Услуга сканирования и распознавания текста на заказ СПб
Часто возникает потребность внести изменения в документы, полученные со сканера, или в оригинал, сохраненный как графический файл с расширениями jpg, tif, png, pdf и другими, делающими редактирование невозможным. «Копицентр» в Санкт-Петербурге выполняет сканирование для последующей работы с файлами с помощью установленного специального программного обеспечения.
Профессионалы полиграфии производят распознавание сканированного текста с картинок, изображений, фотографий, а также при необходимости выполняют дальнейшую обработку. При этом оригиналы для расшифровки допускаются в электронном виде или напечатанные на бумажных носителях.
Распознавание русского текста со сканера
Для приведения в электронный вид книг, журналов, пособий и иных машинописных записей распознавание русского текста со сканера требует намного меньше времени, чем перенабор вручную. Отсканированные страницы предварительно сохраняют как графические файлы или передаются в обработку сразу.
Распознавание русского и английского текстов или копирование происходят намного быстрее, если расшить бумажный носитель и пропустить листы через автоподатчик сканера. Сшитые страницы сканируются вручную, что дороже и занимает больше времени.
Распознавание отсканированного текста и текста с фото изображений
Текстовый файл получают путем распознавания с отсканированного и сохраненного в любом расширении изображения.
Сегодня с помощью фотоаппарата и камеры в мобильнике легко сохранить нужную информацию, к примеру, на стендах. Но часто требуется только текст, а не фотоизображение. В наших копицентрах распознают отсканированный текст с фотографий, картинок, сделанных цифровыми фотоаппаратами и камерами мобильных телефонов.
При этом возможно удаление лишних элементов, а также последующее редактирование. Полученные текстовые файлы с желаемым расширением оператор копицентра записывает на выбранный носитель или отправляет на указанный электронный адрес заказчику.
Сервисы для распознавания текста — подборка лучших | Сканеры | Блог
Заказчик прислал сканы рабочих документов, в университете скинули фотку конспекта? Когда-то тексты умели распознавать только сканеры и то далеко не все. Сейчас же даже приложения на смартфоне могут перевести визуальный текст в редактируемый документ. А в этом материале ищем лучшие сервисы по распознаванию текста для вашего компьютера и смартфона тоже.
Finereaderonline.com
Попробовать тут
Компания ABBYY идет в плане распознавания текстов и обработки цифровых документов впереди всех. В арсенале их софта даже цифровые подписи, которые почти невозможно отличить от настоящих. Finereaderonline поддерживает почти 200 языков, работает быстро и онлайн — ничего не надо устанавливать. Можно выбрать разные форматы для сохранения текста, обработка текста происходит очень быстро и достаточно точно. Единственный нюанс — лимит на загрузку файлов до 100 Мб. Но никто не запрещает вам загрузить несколько документов подряд. Сервис работает полностью онлайн, русифицирован и интуитивно понятен в управлении.
Сервис работает полностью онлайн, русифицирован и интуитивно понятен в управлении.
Sodapdf.
 com
comПопробовать тут
Еще один неплохой сервис, хотя тут нам предлагают скачать прогу отдельно. Правда, чуть менее обученный, чем софт от ABYYY — Sodapdf знает только 46 языков. Впрочем, если вам не нужно переводить с ацтекского или зулу, то проблем не возникнет. Программа условно бесплатная — есть триальная версия, полный функционал стоит от 7 до 17 евро в месяц в зависимости от пакета. Soda умеет конвертировать разные форматы, распознавать тексты, ставить электронные подписи и имеет большой набор инструментов для работы с PDF файлами и изображениями.
WinScan2PDF
Попробовать тут
Элементарная, простая маленькая утилита, которая состоит из трех кнопок: «выбрать источник», «сканировать» и подтвердить или отменить операцию. Поддерживает 23 языка, работает с многостраничными файлами и сохраняет обработанный файл в формате PDF. У этой программы есть одна особенность — она не работает с готовыми файлами и считывает документы только с подключенного сканера.
Free Online OCR
Попробовать тут
Не такой симпатичный, как Finereader, но тоже вполне умелый онлайн-сервис. Англоязычный, слегка устаревший интерфейс, в котором, впрочем, несложно разобраться. Free Online OCR поддерживает 106 языков и распознает текст с большинства самых популярных форматов файлов: JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu. Сохранять готовые доки может не только в PDF, но и в стандарных doc и txt. Кроме текста, может распознать математические уравнения, правильно форматировать текст в колонках и столбцах или обработать только выделенный фрагмент. Качество распознавания довольно высокое даже c картинок низкого качества.
Microsoft OneNote
Попробовать тут
Распознавание текста здесь скорее дополнительная фича, а не основная задача. Вы можете вставить картинку в текущую запись OneNote и правой кнопкой мыши выбрать «Копировать текст из рисунка». Цифровая записная книжка от Microsoft однозначно не подойдет для обработки больших файлов, документов и постоянной работы с файлами. Но может помочь в мелких повседневных задачах — перевести небольшой текст с картинки, скриншота, рекламного макета, чтобы не вводить вручную. Качество распознавания у OneNote не очень высокое, а добавлять в файл многостраничные документы неудобно. Но OneNote и не для этого все-таки.
Но может помочь в мелких повседневных задачах — перевести небольшой текст с картинки, скриншота, рекламного макета, чтобы не вводить вручную. Качество распознавания у OneNote не очень высокое, а добавлять в файл многостраничные документы неудобно. Но OneNote и не для этого все-таки.
Readiris
Попробовать тут
Мощный и удобный конкурент ABBYY FineReader. Быстро и очень чисто распознает даже едва различимые тексты, при этом поддерживает 137 языков, включая русский. Работает очень быстро и легко обрабатывает даже большие объемы текста. Сохраняет исходное форматирование, не игнорируя кавычки, размеры шрифта и стиль написания. Может почистить текст от помарок и предложить исправления в словах. Знает символы, уравнения. Контактирует со сканерами, облачными сервисами, поддерживает кучу форматов. В общем, полноценный и удобный сервис, который не умеет разве что редактировать итоговый файл PDF. Правда, за полный инструментарий придется платить, но есть бесплатная триальная версия.
Img2txt.com
Попробовать тут
Приятный дизайн, понятный интерфейс и высокая скорость обработки текста — что еще нужно для работы? Продвинутые алгоритмы распознавания помогают считывать документы даже плохого качества. Молниеносно конвертирует большие объемы текста, но при желании можно выбрать отдельную область файла для работы. Есть интеграция с Google Documents, хороший инструментарий для работы с документами PDF. Маловато языков — всего 35, но для основных задач этого может вполне хватить.
OCR CuneiForm
Попробовать тут
Шустро и тщательно распознает сфотографированные или отсканированные тексты, графические файлы. Старается сохранить исходную структуру текста, элементов и шрифты. Переводит все в редактируемые форматы на выбор. В общем, стандартный набор функционала. И, что самое главное, полностью бесплатный.
TextGrabber 6
iOS, Android
Полностью бесплатное приложение для смартфонов за авторством компании ABBYY. Собственно, этим все сказано — в TextGrabber 6 все хорошо с распознаванием текста, есть встроенный модуль переводчика. Программа работает с помощью камеры и на распознавание, и на перевод. Поддерживает кучу языков, работает быстро и выглядит приятно.
Программа работает с помощью камеры и на распознавание, и на перевод. Поддерживает кучу языков, работает быстро и выглядит приятно.
FineReader – распознавание текста. Microsoft Office
FineReader – распознавание текста
Ввести со сканера текст в компьютер – задача не слишком трудная. Однако работать с таким текстом невозможно: как и любое сканированное изображение, страница с текстом представляет собой графический файл – обычную картинку. Отсюда возникают проблемы: во-первых, в графическом формате страница занимает слишком много места, и, скажем, отсканированная книга не на каждый жесткий диск поместится. И вторая, самая главная проблема: сканированный текст можно будет только читать, но не редактировать и не вставлять его фрагменты в создаваемый вами документ. Ведь сам сканер распознавать буквы именно как буквы не умеет: они для него – всего лишь пятна и точки черного цвета.
К счастью, на свете существуют программы, способные перевести сканированный текст из графического в текстовый формат – программы распознавания текста или OCR.
Современная OCR должна уметь многое: распознавать тексты, набранные не только определенными шрифтами (именно так работали распознавалки первого поколения), но и самыми экзотическими, вплоть до рукописных. Уметь корректно работать с текстами, содержащими слова на нескольких языках, корректно распознавать таблицы. И самое главное – корректно распознавать не только четко набранные тексты, но и такие, качество которых, мягко говоря, далеко от идеала. Например, текст с пожелтевшей газетной вырезки или третьей машинописной копии. Само собой, распознать текст – это еще полдела. Не менее важно обеспечить возможность сохранения результата в файле популярного текстового (или табличного) формата – скажем, формата Microsoft Word или Excel.
Как видим, для того чтобы получить электронную, готовую к редактированию копию любого печатного текста, программе OCR необходимо выполнить «цепочку» из множества отдельных операций:
Сканирование. За эту работу отвечает, собственно, не программа OCR, а встроенное в систему программное обеспечение вашего сканера. Именно с его помощью вы можете задать нужные вам параметры сканирования – например, разрешение (рекомендуется 300 dpi), цветовой режим (для простых текстов достаточно черно-белого или LineArt) – и выделить ту область документа, которую вам необходимо «скопировать» в компьютер.
Именно с его помощью вы можете задать нужные вам параметры сканирования – например, разрешение (рекомендуется 300 dpi), цветовой режим (для простых текстов достаточно черно-белого или LineArt) – и выделить ту область документа, которую вам необходимо «скопировать» в компьютер.
Сегментация. Полученную со сканера «картинку» подхватывает OCR-программа. Но до распознавания еще далеко – сначала надо отделить текстовые элементы от графики, да и текст в ряде случаев разбить на отдельные куски (например, при многоколоночной верстке).
Распознавани
Проверка орфографии и правка. Встроенная система проверки орфографии «проходится» по тексту, проверяя и корректируя последствия работы системы распознавания. Спорные слова и символы выделяются особым предупреждающим цветом. Потом наступает очередь пользователя, который также может внести свою лепту в этот ответственный процесс.
Сохранение. Для дальнейшей обработки документ должен быть передан «на поруки» соответствующей программе – как правило, одному из продуктов семейства Microsoft Office. Или сохранен в формате, соответствующем его содержанию: текст – в DOC или RTF, таблица – в XLS… Да и встроенную графику желательно в документе оставить…
Все эти операции в большинстве программ OCR могут выполняться как в автоматическом, с помощью программы-мастера, так и в ручном режиме, по отдельности. С двумя первыми и последней операциями с легкостью справится любая программа распознавания. А вот весь процесс целиком по зубам, увы, только нескольким продуктам, разработанным в нашей стране. Тут надо сделать небольшую поправку: на самом деле корректно работать с русским языком умеют практически все современные «распознавалки», вне зависимости от того, где они были разработаны. Более того, в состав Microsoft Office-2003 уже включена абсолютно бесплатная программа распознавания Microsoft Office Document Scanning! Однако для российских пользователей само понятие «программа распознавания текста» чаще всего неразрывно связано с программой FineReader.
