9 способов найти удаленный сайт или страницу
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.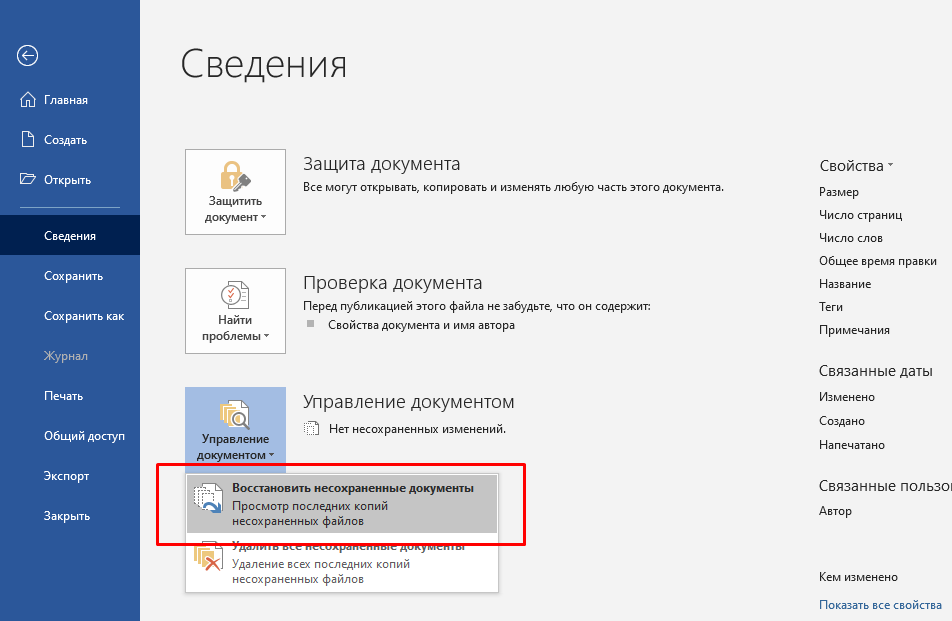
Где https://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета
Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет
К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт».
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari.
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:
Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
О других методах поиска читайте в статье 12 способов найти владельца сайта и узнать про него все.
А о сборе информации про людей читайте в статьях 9 сервисов для поиска информации в соцсетях и 15 фишек для сбора информации о человеке в интернете.
🤓 Хочешь больше? Подпишись на наш Telegram. … и не забывай читать наш Facebook и Twitter 🍒 В закладки iPhones.ru Сервисы и трюки, с которыми найдётся ВСЁ.
- До ←
СкидOS #270
- После →
Разыграй друзей при помощи браузера
Как открыть сохраненную копию сайта, посмотреть с телефона или ПК (метод 2020 года)
В мире современных технологий мы привыкли, что у нас всегда под рукой Интернет, а вместе с ним и миллионы сайтов с различным контентом. Однако у пользователей нередко возникают ситуации, когда доступ к информации на сайте пропадает. Это происходит по нескольким причинам, при этом такая ситуация вовсе не означает, что данные утрачены безвозвратно.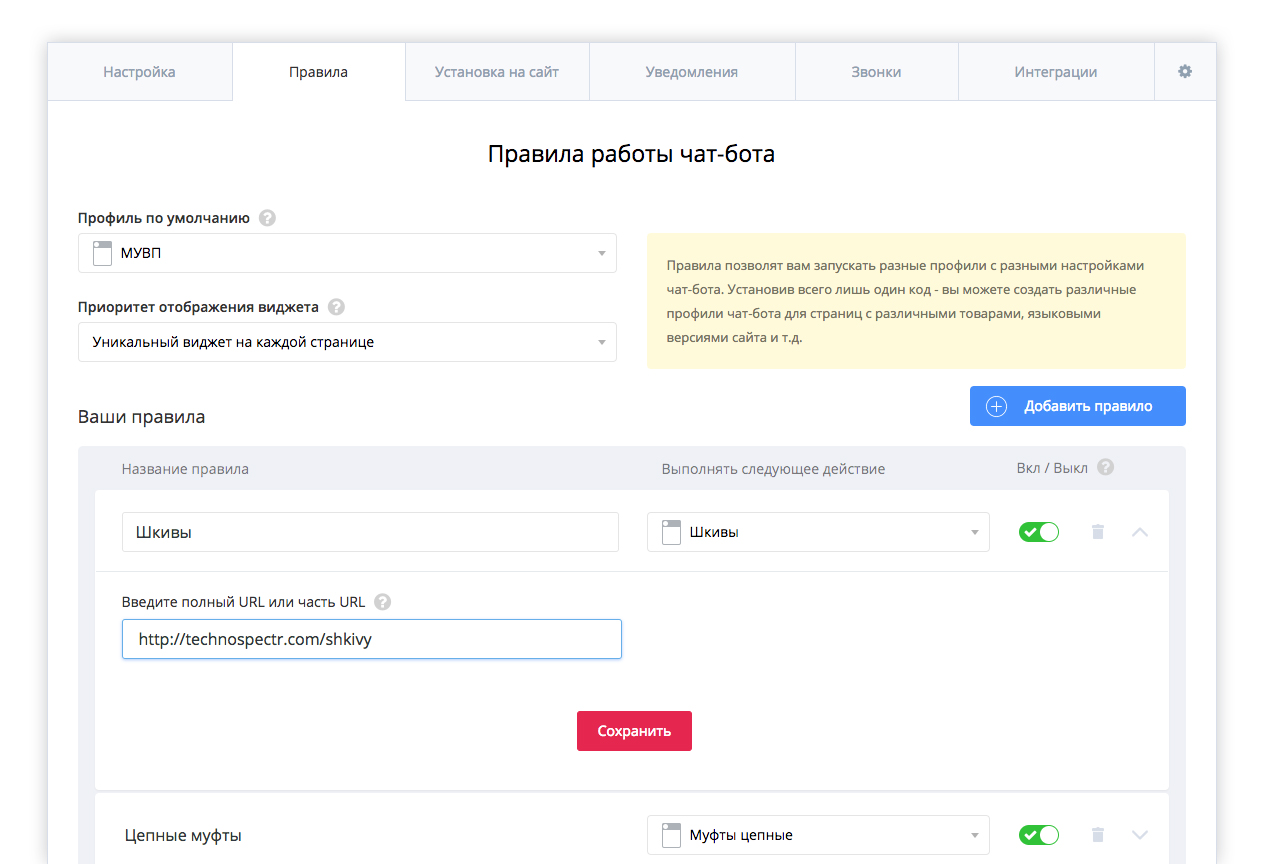 Найти удаленные статьи или страницы сайта помогает кеш Google.
Найти удаленные статьи или страницы сайта помогает кеш Google.
Что такое кеш сайта и зачем он нужен
Поисковая система Google оснащена так называемыми ботами, которые регулярно посещают страницы сайтов и сохраняют их в памяти поисковика. Это и есть кеш, в котором сохраненная копия сайта остается даже в том случае, если сам ресурс был удален. Следует отметить, что боты «гуляют» по Интернету достаточно активно, поэтому информация в кеше, как правило, является актуальной. Однако есть два важных нюанса:
- Чем чаще на сайте появляются новые публикации, тем чаще его посещает бот, а значит, данные будут максимально свежими.
- Нередко случается так, что после удаления статьи с сайта по этой ссылке пользователь видит сообщение об ошибке.
 Однако бот успел посетить эту пустую страницу и сохранил ее в кеш, удалив прошлую актуальную версию.
Однако бот успел посетить эту пустую страницу и сохранил ее в кеш, удалив прошлую актуальную версию.
 Однако бот успел посетить эту пустую страницу и сохранил ее в кеш, удалив прошлую актуальную версию.
Однако бот успел посетить эту пустую страницу и сохранил ее в кеш, удалив прошлую актуальную версию.Разобравшись с особенностями работы кеша Google, стоит понять, для чего поисковая система хранит в памяти старые версии сайтов. Эксперты приводят несколько серьезных аргументов:
- Страница с материалами была удалена с сайта, а вам срочно нужны именно эти данные.
- Часть информации в нужной публикации была изменена на другие материалы.
- Владелец сайта удалил его или закрыл доступ для пользователей.
- Сайт слишком перегружен, в результате чего страницы загружаются долго.
- На сайт обрушилась ддос-атака, поэтому данные оказались временно заблокированы.
- Программисты проводят технические работы, в результате чего открыть нужную страницу невозможно.
Очевидно, что главная причина поиска сохраненных страниц заключается в утерянной информации и попытке восстановить ее с помощью функционала Google. И если с причинами и особенностями кеширования все понятно, можно переходить к главному вопросу: как посмотреть старую версию сайта и сохранить нужные сведения.
Как посмотреть кеш в Google
Существует несколько способов найти удаленные страницы сайтов. Самый простой – воспользоваться стандартным поиском Google и придерживаться следующего алгоритма действий:
- В поисковой строке вводим адрес сайта, с которого нужно восстановить информацию.
- В выдаче находим нужную ссылку, а под ней – маленькую стрелку зеленого цвета.
- При нажатии на стрелку появляется меню, в котором нужно выбрать графу «Сохраненная копия».
- Система автоматически переходит в архив сайтов и открывает нужные страницы.
Если для работы в Интернете вы используете Google Chrome, вам подойдет еще один простой способ, как посмотреть удаленную страницу в кеше. Для этого достаточно перед адресом сайта ввести слово «cache» и поставить двоеточие. На примере сайта htmlbook.ru это будет выглядеть так: «cache:htmlbook.ru» и далее адрес конкретной страницы, которая вам нужна.
Если по каким-то причинам перечисленные методы не подошли, найти кеш страницы можно и таким способом:
- Открываем новую вкладку в браузере и в адресную строку вставляем текст «webcache. googleusercontent.com/search?q=cache:» (кавычки убираем).
- После двоеточия без пробела вставляем адрес сайта или страницы, которую хотим найти в памяти Google.
- Переходим по ссылке и получаем доступ к последней сохраненной версии.
 googleusercontent.com/search?q=cache:» (кавычки убираем).
googleusercontent.com/search?q=cache:» (кавычки убираем).Обратите внимание! Кеш сайта – это преимущественно текстовая информация. Если на странице были размещены изображения, которые владелец удалил, восстановить их может быть не так просто, как непосредственно статью.
Google Cache Browser
У всех перечисленных способов, как посмотреть кеш в Google, есть один существенный недостаток. С их помощью можно увидеть только одну страницу сайта, после чего придется скопировать ссылку на нужный раздел и проделать всю процедуру заново. Чтобы ускорить этот процесс и получить возможность «бродить» по всему сайту, предлагаем воспользоваться сервисом http://cache.nevkontakte.com/#! и изучить все сохраненные данные в один клик.
Чтобы воспользоваться сервисом, достаточно перейти по ссылке и на главной странице ввести адрес сайта, к которому нужен доступ.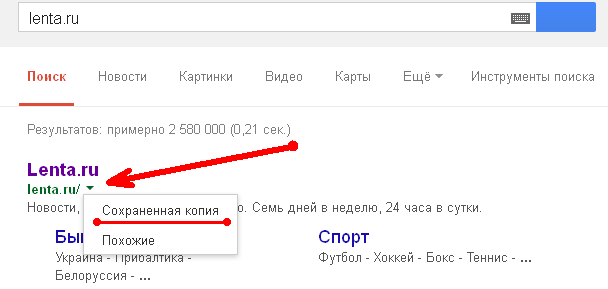 Система автоматически находит сохраненную информацию и предоставляет пользователю.
Система автоматически находит сохраненную информацию и предоставляет пользователю.
Выходим за рамки Google
Понятно, что сохранением страниц и сайтов в кеше занимается не только поисковая система Google. У пользователей есть еще несколько вариантов, как можно найти удаленную статью или другие данные с сайта:
- Кеш Яндекса. Система работает по такому же принципу, однако сохраненные версии могут отличаться от тех, которые хранит Google. Чтобы открыть кеш Яндекса, необходимо ввести в поиске адрес сайта и перейти к сохраненной копии с помощью зеленой стрелочки (точно так же, как и при работе с Google).
- Специализированный поисковик CachedView.com, который не ограничивается Google, а предлагает пользователям доступ к Всемирному архиву Интернета. Работает по принципу Nevkontakte.com.
- Еще один интересный сервис, на который стоит обратить внимание, находится по адресу archive.is. Его главная функция заключается в том, чтобы пользователь мог самостоятельно сохранять нужные страницы сайта. При этом сервис не требует регистрации и является бесплатным. Дополнительное преимущество архива – возможность искать данные среди страниц, которые сохранили другие пользователи.
 При этом сервис не требует регистрации и является бесплатным. Дополнительное преимущество архива – возможность искать данные среди страниц, которые сохранили другие пользователи.
При этом сервис не требует регистрации и является бесплатным. Дополнительное преимущество архива – возможность искать данные среди страниц, которые сохранили другие пользователи.Таким образом, даже удаленные из Интернета материалы можно найти и восстановить. Какой способ для этого выбрать? Рекомендуем не останавливаться на одном методе, а попробовать несколько, чтобы наверняка найти нужную страницу или сайт.
Посмотреть сохраненные страницы сайта
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кеша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:http://www.iphones.ru/
Где http://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета
Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет
К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive. is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
Что делать, если вообще ничего не помогло
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache. googleusercontent.com/search?q=cache:http://www.iphones.ru/
googleusercontent.com/search?q=cache:http://www.iphones.ru/
Где http://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета
Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет
К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:
Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
(4.87 из 5, оценили: 15)
Первые дни Pikabu.ru
Существует настоящая, реальная машина времени, в которой можно ненадолго вернуться в прошлое и увидеть, например, как выглядел тот или иной сайт несколько лет назад. Думаете, никому не нужны копии сайтов многолетней давности? Ошибаетесь! Для очень многих людей сервис по архивированию информации весьма полезен.
Во-первых, это просто интересно! Из чистого любопытства и от избытка свободного времени можно посмотреть, как выглядел любимый, популярный ресурс на заре его рождения.
Во-вторых, далеко не все веб-мастера ведут свои архивы. Знать место, где можно найти информацию, которая была на сайте в какой-то момент, а потом пропала, не просто полезно, а очень важно.
В-третьих, само по себе сравнение является важнейшим методом анализа, который позволяет оценить ход и результаты нашей деятельности. Кстати, при проведении анализа веб-ресурса очень эффективно использовать ряд методов сравнения.
Кстати, при проведении анализа веб-ресурса очень эффективно использовать ряд методов сравнения.
Поэтому наличие уникальнейшего архива веб-страниц интернета позволяет нам получить доступ к огромному количеству аудио-, видео- и текстовых материалов. По утверждению разработчиков, «интернет-архив» хранит больше материалов, чем любая библиотека мира. Мы попали в правильное место!
Что нужно, чтобы найти копии сайтов интернета?
Для того, чтобы отправиться в прошлое, нужно перейти на сайт https://web-beta.archive.org/ и воспользоваться поисковой строкой.
Простой поиск в архиве сохраненных сайтов выдает нам ссылки на все сохраненные копии запрашиваемой страницы.
Из этого скриншота видно, что сайт http://pikabu.ru был создан в 2009 году. Переключаясь на нужный нам год, можно увидеть даты, выделенные кружочками, это и есть даты сохранения копии сайта. Например, в 2009 году, пока можно будет увидеть только две копии от 28 и 29 июня.
Конечно, это потрясающий ресурс! Ведь здесь индексируются и архивируются все сайты интернета! Это не только скриншоты… Имея в руках такой инструмент, можно восстановить массу потерянной со временем информации.
Надо заметить, что, безусловно все восстановить однозначно не получится, так как если на страницах сайта используются элементы Java Script, или скрипты или графика взяты со стороннего сервера, то на восстановление такой информации рассчитывать не придется. Поэтому к сохранению данных своего сайта нужно относиться с особенным вниманием, несмотря ни на что.
Старые версии сайтов вебархив
Что такое веб-архив
21 октября 2017 года. Опубликовано в разделах: Азбука терминов. 30445
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA
Это настоящая библиотека, в которой каждый желающий может открыть интересующий его веб-ресурс, и посмотреть на его содержимое, на ту дату, в которую вебархив посетил сайт и сохранил копию.
Знакомство с archive org или как Валерий нашел старые тексты из веб-архива
В 2010-м году, Валерий создал сайт, в котором он писал статьи про интернет-маркетинг.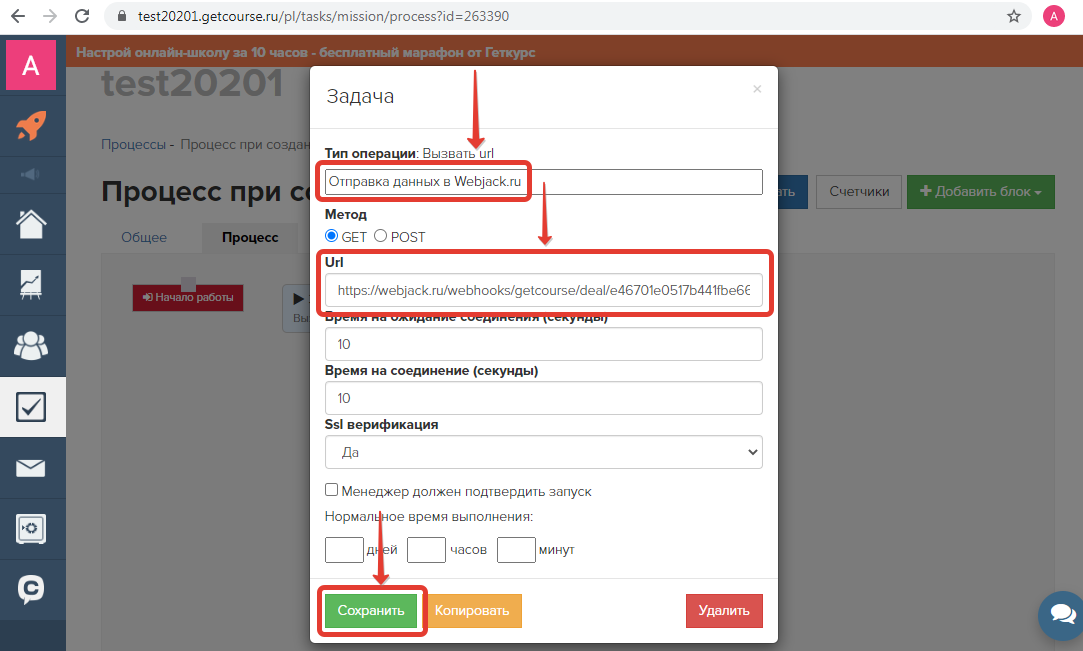 Одну из них он написал о рекламе в Гугл (AdWords) в виде краткого конспекта. Спустя несколько лет ему понадобилась эта информация. Но страница с текстами, некоторое время назад, была им ошибочно удалена. С кем не бывает.
Одну из них он написал о рекламе в Гугл (AdWords) в виде краткого конспекта. Спустя несколько лет ему понадобилась эта информация. Но страница с текстами, некоторое время назад, была им ошибочно удалена. С кем не бывает.
Однако, Валерий знал, как выйти из ситуации. Он уверенно открыл сервис веб-архива, и в поисковой строке ввел нужный ему адрес. Через несколько мгновений, он уже читал нужный ему материал и еще чуть позже восстановил тексты на своем сайте.
История создания Internet Archive
В 1996 году Брюстер Кайл, американский программист, создал Архив Интернета, где он начал собирать копии веб-сайтов, со всей находящейся в них информацией. Это были полностью сохраненные в реальном виде страницы, как если бы вы открыли необходимый сайт в браузере.
Данными веб-архива может воспользоваться каждый желающий совершенно бесплатно. Создавая его, у Брюстера Кайла была основная цель – сохранить культурно-исторические ценности интернет-пространства и создать обширную электронную библиотеку.
В 2001 году был создан основной сервис Internet Archive Wayback Machine, который и сегодня можно найти по адресу https://archive.org . Именно здесь находятся копии всех веб-сервисов в свободном доступе для просмотра.
Чтобы не ограничиваться коллекцией сайтов, в 1999 году начали архивировать тексты, изображения, звукозаписи, видео и программные обеспечения.
В марте 2010 года, на ежегодной премии Free Software Awards, Архив Интернета был удостоен звания победителя в номинации Project of Social Benefit.
