Ваша польза OnlineOCR.net сервис подлежит вашему согласию с условиями использования и настоящей Политикой конфиденциальности. Эта Политика конфиденциальности вступает в силу с момента начала использования сервиса. Вы признаете, что прочитали и поняли условия настоящей политики конфиденциальности и соглашаетесь с ними. Если Вы не согласны с данной политикой конфиденциальности, не используйте OnlineOCR.net или любые материалы и ресурсы, доступные на этом сервисе. 1. Информация, Которую Мы СобираемПри регистрации в onlineocr.net вам будет предложено ввести имя пользователя, адрес электронной почты и пароль. Ваш пароль будет храниться в зашифрованном виде, не читаемом сотрудниками. Если вы забудете пароль, вам будет выслан новый пароль, который вы сможете изменить по своему усмотрению. Собранный адрес электронной почты будет использоваться для отправки сообщения о подтверждении регистрации и любых запрошенных новых паролей или почтовых отправлений, связанных с использованием OnlineOCR. Мы не продаем адреса электронной почты зарегистрированных пользователей третьим лицам. Мы не будем просматривать файлы, загруженные с помощью OnlineOCR.net обслуживание. Мы можем просмотреть информацию о файле (файл расширения, размеры и т. д. но не содержимое вашего файла) для предоставления технической поддержки. OnlineOCR.net использует функцию вашего браузера, называемую cookie, для хранения вашего идентификатора пользователя и государственной информации о том, где вы находитесь на сайте. OnlineOCR.net использует куки, чтобы отслеживать, где вы находитесь на сайте, так как Интернет является средой без гражданства. OnlineOCR.net не сохраняет Вашу личную информацию в файлах cookie. Cookie-это просто небольшой файл данных, который веб-сайт записывает на ваш жесткий диск. Файл cookie не может считывать другие данные с вашего жесткого диска, передавать вирус или читать файлы cookie, созданные другими сайтами.
Вы можете отказаться от файлов cookie, отключив их в своем браузере. OnlineOCR.net не будет работать должным образом без куки включен.Технические детали сводятся к следующим типам информации:
2. Cбор информации Cбор информации
Вы имеете право на получение копии любых персональных данных, которые вы могли предоставить OCRWebService в связи с какой-либо услугой. Вы также имеете право отказаться от всех наших инициатив по сбору данных. Чтобы воспользоваться любым из этих прав, пожалуйста, свяжитесь с нами описанными выше способами. Если вы связываетесь с нами по почте, вы должны указать любые личные идентификаторы, которые вы указали ранее (например, Имя, адрес, номер телефона, адрес электронной почты). Ваш запрос будет рассмотрен в кратчайшие сроки и займет не более 40 дней.Вы также имеете право на исправление любой неточной информации. Если вы обнаружите, что PDF Pro содержит неточную информацию о вас, вы имеете право поручить нам исправить эту информацию. Такие инструкции должны быть в письменной форме или через систему. Ваш запрос будет рассмотрен в кратчайшие сроки и займет не более 40 дней.Мы будем хранить вашу информацию до тех пор, пока ваша учетная запись активна или необходима для предоставления вам услуг.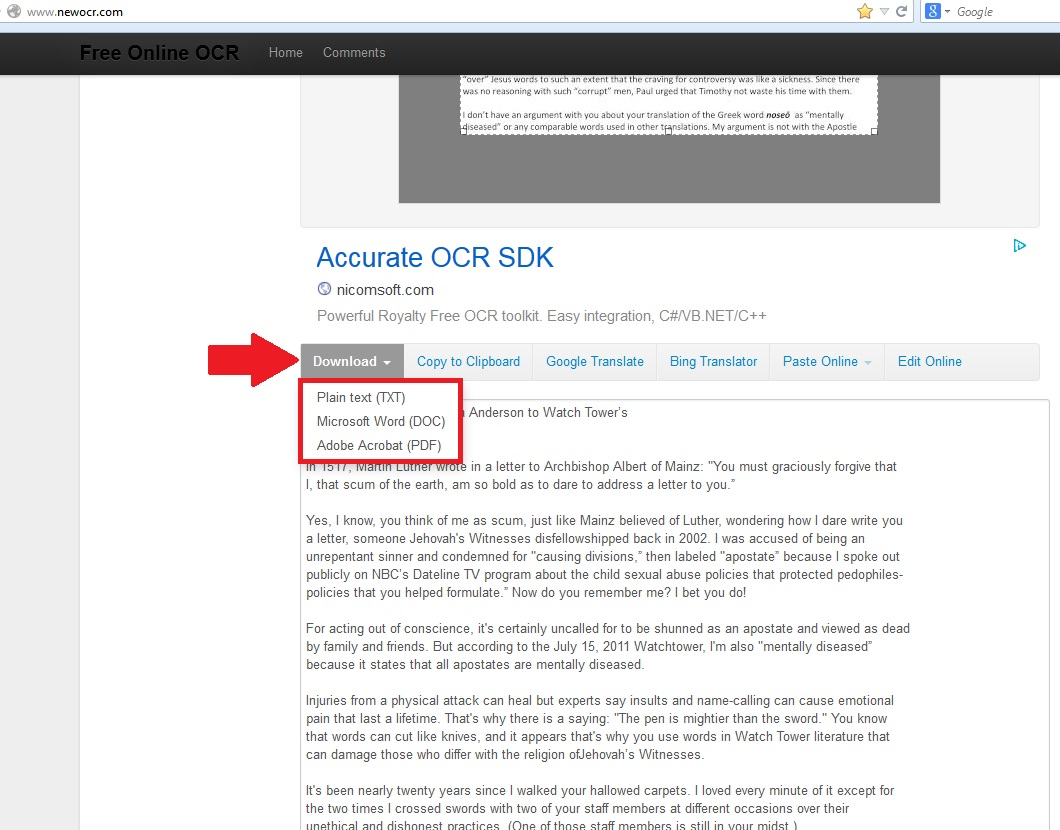 Мы будем хранить и использовать вашу информацию в соответствии с нашими юридическими обязательствами, разрешать споры и обеспечивать соблюдение наших соглашений. Мы будем хранить и использовать вашу информацию в соответствии с нашими юридическими обязательствами, разрешать споры и обеспечивать соблюдение наших соглашений.
При определенных обстоятельствах Вы также можете запросить удаление предоставленных нам данных. Для осуществления этого права вы, как правило, должны выявлять некоторые нарушения закона О защите данных в порядке, в котором мы обрабатываем соответствующие данные. Обратите внимание, что мы можем время от времени удалять данные о Вас или других лицах, которые мы считаем необходимыми.3. Расположение серверов порталаВаша информация может храниться и обрабатываться в любой стране, в которой OnlineOCR.net поддерживайте объекты. В связи с этим, или для целей совместного использования или раскрытия, OnlineOCR.net оставляет за собой право передавать информацию за пределы Вашей страны. Используя ресурсы, вы даете согласие на любую подобную передачу информации за пределы Вашей страны с целью позволить вам использовать ресурсы.
OnlineOCR.net, самостоятельно, имеет право и единоличное усмотрение определять расположение серверов портала и ресурсов.4. Изменения в политике конфиденциальностиДанное положение о конфиденциальности может время от времени изменяться. Любые изменения, обновления или модификации, которые мы делаем, вступают в силу немедленно после публикации на нашем сайте(ах). Если мы собираемся использовать информацию, полученную от пользователей, способом, существенно отличающимся от того, который был указан на момент сбора, мы отправим соответствующим пользователям письменное уведомление об изменении по электронной почте. Дальнейший доступ к нашим сайтам будет означать ваше согласие с любыми изменениями или изменениями в заявлении о конфиденциальности. |
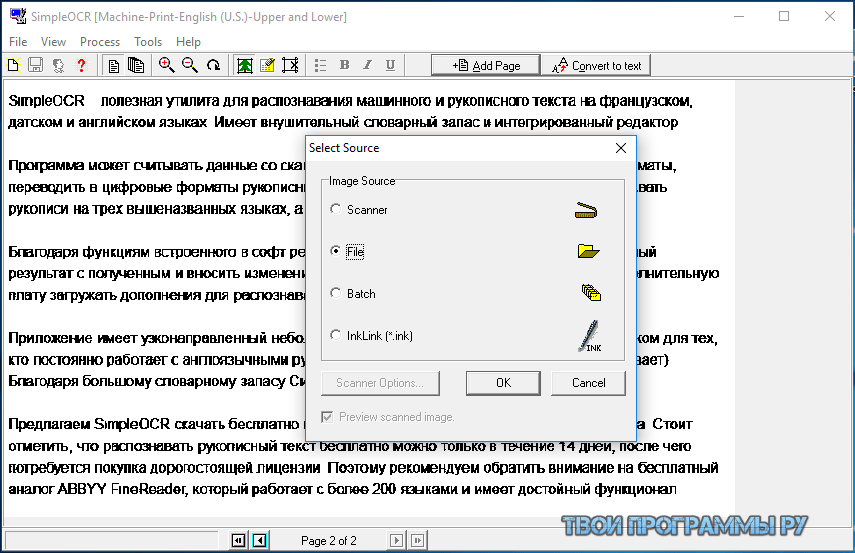
OCR онлайн — бесплатно конвертировать PDF в текст или изображение
Бесплатное распознавание текста
Onlineocr. org — это сервис онлайн-программы оптического распознавания, мы поддерживаем более 46+ языков. OCR — это оптическое распознавание текста на изображениях
org — это сервис онлайн-программы оптического распознавания, мы поддерживаем более 46+ языков. OCR — это оптическое распознавание текста на изображениях
Конвертировать PDF в текст
Используя сервис, вы можете извлечь текст из PDF-документа или изображения: JPG, BMP, TIFF, GIF для дальнейшего редактирования или использования.