Одним из козырей FineReader является поддержка неимоверного количества языков распознавания – 176, в числе которых вы найдете экзотические и древние языки, и даже популярные языки программирования (Basic, С/C++, COBOL, Fortran, Java, Pascal)! Так что FineReader сможет без запинки справиться с древнегреческим свитком или с бледными распечатками исходных текстов программ, сделанных вашими предками лет 30 назад. Как ни странно, большинство пользователей на деле интересуется совсем другим. Офисных работников интересует распознавание типовых форм документов, студентов – возможность быстро «передрать» для реферата многостраничный текст из учебника, сканируя и распознавая книжный разворот целиком, бухгалтеров – возможность автоматического распознавания таблиц и документов на бланках… Все это и многое другое FineReader умеет… или не все, а только частично, в зависимости от модификации продукта.

После завершения распознавания страницы FineReader предложит пользователю выбор: сканировать и распознавать дальше (для многостраничного документа) или сохранить полученный текст в одном из множества популярных форматов – от документов Microsoft Office до HTML или PDF. Можно, впрочем, сразу же перебросить документ в Word или Excel и уже там исправить все огрехи распознавания (без них обойтись просто невозможно). При этом FineReader полностью сохраняет все особенности форматирования документов и графическое оформление.
Данный текст является ознакомительным фрагментом.
Продолжение на ЛитРесурок 30 — Информатика 8 класс
Цель
- Получить представление об OCR – программах распознавания текста, познакомиться с возможностями данных программы
Системы распознавания текста
Для создания электронных библиотек и архивов путем перевода книг и документов в цифровой вариант и при необходимости редактирования полученного по факсу документа используются специальные системы распознавания символов (Optical Character Recognition, OCR).
С помощью сканера можно получить изображение страницы с текстом в графическом формате.
Но работать с этим текстом невозможно, потому что любое сканирование – это всего лишь изображение
Текст можно будет читать, распечатывать, но только не редактировать.
Для перевода графического документа в текстовый файл необходимо провести распознавание текста.
Программное обеспечение для распознавания текста
Преобразование графического изображения в текст занимаются программы, используюшие принцип оптического распознавания.
Современные программы с OCR умеют:
- распознавать тексты, набранные не только разными шрифтами, но и самыми экзотическими, в том числе и рукописных
- корректно работать с текстами, содержащими слова на нескольких языках
- распознавать таблицы
- распознавать нечетко набранные или написанные тексты
Само собой, распознать текст — это еще полдела. После этого нужно обеспечить сохранение результата в файле текстового формата, например Microsoft Word.
После этого нужно обеспечить сохранение результата в файле текстового формата, например Microsoft Word.
В процессе распознавания документов в плохом качестве (машинописный текст, факс) используется метод распознавания символов по наличию определенных структурных элементов — отрезков, колец, дуг.
Любой символ легко описывается с помощью набора значений, определяющих расположение его частей. Например, обе буквы «Н» и буква «И» состоят из трех отрезков. Два из них расположены параллельно друг другу, а третий их соединяет. А различие – лишь в величине углов отрезков.
Самые распространенные системы оптического распознавания текста — ABBYY FineReader и CuneiForm.
ABBYY Finereader является омнифонтовой системой распознавания текстов. Это значит, что она позволяет распознавать тексты, набранные практически любыми шрифтами.
Одним из козырей FineReader является поддержка огромного (для таких программ) количества языков распознавания — более 176 (экзотические, древние языки, популярные языки программирования)
Для запуска процесса распознавания достаточно положить лист бумаги в сканер и нажать кнопку Scan & Read на панели инструментов. Все остальные операции (сканирование, разбивка изображения на части, распознавание текста) выполнятся автоматически.
Все остальные операции (сканирование, разбивка изображения на части, распознавание текста) выполнятся автоматически.
Параметры сканирования
Качество распознавания зависит от качества сканированного изображения.
Его можно регулировать установками параметров сканирования (тип изображения, разрешения, яркости, и т. д.).
Сканирование в режиме «серого» является оптимальным режимом для системы распознавания, так как в нем происходит автоматический подбор яркости.
Самым практичным разрешением для сканирования текстов — 300 dpi, для текстов, набранных мелкимшрифтом — 400-600 dpi.
Рис. Окно программы Cuneiform
Завершение распознавания
Распознав страницы, FineReader предложит сканировать и распознавать дальше (если сканируется книга)или сохранить текст в форматы — от документов Microsoft Office до HTML и PDF.
При распознавании FineReader сохраняет все параметры форматирования документа с его графическим оформлением.
Вопросы
1.Зачем нужны программы распознавания текста?
2. Что такое OCR?
3. Как происходит распознавание текста?
4. Какие программы распознания текста вы знаете?
Программы для распознавания текста
Зачем нужны программы распознавания текста.Программы распознавания текста позволяют работать с отсканированными изображениями. С их помощью выполняется редактирование информации, исправление ошибок, сохранение данных в нужном формате и т.д.
Как работает сканер.
Чтобы лучше понять ценность упомянутых программ разберемся с тем, как работает сканер. Механизм устройства помещен в корпус, верхняя часть которого представлена стеклом. Внутри находится яркая лампа и зеркала. Именно они отвечают за «фотографирование» источника для сканирования. При этом шрифт и изображения считываются в виде цветных, серых или черно-белых точек (в зависимости от модели устройства). А за распознавание текста и картинок отвечает драйвер сканера.
А за распознавание текста и картинок отвечает драйвер сканера.
Полученное изображение является своеобразной фотографией исходного источника, будь то разворот книги, лист формата A4 или справка. Программы для распознавания текста позволяют расширить возможности пользователя, редактировать текст, исправлять ошибки.
Для наглядности рассмотрим пример. Допустим, вам нужно вставить большой кусок текста из книги в дипломную работу. Чтобы не тратить время на перепечатывание с листа, страницы можно отсканировать. Однако этого недостаточно, поскольку вы получите файлы-картинки, которые не подойдут для использования в Microsoft Word. С помощью программ для распознавания текста пользователь отредактирует полученное изображение и сможет вставить информацию в текстовый редактор.
Возможности современных программ для распознавания текста.
Если предстоит сканирование листов с четко прописанными буквами, читабельным, ярким шрифтом, то с такой задачей справится любой сканер. Куда хуже обстоит дело, если речь идет о таких носителях информации, как старые, потрепанные листы бумаги или пожелтевшие газеты. Не каждый драйвер сможет идентифицировать подобный текст, а потому возможности специальной программы придутся как нельзя кстати. С их помощью утраченные области шрифта легко восстановить, дописав на клавиатуре в рамках редактора.
Куда хуже обстоит дело, если речь идет о таких носителях информации, как старые, потрепанные листы бумаги или пожелтевшие газеты. Не каждый драйвер сможет идентифицировать подобный текст, а потому возможности специальной программы придутся как нельзя кстати. С их помощью утраченные области шрифта легко восстановить, дописав на клавиатуре в рамках редактора.
Отдельные программы предоставляют даже такие эксклюзивные возможности, как правка рукописного текста. Правда, для этого нужно, чтобы разрешение картинки было не меньше 300 точек на дюйм. Кроме того, буквы в строке должны быть примерно одной высоты, одного наклона и написаны как можно аккуратнее.
Функцию распознавания рукописного текста поддерживают такие программы, как ABBYY FineReader, CuneiForm (бесплатная утилита), MyScript Stylus, SimpleOCR и другие. Помимо русских символов они идентифицируют буквы, написанные на иностранном языке. Кроме того, программы распознают таблицы и рисунки, перенося их в компьютер для последующего редактирования.
Таким образом, ни один современный пользователь ПК, имеющий сканер, не обойдется без программы распознавания текста. Выбор платных и бесплатных утилит позволит выбрать то, что отвечает именно вашим запросам с точки зрения функциональности.
10 лучших программ OCR 2021 года (бесплатные и платные инструменты)
Опубликовано: 2021-08-07
Программное обеспечение OCR преобразует изображения текста в сканируемые, машиночитаемые онлайн-документы.
Исторически использовавшийся для передачи бумажных документов — паспортов, визитных карточек, банковских выписок и т. Д. — это наиболее распространенный метод оцифровки текста, чтобы его можно было редактировать на компьютере.
Лучшее программное обеспечение для оптического распознавания текста позволяет сканировать и архивировать любой документ на основе изображений в редактируемый PDF-файл.
Сегодня эти инструменты делают управление документами и облачное хранилище быстрым и легким для частных лиц и предприятий.
В этом руководстве я оценил и рассмотрел лучшее программное обеспечение для оптического распознавания текста на основе скорости, простоты использования, возможностей хранения, точности, цен, поддержки и многого другого.
Перейдем к списку.
Отказ от ответственности для партнеров: эта статья содержит партнерские ссылки, за которые я получаю небольшую комиссию бесплатно для вас. Тем не менее, это инструменты, которые я полностью рекомендую, когда дело доходит до программного обеспечения для распознавания текста. Вы можете прочитать мое полное раскрытие информации о партнерстве в моей политике конфиденциальности.
Какое программное обеспечение для оптического распознавания текста самое лучшее?
Вот мой выбор лучшего программного обеспечения для распознавания текста в этом году.
1. Adobe Acrobat Pro DC.
Лучшее универсальное программное обеспечение для оптического распознавания текста для полных решений PDF (14,99 долларов США в месяц).
Adobe Acrobat Pro DC — это программа оптического распознавания текста, которая помогает извлекать текст и преобразовывать отсканированные документы в редактируемые файлы PDF.
Он предоставляет полное решение PDF для любого устройства. Это означает, что вы можете создавать и редактировать интеллектуальные PDF-файлы и конвертировать PDF-файлы в форматы Microsoft Office и JPG. Вы также можете делиться PDF-файлами, подписывать PDF-файлы, а также распечатывать или сжимать прямо из Pro DC.
Adobe также распознает ваш текст и соответствует вашему шрифту — и, наконец, преобразует PDF в этот конкретный шрифт.
Кроме того, инструмент OCR предлагает несколько функций редактирования, включая распознавание текста, добавление комментариев, изменение порядка страниц, объединение файлов и т. Д. Вы также можете выполнять такие функции, как поворот, удаление или обрезка страниц.
Вы даже можете установить мобильное приложение Acrobat Reader, чтобы удалять, переупорядочивать, вставлять или оценивать страницы PDF прямо со своего смартфона. Кроме того, есть приложение Adobe Scan, которое поможет вам сканировать документы, квитанции, доски и многое другое в PDF.
Кроме того, есть приложение Adobe Scan, которое поможет вам сканировать документы, квитанции, доски и многое другое в PDF.
Кроме того, вы можете настраивать файлы, повторно используя несколько страниц PDF из разных файлов. Он также позволяет добавлять поля форм и ссылки в файлы PDF.
Кроме того, Pro DC помогает обмениваться файлами в защищенном формате для комментариев и сравнения. Он также позволяет удалять пароли из защищенных PDF-файлов и собирать отзывы нескольких людей в одном файле.
