Распознавание удостоверяющих документов 193 стран — компания Smart Engines
Smart ID Engine
— высокоточное и безопасное программное обеспечение для распознавания данных 1555 типов удостоверяющих документов 210 юрисдикций мира.
Smart ID Engine (ранее Smart IDReader) работает автономно на конечном устройстве: смартфоне, планшете, умной камере, терминале, персональном компьютере, сервере — автоматически распознавая видео, фотографии или скан образы документов удостоверяющих личность (ДУЛ): паспорта, удостоверения личности (ID карты), водительские удостоверения, визы, виды на жительства, разнообразные свидетельства и др.
Программное обеспечение НЕ передает личные данные ваших клиентов на обработку в сторонние сервисы и/или третьим лицам для ручного ввода, НЕ сохраняет данные — все обработка ведется в локальной оперативной памяти устройства, НЕ требует сетевого соединения.
При использовании Smart ID Engine (Smart IDReader) НЕ требуется выполнять дополнительных действий, связанных с получением согласия субъекта на обработку его персональных данных (юридическое заключение).
Smart ID Engine — инструмент цифровой трансформации процессов дистанционного привлечения и обслуживания клиентов банков, страховых компаний, операторов связи, микрофинансовых организаций, брокеров, туроператоров, риэлтеров, игорного бизнеса, финансовых супермаркетов, онлайн торговли и других отраслей электронной коммерции. С его помощью просто наладить удобное, быстрое, безопасное и бесконтактное обслуживание посетителей банковских и страховых офисов и внесение данных в CRM системы, обеспечив распознавание текста по фото российского паспорта или удостоверений личности других стран. Продукт позволяет организовать продажу финансовых, страховых, транспортных услуг и продуктов, билетов и сим карт в вендинговых машинах и терминалах.
Разработанная нашими специалистами технология оптического распознавания текста: GreenOCR позволяет точно распознавать текст на 100 языках, включая арабский, персидский, урду, японский (кандзи, катакана и хирагана), и специально оптимизирована для минимизации воздействия на окружающую среду в рамках подхода Green AI. А наши технологии Edge OCR и 4D OCR обеспечивают быстрое и автономное распознавание текста в видеопотоке на мобильных устройствах.
А наши технологии Edge OCR и 4D OCR обеспечивают быстрое и автономное распознавание текста в видеопотоке на мобильных устройствах.
Smart ID Engine помогает выявлять и предотвращать попытки мошенничества с документами в процессе оказания услуг, защищая как организацию, так и клиента. Важными преимуществами использования Smart ID Engine являются: соблюдение прав и свобод личности, высокие стандарты безопасности обработки персональных данных (ФЗ-152, GDPR, CCPA), выполнение требований регуляторов (KYC/AML), формирование передового пользовательского опыта и минимизация воздействия на окружающую среду (Green AI).
Поставка Smart ID Engine осуществляется в виде автономного SDK (software developer kit), содержащий все необходимые описания API (application programmable interface) и примеры по интеграции на разных языках программирования.
Подробные сведения о функциональных возможностях, архитектуре, совместимости с различными архитектурами ЭВМ и операционными системами представлены в спецификации.
Заказать продукт
Решение для массового ввода и распознавания документов
Решение для массового ввода и распознавания документов позволяет исключить риски ошибок при ручном вводе и автоматизировать рутинные процессы. С его помощью финансовые службы могут ускорить ввод данных в учетные системы в 3 раза. Компания TerraLink предлагает решения, реализованные на базе продуктов Opentext или ABBYY.
Каждый день компании сталкиваются с проблемой интеграции факсов, электронной почты и бумажных документов в бизнес-процессы. Проблема заключается в том, что, хотя ваши клиенты, поставщики и партнеры могут легко направить вам документы по факсу или электронной почте, обработка полученной информации может быть затруднена.
Это особенно верно, когда информация поступает в различных форматах и различного качества. Часто персоналу приходится вводить эту информацию в системы вручную, что приводит к человеческим ошибкам, дополнительным затратам времени, задержкам обработки, проблемам с обслуживанием клиентов и перерасходу средств.
Решение для распознавания документов и их последующей обработки
Решение TerraLink для массового ввода и распознавания документов автоматизирует ваши процессы, устраняя затраты, задержки и ошибки, связанные с необходимостью ввода данных вручную. Решение совмещает сложную технологию распознавания, проверки и автоматизированные рабочие процессы, чтобы получить данные, непосредственно используемые вашими системами.
При построении решений TerraLink использует промышленные системы массового ввода, чье применение гарантирует наилучшие результаты в соответствии с потребностями наших пользователей:
- OpenText Business Center for SAP Solutions – промышленная система, заслуженно котирующаяся в числе лидеров рынка программных средств массового ввода, представляющая непревзойденные встроенные возможности в части интеграции с хранилищами контента, реализованными на платформах SAP и OpenText.
- Kofax Transformation Module (KTM) – промышленная, лидирующая в мире система для управления массовым вводом документов и их последующей обработкой.

- ABBYY FlexiCapture – наиболее распространенная отечественная система, заслужившая заслуженное признание как в России, так и за рубежом.

Типичные проблемы, связанные с вводом документов
- Информация поступает в разных форматах (факсы, вложения электронной почты, бумажные документы) и разного уровня качества.
- Интеграция входящих документов в бизнес-системы может быть сложной задачей.
- Ручной ввод входящей информации в бизнес-системы приводит к увеличению затрат, человеческим ошибкам, дополнительным рабочим циклам, задержкам обработки, проблемам обслуживания клиентов.
Функционал решения для массового ввода и распознавания документов
- Автоматическая обработка неструктурированных документов различных форматов с использованием технологии распознавания, проверок качества персонала и автоматизированных рабочих процессов.
- Превращение входящих документов в данные, непосредственно используемые бэк-офисными приложениями.
- Предоставление данных в различных форматах, включая XML, CSV и IDOC.
- Поддержка различных протоколов передачи данных, включая SMTP, HTTPS, FTP.
- Точность на уровне поля ваших входящих документов и форм на уровне 99,5%.
- Соблюдение конфиденциальности, безопасности и других норм.
- Ежемесячные отчеты о проверках и исключениях.
- Обеспечение работы ОЦО.
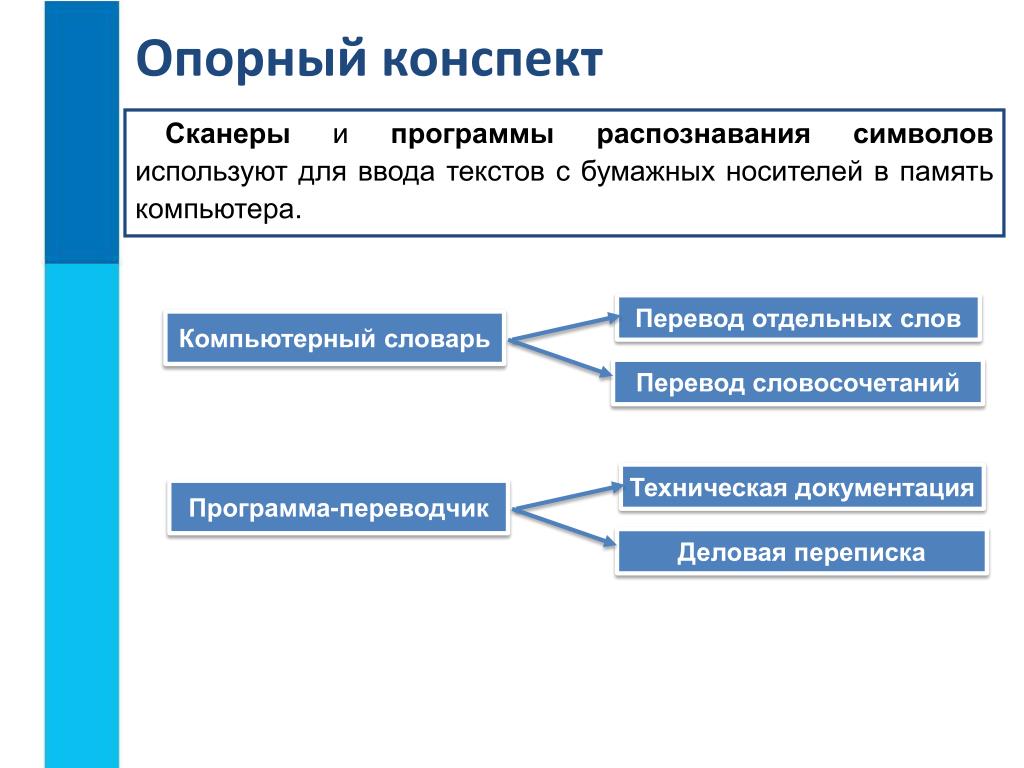
Бизнес-выгоды от внедрения решения для массового ввода и распознавания документов
- Устранение затрат, задержек и ошибок, связанных с необходимостью повторного ввода данных вручную.
- Оптимизация штата сотрудников, отвечающих за первичную обработку поступающих документов
- Оптимизация и автоматизация работы операторов сканирования в филиалах
- Оптимизация затрат на инфраструктуру за счет эффективного управления данными
- Минимизация влияния человеческого фактора при контроле ошибок
- Автоматизированный контроль полноты данных и правильности оформления документов
- Решение проблемы пиковых нагрузок при закрытии учетных периодов
- Сокращение времени исполнения ключевых корпоративных бизнес-процессов за счет перехода на работу с электронными образами документов вместо бумажных.

Результаты наших клиентов
- Увеличение скорости ввода документов почти в 3 раза
- Увеличение скорости ввода данных учетные системы почти в 2,5 раза с одновременным практически полным исключением ошибок
- Повышение скорости обработки документов на всех этапах корпоративных бизнес-процессов почти в 4 раза
- Уменьшение трудозатрат при обработке документов почти в 2 раза
- Снижение нагрузки на каналы передачи данных почти в 3-4 раза, экономия трафика
OCR для распознования документов с помощью нейросети
Арнольд работает страховым консультантом. Ежедневно он тратит 2 часа на правку отчетов и оформление страховых полисов. Агентов в фирме много, но всех объединяет одна проблема: слишком много ручной работы. Время, потраченное на набор текста и исправление ошибок, лучше потратить на общение с клиентами или развитие новых навыков. Все это негативно отражается на бизнесе.
