4 программы для распознавания текста
Знакомство с интерфейсом компьютерных игр и прикладного программного обеспечения может обернуться настоящей головной болью, если вы не знаете языка, который в этом самом интерфейсе используется. Нельзя вот так просто взять и скопировать текст меню в буфер обмена и вставить его в поле переводчика как это обычно мы делаем с текстом документов или веб-сайтов.
К счастью существуют утилиты позволяющие захватывать текст непосредственно с рабочего стола, то есть с изображений и элементов интерфейса. Как и ABBYY FineReader, являющейся одной из самых известных программ для распознания текста, эти утилиты используют технологию OCR. А вот и примеры.
Screenshot Reader
Замечательный коммерческий продукт от компании ABBYY. Утилита позволяет захватывать текст с изображений и преобразовывать его в редактируемый текст. Приложением поддерживается захват выделенной области, экрана, окна.
Извлекать можно не только текст, но и таблицы с последующим экспортом в файл, буфер обмена или Excel.
А еще Screenshot Reader умеет сохранять скриншоты и пересылать их по электронной почте. В общей сложности приложением поддерживается 179 языков. Утилита отличная, но использовать ее лучше вместе с родной ABBYY FineReader.
Capture2Text
Бесплатная портативная программка для распознавания текста. Работает программа с выделенной областью. Поддерживается более 30 языков, однако по умолчанию присутствуют только шесть языков, а именно английский, французский, немецкий, испанский, китайский и японский.
Файлы для русского и прочих языков нужно загружать отдельно с сайта разработчика.
Capture2Text также поддерживает распознание речи, правда особо высоким качеством распознания она похвастать не может. Из недостатков также можно отметить не очень удобный интерфейс.
SimpleOCR
Предназначается эта программа для работы с отсканированными документами, а вот с десктопа похоже захватывать текст она не умеет, по крайней мере, соответствующей опции мне так и не удалось найти.
Русского языка я тоже не нашел, попытка распознать кириллический текст также не увенчалась успехом. В общем SimpleOCR можно представить как некое подобие ABBYY FineReader или лучше сказать пародию на FineReader.
Из достоинств отметить можно разве что низкие требования к системе, малый вес и умение сохранять форматирование исходного файла.
FreeOCR
Еще один аналог FineReader (заметьте именно аналог, а не подобие), который мне так и не удалось установить. По какой-то причине мой Avast заблокировал загрузку файлов программы (устанавливается FreeOCR через веб-инсталлятор) и, в общем, на этом все и завершилось.
Судя по описаниям, работает FreeOCR с уже существующими файлами, то есть захватывать скриншоты как это умеет делать Screenshot Reader программа не может.
Русский язык по умолчанию отсутствуют, загружать и устанавливать языковой пакет нужно отдельно. Несомненным плюсом FreeOCR является бесплатность и простота использования.
Итог
Так что если вам нужна хорошая распознавалка, выбирайте Screenshot Reader, не пожалеете, а еще лучше установить полный пакет ABBYY FineReader.
Стоит этот продукт немало, с другой стороны найти «обработанную» рабочую версию не составит особого труда.
Зачем нужна программа распознавания текста. — Энциклопедия современных знаний
Программа распознавания текстов FineReader, версии от 6 до 11.
В этом уроке мы рассмотрим конструкцию сканера и общие правила сканирования и распознавания текста при помощи программы ABBY Fine Reader. При создании урока использован опыт работы с версиями программы Fine Reader от 6 до 11.
Как устроен сканер.
Бытовой сканер – это оптико-механическое электронное устройство. Механизм сканера помещается в герметический корпус, стеклянный сверху. На это стекло кладётся сканируемый лист или книга в развороте. Под стеклом ездит очень яркая продольная лампа, освещающая сканируемый лист. Вместе с лампой ездит узкое продольное зеркало. Это зеркало постоянно изменяет угол своего наклона так, чтобы проецировать освещённую полоску изображения на продольный фотосчитыватель, расположенный неподвижно на задней стенке сканера.
