традиционная и облачная / Хабр
Привет, Хабр! На тему архитектуры хранилищ данных написано немало, но так лаконично и емко как в статье, на которую я случайно натолкнулся, еще не встречал.
Предлагаю и вам познакомиться с данной статьей в моем переводе. Комментарии и дополнения только приветствуются!
(Источник картинки)
Введение
Итак, архитектура хранилищ данных меняется. В этой статье рассмотрим сравнение традиционных корпоративных хранилищ данных и облачных решений с более низкой первоначальной стоимостью, улучшенной масштабируемостью и производительностью.
Хранилище данных – это система, в которой собраны данные из различных источников внутри компании и эти данные используются для поддержки принятия управленческих решений.
Компании все чаще переходят на облачные хранилища данных вместо традиционных локальных систем. Облачные хранилища данных имеют ряд отличий от традиционных хранилищ:
- Нет необходимости покупать физическое оборудование;
- Облачные хранилища данных быстрее и дешевле настроить и масштабировать;
- Облачные хранилища данных обычно могут выполнять сложные аналитические запросы гораздо быстрее, потому что они используют массовую параллельную обработку.


Традиционная архитектура хранилища данных
Следующие концепции освещают некоторые из устоявшихся идей и принципов проектирования, используемых для создания традиционных хранилищ данных.
Трехуровневая архитектура
Довольно часто традиционная архитектура хранилища данных имеет трехуровневую структуру, состоящую из следующих уровней:
- Нижний уровень: этот уровень содержит сервер базы данных, используемый для извлечения данных из множества различных источников, например, из транзакционных баз данных, используемых для интерфейсных приложений.
- Средний уровень: средний уровень содержит сервер OLAP, который преобразует данные в структуру, лучше подходящую для анализа и сложных запросов. Сервер OLAP может работать двумя способами: либо в качестве расширенной системы управления реляционными базами данных, которая отображает операции над многомерными данными в стандартные реляционные операции (Relational OLAP), либо с использованием многомерной модели OLAP, которая непосредственно реализует многомерные данные и операции.
- Верхний уровень: верхний уровень — это уровень клиента. Этот уровень содержит инструменты, используемые для высокоуровневого анализа данных, создания отчетов и анализа данных.

Kimball vs. Inmon
Два пионера хранилищ данных: Билл Инмон и Ральф Кимбалл предлагают разные подходы к проектированию.
Подход Ральфа Кимбалла основывается на важности витрин данных, которые являются хранилищами данных, принадлежащих конкретным направлениям бизнеса. Хранилище данных — это просто сочетание различных витрин данных, которые облегчают отчетность и анализ. Проект хранилища данных по принципу Кимбалла использует подход «снизу вверх».
Подход Билла Инмона
 Это известно как нисходящий подход к хранилищу данных.
Это известно как нисходящий подход к хранилищу данных.Модели хранилищ данных
В традиционной архитектуре существует три общих модели хранилищ данных: виртуальное хранилище, витрина данных и корпоративное хранилище данных:
- Виртуальное хранилище данных — это набор отдельных баз данных, которые можно использовать совместно, чтобы пользователь мог эффективно получать доступ ко всем данным, как если бы они хранились в одном хранилище данных;
- Модель витрины данных используется для отчетности и анализа конкретных бизнес-линий. В этой модели хранилища – агрегированные данные из ряда исходных систем, относящихся к конкретной бизнес-сфере, такой как продажи или финансы;
- Модель корпоративного хранилища данных предполагает хранение агрегированных данных, охватывающих всю организацию. Эта модель рассматривает хранилище данных как сердце информационной системы предприятия с интегрированными данными всех бизнес-единиц
Звезда vs.
 Снежинка
СнежинкаСхемы «звезда» и «снежинка» — это два способа структурировать хранилище данных.
Схема типа «звезда» имеет централизованное хранилище данных, которое хранится в таблице фактов. Схема разбивает таблицу фактов на ряд денормализованных таблиц измерений. Таблица фактов содержит агрегированные данные, которые будут использоваться для составления отчетов, а таблица измерений описывает хранимые данные.
Денормализованные проекты менее сложны, потому что данные сгруппированы. Таблица фактов использует только одну ссылку для присоединения к каждой таблице измерений. Более простая конструкция звездообразной схемы значительно упрощает написание сложных запросов.
Схема типа «снежинка» отличается тем, что использует нормализованные данные. Нормализация означает эффективную организацию данных так, чтобы все зависимости данных были определены, и каждая таблица содержала минимум избыточности. Таким образом, отдельные таблицы измерений разветвляются на отдельные таблицы измерений.
Таким образом, отдельные таблицы измерений разветвляются на отдельные таблицы измерений.
Схема «снежинки» использует меньше дискового пространства и лучше сохраняет целостность данных. Основным недостатком является сложность запросов, необходимых для доступа к данным — каждый запрос должен пройти несколько соединений таблиц, чтобы получить соответствующие данные.
ETL vs. ELT
ETL и ELT — два разных способа загрузки данных в хранилище.
ETL (Extract, Transform, Load) сначала извлекают данные из пула источников данных. Данные хранятся во временной промежуточной базе данных. Затем выполняются операции преобразования, чтобы структурировать и преобразовать данные в подходящую форму для целевой системы хранилища данных. Затем структурированные данные загружаются в хранилище и готовы к анализу.
