7 бесплатных программ и веб-сервисов для распознавания текста
1. Office Lens
- Распознаёт: снимки камеры.
- Сохраняет: DOCX, PPTX, PDF.
Этот сервис от компании Microsoft превращает камеру смартфона или ПК в мощный сканер документов. С помощью Office Lens вы можете распознать текст на любом физическом носителе и сохранить его в одном из «офисных» форматов или в PDF. Итоговые текстовые файлы можно редактировать в Word, OneNote и других сервисах Microsoft, интегрированных с Office Lens.
Цена: Бесплатно

Цена: Бесплатно
Разработчик: Microsoft Corporation
Цена: Бесплатно
2. Adobe Scan
- Распознаёт: снимки камеры.
- Сохраняет: PDF.
Adobe Scan тоже использует камеру смартфона, чтобы сканировать бумажные документы, но сохраняет их копии только в формате PDF. Результаты удобно экспортировать в кросс-платформенный сервис Adobe Acrobat, который позволяет редактировать PDF-файлы: выделять, подчёркивать и зачёркивать слова, выполнять поиск по тексту и добавлять комментарии.
Разработчик: AdobeЦена: Бесплатно

Цена: Бесплатно
3. Free OCR to Word
- Распознаёт: JPG, TIF, BMP, GIF, PNG, EMF, WMF, JPE, ICO, JFIF, PCX, PSD, PCD, TGA и другие форматы.
- Сохраняет: DOC, DOCX, TXT.
Настольная программа Free OCR to Word распознаёт выбранные пользователем изображения, извлекая из них чистый текст без форматирования. Его можно копировать в буфер обмена, сохранять в формате TXT или экспортировать в Word.
Воспользоваться Free OCR to Word →
4. FineReader Online
- Распознаёт: JPG, TIF, BMP, PNG, PCX, DCX, PDF (не защищённые паролем).
- Сохраняет: DOC, DOCX, XLS, XLSX, ODT, TXT, RTF, PDF, PDF/A.
Онлайновый сервис, который конвертирует не только тексты, но и таблицы. Увы, бесплатные возможности FineReader Online ограничены. После регистрации вам позволят распознать без оплаты всего 10 страниц. Зато каждый месяц будут начислять ещё по пять страниц в качестве бонуса. Поэтому сервис больше подойдёт тем, кто не нуждается в услугах распознавания слишком часто.
Воспользоваться FineReader Online →
5. Online OCR
- Распознаёт: JPG, BMP, TIFF, GIF, PDF.
- Сохраняет: DOCX, XLSX, TXT.
Ещё один сайт, с помощью которого можно распознать тексты и таблицы. В отличие от FineReader, в Online OCR вполне можно обойтись без регистрации. Хотя она может понадобиться, если вы планируете загружать несколько файлов для распознавания за один раз. В то же время FineReader поддерживает больше форматов.
Воспользоваться Online OCR →
6. Free OCR
- Распознаёт: JPG, GIF, TIFF BMP, PNG, PDF.
- Сохраняет: TXT.
Free OCR — простейший онлайн-сервис, извлекающий текст из PDF-файлов и изображений. Результат распознавания — чистый текст без форматирования. Кроме того, сервис может уступать по точности вышеперечисленным аналогам. Зато Free OCR не требует регистрации и справляется с мультиязычными документами.
Воспользоваться Free OCR →
7. Microsoft OneNote
- Распознаёт: популярные форматы изображений.
- Сохраняет: файлы OneNote.
В настольной версии популярного заметочника OneNote тоже есть функция распознавания текста, которая работает с загруженными в сервис изображениями. Если кликнуть правой кнопкой мыши по снимку документа и выбрать в появившемся меню «Рисунок» → «Текст», то всё текстовое содержимое будет скопировано в буфер обмена.
Разработчик: Microsoft CorporationЦена: Бесплатно

Цена: Бесплатно
Если вы не нашли подходящей программы, взгляните на наши предыдущие подборки приложений для Android и iOS.
lifehacker.ru
Что такое технология оптического распознавания символов, или OCR
ABBYY- Контакты
- Интернет-магазин
-
Выберите регион
Global
Global Web Site EnglishNorth America
Canada English Mexico Español United States EnglishSouth America
Brazil Português South America EspañolEurope
France Français Germany Deutsch Italy Italiano United Kingdom English Spain Español Western Europe English Central and Eastern Europe English Croatia Hrvatski Czech Republic Čeština Hungary Magyar Poland Polski Romania Română
www.abbyy.com
Оптическое распознавание текста (OCR) | Яндекс.Облако
В этом разделе описано, как работает возможность распознавание текста (Optical Character Recognition, OCR) в сервисе.
Процесс распознавания текста
Распознавание текста на изображении состоит из двух этапов:
- Определение языковой модели для распознавания текста.
