Оптическое распознавание текста в Екатеринбурге цены на услуги Ру-Скан
Инновационные технологии создания электронных документов
Ваш город: Екатеринбург
[email protected]
620133, Свердловская область,
 Луначарского, 81,
Луначарского, 81,оф. 613
8 (800) 700-56-04 +7 (343) 350-50-69
Главная › Услуги › Распознавание текста
28. 04.2018
04.2018
27.02.2018
На конференции по Арктике19.07.2017
Сердечно благодарим!Содержание:
- Как происходит атрибутирование
- Контроль результата и верификация
Часто компаниям, которые решили оцифровывать свои архивы, недостаточно просто сканов. Их цель — быстрая и удобная работа с источниками. Сканы — это изображения: текст на них можно прочитать, но его не скопировать и вставить в другой документ, если это требуется. Цитату понадобится набрать. А если их много, на это уйдёт немало времени.
Работать с текстами можно только в файлах doc, txt, rtf. Именно в такие и нужно превратить сканы. Этот процесс называется распознаванием отсканированного текста с документа в формате изображения.
Как это происходит
«Ру-Скан» использует ПО, основанное на технологии оптического распознавания текстов (OCR-компоненты). Оно действует в несколько шагов:
- Сначала программа анализирует макет: определяет, где текст, а где иллюстрации.

- Затем разбивает текст на небольшие фрагменты: предложения, отдельные слова и символы.
- И, наконец, идентифицирует символы: определяет, какая перед ней буква или цифра.

На третьем этапе система оптического распознавания текста либо анализирует совокупность отличительных признаков символов и так понимает, какая это буква или цифра. Либо сопоставляет символ с шаблонами, заложенными в его памяти. И это, кстати, не только буквы и цифры, но и другие символы, которые часто используются в текстах: знаки препинания, условные обозначения.
Контроль результата и верификация
Распознавание стандартного текста страницы — дело нескольких секунд. Но сегодня современное ПО справляется с задачами разной сложности. Им по силам распознавание текста таблицы, они справляются с самыми сложными шрифтами.
Отдельно стоит сказать о распознавании рукописного текста в печатный. Это более сложный процесс, ведь у каждого почерка свои особенности.
Сотрудники «Ру-Скан» проходят специальное обучение распознаванию текста. О каких бы источниках ни шла речь, результат распознавания как написанного, так и печатного текста требует обязательного контроля. Во-первых, в зависимости от исходников, у сканов могут быть характеристики, усложняющие распознавание:
- низкое полиграфическое качество;
- недостаточная контрастность текста;
- сложность расположения элементов текста на странице и относительно друг друга.
Если какие-то из этих факторов имели место, программа могла не узнать символ или спутать его с другим. Поэтому специалисты «Ру-Скан» тщательно проверяют получившиеся тексты. Наши опыт и навыки позволяют нам делать это быстро и качественно.
Мы профессионально обработаем ваши материалы и подготовим грамотные текстовые файлы, с которыми будет удобно работать дальше. Цены на услуги распознавания текста вы найдете ниже или на этой странице. Обращайтесь!
Цены на услуги распознавания текста вы найдете ниже или на этой странице. Обращайтесь!
Если вас интересуют наши услуги, цены на них можно узнать здесь. Также обращайтесь по номеру телефона +7 (343) 350-50-69 или 8 800 700 56 04. Мы всегда рады вам помочь!
Высокая скорость распознавания текста
Программное обеспечение собственной разработки
Опыт выполнения государственных контрактов 10 лет
Возможность работ под ключ
Опытные и надежные специалисты
Распознавание текста от А до Я
Оставьте заявку
Ваше имя * Ваш e-mail * Ваш телефон *Что Вас интересует?