1 ШАГ — Скачать
ФайлМаксимум 15 Мб
2 ШАГ — Выберите язык и формат файла
EnglishRussianAfrikaansAmharicArabicAssameseAzerbaijaniAzerbaijani — CyrilicBelarusianBengaliTibetanBosnianBretonBulgarianCatalan; ValencianCebuanoCzechChinese simplifiedChinese traditionalCherokeeWelshDanishGermanDzongkhaGreek, Modern, 1453-EsperantoEstonianBasquePersianFinnishFrenchFrankishIrishGalicianGreek, Ancient, to 1453GujaratiHaitian; Haitian CreoleHebrewHindiCroatianHungarianInuktitutIndonesianIcelandicItalianItalian — OldJavaneseJapaneseKannadaGeorgianGeorgian — OldKazakhCentral KhmerKirghiz; KyrgyzKurdish KurmanjiKoreanKorean verticalKurdishLaoLatinLatvianLithuanianLuxembourgishMalayalamMarathiMacedonianMalteseMongolianMaoriMalayBurmeseNepaliDutch; FlemishNorwegianOccitan post 1500OriyaPanjabi; PunjabiPolishPortuguesePushto; PashtoQuechuaRomanian; Moldavian; MoldovanSanskritSinhala; SinhaleseSlovakSlovenianSindhiSpanish; CastilianSpanish; Castilian — OldAlbanianSerbianSerbian — LatinSundaneseSwahiliSwedishSyriacTamilTatarTeluguTajikTagalogThaiTigrinyaTongaTurkishUighur; UyghurUkrainianUrduUzbekUzbek — CyrilicVietnameseYiddishYorubaText Plain (txt)Microsoft World (docx)Отправить
Использовать сервис OCR
Для начала вам нужно выбрать файл (* . pdf, * .jpeg, * .tiff, * .bmp), который вы должны распознать на своем компьютере. Выберите язык вашего документа.
pdf, * .jpeg, * .tiff, * .bmp), который вы должны распознать на своем компьютере. Выберите язык вашего документа.
Конвертировать PDF в текст
Вам нужно нажать на кнопку «Конвертировать» и дождаться результата. Через несколько секунд или минут ваш документ будет преобразован в текст для редактирования.
Бесплатный сервис
Когда служба завершит преобразование документа, на странице появится поле с редактируемым текстом.
Как распознать текст из JPG в Word онлайн
Способ 1: Convertio
Convertio умеет распознавать текст на многих языках и конвертировать его в DOC для работы с Word. Взаимодействует с различными форматами изображений. В режиме бесплатного использования можно отсканировать до 10 фотографий.
Официальный сайт сервиса Convertio
- Нажмите на кнопку «Выберите файлы», найдите нужный файл через открывшееся окно «Проводника», кликните по «Открыть». При необходимости можно загрузить картинку из облачного хранилища.
- Укажите языки, используемые в загруженном изображении. Измените формат и настройки выбора – для вывода в Word выберите вариант «Документ Microsoft Word (.docx)». Нажмите на «Распознать».
- Поднимитесь в верхнюю часть страницы, нажмите на кнопку «Скачать» напротив готового документа.
- Convertio корректно сохраняет разметку документа, но может распознавать с ошибками при работе с многоцветным фоном.
Способ 2: Img2txt
Img2txt – ещё один популярный бесплатный сервис по распознаванию текста. На данный момент позволяет загружать файлы только с компьютера пользователя – инструмент работы со ссылками находится в разработке.
Официальный сайт сервиса Img2txt
Обратите внимание! Размер загружаемой фотографии не должен превышать 8 Мб.
- Нажмите на «Выберите файл с изображением» и укажите путь к картинке. Можно просто перетащить изображение в указанную область.
- Выберите язык текста, нажмите на «Загрузить» (сервис умеет работать только с изображениями, текст на которых написан на одном конкретном языке).
- Результат распознавания откроется на сайте сервиса. Чтобы скачать его в формате DOCX (для работы в Word), спуститесь в конец страницы, раскройте список «Скачать» и выберите вариант «Microsoft Word».
- В отличие от Convertio, Img2txt сохраняет переносы слов.
Ключевая особенность Img2txt заключается в возможности предварительного просмотра результата распознавания.
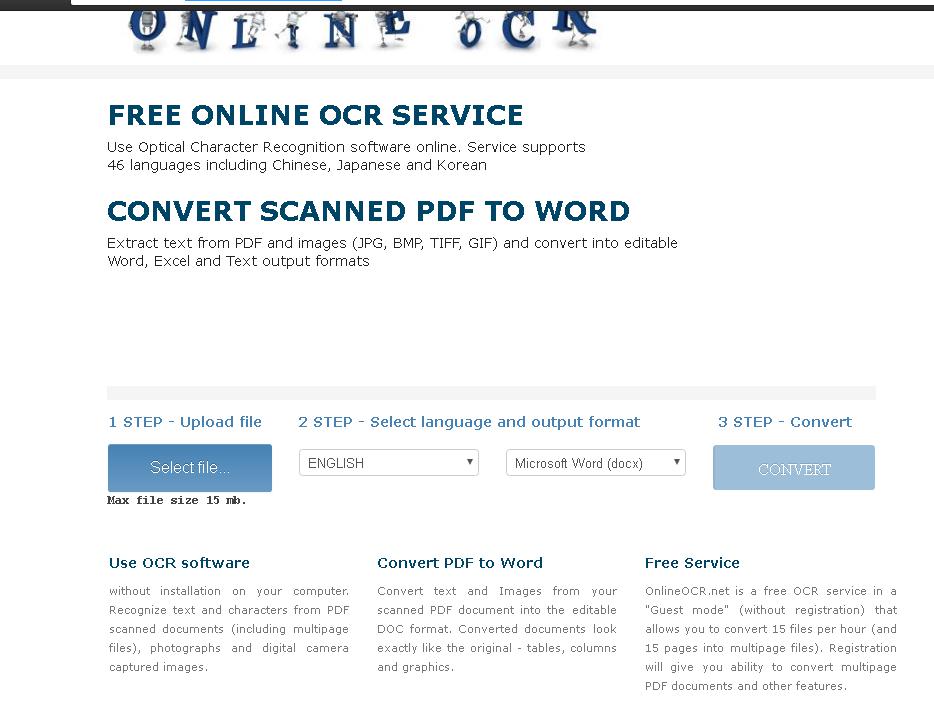
Способ 3: Online OCR
Online OCR – бесплатный сервис оптического распознавания. Поддерживает около 46 языков, умеет обрабатывать фотографии объёмом до 15 Мб.
Поддерживает около 46 языков, умеет обрабатывать фотографии объёмом до 15 Мб.
Официальный сайт сервиса Online OCR
- Для распознавания текста нажмите на кнопку «Файл…» и выберите нужную картинку, укажите язык и выходной формат, кликните по кнопке «Конвертировать». Все действия выполняются на одной странице.
- Нажмите на «Скачать выходной файл» для запуска загрузки документа в формате DOCX.
- Результат сканирования разворота книги в Word отображается в альбомной ориентации.
Для конвертации больших изображений и работы с архивами придётся зарегистрироваться, при этом работу с обычными картинками можно вести без учётной записи.
Способ 4: Free Online OCR
Free Online OCR – сервис, который умеет автоматически определять язык, используемый в распознаваемом тексте.
Официальный сайт Free Online OCR
- Нажмите на кнопку «Обзор…», выберите нужный файл.
- Спуститесь ниже по странице и кликните по «Preview».

- Убедитесь, что сервис правильно определил исходный язык. При необходимости укажите на необходимость поворота изображения или выделите участок, который нужно обработать. Нажмите на «OCR» для запуска процедуры распознавания.
- Спуститесь в конец страницы к результату работы сервиса, нажмите на «Download», выберите «Microsoft Word (DOC)».
- Итоговый результат представлен на скриншоте ниже.

Free Online OCR не умеет работать в пакетном режиме и конвертирует только в DOC. В отличие от других сервисов, этот позволяет вручную определять сканируемую область.
Способ 5: Onlineconvertfree
Onlineconvertfree – простейший онлайн-сервис, с помощью которого можно без регистрации быстро распознать текст на 10 фотографиях.
Официальный сайт сервиса Onlineconvertfree
- Нажмите на «Выберите файл», укажите путь к интересующему изображению.
- Выберите используемые языки, настройте формат вывода. Нажмите на «Распознать».
- Кликните по кнопке загрузки, расположенной напротив готового документа.
- Стоит отметить, что ошибок при распознавании возникает больше, чем при использовании других сервисов.
 Нажмите на «Распознать».
Нажмите на «Распознать».Способ 6: Aspose
Aspose– сервис, который способен извлечь текст из любого изображения и вставить его в документ DOC или DOCX.
Официальный сайт сервиса Aspose
- Для преобразования введите ссылку на картинку или загрузите файл через кнопку «Выберите JPG файлы», укажите язык и формат сохранения, нажмите на кнопку «Начать OCR».
- Для скачивания нажмите на кнопку загрузки. При необходимости файл можно отправить на электронную почту.
- С получившимся текстом можно работать в Word любой версии.
Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.

Помогла ли вам эта статья?
ДА НЕТРаспознать сканированный текст в Word — Какие программы для распознавания текста использовать в офисе
Мы уже рассматривали с Вами программу для распознавания текста с картинки . Но распознавать текст можно не только с помощью программы. Это можно делать с помощью онлайн сервисов, не имея никаких программ на своем компьютере.И действительно, зачем устанавливать какие-то программы, если Вам нужно распознать текст один раз, и в дальнейшем Вы не собираетесь эту программу использовать? Или Вам нужно делать это раз в месяц? В этом случае лишняя программа на компьютере не нужна.
Давайте рассмотрим несколько сервисов, при помощи которых можно распознавать текст с картинки бесплатно, легко и быстро.
Free Online OCR
Очень хорошим сервисом для распознавания текста с картинки онлайн является сервис Free Online OCR. Он не требует регистрации, распознает текст с картинки практически любого формата. работает с 58 языками. Распознаваемость текста у него отличная.
