Как распознать текст
Уже много раз у меня возникала потребность распознать от сканированный текст. В Windows есть мощная программа ABBYY Fine Reader, которая прекрасно справляется с этой задачей. Но незадача в том, что она платная и работает только в Windows. Хотя есть версия и под Linux, но она тоже платная и стоит хороших денег. Но нас волнует вопрос: как можно распознать текст бесплатно?
О чём пойдет речь?
- 1. Как распознать текст онлайн?
- 2. Как распознать текст в Linux?
- 3. Как распознать PDF в Linux?
1. Как распознать текст онлайн?
Это наверное самый просто способ распознать текст. Вот некоторые сервисы для распознавания текста онлайн: onlineocr.ru, finereader.abbyyonline.com, sciweavers.org. В перечисленных трёх есть распознание на русский язык, во многих существующих других русский язык распознать невозможно.
Всем хороши онлайн сервисы для распознания текста, если…если ваш документ МАЛЕНЬКИЙ. Но если у вас журнал Linux Format размером в 100 мегабайт, то распознать онлайн такой документ будет невозможно — сначала нужно переформатировать PDF в графический формат, так как сервисы принимают только отсканированные документы в форматах JPG, BMP, TIF и некоторых других. Без программы, которая могла бы пере конвертировать PDF не обойтись. Но об этом чуть позже.
Без программы, которая могла бы пере конвертировать PDF не обойтись. Но об этом чуть позже.
Поэтому во многих случаях будет лучше, конечно, установить программу для распознания текста, а такая есть и для Linux.
2. Как распознать текст в Linux?
Для этого существует бесплатный движок Cuneiform и графическая оболочка к нему — Yagf. Так же понадобится установить языковые пакеты aspell и aspell-ru. Итак, устанавливаем:
sudo apt-get install cuneiform yagf aspell aspell-ru
sudo apt-get install cuneiform yagf aspell aspell-ru |
Если у вас в репозиториях не оказалось программы Yagf, то вам нужно скачать её с [urlspan]официального сайта[/urlspan]. У меня же она есть в репозиториях ualinux.com. Так же можно подключить дополнительный репозиторий:
sudo add-apt-repository ppa:alex-p/notesalexp