Чтобы оптимизировать работу, сократите бессмысленный ручной труд. В этом поможет OCR.
Что такое OCR?
Оптическое распознавание символов или OCR — это технология для переноса бумажного документа или цифрового изображения в текстовый документ, который легко читать, копировать и редактировать.
OCR пригодится там, где нужно обрабатывать большие объемы текста или работать с бумажными носителями. Страховые компании, банки, государственные учреждения, транспортные компании. Все, кто хочет извлечь текст из изображения, могут делать это проще и быстрее.
Как это работает?
Потребуется цифровое изображение или бумажная распечатка. Специальная программа распознает текст на бумаге или изображении и переводит его в редактируемый текст. Дальше — полная свобода действий и минимум потраченного времени.
Для компании Арнольда мы разработали специальный алгоритм обработки паспортов и водительских прав. Страховые агенты просто фотографируют нужный документ на телефон. Программа сама заполняет ФИО, серию, номер паспорта и другие поля заявления.
Программа сама заполняет ФИО, серию, номер паспорта и другие поля заявления.
В чем выражается польза?
Вы работаете быстрее
Раньше на оформление страховки требовалось 15-20 минут. С помощью нашего OCR-софта все решается за 5 минут и 3 простых шага:
- Сотрудник фотографирует документ
- Поля электронного заявления заполняются автоматически
- Быстро проверяет текст на наличие ошибок
Вы работаете с удовольствием
Чем меньше рутинной работы, тем лучше. Монотонное печатание утомляет. Просто наведите камеру телефона на паспорт, права или любой другой документ. Программа распознает текст и автоматически заполнит необходимые поля.
Так Арнольд и его коллеги перестали тратить время на ручную печать и освободили время для настоящей работы.
Как мы распознавали документы для страховой компании
Рассказываем, как работаем над алгоритмами распознавания текста. С небольшими изменениями процесс общий для обработки любых бумажных документов. Указанные ниже методы мы использовали для распознавания паспорта и водительских прав.
Указанные ниже методы мы использовали для распознавания паспорта и водительских прав.
- Локализация
- Фильтрация
- Извлечение строк
- Распознавание текста по символам или по строкам
Локализация
Это нахождение документа на изображении. Для локализации мы пробовали три основных подхода:
- OpenCV и обученный классификатор Хаара
- Полносверточные нейронные сети
- Аналитический подход на основе поиска связных компонент
В первом подходе документ помечается прямоугольником и обрезается до тех пор, пока в рамке не останется выделенной область с текстом; если документ на видео не найден, то алгоритм продолжает поиск в видеопотоке.
Во втором подходе мы применяем полносверточные нейронные сети. На вход сети подается цветное изображение паспорта. На выходе формируется два канала: первый используется для поиска центра первой страницы паспорта, второй — для поиска центра второй страницы. При этом сеть тренируется предсказывать маску, в которой над центрами страниц паспорта находятся гауссовы пики.
Третий подход мы применили для распознавания паспорта. Использовали шаблон, где на развороте паспорта находились две области с серией и номером документа. Если такой шаблон в кадре, то перед нами паспорт. В основе данного подхода лежит поиск связанных компонент. Смотрите видео ниже.
Фильтрация
Фон документов ламинированный, с бликами света и водяными знаками. Для нейронной сети все это — шум, который мешает распознавать символы. Поэтому мы этот шум постарались убрать. Для этого использовали:
- Алгоритм фильтрации шума fastNlMeansDenoisingColored с окном подходящего размера для затирания линий
- Билатеральный фильтр для получения однородного фона
- Метод адаптивной бинаризации
Извлечение строк
Для водительских прав мы применили OpenCV и детектировали контуры букв.Затем мы разбивали строки на буквы, которые потом подавали на вход нейронной сети для распознавания.
Для извлечения строк паспорта мы применили полносверточную нейронную сеть.
Распознавание текста
Для распознавания текста мы использовали нейронные сети. Текст на правах мы распознавали по буквам с помощью сверточной нейронной сети, обученной на большом датасете изображений букв. Для создания и обучения нейронной сети мы использовали фреймворк Torch.
Текст в паспорте также распознавали с помощью полносверточной нейронной сети. Регистр буквы при распознавании не учитывается. Для обучения сети мы подготовили специальный скрипт — генератор обучающей выборки:
1. Водительское удостоверение
2. Камера
3. Исполняемый бинарный файл
4. Исходные коды C++, из которых собран исполняемый файл
5. Lua скрипт, осуществляющий работу с нейросетью. В нем описана архитектура сети.
6. Бинарный файл с весами сети, подгружаемый Lua скриптом. Веса получены после обучения сети
Почему вашему бизнесу нужны наши алгоритмы распознавания текста
Комбинируя различные подходы, мы добились точности распознавания 90%. Это больше, чем предлагают доступные на рынке инструменты.
Это больше, чем предлагают доступные на рынке инструменты.
Высокая точность достигается за счет специализированного подхода. Мы проверяем множество гипотез и выбираем то, что работает лучше для конкретной бизнес-задачи.
Используйте OCR в бизнесе для распознавания документов. Так вы повысите скорость работы, увеличите продуктивность и освободите сотрудников от малоэффективного ручного труда.
В 1С:Бухгалтерии появилось распознавание документов: как это работает
В 1С:Бухгалтерии с версии 3.0.81 появилась возможность упростить ввод некоторых первичных документов с помощью сервиса распознавания бухгалтерских документов. Специалист 1С:ИТС Тимофей Антипин рассказал, как это работает.
Тратите время на заведение первички вручную? Эта статья для вас.
Неважно, в офисе или дома — теперь для ввода первичных документов достаточно отсканировать или сфотографировать документы и отправить их на распознавание. Если дома нет сканера — смартфон всегда под рукой.
Распознавание документов есть только в сервисе 1С:Фреш в программе 1С:Бухгалтерия. На данный момент доступно распознавание Счетов-фактур, ТОРГ-12, УПД, Актов и Счетов на оплату.
Обращаем внимание, что пользователи с действующим договором 1С:ИТС уровня ПРОФ могут работать в облачном сервисе 1С:Фреш бесплатно
На наш взгляд, распознавание документов — это первое значимое отличие в функционале облачной и коробочной версии, которое позволяет сделать однозначный выбор в пользу 1С:Фреш.
Для того чтобы воспользоваться сервисом распознавания документов в приложении 1С:Бухгалтерия нужно зайти в «Администрирование» — «Настройки распознавания документов» и поставить галочку «Использовать распознавание документов».
Рис. 1 (нажмите, чтобы увеличить)
Представим, что пришли 3 документа, которые надо ввести в информационную базу:
- поступление с УПД;
- один Акт оказанных услуг;
- счет на оплату.
Сканируем документы и получаем файл с изображениями. В приложении 1С:Бухгалтерия откройте «Продажи» или «Покупки» и нажмите «Загрузить документы из сканов (фото)». В открывшемся окне нажмите кнопку «Добавить файлы».
Рис. 2 (нажмите, чтобы увеличить)
Перетащите файлы в открывшееся окно или выберите их с диска.
Рис. 3 (нажмите, чтобы увеличить)
Далее нажмите кнопку «Распознать».
Рис. 4 (нажмите, чтобы увеличить)
В списке задач на распознавание появились новые записи в статусе «В обработке».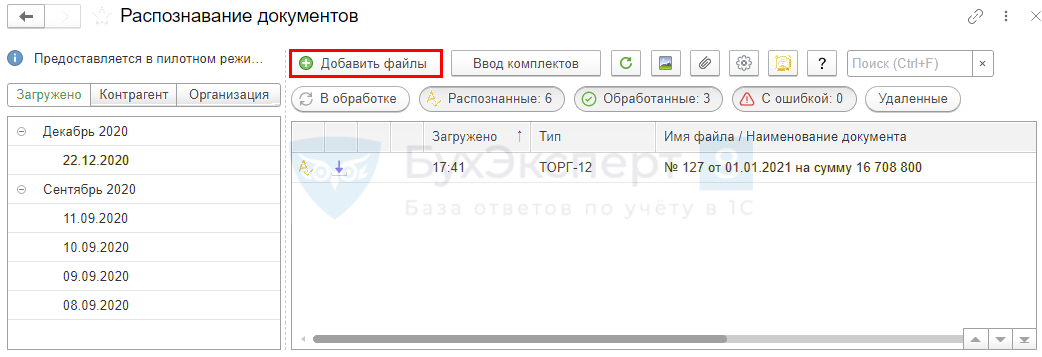
Рис. 5 (нажмите, чтобы увеличить)
Спустя несколько минут документы распознаются и сменят статус на «Распознанные».
Рис. 6 (нажмите, чтобы увеличить)
Открываем первый документ.
Рис. 7 (нажмите, чтобы увеличить)
Слева отображаются основные свойства документа, справа — изображение отсканированного документа, а снизу — табличная часть документа. Далее проверяем номер, дату и сумму и контрагента. Если контрагента нет в информационной базе, 1С предложит создать контрагента по данным отсканированного документа. После проверки корректного заполнения всех полей, нажмите кнопку «Создать документ». В базе создался документ «Поступление услуг».