Это зеркало постоянно изменяет угол своего наклона так, чтобы проецировать освещённую полоску изображения на продольный фотосчитыватель, расположенный неподвижно на задней стенке сканера.
Теперь становится понятным, что изображение считывается сканером в виде тонких ниточек. Каждая ниточка – это цепочка точек. Ниточки распознанных точек постоянно передаются сканером в компьютер. И уже драйвер сканера складывает из этих ниточек изображение и передаёт его запросившей программе в виде графического файла.
Немного упрощённая модель бытового сканера, но зато всё должно стать понятным.
Раньше сканеры подключались к компьютеру через LPT-порт. Но затем скорости этого порта стало не хватать, и сканеры начали подключать через более скоростной USB-порт.
Сканирование одной страницы у хорошего сканера должно занимать до 20 секунд.
После сканирования страницы лампа и зеркало сканера возвращаются на исходную позицию. Это называется обратным ходом сканера. Во время обратного хода можно переворачивать и менять страницы. Современный компьютер успевает за время обратного хода распознать отсканированную страницу.
Современный компьютер успевает за время обратного хода распознать отсканированную страницу.
Крышку сканера при сканировании текста закрывать не обязательно.
Параметры сканирования.
Сканер выдаёт нам картинку. Эта картинка состоит из набора цветных или чёрно-белых точек, для каждой из которых сканер распознаёт цвет.
Плотность распознаваемых точек называется разрешающей способностью сканера. Максимальная разрешающая способность ограничена оптическими возможностями сканера. Разрешение сканера можно регулировать программным путём. Уменьшение разрешения ускоряет работу сканера.
Разрешающая способность измеряется количеством точек на дюйм и обозначается как «dpi». Например, для сканирования нормального текста достаточно установить разрешение в 300 dpi, что составляет примерно 12 точек на миллиметр. Разрешение монитора компьютера меньше 100 dpi. Очень хорошим разрешением для принтера является 600 dpi. Поэтому для бытовых потребностей большего разрешения сканера и не требуется.
Сканирование может производиться в трёх режимах: цветном, сером и чёрно-белом.
Начнём с цветного режима, как естественного. В цветном режиме сканирования сканер определяет цвет для каждой точки. Сканер может различать несколько миллионов цветов или оттенков цветов. Значит, задача сканера – выдать для каждой точки число, которое определяет цвет точки среди миллионов оттенков цветов. Числа выходят большими. Поэтому и файлы цветных рисунков имеют большие размеры. И передача цветного изображения из сканера в компьютер происходит медленнее.
Если нам не важен цвет изображения, то можно облегчить работу сканеру и компьютеру, задав сканирование в сером режиме. При этом сканер будет определять для каждой точки один из 256 оттенков серого цвета. Это все оттенки от абсолютно белого до абсолютно чёрного. При этом сканер выдаёт для каждой точки число от 1 до 256, что значительно меньше миллионов цветных оттенков. Размер серого графического файла на порядок меньше размера цветного файла.
Но для сканирования текста нам и этого много. Нам нужно только отличать чёрные буквы от белой бумаги. Поэтому у сканера есть ещё третий режим сканирования. Это чёрно-белый режим. При чёрно-белом режиме для каждой точки определяется только два варианта цвета. Точка может быть или чёрной, или белой. Графический файл с чёрно-белым изображением тоже имеет на порядок меньший размер, чем файл с серым изображением.
А как же быть с серыми точками?
Сканер устанавливает условную границу серого цвета. Всё, что светлее этой границы, относится к белому цвету. А всё, что темнее, относится к чёрному цвету.
А как сдвигать эту границу, чтобы в чёрный цвет не попали серые пятна на бумаге или чтобы в белый цвет не попали бледные буквы? Эта граница сдвигается при помощи уровня яркости.
Добавляя яркость, мы осветляем серую бумагу. Уменьшая яркость, мы зачерняем бледные буквы.
