ТОП-10 утилит Android, IOS, Windows
Сегодня мы поговорим именно о приложениях, которые выполняют распознавание музыки по звуку! Согласитесь, ведь очень часто бывают ситуации, когда мы идем по городу, сидим в кафе или находимся в каком-то другом месте и слышим очень крутую музыку, но не знаем ее название.
Раньше казалось, что выхода нет, разве что записывать на диктофон и спрашивать каждого, не знает ли он этот трек.
Кто-то записывал слова песни и искал их в поисковиках. Но на дворе XXI век и уже давно есть альтернативные и в 1000 раз более удобные методы распознавания музыки, а именно специальный софт для этого.
Содержание:
Поиск музыки через приложение Google (Android)
Использование инструмента от Гугл выглядит следующим образом:
- На главном экране своего смартфона или планшета сделайте тап и держите его до тех пор, пока не появится новое меню.
- В нем выберете вариант «Виджеты».

- Среди всего списка найдите пункт «Аудиопоиск» перетащите его значок на главный экран.
- Дальше запустите этот инструмент – тот, который вы только что перетащили. Сделать это нужно в момент прослушивания какого-то трека на смартфоне/планшете.

Дальше все просто – если в Гугл найдется эта песня, вы увидите всю информацию о ней, а если нет, соответствующее сообщение.
Данный способ удобен тем что приложение Google установлено почти на всех устройствах под ОС Android и не нужно будет скачивать дополнительных приложений для поиска.
Позитив:
- не нужно что-то устанавливать, кроме операционной системы Андроид 6.0 или выше;
- очень обширная база для поиска – весь Google.
Негатив:
- иногда работает некорректно;
- нельзя дать прослушать трек, который прямо сейчас идет по телевизору или радио.
TrackID
Рис. 1. Программа TrackId
Одно из первых приложений по распознаванию музыки.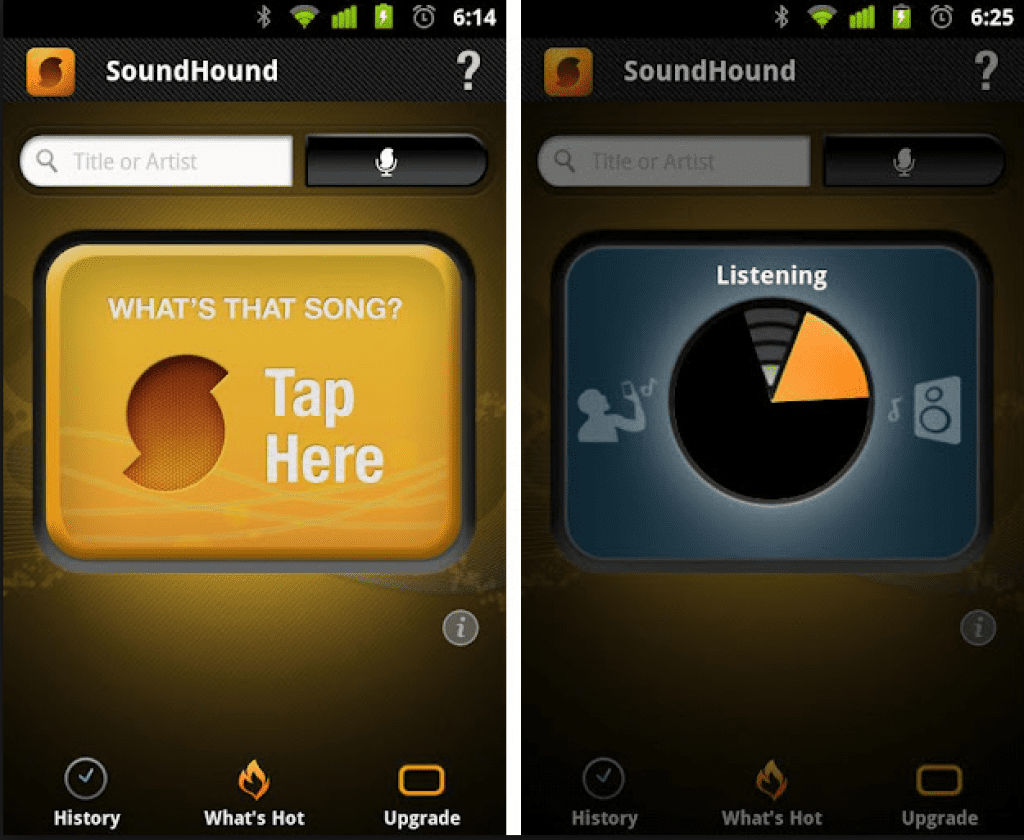 Эту программу создала компания Sony для своей линейки телефонов Walkman и на тот момент это был огромный прорыв в области музыки, так как в далеком 2006 существовало очень мало аналогов этой программы. По умолчанию оно установлено на все телефоны линейки Sony.
Эту программу создала компания Sony для своей линейки телефонов Walkman и на тот момент это был огромный прорыв в области музыки, так как в далеком 2006 существовало очень мало аналогов этой программы. По умолчанию оно установлено на все телефоны линейки Sony.
В Play Market его нет, но можно установить со сторонних ресурсов, достаточно лишь вбить в поиск название программы.
Лучше всего делать это с uptodown.com. Сайт достаточно надежный и проверенный.
Использование TrackId достаточно простое. Юзеру необходимо просто, как и в предыдущем случае, начать воспроизводить какой-то трек и включить единственную большую кнопку на главном экране программы.
Но примечательно, что здесь в качестве источника можно выбрать какой-то файл или даже микрофон.
То есть вы можете включить TrackId и поднести его к телевизору или радио, откуда звучит музыка.
Дальше на экране появится вся информация об исполнителе и его музыке.
Только для этого нужно выбрать источник – нажать на надпись «Recording» под вопросом «What I am listening to?» (переводится как «Откуда я слушаю?») и выбрать другой вариант.
Примечательно, что это ПО тоже работает при помощи поисковиков, но делает это намного лучше, чем программа, сделанная представителями этих же поисковиков. Речь идет об инструменте от Гугл.
Позитив:
- можно прослушивать с микрофона;
- качественная система поиска;
- удобное управление и красивый интерфейс.
Негатив:
- все равно очень много случаев, когда трек не находится.
К слову, фактически, критерий количества найденных песен той или иной программой и был решающим в составлении этого ТОПа. А так, по интерфейсу и быстродействию все образцы ПО достаточно неплохие.
Вернуться к меню ↑SoundHound
Рис. 2. SoundHound
Приложение которое по функционалу похоже на ту программу, которая заняла первое место в нашем рейтинге.
Тоже довольно неплохо определяет музыку.
Скачать его можно на официальном сайте – soundhound.com.
Там, что примечательно, есть ссылки как для Android так и для IOS.
Что касается пользователей продукции Apple, то для них SoundHound – это вообще целая легенда.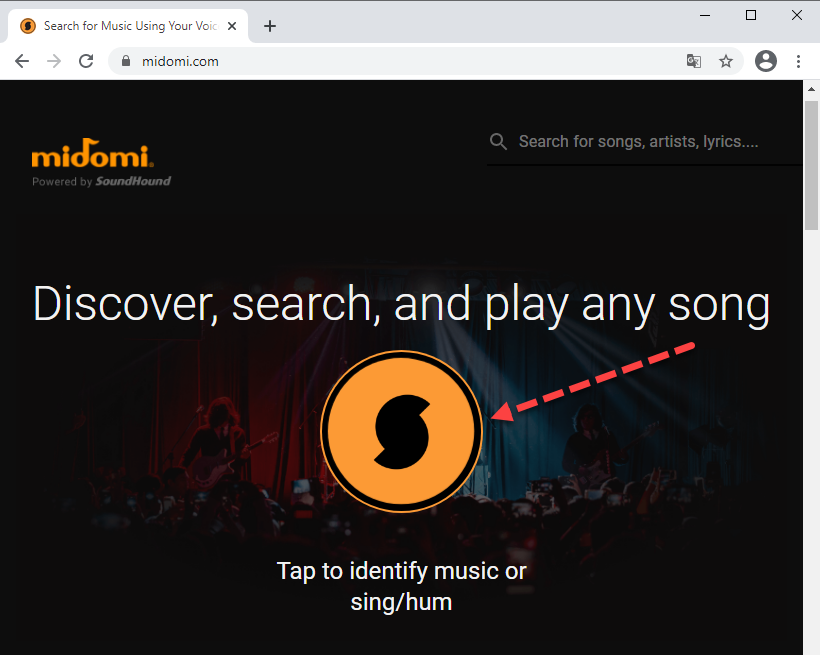
Чаще всего они определяют музыку именно при помощи данного образца программного обеспечения.
