Информация о сайте finereaderonline.com
Здесь вы сможете провести полный анализ сайта, начиная с наличия его в каталогах и заканчивая подсчетом скорости загрузки. Наберитесь немного терпения, анализ требует некоторого времени. Введите в форму ниже адрес сайта, который хотите проанализировать и нажмите «Анализ».
Идёт обработка запроса, подождите секундочку
Чаще всего проверяют:
| Сайт | Проверок |
|---|---|
| vk.com | 90109 |
| vkontakte.ru | 43408 |
| odnoklassniki.ru | 34482 |
| mail.ru | 16616 |
| 2ip.ru | 16465 |
| yandex.ru | 13900 |
| pornolab.net | 9885 |
youtube. | 9142 |
| rutracker.org | 8975 |
| vstatuse.in | 7099 |
Результаты анализа сайта «finereaderonline.com»
| Наименование | Результат | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Скрин сайта | ||||||||||||||||
| Название | Сервис распознавания текста онлайн. Конвертация сканов, PDF в Word, Excel, Txt | |||||||||||||||
| Описание | ABBYY FineReader Online — сервис онлайн распознавания текста, позволяющий распознать текст с фото, картинки, PDF файла и скана (JPEG, TIFF) и преобразовать в редактируемые форматы Word, Excel, Txt, PowerPoint и др | |||||||||||||||
| Ключевые слова | распознавание текста, распознать текст онлайн, распознавание текста онлайн, распознавание онлайн, распознаватель текста, конвертация pdf онлайн, pdf в word онлайн, распознавание текста pdf, онлайн распознавание текста, программа для распознавания текста онлайн, распознать онлайн, распознавание текста онлайн pdf | |||||||||||||||
| Alexa rank | ||||||||||||||||
Наличие в web. archive.org archive.org | http://web.archive.org/web/*/finereaderonline.com | |||||||||||||||
| IP сайта | 13.95.131.115 | |||||||||||||||
| Страна | Неизвестно | |||||||||||||||
| Информация о домене | Владелец: Creation Date: 2007-12-03 13:28:24 Expiration Date: 2020-12-03 13:28:24 | |||||||||||||||
| Посетители из стран |
| |||||||||||||||
| Система управления сайтом (CMS) | узнать | |||||||||||||||
| Доступность сайта | проверить | |||||||||||||||
| Расстояние до сайта | узнать | |||||||||||||||
| Информация об IP адресе или домене | получить | |||||||||||||||
| DNS данные домена | узнать | |||||||||||||||
| Сайтов на сервере | узнать | |||||||||||||||
| Наличие IP в спам базах | проверить | |||||||||||||||
| Хостинг сайта | узнать | |||||||||||||||
| Проверить на вирусы | проверить | |||||||||||||||
| Веб-сервер | microsoft-iis/10.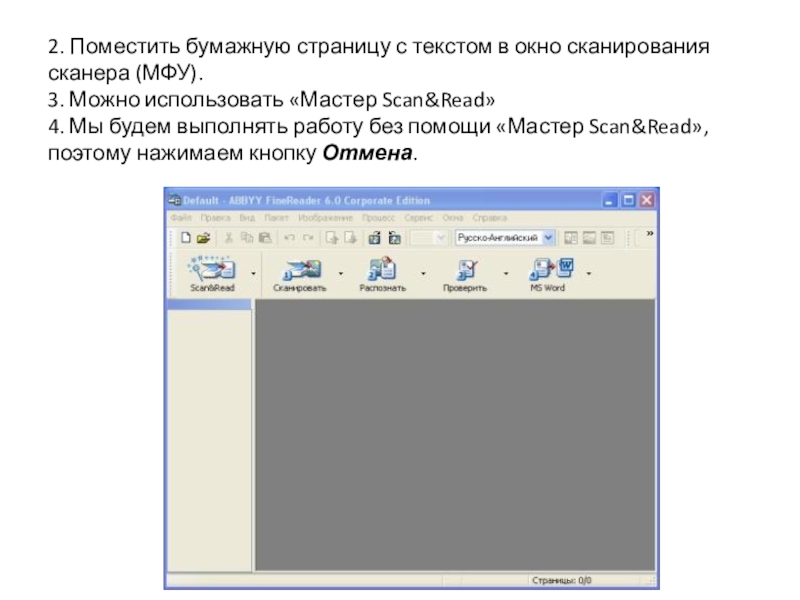 0 0 | |||||||||||||||
| Картинки | 15 | |||||||||||||||
| Время загрузки | 0.08 сек. | |||||||||||||||
| Скорость загрузки | 370.21 кб/сек. | |||||||||||||||
| Объем страницы |
| |||||||||||||||
Получить информер для форума
Если вы хотите показать результаты в каком либо форуме, просто скопируйте нижестоящий код и вставьте в ваше сообщение не изменяя.
[URL=https://2ip.ru/analizator/?url=finereaderonline.com][IMG]https://2ip.ru/analizator/bar/finereaderonline.com.gif[/IMG][/URL]Обзор Сканера CANON Canoscan LIDE300
Сканер CANON Canoscan LIDE300 был приебретен на смену прежнему, тоже CANON, который исправно отработал больше 10 лет сначала на ХР-шке, потом на семерке, но категорически отказался подружиться с десяткой. Официальный сайт CANON с чувством глубокого сожаления подтвердил, что данная модель не поддерживается более. Пришлось искать замену.
Официальный сайт CANON с чувством глубокого сожаления подтвердил, что данная модель не поддерживается более. Пришлось искать замену.
При получении в пунке выдачи проверил внешний вид и комплектацию. Всего комплекта: сам сканер, шнур-переходник mini USB-USB, диск с ПО и инструкция. Технические характеристики дублировать не буду, все они указаны во вкладке «Характеристики». Упакован сканер вот в такую коробку, без защитной пломбы.
Сверху нахоится шнур.
Вот и сам сканер.
Весь комплект.
Оранжевая наклейка предупреждает, что перед использованием нужно сканер разблокировать, переключатель находится на нижней крышке.
Вот и сам переключатель.
Разъем для подключения mini USB.
Кнопки на передней панели, с помощью которых можно произвести сканирование.
Кнопка PDF сохраняет документ соответственно в формате PDF, кнопка AUTO SKAN автоматически определяет наиболее подходящий формат для данного документа, кнопка COPY отправляет документ на печать в принтер без сохранения на компьютер, кнопка SEND отправляет скан как вложение в письмо или на почту. Если полностью поднять крышку на 90 градусов то она слегка отодвигается и можно сканировать хоть книгу, ну книги у меня под рукой не оказалось, а вот пачка бумаги была.
Если полностью поднять крышку на 90 градусов то она слегка отодвигается и можно сканировать хоть книгу, ну книги у меня под рукой не оказалось, а вот пачка бумаги была.
При подключении сканера к ноутбуку на рабочем столе появилось такое сообщение.
Значит сканер готов к работе. Он уже определяется в устройствах и принтерах.
С ним уже можно работать.
Но для того чтобы использовать все возможности сканера нужно установить прилагаемое ПО с диска ну или с сайта. Здесь все стандартно как и при установке любой программы. Во время установки спрашивают согласны ли мы передавать данные о своем сканере и т.д. и т.п. на сайт CANON ? На функциональности это не сказывается. После установки на рабочем столе ярлыка программы не появилось, за то есть ссылка на онлайн справку. Но при нажатии на ПУСК видно, что появились две новые программы.
