теги - это предварительно определенные теги. | Теги XML - это теги, определяемые пользователем. |
| В HTML ограниченное количество тегов. | XML-теги являются расширяемыми. |
| HTML не сохраняет пробелы. | Пробел может быть сохранен в XML. |
HTML-теги используются для отображения данных. |
Ваш комментарий будет первым