И это неудивительно, ведь здесь в качестве результата отображается полная дискография исполнителя, информация о конкретном треке, похожие пески и даже группы.
Для меломанов это потрясающая находка! Но вот по нашему основному критерию, обозначенному выше, есть более крутые программы.
Позитив:
- весьма обширная библиотека данных;
- прекрасная репутация среди пользователей операционной системы iOS;
- система распознавания через динамик.
Негатив:
- очень редко, но все-таки глючит.
MusicBrainz Picard
Рис. 3. MusicBrainz Picard
Это прекрасный, многоплановый инструмент для профессиональных музыкантов. Им пользуется очень много людей, так или иначе связанных с обработкой музыки.
Распознавание треков – это лишь один из инструментов MusicBrainz Picard. Здесь можно менять форматы (речь идет не о mp3, vaw, а о таких вещах, как 10” Vinyl, Cassette, CD и так далее).
Здесь своя огромная база данных музыкальной информации.
Сам поиск происходит при помощи тегов. На сегодняшний день это самая передовая система из всех доступных.
Алгоритм, как и во всех остальных приложениях, заключается в следующем:
- Запускаем приложение. Даем прослушать фрагмент песни. Для этого жмем кнопку «Add files».
- Жмем на кнопку поиска.
- Получаем результат. Он будет представлен в виде информации об исполнителе и треке.
Скачать приложение можно на официальном сайте – picard.musicbrainz.org.
Позитив:
- множество инструментов для обработки музыки;
- понятный интерфейс.
Негатив:
- нельзя прослушать музыку с микрофона.
Audiggle
Рис. 4. Audiggle
Audiggle – это минималистичное приложение, которое поможет быстро узнать нужный вам трек на вашем компьютере.
Оно в разы проще и в хорошем смысле этого слова скромнее, чем MusicBrainz Picard.
Но распознает треки, судя по отзывам и нашим испытаниям, лучше.
Возможно, это связано с тем, что разработчики MusicBrainz Picard решили уделить больше внимания другим инструментам, а не распознаванию музыки.
А вот люди, работавшие с Audiggle, не были обременены необходимостью впихнуть в свое ПО как можно больше инструментов.
Чтобы воспользоваться Audiggle, необходимо просто записать фрагмент песни, запустить программу, нажать «Explore», чтобы загрузить файл, затем «Search», чтобы начать поиск.
Дальше просто подождите, пока программа найдет нужную песню.
Установить данную программу можно с официального сайта – audiggle.com.
Позитив:
- простой интерфейс – разберется любой начинающий юзер;
- результатом можно поделиться в социальной сети.
Негатив:
- мало информации о треке – придется пользоваться поисковиками, чтобы найти больше.
AudioTag
Рис. 5. AudioTag
5. AudioTag
Это не приложение для поиска музыки, а сайт с таким вот сервисом – audiotag.info.
Кстати, приготовьтесь сразу отключить AdBlock, если он у вас есть.
Это намного более удобный вариант, чем любая из вышеперечисленных программ.
Секрет в том, что AudioTag будет работать на абсолютно любой платформе, вплоть до Java.
Использовать его нужно следующим образом:
- Загружаем файл, выбираем пункт «Browsе» или указываем ссылку на песню в интернете.
- Придется пройти верификацию ответив на простой вопрос.
- Результат на экране.
Интересно, что есть и скачиваемая версия ПО. Скачать ее можно по той же ссылке.
Есть платная и бесплатная версия этой программы.
Правда, зачем она нужна, непонятно. Да и есть рассматривать программу, она проиграет всему описанному выше.
Позитив:
- сайт работает на всех устройствах;
- качественная система распознавания.
Негатив:
- невозможно дать прослушать с микрофона.

Midomi
Рис. 6. Midomi
Очень качественная программа, старший брат ранее описанной программы SoundHound.
Интересно, что в отличии от других образцов ПО, некоторые отрывки из песен можно спеть самому.
Это основная отличительная особенность Midomi.
Кроме того, это тоже сайт и он тоже будет работать на абсолютно разны платформах.
Как пользоваться:
- На стартовой странице нажать кнопку поиска.
- Разрешить доступ к камере и микрофону.
- После появится таймер, в этот момент нужно будет спеть или дать программе прослушать отрывок из песни.
- Через пару секунд будет результат.
Ссылка на сайт – midomi.com.
Позитив:
- огромная база данных;
- работа через сайт;
- можно давать прослушивать с микрофона;
- песню можно петь самостоятельно!
Негатив:
- результат немного уже, чем у программ из тройки лидеров.
MusiXmatch
Рис. 7. MusiXmatch
7. MusiXmatch
Также один из представителей программного обеспечения по распознаванию музыки, приобрел популярность в больше части из-за большого количества текста.
Но и музыки MusiXmatch распознает больше, чем остальное ПО в данном ТОПе.
Работает по такому же принципу, как и остальные программы данного типа – жмете на большую кнопку посредине экрана и включаете трек или наоборот.
Ссылка на скачивание — musixmatch.com.
Позитив:
- простота в использовании;
- хороший результат при распознавании.
Негатив:
- работает немного уже, чем то, что мы поставили на второе и первое место
Яндекс с Алисой
Удивительно, что где-то Яндекс переплюнул Гугл, причем конкретно. Алиса – весьма передовой ассистент, который поможет найти любую музыку, связан с инструментом «Яндекс.Музыка».
В Украине будет проблемно использовать этот помощник, для этого есть телеграм-боты Алисы, благодаря которым не нужно будет включать VPN.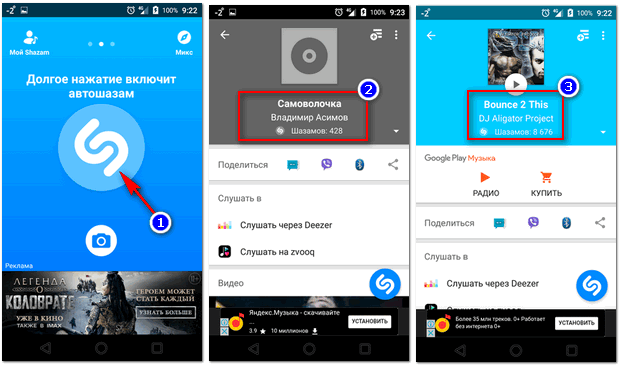
- Ссылка на телеграм-бота – t.me/YaMelodyBot.
Ссылка на «Алису»:
- Android – play.google.com
- IOS – itunes.apple.com
- Windows – alice.yandex.ru/windows
Позитив:
- простота в использовании;
- высокая производительность.
Негатив:
- в Украине запустить будет проблематично.
SHAZAM
Рис. 9. Shazam
И на первом месте самое популярное приложение среди всех приложений по распознаванию музыки. Все-таки ничего лучше пока что не придумали.
Shazam – это крупная музыкальная библиотека. Детальнее о ней вы можете прочесть в нашем материале.
Достаточно лишь нажать в приложении на кружок с логотипом Shazam и в течении 10 секунд вы получите результат. 99% что приложение не ошибется в распознании, но чаще всего проблема в том, что не всегда приложение может найти нужный вам трек, особенно если он мало популярен.
Но ничего лучше все равно нет.
Скачать приложение можно с официального сайта – shazam.com.