А если наш текст напечатан бледными буквами на грязно-серой бумаге, то нужно переходить к серому режиму сканирования, иначе пятна бумаги наложатся на буквы и отличить их станет невозможно.
Опыт сканирования показывает, что наиболее оптимальным является серый режим сканирования. Из-за изгиба бумаги при освещении места разворота книги лампой сканера там образуется тень. При сером режиме сканирования эта тень будет серой и буквы в этом месте будут видны. При чёрно-белом режиме сканирования тень может стать чёрной и буквы, попавшие в область тени, пропадут.
Зачем нужна программа распознавания текста.
Познакомившись со сканером и процессом сканирования, мы понимаем, что сканер можно сравнить с фотоаппаратом. Он выдаёт нам фотографию страницы текста. Это набор очень большого количества цветных или чёрно-белых точек.
А как же выделить текст из этих сотен тысяч и миллионов точек?
Для этого служат очень большие и сложные программы распознавания текста. Проводя сложный и трудоёмкий процесс анализа графического файла, программа распознавания текста отделяет и распознаёт символы или относит скопления точек к разряду рисунков.
На сегодняшний день лучшей в мире программой распознавания текстов является московская программа FineReader, которую мы и будем изучать.
Сканер для Андроид: турбоскан
Похожие статьи.
Написание текста программы
Приложение. текст программы с комментариями.
Текст программы задачи 1.1. цикл с параметром
Алгоритм работы с программой и создания видеофильма
Топ-5 приложений для распознавания текста в 2022 году
Растущая цифровизация реальности, в которой мы живем, создает потребность в цифровизации в различных сферах нашей жизни. Оцифровка письма является примером этого. Печатные тексты, которые мы можем назвать бумажными копиями, сейчас заменяются цифровыми копиями.
В таком случае, как нам оцифровать печатные тексты, чтобы мы могли быстро выполнять свою работу? Что такое оптическое распознавание символов, также называемое распознаванием текста или сокращенно OCR? Что делает OCR и как мы можем извлечь из этого пользу?
На все эти и другие вопросы даны ответы в этой статье. Приятного чтения!
Приятного чтения!
Что такое распознавание текста?
Цифровизация повсюду в нашей жизни. Эта ситуация создает необходимость перевода многих наших рабочих мест в цифровую среду. Например, вы можете даже захотеть оцифровать свои конспекты лекций для удобства архивирования. Или для редактирования и изменения юридических документов может потребоваться сначала перевести печатные документы в цифровой формат, а затем отредактировать и перепечатать их. Примеров таких потребностей гораздо больше.
Оптическое распознавание символов или распознавание текста — это оцифровка печатного текста с помощью программного и аппаратного обеспечения. Другими словами, это цифровое декодирование и кодирование письменных текстов . Этот процесс использует программное и аппаратное обеспечение для оцифровки письменного текста. Аппаратным обеспечением здесь может быть сканер или камера, которая может просматривать написанный текст и передавать его на машину. Тексты, которые мы можем сделать машиночитаемыми, весьма разнообразны. Эти тексты могут быть напечатаны или написаны от руки.
Эти тексты могут быть напечатаны или написаны от руки.
Сегодня распознавание текста стало поддерживаться искусственным интеллектом, что позволило этой технологии сделать большой шаг вперед. Если мы посмотрим на историю распознавания текста или оптического распознавания символов, то можно сказать, что подобные технологии впервые появились в 1910-х годах.
Телеграф и публикации, напечатанные с помощью алфавита Бриля, являются прародителями этой технологии. Несмотря на то, что технология сегодня очень продвинута и используется для самых разных целей, ее историческое существование уходит в далекое прошлое.
Какая технология лежит в основе распознавания текста
Давайте посмотрим, как эта технология работает сегодня и какая технология стоит за ней. Как и в случае с любой машинной технологией на основе ИИ, за этой технологией стоят алгоритмы.