В случае ELT (Extract, Load, Transform) данные сразу же загружаются после извлечения из исходных пулов данных. Промежуточная база данных отсутствует, что означает, что данные немедленно загружаются в единый централизованный репозиторий.
Промежуточная база данных отсутствует, что означает, что данные немедленно загружаются в единый централизованный репозиторий.
Данные преобразуются в системе хранилища данных для использования с инструментами бизнес-аналитики и аналитики.
Организационная зрелость
Базовая структура позволяет конечным пользователям хранилища напрямую получать доступ к сводным данным, полученным из исходных систем, создавать отчеты и анализировать эти данные. Эта структура полезна для случаев, когда источники данных происходят из одних и тех же типов систем баз данных.
Хранилище с промежуточной областью является следующим логическим шагом в организации с разнородными источниками данных с множеством различных типов и форматов данных. Промежуточная область преобразует данные в обобщенный структурированный формат, который проще запрашивать с помощью инструментов анализа и отчетности.
Одной из разновидностей промежуточной структуры является добавление витрин данных в хранилище данных. В витринах данных хранятся сводные данные по конкретной сфере деятельности, что делает эти данные легко доступными для конкретных форм анализа.
Например, добавление витрин данных может позволить финансовому аналитику легче выполнять подробные запросы к данным о продажах, прогнозировать поведение клиентов. Витрины данных облегчают анализ, адаптируя данные специально для удовлетворения потребностей конечного пользователя.
Новые архитектуры хранилищ данных
В последние годы хранилища данных переходят в облако. Новые облачные хранилища данных не придерживаются традиционной архитектуры и каждое из них предлагает свою уникальную архитектуру.
В этом разделе кратко описываются архитектуры, используемые двумя наиболее популярными облачными хранилищами: Amazon Redshift и Google BigQuery.
Amazon Redshift
Redshift требует, чтобы вычислительные ресурсы были подготовлены и настроены в виде кластеров, которые содержат набор из одного или нескольких узлов. Каждый узел имеет свой собственный процессор, память и оперативную память. Leader Node компилирует запросы и передает их вычислительным узлам, которые выполняют запросы.
На каждом узле данные хранятся в блоках, называемых срезами. Redshift использует колоночное хранение, то есть каждый блок данных содержит значения из одного столбца в нескольких строках, а не из одной строки со значениями из нескольких столбцов.
Redshift использует архитектуру MPP (Massively Parallel Processing), разбивая большие наборы данных на куски, которые назначаются слайсам в каждом узле. Запросы выполняются быстрее, потому что вычислительные узлы обрабатывают запросы в каждом слайсе одновременно.
Клиентские приложения, такие как BI и аналитические инструменты, могут напрямую подключаться к Redshift с использованием драйверов PostgreSQL JDBC и ODBC с открытым исходным кодом. Таким образом, аналитики могут выполнять свои задачи непосредственно на данных Redshift.
Redshift может загружать только структурированные данные. Можно загружать данные в Redshift с использованием предварительно интегрированных систем, включая Amazon S3 и DynamoDB, путем передачи данных с любого локального хоста с подключением SSH или путем интеграции других источников данных с помощью API Redshift.
Google BigQuery
Архитектура BigQuery не требует сервера, а это означает, что Google динамически управляет распределением ресурсов компьютера. Поэтому все решения по управлению ресурсами скрыты от пользователя.
BigQuery позволяет клиентам загружать данные из Google Cloud Storage и других читаемых источников данных. Альтернативным вариантом является потоковая передача данных, что позволяет разработчикам добавлять данные в хранилище данных в режиме реального времени, строка за строкой, когда они становятся доступными.
Альтернативным вариантом является потоковая передача данных, что позволяет разработчикам добавлять данные в хранилище данных в режиме реального времени, строка за строкой, когда они становятся доступными.
BigQuery использует механизм выполнения запросов под названием Dremel, который может сканировать миллиарды строк данных всего за несколько секунд. Dremel использует массивно параллельные запросы для сканирования данных в базовой системе управления файлами Colossus. Colossus распределяет файлы на куски по 64 мегабайта среди множества вычислительных ресурсов, называемых узлами, которые сгруппированы в кластеры.
Dremel использует колоночную структуру данных, аналогичную Redshift. Древовидная архитектура отправляет запросы тысячам машин за считанные секунды.
Для выполнения запросов к данным используются простые команды SQL.
Panoply
Panoply обеспечивает комплексное управление данными как услуга. Его уникальная самооптимизирующаяся архитектура использует машинное обучение и обработку естественного языка (NLP) для моделирования и рационализации передачи данных от источника к анализу, сокращая время от данных до значения как можно ближе к нулю.
Интеллектуальная инфраструктура данных Panoply включает в себя следующие функции:
- Анализ запросов и данных — определение наилучшей конфигурации для каждого варианта использования, корректировка ее с течением времени и создание индексов, сортировочных ключей, дисковых ключей, типов данных, вакуумирование и разбиение.
- Идентификация запросов, которые не следуют передовым методам — например, те, которые включают вложенные циклы или неявное приведение — и переписывает их в эквивалентный запрос, требующий доли времени выполнения или ресурсов.
