Какие программы для распознавания текста использовать в офисе — Сводные таблицы Excel 2010
Меня часто спрашивают: «Отсканировали (сфотографировали) страничку, файл открывается, читается. Как теперь внести в этот документ исправления?» Ответ: просто так — никак! То, что вы отсканировали — изображение, картинка, набор разноцветных точек. Редактировать можно только документ, состоящий из знаков (символов).
Самое большее, что вы можете сделать с картинкой — в графическом редакторе (Paint, GIMP и т. п.) закрасить или вырезать на ней отдельные участки и нарисовать буквы и цифры. Редактируемым документом от этого изображение не станет!
Однако решение есть: оптическое распознавание символов (optical character recognition, OCR). Программа анализирует изображение, выделяет из него характерные очертания букв и цифр, а потом создает настоящий редактируемый документ. Примерно то же самое делаете вы, когда читаете написанное и набираете прочитанное на клавиатуре. Правда, в распознавании символов компьютеру еще очень далеко до человека.
Весьма эффективное средство распознавания входит в состав пакета Microsoft Office. В предыдущих версиях пакета этим занималось отдельное приложение Microsoft Office Document Imaging (MODI). В Microsoft Office 2010 задача распознавания возложена на компонент OneNote. Примечательно, что теперь эта функция скромно именуется поиском и копированием текста в рисунках и вызывается «как бы между прочим». Как ею пользоваться?
Распознавание символов с помощью OneNote
- Изображение, текст с которого нужно распознать, любым образом вставьте в заметку OneNote.
 Например, перетащите мышью файл рисунка в окно OneNote или на ленте воспользуйтесь кнопками Вставка → Рисунок — как вам удобнее.
Например, перетащите мышью файл рисунка в окно OneNote или на ленте воспользуйтесь кнопками Вставка → Рисунок — как вам удобнее. - В окне OneNote щелкните на рисунке правой кнопкой мыши и в контекстном меню выберите команду Копировать текст из рисунка (см. рис.). Весь текст, который программа сумеет распознать в изображении, будет скопирован в буфер обмена.
- Вставьте скопированный текст в любой документ. Пункт Поиск текста в рисунках в контекстном меню служит для выбора языка распознавания. Эта настройка позволяет точнее определить набор символов, ведь многие буквы разных алфавитов похожи по начертанию.
 Например, перетащите мышью файл рисунка в окно OneNote или на ленте воспользуйтесь кнопками Вставка → Рисунок — как вам удобнее.
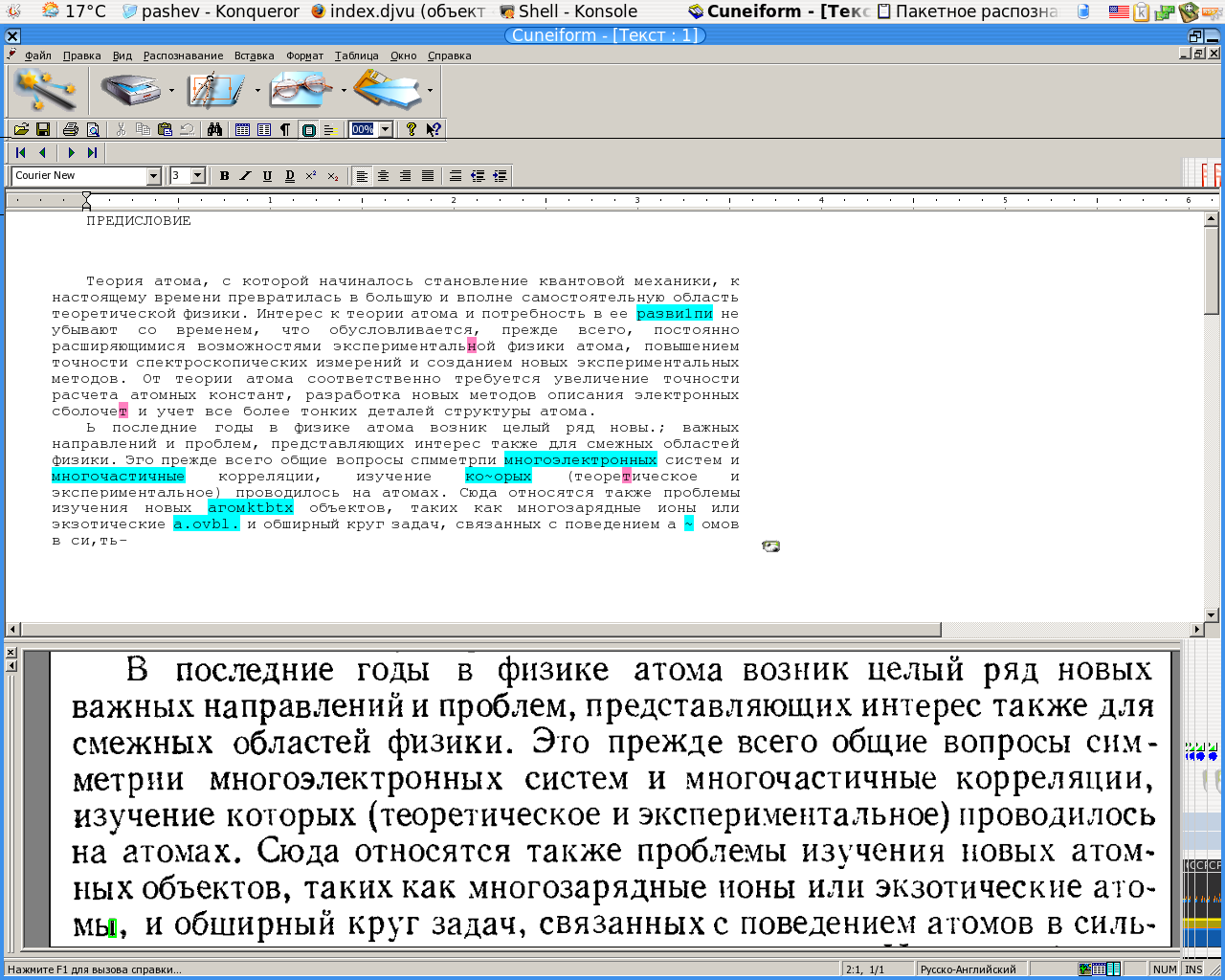
Например, перетащите мышью файл рисунка в окно OneNote или на ленте воспользуйтесь кнопками Вставка → Рисунок — как вам удобнее.Одно из лучших приложений для распознавания документов и таблиц — ABBYY FineReader. Программа легко обрабатывает изображения документов со сложной структурой и очень точно воспроизводит ее в распознанном документе. Хотя в FineReader предусмотрено множество гибких настроек, с большинством типичных задач программа прекрасно справляется «на полном автомате».