Рис. 8 (нажмите, чтобы увеличить)
После создания документа программа автоматически перейдет к вводу следующего распознанного документа.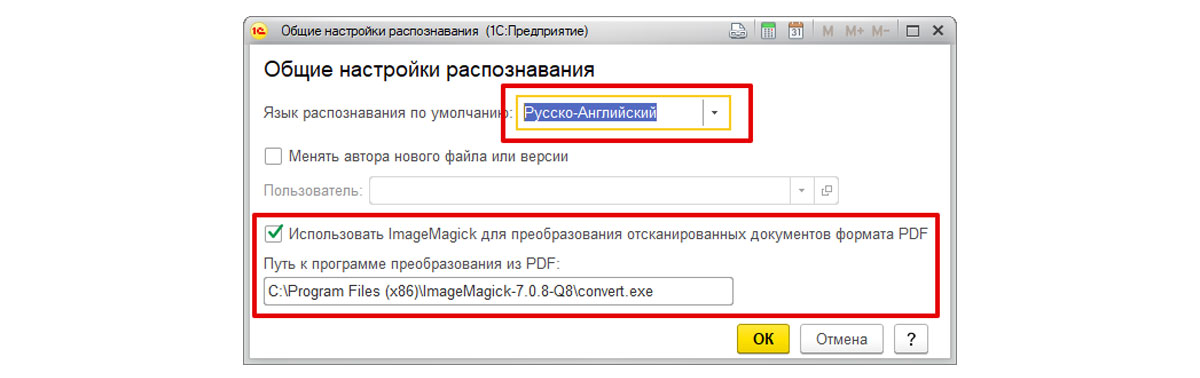 Аналогичным образом создаем оставшиеся документы. Предварительно проверьте корректность автоматического заполнения полей, в том числе наименование номенклатуры, и при необходимости исправьте ошибки.
Аналогичным образом создаем оставшиеся документы. Предварительно проверьте корректность автоматического заполнения полей, в том числе наименование номенклатуры, и при необходимости исправьте ошибки.
Таким образом, всего за несколько минут мы завели в базу 3 документа.
Для ускорения работы рекомендуем сканировать (фотографировать) документы и загружать их по несколько штук.
|
Автор статьи: Тимофей Антипин, специалист отдела 1С:ИТС «АСП-Центр сопровождения». Заказать консультацию |
Вместе с этим читают:
4499 просмотров
Распознавание документов | EnDocs
При автоматизации документооборота часто встречаются задачи по распознаванию документов. EnDocs решает подобные задачи. Мы интегрировали нашу программу с продуктами компании ABBYY.
EnDocs решает подобные задачи. Мы интегрировали нашу программу с продуктами компании ABBYY.
Как это работает
Задачи распознавания документов разные, EnDocs предлагает большой набор инструментов для их решения.
- распознавание штрих-кодов для автоматического прикрепления скана документа к соответствующей карточке. Этот функционал входит в модуль «Поточное сканирование» EnDocs и не требует ПО ABBYY;
- распознавание сканированных документов для осуществления полнотекстового поиска в архиве документов. Для этой цели EnDocs имеет интеграцию с продуктом ABBYY FineReader;
- индексирование документов — внесение атрибутов в регистрационную карточку путем «клика» по этому атрибуту на скане документа. Для этой цели EnDocs имеет интеграцию с продуктом ABBYY Станция индексирования;
- распознавание стандартных форм документов (счетов-фактур, накладных, платежных поручений и т. п.), автоматическое формирование карточки документа со значениями всех полей, содержащихся в скане. Для этой цели EnDocs имеет интеграцию с продуктом ABBYY FlexiCapture;
- визуальное сравнение оригинала документа в формате Microsoft Word с отсканированной копией подписанного документа, получение подтверждения того, что подписан именно согласованный документ и не произошла подмена страницы. Для этой цели в составе EnDocs есть модуль сравнения документов, созданный на базе технологии ABBYY ScanDifFinder.
 Для этой цели EnDocs имеет интеграцию с продуктом ABBYY FlexiCapture;
Для этой цели EnDocs имеет интеграцию с продуктом ABBYY FlexiCapture;- снижение затрат на сканирование и внесение атрибутов документов в карточку в 2–20 раз,
- снижение ошибок ручного ввода данных в 1,5–3 раза,
- снижение рисков подписания некорректного документа,
- решение всех задач, связанных с распознаванием документа,
- возможность доработки системы полностью под ваши нужды!
31.08.2020 Распознавание документов теперь доступно в 1С:Бухгалтерии без установки расширения
В 1С:Бухгалтерии версии 3. 0.81 появилась возможность упростить ввод некоторых первичных документов с помощью сервиса распознавания бухгалтерских документов.
Достаточно отсканировать или сфотографировать документы и отправить их на распознавание. Через несколько минут документы будут распознаны и доступны к вводу в вашем приложении.
Сейчас доступно распознавание Счетов-фактур, ТОРГ-12, УПД, Актов и Счетов на оплату.
Сервис сейчас предоставляется в пилотном режиме, правила его использования могут уточняться в будущем.
Обучающие видео
Смотрите обучающие видео по использованию сервиса распознавания бухгалтерских документов:
 youtube.com/embed/-62VNvrDokU?rel=0″/>
youtube.com/embed/-62VNvrDokU?rel=0″/>
Как воспользоваться
Главная форма (список задач) сервиса доступна в разделах Продажи и Покупки главного меню в разделе Сервис под названием Загрузить документы из сканов (фото).
Доступ к настройкам подсистемы распознавания документов и к списку мобильных приложений открывается через иконки и на главной форме подсистемы.
Также настройки подсистемы распознавания документов можно найти в составе пункта меню Администрирование под названием Настройки распознавания документов.
Отказ от расширения
Расширение Библиотека распознавания больше не понадобится и поддерживаться не будет.
После обновления 1С:Бухгалтерии на версию 3.0.81 при открытии списка задач Вам будет предложено перенести данные из расширения.
Пожалуйста, воспользуйтесь этим предложением, если хотите сохранить все распознанные документы и настроенные мобильные приложения. Впрочем, это необязательно: вы можете не переносить данные и начать использование с чистого листа.
Впрочем, это необязательно: вы можете не переносить данные и начать использование с чистого листа.
После переноса данных (или осознанного отказа от их переноса) расширение можно удалить.
Распознавание документов
В проектах автоматизации документооборота могут возникнуть задачи распознавания документов. WSS Docs позволяет решить все подобные задачи, для этого мы имеем интеграцию с продуктами компании Abbyy:
- Распознавание штрих-кодов для автоматического прикрепления скана документа к соответствующей карточке. Этот функционал входит в модуль «Поточное сканирование» и не требует ПО Abbyy.
- Распознавание сканированных документов для осуществления полнотекстового поиска в архиве документов. Для этой цели WSS Docs имеет интеграцию с продуктом Abbyy Recognition Server.
-
Индексирование документов — внесение атрибутов в регистрационную карточку путем «клика» по этому атрибуту на скане документа. Для этой цели WSS Docs имеет интеграцию с продуктом Abbyy Станция индексирования.
- Распознавание стандартных форм документов (счетов-фактур, накладных, платежных поручений и т.п.), автоматическое формирование карточки документа со значениями всех полей, содержащихся в скане. Для этой цели WSS Docs имеет интеграцию с продуктом Abbyy Flexy Capture.
- Визуальное сравнение оригинала документа в формате Word со скан копией подписанного документа, получение подтверждение того, что подписан именно согласованный документ и не произошла подмена страницы. Для этой цели WSS Docs имеет интеграцию с продуктом Abbyy Comparator.
 Для этой цели WSS Docs имеет интеграцию с продуктом Abbyy Станция индексирования.
Для этой цели WSS Docs имеет интеграцию с продуктом Abbyy Станция индексирования.Автоматическое распознавание документов дает следующий бизнес-эффект:
- Снижение затрат на сканирование и внесение атрибутов документов в карточку в 2-20 раз
- Снижение ошибок ручного ввода данных в 1.5-3 раза
- Снижение рисков подписания некорректного документа
Система WSS Docs позволяет решить все задачи, связанные с распознаванием документа, а также может быть доработана полностью под ваши нужды!
Оставьте заявку
По вашему запросу мы проведем бесплатную демонстрацию системы
WSS Docs, подберем решения для ваших задач и расчитаем стоимость внедрения.
Программное обеспечение для интеллектуального распознавания документов
Распознавание документов с помощью интеллектуального программного обеспечения
Если вы работаете в организации, которая ежедневно обрабатывает большое количество документов, и участвуете в преобразовании этих документов из бумажного формата в электронный посредством процесса сканирования, то вы должны осознавать трудности, связанные с сортировкой и хранение этих документов в соответствии с их тематикой. Даже если вы используете сложную программу OCR для преобразования изображений в текст и затем сохраняете их, вам все равно придется просматривать каждый документ, а затем назначать одну или несколько тем или `тегов ‘каждому, чтобы их можно было сохранить в базе данных. и перекрестные ссылки для последующего интеллектуального анализа данных. Именно здесь вам может помочь интеллектуальное программное обеспечение для распознавания документов.
Именно здесь вам может помочь интеллектуальное программное обеспечение для распознавания документов.
Примеры программного обеспечения для распознавания документов
Ряд компаний предлагает программное обеспечение и услуги для интеллектуального распознавания документов, хотя большинство из них интегрировано со сложными решениями интеллектуального анализа данных или CRM. Вы также можете воспользоваться помощью поставщиков услуг, которые изучат потоки информации в вашей организации, а также программное обеспечение для планирования предприятия, которое вы, возможно, уже используете, а затем предложите индивидуальное решение в соответствии с вашими потребностями.
Преимущества программного обеспечения интеллектуального распознавания документов
Интеллектуальное программное обеспечение для распознавания документов автоматически просматривает большое количество текстовых документов, которые были обработаны с помощью OCR, и прикрепляет к ним теги в соответствии с заранее определенными правилами. Когда программное обеспечение читает документ, оно пытается оценить контекст и тему и присоединяет несколько тегов метаданных, которые затем могут быть сохранены в базе данных и доступны с помощью алгоритма интеллектуального анализа данных. Это не только помогает ускорить ваши запросы, но также помогает в управлении контекстом предприятия, позволяя пользователям из любого офиса искать документы, соответствующие критериям, установленным пользователем.Это также помогает сделать информацию более структурированной и контекстной, тем самым улучшая принятие управленческих решений.
