10 инструментов, которые помогут найти удалённую страницу или сайт
Если, открыв нужную страницу, вы видите ошибку или сообщение о том, что её больше нет, ещё не всё потеряно. Мы собрали сервисы, которые сохраняют копии общедоступных страниц и даже целых сайтов. Возможно, в одном из них вы найдёте весь пропавший контент.
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
1. Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
Есть и альтернативный способ. Введите в браузерную строку следующий URL: http://webcache.googleusercontent.. Замените lifehacker.ru на адрес нужной страницы и нажмите Enter. com/search?q=cache:lifehacker.ru
com/search?q=cache:lifehacker.ru
Сайт Google →
2. Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
Сайт «Яндекса» →
3. Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
Сайт Bing →
4. Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Сайт Yahoo →
Сейчас читают 🔥
Специальные архивные сервисы
Указав адрес нужной веб‑страницы в любом из этих сервисов, вы можете увидеть одну или даже несколько её архивных копий, сохранённых в разное время. Таким образом вы можете просмотреть, как менялось содержимое той или иной страницы. В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
Чтобы проверить наличие копий в одном из этих архивов, перейдите на его сайт. Введите URL нужной страницы в текстовое поле и нажмите на кнопку поиска.
1. Wayback Machine (Web Archive)
Сервис Wayback Machine, также известный как Web Archive, является частью проекта Internet Archive. Здесь хранятся копии веб‑страниц, книг, изображений, видеофайлов и другого контента, опубликованного на открытых интернет‑ресурсах. Таким образом основатели проекта хотят сберечь культурное наследие цифровой среды.
Сайт Wayback Machine →
2. Arhive.Today
Arhive.Today — аналог предыдущего сервиса. Но в его базе явно меньше ресурсов, чем у Wayback Machine. Да и отображаются сохранённые версии не всегда корректно. Зато Arhive.Today может выручить, если вдруг в Wayback Machine не окажется копий необходимой вам страницы.
Сайт Arhive.Today →
3. WebCite
Ещё один архивный сервис, но довольно нишевый. В базе WebCite преобладают научные и публицистические статьи. Если вдруг вы процитируете чей‑нибудь текст, а потом обнаружите, что первоисточник исчез, можете поискать его резервные копии на этом ресурсе.
Сайт WebCite →
Другие полезные инструменты
Каждый из этих плагинов и сервисов позволяет искать старые копии страниц в нескольких источниках.
1. CachedView
Сервис CachedView ищет копии в базе данных Wayback Machine или кеше Google — на выбор пользователя.
Сайт CachedView →
2. CachedPage
Альтернатива CachedView. Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.
Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.
Сайт CachedPage →
3. Web Archives
Это расширение для браузеров Chrome и Firefox ищет копии открытой в данный момент страницы в Wayback Machine, Google, Arhive.Today и других сервисах. Причём вы можете выполнять поиск как в одном из них, так и во всех сразу.
Читайте также 💻🔎🕸
Как открыть сохраненную копию сайта, посмотреть с телефона или ПК (метод 2020 года)
В мире современных технологий мы привыкли, что у нас всегда под рукой Интернет, а вместе с ним и миллионы сайтов с различным контентом. Однако у пользователей нередко возникают ситуации, когда доступ к информации на сайте пропадает. Это происходит по нескольким причинам, при этом такая ситуация вовсе не означает, что данные утрачены безвозвратно. Найти удаленные статьи или страницы сайта помогает кеш Google.
 youtube.com/embed/txJLM2ArSt0″ src=»data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==»/>
youtube.com/embed/txJLM2ArSt0″ src=»data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==»/>
Что такое кеш сайта и зачем он нужен
Поисковая система Google оснащена так называемыми ботами, которые регулярно посещают страницы сайтов и сохраняют их в памяти поисковика. Это и есть кеш, в котором сохраненная копия сайта остается даже в том случае, если сам ресурс был удален. Следует отметить, что боты «гуляют» по Интернету достаточно активно, поэтому информация в кеше, как правило, является актуальной. Однако есть два важных нюанса:
- Чем чаще на сайте появляются новые публикации, тем чаще его посещает бот, а значит, данные будут максимально свежими.
- Нередко случается так, что после удаления статьи с сайта по этой ссылке пользователь видит сообщение об ошибке. Однако бот успел посетить эту пустую страницу и сохранил ее в кеш, удалив прошлую актуальную версию.
Разобравшись с особенностями работы кеша Google, стоит понять, для чего поисковая система хранит в памяти старые версии сайтов. Эксперты приводят несколько серьезных аргументов:
Эксперты приводят несколько серьезных аргументов:
- Страница с материалами была удалена с сайта, а вам срочно нужны именно эти данные.
- Часть информации в нужной публикации была изменена на другие материалы.
- Владелец сайта удалил его или закрыл доступ для пользователей.
- Сайт слишком перегружен, в результате чего страницы загружаются долго.
- На сайт обрушилась ддос-атака, поэтому данные оказались временно заблокированы.
- Программисты проводят технические работы, в результате чего открыть нужную страницу невозможно.
Очевидно, что главная причина поиска сохраненных страниц заключается в утерянной информации и попытке восстановить ее с помощью функционала Google. И если с причинами и особенностями кеширования все понятно, можно переходить к главному вопросу: как посмотреть старую версию сайта и сохранить нужные сведения.
Как посмотреть кеш в Google
Существует несколько способов найти удаленные страницы сайтов. Самый простой – воспользоваться стандартным поиском Google и придерживаться следующего алгоритма действий:
Самый простой – воспользоваться стандартным поиском Google и придерживаться следующего алгоритма действий:
- В поисковой строке вводим адрес сайта, с которого нужно восстановить информацию.
- В выдаче находим нужную ссылку, а под ней – маленькую стрелку зеленого цвета.
- При нажатии на стрелку появляется меню, в котором нужно выбрать графу «Сохраненная копия».
- Система автоматически переходит в архив сайтов и открывает нужные страницы.
Если для работы в Интернете вы используете Google Chrome, вам подойдет еще один простой способ, как посмотреть удаленную страницу в кеше. Для этого достаточно перед адресом сайта ввести слово «cache» и поставить двоеточие. На примере сайта htmlbook.ru это будет выглядеть так: «cache:htmlbook.ru» и далее адрес конкретной страницы, которая вам нужна.
Если по каким-то причинам перечисленные методы не подошли, найти кеш страницы можно и таким способом:
- Открываем новую вкладку в браузере и в адресную строку вставляем текст «webcache.
 googleusercontent.com/search?q=cache:» (кавычки убираем).
googleusercontent.com/search?q=cache:» (кавычки убираем). - После двоеточия без пробела вставляем адрес сайта или страницы, которую хотим найти в памяти Google.
- Переходим по ссылке и получаем доступ к последней сохраненной версии.
 googleusercontent.com/search?q=cache:» (кавычки убираем).
googleusercontent.com/search?q=cache:» (кавычки убираем).Обратите внимание! Кеш сайта – это преимущественно текстовая информация. Если на странице были размещены изображения, которые владелец удалил, восстановить их может быть не так просто, как непосредственно статью.
Google Cache Browser
У всех перечисленных способов, как посмотреть кеш в Google, есть один существенный недостаток. С их помощью можно увидеть только одну страницу сайта, после чего придется скопировать ссылку на нужный раздел и проделать всю процедуру заново. Чтобы ускорить этот процесс и получить возможность «бродить» по всему сайту, предлагаем воспользоваться сервисом http://cache.nevkontakte.com/#! и изучить все сохраненные данные в один клик.
Чтобы воспользоваться сервисом, достаточно перейти по ссылке и на главной странице ввести адрес сайта, к которому нужен доступ.
Выходим за рамки Google
Понятно, что сохранением страниц и сайтов в кеше занимается не только поисковая система Google. У пользователей есть еще несколько вариантов, как можно найти удаленную статью или другие данные с сайта:
- Кеш Яндекса. Система работает по такому же принципу, однако сохраненные версии могут отличаться от тех, которые хранит Google. Чтобы открыть кеш Яндекса, необходимо ввести в поиске адрес сайта и перейти к сохраненной копии с помощью зеленой стрелочки (точно так же, как и при работе с Google).
- Специализированный поисковик CachedView.com, который не ограничивается Google, а предлагает пользователям доступ к Всемирному архиву Интернета. Работает по принципу Nevkontakte.com.
- Еще один интересный сервис, на который стоит обратить внимание, находится по адресу archive.is. Его главная функция заключается в том, чтобы пользователь мог самостоятельно сохранять нужные страницы сайта. При этом сервис не требует регистрации и является бесплатным. Дополнительное преимущество архива – возможность искать данные среди страниц, которые сохранили другие пользователи.
 При этом сервис не требует регистрации и является бесплатным. Дополнительное преимущество архива – возможность искать данные среди страниц, которые сохранили другие пользователи.
При этом сервис не требует регистрации и является бесплатным. Дополнительное преимущество архива – возможность искать данные среди страниц, которые сохранили другие пользователи.Таким образом, даже удаленные из Интернета материалы можно найти и восстановить. Какой способ для этого выбрать? Рекомендуем не останавливаться на одном методе, а попробовать несколько, чтобы наверняка найти нужную страницу или сайт.
Как просмотреть кэшированную версию сайта? | Новости мира IT
В повседневной суете легко забыть о непостоянстве интернета. Страницы могут меняться без предупреждения и даже целые сайты в одночасье пропадают. Связана ли проблема с работой серверов или желанием владельца просто закрыть ресурс, у вас всегда есть возможность просмотреть сохраненную копию сайта
Google регулярно индексирует сайты для улучшения поиска, а вместе с тем и сохраняет копии (снимки) страниц. Веб браузеры для ускорения загрузки сайтов, также сохраняют страницы целиком или их отдельные элементы в кэше, специальной папке на вашем жестком диске. Поэтому в случае недоступности ресурсов существует несколько методов получения доступа к сохраненной копии.
Поэтому в случае недоступности ресурсов существует несколько методов получения доступа к сохраненной копии.
Поиск Google
Просмотр кэшированной страницы в поиске Google начинается точно также, как и выполнение любого поискового запроса. Просто введите название сайта, а затем в результатах поиска, рядом с адресом ресурса кликните на стрелку и выберете пункт Сохраненная копия. После загрузки страницы, Google оповестит вас, о том, что вы просматриваете снимок страницы и о том, когда он был сделан. У вас также будет возможность просмотреть исключительно текст, а также исходный код сайта.
Интернет архив и Wayback Machine
Целый ряд организаций занимается сохранением истории интернета и наиболее известной среди них является некоммерческий Интернет Архив (Internet Archive). Он позволяет получить доступ к огромному множеству сайтов, текстов, видео, аудио, программного обеспечения и картинок, которые трудно найти где-либо еще
Отсортируйте эти данные при помощи Wayback Machine (машина прошлого).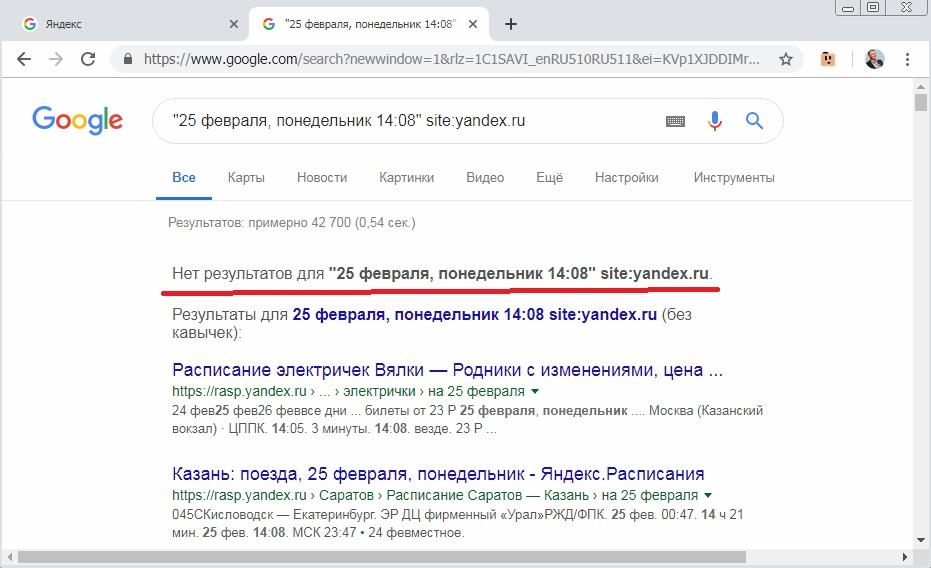 Просматривайте сохраненные копии как работающих сайтов, так и уже канувших в лету. Просто введите адрес ресурса, который хотите увидеть и сервис покажет вам все имеющиеся снимки. Выберите на календаре необходимую дату и посмотрите, как сайт выглядел в это время. Wayback Machine – это отличный инструмент для знакомства с историей интернета.
Просматривайте сохраненные копии как работающих сайтов, так и уже канувших в лету. Просто введите адрес ресурса, который хотите увидеть и сервис покажет вам все имеющиеся снимки. Выберите на календаре необходимую дату и посмотрите, как сайт выглядел в это время. Wayback Machine – это отличный инструмент для знакомства с историей интернета.
Расширения для браузера
Существуют и специальные дополнения для браузеров, позволяющие просматривать сохраненные версии страниц. Расширение Web Cache Viewer позволяет не только загрузить страницу из локального кэша на вашем компьютере, но и также автоматически найти ее при помощи сервиса Wayback Machine. Для пользователей Firefox существует аналогичное дополнение со схожим функционалом Web Archives.
Веб инструменты
Если ни один из вышеперечисленных способов вам не помог, то возможно вам помогут еще пара инструментов. Например, сайт Cached Page позволяет искать копии страниц сразу на нескольких ресурсах – поиск Google, Интернет Архив и WebCite. Также вы можете попробовать сервис Google Cache Checker, который проверяет как давно индексировался сайт и есть ли его сохраненные копии.
Также вы можете попробовать сервис Google Cache Checker, который проверяет как давно индексировался сайт и есть ли его сохраненные копии.
Большой, изогнутый игровой монитор со скидкой
Не забудьте подписаться и поставить лайк. Впереди будет еще много крутых статей.
VK | Facebook | Telegram
Отсутствует сохраненная копия страницы в индексе пс. Инструмент для обновления сохраненной копии в Яндекс.Вебмастере
Что значит «Отсутствует сохранённая копия в Яндексе!» и как это влияет на сайт в целом. Во-первых, если вы продаете ссылки со своего сайта, то отсутствие страниц в кэше Яндекса негативно отразится на доходе веб-мастера.
Например, в Сеопульте есть параметр, контролирующий наличие страницы в кэше поисковой системы.
