Реализуем и сравниваем оптимизаторы моделей в глубоком обучении / Хабр
Реализуем и сравниваем 4 популярных оптимизатора обучения нейронных сетей: оптимизатор импульса, среднеквадратичное распространение, мини-пакетный градиентный спуск и адаптивную оценку момента. Репозиторий, много кода на Python и его вывод, визуализации и формулы — всё это под катом.Введение
Модель — это результат работы алгоритма машинного обучения, выполняемого на некоторых данных. Модель представляет собой то, что было изучено алгоритмом. Это «вещь», которая сохраняется после запуска алгоритма на обучающих данных и представляет собой правила, числа и любые другие структуры данных, специфичные для алгоритма и необходимые для предсказания.
Что такое оптимизатор?
Прежде чем перейти к этому, мы должны знать, что такое функция потерь. Функция потерь — это мера того, насколько хорошо ваша модель прогнозирования предсказывает ожидаемый результат (или значение).
 Функция потерь также называется функцией затрат (дополнительная информация здесь).
Функция потерь также называется функцией затрат (дополнительная информация здесь).В процессе обучения мы стараемся минимизировать потери функции и обновлять параметры для повышения точности. Параметры нейронной сети — это обычно веса связей. В этом случае параметры изучаются на этапе обучения. Итак, сам алгоритм (и входные данные) настраивает эти параметры. Более подробную информацию можно найти здесь.
Таким образом, оптимизатор — это метод достижения лучших результатов, помощь в ускорении обучения. Другими словами, это алгоритм, используемый для незначительного изменения параметров, таких как веса и скорость обучения, чтобы модель работала правильно и быстро. Здесь рассмотрим базовый обзор различных используемых в глубоком обучении оптимизаторов и сделаем простую модель, чтобы понять реализацию этой модели. Я настоятельно рекомендую клонировать этот репозиторий и вносить изменения, наблюдая за моделями поведения.
Некоторые часто используемые термины:
- Обратное распространение
- Градиентный спуск
- Гиперпараметры
- Скорость обучения
Популярные оптимизаторы
Ниже приведены некоторые из самых популярных оптимизаторов:
- Стохастический градиентный спуск (SGD).
- Оптимизатор импульса (Momentum).
- Среднеквадратичное распространение (RMSProp).
- Адаптивная оценка момента (Adam).
1. Стохастический градиентный спуск (особенно мини-пакетный)
Мы используем один пример за раз при обучении модели (в чистом SGD) и обновления параметра. Но мы должны использовать еще один для цикла. Это займет много времени. Поэтому используем мини-пакетный SGD.
Мини-пакетный градиентный спуск стремится сбалансировать устойчивость стохастического градиентного спуска и эффективность пакетного градиентного спуска. Это наиболее распространенная реализация градиентного спуска, используемая в области глубокого обучения. В мини-пакетном SGD при обучении модели мы берем группу примеров (например, 32, 64 примера и т. д.). Такой подход работает лучше, потому что требуется единственный цикл для мини-пакетов, а не для каждого примера. Мини-пакеты выбираются случайным образом для каждой итерации, но почему? Когда мини-пакеты выбираются случайным образом, то при застревании в локальных минимумах некоторые шумные шаги могут привести к выходу из этих минимумов.
д.). Такой подход работает лучше, потому что требуется единственный цикл для мини-пакетов, а не для каждого примера. Мини-пакеты выбираются случайным образом для каждой итерации, но почему? Когда мини-пакеты выбираются случайным образом, то при застревании в локальных минимумах некоторые шумные шаги могут привести к выходу из этих минимумов.
- Частота обновления параметров выше, чем в простом пакетном градиентном спуске, что позволяет обеспечить сходимость надежнее, избегая локальных минимумов.
- Пакетные обновления обеспечивают процесс вычислительно эффективнее, чем стохастический градиентный спуск.
- Если у вас немного оперативной памяти, то мини-пакеты — это лучший вариант. Пакетирование эффективно благодаря отсутствию всех обучающих данных в памяти и реализациям алгоритмов.
def RandomMiniBatches(X, Y, MiniBatchSize):
m = X. shape[0]
miniBatches = []
permutation = list(np.random.permutation(m))
shuffled_X = X[permutation, :]
shuffled_Y = Y[permutation, :].reshape((m,1)) #sure for uptpur shape
num_minibatches = m // MiniBatchSize
for k in range(0, num_minibatches):
miniBatch_X = shuffled_X[k * MiniBatchSize:(k + 1) * MiniBatchSize,:]
miniBatch_Y = shuffled_Y[k * MiniBatchSize:(k + 1) * MiniBatchSize,:]
miniBatch = (miniBatch_X, miniBatch_Y)
miniBatches.append(miniBatch)
#handeling last batch
if m % MiniBatchSize != 0:
# end = m - MiniBatchSize * m // MiniBatchSize
miniBatch_X = shuffled_X[num_minibatches * MiniBatchSize:, :]
miniBatch_Y = shuffled_Y[num_minibatches * MiniBatchSize:, :]
miniBatch = (miniBatch_X, miniBatch_Y)
miniBatches.append(miniBatch)
return miniBatches
shape[0]
miniBatches = []
permutation = list(np.random.permutation(m))
shuffled_X = X[permutation, :]
shuffled_Y = Y[permutation, :].reshape((m,1)) #sure for uptpur shape
num_minibatches = m // MiniBatchSize
for k in range(0, num_minibatches):
miniBatch_X = shuffled_X[k * MiniBatchSize:(k + 1) * MiniBatchSize,:]
miniBatch_Y = shuffled_Y[k * MiniBatchSize:(k + 1) * MiniBatchSize,:]
miniBatch = (miniBatch_X, miniBatch_Y)
miniBatches.append(miniBatch)
#handeling last batch
if m % MiniBatchSize != 0:
# end = m - MiniBatchSize * m // MiniBatchSize
miniBatch_X = shuffled_X[num_minibatches * MiniBatchSize:, :]
miniBatch_Y = shuffled_Y[num_minibatches * MiniBatchSize:, :]
miniBatch = (miniBatch_X, miniBatch_Y)
miniBatches.append(miniBatch)
return miniBatches
Каким будет формат модели? shape[0]
miniBatches = []
permutation = list(np.random.permutation(m))
shuffled_X = X[permutation, :]
shuffled_Y = Y[permutation, :].reshape((m,1)) #sure for uptpur shape
num_minibatches = m // MiniBatchSize
for k in range(0, num_minibatches):
miniBatch_X = shuffled_X[k * MiniBatchSize:(k + 1) * MiniBatchSize,:]
miniBatch_Y = shuffled_Y[k * MiniBatchSize:(k + 1) * MiniBatchSize,:]
miniBatch = (miniBatch_X, miniBatch_Y)
miniBatches.append(miniBatch)
#handeling last batch
if m % MiniBatchSize != 0:
# end = m - MiniBatchSize * m // MiniBatchSize
miniBatch_X = shuffled_X[num_minibatches * MiniBatchSize:, :]
miniBatch_Y = shuffled_Y[num_minibatches * MiniBatchSize:, :]
miniBatch = (miniBatch_X, miniBatch_Y)
miniBatches.append(miniBatch)
return miniBatches
shape[0]
miniBatches = []
permutation = list(np.random.permutation(m))
shuffled_X = X[permutation, :]
shuffled_Y = Y[permutation, :].reshape((m,1)) #sure for uptpur shape
num_minibatches = m // MiniBatchSize
for k in range(0, num_minibatches):
miniBatch_X = shuffled_X[k * MiniBatchSize:(k + 1) * MiniBatchSize,:]
miniBatch_Y = shuffled_Y[k * MiniBatchSize:(k + 1) * MiniBatchSize,:]
miniBatch = (miniBatch_X, miniBatch_Y)
miniBatches.append(miniBatch)
#handeling last batch
if m % MiniBatchSize != 0:
# end = m - MiniBatchSize * m // MiniBatchSize
miniBatch_X = shuffled_X[num_minibatches * MiniBatchSize:, :]
miniBatch_Y = shuffled_Y[num_minibatches * MiniBatchSize:, :]
miniBatch = (miniBatch_X, miniBatch_Y)
miniBatches.append(miniBatch)
return miniBatches
Я даю обзор модели на случай, если вы новичок в глубоком обучении. Она выглядит примерно так:
Она выглядит примерно так:
def model(X,Y,learning_rate,num_iter,hidden_size,keep_prob,optimizer):
L = len(hidden_size)
params = initilization(X.shape[1], hidden_size)
for i in range(1,num_iter):
MiniBatches = RandomMiniBatches(X, Y, 64) # GET RAMDOMLY MINIBATCHES
p , q = MiniBatches[2]
for MiniBatch in MiniBatches: #LOOP FOR MINIBATCHES
(MiniBatch_X, MiniBatch_Y) = MiniBatch
cache, A = model_forward(MiniBatch_X, params, L,keep_prob) #FORWARD PROPOGATIONS
cost = cost_f(A, MiniBatch_Y) #COST FUNCTION
grad = backward(MiniBatch_X, MiniBatch_Y, params, cache, L,keep_prob) #BACKWARD PROPAGATION
params = update_params(params, grad, beta=0.9,learning_rate=learning_rate)
return params
 Если уменьшить вертикальное движение и увеличить горизонтальное, модель будет учиться быстрее, согласны?