- Поиск текста на изображении.
В результате распознавания сервис вернет JSON-объект с распознанным текстом, его расположением на странице и достоверностью распознавания.
Определение языковой модели
Для распознавания текста в сервисе используется модель, обученная на определенном наборе языков. Некоторые языки сильно отличаются друг от друга (например, арабский и китайский), поэтому для них используются разные модели.
Модель выбирается автоматически на основе списка языков, указанных в запросе в свойстве language_codes. Если вы не знаете язык текста, укажите "language_codes": ["*"], чтобы сервис выбрал наиболее подходящую модель.
Для каждой запрошенной возможности (feature) используется только одна модель. Например, если на изображении текст на китайском и японском, то распознан будет только один из этих языков. Чтобы распознать языки из разных моделей, укажите несколько возможностей в запросе.
Примеры смотрите в инструкции Распознавание текста.
Совет
Для текста на русском и английском лучше всего работает англо-русская модель. Чтобы использовать ее укажите один из этих языков или оба, но не указывайте другие языки в той же конфигурации.
Поиск текста на изображении
Сервис выделяет найденный текст на изображении и группирует его по уровням: слова группируются в строки, строки в блоки, блоки в страницы.

В результате сервис возвращает JSON-объект, где для каждого из уровней дополнительно указывается:
- страницы (
pages[]) — размер страницы; - блоки текста (
blocks[]) — расположение текста на странице; - строки (
lines[]) — расположение и достоверность распознавания; - слова (
words[]) — расположение, достоверность, текст и язык, использованный при распознавании.
Чтобы показать расположение текста, сервис возвращает координаты прямоугольника, обрамляющего текст. Координаты — количество пикселей от левого верхнего угла на изображении.
Координаты прямоугольника считаются от левого верхнего угла и указываются против часовой стрелки:
Пример распознанного слова с координатами:
{
"boundingBox": {
"vertices": [{
"x": "410",
"y": "404"
},
{
"x": "410",
"y": "467"
},
{
"x": "559",
"y": "467"
},
{
"x": "559",
"y": "404"
}
]
},
"languages": [{
"languageCode": "en",
"confidence": 0.9412244558
}],
"text": "you",
"confidence": 0.9412244558
}
Требования к изображению
Изображение в запросе должно соответствовать следующим требованиям:
Поддерживаемые форматы файлов: JPEG, PNG, PDF.
MIME-тип файла указывается указывается в свойстве
mime_type. По умолчаниюimage.Максимальный размер файла: 1 МБ.
Размер изображения не должен превышать 20 мегапикселей (длина x ширина).
Достоверность распознавания
Достоверность распознавания показывает уверенность сервиса в результате. Например, значение "confidence": 0.9412244558 для строки we like you
означает, что с вероятностью в 94% текст распознан корректно.
Сейчас достоверность считается только для строк. В значение confidence для слов и языка подставляется значение для confidence строки.
Что дальше
cloud.yandex.ru
ТОП-5 программ для OCR распознавания рукописного текста

Оптическое распознавание символов (англ. Optical Character Recognition – OCR) это новейший метод механического перевода, который преобразует изображения рукописного текста в редактируемый текст на вашем компьютере. Например, он может сделать обычный PDF с отсканированного файла с помощью OCR или PDF на основе изображения, или преобразует рукописный текст в печатный. Технология была разработана в 1933 году, и с каждым годом развивалась. В настоящее время инструменты OCR способны выполнять огромную работу в преобразовании газет, писем, книг и любых других печатных или рукописных материалов в компьютерные редактируемые тексты.
Технология распознавания OCR рукописных текстов в настоящее время используется в больших масштабах, при этом уровень точности транскрипции растет день ото дня, и она уже близка к совершенству. В настоящее время, вы можете просто взять рецепт от врача и использовать технологию OCR, чтобы расшифровать его. Это невероятно!
Скачать бесплатно Скачать бесплатноЧасть 1. Рекомендуемые программы для OCR распознавания рукописных текстов
Поиск лучших программ по OCR распознаванию рукописного текста может стать реальной проблемой, тем более, с тех пор как в Интернете появилось множество таких инструментов. Не беспокойтесь! Мы проанализировали рынок за вас, и выделили 3 лучших инструмента по OCR распознаванию рукописного ввода:
#1. PDFelement Pro
PDFelement ProPDFelement Pro- идеальный инструмент для OCR распознавания PDF-файлов. Он может автоматически распознавать отсканированные файлы PDF и делать их редактируемыми с помощью встроенных инструментов редактирования. Кроме этого, он поддерживает несколько языков OCR. Вы можете легко редактировать ваши PDF-тексты, изображения, ссылки и другие элементы. Также у вас есть возможность конвертировать PDF-файлы в другие форматы.
