Использование функции «Сканер текста» для взаимодействия с контентом фото или видео на iPhone
При просмотре фото или приостановке видео в приложении «Фото» функция «Сканер текста» распознает текст и другую информацию на изображении, позволяя разными способами с ней взаимодействовать. Можно выбрать текст, чтобы скопировать, отправить или перевести его, или использовать быстрые действия, чтобы позвонить по телефону, открыть веб-сайт или конвертировать валюту.
Функция «Сканер текста» доступна на поддерживаемых моделях и может использоваться в приложениях Safari, Камера, Просмотр и т. д.
Включение функции «Сканер текста»
Перед началом использования функции «Сканер текста» убедитесь, что она включена для всех поддерживаемых языков.
Откройте «Настройки» > «Основные» > «Язык и регион».
Включите «Сканер текста» (зеленый цвет означает, что параметр включен).
Копирование, перевод и поиск текста на фото и в видео
Откройте фото или поставьте видео, содержащее текст, на паузу.

Коснитесь , затем коснитесь выбранного текста и удерживайте его.
Используйте точки захвата для выбора нужного текста, затем выполните одно из приведенных ниже действий.
Скопировать текст. Копирование текста для вставки в другое приложение, такое как Заметки или Сообщения.
Выбрать все. Выбор всего текста в кадре.
Найти. Отображение персонализированных веб-предложений.
Перевести. Перевод текста.
Поиск в интернете. Поиск выделенного текста в интернете.
Поделиться. Отправка текста через AirDrop, Сообщения, Почту или другими доступными способами.
В зависимости от того, что изображено на фотографии, можно коснуться быстрого действия в нижней части экрана, чтобы выполнить такие действия, как совершение телефонного вызова, открытие веб-сайта, создание электронного письма, конвертирование валют и многого другого.
Коснитесь для возврата к фото или видео.


Работа с фотографией или видео с помощью быстрых действий
В зависимости от содержания фотографии или видео, можно коснуться быстрого действия в нижней части экрана, чтобы выполнить такие действия, как совершение телефонного вызова, построение маршрута, перевод на другие языки, конвертирование валют и многое другое.
В приложении «Фото» откройте фото или поставьте видео, содержащее текст, на паузу.
Коснитесь .
Коснитесь быстрого действия в нижней части экрана.
Коснитесь для возврата к фото или видео.
Функция «Сканер текста» доступна не во всех регионах и не на всех языках. См. Доступность функций iOS и iPadOS.
См. такжеИспользование функции «Сканер текста» с помощью камеры iPhoneИспользование функции «Что на картинке?» для распознавания объектов на фото на iPhone
цена 125 000 РУБ в Москве
Описание
Характеристики
Отзывы
Самовывоз и доставка
Оплата
Smartec Timex DR Pack 1 комплект сканера Регула 7017 и лицензии на модуль сканирования и распознавания документов.
- Специализированный сканер для распознавания документов
- Поддержка распознавания паспортов, заграничных паспортов, водительских прав
- Использование для ввода данных, как посетителей, так и сотрудников
- Световая индикация режима работы
- Не требует дополнительного источника питания
- Старт сканирования по команде оператора или автоматически по наложению документа
- Устранение бликов от ламинирования и голограмм
- Распознавание текста и обработка графических полей
Комплект Timex DR Pack 1 предназначен для сканирования и распознавания текста документов пользователей и для автоматизации ввода данных при обслуживании посетителей или при регистрации сотрудников. В комплект входят настольный малогабаритный сканер документов Regula и лицензия для распознавания документов Timex DR.
Надежный и простой в обслуживании сканер
Корпус сканера выполнен из пластмассы. Он подключается к компьютеру при помощи USB-кабеля и не требует дополнительного источника питания. За счет того, что сканер не имеет движущихся частей, устройство отличается надежностью, удобством и простотой в обслуживании. Использование сканера для распознавания документов позволяет значительно сократить время регистрации посетителя и минимизировать возможные ошибки, связанные с человеческим фактором.
Он подключается к компьютеру при помощи USB-кабеля и не требует дополнительного источника питания. За счет того, что сканер не имеет движущихся частей, устройство отличается надежностью, удобством и простотой в обслуживании. Использование сканера для распознавания документов позволяет значительно сократить время регистрации посетителя и минимизировать возможные ошибки, связанные с человеческим фактором.