Называется он nic (no index cache) — это означает что у страницы нет «сохраненной копии».
На сегодняшний день в Сеопульте проверяется индекс Яндекса. В перспективе планируют добавить и проверку в Гугле.
Вот как это выглядит на графике. Долгое время траст был равен девяти, но потом резкое падение.
Я стал искать причину отсутствия сохраненной копии сайта в поисковом индексе. И даже написал в службу поддержки TrustLink.
Добрый день. Скажите, пожалуйста с чем может быть связано падение траста у моего блога. Параметр XT за последние два апа Яндекса снизился с 9 до 7. Одновременно и снизился доход в Трастлинк.
Здравствуйте! Этот показатель не является официальным представлением Яндекса, потому причины его паденя нам не известны
То есть уменьшение количества расставленых ссылок сеопультом с этим не связано. А по какой причине наблюдается уменьшение дохода?
При проверке часть страниц, на которых были куплены ссылки, отсутствовала в кэше Яндекса. Ссылки были сняты, потому просел доход.
А не подскажите почему страницы отсутствуют в кэше Яндекса? В индексе есть, а в кэше нет? Как-то можно повлиять на то, чтобы они оказались в кэше?
Это уже вопрос к техподдержке Яндекса, часто апдейт кэша происходит немного позже апдейта выдачи/индекса, отсюда выходит такая проблема
Да, именно так.
 Для достижения максимальной эффективности ссылки необходимо наличие страницы в кэше.
Для достижения максимальной эффективности ссылки необходимо наличие страницы в кэше.Потом я задал вопрос в техподдержку Яндекса.
Добрый день.
Сейчас отсутствует сохранённая копия в Яндексе. Подскажите, пожалуйста в чем причина. Блог работает на Вордпрессе.
Кроме того мой блог имел траст xt = 9. За последние два апдейта траст упал до 7. Я стараюсь улучшать свой блог, а тут два таких негативных момента. С чем это может быть связано и как можно исправить ситуацию?
Адрес сайта: //www.сайт
С уважением, Илья.
И продолжал искать причину.
Статья по теме: Как найти обратные ссылки
Оказывется, после обновления плагинов, флажок напротив значения noarchive был включен. В результате чего на каждой странице моего блога появилась строка, запрещающая кэширование страницы. Возможно по этой причине я потерял две единицы траста.
Убрав этот тег, выключив флажок в плагине Robots Meta , я убедился в его отсутвии на страницах своего блога.
Add noarchive meta tag
Prevents archive.org and Google from putting copies of your pages into their archive/cache.to put copies of your pages into their archive/cache.
Будьте внимательны при настройке плагина Robots Meta для Вордпресс!
Узнав о наличии тега, запрещающега кэширование, я написал в суппорт Трастлинка.
Здоравствуйте. Я уже выяснил причину падения траста и отсутствия копии блога в кэше Яндекса. Видимо при обновлении плагинов Вордпресса на страницах присутствовал тег noarchive. Обнаружив это я немедленно убрав его и сегодня уже траст опять стал 9, поднявшись сразу на 2 единицы Зря оптимизаторы поснимали свои ссылочки.
Здравствуйте! Ожидайте восстановление закупки в ближайшее время.
И тут мне приходит ответ из службы поддержки Яндекса.
Здравствуйте!
Дело в том, что на момент последней индексации страниц, в их коде содержался мета-тег noarchive.
В некоторых случаях, робот может посчитать изменения внесенные на странице незначительными, например, если текст на странице практически не поменялся или изменения касаются только html-разметки. Такие документы не обновляются в нашей поисковой базе, так как внесенные изменения на поиск никак не влияют.
С уважением, Платон Щукин
Служба поддержки Яндекса
//help.yandex.ru/
 Это явный запрет на показ сохраненной копии в результатах поиска. Сейчас тег убран, но сохраненная копия не появится пока робот не обновит документы в нашей поисковой базе.
Это явный запрет на показ сохраненной копии в результатах поиска. Сейчас тег убран, но сохраненная копия не появится пока робот не обновит документы в нашей поисковой базе.На следующий день я опять проверил свой блог в сервисе //xtool.ru/ . И о чудо! Моментальный подъем на 2 единицы!
Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Сохраненная копия в Яндексе — это версия страницы, которая занесена в поисковой системы Яндекс.
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA
При просмотре выдачи результатов поисковика на введенный пользователем запрос в сниппете каждого сайта можно увидеть блок с дополнительной информацией. Одним из разделов блока с дополнительной информацией является «Сохраненная копия».
Одним из разделов блока с дополнительной информацией является «Сохраненная копия».
Чтобы понять, что из себя представляет сохраненная копия Яндекса, разберем простую аналогию. Представьте, что вы написали доклад или сочинение. Вы сдали работу, отправили ее на конкурс, но перед этим успели скопировать. Затем вам нужно еще раз сделать эту работу уже для другого конкурса. Чтобы не писать все заново, не восстанавливать в памяти все детали, вы достаете сохраненный файл и по ней пишите новое сочинение. Сохраненная страница Яндекса выполняет функцию данной копии. С ее помощью можно просмотреть сайт, если по тем или иным причинам нет доступа к интернет-ресурсу.
Для чего нужна сохраненная копия страницы в Яндексе
Прежде всего, отметим, что сохраненная копия в поисковой системе Яндекс — это важный инструмент SEO оптимизатора. С ее помощью можно увидеть, какая версия документа уже проиндексирована роботами поисковой системы и участвует в ранжировании, а какие страницы еще не прошли данный процесс. Таким образом, наличие сохраненной страницы в Яндексе — индикатор успешно пройденной индексации.
Таким образом, наличие сохраненной страницы в Яндексе — индикатор успешно пройденной индексации.
- В ходе работы с интернет-ресурсами могут возникнуть самые различные ситуации. В частности на сайтах периодически осуществляются технические работы: внесение корректировок в дизайн/изменение шаблона /редактирование или удаление текстовых материалов. В ходе данных работ легко можно допустить ошибку, которая ведет к негативным последствиям: исчезновение дизайна/текста/другого элемента, изменение шаблона не по плану и так далее. Наверняка, каждый разработчик сайтов имел такой печальный опыт. Если есть возможность бэкапа или подключен качественный хостинг, через который можно вернуть все как было — прекрасно. Но начинающие ресурсы, как правило, не имеют такой возможности. В этом случае поможет сохраненная копия страницы в Яндекс. С ее помощью можно увидеть, как все было на момент индексации роботами и восстановить вид страницы, исправить ошибки. Но учтите, что хранение страницы в индексе не вечно, и если на нее робот зашел в период, когда она уже была в нерабочем состоянии, вы вполне можете не увидеть старой информации. ..
- Еще одна ситуация, когда полезна будет сохраненная копия страницы в Яндексе: в ходе работы над сайтом вы изменили текстовый материал, с целью увеличения релевантности страниц. Теперь вам нужно посмотреть, выполнено ли обновление страницы, где вы внесли изменения. Сделать это можно просмотрев сохраненную копию.
- Нередко сайты бывают недоступны, причин для этого может быть много: технические неполадки, истек срок хостинга и так далее. Чтобы в этой ситуации зайти на сайт, нужно найти сохраненную копию и просмотреть ее. Таким образом, польза сохраненных страниц Яндекса очевидна.
 ..
..Как посмотреть сохраненную копию страницы в Яндексе
Все современные поисковые системы, и Яндекс не исключение, позволяют пользователям открыть нужные веб-документы через их индекс. Это можно сделать быстро с помощью специальных сервисов или вручную. В первом случае на помощь придут сервисы: Page Promoter в Firefox, RDS bar для Хроме и другие. Однако плагины периодически могут некорректно работать и выходить из строя, поэтому владеть ручным методом тоже нужно.
Первый способ
Открываем поисковик Яндекс и в строке поиска прописываем сам адрес нужной страницы или интересующий запрос. В результатах поиска мы видим, что в сниппете каждого результата есть маленькая стрелочка. Нажимаем на стрелочку и выбираем «Сохраненная копия». После этого мы посетим сайт, его сохраненную страницу от какой-то прошедшей даты.
Второй способ
Способ заключается в применении специальных расширений браузера/плагинов/онлайн сервисов. Наиболее популярным сегодня является «RDS bar». Интерфейс плагина более чем простой, с его помощью можно просмотреть последние изменения страницы, когда страницу в последний раз посещал робот, следовательно и копия предоставляется за это число. Если нужная страница не прошла индексацию Яндекса, ее сохраненная копия не будет отображаться в результатах выдачи поисковика.
Почему нет сохраненной копии страницы в Яндексе
Иногда при поиске сохраненной копии страницы можно не увидеть нужного пункта при нажатии на стрелочку в сниппете. Причин тому может быть несколько:
- Первый вариант — некорректная работа ПС. Сам Яндекс признается, что не гарантирует наличие и показ таких копий для всех страниц в силу большого кол-ва причин.
2. Вторая ситуация — в коде документа находится метатег “robots” и он имеет значение «noarchive» — запрет кэширования. Чтобы избежать падения трафика, необходимо внимательно настраивать подобные вещи.
Чем может грозить отсутствие копии в Яндексе
Само по себе отсутствие копии не будет влиять как-то негативно на продвижение. А вот причины, которые привели к отсутствию могут повредить, поэтому разберитесь с ними.
Чем действительно может обернуться проблема с копиями страниц, так это затруднениями при работе с биржами ссылок.
Например, в Сеопульте сегодня есть параметр, который осуществляет контроль над тем, есть ли сохраненная копия Яндексе. Данный параметр называется NIC — No Index Cache. Он свидетельствует о том, что страница не имеет сохраненной копии. С такого ресурса не будут покупать ссылки, никому не хочется рисковать и платить за то, что может не принести пользы.
Как вы видите, сохраненная копия в Яндексе позволяет решить ряд проблем и оптимизировать использование интернет-трафика. Данные рекомендации позволят оперативно открывать и просматривать их.
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кеша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:http://www.iphones.ru/
Где http://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета
6. Archive.is, для собственного кэша
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com , перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari .
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на
Существует настоящая, реальная машина времени, в которой можно ненадолго вернуться в прошлое и увидеть, например, как выглядел тот или иной сайт несколько лет назад. Думаете, никому не нужны копии сайтов многолетней давности? Ошибаетесь! Для очень многих людей сервис по архивированию информации весьма полезен.
Во-первых, это просто интересно! Из чистого любопытства и от избытка свободного времени можно посмотреть, как выглядел любимый, популярный ресурс на заре его рождения.
Во-вторых, далеко не все владельцы сайтов ведут свои архивы. Знать место, где можно найти информацию, которая была на сайте в какой-то момент, а потом пропала, не просто полезно, а очень важно.
В-третьих, само по себе сравнение является важнейшим методом анализа, который позволяет оценить ход и результаты нашей деятельности. Кстати, при проведении анализа веб-ресурса очень эффективно использовать ряд методов сравнения.
Поэтому наличие уникальнейшего архива веб-страниц интернета позволяет нам получить доступ к огромному количеству аудио-, видео- и текстовых материалов. По утверждению разработчиков, «интернет-архив» хранит больше материалов, чем любая библиотека мира. Мы попали в правильное место!
Что нужно, чтобы найти копии сайтов интернета
Для того, чтобы отправиться в прошлое, нужно перейти на сайт archive.org и воспользоваться поисковой строкой.
Простой поиск в архиве сохраненных сайтов выдает нам ссылки на все сохраненные копии запрашиваемой страницы.
Из этого видно, что сайт сайт был создан в 2012 году (Кстати, важно отметить, с помощью практически идеального хостинга Спринтхост — рекомендую!). Переключаясь на нужный нам год, можно увидеть даты, выделенные кружочками, это и есть даты сохранения копии сайта. Например, в 2015 году, пока можно будет увидеть только одну копию от 7 февраля.
Конечно, это потрясающий ресурс! Ведь здесь индексируются и архивируются все сайты интернета! Это не только скриншоты… Имея в руках такой инструмент, можно восстановить массу потерянной со временем информации.
Надо заметить, что, безусловно все восстановить однозначно не получится, так как если на страницах сайта используются элементы Java Script, или скрипты или графика взяты со стороннего сервера, то на восстановление такой информации рассчитывать не придется. Поэтому к сохранению данных своего сайта нужно относиться с особенным вниманием, несмотря ни на что.
Пользуясь случаем, я сделала скриншоты и восстановила в памяти, как выглядел мой сайт, начиная с 2012 года. Любопытно посмотреть))
Сайт буквально недавно «родился»)) Январь 2012.. .
Проходит время, и хочется что-то изменить… Конец 2012-го.
Наверное, пора уже что-то менять. 2013-й. Это тема, которая и сегодня установлена на моем сайте.
К смене темы отношусь с осторожностью, так как помню последний «переезд», после которого несколько месяцев восстанавливала посещаемость сайта. Как-то не очень удачно получилось.
Надеюсь, что и моим читателям эта замечательная интернет-библиотека — «машина времени» сможет помочь перемещаться во времени, когда они этого захотят. Посмотрите, как выглядели раньше некоторые сайты, еще во времена своего зарождения. Какими раньше были google или яндекс, можно увидеть только на archive.org, аналогов у этого ресурса нет. Приятного путешествия, друзья!
Всякий раз, когда мы разглядываем результаты любого запроса, на странице выводятся ссылки «Сохраненная копия» и «Еще с сайта». Разберем сначала первую из них.
Индексация , всех сайтов, информацию на которых ищет Яндекс, сопровождается созданием копии этих сайтов, которые размещаются на серверах Яндекса. Да, грубо говоря, Яндекс хранит на своих серверах весь Рунет и значительную часть Интернета. Конечно, на серверах, в кэше, размещаются не все страницы сайтов, а также не все элементы сайтов — чаще всего хранится лишь текстовое содержимое. Также не нужно представлять себе Яндекс в качестве некоего суперархива, в который попадают все странички, которые когда-либо были в сети 1Для таких задач есть другие сервисы, например, http://www.archive.org . Кэш Яндекса динамический, его содержимое постоянно обновляется по мере изменения основных сайтов.
Как это использовать? Для чего нужна ссылка «Сохраненная копия». Представим себе, что некоторая газета опубликовала скандальную статью. Поисковый бот Яндекса невозмутимо прошелся по сайту этой газеты и проиндексировал ее, сохранив копию на свой сервер . Тем временем широкая общественность, возмущенная статьей, потребовала удалить ее с сайта, а журналиста, который написал статью — уволить. Главный редактор газеты, посыпая голову пеплом, выполняет эти требования. Статьи на сайте газеты больше нет. Драматические события развиваются чрезвычайно быстро, буквально в течении утра.