Запуск программы ABBYY FineReader
Например, если вы выберете сценарий Сканировать в Microsoft Word, сначала откроется диалоговое окно сканирования. После сканирования первой страницы программа запрашивает, нужно ли сканировать следующую, либо можно переходить к следующему шагу. Когда получены изображения всех страниц, начинается их обработка и распознавание. Ход и результаты распознавания отображаются в главном окне программы. В левой части окна показаны эскизы страниц, а в рабочей области вы видите исходное изображение и рядом с ним — уже распознанный документ.
Главное окно ABBYY FineReader
Результат распознавания FineReader в соответствии со сценарием передает в другую программу или сохраняет. Например, в данном случае автоматически откроется окно Microsoft Word с новым документом. Как правило, в созданном документе заголовки, абзацы и другие составляющие оформления выглядят почти так же, как на исходном изображении. Подбирается даже наиболее похожий шрифт! Другие сценарии позволяют отправить результат распознавания в Microsoft Excel — это удобно, если на оригинале изображена таблица, сохранить его в виде документа Adobe Reader (PDF), вместо сканирования открыть сделанное раньше фото оригинала и т. д.
Подбирается даже наиболее похожий шрифт! Другие сценарии позволяют отправить результат распознавания в Microsoft Excel — это удобно, если на оригинале изображена таблица, сохранить его в виде документа Adobe Reader (PDF), вместо сканирования открыть сделанное раньше фото оригинала и т. д.
Кроме того, программу можно запустить в пошаговом режиме. Для этого на панели инструментов нажмите кнопку Новое задание. Окно выбора сценариев закроется. Нажимая кнопки на панели инструментов, вы сможете последовательно и под полным контролем отсканировать документ или открыть готовое изображение, при необходимости исправить его дефекты и искажения, проанализировать и выделить то, что нужно распознавать, проверить и сохранить результат.
К сожалению, программа FineReader передает документы лишь в приложения Microsoft Office (если они установлены), а с пакетом OpenOffice.org она не знакома. В таком случае очевидный выход — сохранять результаты распознавания в универсальном формате RTF, который прекрасно «понимают» любые редакторы документов. Очень качественное, но коммерческое ПО ABBYY FineReader подходит тем, кто распознает текст с бумажных оригиналов часто и регулярно.
Очень качественное, но коммерческое ПО ABBYY FineReader подходит тем, кто распознает текст с бумажных оригиналов часто и регулярно.