Если мы будем двигаться в хронологическом порядке, нам нужно начать с фазы сканирования . Стадия сканирования может выполняться с помощью сканера или камеры и представляет собой процесс, позволяющий перенести изображение распечатанного документа. После передачи изображения на компьютер компьютер преобразует это изображение в черно-белое, чтобы оно стало понятным . Здесь белые части разделены как фон, а черные части — как «символы». Таким образом, начинается процесс идентификации персонажей.
После передачи изображения на компьютер компьютер преобразует это изображение в черно-белое, чтобы оно стало понятным . Здесь белые части разделены как фон, а черные части — как «символы». Таким образом, начинается процесс идентификации персонажей.
Различные программы распознавания текста могут работать с разными методами. Но процесс аналогичен, за исключением того, что они оцифровывают текст, сосредотачиваясь на одном предложении, блоге или разделе за раз.
В принципе, мы говорили о том, что разные платформы могут работать по-разному. Мы также говорили, что за этой технологией стоят определенные алгоритмы. Давайте взглянем на некоторые из алгоритмов, используемых для распознавания текста.
распознавание текстаРаспознавание образов
Это метод, при котором алгоритмы заранее получают различные образцы . Короче говоря, алгоритмы получают визуальные данные разных шрифтов и форм. Это позволяет им различать и распознавать входящие визуальные данные. На этом этапе необходимо предоставить приложению множество различных шрифтов для безошибочного или малоошибочного приложения.
На этом этапе необходимо предоставить приложению множество различных шрифтов для безошибочного или малоошибочного приложения.
Это попиксельное сопоставление. Этот метод также называется сопоставлением матриц. Этот метод может не работать со многими различными шрифтами, но обычно он лучше работает с базовыми шрифтами.
Обнаружение признаков
Это подразумевает другой принцип работы. Для этого алгоритмы сначала должны принять некоторые правила . Эти правила связаны с формой букв. Например, существует правило, что вертикальная линия и две горизонтальные линии вверху и посередине всегда образуют букву «F». С помощью этих простых эмпирических правил алгоритм узнает, как должны формироваться буквы, и соответствующим образом сопоставляет их.
Современные приложения для оптического распознавания символов или текста ориентированы на текстовые блоги, а не на формы отдельных букв. Тем не менее, важно иметь в виду, что простые ошибки все же могут возникать, и поэтому после обработки можно сделать короткую вычитку.
Где использовать распознавание текста
Распознавание текста, также известное как оптическое распознавание символов, может использоваться для самых разных целей в самых разных областях. В этой части нашей статьи давайте кратко рассмотрим, где можно использовать OCR.
· Быстрый перевод печатного текста
· Сортировка почты для отправки и доставки писем
· Добавление подписанных юридических документов в базу данных предоставление доступа
· Архивирование исторической информации и документов. Например, газеты
· Электронный сбор чеков в банках
· Автоматизированный ввод и обработка данных
· Сканирование и загрузка важных юридических документов для цифровых бюрократических процессов
Все это и многое другое относится к числу применений этой технологии. Области, в которых используются технологии, могут изменяться и расширяться в соответствии с потребностями.
Слабовидящие и слепые пользователи
В 1970-х годах началась работа над изобретением машин, которые распознают письмо, а затем преобразуют его в звук, чтобы слабовидящие пользователи могли пользоваться книгами и письменными документами и слушать их вслух.
Компания, которая создала технологию, была довольно успешной, а затем продала ее другой компании. Технологии пришли в наши дни с развитием искусственного интеллекта и теперь слабовидящие пользователи имеют возможность читать нужные им документы и книги без дополнительного оборудования. Хотя развитие технологий обеспечивает большое преимущество для пользователей с нарушениями зрения, оно также чрезвычайно важно с точки зрения устранения неравенства.
Распознавание текста и ИИ: преимущества для бизнеса
Каков вклад технологий распознавания текста на основе ИИ в ваше рабочее место? Это важная тема для разговора. Эта технология может иметь много преимуществ для вашего бизнеса. Мы можем упомянуть некоторые из этих преимуществ.