sudo add-apt-repository ppa:alex-p/notesalexp |
После установки пакетов идём в меню: Приложения — Офис — Yagf и запускаем программу.
Давайте попробуем распознать какой нибудь журнал в PDF формате. К сожалению, программа может распознать только графические файлы форматов JPEG, PNG, BMP, TIFF, GIF, PNM, PPM, PBM и некоторых других. Как распознать PDF формат? Нужно сначала пере конвертировать PDF в один из тех форматов, которые поддерживает программа. Как это сделать?
3. Как распознать PDF в Linux?
Для того, чтобы сконвертировать PDF в графический формат, мы воспользуемся программой Рdfedit. Лично у меня она есть в репозитории ualinux.com
sudo apt-get install pdfedit
sudo apt-get install pdfedit |
Или можно скачать Pdfedit со страницы разработчиков: launchpad.net/ubuntu/+source/pdfedit
После установки программы идём в меню: Приложения — Графика — PDF Editor
и запускаем приложение:Я сохранил одну страницу в формате .PNG, хотя можно и в другой, пока не знаю, какой лучше.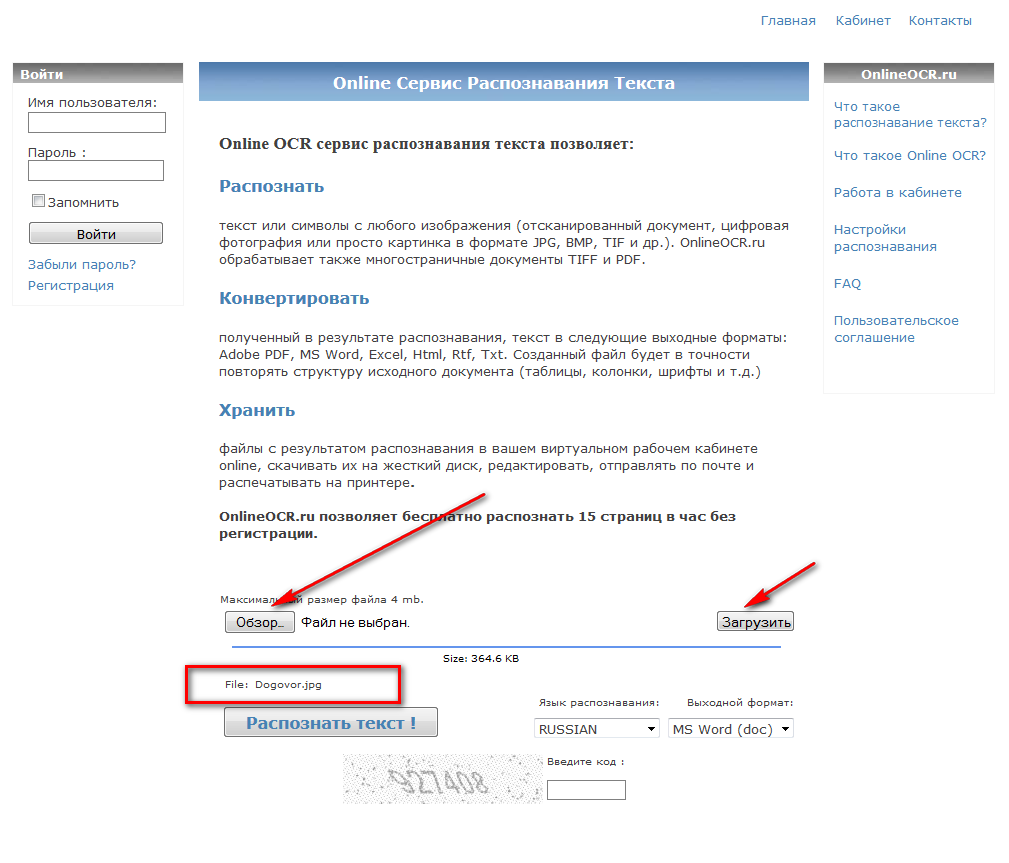 Единственный минус, при сохранении у файла почему-то не прописывается расширение, его мне пришлось дописать вручную, иначе программа файл не увидит.
Единственный минус, при сохранении у файла почему-то не прописывается расширение, его мне пришлось дописать вручную, иначе программа файл не увидит.
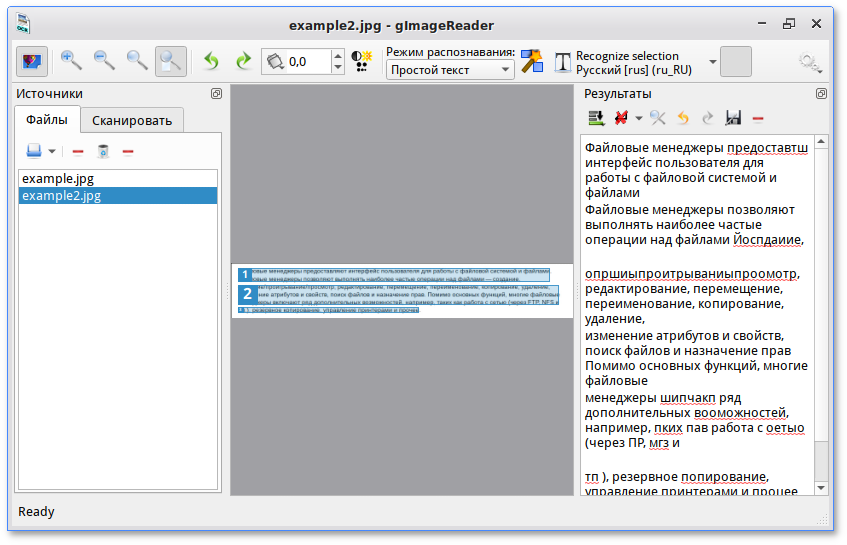
Между прочим это даже хорошо, что распознать текст можно только по одной странице, очень редко нам нужно распознать огромный журнал в PDF, чаще всего всего лишь одну статью. Теперь скормим полученное изображение программе Yagf:
К сожалению распознание не удалось, и причина оказалась банальной: программа PdfEdit сохраняет PDF в ужасно маленьком разрешении — получилось изображение 89 килобайт. И в настройках программы я не нашёл, как увеличить разрешение. Ну что же, отсутствие результата — тоже результат.
Хорошо, что в арсенале Linux много программ и в репозиториях есть мега-программа, которая может выполнить требуемую задачу, преобразовать PDF в изображение. Это известная всем программа
Вот это другое дело, размер той же страницы уже 4 мегабайта!