Первая Print Utility это вероятно для принтера, но принтера CANON у нас нет, поэтому наверное при попытке что либо в ней сделать выходит такое окно : Драйвер не установлен.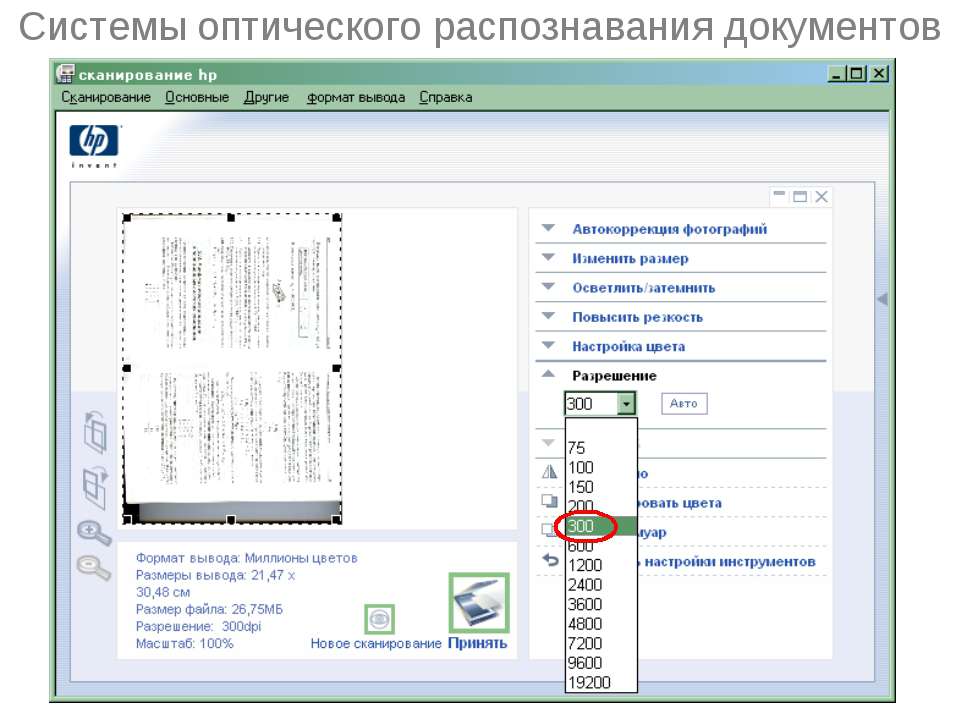
А вот при запуске второй программы SCAN UTILITY открывается рабочее окно программы.
Здесь можно выбрать вариант сканирования: Авто, документ(PDF), Фото,и т.д. Есть еще кнопки Инструкции(отображение руководства) и Параметры.
Нажав кнопку Параметры переходим в другое окно программы с тремя вкладками, в которых можно настроить все параметры по своим требованиям.
Разрешение при сканировании максимальное 600dpi, при распознавании текста 400dpi.
Можно выбрать куда сохранить документ.
Функция OCR — оптическое распознавание текста. Переводит текст со сканируемого документа в электроный вид с возможностью дальнейшего редактирования. По умолчанию текст открывается в блокноте, но можно добавить и другой редактор или офисный пакет. Возможно поддерживается только майкрософтовский офис, но у меня его нет, а в других редакторах текст не выводится, кракозябры одни, не распознает кодировку наверное. Лучше всего выводится в блокноте. Может еще поэкспериментирую с другими редакторами. Примеры сканирования документы, фото.
Примеры сканирования документы, фото.
Распознавание текста в блокноте.
В общем и целом нормальный сканер, компактный,много места не занимает, провод всего один к нему и питание и данные, сканирует достаточно хорошо документы и фото. С помощью встроенного редактора PDF можно так же сканировать или открыть документ и повернуть его. Больше функций там нет,но для большего есть специальзированные программы. Свою основную функцию качественного сканирования сканер выполняет. С распознаванием текста надо наверное еще поэкспериментировать.
Как отредактировать PDF на Mac и распознать текст на изображении
Вскоре после того, как я купил свой первый Mac, встал вопрос о приложении для редактирования PDF. Возможность открывать такие файлы для чтения с помощью встроенной утилиты «Просмотр» была приятным сюрпризом, но когда нужно было отредактировать текст, изображение или добавить подпись, приходилось искать сторонние решения. Apple вроде могла бы добавить мощный редактор PDF в macOS, но, увы, его там нет — и, скорее всего, появится он не раньше, чем приложение «Калькулятор» на iPad.
Годных редакторов PDF для Mac не так много
На ум сразу приходит решение от Adobe, и действительно оно весьма неплохое, но после пробного периода встает вопрос об оформлении подписки. А она стоит совсем недешево. Но скачивать какие-то непонятные программы тоже не хочется, поэтому оптимальный выход — найти альтернативу в Mac App Store. Все приложения, которые туда попадают, проходят тщательный отбор модераторами, так что в их качестве можно быть уверенным.
В итоге выбор остановился на PDFelement 7. Это приложение выполняет все задачи, которые требуются от редактора PDF: позволяет изменять текст и изображения, добавлять аннотации и водяные знаки, объединять несколько PDF-файлов в один и даже извлекать данные из PDF, который сделаны в виде изображения (как большинство сканов, например).
Интерфейс приложения напоминает продукты Microsoft Office, но основные элементы управления размещены слева и справа. Среди них быстрый доступ к редактированию текста, изображений, ссылок, форм и другим инструментам. Справа можно посмотреть оставленные закладки и, например, комментарии других пользователей.
Справа можно посмотреть оставленные закладки и, например, комментарии других пользователей.
Минималистичный интерфейс, похожий на Microsoft Word
Разобраться в приложении можно за несколько секунд, все довольно интуитивно
После недавнего обновления редактировать PDF стало еще удобнее — за пару кликов выделяем цветом интересующий текст, создаем пометки в виде всплывающего или встроенного текста, добавляем аннотации в виде геометрических фигур, линий или стрелок. Либо же вносим изменения в сам текст документа, воспользовавшись клавиатурой. Приложение также позволяет добавлять колонтитулы, номера страниц, водяные знаки и другие элементы оформления.
А вот это прям круто — распознавание картинок в любом PDF
Есть совместное редактирование, так что аннотации увидят все ваши коллеги с доступом к документу
Готовый файл можно экспортировать в один из популярных форматов (не только PDF, но и MS Office, текстовые документы или графические файлы).
Помимо этого, приложение умеет конвертировать файлы в PDF и обратно, создавать PDF из отсканированных изображений, распознавать текст для последующего редактирования. Например, если у вас отсканированная таблица в PDF, вы хотите ее немного подкорректировать и распечатать. Заходите в «Инструменты» и выбираете «Оптическое распознавания текста». И на выходе получаете документ, полностью готовый для редактирования.
Оптическое распознавание текста позволяет перевести любой скан в формат для редактирования
Позаботились разработчики и о конфиденциальности. Для обеспечения дополнительной защиты вы можете внести необходимые настройки доступа. Например, вы можете сами определять границы свободы для пользователей, у которых на компьютере окажется ваш файл, и запретить им редактировать или даже просматривать его при отсутствии необходимого пароля. Все это в дополнение к возможности оставить водяной знак. Инструменты защиты выделены в отдельное меню для удобства.
Защитить документ водяным знаком? Нет ничего проще
В специальном меню доступны опции для защиты и объединения PDF
Кстати, помимо настольной версии у PDFelement имеется и версия для iPhone и iPad, в которой тоже можно аннотировать PDF-документы, хотя и не поддерживается оптическое распознавание текста.
Чем удобно еще такое приложение, как PDFelement 7, так это гибкой системой подписок. Если вам нужны только основные функции, можно оформить стандартную подписку, а для доступа к профессиональным возможностям вроде распознавания текста предусмотрена профессиональная подписка. Но даже в простой подписке вы сможете добавлять аннотации и пометки к документам, объединять файлы в PDF, а также перемещать, удалять и добавлять страницы. Тем же, кто желает максимально близко подружиться с форматом PDF, лучше оформить профессиональную подписку. Поскольку приложение доступно в Mac App Store, есть различные варианты доступа к программе — от подписки на 1, 3 или 12 месяцев до бессрочной лицензии. А если вы не уверены в покупке, вы всегда можете воспользоваться демо-версией, доступной по ссылке ниже.
Название: PDFelement 7
Издатель/разработчик: Wondershare
Цена: Бесплатно / Подписка
Совместимость: Windows, Mac
Ссылка: Установить
Преобразование сканированных документов в текст (технология OCR)
Вы можете сканировать документы и преобразовывать их в текст с помощью программы обработки текста. Технология, позволяющая компьютерам «читать» текст с физических объектов, назывется OCR. Для сканирования и последующего распознавания текста необходимо установить соответствующую программу, например, ABBYY FineReader, которая включена в комплект поставки устройства.
Технология, позволяющая компьютерам «читать» текст с физических объектов, назывется OCR. Для сканирования и последующего распознавания текста необходимо установить соответствующую программу, например, ABBYY FineReader, которая включена в комплект поставки устройства.
|
В некоторых странах приложение ABBYY FineReader Sprint Plus может быть не включено в комплект поставки. |
Перечисленные далее типы документов не могут быть распознаны или затрудняют распознавание:
рукописные тексты;
копии с других копий;
факсы;
текст с плотно расположенными символами или строками;
текст в таблицах или подчеркнутый текст;
текст с наклоном или с размером символов меньше 8 пунктов.