Позитив:
- простота в использовании;
- высокая производительность.
Негатив:
- в сравнении с другими приложениями их нет.
Лучшие приложения для поиска песни по звуку
Если вы один из тех людей, которые любят музыку и открывают для себя новые песни, вам нужен хороший инструмент, позволяющий искать любую песню по звуку. Несмотря на традиционный метод поиска Google, эти приложения, которые мы предлагаем вам, идеально подходят для всех любителей музыки.
Если вы идете по улице и слышите песню, вам нужно только активировать функцию выбранного вами приложения, она даст вам все шансы узнать, о чем эта песня. Таким же образом, независимо от источника воспроизведения, вы сможете быстро получить результаты.
Таким же образом, независимо от источника воспроизведения, вы сможете быстро получить результаты.
Индекс
- 1 Как искать песню по звуку с помощью Google?
- 2 Распознавание музыки
- 3 SoundHound — Поиск музыки
- 4 Распознавайте песни — идентифицируйте
- 5 Shazam: определить музыку
- 6 узнавать песни
Как искать песню по звуку с помощью Google?
Это, несомненно, один из самых простых и доступных маршрутов для всех. Вам просто нужно зайти в приложение Google, который по умолчанию установлен на всех мобильных устройствах. Непрерывно нажимайте кнопку домой, вы также можете активировать ее фразой Эй, Google, и после этого я задаю вопрос, что это за песня?
Тогда вам просто нужно сыграть песню, которую вы хотите открыть для себя, или просто напевай, просто имейте в виду, что вы помните ритм и слова. Через несколько секунд вы получите ответ.
Вот некоторые из приложений, которые позволят вам искать любую песню по звуку:
Распознавание музыки
Это одно из лучших приложений в своем роде, позволяет распознавать любые темы всего за несколько секунд воспроизведения. Одним из преимуществ этого приложения является то, что оно не только дает вам возможность распознавать песни, но в качестве дополнения вы сразу же получите биографию прослушанного исполнителя, а также самые популярные песни этого и открыть для себя другие песни из альбома, который вам принадлежит.
Подпишитесь на наш Youtube-канал
Еще одним преимуществом является доступ, чтобы делиться темами, которые вы изучаете, Вы можете сделать это через различные социальные сети, такие как Facebook, WhatsApp или Twitter. Если вы хотите, чтобы вы могли максимально использовать функцию дискотеки, которую имеет приложение, просто активируйте ее. Он позволяет использовать фонарик мигающим образом, имитируя свет на дискотеке.
Некоторые дополнительные функции:
- Получать всевозможные важные данные об идентифицированной песне, либо название альбома, и треки на нем, и дату его выпуска.
- На ютубе можно посмотреть полное видео песни.
- Все темы будет храниться на странице истории, сразу после идентификации.
Это практичное приложение имеет очень интуитивно понятный и простой способ использования, поэтому его загрузка не вызовет никаких сложностей. Вам просто нужно зайти в Play Маркет, здесь количество загрузок превышает десять миллионов, Его оценка настолько же положительна, что ему удалось получить 4 звезды.
Идентификатор музыки
Разработчик: Музыкальное признание Beatfind
Цена: Это БесплатноSoundHound — Поиск музыки
Это приложение имеет много положительных функций, которые улучшают его работу. Приятный интерфейс и простота использования говорят в его пользу. Система поиска очень интуитивно понятна, вам просто нужно нажать оранжевую кнопку, и изучение темы начнется мгновенно, и вы получите ответ за считанные секунды.
Система поиска очень интуитивно понятна, вам просто нужно нажать оранжевую кнопку, и изучение темы начнется мгновенно, и вы получите ответ за считанные секунды.
Другими не менее привлекательными вариантами являются возможность после того, как песня будет идентифицирована, поиск его текста и биографической информации об исполнителе, который его исполняет, а также изображения, даты выхода их тем и другую полезную информацию.
Приложение также предоставляет вам самое популярное за неделю, так что вы можете быть в курсе всех музыкальных тенденций. Если вам это нужно, вы можете Создайте свою собственную историю поиска, чтобы не потерять свои открытия.
Это привлекательное приложение очень эффективно для поиска любой песни по звуку. Он доступен в Play Store, где его скачали более ста миллионов раз. Имеет положительный рейтинг 4 звезды.
SoundHound — поиск музыки
Разработчик: SoundHound Inc.
Цена: Это БесплатноРаспознавайте песни — идентифицируйте
Если вы ищете эффективный способ поиска песни по звуку, это одно из самых полных приложений, которое поможет вам легко достичь своей цели. Независимо от источника воспроизведения, приложение предоставит вам эффективный сервис, Вы можете исследовать песни, которые слышите на улице, по радио, по телевизору или просто из любого места в Интернете.
Наиболее яркие черты:
- Вы будете иметь доступ к создать страницу истории, Это позволит вам собрать все темы, которые вы ищете.
- Распознавание песен будет осуществляться за очень короткое время.
- Вы также можете поделиться этими темами с друзьями, через разные социальные сети.
Это универсальное приложение можно найти в магазинах Google, Play Store,  Рейтинг 4 звезды был достигнут благодаря положительным отзывам многих интернет-пользователей.
Рейтинг 4 звезды был достигнут благодаря положительным отзывам многих интернет-пользователей.
Распознавайте песни — идентифицируйте
Разработчик: гибрид4приложения
Цена: Это БесплатноShazam: определить музыку
Это одно из передовых приложений для поиска любой песни по звуку. Он имеет отличные функции, которые значительно облегчат эту задачу. Быстро определить песню, которую вы хотите. Другие варианты гарантированно узнавайте через Shazam, самого популярного в вашей стране.
При желании можно получить очень хорошие рекомендации не только по песням, но и по плейлистам, которые несомненно придутся вам по душе. Иметь возможность поделиться своими открытиями со всеми своими друзьями и семья в социальных сетях.
Это успешное приложение, его фигура Загрузки в Play Store составляют 500 миллионов. Он также имеет рейтинг 4 звезды. Отзывы пользователей сети красноречиво говорят о его принятии, отмечая не только его эффективность поиска, но и его мудрые рекомендации.
Shazam
Разработчик: Корпорация Apple
Цена: Это Бесплатноузнавать песни
Это одно из самых полных приложений в нашем списке. Его основная функция позволяет искать любую песню по звуку за считанные секунды, а также Он имеет множество других функций и возможностей, которые делают его очень универсальным.
Вы сможете определить все песни, которые вам нужны, вам просто нужно сыграть их или напеть. Благодаря так называемому всплывающему распознаванию песен вы можете находите темы на других платформах, таких как TikTok, YouTube и даже Instagram.
Это приложение, которое вы можете получить, загрузив его из Play Store. На сегодняшний день у него накопилось более 500 XNUMX загрузок. Его оценка составила 4 звезды.
узнать песню
Разработчик: Исяоцин
Цена: Это БесплатноМы надеемся, что эта статья была для вас полезным инструментом, чтобы открыть для себя приложение, которое позволяет вам легко искать любую песню по звуку. Изучите различные варианты, которые мы вам предлагаем, и найдите идеальный для вас вариант, отвечающий всем требованиям. которые имеют значение с точки зрения качества и простоты. Если вы знаете какие-либо другие приложения для той же цели, которые мы не упомянули, сообщите нам об этом в комментариях. мы читаем тебя
Изучите различные варианты, которые мы вам предлагаем, и найдите идеальный для вас вариант, отвечающий всем требованиям. которые имеют значение с точки зрения качества и простоты. Если вы знаете какие-либо другие приложения для той же цели, которые мы не упомянули, сообщите нам об этом в комментариях. мы читаем тебя
Если эта статья была вам интересна, рекомендуем следующее:
Лучшие офлайн-музыкальные приложения
Распознавание звука ИИ: мечтают ли машины об электромузыке?
Содержание
- Звуки в распознавании ИИ: зачем это делается?
- Распознавание звука AI: как это делается?