Основные функции данной PDF OCR программы:
- Расширенная функция OCR позволяет легко конвертировать и редактировать отсканированные PDF-файлы.
- Редактирование текстов PDF, изображений и ссылок – такое же простое, как и внесение изменений в Word.
- С легкостью добавляйте подпись, пароль, водяные знаки, знаки, нарисованные от руки в PDF-файлы.
- Размещайте комментарии и примечание, где вам необходимо.
- Вы также можете просто создавать PDF из множества других форматов.
- Кроме этого, у вас есть возможность конвертировать PDF в такие форматы, как Excel, MS Word и другие.
#2. iSkysoft PDF Converter Pro
iSkysoft PDF Converter Pro для Mac может стать вам отличным помощником в OCR распознавании отсканированных PDF. Вы можете импортировать PDF-файл, который был на основе изображения, в программу, затем выполнить распознавание OCR и после этого свободно преобразовывать его в другие форматы.
Бесплатная загрузка Бесплатная загрузка
#3. OCR Desktop
Это OCR приложение для настольного компьютера включает в себя искусственный интеллект и нейронные сети для улучшения качества работы. Конвертер курсивного письма PDF в текст обучали более, чем четырём миллионам вариантов шрифтов, так что вы можете быть уверены, преобразованный текст будет точным насколько это вообще возможно. Он также владеет новейшей технологией OCR для решения любой задачи в распознавании почерка. А что, если мы добавим, что приложение является бесплатным для личного использования? Тем не менее, в нем есть реклама, но если вы хотите избавиться от нее, то необходимо получить зарегистрированную версию.

#4. SimpleOCR
SimpleOCR – одна из самых популярных бесплатных программ OCR доступных в сети. Она довольно проста, но в ее арсенале есть все основные функции сканирования и конвертации, которые важны при работе с OCR распознаванием рукописных текстов. Однако если вы хотите расширенные возможности, то тогда вам необходимо воспользоваться платной версией.
#5. TopOCR
Создатели TopOCR говорят, что они создали наиболее мощную систему распознавания, на основе нейронной сети, которая доступна на рынке, а также обещают пользователям лучшие результаты OCR распознавания данных, сделанных с помощью цифровой камеры. Поэтому, если у вас есть письмо, которое вы хотите оцифровать, сфотографируйте его и позвольте TopOCR выполнить свою работу. К сожалению, приложение было бесплатным некоторое время назад, но сегодня вам придется купить его, чтобы использовать. Но разработчики действительно используют сложные алгоритмы обработки изображений, чтобы гарантировать отличный результат!
Часть 2. Советы по распознаванию рукописного текста с помощью OCR
Применение OCR технологии:Технология OCR широко используется во многих сферах: от юристов и учителей до менеджеров и библиотекарей, любой, кто пишет во время своей работы или имеет дело с рукописями, письмами или подобными документами, считает эту технологию невероятной. Вы можете оцифровать любой рукописный документ быстро и просто, превратить его в редактируемый текст, с которым вы можете работать на вашем компьютере.
Советы: Чтобы улучшить использование OCR распознания рукописного текста, убедитесь, что ваши документы написаны четким почерком и чистые, то есть без помарок, а также используйте мощный сканер. Но главное — выберите профессиональную программу распознавания рукописного текста, которая может гарантировать точность редактируемого текста. Если вы решили использовать инструмент OCR на своем компьютере, вам просто нужно выбрать надежное программное обеспечение, доступное в интернете. Вы также можете попробовать использовать онлайн инструменты, но имейте в виду, что они, возможно, имеют довольно ограниченные функции.
pdf.iskysoft.com
OCR online / Habr
С технологией оптического распознавания текста я познакомился где-то в 1997 года, когда купил свой первый, тогде ещё ручной, чёрно-белый сканер Genius ScanMate 256 (кстати, всё ещё рабочий). К сканеру прилагалась программа Direct OCR на 3х дюймовой дискете (блин, откуда-то из подсознания все эти названия всплывают), которая всеми своими силами пыталась доказать, что можно быстро и почти без ошибок текст из книги ввести в компьютер. Ну, доказательства были не очень. FineReader, с которым я познакомился позже, делал это качественнее. Тема распознавания меня заинтересовала, я потратил довольно много времени на научно-популярные статьи о технологиях OCR.В 2001 году я готовил дипломную работу по web-технологиям. Долго думал о том, куда приложить знания. Поскольку меня интересовала технология OCR, я задумал совместить WEB и распознавание текстов. За само распознавание у меня должен был отвечать FineReader. С друзьями мы «разобрали» FineReader на отдельные DLL и выяснили, как вызывать отдельные функции этих библиотек, передавая двоичные данные изображений, и как получать обратно распознанный вариант текста. Над этим всем был построен простейший веб-интерфейс, чтобы загружать картинки, запускать распознавание и получать результат.