Ну вот, теперь совсем другое дело! Есть конечно ошибки, но это мелочи, легко исправить.
Во таким нехитрым способом можно распознать текст из PDF в Linux! Есть и другие способы, но думаю я описал самые простые, проверенные лично мной на практике. А практика — это ВСЁ! МОЖЕТ ВЫ ЗНАЕТЕ ЕЩЁ ПРОСТЫЕ И ЭФФЕКТИВНЫЕ СПОСОБЫ РАСПОЗНАТЬ PDF ФАЙЛЫ?
На блоге Seostage.ru проходит акция «Бесплатный обзор блогов всем желающим» Участвуйте, чтобы получить хорошие советы от знатоков!
Как распознать текст с картинки в Word
ГлавнаяMicrosoft Word
Представьте себе функцию, позволяющую извлечь текст из изображения и быстро вставить его в другой документ. На самом деле это возможно. Вам больше не нужно терять время, набирая все, потому что есть программы, которые используют оптическое распознавание символов (OCR) для анализа букв и слов в изображении, а затем конвертируют их в текст.
В наши дни существует так много бесплатных и эффективных опций, позволяющих извлечь текст из изображения, а не печатать его вручную. Ниже представлены самые удобные и эффективные программы и их сравнение.
Ниже представлены самые удобные и эффективные программы и их сравнение.
Как распознать текст с картинки в Word
Содержание
- Видео — распознавание текста с картинки в WORD
- Извлечение текста с помощью OneNote
- Использование онлайн-сервисов
- Видео — Как распознавать текст с картинки, фотографии или PDF файла
- Как извлечь текст из изображений с помощью ABBY FineReader
- Онлайн версия
- Десктопная версия
- Видео — Как распознать PDF в Word
- Сравнение популярный инструментов распознавания текста
Видео — распознавание текста с картинки в WORD
Извлечение текста с помощью OneNote
OneNote OCR уже на протяжении нескольких лет остается одной из самых лучших программ для распознавания текста. Однако, распознавание это одна из тех менее известных функций, которые пользователи редко используют, но как только вы начнете ее использовать, вы будете удивлены тем, насколько быстрой и точной она может быть. Действительно, способность извлекать текст — одна из особенностей, которая делает OneNote лучше Evernote.
Действительно, способность извлекать текст — одна из особенностей, которая делает OneNote лучше Evernote.
Это стандартная программа, скорее всего вам не придется устанавливать ее самостоятельно. Найдите ее на компьютере в папке Microsoft Office или же с помощью поиска на панели «Пуск». Запустите программу.
Инструкции по извлечению текста:
- Шаг 1. Откройте любую страницу в OneNote, желательно пустую.
Открываем любую страницу в OneNote
- Шаг 2. Перейдите в меню «Вставка»> «Изображения» и выберите файл изображения и настройте язык распознавания.
Выберите файл изображения
- Шаг 3. Щелкните правой кнопкой мыши по вставленному изображению и выберите «Копировать текст с изображения». Он сохранится в буфере обмена.
Копируем текст с изображения
Теперь вы можете вставить его куда угодно. Удалите вставленное изображение, если оно вам больше не нужно.
Вставляем текст куда угодно
На заметку! Это быстрый и удобный способ извлечения текста из картинки, но есть одно «но» — One Note работает подобным образом лишь с латиницей.
Он не распознает русский текст.

Использование онлайн-сервисов
Онлайн-сервисы по распознаванию текста с изображения работают примерно по одному и тому же принципу. В примере ниже использовался Free Online OCR. На этом сайте стоит ограничение. Регистрация даст вам доступ к дополнительным функциям, недоступным для гостей: конвертировать многостраничный PDF (более 15 страниц) в текст, большие изображения и ZIP-архивы, выбирать языки распознавания, конвертировать в редактируемые форматы и многое другое. Распознать короткий тест можно и без регистрации.
- Шаг 1. Откройте сайт бесплатного OCR. Выберите изображение посредством кнопки «Select File». Это может быть и PDF файл.
Открываем сайт бесплатного OCR
- Шаг 2. Выберите язык и нажмите на кнопку «CONVERT».
Выбираем язык и нажимаем на кнопку «CONVERT»
Текст появится в поле ниже. Вы также можете скачать в формате Microsoft Word.