Купить Smartec Timex DR Pack 1 сканер распознавания документов в интернет-магазине СЕК-ГРУПП в Москве: Черницынский проезд, д.3, стр.1 (метро Щелковская). Доставка по России.
| 👍Версия | Timex |
Гарантия 1 год
Мы официальный дилер SmartecSmartec Timex DR Pack 1 комплект сканера Регула 7017 и лицензии на модуль сканирования и распознавания документов.
- Специализированный сканер для распознавания документов
- Поддержка распознавания паспортов, заграничных паспортов, водительских прав
- Использование для ввода данных, как посетителей, так и сотрудников
- Световая индикация режима работы
- Не требует дополнительного источника питания
- Старт сканирования по команде оператора или автоматически по наложению документа
- Устранение бликов от ламинирования и голограмм
- Распознавание текста и обработка графических полей
Комплект Timex DR Pack 1 предназначен для сканирования и распознавания текста документов пользователей и для автоматизации ввода данных при обслуживании посетителей или при регистрации сотрудников. В комплект входят настольный малогабаритный сканер документов Regula и лицензия для распознавания документов Timex DR.
В комплект входят настольный малогабаритный сканер документов Regula и лицензия для распознавания документов Timex DR.
Надежный и простой в обслуживании сканер
Корпус сканера выполнен из пластмассы. Он подключается к компьютеру при помощи USB-кабеля и не требует дополнительного источника питания. За счет того, что сканер не имеет движущихся частей, устройство отличается надежностью, удобством и простотой в обслуживании. Использование сканера для распознавания документов позволяет значительно сократить время регистрации посетителя и минимизировать возможные ошибки, связанные с человеческим фактором.
Рейтинг товара
Отзывов (0)Выбрать интервалза 3 месяцаза 6 месяцевза годза все времяВыбрать оценку12345
Оставьте свой отзыв
Самовывоз
- Москва, Черницынский пр-д, д. 3 стр. 1. метро Щелковская
Доставка курьером СЕК-ГРУПП
- До ТК (СДЭК, ПЭК, Деловые Линии) — 0 Р
- Остальные транспортные компании — 750 Р
- Заказы от 40 000 Р (по ценам сайта) — 0 Р
- В пределах МКАД — 1000 Р (на заказы от 5000 Р — 750 Р)
- Негабарит МКАД — 1000 Р
- За МКАД — 750 Р + 50Р/км
- Негабарит за МКАД — 1500Р + 70Р/км
Мы правильно определили ваш город?
Безналичный расчетОплата осуществляется путем банковского перевода денежных средств с расчетного счета покупателя на наш расчетный счет.
Оплата наличными производится в офисах компании при получении товара со склада по адресам:
- г. Москва, Черницынский проезд, д.3, стр.3
- г. Уфа, Трамвайная улица, д.2, офис 1-02
Стоимость заказа передаётся водителю компании при получении товара.
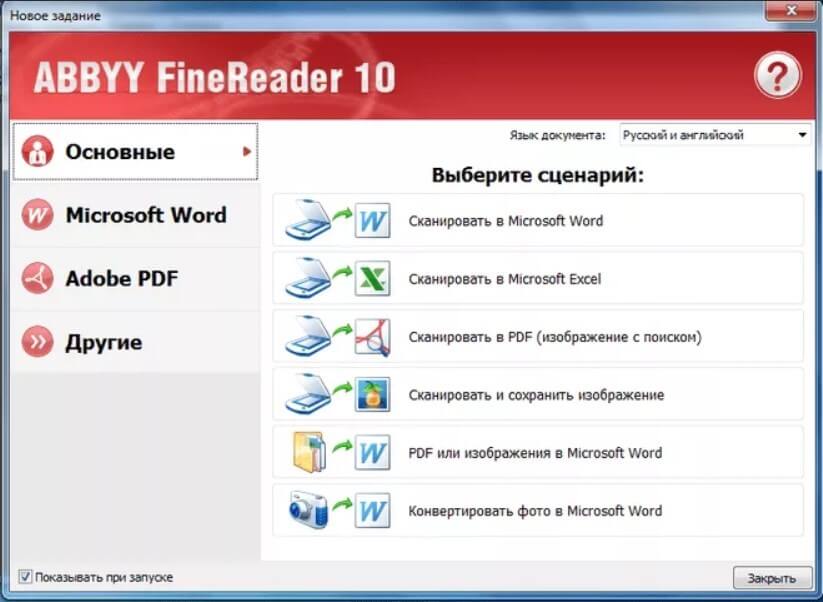
Как сканировать документы с помощью оптического распознавания символов (OCR) | Услуги информационных технологий
Назначение статьи
В этом разделе вы узнаете, как использовать планшетный сканер и OmniPage для оцифровки документ с помощью оптического распознавания символов (OCR) с печатного носителя и сохраните его в редактируемом формате для последующего использования.