Первым ограничением на то время для нас оказалась смешная пропускная способность интернет. Страница A4, отсканированная в качестве 200 точек на дюйм и сохранённая в формате TIFF (который только и воспринимала программа FineReader) могла занимать несколько мегабайт в серых тонах, а если кто по ошибке или незнанию цветной вариант отсканирует, то объём увеличивался в три-четыре раза. Такой огромный по тем временам файл даже по локальной сети пересылался и обрабатывался с трудом, а через публичный Интернет — вообще трудно выполнимая задача.
Второй фактор — стоимость. При такой скорости пересылки файлов отсканированных страниц каждая страница стоила дорого. Мы также приняли во внимание, что обычно используются взломанные версии программ распознавания текстов, который достаются бесплатно или за копейки.
Третий фактор — востребованность. Чтобы человек стал пользоваться онлайн-сервисом по распознаванию текста, надо как минимум три фактора: наличие сканера, наличие Интернет и отсутствие возможности самостоятельно распознать текст. Было трудно представить себе большое количество таких «криворуких» и «глупых» пользователей.
Проект был реализован, но оставлен «под сукном» как бесперспективный.
Два года назад я предлагал своим коллегам по работе обдумать вариант повторной реализации проекта. Ситуация изменилась: интернет стал быстрее (файлы mp3 уже давно больше по объёму, чем отсканированная страница в формате JPG), сканеры стоят чуть ли не повсеместно (а ещё текст можно просто сфотографировать), пользователи стараются не нагружать себе голову всякими программами и пользуются онлайн-сервисами. У FineReader есть API, а FLASH позволяет сделать достаточно удобный web-интерфейс для управления загрузкой и распознаванием. Но мы не пришли к общему мнению и, можно сказать, упустили возможность сделать полезный и востребованный сервис который можно выгодно продать ABBYY или гуглю.
Сейчас компания ABBYY уже сама реализовала онлайн-версию Fine Reader для распознавания текстов (поддерживает 6 языков, включая русский; понимает документы, написанные сразу на нескольких языках, поддерживает ввод в форматах TIFF (включая многостраничные файлы), JPEG, BMP, PNG, PCX, GIF, DjVu; поддерживает вывод в форматах Microsoft® Word, Excel®, Rich Text Format, TXT, searchable PDF).
А на днях хорошо известный сервис Google Docs API продоставил возможность проверить то же самое у себя на демо-странице. Гугль позволяет загрузить изображение в высоком разрешении (до 10 Мегабайт) в формате JPG, PNG или GIF. Распознавание длится около двух минут. Поддерживается пока только латинский алфавит.
Ссылки по теме:
Покопавшись в поисковиках, я нашёл ещё несколько сервисов (некоторые созданы буквально в этом году) по распознаванию текстов в online. Вот некоторые из них:- OnlineOCR (28 языков, включая русский; поддерживает ввод в форматах TIFF (multi-page), JPEG/JPG, BMP, PCX, PNG, GIF, PDF (multi-page), файлы до 20 мб; вывод в PDF, MS Word, MS Excel, HTML, RTF, TXT)
- Free OCR (6 языков, русского нет; ввод в форматах PDF (только первая страница), JPG, GIF, TIFF or BMP, файл до 2х мегабайт; вывод в текстовом формате)
- OCR Terminal (6 языков, русского нет; ввод в форматах PNG, JPEG, GIF, BMP, multi-page TIFF and PDF; вывод в форматах DOC, TXT, RTF, PDF)
- Небольшой список бесплатных и коммерческих систем оптического распознавания в онлайн-режиме
P.S.S. Я бы хотел получить отзыв о работе таких сервисов от хабравцев. Есть ли среди вас те, кто пользовался распознаванием в online-finereader, google docs и других сервисах? Ваш отзыв (а лучше даже примеры распознавания и технические ограничения) я добавлю в пост.
Updated: перенесено в Сервисы.
habr.com
Оптическое распознавание символов — Википедия
Оптическое распознавание символов (англ. optical character recognition, OCR) — механический или электронный перевод изображений рукописного, машинописного или печатного текста в текстовые данные, использующиеся для представления символов в компьютере (например, в текстовом редакторе). Распознавание широко применяется для преобразования книг и документов в электронный вид, для автоматизации систем учёта в бизнесе или для публикации текста на веб-странице. Оптическое распознавание символов позволяет редактировать текст, осуществлять поиск слов или фраз, хранить его в более компактной форме, демонстрировать или распечатывать материал, не теряя качества, анализировать информацию, а также применять к тексту электронный перевод, форматирование или преобразование в речь. Оптическое распознавание текста является исследуемой проблемой в областях распознавания образов, искусственного интеллекта и компьютерного зрения.