Тем временем, некоторый читатель, который проснулся к обеду, заходит в сеть и видит, что форумы и блоги кипят от обсуждений этой статьи. Он набирает в Яндексе ее название, переходит по ссылке на сайт редакции и получает ошибку 404. Статьи, конечно, больше нет, но есть ссылка «Сохраненная копия», перейдя по которой читатель получает удовольствие от шокирующих подробностей копии статьи.
Когда эта ужасная статья исчезнет из кэша Яндекса? Когда поисковый бот, скажем, после обеда еще раз пройдется по сайту газеты и проиндексирует его. Статьи там больше нет, значит содержимое кэша тоже обновится и наступит полная гармония в сети.
Нам, пользователям, остается ловить промежутки времени между переиндексацией Яндекса после удаления некоторых материалов. Можно сказать, что если где-то исчезли материалы, то в течении нескольких часов их еще можно будет вытащить из кэша Яндекса по ссылке «Сохраненная копия».
Конечно, не все столь драматично и интересно. Чаще всего ссылка «Сохраненная копия» помогает, когда материалы основного сайта недоступны по причине банального падения сервера.
«Сохраненная копия» — это возможность увидеть материалы, которые были перемещены, удалены или недоступны. Работает в течение определенного промежутка времени.
Персональный поиск
Терабайтный жесткий диск — это уже не фантастика, а самая обыденная вещь. Фантастикой становится найти документ на таком жестком диске, особенно когда не очень хорошо помнится, когда он был создан, кем он был создан и вообще где он лежит.
Операционная система Windows Vista содержит средства поиска «на лету». Достаточно ввести в проводнике название файла как в окне результатов, тут же будут выведены соответствующие документы.
Яндекс предлагает Персональный поиск http://desktop.yandex.ru/ , который обеспечивает возможность находить файлы и документы на локальном компьютере. Для начала работы скачиваем программу (размером около 4,4 МБ) и устанавливаем ее. Персональный поиск должен вначале проиндексировать все документы, которые находятся на нашем жестком диске. По умолчанию, процесс полной индексации запускается автоматически, когда мы не трогаем центрального процессора не превышает 35%. Однако лучше всего сразу после установки выполнить принудительную индексацию — чтобы получить работающий локальный поиск . Для этого в системном трее (возле часов) щелкаем по иконке установленной программы и в контекстном меню выбираем пункт «Индексация \ Принудительная» ( рис. 1.32 2):
Рис.
1.32.
Скорость завершение процесса зависит от мощности компьютера, размера жесткого диска и количества документов. На двухядерном процессоре с двумя гигабайтами оперативной памяти, набитый под завязку 250 гигабайтный винчестер проиндексировался за пару часов. При этом какого-либо замедления в работе не замечалось — параллельно использовался браузер с множеством открытых вкладок, Microsoft Word , Excel , почта и т.д. Словом, индексация требует определенных затрат машинных ресурсов, но она выполняется гораздо легче, чем, скажем, антивирусное сканирование. В течении индексации иконка Персонального поиска переливается, а как только она становится статичной — значит, можно использовать поиск . Для запуска поиска дважды щелкаем по иконке — открывается браузер , в котором есть строка поиска. Но это только интерфейс — персональный поиск работает без подключения к Интернету. Вводим название файла и результаты отображаются моментально ( рис. 1.33):
Все найденные результаты группируются по вкладкам (табам), расположенным в правой части страницы. На странице помощи Персонального поиска
Яндекс сохраненная копия. Отсутствует сохранённая копия в Яндексе! Что делать, если вообще ничего не помогло
Если кто-то сейчас подумал, что в данном случае речь пойдет о резервной копии сайта, то он ошибается. Сохраненная копия сайта и резервная копия сайта далеко не одно и то же. Восстановить сайт из сохраненной копии сайта вы не сможете.
В интернете есть веб-архив, где находятся сохраненные копии сайтов. Если у вас сайт еще совсем молодой и ему всего несколько месяцев, то скорее всего сохраненная копия сайта в веб-архиве отсутствует. Если же ваш сайт представлен в интернете уже достаточно продолжительное время, то сохраненная копия сайта там должна быть.
Находится этот веб-архив по адресу http://archive.org/web/ и там можно посмотреть как выглядел ваш сайт в определенный промежуток времени. Сразу оговорюсь, что сохраняются копии сайтов далеко не каждый день, а порою даже не каждый месяц. Хотя конечно восстановить сайт из сохраненной копии сайта нельзя, но если повезет, то можно восстановить первоисточники.
Бывают иногда ситуации, что произошел на сайте какой-то сбой, или сайт взломали и какая-то информация оказалась утерянной. В этом случае хотя и не всегда, но может помочь сохраненная копия сайта. Я, например вытащила из сохраненной копии сайта некоторые свои статьи, которые уже считала безнадежно утерянными.
Делается это очень просто. Заходите на сайт http://archive.org/web/ В поле для ввода вводите адрес сайта, сохраненную копию которого вы хотите посмотреть и нажимаете на кнопку «Browse History». Сейчас на изображении в поле для ввода вы можете видеть адрес моего сайта.Попадаете на другую страницу и видите за какой год можно посмотреть сохраненную копию сайта. Там, где сайт сохранялся есть черные пометки.
Выбираете год, за который вы хотите посмотреть сохраненную копию сайта. Дни, когда сайт сохранялся находятся в светло-голубом круге. При нажатии на дату в голубом круге откроется сохраненная копия сайта. Другие даты не активны.
Загружается сохраненная копия сайта достаточно медленно. Сайтов в веб-архиве много.
Здравствуйте! Сегодня пост о наболевшем для большинства из начинающих сайтостроителей. Мне приходилось очень часто в комментариях отвечать на один и тот же вопрос — как удалить страницы из поиска , которые были проиндексированы ранее, но в силу сложившихся обстоятельств были удалены и больше не существуют, но по-прежнему находятся в индексе поисковых систем. Или же в поиске находятся страницы запрещенные к индексации.
В комментариях особо не развернешься, поэтому после очередного вопроса решил уделить данной теме отдельное внимание. Для начала давайте разберемся, каким образом такие страницы могли оказаться в поиске. Примеры буду приводить исходя из собственного опыта, так что если я что-то забуду, то прошу дополнить.
Почему закрытые и удаленные страницы есть в поиске
Причин может быть несколько и некоторые из них я постараюсь выделить в виде небольшого списка с пояснениями. Перед началом дам пояснение что подразумеваю под «лишними» (закрытыми) страницами: служебные или иные страницы, запрещенные к индексации правилами или мета-тегом.
Несуществующие страницы находятся в поиске по следующим причинам:
- Самое банальное — страница удалена и больше не существует.
- Ручное редактирование адреса web-страницы, вследствие чего документ который уже находится в поиске становится не доступным для просмотра. Особое внимание этому моменту нужно уделить новичкам, которые в силу своих небольших знаний пренебрежительно относятся к функционированию ресурса.
- Продолжая мысль о структуре напомню, что по-умолчанию после установки WordPress на хостинг она не удовлетворяет требованиям внутренней оптимизации и состоит из буквенно-цифровых идентификаторов. Приходится на ЧПУ, при этом появляется масса нерабочих адресов, которые еще долго будут оставаться в индексе поисковых систем. Поэтому применяйте основное правило: надумали менять структуру — используйте 301 редирект со старых адресов на новые. Идеальный вариант — выполнить все настройки сайта ДО его открытия, в этом может пригодиться локальный сервер.
- Не правильно настроена работа сервера. Несуществующая страница должна отдавать код ошибки 404 или с кодом 3хх.
Лишние страницы появляются в индексе при следующих условиях:
- Страницы, как Вам кажется, закрыты, но на самом деле они открыты для поисковых роботов и находятся в поиске без ограничений (или не правильно написан robots.txt). Для проверки прав доступа ПС к страницам воспользуйтесь соответствующими инструментами для .
- Они были проиндексированы до того как были закрыты доступными способа.
- На данные страницы ссылаются другие сайты или внутренние страницы в пределах одного домена.
Итак, с причинами разобрались. Стоит отметить, что после устранения причины несуществующие или лишние страницы еще долгое время могут оставаться в поисковой базе — все зависит от или частоты посещения сайта роботом.
Как удалить страницу из поисковой системы Яндекс
Для удаления URL из Яндекс достаточно пройти по ссылке и в текстовое поле формы вставить адрес страницы, которую нужно удалить из поисковой выдачи.
Главное условие успешного запроса на удаление:
- страница должна быть закрыта от индексации правилами robots или мета-тегом noindex на данной странице — в том случае если страница существует, но не должна участвовать в выдаче;
- при попытке обращения к странице сервер должен возвращать ошибку 404 — если страница удалена и более не существует.
При следующем обходе сайта роботом запросы на удаление будут выполнены, а страницы исчезнут из результатов поиска.
Как удалить страницу из поисковой системы Google
Для удаления страниц из поступаем аналогичным образом. Открываем инструменты для веб-мастеров и находим в раскрывающемся списке Оптимизация пункт Удалить URL-адреса и переходим по ссылке.
Перед нами специальная форма с помощью которой создаем новый запрос на удаление:
Нажимаем продолжить и следуя дальнейшим указаниям выбираем причину удаления. По-моему мнению слово «причина» не совсем подходит для этого, но это не суть…
Из представленных вариантов нам доступно:
- удаление страницы страницы из результатов поиска Google и из кэша поисковой системы;
- удаление только страницы из кэша;
- удаление каталога со всеми входящими в него адресами.
Очень удобная функция удаления целого каталога, когда приходится удалять по несколько страниц, например из одной рубрики. Следить за статусом запроса на удаление можно на этой же странице инструментов с возможностью отмены. Для успешного удаления страниц из Google необходимы те же условия, что и для . Запрос обычно выполняется в кратчайшие сроки и страница тут же исчезает из результатов поиска.
Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Сохраненная копия в Яндексе — это версия страницы, которая занесена в поисковой системы Яндекс.
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA
При просмотре выдачи результатов поисковика на введенный пользователем запрос в сниппете каждого сайта можно увидеть блок с дополнительной информацией. Одним из разделов блока с дополнительной информацией является «Сохраненная копия».
Чтобы понять, что из себя представляет сохраненная копия Яндекса, разберем простую аналогию. Представьте, что вы написали доклад или сочинение. Вы сдали работу, отправили ее на конкурс, но перед этим успели скопировать. Затем вам нужно еще раз сделать эту работу уже для другого конкурса. Чтобы не писать все заново, не восстанавливать в памяти все детали, вы достаете сохраненный файл и по ней пишите новое сочинение. Сохраненная страница Яндекса выполняет функцию данной копии. С ее помощью можно просмотреть сайт, если по тем или иным причинам нет доступа к интернет-ресурсу.
Для чего нужна сохраненная копия страницы в Яндексе
Прежде всего, отметим, что сохраненная копия в поисковой системе Яндекс — это важный инструмент SEO оптимизатора. С ее помощью можно увидеть, какая версия документа уже проиндексирована роботами поисковой системы и участвует в ранжировании, а какие страницы еще не прошли данный процесс. Таким образом, наличие сохраненной страницы в Яндексе — индикатор успешно пройденной индексации.
- В ходе работы с интернет-ресурсами могут возникнуть самые различные ситуации. В частности на сайтах периодически осуществляются технические работы: внесение корректировок в дизайн/изменение шаблона /редактирование или удаление текстовых материалов. В ходе данных работ легко можно допустить ошибку, которая ведет к негативным последствиям: исчезновение дизайна/текста/другого элемента, изменение шаблона не по плану и так далее. Наверняка, каждый разработчик сайтов имел такой печальный опыт. Если есть возможность бэкапа или подключен качественный хостинг, через который можно вернуть все как было — прекрасно. Но начинающие ресурсы, как правило, не имеют такой возможности. В этом случае поможет сохраненная копия страницы в Яндекс. С ее помощью можно увидеть, как все было на момент индексации роботами и восстановить вид страницы, исправить ошибки. Но учтите, что хранение страницы в индексе не вечно, и если на нее робот зашел в период, когда она уже была в нерабочем состоянии, вы вполне можете не увидеть старой информации…
- Еще одна ситуация, когда полезна будет сохраненная копия страницы в Яндексе: в ходе работы над сайтом вы изменили текстовый материал, с целью увеличения релевантности страниц. Теперь вам нужно посмотреть, выполнено ли обновление страницы, где вы внесли изменения. Сделать это можно просмотрев сохраненную копию.
- Нередко сайты бывают недоступны, причин для этого может быть много: технические неполадки, истек срок хостинга и так далее. Чтобы в этой ситуации зайти на сайт, нужно найти сохраненную копию и просмотреть ее. Таким образом, польза сохраненных страниц Яндекса очевидна.
Как посмотреть сохраненную копию страницы в Яндексе
Все современные поисковые системы, и Яндекс не исключение, позволяют пользователям открыть нужные веб-документы через их индекс. Это можно сделать быстро с помощью специальных сервисов или вручную. В первом случае на помощь придут сервисы: Page Promoter в Firefox, RDS bar для Хроме и другие. Однако плагины периодически могут некорректно работать и выходить из строя, поэтому владеть ручным методом тоже нужно.
Первый способ
Открываем поисковик Яндекс и в строке поиска прописываем сам адрес нужной страницы или интересующий запрос. В результатах поиска мы видим, что в сниппете каждого результата есть маленькая стрелочка. Нажимаем на стрелочку и выбираем «Сохраненная копия». После этого мы посетим сайт, его сохраненную страницу от какой-то прошедшей даты.
Второй способ
Способ заключается в применении специальных расширений браузера/плагинов/онлайн сервисов. Наиболее популярным сегодня является «RDS bar». Интерфейс плагина более чем простой, с его помощью можно просмотреть последние изменения страницы, когда страницу в последний раз посещал робот, следовательно и копия предоставляется за это число. Если нужная страница не прошла индексацию Яндекса, ее сохраненная копия не будет отображаться в результатах выдачи поисковика.
Почему нет сохраненной копии страницы в Яндексе
Иногда при поиске сохраненной копии страницы можно не увидеть нужного пункта при нажатии на стрелочку в сниппете. Причин тому может быть несколько:
- Первый вариант — некорректная работа ПС. Сам Яндекс признается, что не гарантирует наличие и показ таких копий для всех страниц в силу большого кол-ва причин.
2. Вторая ситуация — в коде документа находится метатег “robots” и он имеет значение «noarchive» — запрет кэширования. Чтобы избежать падения трафика, необходимо внимательно настраивать подобные вещи.
Чем может грозить отсутствие копии в Яндексе
Само по себе отсутствие копии не будет влиять как-то негативно на продвижение. А вот причины, которые привели к отсутствию могут повредить, поэтому разберитесь с ними.
Чем действительно может обернуться проблема с копиями страниц, так это затруднениями при работе с биржами ссылок.