С каждым годом библиотека разрастается, и уже в августе 2016 года объем Webarchive составил 502 миллиарда копий веб-страниц. Все они хранятся на очень больших серверах в Сан-Франциско, Новой Александрии и Амстердаме.
Все про archive.org: как пользоваться сервисом и как достать сайт из веб-архива
Брюстер Кайл создал сервис Internet Archive Wayback Machine, без которого невозможно представить работу современного интернет-маркетинга. Посмотреть историю любого портала, увидеть, как выглядели определенные страницы раньше, восстановить свой старый веб-ресурс или найти нужный и интересный контент — все это можно сделать с помощью Webarchive.
Как на archive.org посмотреть историю сайта
Благодаря веб-сканеру, в библиотеке веб-архива, хранится большая часть интернет-площадок со всеми их страницами. Также, он сохраняет все его изменения. Таким образом, можно просмотреть историю любого веб-ресурса, даже если его уже давно не существует.
Для этого, необходимо зайти на https://web.archive.org/ и в поисковой строке ввести адрес веб-ресурса.
После, некоторого времени, веб-архив выдаст календарь с датами изменений данной страницы и информацию о его создании и количестве изменений за весь период.
Согласно полученной информации, можно узнать, что главная страница нашего сайта была впервые найдена сервисом 24 мая 2014 года. И, с этого времени, по сегодняшний день, ее копия сохранялась 38 раз. Даты изменений на странице отмечены на календаре голубым цветом. Для того, чтобы посмотреть историю изменений и увидеть как выглядел определенный участок веб-ресурса в интересующий вас день, следует выбрать нужный период в ленте с предыдущими годами, и дату в календаре из тех, что предлагает сервис.
Через мгновение, веб-архив откроет запрашиваемую версию на своей платформе, где можно увидеть как выглядел наш сайт в самом первоначальном виде.
Далее, с помощью календаря со стрелками, в самом верху экрана, можно перелистывать страницы, по хронологии их изменений, чтобы отследить, как изменялся внешний вид и их содержание.
Таким образом, можно нырнуть в прошлое и увидеть все его перемены, которые с ним происходили за все время его существования.
Почему вы можете не узнать на Webarchive, как выглядел сайт раньше
Случается такое, что веб-площадка не может быть найден с помощью сервиса Internet Archive Wayback Machine. И происходит это по нескольким причинам:
- правообладатель решил удалить все копии;
- веб-ресурс закрыли, согласно закону о защите интеллектуальной собственности;
- в корневую директорию интернет-площадки, внесен запрет через файл robots.txt
Для того, чтобы сайт в любой момент был в веб-архиве, рекомендуется принимать меры предосторожности и самостоятельно сохранять его в библиотеке Webarchive. Для этого в разделе Save Page Now введите адрес веб-ресурса, который нужно заархивировать, нажмите кнопку Save Page.
Для этого в разделе Save Page Now введите адрес веб-ресурса, который нужно заархивировать, нажмите кнопку Save Page.
Таким образом, для безопасности и сохранности всей информации, необходимо такую процедуру повторять с каждым изменением. Это даст 100% гарантию сохранения ваших страниц на долгое время.
Как недействующий сайт восстановить из веб-архива
Бывают разные ситуации, когда браузер выдает, что такого-то веб-сервиса больше нет. Но данные нужно извлечь. Поможет Webarchive.
И для этого существует два варианта. Первый подходит для старых площадок небольшого размера и хорошо проиндексированных. Просто извлеките данные нужной версии. Далее просматривается код страницы и дошлифовываются вручную ссылки. Процесс несколько трудозатратный по времени и действиям. Поэтому существует другой, более оптимальный способ.
Второй вариант идеален для тех, кто хочет сэкономить время и решить вопрос скачивания, максимально быстро и легко. Для этого нужно открыть сервис восстановления сайта из Webarchive – RoboTools. Ввести доменное имя интересующего портала и указать дату сохраненной его версии. Через некоторое время, задача будет выполнена в полном объеме, с наполнением всех страниц.
Ввести доменное имя интересующего портала и указать дату сохраненной его версии. Через некоторое время, задача будет выполнена в полном объеме, с наполнением всех страниц.
Как найти контент из веб-архива
Webarchive является замечательным источником для наполнения полноценными текстами веб-ресурсов. Есть множество площадок, которые по ряду причин прекратили свое существование, но содержат в себе полезную и нужную информацию. Которая не попадает в индексы поисковых систем, и по сути есть неповторяющейся.
Так, существует свободные домены, которые хранят много интересного материала. Все что нужно, это найти подходящее содержание, и проверить его уникальность. Это очень выгодно, как финансово – ведь не нужно будет оплачивать работу авторов, так и по времени – ведь весь контент уже написан.
Как сделать так, чтобы сайт не попал в библиотеку веб-архива
Случаются такие ситуации, когда владелец интернет-площадки дорожит информацией, размещенной на его портале, и он не хочет, чтобы она стала доступной широкому кругу. В таких ситуациях есть один простой выход – в файле robots.txt, прописать запретную директиву для Webarchive. После этого изменения в настройках, веб-машина больше не будет создавать копии такого веб-ресурса.
В таких ситуациях есть один простой выход – в файле robots.txt, прописать запретную директиву для Webarchive. После этого изменения в настройках, веб-машина больше не будет создавать копии такого веб-ресурса.
– Только качественный трафик из Яндекса и Google
– Понятная отчетность о работе и о планах работ
– Полная прозрачность работ
Как скачать сайт из вебархива
Обращаю ваше внимание на то, что все операции производятся в операционной системе Ubuntu (Linux). Как все это провернуть на Windows я не знаю. Если хотите все проделать сами, а у вас Windows, то можете поставить VirtualBox, а на него установить ту же Ubuntu. И приготовьтесь к тому, что сайт будет качаться сутки или даже двое. Однажды один сайт у меня скачивался трое суток.
По сути, на текущий момент мы имеем два сервиса с архивом сайтов. Это российский сервис web-archiv.ru и зарубежный archive.org. Я скачивал сайты с обоих сервисов. Только вот в случае с первым, тут не все так просто. Для этого был написан скрипт, который требует доработки, но поскольку мне он более не требуется, соответственно я не стал его дорабатывать. В любом случае его вполне достаточно на то, что бы скачать страницы сайта, но приготовьтесь к ошибкам, поскольку очень велика вероятность появления непредусмотренных особенностей того или иного сайта.
Для этого был написан скрипт, который требует доработки, но поскольку мне он более не требуется, соответственно я не стал его дорабатывать. В любом случае его вполне достаточно на то, что бы скачать страницы сайта, но приготовьтесь к ошибкам, поскольку очень велика вероятность появления непредусмотренных особенностей того или иного сайта.
Первым делом я расскажу о том, как скачать сайт с web.archive.org, поскольку это самый простой способ. Вторым способом имеет смысл воспользоваться если по каким-то причинам копия сайта на web.archive.org окажется неполной или её не окажется совсем. Но скорее всего вам вполне хватит первого способа.
Принцип работы веб-архива
Прежде чем пытаться восстанавливать сайт из веб-архива, необходимо понять принцип его работы, который является не совсем очевидным. С особенностями работы сталкиваешься только тогда, когда скачаешь архив сайта. Вы наверняка замечали, попадая на тот или иной сайт, сообщение о том, что домен не продлен или хостинг не оплачен. Поскольку бот, который обходит сайты и скачивает страницы, не понимает что подобная страница не является страницей сайта, он скачивает её как новую версию главной страницы сайта.
Поскольку бот, который обходит сайты и скачивает страницы, не понимает что подобная страница не является страницей сайта, он скачивает её как новую версию главной страницы сайта.
Таким образом получается если мы скачаем архив сайта, то вместо главной страницы будем иметь сообщение регистратора или хостера о том, что сайт не работает. Чтобы этого избежать, нам необходимо изучить архив сайта. Для этого потребуется просмотреть все копии и выбрать одну или несколько где на главной странице страница сайта, а не заглушка регистратора или хостера.
Качаем сайт с web.archive.org
Процесс восстановления сайта из веб-архива я покажу на примере сайта 1mds.ru. Я не знаю что это за сайт, я всего лишь знаю что у него в архиве много страниц, а это значит что сайт не только существовал, но с ним работали.
Для того, что бы открыть архив нужного сайта, нам необходимо пройти по такой вот ссылке:
На 24 ноября 2018 года, при открытии этой ссылки я обнаружил вот такую картину:
Как видите на главной зафиксировались результаты экспериментов с программной частью. Если мы просто скачаем сайт как есть, то в качестве главной будет именно эта страница. нам необходимо избежать попадания в архив таких страниц. Как это сделать? Довольно просто, но для начала необходимо определить когда последний раз в архив добавлялась главная страница сайта. Для этого нам необходимо воспользоваться навигацией по архиву сайта, которая расположена вверху справа:
Если мы просто скачаем сайт как есть, то в качестве главной будет именно эта страница. нам необходимо избежать попадания в архив таких страниц. Как это сделать? Довольно просто, но для начала необходимо определить когда последний раз в архив добавлялась главная страница сайта. Для этого нам необходимо воспользоваться навигацией по архиву сайта, которая расположена вверху справа:
Кликаем левую стрелку ибо правая все равно не активна, и кликаем до тех пор, пока не увидим главную страницу сайта. Возможно кликать придется много, бывает домены попадаются с весьма богатым прошлым. Например сайт, на примере которого я демонстрирую работу с архивом, не является исключением.
Вот мы можем видеть что 2 мая 2018-го бот обнаружил сообщение о том, что домен направлен на другой сайт:
Классика жанра, регистрируешь домен и направляешь его на существующий дабы не тратить лимит тарифа на количество сайтов.
А до этого, 30 марта, там был вообще блог про шитье-вязание.
Долистал я до 23 октября 2017-го и вижу уже другое содержимое:
Тут мы видим уже материалы связанные с воспитанием ребенка. Листаем дальше, там вообще попадается период когда на домене была всего одна страница с рекламой:
А вот с 25 апреля 2011 по 10 сентября 2013-го там был сайт связанный с рекламой. В общем нам нужно определиться какой из этих периодов мы хотим восстановить. К примеру я хочу восстановить блог про шитье-вязание. Мне необходимо найти дату его появления и дату когда этот блог был замечен там последний раз.
Я нашел последнюю дату, когда блог был на домене и скопировал ссылку из адресной строки:
- http://web.archive.org/web/ 20180330034350 /http://1mds.ru:80/
Мне нужны цифры после web/, я их выделил красным цветом. Это временная метка, когда была сделана копия. Теперь мне нужно найти первую копию блога и также скопировать из URL временную метку. Теперь у нас есть две метки с которой и до которой нам нужна копия сайта.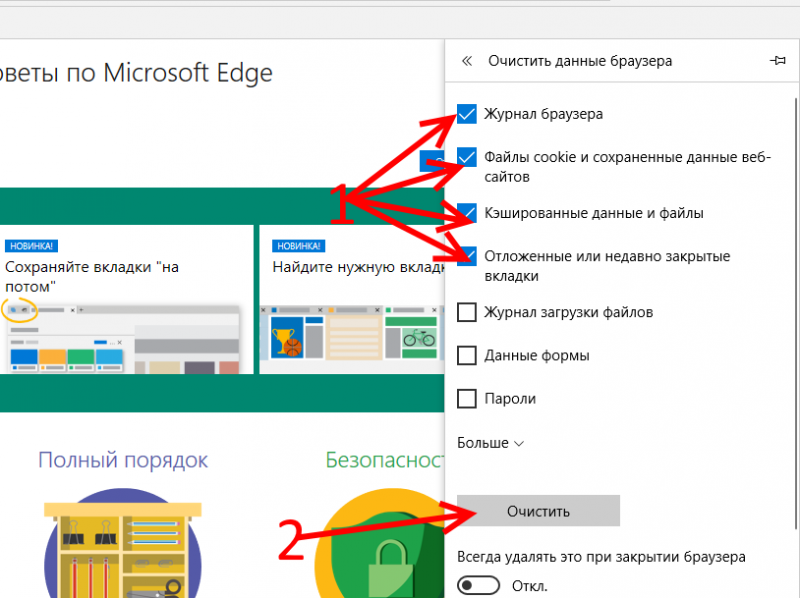 Осталось дело за малым, установить утилиту, которая поможет нам скачать сайт. Для этого потребуется выполнить пару команд.
Осталось дело за малым, установить утилиту, которая поможет нам скачать сайт. Для этого потребуется выполнить пару команд.
- sudo apt install ruby
- sudo gem install wayback_machine_downloader
После чего останется запустить скачивание сайта. Делается это вот такой командой:
- wayback_machine_downloader -f20171223224600 -t20180330034350 1mds.ru
Таким образом мы скачаем архив с 23/12/2017 по 30/03/2018. Файлы сайта будут сохранены в домашней директории в папке «websites/1mds.ru». Теперь остается закинуть файлы на хостинг и радоваться результату.
Качаем сайт с web-arhive.ru
Это самый геморройный вариант ибо у данного сервиса нет возможности скачать сайт как у описанного выше. Соответственно пользоваться этим вариантом есть смысл пользоваться только в случае если нужно скачать сайт, которого нет на web.archive.org. Но я сомневаюсь что такое возможно. Этим вариантом я пользовался по причине того, что не знал других вариантов,а поискать поленился.
В итоге я написал скрипт, который позволяет скачать архив сайта с web-arhive.ru. Но велика вероятность того, что это будет сопровождаться ошибками, поскольку скрипт сыроват и был заточен под скачивание определенного сайта. Но на всякий случай я выложу этот скрипт.
Пользоваться им довольно просто. Для запуска скачивания необходимо запустить этот скрипт все в той же командной строке, где в качестве параметра вставить ссылку на копию сайта. Должно получиться что-то типа такого:
- php get_archive.php “http://web-arhive.ru/view2?time=20160320163021&url=http%3A%2F%2Fremontistroitelstvo.ru%2F”
Заходим на сайт web-arhive.ru, в строке указываем домен и жмем кнопку «Найти». Ниже должны появится года и месяцы в которых есть копии.
Обратите внимание на то, что слева и справа от годов и месяцев есть стрелки, кликая которые можно листать колонки с годами и месяцами.
Остается найти дату с нужной копией, скопировать ссылку из адресной строки и отдать её скрипту.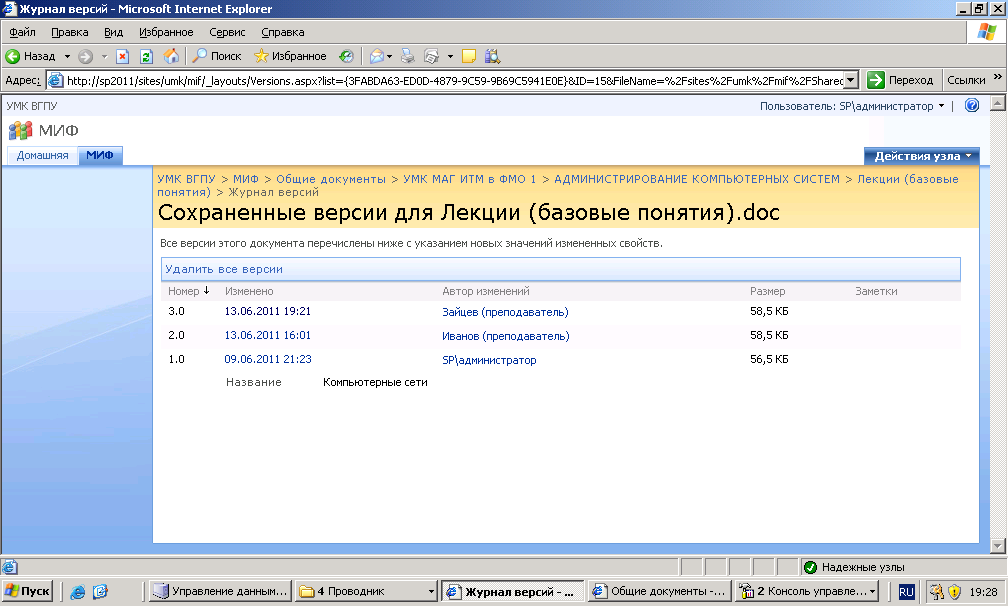 Не забывает помещать ссылку в кавычки во избежание ошибок из-за наличия спецсимволов.
Не забывает помещать ссылку в кавычки во избежание ошибок из-за наличия спецсимволов.
Мало того, что само скачивание сопровождается ошибками, более того, в выбранной копии сайта может не быть каких-то страниц и придется шерстить все копии на предмет наличия той или иной страницы.
Помощь в скачивании сайта из веб-архива
Если у вас вдруг возникли трудности в том, что бы скачать сайт, можете воспользоваться моими услугами. Буду рад помочь. Для начала заполните и отправьте форму ниже. После этого я с вами свяжусь и мы все обсудим.
Как посмотреть удаленную страницу ВКонтакте
Для многих пользователей, ВК – это хранилище личной информации. Фотографии с памятными моментами, видео с прогулки вашей компании, члены которой уже давно разъехались по разным городам и странам. Вы хранили это в социальной сети, а вашу страницу заблокировали? А может друг удалил свой профиль с ценной информацией. Не огорчайтесь! Не все еще потеряно. Можно использовать веб архив ВКонтакте.
Существует выражение «Все, что попадает в интернет, остается там навсегда». Оно очень близко к истине, ведь даже удаленные страницы в ВК и других соц. сетях можно просмотреть. Для этой цели используется три рабочих инструмента.
Как посмотреть удаленную страницу в веб-архиве
Веб-архив – это специальный сервис, который хранит на своем сервере данные со всех страниц, которые есть в интернете. Даже, если сайт перестанет существовать, то его копия все равно останется жить в этом хранилище.
В архиве также хранятся все версии интернет страниц. С помощью календаря разрешено смотреть, как выглядел тот или иной сайт в разное время.
В веб-архиве можно найти и удаленные страницы с ВК. Для этого необходимо выполнить следующие действия.
- Зайти на сайт https://archive.org/.
- В верхнем блоке поиска ввести адрес страницы, которая вам нужна. Скопировать его из адресной строки браузера, зайдя на удаленный аккаунт ВК.
Используя интернет-архив вы, естественно, не сможете написать сообщение, также как узнать когда пользователь был в сети. Но посмотреть его последние добавленные записи и фото очень даже можно.
Но посмотреть его последние добавленные записи и фото очень даже можно.
Страница найдена
Если искомая страница сохранена на сервере веб-архива, то он выдаст вам результат в виде календарного графика. На нем будут отмечены дни, в которые вносились изменения, добавлялась или удалялась информация с профиля ВК.
Выберите дату, которая вам необходима, чтобы увидеть, как выглядела страница. Используйте стрелочки «вперед» и «назад», чтобы смотреть следующий или предыдущий день либо вернитесь на первую страницу поиска и выберите подходящее число в календаре.
Страница не найдена
Может случиться, что необходимая страница не нашлась на сайте WayBackMachine. Это не значит, что вы что-то сделали не правильно, такое часто случается. Возможно, аккаунт пользователя был закрыт от поисковиков и посторонних сайтов и поэтому не попал в архив. WayBackMachine самый популярный сайт, но он не единственный в своем роде. Попробуйте найти в Яндексе или Гугле другие веб-архиви. Искомая страница могла сохраниться на их серверах.
Искомая страница могла сохраниться на их серверах.
Попытайте удачу в поисках архивной версии профиля на этих сайтах:
Также обязательно попробуйте найти страничку на русскоязычном аналоге http://web-arhive.ru/.
Справка. Веб-архивы сохраняют всю информацию, которая попадает в интернет без разбора. Видимо по этой причине, доступ к большинству существующих сервисов заблокирован на территории России Роскомнадзором. Чтобы работать с этими сайтами, воспользуйтесь анонимайзером или прокси-сервером.
Просмотр копии страницы в поисковиках
Зная алгоритмы работы поисковых роботов, можно использовать их возможности в своих целях. Каждый созданный сайт, попадает в Яндекс и Гугл не сразу. Он размещается на специальном сервере и ждет, пока поисковик найдет его и добавит в свою базу. Такие обходы поисковые системы выполняют в среднем один раз в 14 дней. Во время этого процесса они не только добавляют в свою базу новые сайты, но удаляют неработающие. Это значит, что если страничка ВКонтакте была удалена совсем недавно, то возможно ее копия еще сохранилась на серверах поисковиков.