Системы оптического распознавания текста требуют калибровки для работы с конкретным шрифтом; в ранних версиях для программирования было необходимо изображение каждого символа, программа одновременно могла работать только с одним шрифтом. В настоящее время больше всего распространены так называемые «интеллектуальные» системы, с высокой степенью точности распознающие большинство шрифтов. Некоторые системы оптического распознавания текста способны восстанавливать исходное форматирование текста, включая изображения, колонки и другие нетекстовые компоненты.
В 1929 году Густав Таушек (Gustav Tauschek) получил патент на метод оптического распознавания текста в Германии, после чего за ним последовал Гендель (Paul W. Handel), получив патент на свой метод в США в 1933. В 1935 году Таушек также получил патент США на свой метод. Машина Таушека представляла собой механическое устройство, которое использовало шаблоны и фотодетектор.
В 1950 году Дэвид Х. Шепард (David H. Shepard), криптоаналитик из агентства безопасности вооружённых сил Соединённых Штатов, проанализировав задачу преобразования печатных сообщений в машинный язык для обработки компьютером, построил машину, решающую данную задачу. После того как он получил патент США, он сообщил об этом в «Вашингтон Дэйли Ньюз» (27 апреля 1951) и в «Нью-Йорк Таймс» (26 декабря 1953). Затем Шепард основал компанию, разрабатывающую интеллектуальные машины, которая вскоре выпустила первые в мире коммерческие системы оптического распознавания символов.
Первая коммерческая система была установлена на «Ридерс Дайджест» в 1955 году. Вторая система была продана компании «Стандарт Ойл» для чтения кредитных карт для работы с чеками. Другие системы, поставляемые компанией Шепарда, были проданы в конце 1950-х годов, в том числе сканер страниц для национальных воздушных сил США, предназначенный для чтения и передачи по телетайпу машинописных сообщений. IBM позже получила лицензию на использование патентов Шепарда.
Примерно в 1965 году «Ридерс Дайджест» и «Ар-Си-Эй» начали сотрудничество с целью создать машину для чтения документов, использующую оптическое распознавание текста, предназначенную для оцифровки серийных номеров купонов «Ридерс Дайджест», вернувшихся из рекламных объявлений. Для печати на документах барабанным принтером «Ар-Си-Эй» был использован специальный шрифт OCR-A. Машина для чтения документов работала непосредственно с компьютером RCA 301 (одна из первых полупроводниковых ЭВМ). Скорость работы машины была 1500 документов в минуту: она проверяла каждый документ, исключая те, которые она не смогла обработать правильно.
Почтовая служба Соединённых Штатов с 1965 года для сортировки почты использует машины, работающие по принципу оптического распознавания текста, созданные на основе технологий, разработанных исследователем Яковом Рабиновым. В Европе первой организацией, использующей машины с оптическим распознаванием текста, был британский почтамт. Почта Канады использует системы оптического распознавания символов с 1971 года. На первом этапе в центре сортировки системы оптического распознавания символов считывают имя и адрес получателя и печатают на конверте штрихкод. Он наносится специальными чернилами, которые отчётливо видимы в ультрафиолетовом свете. Это делается, чтобы избежать путаницы с полем адреса, заполненным человеком, которое может быть в любом месте на конверте.
В 1974 году Рэй Курцвейл создал компанию «Курцвейл Компьютер Продактс», и начал работать над развитием первой системы оптического распознавания символов, способной распознать текст, напечатанный любым шрифтом. Курцвейл считал, что лучшее применение этой технологии — создание машины чтения для слепых, которая позволила бы слепым людям иметь компьютер, умеющий читать текст вслух. Данное устройство требовало изобретения сразу двух технологий — ПЗС планшетного сканера и синтезатора, преобразующего текст в речь. Конечный продукт был представлен 13 января 1976 во время пресс-конференции, возглавляемой Курцвейлом и руководителями национальной федерации слепых.
В 1978 году компания «Курцвейл Компьютер Продактс» начала продажи коммерческой версии компьютерной программы оптического распознавания символов. Два года спустя Курцвейл продал свою компанию корпорации «Ксерокс», которая была заинтересована в дальнейшей коммерциализации систем распознавания текста. «Курцвейл Компьютер Продактс» стала дочерней компанией «Ксерокс», известной как «Скансофт».