· Позволяет редактировать печатные документы
· Создание цифрового архива документов, к которому вы можете получить доступ в любое время
· Устраняет необходимость в физическом хранилище
· Позволяет выполнять поиск в тексте.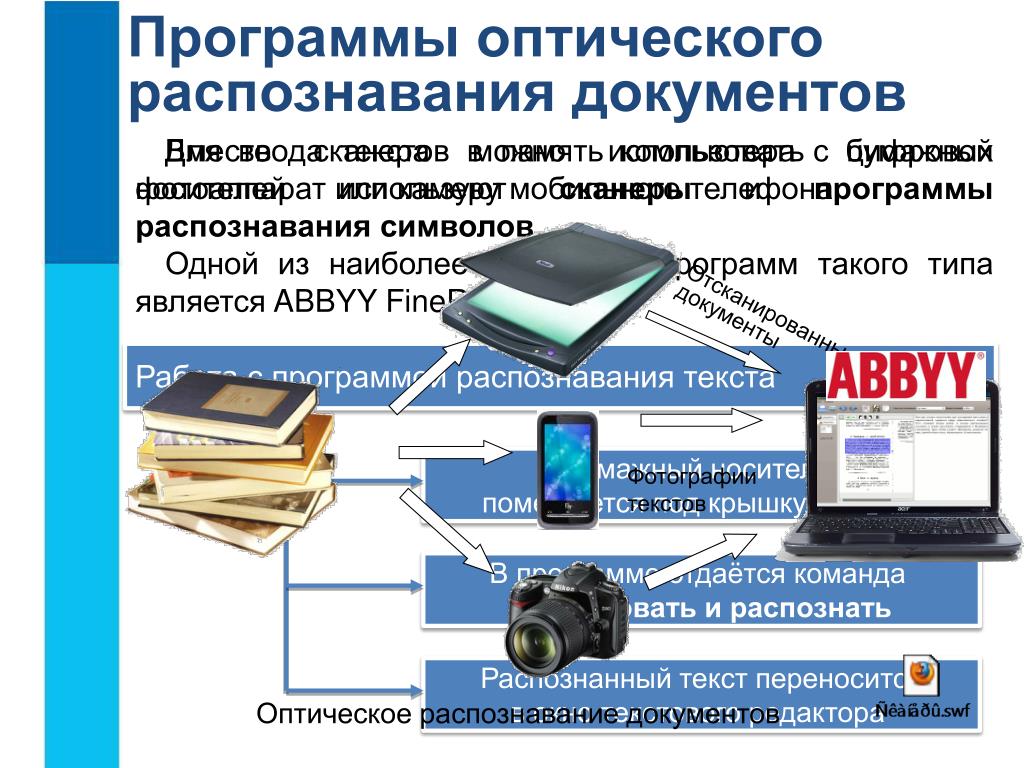 Вы также можете легко отметить важные части.
Вы также можете легко отметить важные части.
· Вы можете создавать новые документы без размытия или ухудшения качества изображений.
· Упрощает ввод данных и экономит время
Допустим, вы решили использовать эту технологию. Какие программы или платформы вы можете использовать для этого? Мы подготовили список предложений, чтобы ответить на этот вопрос.
Распознавание текста с помощью ИИ1.
CameralyzeCameralyze — это платформа решений для искусственного интеллекта без кода. На платформе вы можете воспользоваться практически всеми технологиями искусственного интеллекта и компьютерного зрения по очень доступным ценам. Платформа также предлагает услуги распознавания текста.
Есть важная особенность, которая отличает платформу от многих других конкурентов, вам не нужно никакого программного обеспечения или технических знаний для ее использования . Вы можете просто использовать его из своего веб-браузера. Загрузите отсканированное изображение на платформу, и через несколько секунд ваш текст будет готов!
Загрузите отсканированное изображение на платформу, и через несколько секунд ваш текст будет готов!
Cameralyze обеспечивает необходимую гибкость и позволяет использовать данные по мере необходимости. Короче говоря, это позволяет вам извлечь выгоду из ваших цифровых данных.