Обратитесь к одному из следующих разделов, чтобы выполнить сканирование и распознать текст с помощью программы ABBYY FineReader.
Преобразование сканированных документов в текст в автоматическом режиме
|
Запустите ABBYY FineReader одним из следующих способов. |
 0 Sprint.
0 Sprint.
В Mac OS X: Откройте папкуApplications > ABBYY FineReader 5 Sprint Plus и дважды щелкните значок Launch FineReader 5 Sprint.
Откроется окно ABBYY FineReader.
|
Щелкните значок Scan&Read в верхней части окна. Запустится Epson Scan в ранее выбранном режиме. |
|
Если значок Scan&Read не отображается, выберите Select Scanner в меню Scan&Read, затем EPSON Perfection V30/V300 и щелкните OK. Затем выберите Scan&Read из меню Scan&Read для запуска Epson Scan. |
|
Щелкните Scan (Сканировать). |
 Документ будет отсканирован, преобразован в текст и открыт в окне ABBYY FineReader.
Документ будет отсканирован, преобразован в текст и открыт в окне ABBYY FineReader.|
При работе с ABBYY FineReader следуйте инструкциям справочной системы этой программы. |
Преобразование сканированных документов в текст в офисном режиме
|
Запустите ABBYY FineReader одним из следующих способов. |
В Windows: Выберите кнопку запуска или Start (Пуск) > Programs (Программы) или All Programs (Все программы) > ABBYY FineReader 6 Sprint > ABBYY FineReader 6 Sprint.
В Mac OS X: Откройте папкуApplications > ABBYY FineReader 5 Sprint Plus и дважды щелкните значок Launch FineReader 5 Sprint.
|
Щелкните значок Scan&Read в верхней части окна. Запустится Epson Scan в ранее выбранном режиме. |
|
Если значок Scan&Read не отображается, выберите Select Scanner в меню Scan&Read, затем EPSON Perfection V30/V300 и щелкните OK. Затем выберите Scan&Read из меню Scan&Read для запуска Epson Scan. |
|
Для параметра Image Type (Тип изображения) выберите значение Color (Цвет), Grayscale (Оттенки серого) или Black&White (Черно-белый). |

|
Выберите значение Document Table (Планшет для документов) для параметра Document Source (Источник документа). |
|
Выберите значение параметра Size (Размер), соответствующее размеру загруженных документов. |
|
Выберите 300 для параметра Resolution (Разрешение). |
|
Щелкните Scan (Сканировать). Документ будет отсканирован, преобразован в текст и открыт в окне ABBYY FineReader. |

|
При работе с ABBYY FineReader следуйте инструкциям справочной системы этой программы. |
Преобразование сканированных документов в текст в простом режиме
|
Запустите ABBYY FineReader одним из следующих способов. |
В Windows: Выберите кнопку запуска или Start (Пуск) > Programs (Программы) или All Programs (Все программы) > ABBYY FineReader 6 Sprint > ABBYY FineReader 6 Sprint.
В Mac OS X: Откройте папкуApplications > ABBYY FineReader 5 Sprint Plus и дважды щелкните значок Launch FineReader 5 Sprint.
|
Щелкните значок Scan&Read в верхней части окна. Запустится Epson Scan в ранее выбранном режиме. |
|
Если значок Scan&Read не отображается, выберите Select Scanner в меню Scan&Read, затем EPSON Perfection V30/V300 и щелкните OK. Затем выберите Scan&Read из меню Scan&Read для запуска Epson Scan. |
|
Для параметра Document Type (Тип документа) выберите Magazine (Журнал), Newspaper (Газета) или Text/Line Art (Текст/штриховой рисунок). |

|
Для параметра Image Type (Тип изображения) выберите значение Color (Цвет) или Black&White (Черно-белый). |
|
Для параметра Destination (Назначение) выберите значение Printer (Принтер) или Other (Другое). |
|
Если вы выбрали Other (Другое), для параметра Resolution (Разрешение) выберите значение 300. |
|
Щелкните Scan (Сканировать). |
 Документ будет отсканирован, преобразован в текст и открыт в окне ABBYY FineReader.
Документ будет отсканирован, преобразован в текст и открыт в окне ABBYY FineReader.|
При работе с ABBYY FineReader следуйте инструкциям справочной системы этой программы. |
Преобразование сканированных документов в текст в профессиональном режиме
|
Запустите ABBYY FineReader одним из следующих способов. |
В Windows: Выберите кнопку запуска или Start (Пуск) > Programs (Программы) или All Programs (Все программы) > ABBYY FineReader 6 Sprint > ABBYY FineReader 6 Sprint.
В Mac OS X: Откройте папкуApplications > ABBYY FineReader 5 Sprint Plus и дважды щелкните значок Launch FineReader 5 Sprint.
|
Щелкните значок Scan&Read в верхней части окна. Запустится Epson Scan в ранее выбранном режиме. |
|
Если значок Scan&Read не отображается, выберите Select Scanner в меню Scan&Read, затем EPSON Perfection V30/V300 и щелкните OK. Затем выберите Scan&Read из меню Scan&Read для запуска Epson Scan. |
|
Выберите Reflective (Непрозрачный) для параметра Document Type (Тип документа). |
|
Выберите значение Document Table (Планшет для документов) для параметра Document Source (Источник документа). |
|
Выберите значение Document (Документ) для параметра Auto Exposure Type (Тип автоэкспозиции). |
|
Выберите Black & White (Черно-белый), 24-bit Color (Цветной 24 бита) или 48-bit Color (Цветной 48 бит) для параметра Image Type (Тип изображения). |
|
Выберите 300 для параметра Resolution (Разрешение). |
|
Щелкните Scan (Сканировать). Документ будет отсканирован, преобразован в текст и открыт в окне ABBYY FineReader. |
|
При работе с ABBYY FineReader следуйте инструкциям справочной системы этой программы. |
Программа для распознавания текста с картинки
Бывают ситуации, когда у нас есть книга, физическая, сделанная из бумаги. А Вам просто необходим текст из этой книги, например, в программе Word. И тогда появляется вопрос: как перевести текст из книги реальной в электронный вариант.
Программа для распознавания текста с картинки CuneiForm именно для этого и предназначена. Она распознает сканированный текст, и переводит его в текстовый формат. А после этого Вы уже текст можете редактировать в текстовых редакторах, например, в Word, проводить по тексту полноценную навигацию и поиск, и создавать книги PDF.
Программа CuneiForm была неоднократно признана лучшей по результатам различных тестов, в том числе проводимых Академией наук РФ. Также она получила звание Editor Choice, то есть Выбор редактора, в журнале PC Expert.
Все, что нужно сделать — это открыть в программе скан текста, и затем переконвертировать в текстовый формат.
CuneiForm распознает практически любые печатные шрифты с книг, газет, журналов, бумажных документов.
Также в программе встроена возможность распознавания текста с матричного принтера, печатных машинок, плохих ксерокопий и факсов.
Поддерживается распознавание текста более чем с 20 языков: русского, английского, французского, испанского, украинского, и многих других.
Эта программа стала прообразом многих других мощных комплексных программ для промышленного распознавания документов.
Работа с программой CuneiForm
Чтобы ей воспользоваться, скачайте программу по ссылке:
После скачивания разархивируйте, и запустите файл с расширением exe. Проходите процесс установки. Установка очень простая — Вы принимаете лицензионное соглашение, нажимаете несколько раз Далее, и Установить. После установки нажимаете кнопку Готово.
Программа появится в меню Пуск в списке программ, и ее можно будет через меню запускать. При желании можно сделать ярлык на рабочий стол.
Чтобы завести в программу скан текста, зайдите в меню Файл — Открыть, или перетащите изображение на рабочий стол.
В окне Коррекция разрешения нажмите ОК. Можете проверить разрешение Вашего скана в любом графическом редакторе, например, в Фотошопе. Обычно разрешение определяется программой CuneiForm правильно.
Выбираете в меню пункт Распознавание — Мастер распознавания, или нажимаете кнопку с изображением волшебной палочки, затем кнопку Далее, и выбираете язык текста. Если текст только русский, выбираете язык русский, а не русско-английский, который стоит по умолчанию.