работает с 58 языками. Распознаваемость текста у него отличная.
Пользоваться этим сервисом просто. Когда Вы на него зайдете, перед Вами будет всего два варианта: загрузить файл с компьютера, или вставить URL-адрес картинки, если она находится в Интернете.
Если Ваше изображение находится на компьютере, нажимаете на кнопку Выберите файл, затем выбираете свой файл, и нажимаете на кнопку Upload. Вы увидите свой графический файл ниже, а над ним кнопку OCR. Жмете эту кнопку, и получаете текст, который Вы можете найти в нижней части страницы.
Online OCR Net
Также довольно неплохой сервис, который позволяет распознавать тексты с картинок онлайн бесплатно, и без регистрации. Поддерживает он 48 языков, включая русский, китайский, корейский и японский. Чтобы начать с ним работать, заходите на Online OCR, нажимаете кнопку Select file, и выбираете файл на своем компьютере. Существуют ограничения по размеру — файл не должен весить больше 5 Мбайт.
В соседних полях выбираете язык и расширение текстового документа, в котором будет полученный из картинки текст. После этого вводите капчу внизу, и нажимаете на кнопку Convert справа.
ABBYY FineReader Online
Очень хороший сервис в плане своей многофункциональности. На ABBYY FineReader Online можно не только распознавать текст с картинки, но также и переводит документы из формата PDF в формат Word, переводить таблицы из картинок в Excel, и создавать документы PDF из сканов.
На этом сервисе есть регистрация, но можно обойтись и входом с помощью социальной сети Facebook, сервисов Google+, или Microsoft Account.
Преимущество такого подхода в том, что созданные документы будут храниться в Вашем аккаунте в течении 14 дней, и даже если Вы их удалите из компьютера, можно будет вернуться на сервис, и опять их скачать.
Online OCR Ru
Сервис, похожий на предыдущий, с информацией на русском языке. Принцип работы сервиса Online OCR такой же, как и всех остальных — нажимаете на кнопку Выберите файл, загружаете картинку, выбираете язык и выходной формат текстового документа, и нажимаете на кнопку Распознать текст.
Принцип работы сервиса Online OCR такой же, как и всех остальных — нажимаете на кнопку Выберите файл, загружаете картинку, выбираете язык и выходной формат текстового документа, и нажимаете на кнопку Распознать текст.
Кроме распознавания текста из картинок, сервис предоставляет возможность перевода изображений в форматы PDF, Excel, HTML и другие, причем структура и разметка документа будет соответствовать той, которая была на картинке.
На этом сервисе также есть регистрация, и файлы, созданные Вами с его помощью, будут храниться в Вашем личном кабинете.
(OCR) Онлайн сервисы для распознавания текста с картинки [Обновление Май 2021]
АналитикаАвтор Володимир На чтение 2 мин Просмотров 19 Опубликовано
Последние несколько лет я пользовался одним и тем же сервисом для распознавания текста с изображения и как правильно если есть на изображении какие-то помехи, то текст распознается не всегда идеально и очень часто с битыми словами. В специфике моей работы, после распознавания текста — мне нужно проверять его на уникальность, естественно битые слова только добавляли уникальность тексту.
В специфике моей работы, после распознавания текста — мне нужно проверять его на уникальность, естественно битые слова только добавляли уникальность тексту.
Я уже давно был полюбил один сервис, которым пользовался и решил как-то случайно попробовать распознать текст через другой сервис и мое было огромное удивление, когда другой сервис намного лучше распознал мое изображение чем мой всегда полюбившийся.
Этот рейтинг был построен для того, что бы вы могли взять одно изображения и оценить какой онлайн сервис распознавания текстов для Ваших задач намного лучше подойдет.
OnlineOCR.org
- Onlineocr.org — полностью бесплатный сервис по распознаванию текста на изображении. На текущий момент единственный минус — это нет истории распознавания изображений или архива. Качество распознавания текста достаточно высокое, но что бы добиться этого качества — нужно не забыть указать правильный язык распознавания текста.
Finereaderonline.com
- Finereaderonline. com — это самый популярный платный сервис, а так же качественный. Это не удивительно ведь владелец Adobe Fine Reader.
 com — это самый популярный платный сервис, а так же качественный. Это не удивительно ведь владелец Adobe Fine Reader.
com — это самый популярный платный сервис, а так же качественный. Это не удивительно ведь владелец Adobe Fine Reader.Convertio.co
- Convertio.co — сервис распознавания текста онлайн на текущий момент лучше всех ранжируется в поисковой системе по своему основному ключевому слову, качество распознавание не плохое, но сервис с первого варианта гораздо лучше если распознавать текст на изображении, если распознать текст в PDF файле — тогда этот сервис рекомендую.
Img2txt.com
Convertonlinefree.com
Onlineconvertfree.com
Go4convert.com
Tesseract-OCR-03-Распознавание текста в картинках — Русские Блоги
В этой статье рассказывается об использовании Tesseract-OCR для распознавания текста изображения. При распознавании рукописного текста степень точности может достигать 90%. После обучения уровень точности чрезвычайно высок. Представленное здесь распознавание текста изображения может распознавать английский, числа, китайский и т. Д.
Д.
Распознавание текста изображений Tesseract-OCR
- Tesseract:Механизм OCR с открытым исходным кодом (оптическое распознавание символов, оптическое распознавание символов), разработанный HP Labs и поддерживаемый Google. Мы можем постоянно обучать библиотеку, чтобы постоянно улучшать способность изображений преобразовывать текст; если команде это очень нужно, ее также можно использовать В качестве шаблона разработайте движок OCR, который соответствует вашим потребностям.
- Если вы не установили Tesseract-OCR, обратитесь к:
- Конечно, конфигурационная среда также была загружена из указанной выше статьи. Шаги очень подробны.
Основная тема Распознавание текста изображения
- Я собрал несколько материалов, мне лень их найти и могу скачать напрямую:
- https://pan.baidu.com/s/10XxYJa19KIa8-ENdQkhhHg
- Здесь я выложил картинку: D: \ p
- Нам нужно войти в этот каталог в cmd
- Используйте имя каталога cd для входа в каталог
- Используйте cd . ., чтобы вернуться в предыдущий каталог.
Используйте команду Tesseract:
имя файла tesseract имя сохраненного txt файла -l eng пример:tesseract num1.jpg num1
Здесь -l eng для установки языка, если не написано, по умолчанию используется eng, то есть английский
- Результат:
- Заметка:
- 1. Если здесь сообщается об ошибке, Tesseract не является внутренней или внешней командой, то есть переменная среды не настроена для справки:
https://blog.csdn.net/qq_40147863/article/details/82285920 - 2. Если распознанный текст изображения на китайском языке, будет предложено 0 текст
- 1. Если здесь сообщается об ошибке, Tesseract не является внутренней или внешней командой, то есть переменная среды не настроена для справки:
 ., чтобы вернуться в предыдущий каталог.
., чтобы вернуться в предыдущий каталог.Распознавать рукописный английский
- Узнай картинку eng2.jpg
- Команда ввода: сохранить как eng2.txt
- Сравним результаты:
- Вот неправильное распознавание букв, неправильное распознавание ig как S, включая указанное выше число, тоже неверное
- Это направление, в котором мы должны работать
Узнай китайский
- Чтобы распознать китайский язык, достаточно изменить параметр -l на chi_sim Например:
Для изображения chi1.
jpg с текстом на китайском языке введите путь к изображению и используйте следующую команду:tesseract chi1.jpg chi1 -l chi_sim
Стиль изображения:
- Выполнение заказа:
- результат операции:
 jpg с текстом на китайском языке введите путь к изображению и используйте следующую команду:
jpg с текстом на китайском языке введите путь к изображению и используйте следующую команду:Распознавать английские и смешанные цифровые коды подтверждения
- Например:
Для изображения timg.jpg введите путь к изображению и используйте следующую команду:
tesseract timg.jpg timg
Стиль изображения:
- Выполнение заказа:
- результат операции:
Обучение тессеракту:
- Мы можем добиться более высокой точности распознавания за счет многократного обучения и большего количества данных для обучения.
- Используем обучение jTessBoxEditor
- В связи с установкой и обучением jTessBoxEditor контента стало больше, поэтому я организую другую статью
Ссылки на другие статьи:Эссе Тессеракта
-Это примечание не разрешает никому или организациям перепечатывать
Из пикселей — в буквы: как работает распознавание текста
Что такое OCR?OCR (англ.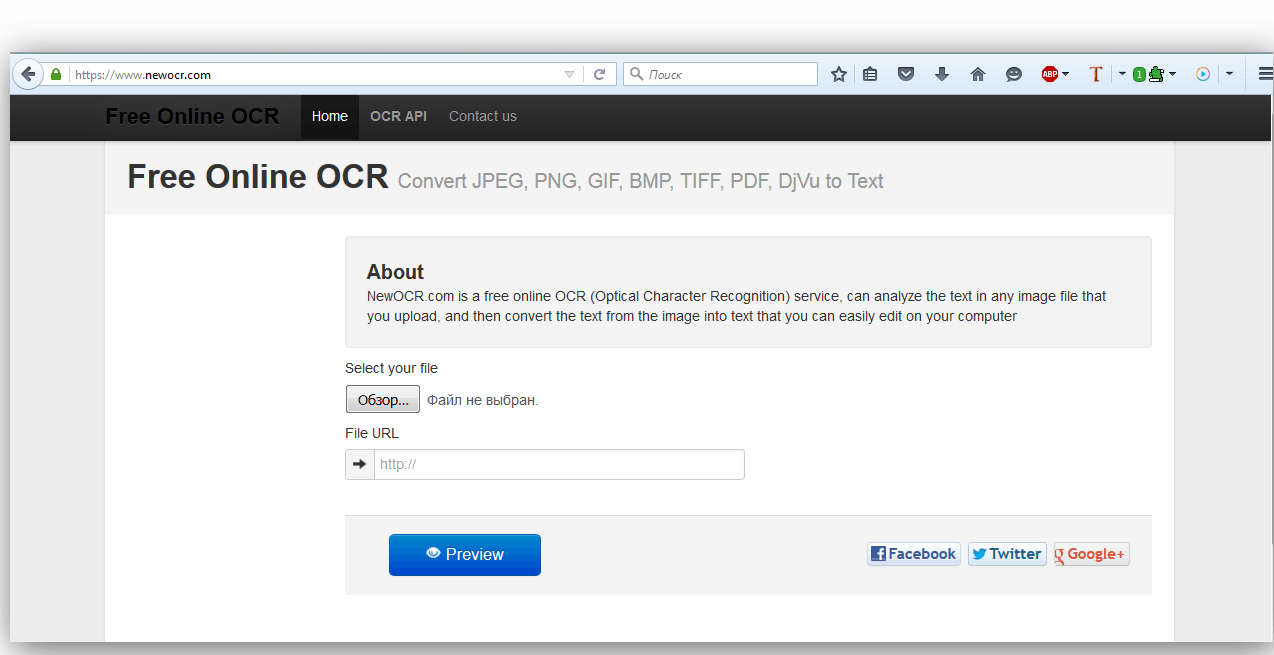 optical character recognition, оптическое распознавание символов) — это технология автоматического анализа текста и превращения его в данные, которые может обрабатывать компьютер.