2.
OmniPage UltimateOmnipage — это приложение, позволяющее выполнять распознавание текста путем загрузки документов и создания цифрового архива. Вы можете использовать Omnipage, установив программное обеспечение на свой компьютер. В приложении также установлены некоторые функции корректуры.
3.
Adobe Acrobat DC ProНе все знают Adobe Acrobat. Приложение для чтения и редактирования PDF-файлов, Acrobat является одним из наиболее широко используемых приложений Adobe. Название приложения расшифровывается как DC Document Cloud. Он также интегрирован с другими приложениями Adobe.
Приложение позволяет сканировать, оцифровывать и редактировать изображения. Это также позволяет вам архивировать ваши документы в Adobe Cloud. Adobe Acrobat и другие приложения Acrobat доступны для покупки.
Это также позволяет вам архивировать ваши документы в Adobe Cloud. Adobe Acrobat и другие приложения Acrobat доступны для покупки.
4.
Abby Fine ReaderУ Эбби в этом отношении очень старая практика. Он используется крупными компаниями в течение многих лет. Приложение позволяет сканировать печатные документы и преобразовывать их в цифровые тексты. Вы также можете сделать корректуру и редактирование.
Еще одной важной особенностью приложения является то, что оно работает более чем на 100 языках, поэтому можно понимать и классифицировать различные документы более чем на 100 языках. Тем не менее, приложение немного сложнее с технической точки зрения и немного сложнее в использовании, чем другие варианты.
5.
Readiris Readiris — это высокоскоростное приложение. Он оцифровывает и хранит тексты. Интерфейс также очень хорошо разработан. Readiris, как и Abbey, является более техническим приложением. На данный момент он отстает от более простых в использовании и более гибких приложений, но ему удается быть в списке благодаря своей скорости.
Bottom Line
OCR или распознавание текста — не очень новая технология. С другой стороны, его разработка с поддержкой искусственного интеллекта является достаточно новой. Это очень важная технология, которая ускорит вашу работу и поможет улучшить ваш бизнес в тот период, когда мы переходим от печатных документов к цифровым.
Cameralyze удовлетворит все ваши потребности благодаря решениям искусственного интеллекта, которые он объединяет на одной платформе. Если вы малый бизнес, растущая компания или человек, который начал свой собственный бизнес, у вас, вероятно, будут общие потребности. Вам нужно сделать много с небольшим количеством времени и ресурсов. На данный момент Cameralyze поддерживает вас своими экономичными и быстрыми решениями.
С Cameralyze вы можете воспользоваться преимуществами решений искусственного интеллекта, улучшить свой бизнес и повысить ценность своих данных без необходимости в техническом персонале, промежуточном персонале или базовых знаниях. Зарегистрируйтесь сейчас, чтобы начать свое приключение с Cameralyze!
Зарегистрируйтесь сейчас, чтобы начать свое приключение с Cameralyze!
Будьте в курсе последних разработок и лучших продуктов в области искусственного интеллекта, посетив блог Cameralyze.
Оптическое распознавание символов Python (OCR): Учебное пособие
Оптическое распознавание символов (OCR) — это технология, которая распознает текст в изображениях, таких как отсканированные документы и фотографии. Возможно, вы сфотографировали текст только потому, что не хотели делать заметки, или потому, что сделать фото быстрее, чем напечатать его. К счастью, благодаря сегодняшним смартфонам мы можем применять OCR, чтобы копировать изображение текста, которое мы сделали раньше, без необходимости его повторного ввода.
Что такое оптическое распознавание символов Python (OCR)?
Python OCR — это технология, которая распознает и извлекает текст из изображений, таких как отсканированные документы и фотографии, с помощью Python. Его можно выполнить с помощью OCR-движка Tesseract с открытым исходным кодом.
Мы можем сделать это на Python, используя несколько строк кода. Одним из наиболее распространенных инструментов OCR является Tesseract. Tesseract — это механизм оптического распознавания символов для различных операционных систем.