Подбор оборудования Услуги по оцифровкеОзнакомился с политикой конфиденциальности, обработкой данных и даю свое согласие на их обработку
OCR — оптическое распознавание символов — Azure Cognitive Services
- Статья
Распознавание текста или оптическое распознавание символов также называется распознаванием текста или извлечением текста. Методы распознавания текста на основе машинного обучения позволяют извлекать печатный или рукописный текст из изображений, таких как плакаты, уличные знаки и наклейки на продукты, а также из таких документов, как статьи, отчеты, формы и счета. Текст обычно извлекается в виде слов, строк и абзацев или текстовых блоков, что обеспечивает доступ к цифровой версии отсканированного текста. Это устраняет или значительно сокращает потребность в вводе данных вручную.
Методы распознавания текста на основе машинного обучения позволяют извлекать печатный или рукописный текст из изображений, таких как плакаты, уличные знаки и наклейки на продукты, а также из таких документов, как статьи, отчеты, формы и счета. Текст обычно извлекается в виде слов, строк и абзацев или текстовых блоков, что обеспечивает доступ к цифровой версии отсканированного текста. Это устраняет или значительно сокращает потребность в вводе данных вручную.
Интеллектуальная обработка документов (IDP) использует OCR в качестве базовой технологии для дополнительного извлечения структуры, связей, ключевых значений, сущностей и других аналитических сведений, ориентированных на документ, с помощью расширенной службы искусственного интеллекта на основе машинного обучения, такой как Распознаватель документов. Распознаватель документов включает оптимизированную для документов версию Read в качестве обработчика OCR, делегируя другим моделям для получения аналитических сведений более высокого уровня.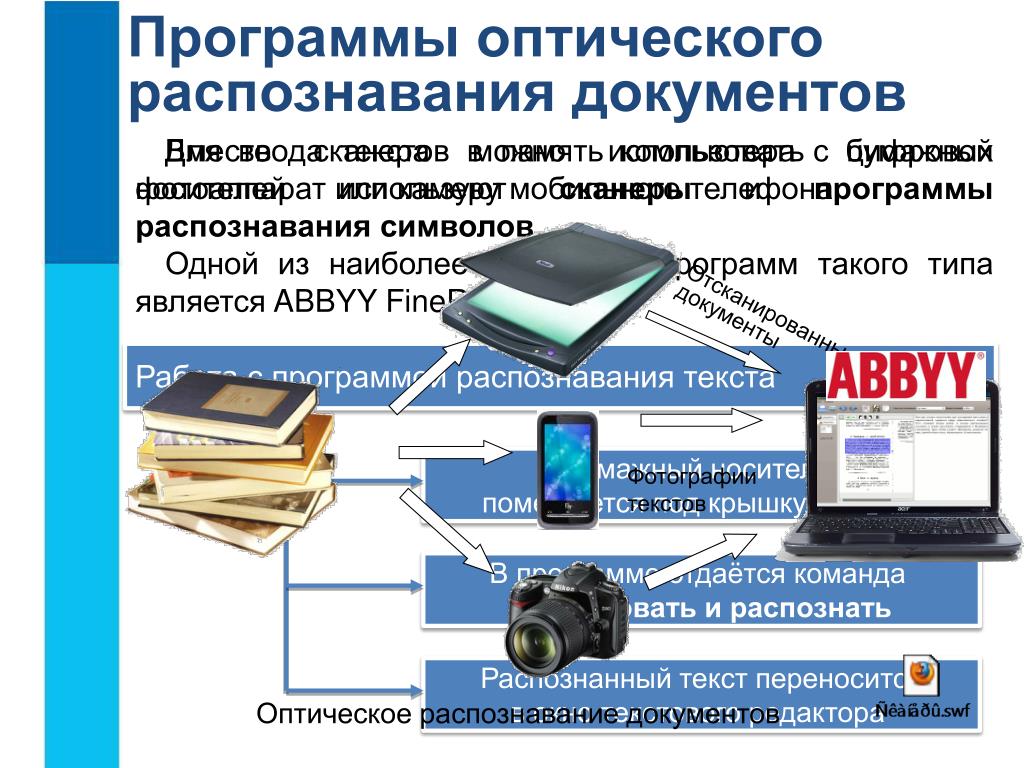 Если вы извлекаете текст из отсканированных и цифровых документов, используйте Распознаватель документов чтение OCR.