- Оптимизация конфигурации сервера с течением времени на основе шаблонов запросов и изучения того, какая настройка сервера работает лучше всего. Платформа плавно переключает типы серверов и измеряет итоговую производительность.
По ту сторону облачных хранилищ данных
Облачные хранилища данных — это большой шаг вперед по сравнению с традиционными подходами к архитектуре. Однако пользователи по-прежнему сталкиваются с рядом проблем при их настройке:
Однако пользователи по-прежнему сталкиваются с рядом проблем при их настройке:
- Загрузка данных в облачные хранилища данных нетривиальна, а для крупномасштабных конвейеров данных требуется настройка, тестирование и поддержка процесса ETL. Эта часть процесса обычно выполняется сторонними инструментами;
- Обновления, вставки и удаления могут быть сложными и должны выполняться осторожно, чтобы не допустить снижения производительности запросов;
- С полуструктурированными данными трудно иметь дело — их необходимо нормализовать в формате реляционной базы данных, что требует автоматизации больших потоков данных;
- Вложенные структуры обычно не поддерживаются в облачных хранилищах данных. Вам необходимо преобразовать вложенные таблицы в форматы, понятные хранилищу данных;
- Оптимизация кластера. Существуют различные варианты настройки кластера Redshift для запуска ваших рабочих нагрузок. Различные рабочие нагрузки, наборы данных или даже различные типы запросов могут потребовать иной настройки. Для достижения оптимальной работы, необходимо постоянно пересматривать и при необходимости дополнительно настраивать конфигурацию;
- Оптимизация запросов — пользовательские запросы могут не соответствовать передовым методам и, следовательно, будут выполняться намного дольше. Вы можете работать с пользователями или автоматизированными клиентскими приложениями для оптимизации запросов, чтобы хранилище данных могло работать так, как ожидалось
- Резервное копирование и восстановление — несмотря на то, что поставщики хранилищ данных предоставляют множество возможностей для резервного копирования ваших данных, их нетривиально настроить и они требуют мониторинга и пристального внимания
 Для достижения оптимальной работы, необходимо постоянно пересматривать и при необходимости дополнительно настраивать конфигурацию;
Для достижения оптимальной работы, необходимо постоянно пересматривать и при необходимости дополнительно настраивать конфигурацию;Ссылка на оригинальный текст: panoply.io/data-warehouse-guide/data-warehouse-architecture-traditional-vs-cloud
Cloud Storage | Облачное объектное хранилище данных с S3 — совместимым api
Объектное хранилище S3
Рассчитать стоимость
Возможности объектного хранилища S3
Моментальное масштабирование
Хранение от мегабайт до петабайт данных. Скорость передачи 1 Gbit/s.
Скорость передачи 1 Gbit/s.
Удобное применение
Легкая интеграция с вашими сервисами. Управление по API S3, UI или через консоль.
Универсальное использование
Бэкапы, фото- и видеофайлы, архивы, ML-модели и многое другое.
Гибкое потребление
Разгрузка дисков виртуальных машин. Без простоев и дефицита.
Поддержка и мониторинг
Техподдержка 24/7, документация на русском языке.
Надежность Cloud Storage
Хранение неструктурированных данных и метаданных объектов в плоском адресном пространстве. Загрузка через multipart upload.
Интеграция S3 с облачными вычислениями для переноса массива данных и автообработки тяжелых объектов.
Георепликация. Совместное использование ресурсов различными приложениями вашего бизнеса.
Аттестация облака в соответствии с 152-ФЗ. Регулярный аудит уровня «большой четверки».
99,99999%
Надежность хранения
SSL
SSL-шифрование
150 петабайт
Полезной емкости
ЦОДы TIER III
На территории РФ
SLA 99,95%
C финансовыми гарантиями
Быстрое внедрение
- Инсталляция S3 SDK и создание приложений, которые работают с объектным хранилищем S3.
- Монтирование бакета в операционную систему как файловое хранилище при помощи S3FS.
- Работа с объектами через интерфейсы файловых менеджеров (CyberDuck, WinSCP, Диск-О).
- Совместимость Cloud Storage с Amazon S3: API, CLI, WinSCP, Java SDK и Python SDK.

С объектным хранилищем S3 вы сможете:
- Утилизировать облачную систему хранения данных на 100%
- Резервировать систему значительно дешевле, чем на HDD
- Хранить и передавать объекты любого типа
- Управлять жизненным циклом объектов и настраивать удаление бэкапов по расписанию
- Разграничивать права доступа через ACL
- Передавать объекты по presigned URL
- Добавлять домены к хранилищу
- Использовать webhooks
Облачное хранилище для бизнеса
Расширение СХД
Мобильные и веб-приложения, игры
Бесконечное масштабирование
Аренда облачного хранилища позволяет автоматически увеличивать объем хранения, когда необходимо, и разгрузить блочные диски. Через S3 API объектное хранилище можно легко интегрировать с любыми приложениями. Hotbox позволяет обрабатывать тысячи запросов в секунду к объекту и передавать данные по сети 1 Gbit/s.