Если уменьшить вертикальное движение и увеличить горизонтальное, модель будет учиться быстрее, согласны?Как минимизировать нежелательные колебания? Следующие оптимизаторы минимизируют их и помогают ускорить обучение.
В SGD или градиентном спуске много колебаний. Нужно двигаться вперед, а не вверх-вниз. Мы должны увеличить скорость обучения модели в правильном направлении, и мы сделаем это с помощью оптимизатора импульса.
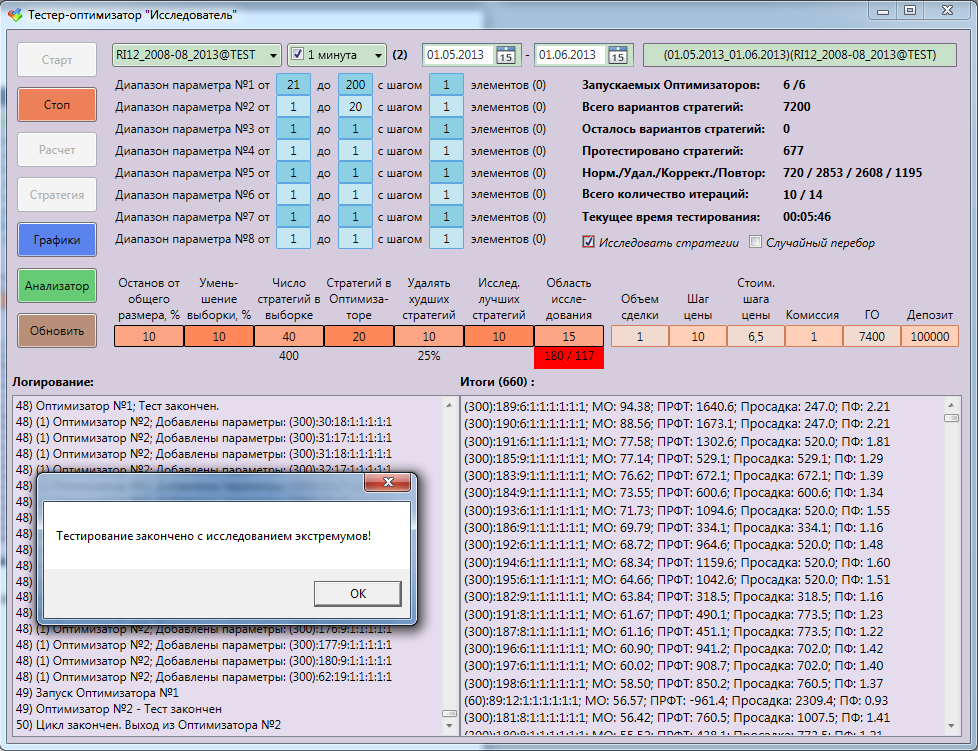
Как видно на рисунке выше, зеленая цветовая линия оптимизатора импульса быстрее других. Важность быстрого обучения можно увидеть, когда у вас большие наборы данных и много итераций. Как внедрить этот оптимизатор?
Нормально значение β около 0,9Видно, что мы создали два параметра — vdW, и vdb — из параметров обратного распространения. Рассмотрим значение β = 0.9, тогда уравнения приобретает вид:
vdw= 0.9 * vdw + 0.1 * dw vdb = 0.9 * vdb + 0.1 * dbКак вы видите,
 Когда визуализация — это график, можно увидеть, что оптимизатор импульса учитывает прошлые градиенты, чтобы сгладить обновление. Вот почему возможно минимизировать колебания. Когда мы использовали SGD, пройденный мини-пакетным градиентным спуском путь колебался в сторону конвергенции. Оптимизатор импульса помогает уменьшить эти колебания.
Когда визуализация — это график, можно увидеть, что оптимизатор импульса учитывает прошлые градиенты, чтобы сгладить обновление. Вот почему возможно минимизировать колебания. Когда мы использовали SGD, пройденный мини-пакетным градиентным спуском путь колебался в сторону конвергенции. Оптимизатор импульса помогает уменьшить эти колебания.def update_params_with_momentum(params, grads, v, beta, learning_rate):
# grads has the dw and db parameters from backprop
# params has the W and b parameters which we have to update
for l in range(len(params) // 2 ):
# HERE WE COMPUTING THE VELOCITIES
v["dW" + str(l + 1)] = beta * v["dW" + str(l + 1)] + (1 - beta) * grads['dW' + str(l + 1)]
v["db" + str(l + 1)] = beta * v["db" + str(l + 1)] + (1 - beta) * grads['db' + str(l + 1)]
#updating parameters W and b
params["W" + str(l + 1)] = params["W" + str(l + 1)] - learning_rate * v["dW" + str(l + 1)]
params["b" + str(l + 1)] = params["b" + str(l + 1)] - learning_rate * v["db" + str(l + 1)]
return params
Репозиторий находится здесь3.