Например, в Сеопульте сегодня есть параметр, который осуществляет контроль над тем, есть ли сохраненная копия Яндексе. Данный параметр называется NIC — No Index Cache. Он свидетельствует о том, что страница не имеет сохраненной копии. С такого ресурса не будут покупать ссылки, никому не хочется рисковать и платить за то, что может не принести пользы.
Как вы видите, сохраненная копия в Яндексе позволяет решить ряд проблем и оптимизировать использование интернет-трафика. Данные рекомендации позволят оперативно открывать и просматривать их.
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кеша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:http://www.iphones.ru/
Где http://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета
6. Archive.is, для собственного кэша
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com , перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari .
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:http://www.сайт/
Где http://www.сайт/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета
6. Archive.is, для собственного кэша
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса..
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com , перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari .
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:
Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com :
А о сборе информации про людей читайте в статьях и .
Сохраненные копии страниц вконтакте. Просмотр удаленной страницы. Что делать если профиль удален
Страница в социальной сети ВКонтакте может многое рассказать о человеке, особенно если он ее ведет активно. На ней можно узнать список его увлечений, дату рождения, посмотреть фотографии, интересующие его записи из различных групп и многое другое. Но если пользователь решил удалить свою страницу ВКонтакте, вся эта информация скрывается. На его странице появляется сообщение, что данный пользователь удалил свой аккаунт, и посмотреть сведения на ней больше не представляется возможным. Но есть несколько способов, как просмотреть удаленную страницу ВКонтакте, о которых мы и расскажем в рамках данной статьи.
Оглавление: Обратите внимание: Приведенные ниже советы актуальные не только когда страница удалена по воле самого пользователя. Также они позволяют посмотреть информацию на страницах, которые были заблокированы администраторами ВКонтакте по той или иной причине.Поиск удаленной страницы ВКонтакте в кеше поисковых систем
Поисковые системы хранят свою базу с информацией обо всех сайтах, в том числе делая их резервные копии. Ими может воспользоваться любой желающий, что позволяет, в том числе, посмотреть информацию о странице удаленного пользователя ВКонтакте.
Важно: Данный метод действует только в том случае, если пользователь удалил свой профиль из ВКонтакте недавно. Если страница удалена уже давно, скорее всего, ее вновь посетил поисковый робот и обновил сохраненную копию.
Следующим образом можно посмотреть информацию об удаленной странице ВКонтакте при помощи поисковой системы Google:
В поисковой системе Yandex открытие сохраненных копий страниц ВКонтакте происходит примерно таким же образом.
Обратите внимание: Социальная сеть ВКонтакте позволяет пользователям настраивать свою приватность. В личных настройках аккаунта имеется возможность настроить видимость страницы в сети. Если в данной настройке указано, что страница видна всем, кроме поисковых сайтов, то найти в Google и Яндекс сохраненные копии страницы не получится, поскольку поисковому роботу воспрещен обход такой страницы.
Просмотр удаленной страницы ВКонтакте в вебархиве
В интернете каждый день сотни сайтов меняются, удаляются, на их месте появляются новые и происходят другие подобные манипуляции. Есть несколько сервисов, которые следят за этими действиями, сохраняя копии сайтов и отдельных страниц. Используя такой сервис, можно посмотреть информацию, которая была размещена на удаленной странице ВКонтакте. Делается это следующим образом:
Стоит отметить, что сервис вебархив не лучшим образом работает с сохранением информации о страницах пользователей ВКонтакте, и если аккаунт был зарегистрирован недавно, велика вероятность, что информация о нем в базе данных сервиса не будет найдена.
Просмотр удаленной страницы ВКонтакте в кеше браузера
Важно: Данный способ могут использовать только те пользователи, которые захотят посмотреть страницу человека, к которому они ранее заходили, но после он ее удалил.
Метод основывается на том, что браузеры хранят копии сайтов, что необходимо для их более быстрой загрузки при необходимости. Если вы некоторое время назад заходили на страницу к пользователю, после чего он ее удалил, у вас есть возможность посмотреть ее сохраненную копию в браузере. Сделать это можно практически в любом браузере, рассмотрим на примере Opera :
Это все способы, позволяющие посмотреть информацию, которая ранее была расположена на удаленной странице ВКонтакте.
Многие пользователи социальной сети ВКонтакте по вине тех или иных обстоятельств вынуждены были некогда произвести удаление аккаунта. Вследствие этого, особенно если профиль был достаточно популярен, становится актуальной такая тема, как просмотр деактивированных персональных страниц.
На сегодняшний день для просмотра деактивированных аккаунтов ВКонтакте вам так или иначе потребуется обратиться к сторонним средствам. В любом возможном случае вам также потребуется доступ к удаленной странице, а именно пользовательский идентификатор.
В рамках рассматриваемого ресурса аккаунт может быть удален окончательно в течение 7 месяцев с момента деактивации. В этом случае некоторые из методов могут не подействовать, так как сам по себе профиль ВКонтакте исчезнет из сети.
Кроме сказанного важно отметить такой аспект, как срок жизни страниц ВК в различных поисковых системах. То есть, на протяжении определенного периода времени удаленный профиль покинет все возможные ресурсы, в базу данных которых был когда-либо занесен с целью упрощения пользовательского поиска.
Аккаунты, в настройках приватности которых была установлена блокировка поисковых систем, к сожалению, невозможно просмотреть, так как в этом случае профиль не сохраняется на других сайтах.
Способ 1: Поиск Яндекс
В первую очередь крайне важно затронуть такую особенность поисковых систем, как автоматическое сохранение копии страницы. Благодаря данной возможности вы можете без проблем открыть страницу пользователя и посмотреть интересующую вам информацию, выполнив несколько несложных действий.
Некоторые другие поисковые системы точно также, как и Яндекс, сохраняют данные о пользователях ВК в собственной базе данных. Однако конкретно Яндекс лучше любых других аналогичных ресурсов работает с запросами по ВКонтакте.
- Откройте в любом удобном браузере официальный сайт поисковой системы Яндекс, воспользовавшись специальной ссылкой.
- В основное текстовое поле на открытом сайте вставьте идентификатор удаленной страницы ВКонтакте.
- Нажмите клавишу «Enter» на клавиатуре или воспользуйтесь кнопкой «Найти» с правой стороны от поискового поля.
- Заметьте, что вы вполне можете удалить вступительную часть используемого URL-адреса, оставив только идентификатор аккаунта и доменное имя сайта VK.
- Среди результатов поиска, при существовании возможности просмотра, первым постом будет выступать разыскиваемый персональный профиль.
- Если вы попытаетесь открыть страницу путем прямого перехода по представленной ссылке, вы будете направлены к уведомлению о том, что аккаунт был удален.
- Чтобы открыть некогда сохраненную версию аккаунта, рядом с сокращенной ссылкой нужного результата кликните по стрелочке, указывающей вниз.
- В раскрывшемся списке выберите пункт «Сохраненная копия» .
- Теперь вам будет представлена страница нужного пользователя в том виде, в котором она последний раз была доступна поисковой системе Яндекс.
Обратите внимание на то, что большая часть ссылок и различных функциональных элементов находится в рабочем состоянии. Однако это замечание является актуальным только тогда, когда профиль находится в деактивированном состоянии незначительный период времени.
На этом с данным методом можно закончить, так как если все условия были соблюдены, вы без каких-либо проблем сможете отыскать информацию об удаленной странице пользователя ВК.
Способ 2: Поиск Google
Данный метод, в отличие от первого, является самым простым в плане просмотра некогда удаленных пользовательских профилей. Однако, несмотря на всю простоту, он имеет множество недостатков, сводящихся к тому, что у вас нет возможности посмотреть детальную информацию о пользователе.
В поисковой системе Google, равно как и в случае вышерассмотренного Яндекса, вы можете посмотреть некогда автоматически сохранненую копию страницы.
Учитывая сказанное, профили ВКонтакте после удаления достаточно быстро исключаются из поисковых запросов, из-за чего вы не сможете увидеть информацию в любое удобное время. Наиболее приемлемым этот метод будет только в тех ситуациях, когда человек, удаливший страницу, еще имеет базовую возможность восстановления в течение 7 месяцев.
Теперь работу с поисковыми системами, с целью просмотра когда-либо удаленных аккаунтов, можно закончить и перейти к более радикальному методу.
Способ 3: Веб-архив
Данный метод, равно как и предшествующий, требует того, что бы пользовательский аккаунт не был скрыт особыми настройками приватности. В особенности это касается поисковых систем, так как практически любой поиск на сторонних сайтах имеет с ними связь.
Этот способ вполне может быть применим не только к ВК, но и к некоторым другим социальным сетям.
Если пользовательский аккаунт полностью соответствует требованиям, можно переходить к использованию специального сервиса, предназначенного для просмотра сайтов в некогда сохраненном состоянии. Тут же важно учесть то, что далеко не все страницы соц. сети ВКонтакте имеют ранее сохраненную копию.
Если вы воспользовались копией, которая была сохранена до момента глобального обновления сайта ВКонтакте, то в ваше пользование будет предоставлен ранний интерфейс VK.
Используя сервис вы просматриваете аккаунты от лица незарегистрированного пользователя. При этом вы не можете пройти авторизацию и, например, прокомментировать какую-либо запись.
Главным минусом данного сервиса является то, что он демонстрирует пользовательские профили ВК на английском языке из-за особенностей региональных настроек сервиса.
В завершение к данному методу важно уделить внимание тому, что практически все ссылки в интернет-архиве являются активными и ведут они к соответствующей странице, сохраненной в точно тот же временной период. В связи с этим вам следует всегда помнить — далеко не все аккаунты социальной сети ВКонтакте имеют подходящие копии в веб-архиве.
То при попытке просмотреть ее, вы получите сообщение об ошибке. Но если вам крайне необходима информацию, которая была на ней?
Есть несколько методов, которые позволяют просмотреть удаленные страницы Вконтакте .
: .Используем вебархив
Это сервис, который хранит в себе историю вебсайтов. В нем можно попытаться найти текстовую копию страницы, которая была опубликована.
Https://archive.org/
По какой-то причине, роскомнадзор заблокировал доступ к нему, поэтому воспользуйтесь любым анонимайзером (см. ). Или попробуйте поменять ip — поставьте адрес другой страны (см. ).
На главной странице архива, есть блок «Wayback Machine» . Здесь вам нужно ввести адрес удаленной страницы, и нажать Enter .
Обратите внимание на интерфейс. В верхней части экрана есть календарь. На нем отображены имеющиеся копии страницы. Если их несколько, вы сможете просмотреть каждую из них. Давайте попробуем отдалиться на 2012 года, и посмотреть, что было на моей странице в то время. На календаре выбираем нужную дату, и получаем вот такой результат.
Если удаленной страницы нет в архиве, вы получите вот такое сообщение.
Просмотр копии профиля в поисковиках
Яндекс и гугл добавляют в свою базу информацию обо всех найденных страницах в сети. Это касается также и аккаунтов в ВК. Версия копии изменяется с каждым обновлением базы (разумеется, при наличии изменений). Этот процесс занимает несколько дней.
Если пользователь совсем недавно, есть шанс, что в поисковых системах еще есть ее сохраненная копия. И мы можем просмотреть ее.
Давайте посмотрим, как это выглядит в яндексе.
Чтобы принцип работы стал более понятен, рассмотрим копию, которая гарантирована существует.
Заходим в яндекс, и набираем в поиске адрес своего аккаунта.
Тот же принцип и в гугл.
Теперь давайте попробуем просмотреть сохраненную копию. Для этого разверните дополнительное меню (кнопка в виде треугольника, расположена рядом с адресом). Здесь нажмите «Сохраненная копия» .
Теперь попробуйте проделать те же действия, для удаленной страницы, которую вы хотите увидеть.
Просмотр кэша браузера
Каждый раз, когда вы открываете страницу сайта, ваш браузер сохраняет ее копию к себе в историю. Это делается для того, чтобы при повторном открытии, не загружать ее заново через интернет, а моментально предоставить вам готовую копию. Это существенно увеличивает скорость работы.
В том случае, если вы совсем недавно заходили к пользователю на страницу, есть вероятность того, что она есть в кэше браузера, и вы можете просмотреть ее.
Давайте сделаем это на примере Mozilla Firefox.
Включите автономный режим. Для этого откройте меню, затем пункт «Разработка» , и далее поставьте галочку «Работать автономно» .
Порядок действий для просмотра удалённой страницы одинаков и тогда, когда профиль стёрли по собственной инициативе, и когда заблокировали принудительно.
При самостоятельном удалении страницы ВКонтакте пользователю дается 6 месяцев, чтобы изменить свое решение. Для восстановления профиля авторизуйтесь и восстановите информацию в один клик.
Для страниц ВК, которые были заморожены из-за подозрения во взломе, при входе отображается инструкция с восстановлением. В основном происходит это через код, который отправляется на привязанный телефон. Страницы, заблокированные по решению сайта, восстанавливаются только через определенное время.
Альтернативный метод – написать в техническую поддержку ВК для решения вопроса в экстренном порядке.
Просмотр сохранённой копии в поисковиках
В случаях, когда надо просмотреть удаленную страницу пользователя, который не желает ее восстанавливать, воспользуйтесь сохраненными копиями. Информация из сети не пропадает бесследно. Существуют ресурсы, которые сохраняют в кэше данные о каждом сайте. Такие сервисы, как сейчас не помогают в поиске страниц из социальных сетей, поэтому остается использование популярных поисковиков.
Удобно просматривать такую информацию через Яндекс. В строку поиска вводится адрес нужного профиля, после чего отобразятся результаты.
В списке выбираете пункт «Сохраненная копия», после чего в новой вкладке будет открыта копия профайла, сохраненная за некоторое время до ее ликвидации.
Такой метод позволяет еще просматривать посты, фотографии, которые пользователи ранее стерли. Аналогичные действия совершаются и в других известных поисковых системах, например Google или Bing.
Восстановить страницу ВК можно разными способами в зависимости от того, как именно она была утеряна (удалена или блокирована). Ниже представлены пошаговые инструкции для восстановления в каждом из случаев. В случае, если они не могут в статье представлен и альтернативный метод. Если же и он Вам не поможет, то обязательно напишите нам в комментариях и мы рассмотрим вашу проблему персонально.
Что делать если профиль удален
Если вы удалили свою страничку VK, то восстановить ее можно в течение 7 месяцев. Никакие деньги за восстановление платить не нужно – если вы видите такую просьбу на странице, то знайте, что это мошенничество.
Проверьте свою систему на вирусы, чтобы избавиться от уведомлений о том, что профиль заблокирован, и вам нужно оплатить его разблокировку.
Чтобы восстановить свою страницу VK:
После повторного нажатия кнопки «Восстановить» можно снова полноценно использовать аккаунт VK – все друзья, сообщения, записи и другая информация со странички останутся нетронутыми.