Установка Python OCR
Tesseract работает на платформах Windows, macOS и Linux. Он поддерживает Unicode (UTF-8) и более 100 языков. В этой статье мы начнем с процесса установки Tesseract OCR и протестируем извлечение текста из изображений.
Первый шаг — установить Tesseract. Чтобы использовать библиотеку Tesseract, нам нужно установить ее в нашей системе. Если вы используете Ubuntu, вы можете просто использовать apt-get для установки Tesseract OCR:
sudo apt-get install Tesseract-ocr
Для пользователей macOS мы будем использовать Homebrew для установки Tesseract.
brew install Tesseract
Для Windows см. документацию по Tesseract.
Начнем с установки pyTesseract.
$ pip install pyTesseract
Еще о Python: 5 способов написать дополнительный код Pythonic
Реализация оптического распознавания символов Python
После завершения установки давайте приступим к применению Tesseract с Python. Сначала мы импортируем зависимости.
из изображения импорта PIL импортировать pyTesseract импортировать numpy как np
Я буду использовать простое изображение для проверки использования Tesseract.
Образец изображения для преобразования Tesseract в текст. | Изображение: Fahmi NufikriДавайте загрузим это изображение и преобразуем его в текст.
имя файла = 'image_01.png' img1 = np.array (Image.open (имя файла)) text = pyTesseract.image_to_string(img1)
Теперь посмотрим на результат.
print(text)
И вот результат.
Результат после запуска OCR в Python. | Скриншот: Фахми Нуфикри Результаты, полученные с Tesseract, достаточно хороши для простых изображений. Однако в реальном мире сложно найти действительно простые изображения, поэтому я добавлю шум, чтобы проверить производительность Tesseract.
Однако в реальном мире сложно найти действительно простые изображения, поэтому я добавлю шум, чтобы проверить производительность Tesseract.
Мы проделаем тот же процесс, что и раньше.
имя файла = 'image_02.png' img2 = np.array (Image.open (имя файла)) текст = pyTesseract.image_to_string(img2) print(text)
Это результат.
Нет результата после попытки извлечь текст из изображения с шумом. | Скриншот: Фахми НуфикриРезультат — ничего. Это означает, что tesseract не может читать слова на изображениях с шумом.
Далее мы попробуем немного обработать изображение, чтобы устранить шум на изображении. Здесь я буду использовать библиотеку OpenCV. В этом эксперименте я использую нормализацию, пороговое значение и размытие изображения.
импортировать numpy как np импортировать cv2norm_img = np.zeros((img.shape[0], img.shape[1])) img = cv2.normalize (img, norm_img, 0, 255, cv2.NORM_MINMAX) img = cv2.threshold(img, 100, 255, cv2.THRESH_BINARY)[1] img = cv2.GaussianBlur(img, (1, 1), 0)
 threshold(img, 100, 255, cv2.THRESH_BINARY)[1]
img = cv2.GaussianBlur(img, (1, 1), 0)
threshold(img, 100, 255, cv2.THRESH_BINARY)[1]
img = cv2.GaussianBlur(img, (1, 1), 0) Результат будет таким:
Образец изображения с очищенным шумом, чтобы был виден текст. | Изображение: Fahmi NufikriТеперь, когда изображение достаточно чистое, мы попробуем еще раз, используя тот же процесс, что и раньше. И это результат.
Результат показывает, что OCR распознал текст. | Скриншот: Fahmi NufikriКак видите, результаты соответствуют нашим ожиданиям.
Произошла ошибка.
Невозможно выполнить JavaScript. Попробуйте посмотреть это видео на сайте www.youtube.com или включите JavaScript, если он отключен в вашем браузере.
Видео, знакомящее с основами использования PyTesseract для извлечения текста из изображений. | Видео: ProgrammingKnowledge. Сначала мы введем зависимости, которые нам нужны.из импорта pyTesseract Вывод импортировать pyTesseract import cv2
Я буду использовать простое изображение, как в приведенном выше примере, чтобы проверить использование Tesseract.