 Среднеквадратичное распространение
Среднеквадратичное распространение Среднеквадратичное распространение корня (RMSprop) — это экспоненциально затухающее среднее значение. Существенным свойством RMSprop является то, что вы не ограничены только суммой прошлых градиентов, но вы более ограничены градиентами последних временных шагов. RMSprop вносит свой вклад в экспоненциально затухающее среднее значение прошлых «квадратичных градиентов». В RMSProp мы пытаемся уменьшить вертикальное движение, используя среднее значение, потому что они суммируются приблизительно до 0, принимая среднее значение. RMSprop предоставляет среднее значение для обновления.Источник
Посмотрите на приведенный ниже код. Это даст вам базовое представление о том, как внедрить этот оптимизатор. Все то же самое, что и с SGD, мы должны изменить функцию обновления.
def initilization_RMS(params):
s = {}
for i in range(len(params)//2 ):
s["dW" + str(i)] = np.zeros(params["W" + str(i)].shape)
s["db" + str(i)] = np. zeros(params["b" + str(i)].shape)
return s
def update_params_with_RMS(params, grads,s, beta, learning_rate):
# grads has the dw and db parameters from backprop
# params has the W and b parameters which we have to update
for l in range(len(params) // 2 ):
# HERE WE COMPUTING THE VELOCITIES
s["dW" + str(l)]= beta * s["dW" + str(l)] + (1 - beta) * np.square(grads['dW' + str(l)])
s["db" + str(l)] = beta * s["db" + str(l)] + (1 - beta) * np.square(grads['db' + str(l)])
#updating parameters W and b
params["W" + str(l)] = params["W" + str(l)] - learning_rate * grads['dW' + str(l)] / (np.sqrt( s["dW" + str(l)] )+ pow(10,-4))
params["b" + str(l)] = params["b" + str(l)] - learning_rate * grads['db' + str(l)] / (np.sqrt( s["db" + str(l)]) + pow(10,-4))
return params
 zeros(params["b" + str(i)].shape)
return s
def update_params_with_RMS(params, grads,s, beta, learning_rate):
# grads has the dw and db parameters from backprop
# params has the W and b parameters which we have to update
for l in range(len(params) // 2 ):
# HERE WE COMPUTING THE VELOCITIES
s["dW" + str(l)]= beta * s["dW" + str(l)] + (1 - beta) * np.square(grads['dW' + str(l)])
s["db" + str(l)] = beta * s["db" + str(l)] + (1 - beta) * np.square(grads['db' + str(l)])
#updating parameters W and b
params["W" + str(l)] = params["W" + str(l)] - learning_rate * grads['dW' + str(l)] / (np.sqrt( s["dW" + str(l)] )+ pow(10,-4))
params["b" + str(l)] = params["b" + str(l)] - learning_rate * grads['db' + str(l)] / (np.sqrt( s["db" + str(l)]) + pow(10,-4))
return params
zeros(params["b" + str(i)].shape)
return s
def update_params_with_RMS(params, grads,s, beta, learning_rate):
# grads has the dw and db parameters from backprop
# params has the W and b parameters which we have to update
for l in range(len(params) // 2 ):
# HERE WE COMPUTING THE VELOCITIES
s["dW" + str(l)]= beta * s["dW" + str(l)] + (1 - beta) * np.square(grads['dW' + str(l)])
s["db" + str(l)] = beta * s["db" + str(l)] + (1 - beta) * np.square(grads['db' + str(l)])
#updating parameters W and b
params["W" + str(l)] = params["W" + str(l)] - learning_rate * grads['dW' + str(l)] / (np.sqrt( s["dW" + str(l)] )+ pow(10,-4))
params["b" + str(l)] = params["b" + str(l)] - learning_rate * grads['db' + str(l)] / (np.sqrt( s["db" + str(l)]) + pow(10,-4))
return params
Adam — один из самых эффективных алгоритмов оптимизации в обучении нейронных сетей. Он сочетает в себе идеи RMSProp и оптимизатора импульса.
 Вместо того чтобы адаптировать скорость обучения параметров на основе среднего первого момента (среднего значения), как в RMSProp, Adam также использует среднее значение вторых моментов градиентов. В частности, алгоритм вычисляет экспоненциальное скользящее среднее градиента и квадратичный градиент, а параметры
Вместо того чтобы адаптировать скорость обучения параметров на основе среднего первого момента (среднего значения), как в RMSProp, Adam также использует среднее значение вторых моментов градиентов. В частности, алгоритм вычисляет экспоненциальное скользящее среднее градиента и квадратичный градиент, а параметры beta1 и beta2 управляют скоростью затухания этих скользящих средних. Каким образом?def initilization_Adam(params):
s = {}
v = {}
for i in range(len(params)//2 ):
v["dW" + str(i)] = np.zeros(params["W" + str(i)].shape)
v["db" + str(i)] = np.zeros(params["b" + str(i)].shape)
s["dW" + str(i)] = np.zeros(params["W" + str(i)].shape)
s["db" + str(i)] = np.zeros(params["b" + str(i)].shape)
return v, s
def update_params_with_Adam(params, grads,v, s, beta1,beta2, learning_rate,t):
epsilon = pow(10,-8)
v_corrected = {}
s_corrected = {}
# grads has the dw and db parameters from backprop
# params has the W and b parameters which we have to update
for l in range(len(params) // 2 ):
# HERE WE COMPUTING THE VELOCITIES
v["dW" + str(l)] = beta1 * v["dW" + str(l)] + (1 - beta1) * grads['dW' + str(l)]
v["db" + str(l)] = beta1 * v["db" + str(l)] + (1 - beta1) * grads['db' + str(l)]
v_corrected["dW" + str(l)] = v["dW" + str(l)] / (1 - np. -8) (не слишком сильно влияет на обучение)
Зачем этот оптимизатор?Его преимущества:
 -8) (не слишком сильно влияет на обучение)
Зачем этот оптимизатор?
-8) (не слишком сильно влияет на обучение)
Зачем этот оптимизатор?- Простая реализация.
- Вычислительная эффективность.
- Небольшие требования к памяти.
- Инвариант к диагональному масштабированию градиентов.
- Хорошо подходит для больших с точки зрения данных и параметров задач.
- Подходит для нестационарных целей.
- Подходит для задач с очень шумными или разреженными градиентами.
- Гиперпараметры имеют наглядную интерпретацию и обычно требуют небольшой настройки.
Давайте построим модель и посмотрим, как гиперпараметры ускоряют обучение
Давайте проведем практическую демонстрацию того, как ускорить обучение. В этой статье мы не будем объяснять другие вещи (инициализацию, отсев,
forward_prop, back_prop, градиентный спуск и т. д.). Необходимые дл обучения Функции уже встроены в NumPy. Если вы хотите взглянуть на это, вот ссылка!
Если вы хотите взглянуть на это, вот ссылка!
Давайте начнем!
Я создаю обобщенную модельную функцию, работающую для всех обсуждаемых здесь оптимизаторов.
1. Инициализация:
Мы инициализируем параметры с помощью функции инициализации, которая принимает входные данные, такие как features_size (в нашем случае 12288) и скрытый массив размеров (мы использовали [100,1]) и данный вывод как параметры инициализации. Существует другой метод инициализации. Я призываю прочитать эту статью.
def initilization(input_size,layer_size):
params = {}
np.random.seed(0)
params['W' + str(0)] = np.random.randn(layer_size[0], input_size) * np.sqrt(2 / input_size)
params['b' + str(0)] = np.zeros((layer_size[0], 1))
for l in range(1,len(layer_size)):
params['W' + str(l)] = np.random.randn(layer_size[l],layer_size[l-1]) * np.sqrt(2/layer_size[l])
params['b' + str(l)] = np.zeros((layer_size[l],1))
return params
2. Прямое распространение:
Прямое распространение:В этой функции входные данные — это X, а также параметры, протяженность скрытых слоев и отсев, которые используются в технике отсева.
Я установил значение 1, так что никакого эффекта на тренировке не будет видно. Если ваша модель переобучена, то вы можете установить другое значение. Я применяю отсев только на четных слоях.
Мы вычисляем значение активации для каждого слоя с помощью функции forward_activation.