optical character recognition, оптическое распознавание символов) — это технология автоматического анализа текста и превращения его в данные, которые может обрабатывать компьютер.
Когда человек читает текст, он распознает символы с помощью глаз и мозга. У компьютера в роли глаз выступает камера сканера, которая создает графическое изображение текстовой страницы (например, в формате JPG). Для компьютера нет разницы между фотографией текста и фотографией дома: и то, и другое — набор пикселей.
Именно OCR превращает изображение текста в текст. А с текстом уже можно делать что угодно.
Как это устроено?
Представьте, что в алфавите есть только одна буква «А». Сделает ли это задачу преобразования картинки в текст проще? Нет. Дело в том, что у каждой буквы (и любой другой графемы) есть аллографы — различные варианты начертания.
Варианты начертания буквы «а».Человек легко поймет, что все это буква «А». Для компьютера же есть два способа решения проблемы: распознавать символы целостно (распознавание паттерна) или выделять отдельные черты, из которых состоит символ (выявление признаков).
Распознавание паттерна
В 1960-х годах был создан специальный шрифт OCR-A, который использовался в документах типа банковских чеков. Каждая буква в нем была одинаковой ширины (т.н. шрифт фиксированной ширины или моноширинный шрифт).
Образец шрифта OCR-AПринтеры для чеков работали с этим шрифтом, и для его распознавания было разработано программное обеспечение. Поскольку шрифт был стандартизирован, его распознавание стало относительно простой задачей. Следующим шагом стало обучение программ OCR распознавать символы еще в нескольких самых распространенных шрифтах (Times, Helvetica, Courier и т.д.).
Выявление признаков
Этот способ еще называют интеллектуальным распознаванием символов (англ. intelligent character recognition, ICR). Представьте, что вы — OCR-программа, которой дали множество разных букв, написанных разными шрифтами. Как вам отобрать из этого множества все буквы «А», если каждая из них немного отличается от другой?
Можно использовать такое правило: если видишь две линии, сходящиеся наверху в центре под углом, а посередине между ними горизонтальная линия, то это буква «А».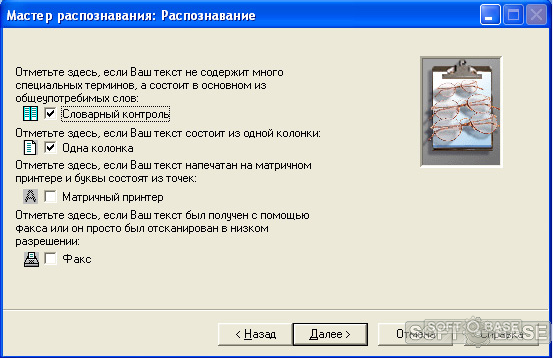 Это правило поможет распознать все буквы «А» независимо от шрифта. Вместо распознавания паттерна выделяются характерные индивидуальные черты, из которых состоит символ. Большинство современных омнишрифтовых (умеющих распознавать любой шрифт) OCR-программ работают по этому принципу. Чаще всего в них используются классификаторы на основе машинного обучения (т.к. фактически перед нами стоит задача классификации картинок по классам-буквам) в последнее время некоторые OCR-движки перешли на нейронные сети.
Это правило поможет распознать все буквы «А» независимо от шрифта. Вместо распознавания паттерна выделяются характерные индивидуальные черты, из которых состоит символ. Большинство современных омнишрифтовых (умеющих распознавать любой шрифт) OCR-программ работают по этому принципу. Чаще всего в них используются классификаторы на основе машинного обучения (т.к. фактически перед нами стоит задача классификации картинок по классам-буквам) в последнее время некоторые OCR-движки перешли на нейронные сети.
Что делать с рукописным вводом?
Человек способен догадаться о смысле предложения, даже если оно написано самым неразборчивым почерком (если речь не идет о рецепте на лекарства, конечно).
Задачу для компьютера иногда упрощают. Например, людей просят писать почтовый индекс в специальном месте на конверте специальным шрифтом. Формы, созданные для дальнейшей обработки компьютером, обычно имеют отдельные поля, которые просят заполнять печатными буквами.
Планшеты и смартфоны, которые поддерживают рукописный ввод, часто используют принцип выявления признаков. При написании буквы «А» экран «чувствует», что сначала пользователь написал одну линию под углом, затем вторую, и, наконец, провел горизонтальную черту между ними. Компьютеру помогает то, что все признаки появляются последовательно, один за другим, в отличие от варианта, когда весь текст уже записан от руки на бумаге.
При написании буквы «А» экран «чувствует», что сначала пользователь написал одну линию под углом, затем вторую, и, наконец, провел горизонтальную черту между ними. Компьютеру помогает то, что все признаки появляются последовательно, один за другим, в отличие от варианта, когда весь текст уже записан от руки на бумаге.
OCR по шагам
Предобработка
Чем лучше качество исходного текста на бумажном носителе, тем лучше будет качество распознавания. А вот старый шрифт, пятна от кофе или чернил, заломы бумаги понижают шансы.
Большинство современных OCR-программ сканируют страницу, распознают текст, а затем сканируют следующую страницу. Первый этап распознавания заключается в создании копии черно-белого цвета или в оттенках серого. Если исходное отсканированное изображение идеально, то все черное — это символы, а все белое — фон.
Распознавание
Хорошие OCR-программы автоматически отмечают трудные элементы структуры страницы — колонки, таблицы и картинки. Все OCR-программы распознают текст последовательно, символ за символом, словом за словом и строчка за строчкой.
Все OCR-программы распознают текст последовательно, символ за символом, словом за словом и строчка за строчкой.
Сначала OCR-программа объединяет пиксели в возможные буквы, а буквы — в возможные слова. Затем система сопоставляет варианты слов со словарем. Если слово найдено, оно отмечается как распознанное. Если слово не найдено, программа предоставляет наиболее вероятный вариант и, соответственно, качество распознавания будет не таким высоким.
Постобработка
Некоторые программы дают возможность просмотреть и исправить ошибки на каждой странице. Для этого они используют встроенную проверку орфографии и выделяют неверно написанные слова, что может указывать на неправильное распознавание. Продвинутые OCR-программы используют так называемый метод поиска соседа, чтобы найти слова, которые часто встречаются рядом. Этот метод позволяет исправить неверно распознанное словосочетание «тающая собака» на «лающая собака».
Кроме того, некоторые проекты, которые занимаются оцифровкой и распознаванием текстов, прибегают к помощи волонтеров: распознанные тексты выкладываются в открытый доступ для вычитки и проверки ошибок распознавания.
Особые случаи
Для высокой точности распознавания исторического текста с необычными графическими символами, отличающимися от современных шрифтов, необходимо извлечь соответствующие изображения из документов. Для языков с небольшим набором символов это можно сделать вручную, но для языков со сложными системами письменности (например, иероглифических) ручной сбор этих данных нецелесообразен.
Для распознавания исторических китайских текстов требуется внести в OCR-программу как минимум 3000 символов, которые имеют разную частотность. Если для распознавания исторических английских текстов достаточно ручной разметки нескольких десятков страниц, то аналогичный процесс для китайского языка потребует анализа десятков тысяч страниц.
В то же время многие исторические варианты китайской письменности имеют высокую степень сходства с современным письмом, поэтому модели распознавания символов, обученные на современных данных, часто могут давать приемлемые результаты на исторических данных, хоть и со сниженной точностью. Этот факт вместе с использованием корпусов позволяет создать систему для распознавания исторических китайских текстов. Для этого исследователь Д. Стеджен (Donald Sturgeon) из Гарварда обработал два корпуса: корпус транскрибированных исторических документов и корпус отсканированных документов желаемого стиля.
Этот факт вместе с использованием корпусов позволяет создать систему для распознавания исторических китайских текстов. Для этого исследователь Д. Стеджен (Donald Sturgeon) из Гарварда обработал два корпуса: корпус транскрибированных исторических документов и корпус отсканированных документов желаемого стиля.
После предварительной обработки изображений и этапов сегментации символов процедура извлечения обучающих данных состояла из:
1) применения модели распознавания символов, обученной исключительно на современных документах, к историческим документам для получения промежуточного результата оптического распознавания с низкой точностью;
2) использование этого промежуточного результата для соотнесения изображения с его вероятной транскрипцией;
3) извлечение изображений размеченных символов на основе этого соотнесения;
4) выбор из размеченных символов подходящих обучающих примеров.
Полученные данные могут использоваться без проверки для обучения новой модели распознавания символов, позволяющей достичь более высокой точности на аналогичном материале.