- Скопируйте адрес страницы, которую нужно найти, из адресной строки браузера.
- Вставьте эту ссылку в поисковую строку Яндекса или Гугла и нажмите «Поиск».
- Если страница все еще храниться в поисковике, то она будет первой в результатах выдачи. Справа от ссылки находится еле заметный треугольник. Нажмите на него.
- В открывшемся меню выберите «Сохранённая копия».
Перед вами откроется последняя версия страницы, которую сохранил Яндекс или Гугл. Сохраните фото, видео и всю прочую необходимую информацию себе на компьютер, так как совсем скоро сохраненная копия будет удалена с серверов поисковых машин.
Справка. Страница должна быть открыта для индексирования поисковиками в настройках аккаунта ВКонтакте. Если она была скрыта от них, то, соответственно, и сохраненной копии вы найти не сможете.
Кэш браузера
Если ни один из представленных ваше способов не помог вам найти нужную страницу, остается надеяться только на то, что копия уже сохранена на вашем компьютере. Большинство современных браузеров сохраняет информацию посещенных сайтов. Это необходимо для ускорения загрузки. Попробуйте открыть необходимую страницу в автономном режиме.
Большинство современных браузеров сохраняет информацию посещенных сайтов. Это необходимо для ускорения загрузки. Попробуйте открыть необходимую страницу в автономном режиме.
В браузере Mozilla Firefox это делается следующим образом:
- зайдите в меню, нажав кнопку в виде трех горизонтальных полос;
- выберите пункт «Веб-разработка»;
- в этом подменю нажмите «Работать автономно».
Когда вы перешли в автономный режим, браузер не сможет загружать никакую информацию из интернета. Он будет использовать только те данные, которые сохранил на компьютере. Введите в адресную строку адрес нужной вам страницы и нажмите «Enter». Если на компьютере есть сохраненная версия аккаунта, то браузер загрузит его. В противном случае он скажет, что страница не найдена и напомнит вам, что он работает в автономном режиме.
Важно! После проведенного эксперимента не забудьте отключить автономный режим. Если этого не сделать, браузер не сможет подключиться к интернету.
Как видите, даже из самых, казалось бы, безвыходных ситуаций можно найти выход. Если же ни один из способов вам не помог, то позвоните другу и попросите восстановить страницу. А также отправьте ему ссылку на сайт vkbaron.ru, чтобы он видел, сколько всего интересного можно делать в социальной сети Вконтакте. В случае если вы пытаетесь сохранить информацию со своей страницы, которую кому-то удалось взломать, обязательно ознакомьтесь со статьей о составлении пароля, который не сможет подобрать ни один хакер.
Как работать с WebArchive: инструкция
Интернет появился около 37 лет назад, за этот период он все время менялся — что-то совершенствовалось, что-то убиралось, а что-то наоборот появлялось. Сайты постоянно меняли оформление, контент, кнопки и т.д. Для того, чтобы отследить эти изменения в целом или же какой-то конкретной нише, просмотреть сайт конкурентов, который уже не ведется или просмотреть историю интересующего вас сайта/домена — существует Web Archive.
Что такое Web Archive
WebArchive — бесплатный сервис, так называемая машина времени, которая ориентирована исключительно на сайты. Данный сервис хранит архивные данные с историей каждого ресурса, которые включают в себя целые страницы с контентом, заголовками, ссылками, изображениями и т.д.
Отслеживание истории домена необходимо не только в целях интересного времяпровождения, но и позволит вам узнать необходимую для продвижения вашего сайта информацию, такую как:
- Возраст домена, здесь мы уже описывали зачем вам нужны эти данные;
- Тематичность домена — WebArchive позволит вам узнать, не менялась ли тематика данного домена за время его существования, а если менялась, то когда и на какую;
- Увидеть, как сайт выглядел раньше — такая информация будет полезна при покупке б/у доменов;
- Просмотреть удаленный контент на сайте;
- Проверить домен на “чистоту” перед покупкой;
- Восстановить сайт, если до этого вы не сделали резервную копию;
- Отыскать уникальный контент с ресурсов в необходимой для вас нише.
Машина времени сайтов (англ. Wayback Machine) — один из главных проектов archive.org. Данный сервис не является коммерческим и был создан в 1996 году американским программистом Брюстером Кейлом. Архив сайтов имеет четкую цель — искать и собирать копии ресурсов вместе с изображениями, ссылками и контентом для дальнейшей возможности свободного просматривания информации любыми пользователями.
База web archive собиралась на протяжении 20 лет, в ней находится 280 миллиардов страницы, 12 миллионов статей и книг, миллион картинок, а также 100 тысяч программ.
Как пользоваться WebArchive
Сервис крайне прост и удобен в использовании. Приведем пошаговую инструкцию:
1. Заходим на главную страницу сайта — https://web.archive.org/
2. Введите в поиск интересующий вас сайт или же ключевое слово в нужном вам нише и нажмите Enter(подойдет для тех, кто хочет просмотреть все сайты, которые подходят для введенного КС)
3. Появится информация о ресурсе: сколько было сделано резервных копий сайта и с какой даты хранится информация о данном сайте
4. Внизу также будет календарь с отметками по годам, вы можете выбрать интересующий вас год
Внизу также будет календарь с отметками по годам, вы можете выбрать интересующий вас год
Проверьте позиции своего сайта прямо сейчас!
После этого на календаре голубым цветом будут выделены отметки, которые указывают на создание копий, вы можете выбрать любую из этих отметок.
5. После выбора отметки вас перебросит на копию сайта в выбранную вами дату. Например, вот так выглядел ресурс Liveinternet 27 марта 2012 года
6. Также вы можете получить общие статистические данные о нужном вам проекте. Для этого под строкой ввода нужно нажать Summary of
7. Еще вы можете ознакомиться с картой сайта, для этого необходимо нажать на кнопку Site Map под строкой ввода сайта
Алгоритм действий прост, а работа с сайтом не займет более 10-ти минут.
Как исключить свой сайт из WebArchive
Если вы по определенным причинам не хотите, чтобы ваш сайт попал в веб архив, то можно прописать запретную директиву в robots. txt вашего сайта, она должна выглядеть так:
txt вашего сайта, она должна выглядеть так:
После изменений в robots.txt машина времени перестанет делать резервные копии на ваш сайт, а уже имеющиеся сохранения будут удалены. Однако не забывайте, что данные изменения работают только тогда, когда есть доступ к robots.txt вашего сайта и если вы не будете продлевать использование вашего домена, то все изменения будут аннулированы и ваш сайт снова появится на WebArchive для просмотра всех желающих.
Похожие статьи
Руководство по созданию и внедрению микроразметки для вашего сайта
Как использовать микроразметку, чтобы выделить свой сайт в результате поиска и пользователи чаще переходили на него. Самый действенный метод достижения этой цели – работа со структурированными данными. В этой статье мы постараемся разобраться, что же такое структурированные данные и как их можно внедрить на свой сайт.
Микроразметка Schema.org: как использовать для SEO-продвижения
Schema.org — это стандарт семантической разметки (микроразметки) данных на сайтах в сети Интернет. В этой статье мы рассмотрим, что из себя представляет микроразметка, как она позволяет передавать поисковикам основную информацию со страницы, а также в чем её польза для SEO-оптимизации.
В этой статье мы рассмотрим, что из себя представляет микроразметка, как она позволяет передавать поисковикам основную информацию со страницы, а также в чем её польза для SEO-оптимизации.
12 уникальных SEO-инструментов для эффективных заголовков
Существует огромное количество инструментов, которые помогут вам создать идеальное название страницы. Выбор зависит только от ваших целей и предпочитаемых методов.
Программа для восстановления сайтов из
вебархива.WebArchive Downloader 6.0 – профессиональное программное обеспечение для скачивания сайта и страниц из интернет архива web.archive.org.
Основные преимущества программы:
- Сохраняет все файлы — стили CSS, скрипты, изображения, страницы
- Создает внутреннюю перелинковку страниц сайта
- Возможны два вида внутренних ссылок: файловые и доменные
- Удаляет из текста страниц всю служебную информацию
- Восстанавливать сайт из вебархива на конкретную дату
- Поддерживает три вида кодировки страниц
- Автоматический процесс закачки контента сайта
- Сохраняет полную навигацию по сайту
Применяя WebArchive Downloader 6.
 0 вы выбираете:
0 вы выбираете:Экономию
денег
Не нужно платить каждый раз за скачивание сайта из web архива. Достаточно один раз просто купить программу.
Автоматизацию
процесса
WebArchive Downloader 6.0 автоматизирует процесс сохранения страниц сайта, изображений и прочего контента.
Больше
времени
Ручной метод сохранения страниц из вебархива очень нудный и занимает много времени. WebArchive Downloader делает это пока вы отдыхаете.
Готовый
сайт
Скачанный сайт, при нормальном его качестве, практически сразу можно размещать на хостинг.
Уникальный
контент
Найдите брошенный домен и получите уникальные статьи и материал для своего сайта.
Сохраненная копия страницы в Яндексе: что это, как посмотреть
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем
Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Сохраненная копия в Яндексе — это версия страницы, которая занесена в поисковой индекс системы Яндекс.
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA
При просмотре выдачи результатов поисковика на введенный пользователем запрос в сниппете каждого сайта можно увидеть блок с дополнительной информацией. Одним из разделов блока с дополнительной информацией является «Сохраненная копия».
Чтобы понять, что из себя представляет сохраненная копия Яндекса, разберем простую аналогию. Представьте, что вы написали доклад или сочинение. Вы сдали работу, отправили ее на конкурс, но перед этим успели скопировать. Затем вам нужно еще раз сделать эту работу уже для другого конкурса . Чтобы не писать все заново, не восстанавливать в памяти все детали, вы достаете сохраненный файл и по ней пишите новое сочинение. Сохраненная страница Яндекса выполняет функцию данной копии. С ее помощью можно просмотреть сайт, если по тем или иным причинам нет доступа к интернет-ресурсу.
Затем вам нужно еще раз сделать эту работу уже для другого конкурса . Чтобы не писать все заново, не восстанавливать в памяти все детали, вы достаете сохраненный файл и по ней пишите новое сочинение. Сохраненная страница Яндекса выполняет функцию данной копии. С ее помощью можно просмотреть сайт, если по тем или иным причинам нет доступа к интернет-ресурсу.
Для чего нужна сохраненная копия страницы в Яндексе
Прежде всего, отметим, что сохраненная копия в поисковой системе Яндекс — это важный инструмент SEO оптимизатора. С ее помощью можно увидеть, какая версия документа уже проиндексирована роботами поисковой системы и участвует в ранжировании, а какие страницы еще не прошли данный процесс. Таким образом, наличие сохраненной страницы в Яндексе — индикатор успешно пройденной индексации.
- В ходе работы с интернет-ресурсами могут возникнуть самые различные ситуации. В частности на сайтах периодически осуществляются технические работы: внесение корректировок в дизайн/изменение шаблона /редактирование или удаление текстовых материалов. В ходе данных работ легко можно допустить ошибку, которая ведет к негативным последствиям: исчезновение дизайна/текста/другого элемента, изменение шаблона не по плану и так далее. Наверняка, каждый разработчик сайтов имел такой печальный опыт. Если есть возможность бэкапа или подключен качественный хостинг, через который можно вернуть все как было — прекрасно. Но начинающие ресурсы, как правило, не имеют такой возможности. В этом случае поможет сохраненная копия страницы в Яндекс. С ее помощью можно увидеть, как все было на момент индексации роботами и восстановить вид страницы, исправить ошибки. Но учтите, что хранение страницы в индексе не вечно, и если на нее робот зашел в период, когда она уже была в нерабочем состоянии, вы вполне можете не увидеть старой информации…
- Еще одна ситуация, когда полезна будет сохраненная копия страницы в Яндексе: в ходе работы над сайтом вы изменили текстовый материал, с целью увеличения релевантности страниц. Теперь вам нужно посмотреть, выполнено ли обновление страницы, где вы внесли изменения. Сделать это можно просмотрев сохраненную копию.
- Нередко сайты бывают недоступны, причин для этого может быть много: технические неполадки, истек срок хостинга и так далее. Чтобы в этой ситуации зайти на сайт, нужно найти сохраненную копию и просмотреть ее. Таким образом, польза сохраненных страниц Яндекса очевидна.
 В ходе данных работ легко можно допустить ошибку, которая ведет к негативным последствиям: исчезновение дизайна/текста/другого элемента, изменение шаблона не по плану и так далее. Наверняка, каждый разработчик сайтов имел такой печальный опыт. Если есть возможность бэкапа или подключен качественный хостинг, через который можно вернуть все как было — прекрасно. Но начинающие ресурсы, как правило, не имеют такой возможности. В этом случае поможет сохраненная копия страницы в Яндекс. С ее помощью можно увидеть, как все было на момент индексации роботами и восстановить вид страницы, исправить ошибки. Но учтите, что хранение страницы в индексе не вечно, и если на нее робот зашел в период, когда она уже была в нерабочем состоянии, вы вполне можете не увидеть старой информации…
В ходе данных работ легко можно допустить ошибку, которая ведет к негативным последствиям: исчезновение дизайна/текста/другого элемента, изменение шаблона не по плану и так далее. Наверняка, каждый разработчик сайтов имел такой печальный опыт. Если есть возможность бэкапа или подключен качественный хостинг, через который можно вернуть все как было — прекрасно. Но начинающие ресурсы, как правило, не имеют такой возможности. В этом случае поможет сохраненная копия страницы в Яндекс. С ее помощью можно увидеть, как все было на момент индексации роботами и восстановить вид страницы, исправить ошибки. Но учтите, что хранение страницы в индексе не вечно, и если на нее робот зашел в период, когда она уже была в нерабочем состоянии, вы вполне можете не увидеть старой информации… Сделать это можно просмотрев сохраненную копию.
Сделать это можно просмотрев сохраненную копию.Как посмотреть сохраненную копию страницы в Яндексе
Все современные поисковые системы, и Яндекс не исключение, позволяют пользователям открыть нужные веб-документы через их индекс. Это можно сделать быстро с помощью специальных сервисов или вручную. В первом случае на помощь придут сервисы: Page Promoter в Firefox, RDS bar для Хроме и другие. Однако плагины периодически могут некорректно работать и выходить из строя, поэтому владеть ручным методом тоже нужно.
Первый способ
Открываем поисковик Яндекс и в строке поиска прописываем сам адрес нужной страницы или интересующий запрос. В результатах поиска мы видим, что в сниппете каждого результата есть маленькая стрелочка. Нажимаем на стрелочку и выбираем «Сохраненная копия». После этого мы посетим сайт, его сохраненную страницу от какой-то прошедшей даты.
Нажимаем на стрелочку и выбираем «Сохраненная копия». После этого мы посетим сайт, его сохраненную страницу от какой-то прошедшей даты.
Второй способ
Способ заключается в применении специальных расширений браузера/плагинов/онлайн сервисов. Наиболее популярным сегодня является «RDS bar». Интерфейс плагина более чем простой, с его помощью можно просмотреть последние изменения страницы, когда страницу в последний раз посещал робот, следовательно и копия предоставляется за это число. Если нужная страница не прошла индексацию Яндекса, ее сохраненная копия не будет отображаться в результатах выдачи поисковика.
Почему нет сохраненной копии страницы в Яндексе
Иногда при поиске сохраненной копии страницы можно не увидеть нужного пункта при нажатии на стрелочку в сниппете. Причин тому может быть несколько:
- Первый вариант — некорректная работа ПС. Сам Яндекс признается, что не гарантирует наличие и показ таких копий для всех страниц в силу большого кол-ва причин.

2. Вторая ситуация — в коде документа находится метатег “robots” и он имеет значение «noarchive» — запрет кэширования. Чтобы избежать падения трафика, необходимо внимательно настраивать подобные вещи.
Чем может грозить отсутствие копии в Яндексе
Само по себе отсутствие копии не будет влиять как-то негативно на продвижение. А вот причины, которые привели к отсутствию могут повредить, поэтому разберитесь с ними.
Чем действительно может обернуться проблема с копиями страниц, так это затруднениями при работе с биржами ссылок.
Например, в Сеопульте сегодня есть параметр, который осуществляет контроль над тем, есть ли сохраненная копия Яндексе. Данный параметр называется NIC — No Index Cache. Он свидетельствует о том, что страница не имеет сохраненной копии. С такого ресурса не будут покупать ссылки, никому не хочется рисковать и платить за то, что может не принести пользы.
Как вы видите, сохраненная копия в Яндексе позволяет решить ряд проблем и оптимизировать использование интернет-трафика. Данные рекомендации позволят оперативно открывать и просматривать их.
Данные рекомендации позволят оперативно открывать и просматривать их.
Отсутствует сохраненная копия страницы в индексе пс. Инструмент для обновления сохраненной копии в Яндекс.Вебмастере
Что значит «Отсутствует сохранённая копия в Яндексе!» и как это влияет на сайт в целом. Во-первых, если вы продаете ссылки со своего сайта, то отсутствие страниц в кэше Яндекса негативно отразится на доходе веб-мастера.
Например, в Сеопульте есть параметр, контролирующий наличие страницы в кэше поисковой системы.
Называется он nic (no index cache) — это означает что у страницы нет «сохраненной копии».
На сегодняшний день в Сеопульте проверяется индекс Яндекса. В перспективе планируют добавить и проверку в Гугле.
Вот как это выглядит на графике. Долгое время траст был равен девяти, но потом резкое падение.
Я стал искать причину отсутствия сохраненной копии сайта в поисковом индексе. И даже написал в службу поддержки TrustLink.
Добрый день. Скажите, пожалуйста с чем может быть связано падение траста у моего блога. Параметр XT за последние два апа Яндекса снизился с 9 до 7. Одновременно и снизился доход в Трастлинк.
Здравствуйте! Этот показатель не является официальным представлением Яндекса, потому причины его паденя нам не известны
То есть уменьшение количества расставленых ссылок сеопультом с этим не связано. А по какой причине наблюдается уменьшение дохода?
При проверке часть страниц, на которых были куплены ссылки, отсутствовала в кэше Яндекса. Ссылки были сняты, потому просел доход.
А не подскажите почему страницы отсутствуют в кэше Яндекса? В индексе есть, а в кэше нет? Как-то можно повлиять на то, чтобы они оказались в кэше?
Это уже вопрос к техподдержке Яндекса, часто апдейт кэша происходит немного позже апдейта выдачи/индекса, отсюда выходит такая проблема
Да, именно так. Для достижения максимальной эффективности ссылки необходимо наличие страницы в кэше.

Потом я задал вопрос в техподдержку Яндекса.
Добрый день.
Сейчас отсутствует сохранённая копия в Яндексе. Подскажите, пожалуйста в чем причина. Блог работает на Вордпрессе.
Кроме того мой блог имел траст xt = 9. За последние два апдейта траст упал до 7. Я стараюсь улучшать свой блог, а тут два таких негативных момента. С чем это может быть связано и как можно исправить ситуацию?
Адрес сайта: //www.сайт
С уважением, Илья.
И продолжал искать причину.
Статья по теме: Как найти обратные ссылки
Оказывется, после обновления плагинов, флажок напротив значения noarchive был включен. В результате чего на каждой странице моего блога появилась строка, запрещающая кэширование страницы. Возможно по этой причине я потерял две единицы траста.
Убрав этот тег, выключив флажок в плагине Robots Meta , я убедился в его отсутвии на страницах своего блога.
Add noarchive meta tag
Prevents archive.
 org and Google from putting copies of your pages into their archive/cache.to put copies of your pages into their archive/cache.
org and Google from putting copies of your pages into their archive/cache.to put copies of your pages into their archive/cache.Будьте внимательны при настройке плагина Robots Meta для Вордпресс!
Узнав о наличии тега, запрещающега кэширование, я написал в суппорт Трастлинка.
Здоравствуйте. Я уже выяснил причину падения траста и отсутствия копии блога в кэше Яндекса. Видимо при обновлении плагинов Вордпресса на страницах присутствовал тег noarchive. Обнаружив это я немедленно убрав его и сегодня уже траст опять стал 9, поднявшись сразу на 2 единицы Зря оптимизаторы поснимали свои ссылочки.
Здравствуйте! Ожидайте восстановление закупки в ближайшее время.