Необходимые материалы
Чтобы отсканировать документ, убедитесь, что у вас есть следующее:
- Компьютер
- Планшетный сканер
- Программное обеспечение OCR, такое как OmniPage
- Документ для сканирования
Шаги к разрешению
Важное примечание:
как настроить и установить новый сканер. Пожалуйста, обратитесь к настройке/установке продукта
руководства, прилагаемые к устройству, для получения дополнительной информации об этих шагах.
Пожалуйста, обратитесь к настройке/установке продукта
руководства, прилагаемые к устройству, для получения дополнительной информации об этих шагах.
Большинство программ оптического распознавания символов имеют множество различных функций, которые можно использовать для оцифровки документы в редактируемый текст. Эти направления представят один из методов достижения эта цель.
- Запуск OmniPage
- На стартовой странице щелкните Сканировать документ .
- После того, как сканер прогреется, изображение для предварительного просмотра документа будет отображаться, как показано на рисунке. на изображении ниже.
- Выберите параметр Черно-белое изображение или текст . Затем настройте область в окне так, чтобы был заключен весь нужный текст.
Щелкните Сканировать.
- После сканирования страницы вас спросят, хотите ли вы Остановить загрузку страниц или Добавить больше страниц . Выберите вариант, наиболее подходящий для ваших нужд. Повторяйте шаги 4 и 5, пока все страницы были отсканированы, затем нажмите Остановить загрузку страниц .
- Теперь OmniPage будет выполнять оптическое распознавание символов. Нажмите Автоматическая кнопка на панели инструментов.
- Корректор OCR отобразит все слова, которые он не распознает, и отобразит их как Подозрительное слово . Если слово/объект допустимо, нажмите
- После завершения OCR нажмите кнопку Сохранить в файлы и выберите Сохранить в файлы .
- В диалоговом окне Сохранить в файл выберите место назначения, в которое вы хотите сохранить файл (рабочий стол, флешка и т.д.) и выполните следующие действия:
 Затем настройте область в окне так, чтобы был заключен весь нужный текст.
Щелкните Сканировать.
Затем настройте область в окне так, чтобы был заключен весь нужный текст.
Щелкните Сканировать.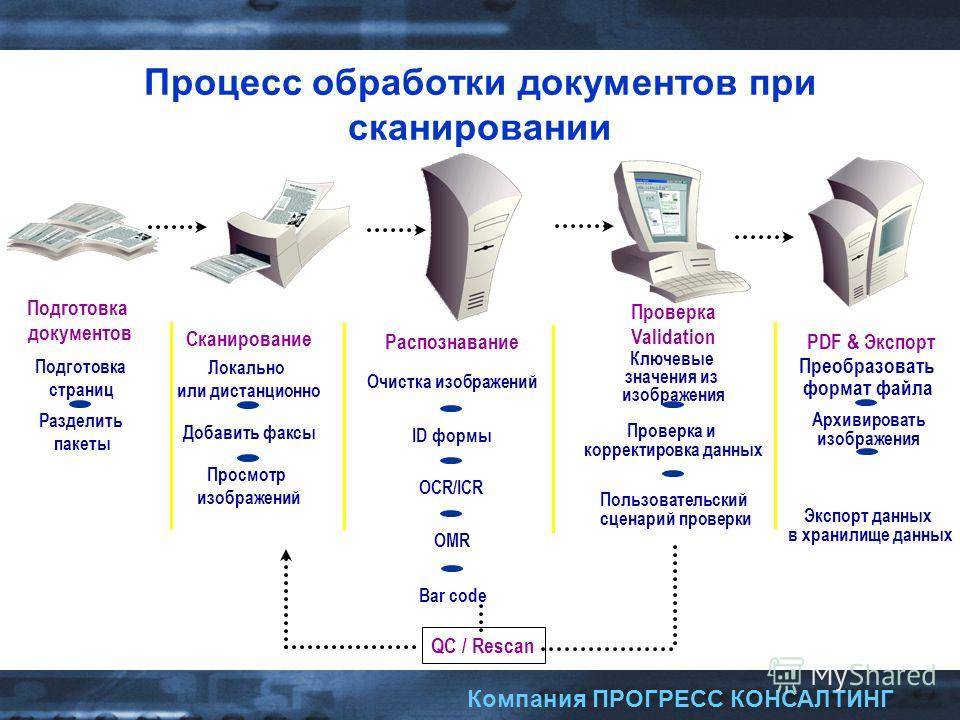 Если слово/объект допустимо, нажмите
Если слово/объект допустимо, нажмите - В поле Имя файла введите имя вашего файла.
