История изменений
- Главная
- История изменений
Описание того что происходило на сайте
| Version | Описание |
|---|---|
| 0.6.6.1 |
|
| 0.6.6.0 | Из улучшений которые видно на сайте:
Из того что не видно:
|
| 0.6.5.1 | Мелкие правки и исправления для PDF |
| 0.6.5.0 |
|
| 0.6.4.2 | Данное обновление затрагивает 26 файлов. Из того что было сделано:
|
0. 6.4.1 6.4.1 |
|
| 0.6.4 | Новый Deploy скрипт под Laravel. Рефакторинг JS |
| 0.6.3 | Fallback загрузка для тех кто на старых браузерах. Оптимизация загрузки стилей, мелкие правки |
| 0.6.2 | Обновление Лары 5.7 -> 5.8, багфиксы |
| 0.6.1 | Добавлены новые языки распознаваний. Мелкие правки |

Распознать текст (OCR) онлайн — IMG online
Главное нужно указать изображение с текстом на вашем компьютере или телефоне, обязательно выбрать основной язык текста и нажать кнопку OK внизу страницы. Остальные настройки уже выставлены по умолчанию.
Остальные настройки уже выставлены по умолчанию.
Пример сфотографированного текста из книги и скриншот распознанного текста на этой фотографии:
В зависимости от размера исходного изображения и количества текста обработка может продлиться около 1 минуты.
Для достижения лучшего результата распознания текста желательно обратить внимание на подсказки возле настроек. Перед обработкой изображение нужно повернуть на нормальный угол, чтобы текст шёл в правильном направлении и небыл перевёрнут вверх ногами, а также желательно обрезать лишние однотонные края без текста, если они есть.
Исходное изображение никак не изменяется, вам будет предоставлен распознанный текст в обычном текстовом документе в формате .txt с кодировкой utf-8 и после обработки его можно будет открыть прямо в окне браузера или же после скачивания – в любом текстовом редакторе.
Основной язык текста №1: Азербайджанский (Azerbaijani)Албанский (Albanian)Английский (English)Английский средний (Middle English 1100-1500)Арабский (Arabic)Африкаанс (Afrikaans)Баскский (Basque)Белорусский (Belarusian)Бенгальский (Bengali)Болгарский (Bulgarian)Венгерский (Hungarian)Вьетнамский (Vietnamese)Галисийский (Galician)Голландский (Dutch)Греческий (Greek)Греческий древний (Ancient Greek)Датский (Danish)Иврит (Hebrew)Индонезийский (Indonesian)Исландский (Icelandic)Испанский (Spanish)Испанский (старый) (Spanish old)Итальянский (Italian)Итальянский (старый) (Italian old)Каннада (Kannada)Каталанский (Catalan)Китайский традиционный (Chinese Traditional)Китайский упрощенный (Chinese Simplified)Корейский (Korean)Латышский (Latvian)Литовский (Lithuanian)Македонский (Macedonian)Малайский (Malay)Малаялам (Malayalam)Мальтийский (Maltese)Немецкий (German)Норвежский (Norwegian)Польский (Polish)Португальский (Portuguese)Румынский (Romanian)Русский (Russian)Сербский (латинский) (Serbian latin)Словацкий (Slovakian)Словенский (Slovenian)Суахили (Swahili)Тагальский (Tagalog)Тайский (Thai)Тамильский (Tamil)Телугу (Telugu)Турецкий (Turkish)Украинский (Ukrainian)Финский (Finnish)Франкский (Frankish)Французский (cредний) (Middle French)Французский (French)Хинди (Hindi)Хорватский (Croatian)Чероки (Cherokee)Чешский (Czech)Шведский (Swedish)Эсперанто (Esperanto)Эсперанто альтернативный (Esperanto alternative)Эстонский (Estonian)Японский (Japanese) ← нужно выбрать существующий
Дополнительные языки, которые нужно распознать:
№2: Не распознаватьАзербайджанский (Azerbaijani)Албанский (Albanian)Английский (English)Английский средний (Middle English 1100-1500)Арабский (Arabic)Африкаанс (Afrikaans)Баскский (Basque)Белорусский (Belarusian)Бенгальский (Bengali)Болгарский (Bulgarian)Венгерский (Hungarian)Вьетнамский (Vietnamese)Галисийский (Galician)Голландский (Dutch)Греческий (Greek)Греческий древний (Ancient Greek)Датский (Danish)Иврит (Hebrew)Индонезийский (Indonesian)Исландский (Icelandic)Испанский (Spanish)Испанский (старый) (Spanish old)Итальянский (Italian)Итальянский (старый) (Italian old)Каннада (Kannada)Каталанский (Catalan)Китайский традиционный (Chinese Traditional)Китайский упрощенный (Chinese Simplified)Корейский (Korean)Латышский (Latvian)Литовский (Lithuanian)Македонский (Macedonian)Малайский (Malay)Малаялам (Malayalam)Мальтийский (Maltese)Немецкий (German)Норвежский (Norwegian)Польский (Polish)Португальский (Portuguese)Румынский (Romanian)Русский (Russian)Сербский (латинский) (Serbian latin)Словацкий (Slovakian)Словенский (Slovenian)Суахили (Swahili)Тагальский (Tagalog)Тайский (Thai)Тамильский (Tamil)Телугу (Telugu)Турецкий (Turkish)Украинский (Ukrainian)Финский (Finnish)Франкский (Frankish)Французский (cредний) (Middle French)Французский (French)Хинди (Hindi)Хорватский (Croatian)Чероки (Cherokee)Чешский (Czech)Шведский (Swedish)Эсперанто (Esperanto)Эсперанто альтернативный (Esperanto alternative)Эстонский (Estonian)Японский (Japanese)№3: Не распознаватьАзербайджанский (Azerbaijani)Албанский (Albanian)Английский (English)Английский средний (Middle English 1100-1500)Арабский (Arabic)Африкаанс (Afrikaans)Баскский (Basque)Белорусский (Belarusian)Бенгальский (Bengali)Болгарский (Bulgarian)Венгерский (Hungarian)Вьетнамский (Vietnamese)Галисийский (Galician)Голландский (Dutch)Греческий (Greek)Греческий древний (Ancient Greek)Датский (Danish)Иврит (Hebrew)Индонезийский (Indonesian)Исландский (Icelandic)Испанский (Spanish)Испанский (старый) (Spanish old)Итальянский (Italian)Итальянский (старый) (Italian old)Каннада (Kannada)Каталанский (Catalan)Китайский традиционный (Chinese Traditional)Китайский упрощенный (Chinese Simplified)Корейский (Korean)Латышский (Latvian)Литовский (Lithuanian)Македонский (Macedonian)Малайский (Malay)Малаялам (Malayalam)Мальтийский (Maltese)Немецкий (German)Норвежский (Norwegian)Польский (Polish)Португальский (Portuguese)Румынский (Romanian)Русский (Russian)Сербский (латинский) (Serbian latin)Словацкий (Slovakian)Словенский (Slovenian)Суахили (Swahili)Тагальский (Tagalog)Тайский (Thai)Тамильский (Tamil)Телугу (Telugu)Турецкий (Turkish)Украинский (Ukrainian)Финский (Finnish)Франкский (Frankish)Французский (cредний) (Middle French)Французский (French)Хинди (Hindi)Хорватский (Croatian)Чероки (Cherokee)Чешский (Czech)Шведский (Swedish)Эсперанто (Esperanto)Эсперанто альтернативный (Esperanto alternative)Эстонский (Estonian)Японский (Japanese)№4: Не распознаватьАзербайджанский (Azerbaijani)Албанский (Albanian)Английский (English)Английский средний (Middle English 1100-1500)Арабский (Arabic)Африкаанс (Afrikaans)Баскский (Basque)Белорусский (Belarusian)Бенгальский (Bengali)Болгарский (Bulgarian)Венгерский (Hungarian)Вьетнамский (Vietnamese)Галисийский (Galician)Голландский (Dutch)Греческий (Greek)Греческий древний (Ancient Greek)Датский (Danish)Иврит (Hebrew)Индонезийский (Indonesian)Исландский (Icelandic)Испанский (Spanish)Испанский (старый) (Spanish old)Итальянский (Italian)Итальянский (старый) (Italian old)Каннада (Kannada)Каталанский (Catalan)Китайский традиционный (Chinese Traditional)Китайский упрощенный (Chinese Simplified)Корейский (Korean)Латышский (Latvian)Литовский (Lithuanian)Македонский (Macedonian)Малайский (Malay)Малаялам (Malayalam)Мальтийский (Maltese)Немецкий (German)Норвежский (Norwegian)Польский (Polish)Португальский (Portuguese)Румынский (Romanian)Русский (Russian)Сербский (латинский) (Serbian latin)Словацкий (Slovakian)Словенский (Slovenian)Суахили (Swahili)Тагальский (Tagalog)Тайский (Thai)Тамильский (Tamil)Телугу (Telugu)Турецкий (Turkish)Украинский (Ukrainian)Финский (Finnish)Франкский (Frankish)Французский (cредний) (Middle French)Французский (French)Хинди (Hindi)Хорватский (Croatian)Чероки (Cherokee)Чешский (Czech)Шведский (Swedish)Эсперанто (Esperanto)Эсперанто альтернативный (Esperanto alternative)Эстонский (Estonian)Японский (Japanese)№5: Не распознаватьАзербайджанский (Azerbaijani)Албанский (Albanian)Английский (English)Английский средний (Middle English 1100-1500)Арабский (Arabic)Африкаанс (Afrikaans)Баскский (Basque)Белорусский (Belarusian)Бенгальский (Bengali)Болгарский (Bulgarian)Венгерский (Hungarian)Вьетнамский (Vietnamese)Галисийский (Galician)Голландский (Dutch)Греческий (Greek)Греческий древний (Ancient Greek)Датский (Danish)Иврит (Hebrew)Индонезийский (Indonesian)Исландский (Icelandic)Испанский (Spanish)Испанский (старый) (Spanish old)Итальянский (Italian)Итальянский (старый) (Italian old)Каннада (Kannada)Каталанский (Catalan)Китайский традиционный (Chinese Traditional)Китайский упрощенный (Chinese Simplified)Корейский (Korean)Латышский (Latvian)Литовский (Lithuanian)Македонский (Macedonian)Малайский (Malay)Малаялам (Malayalam)Мальтийский (Maltese)Немецкий (German)Норвежский (Norwegian)Польский (Polish)Португальский (Portuguese)Румынский (Romanian)Русский (Russian)Сербский (латинский) (Serbian latin)Словацкий (Slovakian)Словенский (Slovenian)Суахили (Swahili)Тагальский (Tagalog)Тайский (Thai)Тамильский (Tamil)Телугу (Telugu)Турецкий (Turkish)Украинский (Ukrainian)Финский (Finnish)Франкский (Frankish)Французский (cредний) (Middle French)Французский (French)Хинди (Hindi)Хорватский (Croatian)Чероки (Cherokee)Чешский (Czech)Шведский (Swedish)Эсперанто (Esperanto)Эсперанто альтернативный (Esperanto alternative)Эстонский (Estonian)Японский (Japanese) Порядок указания языков значения не имеет. Если на изображении есть только символы основного языка №1, то дополнительные языки от №2 до №5 лучше «не распознавать» для более точной обработки.
Порядок указания языков значения не имеет. Если на изображении есть только символы основного языка №1, то дополнительные языки от №2 до №5 лучше «не распознавать» для более точной обработки.Предварительная оптимизация изображения
Предварительное улучшение отсканированного текста
Если отсканированный текст качественный, то для эксперимента можно сначала отключить улучшение отсканированного текста, а потом и оптимизацию изображения. Иногда это может помочь даже тогда, когда текст вообще не распознается.
Программа OCR для распознавания текста на изображении: 1 2
Если не будет получаться нормально распознать текст первой программой, то можно попробовать переключиться на вторую (работает быстрее) или же проще говоря – выбрать лучший результат из двух.
Обработка обычно длится 20-60 секунд.