Первой коммерчески успешной программой, распознающей кириллицу, была программа «AutoR» российской компании «ОКРУС». Программа начала распространяться в 1992 году, работала под управлением операционной системы DOS и обеспечивала приемлемое по скорости и качеству распознавание даже на персональных компьютерах IBM PC/XT с процессором Intel 8088 при тактовой частоте 4,77 МГц. В начале 90-х компания Hewlett-Packard поставляла свои сканеры на российский рынок в комплекте с программой «AutoR». Алгоритм «AutoR» был компактный, быстрый и в полной мере «интеллектуальный», то есть по-настоящему шрифтонезависимый. Этот алгоритм разработали и испытали ещё в конце 60-х два молодых биофизика, выпускники МФТИ — Г. М. Зенкин и А. П. Петров. Свой метод распознавания они опубликовали в журнале «Биофизика» в номере 12, вып. 3 за 1967 год. В настоящее время алгоритм Зенкина-Петрова применяется в нескольких прикладных системах, решающих задачу распознавания графических символов. На основе алгоритма компанией Paragon Software Group в 1996 была создана технология PenReader. Г.М Зенкин продолжил работу над технологией PenReader в компании Paragon Software Group[1]. Технология используется в одноимённом продукте компании[2].
В 1993 году вышла технология распознавания текстов российской компании ABBYY. На её основе создан ряд корпоративных решений и программ для массовых пользователей. В частности, программа для распознавания текстов ABBYY FineReader, приложения для распознавания текстовой информации с мобильных устройств, система потокового ввода документов и данных ABBYY FlexiCapture. Технологии распознавания текстов ABBYY OCR лицензируют международные ИТ-компании, такие как Fujitsu, Panasonic, Xerox, Samsung[3], EMC и другие.
Текущее состояние технологии оптического распознавания текста[править | править код]
Точное распознавание латинских символов в печатном тексте в настоящее время возможно, только если доступны чёткие изображения, такие, как сканированные печатные документы. Точность при такой постановке задачи превышает 99 %, абсолютная точность может быть достигнута только путём последующего редактирования человеком. Проблемы распознавания рукописного «печатного» и стандартного рукописного текста, а также печатных текстов других форматов (особенно с очень большим числом символов) в настоящее время являются предметом активных исследований.
Точность работы методов может быть измерена несколькими способами и поэтому может сильно варьироваться. К примеру, если встречается специализированное слово, не используемое для соответствующего программного обеспечения, при поиске несуществующих слов, ошибка может увеличиться.
Распознавание символов онлайн иногда путают с оптическим распознаванием символов. Последний — это офлайн-метод, работающий со статической формой представления текста, в то время как онлайн-распознавание символов учитывает движения во время письма. Например, в онлайн-распознавании, использующем PenPoint OS или планшетный ПК, можно определить, с какой стороны пишется строка: справа налево или слева направо.
Онлайн-системы для распознавания рукописного текста «на лету» в последнее время стали широко известны в качестве коммерческих продуктов. Алгоритмы таких устройств используют тот факт, что порядок, скорость и направление отдельных участков линий ввода известны. Кроме того, пользователь научится использовать только конкретные формы письма. Эти методы не могут быть использованы в программном обеспечении, которое использует сканированные бумажные документы, поэтому проблема распознавания рукописного «печатного» текста по-прежнему остаётся открытой. На изображениях с рукописным «печатным» текстом без артефактов может быть достигнута точность в 80 % — 90 %, но с такой точностью изображение будет преобразовано с десятками ошибок на странице. Такая технология может быть полезна лишь в очень ограниченном числе приложений.
Ещё одной широко исследуемой задачей является распознавание рукописного текста. В данное время достигнутая точность даже ниже, чем для рукописного «печатного» текста. Более высокие показатели могут быть достигнуты только с использованием контекстной и грамматической информации. Например, в ходе распознания искать целые слова в словаре легче, чем пытаться выявить отдельные знаки из текста. Знание грамматики языка может также помочь определить, является ли слово глаголом или существительным. Формы отдельных рукописных символов иногда могут не содержать достаточно информации, чтобы точно (более 98 %) распознать весь рукописный текст.
Для решения более сложных задач в области распознавания используются, как правило, интеллектуальные системы распознавания, такие, как искусственные нейронные сети.
Для калибровки систем распознавания текста создана стандартная база данных MNIST, состоящая из изображений рукописных цифр.
ru.wikipedia.org
Вся правда об OCR
Поколения программ OCR
Перед тем как начать рассмотрение OCR-систем, давайте сначала хотя бы минимально приведем их классификацию для удобства рассмотрения. На данный момент выделяют OCR-системы, а также ICR-системы. Несколько упрощая суть отличий между ними, можно считать, что ICR-системы – это следующее поколение в развитии OCR-систем. В ICR гораздо более активно и серьёзно используются возможности искусственного интеллекта, в частности, ICR-системы часто используются для распознавания рукописных текстов, декоративных непостоянных шрифтов, а также, как самый яркий пример, преодолению тех же систем по защите от спам-ботов – каптч (captcha). Третий, пока ещё только теоретический уровень качества распознавания текста, это IWR, в которой считываются и распознаются не отдельные символы/точки, а считываются и распознаются фразы целиком.