- В разделе Сохранить как выберите Текст.
- В раскрывающемся окне Тип файлов выберите Microsoft Word 2007/2010 (*. docx).
- В разделе «Уровень форматирования» выберите «Перетекающая страница»
- В разделе «Параметры файла» выберите «Создать один файл для всех страниц».
- В разделе Диапазон страниц выберите Все страницы
- Нажмите «ОК»
 docx).
docx).Дополнительная информация
Точность
Распознавание латиницы, машинописного текста все еще не является 100% точным даже там, где
доступно четкое изображение. Некоторые исследования показывают, что коммерческое программное обеспечение для оптического распознавания символов
от 71% до 98% точности. Важно отметить, что все документы OCR должны
быть проверены как на точность (правильные слова), так и на форматирование. Распознавание руки
печать, рукописный почерк и печатный текст другими шрифтами (особенно в некоторых
Символы восточноазиатского языка, которые имеют много штрихов для одного символа)
области, которые все еще активно разрабатываются издателями программного обеспечения OCR.
Некоторые исследования показывают, что коммерческое программное обеспечение для оптического распознавания символов
от 71% до 98% точности. Важно отметить, что все документы OCR должны
быть проверены как на точность (правильные слова), так и на форматирование. Распознавание руки
печать, рукописный почерк и печатный текст другими шрифтами (особенно в некоторых
Символы восточноазиатского языка, которые имеют много штрихов для одного символа)
области, которые все еще активно разрабатываются издателями программного обеспечения OCR.
Оптическое распознавание символов | Службы управления записями
Оптическое распознавание символов или OCR — это технология, которая распознает текст в цифровом изображении. Процесс преобразования отсканированного изображения в распознаваемые символы может сделать отсканированные документы доступными для поиска, чтобы найти уникальные ключевые термины или фразы в файле. У вас может быть отсканированный документ длиной 200 страниц, но вам нужно найти только те страницы, на которых упоминается название вашего отдела. Или, может быть, у вас есть целый общий диск с отсканированными документами, и вам нужно найти каждый документ, содержащий определенный номер бюджета. Этот ресурс объяснит, как преобразовать PDF-файлы, чтобы сделать текст распознаваемым, а затем объяснит, как лучше всего искать эти файлы.
У вас может быть отсканированный документ длиной 200 страниц, но вам нужно найти только те страницы, на которых упоминается название вашего отдела. Или, может быть, у вас есть целый общий диск с отсканированными документами, и вам нужно найти каждый документ, содержащий определенный номер бюджета. Этот ресурс объяснит, как преобразовать PDF-файлы, чтобы сделать текст распознаваемым, а затем объяснит, как лучше всего искать эти файлы.
По мере того, как мы движемся к цифровому будущему, пришло время отказаться от бумаги и улучшить ваши электронные данные. Сканирование бумажных документов — отличный способ сделать информацию более доступной и надежной. К сожалению, по умолчанию отсканированный документ представляет собой не более чем фотографию высокой четкости. В результате пользователи не могут легко редактировать содержимое этих отсканированных изображений и не могут легко выполнять поиск по содержимому файла.
Представьте, что вы отсканировали документ с гербом Вашингтонского университета. В то время как наши глаза могут читать и интерпретировать, что на отсканированном изображении написано «Вашингтонский университет» и «1861», ваша компьютерная программа может не распознать или интерпретировать автоматически, что отсканированный документ имеет читаемые символы. В результате после сканирования записи единственный способ для пользователей легко узнать, что содержится в файле, — это стратегически использовать структуры папок, соглашения об именах файлов и фактически читать документ.