Источники:
- Optical character recognition (OCR)
- Unsupervised Extraction of Training Data for Pre-Modern Chinese OCR
Преобразование изображения PDF в читаемый PDF | Технологические решения
Метод 1. Средство сканирования и распознавания текста
Enhance Scans Tool попытается превратить отсканированные изображения или фотографии бумажных документов в PDF-файлы с возможностью выбора текста. Этот инструмент также очистит контраст страницы и сгладит страницы, где текст может изгибаться из-за книжных переплетов.
Шаг 1. Выберите Scan and OCR Tool
.Выберите инструмент «Сканирование и распознавание текста» на панели инструментов в правой части экрана.В верхней части экрана откроется панель инструментов.
Шаг 2.
 Выберите вариант улучшения.
Выберите вариант улучшения.Чтобы улучшить качество документа, выберите параметр «Улучшить» на панели инструментов «Улучшить сканирование», затем выберите «Отсканированный документ».
Шаг 3.Узнавайте и улучшайте
Установите флажок «Распознать текст» и нажмите кнопку «Улучшить». После завершения распознавания текста сохраните документ.
Шаг 4. Правильно распознать текст
По-прежнему в инструменте «Улучшить сканирование» откройте раскрывающийся список «Распознать текст» и выберите «Исправить распознанный текст».Установите флажок «Проверить распознанный текст» и просмотрите подозрительный текст, обнаруженный инструментом, исправьте при необходимости и нажмите «Принять». Сохраните ваш документ.
Сохраните ваш документ.
Шаг 5. Автоматическая маркировка документа
После того, как весь текст будет распознан, перейдите на панель тегов и щелкните правой кнопкой мыши на Нет доступных тегов. Выберите опцию «Добавить теги в документ». Функция Auto-Tag попытается интерпретировать ваш документ на основе размера и стиля шрифтов, которые вы использовали.Более крупный и жирный текст обычно распознается как заголовок 1 и заголовок 2, даже если они не должны быть заголовками.
Шаг 6. Проверьте и обновите теги документа
Параметр автоматической пометки не будет на 100% правильным. При необходимости проверьте и обновите теги документа. Сохраните ваш документ.
Метод 2. Инструмент редактирования PDF
Параметр «Редактировать PDF-файл» не будет пытаться исправить качество сканирования до распознавания текста и не даст вам возможность исправить распознанный текст.
Шаг 1. Выберите инструмент «Редактировать PDF»
Выберите инструмент «Редактировать PDF» на панели инструментов в правой части экрана.
Acrobat Pro автоматически запустит распознавание текста для вашего документа. После завершения сканирования вы сможете редактировать и выделять большую часть текста в документе. Не забудьте сохранить документ.
Если вы не можете выделить весь текст, определите, является ли текст изображением или нет.Некоторые изображения текста или рукописного ввода могут не распознаваться OCR.
Мы не рекомендуем использовать изображения текста, потому что текст, встроенный в изображения, не может быть обработан вспомогательными технологиями, такими как программы чтения с экрана. В то же время изображения текста создают проблему для мобильной реакции, поскольку изображения текста могут искажаться и становиться неразборчивыми при открытии на мобильном устройстве или планшете.
 Вы можете попробовать «Улучшенное сканирование» в качестве другого варианта распознавания текста.Короткий раздел рукописного ввода, как и подписи, может быть помечен как рисунок и снабжен альтернативным текстом с соответствующим ему текстом. Для более длинных рукописных документов рассмотрите возможность повторного ввода текста в новый документ.
Вы можете попробовать «Улучшенное сканирование» в качестве другого варианта распознавания текста.Короткий раздел рукописного ввода, как и подписи, может быть помечен как рисунок и снабжен альтернативным текстом с соответствующим ему текстом. Для более длинных рукописных документов рассмотрите возможность повторного ввода текста в новый документ.Шаг 2. Автоматическая маркировка документа
После того, как весь текст будет распознан, перейдите на панель тегов и щелкните правой кнопкой мыши на Нет доступных тегов. Выберите опцию «Добавить теги в документ». Функция Auto-Tag попытается интерпретировать ваш документ на основе размера и стиля шрифтов, которые вы использовали.Более крупный и жирный текст обычно распознается как заголовок 1 и заголовок 2, даже если они не должны быть заголовками.
Шаг 3. Проверьте и обновите теги документа
Параметр автоматической пометки не будет на 100% правильным. При необходимости проверьте и обновите теги документа. Сохраните ваш документ.
При необходимости проверьте и обновите теги документа. Сохраните ваш документ.
Что такое оптическое распознавание символов? — Когнитивные службы Azure
- Статья .
- 3 минуты на чтение
Оцените свой опыт
да Нет
Любой дополнительный отзыв?
Отзыв будет отправлен в Microsoft: при нажатии кнопки «Отправить» ваш отзыв будет использован для улучшения продуктов и услуг Microsoft.Политика конфиденциальности.
Представлять на рассмотрение
Спасибо.
В этой статье
Оптическое распознавание символов (OCR) позволяет извлекать печатный или рукописный текст из изображений, таких как фотографии уличных знаков и продуктов, а также из документов — счетов-фактур, счетов, финансовых отчетов, статей и т. Д. Технологии Microsoft OCR поддерживают извлечение печатного текста на нескольких языках.Чтобы начать, следуйте инструкциям по быстрому запуску.
Д. Технологии Microsoft OCR поддерживают извлечение печатного текста на нескольких языках.Чтобы начать, следуйте инструкциям по быстрому запуску.
Эта документация содержит следующие типы статей:
- Краткое руководство — это пошаговые инструкции, которые позволяют совершать звонки в службу и получать результаты в кратчайшие сроки.
- Руководства с практическими рекомендациями содержат инструкции по использованию службы более конкретными или индивидуальными способами.
Прочитать API
Computer Vision Read API — это новейшая технология распознавания текста в Azure (узнайте, что нового), которая извлекает печатный текст (на нескольких языках), рукописный текст (на нескольких языках), цифры и символы валюты из изображений и многостраничных документов PDF.Он оптимизирован для извлечения текста из изображений с большим объемом текста и многостраничных PDF-документов на разных языках. Он поддерживает обнаружение как печатного, так и рукописного текста в одном изображении или документе.
Входные требования
Вызов Read принимает изображения и документы в качестве входных данных. К ним предъявляются следующие требования:
- Поддерживаемые форматы файлов: JPEG, PNG, BMP, PDF и TIFF
- Для файлов PDF и TIFF обрабатывается до 2000 страниц (только первые две страницы для бесплатного уровня).
- Размер файла должен быть менее 50 МБ (6 МБ для уровня бесплатного пользования) и размером не менее 50 x 50 пикселей и не более 10000 x 10000 пикселей.
Поддерживаемые языки
Read API поддерживает 122 языка для печатного текста и 7 языков для рукописного текста, включая языки и функции предварительного просмотра.
OCR для печатного текста включает поддержку английского, французского, немецкого, итальянского, португальского, испанского, китайского, японского, корейского и русского языков (предварительная версия), а также языков латиницы и кириллицы с последним обновлением предварительной версии.
OCR для рукописного текста включает поддержку английского языка и предварительный просмотр французского, немецкого, итальянского, португальского, испанского и китайского языков.
См. Как указать версию модели для использования языков и функций предварительного просмотра. См. Полный список языков, поддерживающих OCR. Модель предварительного просмотра включает все улучшения текущей версии GA.
Ключевые особенности
Read API включает следующие функции.
- Распечатать извлечение текста на 122 языках
- Извлечение рукописного текста на семи языках
- Текстовые строки и слова с указанием местоположения и оценки достоверности
- Идентификация языка не требуется
- Поддержка смешанного языка, смешанного режима (печатный и рукописный)
- Выберите страницы и диапазоны страниц из больших многостраничных документов
- Параметр естественного порядка чтения для вывода текстовой строки (только латиница)
- Классификация рукописного ввода для строк текста (только латиница)
- Доступен как контейнер Distroless Docker для локального развертывания
Узнайте, как использовать функции распознавания текста.
Используйте облачный API или разверните локально
Облачные API-интерфейсы Read 3.x являются предпочтительным вариантом для большинства клиентов из-за простоты интеграции и быстрой производительности сразу после установки. Azure и служба компьютерного зрения обеспечивают масштабирование, производительность, безопасность данных и соответствие нормативным требованиям, в то время как вы сосредотачиваетесь на удовлетворении потребностей своих клиентов.
Для локального развертывания контейнер Read Docker (предварительная версия) позволяет развернуть новые возможности OCR в вашей собственной локальной среде.Контейнеры отлично подходят для конкретных требований к безопасности и управлению данными.
Конфиденциальность и безопасность данных
Как и все службы Cognitive Services, разработчики, использующие службу компьютерного зрения, должны знать политику Microsoft в отношении данных клиентов. См. Страницу Cognitive Services в Центре управления безопасностью Microsoft, чтобы узнать больше.
Следующие шаги
PDF7: выполнение оптического распознавания символов в отсканированном PDF-документе для отображения фактического текста
Цель этого метода — гарантировать, что визуально отображаемый текст представлен таким образом, что его можно воспринимать без его визуальное представление, мешающее его читабельности.
Документ, состоящий из отсканированных изображений текста, изначально недоступен потому что содержание документа — изображения, а не текст, доступный для поиска. Вспомогательные технологии не могут читать или извлекать слова; пользователи не могут выделять, редактировать, изменять размер или перекомпоновку текста, а также они не могут изменять текст и фон цвета; и авторы не могут управлять PDF-файлом для обеспечения доступности.
По этим причинам авторам следует использовать фактический текст, а не изображения.
текста, используя инструмент разработки, такой как Microsoft Word или Oracle Open
Office для создания и преобразования содержимого в PDF.
Если авторы не имеют доступа к исходному файлу и инструменту разработки, отсканированные изображения текста можно преобразовать в PDF с помощью оптических символов распознавание (OCR). Затем Adobe Acrobat Pro можно использовать для создания доступных текст.