#activations-----------------------------------------------
def forward_activation(A_prev, w, b, activation):
z = np.dot(A_prev, w.T) + b.T
if activation == 'relu':
A = np.maximum(0, z)
elif activation == 'sigmoid':
A = 1/(1+np.exp(-z))
else:
A = np.tanh(z)
return A
#________model forward ____________________________________________________________________________________________________________
def model_forward(X,params, L,keep_prob):
cache = {}
A =X
for l in range(L-1):
w = params['W' + str(l)]
b = params['b' + str(l)]
A = forward_activation(A, w, b, 'relu')
if l%2 == 0:
cache['D' + str(l)] = np. random.randn(A.shape[0],A.shape[1]) < keep_prob
A = A * cache['D' + str(l)] / keep_prob
cache['A' + str(l)] = A
w = params['W' + str(L-1)]
b = params['b' + str(L-1)]
A = forward_activation(A, w, b, 'sigmoid')
cache['A' + str(L-1)] = A
return cache, A
3. Обратное распространение: random.randn(A.shape[0],A.shape[1]) < keep_prob
A = A * cache['D' + str(l)] / keep_prob
cache['A' + str(l)] = A
w = params['W' + str(L-1)]
b = params['b' + str(L-1)]
A = forward_activation(A, w, b, 'sigmoid')
cache['A' + str(L-1)] = A
return cache, A
random.randn(A.shape[0],A.shape[1]) < keep_prob
A = A * cache['D' + str(l)] / keep_prob
cache['A' + str(l)] = A
w = params['W' + str(L-1)]
b = params['b' + str(L-1)]
A = forward_activation(A, w, b, 'sigmoid')
cache['A' + str(L-1)] = A
return cache, A
Здесь мы пишем функцию обратного распространения. Она вернет grad (наклон). Мы используем grad при обновлении параметров, (если вы об этом не знаете). Рекомендую прочитать эту статью.
def backward(X, Y, params, cach,L,keep_prob):
grad ={}
m = Y.shape[0]
cach['A' + str(-1)] = X
grad['dz' + str(L-1)] = cach['A' + str(L-1)] - Y
cach['D' + str(- 1)] = 0
for l in reversed(range(L)):
grad['dW' + str(l)] = (1 / m) * np.dot(grad['dz' + str(l)].T, cach['A' + str(l-1)])
grad['db' + str(l)] = 1 / m * np.sum(grad['dz' + str(l)].T, axis=1, keepdims=True)
if l%2 != 0:
grad['dz' + str(l-1)] = ((np. dot(grad['dz' + str(l)], params['W' + str(l)]) * cach['D' + str(l-1)] / keep_prob) *
np.int64(cach['A' + str(l-1)] > 0))
else :
grad['dz' + str(l - 1)] = (np.dot(grad['dz' + str(l)], params['W' + str(l)]) *
np.int64(cach['A' + str(l - 1)] > 0))
return grad
Мы уже видели функцию обновления оптимизаторов, так что используем ее здесь. Внесем небольшие изменения в функцию модели из обсуждения SGD. dot(grad['dz' + str(l)], params['W' + str(l)]) * cach['D' + str(l-1)] / keep_prob) *
np.int64(cach['A' + str(l-1)] > 0))
else :
grad['dz' + str(l - 1)] = (np.dot(grad['dz' + str(l)], params['W' + str(l)]) *
np.int64(cach['A' + str(l - 1)] > 0))
return grad
dot(grad['dz' + str(l)], params['W' + str(l)]) * cach['D' + str(l-1)] / keep_prob) *
np.int64(cach['A' + str(l-1)] > 0))
else :
grad['dz' + str(l - 1)] = (np.dot(grad['dz' + str(l)], params['W' + str(l)]) *
np.int64(cach['A' + str(l - 1)] > 0))
return grad
def model(X,Y,learning_rate,num_iter,hidden_size,keep_prob,optimizer):
L = len(hidden_size)
params = initilization(X.shape[1], hidden_size)
costs = []
itr = []
if optimizer == 'momentum':
v = initilization_moment(params)
elif optimizer == 'rmsprop':
s = initilization_RMS(params)
elif optimizer == 'adam' :
v,s = initilization_Adam(params)
for i in range(1,num_iter):
MiniBatches = RandomMiniBatches(X, Y, 32) # GET RAMDOMLY MINIBATCHES
p , q = MiniBatches[2]
for MiniBatch in MiniBatches: #LOOP FOR MINIBATCHES
(MiniBatch_X, MiniBatch_Y) = MiniBatch
cache, A = model_forward(MiniBatch_X, params, L,keep_prob) #FORWARD PROPOGATIONS
cost = cost_f(A, MiniBatch_Y) #COST FUNCTION
grad = backward(MiniBatch_X, MiniBatch_Y, params, cache, L,keep_prob) #BACKWARD PROPAGATION
if optimizer == 'momentum':
params = update_params_with_momentum(params, grad, v, beta=0. 9,learning_rate=learning_rate)
elif optimizer == 'rmsprop':
params = update_params_with_RMS(params, grad, s, beta=0.9,learning_rate=learning_rate)
elif optimizer == 'adam' :
params = update_params_with_Adam(params, grad,v, s, beta1=0.9,beta2=0.999, learning_rate=learning_rate,t=i) #UPDATE PARAMETERS
elif optimizer == "minibatch":
params = update_params(params, grad,learning_rate=learning_rate)
if i%5 == 0:
costs.append(cost)
itr.append(i)
if i % 100 == 0 :
print('cost of iteration______{}______{}'.format(i,cost))
return params,costs,itr
Обучение с мини-пакетами 9,learning_rate=learning_rate)
elif optimizer == 'rmsprop':
params = update_params_with_RMS(params, grad, s, beta=0.9,learning_rate=learning_rate)
elif optimizer == 'adam' :
params = update_params_with_Adam(params, grad,v, s, beta1=0.9,beta2=0.999, learning_rate=learning_rate,t=i) #UPDATE PARAMETERS
elif optimizer == "minibatch":
params = update_params(params, grad,learning_rate=learning_rate)
if i%5 == 0:
costs.append(cost)
itr.append(i)
if i % 100 == 0 :
print('cost of iteration______{}______{}'.format(i,cost))
return params,costs,itr
9,learning_rate=learning_rate)
elif optimizer == 'rmsprop':
params = update_params_with_RMS(params, grad, s, beta=0.9,learning_rate=learning_rate)
elif optimizer == 'adam' :
params = update_params_with_Adam(params, grad,v, s, beta1=0.9,beta2=0.999, learning_rate=learning_rate,t=i) #UPDATE PARAMETERS
elif optimizer == "minibatch":
params = update_params(params, grad,learning_rate=learning_rate)
if i%5 == 0:
costs.append(cost)
itr.append(i)
if i % 100 == 0 :
print('cost of iteration______{}______{}'.format(i,cost))
return params,costs,itr
params, cost_sgd,itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='minibatch')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))
Вывод при подходе с мини-пакетами:cost of iteration______100______0.Обучение с оптимизатором импульса
 35302967575683797
cost of iteration______200______0.472914548745098
cost of iteration______300______0.4884728238471557
cost of iteration______400______0.21551100063345618
train_accuracy------------ 0.8494208494208494
35302967575683797
cost of iteration______200______0.472914548745098
cost of iteration______300______0.4884728238471557
cost of iteration______400______0.21551100063345618
train_accuracy------------ 0.8494208494208494
params,cost_momentum, itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='momentum')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))
Вывод оптимизатора импульса:cost of iteration______100______0.36278494129038086 cost of iteration______200______0.4681552335189021 cost of iteration______300______0.382226159384529 cost of iteration______400______0.18219310793752702 train_accuracy------------ 0.8725868725868726Тренировка с RMSprop
params,cost_rms,itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='rmsprop')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))
Вывод RMSprop:cost of iteration______100______0.Тренировка с Adam
 2983858963793841
cost of iteration______200______0.004245700579927428
cost of iteration______300______0.2629426607580565
cost of iteration______400______0.31944824707807556 train_accuracy------------ 0.9613899613899614
2983858963793841
cost of iteration______200______0.004245700579927428
cost of iteration______300______0.2629426607580565
cost of iteration______400______0.31944824707807556 train_accuracy------------ 0.9613899613899614params,cost_adam, itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='adam')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))
Вывод Adam:cost of iteration______100______0.3266223660473619 cost of iteration______200______0.08214547683157716 cost of iteration______300______0.0025645257286439583 cost of iteration______400______0.058015188756586206 train_accuracy------------ 0.9845559845559846Вы видели разницу в точности между ними? Мы использовали те же параметры инициализации, ту же скорость обучения и то же количество итераций; отличается только оптимизатор, но посмотрите на результат!