Существует несколько систем, причисляющих себя к категории ICR. Это, прежде всего, FineReader, OmniPage Professional, Readiris Corporate, Type Reader Desktop. Давайте сравним их всех и рассмотрим существующие альтернативы.
Известные отечественные продукты
ABBYY FineReader – один из лидеров рынка OCR, текущая версия продукта 10. Он выпускается в версиях под все ОС Windows, а также под ОС Mac OS X и Linux. Доступна также ограниченная веб-версия этого пакета для оптического распознавания. Сейчас в FineReader поддерживаются около 190 международных языков, кроме этого поддерживается восстановление не только текста исходного документа, но также и его структуры, что особенно полезно при работе с деловыми документами, где важна не только содержательная часть, но и внешняя сторона оформления и композиции документа.
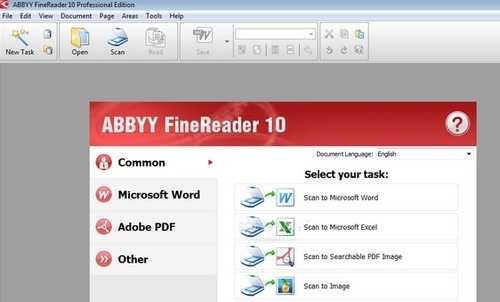
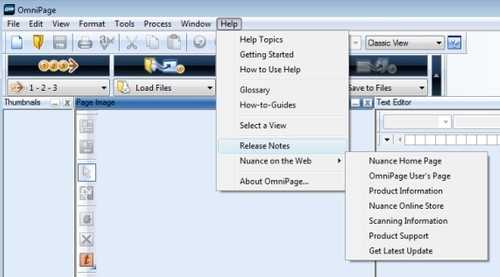
Конкурент FineReader, с которым его постоянно сравнивают – OmniPage от компании Nuance Communications (бывшая ScanSoft). Во многом очень похож по возможностям на FineReader, в частности, как и его конкурент, имеет очень хорошую поддержку распознавания фотографий полученных напрямую с цифровых камер, умеет конвертировать распознанный текст в форматы PDF, Microsoft Word и Excel, HTML, распознает более 120 языков. Текущая версия 17 поставляется как в версии для всех Windows-систем, так и в версиях для MacOS 9 и MacOS X, а также имеются версии для Linux и FreeBSD. Скорость распознавания OmniPage 17 примерно равна FineReader 10 – это одни из самых сравнительно медленных программ такого рода. Обе программы по своим возможностям часто сравниваются друг с другом и это неудивительно, т.к. их возможности во многом эквивалентны.
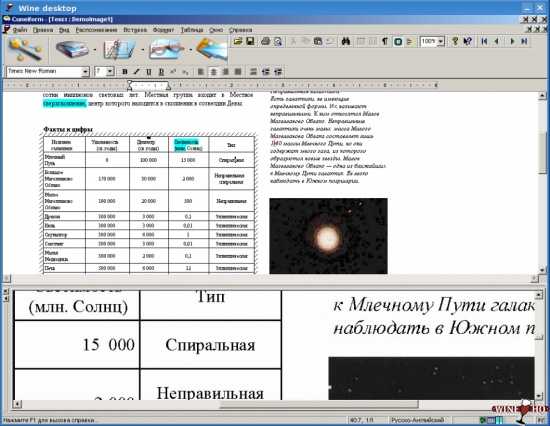
Перейдем к следующему заметному игроку на рынке OCR. Это продукт CuneiForm от российской компании Cognitive Technologies. Самый большой текущий минус этого проекта состоит в том, что ещё в конце 2007 года Cognitive Technologies забросила свой продукт, после чего он никак не обновлялся и не развивался все это время. Сам движок этой OCR был выпущен под максимально свободной лицензией BSD в виде исходных текстов. Из-за специфики технологии распознавания этой программы, которую, кстати, многие эксперты считают тупиковой, CuneiForm в состоянии уверенно распознавать только печатные тексты, и не в состоянии работать с рукописными и декоративными текстами, т.е. это – классическая OCR-система. Текущая и окончательная версия программы – 12. Написана она в виде кроссплатформенного приложения и может запускаться на Windows, Mac OS X, Linux. На данный момент стараниями сторонних разработчиков этот движок распространяется и развивается под названием OpenOCR, впрочем, в силу открытости ядра, эту систему также использует множество других OCR-продуктов, например OCRFeeder.
Зарубежные продукты
Три других известных продукта получили малое распространение на территории СНГ в силу полного отсутствия представителей и маркетинга, но известны на Западе и достойны хотя бы краткого упоминания, хотя бы потому, что также позиционируют себя как продукты ICR-класса.