Что делать если аккаунт заблокирован
Если страница VK была не просто удалена, а заблокирована за рассылку спама или иную подозрительную деятельность, то восстановить ее можно с помощью специальной формы.
Сервис автоматически найдет страницу, которая подходит под указанные вами требования. Если обнаружен верный аккаунт, нажмите «Да, это нужная страница», чтобы вернуть доступ к профилю. На номер, привязанный к профилю, придет сообщение с кодом. Введите его и кликните «Сменить пароль». Если нет доступа к телефону или сообщение не приходит, то щелкните по ссылке «Нажать здесь».
Появится небольшая анкета из трех пунктов – если ее заполнить, то можно вернуть свою страничку, привязав ее к другому номеру телефона. Вам нужно:
- Указать другой номер, к которому будет осуществлена привязка аккаунта VK.
- Написать логин, по которому вы заходили раньше на свою страницу (номер или адрес электронной почты).
- Ввести старый пароль (можно оставить это поле пустым).
Восстановление аккаунта возможно лишь в том случае, если в профиле есть ваши фотографии. Анонимные страницы без фото вернуть трудно, даже если вы предоставите полную информацию о старом пароле и логине.
Если профиль заблокирован за нарушение правил сайта, то в информации о блокировке будет указана конкретная причина и срок окончания бана. До окончания этого срока вернуть доступ к страничке нельзя . Если правила вы не нарушали (вашу страницу взломали и использовали третьи лица), то сообщите об этом в службу поддержки – подробно порядок обращения будет рассмотрен ниже.
Что делать если логин и пароль утерян
Описанная выше форма позволит вам восстановить свою страничку VK, если вы забыли от неё логин и пароль. Это довольно распространенная проблема среди пользователей, поэтому администрация Вконтакте сделала процедуру максимально простой, но безопасной – можно восстановить только свою страничку, доступ в чужой аккаунт получить не получится.
Страница найдена, но чтобы её восстановить придется отправить заявку, в которой необходимо указать старый номер, доступный номер, а также пароль от аккаунта. Если в профиле есть ваши фотографии, то можно обойтись без пароля, но тогда есть вероятность, что администрация ВКонтакте отклонит вашу просьбу.
Альтернативный метод
Если профиль был взломан, а затем заблокирован за действия, нарушающие правила VK, вы не можете вспомнить логин (пароль) или у вас не получается найти адрес своего аккаунта, то попробуйте восстановить доступ напрямую через службу поддержки ВКонтакте.
Примечание: чтобы воспользоваться этой возможностью, вам нужно быть авторизованным на сайте. Если решите создать для обращения новую страницу, ни в коем случае не привязывайте ее к тому же номеру, что и старую, иначе вы рискуете потерять доступ к старому аккаунту. Можно открыть страницу поддержки из профиля другого человека – так будет безопаснее.
Сохраненные копии страниц – это не то, что находится в индексе
Издавна SEO-специалисты используют сохраненную копию страницы в поисковике для анализа индексации произведенных на странице изменений. Однако еще четыре года назад я заметил, что в Яндексе сохраненная копия может не совпадать с той версией страницы, которая реально находится на данный момент в поисковом индексе и используется в ранжировании. Сегодня мне хотелось бы проверить, можно сейчас ли доверять сохраненной копии Яндекса. Ну, и заодно посмотреть, как с этим обстоят дела у его основного конкурента на отечественном рынке поиска – Google.Для анализа мне понадобится страница, на которой публикуется текущая дата. Сопоставляя дату, которая находится в сохраненной копии с датой, по которой эта страница находится в поисковике, и которая может показываться при этом в ее сниппете, можно сделать вывод о соответствии версии страницы, демонстрируемой в сохраненной копии и версии страницы, находящейся в поисковом индексе. Для нашей цели как нельзя подойдет главная страница Яндекса.
Итак, анализируем сначала ситуацию в самом Яндексе, найдя главную страницу Яндекса с помощью документированного оператора url: запросом url:yandex.ru и открыв ее сохраненную копию. Находим в ней дату (на момент анализа – это «25 февраля, понедельник, 22:23»):
Итак, попробуем найти по точной текстовой фразе с этой датой в Яндексе его главную страницу. Увы, но сделать этого не удалось. Мы получаем сообщение, что точного совпадения не нашлось:
Получается, в поисковом индексе находится версия главной страницы Яндекса от другой даты. С помощью несложных манипуляций с изменением даты в поисковой фразе убеждаемся, что в индексе содержится более ранняя версия главной страницы Яндекса. К сожалению, Яндекс не соизволил нас порадовать показом текстового соответствия в сниппете (видимо, считая данный текст служебным и малозначимым), однако отсутствие фразы «Точного совпадения не нашлось» красноречиво свидетельствует о том, что именно данная фраза содержится в той версии страницы, что находится на данный момент в поисковом индексе:
Более того, можно убедиться в том, что сохраненная копия в Яндексе может иметь несколько версий, показываемых попеременно. Так, обновляя страницу с сохраненной копией главной страницы в Яндексе, мы можем время от времени увидеть другую ее версию с другой датой (в моем случае – «24 февраля, воскресенье 22:37»), но все равно не совпадающей с той, по которой страница находится в индексе:
Итак, ситуация в Яндексе не изменилась. Сохраненная копия по-прежнему не совпадает с той, что находится в индексе и участвует в ранжировании.
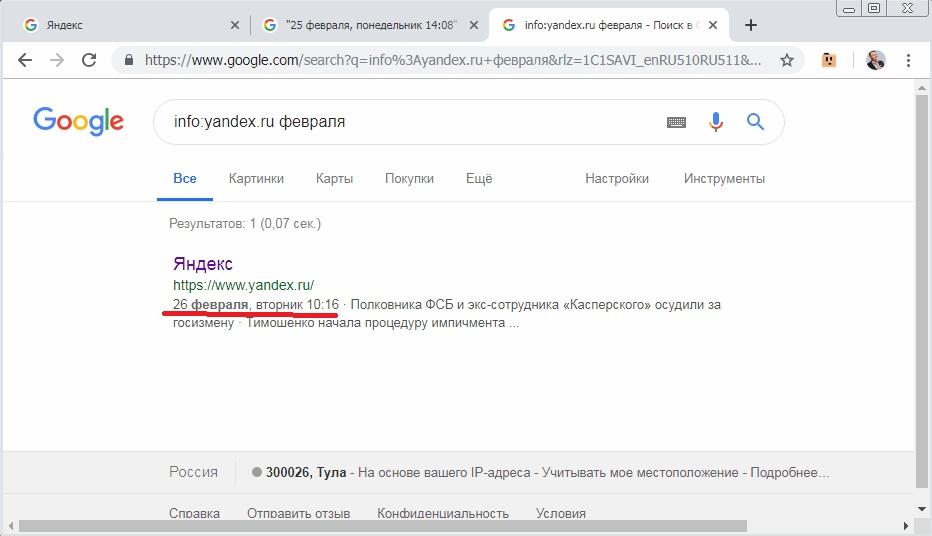
Ну, а что же по этому поводу думает Google? Сохраненную копию страницы можно посмотреть напрямую с помощью оператора cache. Делаем в Google запрос cache:yandex.ru, получаем сохраненку и находим в ней дату:
К сожалению, оператор site: в Google в случае его применения к главной странице сайта показывает выдачу по всему сайту, и по запросу по дате без времени мы получаем достаточно много страниц с сайта в выдаче (с сервиса Яндекс.Погода и т.п.), что затрудняет анализ. Но добавив в запрос время, убеждаемся, что по точной фразе выдача пуста:
Для того, чтоб облегчить нахождение даты версии, находящейся в индексе, воспользуемся одним интересным приемом. Есть в Google оператор получения сведений о странице info:, который показывает сниппет указанной страницы в случае наличия ее в индексе. К сожалению, этот оператор не желает корректно работать в связке с поисковым запросов, т.е. не является аналогом оператора site:. Однако, если справа от этого оператора использовать какой-либо термин, то в случае наличия его точного вхождения в тексте страницы, мы можем увидеть сниппет с подсветкой этого термина. Используя в качестве такого термина название текущего месяца в соответствующем падеже, получаем отображение даты в сниппете, и убеждаемся в том, что она не совпадает с той, что содержится в сохраненке:
Проверим с помощью запроса по точной фразе, что в поисковом индексе действительно находится версия страницы с указанной датой:
Любопытно, что в Яндексе версия анализируемой страницы в сохраненной копии свежее версии в индексе, а в Google – наоборот.
Итого в результате несложного анализа убеждаемся в том, что ни в Яндексе, ни в Google нельзя быть уверенным в том, что версия страницы, показываемая в сохраненной копии, используется для ранжирования. И этот факт обязательно необходимо учитывать при анализе поисковой выдачи дабы избежать ложных выводов.
Как просмотреть кэшированную версию веб-сайта
Легко забыть о непостоянстве Интернета. Страницы редактируются без предупреждения, и веб-сайты могут исчезнуть в мгновение ока.
Существует множество способов потерять доступ к сайту или веб-странице. Возможно, серверы не работают, или, возможно, владелец сайта изменил или удалил контент, который вы пытаетесь найти. В этих случаях одним из вариантов является просмотр кэшированной версии.
Google регулярно сканирует Интернет в поисках новых страниц для индексации, а также сохраняет резервные копии сканируемых страниц.Веб-браузеры делают то же самое, чтобы страницы загружались быстрее. Эти снимки сохраняются в кэше — области вашего локального жесткого диска, которая временно становится доступной, если сайт выходит из строя или какое-то содержимое удаляется. Не все веб-сайты индексируются Google или сохраняются в кеше, но вот как получить к ним доступ.
Просмотр кэша
Чтобы просмотреть кэш страницы, запустите поиск и найдите страницу, которую вы ищете. В Google щелкните меню с тремя точками рядом с результатом, чтобы открыть всплывающую страницу Об этом результате .Нажмите кнопку Cached во всплывающем окне, чтобы просмотреть кешированную версию веб-сайта.
Когда сайт загрузится, Google сообщит вам, что это более старая версия, и укажет, когда был сделан снимок. У вас также будет возможность просмотреть текстовую версию страницы, а также ее исходный код. Однако имейте в виду, что вы не сможете переходить к другим страницам и оставаться в кэшированной версии; вы попадете на действующий сайт, если попытаетесь.
Пользователям Bing нужно только найти результат поиска, который они ищут, а затем щелкнуть стрелку рядом с URL-адресом сайта.Выберите «Кэшировано» в небольшом меню, чтобы открыть кешированную версию веб-сайта с баннером, указывающим, что это не действующая страница.
Намного более простой способ просмотреть кэшированный веб-сайт — использовать модификатор поиска. введите cache: в адресной строке и добавьте URL-адрес, не оставляя пробела. Браузер откроет кешированную версию рассматриваемого веб-сайта.
Машина обратного пути
Пока что просмотр кешированных версий веб-сайтов. Ряд организаций посвящены сохранению истории Интернета; наиболее заметным является некоммерческий Интернет-архив, в котором размещаются веб-сайты, тексты, видео, аудио, программное обеспечение и изображения, которые трудно найти где-либо еще.Вы можете просматривать даже более старые версии веб-сайтов с помощью Wayback Machine, которая работает как для живых, так и для автономных веб-сайтов.
Введите URL-адрес, который вы хотите изучить, и поисковая машина по архивам покажет календарь, который указывает, когда Wayback Machine просканировала эту страницу. Щелкните дату в календаре, чтобы увидеть, как сайт выглядел в тот день. Wayback Machine — отличный способ просмотреть историю Интернета; заархивированные версии PCMag.com датируются 19 декабря 1996 года.
Архив.Сегодня
Архивный веб-сайт Archive.Today позволяет пользователям сохранять текущие веб-страницы, а также искать существующие записи, которые были ранее сохранены. Ввод URL-адреса для сохранения позволяет просматривать веб-страницу в том виде, в котором она существует в настоящее время, сохранять ее на сайте и загружать страницу на свой компьютер.
Если вы хотите просмотреть заархивированные версии веб-сайта, введите URL-адрес в соответствующую строку поиска, и Archive.Today заполнит результаты для домашней страницы и связанных отдельных страниц.Если существует несколько версий одной и той же страницы, они будут сложены вместе для удобства просмотра.
Веб-сайт PCMag, например, заархивирован еще в 2012 году и в настоящее время имеет четыре различных версии домашней страницы, сохраненных в сервисе.
Расширения браузера также могут обращаться к кэшированным сайтам. Добавьте средство просмотра веб-кэша в Chrome и щелкните правой кнопкой мыши любую страницу, чтобы просмотреть версию веб-страницы для Google или Wayback Machine. Расширение Web Archives для Chrome и Firefox идет еще дальше, позволяя просматривать кешированные версии веб-страниц из более чем десятка поисковых систем, включая Bing, Baidu и Yandex.
Другие онлайн-инструменты включают Cached Page, которая выполняет поиск по заданному URL-адресу в веб-кэше Google, Internet Archive и службу архивирования WebCite. Google Cache Checker также проверяет, проиндексирован ли сайт Google, и открывает все найденные кешированные веб-страницы.
Нравится то, что вы читаете?
Подпишитесь на информационный бюллетень Tips & Tricks , чтобы получить советы экспертов, которые помогут вам максимально эффективно использовать свои технологии.
Этот информационный бюллетень может содержать рекламу, предложения или партнерские ссылки.Подписка на информационный бюллетень означает ваше согласие с нашими Условиями использования и Политикой конфиденциальности. Вы можете отказаться от подписки на информационные бюллетени в любое время.
Сохранение и загрузка копий веб-сайта | Документация Plesk Obsidian
Работая над содержанием и дизайном веб-сайта, вы можете сэкономить несколько копий каждого сайта на сервер и восстановление сайтов с сохраненные копии (также называемые снимками ). Сохранение копий сайта может пригодится в следующих случаях:
- Вы хотите подготовить несколько версий одного и того же веб-сайта, чтобы позже можно загрузить их для просмотра, выбрать лучший дизайн или самый соответствующую версию и опубликуйте в Интернете.
- Вы хотите внести существенные изменения или поэкспериментировать с дизайном сайта или контент, но убедитесь, что вы можете безопасно отменить изменения, что-нибудь пойдет не так.
Примечание: Изображения из галереи изображений Модули не сохраняются в снимки. Изображения хранятся в вашей учетной записи.
Для сохранения текущего дизайна и содержания сайта:
В главном меню редактора Presence Builder щелкните значок рядом с опцией Сохранить .
Примечание: Если вы нажмете Сохранить , копия сайта с быстрым сохранением будет сохранена под имя автоматически сохраняемый снимок . Вы сможете восстановить сайт из этой копии позже, нажав Вернуть в главном меню.