Конвертировать PDF в текст — Конвертируйте PDF в текст онлайн
Существует простой способ редактирования текста в формате PDF: преобразуйте ваши документы в формате PDF в текст с помощью OCR (оптического распознавания символов).
 Если вам интересно, как извлечь текст из PDF, вы не ошибетесь, используя PDF2Go.
Если вам интересно, как извлечь текст из PDF, вы не ошибетесь, используя PDF2Go.Перетащите файлы сюда
Преобразовать
Отсканированные страницы будут изображениями.
Premium
Преобразование с помощью OCRОтсканированные страницы будут преобразованы в текст, который можно редактировать.
Исходный язык вашего файла
Чтобы получить наилучшие результаты, выберите все языки, содержащиеся в вашем файле.
Применить фильтр: Применить фильтр Без фильтраСерый фильтр
Информация: Пожалуйста, включите JavaScript для корректной работы сайта.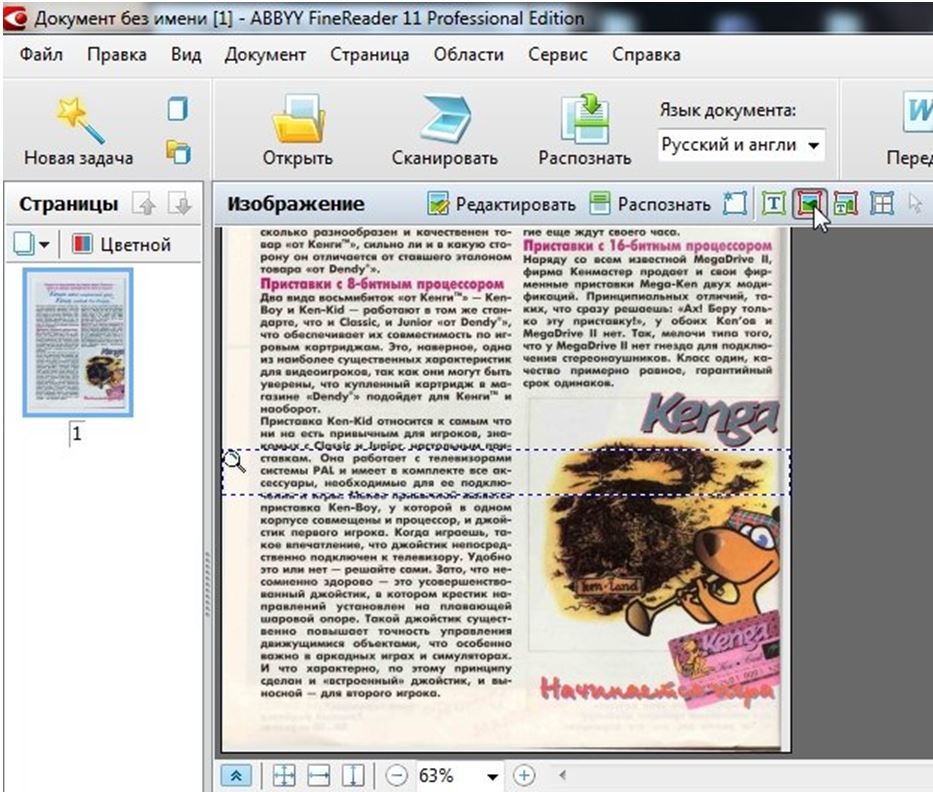
Как извлечь текст из документов PDF
- Загрузите документ PDF.
- Нажмите «Пуск».
Преобразование PDF в текст с помощью OCR
бесплатно и куда угодно
Преобразование PDF в текст
Вы когда-нибудь задумывались, как редактировать текст в документах PDF? У нас есть решение для вас. Просто преобразуйте документ PDF в текст. С помощью оптического распознавания символов (OCR) вы можете извлечь любой текст из документа PDF в простой текстовый файл.
Все очень просто: просто загрузите PDF-файл, а мы сделаем все остальное. После того, как вы предоставили свой файл, PDF2Go будет использовать OCR, чтобы получить текст из вашего PDF и сохранить его как файл TXT.