Когда программное обеспечение читает документ, оно пытается оценить контекст и тему и присоединяет несколько тегов метаданных, которые затем могут быть сохранены в базе данных и доступны с помощью алгоритма интеллектуального анализа данных. Это не только помогает ускорить ваши запросы, но также помогает в управлении контекстом предприятия, позволяя пользователям из любого офиса искать документы, соответствующие критериям, установленным пользователем.Это также помогает сделать информацию более структурированной и контекстной, тем самым улучшая принятие управленческих решений.
Руководство по IDP для новичков | Блог
Организации, чей бэк-офис часами занимается сортировкой, классификацией и извлечением данных из документов, знают, насколько медленной и утомительной может быть эта работа. Благодаря интеллектуальному распознаванию документов предприятия видят истинные преимущества автоматизированной обработки документов. Если вы работаете в компании, которая ежедневно обрабатывает большой объем документов, вы, вероятно, знаете, сколько проблем связано с преобразованием этих документов в цифровые. Обработка требует часов кропотливой работы. Люди должны сканировать, а затем отсортировать документы, добавляя теги к каждому из них, чтобы их можно было хранить и делать перекрестные ссылки.
Обработка требует часов кропотливой работы. Люди должны сканировать, а затем отсортировать документы, добавляя теги к каждому из них, чтобы их можно было хранить и делать перекрестные ссылки.
Как вы понимаете, этот ручной процесс является дорогостоящим, подверженным ошибкам, медленным и недостаточно использует ценные человеческие ресурсы. Другими словами, головная боль!
Однако благодаря технологиям на базе искусственного интеллекта эти ручные процессы можно оптимизировать таким образом, чтобы сократить время обработки, повысить точность и значительно снизить необходимость вмешательства человека.
Одной из таких технологий является интеллектуальное распознавание документов (IDR).
ЧТО ТАКОЕ ИНТЕЛЛЕКТУАЛЬНОЕ РАСПОЗНАВАНИЕ ДОКУМЕНТОВ? Intelligent Document Recognition (IDR) — это технология на базе искусственного интеллекта, которая может классифицировать различные типы структурированных и неструктурированных документов, сохранять их в правильной категории и формате и извлекать их для различных целей. (Здесь, в Nexus, мы также используем термин «модель анализа макета».)
(Здесь, в Nexus, мы также используем термин «модель анализа макета».)
IDR использует основанные на правилах модели ИИ и оптическое распознавание символов (OCR) для правильной характеризации и классификации документов.Проще говоря, IDR позволяет сканировать или импортировать различные типы документов в систему, не требуя предварительной сортировки.
КАК РАБОТАЕТ ИНТЕЛЛЕКТУАЛЬНОЕ РАСПОЗНАВАНИЕ ДОКУМЕНТОВ?IDR имеет три основных возможности:
- Классификация : IDR может интерпретировать информацию и шаблоны в документах и классифицировать их по различным типам документов. Если документ, который был отсканирован в систему, содержит, например, слово «расчетная ведомость», то программа автоматически обнаружит, что она обрабатывает расчетную ведомость.Конечно, это очень упрощенный пример. Программное обеспечение IDR может классифицировать более сложные и детализированные документы, в которых могут присутствовать различные термины, с соответствующей пометкой каждого из полей.
- Извлечение : после классификации IDR автоматически извлекает соответствующие данные из документов. Извлекаемые данные зависят от потребностей каждой отдельной организации. Эти данные могут использоваться для запуска бизнес-процесса или для заполнения существующей базы данных, такой как система управления взаимоотношениями с клиентами (CRM).
- Версия : программное обеспечение IDR затем экспортирует данные в рабочий процесс, созданный организацией, что позволяет их немедленно использовать.
Программное обеспечение IDR также построено на основе набора правил обучения, что позволяет ему проходить обучение и постоянно улучшать его по мере того, как вы его используете.
ПРЕИМУЩЕСТВА ИНТЕЛЛЕКТУАЛЬНОГО РАСПОЗНАВАНИЯ ДОКУМЕНТОВ
IDR зарекомендовал себя как очень полезный для предприятий с тяжелыми бэк-офисными процессами, которые хотят оптимизировать свои операции.Некоторые из преимуществ IDR следующие:
Более высокая скорость
Избавляя людей от ручного ввода и проверки данных, IDR экономит время, автоматизируя очень трудоемкий процесс.
Повышенная точностьIDR использует такие методы проверки, как макет документа и близость, и значительно снижает вероятность ошибки, связанной с человеческим фактором. Это также снижает шансы компании на нарушение любых нормативных требований.
Меньшие затраты
IDR сокращает расходы, связанные с исправлением ошибок и штрафами за несоблюдение.
Лучшее использование человеческих ресурсов
Освободив сотрудников от рутинных, повторяющихся задач, они могут сосредоточить свои таланты на более важных задачах и принятии решений.
Более легкий поиск
Программное обеспечениеIDR позволяет пользователям из любого отдела или офиса быстро и легко искать документы, соответствующие критериям, установленным пользователем.
Таким образом, интеллектуальное распознавание документов может быть очень полезным инструментом для любого бизнеса, имеющего дело с большими объемами документов.Конечно, существуют более сложные решения IDR, которые используют более сложный ИИ, обладают высокой гибкостью и могут удовлетворить более широкий спектр потребностей, но поскольку это руководство для новичков, мы на этом остановимся.
Если вы хотите узнать больше о том, как использовать IDR для оптимизации бизнес-процессов, свяжитесь с одним из наших представителей. Он или она будет более чем счастлив объяснить, как система интеллектуальной обработки документов Nexus FrontierTech помогает организациям повысить свою эффективность.
% PDF-1.6 % 4 0 obj > эндобдж xref 4 603 0000000016 00000 н. 0000013220 00000 н. 0000013316 00000 п. 0000013689 00000 п. 0000013825 00000 п. 0000014355 00000 п. 0000014896 00000 п. 0000017261 00000 п. 0000017658 00000 п. 0000017951 00000 п. 0000018064 00000 п. 0000018175 00000 п. 0000018244 00000 п. 0000018323 00000 п. 0000018685 00000 п. 0000018962 00000 п. 0000019115 00000 п. 0000019140 00000 п. 0000019447 00000 п. 0000023288 00000 н. 0000023670 00000 п. 0000024144 00000 п. 0000024230 00000 п. 0000030485 00000 п. 0000030989 00000 п. 0000031597 00000 п. 0000031680 00000 п. 0000034972 00000 п. 0000035305 00000 п. 0000035741 00000 п. 0000037366 00000 п. 0000037674 00000 п. 0000038036 00000 п. 0000038113 00000 п. 0000038160 00000 п. 0000038237 00000 п. 0000038284 00000 п. 0000038345 00000 п. 0000038392 00000 п. 0000038453 00000 п. 0000038500 00000 н. 0000038556 00000 п. 0000038603 00000 п. 0000038659 00000 п. 0000038706 00000 п. 0000038762 00000 п. 0000038809 00000 п. 0000038865 00000 п. 0000038912 00000 п. 0000038968 00000 п. 0000039015 00000 н. 0000039071 00000 п. 0000039118 00000 п. 0000039174 00000 п. 0000039221 00000 п. 0000039277 00000 п. 0000039324 00000 п. 0000039397 00000 п. 0000039444 00000 п. 0000039500 00000 н. 0000039547 00000 п. 0000039603 00000 п. 0000039650 00000 п. 0000039706 00000 п. 0000039753 00000 п. 0000039809 00000 п. 0000039856 00000 п. 0000039912 00000 н. 0000039959 00000 н. 0000040015 00000 п. 0000040062 00000 п. 0000040118 00000 п. 0000040165 00000 п. 0000040221 00000 п. 0000040268 00000 п. 0000040329 00000 п. 0000040376 00000 п. 0000040437 00000 п. 0000040484 00000 п. 0000040561 00000 п. 0000040608 00000 п. 0000040669 00000 п. 0000040716 00000 п. 0000040768 00000 п. 0000040815 00000 п. 0000040876 00000 п. 0000040923 00000 п. 0000040988 00000 п. 0000041035 00000 п. 0000041091 00000 п. 0000041138 00000 п. 0000041199 00000 н. 0000041246 00000 п. 0000041873 00000 п. 0000041927 00000 н. 0000042000 00000 н. 0000042047 00000 п. 0000042121 00000 п. 0000042170 00000 п. 0000042240 00000 п. 0000042289 00000 п. 0000042355 00000 п. 0000042404 00000 п. 0000042474 00000 п. 0000042523 00000 п. 0000042593 00000 п. 0000042642 00000 п. 0000059106 00000 п. 0000077110 00000 п. 0000077139 00000 п. 0000077386 00000 п. 0000077727 00000 п. 0000077850 00000 п. 0000077996 00000 п. 0000078345 00000 п. 0000078468 00000 п. 0000078614 00000 п. 0000078861 00000 п. 0000079165 00000 п. 0000079288 00000 п. 0000079434 00000 п. 0000079738 00000 п. 0000079861 00000 п. 0000080007 00000 п. 0000080254 00000 п. 0000080554 00000 п. 0000080677 00000 п. 0000080823 00000 п. 0000081070 00000 п. 0000081369 00000 п. 0000081492 00000 п. 0000081638 00000 п. 0000081885 00000 п. 0000082182 00000 п. 0000082305 00000 п. 0000082451 00000 п. 0000082698 00000 п. 0000082993 00000 п. 0000083116 00000 п. 0000083262 00000 н. 0000083509 00000 п. 0000083803 00000 п. 0000083926 00000 н. 0000084072 00000 п. 0000084319 00000 п. 0000084610 00000 п. 0000084733 00000 п. 0000084879 00000 п. 0000085126 00000 п. 0000085412 00000 п. 0000085535 00000 п. 0000085681 00000 п. 0000085928 00000 п. 0000086210 00000 п. 0000086333 00000 п. 0000086479 00000 п. 0000086726 00000 п. 0000087073 00000 п. 0000087196 00000 п. 0000087342 00000 п. 0000087589 00000 п. 0000087869 00000 п. 0000087992 00000 п. 0000088138 00000 п. 0000088416 00000 п. 0000088539 00000 п. 0000088685 00000 п. 0000088932 00000 п. 0000089244 00000 п. 0000089367 00000 п. 0000089513 00000 п. 0000089760 00000 п. 00000