Этот способ имеет ряд преимуществ:
- Вам не придется скачивать и устанавливать стороннее программное обеспечение.

- Итог можно скачать в виде текстового документа.
- Это быстро.
- Более того на сайте можно распознавать текст на одном из множества предложенных языков.

Видео — Как распознавать текст с картинки, фотографии или PDF файла
Как извлечь текст из изображений с помощью ABBY FineReader
Существует две версии этой программы. Одна работает в автоматическом режиме онлайн, другая же — десктопная, ее придется скачать и установить на компьютер. Обе — платные. Однако в онлайн-версии можно бесплатно распознать текст с не более 5 страниц, а в установленной программе первое время действует пробный бесплатный период. На сегодня это один из лучших инструментов для распознавания текста с картинки.
Онлайн версия
- Шаг 1. Перейдите на сайт FineReader.
Открываем сайт FineReader
- Шаг 2. Загрузите изображение. Выберите нужный вам язык и нажмите на кнопку регистрации. Следуйте указаниям на сайте. Как только вы зарегистрируетесь, сайт перенаправит вас на другую страницу. Нажмите на кнопку «Распознать» и дождитесь окончания процесса.
 Как только вы зарегистрируетесь, сайт перенаправит вас на другую страницу. Нажмите на кнопку «Распознать» и дождитесь окончания процесса.
Как только вы зарегистрируетесь, сайт перенаправит вас на другую страницу. Нажмите на кнопку «Распознать» и дождитесь окончания процесса.Загружаем файл, выбираем язык, выбираем формат сохранения
Текст сохранится в формате docs. Скачайте его.
Десктопная версия
- Шаг 1. Запустите FreeReader и нажмите «Сканировать изображение», чтобы выбрать файл, содержащий текст. Он загрузится в программу, при необходимости их можно отредактировать, чтобы улучшить распознаваемость текста. Программа предложит вам выделить область, текст с которой нужно распознать.
- Шаг 2. Извлечение текста. Нажмите «Распознать», чтобы извлечь текст из выделения. Выбранный текст будет отображаться в текстовом окне через несколько секунд. Извлекаем текст
Шаг 3. Проверка. В этой программе есть функция проверки. Нажав на эту кнопку, пользователь на экране будет видеть некорректно распознанные слова и фрагмент оригинала. На этом этапе можно быстро исправить практически все ошибки программы.
На этом этапе можно быстро исправить практически все ошибки программы.
Шаг 4. Сохраните текст любым из предложенных способов.
Сохраняем текст
Обратите внимание:
- Во-первых, вам нужно убедиться, что исходное изображение четкое, хорошего качества.
- Во-вторых, выбор правильного механизма OCR важен, и вам нужно учитывать их сильные и слабые стороны.
- В-третьих, убедитесь, что ваши изображения масштабированы до нужного размера (не менее 300 DPI).
- Низкая контрастность приведет к плохому OCR, поэтому вам необходимо исправить это до распознавания.
- Удалите шумы и дефекты.
- Если изображение перекошено, отредактируйте его.
Видео — Как распознать PDF в Word
Сравнение популярный инструментов распознавания текста
| Название программы | OneNote | FineReader OCR Online | Free Online OCR |
|---|---|---|---|
| Условия использования | Стандартная программа, входящая в пакет Microsoft Office. Как правило, присутствует на всех компьютерах ОС Windows Как правило, присутствует на всех компьютерах ОС Windows | Онлайн версия программы. До 5 страниц бесплатно при регистрации | Бесплатный онлайн-сервис. Не требует регистрации |
| Скорость | Мгновенное распознавание | Процесс происходит на сервере. Время ожидания не больше 5 минут | Мгновенное распознавание |
| Особенности | Это не главная функция программы, а лишь побочная. Хоть она и достаточно хороша, не ждите от нее совершенства | Сокращенная версия основной программы. В полной компьютерной версии намного больше опций, повышающих качество распознавания. Доступно распознавание теста сразу на нескольких языках, если в тексте есть вставки на другом языке. Сохраняет форматирование | Скорость. Доступность |
| Число доступных языков | В русскоязычной версии программы доступно три языка: русский, английский, немецкий | Множество языков | Множество языков |
| Результат |
Хотя рынок заполнен программным обеспечением OCR, которое может извлекать текст из изображений, хорошая программа OCR должна делать больше, чем просто распознавание текста. Она должна поддерживать макет содержимого, текстовые шрифты и графику как в исходном документе.