Первый их них — это пакет Readiris от компании I.R.I.S. Group, который представляет собой очень серьёзный OCR-продукт. Достаточно сказать, что начиная с cентября 2006 года технология от компании I.R.I.S. была лицензирована и используется в продуктах Adobe systems. Согласно внутреннему тестированию самой Adobe эта технология оказалось самой удачной из всех рассмотренных на рынке. Нужно заметить, что это стороннее решение “похоронило” свою собственную разработку OCR-движка Adobe, которая поставлялась многие годы в рамках решения Aсrobat Capture, и вот теперь новый OCR Adobe доступен в виде отдельного плагина для других популярных продуктов Acrobat. Последняя версия Readiris — 12, поддерживаются все версии Windows и MacOS X и работа с более чем 120 языками.
Следующая крупная разработка от американской компании ExperVision, Inc – TypeReader. Этот движок разработан в тесном сотрудничестве с Университетом Невада в Лас-Вегасе. Этот движок распространяется по миру сразу во многих формах, начиная от интегрирования его в крупные западные системы документооборота (Document Imaging Management, DIM) и заканчивая участием во многих американских программах по автоматической обработке форм (Forms Processing Services, FPS). Например, в 2008 году газета Los Angeles Times после собственного тестирования ведущих мировых OCR выбрала для своего внутреннего использования как раз именно TypeReader. Хочется заметить, что данный продукт доступен как в традиционном десктопном исполнении (Windows, MacOS, Linux), в виде корпоративного веб-сервиса, так и в форме облачного арендуемого приложения, способного обрабатывать любые объемы распознаваемого текста в очень короткие сроки.
Также из известных за рубежом продуктом стоит упомянуть LEADTools – это продвинутый ICR-движок, решающий сложные задачи распознавания анкет и рукописных текстов. Он поставляется как SDK, что позволяет удобно и органично встраивать его в корпоративные продукты. Очень важная особенность этого решения состоит в том, что здесь на каждый подключенный язык используются собственные словари для усиления точности проверки распознанных слов и выражений. Продукт доступен как в виде веб-сервисов, так и в традиционном программном виде в 32- и 64-битных версиях для ОС Windows всех версий.
Бесплатные OCR-решения
Интересный собственный движок развивает и Google. Tesseract – это первоначально закрытый коммерческий OCR-движок, который создала Hewlett-Packard, работая над ним в промежутке между 1985 и1995 годами. Но после закрытия проекта и прекращения его развития, HP выпустила его код как open source в 2005 году. Разработку сразу подхватила Google, лицензируя уже свой продукт под свободной лицензией Apache. На данный момент Tesseract считается одним из самых точных и качественных бесплатных движков из всех существующих. Нужно при этом четко представлять, что Tesseract – это классическая OCR для “сырой” обработки текста, т.е. в нем нет ни графической оболочки для удобного управления процессом, ни многих других дополнительных функций. Это обычная консольная утилита (есть версии для Windows, MacOS, Linux), на вход которой подается изображение в формате TIFF, а на выходе Tesseract выдает “чистый текст”. При этом никакого анализа компоновки текста или стилей оформления здесь не производится, это процесс распознавания в его простейшей форме. Для большего удобства работы, в качестве графического фронтенда, с этим движком можно использовать многие утилиты, например известные OCRopus или OCRFeeder. Но все же хочется отметить, что качество бесплатного CuneiForm/OpenOCR немного превосходит показатели Tesseract, хотя во многом это полностью аналогичные продукты.
Кроме бесплатного Tesseract ещё стоит упомянуть и SimpleOCR. SimpleOCR очень достойное решение для OCR, и хотя оно не развивается уже с 2008 года, но оно как минимум ничем не уступает Tesseract. Продукт бесплатен для любого некоммерческого использования, и поставляется для Windows всех версий. Из сильных минусов – поддержка только двух языков: английского и французского.
Кроме традиционных десктоповых бесплатных решений, существует множество альтернативных онлайн-сервисов, бесплатно предлагающих OCR и основанных на самых разных и экзотических движках, которые вы можете опробовать самостоятельно: CVisionTech, OnlineOCR, FreeOCR, OCRTerminal, GoodOCR.
Сейчас в мире существует более чем 100 самых различных OCR-движков, мы попытались рассмотреть и сравнить здесь лишь самые известные и качественные из них. Среди них существует также большое множество бесплатных OCR-программ любительского уровня, но их качество распознавания существенно ниже их коммерческих аналогов. Для успешного решения бизнес задач (и других серьёзных повседневных задач) лучше ориентироваться на коммерческие системы ICR-класса.
internetno.net
Ваш комментарий будет первым