Этот пример показан с Adobe Acrobat Pro. Существуют и другие программные инструменты, выполняющие аналогичные функции. См. Список других программных инструментов в PDF Authoring Tools, которые обеспечивают поддержку специальных возможностей.
В этом примере используется простое сканированное изображение текста на одной странице.Для обеспечения что фактический текст хранится в документе, выполните следующие действия:
Отсканируйте документ с максимально возможным разрешением для улучшения производительность OCR.
Загрузите отсканированный документ в Acrobat Acrobat Pro. Выберите Документ> OCR. Распознавание текста> Распознать текст с помощью OCR …
В следующем диалоговом окне выберите переключатель Все страницы в разделе Страницы (или Текущая страница, если вы конвертируете только одну страницу), а затем выберите OK.
В списке «Настройки» выберите «Изменить». В следующем диалоговом окне выберите Форматированный текст и графика в раскрывающемся списке «Стиль вывода PDF». Это важно для обеспечения доступности.
В зависимости от разрешения и четкости текста OCR преобразует изображения слов и символов в фактический текст. Напишите что Acrobat Pro не распознает, указан как «подозреваемый в распознавании текста» или текстовый элемент, который, как подозревает Acrobat, был распознан неправильно.
Чтобы исправить подозреваемых, выберите «Документ»> «Распознавание текста с оптическим распознаванием текста»> «Найти». Первый подозреваемый OCR. Acrobat Pro представляет каждого подозреваемого по одному, которые можно исправить с помощью инструментов редактирования Acrobat Pro.
Выполнить «Расширенный»> «Специальные возможности»> «Добавить теги в документ»
Тест на доступность: «Дополнительно»> «Специальные возможности»> «Полный» Проверить …

Примечание: В качестве альтернативы вы можете использовать Документ> OCR Распознавание текста> Найти всех подозреваемых OCR для отображения всех подозреваемых OCR в то же время для более быстрого редактирования.
На следующем изображении показан отсканированный одностраничный документ в Adobe Acrobat. Pro.
На следующем изображении показано преобразованное содержимое после добавления тегов в
документ. Возможно, потребуется использовать TouchUp Reading
Инструмент «Заказ» и панель «Теги», чтобы правильно пометить контент для предполагаемого
итоговый документ. Для этого примера изображение спирального переплета книги
был отмечен при преобразовании. Использовался инструмент TouchUp Reading Order.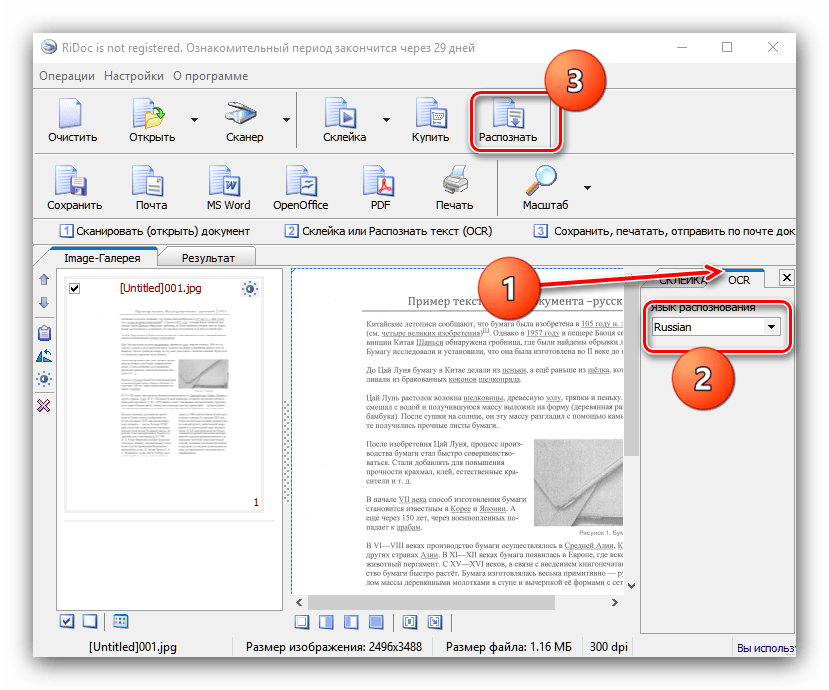 , чтобы скрыть изображение как фоновое (декоративное) (см. PDF4: Скрытие декоративных изображений с помощью тега Artifact в документах PDF ).Рецепт
заголовки были помечены как заголовки первого уровня.
, чтобы скрыть изображение как фоновое (декоративное) (см. PDF4: Скрытие декоративных изображений с помощью тега Artifact в документах PDF ).Рецепт
заголовки были помечены как заголовки первого уровня.
Примечание. Acrobat Pro может автоматически добавлять теги при запуске файла. через OCR.
Этот пример показан в действии на рабочем примере генерации фактического текста и результата выполнения OCR.
Ресурсы предназначены только для информационных целей, без поддержки.
Процедура
Для каждой страницы, преобразованной в текст с помощью OCR, убедитесь, что результат PDF-файл был преобразован правильно одним из следующих способов:
Прочтите PDF-документ с помощью средства чтения с экрана или инструмента, который читает вслух, прислушиваясь к тому, что весь текст читается правильно и в правильном порядке чтения.
Сохраните документ как текст и убедитесь, что преобразованный текст является полным и в правильном порядке чтения.
Используйте инструмент, способный отображать преобразованный контент чтобы открыть документ PDF и убедиться, что весь текст был преобразован и находится в правильном порядке чтения.
Используйте инструмент, открывающий доступ к документу API и убедитесь, что весь текст преобразован и находится в правильном порядок чтения.

Ожидаемые результаты
Если это достаточный метод для критерия успеха, неудача этой процедуры тестирования не обязательно означает, что критерий успеха не был удовлетворен каким-либо другим способом, только то, что этот метод не был успешным реализованы и не могут использоваться для подтверждения соответствия.
OCR не распознает текст в Adobe Acrobat Professional | Small Business
Оптическое распознавание символов предоставляет почти автоматизированные средства оцифровки текста со отсканированных страниц, устраняя необходимость их повторного набора.Adobe Acrobat Professional включает в себя возможности оптического распознавания текста, которые позволяют сохранять отсканированные результаты непосредственно в форматах Rich Text Format или в форматах файлов Microsoft Word DOC и DOCX. Если вы открываете документ в Acrobat Professional, но программа отказывается распознавать текст, четко видимый на странице, проверьте исходный файл на предмет некоторых распространенных проблем, которые могут вызвать проблемы с распознаванием текста.
Если вы открываете документ в Acrobat Professional, но программа отказывается распознавать текст, четко видимый на странице, проверьте исходный файл на предмет некоторых распространенных проблем, которые могут вызвать проблемы с распознаванием текста.
Live Text
Возможно, наименее очевидная причина сбоев оптического распознавания текста в Acrobat Professional — это попытка оцифровывать страницу, которая уже содержит живой текст.Если вам абсолютно необходимо запустить OCR для текста, который вы можете скопировать в буфер обмена и вставить в текстовый редактор или экспортировать из Acrobat непосредственно в текстовый формат, вы должны сначала преобразовать живой текст вашего файла в пиксели. В противном случае вы увидите сообщение об ошибке, сообщающее об ошибке распознавания.
Перекошенный или размытый источник
Отсканированные изображения с низким разрешением менее 150 пикселей на дюйм обеспечивают плохой исходный материал для возможностей оптического распознавания текста Acrobat Professional, а также других программ оптического распознавания текста. Точно так же, если ваши отсканированные изображения получаются искаженными, вероятность получения хороших результатов снижается. Для исправления проблем с низким разрешением обычно требуется повторное сканирование источника при более высоком значении ppi, предпочтительно 300 ppi. Если вы сканируете распечатанные страницы на сканере для полиграфии, в котором отсутствует устройство подачи документов, найдите время, чтобы правильно расположить бумагу на стекле сканера, или откройте отсканированные изображения в программе, которая поможет вам выровнять их, например в Adobe Photoshop.
Точно так же, если ваши отсканированные изображения получаются искаженными, вероятность получения хороших результатов снижается. Для исправления проблем с низким разрешением обычно требуется повторное сканирование источника при более высоком значении ppi, предпочтительно 300 ppi. Если вы сканируете распечатанные страницы на сканере для полиграфии, в котором отсутствует устройство подачи документов, найдите время, чтобы правильно расположить бумагу на стекле сканера, или откройте отсканированные изображения в программе, которая поможет вам выровнять их, например в Adobe Photoshop.
Оригинал низкого качества
Хотя сканирование с высоким разрешением улучшает результаты оптического распознавания текста, обеспечивая Acrobat Professional более качественным исходным материалом, старая поговорка «мусор на входе, мусор на выходе» применяется, когда ваш оригинал низкого качества.Сканирование отправленных по факсу материалов и распечаток с принтера для микрофильмов или микрофиш может дать худшие результаты оптического распознавания текста.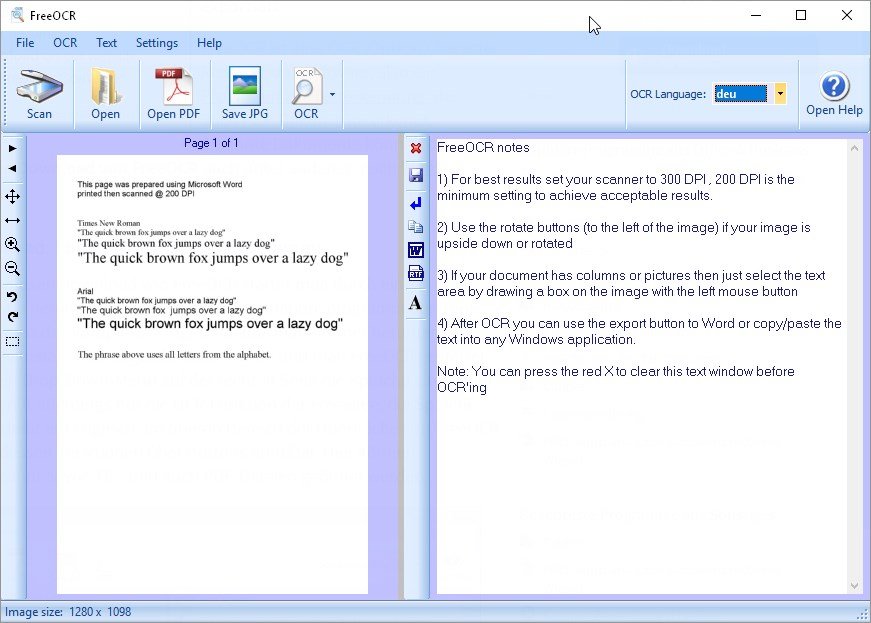 Если такие источники являются вашей единственной формой ввода, запланируйте потратить время, необходимое для исправления вывода OCR, или перепечатайте текст, если он короткий.