Ключевая особенность:
- Разделение PDF-файлов — его разделитель PDF-файлов помогает разделить несколько PDF-файлов на разные документы, указав размер файла, количество страниц или закладки верхнего уровня.
- Подпись — запросите подпись на документах у других и добавьте свою подпись. Вы также можете мгновенно преобразовать физические формы в заполняемые формы PDF посредством сканирования.
- Стандарты ISO — конвертируйте PDF-файлы в соответствующие файлы с помощью мастера или профиля.
 Вы также можете проверять PDF-файлы на соответствие критериям PDF / X, PDF / VT, PDF / A или PDF / E.
Вы также можете проверять PDF-файлы на соответствие критериям PDF / X, PDF / VT, PDF / A или PDF / E.
 Вы также можете проверять PDF-файлы на соответствие критериям PDF / X, PDF / VT, PDF / A или PDF / E.
Вы также можете проверять PDF-файлы на соответствие критериям PDF / X, PDF / VT, PDF / A или PDF / E.Плюсы:
- Часть Adobe, которая хорошо интегрируется с их ПО для редактирования фотографий, инструментами управления фотографиями и ПО для графического дизайна.
- Используйте Action Wizard для настройки и создания PDF-файлов, экономя при этом количество нажатий клавиш и время.
- Проверьте доступность PDF-файла с помощью средства проверки читаемости.
- Автоматически сканировать тексты с бумаги и преобразовывать их в редактируемые документы.
- Сжимайте файлы PDF с помощью оптимизированного онлайн-инструмента PDF без потери качества, чтобы упростить хранение и управление.
- Конвертируйте PDF в несколько форматов, включая PNG, TIFF или JPEG.
- 7-дневная бесплатная пробная версия.
Цена:
Стоимость Adobe Acrobat Pro DC составляет 14,99 долларов в месяц. Вы также можете использовать Acrobat Standard DC за 12,99 долларов в месяц для создания, редактирования и подписания PDF-файлов.
Начните с бесплатной пробной версии Adobe Acrobat Pro DC.
Попробуйте Adobe Acrobat Pro DC
2. OmniPage Ultimate от Kofax.
Лучше всего подходит для пакетной обработки в реальном времени (499 долларов США).
Omnipage Ultimate — это приложение для оптического распознавания символов (OCR), которое может помочь вам превратить бумагу, PDF-файлы и изображения в цифровые файлы. По сути, он преобразует формы и файлы PDF в редактируемые документы, которые вы можете редактировать, архивировать и публиковать. Однако программное обеспечение поддерживает только систему Windows, поэтому вы не можете использовать его на своем Mac.
Кроме того, программа OCR позволяет автоматически отправлять преобразованные файлы PDF в заранее запрограммированные рабочие процессы. А его eDiscovery Assistant помогает конвертировать как отдельные, так и групповые PDF-файлы в файлы с возможностью поиска.
Кроме того, Omnipage обеспечивает точность распознавания текста, эквивалентную цифровой камере, и воспроизводит документы в нескольких форматах. Это также помогает вам запланировать большое количество файлов для пакетной обработки прямо из писем или папок. Все это происходит с помощью недокументированной автоматизации, обеспечивающей обработку документов в реальном времени.
Это также помогает вам запланировать большое количество файлов для пакетной обработки прямо из писем или папок. Все это происходит с помощью недокументированной автоматизации, обеспечивающей обработку документов в реальном времени.
Интеграция со всеми типами сканеров, включая мобильные сканеры, также пригодится для обработки документов.
Ключевая особенность:
- Mobile Document Capture — помогает захватывать текст с камеры смартфона для преобразования изображений в текст.
- Распознавание языков — он поддерживает более 120 языков, чтобы помочь вам редактировать, обрабатывать и хранить документы практически из любой точки мира.
- Сервер OmniPage — используйте сервер OmniPage для более быстрой обработки документов для анализа данных и архивирования. Вы можете использовать его для регулярной обработки огромного количества документов.
Плюсы:
- Он предлагает поддержку широкого спектра форматов, включая Microsoft Office, PDF, Word, Excel, PowerPoint, Corel WordPerfect, HTML, ePub и т. Д.
- Сканируйте документы в любой формат и отправляйте в любую точку сети.
- Используйте Amazon Kindle Recognition для отправки преобразованных документов непосредственно в устройство для чтения электронных книг.
- Выполняйте повторяющиеся задания более точно, создавая свои собственные рабочие процессы.
- Инструмент поддерживает форматирование исходных документов.
- Интегрируйте функции распознавания текста в приложения для виртуальной поддержки операционных систем для компьютеров и смартфонов.
 Д.
Д.Цена:
Единовременная стоимость OmniPage Ultimate составляет 499 долларов США. Первоначально вы также получаете 15-дневную бесплатную пробную версию, чтобы познакомиться с программным обеспечением OCR.
Начните с 15-дневной бесплатной пробной версии OmniPage Ultimate.
Попробуйте OmniPage Ultimate
3. ABBYY FineReader PDF 15.
Лучше всего подходит для исправления предложений и выравнивания документов (199 долларов США).
ABBYY FineReader PDF 15 — это решение для работы с PDF, которое включает технологию распознавания текста на основе искусственного интеллекта для создания и улучшения всех типов PDF-документов. Он также помогает оцифровывать, извлекать, защищать, сотрудничать и совместно использовать несколько типов документов в одном рабочем процессе.
Кроме того, он позволяет исправлять абзацы и предложения и даже исправлять макет документов.
ABBYY помогает добавлять примечания к любой части файла PDF с помощью текстового поля, заметок и широкого набора рисунков и инструментов разметки. Вы также можете комментировать пометки или отвечать на комментарии. Сделайте более прозрачным назначение комментариев разным соавторам.
Он также позволяет искать комментарии по сортировке, фильтру и ключевым словам. Есть даже возможность собрать более одной цифровой подписи на документе.
Другие важные функции включают сравнение документов в разных форматах, автоматизацию процедур оцифровки и преобразования, создание заполняемых форм PDF и т. Д.
Д.
Кроме того, недавно он получил новые обновления, которые включают:
- Он может преобразовывать готические шрифты в редактируемые документы или PDF-файлы с возможностью поиска.
- Помощник по выравниванию помогает автоматически выравнивать текст или изображения.
- Инструмент создает файлы меньшего размера без потери визуального качества при преобразовании PDF-файлов.
Ключевая особенность:
- Формы PDF — заполните интерактивные поля в отсканированных документах и формах PDF, чтобы включить текст в требуемых местах. Он также поддерживает цифровые подписи и факсимильные сообщения для электронной подписи.
- Разделение документов PDF — разделяйте большие файлы PDF на несколько коротких файлов в соответствии с требованиями к размеру. Он также позволяет сохранять главы документов в виде отдельных файлов PDF.
- Удаление скрытой информации — исключите риск случайного обмена конфиденциальными данными в файле PDF, удалив скрытые данные и объекты. Он помогает удалять текстовые слои, добавленные с помощью OCR, вложений, комментариев и аннотаций, закладок, ссылок, метаданных, мультимедиа, сценариев, действий и данных форм.
 Он помогает удалять текстовые слои, добавленные с помощью OCR, вложений, комментариев и аннотаций, закладок, ссылок, метаданных, мультимедиа, сценариев, действий и данных форм.
Он помогает удалять текстовые слои, добавленные с помощью OCR, вложений, комментариев и аннотаций, закладок, ссылок, метаданных, мультимедиа, сценариев, действий и данных форм.Плюсы:
- Создавайте различные уровни защиты паролем для файлов PDF.
- Проверьте цифровую подпись, чтобы убедиться в ее целостности и подлинности.
- Конвертируйте файлы PDF в несколько редактируемых форматов, включая Microsoft Excel, Word и другие.
- Разделите документы PDF по количеству страниц, размеру файла или закладкам.
- Используйте сжатие MRC, чтобы уменьшить размер файла PDF до 20 раз.
Цена:
ABBYY FineReader PDF 15 предлагает три платных плана:
- Стандарт: единовременный платеж в размере 199 долларов США
- Корпоративный: единовременный платеж в размере 299 долларов США
- Корпоративное лицензирование: на основе расценок (для крупных организаций)
Начните работу с 7-дневной бесплатной пробной версией ABBYY FineReader.
Попробуйте ABBYY FineReader PDF
4. Readiris.
Лучше всего подходит для преобразования текстовых файлов в аудиофайлы (49 долларов США).
Readiris — это программное обеспечение для публикации PDF и OCR, которое помогает редактировать и комментировать, объединять, разделять, защищать и подписывать ваши файлы PDF. Он также позволяет редактировать, конвертировать и преобразовывать бумажные файлы в несколько цифровых форматов всего несколькими щелчками мыши.
Кроме того, он предлагает множество инструментов для прикрепления комментариев, аннотаций и гипертекстовых строк для прямого доступа к прикрепленным документам.
Вы также можете конвертировать изображения, PDF-файлы и тексты для редактирования в необходимом формате, включая Word, PowerPoint, Excel или индексированный PDF-файл. Он также оснащен новым механизмом распознавания, который обеспечивает более быстрое управление документами.
Кроме того, Readiris помогает подписывать и защищать ваши PDF-файлы и отправлять их в электронном виде. Дополнительные функции включают пакетное преобразование документов, считывание и кодирование штрих-кода, разделение и объединение ваших PDF-файлов и многое другое.
Дополнительные функции включают пакетное преобразование документов, считывание и кодирование штрих-кода, разделение и объединение ваших PDF-файлов и многое другое.
Ключевая особенность:
- Аудиофайлы — Readiris преобразует текстовые файлы в аудиофайлы .mp3 и .wav. Вы также можете слушать аудиофайлы на любом устройстве, включая смартфоны, планшеты или настольные компьютеры.
- Словесная аннотация — предлагает вербальное распознавание, чтобы помочь вам встроить устную аннотацию в файлы PDF.
- Мультиформатный импорт — вы можете импортировать файлы в нескольких форматах, включая PDF, DOC, JPEG, RTF, PNG, JPEG, PPT и другие.
Плюсы:
- Инструмент совместим со всеми сканерами Twain.
- Поворачивайте и корректируйте перевернутые и наклоненные документы.
- Преобразуйте книги и документы в формат EPUB на устройстве для чтения электронных книг.
- Измените текст, встроенный в изображения.
- Readiris поддерживает более 130 языков.
- 30-дневная гарантия возврата денег.
- Бесплатная онлайн-техническая поддержка.
- Используйте технологию IRIS iHQC для сжатия файлов PDF до 50 процентов.

Цена:
Readiris предлагает три дополнительных продукта:
- Readiris PDF 17: 49 долларов США
- Readiris Pro 17: 59 долларов США
- Readiris Corporate 17: 89 долларов США
5. SimpleOCR.
Лучше всего подходит для людей, которым нужен бесплатный инструмент распознавания текста (Freeware).
SimpleOCR — это бесплатная программа OCR, которая предлагает разработчикам бесплатный OCR SDK для использования в пользовательских приложениях. Он работает со всеми версиями Windows и требует только драйвера TWAIN для максимальной совместимости со сканерами.