Worry Free Conversion
С PDF2Go вам не нужно беспокоиться о вредоносном ПО, влияющем на ваш компьютер, или приложениях, занимающих драгоценное место на вашем телефоне.
Как онлайн-сервис, этот конвертер PDF в OCR не требует установки или даже регистрации для извлечения текста из файлов PDF.
Для сканирования и прочего
Забудьте о копировании текста из отсканированной книги или статьи вручную. Если вы конвертируете PDF в текст с помощью этого простого онлайн-инструмента, вы можете легко извлечь текст из любого имеющегося у вас скана — даже из изображений.
Если у вас есть PDF-файл, который не позволяет копировать текст, пропустите его через наш конвертер PDF в текст, чтобы получить простой TXT-файл, содержащий весь текст вашего PDF-документа.
Вопросы безопасности?
Когда вы загружаете PDF-файл для преобразования в текст, последнее, что вам нужно, — это беспокоиться о том, что произойдет с вашим файлом. Мы можем принять эти заботы от вас.
Мы можем принять эти заботы от вас.
Ваш файл останется вашим на всех этапах пути. Нам не передаются никакие права, и никто не проверяет содержимое вашего файла. Дополнительную информацию можно найти в нашей Политике конфиденциальности.
Что я могу конвертировать?
С помощью этого онлайн-конвертера вы можете делать именно то, что он говорит: конвертировать PDF в текст. Любой PDF-файл, который вы конвертируете, будет преобразован в простой и удобный для открытия текстовый файл.
От:Adobe PDF
Кому:Обычный текст TXT
Используйте OCR Online
Все, что вам нужно, чтобы PDF2Go взял на себя ваши потребности в преобразовании PDF, — это стабильное подключение к Интернету и любой браузер. Вы также не ограничены одним компьютером или устройством. Преобразование PDF-документов в TXT из:
- домашний
- работа
- на дороге
- где угодно
Оцените этот инструмент 3,5 /5
Вам нужно преобразовать и загрузить хотя бы 1 файл, чтобы оставить отзыв
Отзыв отправлен
Спасибо за ваш голос
Преобразователь изображения в текст — извлечение текста из изображения
Онлайн-преобразователь изображения в текст преобразует любое изображение в редактируемый текст. Мы разработали этот инструмент, используя OCR (оптическое распознавание символов). Tesseract и другие библиотеки Python используются для уточнения извлеченного текста.
Мы разработали этот инструмент, используя OCR (оптическое распознавание символов). Tesseract и другие библиотеки Python используются для уточнения извлеченного текста.
| 🎯 Форматы | JPG, PNG, GIF и т. д. |
| 💲 Цена | Бесплатный неограниченный доступ |
| 🗺 Языки | EN ID DE FR ES и другие |
Основанный на технологии оптического распознавания символов инструмент преобразования изображения в текст разработан с использованием передовых библиотек и моделей распознавания текста.
Разные модели символов классифицируются по разным прототипам. Обычно инструмент распознавания изображений выполняет следующие функции:
Основные характеристики нашего конвертера изображений в текст
Средство извлечения изображений с низким разрешением:
Наш средство извлечения текста из изображений может легко извлекать текст из размытых изображений и изображений с низким разрешением. Изображения книг, самописных работ и скриншотов тусклые и не могут быть легко восприняты. Тем не менее, этот инструмент может получать данные из таких изображений с высокой точностью.
Изображения книг, самописных работ и скриншотов тусклые и не могут быть легко восприняты. Тем не менее, этот инструмент может получать данные из таких изображений с высокой точностью.
Обнаружение математического синтаксиса:
Этот конвертер фотографий в текст содержит широкий спектр данных, введенных в него с помощью машинного обучения. Вы можете использовать его для точного извлечения математических выражений из изображений. Арифметические уравнения и полиномиальные выражения часто бывают сложными, но наш инструмент идентифицирует их как человеческие.
Бесплатное использование:
Этот инструмент доступен для всех. Вы можете копировать текст с изображений без регистрации.