Если такие источники являются вашей единственной формой ввода, запланируйте потратить время, необходимое для исправления вывода OCR, или перепечатайте текст, если он короткий.
Формы и графика
Программа оптического распознавания текста лучше всего работает, когда вы представляете ее с четкими непрерывными полосами текста в полностраничных столбцах. Если исходный материал включает текст в рамке, такой как формат формы, или большое количество графического материала, качество распознавания может снизиться, поскольку программное обеспечение изо всех сил пытается отличить текст от нетекстового материала.В крайних случаях вы можете сделать фотокопию формы и очистить некоторые ее поля и строки, прежде чем пытаться отсканировать и распознать ее содержимое.
Ссылки
Биография писателя
Элизабет Мотт писала с 1983 года. Мотт имеет большой опыт написания рекламных текстов для всего, от кухонной техники и финансовых услуг до образования и туризма. Она имеет степень бакалавра искусств и магистра искусств по английскому языку в Университете штата Индиана.
Распознавание текста (OCR) | База знаний Scanner Pro
Оптическое распознавание символов (OCR) — это интеллектуальная технология распознавания текста, которая распознает текст на отсканированных изображениях и делает их доступными для поиска.После того, как отсканированное изображение или изображение проходят обработку OCR, их легко читать, выбирать и копировать в другие приложения.
Предварительные требования
Улучшенная технология распознавания текста, описанная в этой статье, доступна в Scanner Pro 8.0 или более поздних версиях. Для тех, кто ранее покупал Scanner Pro, эта функция бесплатна. Новые клиенты могут найти информацию о подписке здесь.
Выберите язык для распознавания текста
Scanner Pro по умолчанию распознает текст на автоматически предварительно выбранных языках на основе латиницы.Чтобы переключиться на другой язык для обработки отсканированных изображений, выполните следующие действия:
- Откройте настройки Scanner Pro и коснитесь Распознавание текста (OCR) .
- Убедитесь, что переключатель Автоматическое распознавание текста (OCR) включен.
- Отключите языков на основе латиницы. Переключатель и выберите один язык из списка.
- Нажмите Сохранить .

Распознавать, копировать и передавать текст
- Откройте сканированное изображение в Scanner Pro и коснитесь Текст на нижней панели инструментов.
- Выберите Документ или вкладку Текст вверху. Вкладка «Документ» содержит отсканированное изображение с текстовым слоем на нем, а вкладка «Текст» содержит текст, извлеченный из отсканированного изображения.
- Если язык сканирования отличается от того, который обычно используется в тексте ваших сканированных изображений, нажмите Язык на нижней панели инструментов и убедитесь, что выбран правильный язык:
- Если язык этого сканирования — язык на основе латиницы , убедитесь, что переключатель языка на основе латиницы включен.
- Если язык сканирования не является латинским и отличается от того, который вы выбрали вручную в настройках, выберите новый язык из списка и нажмите Повторная обработка .
Затем выберите и скопируйте необходимую часть текста, нажмите Копировать все на нижней панели инструментов или выберите Поделиться , чтобы экспортировать текстовый слой в другие приложения. Закончив работу с текстом, нажмите Готово в правом верхнем углу.
Отключить автоматическое распознавание текста
Автоматическое распознавание текста включено по умолчанию, и это позволяет быстро распознавать и искать содержимое ваших отсканированных изображений.Чтобы выключить его, откройте Настройки Scanner Pro> Распознавание текста (OCR) и отключите переключатель Автоматическое распознавание текста (OCR) . После этого вас будут спрашивать, распознавать ли текст или нет, каждый раз, когда вы нажимаете Текст на нижней панели инструментов или пытаетесь выполнить поиск в документе.
Privacy
Обратите внимание, что Scanner Pro использует модель OCR на устройстве. Это означает, что мы не загружаем распознанный текст в какое-либо облачное хранилище, и он безопасно хранится только на вашем устройстве.Чтобы узнать, как мы обрабатываем ваши данные, чтобы обеспечить их безопасность, ознакомьтесь с нашей Политикой конфиденциальности. Его можно найти на нашем веб-сайте или напрямую через Настройки Scanner Pro> Политика конфиденциальности .
Устранение неполадок
Если у вас возникли проблемы с функцией распознавания текста в Scanner Pro, убедитесь, что у вас установлено приложение версии 8.0 или более поздней. Затем попробуйте выйти из приложения и запустить его снова. Если на данный момент ситуация не решена, обратитесь в нашу службу поддержки, выполнив следующие действия:
- Запустите Scanner Pro и коснитесь значка настроек в левом верхнем углу.
- Прокрутите вниз и коснитесь Поддержка > Отправить отзыв .
- Появится новое окно электронной почты. В своем сообщении опишите проблему.
- Нажмите Отправьте , и наша служба поддержки свяжется с вами, чтобы решить проблему.
Мы будем благодарны за ваш отзыв, который поможет нам улучшить статью:
Спасибо! Расскажите подробнее о своем опыте работы со Scanner Pro. Справочный центр:
Как работает оптическое распознавание символов
Как работает оптическое распознавание символов
Оптическое распознавание символов (OCR) позволяет превращать отсканированные изображения в текст, чтобы вы могли превращать бумажные документы в редактируемые цифровые документы с возможностью поиска.Это может помочь уменьшить объем физического пространства, необходимого для хранения документов, и может значительно улучшить рабочие процессы, связанные с этими документами. Это снижает риск потери или неправильного оформления документов и, во многих случаях, устраняет необходимость вручную обрабатывать документы или изменять ввод информации, что может привести к ошибкам. И это может снизить затраты на ручную обработку.
Как это работает?
OCR анализирует светлые и темные узоры, из которых состоят буквы и цифры, чтобы превратить отсканированное изображение в текст.Системы оптического распознавания символов должны распознавать символы в различных шрифтах, поэтому применяются правила, помогающие системе сопоставить то, что она видит на изображении, с правильными буквами или цифрами.
В то время как ранние системы OCR были разработаны для работы с одним конкретным шрифтом, который был специально создан для этой цели, некоторые современные системы OCR могут даже распознавать почерк людей. Эта технология называется интеллектуальным распознаванием символов (ICR).
Для оптимальной работы оптического распознавания символов важно сканировать как можно более четкую версию документа.Размытый текст или отметки на копии могут стать причиной ошибок.
ПрограммыOCR распознают текст символ за символом, но результат настолько быстр, что может быть мгновенным. Вы можете проверять наличие ошибок по ходу или в конце процесса, а некоторые программы имеют автоматическое обнаружение ошибок.
Какие преимущества дает OCR?
Базовая технология OCR существует с конца 1920-х годов. С тех пор он стал намного сложнее, и теперь он может конвертировать даже очень сложные документы быстро и с небольшим количеством ошибок.Когда документы конвертируются из исходного формата в новый формат, они выглядят точно так же, как оригинал, с точным воспроизведением всего форматирования.
Есть шесть основных способов, которыми OCR помогает бизнесу сегодня:
- Автоматизация рабочих процессов
Компании, которые полагаются на большой объем бумажной работы, могут сэкономить время и повысить производительность за счет пакетного сканирования. Файлы можно сканировать и индексировать для удобства. Документы, требующие действий, такие как счета-фактуры, можно вводить в автоматизированные рабочие процессы, которые сопровождают их через соответствующие процессы утверждения и оплаты. - Превратить файлы, доступные только для чтения, в редактируемый текст
Решения OCR извлекают текст, доступный только для чтения, из файлов, таких как PDF-файлы, чтобы вы могли его редактировать, использовать в других документах и искать его. - Создание звуковых файлов
Вы можете сэкономить время, которое тратите на чтение длинных или сложных документов, превратив их в звуковой файл с естественным звуком. Таким образом, вы можете слушать документ в дороге или в тренажерном зале, что повысит вашу продуктивность.Это также обеспечивает слепым и слабовидящим людям доступ к письменному тексту. - Перевести на иностранные языки
Есть несколько решений OCR, которые могут конвертировать документы с более чем 180 иностранных языков. - Управление формами и анкетами
Управление заполненными вручную формами и анкетами раньше занимало много часов времени и усилий. OCR позволяет мгновенно сканировать документы, превращая информацию в доступный для поиска текст, чтобы вы могли извлечь полезную информацию или быстрее принять меры. - Более быстрый и точный ввод данных
Используя OCR и оцифровку источников данных, вы можете автоматизировать ввод данных и избежать необходимости повторно вводить информацию в системы. Это может сэкономить время и устранить ошибки, которые могут закрасться, когда люди вводят данные вручную.
Запросить цитату
Использование движка Tesseract OCR в R
Пакет tesseract предоставляет R-привязки Tesseract: мощный механизм оптического распознавания символов (OCR), поддерживающий более 100 языков.Движок имеет широкие возможности настройки для настройки алгоритмов обнаружения и получения наилучших возможных результатов.