Он предлагает обширный словарь, содержащий более 120 000 слов, для эффективного распознавания слов в ваших документах. Кроме того, вы также можете добавлять новые слова через текстовый редактор.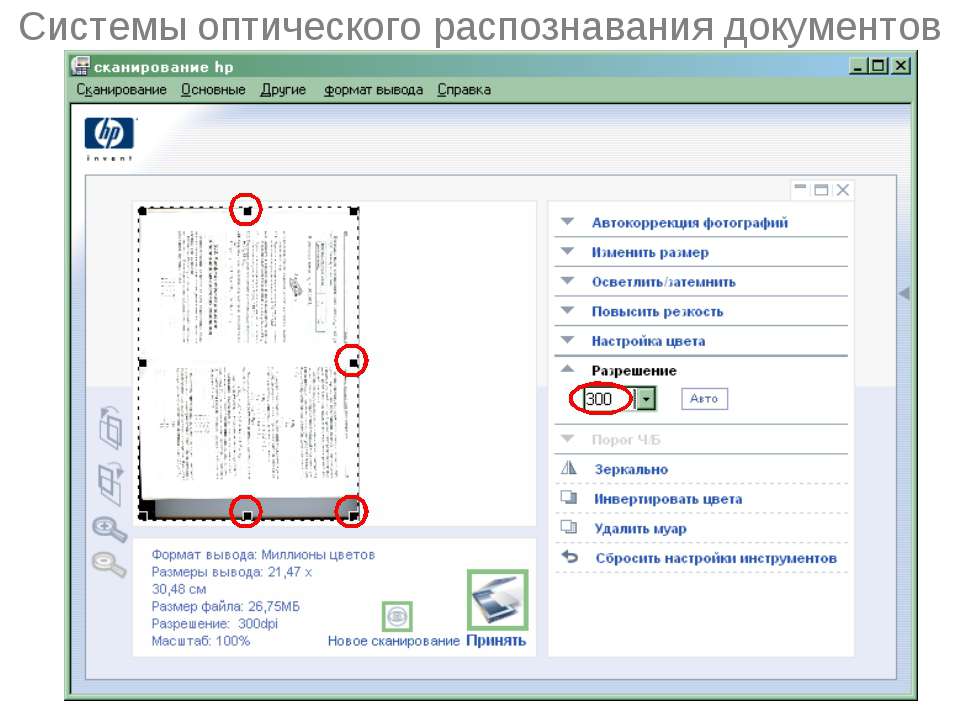
Кроме того, вы можете использовать функцию удаления пятен или «зашумленный документ» SimpleOCR, чтобы повысить точность нечетких копий и факсов. Он также распознает несколько элементов форматирования, включая курсив, подчеркивание и полужирный шрифт, чтобы сохранить исходный формат документов.
Кроме того, имеется встроенная программа проверки орфографии, которая помогает исправлять ошибки в преобразованном тексте.
Ключевая особенность:
- Сохранение изображения — вы можете использовать его для захвата и сохранения изображений из документов, чтобы избавиться от необходимости импортировать изображения отдельно.
- Пакетное распознавание текста — обработка нескольких документов или пакетов файлов с помощью одной команды.
- Исправление ошибок — он автоматически выделяет потенциальные ошибки, чтобы упростить вычитку текста.
Плюсы:
- Используйте Zone OCR для добавления текста из определенной части документа.
- Вы можете сохранить преобразованные файлы в формате DOC или TXT.
- Он поддерживает извлечение обычного текста.
- Совместимость со сканерами TWAIN.
- Инструмент поддерживает распознавание на французском и английском языках.
- Это бесплатно для личного использования.
Цена:
Программное обеспечение можно использовать бесплатно. Однако платные версии начинаются с 25 долларов и достигают 2500 долларов.
6. Тессеракт.
Лучше всего подходит для обнаружения спама в изображениях Gmail (бесплатно).
Tesseract — это бесплатное программное обеспечение для распознавания текста, выпущенное под лицензией Apache. Этот открытый исходный код также поддерживает форматирование выходного текста, анализ макета страницы и позиционную информацию hOCR. Кроме того, он использует библиотеку Leptonica для поддержки нескольких форматов изображений.
Инструмент лучше всего подходит для обнаружения текста на мобильных устройствах, видео и обнаружения спама в изображениях Gmail. Он также способен обнаруживать пропорциональные и моноширинные тексты.
Он также способен обнаруживать пропорциональные и моноширинные тексты.
Более того, он может распознавать более 100 языков. Помимо английского, он поддерживает другие западные языки, такие как французский, немецкий, итальянский, испанский, голландский и бразильский португальский. Кроме того, вы можете обучить Tesseract распознавать больше языков. Кроме того, программа OCR может обрабатывать языки с написанием справа налево, например иврит, арабский и другие.
Ключевая особенность:
- Поиск линий — он предоставляет механизм поиска линий для распознавания перекошенных страниц без деактивации, чтобы предотвратить потерю качества изображения.
- Подгонка базовой линии — используется квадратичный сплайн для более точной подгонки базовых линий в документы. Tesseract также может обрабатывать изогнутые базовые линии.
- Распознавание слов — распознает слова для выявления и уменьшения неточностей в отсканированных документах.

Плюсы:
- Он организует капли текста в выровненные текстовые строки.
- Он поддерживает Windows, Linux и Mac OS X.
- Tesseract может распознавать и исправлять маленькие заглавные буквы и нечеткие пробелы.
- Вы можете обучить программное обеспечение обнаружению других скриптов и языков.
- Он использует лингвистический анализ для определения наиболее вероятных слов из символов.
- Программа распознавания текста распознает как пропорциональные, так и непропорциональные слова.
Цена:
Tesseract — это полностью бесплатный инструмент с открытым исходным кодом.
7. Microsoft OneNote.
Лучше всего подходит для создания и систематизации заметок (69,99 долларов в год).
Microsoft OneNote — это инструмент OCR, который помогает делать заметки, собирать информацию, цифровые формы, вырезки экрана, заметки и т. Д. Кроме того, он позволяет копировать текст с изображения или распечатки файла и вставлять его в заметки для редактирования текста.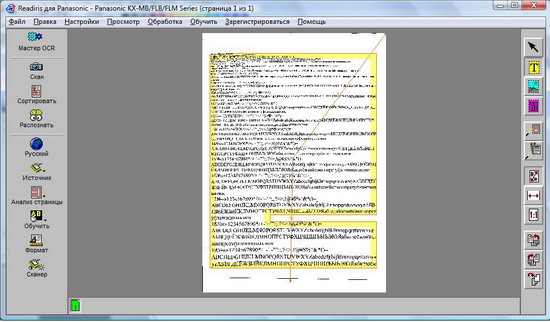
Теперь вы даже можете разделять и систематизировать свои заметки по разным разделам и страницам — и перемещаться по ним с помощью панели поиска. Кроме того, все ваши заметки сохраняются сами по себе, и вы можете найти свои заметки там, где вы их оставили. Вы также получите возможность редактировать свои заметки с помощью выделения, ввода текста или рукописных аннотаций.
Не только это, но вы также можете создавать заметки вместе со своими коллегами в OneNote. Эта функция также помогает вам делиться своими идеями с коллегами и сотрудниками.
Кроме того, опция тегов To-Do помогает вам помечать свои заметки, чтобы не пропустить ни одну из ваших важных заметок.
Инструмент также позволяет записывать аудиозаметки, вставлять онлайн-видео и добавлять файлы. В образовательных целях вы можете использовать OneNote для организации уроков в цифровых записных книжках с возможностью поиска и создания библиотеки содержимого для совместного использования.
Кроме того, вы можете использовать OneNote на своем мобильном телефоне где угодно и когда угодно. Мобильное приложение доступно на всех платформах, таких как iOS, Android и Windows.
Мобильное приложение доступно на всех платформах, таких как iOS, Android и Windows.
Ключевая особенность:
- Вырезать и сохранить — OneNote предоставляет веб-клиппер, который поможет вам сохранить контент одним щелчком мыши.
- Редактор — встроенное программное обеспечение редактора поможет вам выявить и исправить грамматические проблемы в вашем тексте.
- Обнаружение и восстановление программ-вымогателей OneDrive — эта функция помогает защитить все ваши файлы от цифровых и вирусных атак.
- Личное хранилище OneDrive — теперь вы можете сохранять важные файлы с дополнительным уровнем безопасности, таким как двухэтапная проверка.
Плюсы:
- Вы можете рисовать на своих заметках стилусом или пальцами.
- Добавляйте в свои заметки файлы, онлайн-видео, аудиозаметки.
- Он обеспечивает доступ до 6 участников.
- До 1 ТБ хранилища на человека.
- Вы также получаете доступ к другим приложениям Microsoft Office Mobile, таким как Word, Excel и PowerPoint.

Цена:
Microsoft OneNote поставляется с тремя тарифными планами:
- Office для дома и учебы: 149,99 долларов США (единовременная покупка)
- Microsoft 365 Personal: 69,99 долларов США в год
- Семейство Microsoft 365: 99,99 долларов США в год
Вы также получаете месячную пробную версию с семейным планом Microsoft 365.
8. Amazon Textract.
Лучше всего подходит для сканирования юридических документов (бесплатно до 1000 страниц).
Amazon Textract — это программа для машинного обучения, которая автоматически извлекает данные и текст из отсканированных документов. Кроме того, он использует технологию OCR для извлечения данных из форм и таблиц и автоматического определения напечатанного текста и чисел.
Инструмент больше всего подходит для сканирования резюме, юридического документа, книжной страницы и т. Д.
Д.
Извлечение данных не требует ручных усилий или ручного ввода. Не только это, но все они также утверждают, что обрабатывают миллионы страниц документов за часы.
Программное обеспечение также автоматически определяет макет документа и основные элементы. Он также позволяет извлекать данные из различных документов и представлять их в табличной форме. Это помогает быстро анализировать документы, которые в основном состоят из структурированных данных, таких как медицинские отчеты, финансовые отчеты, отчеты об инвентаризации и т. Д.
Кроме того, программное обеспечение OCR интегрируется с Amazon Augmented AI (Amazon A2I) для просмотра текста, извлеченного из отсканированных документов.
Ключевая особенность:
- Извлечение форм — Amazon Textract автоматически определяет ключевые значения в документах.
- Предопределенная схема — она имеет предопределенную схему для извлечения всех данных в виде строк и столбцов.
- Автоматическая обработка документов — вы можете создавать автоматизированные рабочие процессы для обработки документов без вмешательства человека. Amazon Textract может хранить данные, необходимые для автоматической обработки всех данных и текста.

Плюсы:
- Это веб-инструмент, хотя вы можете загрузить его через командную строку.
- Инструмент позволяет бесплатно конвертировать до 1000 страниц.
- Совместимость с Интернетом, Windows, macOS и Linux.