00000 п. 00000
00000 п. 0000000000 п. 0000090556 00000 п. 0000090875 00000 п. 0000090998 00000 н. 0000091144 00000 п. 0000091429 00000 н. 0000091552 00000 п. 0000091698 00000 п. 0000091945 00000 п. 0000092262 00000 п. 0000092385 00000 п. 0000092531 00000 п. 0000092778 00000 п. 0000093063 00000 п. 0000093186 00000 п. 0000093332 00000 п. 0000093579 00000 п. 0000093901 00000 п. 0000094024 00000 п. 0000094170 00000 п. 0000094417 00000 п. 0000094701 00000 п. 0000094824 00000 н. 0000094970 00000 п. 0000095217 00000 п. 0000095561 00000 п. 0000095684 00000 п. 0000095830 00000 п. 0000096077 00000 п. 0000096400 00000 п. 0000096523 00000 п. 0000096669 00000 п. 0000096958 00000 п. 0000097081 00000 п. 0000097227 00000 п. 0000097474 00000 п. 0000097798 00000 п. 0000097921 00000 п. 0000098067 00000 п. 0000098314 00000 п. 0000098606 00000 п. 0000098729 00000 п. 0000098875 00000 п. 0000099122 00000 н. 0000099453 00000 п. 0000099576 00000 п. 0000099722 00000 н. 0000099969 00000 п. 0000100263 00000 н. 0000100386 00000 н. 0000100532 00000 н. 0000100779 00000 н. 0000101111 00000 н. 0000101234 00000 н. 0000101380 00000 н. 0000101627 00000 н. 0000101922 00000 н. 0000102045 00000 н. 0000102191 00000 п. 0000102438 00000 п. 0000102764 00000 н. 0000102887 00000 п. 0000103033 00000 н. 0000103328 00000 н. 0000103451 00000 н. 0000103597 00000 п. 0000103844 00000 н. 0000104178 00000 п. 0000104301 00000 п. 0000104447 00000 н. 0000104694 00000 н. 0000105027 00000 н. 0000105150 00000 н. 0000105296 00000 н. 0000105543 00000 н. 0000105840 00000 н. 0000105963 00000 н. 0000106109 00000 п. 0000106356 00000 п. 0000106688 00000 п. 0000106811 00000 н. 0000106957 00000 п. 0000107204 00000 н. 0000107503 00000 н. 0000107626 00000 н. 0000107772 00000 н. 0000108019 00000 н. 0000108351 00000 п. 0000108474 00000 п. 0000108620 00000 н. 0000108920 00000 н. 0000109043 00000 н. 0000109189 00000 п. 0000109436 00000 н. 0000109768 00000 н. 0000109891 00000 н. 0000110037 00000 н. 0000110284 00000 п. 0000110582 00000 н. 0000110705 00000 н. 0000110851 00000 п. 0000111186 00000 н. 0000111309 00000 н. 0000111455 00000 н. 0000111755 00000 н. 0000111878 00000 н. 0000112024 00000 н. 0000112271 00000 н. 0000112606 00000 н. 0000112729 00000 н. 0000112875 00000 н. 0000113122 00000 н. 0000113457 00000 н. 0000113580 00000 н. 0000113726 00000 н. 0000113973 00000 н. 0000114272 00000 н. 0000114395 00000 н. 0000114541 00000 н. 0000114877 00000 н. 0000115000 00000 н. 0000115146 00000 н. 0000115449 00000 н. 0000115572 00000 н. 0000115718 00000 н. 0000115965 00000 н. 0000116302 00000 н. 0000116425 00000 н. 0000116571 00000 н. 0000116818 00000 н. 0000117120 00000 н. 0000117243 00000 н. 0000117389 00000 н. 0000117636 00000 н. 0000117974 00000 н. 0000118097 00000 н. 0000118243 00000 н. 0000118490 00000 н. 0000118792 00000 н. 0000118915 00000 н. 0000119061 00000 н. 0000119308 00000 н. 0000119647 00000 н. 0000119770 00000 н. 0000119916 00000 н. 0000120163 00000 н. 0000120503 00000 н. 0000120626 00000 н. 0000120772 00000 н. 0000121019 00000 н. 0000121350 00000 н. 0000121473 00000 н. 0000121619 00000 н. 0000121942 00000 н. 0000122065 00000 н. 0000122211 00000 н. 0000122458 00000 н. 0000122774 00000 н. 0000122897 00000 н. 0000123043 00000 н. 0000123290 00000 н. 0000123603 00000 н. 0000123726 00000 н. 0000123872 00000 н. 0000125885 00000 н. 0000127497 00000 н. 0000128711 00000 н. 0000128917 00000 н. 0000129123 00000 н. 0000129329 00000 н. 0000129535 00000 н. 0000129741 00000 н. 0000130011 00000 н. 0000130727 00000 н. 0000131443 00000 н. 0000132159 00000 н. 0000133136 00000 н. 0000133342 00000 п. 0000133548 00000 н. 0000133762 00000 н. 0000133968 00000 н. 0000134174 00000 н. 0000134380 00000 н. 0000134586 00000 н. 0000134792 00000 н. 0000134998 00000 н. 0000135204 00000 н. 0000136228 00000 п. 0000136499 00000 н. 0000137215 00000 н. 0000137931 00000 н. 0000138647 00000 н. 0000138853 00000 н. 0000139059 00000 н. 0000139271 00000 н. 0000139477 00000 н. 0000139683 00000 н. 0000140519 00000 п. 0000140725 00000 н. 0000140931 00000 н. 0000141137 00000 н. 0000141343 00000 н. 0000141549 00000 н. 0000141826 00000 н. 0000142542 00000 н. 0000143258 00000 н. 0000143974 00000 н. 0000144750 00000 н. 0000144956 00000 н. 0000145171 00000 н. 0000145381 00000 н. 0000145587 00000 н. 0000145793 00000 н. 0000145999 00000 н. 0000146205 00000 н. 0000146414 00000 н. 0000146623 00000 н. 0000146892 00000 н. 0000147171 00000 н. 0000147887 00000 н. 0000148603 00000 н. 0000148809 00000 н. 0000149022 00000 н. 0000149235 00000 п. 0000149441 00000 п. 0000149652 00000 н. 0000150368 00000 н. 0000150574 00000 н. 0000150780 00000 н. 0000150986 00000 н. 0000151199 00000 н. 0000151415 00000 н. 0000151695 00000 н. 0000152411 00000 н. 0000153127 00000 н. 0000153843 00000 н. 0000154049 00000 н. 0000154255 00000 н. 0000154461 00000 н. 0000154667 00000 н. 0000154873 00000 н. 0000155087 00000 н. 0000155293 00000 н. 0000155499 00000 н. 0000155712 00000 н. 0000155923 00000 н. 0000156639 00000 н. 0000156909 00000 н. 0000157625 00000 н. 0000158341 00000 н. 0000158547 00000 н. 0000158761 00000 н. 0000158967 00000 н. 0000159173 00000 н. 0000159383 00000 н. 0000159594 00000 н. 0000159800 00000 н. 0000160006 00000 н. 0000160239 00000 н. 0000160956 00000 н. 0000161672 00000 н. 0000162388 00000 н. 0000163993 00000 н. 0000164199 00000 н. 0000164405 00000 н. 0000164614 00000 н. 0000164820 00000 н. 0000165026 00000 н. 0000165233 00000 н. 0000165443 00000 н. 0000165649 00000 н. 0000165855 00000 н. 0000166066 00000 н. 0000166330 00000 н. 0000167047 00000 н. 0000167763 00000 н. 0000168479 00000 н. 0000168685 00000 н. 0000168899 00000 н. 0000169105 00000 н. 0000169311 00000 н. 0000169518 00000 н. 0000169729 00000 н. 0000169940 00000 н. 0000170146 00000 п. 0000170420 00000 н. 0000171137 00000 н. 0000171853 00000 н. 0000172060 00000 н. 0000172266 00000 н. 0000172473 00000 н. 0000172679 00000 н. 0000172885 00000 н. 0000173098 00000 н. 0000173311 00000 н. 0000173517 00000 н. 0000173723 00000 н. 0000173997 00000 н. 0000174714 00000 н. 0000175431 00000 н. 0000176147 00000 н. 0000176353 00000 п. 0000176559 00000 н. 0000176770 00000 н. 0000176986 00000 н. 0000177192 00000 н. 0000177398 00000 н. 0000177604 00000 н. 0000177817 00000 н. 0000178094 00000 н. 0000178811 00000 н. 0000179017 00000 н. 0000179223 00000 н. 0000179436 00000 н. 0000179647 00000 н. 0000179861 00000 н. 0000180067 00000 н. 0000180273 00000 н. 0000180479 00000 н. 0000180761 00000 н. 0000181478 00000 н. 0000182195 00000 н. 0000182408 00000 н. 0000182614 00000 н. 0000182820 00000 н. 0000183027 00000 н. 0000183233 00000 н. 0000183446 00000 н. 0000183652 00000 н. 0000183858 00000 н. 0000184064 00000 н. 0000184346 00000 н. 0000185063 00000 н. 0000185780 00000 н. 0000186086 00000 н. 0000186292 00000 н. 0000186501 00000 н. 0000186714 00000 н. 0000186923 00000 н. 0000187129 00000 н. 0000187335 00000 н. 0000187541 00000 н. 0000187747 00000 н. 0000188463 00000 н. 0000188684 00000 н. 00001
00000 н. 0000190528 00000 н. 0000190813 00000 н. 0000191530 00000 н. 0000191826 00000 н. 0000192092 00000 н. 0000192306 00000 н. 0000192518 00000 н. 0000192729 00000 н. 0000192938 00000 н. 0000193149 00000 н. 0000193865 00000 н. 0000194581 00000 н. 0000195297 00000 н. 0000195533 00000 н. 0000196250 00000 н. 0000196646 00000 н. 0000197370 00000 н. 0000197581 00000 н. 0000197793 00000 н. 0000198509 00000 н. 0000199225 00000 н. 0000199511 00000 н. 0000200227 00000 н. 0000200958 00000 н. 0000201675 00000 н. 0000202392 00000 н. 0000202641 00000 н. 0000203357 00000 н. 0000203563 00000 н. 0000204279 00000 н. 0000204995 00000 н. 0000205711 00000 н. 0000206574 00000 н. 0000207464 00000 н. 0000208400 00000 н. 0000209227 00000 н. 0000209855 00000 н. 0000209911 00000 н. 0000210722 00000 н. 0000211498 00000 п. 0000212214 00000 н. 0000212420 00000 н. 0000212626 00000 н. 0000214178 00000 н. 0000214384 00000 п. 0000214590 00000 н. 0000214796 00000 н. 0000215002 00000 н. 0000215269 00000 н. 0000215985 00000 н. 0000216701 00000 н. 0000217913 00000 н. 0000218119 00000 н. 0000218325 00000 н. 0000218531 00000 н. 0000218737 00000 н. 0000218943 00000 н. 0000219149 00000 п. 0000220385 00000 н. 0000220639 00000 н. 0000221355 00000 н. 0000222071 00000 н. 0000222280 00000 н. 0000223556 00000 н. 0000223814 00000 н. 0000224530 00000 н. 0000225246 00000 н. 0000225962 00000 н. 0000227274 00000 н. 0000227480 00000 н. 0000227691 00000 н. 0000227897 00000 н. 0000228103 00000 н. 0000228309 00000 н. 0000229642 00000 н. 0000229906 00000 н. 0000230622 00000 н. 0000231338 00000 п. 0000232054 00000 н. 0000232260 00000 н. 0000232471 00000 н. 0000232677 00000 н. 0000012356 00000 п. трейлер ] / Назад 578175 >> startxref 0 %% EOF 606 0 объект > поток h ެ OHQǿofgw \ 5sK ˢ && 5% «eCXX! $ GD).t`% (1 & Hx 谅? QC> |}
Программное обеспечение для захвата и распознавания документов
РешенияOpenText Business Network способствуют эффективному, безопасному и совместимому потоку информации внутри и за пределами предприятия от любого отправителя к любому получателю в любом формате. Business Network охватывает всю цепочку создания стоимости B2B, обеспечивая огромный, постоянно увеличивающийся объем транзакционных данных через множество носителей, включая электронный факс, совместное использование файлов, защищенную электронную почту, электронный обмен данными (EDI) и управляемую передачу файлов.