Она должна поддерживать макет содержимого, текстовые шрифты и графику как в исходном документе.
Понравилась статья?
Сохраните, чтобы не потерять!
Рекомендуем похожие статьи
Распознавание текста в отсканированных документах PDF
- Введение
- В этом учебном пособии показано, как сделать отсканированные PDF-документы доступными для поиска с помощью операции «Распознать текст».
доступны в программном обеспечении Adobe® Acrobat®. Изначально отсканированные PDF-документы не содержат текста, доступного для поиска.
Каждая страница — это просто изображение. Операция «Распознавание текста» (также известная как «Оптическое распознавание символов» или OCR)
обрабатывает каждую страницу и создает невидимый слой текста, который можно искать или копировать и
вставлен в новый документ. Текст с возможностью поиска добавляется за изображением страницы, поэтому внешний вид
страницы не меняются.
- Зачем распознавать текст?
- Если в документе нет текста для поиска, то это существенно ограничивает его функциональность. Документ нельзя использовать для какой-либо текстовой обработки, такой как автоматическое создание закладок и ссылок, текстовый поиск и извлечение, редактирование на основе ключевых слов и т. д.
- Доступен ли для поиска мой PDF-файл?
- Откройте документ PDF в Adobe® Acrobat® и попробуйте выделить любой текст на страница с инструментом выделения. Если вы можете выделить текстовую строку и скопировать/вставить ее в текстовый редактор (например, Блокнот, Microsoft Word или Outlook), то документ содержит текст с возможностью поиска. Если вы не можете выделить текст на странице, документ недоступен для поиска.
- Качество сканирования
- Чтобы применить операцию «Распознать текст» к PDF, исходное разрешение сканера должно быть установлено на 72 dpi или выше. Обратите внимание, что сканирование с разрешением 300 dpi дает лучший текст для преобразования. При разрешении 150 dpi точность распознавания немного ниже.
- Предпосылки
- Чтобы использовать это руководство, на вашем компьютере должна быть установлена копия Adobe® Acrobat®. Вы можете скачать пробную версию Adobe® Acrobat®.

 Обратите внимание, что сканирование с разрешением 300 dpi дает лучший текст для преобразования. При разрешении 150 dpi точность распознавания немного ниже.
Обратите внимание, что сканирование с разрешением 300 dpi дает лучший текст для преобразования. При разрешении 150 dpi точность распознавания немного ниже.- Шаг 1. Откройте PDF-документ
- Запустите приложение Adobe® Acrobat® и с помощью меню «Файл > Открыть…» откройте отсканированный PDF-документ.
- Шаг 2. Запустите инструмент «Улучшение сканирования»
- Выберите «Инструменты» на главной панели инструментов. Дважды щелкните инструмент «Улучшить сканирование».
- Шаг 3. Выберите PDF-документ(ы) для обработки
- Разверните раскрывающееся меню «Распознать текст». Выберите «В этом файле», чтобы обработать открытый в данный момент PDF-документ. При необходимости нажмите «В нескольких файлах…», чтобы выбрать несколько файлов PDF или папку для обработки.
- Шаг 4. Укажите параметры
- Параметры «Распознать текст» отображаются на панели инструментов второго уровня. Выберите диапазон страниц и язык для распознавания текста. При необходимости нажмите «Настройки», чтобы открыть диалоговое окно «Распознавание текста», и укажите нужные параметры.
- Диалоговое окно «Распознавание текста» позволяет задать общие параметры распознавания текста.
- Укажите язык, который модуль OCR будет использовать для идентификации символов в раскрывающемся меню «Язык документа».
- Выберите стиль вывода PDF, который определяет тип PDF для вывода. Выберите один из следующих параметров в раскрывающемся меню «Вывод»: .
- Изображение с возможностью поиска — обеспечивает возможность поиска и выбора текста. Этот параметр сохраняет исходное изображение, выравнивает его по мере необходимости и помещает на него невидимый текстовый слой. Выбор «изображения с пониженной частотой дискретизации» в этом же диалоговом окне определяет, будет ли изображение уменьшено и в какой степени.
- Изображение с возможностью поиска (точное) — обеспечивает возможность поиска и выбора текста. Этот параметр сохраняет исходное изображение и помещает на него невидимый текстовый слой. Рекомендуется для случаев, требующих максимальной точности исходного изображения.