И тут мне приходит ответ из службы поддержки Яндекса.
Здравствуйте!
Дело в том, что на момент последней индексации страниц, в их коде содержался мета-тег noarchive. Это явный запрет на показ сохраненной копии в результатах поиска. Сейчас тег убран, но сохраненная копия не появится пока робот не обновит документы в нашей поисковой базе.
В некоторых случаях, робот может посчитать изменения внесенные на странице незначительными, например, если текст на странице практически не поменялся или изменения касаются только html-разметки. Такие документы не обновляются в нашей поисковой базе, так как внесенные изменения на поиск никак не влияют.
С уважением, Платон Щукин
Служба поддержки Яндекса
//help.yandex.ru/

На следующий день я опять проверил свой блог в сервисе //xtool.ru/ . И о чудо! Моментальный подъем на 2 единицы!
Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Сохраненная копия в Яндексе — это версия страницы, которая занесена в поисковой системы Яндекс.
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA
При просмотре выдачи результатов поисковика на введенный пользователем запрос в сниппете каждого сайта можно увидеть блок с дополнительной информацией. Одним из разделов блока с дополнительной информацией является «Сохраненная копия».
Одним из разделов блока с дополнительной информацией является «Сохраненная копия».
Чтобы понять, что из себя представляет сохраненная копия Яндекса, разберем простую аналогию. Представьте, что вы написали доклад или сочинение. Вы сдали работу, отправили ее на конкурс, но перед этим успели скопировать. Затем вам нужно еще раз сделать эту работу уже для другого конкурса. Чтобы не писать все заново, не восстанавливать в памяти все детали, вы достаете сохраненный файл и по ней пишите новое сочинение. Сохраненная страница Яндекса выполняет функцию данной копии. С ее помощью можно просмотреть сайт, если по тем или иным причинам нет доступа к интернет-ресурсу.
Для чего нужна сохраненная копия страницы в Яндексе
Прежде всего, отметим, что сохраненная копия в поисковой системе Яндекс — это важный инструмент SEO оптимизатора. С ее помощью можно увидеть, какая версия документа уже проиндексирована роботами поисковой системы и участвует в ранжировании, а какие страницы еще не прошли данный процесс. Таким образом, наличие сохраненной страницы в Яндексе — индикатор успешно пройденной индексации.
Таким образом, наличие сохраненной страницы в Яндексе — индикатор успешно пройденной индексации.
- В ходе работы с интернет-ресурсами могут возникнуть самые различные ситуации. В частности на сайтах периодически осуществляются технические работы: внесение корректировок в дизайн/изменение шаблона /редактирование или удаление текстовых материалов. В ходе данных работ легко можно допустить ошибку, которая ведет к негативным последствиям: исчезновение дизайна/текста/другого элемента, изменение шаблона не по плану и так далее. Наверняка, каждый разработчик сайтов имел такой печальный опыт. Если есть возможность бэкапа или подключен качественный хостинг, через который можно вернуть все как было — прекрасно. Но начинающие ресурсы, как правило, не имеют такой возможности. В этом случае поможет сохраненная копия страницы в Яндекс. С ее помощью можно увидеть, как все было на момент индексации роботами и восстановить вид страницы, исправить ошибки. Но учтите, что хранение страницы в индексе не вечно, и если на нее робот зашел в период, когда она уже была в нерабочем состоянии, вы вполне можете не увидеть старой информации. ..
- Еще одна ситуация, когда полезна будет сохраненная копия страницы в Яндексе: в ходе работы над сайтом вы изменили текстовый материал, с целью увеличения релевантности страниц. Теперь вам нужно посмотреть, выполнено ли обновление страницы, где вы внесли изменения. Сделать это можно просмотрев сохраненную копию.
- Нередко сайты бывают недоступны, причин для этого может быть много: технические неполадки, истек срок хостинга и так далее. Чтобы в этой ситуации зайти на сайт, нужно найти сохраненную копию и просмотреть ее. Таким образом, польза сохраненных страниц Яндекса очевидна.
 ..
..Как посмотреть сохраненную копию страницы в Яндексе
Все современные поисковые системы, и Яндекс не исключение, позволяют пользователям открыть нужные веб-документы через их индекс. Это можно сделать быстро с помощью специальных сервисов или вручную. В первом случае на помощь придут сервисы: Page Promoter в Firefox, RDS bar для Хроме и другие. Однако плагины периодически могут некорректно работать и выходить из строя, поэтому владеть ручным методом тоже нужно.
Первый способ
Открываем поисковик Яндекс и в строке поиска прописываем сам адрес нужной страницы или интересующий запрос. В результатах поиска мы видим, что в сниппете каждого результата есть маленькая стрелочка. Нажимаем на стрелочку и выбираем «Сохраненная копия». После этого мы посетим сайт, его сохраненную страницу от какой-то прошедшей даты.
Второй способ
Способ заключается в применении специальных расширений браузера/плагинов/онлайн сервисов. Наиболее популярным сегодня является «RDS bar». Интерфейс плагина более чем простой, с его помощью можно просмотреть последние изменения страницы, когда страницу в последний раз посещал робот, следовательно и копия предоставляется за это число. Если нужная страница не прошла индексацию Яндекса, ее сохраненная копия не будет отображаться в результатах выдачи поисковика.
Почему нет сохраненной копии страницы в Яндексе
Иногда при поиске сохраненной копии страницы можно не увидеть нужного пункта при нажатии на стрелочку в сниппете.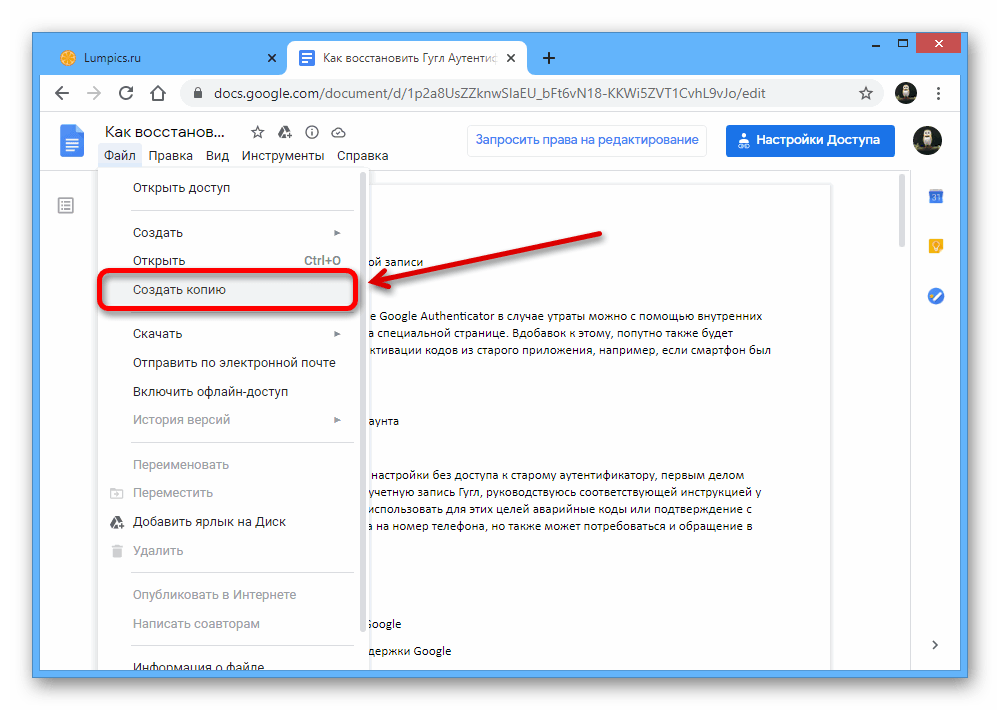 Причин тому может быть несколько:
Причин тому может быть несколько:
- Первый вариант — некорректная работа ПС. Сам Яндекс признается, что не гарантирует наличие и показ таких копий для всех страниц в силу большого кол-ва причин.
2. Вторая ситуация — в коде документа находится метатег “robots” и он имеет значение «noarchive» — запрет кэширования. Чтобы избежать падения трафика, необходимо внимательно настраивать подобные вещи.
Чем может грозить отсутствие копии в Яндексе
Само по себе отсутствие копии не будет влиять как-то негативно на продвижение. А вот причины, которые привели к отсутствию могут повредить, поэтому разберитесь с ними.
Чем действительно может обернуться проблема с копиями страниц, так это затруднениями при работе с биржами ссылок.
Например, в Сеопульте сегодня есть параметр, который осуществляет контроль над тем, есть ли сохраненная копия Яндексе. Данный параметр называется NIC — No Index Cache. Он свидетельствует о том, что страница не имеет сохраненной копии. С такого ресурса не будут покупать ссылки, никому не хочется рисковать и платить за то, что может не принести пользы.
С такого ресурса не будут покупать ссылки, никому не хочется рисковать и платить за то, что может не принести пользы.
Как вы видите, сохраненная копия в Яндексе позволяет решить ряд проблем и оптимизировать использование интернет-трафика. Данные рекомендации позволят оперативно открывать и просматривать их.
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кеша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:http://www.iphones.ru/
Где http://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета
6. Archive.is, для собственного кэша
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com , перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari .
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на
Существует настоящая, реальная машина времени, в которой можно ненадолго вернуться в прошлое и увидеть, например, как выглядел тот или иной сайт несколько лет назад. Думаете, никому не нужны копии сайтов многолетней давности? Ошибаетесь! Для очень многих людей сервис по архивированию информации весьма полезен.
Думаете, никому не нужны копии сайтов многолетней давности? Ошибаетесь! Для очень многих людей сервис по архивированию информации весьма полезен.
Во-первых, это просто интересно! Из чистого любопытства и от избытка свободного времени можно посмотреть, как выглядел любимый, популярный ресурс на заре его рождения.
Во-вторых, далеко не все владельцы сайтов ведут свои архивы. Знать место, где можно найти информацию, которая была на сайте в какой-то момент, а потом пропала, не просто полезно, а очень важно.
В-третьих, само по себе сравнение является важнейшим методом анализа, который позволяет оценить ход и результаты нашей деятельности. Кстати, при проведении анализа веб-ресурса очень эффективно использовать ряд методов сравнения.
Поэтому наличие уникальнейшего архива веб-страниц интернета позволяет нам получить доступ к огромному количеству аудио-, видео- и текстовых материалов. По утверждению разработчиков, «интернет-архив» хранит больше материалов, чем любая библиотека мира. Мы попали в правильное место!
Мы попали в правильное место!
Что нужно, чтобы найти копии сайтов интернета
Для того, чтобы отправиться в прошлое, нужно перейти на сайт archive.org и воспользоваться поисковой строкой.
Простой поиск в архиве сохраненных сайтов выдает нам ссылки на все сохраненные копии запрашиваемой страницы.
Из этого видно, что сайт сайт был создан в 2012 году (Кстати, важно отметить, с помощью практически идеального хостинга Спринтхост — рекомендую!). Переключаясь на нужный нам год, можно увидеть даты, выделенные кружочками, это и есть даты сохранения копии сайта. Например, в 2015 году, пока можно будет увидеть только одну копию от 7 февраля.
Конечно, это потрясающий ресурс! Ведь здесь индексируются и архивируются все сайты интернета! Это не только скриншоты… Имея в руках такой инструмент, можно восстановить массу потерянной со временем информации.
Надо заметить, что, безусловно все восстановить однозначно не получится, так как если на страницах сайта используются элементы Java Script, или скрипты или графика взяты со стороннего сервера, то на восстановление такой информации рассчитывать не придется. Поэтому к сохранению данных своего сайта нужно относиться с особенным вниманием, несмотря ни на что.
Поэтому к сохранению данных своего сайта нужно относиться с особенным вниманием, несмотря ни на что.
Пользуясь случаем, я сделала скриншоты и восстановила в памяти, как выглядел мой сайт, начиная с 2012 года. Любопытно посмотреть))
Сайт буквально недавно «родился»)) Январь 2012.. .
Проходит время, и хочется что-то изменить… Конец 2012-го.
Наверное, пора уже что-то менять. 2013-й. Это тема, которая и сегодня установлена на моем сайте.
К смене темы отношусь с осторожностью, так как помню последний «переезд», после которого несколько месяцев восстанавливала посещаемость сайта. Как-то не очень удачно получилось.
Надеюсь, что и моим читателям эта замечательная интернет-библиотека — «машина времени» сможет помочь перемещаться во времени, когда они этого захотят. Посмотрите, как выглядели раньше некоторые сайты, еще во времена своего зарождения. Какими раньше были google или яндекс, можно увидеть только на archive. org, аналогов у этого ресурса нет. Приятного путешествия, друзья!
org, аналогов у этого ресурса нет. Приятного путешествия, друзья!
Всякий раз, когда мы разглядываем результаты любого запроса, на странице выводятся ссылки «Сохраненная копия» и «Еще с сайта». Разберем сначала первую из них.
Индексация , всех сайтов, информацию на которых ищет Яндекс, сопровождается созданием копии этих сайтов, которые размещаются на серверах Яндекса. Да, грубо говоря, Яндекс хранит на своих серверах весь Рунет и значительную часть Интернета. Конечно, на серверах, в кэше, размещаются не все страницы сайтов, а также не все элементы сайтов — чаще всего хранится лишь текстовое содержимое. Также не нужно представлять себе Яндекс в качестве некоего суперархива, в который попадают все странички, которые когда-либо были в сети 1Для таких задач есть другие сервисы, например, http://www.archive.org . Кэш Яндекса динамический, его содержимое постоянно обновляется по мере изменения основных сайтов.
Как это использовать? Для чего нужна ссылка
«Сохраненная копия».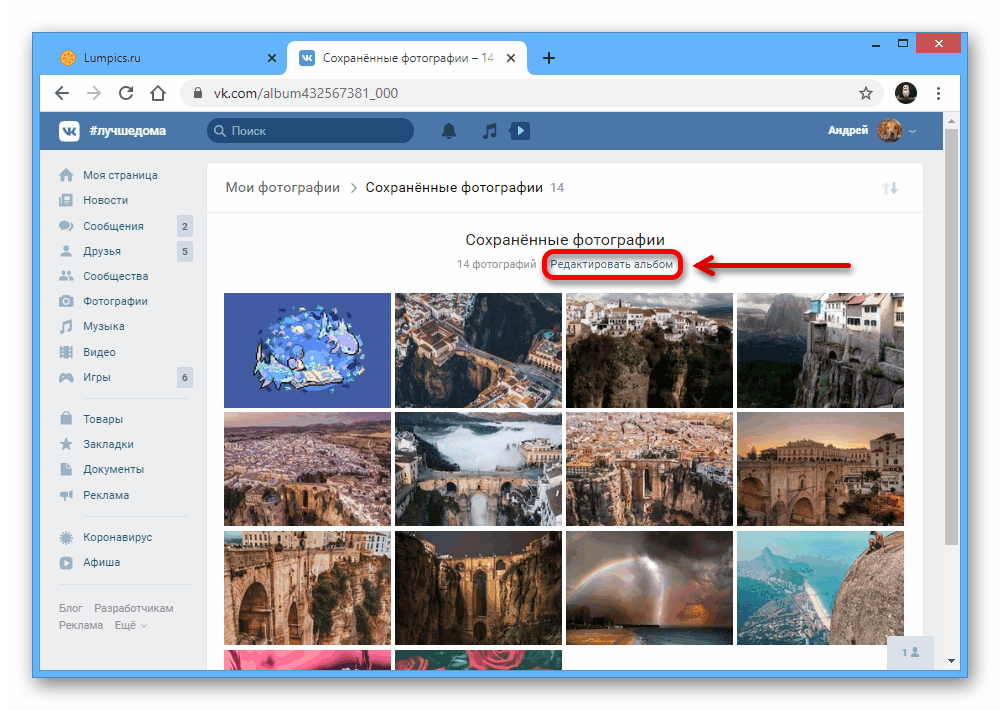 Представим себе, что некоторая газета опубликовала скандальную статью. Поисковый бот Яндекса невозмутимо прошелся по
сайту этой газеты и проиндексировал ее, сохранив копию на свой сервер
. Тем временем широкая общественность, возмущенная статьей, потребовала удалить ее с сайта, а журналиста, который написал статью — уволить. Главный редактор газеты, посыпая голову пеплом, выполняет эти требования. Статьи на сайте газеты больше нет. Драматические события развиваются чрезвычайно быстро, буквально в течении утра.
Представим себе, что некоторая газета опубликовала скандальную статью. Поисковый бот Яндекса невозмутимо прошелся по
сайту этой газеты и проиндексировал ее, сохранив копию на свой сервер
. Тем временем широкая общественность, возмущенная статьей, потребовала удалить ее с сайта, а журналиста, который написал статью — уволить. Главный редактор газеты, посыпая голову пеплом, выполняет эти требования. Статьи на сайте газеты больше нет. Драматические события развиваются чрезвычайно быстро, буквально в течении утра.
Тем временем, некоторый читатель, который проснулся к обеду, заходит в сеть и видит, что форумы и блоги кипят от обсуждений этой статьи. Он набирает в Яндексе ее название, переходит по ссылке на сайт редакции и получает ошибку 404. Статьи, конечно, больше нет, но есть ссылка «Сохраненная копия», перейдя по которой читатель получает удовольствие от шокирующих подробностей копии статьи.
Когда эта ужасная статья исчезнет из кэша Яндекса? Когда поисковый бот, скажем, после обеда еще раз пройдется по
сайту газеты и проиндексирует его.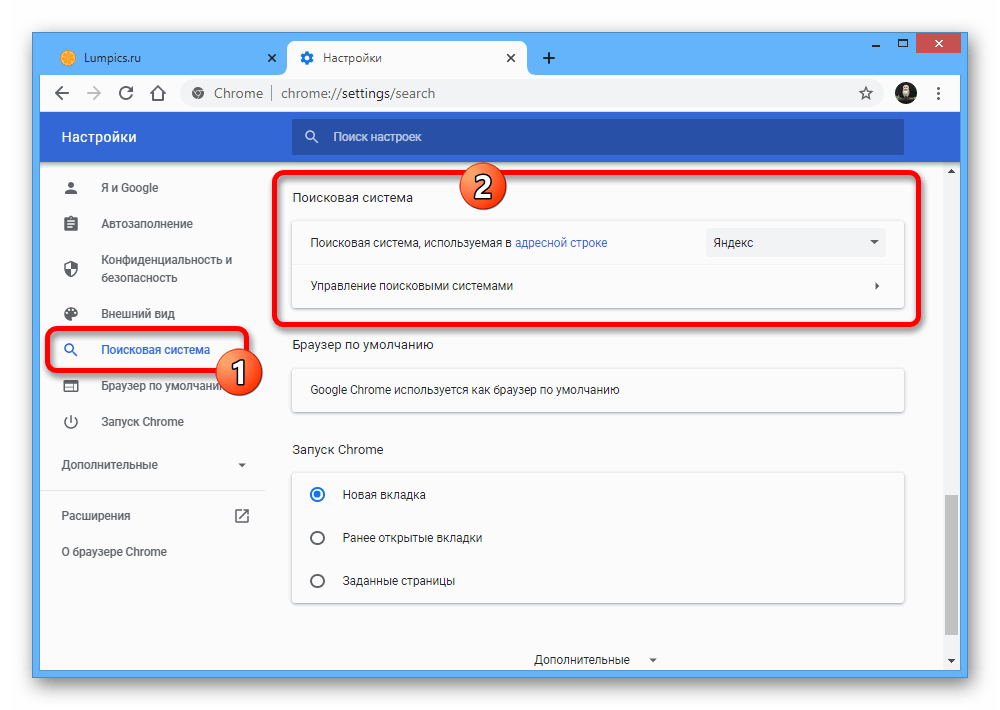 Статьи там больше нет, значит содержимое кэша тоже обновится и наступит полная гармония в сети.
Статьи там больше нет, значит содержимое кэша тоже обновится и наступит полная гармония в сети.
Нам, пользователям, остается ловить промежутки времени между переиндексацией Яндекса после удаления некоторых материалов. Можно сказать, что если где-то исчезли материалы, то в течении нескольких часов их еще можно будет вытащить из кэша Яндекса по ссылке «Сохраненная копия».
Конечно, не все столь драматично и интересно. Чаще всего ссылка «Сохраненная копия» помогает, когда материалы основного сайта недоступны по причине банального падения сервера.