- Преобразование аудио в текст
- Аннотации данных для распознавания звука AI
- Заключение: Распознавание звука как универсальный инструмент
За последние пару лет искусственный интеллект стал нарицательным для бизнеса в любой отрасли на рынке. Если есть данные, которые нужно собирать и использовать, организация может извлечь выгоду из внедрения ИИ как части своего рабочего процесса.
Если есть данные, которые нужно собирать и использовать, организация может извлечь выгоду из внедрения ИИ как части своего рабочего процесса.
Тип данных определяет задачи и, в свою очередь, тип используемых алгоритмов. Распознавание, возможно, является одной из самых громких и ярких из этих задач. Тем не менее, по иронии судьбы, среди большого разнообразия типов алгоритмов распознавания нет более тихого и молчаливого, чем ИИ распознавания звука .
Когда мы думаем об искусственном интеллекте распознавания, мы думаем о распознавании изображений (будь то обнаружение лиц или эмоций), OCR, который помогает расшифровывать символы (слова и числа) и превращать их в редактируемый текст для печати. Однако, если копнуть глубже, распознавание звука в наше время есть везде.
- Это ваш домашний помощник, слушающий ваши просьбы включить определенный трек и рассказывающий вам анекдоты, когда вы чувствуете себя подавленным.
- Именно модели автоматизации позволяют преобразовывать утомительные, бесконечные встречи в краткие бизнес-отчеты.
- Именно в CRM-системах используется определенный набор алгоритмов для сбора наиболее важной информации о клиенте и использования ее в своих (и компании) интересах.

Мы действительно не думаем об искусственном интеллекте для распознавания звука, поскольку это очень важно для человека: слушать и быть услышанным. Итак, давайте посмотрим, как мы можем помочь компьютеру слышать так же, как и мы, и поможет ли это улучшить общение между людьми и машинами или даже улучшить общение между людьми.
Звуки при распознавании ИИ: зачем это делается?
Хотя мы можем не думать об этом как о чем-то новаторском, распознавание звука на самом деле играет огромную роль как в комфорте нашей современной жизни, так и в дальнейшем развитии человечества. Он предлагает удивительное количество возможностей для практической реализации.
Типология алгоритмов распознавания звукаВот несколько групп различных алгоритмов обнаружения звука, которые могут дать вам представление о гибкости и универсальности этого типа модели распознавания:
- Распознавание музыки . Вероятно, тот, с которым каждый из нас больше всего знаком, распознавание музыки относится к алгоритмам, способным обнаруживать и классифицировать музыку. Эти модели могут быть вполне моделями, например, чем-то, что навешивает ярлык определенного жанра на композицию. Или это может быть сложный и всемирно известный алгоритм, подобный тому, что лежит в основе Shazam, нашего любимого программного обеспечения для распознавания музыки.
- Распознавание речи . Еще один чрезвычайно популярный класс алгоритмов распознавания звука, его можно найти в самых разных контекстах. В бизнесе он может служить для записи речи во время встречи. В частной жизни он используется для распознавания голоса в виртуальных помощниках (чат-ботах) и домашних помощниках, таких как Alexa или Siri.
- Помощь инвалидам . Потеря слуха может стать большой трагедией для человека, живущего в акустическом мире. Вот почему слуховые аппараты или распознавание активности для пожилых пользователей, созданные с помощью моделей распознавания звука, могут быть очень эффективными, если не необходимыми для людей с такими ограниченными возможностями. Производители предметов домашнего обихода и гаджетов давно начали внедрять такие функции в свою продукцию. Например, совсем недавно Apple представила новую функцию специальных возможностей распознавания звука для своей iOS 14.
- Системы наблюдения . Этот класс моделей распознавания звука можно разделить на два: звуковой мониторинг и звуковая верификация. По мере роста внимания к безопасности все более востребованы звуковые системы, способные обнаруживать различные сигналы автоматизированного мониторинга (такие как сигналы тревоги, звуки взлома и проникновения или насилия и даже необычные для промышленных условий звуки). С другой стороны, идет разработка технологии акустических отпечатков пальцев, которая станет еще одним важным компонентом как частной, так и деловой безопасности. Кроме того, распознавание звука имеет большой потенциал как часть надежных проектов ИИ, таких как видеоаналитика и обнаружение событий.
- Распознавание природных звуков . Эти модели обнаружения звука, хотя и не так распространены, как предыдущие, дают возможность изучить окружающий мир и узнать больше о разных видах, живущих рядом с нами. Технология распознавания естественного звука широко используется в океанографии, прогнозировании погоды, термометрии и т. д.
 Вероятно, тот, с которым каждый из нас больше всего знаком, распознавание музыки относится к алгоритмам, способным обнаруживать и классифицировать музыку. Эти модели могут быть вполне моделями, например, чем-то, что навешивает ярлык определенного жанра на композицию. Или это может быть сложный и всемирно известный алгоритм, подобный тому, что лежит в основе Shazam, нашего любимого программного обеспечения для распознавания музыки.
Вероятно, тот, с которым каждый из нас больше всего знаком, распознавание музыки относится к алгоритмам, способным обнаруживать и классифицировать музыку. Эти модели могут быть вполне моделями, например, чем-то, что навешивает ярлык определенного жанра на композицию. Или это может быть сложный и всемирно известный алгоритм, подобный тому, что лежит в основе Shazam, нашего любимого программного обеспечения для распознавания музыки. Производители предметов домашнего обихода и гаджетов давно начали внедрять такие функции в свою продукцию. Например, совсем недавно Apple представила новую функцию специальных возможностей распознавания звука для своей iOS 14.
Производители предметов домашнего обихода и гаджетов давно начали внедрять такие функции в свою продукцию. Например, совсем недавно Apple представила новую функцию специальных возможностей распознавания звука для своей iOS 14. Эти модели обнаружения звука, хотя и не так распространены, как предыдущие, дают возможность изучить окружающий мир и узнать больше о разных видах, живущих рядом с нами. Технология распознавания естественного звука широко используется в океанографии, прогнозировании погоды, термометрии и т. д.
Эти модели обнаружения звука, хотя и не так распространены, как предыдущие, дают возможность изучить окружающий мир и узнать больше о разных видах, живущих рядом с нами. Технология распознавания естественного звука широко используется в океанографии, прогнозировании погоды, термометрии и т. д.Хотя этот список не является исчерпывающим, он дает общее представление о том, насколько широк набор возможностей для распознавания звука. Но есть еще один вопрос, на который нужно ответить: как работает эта магия ИИ?
Распознавание звука AI: как это делается?
Когда технология распознавания голоса работает… а когда нетМногочисленные задачи распознавания звука имеют немного разный подход, но суть у них одинакова. Вот список шагов, которые проходит каждый алгоритм распознавания звука:
- Прежде всего, модель распознавания звука записывает звуки, которые она слышит. Они могут быть в разных формах, живые или уже записанные. Этот шаг важен, так как он позволяет модели создать основу для дальнейшей обработки звуков.
- Далее модель анализирует записи. Это означает, что записанные звуки сравниваются с данными, на которых обучалась модель. Чем качественнее был процесс обучения и чем качественнее данные, тем быстрее и точнее будет прогноз.
- Наконец, модель обеспечивает осмысленные выходные данные. Это может быть что угодно: от поиска ответа на ваш запрос до расшифровки речи в редактируемый текст до просмотра базы данных похожих звуков с использованием метода классификации для точного определения источника звука.

Преобразование аудио в текст
Как работает распознавание речиСтоль же простая задача, как транскрипция аудио в текст, которую мы считаем само собой разумеющейся в наших домашних помощниках и чат-ботах, требует как минимум трех основных шагов для преобразования человеческого ввода (вопроса или запроса) в машинный вывод (вопрос или запрос). отвечать).
ASR (автоматическое распознавание речи) используется для разбиения речи (живой или записанной) на сегменты. Затем алгоритм анализирует звуки с помощью NLP (обработка естественного языка) и предсказывает, каким словам на данном языке они могут соответствовать. Это позволяет машине найти подходящий ответ на запрос пользователя. Наконец, TTS (преобразование текста в речь) преобразует ответ в человеческую речь.