В то время как наши глаза могут читать и интерпретировать, что на отсканированном изображении написано «Вашингтонский университет» и «1861», ваша компьютерная программа может не распознать или интерпретировать автоматически, что отсканированный документ имеет читаемые символы. В результате после сканирования записи единственный способ для пользователей легко узнать, что содержится в файле, — это стратегически использовать структуры папок, соглашения об именах файлов и фактически читать документ.
Однако у вас под рукой есть удивительные инструменты, которые могут превратить отсканированные документы в ценные информационные активы путем преобразования отсканированных изображений в доступные для поиска символы. Этот процесс преобразования отсканированных изображений в доступные для поиска символы известен как оптическое распознавание символов или OCR. Применяя процесс OCR к приведенному выше примеру изображения, программа может понять, что в отсканированном документе выше есть слова «Вашингтонский университет» и «1861». После преобразования отсканированного документа пользователи могут легко выполнять поиск в отдельном документе или среди документов в папках по определенным словам или фразам.
После преобразования отсканированного документа пользователи могут легко выполнять поиск в отдельном документе или среди документов в папках по определенным словам или фразам.
Одна из самых простых программ для проведения этого процесса преобразования OCR находится в Adobe Acrobat Pro. Рекомендуется сканировать бумажные документы в файлы PDF, поэтому Adobe Acrobat Pro является очевидным выбором при работе с файлами PDF. Однако для использования этих возможностей требуется подписка Adobe Acrobat Pro. Вы не сможете использовать процесс преобразования OCR с помощью Adobe Reader.
Преобразование большинства форматов файлов Microsoft Word, Excel или PowerPoint не требуется. Это связано с тем, что текст уже распознается в этих программах, и пользователи уже имеют возможность редактировать или вносить изменения в содержимое файлов этих типов. Вместо этого этот ресурс сможет направлять пользователей в том, как распознавать файлы PDF и как после этого использовать функции расширенного поиска.
OCR также помогает сделать документ более доступным. Обратитесь к веб-сайту UWIT для получения дополнительной информации о правилах доступности.
Узнайте, как:
OCR Преобразование файлов PDF с помощью Adobe Acrobat Pro:
- Распознавание текста в одном документе PDF
- Распознавание текста в нескольких документах PDF
Поиск текста
- Поиск текста в одном документе PDF
- Поиск по документам PDF с помощью расширенного поиска Adobe
- Поиск по папкам с помощью функций поиска Windows
Распознавание текста в одном документе PDF
Процесс распознавания текста в Adobe Acrobat называется распознаванием текста. Первый шаг — открыть PDF-документ, который вы хотите включить для расширенных возможностей поиска. Затем на панели инструментов в верхней части документа:
- Нажмите Инструменты
- Click Расширенное сканирование
- На верхней панели инструментов появится ряд новых опций, в том числе Вставка ; Улучшение ; Распознавание текста
- Нажмите на A A Распознать текст , и появится раскрывающееся меню.
- Нажмите кнопку В этом файле
- Появится новая панель инструментов
- Убедитесь, что выбрано:
- Все страницы
- Язык: английский (США)
- Настройки должны выглядеть так:
- Все страницы
- Язык документа: английский (США)
- Вывод: изображение с возможностью поиска
- Понизить разрешение до: 600 dpi
- Нажмите ОК
- Нажмите кнопку Распознать текст
- В нижней части страницы появится строка состояния, пока Adobe распознает текст в документе PDF.
- Обязательно сохраните документ, который вы открыли после завершения преобразования.
- Нажатие кнопки «Сохранить» и перезапись существующего файла является благоразумным. Перезаписывая существующий файл, вы исключаете создание дубликатов. Процесс OCR фактически не изменяет содержимое отсканированной записи, поэтому нет необходимости поддерживать две копии одного и того же файла.
- Нажатие кнопки «Сохранить» и перезапись существующего файла является благоразумным. Перезаписывая существующий файл, вы исключаете создание дубликатов. Процесс OCR фактически не изменяет содержимое отсканированной записи, поэтому нет необходимости поддерживать две копии одного и того же файла.