Существуют ли бесплатные альтернативы?
Давний конкурент ABBYY — компания Cognitive Technologies в 2007 г. выпустила бесплатную версию программы CuneiForm и открыла ее исходные тексты. С тех пор поддержкой проекта (www.cuneiform.ru) занялось сообщество программистов, а сама программа сегодня работает на платформах Windows, Linux, FreeBSD и Mac OS X. Другой полностью свободный проект — Tesseract. Бесплатная программа COCR2 примечательна тем, что распознает китайские иероглифы. В связке с электронным переводом, например Переводчиком Google, это приложение дает удивительную возможность прочитать и понять документацию на китайском прямо «с листа»! Коммерческими программами Readiris и CrystalOCR комплектуются многие МФУ. Для конечного пользователя OEM-лицензия является бесплатной — фактически она была оплачена при покупке аппарата.
Сервисы распознавания символов появились и в Интернете: FineReaderOnline. ru, Onlineocr.ru, Liveocr.com и некоторые другие. С помощью формы на веб-странице указывается путь к файлу изображения на вашем компьютере, а результат распознавания выдается опять же через Интернет. В принципе, сервисы работают на коммерческой основе: нужно зарегистрироваться на сайте и оплатить услугу. Однако ограниченное число страниц в течение суток они обрабатывают бесплатно.
ru, Onlineocr.ru, Liveocr.com и некоторые другие. С помощью формы на веб-странице указывается путь к файлу изображения на вашем компьютере, а результат распознавания выдается опять же через Интернет. В принципе, сервисы работают на коммерческой основе: нужно зарегистрироваться на сайте и оплатить услугу. Однако ограниченное число страниц в течение суток они обрабатывают бесплатно.
Программы для распознавания текста — Androfon.ru
Последнее обновление: 12/07/2022
Часто в рабочих или личных целях пользователи сталкиваются с необходимостью распознавания текста, с целью извлечения, редактирования или сохранения в другом формате. Наиболее чаще с необходимостью распознавания текста сталкиваются студенты и офисные работники, а ещё переводчики журналов, комиксов и манги. В статье мы рассмотрим настольные и мобильные, а так же облачные сервисы, что помогут быстро и качественно распознать текст.
Содержание
Программы для компьютера
Настольные программы предназначены для ПК и ноутбука. Такие приложения оптимально держать при регулярном использовании функции распознавания текста.
Такие приложения оптимально держать при регулярном использовании функции распознавания текста.
Читайте также:
Как конвертировать pdf в word
Программа для чтения PDF
ABBYY FineReader
Официальная страницаДанная утилита – лидер в области оптического распознавания текста. Программа рассчитана на распознание отсканированных файлов в реальном времени, а так же готовых документов. В процессе конвертирования сохраняется точный размер, цвет и шрифт текста. Готовый документ легко сохранить в PDF или другом формате.
Подробный обзор программы читайте в нашем отдельном материале.
Основные преимущества:
- Наличие модуля для сравнения и поиска отличий двух документов.
- Распознание текста на более 170 языках.
- Отправка отредактированного документа по электронной почте или сохранение в популярных офисных форматах.
- Возможность сканирования текста стационарным сканером, МФУ или камерой.
- Полноценное редактирование PDF файлов: добавление или удаление страниц, изменение текста, установка водяного знака и т. д.
- Поддержка актуальных версий Windows: 7, 8 и 10.
- Дружелюбный интерфейс.
- 30-дневная бесплатная версия для ознакомления.
 д.
д.Основные недостатки:
- Программа нуждается в покупке лицензионного ключа на год или на постоянной основе. На стоимость влияет версия программы.
- Некоторые функции не доступны в базовой версии.
- Высокая стоимость отдельных модулей. Например, модуль для сравнения двух документов на постоянной основе обойдется примерно в 500 USD.
- Иногда текст распознается некорректно и нуждается в ручном редактировании.
- При работе с DOC форматом документ обязательно конвертируется в PDF, после чего требуется обратно сохранять отредактированный файл.
Scanitto Pro
Официальная страницаПрограмма предназначена для сканирования документов и изображений, при этом поддерживает функцию оптического распознавания текста с последующим редактированием. Модель распространения условно-бесплатная. После ознакомления с 30-дневной пробной версией требуется купить лицензионный ключ на год – 500 RUB или же купить программу на постоянной основе за 5500 RUB.
Основные возможности:
- Настройка параметров сканирования – разрешение, цветность, выбор области сканирования, формат сохранения отсканированных файлов.
- Возможность сохранения файлов в формате PDF.
- Копирование документов со сканера на принтер.