Через S3 API объектное хранилище можно легко интегрировать с любыми приложениями. Hotbox позволяет обрабатывать тысячи запросов в секунду к объекту и передавать данные по сети 1 Gbit/s.
Доступ к файлам можно быстро получать из любой точки мира. Подключение CDN позволит быстро раздавать контент по всему миру со средней задержкой в 20 мс и дополнительной защитой трафика через AntiDDoS.
Хранение любых лог-файлов
Хранение файлов с записями событий в хронологическом порядке — обычно это протоколирование работы системы и записи внешних событий, например информации о посетителях сайта/приложения.
Бэкапы и аварийное восстановление
Хранение истории и архивов
Потоковая раздача мультимедиа
Хостинг статических файлов
Хранение больших данных
Экономия от 50% на хранении
Стоимость облачного хранилища зависит от типа хранения данных. Режим можно переключать в любое время.
hotbox
Хранение дороже, трафик дешевле
Горячее хранение для часто используемых данных: доставки мультимедиа и объектов для обработки.
icebox
Хранение дешевле, трафик дороже
Холодное хранение для редко используемых данных: архивов, резервных копий, журналов.
glacier
Длительное хранение
Для резервных копий и архивов объемом от 100 ТБ с мгновенным доступом.
Рассчитайте стоимость аренды облачного хранилища
Стоимость услуги зависит от использованного объема, биллинг производится с точностью до секунды. Входящий трафик бесплатный.
Миграция данных из S3-совместимых хранилищ
Перенесите любой объем данных из Amazon S3 в объектное хранилище Cloud Storage от VK Cloud
- Управление проектом с помощью API, CLI, WinSCP, Java SDK и Python SDK
- Управление жизненным циклом объектов и удаление бэкапов по расписанию
- Разграничение прав доступа через Access Control List (ACL)
- Высокая скорость передачи данных 1 Гбит/с.
Консистентная миграция
Миграция данных с минимальным простоем в работе сервисовБезопасность
Объектное S3-хранилище с тройной георепликацией, аттестованное по ФЗ-152Неограниченное масштабирование
Храните и передавайте объекты любого типа: от мегабайта до петабайт данныхБольше возможностей инфраструктуры
- Безлимитный трафик 1 Gbit/s и статические внешние IP-адреса
- Быстрая работа с данными на SSD, High-IOPS и NVMe
- KVM — быстрая среда виртуализации с открытым кодом
- Private DNS, балансировщик нагрузок, VPN, Firewall
Подробнее
Подробнее
Быстрая сеть доставки контента
- Разгрузка сервера-источника на 90% от раздачи статического контента
- Увеличение загрузки аудио- и видеоконтента без буферизации
- Ускорение скачивания в несколько раз вне зависимости от местонахождения
- Усиление защиты от DDoS-атак за счет большой емкости сети
Подробнее
Подробнее
Понятный интерфейс
Удобное управление виртуальными машинами, базами данных, облачным хранилищем и другими облачными сервисами VK Cloud
Узнайте больше
Как упростить хранение данных и организовать бесконечно масштабируемый ист.
 ..
..Хамзет Шогенов
Архитектура S3: 3 года эволюции VK Cloud Storage
Владимир Перепелица
Нам доверяют свой бизнес
У нас есть Сloud-технологии и сервисы, которые помогают компаниям решать самые важные задачи.
FAQ
Как работает S3-совместимое хранилище (S3 compatible storage)?
Оно представляет собой сервис для хранения любых объектов, взаимодействует с приложениями через программный интерфейс — S3 API. Сервис рассчитан на сохранение и извлечение любых объемов данных, обеспечивает надежную и масштабируемую инфраструктуру, доступную из любой точки мира. Управление корпоративным хранилищем данных осуществляется через простой интерфейс панели управления в личном кабинете пользователя VK Cloud.
Кому подходит услуга облачного хранилища?
Какие данные можно хранить в S3-хранилище?
Есть ли ограничения по объему хранимых данных?
Какие преимущества у S3 Cloud?
В чем особенность объектных облачных хранилищ для бизнеса?
Возможна ли автоматизация работы при объектном хранении данных?
Где находятся ЦОДы?
Какие у вас IP?
Насколько безопасно хранить данные в S3 облачном хранилище?
Насколько надежно объектное хранилище данных от VK Cloud?
S3 API — основной протокол доступа?
Как подключить сервис?
Как я могу контролировать потребление ресурсов?
От чего зависит стоимость облачного хранилища?
Не нашли ответ на свой вопрос?
Задайте его нам через форму обратной связи, и мы оперативно ответим
Задать вопрос
3500 разработчиков
300 репозиториев открытого кода
20000 компаний используют технологии и цифровые решения VK
3500 разработчиков
300 репозиториев открытого кода
20000 компаний используют технологии и цифровые решения VK
3500 разработчиков
300 репозиториев открытого кода
20000 компаний используют технологии и цифровые решения VK
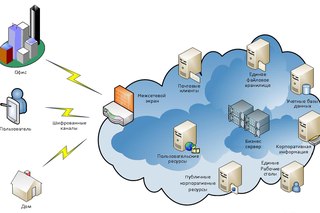
Что такое виртуальное хранилище? | Определение из TechTarget
Дата центрК
- Сара Уилсон, Помощник редактора сайта
Виртуальное хранилище — это объединение физического хранилища из нескольких сетевых устройств хранения в одно устройство хранения, управляемое с центральной консоли.