«Сохраненная копия» — это возможность увидеть материалы, которые были перемещены, удалены или недоступны. Работает в течение определенного промежутка времени.
Персональный поиск
Терабайтный жесткий диск
— это уже не фантастика, а самая обыденная вещь. Фантастикой становится найти документ на таком жестком диске, особенно когда не очень хорошо помнится, когда он был создан, кем он был создан и вообще где он лежит.
Операционная система Windows Vista содержит средства поиска «на лету». Достаточно ввести в проводнике название файла как в окне результатов, тут же будут выведены соответствующие документы.
Яндекс предлагает Персональный поиск http://desktop.yandex.ru/ , который обеспечивает возможность находить файлы и документы на локальном компьютере. Для начала работы скачиваем программу (размером около 4,4 МБ) и устанавливаем ее. Персональный поиск должен вначале проиндексировать все документы, которые находятся на нашем жестком диске. По умолчанию, процесс полной индексации запускается автоматически, когда мы не трогаем центрального процессора не превышает 35%. Однако лучше всего сразу после установки выполнить принудительную индексацию — чтобы получить работающий локальный поиск . Для этого в системном трее (возле часов) щелкаем по иконке установленной программы и в контекстном меню выбираем пункт «Индексация \ Принудительная» ( рис. 1.32 2):
Рис.
1. 32.
32.
Скорость завершение процесса зависит от мощности компьютера, размера жесткого диска и количества документов. На двухядерном процессоре с двумя гигабайтами оперативной памяти, набитый под завязку 250 гигабайтный винчестер проиндексировался за пару часов. При этом какого-либо замедления в работе не замечалось — параллельно использовался браузер с множеством открытых вкладок, Microsoft Word , Excel , почта и т.д. Словом, индексация требует определенных затрат машинных ресурсов, но она выполняется гораздо легче, чем, скажем, антивирусное сканирование. В течении индексации иконка Персонального поиска переливается, а как только она становится статичной — значит, можно использовать поиск . Для запуска поиска дважды щелкаем по иконке — открывается браузер , в котором есть строка поиска. Но это только интерфейс — персональный поиск работает без подключения к Интернету. Вводим название файла и результаты отображаются моментально ( рис. 1.33):
Все найденные результаты группируются по
вкладкам (табам), расположенным в правой части страницы. На странице помощи Персонального поиска
На странице помощи Персонального поиска
Как восстанавливать сайты из Веб Архива
Выбор огранияения ДО при восстановлении сайтов из веб-архива
В прошлый раз мы рассказали вам, как подготовить домен к восстановлению и о том, как открыть индексацию через robots.txt. Сегодня вы узнаете, как выбрать дату полностью работоспособной версии старого сайта из веб-архива.
Когда домен заканчивается, на сайте может появится заглушка домен-провайдера или хостера. Перейдя на такую страницу, веб-архив будет ее сохранять, как полностью рабочую, отображая соответственную информацию в календаре. Если по такой дате из календаря восстановить сайт, то, вместо нормальной страницы мы получим ту самую заглушку. Как этого избежать и узнать дату работоспособности всех страниц сайта, по которой его можно восстановить?
Инструкция по выбору даты на примере домена Trimastera.ru
На главной странице вводим домен и открываем календарь веб-архива.
Ищем последнюю рабочую версию, которая будет помечена синим цветом. Открываем, и смотрим как она выглядит, если это парковка регистратора доменов, смотреим дальше. Находим время, когда контент был архивирован.
Внимание, timestamp который мы видим по ссылке ― это дата и время сохранения лишь html-кода этой страницы, но не CSS стилей на ней, ни картинок, ни скриптов. Все они имеют свои даты сохранения, порой значительно отличающиеся от даты html файла. Для того, чтобы веб-архив полностью сохранил страницу со всеми ее элементами, нужно время. Начиная с кода страницы, сохраняются все элементы с задержкой от нескольких секунд до нескольких дней, а иногда даже больше. Поэтому, если ввести именно этот timestamp как дату «to» домена, восстановится лишь часть страницы.
Переходим в инструмент DevTools для определения, откуда подгружаются все элементы сайта. Для этого нажимает одновременно клавиши ctrl+shift+i или F12 в вашем браузере. Видим инструмент анализа исходного кода.
Выбираем вкладку Network, убираем галочку persist logs. Нажимаем F5 или обновляем страницу.
В поле фильтра вводим искомый домен Trimastera.ru. Для общего понимания, фильтр даже при частичном вводе имени домена отобразит информацию, и все, что будет прописано через пробел, определяется инструментом, как дополнительный фильтр к поиску.
Т.е. одновременно введя имя домена Trimastera и 201803 (как год и месяц последнего сохранения рабочей версии сайта исходя из верной «синей» даты на календаре) мы получим все ссылки (без внешних стилей, картинок и других внешних ресурсов).
На примере данного домена мы видим много url c 302 кодом, так как веб-архив элементам, расположенным на странице, присваивал такой же timestamp, но при переходе на сам элемент, веб-архив делает редирект на timestamp уже оригинальный.
Рассмотрим на примере страницы со стилями style.css. Главный timestamp у нас отображается тот же, что и всей страницы сайта, но переходе на адрес размещения стиля (url непосредственно стиля) мы видим другой timestamp, именно этого элемента.
Поочередно в поиске меняем дату 201803, на большую или меньшую, чтобы определить, были ли в этот период работоспособные страницы, т.е. с кодом 200. Таким образом мы подтверждаем, что март 2018-го ― последний период рабочей индексации сайта.
В поле фильтра можно задавать и более широкий промежуток времени, к примеру, только год. Но при постановке такой даты «to», веб-архив будет рассматривать версию за последнюю секунду 2018-го, а в тот момент, как мы видим, сайт не работал. Указание более точного периода, вплоть до секунд, может не захватить отдельные медиа или текстовые элементы, проиндексированные позже.
Открывает инструмент Site Map. Видим, что за 2019 год у нас нет внутренних страниц сайта.
Открываем 2018-й, и видим, что структура сайта отображается, значит, сайт индексировался.
Просматриваем выборочно некоторые страницы в новых вкладках за 2018 год. Как мы видим, timestamp таких страниц зафиксирован 15 марта, хотя и в разное время. Этим самым мы проверяем утверждение про месяц последней работоспособности страниц.
Этим самым мы проверяем утверждение про месяц последней работоспособности страниц.
Открываем инструмент Summary за выбранный нами 2018 год. Проверяем в таблице столбик New URLs. За период 2018 года новых ссылок не индексировалось, значит, на момент восстановления мы будем выкачивать из архива последнюю версию сайта.
Открываем инструмент Explore. Анализируем выдачу url в таблице. Если до этого домен был подготовлен верно благодаря файлу robots.txt, мы увидим таблицу всех ссылок на этот год.
Проверим гипотезу о том, что файл robots.txt закрывает индексирование. Смотрим в календаре все версии документа robots.txt, и видим, что 13 июля 2018 года сайт был закрыт.
Если вы столкнулись с подобной ситуацией, нужно провести подготовку домена с помощью внедрения нового файла robots.txt, о чем мы рассказали в прошлом гайде.
После успешной подготовки robots.txt в инструменте Explore все ссылки, которые выдаются на интересующий год, сортируем по дате «to» таким образом, чтобы самые последние были вверху. Нас интересуют только те ссылки, которые не имеют редиректа, заглушек, или других внешних элементом (не касаемых содержимого сайта). Самая последняя дата последнего url и будет является крайней датой индексации (сохранения) актуальной версии материалов сайта.
Нас интересуют только те ссылки, которые не имеют редиректа, заглушек, или других внешних элементом (не касаемых содержимого сайта). Самая последняя дата последнего url и будет является крайней датой индексации (сохранения) актуальной версии материалов сайта.
Анализ инструментом Explore, как и в целом работа с датой «to» домена, должна проводится спустя 24-72 часа после загрузки нового файла robots.txt, как мы помним, для того чтобы веб-архив правильно проиндексировал все элементы сайта.
В нашем примере мы не можем отсортировать файлы в веб-архиве, так как до этого не было проведено шага с загрузкой файла robots.txt на новом домене и хостинге.
Сложности при поиске даты «to»
Пример: Сайт mastersila.ru
Проходим те же этапы, что и на прошлом примере:
На календаре сохранения сайта ищем «синюю» дату сохранения (в нашем случае, 4 декабря 2016-го) проверяем отсутствие редиректа и других ошибок. На сохраненной версии страницы переходим к инструменту DevTools (F12 и обновляем через F5). Точно также вводим в поле фильтра часть домена и дату, бОльшую от рассматриваемой (2017). Так как за отобранный период мы не видим ссылок с кодом 200, последняя работоспособность сайта была зафиксирована в 2016 году.
Точно также вводим в поле фильтра часть домена и дату, бОльшую от рассматриваемой (2017). Так как за отобранный период мы не видим ссылок с кодом 200, последняя работоспособность сайта была зафиксирована в 2016 году.
Открываем инструмент Site Map и проверяем гипотезу. В большинстве случаев, в инструменте Site Map последний год отображения структуры и будет последним годом работоспособности сайта.
Как мы видим, последний год сохранения ― 2016, что подтверждает наше предположение. Именно в этот период у нас отображается рабочая структура, сохраненная веб-архивом. Переходим к инструменту Summary. Просматриваем результаты в разделе New URLs за период 2016 года. Как видим, в этот период новых уникальных ссылок сгенерировалось 39, значит, в этом году сайт был в последний раз работоспособный с актуальными версиями страниц.
Открываем инструмент Explore. Так как у нас выводится таблица результатов, сайт открыт к индексированию, значит robots.txt на нем не закрывал доступ ботам. Сортируем результаты от последнего. Проверяем ссылки на работоспособность, исключая ссылки с редиректом и ошибками. За 2018 год все ссылки ― редирект. За 2017 отображаются новые материалы, проиндексированные 3 марта.
Сортируем результаты от последнего. Проверяем ссылки на работоспособность, исключая ссылки с редиректом и ошибками. За 2018 год все ссылки ― редирект. За 2017 отображаются новые материалы, проиндексированные 3 марта.
Проверяем ссылки, и видим, что это редирект-страницы. Значит, их не стоит рассматривать как рабочие страницы, необходимые к восстановлению.
Проверяем ссылки за 2016 год. Подтверждаем гипотезу, что декабрь 2016-го ― наша дата «to» для домена, так как ссылки рабочие.
Пример : Сайт Gkvolga.ru
Как и в прошлых примерах, смотрим последнюю версию сайта за 2018 год. Определим, что в марте 2015-го сайт работал.
Снова выбираем инструмент DevTools через F12+F5 в выбранной нами версии за 18 марта 2015 года. Как и раньше, вводим название домена и методом подбора даты ищем период последней выгрузки кода 200 с сайта. Методом отбора по месяцам также подтверждаем, что март 2015-го ― последний период работоспособности сайта. Переходим на инструмент Summary. Открываем предполагаемый год ― 2015.
Переходим на инструмент Summary. Открываем предполагаемый год ― 2015.
Видим, что в этот период было сгенерировано 2 новых файла. Если бы было создано много файлов, мы искали бы их в апреле, мае. Но 2 файла мы будем искать в указанный месяц — устанавливая дату «to» 201503.
Для подтверждения наших догадок открываем инструмент Explore (на 2015 год), и видим, что данные сайта уже не индексируются (нет выгрузки таблицы).
Т.е. на сайте установлены ограничения robots.txt. Делаем вывод, что определенная нами дата является последней, когда сайт был работоспособным.
Этот видео гайд есть на Youtube:
Как восстанавливать сайты из Веб Архива — archive.org. Часть 1
Как восстанавливать сайты из Веб Архива — archive.org. Часть 2
Использование материалов статьи разрешается только при условии размещения ссылки на источник:  com/ru/blog/3-how-does-it-works-archiveorg/»>
https://archivarix.com/ru/blog/3-how-does-it-works-archiveorg/
com/ru/blog/3-how-does-it-works-archiveorg/»>
https://archivarix.com/ru/blog/3-how-does-it-works-archiveorg/
Как просматривать старые версии веб-сайтов (и почему вам это нужно)
Интернет движется с головокружительной скоростью. Веб-сайты постоянно обновляются и обновляются. В некоторых случаях информация теряется в этом процессе, будь то из-за того, что сайт был отключен, или просто из-за неправильного хранения.
Исторические онлайн-записи позволяют просматривать старые версии веб-сайтов, записанные в определенные моменты времени. Возможность делать это полезна не только для путешествий по переулкам памяти, так что давайте поговорим об интернет-архивах!
Подпишитесь на наш канал Youtube
Почему вы хотите видеть старые версии веб-сайтов
Существует множество причин, по которым вы можете захотеть увидеть старые версии ваших любимых (или наиболее часто используемых) веб-сайтов. На многих сайтах со временем меняется многое, в том числе:
На многих сайтах со временем меняется многое, в том числе:
- Их общий вид
- Данные, к которым у вас есть доступ
- Отдельные страницы, которые удаляются или обновляются
Рассмотрим, например, наш собственный веб-сайт. Он существует с 2008 года, и, как вы можете себе представить, с его первых дней многое изменилось:
Возможность заглянуть в прошлое невероятно полезна. Вы можете найти вдохновение для дизайна на старых веб-сайтах и получить доступ к мультимедийным файлам, которые больше не доступны.
Что еще более важно, интернет-архивы позволяют вам видеть информацию, которая была утеряна временем. Например, если один из ваших любимых веб-сайтов отключается от сети, вы сможете найти его сохраненную копию в Интернете:
Наличие доступа к старым версиям веб-сайтов также позволяет в некоторых случаях обойти цензуру. Если ваш интернет-провайдер (ISP) или правительство подвергает цензуре часть Интернета, вы можете преодолеть эти барьеры и просмотреть заархивированные сайты.
Помимо более практических причин, очень важно вести учет Интернета, каким он был и есть сегодня. Интернет-архивы выполняют ту же функцию, что и библиотеки, позволяя нам заглянуть в прошлое и увидеть, как все изменилось с течением времени.
3 инструмента, которые можно использовать для просмотра старых версий веб-сайтов
Существует удивительное количество служб, которые хранят или кэшируют старые копии веб-сайтов. В большинстве случаев они делают «снимки» определенных сайтов и страниц по запросу.Это означает, что вы можете получить архив, который со временем сохраняет тысячи копий вашего веб-сайта, в зависимости от его популярности. Давайте посмотрим на некоторые из этих услуг и на то, что они могут предложить.
1. Машина обратного пути Интернет-архива
The Internet Archive — это некоммерческая организация, которая занимается созданием цифровой библиотеки веб-сайтов, книг, аудиозаписей, видео, изображений и даже программного обеспечения. Если вы хотите убить немного времени, в Интернет-архиве есть даже эмулированные версии старых игр, в которые можно играть прямо из браузера:
Что касается веб-сайтов, то в Интернет-архиве хранится более 448 миллиардов страниц, и вы можете перемещаться по ним с помощью инструмента Wayback Machine:
Для начала введите URL-адрес веб-сайта, который хотите проверить.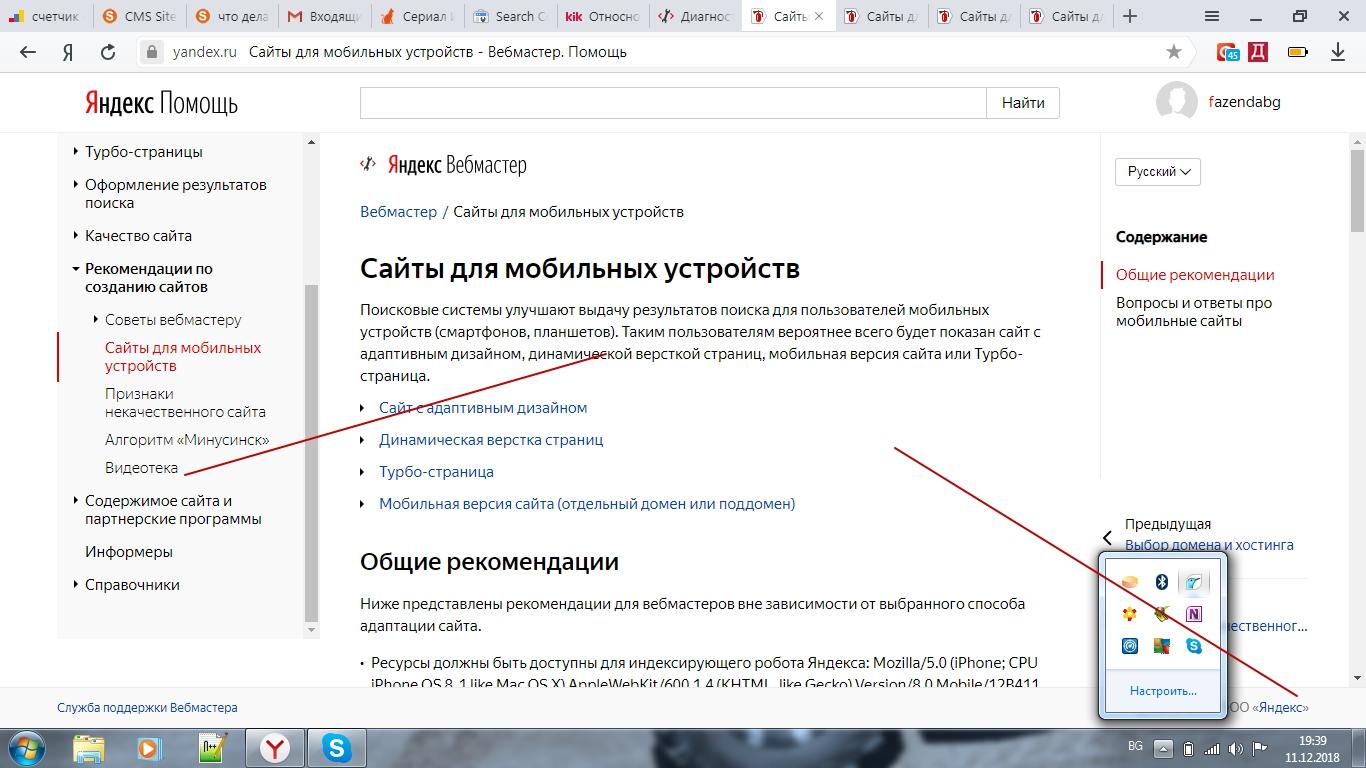 Wayback Machine покажет вам график, который отслеживает, как часто копии этого веб-сайта сохранялись за эти годы. Если вы выберете конкретный год на этой диаграмме, вы сможете получить доступ к отдельным копиям сайта с помощью календаря:
Wayback Machine покажет вам график, который отслеживает, как часто копии этого веб-сайта сохранялись за эти годы. Если вы выберете конкретный год на этой диаграмме, вы сможете получить доступ к отдельным копиям сайта с помощью календаря:
Чтобы дать вам представление о том, насколько тщательным является этот архив, Wayback Machine сохранила более 19 700 копий веб-сайта Elegant Themes.
После того, как вы выберете снимок, который хотите видеть, Wayback Machine загрузит эту кэшированную копию в новой вкладке:
Имейте в виду, что время загрузки, вероятно, будет не таким быстрым, как вы привыкли.Однако как только страница загрузится, вы сможете взаимодействовать с ней как обычно. Вы можете переходить со страницы на страницу, сохранять изображения, читать комментарии и т. Д.
Однако в некоторых случаях вы не сможете перемещаться по старым кэшированным копиям веб-сайта. Это связано с тем, что некоторые страницы, на которые есть ссылки, могут не кэшироваться, что характерно для сайтов с огромными библиотеками контента.
2. oldweb.today
oldweb.today — это служба, которая позволяет загружать копии старых веб-сайтов, имитируя старые браузеры, чтобы обеспечить вам полноценную работу.Если вы никогда не испытывали радости от использования Netscape или старых версий Internet Explorer, oldweb.today может помочь вам избавиться от этого зуда.
Эта служба извлекает копии страниц, которые вы хотите просмотреть, из сторонних архивов. К ним относятся Интернет-архив и национальные библиотеки со всего мира, что обеспечивает довольно комплексное обслуживание.