- Оптическое распознавание текста, включая быстрое распознание при использовании многоядерных процессоров.
- Распознание популярных языков: Английский, Итальянский, Русский, Немецкий, Французский, Испанский.
- Загрузка информации в облачное хранилище.
Основные преимущества:
- Совместимость со всеми популярными сканерами.
- Настройка качества сканирования.
- Поддержка облачных дисков.
- Функция оптического распознавания текста с сохранением в DOCX, RTF или TXT.
- Сохранение отсканированных документов в популярные форматы файлов.
- Поддержка устаревших и актуальных версий ОС Windows.

Основные недостатки:
- Необходимость покупки лицензии или полной версии программы.
- Пробная версия действует 30 дней.
- Мало распознаваемых языков.
OCR CuneiForm
Бесплатная программа для распознания текста отсканированных или сфотографированных документов. Причем в процессе распознания сохраняется исходная структура документа и печатные шрифты. Так же поддерживается редактирование распознанных текстов.
Основные возможности:
- Сканирование документов при помощи сканера.
- Оптическое распознавание и редактирование электронных документов/изображений.
- Пакетная обработка документов.
- Адаптивное распознавание контента.
- Периодическое обновление алгоритмов распознавания.
Основные преимущества:
- Бесплатная модель распространения.
- Распознавание и редактирование текста.
- Совместимость с устаревшими версиями ОС Windows — XP, Vista и Se7en.
- Достойное качество распознания текста и графики.
- Периодический выход обновлений.

Основные недостатки:
- В процессе распознания текста возможны подвисания программы.
- Посредственный интерфейс.
Readiris
Официальная страницаПриложение предназначено для создания и редактирования PDF файлов. Так же для конвертации документов в другие форматы, а ещё конвертирования бумажных вариантов в цифровой формат за счет оптического распознания текста. Правда рукописный текст с обычной тетради распознать не удается.
После короткой регистрации разработчики предлагают бесплатную версию программы для ознакомления. Цена базовой версии на 1 ПК – 49 USD, расширенная – 99 USD, корпоративная – 199 USD. При покупке ключей на несколько ПК предоставляется скидка.
Основные возможности:
- Создание, редактирование, объединение, сжатие и прочие операции с PDF файлами.
- Функция оптического распознавания текста.
- Поддержка 30 языков в базовой версии программы, 138 языков в расширенной и корпоративной версии.
- Преобразование документов в файлы Microsoft Office .
- Пакетная обработка документов.

Основные преимущества:
- Набор необходимых инструментов для работы с PDF файлами.
- Оптическое сканирование и редактирование изображений/документов.
- Возможность прослушивания книг и других документов.
- Преобразование документов в популярные форматы файлов.
Основные недостатки:
- Необходимость покупки лицензионного ключа.
- Разграничение возможностей для каждой версии программы. Наиболее функциональна только корпоративная версия.
- Сложности с распознанием рукописного текста.
Онлайн сервисы
Использование облачных технологий актуально в редких случаях распознания текста и небольшого объема. В таком случае не требуется устанавливать настольную программу, где для нормального функционирования требуется приобрести дорогостоящую лицензию.
Convertio
Официальная страницаСервис позволяет бесплатно распознать до 10 страниц в день. Свыше нормы требуется регистрация с оплатой предоплаченного пакета. Стоимость минимального пакета в 50 страниц – 5 USD. Детальнее о предоплаченных пакетах смотрите на странице с расценками.
Свыше нормы требуется регистрация с оплатой предоплаченного пакета. Стоимость минимального пакета в 50 страниц – 5 USD. Детальнее о предоплаченных пакетах смотрите на странице с расценками.
Основные возможности:
- Анализ и распознание текста из PDF и популярных графических форматов файлов – PDF, JPG, BMP, GIF, JP2, JPEG, PBM, PCX, PGM, PNG, PPM, TGA, TIFF и WBMP.
- Пакетная обработка файлов, добавленных с ПК, облачного диска DropBox/Google Drive или по ссылке.
- Распознание до двух языков. Поддержка 74 языков.
- Выбор одного и 10 выходных форматов.
- Настройка распознавания: все страницы или определенный диапазон.
- Возможность скачать или сохранить результат на облачном диске – DropBox или Google Drive.
Основные преимущества:
- Распознавание текста из 2 двух форматов, суммарно 15 расширений файлов.
- Возможность загрузить и обрабатывать несколько файлов сразу.
- Указание файла с ПК, из облачного диска или по ссылке.
- Выбор выходного формата распознанного текста.
- Одновременное распознавание двух языков из 74.