Mini-batch accuracy : 0.Графическая визуализация модели Вы можете обратиться в репозиторий, если у вас есть сомнения по поводу кода.
 8494208494208494
momemtum accuracy : 0.8725868725868726
Rms accuracy : 0.9613899613899614
adam accuracy : 0.9845559845559846
8494208494208494
momemtum accuracy : 0.8725868725868726
Rms accuracy : 0.9613899613899614
adam accuracy : 0.9845559845559846Резюме
источник
Как мы уже видели, оптимизатор Adam дает хорошую точность по сравнению с другими оптимизаторами. На рисунке выше видно, как модель учится на итерациях. Momentum дает скорость SGD, а RMSProp дает экспоненциальное среднее значение веса для обновленных параметров. Мы использовали меньше данных в приведенной выше модели, но мы увидим больше преимуществ оптимизаторов при работе с большими наборами данных и многими итерациями. Мы обсудили основную идею оптимизаторов, и я надеюсь, что это даст вам некоторую мотивацию узнать больше об оптимизаторах и использовать их!Ресурсы
- Курс по Coursera — это даст более детальное представление о глубоком обучении
- Алгоритм оптимизации — основы оптимизации
Перспективы нейронных сетей и глубокого машинного обучения просто огромны, и по самым скромным оценкам, их влияние на мир будет примерно таким же, как влияние электричества на промышленность в XIX веке.
 Те специалисты, которые оценят эти перспективы раньше всех, имеют все шансы стать во главе прогресса. Для таких людей мы сделали промокод HABR, который дает дополнительные 10% к скидке на обучение, указанной на баннере.
Те специалисты, которые оценят эти перспективы раньше всех, имеют все шансы стать во главе прогресса. Для таких людей мы сделали промокод HABR, который дает дополнительные 10% к скидке на обучение, указанной на баннере.- Курс по Machine Learning
- Курс «Математика и Machine Learning для Data Science»
- Продвинутый курс «Machine Learning Pro + Deep Learning»
- Онлайн-буткемп по Data Science
- Обучение профессии Data Analyst с нуля
- Онлайн-буткемп по Data Analytics
- Обучение профессии Data Science с нуля
- Курс «Python для веб-разработки»
Eще курсы
- Курс по аналитике данных
- Курс по DevOps
- Профессия Веб-разработчик
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
- Профессия Java-разработчик с нуля
- Курс по JavaScript
Рекомендуемые статьи
- Как стать Data Scientist без онлайн-курсов
- 450 бесплатных курсов от Лиги Плюща
- Как изучать Machine Learning 5 дней в неделю 9 месяцев подряд
- Сколько зарабатывает аналитик данных: обзор зарплат и вакансий в России и за рубежом в 2020
- Machine Learning и Computer Vision в добывающей промышленности
Тест Lossless-оптимизаторов изображений (PNG и JPG) / Хабр
Для многих не секрет, что большинство изображений в форматах JPEG и PNG содержат избыточную информацию, которая может быть удалена без потери качества. Обычно это достигается за счет эвристических алгоритмов перебора различных параметров компрессии и выбора наименее затратного варианта. Применение оптимизаторов особенно важно на файлах, которые используются на посещаемых сайтах, для экономии дискового пространства, трафика и уменьшения времени загрузки страниц у пользователей. Программ такого типа довольно много и мы поставили себе цель найти какие же оптимизаторы сжимают лучше и работают быстро.
Обычно это достигается за счет эвристических алгоритмов перебора различных параметров компрессии и выбора наименее затратного варианта. Применение оптимизаторов особенно важно на файлах, которые используются на посещаемых сайтах, для экономии дискового пространства, трафика и уменьшения времени загрузки страниц у пользователей. Программ такого типа довольно много и мы поставили себе цель найти какие же оптимизаторы сжимают лучше и работают быстро.В тесте принимали участие следующие программы.
Для PNG:
1. Leanify 0.4.3 (x64)
2. pingo v0.79c
3. pinga v0.09
4. OptiPNG 0.7.6
5. pngout
6. PngOptimizer 2.5 (x64)
7. advpng aka AdvanceCOMP v1.23
8. ECT 0.6 (x64)
9. TruePNG 0.6.2.2
10. pngwolf-zopfli 1.1.1 (x64)
Для JPEG:
1. Leanify 0.4.3 (x64)
2. pingo v0.79c
3. ECT 0.6 (x64)
4. mozjpeg 3.2 (x64)
5. jhead 3.00
6. jpegoptim v1.4.4 (x64)
jpegoptim v1.4.4 (x64)
7. jpegtran
Было отобрано 100 PNG файлов и 100 JPG файлов в качестве тестовой выборки. Разных размеров и разрешения от совсем маленьких до огромных. Каждая из программ была запущена на всём наборе. Считался размер файла после оптимизации и сколько времени потребовалось программе на оптимизацию. Сводные таблицы приведены ниже.