Цена:
Тарифы зависят от формы извлекаемых данных:
- API обнаружения текста документа (OCR): 0,0015 USD за страницу
- Анализировать Document API для страниц с таблицами: 0,015 USD / страница
- Анализировать Document API для страниц с формами: 0,05 доллара США за страницу
- Анализировать Document API для страниц с таблицами и формами: 0,015 USD + 0,05 USD за страницу
Новые пользователи могут анализировать до 1000 страниц в месяц с помощью API обнаружения текста документа и до 100 страниц в месяц с помощью API анализа документов в течение первых трех месяцев.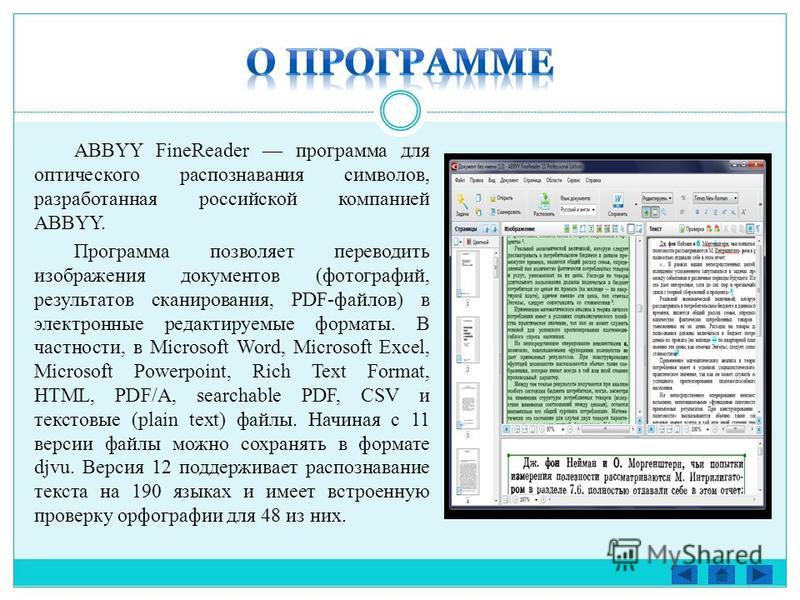
9. Документы Google.
Лучше всего подходит для частных лиц и небольших предприятий (бесплатно).
Google Docs — это веб-программа для обработки текста, которая предоставляет функции редактирования и стилизации, которые помогут вам форматировать текст и абзацы.
Он также имеет функцию распознавания текста, которая позволяет бесплатно конвертировать файлы PDF в редактируемый текст.
Вам просто нужно выполнить несколько простых шагов, в том числе:
- Загрузите файл PDF на Google Диск.
- Затем щелкните файл правой кнопкой мыши и выберите Открыть с помощью> Документы Google.
- Файл будет преобразован в редактируемый файл Google Doc. Однако списки, таблицы, столбцы, сноски и концевые сноски могут не обнаруживаться.
Помимо этого, документы Google могут обнаруживать сотни шрифтов. Кроме того, вы можете добавлять изображения, рисунки, изображения и многое другое в преобразованный документ.
Вы даже можете поделиться своими документами с кем угодно и предоставить им доступ к этим документам в режиме реального времени. Документы Google также помогают вам определить, когда кто-то редактирует ваш документ и какие изменения они вносят.
Теперь вам не нужно снова нажимать кнопку сохранения. Все изменения в документе автоматически сохраняются в облачном хранилище Google Drive. Кроме того, вы получаете историю изменений, кто вносил изменения, какие изменения они внесли, и многое другое.
Ключевая особенность:
- Редактируйте в режиме реального времени — поделитесь преобразованными документами с членами вашей команды и предоставьте им доступ для редактирования в режиме реального времени. Вы также можете просмотреть изменения в выделенных текстах.
- Общайтесь и комментируйте — общайтесь с другими прямо из документа или добавьте комментарий, чтобы передать все, что вы хотите.
Плюсы:
- Голосовой набор.
- Получите бесплатные шаблоны для всех типов документов, таких как резюме, отчеты и многое другое.
- Получайте доступ к Документам Google где угодно и когда угодно с телефона, компьютера, ноутбука или планшета.
- Документы Google поддерживают все форматы файлов.
- Вы можете легко проверить общее количество слов.
- Проверка орфографии и грамматики.

Цена:
Документы Google бесплатны.
10. Россум.
Лучше всего подходит для сканирования счетов и извлечения данных (на основе цитат).
Rossum — это программа оптического распознавания текста на основе искусственного интеллекта, которая помогает извлекать данные из счетов и сокращает объем ручного ввода данных. Они утверждают, что точно собирают 98% данных из любых деловых документов и счетов-фактур. Не только это, они также помогают уменьшить количество ошибок.
Кроме того, Rossum не устанавливает ограничений для любого типа шаблона и может собирать данные из любого счета-фактуры любого стиля. Вы можете добавлять или изменять данные и оставлять отзывы после преобразования или сканирования документа.
Вы можете добавлять или изменять данные и оставлять отзывы после преобразования или сканирования документа.
А благодаря возможностям искусственного интеллекта программное обеспечение изучает и сохраняет данные из каждого счета-фактуры и становится умнее по мере использования. Он использует технологию пространственного распознавания текста для сканирования счетов-фактур, чтобы понять их возможное значение, структуру и шаблоны.
Кроме того, Россум автоматически предлагает пользователям просматривать и проверять счета, в отношении которых их программное обеспечение не уверено.
Ключевая особенность:
- Любой тип документа — Rossum совместим и может извлекать данные из всех типов документов, включая счета-фактуры, заказы на поставку и коносаменты.
- Обширная интеграция — обеспечивает интеграцию с многочисленными сторонними бизнес-системами, такими как SAP, Microsoft Dynamics, Netsuite и QuickBooks.
Плюсы:
- Он поддерживает такие форматы, как PDF, JPG и PNG.
- Их программное обеспечение может экспортировать данные в четырех форматах, таких как CSV, JSON, XLSX или XML.
- Программное обеспечение обеспечивает поддержку по электронной почте NBD.
- Неограниченные пользователи могут иметь доступ к одной учетной записи.
- Сканируйте несколько документов одновременно.

Цена:
Ценовые планы.
Что такое программа оптического распознавания текста?
Программное обеспечение OCR использует технологию OCR (оптического распознавания символов) для распознавания печатного или рукописного текста внутри цифровых файлов или физических документов. Его основные функции включают изучение текста в документе и преобразование его в код для обработки данных. На языке непрофессионала программное обеспечение OCR также известно как инструмент распознавания текста.
Кроме того, в системах оптического распознавания текста используется комбинация программного и аппаратного обеспечения для преобразования физических документов в читаемые символы для машин. Он использует оптический сканер или специализированную печатную плату для чтения или копирования текстов, а его программное обеспечение обычно выполняет расширенную обработку.
Программное обеспечение также использует искусственный интеллект (AI) для продвинутых способов интеллектуального распознавания символов (ICR), включая идентификацию языка и стили почерка.
Программное обеспечение OCR полезно для преобразования бумажных копий юридических или исторических документов в файлы PDF для архивирования или обработки данных. После создания электронной копии вы можете форматировать, редактировать и искать документы так же, как и при поиске других электронных копий.
Какие функции вам нужны в программе оптического распознавания текста?
Вот несколько важных функций, на которые вы должны обратить внимание в инструменте распознавания текста:
- Анализ макета — он должен иметь возможность автоматически обнаруживать все столбцы текста, разделения, таблиц, изображений и т. Д.
- Поиск — он должен предлагать простые функции поиска по ключевым словам, фильтрам, заголовкам и т. Д.
- Разделить — у вас должна быть возможность разбивать длинные документы на несколько более коротких документов для упрощения загрузки и управления.
- Распознавание языков. Распознавание нескольких языков может помочь вам обрабатывать, редактировать и хранить документы на нескольких языках со всего мира.
- Поддержка формата — он должен поддерживать файлы импорта в нескольких форматах, включая MS Office, PDG, JPG и другие.
- Определение макета — помогает сохранить исходный формат и макет документа. Вы также можете настроить формат в соответствии с вашими требованиями.
- Цифровая подпись — вы должны иметь возможность ставить и принимать цифровые подписи на документах из удаленных мест.
- Сотрудничество — он должен предлагать широкое сотрудничество между членами команды для управления комментариями.
Управляющее резюме.
Вам может потребоваться оцифровка печатных или рукописных документов, независимо от того, ведете ли вы бизнес или занимаетесь какой-либо работой в Интернете. К счастью, вы можете быстро выполнить эту задачу с помощью этих инструментов распознавания текста.
Если вы ищете простое программное обеспечение для распознавания текста со стандартными функциями, я бы порекомендовал Google Docs, Tesseract и SimpleOCR. А для сканирования бизнес-документов, таких как счета-фактуры, вы можете попробовать Rossum.
В качестве своего фаворита я предлагаю вам использовать Adobe Acrobat Pro DC, поскольку он является лучшим программным обеспечением для оптического распознавания текста для полных решений PDF и включает в себя такие функции, как:
- Извлечение текста и преобразование отсканированных документов в редактируемые файлы PDF.
- Функции редактирования, такие как распознавание текста, добавление комментариев, изменение порядка страниц, объединение файлов и т. Д.
- Сжатие файлов PDF без потери качества.
- Преобразование PDF-файлов в несколько форматов.
- Добавление и запрос подписей на PDF-документах.
Испытайте эти инструменты OCR воочию и посмотрите, как они работают на вас. К счастью, многие из них поставляются с бесплатными пробными периодами или планами freemium.
Какой из этих инструментов OCR вы планируете использовать и почему? Позвольте мне знать в комментариях ниже.
Программы оптического распознавания документов — урок. Информатика, 7 класс.
Для быстрого перевода текста с бумажных носителей в электронный вид используют сканеры и программы распознавания символов.
После обработки документа сканером получается графическое изображение документа (графический образ). Но графический образ еще не является текстовым документом. Человеку достаточно взглянуть на лист бумаги с текстом, чтобы понять, что на нем написано. С точки зрения компьютера, документ после сканирования превращается в набор разноцветных точек, а вовсе не в текстовый документ.
Проблема распознавания текста в составе точечного графического изображения является весьма сложной. Подобные задачи решают с помощью специальных программных средств, называемых средствами распознавания образов.
Наиболее широко известна и распространена такая программа отечественных производителей — ABBYY FineReader.
Эта программа предназначена для распознавания текстов на русском, английском, немецком, украинском, французском и многих других языках (на 179 языках), а также для распознавания смешанных двуязычных текстов.
Возможности программы ABBYY FineReader:
- Работает с разными моделями сканеров.
- Позволяет из бумажных документов, PDF-файлов и цифровых фото сделать редактируемый текст.
- Позволяет объединять сканирование и распознавание в одну операцию, работать с пакетами документов (многостраничными документами) и с бланками.
- Позволяет редактировать распознанный текст и проверять его орфографию.
- Сохраняет внешний вид документа, а также его структуру, то есть, расположение слов, абзацев, таблиц, изображений, заголовков и нумерация страниц останутся такими же, как и в оригинале.
- Экспортирует тексты в Word, Excel, PowerPoint или Outlook.
Преобразование бумажного документа в электронный вид происходит в пять этапов. Каждый из этих этапов программа FineReader может выполнять как автоматически, так и под контролем пользователя. Если все этапы проводятся автоматически, то преобразование документа происходит за один прием.