Снижение затрат на процессы обмена информацией B2B: Автоматизация рабочих процессов, ускорение обмена данными и обеспечение соблюдения нормативных требований при одновременном снижении административной нагрузки при обмене информацией B2B за счет перемещения управления системами (распространение факсов и документов, интеграция данных, совместное использование файлов и другие) в облако.
Повышение соответствия и безопасности информации: Распространение политик управления на все информационные каналы, такие как электронная почта и передача файлов, для поддержания полностью прозрачного контрольного журнала и управления потоком информации надежным образом повышает способность организаций уверенно решать требования безопасности, запросы регулирующих органов и судебные разбирательства.
Увеличьте влияние информации: Компании могут усилить влияние информации, создав эффективные каналы связи по всей сети, чтобы получать нужную информацию нужному человеку в нужное время на любом устройстве.
Ускорение времени до транзакции: Организациям необходимо обмениваться информацией для ведения бизнеса. Заказы, отгрузки, счета-фактуры, отчеты — использование унифицированного последовательного метода обмена информацией между бизнес-каналами и сокращение времени до транзакции — безопасное ведение бизнеса.
Присутствие по всему миру: С экспертами по всему миру мы можем помочь вам с любым из вышеперечисленных вопросов, будь то Китай, Сингапур, Германия или Северная Америка. Посетите наши офисы, чтобы узнать больше.
Распознавание и поиск документов XVIII, подробности конференции
Улучшенный алгоритм сегментации изображения документа с использованием морфология с несколькими разрешениямиБумага 7874-12
Авторы):
Показать аннотацию
Сегментация страниц на текстовые и нетекстовые компоненты является важным этапом предварительной обработки перед операцией распознавания текста.Если это не будет сделано должным образом, механизм классификации OCR создаст ненужный текст из-за наличия нетекстовых компонентов. В этой статье описываются усовершенствования алгоритма сегментации текста / изображения, описанного Блумбергом [1], который также доступен в его открытой библиотеке Leptonica [2]. Изменения приводят к значительным улучшениям по сравнению с алгоритмом Bloomberg в тестовых изображениях соревнований сегментации страниц UW-III, UNLV, ICDAR 2009 и наборах данных принципиальных схем.
Простая и эффективная система обнаружения подписей к рисункам для старых документовБумага 7874-28
Авторы):
Показать аннотацию
Обозначение подписей к рисункам имеет широкое применение при получении высоких качественные электронные книги, такие как книги Kindle или книги для iPad.В этой статье, мы представляем основанную на правилах систему для обнаружения горизонтальных подписей к фигурам в документах старого образца. Наш алгоритм состоит из трех шагов: (i) сегментировать изображения на области разных типов, такие как тексты и цифры, (ii) поиск лучшего кандидата области субтитров на основе эвристические правила, такие как выравнивание областей и расстояния, и (iii) расширить области подписи, идентифицированные на шаге (ii), с соседними текстовые области для исправления ошибок чрезмерной сегментации.Мы тестируем наш алгоритм на 81 изображении, собранном из старых книги, в которых каждое изображение содержит хотя бы одну область рисунка. Мы показываем что этот подход может правильно определять подписи к рисункам из изображения с разными макетами, и мы также измеряем его характеристики как с точки зрения точности, так и скорости отзыва.
Распознавание абзацев на основе переформатирования для электронных книг в PDFБумага 7874-29
Авторы):
Показать аннотацию
При чтении электронных книг на портативных устройствах контент иногда следует перекомпоновывать и перекомпоновывать для адаптации к мобильным устройствам с маленьким экраном.Судя по читательской практике, разумно переформатировать текст по абзацам. Следовательно, в данной статье рассматривается это требование и предлагается набор новых методов распознавания абзацев для электронных книг в формате PDF. Предлагаемые методы состоят из трех этапов, а именно: анализ физической структуры, сегментация абзацев и определение порядка чтения. Мы используем свойство локального упорядочивания документов PDF и стиль макета книг для улучшения результатов традиционного распознавания страниц.Кроме того, мы применяем оптимальное соответствие технологии двудольного графа для определения порядка чтения абзацев. Эксперименты показывают, что наши методы достигают высокой точности. Примечательно, что это исследование было применено в коммерческом программном пакете для производства китайских электронных книг.
Обнаружение и удаление линии линииБумага 7874-30
Авторы):
Показать аннотацию
В этой статье мы представляем процедуру удаления управляющих линий из рукописного изображения документа, которая не требует каких-либо задач предварительной или постобработки и не нарушает существующие символы.Мы пользуемся преимуществами общих свойств управляющих линий, таких как равномерная ширина, предсказуемый интервал, положение по сравнению с текстом и т. Д. Предлагаемая процедура также может обнаруживать наличие управляющих линий на странице, поэтому она не влияет на изображения документа без управляющих линий. Система оценивается на синтетических изображениях страниц на пяти разных языках и сравнивается с предыдущей методологией.
Распознавание логотипа естественной сцены с помощью функции совместного повышения селекция в выделенных регионахБумага 7874-31
Авторы):
Показать аннотацию
Логотипы считаются ценной интеллектуальной собственностью и ключевым компонентом деловой репутации компании.В этой статье мы предлагаем метод распознавания логотипа естественной сцены, который не требует сегментации и позволяет обрабатывать изображения очень быстро и обеспечивает высокую скорость распознавания. Классификаторы для каждого логотипа обучаются совместно, а не независимо. Таким образом, общие черты могут быть разделены между несколькими классами для лучшего обобщения. Чтобы иметь дело с большим диапазоном соотношений сторон различных логотипов, для описания каждого класса извлекается набор значимых областей интереса (ROI). Мы гарантируем, что выбранные ROI будут как индивидуально информативными, так и слабо зависимыми два на два в соответствии с критериями максимизации условной энтропии класса.Результаты экспериментов на большой базе данных логотипов демонстрируют эффективность и действенность предлагаемого нами метода.
Платформа для улучшения использования цифрового корпуса: навигация в режиме изображенийБумага 7874-32
Авторы):
Показать аннотацию
В этой статье мы предлагаем новую систему для улучшения навигации внутри цифровых корпусов.Эта система основана на автоматической индексации в режиме изображения и обеспечивает пользователю интуитивно понятную навигацию в интерактивном режиме. Ключевые слова и контейнеры извлекаются непосредственно из изображений документа для создания индекса режима изображения, который показывает ключевые слова в виде вырезанных изображений их фактического внешнего вида. Наш подход воссоздает краткое изложение структурированных документов, следуя указаниям, данным самими создателями документа. Наша система подробно описана в общем случае и представлены образцы приложений на рукописном корпусе 19 века и корпусе машинописных текстов 18 века.Этот подход, разработанный для документов, недоступных в противном случае, может быть применен к любому корпусу, где можно идентифицировать ключевые слова и контейнеры.
Калибровка параметров для синтеза реалистично выглядящих изменчивость автономного почеркаБумага 7874-33
Авторы):
Показать аннотацию
Руководствуясь общепринятым принципом, что чем больше обучающих данных, тем выше производительность системы распознавания, мы провели эксперименты, попросив испытуемых провести тест на смеси реальных английских рукописных текстовых строк и текстовых строк, измененных по сравнению с существующим почерком с различной степенью искажения.Идея создания синтетического почерка основана на методе возмущения Т. Варги и Х. Бунке, который искажает всю текстовую строку. Наши эксперименты преследуют две цели. Во-первых, мы хотим откалибровать оптимальные настройки параметров искажения для модели возмущений Варги и Бунке. Во-вторых, мы намерены сравнить влияние настроек параметров на разные стили письма, блочное, курсивное и смешанное. По предварительным экспериментальным результатам мы определили соответствующие диапазоны для амплитуды параметра и обнаружили, что настройки параметров должны изменение для разных стилей почерка.После того, как будут найдены правильные настройки параметров, мы создадим большое количество наборов для обучения и тестирования для создания лучших автономных систем распознавания рукописного ввода.