Нажимаете Далее, читаете и отмечаете соответствующие Вашему тексту пункты, затем еще раз нажимаете Далее.
После этого можете выбрать или редактирование текста в программе, или экспортирование в форматы Word, Excel или Ефрат.
Если выбираете редактирование в программе, то можете прямо в ней проверить и подкорректировать полученный текст. Возможности редактирования в этой программе достаточно серьезные, как в хорошем блокноте.
Лично мне программа очень понравилась. Правда, был один казус — сначала я ей попытался вместо скана подскуть скриншот, сделанный в FSCapture. Скриншот не прошел — программа его не захотела распознавать. Но когда я ей дал действительно сканированный текст, она справилась без труда — за секунду выдала результат в текстовом формате.
Еще один момент: в скачанном архиве программы Вы увидите вордовский документ. Он касается возможных ошибок при работе со сканами, сделанными сканерами некоторых моделей. Так что, если что-то не получается — прочтите его, возможно, там Вы найдете причину ошибки, и устраните ее.
Видео о работе с программой для распознавание текста CuneiForm
Более подробные сведения Вы можете получить в разделах «Все курсы» и «Полезности», в которые можно перейти через верхнее меню сайта. В этих разделах статьи сгруппированы по тематикам в блоки, содержащие максимально развернутую (насколько это было возможно) информацию по различным темам.
Также Вы можете подписаться на блог, и узнавать о всех новых статьях.
Это не займет много времени. Просто нажмите на ссылку ниже:
Подписаться на блог: Дорога к Бизнесу за Компьютером
Проголосуйте и поделитесь с друзьями анонсом статьи на Facebook:
Как из картинки вытащить текст в Word
Перед каждым пользователем ПК хоть раз возникала необходимость получения текстовой информации из картинок. Работая в программах для набора, иногда приходится перепечатывать текст, находящийся в растровом или векторном изображении. Этот долгий процесс можно сократить, если знать, как из картинки вытащить текст в Word.
Для преобразования текста на картинке в документ Ворд — следуйте инструкциям ниже
Выход из ситуации
Обычно процесс распознавания с изображения достаточно трудоёмкий. В нём основную работу придётся делать вручную, но конечный результат сэкономит общее затраченное время. Это бывает необходимо, когда в распоряжении присутствует только электронное изображение документа или страницы книги, с которой нужно вытащить текст.
Вместо собственноручного перепечатывания информации, можно воспользоваться специализированными программами и сервисами, которые автоматизируют эту работу. Они позволяют распознать текст, используя картинки большинства популярных форматов, среди которых jpg, gif и png.
Порядок работ
Если данные находятся на печатном документе, с него придётся предварительно сделать изображение. Для этого потребуется сканер. Также это бывает необходимо, если текст на картинке имеет плохое разрешение или он размытый. К сканеру должны прилагаться «родные» драйвера и программы, которые позволят перевести всё в высоком качестве. На результат влияет не только чёткость букв, но и их «ровное» положение, а также отсутствие помех.
Если вам необходимо получить текст с бумажного носителя — потребуется сканер
При неимении сканера можно обойтись фотоаппаратом. В этом случае потребуется правильно выставить свет. На следующем этапе требуется использование специальных программ, которые позволят непосредственно распознать текст с jpg. Среди таких программ особое место занимает ABBYY FineReader, которая считается лидером на рынке. Она платная, но её качество соответствует стоимости.
Особенности процесса
В функционале программного обеспечения присутствует много функций, позволяющих работать с большинством шрифтов. Среди передовых возможностей присутствует способность распознать рукописный текст Word из jpg. Она имеет много преимуществ:
- выбор качества. Пользователь может сам остановить предпочтительное качество для сканирования. Лучше выбирать не ниже 300 DPI, чтобы программа затрагивала для обработки даже мелкие детали, и смогла работать с мелкими шрифтами.
- цветность. Необходимо, когда на изображении присутствуют таблицы или другая символика. В других же вариантах предпочтительно выбирать чёрно-белый режим, который уберёт смещения цветового диапазона с букв, сделав их чище. Цветной режим подойдёт для ярких картинок, где важно передать цвет текста.
- фотография. Если картинка выполнена снимком, программа повысит приоритет сканирования. Также можно непосредственно с ABBYY FineReader сфотографировать текст, чтобы распознать его в jpg. Правда, это сильно ухудшит качество, отчего финальный результат будет иметь много ошибок.
Среди аналогичных программ присутствуют также бесплатные сервисы. Среди них выделяется также Google Drive, которая доступная непосредственно в браузере. Работа с OCR Convert имеет среднее качество, поэтому подходит для тех, у кого изображение имеет высокое расширение и чёткие шрифты. Сервис i2OCR предлагает аналогичные услуги, только картинки можно ещё загрузить с URL-ссылки. Они имеют больше любительский формат, поэтому не рассматриваются для профессионального использования.
Открыв картинку через Google Документы, вы получите документ с уже распознанным текстом
Получить результат
После начала сканирования обычно проходит пару минут, чтобы получить результат. Этот показатель зависит от сложности и количества располагаемого текста. После старта работы, программы в автоматическом режиме будут выделять участки для проверки, и преобразовать их. После окончания процесса, можно повторно распознать jpg данные, или сосредоточиться на определённых участках документа.
Готовый результат экспортируется в файл Word. Полученный текст можно редактировать при наблюдении ошибок, или продолжить с ним дальнейшую работу. Распознать текст с jpg картинок не представляет труда, если правильно подготовить изображение. Этот процесс может существенно сэкономить время, в отличие от ручного перепечатывания информации.
Поскольку работа с распознаванием текста с картинки требует качественного исходника, нужно изначально найти изображение с высоким разрешением. Это ускорит сам процесс обработки данных, а также уменьшит общий объем ошибок.
Что такое OCR и для чего оно используется?
Если вы работаете в офисе, оборудованном сканером документов, вы, вероятно, не раз задумывались об оптическом распознавании символов (OCR). Но что такое OCR? А для чего это используется? В этой статье объясняется, что такое распознавание текста, и рассматриваются наиболее популярные варианты использования.
Что такое OCR?
Буквально OCR означает оптическое распознавание символов. Это широко распространенная технология распознавания текста внутри изображений, например отсканированных документов и фотографий.Технология OCR используется для преобразования практически любого изображения, содержащего письменный текст (напечатанный, рукописный или напечатанный), в машиночитаемые текстовые данные.
Технология оптического распознавания символов стала популярной в начале 1990-х годов при попытке оцифровывать исторические газеты. С тех пор технология претерпела несколько улучшений. В настоящее время решения обеспечивают почти идеальную точность распознавания текста. Расширенные методы, такие как зональное распознавание текста, используются для автоматизации сложных рабочих процессов на основе документов.
Для чего используется OCR? Популярные варианты использования OCR
Вероятно, наиболее известный вариант использования OCR — это преобразование печатных бумажных документов в машиночитаемые текстовые документы.После того, как отсканированный бумажный документ проходит обработку OCR, текст документа можно редактировать с помощью текстовых процессоров, например:
- Microsoft Word
- Google Docs
До появления технологии OCR единственным вариантом оцифровки печатных бумажных документов была путем повторного ввода текста вручную. Это не только занимало много времени, но и сопровождалось неточностями и опечатками.
OCR часто используется как «скрытая» технология, на которой работают многие известные системы и услуги в нашей повседневной жизни.Менее известные, но не менее важные варианты использования технологии OCR включают автоматизацию ввода данных, индексацию документов для поисковых систем, автоматическое распознавание номерных знаков, а также помощь слепым и слабовидящим людям.
Технология оптического распознавания символов оказалась чрезвычайно полезной при оцифровке исторических газет и текстов, которые теперь были преобразованы в форматы с полной возможностью поиска и сделали доступ к этим более ранним текстам проще и быстрее.
Используют ли банки оптическое распознавание символов (OCR)?В этом быстро меняющемся мире банк является одним из тех учреждений, которые чаще всего используют OCR.Оцифровка документов в банковском секторе очень полезна. Многие банки используют технологию OCR для повышения безопасности транзакций и управления рисками.
Использование программного обеспечения OCR в банках также позволяет сканировать важные рукописные гарантийные документы многих клиентов, такие как их кредитные документы и многое другое. Кроме того, включение программного обеспечения распознавания лиц с оптическим распознаванием текста также значительно примечательно, поскольку оно обеспечивает двухуровневую безопасность банкоматов.