Пять этапов процесса обработки документа с помощью программы ABBYY FineReader:
- Сканирование документа (кнопка Сканировать).
- Сегментация документа (кнопка Сегментировать).
- Распознавание документа (кнопка Распознать).
- Редактирование и проверка результата (кнопка Проверить).
- Сохранение документа (кнопка Сохранить).
1) На этапе сканирования производится получение изображений при помощи сканера и сохранение их в виде, удобном для последующей обработки. Чтобы начать сканирование, надо включить сканер и щелкнуть на кнопке Сканировать.
2) Второй этап работы — сегментация, разбиение страницы на блоки текста. Если страница содержит колонки, иллюстрации, врезки, подрисуночные подписи или таблицы, то порядок распознавания требует коррекции. Содержимое страницы разбивается на блоки, внутри каждого из которых распознавание осуществляется в естественном порядке. Блоки нумеруются, исходя из порядка включения их в документ. При автоматической сегментации (кнопка Сегментировать) определение границ блоков осуществляется автоматически. При этом учитываются поля документа, просветы между колонками, рамки.
3) Процесс распознавания текста после сегментации начинается с щелчка на кнопке Распознать и полностью автоматизирован.
4) Когда распознавание данной страницы завершается, полученный текстовый документ отображается в окне Текст. Заключительные этапы работы позволяют отредактировать полученный текст с помощью средств, напоминающих текстовый редактор WordPad. Провести проверку орфографии с учетом трудностей распознавания позволяет кнопка Проверить.
5) По щелчку на кнопке Сохранить запускается Мастер сохранения результатов. Он позволяет сохранить распознанный текст или передать его в другую программу (например, в Microsoft Word) для последующей обработки полученный текст можно сохранить в виде форматированного или неформатированного документа.
|
|
Конвертировать PDF в Word через электронную почту OCR
Электронная почта OCR позволяет распознавать документы PDF, отсканированные изображения и конвертировать в редактируемые форматы вывода Word, Text, Excel, PDF, Html по электронной почте.
Отправляйте файлы PDF или изображения и получайте преобразованные документы с оптическим распознаванием текста так же легко, как по электронной почте, со своего настольного компьютера, ноутбука или беспроводного устройства.
Перед тем, как использовать службу Email OCR, вы должны создать учетную запись onlineocr с адресом электронной почты и иметь достаточно доступных страниц.
Как это работает:
- Открыть исходящее сообщение электронной почты
- В поле «Кому» введите
- Прикрепите файл (ы) или ZIP-архив, который вы хотите распознать, к исходящему электронному письму (максимум 30 Мб)
- Необязательно: определите параметры распознавания в теле сообщения электронной почты
- Отправить электронное письмо
Через несколько минут вы получите преобразованные файлы в виде вложений во входящее сообщение электронной почты.
О настройках распознавания:
По умолчанию настройки распознавания:
-lang: english -output: docx -tobw: true -combine: false -pagerange: all -createzip: false
Что это означает:
| -язык | — Указывает язык (и) распознавания, по умолчанию английский |
| -выход | — Задает формат (ы) вывода, по умолчанию MS Word |
| -tobw | — Преобразование входного изображения в черно-белое, по умолчанию включено |
| -combine | — Объединение выходных файлов в многостраничный документ, по умолчанию отключено |
| -pagerange | — Диапазон страниц.Например «1-20», «все» — будут распознаны все страницы. По умолчанию все страницы. Только для одного документа в электронном письме. |
| -createzip | — Поместите выходные файлы в единый zip-архив |
Итак, вы можете отправлять электронную почту без специальных настроек распознавания, а изображение будет распознаваться с настройками по умолчанию.
Например:
——————————————- ————————-
Привет, OCR!
С уважением,
Джон
—————————————— —————————
+ прикрепленные изображения
Изображение будет распознано на английском языке и экспортировано в формат MS Word.Перед обработкой изображение будет преобразовано в черно-белое. Для многостраничного документа будут распознаны все страницы.
Если вы хотите распознать изображение на английском и португальском языках и преобразовать его в формат TXT, отправьте следующее электронное письмо:
———————————————— ———————
Привет!
-язык: английский, португальский -выход: txt
С уважением,
——————————— ————————————
+ прикрепленные изображения
Существуют разные примеры использования командная строка:
-lang: spanish -output: docx, xlsx
Изображение будет распознано на испанском языке и преобразовано в форматы MS Word и Excel.Остальные настройки по умолчанию.
-lang: english, german -output: txt -combine: true
Изображение будет распознано на английском и немецком языках и преобразовано в формат обычного текста. Выходные файлы будут объединены в один многостраничный документ. Остальные настройки по умолчанию.
-pagerange: 1-20
Если вы отправите один многостраничный файл PDF или TIFF, будут распознаны только первые 20 страниц. Остальные настройки по умолчанию.
-output: doc -createzip: true
Если вы отправляете электронное письмо с несколькими изображениями, преобразованные файлы DOC будут заархивированы в один zip-архив. Остальные настройки по умолчанию.
Или вы можете создать настройки распознавания и скопировать и вставить в электронное письмо с помощью формы ниже:
5 лучших сканеров OCR в 2020 году
Давайте рассмотрим каждый продукт в отдельности.
| Продукт | Формат | Область сканирования | Возможности подключения | Листов в минуту | Изображений в минуту | Размер АПД | Ежедневный рабочий цикл | Цена | A4 | 8.27 дюймов x 11,69 дюймов | SuperSpeed USB 3.0, беспроводная связь и Ethernet (дополнительно) | 35 | 70 | 50 листов | 4000 листов | Щелкните для получения дополнительной информации |
|---|
В этом сканере документов используется ПЗС-датчик (устройство с зарядовой связью) для создания цифровых изображений с оптическим разрешением 600 точек на дюйм.Для OCR 600 dpi более чем достаточно для максимальной точности распознавания символов. Мы проверили это, чтобы выяснить, действительно ли вам нужно более 600 точек на дюйм, и обнаружили, что существует предел где-то около разрешения изображения 400 точек на дюйм, после которого больше не будет прироста достоверности символов и точности распознавания текста от высококачественных изображений. Очевидно, здесь речь идет о символах, которые были напечатаны стандартным размером шрифта. Объявления, например, имеют более мелкие символы, и разрешение 600 dpi определенно будет иметь значение, но в целом не настолько.
Программа может выводить отсканированные изображения в форматах Bitmap, JPEG, TIFF и PNG. После запуска их через программное обеспечение оптического распознавания текста сканера, вы можете преобразовать их в доступные для поиска PDF-файлы, редактируемые документы Word, файлы Microsoft Excel XLS, RTF, TXT и HTML. Мы используем это программное обеспечение специально для сбора данных, а также для оцифровки книг вместе с Adobe Acrobat и другими механизмами распознавания текста. Приложение Acrobat преобразует отсканированные документы только в PDF, и его главным преимуществом является интеллектуальная функция сжатия PDF.Если мы хотим создавать PDF-документы, которые используются для архивирования документов, мы используем серверное распознавание текста ABBYY.
Этот сканер изображений также довольно быстр: он может сканировать 35 страниц в минуту и вмещает до 50 документов в лотке АПД. Epson рекомендует сканировать с помощью этого устройства до 4000 листов в день, что должно покрыть большую часть ваших офисных потребностей. Сканер может обрабатывать любые документы размером до A4 и имеет отличные возможности подключения: порт SuperSpeed USB 3.0 и беспроводное соединение. А если этих двух недостаточно, вы также можете купить дополнительное подключение к сети Ethernet.
Fujitsu ScanSnap IX1500 имеет программу оптического распознавания символов ABBYY FineReader для ScanSnap OCR в комплекте программного обеспечения. Несмотря на то, что это не полная версия решения для программирования OCR от ABBYY и более простое программное обеспечение, оно по-прежнему отлично работает. Приложение может без проблем преобразовывать изображения в текст, и вы можете выводить бумажные документы в файлы различных форматов, например Word Doc, в котором вы можете редактировать текст с помощью приложений для обработки текстов Microsoft или электронных таблиц Excel XLS.Сканер имеет скорость сканирования 30 стр. / Мин, оптическое разрешение 600 точек на дюйм и, что наиболее важно, сенсорный экран для управления им.
В этом дуплексном сканере документов замечательно то, что он сканирует прямо в облако без необходимости в компьютере. После сканирования ваших документов все документы и изображения загружаются непосредственно на Google Диск, Dropbox, Evernote или OneDrive. При сканировании устройство может автоматически обрезать, выравнивать, корректировать края, удалять фон и выполнять ряд других аналогичных функций, устраняющих необходимость в редактировании фотографий. Это сканер для Mac и ПК, и драйверы для обоих доступны на официальном сайте продукта.
Еще одним преимуществом является то, что при покупке сканера вы можете получить доступ ко всей экосистеме приложений ScanSnap с функциями для управления документами или любого другого приложения, которое вы только можете придумать.
Если вам нужен портативный сканер с пакетом ABBYY от Fujitsu, мы рекомендуем Fujitsu Scansnap s1300i.
| Продукт | Формат | Область сканирования | Возможности подключения | Листов в минуту | Изображений в минуту | Размер АПД | Дневной рабочий цикл | Цена | A4 | 8.27 дюймов x 11,69 дюймов | SuperSpeed USB 3.0 и Wi-Fi | 35 | 70 | 50 листов | 4000 листов | Щелкните для получения дополнительной информации |
|---|
Плотность пикселей ПЗС-сенсора этого сканера документов такая же — 600 точек на дюйм без использования какой-либо интерполяции, и скорость сканирования такая же.CCD означает, что цвета RGB на фотографиях будут немного более яркими и точными. Эти 2 сканера очень похожи. Оба имеют автоподатчик документов емкостью 50 листов и одинаковую возможность подключения через USB-кабель и беспроводное сетевое соединение. С ES-500W вы не можете купить дополнительный порт Ethernet. Глубина цвета в градациях серого составляет 8 бит, а для цвета — 24 бита.
Программное обеспечение, поставляемое с этим сканером OCR, состоит из: Epson Scan 2, Epson ScanSmart Software, Nuance OmniPage Optical Character Recognition (OCR), NewSoft Presto! BizCard.
Epson также делает отличный сканер фотографий, Epson FastFoto — отличный выбор.
| Продукт | Формат | Область сканирования | Возможности подключения | Листов в минуту | Изображений в минуту | Размер АПД | Дневной цикл | Цена | A4 | 8,27 дюйма x 11,69 дюйма | USB 2.0 | 40 | 80 | 50 листов | 6000 листов | Щелкните для получения дополнительной информации |
|---|
В большинстве случаев технология распознавания образов, встроенная в приложение сканера документов, имеет более низкую точность распознавания глифов. Но преимущество в том, что все стало проще, вам не нужно запускать отсканированные документы через какое-либо другое приложение. Что хорошо, так это то, что приложение также имеет зональное распознавание текста, поэтому вы можете легко обрабатывать формы и стандартизированные документы.
Программное обеспечение сканера совместимо с обеими операционными системами, будь то Windows 10 или Mac OS X.