Таблица 1. Лучшие оптимизаторы PNG по уровню компрессии
| Максимум | 88.49 | |
| 1 место | ECT | 88.98 |
| 2 место | Leanify | 89.62 |
| 3 место | Pingo | 89.69 |
| 4 место | pngwolf | 91.34 |
| 5 место | pngout | 91.85 |
| 6 место | TRUEPng | 93.01 |
| 7 место | Optipng | 94. 19 19 |
| 8 место | pinga | 94.8 |
| 9 место | PNGOptimizer | 95.13 |
| 10 место | advpng | 97.27 |
| 1 место | PNGOptimizer | 00:04:08 |
| 2 место | pinga | 00:21:41 |
| 3 место | Pingo | 00:23:15 |
| 4 место | TruePNG | 01:53:29 |
| 5 место | Leanify | 01:57:00 |
| 6 место | pngout | 02:53:09 |
| 7 место | pngwolf | 02:55:26 |
| 8 место | ECT | 03:06:08 |
| 9 место | advpng | 03:25:34 |
| 10 место | Optipng | 03:39:05 |
 Сводная таблица по PNG оптимизаторам
Сводная таблица по PNG оптимизаторам| ПО | Speed Rank | Compression Rank | Overall rank | Open source |
|---|---|---|---|---|
| Pingo | 3 | 3 | 6 | - |
| Leanify | 5 | 2 | 7 | + |
| ECT | 8 | 1 | 9 | + |
| PNGOptimizer | 1 | 9 | 10 | + |
| TruePNG | 4 | 6 | 10 | - |
| pinga | 2 | 8 | 10 | - |
| pngout | 6 | 5 | 11 | + |
| pngwolf | 7 | 4 | 11 | + |
| Optipng | 10 | 7 | 17 | + |
| advpng | 9 | 10 | 19 | + |
 Лучшие оптимизаторы JPG по уровню компрессии
Лучшие оптимизаторы JPG по уровню компрессии| 1 место | ECT | 89.996 |
| 1 место | pingo | 89.996 |
| 1 место | leanify | 89.997 |
| 1 место | mozjpeg | 89.999 |
| 5 место | jpegoptim | 90.880 |
| 6 место | jpegtran | 90.924 |
| 7 место | jhead | 99.592 |
| 1 место | jhead | 00:00:25 |
| 2 место | jpegtran | 00:00:52 |
| 3 место | jpegoptim | 00:01:03 |
| 4 место | leanify | 00:01:30 |
| 5 место | pingo | 00:01:42 |
| 6 место | mozjpeg | 00:01:55 |
| 7 место | ECT | 00:02:52 |
 Сводная таблица по JPG оптимизаторам
Сводная таблица по JPG оптимизаторам| Soft | Speed Rank | Compression Rank | Overall rank | Open source |
|---|---|---|---|---|
| leanify | 4 | 1 | 5 | + |
| jpegoptim | 3 | 2 | 5 | + |
| jpegtran | 2 | 3 | 5 | + |
| jhead | 1 | 4 | 5 | + |
| pingo | 5 | 1 | 6 | - |
| mozjpeg | 6 | 1 | 7 | + |
| ECT | 7 | 1 | 8 | + |
Параметры запусков
Тестирование проводилось на платформе Windows 10 (x64), i7 — 4930K, 32gb RAM. Все программы где стоит плюсик в графе Open Source соберутся на Linux. Не работают под Linux только 3 программы: Pingo, Pinga и TRUEpng.
Все программы где стоит плюсик в графе Open Source соберутся на Linux. Не работают под Linux только 3 программы: Pingo, Pinga и TRUEpng.PNG:
Leanify -i 15 -q Pingo -s4 pinga -lossless -more Optipng -o7 -strip all -quiet pngout /s0 /q /y /r /d0 /mincodes0 /k1 PngOptimizer -file advpng -z -q -4 -i 20 ECT --allfilters --mt-deflate -strip --strict -quiet -9 TruePNG /i0 /tz /quiet /y /md remove all /g0 /o4 pngwolf --strip-optional --out-deflate=zopfli,iter=30 --in= --out=JPEG:
Leanify -i 15 -q Pingo -s4 ECT --mt-deflate -strip -progressive --allfilters --strict -quiet -9 mozjpegtran -outfile -progressive jhead -autorot -purejpg -di -dx -dt -zt -q jpegoptim --strip-all -o -q --all-progressive jpegtran -copy none -progressiveДля своих внутренних целей решили использовать Leanify. И сделали небольшой тестовый сайтик, если кому-то нужно оптимизировать небольшое число изображений он-лайн:
→ lossless-image-optimization.com
Для локального запуска можно использовать FileOptimizer. Он запускает последовательно почти все указанные выше оптимизаторы один за одним на одном файле и как следствие работает достаточно долго, но выдаёт результат близкий к максимальному.
Он запускает последовательно почти все указанные выше оптимизаторы один за одним на одном файле и как следствие работает достаточно долго, но выдаёт результат близкий к максимальному.
Ссылки
→ Архив с тестовыми файлами PNG (100 штук)
→ Архив с тестовыми файлами JPG (100 штук)
→ Подробная таблица по всем файлам на Google.Docs
Обзоры и рейтинги D&B Optimizer 2023
Оценка 7,5 из 10
- Анализ продаж
D&B Optimizer — это программное решение для аналитики продаж, предлагаемое Dun & Bradstreet и представленное поставщиком как безопасная облачная платформа, которая оптимизирует данные, помогает пользователям профилировать лучшие возможности и ориентироваться на аудиторию, которую они хотят охватить.
Подробнее Мы используем инструмент очистки и обогащения NetProspex. Мы загружаем нашу маркетинговую базу данных, и инструмент NetProspex сравнивает наши записи со своими. …
…
Мы используем NetProspex для отдела продаж и маркетинга. Он интегрирован с нашей системой автоматизации маркетинга и обновляет/дополняет …
Продолжить чтениеПрочитать все отзывыВернуться к навигацииПлата за настройку начального уровня?
Предложения
Хотите, чтобы мы сообщили поставщику, что вам нужны цены?
8 человек тоже хотят цены
Альтернативные цены
Вернуться к навигацииОптимизатор D&B для Microsoft Demo
YouTube
Вернуться к навигации- О
- Интеграции
- Конкуренты
- Технические подробности
- Загружаемые файлы
Что такое D&B Optimizer?
Предоставляет отделам продаж и маркетинга B2B то, что поставщик описывает как точные, полные и полезные данные. Очищайте и обогащайте данные о компании и контактах и интегрируйте их в системы CRM и MAP организации. D&B Optimizer от Dun & Bradstreet призван служить фундаментальным строительным блоком для согласования команд и предоставления ценной бизнес-аналитики по более чем 420 миллионам бизнес-записей и корпоративных иерархий.
Очищайте и обогащайте данные о компании и контактах и интегрируйте их в системы CRM и MAP организации. D&B Optimizer от Dun & Bradstreet призван служить фундаментальным строительным блоком для согласования команд и предоставления ценной бизнес-аналитики по более чем 420 миллионам бизнес-записей и корпоративных иерархий.
Повысьте производительность отделов продаж за счет отказа от ручного труда и автоматизации ввода данных.
Выявляйте возможности перекрестных и дополнительных продаж благодаря полному обзору корпоративных связей и родословных.
Ускорьте взаимодействие, установив приоритеты учетных записей на основе 100 полей расширенной информации об учетной записи.
Установите процессы управления данными, включая обогащение в режиме реального времени, чтобы обеспечить полноту данных и высокий уровень точности для данных учетной записи.
На основе бизнес-данных и аналитических данных Dun & Bradstreet Data Cloud данные собираются из десятков тысяч источников и постоянно отслеживаются на предмет изменений, чтобы предоставить пользователям качественные данные B2B, необходимые для ускорения роста, управления рисками, снижения затрат и преобразования бизнеса.
- Категории
- Информация о продажах
Скриншоты D&B Optimizer
Видео D&B Optimizer
Оценки Salesforce 91% данных CRM неполные, а 70% ежегодно устаревают. Не будьте статистикой. С помощью D&B Optimizer for Salesforce вы можете постоянно очищать, сопоставлять и обогащать данные в своей среде Salesforce и предоставлять своим командам по продажам и маркетингу более точные и полезные данные.
Интеграция с D&B Optimizer
- Adobe Marketo Engage
- Microsoft Dynamics 365
- Salesforce
- Oracle Eloqua
- Microsoft CDS
- Demandbase Sales Intelligence Cloud. 0111 Типы развертывания
Программное обеспечение как услуга (SaaS), облачное или веб-интерфейс Операционные системы Не указано Мобильное приложение Нет 901 14 Загружаемые файлы D&B Optimizer
Вернуться к навигацииD&B Connect
Сравнить
D&B Hoovers
Сравнить
ZoomInfo SalesOS
Сравнить
Data.
com (прекращено) 9 0002 СравнитьSnowflake
Сравнить
Clearbit
Сравнить
Crunchbase
Сравнить
Lead411
Сравнить
Salesforce
Сравнить
Центр продаж HubSpot
Сравнить
Вернуться к навигацииВарианты использования и объем развертывания
Мы используем инструмент NetProspex для очистки и обогащения. Мы загружаем нашу маркетинговую базу данных, и инструмент NetProspex сравнивает наши записи со своими. Затем они помогают нам заполнить неполные данные, которые у нас есть. Он также помечает элементы, которые могут быть потенциальными проблемами для нас, например недоставляемые адреса электронной почты. Это помогает повысить качество информации, предоставляемой нашему отделу продаж, когда они достаточно подготовлены, чтобы стать квалифицированными маркетологами.