Имейте в виду, что OCR (распознавание образов в целом) — очень сложная проблема для компьютеров. Результаты редко бывают идеальными, а точность быстро снижается с повышением качества входного изображения. Но если вы можете добиться приемлемого качества входных изображений, Tesseract часто может помочь извлечь большую часть текста из изображения.
Языковые данные
Механизм распознавания текста tesseract использует в распознаваемых словах обучающие данные для конкретного языка.Алгоритмы OCR склоняются к словам и предложениям, которые часто встречаются вместе на определенном языке, как это делает человеческий мозг. Поэтому наиболее точные результаты будут получены при использовании данных обучения на правильном языке.
Используйте tesseract_info () , чтобы вывести список языков, которые у вас в настоящее время установлены.
tesseract_info () $ путь к данным
[1] "/ usr / local / share / tessdata /"
$ в наличии
[1] "eng" "osd" "snum"
$ версия
[1] «5.0,0 "
$ конфиги
[1] "альт" "ambigs.train" "api_config" "bigram" "box.train"
[6] "box.train.stderr" "цифры" "get.images" "hocr" "inter"
[11] "каннада" "строковый ящик" "файл журнала" "lstm.train" "lstmbox"
[16] «lstmdebug» «makebox» «pdf» «тихий» «rebox»
[21] "strokewidth" "tsv" "txt" "unlv" "wordstrbox" По умолчанию в пакет R входят только данные для обучения английскому языку.Пользователи Windows и Mac могут установить дополнительные данные обучения с помощью tesseract_download () . Давайте сделаем OCR снимок экрана из Википедии на голландском (Нидерланды)
# Необходимо выполнить загрузку только один раз:
tesseract_download ("nld") # Теперь загружаем словарь
(голландский <- tesseract ("nld"))
текст <- ocr ("https://jeroen.github.io/images/utrecht2.png", engine = dutch)
кот (текст) Как сразу видно: почти идеально! (Хорошо, просто верьте мне на слово).
Предварительная обработка с помощью Magick
Точность процесса распознавания текста зависит от качества входного изображения. Часто можно улучшить результаты, правильно масштабируя изображение, удаляя шум и артефакты или обрезая область, где есть текст. См. Вики по tesseract: улучшение качества для получения важных советов по улучшению качества входного изображения.
Пакет awesome magick R имеет множество полезных функций, которые можно использовать для улучшения качества изображения. Что стоит попробовать:
- Если ваше изображение перекошено, используйте
image_deskew ()иimage_rotate (), чтобы сделать текст горизонтальным. -
image_trim ()обрезает пробелы на полях. Увеличьте параметрfuzz, чтобы он работал для шумных пробелов. - Используйте
image_convert (), чтобы преобразовать изображение в оттенки серого, что может уменьшить количество артефактов и улучшить текст. - Если ваше изображение очень большое или маленькое, изменение размера с помощью
image_resize ()может помочь tesseract определить размер текста. - Используйте
image_modulate ()илиimage_contrast ()илиimage_contrast ()для настройки яркости / контрастности, если это проблема. - Попробуйте
image_reducenoise ()для автоматического удаления шума. Ваш пробег может отличаться. - С помощью
image_quantize ()вы можете уменьшить количество цветов в изображении. Иногда это может помочь увеличить контраст и уменьшить количество артефактов. - Настоящие ниндзя с изображениями могут использовать
image_convolve ()для использования собственных методов свертки.
Ниже приведен пример сканирования OCR из онлайн-курса искусственного интеллекта. Код преобразует его в черно-белое и изменяет размер + обрезает изображение перед подачей его в тессеракт, чтобы получить более точные результаты распознавания текста.
библиотека (магия) Связывание с ImageMagick 6.9.12.29
Включенные функции: fontconfig, freetype, ghostscript, lcms, webp
Отключенные функции: cairo, fftw, heic, pango, raw, rsvg, x11 input <- image_read ("https://jeroen.github.io/images/bowers.jpg")
текст <- ввод%>%
image_resize ("2000x")%>%
image_convert (type = 'Grayscale')%>%
image_trim (fuzz = 40)%>%
image_write (format = 'png', density = '300x300')%>%
тессеракт :: ocr ()
кот (текст) Жизнь и творчество
Фредсон Бауэрс
к
ГРАММ.ТОМАС ТАНСЕЛЛ
В КАЖДОЙ ОБЛАСТИ КОНЦЕПЦИИ ЕСТЬ НЕСКОЛЬКО ЦИФРОВ, КОТОРЫЕ ПРИНИМАЮТСЯ
уступчивость и влияние делают их символами своего времени;
их карьера и творчество становятся ориентирами, по которым
поле измеряется и рассказывается его история. В родственных занятиях
аналитическая и описательная библиография, текстологическая критика и научная
редактирования, Фредсон Бауэрс был такой фигурой, доминирующей четыре десятилетия
после 1949 г., когда были опубликованы его «Принципы библиографического описания».
лизнул.К 1973 году этот период уже назывался «эпохой бауэрса»:
в том же году Норман Сандерс, написавший главу о текстологической стипендии
для Шекспира Стэнли Уэллса: Избранные библиографии, дал это название
раздел его эссе. Для большинства людей этого было бы достаточно
подняться до такой позиции в такой сложной области, как шекспировские тексты.
исследования; но Дачи сыграли не менее важную роль и в других областях.
Например, редакторы американских авторов XIX века
также следует называть недавнее прошлое «веком дач», как писатели
описательных библиографий авторов и прессы.Его повсеместность в
обширная область библиографического и текстологического исследования, его, казалось бы, ком-
полное владение им отличало его от его прославленных предшественников.
Сорса и сделал его олицетворением библиографической науки в
его время.
Когда в 1969 году Бауэрс был награжден Золотой медалью Библии.
графического общества в Лондоне, цитата Джона Картера относилась к
Принципы как «величественные» называют текущие проекты Бауэрса «грозными»,
сказал, что он «наложил критическую дисциплину» на тексты нескольких
авторы описали «Исследования в области библиографии» как «великий и продолжающийся
достижение »и включил в число своих характеристик« бескомпромиссное
серьезность цели »и« профессиональная напряженность.«Дач не было
не привык к такой энкомии, но он также испытал свою долю
нападки: его научные позиции не пользовались всеобщей популярностью, и он
выразил их с агрессивностью, которая казалась рассчитанной на Чтение из файлов PDF
Если ваши изображения хранятся в файлах PDF, их сначала необходимо преобразовать в соответствующий формат изображения. Мы можем сделать это в R, используя функцию pdf_convert из пакета pdftools. Используйте высокое разрешение для сохранения качества изображения.
pngfile <- pdftools :: pdf_convert ('https://jeroen.github.io/images/ocrscan.pdf', dpi = 600) Преобразование страницы 1 в ocrscan_1.png ... готово! текст <- tesseract :: ocr (pngfile)
кот (текст) | САПОРСКИЙ ПЕРЕУЛОК - БУЛ - СПОРТ - Bh35 8 ER
ТЕЛЕФОННЫЙ БУЛ (94513) 51617 - ТЕЛЕКС 123456
Наш Ref. 350 / PJC / EAC 18 января 1972 г.
Доктор П.Н. Кундалл,
ООО "Майнинг Сюрвейз",
Холройд-роуд,
Чтение,
Беркс.
Дорогой Пит,
Разрешите познакомить вас со средством факсимильной связи.
коробка передач.В факсимильной связи фотоэлемент выполняет растровое сканирование
тематическая копия. Вариации плотности печати на документе
заставляют фотоэлемент генерировать аналогичный электрический видеосигнал.
Этот сигнал используется для модуляции несущей, которая передается на
удаленный пункт назначения по радио или кабельной линии связи.
На удаленном терминале демодуляция восстанавливает видео
сигнал, который используется для модуляции плотности печати, производимой
печатающее устройство. Это устройство сканирует в режиме растрового сканирования синхронизировано
с этим на передающем терминале.В результате факсимиле
создается копия тематического документа.
Возможно, у вас есть использование этого средства в вашей организации.
Искренне Ваш,
4г, е
П.Дж. Кросс
Руководитель группы - факсимильные исследования
Зарегистрирован в Англии: № 2038.
Зарегистрированный офис № 1: GO Vicara Lane, Ilford. Эссекс. Параметры управления Tesseract
Tesseract поддерживает сотни параметров управления, которые изменяют механизм распознавания текста. Используйте tesseract_params () , чтобы вывести список всех параметров с их значениями по умолчанию и кратким описанием.Он также имеет удобный аргумент filter для быстрого поиска параметров, соответствующих определенной строке.
# Список всех параметров с * цветом * в названии или описании
tesseract_params ('цвет') # Tibble: 2 × 3
param default desc
*
1 editor_image_word_bb_color 7 Цвет границы слова
2 editor_image_blob_bb_color 4 Цвет ограничивающей рамки Blob Обратите внимание, что некоторые параметры управления изменились между Tesseract Engine 3 и 4.
tesseract :: tesseract_info () ['версия'] $ версия
[1] «5.0.0» Белый / черный список символов
Одним из важных параметров является tessedit_char_whitelist , который ограничивает вывод ограниченным набором символов. Это может быть полезно для чтения, например, чисел, таких как банковский счет, почтовый индекс или счетчик газа.
Параметр белого списка работает для всех версий движка Tesseract 3, а также версий движка 4.1 и выше, но, к сожалению, не работал в Tesseract 4.0.
чисел <- tesseract (options = list (tessedit_char_whitelist = "$ .0123456789"))
cat (ocr ("https://jeroen.github.io/images/receipt.png", engine = numbers)) $ 90,52
81,52 долл. США
9,00 долларов США
90,52 долл. США Чтобы проверить, действительно ли это работает, посмотрите, что произойдет, если мы удалим $ из tessedit_char_whitelist :
# Не допускать никаких знаков доллара
числа2 <- tesseract (options = list (tessedit_char_whitelist = ".
Ваш комментарий будет первым