Этот сканер OCR быстрее, чем модели Epson, со скоростью 40 страниц в минуту благодаря своей системе подачи, рассчитанной на 200000 документов и датчик CIS (контактный датчик изображения) с одинаковым количеством пикселей на дюйм. Единственное, что подводит этот сканер документов, — это то, что у него есть только соединение USB 2.0, поэтому вы можете подключить его только к одному компьютеру, его нельзя использовать совместно.
Приложение CaptureOnTouch может синхронизировать ваш сканер со всеми популярными учетными записями облачных хранилищ, такими как Google Диск, Dropbox, OneDrive или Evernote. Canon также предоставляет драйверы ISIS и Twain для этого конкретного сканера OCR.
Canon также производит другую модель для офисных документов и преобразования PDF, Canon imageformula R40, но в ней используется программное обеспечение ReadIris PDF, а не Iris ReadIris Pro. Если вам нужна планшетная версия, Canon Canoscan Lide 400 — лучший вариант, который интегрирует OCR в свое приложение для сканирования, поэтому это полноценный текстовый сканер OCR, но имейте в виду, что он может экспортировать только в файлы PDF.
| Продукт | Формат | Область сканирования | Возможности подключения | Листов в минуту | Изображений в минуту | Размер АПД | Ежедневный рабочий цикл | Цена | A4 | 8,27 дюйма x 11,69 дюйма | Gigabit Ethernet и SuperSpeed USB 3.0 | 50 | 100 | 50 листов | 5000 листов | Щелкните для получения дополнительной информации |
|---|---|---|---|---|---|---|---|---|
| Централизованная настройка действий сканирования и доставки | С PaperCut системный администратор настраивает сканирование централизованно, после чего пользователи могут сканировать на любом устройстве:
|
| Улучшение качества сканирования и вывода | PaperCut поставляется с наиболее часто используемыми функциями прямо «из коробки», чтобы всегда обеспечивать отличное сканирование:
|
| Отправляйте отсканированные изображения прямо туда, где они вам нужны | Сканирование в вашу домашнюю папку, электронную почту, Office 365, Google Drive, SharePoint … Безопасная доставка TLS-шифрование является стандартным) Пользователи проходят облачную аутентификацию (OAUTH) один раз для всех машин После доставки используйте поиск по ключевым словам (да, PDF-файлы с оптическим распознаванием текста доступны для поиска по ключевым словам) |
Пример реального мира
Есть много советов по сканированию.Для начала:
Крупное предприятие
Данные — это жизненная сила бизнеса. Упростите перенос данных с бумаги в свои цифровые бизнес-системы.
Крупная строительная компания постоянно нанимает новых рабочих для многих действующих проектов. Прием на работу каждого нового сотрудника включает в себя ряд налоговых, конфиденциальных, охранных и сертификационных форм, которые по закону должны храниться в течение семи лет.
Формы собираются для каждого сотрудника отделом кадров и складываются вместе для сканирования.Налоговые формы являются односторонними, а формы OHS — двусторонними.
Действие сканирования настроено для захвата пакета всех форм в дуплексном режиме, их распознавания, удаления пятен для очистки каждой страницы, а затем использования удаления пустых страниц для автоматического удаления пустых оборотных сторон налоговых форм из вывода.
Оцифрованный документ вместе с файлом метаданных, содержащим информацию о нем, доставляется в папку в сети компании, которую контролирует их система управления документами (DMS).
DMS забирает файл и на основе метаданных и текста OCR сохраняет его в правильном архиве кадров с политикой хранения в течение семи лет. Если кому-то нужна копия одной из форм, можно легко выполнить поиск по тексту OCR или просмотреть по метаданным, используемым для заполнения.
Особенности более подробно
Следующее содержимое объясняет ряд функций, упомянутых в приведенном выше примере.
Облако OCR
OCR (оптическое распознавание символов) — это технология, с помощью которой делает отсканированные документы интеллектуальными. — текстовые поисковые, редактируемые и намного более полезные.
Традиционно оптическое распознавание текста было сложным и дорогостоящим для пользователей, требующим специализированных сторонних инструментов. PaperCut изменил все это с помощью нашего облачного решения для распознавания текста. Это облачная служба оптического распознавания текста, доступная без дополнительной оплаты всем оплаченным клиентам PaperCut MF.
Насколько сложно настроить Cloud OCR? Ну как сложно поставить галочку? Это все, что вам нужно сделать, чтобы включить OCR Cloud для любого действия сканирования PaperCut. Пока ваш сервер PaperCut MF подключен к Интернету, он автоматически начнет использовать защищенные серверы OCR.
Наши облачные сервисы размещены в региональных центрах обработки данных в Америке, Европе и Австралии, поэтому вы можете выполнять свои обязательства в отношении суверенитета данных и соблюдения нормативных требований в большинстве уголков мира.
Находите информацию в отсканированных документах — так же, как и в любом другом документеСамостоятельное распознавание текста
Если вы предпочитаете, чтобы отсканированных документов оставались на месте , мы также предлагаем решение для локального распознавания текста. Вы можете установить его вместе с сервером приложений PaperCut или масштабировать для растущей рабочей нагрузки сканирования, установив его на одном или нескольких независимых серверах.
И это полностью прозрачно для ваших пользователей. Самостоятельное распознавание текста обеспечивает такое же взаимодействие с пользователем на устройстве, как и при настройке действий сканирования с использованием OCR Cloud.
PaperCut MF с автоматическим масштабированием OCRPDF-A
PaperCut может создавать настоящие файлы PDF-A для архивирования документов. Обычные PDF-файлы не всегда являются полностью самодостаточными, со ссылками на шрифты, определенные извне через Интернет. Это означает, что точность заархивированного документа может быть потеряна со временем, если шрифт больше не доступен.
ДокументыPDF-A полностью автономны и могут быть безопасно заархивированы в течение длительного периода времени с гарантией, что они сохранят свою верность . Это также международный стандарт ISO, поэтому вы знаете, что программное обеспечение для чтения PDF-A будет существовать в долгосрочной перспективе.
Разделение пакета и удаление пустых страниц
Когда вы сканируете стопку форм или счетов-фактур, вам нужен отдельный выходной файл PDF для каждого документа , а не один огромный PDF-файл, который нужно вручную разделить и сохранить обратно на рабочий стол.И не все формы имеют одинаковую длину. Что, если некоторые из них состоят из двух страниц, а некоторые из них — трех или четырех? Вы можете настроить пакетное разделение PaperCut для вставки пустой страницы для разделения каждого документа в стопке, независимо от количества страниц. Прохладный!
И не заставляйте нас начинать с пустых страниц! Насколько раздражает, когда в отсканированных документах есть бесполезные пустые страницы, которые нужно пропускать при чтении? Не волнуйтесь, PaperCut может автоматически удалять пустые страницы , делая отсканированные документы более удобными для людей.Отлично!
Улучшение изображения (устранение пятен и выравнивание)
Что происходит, если оригинал документа имеет дефекты или неправильно размещен на стекле? В результате сканирование выглядит плохо, и этот шум на изображении означает, что процесс распознавания текста занимает больше времени и не такой точный.
Некоторые высококачественные МФД выполняют внутреннее улучшение изображения, поэтому качество отсканированного документа может варьироваться от устройства к устройству.
PaperCut улучшения изображения исправляют и выпрямляют ваше изображение перед этапом OCR, улучшая как внешний вид документа, так и качество вывода OCR.Это беспроигрышный вариант.
Кроме того, вы получите более стабильное качество продукции для всего парка МФУ. Это беспроигрышный вариант!
Действия при сканировании с использованием групповых разрешений
Действия сканированияPaperCut позволяют системному администратору заранее определять то, что остается неизменным от сканирования к сканированию. Например, если все счета-фактуры необходимо сканировать в формате PDF с разрешением 300 точек на дюйм, то администратор может определить эти параметры заранее в действии сканирования «счет-фактура» — пользователям не нужно беспокоиться о деталях .
Действия сканирования в PaperCut MF теперь просты и понятны — вы можете настроить параметры в соответствии с вашими требованиямиSysAdmin также может контролировать, какие пользователи получают доступ к определенным действиям сканирования — пользователи видят только те действия сканирования, которые им нужны, поэтому они могут быстро выбирать правый. Для этого мы используем ваши существующие группы AD, чтобы сделать управление доступом бесшовным и автоматическим.
Настройте доступ к действиям сканирования, чтобы пользователи видели только те действия, которые им важны.Хотите узнать больше…?
+ У нас есть много других мест, где вы можете узнать больше.Вот некоторые:
Выполнение оптического распознавания текста отсканированного PDF-документа для отображения фактического текста
Пример 1: Создание фактического текста, а не изображений текста с использованием Adobe Acrobat 9 Pro
Этот пример показан с Adobe Acrobat Pro. Есть и другие программные инструменты, которые выполняют аналогичные функции. См. Список других программных инструментов в.
В этом примере используется простое сканированное изображение текста на одной странице.Для обеспечения что фактический текст хранится в документе, выполните следующие действия:
- Отсканируйте документ с максимально возможным разрешением для улучшения производительность OCR.
- Загрузите отсканированный документ в Acrobat Pro. Выберите Документ> OCR. Распознавание текста> Распознать текст с помощью OCR …
- В следующем диалоговом окне выберите переключатель «Все страницы» в разделе «Страницы». (или Текущая страница, если вы конвертируете только одну страницу), а затем выберите OK.
- В списке «Настройки» выберите «Изменить». В следующем диалоговом окне выберите Форматированный текст и графика в раскрывающемся списке «Стиль вывода PDF». Это важно для обеспечения доступности.
- В зависимости от разрешения и четкости текста OCR преобразует изображения слов и символов в фактический текст.Напишите что Acrobat Pro не распознает, указан как «подозреваемый в распознавании текста» или текстовый элемент, который, как подозревает Acrobat, был распознан неправильно.
- Чтобы исправить подозреваемых, выберите «Документ»> «Распознавание текста»> «Найти». Первый подозреваемый OCR. Acrobat Pro представляет каждого подозреваемого по одному, которые можно исправить с помощью инструментов коррекции Acrobat Pro.
- Выполните «Дополнительно»> «Специальные возможности»> «Добавить теги к документу »
- Тест на доступность: Advanced> Accessibility> Full Проверять…
Примечание
В качестве альтернативы вы можете использовать «Документ»> «Оптическое распознавание текста». Распознавание текста> Найти всех подозреваемых OCR для отображения всех подозреваемых OCR в то же время для более быстрого редактирования.
На следующем изображении показан отсканированный одностраничный документ в Adobe Acrobat. Pro.
Рис. 1 Отсканированная страница в Acrobat Pro с рецептами супов.На следующем изображении показано преобразованное содержимое после добавления тегов в документ. Возможно, потребуется использовать TouchUp Reading Инструмент заказа и панель тегов, чтобы правильно пометить контент для предполагаемого итоговый документ.В этом примере изображение спирального переплета книги был отмечен при преобразовании. Использовался инструмент TouchUp Reading Order. скрыть изображение как фоновое (декоративное) изображение (см.). Рецепт заголовки были помечены как заголовки первого уровня.