Затем алгоритм анализирует звуки с помощью NLP (обработка естественного языка) и предсказывает, каким словам на данном языке они могут соответствовать. Это позволяет машине найти подходящий ответ на запрос пользователя. Наконец, TTS (преобразование текста в речь) преобразует ответ в человеческую речь.
Итак, когда в следующий раз вы попросите Siri рассказать вам анекдот, не раздражайтесь по существу шутки. Имейте в виду, что алгоритм под капотом вашего смартфона проходит сложный процесс распознавания звука только для вашего развлечения.
Аннотация данных для распознавания звука AI
Создание алгоритма распознавания звука — довольно сложная задача, поскольку для ее выполнения требуется несколько основных шагов. С одной стороны, вам нужна команда разработчиков и инженеров данных для разработки модели машинного обучения. С другой стороны, большая часть вашего времени будет потрачена на сбор, анализ, обработку и аннотирование данных.
Последняя часть часто упускается из виду инженерами данных, поскольку это менее творческий, более утомительный и гораздо более трудоемкий процесс, чем разработка модели машинного обучения. Однако, чтобы приступить к обучению алгоритма, вам нужно убедиться, что у вас есть хороший, качественный и объемный набор данных.
Однако, чтобы приступить к обучению алгоритма, вам нужно убедиться, что у вас есть хороший, качественный и объемный набор данных.
В частности, аннотация данных является важным процессом добавления меток к частям данных. Это важно, потому что машины не анализируют звуки так, как это делают люди. Этикетки нужны, чтобы научить машины понимать, что мы хотим, чтобы они услышали, и что означают эти звуки.
Поскольку это очень трудоемкая задача, многие компании ищут партнеров по аннотации. Это избавляет компании от необходимости отвлекаться от основного продукта и помогает расставить приоритеты в творческих процессах. Если вам нужна помощь с маркировкой данных для распознавания звука, свяжитесь с нами по адресу Label Your Data, и мы без проблем проведем вас через все подводные камни.
Заключение: Распознавание звука как универсальный инструмент
Распознавание звука — универсальный и гибкий инструмент, полезный как для бизнеса, так и для частных пользователей Возможно, мы не считаем распознавание звука особенно интересной технологией. Тем не менее, его использование сегодня очень широко. В вашем телефоне и домашнем помощнике, в CRM-системах, в бизнес-чат-ботах и в научном оборудовании вы можете найти алгоритмы распознавания звука практически везде.
Тем не менее, его использование сегодня очень широко. В вашем телефоне и домашнем помощнике, в CRM-системах, в бизнес-чат-ботах и в научном оборудовании вы можете найти алгоритмы распознавания звука практически везде.
Это инструмент, который помогает людям лучше общаться с машинами. С появлением персональных виртуальных помощников стало возможным использовать мощь компьютера для облегчения повседневной жизни и облегчения ума, когда дело доходит до рутинных задач.
Технология распознавания звука также помогает нам оставаться на связи с другими людьми. Применение таких алгоритмов, как персональные переводчики и помощники по инвалидности, указывает на то, что ИИ для распознавания звуков может сделать нас на шаг ближе к лучшему пониманию друг друга.
Получить уведомление ⤵
Получать еженедельную электронную почту каждый раз, когда мы публикуем что-то новое:
Пожалуйста, прочтите наше уведомление о конфиденциальности
Подпишитесь на обновления
✔︎ Поздравляем! Вы в списке.
Получить мгновенную смету аннотаций данных
Какой тип данных вам нужно аннотировать?
Рассчитать стоимость ▶︎Анализ звука с помощью машинного обучения: создание приложения для обнаружения звука на основе ИИ
Время чтения: 15 минутМы живем в мире звуков: приятные и раздражающие, низкие и высокие, тихие и громкие, они влияют на наше настроение и наши решения. Наш мозг постоянно обрабатывает звуки, чтобы дать нам важную информацию об окружающей среде. Но акустические сигналы могут сказать нам еще больше, если анализировать их с помощью современных технологий.
Сегодня у нас есть искусственный интеллект и машинное обучение для извлечения информации, неслышимой для человека, из речи, голосов, храпа, музыки, промышленного и дорожного шума и других типов акустических сигналов. В этой статье мы поделимся тем, что узнали при создании решений для распознавания звука на основе ИИ для проектов в области здравоохранения.
В частности, мы объясним, как получить аудиоданные, подготовить их к анализу и выбрать правильную модель машинного обучения для достижения максимальной точности предсказания. Но сначала давайте рассмотрим основы: что такое анализ звука и что делает работу с аудиоданными такой сложной задачей.
Но сначала давайте рассмотрим основы: что такое анализ звука и что делает работу с аудиоданными такой сложной задачей.
Что такое аудиоанализ?
Аудиоанализ — это процесс преобразования, исследования и интерпретации аудиосигналов, записанных цифровыми устройствами. Стремясь понять звуковые данные, он применяет ряд технологий, включая современные алгоритмы глубокого обучения. Аудиоанализ уже получил широкое распространение в различных отраслях, от развлечений до здравоохранения и производства. Ниже мы приведем наиболее популярные варианты использования.
Распознавание речи
Распознавание речи касается способности компьютеров различать произносимые слова с помощью методов обработки естественного языка. Это позволяет нам управлять ПК, смартфонами и другими устройствами с помощью голосовых команд и диктовать тексты машинам вместо ручного ввода. Siri от Apple, Alexa от Amazon, Google Assistant и Cortana от Microsoft — популярные примеры того, насколько глубоко технология проникла в нашу повседневную жизнь.
Распознавание голоса
Распознавание голоса предназначен для идентификации людей по уникальным характеристикам их голоса, а не для выделения отдельных слов. Подход находит применение в системах безопасности для аутентификации пользователей. Например, биометрический движок Nuance Gatekeeper проверяет сотрудников и клиентов по их голосам в банковском секторе.
Распознавание музыки
Распознавание музыки — это популярная функция таких приложений, как Shazam, которая помогает идентифицировать неизвестные песни по короткому образцу. Еще одним применением музыкального аудиоанализа является классификация жанров: скажем, Spotify использует собственный алгоритм для группировки треков по категориям (их база данных содержит более 5000 жанров)9.0003
Распознавание звуков окружающей среды
Распознавание звуков окружающей среды фокусируется на идентификации окружающих нас шумов, обещая множество преимуществ для автомобильной и производственной промышленности. Это жизненно важно для понимания окружения в приложениях IoT.
Это жизненно важно для понимания окружения в приложениях IoT.
Такие системы, как Audio Analytic, «прислушиваются» к событиям внутри и снаружи автомобиля, позволяя автомобилю вносить коррективы для повышения безопасности водителя. Другим примером является технология SoundSee от Bosch, которая может анализировать шумы машин и упрощает профилактическое обслуживание для контроля состояния оборудования и предотвращения дорогостоящих отказов.
Здравоохранение — еще одна область, где может пригодиться распознавание звуков окружающей среды. Он предлагает неинвазивный тип удаленного мониторинга пациента для обнаружения таких событий, как падение. Кроме того, анализ кашля, чихания, храпа и других звуков может облегчить предварительный скрининг, определение статуса пациента, оценку уровня заражения в общественных местах и так далее.
Примером такого анализа в реальной жизни является Sleep.ai, который обнаруживает скрежетание зубами и звуки храпа во время сна. Решение, созданное AltexSoft для голландского стартапа в области здравоохранения, помогает стоматологам выявлять и контролировать бруксизм, чтобы в конечном итоге понять причины этой аномалии и лечить ее.
Независимо от того, какие звуки вы анализируете, все начинается с понимания аудиоданных и их специфических характеристик.
Что такое аудиоданные?