преобразует сервер, обычно сервер X86, в контроллер хранилища, а хранилище внутри сервера — в систему хранения. Преимущество виртуализации заключается в том, что стандартное оборудование или менее дорогое хранилище можно использовать для обеспечения функциональности корпоративного класса. Виртуализация системы хранения также помогает администратору системы хранения данных выполнять задачи резервного копирования, архивирования и восстановления с меньшими затратами времени, маскируя реальную сложность сети хранения данных (SAN).
Продукты для виртуальных хранилищEnterprise включают платформу Virtual Storage Platform (VSP) Hitachi Data Systems, IBM SAN Volume Controller (SVC) и NetApp V-Series. Программные виртуальные устройства хранения, такие как Lefthand от HP или SANsymphony от DataCore Software, также являются вариантами для предоставления и работы с виртуальным хранилищем.
См. также: виртуализация хранилища , программно-определяемое хранилище, гипервизор хранилища
Последнее обновление: июнь 2013 г.
- Облачное и виртуальное хранилище
- Технология виртуализации хранилища HDS
- Как VSA могут улучшить хранилище
- Руководство по виртуализации хранилища
виртуализация хранилища
Автор: Рич Кастанья
виртуальный LUN (номер виртуального логического устройства)
Автор: Роберт Шелдон
необработанное сопоставление устройств
Автор: Рахул Авати
виртуализация
Автор: Кейт Браш
SearchWindowsServer
- Получите полный контроль над своей инфраструктурой с помощью специальной MMC
Microsoft предоставляет отличные инструменты администрирования, такие как PowerShell и Server Manager.
Но не пренебрегайте почтенным Microsoft… - Советы, как избежать проблем при переходе с Exchange 2010 на Office 365
Теперь, когда Exchange Server 2010 и Exchange 2013 являются устаревшими продуктами, администраторам следует предпринять усилия по миграции, чтобы избежать …
- Microsoft исправляет нулевой день Windows во вторник с апрельским патчем
То, что было старым, снова стало новым, так как несколько обновлений безопасности из прошлого вернулись в этом месяце, чтобы увеличить общее количество …
 Но не пренебрегайте почтенным Microsoft…
Но не пренебрегайте почтенным Microsoft…Облачные вычисления
- Как создать оповещение CloudWatch для инстанса EC2
Аварийные сигналы CloudWatch — это строительные блоки инструментов мониторинга и реагирования в AWS. Познакомьтесь с ними, создав Amazon…
- 5 способов восстановить виртуальную машину Azure
Существуют различные способы восстановления виртуальной машины Azure.
Узнайте, почему вам нужно восстановить виртуальную машину, доступные методы восстановления и какие… - Преимущества и ограничения Google Cloud Recommender
Расходы на облако могут выйти из-под контроля, но такие службы, как Google Cloud Recommender, предоставляют информацию для оптимизации ваших рабочих нагрузок. Но…
 Узнайте, почему вам нужно восстановить виртуальную машину, доступные методы восстановления и какие…
Узнайте, почему вам нужно восстановить виртуальную машину, доступные методы восстановления и какие…Хранение
- Рекомендации по хранению данных NFT
NFT — это тенденция на цифровом рынке, но где и как предприятия должны их хранить? Есть три основных варианта…
- Что лежит за йоттабайтом?
Как только данные будут измеряться в йоттабайтах, миру потребуются новые термины для прогнозирования данных. Вот где два новых термина — …
- Pure объединяет блочное и файловое хранилище в одном массиве FlashArray
Pure Storage расширил рынок унифицированных хранилищ, предоставив нативную поддержку файлов, блоков и виртуальных машин в массиве FlashArray, что может .
..
Определение, преимущества и подробное руководство
Виртуальное хранилище — это несколько физических устройств хранения, объединенных в одно устройство хранения, например сеть хранения данных (SAN). Программное обеспечение виртуализации хранилища используется для создания виртуального хранилища из недорогого стандартного оборудования, а контроллеры хранилища используются для управления комбинированным пространством из различных физических устройств хранения в сети. В этой статье обсуждается принцип работы виртуального хранилища, его преимущества и отличия от облачного хранилища. Также подробно описывается роль виртуального хранилища в периферийных вычислениях и то, как решения виртуального хранения работают с Parallels® Remote Application Server (RAS).
Основы виртуального хранилища
До появления виртуализации на типичном сервере размещалось одно приложение. Если у вас было несколько приложений, вы инвестировали в серверы для размещения каждого приложения. Например, у вас могли быть отдельные серверы печати и электронной почты. Это означало, что центры обработки данных содержали большое количество физического оборудования и требовали значительных финансовых вложений.
Например, у вас могли быть отдельные серверы печати и электронной почты. Это означало, что центры обработки данных содержали большое количество физического оборудования и требовали значительных финансовых вложений.
Затем IBM начала виртуализировать мейнфреймы, а вскоре VMware привнесла виртуализацию на серверы x86. Вскоре после этого появилась виртуализация рабочих столов и приложений.