Автоматическая сегментация панелей субфигурных изображений для мультимодальных перевозок. поиск биомедицинских документовБумага 7874-34
Авторы):
Показать аннотацию
Биомедицинские изображения часто используются для поддержки принятия клинических решений (CDS), в образовательных целях и в исследованиях.Они появляются в биомедицинских публикациях и не могут быть осмысленно извлечены с использованием преимущественно текстовых поисковых систем. Эта задача может быть выполнена путем автоматического аннотирования таких изображений с точки зрения их полезности для CDS. Мы предложили анализ изображения фигур для методов контент-ориентированного поиска изображений (CBIR). Затем извлеченные элементы изображения могут быть связаны с идентифицированными биомедицинскими концепциями, извлеченными из метатекста в подписях к рисункам и обсуждения в полном тексте для улучшенного гибридного (текст и изображение) поиска биомедицинских статей.Проблемой на пути к этой цели является отделение отдельных панелей от многопанельного рисунка, который часто встречается как одно изображение в биомедицинской статье. В этой работе мы представляем методы, которые добавляют надежности нашим предыдущим усилиям, которые были ограничены по своему объему. Мы представляем новый алгоритм кластеризации оптимизации роя частиц (PSO) для поиска связанных компонентов фигуры. Результаты предварительной оценки очень многообещающие: площадь под кривой ROC составляет 94,9% для обычных (не иллюстративных) изображений фигур и 92.Точность 1% для иллюстративных изображений. В настоящее время проводятся более интенсивные испытания, чтобы оценить влияние автоматической сегментации панели фигур на аннотации изображений и поиск биомедицинских документов.
Новый метод коррекции перспективы изображения документаБумага 7874-35
Авторы):
Показать аннотацию
В данной статье предлагается метод коррекции перспективного искажения прямоугольных документов.Эта схема использует ортогональность краев документа, позволяя восстановить соотношение сторон исходного документа. Результаты, полученные после корректировки перспективы нескольких изображений документов, снятых с помощью мобильного телефона, сравниваются с результатами, полученными при оцифровке тех же документов с помощью нескольких моделей сканеров.
Надежный метод поиска ключевых слов для текста с оптическим распознаванием текстаБумага 7874-36
Авторы):
Показать аннотацию
Системы управления документами стали важными из-за растущей популярности электронной подачи документов и сканирования книг, журналов, руководств и т. Д., через сканер или цифровую камеру для хранения или чтения на ПК или в электронной книге. Текстовая информация, полученная с помощью оптического распознавания символов (OCR), обычно добавляется в электронные документы для поиска документов. Поскольку тексты, созданные с помощью OCR, обычно содержат ошибки распознавания символов, для решения этой проблемы были введены надежные методы поиска. В этой статье мы предлагаем метод поиска, устойчивый как к сегментации символов, так и к ошибкам распознавания. В предлагаемом методе вставка шумовых символов и отбрасывание символов при поиске ключевого слова обеспечивает устойчивость к ошибкам сегментации символов, а замена символов в ключевом слове кандидата на распознавание для каждого символа в OCR или любого другого символа обеспечивает устойчивость к ошибкам распознавания символов. .Скорость отзыва предлагаемого метода была на 15% выше, чем у традиционного метода. Однако точность была на 64% ниже.
Распознавание медицинских символов в Интернете с помощью планшетного ПКБумага 7874-37
Авторы):
Показать аннотацию
В этой статье мы описываем схему повышения удобства использования системы распознавания рукописного ввода планшетного ПК путем включения символов, которые не являются частью библиотеки символов планшетных ПК.Цель этой работы — сделать распознавание почерка более полезным для медицинских работников, привыкших использовать медицинские символы в медицинских записях. Тот факт, что медицинские сокращения похожи на символы, усложняет эту задачу. В документе также описываются наши усилия по созданию корпуса медицинских символов и не-символов, которые потенциально могут быть идентифицированы как символы. Используя данные из этого корпуса, мы демонстрируем, что этот новый модуль распознавания символов является надежным и расширяемым, поскольку мы сообщаем о хороших результатах как для набора медицинских символов, так и для расширенного набора для тестирования символов, который включает выбранные математические символы.Наконец, мы показали, что использование архитектуры с несколькими классификаторами обеспечивает высокую производительность.
Характеристики оспариваемых бюллетеней МиннесотыБумага 7874-38
Авторы):
Показать аннотацию
Фотокопии избирательных бюллетеней, оспоренных на выборах в Миннесоте в 2008 году, которые являются общедоступными, были отсканированы на высокоскоростном сканере и опубликованы на веб-сайте общественного радио.6727 PDF-файлов были загружены, преобразованы в изображения TIF и размещены на веб-сайте PERFECT. На основе обзора соответствующих аспектов обработки изображений бумажных избирательных механизмов и дополнительных статистических данных и наблюдений за опубликованными выборочными данными представлены надежные инструменты для определения основной сетки целей в этих бюллетенях независимо от перекоса, отсечения и другие ухудшения, вызванные высокоскоростным копированием и оцифровкой. Точность и скорость метода, основанного на индексных отметках, продемонстрирована на случайной выборке из 102 бюллетеней.
Классификация текстовых и нетекстовых областей на основе ускоренияБумага 7874-41
Авторы):
Показать аннотацию
Анализ макета — важный процесс для понимания изображения документа и поиска информации.Анализ макета документа зависит от сегментации страницы и классификации блоков. В этой статье описываются алгоритмы извлечения блоков из изображений документа и метод повышения, позволяющий классифицировать эти блоки как текстовые или нет. Вектор признаков, который подается в классификатор повышения, состоит из гистограммы длин серий в четырех направлениях и связанных компонентов компонентов, как фона, так и переднего плана. Используя комбинацию функций с помощью классификатора повышения, мы получаем точность 99,5% на нашей тестовой коллекции.
OMR ранних рукописей plainchant в квадратных обозначениях: двухэтапный системаБумага 7874-42
Авторы):
Показать аннотацию
В то время как оптическое распознавание музыки (OMR) современных печатных и рукописных документов считается решенной проблемой, в то время как многие коммерческие системы доступны сегодня, OMR древних музыкальных рукописей все еще остается открытой проблемой.В нашей статье мы представляем систему OMR деградированных западных рукописей равнинных земель в квадратной нотации с XIV по XVI века. В системе два основных блока, первый занимается извлечением и распознаванием символов, а второй действует как этап обнаружения ошибок для выходов первого блока. Для извлечения символов мы используем широко известные методы обработки изображений, такие как фильтрация Собеля и преобразование Хафа, а также SVM для классификации. Этап обнаружения ошибок реализован со скрытой марковской моделью (HMM), которая использует преимущества априорных знаний для этого конкретного вида музыки.
Ключ в будущее: интеллектуальное распознавание документов
Бумага для печати и движущаяся бумага дороги и требуют много времени. Компании, которым необходимо сократить эти расходы и более эффективно управлять процессами, просто конвертируют документы, отправленные по почте, в факсы или PDF-файлы, отправленные по электронной почте. С точки зрения получателя, все входящие документы неструктурированы или частично структурированы.Документы, основанные на изображениях или данных (например, обычный PDF), могут выглядеть одинаково (все счета-фактуры), но элементы данных не содержат понятных метатегов. Следовательно, каждый документ необходимо рассматривать и интерпретировать в едином формате, понятном для внутренних процедур ИТ. А это дорогостоящий процесс.
Захват данных из изображений с использованием традиционной обработки форм основан на знании конкретного макета формы, чтобы вы могли создать шаблон, чтобы определить, какие поля нужно захватить, правила, которые следует использовать для каждого поля, и любые проверки перекрестных полей.Шаблон также определяет связанные метаданные вывода для полей. Выходные данные обычно разделяются запятыми или помечаются тегами XML, хотя в некоторых случаях это может быть электронный обмен данными (EDI). Он работает хорошо только в том случае, если макет форм такой же или когда четкие идентификаторы определяют формат. Это ограничило обработку форм оборотными документами или регулируемыми формами, такими как налоговые декларации, заявки на кредитные карты, медицинские претензии и т. Д.
Захват изображений для индексации с помощью программного обеспечения для пакетного захвата требует ручной вставки закодированных пакетов и разделителей документов между документами, которые предоставляют автоматизированные поиск метаданных индекса.Скрипты выпуска форматируют изображения и данные для решения для внутреннего управления документами (DM) или управления корпоративным контентом (ECM). Для сбора данных из неструктурированных, неизвестных макетов данных можно использовать поисковые системы. Они ищут в неструктурированном тексте и извлекают контекстно релевантные документы и фразы. Однако для создания понятных метаданных для вывода в бизнес-процессы требуются бизнес-правила, а это означает, что программное обеспечение должно понимать, что это за документ.
Новый интеллектуальное распознавание документов (IDR) — технология, первоначально разработанная для обработки счетов и электронной почты, — использует методы из каждой из вышеперечисленных областей и устраняет ограничения.Больше не нужно знать, как выглядит макет формы. Больше не нужно вставлять разделители. Предварительная сортировка больше не требуется. Определенные правила могут сделать данные понятными. IDR может определить категорию документа и применить соответствующие бизнес-правила.
IDR, который также называется интеллектуальным сбором данных (см. P.10, июль / август, KMWorld, том 15, № 7, статья Роберта Смоллвуда, также опубликованная в Интернете), работает намного больше, чем люди, полагаясь на обучение и внутренние знания. макета и содержимого общих типов форм, которые используются для понимания и извлечения необходимой информации и запуска рабочих процессов.Это расширяет типы форм, которые могут быть получены, и снижает затраты, но IDR также существенно меняет возможности сбора данных в ряд инструментов, которые могут интерпретировать и извлекать данные из всех видов неструктурированной информации.