Аудиоданные представляют аналоговые звуки в цифровом виде, сохраняя основные свойства оригинала. Как мы знаем из школьных уроков физики, звук — это волна колебаний, проходящая через среду, такую как воздух или вода, и достигающая в конце концов наших ушей. Он имеет три ключевые характеристики, которые необходимо учитывать при анализе аудиоданных: период времени, амплитуда и частота.
Время Период — это то, как долго длится определенный звук или, другими словами, сколько секунд требуется для завершения одного цикла колебаний.
Амплитуда — это интенсивность звука, измеряемая в децибелах (дБ), которую мы воспринимаем как громкость.
Частота , измеряемая в герцах (Гц), показывает, сколько звуковых колебаний происходит в секунду. Люди интерпретируют частоту как низкий или высокий тон .
Люди интерпретируют частоту как низкий или высокий тон .
В то время как частота является объективным параметром, высота звука субъективна. Диапазон человеческого слуха лежит между 20 и 20 000 Гц. Ученые утверждают, что большинство людей воспринимают как низкий тон все звуки ниже 500 Гц — например, рев двигателя самолета. В свою очередь, высоким тоном для нас является все, что выше 2000 Гц (например, свист.)
Форматы файлов аудиоданных
Подобно текстам и изображениям, аудио представляет собой неструктурированные данные, что означает, что они не организованы в таблицы со связанными строками и столбцами. Вместо этого вы можете хранить аудио в различных форматах файлов, таких как
- WAV или WAVE (формат аудиофайла Waveform), разработанных Microsoft и IBM. Это формат файла без потерь или необработанный, что означает, что он не сжимает исходную звуковую запись;
- AIFF (формат файла обмена аудио), разработанный Apple. Как и WAV, он работает с несжатым звуком;
- FLAC (бесплатный аудиокодек без потерь), разработанный Xiph. Org Foundation, который предлагает бесплатные мультимедийные форматы и программные инструменты. Файлы FLAC сжимаются без потери качества звука.
- MP3 (аудиослой mpeg-1 3), разработанный Обществом Фраунгофера в Германии и поддерживаемый во всем мире. Это наиболее распространенный формат файлов, поскольку он позволяет легко хранить музыку на портативных устройствах и пересылать туда и обратно через Интернет. Хотя mp3 сжимает звук, он по-прежнему обеспечивает приемлемое качество звука.
 Org Foundation, который предлагает бесплатные мультимедийные форматы и программные инструменты. Файлы FLAC сжимаются без потери качества звука.
Org Foundation, который предлагает бесплатные мультимедийные форматы и программные инструменты. Файлы FLAC сжимаются без потери качества звука.Мы рекомендуем использовать файлы aiff и wav для анализа, так как они не пропускают информацию, присутствующую в аналоговых звуках. В то же время имейте в виду, что ни те, ни другие аудиофайлы нельзя напрямую скармливать моделям машинного обучения. Чтобы сделать звук понятным для компьютеров, данные должны быть преобразованы.
Основы преобразования аудиоданных, которые нужно знать
Прежде чем углубиться в обработку аудиофайлов, нам нужно ввести определенные термины, с которыми вы столкнетесь почти на каждом этапе нашего путешествия от сбора звуковых данных до получения прогнозов машинного обучения. Стоит отметить, что аудиоанализ предполагает работу с изображениями, а не прослушивание.
Стоит отметить, что аудиоанализ предполагает работу с изображениями, а не прослушивание.
Форма волны — это базовое визуальное представление аудиосигнала, отражающее изменение амплитуды во времени. График отображает время по горизонтальной оси (X) и амплитуду по вертикальной оси (Y), но не говорит нам, что происходит с частотами.
Пример сигнала. Источник: Обработка звуковых сигналов для машинного обучения
Спектр или спектральный график представляет собой график, на котором по оси X показана частота звуковой волны, а по оси Y — ее амплитуда. Этот тип визуализации звуковых данных помогает вам анализировать частотный контент, но пропускает временную составляющую.
Пример графика спектра. Источник: Analytics Vidhya
Спектрограмма представляет собой подробное представление сигнала, которое охватывает все три характеристики звука. Вы можете узнать о времени по оси x, частоте по оси y и амплитуде по цвету. Чем громче событие, тем ярче цвет, а тишина представлена черным цветом. Иметь три измерения на одном графике очень удобно: это позволяет отслеживать, как меняются частоты во времени, исследовать звук во всей его полноте, на глаз выявлять различные проблемные места (например, шумы) и паттерны.
Вы можете узнать о времени по оси x, частоте по оси y и амплитуде по цвету. Чем громче событие, тем ярче цвет, а тишина представлена черным цветом. Иметь три измерения на одном графике очень удобно: это позволяет отслеживать, как меняются частоты во времени, исследовать звук во всей его полноте, на глаз выявлять различные проблемные места (например, шумы) и паттерны.
Пример спектрограммы. Источник: iZotope
Спектрограмма мела , где мел означает мелодия, представляет собой разновидность спектрограммы, основанную на шкале мела, которая описывает, как люди воспринимают звуковые характеристики. Наше ухо различает низкие частоты лучше, чем высокие. Вы можете проверить это сами: Попробуйте сыграть тоны от 500 до 1000 Гц, а затем от 10 000 до 10 500 Гц. Первый частотный диапазон, казалось бы, намного шире второго, хотя на самом деле это одно и то же. Спектрограмма мела включает в себя эту уникальную особенность человеческого слуха, преобразуя значения в герцах в шкалу мела. Этот подход широко используется для классификации жанров, обнаружения инструментов в песнях и распознавания речевых эмоций.
Этот подход широко используется для классификации жанров, обнаружения инструментов в песнях и распознавания речевых эмоций.
Пример мел спектрограммы. Источник: Devopedia
Преобразование Фурье (FT) — это математическая функция, которая разбивает сигнал на пики различной амплитуды и частоты. Мы используем его для преобразования сигналов в соответствующие графики спектра, чтобы посмотреть на тот же сигнал под другим углом и выполнить частотный анализ. Это мощный инструмент для понимания сигналов и устранения ошибок в них.
Быстрое преобразование Фурье (БПФ) — это алгоритм вычисления преобразования Фурье.
Применение БПФ для просмотра того же сигнала с точки зрения времени и частоты. Источник: NTi Audio
Кратковременное преобразование Фурье (STFT) представляет собой последовательность преобразований Фурье, преобразующих сигнал в спектрограмму.
Программное обеспечение для анализа звука
Конечно, вам не нужно выполнять преобразования вручную. Вам также не нужно понимать сложную математику, лежащую в основе FT, STFT и других методов, используемых в аудиоанализе. Все эти и многие другие задачи выполняются автоматически программным обеспечением для анализа звука, которое в большинстве случаев поддерживает следующие операции:
- импорт аудиоданных
- добавить аннотации (метки),
- редактировать записи и разбивать их на части,
- удалить шум,
- преобразовывать сигналы в соответствующие визуальные представления (формы сигналов, графики спектра, спектрограммы, мел-спектрограммы),
- выполнять операции предварительной обработки,
- анализ временного и частотного содержания,
- извлечения аудиофункций и многое другое.
Самые передовые платформы также позволяют обучать модели машинного обучения и даже предоставляют предварительно обученные алгоритмы.
Вот список наиболее популярных инструментов, используемых для анализа звука.
Audacity — это бесплатный аудиоредактор с открытым исходным кодом, позволяющий разделять записи, удалять шумы, преобразовывать сигналы в спектрограммы и маркировать их. Audacity не требует навыков программирования. Тем не менее, его набор инструментов для анализа звука не очень сложен. Для дальнейших шагов вам необходимо загрузить свой набор данных в Python или переключиться на платформу, специально предназначенную для анализа и/или машинного обучения.
Разметка аудиоданных в Audacity. Источник: Towards Data Science
Пакет Tensorflow-io для подготовки и аугментации аудиоданных позволяет выполнять широкий спектр операций — удаление шумов, преобразование волновых форм в спектрограммы, частотную и временную маскировку, чтобы сделать звук отчетливо слышимым, и более. Инструмент принадлежит экосистеме TensorFlow с открытым исходным кодом, охватывающей сквозной рабочий процесс машинного обучения. Таким образом, после предварительной обработки вы можете обучать модель машинного обучения на той же платформе.