Ищете программу распознавания текста? Попробуйте Docparser
Docparser — это надежный программный инструмент для распознавания текста с возможностью синтаксического анализа текста из PDF, DOC, DOCX и т. Д.Просто отсканируйте распечатанный документ и отправьте его в свою учетную запись Docparser. Установив правила синтаксического анализа, вы сможете извлекать нужный текст прямо из исходных документов и отправлять проанализированные данные сотням наших партнеров по интеграции, включая Excel, Google Таблицы и многие другие. Попробуйте бесплатно.
Автор: Джошуа Харрис
Привет, я Джошуа. Каждый день я общаюсь с людьми, использующими наш инструмент, чтобы научиться делать его лучше. Разберите несколько PDF-файлов и дайте мне знать, что вы думаете.Просмотреть все сообщения Джошуа Харриса
Что такое OCR? Введение в оптическое распознавание символов
Оптическое распознавание символов (OCR) определяет процесс механического или электронного преобразования сканированных изображений рукописного, набранного или напечатанного текста в машинно-кодированный текст. Думайте об этом как о процессе преобразования аналоговых данных в цифровые.
Из этой вводной статьи вы узнаете о:
- Что такое технология OCR?
- Как работает оптическое распознавание символов?
Вам не нужно быть опытным разработчиком или техническим специалистом, чтобы узнать, что такое OCR, и понять, как оно работает.Здесь мы собираемся объяснить технологию с минимальным количеством технического жаргона.
Если вы уже знаете, что такое OCR, просто перейдите к разделу о том, как оно работает, или начните с примеров того, что вы можете делать с этой технологией.
Что такое OCR?
Поскольку OCR означает оптическое распознавание символов, технология OCR решает проблему распознавания всех видов различных символов. И рукописные, и печатные символы могут быть распознаны и преобразованы в машиночитаемый формат цифровых данных.
Придумайте любой серийный номер или код, состоящий из цифр и букв, которые вам нужно оцифровать. Используя OCR, вы можете преобразовать эти коды в цифровой выход. В этой технологии используется множество различных техник. Проще говоря, сделанное изображение обрабатывается, символы извлекаются, а затем распознаются.
OCR не учитывает фактическую природу объекта, который вы хотите сканировать. Он просто «смотрит» на персонажей, которых вы хотите преобразовать в цифровой формат.Например, если вы отсканируете слово, оно узнает и распознает буквы, но не значение слова.
Шаг 3. Постобработка в OCR
Постобработка — это еще один метод исправления ошибок, обеспечивающий высокую точность распознавания текста. Точность можно еще больше повысить, если ограничить вывод лексиконом. Таким образом, алгоритм может вернуться к списку слов, которые могут встречаться, например, в отсканированном документе.
OCR используется не только для определения правильных слов, но также может считывать числа и коды.Это полезно для идентификации длинных цепочек цифр и букв, например серийных номеров, используемых во многих отраслях промышленности.
Чтобы лучше справляться с различными типами входного OCR, некоторые поставщики начали разрабатывать специальные системы OCR. Эти системы могут работать со специальными изображениями, а для повышения точности распознавания, даже более того, они объединили различные методы оптимизации.
Например, они использовали бизнес-правила, стандартные выражения или обширную информацию, содержащуюся в цветном изображении.Эта стратегия объединения различных методов оптимизации называется «ориентированным на приложения» или «настраиваемым ОРС». Он используется в таких приложениях, как OCR для визитных карточек, OCR для счетов и OCR для идентификационных карт.
Примеры использования технологии OCR
Возможности использования программного обеспечения для оптического распознавания символов широко распространены, поскольку OCR можно комбинировать с широким спектром технологий. Вот несколько примеров возможных вариантов использования, включая программное обеспечение для оптического распознавания текста:
2. Маркетинговые кампании с OCR
Ведущие бренды используют OCR для проведения инновационных и увлекательных кампаний, направленных на привлечение клиентов.Подумайте обо всех кодах ваучера, которые клиенты могут погасить, введя их. Или о числах, напечатанных на внутренней стороне крышки от бутылки, которые вам нужно забрать.
Все эти кампании могут использовать OCR путем интеграции программного обеспечения, которое легко интегрируется в веб-сайты и приложения компании. Таким образом, они сводят к минимуму трудности, связанные с онлайн-регистрацией, и избавляют клиентов от необходимости вводить ряд цифр и букв.
Посмотрите, как PepsiCo использует OCR в одной из своих маркетинговых кампаний в Турции для сканирования кодов ваучеров внутри пакетов своих популярных чипов, таких как Lays, Ruffles и Doritos:
Инструменты оптического распознавания текста
Существует множество программ оптического распознавания текста, которые специализируются на одном конкретном сценарии использования, таком как сканирование кредитных карт или сканирование документов.Но OCR может быть полезным во многих сферах нашей жизни. Компаниям часто требуется сочетание решений OCR, и поэтому лучше работать с поставщиками, которые могут выполнять несколько видов сканирования.
Подробнее о технологии оптического распознавания текста
Anyline OCR SDK и демонстрационные приложения
Технология мобильного сканированияAnyline доступна для интеграции в ваше мобильное приложение или веб-сайт в виде кроссплатформенного OCR SDK (комплект для разработки программного обеспечения). Протестируйте наши решения на Android, iOS, Windows и других платформах и устройствах уже сегодня.Приложение Anyline OCR для мобильного сканирования может быть легко интегрировано в любое приложение или на любой веб-сайт. Загрузите наш SDK OCR и получите бесплатную 30-дневную пробную версию, чтобы увидеть, как решения OCR и технология мобильного сканирования оптимизируют рабочие процессы и бизнес-процессы.
Наша демонстрация SDK для мобильного сканирования включает доступ ко всем следующим решениям оптического распознавания текста:
Anyline SDK предоставляет решения для мобильного сканирования с оптическим распознаванием текста для многих различных отраслей и широкого спектра различных сценариев использования.
OCR Сканирование | Scanbot
Термин OCR является сокращением от «Оптического распознавания символов.«Поскольку эта новая технология постоянно упоминается в отношении управления документами и автоматизации документов, у вас может возникнуть один вопрос: что такое оптическое распознавание символов? И как я могу получить пользу от этой функции? Вкратце, оптическое распознавание символов означает процесс обнаружения текста в цифровых изображениях с использованием очень сложных алгоритмов компьютерного зрения. Он превращает документы в PDF за секунды!
Как работает OCR?
Оптическое распознавание символов — это технология обработки изображений, которая обеспечивает удобный способ извлечения данных из бумажных документов и преобразования их в цифровой формат.Во время этого процесса алгоритм распознает символы в печатных документах и создает PDF-файлы с возможностью поиска и редактирования. Часто применяется в рабочих процессах автоматизации бизнес-процессов.
Каковы преимущества использования программного обеспечения OCR?
Оцифровка документов с помощью OCR на устройстве значительно увеличивает производительность. А именно, автоматическая обработка данных ускоряет ваш рабочий процесс до 40 раз по сравнению с ручным вводом информации, содержащейся в ваших документах.Более того, использование таких решений повышает стандарты безопасности, поскольку дорогостоящее и часто небезопасное локальное хранилище конфиденциальных данных становится избыточным.
Зачем вам нужен OCR SDK, чтобы упростить рабочие процессы?
В настоящий момент вы, вероятно, тратите огромное количество времени и ресурсов на захват или обработку тысяч документов. Используя Scanbot OCR Scanner SDK, вы можете повысить свою продуктивность и оптимизировать бизнес-процессы. Большинство SDK можно настроить в соответствии с вашими потребностями, что делает его гибким, быстрым и простым решением для различных отраслей, таких как банковское дело, страхование, логистика, бухгалтерский учет или здравоохранение.
Еще одно преимущество: после сканирования бумажного документа вам не придется беспокоиться о неэффективных и дорогостоящих вариантах хранения физической копии!
Правильно ли программное обеспечение, предоставляемое Scanbot SDK?
Точность извлечения критически важна для получения безупречных цифровых форматов и включения функций поиска. Поскольку Scanbot SDK включает такие технологии, как машинное обучение, для оптимизации распознавания и извлечения данных, это идеальный выбор для выполнения этой задачи.Тем не менее, высокая точность начинается еще до того, как будет выполнено сканирование. Наша система пользовательского руководства обеспечит наилучшее качество, чтобы гарантировать вам идеальное распознавание текста.