VMware представила концепцию уровня гипервизора, которая позволяла виртуализировать такие компоненты, как ЦП, память и жесткие диски. Фрагменты этих ресурсов затем могут быть назначены нескольким виртуальным машинам (ВМ), работающим на одном и том же физическом оборудовании. Таким образом, стало возможным выполнение нескольких приложений на одном сервере.
Растущее число бизнес-приложений на предприятии также означало потребность в большем объеме памяти. Увеличение требований к пространству привело к внедрению более совершенного оборудования для хранения данных в виде SAN и сетевых хранилищ (NAS).
Виртуальное хранилище вскоре стало возможным, так как концепция виртуализации вскоре распространилась на физическое хранилище. Вскоре стало возможным определять виртуальные SAN на том же оборудовании, на котором работает гипервизор. Сети также стали виртуализированными. Все эти разработки помогли снизить стоимость установки центра обработки данных.
Преимущества виртуального хранилища
Виртуальное хранилище имеет ряд преимуществ по сравнению с другими формами хранения, в том числе следующие:
- Более быстрая миграция данных: Программное зеркальное отображение лучше всего работает с виртуализацией хранилища. Таким образом, миграция данных не только быстрее в виртуальном хранилище, но и время простоя также минимально, если вообще отсутствует.
- Более простое управление: Поскольку все управление осуществляется через центральную консоль, виртуальным хранилищем может управлять один человек даже на уровне предприятия. Таким образом, простота виртуального хранилища приводит к снижению трудозатрат.
- Варианты гибкого массива хранения: Несмотря на то, что с виртуальной SAN доступен более широкий набор вариантов хранения, они прозрачны для SAN, что означает, что он видит и обрабатывает эти разные варианты как одно и то же. Это еще больше упрощает управление виртуальной SAN.
- Снижение затрат: Виртуальная сеть хранения данных требует меньше оборудования и ресурсов для работы по сравнению с другими типами хранилищ. Вы также можете масштабировать свое виртуальное хранилище по мере роста ваших требований.
- Предсказуемые затраты: Виртуальные SAN стоят меньше, чем другие варианты хранения. Даже если ваши требования изменятся, добавление дополнительного места позже не будет стоить дороже, чем альтернативы.
- Улучшенный доступ к данным: Поскольку вы управляете всеми своими устройствами централизованно, ваши пользователи не теряют легкий доступ к вашим данным. Если они потеряют доступ, им нужно будет только перейти на новую виртуальную машину (ВМ), чтобы сохранить доступ к вашим данным. Вы также можете использовать любую конечную точку для доступа к своим данным.
- Минимальное нарушение работы сети: При возникновении проблемы необходимо отключить только ту часть вашей виртуальной SAN, в которой возникли проблемы, при этом остальная часть вашего общего хранилища все еще может работать.
- Расширенный доступ: Виртуальное хранилище доступно любому, у кого есть необходимые ресурсы. Вам также не нужно обслуживать дорогостоящее оборудование. Вместо этого вы получаете доступного поставщика, который предоставит то, что вам нужно.
 Таким образом, простота виртуального хранилища приводит к снижению трудозатрат.
Таким образом, простота виртуального хранилища приводит к снижению трудозатрат. Если они потеряют доступ, им нужно будет только перейти на новую виртуальную машину (ВМ), чтобы сохранить доступ к вашим данным. Вы также можете использовать любую конечную точку для доступа к своим данным.