Плюсы и минусы
Завершение данных
Анализ данных
Точность
Вероятность рекомендации
NetProspex особенно хорошо подходит для того, чтобы помочь вашей организации поддерживать точную базу данных.
Это помогает использовать инструменты NetProspex не реже одного раза в квартал, чтобы поддерживать точность. Это также помогает заполнить любые неполные записи, которые могут замедлить ваш бизнес-процесс, и устраняет барьеры во время воронки продаж.Рейтинги функций оптимизатора D&B
- Поиск (6)
- Расширенный поиск
- Выявление новых потенциальных клиентов
- Список качество
- Загрузка/выгрузка списка
- Ориентация на идеальных клиентов
- Время загрузки/доступ к данным
- Стандарты данных аналитики продаж (3)
66. 66666666666667%
6,7
- Контактная информация
- Информация о компании
- Информация об отрасли
- Расширение данных и квалификация потенциальных клиентов (9)
44,44444444444444%
90 002 4.4- Процесс квалификации лидов
- Умные списки и рекомендации
- Интеграция с Salesforce
- Профили компаний/бизнесов
- Оповещения и напоминания
- Гигиена данных
- Автоматическое обновление данных
- Фильтры и сегментация
- Функции эл.
0209Возврат инвестиций
Рассмотренные альтернативы
Ранее мы использовали Zoominfo для поиска новых потенциальных клиентов или потенциальных клиентов, похожих на те, которые уже были в нашей базе данных. Мы обнаружили, что у Zoominfo в целом могло быть больше записей, но их данные были не такими точными. Мы также искали инструмент, который мог бы помочь оценивать наши текущие интересы на более регулярной основе, чего Zoominfo не мог предоставить.
Другое используемое программное обеспечение
HubSpot, Salesforce.com, InsightSquared, Yesware, Conversica, Hootsuite Pro, SalesLoft отдел продаж и маркетинга. Он интегрирован с нашей системой автоматизации маркетинга и обновляет/дополняет запись о входящих лидах. Мы также используем его, чтобы найти людей в рамках определенной персоны. В настоящее время мы внедряем интеграцию с нашей CRM, чтобы обеспечить больше маркетинга на основе учетных записей.
Плюсы и минусы
Обновить и исправить данные.
Интегрируйте с вашими системами автоматизации продаж и маркетинга.
Помогите сохранить обновленные записи.
Вероятность рекомендации
Вы всегда хотите свести к минимуму импорт списков, которые не являются обязательными. Он идеально подходит для заполнения и исправления входящих лидов.
Рейтинги функций оптимизатора D&B
- Поиск (6)
83.33333333333334%
8.3
- Расширенный поиск
- Выявление новых лидов 9 (3) 1
83.33333333333334%
8.3
- Контактная информация
- Информация о компании
- Информация об отрасли
- Расширение данных и квалификация потенциальных клиентов (9)
55,55555555555556%
90 002 5.6- Процесс квалификации лидов
- Умные списки и рекомендации
- Интеграция с Salesforce
- Профили компаний/бизнесов
- Оповещения и напоминания
- Гигиена данных
- Автоматическое обновление данных
- Фильтры и сегментация
- Функции эл. 0209
Окупаемость инвестиций
Вернуться к навигацииSystweak Advanced System Optimizer обзор
Когда вы покупаете по ссылкам на нашем сайте, мы можем получать партнерскую комиссию. Вот как это работает.
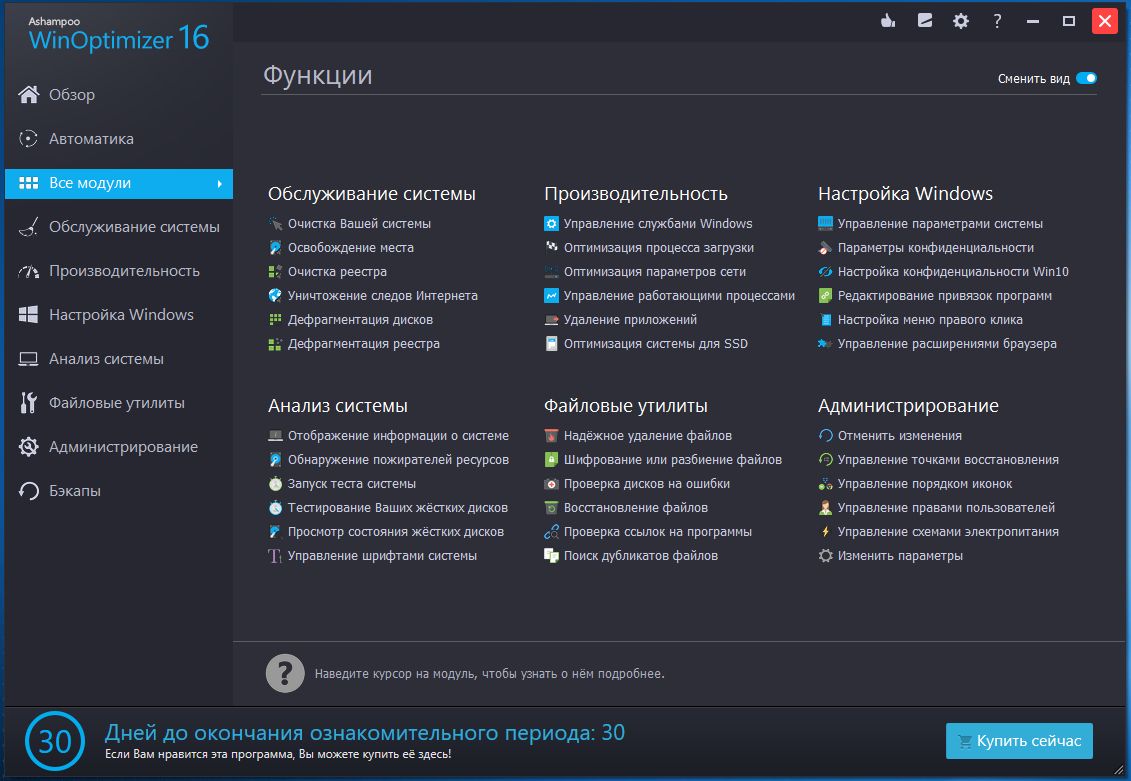
Это единственный инструмент оптимизации Windows, который вам нужен?
(Изображение: © Systweak)
ТехРадар Вердикт
Advanced System Optimizer включает в себя набор функций, которые постоянно оптимизируют ваш ПК для достижения максимальной производительности. Примеры включают очистку ненужных файлов, дефрагментацию диска, резервное копирование и восстановление системных файлов. Это полезный инструмент для каждого пользователя ПК, которому нужна максимальная скорость и производительность.
ЛУЧШИЕ ПРЕДЛОЖЕНИЯ СЕГОДНЯ
Плюсы
- +
Практичный набор функций
- +
Удобный интерфейс
- +
Доступна бесплатная версия
- +
Быстрая загрузка и установка
Почему вы можете доверять TechRadar Мы тратим часы на тестирование каждого продукта или услуги, которые мы рассматриваем, поэтому вы можете быть уверены, что покупаете лучшее.