Если вы извлекаете текст из отсканированных и цифровых документов, используйте Распознаватель документов чтение OCR.
Обработчик OCR
Модуль OCR для чтения майкрософт состоит из нескольких расширенных моделей на основе машинного обучения, поддерживающих глобальные языки. Это позволяет им извлекать печатный и рукописный текст, включая смешанные языки и стили письма. Чтение доступно как облачная служба и локальный контейнер для гибкого развертывания. В последней предварительной версии он также доступен в виде синхронного API для отдельных сценариев, не относящихся к документам, только для изображений, с повышением производительности, что упрощает реализацию пользовательского интерфейса с помощью OCR.
Предупреждение
Не рекомендуется использовать устаревший API OCR Компьютерное зрение в версии 3.2 и API RecognizeText в операциях версии 2.1.
Выпуски OCR (чтение)
Важно!
Выберите выпуск для чтения, который лучше всего соответствует вашим требованиям.
| Входные данные | Примеры | Чтение выпуска | Преимущество |
|---|---|---|---|
| Изображения: общие, в дикие образы | наклейки, уличные знаки и плакаты | предварительная версия Компьютерное зрение версии 4.0 | Оптимизировано для общих изображений, не относящихся к документам, с синхронным API с улучшенной производительностью, что упрощает внедрение OCR в сценарии взаимодействия с пользователем. |
| Документы: цифровые и отсканированные, включая изображения | книги, статьи и отчеты | Распознаватель документов | Оптимизировано для отсканированных текстов и цифровых документов с асинхронным API для автоматизации интеллектуальной обработки документов в большом масштабе. |
Сведения об общедоступной версии Компьютерное зрение версии 3.2
Ищете последнюю Компьютерное зрение общедоступной версии 3.2 для чтения? Обратите внимание, что все будущие улучшения OCR для чтения будут частью двух новых служб, перечисленных выше. Дальнейших обновлений Компьютерное зрение версии 3.2 не будет. Чтобы продолжить, ознакомьтесь с общими сведениями и кратким руководством по Компьютерное зрение версии 3.2.
Дальнейших обновлений Компьютерное зрение версии 3.2 не будет. Чтобы продолжить, ознакомьтесь с общими сведениями и кратким руководством по Компьютерное зрение версии 3.2.
Использование OCR
Попробуйте OCR с помощью Vision Studio. Затем перейдите по одной из ссылок на выпуск Read, который лучше всего соответствует вашим требованиям.
Опробовать Vision Studio
Языки, поддерживаемые OCR
Обе версии для чтения, доступные сегодня в Компьютерное зрение поддерживают несколько языков для печатного и рукописного текста. Распознавание текста для печатного текста включает поддержку английского, французского, немецкого, итальянского, португальского, испанского, китайского, японского, корейского, русского, арабского, хинди и других международных языков, использующих латиницу, кириллицу, арабский и деванагари. Распознавание текста для рукописного текста включает поддержку английского, китайского (упрощенного), французского, немецкого, итальянского, японского, корейского, португальского и испанского языков.
См. полный список языков, поддерживаемых OCR.
Общие функции OCR
Модель чтения OCR доступна в Компьютерное зрение и Распознаватель документов с общими базовыми возможностями при оптимизации для соответствующих сценариев. В следующем списке перечислены общие возможности:
- Извлечение печатного и рукописного текста на поддерживаемых языках
- Страницы, текстовые строки и слова с оценкой расположения и достоверности
- Поддержка смешанных языков, смешанный режим (печать и рукописный ввод)
- Функция доступна как контейнер Distroless Docker для локального развертывания
Использование облачных API OCR или развертывание локальной среды
Облачные API являются предпочтительным вариантом для большинства клиентов из-за простоты интеграции и быстрой производительности. Azure и служба Компьютерное зрение обеспечивают масштабирование, производительность, безопасность данных и соответствие требованиям, а вы можете сосредоточиться на обслуживании своих клиентов.