Таким образом, после предварительной обработки вы можете обучать модель машинного обучения на той же платформе.
Librosa — это библиотека Python с открытым исходным кодом, в которой есть почти все, что вам нужно для анализа звука и музыки. Он позволяет отображать характеристики аудиофайлов, создавать все типы визуализации аудиоданных и извлекать из них функции, и это лишь некоторые из возможностей.
Audio Toolbox от MathWorks предлагает множество инструментов для обработки и анализа аудиоданных, от маркировки до оценки показателей сигнала и извлечения определенных функций. Он также поставляется с предварительно обученными моделями машинного обучения и глубокого обучения, которые можно использовать для анализа речи и распознавания звука.
Этапы анализа аудиоданных
Теперь, когда у нас есть общее представление о звуковых данных, давайте взглянем на ключевые этапы сквозного проекта анализа аудио.
- Получите аудиоданные проекта , сохраненные в стандартных форматах файлов.
- Подготовьте данные для вашего проекта машинного обучения с помощью программных средств
- Извлечение звуковых характеристик из визуальных представлений звуковых данных.
- Выберите — модель машинного обучения, а — обучать аудиофункциям.

Этапы анализа звука с помощью машинного обучения
Сбор голосовых и звуковых данных
У вас есть три варианта получения данных для обучения моделей машинного обучения: использовать бесплатные звуковые библиотеки или наборы аудиоданных, приобрести их у поставщиков данных или собрать его с привлечением экспертов предметной области.
Бесплатные источники данных
В Интернете много таких источников. Но что мы в данном случае не контролируем, так это качество и количество данных, а также общий подход к записи.
Библиотеки звуков — это бесплатные аудиофайлы, сгруппированные по темам. Такие источники, как Freesound и BigSoundBank, предлагают голосовые записи, звуки окружающей среды, шумы и, честно говоря, всевозможные вещи. Например, вы можете найти саундскейп аплодисментов и набор со звуками скейтборда.
Такие источники, как Freesound и BigSoundBank, предлагают голосовые записи, звуки окружающей среды, шумы и, честно говоря, всевозможные вещи. Например, вы можете найти саундскейп аплодисментов и набор со звуками скейтборда.
Самое главное, что звуковые библиотеки не готовятся специально для проектов машинного обучения. Таким образом, нам необходимо выполнить дополнительную работу по комплектованию комплектов, маркировке и контролю качества.
Наборы аудиоданных , напротив, создаются с учетом конкретных задач машинного обучения. Например, набор данных Bird Audio Detection Лаборатории машинного прослушивания содержит более 7000 отрывков, собранных в ходе проектов биоакустического мониторинга. Другим примером является набор данных ESC-50: Классификация звуков окружающей среды, содержащий 2000 помеченных аудиозаписей. Каждый файл длится 5 секунд и принадлежит к одному из 50 семантических классов, организованных в пять категорий.
Одна из крупнейших коллекций аудиоданных — AudioSet от Google. Он включает более 2 миллионов 10-секундных звуковых клипов с человеческими метками, извлеченных из видео на YouTube. Набор данных охватывает 632 класса, от музыки и речи до звуков осколков и зубной щетки.
Он включает более 2 миллионов 10-секундных звуковых клипов с человеческими метками, извлеченных из видео на YouTube. Набор данных охватывает 632 класса, от музыки и речи до звуков осколков и зубной щетки.
Коммерческие наборы данных
Коммерческие аудио наборы для машинного обучения определенно более надежны с точки зрения целостности данных, чем бесплатные. Мы можем порекомендовать ProSoundEffects продавать наборы данных для обучения моделей для распознавания речи, классификации звуков окружающей среды, разделения источников звука и других приложений. Всего у компании 357 000 файлов, записанных экспертами по звуку фильмов и классифицированных по 500+ категориям.
Но что, если звуковые данные, которые вы ищете, слишком специфичны или редки? Что делать, если вам нужен полный контроль над записью и маркировкой? Что ж, тогда лучше делайте это в партнерстве с надежными специалистами из той же отрасли, что и ваш проект по машинному обучению.
Экспертные наборы данных
При работе с Sleep. ai нашей задачей было создать модель, способную идентифицировать скрежещущие звуки, которые люди с бруксизмом обычно издают во время сна. Понятно, что нужны были специальные данные, недоступные в открытых источниках. Кроме того, надежность и качество данных должны были быть самыми лучшими, чтобы мы могли получить достоверные результаты.
ai нашей задачей было создать модель, способную идентифицировать скрежещущие звуки, которые люди с бруксизмом обычно издают во время сна. Понятно, что нужны были специальные данные, недоступные в открытых источниках. Кроме того, надежность и качество данных должны были быть самыми лучшими, чтобы мы могли получить достоверные результаты.
Чтобы получить такой набор данных, стартап сотрудничал с лабораториями сна, где ученые наблюдают за людьми, пока они спят, чтобы определить здоровый режим сна и диагностировать нарушения сна. Специалисты используют различные устройства для записи мозговой активности, движений и других событий. Для нас они подготовили размеченный набор данных, содержащий около 12 000 образцов скрежещущих и храпящих звуков.
Подготовка аудиоданных
В случае Sleep.io наша команда пропустила этот шаг, доверив специалистам по сну задачу подготовки данных для нашего проекта. То же самое относится и к тем, кто покупает аннотированные звуковые коллекции у поставщиков данных. Но если у вас есть только необработанные данные, то есть записи, сохраненные в одном из форматов аудиофайлов, вам необходимо подготовить их для машинного обучения.
Но если у вас есть только необработанные данные, то есть записи, сохраненные в одном из форматов аудиофайлов, вам необходимо подготовить их для машинного обучения.
Маркировка аудиоданных
Маркировка или аннотация данных — это пометка необработанных данных с правильными ответами для запуска контролируемого машинного обучения. В процессе обучения ваша модель научится распознавать закономерности в новых данных и делать правильные прогнозы на основе меток. Таким образом, их качество и точность имеют решающее значение для успеха проектов машинного обучения.
Хотя маркировка предполагает помощь программных средств и некоторую степень автоматизации, по большей части она по-прежнему выполняется вручную профессиональными аннотаторами и/или экспертами в предметной области. В нашем проекте по обнаружению бруксизма эксперты по сну прослушали аудиозаписи и пометили их ярлыками скрежета или храпа.
Узнайте больше о подходах к аннотированию из нашей статьи Как организовать маркировку данных для машинного обучения
Предварительная обработка аудиоданных
Помимо обогащения данных значимыми тегами, мы должны предварительно обработать звуковые данные, чтобы повысить точность предсказания. Вот самые основные шаги для проектов по распознаванию речи и классификации звуков.
Вот самые основные шаги для проектов по распознаванию речи и классификации звуков.
Кадрирование означает разрезание непрерывного звукового потока на короткие фрагменты (кадры) одинаковой длины (обычно 20-40 мс) для дальнейшей посегментной обработки.
Работа с окнами — это фундаментальный метод обработки звука, позволяющий свести к минимуму спектральную утечку — распространенную ошибку, которая приводит к размытию частоты и ухудшению точности амплитуды. Существует несколько оконных функций (Хемминга, Хэннинга, Плоской вершины и т. д.), применяемых к разным типам сигналов, хотя вариант Хэннинга хорошо работает в 95% случаев.
По сути, все окна делают одно и то же: уменьшают или сглаживают амплитуду в начале и конце каждого кадра, увеличивая ее в центре, чтобы сохранить среднее значение.
Форма сигнала до и после работы с окнами. Источник: National Instruments .
Метод Overlap-Add (OLA) предотвращает потерю жизненно важной информации, которая может быть вызвана работой с окнами . OLA обеспечивает 30-50-процентное перекрытие между соседними кадрами, что позволяет изменять их без риска искажения. В этом случае исходный сигнал можно точно восстановить по окнам.