Однако, как и следовало ожидать, эмуляция старых браузеров и получение данных из нескольких источников требует времени. oldweb.today часто требует от вас подождать в виртуальной очереди, прежде чем вы сможете увидеть то, что хотите:
По окончании ожидания служба запустит эмулируемую версию браузера, который вы выбрали, и отобразит веб-сайт, который вы хотели увидеть:
Каким бы увлекательным ни было просмотр старых веб-сайтов, время ожидания означает, что oldweb. today — не лучший вариант, если вы хотите проверить несколько версий одного и того же сайта. Ожидание часто может длиться несколько минут, так что время складывается довольно быстро.
today — не лучший вариант, если вы хотите проверить несколько версий одного и того же сайта. Ожидание часто может длиться несколько минут, так что время складывается довольно быстро.
3. Библиотека Конгресса
В Американской библиотеке Конгресса находится самая большая коллекция книг, записей, газет, и веб-сайтов в мире. Однако его коллекция веб-сайтов работает иначе, чем два предыдущих предложения.
Если вы попытаетесь найти определенный веб-сайт с помощью функции поиска в библиотеке, вы, вероятно, найдете набор случайных результатов.Вот что появляется, когда мы ищем «reddit», например:
Когда вы открываете отдельные ссылки, библиотека позволяет вам просматривать страницы, которые хранятся в ней, используя систему, идентичную Wayback Machine:
Библиотека также сохраняет описания и другую полезную информацию для каждого веб-сайта в своем архиве, что делает ее особенно полезной для исследования:
Точно так же вы можете просматривать сам архив, не выполняя поиск, поскольку библиотека предлагает подробную систему категорий, которая включает в себя все его записи:
Хотя архив веб-сайта библиотеки не такой обширный, как у Wayback Machine, он предлагает гораздо больше деталей. Библиотека также позволяет вам просматривать информацию, не думая о конкретном веб-сайте, чего не могут сделать другие архивы.
Библиотека также позволяет вам просматривать информацию, не думая о конкретном веб-сайте, чего не могут сделать другие архивы.
С другой стороны, эта библиотека также содержит огромную коллекцию изображений, которые вы можете использовать бесплатно, иногда без указания авторства:
Некоторые из этих наборов являются изображениями из Интернета. Это делает этот сайт ценным ресурсом для стоковой графики, если вам когда-нибудь надоест более традиционные варианты.
Заключение
Есть много практических причин, по которым вам стоит взглянуть на старые версии определенных веб-сайтов.Возможно, вы ищете контент, которого больше нет, и изображения, которые хотите использовать повторно, а может быть, вы просто пытаетесь обойти цензуру.
В любом случае, интернет-архивы служат для всех нас огромной общественной услугой. Вот три ваших лучших варианта, если вы хотите заглянуть в прошлое Интернета:
- Машина обратного пути Интернет-архива: Навигация по самому большому архиву кэшированных страниц в Интернете.
- oldweb.today: Используйте эмулированные версии старых браузеров для навигации по веб-сайтам из прошлого.
- Библиотека Конгресса: Просмотрите библиотеку, используя подробную систему категорий, или просмотрите определенные веб-сайты.

Какой ваш любимый старый веб-сайт больше не существует? Поделитесь своими воспоминаниями в разделе комментариев ниже!
Миниатюра статьи изображение Leremy / shutterstock.com
Находите, просматривайте и загружайте старые версии веб-сайтов (которые больше не существуют)
С помощью Wayback Machine вы сможете получить доступ к старым веб-страницам, которые больше не доступны по их предыдущему URL-адресу.Таким образом вы сможете как минимум найти и сохранить текстовое содержимое нужной страницы. Но иногда вам нужно больше, чем просто текст старой статьи. Иногда проблема больше. Возможно, страницы больше нет, и резервная копия тоже не помогает. Возможно, вы хотите загрузить весь веб-сайт, чтобы отредактировать или сохранить исходный код, отфильтровать неработающие ссылки или протестировать старую версию своего веб-сайта для оптимизации SEO. Все это возможно с помощью Wayback-Machine-Downloader.
Возможно, вы хотите загрузить весь веб-сайт, чтобы отредактировать или сохранить исходный код, отфильтровать неработающие ссылки или протестировать старую версию своего веб-сайта для оптимизации SEO. Все это возможно с помощью Wayback-Machine-Downloader.
На GitHub есть загрузчик с открытым исходным кодом, а именно Wayback Machine Downloader.Сначала вы должны установить Ruby. Но вам не нужно быть профессионалом Ruby, чтобы использовать программу. Разработчики перечисляют наиболее важные команды кода прямо на странице загрузки. Введите требуемый URL-адрес, и программа загрузит соответствующие файлы на ваш компьютер. Он автоматически создает страницы index.html, совместимые с Apache и NGINX. Опытные пользователи могут более подробно определять настройки для меток времени, URL-фильтров и снимков.
Веб-инструмент Archivarix подходит для небольших веб-сайтов или блогов благодаря четко структурированному пользовательскому интерфейсу.Услуга предоставляется бесплатно, если она используется для веб-сайтов с менее чем 200 файлами, в противном случае взимается плата. Вы должны зарегистрироваться, чтобы использовать Archivarix. Затем просто введите желаемый домен и определите параметры оптимизации и структуры ссылок с помощью нескольких щелчков мышью. Затем введите свой адрес электронной почты. Если загрузка из архива Интернет-сайта завершена, Archivarix отправляет zip-файл на этот адрес.
Archive.org сам по себе не предлагает загрузчик веб-сайтов. Однако, как член библиотеки, я.е. зарегистрированный пользователь, миллионы текстов, изображений и аудиофайлов доступны для скачивания. Если у вас есть права на что-то, вы можете загрузить это для публичного некоммерческого использования, как это делает НАСА с большей частью своих аудио- и визуальных материалов. Например, следующее видео, снятое ISS, заархивировано как обычное произведение по лицензии Creative Commons.
Как просмотреть кэшированную версию веб-сайта
Легко забыть о непостоянстве Интернета. Страницы редактируются без предупреждения, и веб-сайты могут исчезнуть в мгновение ока.
Существует множество способов потерять доступ к сайту или веб-странице. Возможно, серверы не работают, или, возможно, владелец сайта изменил или удалил контент, который вы пытаетесь найти. В этих случаях одним из вариантов является просмотр кэшированной версии.
Google регулярно сканирует Интернет в поисках новых страниц для индексации, а также сохраняет резервные копии сканируемых страниц. Веб-браузеры делают то же самое, чтобы страницы загружались быстрее. Эти снимки сохраняются в кэше — области вашего локального жесткого диска, которая временно становится доступной, если сайт выходит из строя или какое-то содержимое удаляется.Не все веб-сайты индексируются Google или сохраняются в кеше, но вот как получить к ним доступ.
Объявление
Поиск Гугл
Просмотр кэшированной страницы Google начинается так же, как и любой другой поиск. После того, как вы ввели свой запрос и нашли результат поиска, щелкните стрелку рядом с URL-адресом и выберите опцию Кэширование, чтобы просмотреть самую последнюю сохраненную версию страницы Google.
Когда сайт загрузится, Google уведомит вас, что это более старая версия, и укажет, когда был сделан снимок.У вас также будет возможность просмотреть текстовую версию страницы, а также ее исходный код. Однако имейте в виду, что вы не сможете переходить к другим страницам и оставаться в кэшированной версии; вы попадете на действующий сайт, если попытаетесь.
Адресная строка Chrome
Если вы используете веб-браузер Chrome, введите cache: в адресной строке и добавьте URL-адрес, не оставляя пробела. Браузер откроет кешированную версию рассматриваемого веб-сайта, как если бы вы использовали Google.
Wayback Machine
Пока что просмотр кешированных версий веб-сайтов. Ряд организаций посвящены сохранению истории Интернета; наиболее заметным является некоммерческий Интернет-архив, в котором размещаются веб-сайты, тексты, видео, аудио, программное обеспечение и изображения, которые трудно найти где-либо еще. Вы можете просматривать даже более старые версии веб-сайтов с помощью Wayback Machine, которая работает как для живых, так и для автономных веб-сайтов.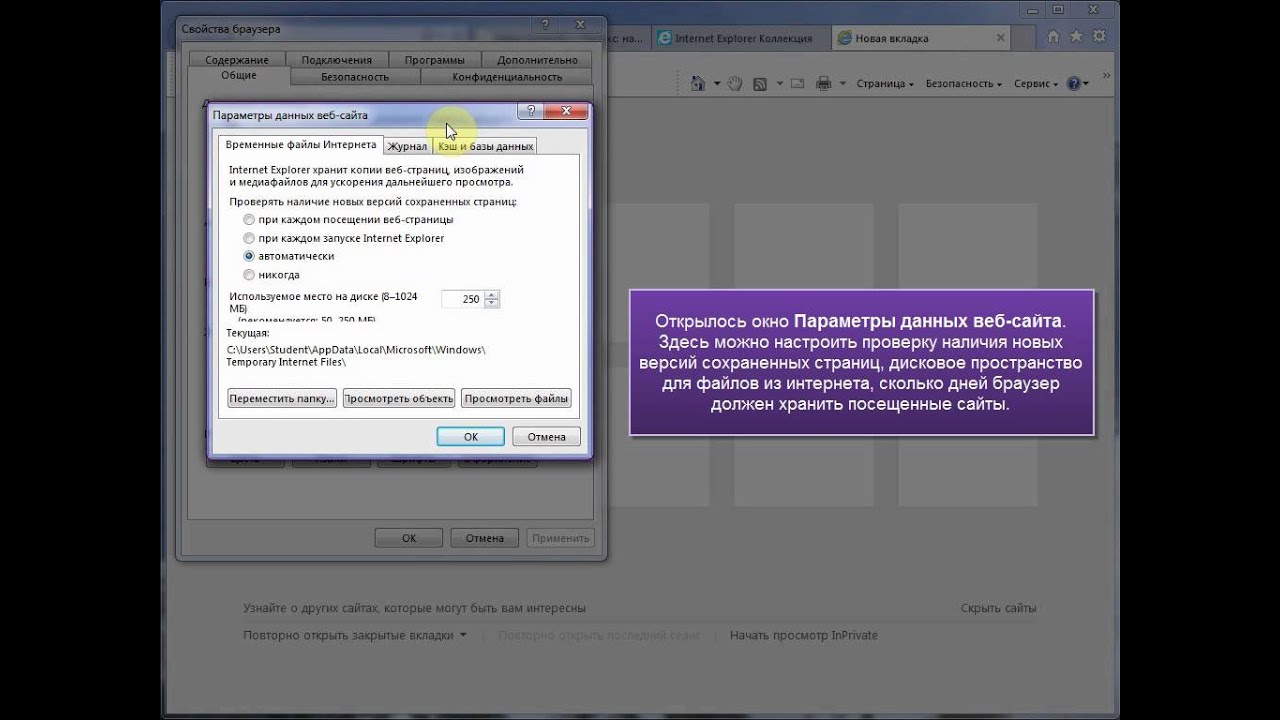
Введите URL-адрес, который вы хотите изучить, и поисковая машина по архивам покажет календарь, который указывает, когда Wayback Machine просканировала эту страницу.Щелкните дату в календаре, чтобы увидеть, как сайт выглядел в этот день. Wayback Machine — отличный способ просмотреть историю Интернета; заархивированные версии PCMag.com датируются 19 декабря 1996 г.
Архив сегодня
Архивный веб-сайт Archive.Today позволяет пользователям сохранять текущие веб-страницы, а также искать существующие записи, которые были ранее сохранены. Ввод URL-адреса для сохранения позволяет просматривать веб-страницу в том виде, в котором она существует в настоящее время, сохранять ее на сайте и загружать страницу на свой компьютер.
Если вы хотите просмотреть заархивированные версии веб-сайта, введите URL-адрес в соответствующую строку поиска, и Archive.Today заполнит результаты для домашней страницы и связанных отдельных страниц. Если существует несколько версий одной и той же страницы, они будут сложены вместе для удобства просмотра.
Веб-сайт PCMag, например, заархивирован еще в 2012 году и в настоящее время имеет четыре различных версии домашней страницы, сохраненных в сервисе.
Расширения браузера
Расширения браузера также могут обращаться к кэшированным сайтам.Добавьте средство просмотра веб-кэша в Chrome и щелкните правой кнопкой мыши любую страницу, чтобы просмотреть версию веб-страницы для Google или Wayback Machine. Расширение View Page Archive & Cache для Chrome и Firefox идет еще дальше, позволяя просматривать кешированные версии веб-страниц из более чем десятка поисковых систем, включая Bing, Baidu и Yandex.
Нужны доказательства для вашего дела? 7 способов найти старые версии веб-сайтов для стертого содержимого
Что делать, если вы подаете дело в суд, думали, что ваше доказательство находится на веб-сайте, но сайт стер это доказательство? Вот 7 способов найти старые версии веб-сайтов.
Учитывая огромное количество веб-сайтов, которые сегодня находятся в сети, и всю информацию, которую они хранят, вполне естественно, что время от времени юридической фирме может потребоваться получить информацию с сайта для доказательства. Проблема в том, что как только ответчик узнает о том, что вы собираетесь подать в суд, он может изменить свой веб-сайт так, чтобы это было ему выгодно.
Проблема в том, что как только ответчик узнает о том, что вы собираетесь подать в суд, он может изменить свой веб-сайт так, чтобы это было ему выгодно.
В таком случае вы можете подумать, что потеряли ключевую информацию в поддержку своего дела. К счастью, вам еще не повезло!
Сегодняшний Интернет, к лучшему или к худшему, создает резервные копии старых версий веб-сайтов.Они делают это, заставляя свои инструменты «ползать» по Интернету и фотографировать все, что видят.
Между этим и другими творческими средствами вы можете найти нужные удаленные веб-страницы. Вот несколько советов по лучшим вариантам восстановления.
1. Сделайте юридический запрос
Хотя мы можем лично говорить об эффективности этого, теоретически ваша фирма может обратиться к ответчику с юридическим запросом о передаче старых версий веб-сайта. Этот запрос может быть связан с вашим обвинением в сговоре с целью уничтожения улик.
Юридические группы защиты могут иметь другую точку зрения, которая может создать тупик.![]() Тем не менее, если спросить, нечего терять.
Тем не менее, если спросить, нечего терять.
Вы можете обнаружить, что напуганные обвиняемые, которые не спешат добираться до юридического совета, быстро подчиняются.
2. Загляните в кэш своего браузера
Кэш— это сохраненная информация с посещенных вами сайтов, которая хранится на вашем локальном компьютере. Цель кеширования — позволить людям, которые уже посещали сайты раньше, быстро загружать страницы, вместо того, чтобы загружать их заново с нуля.
В зависимости от настроек вашего браузера кеш сайта может быть сохранен на вашем компьютере. Получив доступ к этому кешу, вы теоретически могли видеть старые версии веб-сайтов. Ваша возможность сохранить кеш страницы частично зависит от настроек кеша соответствующего сайта.
3. Проверьте кэш Google
Когда Google сканирует веб-сайты в поисковой системе, он сохраняет кешированные версии страниц. К этим кешированным страницам можно получить доступ через результаты поиска, чтобы увидеть исторические версии веб-сайта.
Чтобы просмотреть кешированную версию страницы результатов поиска Google, просто нажмите стрелку раскрывающегося списка рядом с адресом веб-сайта, наведите указатель мыши на «кэшировано» и нажмите.
4. Попробуйте кэш другой поисковой системы
Может показаться, что это так, но Google определенно не единственная поисковая система в городе. Другие поисковые системы, такие как Yahoo и Bing, также сканируют и индексируют страницы. Поэтому, если в кеше Google не отображаются результаты, которые вы хотите найти, возможно, это покажет Bing или Yahoo.
Перейдите к этим системам, просмотрите разделы их кэшированных страниц и посмотрите, что доступно.
5. Попробуйте Wayback Machine
Один из самых популярных способов просмотра старых версий веб-сайтов — через Wayback Machine. Эта «машина» на самом деле является веб-сайтом, созданным Интернет-архивом.
Назначение Wayback Machine — поиск в сети для сохранения страниц и создания сжатой цифровой записи. Затем эти страницы индексируются в календаре, который позволяет пользователям быстро и легко просматривать исторические версии страниц и понимать, когда эти страницы были активными.
Затем эти страницы индексируются в календаре, который позволяет пользователям быстро и легко просматривать исторические версии страниц и понимать, когда эти страницы были активными.
Например, вот сохраненная на Wayback Machine версия старой версии Amazon.com.
The Wayback Machine не является надежным, поскольку пользователи могут размещать маршруты в файле robots.txt своего сайта, который сообщает Wayback Machine не сохранять свои страницы. Инструмент должен соответствовать таким запросам, поскольку сохранение работ других людей, защищенных авторским правом, является средством нарушения.
6. Перейти на веб-сайт
Когда интернет-авторы ссылаются на источники в Интернете, эти исходные материалы часто меняются.Это создает условия, при которых авторы обращаются к страницам, которые могут больше не содержать приемлемой информации.
Например, предположим, что учитель должен был предложить веб-сайт, который им нравится, и поделился ссылкой на него. Если этот веб-сайт позже преобразован в нечто неприемлемое, у этого учителя могут быть проблемы. Чтобы решить эту проблему, Webcite решил архивировать старые версии страниц, чтобы люди могли ссылаться на эти архивы, а не на динамические исходные страницы.
Если этот веб-сайт позже преобразован в нечто неприемлемое, у этого учителя могут быть проблемы. Чтобы решить эту проблему, Webcite решил архивировать старые версии страниц, чтобы люди могли ссылаться на эти архивы, а не на динамические исходные страницы.
Возможно, у Webcite есть архивная копия страницы, на которую нужно ссылаться.
7. Сохраните сайт на локальном компьютере
Чтобы использовать этот способ доступа к старым версиям веб-сайтов, необходима дальновидность. Если вы все еще в состоянии сделать это, сохранить сайт для поддержки процедуры импичмента обвиняемых (прочтите это, чтобы узнать больше) или чего-либо еще, просто нажмите «Ctrl + S» на ПК.
В результате ваш браузер загрузит текущую версию страницы, на которой вы находитесь. На этом этапе поиск нужного вам контента можно осуществить, зайдя в директорию сохранения вашего браузера.
Доступ к старым версиям веб-сайтов проще, чем когда-либо
Если вы почерпнули что-нибудь из нашего краткого руководства по поиску старых версий веб-сайтов, мы надеемся, что получить доступ к архивным данным веб-сайтов просто! Все, что вам нужно сделать, это просмотреть варианты, доступные вам онлайн и офлайн.
Когда вы это сделаете, скорее всего, вы сможете получить данные, необходимые для создания дела, над которым работаете.
Интернет может быть непростым делом даже для юристов (иногда особенно для юристов)! Если вам требуется электронное руководство или информация по другим темам, относящимся к праву, просмотрите больше материалов в нашей онлайн-публикации.
Просмотры сообщений: 1,158
Просмотр истории версий нового сайта Google
Кто затронул
Конечные пользователиЗачем вам это нужно
История версий позволяет редакторам сайта легко:- Вернуться к предыдущим версиям сайта
- Восстановить удаленное содержимое сайта
- Просмотр истории тех, кто вносил изменения в сайт
Как начать работу
- Администраторы : Никаких действий не требуется, поскольку эта функция будет доступна по умолчанию для вновь созданных сайтов после ее развертывания для пользователя. Внедрение не будет осуществляться на основе домена — оно будет развертываться на вновь созданных сайтах для каждого пользователя и на существующих сайтах для каждого отдельного сайта. Не все ваши пользователи получат доступ к этой функции одновременно.
 Внедрение не будет осуществляться на основе домена — оно будет развертываться на вновь созданных сайтах для каждого пользователя и на существующих сайтах для каждого отдельного сайта. Не все ваши пользователи получат доступ к этой функции одновременно.
Внедрение не будет осуществляться на основе домена — оно будет развертываться на вновь созданных сайтах для каждого пользователя и на существующих сайтах для каждого отдельного сайта. Не все ваши пользователи получат доступ к этой функции одновременно.Дополнительные сведения
Как узнать, доступна ли история версий для моего сайта?
Вы увидите «Журнал версий» в качестве опции, когда вы нажмете дополнительное (трехточечное) меню при редактировании сайта или когда вы выберете «Все изменения, сохраненные на Диске» в верхней строке меню.
Будет ли история версий доступна для существующих сайтов?