Узнайте больше о том, как мы тестируем.Systweak — индийская технологическая компания, которая продает программные инструменты для оптимизации, обслуживания и обеспечения безопасности для ПК и мобильных устройств. Advanced System Optimizer — один из ее хорошо известных продуктов. Он включает в себя обширный набор функций, которые в совокупности работают на повышение скорости и производительности вашего ПК.
Systweak выпустила первую версию Advanced System Optimizer в 2002 году. С тех пор многие другие обновленные версии были удалены. Мы проверяем последнюю версию на основе определенных критериев, включая цены, функции, поддержку клиентов, удобство использования и т. д.
Systweak также добавляет копию своего программного обеспечения PhotoStudio v2.1 при каждой покупке Advanced System Optimizer (Изображение предоставлено Systweak)Планы и цены
Существует бесплатная версия Advanced System Optim izer каждый может получить. Однако эта версия имеет ограниченные возможности по сравнению с премиальной версией, которая открывает полную функциональность программного обеспечения.
Таким образом, вам придется заплатить за премиум-версию, чтобы получить максимальную отдачу от Advanced System Optimizer.Премиум-версия доступна по подписке. Годовая подписка на один ПК стоит 50 долларов. Лучший способ получить его — заплатить непосредственно на официальном сайте Systweak. Компания предлагает 60-дневную гарантию возврата денег за каждую покупку.
Особенности
Advanced System Optimizer предлагает множество полезных функций для оптимизации скорости и производительности вашего ПК, в том числе;
Удалите ненужные ненужные файлы с вашего ПК и многое другое (Изображение предоставлено Systweak)Средство очистки системы
Средство очистки системы находит и удаляет ненужные и бесполезные файлы с вашего компьютера. Ненужные файлы замедляют работу вашего ПК, потому что они занимают ценное пространство, которое можно было бы использовать в другом месте. Удаление этих ненужных файлов поможет повысить скорость и производительность вашего компьютера.
Дефрагментация подразумевает реорганизацию данных, хранящихся на жестком диске, таким образом, чтобы связанные фрагменты данных группировались в непрерывном порядке. Дефрагментация жестких дисков помогает повысить скорость доступа к данным и общую производительность ПК. Вы можете дефрагментировать жесткий диск с помощью Advanced System Optimizer.
Advanced System Optimizer также имеет несколько примечательных функций безопасности (Изображение предоставлено Systweak)Безопасное удаление
Эта функция позволяет безвозвратно удалять данные для безопасного удаления. Это полезно для людей, которые работают с конфиденциальными документами или если вам нужно стереть данные вашего компьютера перед его продажей, пожертвованием или переработкой.
Advanced System Optimizer включает инструмент для резервного копирования ценных данных, документов и других файлов и их восстановления в любое время. Рекомендуется регулярно делать резервную копию вашего ПК, чтобы свести к минимуму ущерб от возможных случаев потери данных.
Представьте разочарование от потери всех или части данных вашего ПК без резервного копирования? Вы не хотите знать.Вы также можете создавать резервные копии системных файлов и при необходимости восстанавливать старые.
Запускайте игры в режиме песочницы, чтобы не отвлекаться (Изображение предоставлено Systweak)Game Optimizer
Вы можете наслаждаться играми без отвлекающих факторов, запуская компьютерные игры в специальном режиме песочницы. Песочница — это изолированная среда, которая позволяет вам запускать программы, не затрагивая другие части вашей системы. Запуск игр в песочнице делает игровой процесс более плавным и быстрым.
Оптимизатор памяти освобождает временную оперативную память для любого текущего процесса на вашем ПК. Чем свободнее ваша оперативная память, тем быстрее работают приложения на вашем компьютере.
Вы можете зашифровать важные файлы паролем для предотвращения несанкционированного доступа.
После каждого сеанса просмотра вы можете удалить свою историю и все файлы cookie для отслеживания, чтобы защитить свою личность в Интернете.
Advanced System Optimizer имеет простой, хотя и устаревший интерфейс (Изображение предоставлено Systweak)Интерфейс и используется
Advanced System Optimizer удобен в использовании, начиная с этапа загрузки и установки. После получения установочного файла с официального сайта установка на нашем ПК заняла около минуты. После этого мы начали пользоваться приложением.
Программное обеспечение имеет аккуратный, лаконичный интерфейс, который упрощает понимание. Все его функции сгруппированы в восемь различных меню для быстрого доступа.
Вы не найдете никаких вариантов самопомощи на сайте Systweak (Изображение предоставлено Systweak)Поддержка
Systweak обеспечивает поддержку клиентов по электронной почте. Подробная страница часто задаваемых вопросов и руководство пользователя для Advanced System Optimizer также доступны на веб-сайте компании.
Конкуренты
Некоторые стандартные альтернативы Advanced System Optimizer включают Piriform CCleaner и Reviversoft PC Reviver.
Они имеют сопоставимые характеристики, но различаются ценой. CCleaner значительно дешевле: 30 долларов за годовую лицензию на один ПК по сравнению с 50 долларами за Advanced System Optimizer. PC Reviver немного более доступен по цене 43 доллара за тот же пакет подписки.Окончательный вердикт
Advanced System Optimizer — отличный инструмент, обеспечивающий максимально эффективную работу вашего компьютера. Однако у него есть определенные недостатки, такие как более высокая стоимость, чем у конкурирующих инструментов.
- Поддерживайте максимальную производительность вашего ПК с помощью лучших системных утилит и программного обеспечения для восстановления Windows
Systweak Advanced System Optimizer: сравнение цен0003
Стефан всегда был любителем техники. Он получил степень магистра инженерной геологии, но вскоре обнаружил, что вместо этого у него есть способности к письму. Поэтому он решил совместить свои новообретенные увлечения на всю жизнь и стать техническим писателем.
 com (прекращено) 9 0002 Сравнить
com (прекращено) 9 0002 Сравнить Это помогает использовать инструменты NetProspex не реже одного раза в квартал, чтобы поддерживать точность. Это также помогает заполнить любые неполные записи, которые могут замедлить ваш бизнес-процесс, и устраняет барьеры во время воронки продаж.
Это помогает использовать инструменты NetProspex не реже одного раза в квартал, чтобы поддерживать точность. Это также помогает заполнить любые неполные записи, которые могут замедлить ваш бизнес-процесс, и устраняет барьеры во время воронки продаж. 0209
0209
 0209
0209 Узнайте больше о том, как мы тестируем.
Узнайте больше о том, как мы тестируем. Таким образом, вам придется заплатить за премиум-версию, чтобы получить максимальную отдачу от Advanced System Optimizer.
Таким образом, вам придется заплатить за премиум-версию, чтобы получить максимальную отдачу от Advanced System Optimizer.
 Представьте разочарование от потери всех или части данных вашего ПК без резервного копирования? Вы не хотите знать.
Представьте разочарование от потери всех или части данных вашего ПК без резервного копирования? Вы не хотите знать.
 Они имеют сопоставимые характеристики, но различаются ценой. CCleaner значительно дешевле: 30 долларов за годовую лицензию на один ПК по сравнению с 50 долларами за Advanced System Optimizer. PC Reviver немного более доступен по цене 43 доллара за тот же пакет подписки.
Они имеют сопоставимые характеристики, но различаются ценой. CCleaner значительно дешевле: 30 долларов за годовую лицензию на один ПК по сравнению с 50 долларами за Advanced System Optimizer. PC Reviver немного более доступен по цене 43 доллара за тот же пакет подписки.
Ваш комментарий будет первым