Поддерживает ли Scanbot OCR SDK различные языки?
В международной деловой среде способность распознавать и обрабатывать большое количество языков имеет важное значение при выполнении распознавания текста в документе. В настоящее время большинство решений могут распознавать более 100 языков, но ограничены латинскими символами.SDK Scanbot дополнительно поддерживает различные арабские и азиатские языки.
Вы заинтересованы в интеграции OCR SDK в свой рабочий процесс? Ознакомьтесь со следующей информацией о различных решениях, ценах и интеграции.
Офлайн и онлайн-решения
Офлайн-решения основаны на распознавании и хранении документов только на устройстве. Поэтому они соблюдают стандарты обработки данных, такие как GDPR / DSGVO. Это очень важно для обработки конфиденциальных данных в страховом или банковском секторе.Благодаря гибкости SDK его нельзя использовать просто как автономное решение. Ваши разработчики могут реализовать его в любом приложении и сделать возможным обмен документами в Интернете или заблокировать эту опцию, чтобы предотвратить проблемы с конфиденциальностью.
Как интегрировать Scanbot OCR SDK в свой рабочий процесс?
SDK сканера OCR можно легко интегрировать в существующее мобильное приложение. В зависимости от платформы разработки внедрение занимает всего три рабочих дня и обеспечивает плавную и быструю интеграцию.
Объем и решения с фиксированной ставкой
Модели объема и фиксированной ставки являются наиболее распространенными моделями ценообразования для SDK распознавания текста (OCR). В то время как объемные модели взимают цену за документ или пользователя плюс плату за установку, решения с фиксированной ставкой относятся к установленной цене независимо от количества отсканированных документов. Таким образом, при оцифровке больших или непредсказуемых объемов документов модель ценообразования с фиксированной ставкой позволяет работать с заранее определенным бюджетом. Чтобы гарантировать прозрачность и расчет затрат, мы предлагаем исключительно фиксированные решения без скрытых комиссий, исходя из вашего личного бюджета.
Заинтересовались ли мы этой статьей об оптическом распознавании символов и преимуществах внедрения технологии оптического распознавания текста в ваше приложение? Тогда не стесняйтесь обращаться к нашему менеджеру по продажам для получения дополнительной информации. Мы будем рады обсудить ваши идеи. Если вы хотите узнать больше об использовании распознавания текста в страховой отрасли, ознакомьтесь с этим сообщением в блоге .
Вы можете сканировать документ и преобразовывать текст в формат, который можно редактировать с помощью текстового редактора.Этот процесс называется OCR (оптическое распознавание символов). Чтобы сканировать и использовать OCR, вам необходимо использовать программу OCR, такую как программа ABBYY FineReader, поставляемая вместе со сканером. Программа оптического распознавания текстане может распознать или испытывает трудности с распознаванием следующих типов документов или текста. Рукописные символы Элементы, скопированные с других копий Факсы Текст с короткими интервалами или межстрочным интервалом Табличный или подчеркнутый текст Курсивные или курсивные шрифты и размер шрифта менее 8 пунктов См. Один из этих разделов, чтобы сканировать и преобразовывать текст с помощью ABBYY FineReader. Офисный режим : Преобразование в редактируемый текст в офисном режиме Стандартный режим : Преобразование в редактируемый текст в простом режиме Профессиональный режим : Преобразование в редактируемый текст в профессиональном режимеПреобразование в редактируемый текст в офисном режиме
Mac OS X : Выберите Приложения > ABBYY FineReader 5 Sprint Plus и дважды щелкните значок Запустить FineReader 5 Sprint .
Преобразование в редактируемый текст в простом режиме
Mac OS X : Выберите Приложения > ABBYY FineReader 5 Sprint Plus и дважды щелкните значок Запустить FineReader 5 Sprint .
Преобразование в редактируемый текст в профессиональном режиме
Mac OS X : Выберите Приложения > ABBYY FineReader 5 Sprint Plus и дважды щелкните значок Запустить FineReader 5 Sprint .
|
Оптическое распознавание символов | Как OCR помогает при чтении? | Разобрался
Ответ:
Оптическое распознавание символов (OCR) играет важную роль в преобразовании печатных материалов в цифровые текстовые файлы. Эти цифровые файлы могут быть очень полезны детям и взрослым, которым трудно читать.Это связано с тем, что цифровой текст можно использовать с программами, поддерживающими чтение различными способами.
OCR был впервые представлен в 1990-х годах. Перенесемся в сегодняшний день, и вы обнаружите, что OCR встроено в программное обеспечение многих программ и устройств, включая некоторые компьютеры, планшеты, телефоны и принтеры. Многие из этих устройств могут автоматически преобразовывать отсканированный или сфотографированный документ в цифровой текст.
Но прежде чем мы углубимся в OCR, давайте поговорим немного о цифровом тексте.
Цифровой текст — один из нескольких форматов, которые делают печатную информацию доступной для большего числа людей. (Другие форматы включают аудио, крупный шрифт и шрифт Брайля.) Цифровой текст особенно полезен для читателей, испытывающих трудности, включая тех, кто имеет различия в обучении, такие как дислексия. Цифровой формат позволяет читателям видеть слова на экране и одновременно слышать их чтение вслух. Это дает больше способов взаимодействия с информацией. Это также может помочь детям развить навыки самостоятельного чтения.
Какая связь между напечатанным на бумаге, цифровым текстом и оптическим распознаванием текста? Один из способов преобразовать печатный материал в цифровой — использовать сканер. Сканер создает фотографию отпечатанного материала. Эту фотографию, часто называемую изображением, можно отобразить на устройстве с экраном.
Но сканирование — это только первый шаг. Фотография сама по себе не позволяет программам выделять слова или добавлять другие функции, которые могут помочь вашей дочери в чтении. Здесь на помощь приходит OCR.
OCR «смотрит» на фотографию (поэтому его название начинается с «оптического») и распознает формы различных букв, цифр и других символов. Он использует распознавание символов для преобразования фотографии документа в текстовый файл. Во многих случаях цифровая версия сохраняет «внешний вид» оригинала.
OCR позволяет вносить изменения в цифровой текст. Что можно сделать с цифровым текстом, зависит от того, какое программное обеспечение для чтения вы используете. Общие варианты включают:
Выделение слов, предложений или абзацев
Произнесение слов вслух с помощью преобразование текста в речь
Изменение цветов и размера текста
Размещение цифровых «закладок», которые позволяют пользователям перемещаться по тексту (например, переходить непосредственно от содержания к главе четвертой)
По сути, OCR позволяет вам вносить изменения в отсканированный документ и перемещаться с места на место внутри него — так же, как вы можете с любым текстовым документом на вашем компьютере.
Допустим, у вашей дочери есть лист с домашним заданием, который она с трудом читает. Вы можете отсканировать и преобразовать лист с домашним заданием в цифровой текст. Вы можете узнать, как это сделать, посмотрев обучающие материалы на YouTube. (Введите термин «оптическое распознавание символов» в поле поиска.) После преобразования листа в цифровой файл она сможет использовать инструменты на своем компьютере, чтобы помочь ей прочитать его.
Но прежде чем она нырнет, тебе нужно сделать еще кое-что. Внимательно просмотрите весь документ и исправьте все ошибки, которые могло быть допущено программой распознавания текста.Это может занять лота и усилий, если вы сканируете длинный документ. Но это важный шаг в процессе. Без такой проверки цифровой файл может оказаться не очень полезным для вашего ребенка.
Также неплохо узнать, создал ли кто-нибудь уже цифровую версию. Например, Bookshare и Learning Ally имеют большие библиотеки книг и других материалов, преобразованных в цифровые текстовые и / или аудиоформаты. Эти тексты «очищены» и готовы к использованию.
Спросите также в школе или местной библиотеке вашего ребенка о доступных форматах. Если сначала проконсультироваться с этими организациями, время, которое вы сэкономите на сканировании и проверке документов, может освободить вас, чтобы тратить больше времени на помощь дочери в других важных делах.
Вперед и вперед к самостоятельному чтению без стресса для вашей дочери!
7 способов преобразования изображений в текст с помощью OCR
В нашу цифровую эпоху нередко приходится сталкиваться с необходимостью извлекать текст из изображения, чтобы сделать его редактируемым.Это особенно верно из-за нашей зависимости от бумажных документов, которые можно редактировать в цифровом виде только с помощью программного обеспечения OCR.