Мы постепенно вводим историю версий для существующих сайтов в течение 2020 года и ожидаем, что большинство существующих сайтов будут иметь историю версий к концу года.
Из-за изменений, необходимых для предоставления пользователям этой функции, история версий будет доступна для каждого сайта для существующих сайтов и для каждого пользователя для вновь созданных сайтов. Таким образом, пока эта функция не будет полностью развернута, пользователи могут иметь историю версий для одних сайтов, но не для других.
Таким образом, пока эта функция не будет полностью развернута, пользователи могут иметь историю версий для одних сайтов, но не для других.
Если пользователь, у которого включена история версий, создает новый сайт, будут ли другие редакторы иметь доступ к истории версий на этом сайте?
Да, после того, как сайт был создан пользователем с включенной историей версий, другие пользователи, редактирующие этот сайт, смогут получить доступ к истории версий этого сайта.
Когда история версий начинает собирать и сохранять изменения содержимого сайта?
Любые изменения, сделанные до того, как история версий станет доступной, не будут сохранены.Изменения регистрируются только после того, как функция становится доступной для этого конкретного сайта.
Что считается «вновь созданным» сайтом?
Любой сайт, созданный с главного экрана Сайтов, Google Диска или sites.new, считается вновь созданным сайтом и будет иметь историю версий, как только функция станет доступной для создателя сайта.
Преобразование сайта из классических Сайтов Google в новые Сайты Google или создание копии существующего нового Сайта Google не считается вновь созданным сайтом.
Полезные ссылки
Доступность
Сведения о развертывании Недавно созданные сайты:
- Домены быстрого выпуска: расширенное развертывание (потенциально более 15 дней для видимости функций) начиная с 4 декабря 2019 г.
- Запланировано Домены выпуска: расширенное развертывание (потенциально более 15 дней для видимости функций), начиная с 4 декабря 2019 г.
Существующие сайты:
- Мы ожидаем, что большинство существующих сайтов будут иметь историю версий к концу 2020 года. Мы обновим эту публикацию, как только начнется развертывание и как только оно будет завершено.
Выпуски G Suite
- Доступно для всех выпусков G Suite
Включено / выключено по умолчанию?
- Эта функция будет доступна по умолчанию.
Будьте в курсе последних новостей о выпуске G Suite
Что изменилось
Мы начинаем добавлять историю версий для сайтов, созданных в новых Google Сайтах, что очень востребовано владельцами и редакторами наших сайтов.История версийбудет разворачиваться в течение 2020 года как для пользователей, создающих новые сайты, так и для уже существующих сайтов. История версий будет постепенно включаться для каждого пользователя для вновь созданных сайтов, в то время как отдельное развертывание позволит включить историю версий для ранее существующих сайтов. Мы ожидаем:
- К марту 2020 года у всех пользователей будет включена история версий для вновь созданных сайтов
- К концу 2020 года на большинстве существующих сайтов будет включена история версий
Кто затронул
Конечные пользователиПочему вы? d использовать его
История версий позволяет редакторам сайта легко:- Вернуться к предыдущим версиям сайта
- Восстановить удаленное содержимое сайта
- Просмотр истории того, кто внес изменения на сайт
Как начать работу
- Администраторы : никаких действий не требуется, так как эта функция будет доступна по умолчанию для вновь созданных сайтов после ее развертывания для пользователя.Внедрение не будет осуществляться на основе домена — оно будет развертываться на вновь созданных сайтах для каждого пользователя и на существующих сайтах для каждого отдельного сайта. Не все ваши пользователи получат доступ к этой функции одновременно.
Дополнительные сведения
Как узнать, доступна ли история версий для моего сайта?
Вы увидите «Журнал версий» в качестве опции, когда вы нажмете дополнительное (трехточечное) меню при редактировании сайта или когда вы выберете «Все изменения, сохраненные на Диске» в верхней строке меню.
Будет ли история версий доступна для существующих сайтов?
Мы постепенно вводим историю версий для существующих сайтов в течение 2020 года и ожидаем, что большинство существующих сайтов будут иметь историю версий к концу года.
Из-за изменений, необходимых для предоставления пользователям этой функции, история версий будет доступна для каждого сайта для существующих сайтов и для каждого пользователя для вновь созданных сайтов. Таким образом, пока эта функция не будет полностью развернута, пользователи могут иметь историю версий для одних сайтов, но не для других.
Если пользователь, у которого включена история версий, создает новый сайт, будут ли другие редакторы иметь доступ к истории версий на этом сайте?
Да, после того, как сайт был создан пользователем с включенной историей версий, другие пользователи, редактирующие этот сайт, смогут получить доступ к истории версий этого сайта.
Когда история версий начинает собирать и сохранять изменения содержимого сайта?
Любые изменения, сделанные до того, как история версий станет доступной, не будут сохранены.Изменения регистрируются только после того, как функция становится доступной для этого конкретного сайта.
Что считается «вновь созданным» сайтом?
Любой сайт, созданный с главного экрана Сайтов, Google Диска или sites.new, считается вновь созданным сайтом и будет иметь историю версий, как только функция станет доступной для создателя сайта.
Преобразование сайта из классических Сайтов Google в новые Сайты Google или создание копии существующего нового Сайта Google не считается вновь созданным сайтом.
Полезные ссылки
Доступность
Сведения о развертывании Недавно созданные сайты:
- Домены быстрого выпуска: расширенное развертывание (потенциально более 15 дней для видимости функций) начиная с 4 декабря 2019 г.
- Запланировано Домены выпуска: расширенное развертывание (потенциально более 15 дней для видимости функций), начиная с 4 декабря 2019 г.
Существующие сайты:
- Мы ожидаем, что большинство существующих сайтов будут иметь историю версий к концу 2020 года. Мы обновим эту публикацию, как только начнется развертывание и как только оно будет завершено.
Выпуски G Suite
- Доступно для всех выпусков G Suite
Включено / выключено по умолчанию?
- Эта функция будет доступна по умолчанию.
Будьте в курсе последних новостей о выпуске G Suite
Как просматривать утерянные веб-страницы
Если веб-страница, которую вы хотели открыть, недоступна — причины могут варьироваться от временной сетевой проблемы до полного удаления страницы с веб-сайта — тогда вам не нужно терять надежду.На самом деле можно восстановить резервные копии большинства страниц из Интернета с помощью небольшого ноу-хау. Весь процесс невероятно прост, и вы найдете его очень полезным, если изучите тему и обнаружите, что ссылки, которые вы сохраняли в течение недель или даже месяцев, больше не работают.
Если вы хотите прочитать веб-страницу, которая была удалена или по другим причинам недоступна, это то, что вы можете сделать.
Wayback Machine
Архив.Организация Wayback, вероятно, является лучшим инструментом для восстановления любой удаленной веб-страницы. Это часть Интернет-архива, некоммерческой организации, которая пытается дублировать весь контент в Интернете. Он сохранил более 435 миллиардов веб-страниц, что, вероятно, не весь контент в Интернете, но все же впечатляет. Страницы фиксируются несколько раз, поэтому, например, мы использовали Wayback Machine, чтобы просмотреть домашнюю страницу NDTV Gadgets в течение нескольких разных лет, и увидели, что наш дизайн со временем эволюционировал.
Вот как им пользоваться.
Откройте сайт Wayback.
Введите URL-адрес отсутствующего веб-сайта или веб-страницы, которую вы хотите открыть, в поле вверху.
Нажмите Обзор истории .
Вы увидите представление календаря. Выберите год вверху, а затем дату из списка месяцев ниже.
Вот и все! Вам будет показана сохраненная версия страницы с этой даты.
Кэш поисковой системы
Если вы ищете страницу, которая была недавно удалена, то, возможно, будет проще найти ее с помощью поисковой системы, такой как Google, Yahoo или Bing.Пока вы можете найти веб-страницу в поисковой системе, вы также сможете загрузить резервную копию страницы. Вот как это работает:
Откройте понравившуюся поисковую систему. Кеширование Google очень хорошее, поэтому мы рекомендуем вам его использовать.
Вставьте ссылку на отсутствующую веб-страницу в строку поиска, если она вам известна, или просто выполните поиск страницы, чтобы найти нужную ссылку.
Под синим текстом ссылки вы увидите строку зеленого текста, которая является URL-адресом веб-страницы.Щелкните стрелку вниз рядом с зеленым текстом URL-адреса.
Нажмите Кэшировано . Это покажет вам сохраненную версию нужной страницы, а также подробную информацию о том, когда была сделана резервная копия.
Если эта страница не загружается должным образом, вы можете попробовать щелкнуть Текстовая версия вверху справа. Это приведет к потере всех изображений, которые были на странице, но, если они загружаются неправильно, это все равно позволит вам получить важные данные, которые вам нужны.
Сохранение необходимых веб-страниц
Если вы хотите сохранить веб-страницы для исследовательских целей, лучше сохранить их заранее. Сделать это из браузера очень просто:
Перейдите на веб-сайт, который хотите сохранить.
Нажмите Ctrl + S .
Дайте ему любое имя файла и нажмите Сохранить .
Эта страница сохранит страницу на вашем компьютере, и вы сможете получить к ней доступ в любое время.Если вы не используете свой компьютер, вы всегда можете использовать сторонние сервисы, такие как Pocket, для сохранения веб-страниц для чтения в автономном режиме — после установки расширения сохранять страницы так же просто, как нажимать кнопку Pocket в своем браузере, когда вы ‘ повторно прочтите страницу, которую вы хотите сохранить, или щелкните правой кнопкой мыши ссылку и выберите Сохранить в Pocket .
Для получения дополнительных руководств посетите наш раздел «Как сделать».
Получение и архивирование информации с веб-сайтов — документация The Kit 1.0
Вкратце: Вы изучите способы найти и восстановить исторические и «потерянные» информация с веб-сайтов, чтобы служить доказательством того, что что-то существовало онлайн, а также способы архивирования и сохранения ваших собственных копий веб-страниц для дальнейшего использования.
Иногда, когда вы хотите проверить информацию в Интернете, вы попадаете следуя по следу, ведущему к неработающим ссылкам или к веб-сайтам, которые доступно больше.
В других случаях вы встретите веб-сайты с важной информацией, которая может повысить ценность истории, но вы не осознаете ее ценность, пока потом.
Когда вы повторно посетите этот веб-сайт, чтобы задокументировать его, вы можете обнаружить, что он больше не существует, что конкретная веб-страница, которую вы помните был удален или что нужная вам информация больше не доступен и был заменен новым контентом.
Вы, вероятно, столкнетесь со всеми этими проблемами в какой-то момент во время ход ваших расследований.
Что, если бы существовал способ отправиться в прошлое и получить копию эта веб-страница или даже ее часть до того, как она была изменена или взята вниз?
К счастью, есть несколько простых способов восстановить старый контент и удалить его. страниц, чтобы вы по-прежнему могли ссылаться на них в своем расследовании. Вы можете также сохраните доступные в данный момент страницы, чтобы вы могли использовать их позже, даже если они тем временем изменены или удалены.
Есть несколько таких сервисов, которые автоматически архивируют предыдущие версии сайтов. Помимо контента, эти цифровые архивы часто содержат информацию, которая может помочь вам идентифицировать другие важные данные, такие как как владелец веб-сайта, полезные имена, контактные данные, документы и ссылки на другие сайты. Некоторые из этих услуг позволяют вам вносить свой вклад в список веб-сайтов, которые они архивируют, время от времени сохраняя веб-страницы вручную на ваш выбор. Затем вы (и другие) можете получить снимки этих веб-сайты позже.
Скриншот копии Wayback удаленной в настоящее время веб-страницы Facebook в разделе «Истории успеха — Правительство и политика».
Что еще важнее, некоторые старые контент доступен, так как некоторые старые ссылки с заархивированной страницы все еще работают, поэтому вы можете на самом деле читал о деталях их проектов политической кампании.
В архивных версиях подобных веб-сайтов сохраняется информация, которая может быть невероятно ценным для следователей.
Безопасность прежде всего!
Когда вы направляете службу архивации на интересующую вас веб-страницу, она просканирует эту веб-страницу и сохранит ее копию.Когда это произойдет, веб-страница, находящаяся в архиве, автоматически добавит запись к текущему «Журнал доступа» (который ведется на большинстве веб-сайтов) о том, когда и по какому IP адресов, он был посещен.
Внимательный администратор сайта или автоматизированный процесс может затем поймите, что часть их сайта была заархивирована Wayback Machine.
Это, в свою очередь, может дать им ключ к разгадке того, что кто-то расследует конкретный фрагмент контента или лицо, имеющее к ним отношение. В некоторых случаях это само по себе может уменьшить влияние вашего расследования, если вы являются деликатными и должны храниться вдали от посторонних глаз, поскольку хоть какое-то время.
Как минимум, администратор сайта может иметь заархивированные материалы. удалено из Wayback Machine. (Это одна из причин, почему это хороший идея сделать свою собственную офлайн-копию всего, что важно для вашего расследование.) Этот администратор может также удалить или изменить аналогичные контент, который вы еще не нашли.
Большинство служб архивирования также хранят журналы доступа.
Webcite , например, записывает операционную систему компьютера и Интернет браузер каждого пользователя, а также доменное имя интернет-службы каждого пользователя провайдеры (политика конфиденциальности Webcite).это поэтому рекомендуется активировать виртуальную частную сеть (VPN) или использовать Tor Браузер при работе с архивами.
Кроме того, некоторые службы требуют, чтобы каждый пользователь создал учетную запись, чтобы выберите имя пользователя, чтобы предоставить платежную информацию, чтобы подтвердить электронную почту адресов или связать профиль в социальных сетях.
Вам следует рассмотреть возможность создания отдельного набора учетных записей для использования с такими сервисами, чтобы разделить (отделить) ваши следственная работа с использованием вашей личной информации в Интернете.
В некоторых случаях вы можете даже захотеть создать одноразовую «идентификационную информацию» для конкретного расследования и избавиться от нее после завершения исследования.
В любом случае первым шагом будет создание относительно безопасного, разделенная учетная запись электронной почты, которую вы можете довольно легко сделать на tutanota.de или protonmail.com.
Оплата коммерческих услуг способом, не имеющим обратной связи с вашим личность намного сложнее. Если вы живете в регионе, где вы можете купить предоплаченную кредитную карту наличными, это может быть вашим лучшим вариантом вариант.
В потенциальной ситуации выше — администратор сайта, который замечает внезапный интерес со стороны Wayback Machine — стоит отметить что предмет вашего расследования не обязательно может отследить это интерес вернулся к вам. Если вы, ваша служба архивирования заслуживает доверия, и если никто не имеет доступа как к журналам веб-сайта, так и к архиву журналы службы, этому администратору может быть трудно подключиться точки.
Тем не менее, лучше принять меры предосторожности, рекомендованные выше, чем полагаться на это предположение.- Предположим, например, что только горстка IP-адресов просмотрели заархивированную страницу в тот же день, когда она была добавлен в Wayback Machine. Было бы легко понять выяснилось, что за ними наблюдают с определенного места.
Любое небольшое вложение времени, прежде чем вы начнете свое расследование, может помочь вам ограничить такого рода риски.
Архивирование и получение контента с помощью Wayback Machine
The Wayback Machine является проектом некоммерческий Интернет в Сан-Франциско Архив, цифровая библиотека, которая была посвященный сохранению миллиардов веб-сайтов с 1996 года, в рамках усилия по архивированию Интернета и обеспечению всеобщего доступа для всех знание.По состоянию на начало 2019 года в нем хранится около 345 миллиардов веб-сайты.
Машина обратного пути
The Wayback Machine — незаменимый инструмент для исследователей, историков, исследователи и ученые. Он находится в свободном доступе для общественности и может помочь вам получить доступ к архивным снимкам веб-страниц, сделанным в различных точках во время.
Автоматические сканеры Wayback Machine (также называемые пауками) могут получать доступ и архивировать практически любой общедоступный веб-сайт. Однако у роботов нет фиксированного шаблон принятия решения о том, какие веб-сайты они посещают и как часто они это делают, поскольку они подвержены ограниченным ресурсам и политическим решениям, которые влияют на их работу.
В результате вы не всегда можете найти архивную версию из определенного день, месяц или даже год. Кроме того, веб-сайты могут отказаться от заархивированы такими сервисами, как Wayback Machine. Публикуя набор ограничения в текстовом файле robots.txt, веб-сайт может указать поисковые роботы, чтобы исключить часть или все его содержание из архива или индексация. Тем не менее, огромный массив данных Wayback Machine будет вероятно, будет незаменим во многих ваших исследованиях.
Примечание:
Роботы.txt — это файл, который находится на веб-сайте и перечисляет части сайт, который должен или не должен быть доступен сканерам. Если на сайте есть файл robots.txt, вы можете просмотреть его, добавив «/robots.txt» в его домен. или субдомен. Например: https://google.com/robots.txt.
Веб-сайты могут использовать этот файл для блокировки поисковых роботов от Wayback Machine, из поисковых систем, таких как Google, или из любого другого индексирования или архивирования служба. Есть ряд причин, по которым некоторые администраторы веб-сайтов выберите роботов с ограничениями.txt: чтобы ограничить расходы на пропускную способность и снизить нагрузку на перегруженные серверы, чтобы защитить изображения товарных знаков или оставить незаконченными например, не показывать веб-сайты в результатах поиска. В некоторых случаях, однако они делают это для того, чтобы скрыть потенциально конфиденциальный контент.
В то время как Wayback Machine не всегда исполнять с этими ограничениями по-прежнему есть много веб-сайтов, которые его сканеры отказаться от архивации из-за директив robots.txt. Если у вас есть проблемы с использованием Wayback Machine для просмотра или архивирования некоторых, но не всех страницы на веб-сайте, вы можете проверить его robots.txt, чтобы узнать, есть ли части сайта «запрещены».
Помимо простого интерфейса для автоматического получения заархивированные веб-сайты, Wayback Machine также позволяет вручную хранить снимки веб-страниц, чтобы вы могли убедиться, что они внезапно не пропадать.
Эта служба может не только архивировать веб-страницы, относящиеся к вашему расследования, но это также дает вам простой способ цитировать исследования и ссылки на контент по мере того, как ваше расследование обретает форму.
Хотя часто бывает полезно сохранять копии важных файлов в формате HTML или PDF, веб-страниц на свои устройства, чтобы убедиться, что у вас есть несколько резервные копии, архивирование их с помощью Wayback Machine может добавить элемент нейтралитет и доверие, если вы в конечном итоге поделитесь этими архивами с другими. Кроме того, для большинства людей это намного удобнее, чем поддерживать автономная библиотека цифровых файлов.
Поиск страниц с помощью Wayback Machine
Чтобы найти страницу, которая больше не доступна, или просмотреть старую версию веб-страницы, просто перейдите на https: // web.archive.org и войдите в сеть адрес, который вы ищете.
Если страница ранее была заархивирована, даты ее сохранения будут появляются в календаре текущего года. Вы можете перейти к предыдущему лет, используя временную шкалу, которая также отображает график того, как часто страница архивировалась каждый год. После нажатия на год, в котором вы находитесь интересно, архивы этого года будут отмечены в календаре значком цветные точки.
Здесь мы используем пример https: // cambridgeanalytica.org /, веб-сайт, который был закрыт в 2018 году из-за закрытия компании (см. выше пример скандала с Cambridge Analytica).
Скриншот календаря Wayback Machine для доступа к веб-сайту Cambridge Analytica
Синяя точка означает, что на данном веб-сайте был сделан полный захват веб-страницы. Дата. Обычно это именно те архивы, которые вы ищете. Зеленые точки указывает на то, что когда сканер получил доступ к этому веб-адресу, он был автоматически перенаправляется на другую страницу того же сайта.Эти архивы могут не содержать того контента, который вы ищете. Оранжевые и красные точки указывают на то, что во время архивирования произошла ошибка. процесс, возможно, из-за ошибки сканера или веб-сайта сервер. Большая точка означает, что несколько архивы хранились в тот день. Вы можете навести на них курсор, чтобы выбрать конкретные архивируются в зависимости от времени суток.
После выбора архивной версии страницы Wayback Machine Панель навигации отображается в верхней части экрана.Это позволяет вам просматривать различные архивы этой страницы с помощью шкалы времени или нажав на кнопки «следующий» и «предыдущий».