Теперь давайте загрузим это изображение и извлечем данные.
имя файла = 'image_01.png' image = cv2.imread(filename)
Это отличается от того, что мы делали в предыдущем примере. В предыдущем примере мы сразу превратили изображение в строку. В этом примере мы преобразуем изображение в словарь.
результатов = pyTesseract.image_to_data(изображение, output_type=Output.DICT)
Следующие результаты являются содержимым словаря.
{
«уровень»: [1, 2, 3, 4, 5, 5, 5],
'номер_страницы': [1, 1, 1, 1, 1, 1, 1],
'номер_блока': [0, 1, 1, 1, 1, 1, 1],
'par_num': [0, 0, 1, 1, 1, 1, 1],
'line_num': [0, 0, 0, 1, 1, 1, 1],
'номер_слова': [0, 0, 0, 0, 1, 2, 3],
«слева»: [0, 26, 26, 26, 26, 110, 216],
«верх»: [0, 63, 63, 63, 63, 63, 63],
«ширина»: [300, 249, 249, 249, 77, 100, 59],
«высота»: [150, 25, 25, 25, 25, 19, 19],
'conf': ['-1', '-1', '-1', '-1', 97, 96, 96],
'текст': ['', '', '', '', 'Тестирование', 'Tesseract', 'OCR']
} Я не буду объяснять назначение каждого значения в словаре.
conf ключ для определения границы обнаруженного текста. Теперь мы извлечем координаты ограничивающей рамки текстовой области из текущего результата и укажем желаемое значение достоверности. Здесь я буду использовать значение conf = 70. Код будет выглядеть так:
для i в диапазоне (0, len(результаты["текст"])): х = результаты ["слева"] [i] y = результаты["верхний"][i] w = результаты["ширина"][i] h = результаты["высота"][i] текст = результаты["текст"][i] conf = int(результаты["conf"][i]) если конф > 70: text = "".join([c, если ord(c) < 128, иначе "" для c в тексте]).strip() cv2.rectangle (изображение, (x, y), (x + w, y + h), (0, 255, 0), 2) cv2.putText (изображение, текст, (х, у - 10), cv2.FONT_HERSHEY_SIMPLEX, 0,5, (0, 0, 200), 2)
Теперь, когда все настроено, мы можем отобразить результаты, используя этот код.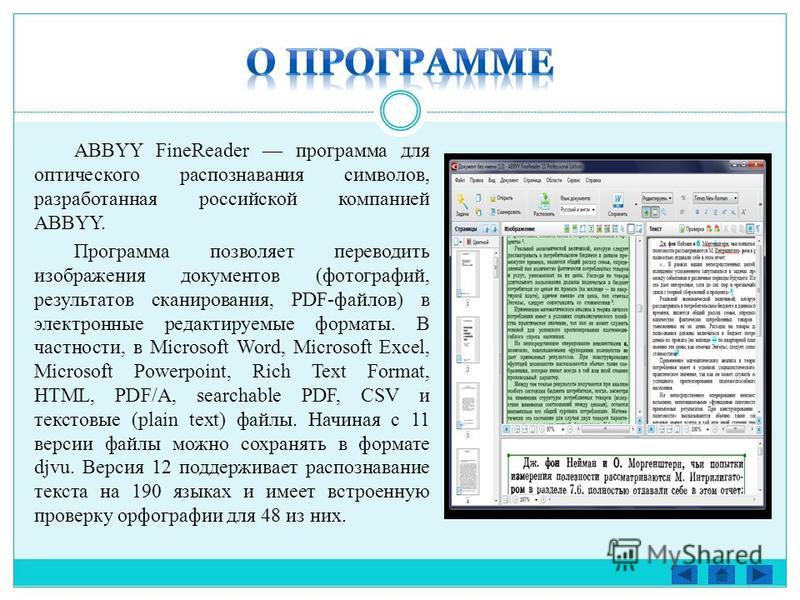
Ваш комментарий будет первым