Информация может быть введена в виде отсканированной бумаги или информации в формате документа, независимо от того, ориентирована ли она на данные, например в формате Word или PDF, или на основе изображений. Как правило, это включает и использует несколько различных методов, включая распознавание образов, OCR и другие системы распознавания и поиска, для поиска и извлечения необходимой информации перед применением к ней бизнес-правил.Это стало причиной того, что DICOM / Kofax купила Mohomine и LCI, Captiva купила SWT и одна из причин покупки Verity Cardiff.
IDR позволяет анализировать неструктурированную, немаркированную информацию, поступающую в корпорацию или организацию, и управлять ею. Он может обеспечить понимание клиентской части, необходимое для поддержки приложений управления бизнес-процессами (BPM) и бизнес-аналитики (BI), а также традиционных систем бухгалтерского учета и управления документами или записями.
Крупные компании в сфере BPM и BI начинают осознавать важность этого, и большой новостью 2005 года стало приобретение EMC Captiva — крупного поставщика решений для ввода данных. Покупка заставила многих взглянуть на захват в новом свете. EMC заявила, что это приобретение должно было улучшить управление жизненным циклом документов. Хотя этот термин плохо понимается за пределами отрасли хранения данных, EMC явно видела гораздо больше, чем просто сбор документов. Capture превращается в критически важную потребность в бизнес-системах, которая улучшает основные бизнес-процессы и повышает конкурентоспособность за счет развития понимания документов на основе бизнес-правил.
Согласно нашим исследованиям, рынок программного обеспечения для захвата вырос на 18 процентов в период с 2004 по 2005 год до 1,1 миллиарда долларов США по стоимости пользователя — по сравнению с 14 процентами в предыдущем периоде. Мы разбиваем это на четыре подсегмента, которые мы называем:
- ad hoc и настольное сканирование — используется офисными работниками, которые хотят преобразовать бумажные документы в удобные электронные документы, над которыми они могут работать или сотрудничать. Используемые устройства — это низкоскоростные сканеры или подключенные к сети офисные цифровые копировальные аппараты (многофункциональные устройства).
- пакетное и распределенное пакетное сканирование — используется для переноса документов в централизованное хранилище документов или используется для их классификации и максимально быстрой маршрутизации в централизованную точку.
- полнотекстовый захват OCR — преобразует текстовые документы, такие как отсканированные журнальные статьи, в данные ASCII, которые можно редактировать, управлять ими или использовать для поиска документов.
- захват транзакций и управление процессами — ранее формы обработки. Подобно пакетному и распределенному пакетному захвату, но выходные данные ориентированы на данные и используются для предоставления данных для использования в бизнес-процессе.
Каждый из этих подсегментов показал некоторые интересные тенденции. Первые три выросли более чем на 20 процентов, что было вызвано рядом ключевых проблем, которые вместе вызывают рыночный стресс:
- Повышение скорости бизнеса, которое требует перемещения документов в электронном виде, а не по почте или курьерам. Входящая бумага должна быть преобразована в изображение как можно ближе к точке входа в корпорацию или, предпочтительно, отправителем, используя факс-серверы или отправленные по электронной почте PDF-файлы.Это вызывает переход от централизованного сканирования к распределенному.
- Бизнесу нужно сократить расходы. Расходы на обработку, перемещение и хранение бумаги можно уменьшить или исключить путем преобразования ее в изображение в сочетании с небольшими системами DM, а инструменты совместной работы в офисе, такие как Microsoft SharePoint, могут повысить эффективность.
- Необходимость оптимизации использования бизнес-оборудования. Автономные копировальные аппараты часто используются недостаточно. Объединяя их в сеть, корпорации могут использовать их для печати, отправки факсов и сканирования, а также для копирования.Компании ищут другие альтернативы, такие как распределенные сканеры и принтеры, а производители копировальных устройств делают рывок на рынки захвата.
- Доступность недорогих (менее 1000 долларов США), простых в использовании (одна кнопка), быстрых (25 страниц в минуту и более) распределенных двусторонних настольных сканеров.
- Полнотекстовый поиск на рабочем столе все чаще используется для поиска документов и управления ими в небольшом офисе.
- Изображения стандартизированы и принимаются так же, как и данные. В частности, PDF и Интернет заставили пользователей перестать различать изображения и данные.Гибридное изображение с возможностью поиска в сочетании с улучшенным оптическим распознаванием символов (OCR) помогло в этом, размыв линию.
Сектор сбора транзакций и управления процессами в настоящее время является крупнейшим сегментом, на который приходится 34 процента всего рынка, но он рос медленнее всего — 7 процентов, упав с 38 процентов от общего числа. Это может показаться нелогичным, потому что эти технологии, основанные на обработке форм, являются ключом к будущему росту и используются в системах управления знаниями (KM).Однако сейчас большая часть сегмента по-прежнему состоит из продаж, ориентированных на фиксированные шаблоны. Эта проверенная технология обработки форм предлагает значительное снижение затрат по сравнению с вводом данных внутри компании или даже обработкой в офшорной зоне, стоимость которой возрастает, если формы известны.
Пожалуйста, включите JavaScript, чтобы просматривать комментарии от Disqus.Обработка изображений и управление электронными документами
«Наша цель заключалась в том, чтобы сделать весь процесс заказа и получения быстрым, кратким и доступным в цифровом виде.Единственный способ сделать это эффективным и рентабельным способом — отказаться от бумажных документов во всех сферах нашего бизнеса, и DocuSyst привела нас к этому … »— Марк Кулиговски, Директор по маркетингу и ИТ, Johnson-Rose Corp
Используйте программное обеспечение для распознавания документов, чтобы сократить время, необходимое для ввода данных, путем чтения компьютерных или рукописных форм. Эти типы решений делают сбор информации из форм быстрым, точным и могут уменьшить количество ошибок.
Ниже приведены ключевые особенности распознавания документов и их преимущества:
(Показать все) (Скрыть все)
OCR — Получение изображения документа и распознавание набранного текста для использования для поиска или идентификации документа
Сокращение от оптического распознавания символов, этот процесс считывает напечатанный текст на изображении документа и делает его доступным за пределами изображения. В основном используется для создания PDF-файлов с возможностью поиска, автоматической пометки документов метаданными или сокращения ввода данных путем извлечения содержимого формы и отправки в базу данных (т.е. Счета-фактуры, заказы на поставку и другие формы документов). OCR также увеличивает продуктивность Google Search Appliance и SharePoint.
ICR — Получение изображения документа и распознавание рукописной информации или сложных структур таблиц
Сокращенно от Intelligent Character Recognition, этот процесс считывает рукописный текст в документе и делает его доступным для других приложений. В основном используется для уменьшения количества вводимых данных путем извлечения содержимого формы и отправки в базу данных (т.е.е. Документы обследования, полевые информационные формы, карточки для пожертвований и квитанции об оплате коммунальных услуг). ICR также увеличивает производительность Google Search Appliance и SharePoint.
Преобразование документов — преобразование изображений документов в текстовые документы, электронные таблицы или другие форматы с сохранением макета изображения
Преобразование изображений в редактируемые документы Microsoft Office. Это позволяет офисам сканировать отчеты или другие документы и создавать документы Word или Excel без потери форматирования и структуры изображения.Например, преобразование бухгалтерских отчетов в электронные таблицы Excel или контракты в Microsoft Word.
Извлечение данных — чтение информации из изображения или бумажного документа и отправка ее в другое приложение
Сканирование и чтение текста, рукописного ввода, штрих-кодов и флажков. Текст можно распознать более чем на 100 языках. Затем информацию можно отправлять в базы данных, электронные таблицы, системы управления документами или SharePoint.
Классификация документов — Нет необходимости делать разделительные листы при сканировании. Программное обеспечение теперь может идентифицировать документ по внешнему виду
Процесс, с помощью которого программное обеспечение идентифицирует документ на основе информации, содержащейся в документе. Например, отсканируйте пакет счетов-фактур, заказов на поставку и контрактов в одной группе страниц, и программа отсортирует документы и соответствующим образом разделит их.
Проверка — легко подтвердить, что информация, распознанная в процессе OCR или ICR, верна
Процесс, с помощью которого программное обеспечение распознавания выполняет поиск в базе данных или проверяет итоговые значения столбцов, чтобы убедиться, что распознанная информация является точной.Это увеличивает время обработки и повышает точность.
Business Card Reader — Устранение необходимости ввода контактов в базу данных с помощью решений для чтения визитных карточек
Его можно использовать на ПК или даже на смартфоне для захвата информации с визитных карточек и быстрого заполнения адресной книги.
Удаленная обработка
Решения, которые позволяют удаленным офисам или пользователям сканировать документы и направлять их в центральную точку обработки.
Language Translation — Можно распознать более 150 языков!
Используйте программное обеспечение для перевода документов на более 100 языков. Также доступны приложения для смартфонов, позволяющие пользователю сфотографировать слово на иностранном языке (знак, меню ресторана и т. Д.) И преобразовать его на другой язык с произношением.
Внедрение пакета программного обеспечения для управления документами поможет вашему офису систематизировать, находить и обмениваться документами в безопасной и управляемой среде.Он также будет отслеживать несколько версий документов, отправлять напоминания и уведомления по электронной почте для просмотра и многое другое. Решения могут быть установлены на сервере вашей компании или размещены в надежно управляемом хранилище.
Позвольте DocuSyst помочь со сканированием и индексированием документов, чтобы сэкономить ваше время и ресурсы. Мы можем сканировать ваши документы в PDF-файлы с возможностью текстового поиска, чтобы упростить поиск информации. У вас уже есть PDF-изображения, которые не распознаются? DocuSyst может распознавать миллионы страниц и сжимать их для уменьшения размера файлов.
Ваш комментарий будет первым