* Заархивированная страница Cambridge Analytica в Wayback Machine *
Совет:
Чтобы помочь установить действительность ваших онлайн-доказательств, вам может потребоваться проверить точную дату и время, когда Wayback Machine просканировала и заархивировала веб-страницу. Вы можете сделать это, проверив «отметку времени», встроенную в веб-адрес архива.Эта метка времени имеет формат из четырех цифр года, за которым следуют две цифры месяца, дня и т. Д. час, минута и секунда, когда архив был захвачен. Вы можете найти его между «https://archive.org/web/» и веб-адресом заархивированной страницы. Например, следующий архив был снят в 2017 году, 31 st августа, в 06:00 и 27 секунд: https://web.archive.org/web/20170831060027/https://cambridgeanalytica.org.
Методы быстрого поиска с помощью браузера
The Wayback Machine также позволяет запрашивать определенный веб-сайт. архив, который он хранит, не просматривая его интерфейс поиска.Вместо этого вы можете сделать это в собственном браузере, правильно зайдя в отформатированный веб-адрес.
Просто добавьте адрес веб-сайта в конец Wayback Machine. адрес:
«https://web.archive.org/www.yoursite.com/» (где «www.yoursite.com/» — это любой сайт, на котором вы хотите выполнить поиск)
- Ваш браузер отобразит последнюю заархивированную версию сайта, который вы желаю посмотреть.
Далее:
- Если вы разделите два адреса звездочкой (*), ваш браузер загрузит представление календаря архива: «Https: // web.archive.org/*/www.yoursite.com/ ”
- Если вы также добавите звездочку в конец, Wayback Machine будет показать вам все архивы в этом домене, а не только домашняя страница: «https://web.archive.org/*/www.yoursite.com/*»
Например, переход к https://web.archive.org/web/*/cambridgeanalytica.org/* отобразит постраничный список всех cambridgeanalytica.org страницы, заархивированные Wayback Machine.
Список страниц Cambridge Analytica в Wayback Machine
Использование Wayback Machine для архивирования веб-страниц
Еще одной ключевой особенностью Wayback Machine является возможность архивирования веб-страницы по запросу.
Если вы хотите сохранить и сохранить информацию для расследование или обеспечение доступности вашей опубликованной работы, вы можете перейти на https://archive.org/web и найти «Сохранить страницу Сейчас »к нижнему правому углу страницы. Просто введите веб-адрес (например, «http://www.yoursite.com/projects») и щелкните кнопку «СОХРАНИТЬ СТРАНИЦУ».
Если только указанный вами веб-сайт не запретил доступ к Интернет-архиву краулеры, как описано в файле robots.txt выше, Wayback Машина начнет его архивирование. Вы увидите индикатор выполнения, который будет сообщит вам, когда страница будет сохранена. В этот момент вы будете может просматривать архив страницы, а на временной шкале будут отображаться любые предыдущие снимки с этого сайта.
Веб-страница Saving Guardian на Cambridge Analytica в Wayback Machine
Сохраненная веб-страница Guardian на Cambridge Analytica в Wayback Machine
Примечание:
Приведенные выше шаги будут архивировать только отправленную вами страницу. («Http: // www.yoursite.com/projects », в данном случае) не весь контент на этом веб-сайте. Если вы хотите заархивировать весь веб-сайт с помощью этого метода, вы нужно подавать каждую страницу отдельно.
Кроме того, эта функция не гарантирует, что регулярные архивы страница будет сохранена в будущем, так что вы можете захотеть вернуться Wayback Machine время от времени запрашивать дополнительные снимки.
Скачивание содержимого архива
К сожалению, Интернет-архив не позволяет выполнять поиск в полный текст всех сайтов в огромном архиве.Хотя он предлагает функция поиска по основным страницам определенных архивов, она не в настоящее время индексируются все 345 миллиардов страниц. Если вы хотите искать через заархивированный контент из определенного домена, однако есть способ сделать это.
Если вы установите язык программирования Ruby на своем компьютер (версия 1.9.2 или выше), вы можете использовать Wayback Машина Загрузчик сценарий для загрузки всех заархивированных файлов в данном домене. Этот сценарий позволяет указать диапазон дат, который вы хотите загрузить, что может будет полезно, если вы работаете с сайтами, которые были заархивированы для несколько лет.
Ограничения Wayback Machine
Как упоминалось выше, не все веб-сайты автоматически или регулярно заархивировано Wayback Machine.
сайтов выбираются на основе алгоритмов, использующих такие критерии, как частота люди посещают их и как часто другие веб-сайты ссылаются на них (что также показатель достоверности). Некоторые из этих данных получены из рейтинги составлены Alexa , ведущим веб-трафик, статистика и аналитика компании.
Кроме того, Интернет-архив запускает собственные поисковые роботы и работает с сотни добровольцев, которые выполняют поиск и архивируют веб-сайты в сохранить изобилие информации в Интернете.
Хотя вы можете архивировать определенные страницы вручную, как показано выше, вы не можете влиять на набор веб-сайтов, которые Wayback Machine будет автоматически и регулярно архивировать.
У Wayback Machine есть и другие ограничения. Примеры включают:
- Сайты, защищенные паролем, не архивируются.
- Динамические веб-сайты, которые в значительной степени полагаются на JavaScript, не могут быть заархивированы правильно.
- Администраторы веб-сайтов могут явным образом требовать, чтобы их сайты не можно заархивировать, опубликовав ограничительный файл robots.txt, как см. выше, или отправив прямой запрос в Интернет-архив.
- Администраторы веб-сайта могут запросить ранее заархивированный контент быть удаленным из Wayback Machine.
- В настоящее время полнотекстовый поиск в Интернете недоступен. Архив.
Пример:
Чтобы проиллюстрировать, как иногда могут исчезать архивы, был использован Интернет-архив. недавно был в центре дебатов по поводу блога журналиста Джой-Энн. Рид. Адвокаты Рейда обратились к Интернет-архиву и попытались удалить заархивированные версии ее блога, утверждая, что некоторые из ее статьями манипулировала неизвестная сторона, вставившая мошенническое содержание в ее трудах — содержание, которое затем было заархивировано с блог.
Когда это не помогло, блог Рейда просто изменили свои robots.txt файл, чтобы ограничить доступ сканеров Wayback Machine. Когда поисковые роботы уловили изменение и автоматически удалили архив в целом. Этот случай показывает, как люди и организации может использовать как юридические, так и технические средства для удаления содержания из этих сторонние архивы.
В Европейском Союзе и некоторых других регионах Право на забвение предоставляет людям возможность запрашивать поисковые системы и цифровые архивы удаляют связанный с ними проиндексированный контент, который, по их мнению, вредные или клеветнические.Это право имеет ограничения, поэтому не все могут или будут удалены по запросу, но стоит помнить, что некоторые субъекты вашего расследования (политики, преступники и др. противоречивые цифры) могли использовать возможность снести связанный с ними интернет-контент, имеющий отношение к вашему расследованию.
Примечание:
Имейте в виду, что доменные имена можно продавать, а заброшенные доменные имена можно перерегистрировать. Как В результате иногда одним доменом с течением времени управляют несколько владельцев.В таких случаях веб-сайт архивная история может быть непостоянной, а старые материалы могут не иметь отношения к вашему расследованию.
Другие способы получения и архивирования веб-страниц
Архив сегодня
Archive.today (ранее archive.is) веб-страницы очень похожи на Wayback Machine.
Archive.today отличается, однако, хранением только отдельных страниц, а не чем целые веб-сайты, и делает это только по запросу пользователей, не автоматически.
Вот пример заархивированных страниц из https://cambridgeanalytica.org/:
* Cambridge Analytica доступно в Archive.today *
Поскольку он не сканирует сайты, у него нет почти полного информацию вы можете найти на Wayback Machine.
Однако он предоставляет три ключевые функции:
- Во-первых, в отличие от Wayback Machine, он позволяет искать по всему текст его архивов.
- Во-вторых, он игнорирует любые ограничения, которые могут быть указаны в роботы.txt веб-сайтов, которые он архивирует. В результате это может сохранять снимки некоторых страниц, которые Wayback Machine не может, такие как общедоступные профили в Facebook и сообщения в Twitter.
- В-третьих, он также сохраняет как текстовую копию, так и графический снимок экрана заархивированных страниц. Иногда это дает большая точность, чем сохранение самой страницы, особенно когда архивирование быстро меняющегося содержимого (например, прокручивающихся изображений или снимки сообщений форума и т. д.).
Вы можете найти архив веб-страницы, введя ее точный веб-адрес (например, как «https: // cambridgeanalytica.org ») или используйте подстановочный знак (*) чтобы найти заархивированные поддомены или подкаталоги веб-сайта (например, «* .Cambridgeanalytica.org»). Вот поиск * .cambridgeanalytica.org в архиве сегодня:
Найдите Cambridge Analytica в архиве. Сегодня
Как и Wayback Machine, archive.today предоставляет вам прямые ссылки к заархивированному контенту с использованием веб-адресов со встроенными отметками даты, вроде следующего: http://archive.today/2018.01.01-042001/ https://ocean.cambridgeanalytica.org/
Совет:
Archive.today также предлагает сервис Tor onion на сайте archivecaslytosk.onion. Доступ к сервисам Onion можно получить только через браузер Tor, но они упрощают сохранение ваших взаимодействие с сервисом анонимно. Это особенно полезно и жизненно важно, если вы исследуете деликатная тема, или вы подозреваете, что ваши действия в Интернете могут отслеживаться.
Кэш Google
Google Cache — еще один способ найти страницу, которая была недавно занята вниз или недоступен по иным причинам.
Когда Google обращается к веб-странице, он создает кэшированную версию или копию этой страницы в качестве резервный. Он часто делает эти копии доступными в результатах поиска.
Чтобы получить доступ к кэшированной версии страницы Google, используйте поисковая система для поиска страницы, которую вы хотите найти, нажмите на маленькая стрелка справа от веб-адреса результата поиска и выберите «Кэшировано». Это загрузит кешированную версию веб-сайта, который был поддержан поднял Google, когда его сканеры ранее проиндексировали сайт.
Скриншот Google Cache
В приведенном выше случае мы попытались найти кеш ныне несуществующей веб-сайт http://cambridgeanalytica.org/, но по состоянию на 28 февраля 2019 г. больше не доступен в поиске Google (мы могли найти только веб-форму вместо). Однако его кешированная версия все еще была доступна 26 декабря. Февраль 2019 г., и, как показано ниже, мы смогли захватить с помощью архив.сегодня
Cambridge Analytica в архиве.сегодня
В отличие от упомянутых выше служб архивирования, кеш Google не предоставить исторические записи о страницах, которые он хранит.
Вместо этого он отображает содержимое этих страниц в последний раз, когда поисковые роботы получили к ним доступ, поэтому они могут выявить контент, который отсутствует в текущую версию веб-страницы или предоставить вам доступ к странице, на которой с тех пор был снят.
Обнаружение кэшированной веб-страницы указывает на то, что она когда-то существовала, но кеши часто перезаписываются обновленным содержимым или полностью исчезают (как в нашем случае выше).Кроме того, администраторы веб-сайтов могут запросить у Google удаление страниц из кеша.
По той или иной причине Google не может долго хранить кешированную страницу. достаточно, чтобы вы могли использовать его в качестве доказательства в своем расследовании, так что это часто бывает полезно создать резервную копию самой кэшированной страницы с помощью дополнительных сервис, такой как archive.today, и сделать свою собственную автономную копию как резервный. Снимки экрана и PDF-файлы полезны для документирования того, как вы нашли конкретная версия страницы и может помочь вам позже, если вам нужно продемонстрировать, что информация точна.
Совет:
Когда вы архивируете веб-страницу с помощью службы, такой как Wayback Machine или archive.today, особенно если у нее длинный и сложный веб-адрес, например, архивная копия записи в Google Cache, обязательно запишите эту ссылку где-нибудь в файле на вашем компьютере. компьютер, в защищенной облачной папке или в другом месте. Полагаться на историю вашего браузера для поиска таких вещей — верный путь к катастрофе.
Веб-сайт
Webcite — это бесплатный сервис, предлагает способ сохранить ссылки, которые были процитированы в статьях или журналы, включая веб-страницы или другой цифровой контент в Интернете.
Веб-сайт
Этой службой обычно пользуются авторы, редакторы, исследователи и издатели, которые хотят сохранить онлайн-ссылки в своей работе.
WebCite позволяет быстро вручную сохранять отдельные веб-страницы. адреса. Также есть служба, которая автоматически «прочесывает» загруженные текстовые документы, чтобы сохранить все цитаты из онлайн-источники.
WebCite поддерживает несколько различных способов поиска цитируемого материала. В Помимо удобочитаемых и сокращенных веб-адресов, WebCite также предоставляет цитаты с более продвинутыми справочными форматами, такими как DOI (Digital Идентификатор объекта) и криптографические хэши.
Вы можете отправлять контент в WebCite, используя букмарклет или веб-форму по адресу https://www.webcitation.org/archive.
Примечание: Визуальные мониторы
Еще одна возможность получать содержимое веб-сайта и оставаться в курсе, если таковые имеются изменения происходят в использовании визуальных мониторов сайта. Это услуги, которые может отслеживать и отслеживать визуальные изменения на веб-страницах, происходят ли они в код, изображения, текст и т. д. Они могут быть очень полезны для исследователей и помочь автоматизировать часть работы, если вам нужно отслеживать множество веб-сайтов, полезны в вашем расследовании.
Visual site отслеживает архивные веб-страницы иначе, чем инструменты и услуги, которые мы исследовали выше. Вы оказываете услугу особую раздел веб-страницы для просмотра, и он делает снимок, а затем отслеживает страницу для видимых изменений.
Если будут какие-то изменения, большие или маленькие, монитор сайта пришлет вам электронное письмо, чтобы вы знали.
В электронном письме будет ссылка на веб-сайт, на котором вы можете увидеть больше Детали. Некоторые мониторы сайтов прикрепляют скриншоты до и после изменять.
Как следователь, вы можете использовать монитор участка в сочетании с служба архивации, чтобы быть в курсе важных обновлений веб-сайта.
Чтобы уведомлять вас об изменениях, эти инструменты требуют, чтобы вы настроили учетной записи и предоставить им доступ к адресу электронной почты или телефону номер. Вы можете избежать раскрытия своей истинной личности и контактных данных, создание отдельного адреса электронной почты, особенно если вы работаете с конфиденциальными расследования.
Визуализация
Visualping предлагает бесплатный план, который позволяет контролировать до 62 веб-страниц в месяц.Это означает, что он может проверить все, что находится между двумя веб-страниц в день (он дает вам обновления для двух разных веб-страниц ежедневно, если происходят изменения) или несколько страниц в неделю, до 62 веб-страниц a в месяц (где он проверяет 62 страницы на предмет изменений один раз в месяц) — или другое комбинации, которые работают на вас. Бесплатная версия может запускать проверки ежечасно, ежедневно, еженедельно или ежемесячно для сравнения веб-страницы с ее предыдущими версиями и сообщать вам по электронной почте об изменениях текста, изображений, ключевых слов или любые выбранные области страницы занимают место.Сервис также работает через Tor Браузер, и мы рекомендуем использовать эту опцию для дополнительного уровня конфиденциальность и безопасность.
Скриншот Visualping
ChangeTower
ChangeTower предлагает бесплатный план, который отслеживает до трех веб-сайтов и проводит до шести проверок в день (в этом случае может сканировать веб-сайт для смены два раза в день). Он может отслеживать определенный URL (веб-страницу), весь веб-сайт или различные варианты (вы можете выбрать, какие страницы веб-сайт, который вы хотите отслеживать).Он может искать изменения в содержании (текст), визуальный контент, HTML, ключевые слова и т. д. В бесплатном плане хранятся ваши мониторинг результатов до месяца. Сервис также работает через Tor Браузер, и мы рекомендуем использовать эту опцию для дополнительного уровня конфиденциальность и безопасность.
Скриншот ChangeTower
Опубликовано в апреле 2019 г.
Глоссарий
журнал доступа к термину
Журнал доступа — a файл, в котором записываются все просмотры веб-сайта и документов, изображений и другие цифровые объекты на этом веб-сайте.Он включает такую информацию как кто посещал сайт, откуда, как долго и какой контент они доступ
терм-алгоритм
Алгоритм — установленная последовательность шагов для решения конкретной проблема.
ширина полосы
Пропускная способность — в вычислениях максимальная скорость передачи информации на единица времени по заданному пути.
термин-букмарклет
Букмарклет — сложный веб-адрес, который вы можете добавить в свой список «закладки» или «избранное» браузера.Когда вы щелкаете букмарклет, он обычно отправляет информацию о странице, которую вы в настоящее время посещаете сторонний сервис.
термин-сломанная ссылка
Неработающая ссылка — URL-адрес, к которому больше не прикреплены нужные данные.
просмотр терминов повторное расширение
Расширение браузера — также называемые надстройками, они представляют собой небольшие части программное обеспечение, используемое для расширения функциональных возможностей веб-браузера. Эти могут быть чем угодно из расширений, которые позволяют делать скриншоты посещаемые вами веб-страницы на тех, кто проверяет и исправляет вашу орфографию или блокирование нежелательных добавлений с веб-сайтов.
термокэш
Кэш — временное высокоскоростное хранилище данных, которые были использованы или обрабатывается и может быть быстро восстановлен, вместо того, чтобы посещать исходный источник или повторные вычисления, связанные с запрошенными данными.
краулеры
Сканеры — программное обеспечение, которое автоматически просматривает интернет-страницы для выполнять типично исследовательские функции.
термин-криптографический хэш
Криптографический хеш — способ идентификации данных путем отправки файла или другая часть информации через алгоритм, который суммирует ее с буквенно-цифровая строка фиксированной длины (комбинация букв и числа до 100 знаков).Эту струну очень сложно сломать математически, что означает, что вы можете передать его кому-нибудь в помощь определить, является ли файл большего размера правильным или нетронутым.
справочник терминов
Каталог — контейнер, который используется для категоризации файлов или других контейнеры файлов и данных.
срок-дои
Цифровой идентификатор объекта (DOI) — уникальный идентификатор, который относится к опубликованной работе, аналогично ISBN, но для работ, опубликованных в цифровом виде.Распределение и администрирование DOI координируется DOI Foundation https://www.doi.org/.
термин-доменное имя
Доменное имя — также называемое веб-доменом, обычно используется для доступа к веб-сайту, который преобразуется в IP-адрес.
термин-ip
IP-адрес — набор числа, используемые для идентификации компьютера или местоположения данных, к которому вы подключаетесь на (например, 213.108.108.217)
термин-вредоносное ПО
Вредоносное ПО — вредоносное ПО, которое обычно скрыто от пользователей.
термин-роботstxt
Robots.txt — файл на веб-сайте, который инструктирует автоматизированные программы (боты / роботы / сканеры) о том, как вести себя с данными на веб-сайте.
термин-сервер
Веб-сервер — также известный как «Интернет-сервер», система, которая размещает веб-сайты и доставляет их контент и услуги в конечные пользователи через Интернет.
срок-скриншот
Скриншот — изображение экрана устройства, снятое в цифровом формате.
термин-сценарий
Скрипт — список команд, выполняемых программой.
термин-поддомен
Поддомен — обычно дополнительный идентификатор добавляется перед доменным именем, чтобы указать подкатегорию данных или страниц. например, google.com — это доменное имя, translate.google.com — это субдомен.
термин сторонний
Третье лицо — физическое или юридическое лицо, не являющееся непосредственно часть контракта, но, тем не менее, может иметь связанную с ним функцию.
терминатор
Браузер Tor — a браузер, который сохраняет конфиденциальность ваших действий в Интернете, маскируя ваши идентичность и защита вашего веб-трафика от многих форм Интернета наблюдение
база терминов
База пользователей — список пользователей, связанных с определенной платформой или системой.
термин-vpn
VPN — программное обеспечение, которое создает зашифрованный «туннель» из ваше устройство на сервер, управляемый вашим поставщиком услуг VPN, маскируя ваши фактический IP-адрес при посещении веб-сайтов
термин-сайт
Сайт — набор страниц или данные, предоставляемые удаленно, обычно для людей с Интернетом или сетью доступ.
термин-веб-страница
Веб-страница — документ (страница), который доступны через Интернет, отображаются в веб-браузере.
.
Ваш комментарий будет первым