Если они потеряют доступ, им нужно будет только перейти на новую виртуальную машину (ВМ), чтобы сохранить доступ к вашим данным. Вы также можете использовать любую конечную точку для доступа к своим данным.Виртуальное хранилище и облачное хранилище
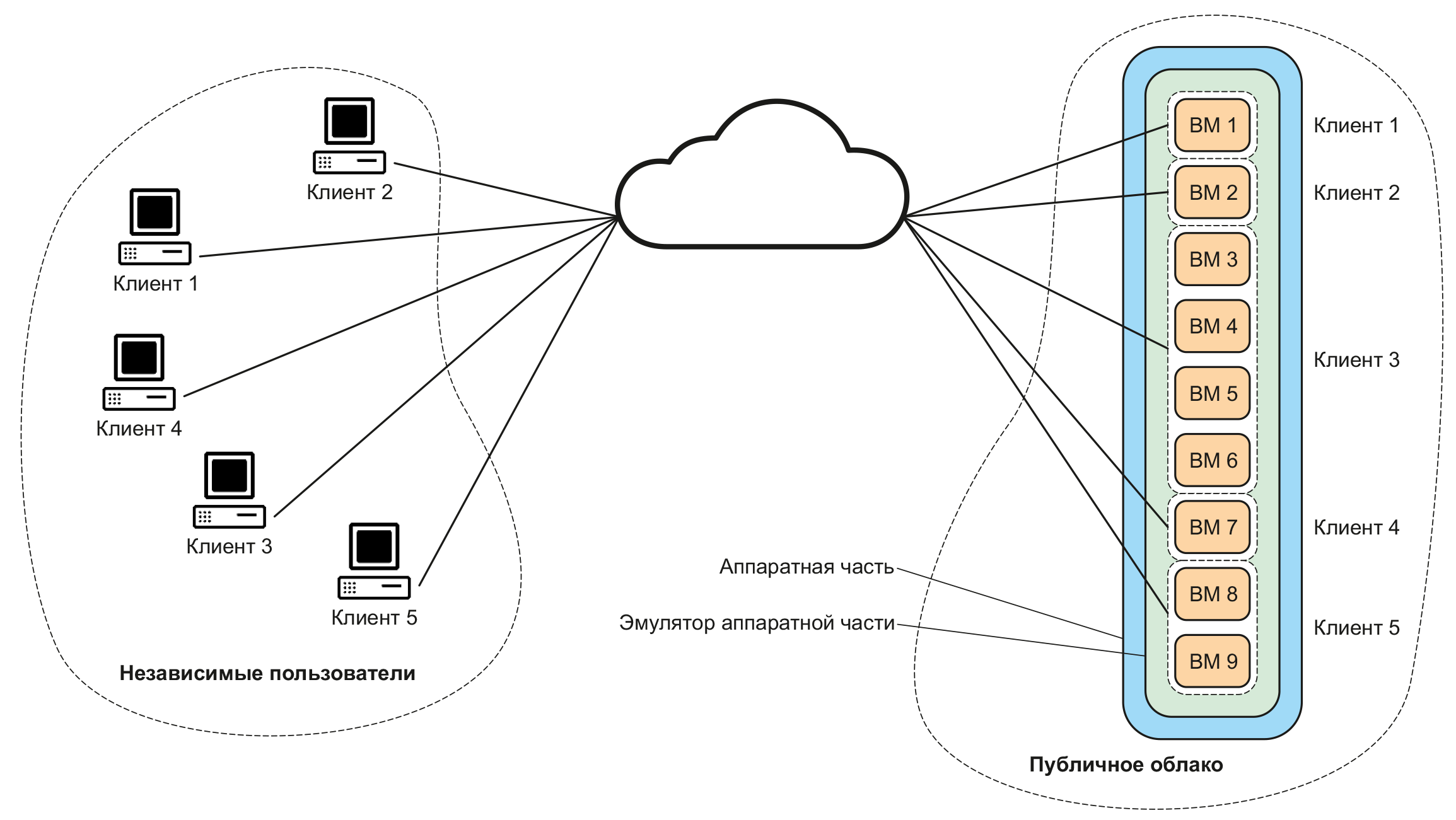
Поскольку они одновременно абстрагируют и объединяют ресурсы, виртуальную память легко спутать с облачной. Важно знать их различия, чтобы вы могли отличить их друг от друга.
В виртуальном хранилище доступное пространство на физическом оборудовании объединяется в программно-определяемое хранилище, доступное с любого устройства конечного пользователя. Хотя кажется, что в среде существует одна физическая сеть хранения данных, на самом деле существует несколько физических аппаратных средств, на которых размещается доступное пространство, а технология виртуализации хранилища используется для объединения этих ресурсов вместе, с учетом термина «виртуальное хранилище». В сочетании с виртуальными машинами гипервизоры, находящиеся в физическом оборудовании, заботятся о выделении дискового пространства в сети для каждой виртуальной машины, помимо использования для выделения других общих ресурсов в среде, например, вычислительной мощности и памяти.
Хотя кажется, что в среде существует одна физическая сеть хранения данных, на самом деле существует несколько физических аппаратных средств, на которых размещается доступное пространство, а технология виртуализации хранилища используется для объединения этих ресурсов вместе, с учетом термина «виртуальное хранилище». В сочетании с виртуальными машинами гипервизоры, находящиеся в физическом оборудовании, заботятся о выделении дискового пространства в сети для каждой виртуальной машины, помимо использования для выделения других общих ресурсов в среде, например, вычислительной мощности и памяти.
Таким образом, технология виртуализации позволяет создавать несколько сред из одной или нескольких физических систем. Это также позволяет вам выделять ресурсы для этих сред, чтобы они могли выполнять ваши конкретные варианты использования.
С другой стороны, облачное хранилище относится к тому, как ваши данные хранятся в виртуальных программных пулах на базе облака. Фактическое хранилище может располагаться на нескольких физических серверах в одном или нескольких центрах обработки данных, принадлежащих поставщику облачных услуг, ответственному за обеспечение доступа к вашим данным и их обслуживание. Эти центры обработки данных могут быть где угодно. Вы можете получить доступ к своим данным через службы, предоставляемые вашим провайдером, или с помощью собственного программного обеспечения, которое может быть интегрировано с интерфейсами прикладного программирования (API) провайдера. Облачное хранилище для настольных компьютеров, шлюзы облачных хранилищ и веб-системы управления контентом также могут быть доступны для доступа к вашим данным.
Эти центры обработки данных могут быть где угодно. Вы можете получить доступ к своим данным через службы, предоставляемые вашим провайдером, или с помощью собственного программного обеспечения, которое может быть интегрировано с интерфейсами прикладного программирования (API) провайдера. Облачное хранилище для настольных компьютеров, шлюзы облачных хранилищ и веб-системы управления контентом также могут быть доступны для доступа к вашим данным.