Работает с несколькими языками:
Отличительной особенностью этого инструмента является его универсальность при понимании многих языков. С помощью этого инструмента вы можете преобразовать изображения на нескольких языках в текст. Эти языки включают китайский, индонезийский, датский, немецкий, английский, испанский, французский, итальянский, польский, португальский, румынский, шведский, чешский, русский, тайский и корейский.
Поддержка нескольких форматов файлов
Этот конвертер фототекста поддерживает несколько форматов файлов изображений. Вы можете загрузить изображения в следующем формате файла, чтобы получить из них текст. Изображение в текстовый инструмент Использует
Изображение в текстовый экстрактор имеет несколько применений. Это позволяет нам извлекать текст из изображений и отсканированных документов. Делает контент:
- Доступный для поиска
- Редактируемый
- Доступный
Кроме того, некоторые способы преобразования изображения в текст обсуждаются ниже:
Извлечение данных:
столы и другие документы для создания баз данных и электронных таблиц.
Доступность:
Печатные или рукописные документы доступны только для визуально присутствующих пользователей. Преобразование изображений в текст затем может быть прочитано вслух программами чтения с экрана.
Оцифровка книг:
Электронные книги — один из лучших источников чтения. Преобразование печатных книг в цифровой текст делает их более удобными для поиска, а распространение также намного проще, чем физические книги.
Преобразование печатных книг в цифровой текст делает их более удобными для поиска, а распространение также намного проще, чем физические книги.
PDF-файлы с возможностью поиска:
PDF-файлы доступны для поиска в Google. Иногда Google показывает результаты из pdf-документов. Преобразование отсканированных документов в PDF-файлы с возможностью поиска упрощает поиск в документе и делает его доступным для поисковых роботов.
Редактирование текста:
Одним из лучших преимуществ преобразования изображения в текст является редактирование. Поскольку тексты легко редактируются и исправляются.
Анализ данных:
Анализировать изображения данных очень сложно. Извлекайте текст из изображений для дальнейшего анализа, например, при исследовании рынка и анализе контента.
Образовательные цели:
Учащиеся могут преобразовывать отсканированные конспекты, учебники и конспекты лекций в текст для лучшей организации.
Вы можете превратить рукописные заметки в класс в текст, используя наш онлайн-конвертер изображений в текст.
Юридические и комплаенс:
Юридические документы в основном отправляются в печатном формате. Используя конвертер изображений в текст, вы можете извлекать ключевую информацию из юридических документов, контрактов или государственных форм.
С помощью этого преобразователя изображений в текст мы можем преобразовать печатные документы в цифровые версии.
Автоматизация бизнеса:
Обычная бумажная работа стала антиквариатом в ведении бизнеса. Автоматизированные предприятия сейчас лидируют в деловом мире.
В частности, ручная работа с документами для создания баз данных требует очень много времени и средств.
С помощью конвертера изображения в текст вы можете упростить всю свою административную работу. Кроме того, он может оптимизировать ваше оборудование, индексируя необходимую информацию.
Кто может использовать наш конвертер изображений в текст?
1. Офисы
Наш конвертер изображений в текст — отличный инструмент для упрощения задач ввода данных в офисах. Он может легко преобразовывать счета, квитанции и другие важные документы в редактируемые текстовые форматы.
Он может легко преобразовывать счета, квитанции и другие важные документы в редактируемые текстовые форматы.
Сотрудники офиса могут использовать этот преобразователь для удобного извлечения необходимой информации из этих документов. Более того, с Imagetotext.io офисы могут легко поддерживать свои базы данных, сканируя и оцифровывая документы. Это в конечном итоге снижает риск ошибок при ручном вводе данных.
2. Частные лица
Частные лица могут использовать наш конвертер фотографий в текст для различных личных задач. Это может быть оцифровка рукописных заметок и преобразование печатных книг в электронные.
Более того, наш инструмент для преобразования скриншотов в текст способен извлекать читаемый текст из скриншотов. Это экономит время и нервы при копировании, редактировании или поиске определенной информации на изображении.
3. Оцифровка документов
С помощью этого преобразователя изображений в текст вы можете преобразовывать печатные документы в оцифрованные версии, чтобы сделать их легко доступными для поиска, редактирования и совместного использования.
Ваш комментарий будет первым