- Редактируемый текст и изображения — синтезирует новый пользовательский шрифт, максимально приближенный к оригиналу, и сохраняет фон страницы, используя копию с низким разрешением.
- Раскрывающееся меню «Уменьшить до» позволяет уменьшить количество пикселей в цветных, полутоновых и монохромных изображениях после завершения OCR. Выберите степень понижающей дискретизации для применения. Параметры с более высокими номерами уменьшают дискретизацию, создавая PDF-файлы с более высоким разрешением.
- Нажмите «ОК», чтобы сохранить изменения и закрыть диалоговое окно.
- Шаг 5 — Начать обработку
- Нажмите кнопку «Распознать текст», чтобы начать распознавание текста.
- Шаг 6. Проверка результатов
- Проверить результаты. Распознавание текста создает слой текста в PDF-файле, который можно искать или копировать и вставлять в новый документ.
- Когда вы запускаете OCR на отсканированном отпечатке, Acrobat® анализирует растровые изображения текста и заменяет эти растровые области словами и символами. Если идеальная замена неопределенна, программа помечает слово как подозрительное. Подозреваемые отображаются в PDF как исходное растровое изображение слова, но текст включается в невидимый слой за растровым изображением слова. Этот метод делает слово доступным для поиска, даже если оно отображается в виде растрового изображения.
- Обратите внимание, что операция OCR не гарантирует правильное распознавание всего текста в документе PDF. Точность распознавания текста во многом зависит от качества отсканированного документа, но есть много других факторов, которые могут повлиять на результат.
- Пример 1: 100% точность распознавания
- Первый пример показывает правильное распознавание текста. В исходном PDF-файле нет текста, доступного для выбора или поиска.
Текст можно выделить и скопировать/вставить в полученный PDF-файл.
Выделенный текст был скопирован/вставлен в текстовый редактор для отображения результатов распознавания текста. Все символы были правильно идентифицированы в следующем примере:
- Пример 2: Распознавание с небольшим количеством ошибок
- Второй пример иллюстрирует случай, когда некоторые символы распознаются некорректно. Хотя текст доступен для поиска, он не соответствует исходному изображению. Ошибок на странице мало: «security» неправильно распознается как «securitv», последняя цифра 9 распознается как 2: «123-456-789» вместо «123-456-782»:
- Пример 3: Низкая точность
- Третий пример иллюстрирует случай с большим количеством ошибок распознавания.
Хотя текст по-прежнему доступен для поиска, он бесполезен для каких-либо практических целей. Слово «КОНФИДЕНЦИАЛЬНО» распознается как «C9NFJDtNTJAL»:
- Adobe® Acrobat® позволяет исправлять «подозрительные» слова, если идеальная замена сомнительна.
- При необходимости выберите «Распознать текст > Исправить распознанный текст» на панели инструментов «Улучшение сканирования». Acrobat выявляет предполагаемые текстовые ошибки и отображает изображение и текст рядом. Все подозрительные слова на странице заключены в рамки. Щелкните выделенный объект или поле в документе, а затем исправьте его в поле «Распознано как» на панели инструментов. Нажмите «Принять», как только слово будет исправлено. Следующий подозреваемый выделяется автоматически. Исправьте ошибки по мере необходимости. Нажмите «Принять» для каждого исправления. Нажмите «Закрыть» на панели инструментов второго уровня, когда задача будет завершена.
- Adobe® Acrobat® позволяет исправлять «подозрительные» слова, если идеальная замена сомнительна.
- Шаг 7. Сохранение PDF-документа с возможностью поиска
- Не забудьте сохранить обработанный PDF-документ. Нажмите «Файл > Сохранить как…» в главном меню.
- Нажмите здесь, чтобы просмотреть список всех доступных пошаговых руководств.
 Выберите «В этом файле», чтобы обработать открытый в данный момент PDF-документ. При необходимости нажмите «В нескольких файлах…», чтобы выбрать несколько файлов PDF или папку для обработки.
Выберите «В этом файле», чтобы обработать открытый в данный момент PDF-документ. При необходимости нажмите «В нескольких файлах…», чтобы выбрать несколько файлов PDF или папку для обработки. Выберите один из следующих параметров в раскрывающемся меню «Вывод»:
Выберите один из следующих параметров в раскрывающемся меню «Вывод»:
 Если идеальная замена неопределенна, программа помечает слово как подозрительное. Подозреваемые отображаются в PDF как исходное растровое изображение слова, но текст включается в невидимый слой за растровым изображением слова. Этот метод делает слово доступным для поиска, даже если оно отображается в виде растрового изображения.