В открывшемся списке выберите свободный слот для сохранения, введите имя для резервную копию и нажмите Сохранить .
Для восстановления сайта из сохраненной копии:
В главном меню редактора Presence Builder щелкните значок рядом с опцией Вернуть .
Примечание: Если вы нажмете Вернуть , сайт будет восстановлен из Быстрая копия, созданная при последнем нажатии Сохранить .
В открывшемся списке выберите копию сайта и нажмите Загрузить .
Щелкните Да , чтобы подтвердить, что вы хотите восстановить.
Чтобы скачать копию сайта:
- В главном меню редактора Presence Builder щелкните значок рядом с опцией Сохранить .
- Найдите копию, которую хотите загрузить, и щелкните значок (Загрузить).
- Выберите каталог на вашем компьютере, в котором вы хотите сохранить файл. и нажмите ОК .
Для загрузки копии сайта:
- В главном меню редактора Presence Builder щелкните значок рядом с опцией Вернуть .
- Щелкните значок (Загрузить) рядом со слотом, в который вы хотите загрузить копию.
- Перейдите к файлу моментального снимка сайта в формате SSB и выберите его.
- Если вы хотите восстановить сайт из загруженного снимка, выберите его. и щелкните Загрузить .
Чтобы удалить копию сайта:
- В главном меню редактора Presence Builder щелкните значок рядом с опцией Сохранить .
- Найдите копию сайта, которую вы хотите удалить, и щелкните соответствующий значок (Удалить).
Как копировать текст и изображения с веб-страницы
Обновлено: 16.08.2021, Computer Hope
Копирование текста или изображения с веб-страницы может быть полезно для создания заметок или создания документации.Щелкните ссылку ниже, чтобы получить справку о том, как копировать текст и изображения с веб-страницы, а также другую полезную информацию.
ПримечаниеИнструкции на этой странице предназначены для копирования содержимого веб-страницы с компьютера, а не с планшета или смартфона.
Как скопировать текст с веб-страницы
Чтобы скопировать текст с веб-страницы, найдите начало текста, который вы хотите скопировать. Нажмите и удерживайте левую кнопку мыши. Затем перетащите мышь из верхнего левого угла в нижний правый угол раздела текста, который вы хотите скопировать.
Чтобы скопировать выделенный текст, нажмите на клавиатуре сочетание клавиш Ctrl + C или щелкните правой кнопкой мыши выделенный текст и выберите Копировать .
Чтобы вставить текст, поместите курсор в соответствующее место и нажмите сочетание клавиш Ctrl + V или щелкните правой кнопкой мыши то место, куда вы хотите вставить текст, и выберите Вставить .
Текст копируется с веб-страницы в новый или существующий документ.Оттуда вы можете изменить форматирование текста (полужирный, курсив, цвет или размер шрифта и т. Д.).
КончикПри вставке текста в программу, поддерживающую форматирование, например Microsoft Word, можно скопировать формат, шрифт и макет текста. Если вы хотите скопировать текст без форматирования, используйте функцию специальной вставки или вставки текста программы, в которую вы вставляете текст.
Как скопировать изображение с веб-страницы
Чтобы сохранить (загрузить) изображение, щелкните правой кнопкой мыши любое изображение на веб-сайте, чтобы просмотреть меню свойств этого изображения, как показано ниже.Если вы хотите скопировать это изображение в другой документ, выберите в меню опцию Копировать изображение . Если вы хотите сохранить файл изображения на свой компьютер, чтобы его можно было использовать или загрузить в другом месте, выберите опцию Сохранить изображение как .
ПримечаниеПриведенный выше пример контекстного меню находится в Google Chrome. Если вы используете Internet Explorer или другой обозреватель Интернета, параметры вашего меню могут отличаться. Вы можете увидеть варианты для Копировать и Сохранить изображение как .Используйте эти параметры вместо указанных выше для достижения тех же результатов.
Если вы выбрали опцию Сохранить изображение как, откроется окно Сохранить как или Сохранить изображение , в котором вы сможете выбрать место для сохранения изображения и изменить имя. Нажмите кнопку Сохранить , чтобы сохранить изображение на свой компьютер.
ПримечаниеНекоторые веб-страницы могут отключать возможность щелчка правой кнопкой мыши или иметь настройку страницы, чтобы предотвратить копирование или сохранение изображений с использованием вышеуказанного метода.
Вставка изображения
Если вы выбрали опцию Копировать изображение, это изображение сохраняется в буфер обмена. Чтобы вставить изображение, переместите курсор туда, куда вы хотите вставить, и нажмите Ctrl + V или щелкните правой кнопкой мыши то место, куда вы хотите вставить изображение, и выберите Вставить .
ПримечаниеПрограмма с обычным текстом, такая как Блокнот, не поддерживает изображения, и функция вставки недоступна.
Законно ли копировать текст и изображения веб-сайта?
Копирование текста и изображений не является незаконным.Однако то, как вы используете информацию, может быть ограничено авторским правом веб-страницы. Например, копирование всего текста с веб-страницы и использование его на другой веб-странице противоречит авторским правам большинства сайтов, поскольку дублирует их содержание.
Если вы не уверены в правилах авторского права, обратитесь к автору статьи или веб-мастеру веб-страницы с просьбой разрешить использование их содержания.
КончикБольшая часть информации, относящейся к авторскому праву, находится в ссылках на авторские права или юридических страницах в нижней части большинства веб-страниц.
Дополнительные советы по копированию текста и изображений с сайта
Онлайн-сервисы
Существует несколько онлайн-сервисов, помогающих обмениваться текстом между компьютерами и другими пользователями Интернета в Интернете. Ниже представлены два наших фаворита.
Pastebin — Одно из лучших мест для вставки кода и другого текста. Сервис не требует входа в систему для вставки текста, но предлагает вариант входа для тех, кто хочет редактировать или удалять опубликованный текст. Сервис также имеет плагины для браузера для вставки текста и приложений для всех основных смартфонов и планшетов.
Evernote — Один из самых популярных онлайн-сервисов обмена. Evernote — это бесплатный сервис для совместной работы и создания заметок, который позволяет сохранять заметки, вырезки, видео, изображения, текстовые документы и многое другое.
Плагины для браузера
ScrapBook — Этот замечательный плагин позволяет любому пользователю Firefox сохранять веб-страницы и даже фрагменты веб-страниц для последующего чтения и редактирования или просмотра.
Наше руководство по сохранению вашего сайта для мамонта
Поддержание вашего веб-сайта предполагает наличие специальной стратегии резервного копирования.Хотя резервное копирование важно, это не единственный способ сохранить ваш сайт. Естественным продолжением резервного копирования является архивирование веб-сайта, хотя это дополнительные процессы.
Есть несколько гибких способов заархивировать веб-сайт. Хорошая новость в том, что все они удобны и доступны. Вам просто нужно выбрать правильное решение, соответствующее вашим потребностям и требованиям.
В этом посте мы рассмотрим, как архивировать веб-сайт. Мы также рассмотрим различные типы архивирования, с которыми вы столкнетесь, рассмотрим несколько наиболее известных инструментов архивирования сайтов и обсудим несколько советов по архивированию вашего сайта.
Хотите посмотреть видео версию?
Введение в архивирование веб-сайтов
Архивирование веб-сайта означает сохранение содержимого, данных и носителей для использования в будущем. Используя специальный сервис, такой как Wayback Machine (хотя мы рассмотрим другие решения позже), вы можете просматривать старые версии веб-сайта.
Как сайт Kinsta выглядел в 2015 году — мы прошли долгий путь!
С технической точки зрения сканеры делают снимки веб-сайта, который представляет собой сам архив.Вы можете получить к нему доступ, используя простой календарь, и при желании просмотреть каждую итерацию в формате временной шкалы.
Архив календаря Wayback Machine для веб-сайта Kinsta.
Что касается того, почему существуют такие решения, как Wayback Machine, мы должны вернуться в начало 2000-х годов. Пузырь доткомов почти лопнул; многие предприятия падали. Некоторые популярные веб-сайты были закрыты или заброшены, осталось мало воспоминаний.
Как и другие медиаформаты до Интернета, такие как музыка и телевидение, эти веб-сайты имели историческую и ностальгическую ценность.Их сохранение означало дать будущим пользователям Интернета представление о том, как далеко мы ушли от прежних технологий.
Интернет-архив запустил Wayback Machine, чтобы помочь сохранить веб-сайты. Если сайт был там заархивирован, вы можете увидеть, как сайт развивался за эти годы.
Для архивирования веб-сайта требуется множество поисковых роботов, в том числе огромные отдельные обходы, на выполнение которых могут потребоваться годы. Ворчание, необходимое для выполнения ползучих «экспедиций» и хранения полученных снимков, огромно.
Например, первый сервер Wayback Machine на 100 терабайт (ТБ) начал работать в 2004 году. К концу 2020 года Wayback Machine хранила более 70 петабайт (ПБ) данных. Это более 70 000 терабайт.
Однако не всем нравится работа, которую выполняет Интернет-архив. Было несколько дискуссий и юридических проблем, основанных на том, нарушает ли архив веб-сайта существующие проблемы авторского права.
Тем не менее, учитывая значительный рост количества хранимых архивов, существует явное желание сохранить веб-сайты.
Готовы заархивировать свой сайт? 👀 Хорошие новости: это достаточно удобный процесс. 😄 Самая важная часть — это выбор правильного решения, отвечающего потребностям и требованиям вашего сайта. Смотрите все варианты здесь ⬇️Нажмите, чтобы твитнуть
Почему нужно архивировать веб-сайт
Есть много причин для желания архивировать веб-сайт, помимо просто ностальгических причин. Для аналогии из реального мира посмотрите на GitHub.
ИнфраструктураGitHub очень похожа на интернет-архив.
Github хранит репозитории проекта вместе с каждой сделанной «фиксацией». Чтобы сравнить это с архивированием в Интернете, репозитории представляют собой весь архив, а коммиты — это моментальные снимки.
Архивы ценны точно так же, как репозитории Git. Например, вы можете посмотреть на предыдущие версии своего сайта — даже сделанные много лет назад — чтобы повлиять на ваш текущий выбор дизайна.
Кроме того, вы можете быть обязаны по закону заархивировать свой сайт, особенно если вы работаете в финансовой или юридической сфере.
Наконец, если вам не повезло участвовать в судебном процессе вокруг вашего сайта, ваши архивы будут ценным доказательством. Если вы можете представить четкие и полные архивы сайта, вы можете прекратить споры даже до того, как в дело вступят суды.
Разница между резервным копированием и архивированием
Прежде чем мы поговорим о различных доступных типах веб-архивирования, стоит вернуться к теме, которую мы затронули ранее. На бумаге резервная копия сайта и архив сайта выглядят одинаково.Однако они выполняют разные работы, которые дополняют друг друга. В двух словах:
- Резервное копирование основано на данных. Их больше заботит сохранение данных вашего сайта. Учитывая, что резервные копии жизненно важны, если вам нужно восстановить ваш сайт, полное резервное копирование ваших данных имеет первостепенное значение.
- Архивы сохраняют контекст над данными. Если вы пролистаете архив любимого веб-сайта, вы заметите, что его функциональность часто неоднородна. Однако дизайн и статическое содержимое сайта обычно остаются без изменений.
Стоит отметить, что архивирование вовсе не означает отказ от усилий по сохранению данных. Действительно, одним из преимуществ является то, что пользователи могут перемещаться по вашему сайту, как если бы он был действующим. Даже в этом случае, учитывая, что такие сайты, как Wayback Machine, существуют как виртуальная «дорожка памяти», сохранение визуальных элементов в неприкосновенности имеет более высокий приоритет, чем сохранение функциональности серверной части.
Короче говоря, вы захотите использовать для своего сайта и резервные копии, и архивы — первые в качестве ежедневной защиты на случай худшего, а вторые — как дополнительный способ документировать эволюцию вашего сайта.
Различные типы веб-архивирования, с которыми вы столкнетесь
Веб-архивирование — это не просто одно и то же. Вы можете встретить несколько разных типов. Вот разбивка каждого:
- На стороне клиента: Конечный пользователь сохраняет версию рассматриваемого веб-сайта. Он простой, масштабируемый и позволяет без проблем архивировать веб-сайт.
- На стороне сервера: Подход Wayback Machine и других классифицируется как архивирование на стороне сервера.Он использует сканеры и другие технологии для архивирования веб-сайта, но также требует уровня согласия, которого нет при архивировании на стороне клиента.
- На основе транзакции: Хотя это по-прежнему основано на архивировании на стороне сервера, оно более сложное и требует явного согласия владельца сайта. По сути, он архивирует транзакции сайта между конечным пользователем и сервером.
Для простых веб-сайтов со статическими данными в сочетании со стратегией организованного архивирования архивирование на стороне клиента должно отвечать всем требованиям.Однако большинство других сайтов отдают предпочтение архивам на стороне сервера — для большинства веб-сайтов архивирование на основе транзакций не требуется.
Наконец, и мы обсудим это более подробно в статье, вы также захотите подумать, где и как хранятся ваши архивы. Например, локальный архив — неплохой выбор, но вы можете увидеть, что он исчезнет, если у вас случится сбой компьютера. С другой стороны, у вас меньше контроля над тем, что хранится в архиве, если вы выберете стороннее решение.
Как и следовало ожидать, ответ здесь — использовать многогранный подход к архивированию веб-сайта.Мы предлагаем обращаться с архивами как с резервными копиями: хранить три разные копии в разных местах и как-то синхронизировать.
Вы также можете сделать один из архивов активным, чтобы вы могли использовать все функциональные возможности на стороне сервера на своем сайте. Результатом является веб-сайт с надежной стратегией резервного копирования и архивирования, который остается полезным для других.
Руководство для новичков по средствам архивирования и сайтам в Интернете
Существует множество решений для архивирования веб-сайта.Мы рассмотрим несколько наиболее популярных из них, а также наше мнение о том, как они могут вам подойти.
1. Машина обратного пути
Машина обратного пути.
Прежде всего, давайте обсудим Wayback Machine. Это был первый в своем роде инструмент, поэтому он стал эталоном для других инструментов архивирования.
Таким образом, он, вероятно, будет первым, кто хочет заархивировать веб-сайт. У него есть много способов создания и загрузки архивов и даже специальный API для его функциональности.Стоит отметить, что это также решение для архивирования на стороне сервера.
Тем не менее, из-за того, как он сканирует и архивирует веб-сайты, Wayback Machine не сможет сохранить все функциональные возможности вашего сайта. Тем не менее, он считается отраслевым стандартом для веб-архивистов и абсолютно бесплатен. Позже в этой статье мы покажем вам, как архивировать веб-сайт с помощью Wayback Machine.