Распознавание текста в нескольких документах PDF
У вас может быть целая папка, заполненная ранее отсканированными документами, которые вы хотите улучшить. Эти инструкции позволят вам конвертировать с помощью оптического распознавания символов сразу несколько PDF-документов.
Предупреждение. Вы не сможете открывать другие файлы Adobe PDF во время процесса распознавания, поэтому обязательно планируйте заранее. Если у вас есть более десяти файлов или , файлы имеют длину в сотни страниц, рассмотрите возможность подождать до конца дня, чтобы сделать это, чтобы он мог обработать все, пока вы находитесь вдали от компьютера.
- Откройте PDF-документ
- Щелкните Инструменты
- Click Расширенное сканирование
- На верхней панели инструментов в верхней части окна появится ряд новых параметров, включая Вставить ; Улучшение ; Распознавание текста
- Нажмите на AA Распознать текст , и появится раскрывающееся меню.
- Нажмите В нескольких файлах…
- Появится всплывающее окно с документом, над которым вы только что работали, уже в списке
- Добавьте другие файлы для распознавания текста:
Это можно сделать двумя способами. Один из способов — найти файлы в программе и выбрать их для добавления в очередь (вариант A). Кроме того, вы можете вручную перетащить файлы в очередь (вариант B).- Вариант A:
- В левом верхнем углу есть кнопка Добавить файлы…
- Нажмите на эту кнопку
- В раскрывающемся меню выберите Добавить файлы…
- Выберите дополнительные файлы, в которых вы хотите распознавать текст.
- Вы можете выбрать несколько документов, удерживая кнопку Ctrl
- Вы можете выбрать все документы в папке, нажав Ctrl + A
- Нажмите Открыть
- PDF-документ или несколько PDF-файлов теперь будут добавлены в список.
- Повторите этот процесс для всех нужных файлов PDF.
- Если вы хотите отменить выбор файлов, которые были помещены во всплывающее окно для распознавания текста, щелкните имя файла, чтобы оно было выделено. Нажмите Удалить кнопку в нижнем левом углу
- Когда вы будете готовы, нажмите кнопку OK
- В левом верхнем углу есть кнопка Добавить файлы…
- Вариант B:
- Кроме того, вы можете перетаскивать файлы из файловых структур Windows в пустое пространство списка Adobe. Вам нужно будет открыть исходную папку и Adobe Acrobat, чтобы вы могли просматривать оба приложения на одном экране.
- Вы можете выбрать несколько документов, удерживая кнопку Ctrl. После выбора просто перетащите его в пустое место на экране Adobe Acrobat.
- Вы можете выбрать все документы в папке, нажав Ctrl + A. После выбора просто перетащите в пустое пространство на экране Adobe Acrobat.
- Файлы PDF будут добавлены в список, как только вы отпустите курсор
- Вы можете повторять этот процесс перетаскивания, пока не будут добавлены все файлы.
- Если вы хотите отменить выбор файлов, которые были помещены во всплывающее окно для распознавания текста, щелкните имя файла, чтобы оно было выделено. Нажмите Удалить кнопку в нижнем левом углу
- Когда будете готовы, нажмите кнопку OK
- После нажатия OK появится новое всплывающее окно
- Сохраните все настройки и варианты выбора.
- Целевая папка: та же папка, которая была выбрана при запуске
- Именование файлов: сохранить исходные имена файлов
- Флажок перезаписывать существующие файлы
- Нажмите ОК
Перезапись существующих файлов предусмотрительна. Перезаписывая существующие файлы, вы исключаете создание дубликатов одной и той же записи. Фактическое содержание записи останется неизменным. Все, что делает этот процесс, — делает существующий контент более доступным и доступным для поиска.
- Появится всплывающее окно
- Сохранить страницы как выбранные «Все страницы»
- Сохранить настройки как есть
- Язык документа: английский (США)
- Вывод: изображение с возможностью поиска
- Понизить разрешение до: 600 dpi
- Сохраните все настройки и варианты выбора.
- Появится строка состояния, пока Adobe распознает текст во всех документах PDF
- Кроме того, вы можете перетаскивать файлы из файловых структур Windows в пустое пространство списка Adobe. Вам нужно будет открыть исходную папку и Adobe Acrobat, чтобы вы могли просматривать оба приложения на одном экране.