Если идеальная замена неопределенна, программа помечает слово как подозрительное. Подозреваемые отображаются в PDF как исходное растровое изображение слова, но текст включается в невидимый слой за растровым изображением слова. Этот метод делает слово доступным для поиска, даже если оно отображается в виде растрового изображения. Все символы были правильно идентифицированы в следующем примере:
Все символы были правильно идентифицированы в следующем примере:
Преобразование файла PDF, состоящего только из изображений, с помощью распознавания текста в Adobe Acrobat Pro | Справка
Adobe Acrobat Pro DC имеет встроенную функцию оптического распознавания символов (OCR), которая распознает большую часть текста и позволяет преобразовывать PDF-файлы, содержащие только изображения, в удобочитаемые. Вы можете распознавать текст несколькими способами. Не забудьте использовать максимально возможное качество сканирования.
Способ 1: инструмент сканирования и оптического распознавания символов
Инструмент улучшения сканирования попытается преобразовать отсканированные документы или фотографии бумажных документов в PDF-файлы с выбираемым текстом. Этот инструмент также очистит контраст страницы и сгладит страницы, где текст может искривляться из-за переплетов книг.
Шаг 1. Выберите инструмент «Сканирование и распознавание»
Выберите инструмент «Сканирование и распознавание» на панели инструментов в правой части экрана. Это откроет панель инструментов в верхней части экрана.
Шаг 2. Выберите параметр «Улучшить»
Чтобы улучшить качество документа, выберите параметр «Улучшение» на панели инструментов «Улучшение сканирования», затем выберите «Отсканированный документ».
Шаг 3. Распознавание и улучшение
Установите флажок «Распознать текст», затем нажмите кнопку «Улучшить». После завершения распознавания текста сохраните документ.
Шаг 4. Исправьте распознанный текст
В инструменте «Улучшение сканирования» откройте раскрывающийся список «Распознать текст» и выберите «Исправить распознанный текст». Установите флажок «Просмотреть распознанный текст» и просмотрите подозрительный текст, найденный инструментом, при необходимости исправьте его и нажмите «Принять». Сохраните документ.
Сохраните документ.
Шаг 5. Документ с автоматическим добавлением тегов
После того, как весь текст будет распознан, перейдите на панель тегов, щелкните правой кнопкой мыши пункт Нет доступных тегов. Выберите опцию «Добавить теги в документ». Функция Auto-Tag попытается интерпретировать ваш документ на основе размера и стиля шрифтов, которые вы использовали. Более крупный и жирный текст обычно распознается как Заголовок 1 и Заголовок 2, даже если они не должны быть заголовками.
Шаг 6. Проверка и обновление тегов документа
Параметр автоматической пометки не будет на 100% правильным. Проверьте и при необходимости обновите теги документа. Сохраните документ.
Способ 2: инструмент «Редактировать PDF»
Параметр «Инструмент редактирования PDF» не пытается исправить качество сканирования перед распознаванием текста и не дает возможности исправить распознанный текст.
Шаг 1. Выберите инструмент «Редактировать PDF»
Выберите инструмент «Редактировать PDF» на панели инструментов в правой части экрана.
Acrobat Pro автоматически запустит OCR для вашего документа. После завершения сканирования вы сможете редактировать и выделять большую часть текста в документе. Не забудьте сохранить документ.
Если вы не можете выделить весь текст, определите, является ли текст изображением или нет. Некоторые изображения текста или рукописного текста могут не распознаваться OCR.
Мы не рекомендуем использовать изображения текста, поскольку текст, встроенный в изображения, не может быть воспроизведен вспомогательными технологиями, такими как программы чтения с экрана. В то же время изображения текста создают проблему для мобильных устройств, поскольку изображения текста могут искажаться и становиться неразборчивыми при открытии на мобильном устройстве или планшете. Вы можете попробовать Enhance Scan в качестве еще одного варианта OCR. Короткий раздел рукописного ввода, как и подписи, может быть помечен как рисунок и снабжен альтернативным текстом с соответствующим текстом.

Ваш комментарий будет первым