2. Архив. Сегодня
Сайт Archive.today.
Далее идет Архив.Cегодня. Он во многом похож на Wayback Machine — вплоть до почти «ретро» дизайна сайта. Его серверы данных расположены в Европе, но он подходит к архивированию иначе, чем Wayback Machine.
Во-первых, Archive.today не основан на поисковых роботах, работающих в Интернете. Вместо этого вы отправляете свои URL-адреса и соглашаетесь на включение в архив. Кроме того, его список функций более прост, чем у других решений. Например, не существует надежной политики удаления, а процесс архивирования исключает определенные типы мультимедиа и файлов.
Тем не менее, это бесплатно и подходит, если вам нужно бесплатное место для хранения архивов. На сайте даже есть функция поиска для поиска ранее заархивированных сайтов.
3. Эритрикс
Веб-сайт Heritrix.
В этом посте мы упоминали Интернет-архив и Wayback Machine почти как взаимозаменяемые. Однако Wayback Machine — это всего лишь одна услуга, а Internet Archive предлагает несколько других продуктов для архивирования помимо нее. Heritrix — это бесплатный инструмент с открытым исходным кодом, созданный в результате сотрудничества Internet Archive и скандинавских библиотек.
По сути, это веб-сканер, а не полнофункциональный инструмент для архивирования. Однако вы можете упаковать все результаты сканирования вместе. В прошлом этого не было, но теперь Wayback Machine использует Heritrix для сканирования сайтов с целью включения их в свой собственный сайт. Более того, большое количество библиотек и учреждений используют Heritrix для создания архивов.
Несмотря на впечатляющие характеристики, установка Heritrix требует определенных технических знаний. У него нет удобного интерфейса для его установки, поэтому вам понадобятся знания Git, GitHub и командной строки.
Как и другие подобные решения, Heritrix можно использовать совершенно бесплатно, поэтому он подходит в качестве экономичного решения для самоархивирования.
4. Уровень интеграции веб-архивирования (WAIL)
Веб-сайт уровня интеграции веб-архивирования (WAIL).
Если вы ищете Heritrix для архивации веб-сайта, но вас отталкивают технические знания, необходимые для простой установки программного обеспечения, для вас есть потенциальное решение. Уровень интеграции веб-архивирования (WAIL) — это бесплатное кроссплатформенное настольное приложение с открытым исходным кодом, которое предоставляет вам функциональный графический интерфейс пользователя (GUI) для использования вместе с установщиком.
Хорошая новость в том, что Heritrix — это поисковая машина WAIL. Это означает, что вы можете использовать всю мощь Heritrix, не просматривая GitHub и командную строку. Кроме того, WAIL использует движок OpenWayback для «воспроизведения» веб-архивов.
Таким образом, у вас есть полнофункциональный инструмент веб-архивирования, готовый к работе на вашем компьютере. Мы также покажем вам, как именно работает WAIL, позже в этой статье.
5. Стиллио
Веб-сайт Стиллио.
Наш предпоследний инструмент архивирования оплачивается как автоматическое решение, которое делает моментальные снимки через заданные интервалы.Stillio — это сервис премиум-класса, который внешне отличается от других решений для архивирования.
Веб-сайт выглядит привлекательно и дает вам множество возможностей для создания архива, который точно соответствует вашим требованиям. Например, вы можете добавлять теги и настраиваемые заголовки к своим URL-адресам.
Более того, вы можете хранить архивы в Dropbox, Google Диске и других сторонних сервисах.
Однако у Stillio есть один огромный недостаток: он не поддерживает архивирование на стороне сервера. Вы ограничены скриншотами своего веб-сайта, а не полным архивом данных.Для многих приложений этого недостаточно.
Тем не менее, Stillio может быть полезен в некоторых случаях, например, в качестве инструмента управления брендом и отслеживания. Например, вы можете делать скриншоты сайтов конкурентов или результатов поисковых систем. Он также отлично подходит для проверки содержания.
Цены наStillio начинаются с 29 долларов в месяц и повышаются для четырех уровней до 299 долларов в месяц. Это серьезный вопрос, особенно когда есть бесплатные альтернативы с более мощными функциями. Но если он идеально подходит для вашего варианта использования, то на него стоит взглянуть!
6.Заморозка страниц
Веб-сайт Pagefreezer.
Наше окончательное решение — еще один автоматизированный инструмент. Pagefreezer предлагает многие из тех же преимуществ, что и Stillio, но он также архивирует контент социальных сетей, текстовые сообщения, полные сайты и платформы для совместной работы корпоративного уровня.
Подпишитесь на информационный бюллетень
Хотите узнать, как мы увеличили трафик более чем на 1000%?
Присоединяйтесь к 20 000+ других, которые получают нашу еженедельную рассылку с инсайдерскими советами по WordPress!
Подпишитесь сейчасНа первый взгляд, Pagefreezer кажется более надежным решением, чем Stillio, и будет иметь большую ценность в различных случаях использования.
Например, если по закону вы должны полностью заархивировать сайт, Pagefreezer отвечает всем требованиям. Это позволяет автоматизировать количество снимков и просматривать их с помощью браузера архива сайта и инструмента сравнения.
В целом, Pagefreezer — отличное решение корпоративного уровня для архивирования рабочих мест. Компании, использующие Yammer или Salesforce’s Chatter, будут стремиться к этому типу решений, как и пользователи Workplace.
Что такое формат файла веб-архива (WARC)?
Если вы изучаете, как заархивировать веб-сайт, вы столкнетесь с форматом веб-архива (WARC).Это упакованная комбинация различных файлов архива вашего сайта, которая делает его портативным и автономным.
Интернет-архив создал WARC для долговременного хранения веб-данных. Международный консорциум сохранения в Интернете (IIPC) опубликовал полную спецификацию формата файла. В нем будут храниться изображения, метаданные и практически все, что нужно вашему сайту для автономной работы.
Изначально WARC был просто удобным файловым форматом, но теперь он стал международным стандартом ISO для цифровых архивов.Таким образом, он был принят правительствами и другими официальными органами. Фактически, существует несколько вариантов использования, в которых файл WARC жизненно важен:
- E-discovery : Это процесс во время судебного разбирательства, когда цифровые записи исследуются и представляются для включения в судебное разбирательство. Для записей в социальных сетях файл WARC соответствует правовому стандарту E-discovery.
- Свобода информации (FOI): Есть много правительств и официальных органов, которые используют законы FOI и Open Records, чтобы предлагать услуги «Право на информацию» (RTK) избирателям штата.Формат WARC идеален для цифровых записей.
WARC используется многими различными решениями для архивирования и поисковыми роботами, такими как StormCrawler и Apache Nutch. Вы также можете настроить параметры инструмента командной строки, такого как Wget, для получения и упаковки запросов в виде файлов WARC. Мы обсудим это более подробно в ближайшее время.
Есть много других инструментов, которые также могут выводить в файлы WARC. Например, это может сделать инструмент для сохранения веб-страниц с открытым исходным кодом.
В качестве альтернативы grab-site представляет собой веб-приложение, помогающее сканировать архивы в виде файлов WARC.
Открытие файла WARC зависит от используемого инструмента. Независимо от того, какое решение вы предпочитаете, имейте в виду, что некоторые из этих инструментов давно не обновлялись.
Таким образом, вы захотите убедиться, что выбранное вами решение работает с вашей текущей системой и будет доступно для использования в будущем. Вы избавитесь от множества головных болей, если откажетесь от инструмента, который может быть прекращен или заброшен, пока вы находитесь в середине проекта архивирования.
Советы по управлению автономными архивами
Прежде чем мы перейдем к архивации веб-сайта, давайте уделим несколько минут тому, чтобы помочь вам организовать существующие архивы.Мы затронули эту тему, но наличие основательного подхода сделает ваши архивы более управляемыми. Пользователи вашего сайта также получат больше пользы от хорошо организованного архива.
Вы должны помнить о трех ключевых элементах:
- Частота: Решите, как часто вы хотите архивировать сайт. Огромным, динамичным, сложным сайтам с почти ежедневными изменениями потребуется более частое создание моментальных снимков, чем статическим сайтам.
- Местоположение: Как и резервные копии, вы должны сохранять архивы в нескольких разных местах, включая облако.Следуйте правилу 3-2-1 для дополнительной уверенности. Мы также можем предложить больше, если вы хотите охватить всю глубину своего сайта.
- Структура: Как и в каталогах вашего компьютера, вам следует использовать явные папки, разделенные на имена архивов сайта и дату архивации конкретного сайта.
Хотя вы можете еще больше расширить администрирование архива, эти три совета помогут вам начать архивирование с правильной ноги.
5 способов заархивировать веб-сайт
Ниже мы предложим пять различных способов архивирования веб-сайта.Мы заказали решения, исходя из их относительной сложности. Однако, если вы найдете решение, которое, по вашему мнению, будет работать для ваших текущих потребностей, не стесняйтесь погрузиться в него и найти больше.
1. Сохраните одну страницу на локальном компьютере
Прежде всего, давайте обсудим наиболее простое решение. Это замечательно, если вам нужно заархивировать одну страницу, и, что еще лучше, функциональность уже есть практически в каждом браузере.
Для начала откройте свой любимый браузер и перейдите на веб-сайт, который хотите заархивировать.После загрузки страницы перейдите в меню браузера File и найдите опцию Save Page As :
Меню «Файл»Firefox содержит функции, необходимые для сохранения отдельной веб-страницы.
Затем нажмите на опцию сохранения страницы, после чего браузер покажет вам диалоговое окно.
Здесь выберите имя для вашей страницы (хотя по умолчанию это нормально). Кроме того, убедитесь, что вы сохраняете всю страницу, а не только ее HTML. Это сохранит сайт с максимальной функциональностью.
2. Используйте DevKinsta для архивации вашего веб-сайта WordPress
DevKinsta также может помочь вам заархивировать веб-сайт.
Мы считаем DevKinsta важным инструментом для создания и развертывания веб-сайтов WordPress. Однако у него есть еще одна нить: он помогает вам архивировать и ваши веб-сайты, размещенные на Kinsta.
Мы рассмотрели весь процесс загрузки внешней резервной копии MyKinsta в DevKinsta в одной из статей нашей базы знаний. Подводя итог:
- Создайте и загрузите резервную копию в MyKinsta.
- Создайте новый сайт с DevKinsta.
- Импортируйте ваш контент и базу данных.
- Выполните поиск и замену в своей базе данных, чтобы изменить имя URL с вашего действующего сайта на новый локальный архив.
На этом этапе вы можете открыть свой сайт в DevKinsta и использовать его, как если бы он был действующим.
3. Используйте онлайн-архив (например, Wayback Machine)
Ни одно руководство не будет полным без демонстрации того, как работает Wayback Machine. К счастью, процесс прост.Тем не менее, обратите внимание, что этот метод позволяет вам архивировать только отдельные страницы (хотя подписка Archive-It позволяет вам архивировать полные сайты).
Для этого подхода перейдите на домашнюю страницу Wayback Machine и воспользуйтесь формой Save Page Now :
Форма «Сохранить страницу сейчас» на веб-сайте Wayback Machine.
Чтобы заархивировать страницу, просто добавьте URL-адрес, который вы хотите сохранить, в эту форму, затем щелкните Сохранить страницу . В зависимости от размера или сложности страницы вам может потребоваться несколько минут, пока поисковый робот и движок сделают свое дело.Возможно, страница выглядит так, как будто она разбилась. Некоторое время в ходе тестирования мы сталкивались с «белым экраном смерти» (WSoD).
Однако, как только страница будет заархивирована, Wayback Machine перенаправит вас на новую, выделенную страницу.
Страница Кинста заархивирована на Wayback Machine.
Обратите внимание, что вы также можете использовать букмарклет и расширение браузера для архивации веб-сайта. Фактически, большинство современных браузеров имеют эти параметры прямо из коробки, включая Google Chrome, Firefox и Safari.
4. Установите уровень интеграции веб-архивирования (WAIL)
Ваш первый шаг в этом подходе — загрузить сам WAIL и установить его. К счастью, для этого инструмента есть специальный установщик (хотя, поскольку программа написана на Python, в ней используется модуль PyInstaller).
Процесс установки очень прост. Независимо от вашей операционной системы (ОС) вы можете выполнить следующее:
- Перейдите на сайт WAIL и загрузите соответствующий установщик для своей ОС.
- Разархивируйте файл для версии Windows или смонтируйте образ DMG для macOS.
- В появившемся диалоговом окне для macOS перетащите значок приложения в папку Applications . Для пользователей Windows просто перетащите распакованную папку на корневой диск C: \ .
- Запустите WAIL.app или WAIL.exe (в зависимости от вашей ОС).
После открытия WAIL вы увидите его минимальный интерфейс:
Интерфейс WAIL предоставляет вам три варианта.
Теперь вам доступны три варианта на выбор: просмотреть архив, проверить его статус или заархивировать веб-сайт. Кнопки немного сбивают с толку, поскольку вы можете читать слева направо. Однако при первом запуске у вас ничего не останется в архивах.
Вместо этого введите URL-адрес сайта, который вы хотите заархивировать, и щелкните Архивировать сейчас! Вы увидите, что WAIL начинает сканирование веб-сайта. Проверить статус сканирования можно на вкладке Advanced > Heritrix :
WAIL показывает текущий статус задания сканирования.
Когда это будет сделано, появится сообщение «Успешно». На этом этапе вы можете нажать кнопку Просмотреть архив на вкладке Basic . В браузере откроется ваш заархивированный сайт, готовый для просмотра.
5. Используйте Wget, если вам удобно пользоваться командной строкой
Для нашего последнего метода архивирования веб-сайта вам понадобится несколько вещей, прежде чем вы начнете:
- Доступ к компьютеру из командной строки
- Подходящий инструмент командной строки, такой как командная строка Windows или терминал в macOS и Linux
- Wget установлен на вашем компьютере
Скорее всего, у вас уже будут первые два.
В macOS вы можете установить Wget через Homebrew с помощью команды brew install wget . Обратите внимание, что вам также необходимо установить Homebrew, но это займет всего несколько секунд. В Linux Wget предустановлен в большинстве основных дистрибутивов.
Если вы пользователь Windows, возможно, вам будет сложнее установить Wget на свой компьютер. Хотя в Интернете есть учебные пособия, они не кажутся единообразными для разных компьютеров. Вместо этого мы рекомендуем вам зайти на официальный сайт Wget и проверить некоторые из доступных двоичных файлов Windows, так как они, скорее всего, подойдут вам.
Как бы то ни было, после того, как вы установили Wget, пользоваться им очень просто. Сначала перейдите в каталог в новом окне терминала. Здесь мы тоже создаем каталог, но этот шаг необязательный:
cd-документы && архив mkdir && cd архив
Обратите внимание, что Wget будет загружать все загрузки в любой рабочий каталог. В данном случае мы указали папку для наших файлов.