Рис. 2 Преобразованная страница с тегами в Acrobat Pro, на которой показаны рецепты супов. Название каждого супа заголовок первого уровня. Изображение спирального переплета книги было скрыто как декоративное. изображение.Примечание. Acrobat Pro может автоматически добавлять теги при запуске файла. через OCR.
Этот пример показан в действии на рабочем примере генерации фактического текста и результата выполнения OCR.
Что такое OCR? Введение в оптическое распознавание символов
Оптическое распознавание символов (OCR) определяет процесс механического или электронного преобразования сканированных изображений рукописного, набранного или напечатанного текста в машинно-кодированный текст.Думайте об этом как о процессе преобразования аналоговых данных в цифровые.
Из этой вводной статьи вы узнаете о:
- Что такое технология OCR?
- Как работает оптическое распознавание символов?
Вам не нужно быть опытным разработчиком или техническим специалистом, чтобы узнать, что такое OCR, и понять, как оно работает. Здесь мы собираемся объяснить технологию с минимальным количеством технического жаргона.
Если вы уже знаете, что такое OCR, просто перейдите к разделу о том, как оно работает, или начните с примеров того, что вы можете делать с этой технологией.
Что такое OCR?
Поскольку OCR означает оптическое распознавание символов, технология OCR решает проблему распознавания всех видов различных символов. И рукописные, и печатные символы могут быть распознаны и преобразованы в машиночитаемый цифровой формат данных.
Придумайте любой серийный номер или код, состоящий из цифр и букв, которые вам нужно оцифровать. Используя OCR, вы можете преобразовать эти коды в цифровой выход. В этой технологии используется множество различных техник.Проще говоря, сделанное изображение обрабатывается, символы извлекаются, а затем распознаются.
OCR не учитывает фактическую природу объекта, который вы хотите сканировать. Он просто «смотрит» на персонажей, которых вы хотите преобразовать в цифровой формат. Например, если вы отсканируете слово, оно узнает и распознает буквы, но не значение слова.
Как работает оптическое распознавание символов?
Давайте рассмотрим три основных этапа оптического распознавания символов: предварительная обработка изображения; распознавание символов; и постобработка вывода.
Шаг 1. Предварительная обработка изображения в OCR
Программное обеспечениеOCR часто предварительно обрабатывает изображения, чтобы повысить шансы на успешное распознавание. Целью предварительной обработки изображения является улучшение фактических данных изображения. Таким образом подавляются нежелательные искажения и улучшаются определенные характеристики изображения. Эти два процесса важны для следующих шагов.
Шаг 2: Распознавание символов в OCR
Распознавание знаков номерных знаков
Для фактического распознавания символов важно понимать, что такое «извлечение признаков».Когда входные данные слишком велики для обработки, выбирается только сокращенный набор функций. Ожидается, что выбранные функции будут важными, в то время как те, которые предположительно являются избыточными, игнорируются. При использовании сокращенного набора данных вместо исходного большого, производительность увеличивается.
Для процесса OCR это важно, поскольку алгоритм должен обнаруживать определенные части или формы оцифрованного изображения или видеопотока.
Попробуйте наше демонстрационное приложение Узнайте больше о нашем сканере номерных знаковШаг 3. Постобработка в OCR
Постобработка — это еще один метод исправления ошибок, обеспечивающий высокую точность распознавания текста.Точность можно еще больше повысить, если ограничить вывод лексиконом. Таким образом, алгоритм может вернуться к списку слов, которые могут встречаться, например, в отсканированном документе.
OCR используется не только для определения правильных слов, но также может считывать числа и коды. Это полезно для идентификации длинных цепочек цифр и букв, например серийных номеров, используемых во многих отраслях промышленности.
Чтобы лучше справляться с различными типами входного OCR, некоторые поставщики начали разрабатывать специальные системы OCR.Эти системы могут работать со специальными изображениями, а для повышения точности распознавания, даже более того, они объединили различные методы оптимизации.
Например, они использовали бизнес-правила, стандартные выражения или обширную информацию, содержащуюся в цветном изображении. Эта стратегия объединения различных методов оптимизации называется «ориентированным на приложения» или «настраиваемым ОРС». Он используется в таких приложениях, как OCR для визитных карточек, OCR для счетов и OCR для идентификационных карт.
Примеры использования технологии OCR
Возможности использования программного обеспечения для оптического распознавания символов широко распространены, поскольку OCR можно комбинировать с широким спектром технологий.Вот несколько примеров возможных вариантов использования, включая программное обеспечение OCR:
1. Процессы идентификации в OCR
Машиносчитываемая зона (МСЗ) в паспорте
Паспорта и удостоверения личности имеют машиночитаемую зону (МСЗ), которую можно сканировать. OCR может ускорить процесс идентификации и регистрации людей. Это полезно для сил безопасности на границах или других контрольно-пропускных пунктах. Его также можно использовать в коммерческих целях для увеличения взаимодействия с клиентами, например, для регистрации в отелях или для регистрации в банках и других компаниях.
Попробуйте наш сканер паспортов и удостоверений личности Узнайте больше о решениях для цифровой идентификации с высоким уровнем безопасности — Бесплатная электронная книга2. Маркетинговые кампании с OCR
Ведущие бренды используют OCR для проведения инновационных и увлекательных кампаний, направленных на привлечение клиентов. Подумайте обо всех кодах купонов, которые клиенты могут погасить, введя их. Или о числах, напечатанных на внутренней стороне крышки от бутылки, которые вам нужно забрать.
Все эти кампании могут использовать OCR путем интеграции программного обеспечения, которое легко интегрируется в веб-сайты и приложения компании.Таким образом, они минимизируют препятствия при онлайн-регистрации и избавляют клиентов от необходимости вводить ряд цифр и букв.
Посмотрите, как PepsiCo использует OCR в одной из своих маркетинговых кампаний в Турции для сканирования кодов ваучеров внутри пакетов своих популярных чипов, таких как Lays, Ruffles и Doritos:
Маркетинговые кампании с OCR — PepsiCo Turkey
3. OCR в платежных процессах
IBAN Сканирование с OCR
Международный номер банковского счета (IBAN) служит для идентификации банковских счетов за границей.IBAN может быть разной длины и состоять из букв и цифр. Чтобы упростить международные транзакции, банковские приложения могут легко интегрировать программное обеспечение OCR. Таким образом, их клиенты могут сканировать свой IBAN вместо того, чтобы утомительно вводить его.
Попробуйте наш сканер IBAN Связаться с намиИнструменты оптического распознавания текста
Существует множество программ оптического распознавания текста, которые специализируются на одном конкретном сценарии использования, таком как сканирование кредитных карт или сканирование документов. Но OCR может быть полезно во многих сферах нашей жизни.Компаниям часто требуется сочетание решений OCR вместе, и поэтому лучше работать с поставщиками, которые могут выполнять несколько видов сканирования.
Подробнее о технологии оптического распознавания текста
Anyline OCR SDK и демонстрационные приложения
Технология мобильного сканированияAnyline доступна для интеграции в ваше мобильное приложение или веб-сайт в виде кроссплатформенного OCR SDK (комплект для разработки программного обеспечения). Протестируйте наши решения на Android, iOS, Windows и других платформах и устройствах уже сегодня.Приложение Anyline OCR для мобильного сканирования может быть легко интегрировано в любое приложение или на любой веб-сайт. Загрузите наш SDK OCR и получите бесплатную 30-дневную пробную версию, чтобы увидеть, как решения OCR и технология мобильного сканирования оптимизируют рабочие процессы и бизнес-процессы.
Наша демонстрация SDK для мобильного сканирования включает доступ ко всем следующим решениям оптического распознавания текста:
Anyline SDK предоставляет решения для мобильного сканирования с улучшенным оптическим распознаванием текста для многих различных отраслей и широкого спектра различных сценариев использования.
Получите свое решение сегодня!
Как я могу выполнить оптическое распознавание символов (OCR) на моем отсканированном документе? — Школа математики
Сначала отсканируйте изображение с помощью сканера (например,грамм. Xsane). Убедитесь, что изображение высококонтрастное и не содержит пятнышек, так как это запутает программу.
Настройки Xsane
— XSane-> Настройка-> Тип файла
Проверить:
Уменьшить 16-битное изображение до 8-битного
Установить:
TIFF zip коэффициент сжатия до 1
TIFF 16-битное сжатие изображения без сжатия
TIFF 8-битное сжатие изображения до нет сжатие
Линейное изображение в формате TIFF сжатие без сжатия
Есть несколько вариантов использования Tesseract с Xsane:
— Сканировать в *.tif, затем используйте tesseract в командной строке для OCR
tesseract inputimage.tif outputtext -l eng
— Сканируйте в PDF, затем используйте pdf2tif, затем tesseract.
pdf2tif filename.pdf (создает изображения в формате tif для каждой страницы)
— ocr.sh возьмет все файлы pdf в текущем каталоге и превратит их в txt.
Получите pdf2tif и ocr.sh с: http://www.groklaw.net/articlebasic.php?story=20061210115516438
окр.sh имя_файла-01.tif
— Настройте Xsane-> Setup-> OCR для использования сценария tesseract xsane2tess (требуется каталог tmp в домашнем каталоге пользователя. Вы можете отредактировать сценарий, чтобы изменить TEMP_DIR на что-то другое)
Команда OCR = xsane2tess -l eng
Параметр входного файла: -i
Параметр выходного файла: -o
Тессеракт с русским
tesseract <файл> .tif <выходной_файл> -l rus
————————————————- —————————————
Как профессионально сканировать и распознавать текст с помощью инструментов с открытым исходным кодом
http://www.linux.com/feature/138511
ПРИМЕЧАНИЕ: для работы tesseract файл tiff, в котором он запущен, необходимо переименовать, чтобы он заканчивался на .tif (не .tiff), И это должно быть изображение без альфа-канала. Если вы переименовали файл, а тессеракт по-прежнему не работает, вероятно, проблема в этом.Используйте утилиту преобразования изображений с возможностью удаления альфа-каналов, чтобы повторно сохранить изображение. Для массового преобразования изображений я рекомендую Imagemagick (это gpl и хорошо работает на Mac).
, чтобы отобразить ваше изображение в формате TIFF, выполните:
tesseract inputimage.tif outputtext -l eng
, и вы должны получить файл с именем outputtext.txt.
Tesseract также может использовать библиотеку libtiff. (www.libtiff.org)
Без libtiff Tesseract может читать только несжатые и сжатые G3 файлы TIFF.
Этот код представляет собой необработанный механизм распознавания текста. У него НЕТ АНАЛИЗА РАЗМЕЩЕНИЯ СТРАНИЦЫ, НЕТ ФОРМАТИРОВАНИЯ ВЫХОДА
и НЕТ пользовательского интерфейса. Он может обрабатывать изображение только одного столбца и создавать из него текст. Он может обнаруживать фиксированный шаг по сравнению с пропорциональным текстом. Начиная с версии 2.0, Tesseract полностью поддерживает Unicode (UTF-8) и может распознавать 6
языков «из коробки».
————————————————- ————————————————— ————-
.
Ваш комментарий будет первым