Для локального развертывания контейнер Docker для чтения позволяет развернуть общедоступные возможности OCR Компьютерное зрение версии 3.2 в собственной локальной среде. Контейнеры соответствуют конкретным требованиям к безопасности и управлению данными.
Конфиденциальность и безопасность данных OCR
Как и в случае со всеми другими Cognitive Services, разработчикам, использующим API компьютерного зрения, следует учитывать политику корпорации Майкрософт касательно клиентских данных. Дополнительные сведения см. на странице о Cognitive Services Центра управления безопасностью Майкрософт.
Дальнейшие действия
- Распознавание текста для общих (недокументных) изображений: воспользуйтесь кратким руководством по REST API анализа изображений Компьютерное зрение 4.0 (предварительная версия).
- Распознавание текста для документов PDF, Office и HTML и изображений документов: начните с Распознаватель документов чтение.
- Ищете предыдущую общедоступную версию? Ознакомьтесь с краткими руководствами по пакету SDK для Компьютерное зрение 3. 2 ga или REST API.
 2 ga или REST API.
2 ga или REST API.Convert PDF to Word — бесплатный конвертер PDF в Word
Зачем конвертировать из PDF в Microsoft Word? Легко, это делает ваши PDF-файлы редактируемыми! Захватывайте текст, редактируйте PDF-файлы и многое другое.
Перетащите файлы сюда
Преобразование файлов PDF в: Microsoft Word (*.docx)Word 2003 или старше (*.doc)
Метод оптического распознавания символов
Распознавание LayoutText
Чтобы получить наилучшие результаты, выберите все языки, содержащиеся в вашем файле.
Улучшить распознавание текста Применить фильтр:  Please note that the resulting document will lose its colors»/>
Применить фильтр
Без фильтраСерый фильтр
Please note that the resulting document will lose its colors»/>
Применить фильтр
Без фильтраСерый фильтр
Информация: Пожалуйста, включите JavaScript для корректной работы сайта.
РекламаКак преобразовать PDF в Word?
- Загрузите свой PDF-документ выше.
- Выберите нужную версию Microsoft Word.
- Необязательно: улучшите результат, выбрав метод OCR, указав язык исходного текста и т. д.
- Нажмите «Пуск».
Оцените этот инструмент 3,1 /5
Вам нужно преобразовать и загрузить хотя бы 1 файл, чтобы оставить отзыв
Отзыв отправлен
Спасибо за ваш голос
Из JPG в PDF — Преобразование изображений в PDF
Преобразование изображений JPG в PDF.
 Мы можем показать вам, как преобразовать JPG в PDF и, таким образом, извлечь текст из любого изображения. Фотографии, картинки, скриншоты, сканы — этот онлайн-инструмент поможет вам получить нужный текст.
Мы можем показать вам, как преобразовать JPG в PDF и, таким образом, извлечь текст из любого изображения. Фотографии, картинки, скриншоты, сканы — этот онлайн-инструмент поможет вам получить нужный текст.Перетащите файлы сюда
Исходные языки вашего файлаЧтобы получить наилучшие результаты, выберите все языки, содержащиеся в вашем файле.
Применить фильтр: Применить фильтр Без фильтраСерый фильтр
Версия PDF без изменений
1.41.51. 61.72.0
61.72.0
Исправление кривых изображений.
Включить выравниваниеИнформация: Пожалуйста, включите JavaScript для правильной работы сайта.
РекламаКак конвертировать JPG в PDF?
- Загрузите изображение в формате JPG.
- Выберите язык, на котором написан текст JPG. (необязательно)
- Выберите версию PDF, если хотите конкретную. (опционально)
- Включить коррекцию перекоса, если фотография или изображение кривые. (опционально)
- Начать преобразование.

Ваш комментарий будет первым