- Вариант A:



Вернуться к началу страницы
Поиск текста в одном документе PDF
Приведенные ниже инструкции позволяют найти определенное слово или фразу в документе PDF, который вы преобразовали с помощью процесса OCR.
- Открытие документа PDF с помощью Adobe Acrobat Pro
- Перейдите на вкладку Редактировать , расположенную в левом верхнем углу.
- Нажмите на Найдите (или нажмите Ctrl+F)
- Появится всплывающее окно под названием Find
- Введите слово или фразу, которую вы хотите найти
- Нажмите Далее
- Начиная со страницы, на которой вы находитесь, Adobe будет искать каждый экземпляр в документе, соответствующий параметрам поиска, и выделять их
- Нажав Next , вы перейдете к следующему результату в документе.
- Когда у вас больше не будет новых результатов поиска, появится всплывающее окно с сообщением о том, что совпадений больше не найдено.
- Если вы хотите выполнить более расширенный поиск в документе, обратитесь к приведенным ниже инструкциям по использованию функций расширенного поиска
К началу страницы
Поиск в документах PDF с помощью расширенного поиска Adobe
Приведенные ниже инструкции позволяют найти конкретное слово или фразу в любых и всех записях PDF, текст которых был распознан. Возможно, вы ищете номер бюджета в нескольких файлах и папках. Возможно, вы ищете имя студента или факультета. Этот метод найдет все случаи появления ключевого слова или фразы.
Возможно, вы ищете номер бюджета в нескольких файлах и папках. Возможно, вы ищете имя студента или факультета. Этот метод найдет все случаи появления ключевого слова или фразы.
ПРЕДУПРЕЖДЕНИЕ. Прежде чем начать, всегда держите открытым один PDF-документ при использовании расширенного поиска. Если вы закроете последний PDF-документ, он закроет все приложение Adobe Acrobat вместе с результатами расширенного поиска.
- Открытие документа PDF с помощью Adobe Acrobat Pro
- Перейдите на вкладку Редактировать , расположенную в левом верхнем углу.
- Нажмите на Advanced Search (или нажмите Shift+Ctrl+F)
- Появится всплывающее окно под названием «Поиск
- ». Нажмите на кружок рядом с: Все PDF-документы в
- Щелкните раскрывающееся меню папки и выберите папку, в которой вы хотите выполнить поиск.
- Если вы не найдете нужную папку в предлагаемом списке. Выберите Поиск местоположения. ..
- В новом всплывающем окне просмотрите и найдите папку, в которой вы хотите выполнить поиск, и нажмите OK
- Если вы не найдете нужную папку в предлагаемом списке. Выберите Поиск местоположения.
- Введите слово или фразу для поиска
- Установите любой из четырех флажков, если применимо
- Нажмите Поиск
- Затем вы можете развернуть результаты, щелкнув значок стрелки рядом с именем документа.
- При этом будет показано, сколько раз и краткое место в документе встречается слово/фраза.
- Если вы наведете указатель мыши на маленький значок Adobe или на заголовок PDF-файла, вы сможете найти местоположение документа.
- Если щелкнуть результат поиска, он автоматически откроет PDF-документ и перейдет к месту в документе слова/фразы.
 ..
.. К началу страницы
Поиск по папкам с использованием функций поиска Windows
Знакомая всем нам функция поиска Windows ищет только названия файлов. Следуя приведенным ниже инструкциям, вы сможете искать и находить определенное слово или фразу в отдельных документах в проводнике Windows. После преобразования PDF-файла с помощью описанных выше процессов OCR эти инструкции помогут сделать этот PDF-файл доступным для обнаружения при использовании функций поиска Windows File Explorer.
Следуя приведенным ниже инструкциям, вы сможете искать и находить определенное слово или фразу в отдельных документах в проводнике Windows. После преобразования PDF-файла с помощью описанных выше процессов OCR эти инструкции помогут сделать этот PDF-файл доступным для обнаружения при использовании функций поиска Windows File Explorer.
- Откройте проводник Windows для верхней папки, в которой вы хотите выполнить поиск.
- В этом примере первоначальный поиск не дал результатов
- В этом раскрывающемся меню можно сузить параметры поиска, включая формат файла, размер файла, теги и измененные данные.

Ваш комментарий будет первым