Оптическое распознавание символов (OCR) — это технология распознавания образов на основе ИИ, позволяющая идентифицировать текст внутри изображения и превращать его в редактируемый цифровой документ. Если вам когда-нибудь понадобится сделать редактируемые цифровые данные, такие как квитанции, счета-фактуры или банковские выписки, обычно в формате изображения, то программное обеспечение OCR может вам помочь.
К счастью, многие инструменты позволяют использовать технологию распознавания текста для извлечения текста из изображений.Если вы хотите преобразовать изображения в текст на ПК, телефоне или в Интернете, для этого есть инструмент.
В этом посте будут перечислены несколько инструментов распознавания текста, которые помогут вам извлекать текст из изображений на разных устройствах. В зависимости от ваших потребностей, вам подойдет один из этих инструментов.
№1. Преобразование изображений в текст онлайн
В Интернете есть множество инструментов OCR, которые позволят вам извлекать текст из изображений на любом устройстве. Все, что вам нужно, это браузер и подключение к Интернету, чтобы начать использовать этот инструмент (как на ПК, так и на мобильном телефоне).Я пробовал много онлайн-инструментов OCR, и New OCR дал наилучшие результаты для всех изображений, которые я использовал. Услуга полностью бесплатна и очень проста в использовании.
Просто нажмите Выберите файл и загрузите изображение.
После этого щелкните Preview , а затем щелкните OCR , чтобы обработать изображение.
Извлеченный текст будет отображаться ниже в редактируемом текстовом поле, и вы можете либо скопировать его, либо загрузить как файл TXT, Doc или PDF.
По моему опыту, инструмент извлекал текст без ошибок и отлично копировал формат и интервалы. Однако он не распознает шрифты и размер текста, поэтому весь текст является простым.
Инструмент также поддерживает извлечение текста на 122 языках, и вы можете извлекать текст из JPG, PMG, PGM, GIF, BMP, TFF, PDF и DjVu.
№2. Используйте Документы Google для извлечения текста из изображений
Если вы уже используете Google Docs для создания документов, вам не нужны никакие другие инструменты для извлечения текста из изображений.В версии Google Docs для настольных ПК вы можете загрузить изображение и использовать встроенную технологию распознавания текста для извлечения текста из изображения.
Вот как это сделать:
Откройте Google Диск и войдите в систему.
Щелкните New и выберите в меню File Upload , чтобы загрузить свое изображение.
После загрузки щелкните изображение правой кнопкой мыши и выберите Google Docs из параметра Открыть с помощью .
Вот и все; изображение откроется в Документах Google с извлеченным текстом прямо под изображением.
Интересно, что Google Docs пытается определить размер, тип и даже цвет шрифта для каждого слова. Также соблюдаются форматирование и интервалы.
Хотя он работал нормально для большинства протестированных мной изображений и правильно извлекал текст с небольшими ошибками форматирования, он действительно испортил одно из изображений квитанции. Размер и цвет шрифта полностью отличался от изображения, что делало его очень некрасивым. К счастью, такую ошибку легко исправить, выделив весь текст и выбрав шрифт по умолчанию.
Из всех протестированных мною инструментов распознавания текста Документы Google показали наилучшее извлечение текста, максимально приближенного к изображению.
№3. Преобразование изображений в текст в Windows
Если вы предпочитаете конвертировать изображения на ПК с Windows, тогда доступно множество инструментов распознавания текста. Easy Screen OCR — это выдающееся программное обеспечение для распознавания текста для Windows, которое обеспечивает точное извлечение текста. Это небольшой инструмент размером всего 7 МБ, который работает из панели задач. Вы можете сделать новый снимок экрана для извлечения текста или загрузить файл изображения.
Чтобы использовать его, щелкните правой кнопкой мыши его значок на панели задач и выберите Image OCR .
Откроется небольшое окно, в котором вы можете перетащить изображение, и оно автоматически обработает его. Извлеченный текст отобразится в новом разделе, где вы можете его скопировать.
Инструмент определенно очень точно извлекает текст, но не учитывает форматирование или шрифты. Вы получите простой текст с размером и интервалом по умолчанию. Вы не можете экспортировать текст в документ; есть кнопка Копировать , чтобы скопировать весь извлеченный текст.
К сожалению, бесплатная версия Easy Screen OCR имеет только ограниченное количество бесплатных сканирований; вам нужно будет получить подписку pro для неограниченного использования. Если вы ищете совершенно бесплатный инструмент OCR для Windows, стоит попробовать FreeOCR. Это неплохо, но я заметил небольшие ошибки при извлечении текста. Хотя он работает и в автономном режиме, так что это может быть именно то, что вам нужно.
№4. Извлечение текста из изображений на Android
Существует множество приложений для Android, позволяющих преобразовывать изображения в текст.Не только это, но вы также можете сканировать текст на ходу, поскольку все телефоны Android имеют встроенные камеры. Сканер текста — мое любимое приложение для распознавания текста для Android, поскольку оно позволяет извлекать текст из изображений в автономном режиме. Он также предлагает неограниченное количество бесплатных сканирований на нескольких языках.
Единственным существенным недостатком является реклама бесплатной версии, которая может быть очень навязчивой, но вы можете использовать ее без Интернета, чтобы избежать рекламы, поскольку она работает в автономном режиме. Вы также можете перейти на профессиональную версию, чтобы удалить рекламу и ускорить обработку.
В правом верхнем углу приложения есть кнопка для выбора изображений из галереи и кнопка в правом нижнем углу для использования камеры для создания текстовой фотографии. Используйте любой из этих вариантов для загрузки фотографии, и приложение автоматически обработает и покажет извлеченный текст. Вы можете переключаться между текстом и изображением, используя кнопки внизу, чтобы сравнивать их.
Text Scanner отлично извлекал текст из всех изображений, которые я пробовал, без каких-либо ошибок. Однако он использовал шрифты по умолчанию и не пытался копировать форматирование, как большинство других инструментов распознавания текста.Вы также не можете экспортировать извлеченный текст в конкретный формат документа, и есть только возможность скопировать или поделиться текстом.
№ 5. Используйте расширение OCR Chrome
Если вы особенно хотите извлекать текст из изображений в Интернете, вам может помочь расширение Chrome. Мне нравятся два расширения для этой цели: Copyfish и Project Naptha. Из этих двух мне больше всего нравится Project Naptha, поскольку он автоматически делает выбираемым весь текст внутри изображений в Интернете.
Вам не нужно ничего делать, просто установите расширение, и оно сделает каждое изображение в Интернете доступным для выбора.Когда вы найдете изображение с текстом внутри, удерживайте нажатой левую кнопку мыши, чтобы выбрать и скопировать его. Конечно, он не идеален для извлечения, но с изображениями, которые я использовал, он работал нормально. У него даже есть возможность перевести выделенный текст, если вы хотите.
Если вместо этого вы хотите сканировать и конвертировать изображения по запросу, то Copyfish — гораздо лучший вариант. После установки Copyfish вы можете нажать на кнопку расширения, чтобы открыть инструмент для выбора местоположения текста, который вы хотите извлечь. Как только область выбрана, Copyfish скопирует изображение выделенной области в своем интерфейсе, а затем использует OCR для извлечения текста.
Извлеченный текст можно скопировать с помощью специальной кнопки. Вы даже можете перевести его, используя кнопку, чтобы открыть текст напрямую в Google Translate. Для достижения наилучших результатов убедитесь, что изображение открыто с максимально возможным разрешением, так как Copyfish просто делает снимок экрана, поэтому лучшее качество изображения обеспечит более точное извлечение.
№6. Преобразование изображений в текст на Mac
Честно говоря, для macOS не так много хороших инструментов распознавания текста. Если вы хотите использовать хорошее программное обеспечение для оптического распознавания текста для macOS, вам потребуется платное.Readiris — один из самых мощных инструментов распознавания текста для macOS, но это больше, чем просто инструмент распознавания текста. Это полноценный инструмент для создания и редактирования PDF-файлов с множеством расширенных функций для извлечения текста из PDF-файлов и изображений.
Инструмент поставляется с пробной версией, которая дает доступ ко всем функциям в течение 10 дней. Если вам нравится этот инструмент, вы можете купить одну из профессиональных версий в зависимости от ваших потребностей. Вы можете использовать Readiris для извлечения из изображений / PDF-файлов, сохраненных на вашем компьютере, или делать снимки экрана любого изображения и извлекать из него текст.