OLA обеспечивает 30-50-процентное перекрытие между соседними кадрами, что позволяет изменять их без риска искажения. В этом случае исходный сигнал можно точно восстановить по окнам.
Пример работы с окнами с перекрытием. Источник: Wiki Университета Аалто
Узнайте больше об этапе предварительной обработки и методах, которые он использует, из нашей статьи Подготовка ваших данных для машинного обучения и видео ниже.
https://youtu.be/P8ERBy91Y90
Аудиофункции или дескрипторы — это свойства сигналов, вычисляемые на основе визуализации предварительно обработанных аудиоданных. Они могут принадлежать к одному из трех доменов
- временных доменов, представленных осциллограммами,
- частотных областей, представленных графиками спектра, и
- временных и частотных областей, представленных спектрограммами.
Визуализация аудиоданных: форма сигнала для временной области, спектр для частотной области и спектрограмма для частотно-временной области. Источник: Типы аудиофункций для машинного обучения.
Источник: Типы аудиофункций для машинного обучения.
Характеристики во временной области
Как мы упоминали ранее, характеристики во временной области или временные характеристики извлекаются непосредственно из исходных сигналов. Обратите внимание, что волновые формы не содержат много информации о том, как на самом деле будет звучать произведение. Они показывают только то, как амплитуда изменяется со временем. На изображении ниже мы видим, что сигналы состояния воздуха и сигналов сирены выглядят одинаково, но, конечно же, эти звуки не будут похожими.
Примеры сигналов. Источник: Towards Data Science
Теперь давайте перейдем к некоторым ключевым функциям, которые мы можем извлечь из сигналов.
Огибающая амплитуды (AE) отслеживает пики амплитуды в кадре и показывает, как они изменяются во времени. С помощью AE вы можете автоматически измерять продолжительность отдельных частей звука (как показано на рисунке ниже). AE широко используется для обнаружения начала, чтобы указать, когда начинается определенный сигнал, а также для классификации музыкальных жанров.
AE широко используется для обнаружения начала, чтобы указать, когда начинается определенный сигнал, а также для классификации музыкальных жанров.
Амплитуда огибающей тико-тико пения птиц. Источник: Seewave: Принципы анализа звука
Кратковременная энергия (STE) показывает изменение энергии в коротком речевом кадре.
Это мощный инструмент для разделения вокализованных и невокализованных сегментов.
Среднеквадратическая энергия (RMSE) дает вам представление о средней энергии сигнала. Его можно вычислить по форме волны или спектрограмме. В первом случае вы получите результат быстрее. Тем не менее, спектрограмма обеспечивает более точное представление энергии во времени. RMSE особенно полезен для сегментации звука и классификации музыкальных жанров.
Скорость пересечения нуля (ZCR) подсчитывает, сколько раз сигнальная волна пересекает горизонтальную ось в кадре. Это одна из наиболее важных акустических характеристик, широко используемая для обнаружения присутствия или отсутствия речи и различения шума и тишины, а музыки и речи.
Характеристики частотной области
Признаки частотной области извлечь труднее, чем временные, поскольку процесс включает преобразование сигналов в графики спектра или спектрограммы с использованием FT или STFT. Тем не менее, именно частотное содержание раскрывает многие важные звуковые характеристики, невидимые или трудноразличимые во временной области.
Наиболее распространенные функции частотной области включают
- среднюю или среднюю частоту,
- медианная частота при разделении спектра на две области с одинаковой амплитудой,
- отношение сигнал-шум (SNR) при сравнении силы желаемого звука с фоновым носом, Отношение энергии полосы
- (BER), изображающее отношения между более высокими и более низкими частотными диапазонами. Другими словами. он измеряет, насколько низкие частоты преобладают над высокими.
Конечно, в этом домене есть множество других свойств, на которые стоит обратить внимание. Напомним, что он говорит нам, как звуковая энергия распространяется по частотам, а временная область показывает, как сигнал изменяется во времени.
Характеристики частотно-временной области
Эта область объединяет как временные, так и частотные компоненты и использует различные типы спектрограмм для визуального представления звука. Вы можете получить спектрограмму из сигнала, применяя кратковременное преобразование Фурье.
Одной из самых популярных групп характеристик частотно-временной области является мел-частотные кепстральные коэффициенты (MFCC) . Они работают в диапазоне человеческого слуха и поэтому основаны на шкале мела и спектрограммах мела, которые мы обсуждали ранее.
Неудивительно, что первоначальное применение MFCC — это распознавание речи и голоса. Но они также оказались эффективными для обработки музыки и акустической диагностики в медицинских целях, в том числе для обнаружения храпа. Например, одна из недавних моделей глубокого обучения, разработанная Инженерной школой (Университет Восточного Мичигана), была обучена на 1000 MFCC-изображениях (спектрограммах) звуков храпа.
Форма волны звука храпа (a) и ее спектрограмма MFCC (b) по сравнению с формой волны звука смыва унитаза (c) и соответствующим изображением MFCC (d). Источник: Модель глубокого обучения для обнаружения храпа ( Electronic Journal, Vol.8, Issue 9 )
временная и частотная области. В сочетании они создавали богатые профили скрежещущих и храпящих звуков.
Выбор и обучение моделей машинного обучения
Поскольку звуковые функции представлены в визуальной форме (в основном в виде спектрограмм), они становятся объектом распознавания изображений, основанного на глубоких нейронных сетях. Существует несколько популярных архитектур, показывающих хорошие результаты в обнаружении и классификации звука. Здесь мы сосредоточимся только на двух обычно используемых для выявления проблем со сном по звуку.
Сети с долговременной кратковременной памятью (LSTM)
Сети с долговременной кратковременной памятью (LSTM) известны своей способностью выявлять долгосрочные зависимости в данных и запоминать информацию из многочисленных предыдущих шагов. Согласно исследованию обнаружения апноэ во сне, LSTM могут достигать точности 87 процентов при использовании функций MFCC в качестве входных данных для отделения нормальных звуков храпа от ненормальных.
Согласно исследованию обнаружения апноэ во сне, LSTM могут достигать точности 87 процентов при использовании функций MFCC в качестве входных данных для отделения нормальных звуков храпа от ненормальных.
Другое исследование показывает еще лучшие результаты: LSTM классифицировал нормальный и ненормальный храп с точностью 95,3%. Нейронная сеть была обучена с использованием пяти типов функций, включая MFCC и кратковременную энергию из временной области. Вместе они представляют различные характеристики храпа.
Сверточные нейронные сети (CNN)
Сверточные нейронные сети лидируют в области компьютерного зрения в здравоохранении и других отраслях. Их часто называют , что является естественным выбором для задач распознавания изображений . Эффективность архитектуры CNN при обработке спектрограмм еще раз доказывает справедливость этого утверждения.
В вышеупомянутом проекте Инженерной школы (Университет Восточного Мичигана) модель глубокого обучения на основе CNN достигла точности 96 процентов в классификации храпящих и нехрапящих звуков.
Почти такие же результаты получены для комбинации архитектур CNN и LSTM. Группа ученых из Технологического университета Эйндховена применила модель CNN для извлечения признаков из спектрограмм, а затем запустила LSTM, чтобы классифицировать выходные данные CNN на события, связанные с храпом и без храпа. Значения точности варьируются от 94,4 до 95,9 процента в зависимости от расположения микрофона, используемого для записи звуков храпа.
Для проекта Sleep.io команда специалистов по данным AltexSoft использовала две CNN (для обнаружения храпа и скрипа) и обучила их на платформе TensorFlow. После того, как модели достигли точности более 80 процентов, они были запущены в производство. Их результаты постоянно улучшались по мере роста числа входных данных, полученных от реальных пользователей.
Создание приложения для обнаружения храпа и скрежетания зубами
Чтобы сделать наши алгоритмы классификации звуков доступными для широкой аудитории, мы упаковали их в приложение для iOS Do I Snore or Grind, которое вы можете бесплатно загрузить из App Store.
Ваш комментарий будет первым