Считается, что облачные вычисления существуют, когда вы используете любую комбинацию «голого железа», виртуализации и контейнерного программного обеспечения для определения ресурсов в сети. Windows, Linux или любая операционная система (ОС), выбранная провайдером, может поддерживать облачные вычисления. Несколько общедоступных или частных облаков и даже комбинации или гибриды этих двух типов облаков могут составлять облачную среду.
Хотя виртуализация может обеспечить облачные вычисления, ее возможности ограничены по сравнению с последней. Облачные вычисления включают в себя весь спектр виртуализации и многое другое — поставщики облачных услуг используют технологии, отличные от виртуализации, чтобы адаптировать свои услуги к потребностям своих клиентов.
Облачные вычисления включают в себя весь спектр виртуализации и многое другое — поставщики облачных услуг используют технологии, отличные от виртуализации, чтобы адаптировать свои услуги к потребностям своих клиентов.
Виртуальное хранилище и периферийные вычисления
Говорят, что сайты, находящиеся за пределами досягаемости вашего традиционного центра обработки данных или облачной инфраструктуры, находятся на границе вашей сети. Таким образом, граничные вычисления относятся к децентрализованному типу ИТ-инфраструктуры, где обработка выполняется рядом с этими площадками, а не в центре обработки данных или в облаке. Филиалы и удаленные офисы, производственные предприятия и розничные магазины — вот некоторые примеры сред, которые могут извлечь выгоду из периферийных вычислений.
Традиционная ИТ-инфраструктура требует значительных инвестиций в пропускную способность сети и физическое оборудование. В облаке ответственность за управление инфраструктурой, включая обслуживание сети и оборудования, ложится на провайдера. Тем не менее, чтобы ваши пользователи с сайтов, удаленных от ваших серверов, могли находиться в центре обработки данных и в облаке, вы должны убедиться, что инфраструктура поставщика облачных услуг имеет достаточную пропускную способность и оборудование.
Тем не менее, чтобы ваши пользователи с сайтов, удаленных от ваших серверов, могли находиться в центре обработки данных и в облаке, вы должны убедиться, что инфраструктура поставщика облачных услуг имеет достаточную пропускную способность и оборудование.
В периферийных вычислениях инфраструктура строится вокруг серверов, расположенных на границе вашей сети. Вместо того, чтобы передавать данные в традиционные центры обработки данных или облако, вычислительные ресурсы и ресурсы хранения подключаются к серверам, что позволяет ускорить обработку, поскольку данные не должны перемещаться далеко от ваших пользователей.
Используя программное обеспечение, установленное на пограничных серверах, вместе с технологией виртуализации и программно-определяемым хранилищем, пограничные вычисления обеспечивают высокую доступность за счет общего хранилища, такого как виртуальные сети хранения данных. Таким образом, виртуальное хранилище необходимо для периферийных вычислений, поскольку оно обеспечивает производительность пользователей и удовлетворенность клиентов.
Кроме того, для периферийных вычислений требуется более дешевое оборудование, чем обычно используемое в центрах обработки данных, которое должно соответствовать минимальным стандартам для снижения задержек, а также требовать адекватной пропускной способности. Это также позволяет сайтам работать независимо друг от друга, что позволяет вашей организации продолжать работу, даже когда в вашем центре обработки данных происходит авария или ваше облако выходит из строя.
Виртуальные решения для хранения данных с Parallels RAS
Parallels RAS — это решение для удаленной работы, которое обеспечивает безопасный доступ к виртуальным рабочим столам и приложениям с любого конечного устройства. Облегченный клиент Parallels, поставляемый с платформой, поддерживает устройства под управлением Windows, macOS, Linux, Android, iOS/iPadOS и Chrome OS, а также любой совместимый браузер HTML5.
Parallels RAS повышает безопасность данных, ограничивая доступ на основе разрешений пользователей и групп, устройств и местоположений, а также поддерживая многофакторную аутентификацию (MFA) и шифрование Федерального стандарта обработки информации (FIPS) 140-2. Его готовые к использованию возможности автоматической подготовки и автоматического масштабирования упрощают развертывание и обслуживание вашей ИТ-инфраструктуры.
Его готовые к использованию возможности автоматической подготовки и автоматического масштабирования упрощают развертывание и обслуживание вашей ИТ-инфраструктуры.
Parallels RAS предоставляет центральную консоль для управления рабочими нагрузками и ресурсами, а также различные предварительно настроенные оптимизации для виртуального рабочего стола Azure, узла сеансов удаленных рабочих столов (RDSH) и интеграции с виртуальными рабочими столами (VDI). Он совместим с Windows Server 2008 и выше и поддерживает все основные гипервизоры, включая Microsoft Hyper-V, VMware ESXi, Nutanix Acropolis (AHV) и Scale Computing HC3.
Используя шаблоны виртуальных машин, настроенные в соответствии с вашими бизнес-требованиями, вы можете мгновенно развертывать виртуальные рабочие столы и приложения в своей организации, используя любую комбинацию RDSH, VDI, гипервизоров, гиперконвергентных систем, общедоступных и частных облаков. Эта всесторонняя поддержка делает Parallels RAS идеальным решением для использования в виртуальных центрах обработки данных, что позволяет использовать многие преимущества виртуализации в традиционных центрах обработки данных за счет виртуальных вычислений, хранения и сетевых кластеров.
Ваш комментарий будет первым