Помимо извлечения, вы можете комментировать PDF-файлы, добавлять голосовые комментарии, разделять / объединять PDF-файлы, добавлять водяные знаки, сохранять отсканированные изображения в Интернете, преобразовывать текст в аудио и многое другое. Если вам нужны и инструмент OCR, и менеджер PDF, Readiris стоит вложения.
Если вам нужен более дешевый инструмент распознавания текста для Mac, то стоит попробовать и Picatext. Всего за 3,99 доллара вы можете извлекать текст из сохраненных изображений или новых снимков экрана. Извлеченный текст автоматически копируется и легко вставляется куда угодно, и у вас даже есть возможность выбрать шрифт по умолчанию.
№ 7. Используйте приложение OCR для iOS
Scanner Pro — одно из лучших приложений для оптического распознавания текста и сканирования документов для iOS. Большинство функций приложения доступны бесплатно, но, к сожалению, вам придется оформить подписку Plus за 19,99 долларов в год, чтобы использовать функцию преобразования изображения в текст.
Основная функция приложения — сканировать бумажные документы и сохранять их в виде файлов PDF с идеальным форматированием. Его профессиональная подписка позволяет извлекать текст из этих сканированных изображений. Бесплатная версия сканирует документы, но сохраняет их с водяным знаком.
Еще одна интересная функция — это текстовый поиск, который позволяет искать изображения, используя текст внутри изображения. Сюда входят все отсканированные изображения и файлы PDF, которыми вы поделились.
Если вам нужно более простое и бесплатное приложение OCR для iOS, стоит попробовать OCR на английском языке. Он позволяет либо делать фотографии документов для обработки, либо загружать фотографии из хранилища. Все функции приложения бесплатны, но вы можете получить профессиональную версию без рекламы.
Подведение итогов
Лично мне не нужно слишком часто извлекать текст из изображений, но я всегда использую онлайн-инструмент оптического распознавания текста, когда это нужно.Онлайн-инструменты можно использовать с любого устройства, их не нужно загружать, поэтому они идеально подходят для периодического использования. Я также рекомендую использовать инструмент Google Docs OCR, если у вас сложное изображение с другим форматированием и шрифтами. По моему опыту, Google Docs лучше всех скопировал текст в его исходной форме.
Как оптимизировать и улучшить результаты оптического распознавания символов (OCR)
Автоматическое распознавание текста на изображениях или отсканированных документах с помощью оптического распознавания символов (OCR)
Текст, хранящийся в графических форматах, таких как JPG, PNG, TIFF или GIF (т.е.е. сканы, фотографии или скриншоты) не могут быть найдены стандартным полнотекстовым поиском. Таким образом, этот усилитель обогащает метаданные изображений, такие как имя файла, формат и размер, результатами автоматического распознавания текста или оптического распознавания символов (OCR) с помощью бесплатного программного обеспечения OCR с открытым исходным кодом, такого как Tesseract.
Поскольку большая часть информации недоступна для поиска с помощью полнотекстового поиска, поскольку она находится в графических форматах, встроенных в документы PDF или презентации Powerpoint (т.е. снимки экрана вместо текстового формата), средство улучшения также извлекает изображения из файлов PDF для автоматического распознавания текста (OCR).
Включить OCR
OCR включено по умолчанию в пакетах Debian и Ubuntu, а также в пакетах виртуальных машин, таких как Open Semantic Desktop Search или Open Semantic Search Appliance. Если вы строите свою поисковую систему из открытого исходного кода, включите OCR, установив программное обеспечение с открытым исходным кодом Tesseract OCR.
Если вы отключили / включили OCR, вам следует также отключить / включить OCR для изображений в файлах PDF, поскольку многие файлы PDF сканируются и содержат много текстовых данных только в виде графики.
Как оптимизировать настройки OCR для улучшения результатов OCR
Вы можете оптимизировать OCR, чтобы найти больше различными способами, которые можно комбинировать для получения оптимальных результатов OCR с меньшим количеством ошибок OCR:
Разрешение сканирования
При самостоятельном сканировании документов отсканируйте или сохраните изображения с более высоким разрешением, чтобы система распознавания текста могла анализировать более подробную информацию о символах.
Язык словаря
Так как OCR использует словарь для конкретного языка, установите язык OCR на свой язык или на несколько языков, которые используются в ваших документах.
Дополнительные пользовательские словарные статьи OCR из тезауруса и онтологий
Полностью интегрирован «из коробки» в следующем выпуске с открытым исходным кодом:
Понятия, слова и имена названных объектов, таких как организации, места, места или лица, которые важны для вас, поэтому вы добавили их в свой тезаурус или которые включены в списки имен или онтологий (например, списки имен соответствующих лиц из внутренних источники метаданных или из открытых источников данных, таких как Викиданные), которые вы определили для фасетного поиска / интерактивных фильтров и / или аналитики / агрегированных обзоров, также лучше распознаются OCR отсканированных документов.
Таким образом, ваши дополнительные знания в предметной области / словарь из тезауруса, списков и онтологий используются дополнительно к словарю Tesseract OCR для конкретного языка OCR.
Поскольку во многих отсканированных устаревших файлах на бумаге имена полностью написаны заглавными буквами, этот автоматически созданный пользовательский словарь OCR / список слов OCR также включает вариант каждого слова в верхнем регистре.
Таким образом, вам следует подумать о том, чтобы перестроить ваши важные файлы индекса / переиндексации принудительно (чтобы они снова анализировались и переиндексировались, даже если еще в индексе) после добавления очень важных слов или имен в тезаурус или предоставляемых (новыми или измененными) онтологиями.
Отключить использование словарей и списков слов
Результаты OCR для неизвестных имен, которых нет в таких управляемых списках или словарях, лучше, если использование словарей и списков выключено.
Если у вас достаточно ресурсов ЦП при индексировании, вы можете объединить результаты обеих настроек, чтобы проиндексировать больше имен или слов из отсканированных документов с правильным написанием, поскольку поисковая система найдет все результаты как различных, так и технически оппонентов стратегий распознавания текста.
Автоматическое выравнивание и вращение сканов низкого качества перед OCR
Многие документы сканируются с перекосом.
Автоматическое выравнивание сканов такого низкого качества с помощью Scantailor до того, как OCR может улучшить результаты OCR.
Следовательно, подключаемый модуль Scantailor включен, если не отключен из-за проблем с производительностью.
Обучающие символы и шрифты
Вы можете обучить механизм OCR с помощью специальных шрифтов, используемых в ваших документах, чтобы улучшить модель машинного обучения для распознавания символов этих шрифтов.
Как управлять ошибками и сбоями OCR
Несмотря на всю эту оптимизацию, автоматическое распознавание символов может давать сбой и возникать ошибки OCR, такие как неправильно распознанные слова или имена.
Таким образом, существуют интегрированные инструменты для ручной обработки и управления сбоями OCR на уровне документа для отдельных документов или на мета уровне для всех документов:
Обработка сбоев OCR с помощью совместной маркировки и аннотации
Для отдельных документов с ошибками OCR вы можете добавить аннотации или теги со словами, которые были неправильно распознаны механизмом OCR, чтобы поисковая система могла найти их, несмотря на эти ошибки OCR, из-за правильного написания тегов или аннотаций.
Управление сбоями распознавания текста с помощью тезауруса (скрытые метки)
Управление общими сбоями OCR для всех документов с помощью записей тезауруса для управления ошибками OCR (скрытые метки)
Поскольку вы обрабатываете этот сбой OCR на мета уровне, исправление может быть автоматически применено к новым документам с такими же неверно распознанными словами или именами.
Рекомендатель может анализировать корпус на предмет опечаток / ошибок распознавания текста в записи тезауруса и рекомендовать такие орфографические ошибки для добавления в тезаурус в качестве скрытой метки одним щелчком мыши.
Объединение результатов OCR нескольких инструментов OCR
Нет идеального механизма распознавания текста.
Итак, в некоторых проектах мы использовали, например, Abby Finereader для распознавания изображений в PDF-файлах и дополнительно к встроенному Tesseract OCR. Каждый из них распознал слова или имена, на которых не удалось выполнить другое программное обеспечение OCR.
Ваш комментарий будет первым