Затем вам нужно просканировать сайт и получить файлы.Каждое действие вызывается с помощью команды wget , и вам нужно использовать следующий формат:
wget "https://kinsta.com/" --warc-file = "kins"
При нажатии клавиши Enter начнется загрузка kinsta.com в файл index.html и создание файла WARC с именем kins-00000.warc.gz .
Сайт заархивирован как файл WARC.
Wget — мощный инструмент, который позволяет использовать множество команд и параметров. Например, вы можете использовать команду --mirror для создания файла WARC, содержащего полное зеркало вашего сайта.Вы также можете использовать команду --no-warc-compress для записи несжатых файлов, хотя это, очевидно, займет больше места при загрузке. Оптимальный подход — использование встроенного компрессора.
Архивирование вашего веб-сайта похоже на создание капсулы времени ⏳ … и, к счастью, с помощью этого руководства легко начать работу. ✅Нажмите, чтобы написать в Твиттере
Сводка
Веб-архивирование выросло из необходимости документировать быстро меняющиеся формы Интернета.Теперь у него есть несколько допустимых приложений — например, в случае юридических файлов и требований. Независимо от ваших потребностей, наличие хорошо структурированного и организованного архива может дополнить вашу общую стратегию резервного копирования.
К счастью, существует множество решений, которые могут помочь. Большинство браузеров предлагают возможность сохранять веб-страницу на вашем компьютере, хотя такие решения, как DevKinsta, также являются подходящими инструментами для этой работы. Однако специализированные инструменты архивирования, такие как Wayback Machine, Heritrix, WAIL и Wget, являются особенно надежными решениями и предлагают стандартизированные форматы файлов для работы.
Вызывает ли эта статья желание заархивировать собственный веб-сайт? Поделитесь своими мыслями и мнениями в разделе комментариев ниже!
Экономьте время, деньги и повышайте производительность сайта с помощью:
- Мгновенная помощь от экспертов по хостингу WordPress, 24/7.
- Cloudflare Enterprise интеграция.
- Глобальный охват аудитории с 28 центрами обработки данных по всему миру.
- Оптимизация с помощью нашего встроенного мониторинга производительности приложений.
Все это и многое другое в одном плане без долгосрочных контрактов, поддержки миграции и 30-дневной гарантии возврата денег. Ознакомьтесь с нашими планами или поговорите с отделом продаж, чтобы найти план, который подходит именно вам.
Как найти старые или просроченные веб-сайты
Q. Иногда я захожу на старый веб-сайт и обнаруживаю, что он заменен страницей с рекламой. Куда делись все оригинальные сайты?
A. Многие действующие веб-сайты с годами потемнели, поскольку их владельцы отключили серверы, на которых размещались страницы, для публичного просмотра и отказались от зарегистрированных доменных имен, которые когда-то направляли посетителей на сайт.Известно, что другие предприниматели используют доменные имена с истекшим сроком действия для других целей, например, размещая страницы с рекламными ссылками (или другим контентом), чтобы приветствовать людей, ищущих исходный веб-сайт.
Если вы испытываете ностальгию по тому, как раньше выглядели некоторые старые сайты, вы можете увидеть копии страниц такими, какими они когда-то были, посетив Wayback Machine, расширяющуюся коллекцию из 455 миллиардов веб-страниц, которая продолжает расти. (И да, этот сайт был назван в честь машины времени, которую использовал мистер Ф.Персонаж Пибоди из мультсериала, впервые вышедшего в эфир в конце 1950-х годов.)
Хотя запасы Wayback Machine датируются серединой 1990-х годов, не все веб-сайты включены в коллекцию. Но вы, вероятно, сможете найти образцы большинства коммерческих сайтов за последние 15 лет или около того. Просто введите адрес сайта, который вы ищете, чтобы увидеть, что могло быть сохранено.
The Wayback Machine является частью Интернет-архива, бесплатной онлайн-библиотеки цифровых носителей и электронных артефактов.Помимо коллекции веб-страниц, Интернет-архив также содержит исследовательскую библиотеку программ телевизионных новостей, записей живой музыки и других аудио- и текстовых файлов, а также электронных книг, фильмов и тысяч старых компьютерных программ, включая видеоигры для игровых автоматов. , компьютеры и консоли.
Как найти правильную скорость широкополосного доступа
Q. Моя текущая широкополосная услуга медленная, и загрузка фильма занимает целую вечность. Я хочу перейти на более быстрый уровень, но это становится дорого.Какая скорость мне нужна для потоковой передачи фильма Netflix без остановки, видеозвонка или загрузки взятого напрокат цифрового фильма за меньшее время, чем требуется для его просмотра?
A. При расчете необходимой скорости учитывайте все действия в сети, которые вы хотите выполнять (потоковая передача, загрузка, игры, видеоконференции и т. Д.), И проверьте минимальную скорость соединения, необходимую для каждого из них. Обычно вы можете найти рекомендации, перечисленные на веб-сайтах компаний и служб, которыми вы пользуетесь.Действия, связанные с видео, обычно требуют большей скорости и пропускной способности сети, чем такие вещи, как потоковая передача звука или базовый просмотр веб-страниц.
Например, Netflix рекомендует соединение со скоростью не менее трех мегабит в секунду для потоковой передачи видео в стандартном разрешении и соединение со скоростью пять мегабит в секунду для просмотра контента высокой четкости без заиканий или буферизации. (Если вы выбираете новую широкополосную компанию, исходя из ваших потребностей в потоковой передаче видео, Netflix ежемесячно публикует собственный рейтинг скорости интернет-провайдеров в своем блоге.) Как и в случае с потоковой передачей, скорость загрузки файлов может пострадать из-за общей перегрузки Интернета и сервера, но соединение со скоростью 25 мегабит в секунду может позволить вам загрузить файл фильма размером шесть гигабайт менее чем за 20 минут.
Служба видеозвонков Skype от Microsoft рекомендует подключение со скоростью 1,5 мегабит в секунду для видеозвонков высокой четкости, а на странице поддержки Google Hangouts предлагается скорость 2,6 мегабита в секунду в качестве «идеальной пропускной способности для наилучшего взаимодействия». Сайты поддержки большинства онлайн-видеоигр должны также указать минимальную скорость широкополосного соединения среди требований к процессору, памяти и другим аппаратным факторам.Если вы планируете публиковать собственные фотографии или видео в Интернете, план, предлагающий приличную скорость загрузки данных, заставит вас меньше ждать этого.
После того, как вы собрали свои выводы о скоростях подключения для предпочитаемых вами онлайн-сервисов, проверьте пакеты, доступные у местных интернет-провайдеров, предлагающих кабельное, спутниковое, оптоволоконное или широкополосное соединение DSL. Например, если вам в первую очередь нужны плавные потоки фильмов высокой четкости от Netflix, получите тарифный план, который предлагает как минимум рекомендуемое соединение со скоростью пять мегабит в секунду.Также следует учитывать количество людей, одновременно использующих широкополосное соединение, поэтому вы можете получить более быстрый план, если в семье есть онлайн-геймеры, а также любители кино.
По мере того, как провайдеры Интернет-услуг наращивали свои широкополосные сети на протяжении многих лет, они смогли расширить свои предложения, чтобы удовлетворить более широкий диапазон потребностей клиентов и бюджетов, поэтому вы можете увидеть четыре или пять предлагаемых планов обслуживания; максимальная скорость загрузки и выгрузки должна быть указана для каждого уровня обслуживания.В январе этого года Федеральная комиссия по связи обновила свой эталонный показатель для «широкополосного доступа» на 2010 год со скорости загрузки с четырех мегабит в секунду до 25 мегабит в секунду, поэтому названия и типы планов, предлагаемые провайдерами, могут снова измениться в будущем.
Как сохранить веб-сайты на жесткий диск
Есть несколько способов сохранить веб-сайт на локальный жесткий диск, и они во многом зависят от ваших потребностей. Если вы хотите сохранить только текстовую информацию, вы можете просто скопировать и вставить содержимое в локальный текстовый файл на вашем компьютере.Если вы хотите сохранить ссылки, вам необходимо сохранить страницу в формате HTML. В большинстве браузеров есть возможность сохранить веб-сайт локально, но что, если вам нужно несколько страниц или также нужна информация о ссылках?
Вы можете открыть любой веб-сайт и сохранить его. У этого есть недостатки. Во-первых, между сохраненными страницами нет ссылочной структуры. Если вы хотите открыть страницу 1, вам нужно найти индексный файл для страницы 1, который отличается от всех других страниц. Он отлично подходит для отдельных страниц, но не подходит для целых веб-сайтов или сетей.
Прежде чем я начну с решения, я хотел бы указать на некоторые из причин, по которым кто-то хотел бы сохранить веб-сайт на локальный диск:
- Страх, что сайт будет удален. (Может быть, это размещенный на хосте @ geocities или аналогичный сайт, все знают, что сайты, как правило, появляются и исчезают довольно быстро на бесплатных веб-хостах)
- Для просмотра в автономном режиме. Возможно, у вас нет единой ставки, и вам нужно платить за минуты, которые вы находитесь в сети. Также может быть, что вы хотите перенести веб-сайт на компьютер, у которого нет подключения к Интернету.Это включает случай, когда вы хотите установить новую ОС, например Linux и испытываете трудности с настройкой подключения к Интернету. Вы можете сохранить учебные сайты на свой компьютер, прежде чем вносить изменения.
- Вы коллекционер. Возможно, вы хотите загрузить сайт, на котором ежедневно публикуются изображения, музыкальные файлы или чит-коды к играм.
Инструмент:
Мы будем использовать бесплатный инструмент Httrack, который доступен для персональных компьютеров под управлением windows, mac os x и linux.Загрузите его с официального сайта httrack.com
Каждый веб-сайт, который вы сохраняете на локальном диске, хранится в файле проекта. Первым шагом после запуска httrack является создание нового проекта, щелкнув ДАЛЕЕ.
Добавьте основную информацию о проекте, название и категорию, а также путь, по которому вы хотите его сохранить. Я предлагаю диск, на котором достаточно места для всех файлов веб-сайта. Обратите внимание, что вы не можете создать новый каталог в самой программе.
Это экран наиболее важных опций для вашего проекта. Вы выбираете действие и добавляете URL-адреса для выполнения этого действия. Если вы хотите загрузить весь веб-сайт, выберите «Загрузить веб-сайты» и добавьте URL-адреса в поле веб-адреса.
Если вы хотите загрузить файлы только определенных типов, выберите Получить отдельные файлы. Вы указываете типы файлов, щелкая по заданным параметрам и выбирая правила сканирования.
Вы можете добавить URL-адреса, просто введя их в текстовое поле или нажав кнопку «Добавить URL».Нажатие кнопки «Добавить URL» позволяет вам войти на веб-сайт, который вы хотите загрузить, и добавить информацию для входа на этот веб-сайт. Httrack также позволяет захватывать URL-адреса с помощью прокси.
Установить параметры открывает страницу параметров проекта. Вы можете указать здесь много информации. Глубина сканирования веб-сайтов, переход по внешним ссылкам, включение / исключение файлов и каталогов и многое другое.
По умолчанию загружаются все внутренние веб-сайты, а загрузка внешних веб-сайтов запрещена.
Это означает, что если вы хотите загрузить только веб-сайт, попробуйте настройки по умолчанию и посмотрите на результат.Файлы php будут сохранены как html.
Ссылки:
Руководство по командной строке
Часто задаваемые вопросы
Форум Httrack
Объяснение параметров
Как просматривать потерянные веб-страницы
Если веб-страница, которую вы хотели открыть, недоступна — причины могут варьироваться от временной проблемы с сетью до страница полностью удаляется с сайта — тогда не нужно терять надежду. На самом деле можно восстановить резервные копии большинства страниц из Интернета с помощью небольшого ноу-хау.Весь процесс невероятно прост, и вы найдете его очень полезным, если изучите тему и обнаружите, что ссылки, которые вы сохраняли в течение недель или даже месяцев, больше не работают.
Если вы хотите прочитать веб-страницу, которая была удалена или по другим причинам недоступна, это то, что вы можете сделать.
Wayback Machine
Archive.org Wayback, вероятно, лучший инструмент для восстановления любой удаленной веб-страницы. Это часть Интернет-архива, некоммерческой организации, которая пытается дублировать весь контент в Интернете.Он сохранил более 435 миллиардов веб-страниц, что, вероятно, не весь контент в Интернете, но все же впечатляет. Страницы фиксируются несколько раз, поэтому, например, мы использовали Wayback Machine, чтобы просмотреть домашнюю страницу NDTV Gadgets в течение нескольких разных лет, и увидели, что наш дизайн со временем эволюционировал.
Вот как им пользоваться.
Откройте сайт Wayback.
Введите URL-адрес отсутствующего веб-сайта или веб-страницы, которую вы хотите открыть, в поле вверху.
Щелкните Обзор истории .
Вы увидите представление календаря. Выберите год вверху, а затем дату из списка месяцев ниже.
Вот и все! Вам будет показана сохраненная версия страницы с этой даты.
Кэш поисковой системы
Если вы ищете страницу, которая была недавно удалена, то, возможно, будет проще найти ее с помощью поисковой системы, такой как Google, Yahoo или Bing.Пока вы можете найти веб-страницу в поисковой системе, вы также сможете загрузить резервную копию страницы. Вот как это работает:
Откройте понравившуюся поисковую систему. Кеширование Google очень хорошее, поэтому мы рекомендуем вам его использовать.
Вставьте ссылку на отсутствующую веб-страницу в строку поиска, если вы ее знаете, или просто выполните поиск страницы, чтобы найти нужную ссылку.
Под синим текстом ссылки вы увидите строку зеленого текста, которая является URL-адресом веб-страницы.Щелкните стрелку вниз рядом с зеленым текстом URL-адреса.
Нажмите Кэшировано . Это покажет вам сохраненную версию нужной страницы, а также подробную информацию о том, когда была сделана резервная копия.
Если эта страница не загружается должным образом, вы можете попробовать щелкнуть Текстовая версия в правом верхнем углу. Это приведет к потере всех изображений, которые были на странице, но, если они загружаются неправильно, это все равно позволит вам получить важные данные, которые вам нужны.
Сохранение необходимых веб-страниц
Если вы хотите сохранить веб-страницы для исследовательских целей, лучше сохранить их заранее. Сделать это из браузера очень просто:
Перейдите на веб-сайт, который хотите сохранить.
Нажмите Ctrl + S .
Дайте ему любое имя файла и нажмите Сохранить .
Эта страница сохранит страницу на вашем компьютере, и вы сможете получить к ней доступ в любое время.
Ваш комментарий будет первым