- Сохранение готового результата на ПК или в облачный диск.

Основные недостатки:
- Суточное ограничение при распознании – 10 страниц.
- Что бы распознать больше страниц требуется купить предоплаченный пакет.
- Одновременно распознаются только 2 языка.
- Часто не удается распознать страницу.
img2txt
Официальная страницаБесплатный сервис для распознания текста из PDF и графических файлов.
Основные возможности:
- Локальная загрузка файла или с указанием по ссылке.
- Поддержка распознания 37 языков.
- Неограниченное количество запросов.
- Формат загружаемых файлов: pdf, jpg, jpeg, png и bmp.
Основные преимущества:
- Сервис бесплатный.
- Нет ограничений на количество распознаний.
- Не требуется регистрация.
- Указание до 37 языков при распознавании текста.
- 5 форматов загружаемых файлов.

Основные недостатки:
- Максимальный размер файла для распознания – 8 МБ.
- Ограничение на распознание в 50 страниц за один раз.
- Невозможно скачать распознанный документ.
- Мало поддерживаемых форматов для распознания.
Мобильные приложения
Программы для смартфона/планшета позволят отсканировать и оцифровывать текст с изображений на мобильном устройстве. Удобный вариант, когда под рукой нет компьютера или затруднено использование интернета. В качестве примера рассмотрим распознание текста в программе Office Lens. В качестве альтерантивы вам стоит так же обратить внимание на Adobe Scan и Simple OCR.
Microsoft Office Lens — PDF Scanner
СКАЧАТЬ БЕСПЛАТНОНаиболее функциональное приложение для сканирования и распознания текста. Для оптического распознания требуется сделать фотографию, обрезать участок при необходимости, а затем выбрать вариант – Word (OCR Document). Что бы посмотреть оцифрованный документ на мобильное устройство необходимо установить Word или другой офисный редактор.
Что касается потребления оперативной памяти, система сообщает о 71 МБ, поэтому программа хорошо сойдет для маломощных устройств. А вот если использовать дополнительно программу Microsoft Word для просмотра распознанного текста, тогда суммарный объем ОЗУ двух программ составит 321 МБ. Минимальная версия Android для установки Office Lens – 5.0 или выше.
Вывод
Представленные в статье программы позволяют произвести распознавание текста из PDF и графического файла, с целью извлечения текста. Программы для ПК целесообразно держать при регулярном извлечении текста. Так же настольные версии демонстрируют наилучший результат обработки. Облачные сервисы рационально использовать при нечастой обработке. А мобильные программы пригодятся при оцифровке в дорожных условиях или при отсутствии мобильного интернета.
А как часто вы пользуетесь оцифровкой документов? Какой предпочитаете софт? Поделитесь своим мнением в комментариях под статьей.
Связанные записи
Что такое OCR (оптическое распознавание символов): как это работает и применение
OCR — это технология, которая анализирует текст страницы и превращает буквы в код, который можно использовать для обработки информации. OCR — это метод обнаружения печатных или рукописных текстовых символов внутри цифровых изображений бумажных файлов, например, при сканировании бумажных записей (оптическое распознавание символов). Системы OCR — это аппаратные и программные системы, которые превращают физические документы в машиночитаемый текст.
OCR — это метод обнаружения печатных или рукописных текстовых символов внутри цифровых изображений бумажных файлов, например, при сканировании бумажных записей (оптическое распознавание символов). Системы OCR — это аппаратные и программные системы, которые превращают физические документы в машиночитаемый текст.
Эти цифровые версии могут быть очень полезны для детей и молодых людей, которым трудно читать. Именно поэтому цифровой текст можно использовать с несколькими программными пакетами, повышающими удобочитаемость. Текст копируется или считывается с помощью таких технологий, как оптический сканер или специальная печатная плата, а программное обеспечение выполняет дальнейший анализ. Основным применением OCR является преобразование печатных юридических или исторических документов в PDF-файлы. Пользователи могут изменять, стилизовать и анализировать документ, как если бы он был создан с помощью текстового процессора, после его сохранения в формате pdf.
Как работает оптическое распознавание символов?
Система оптического распознавания символов состоит из аппаратного и программного обеспечения. Сервис предназначен для анализа содержимого физического документа и преобразования элементов в сценарий, который впоследствии можно использовать для обработки данных.
Сервис предназначен для анализа содержимого физического документа и преобразования элементов в сценарий, который впоследствии можно использовать для обработки данных.
Например, рассмотрим почтовые службы и службы сортировки почты. OCR имеет решающее значение для их способности быстро обрабатывать исходные и обратные адреса, чтобы можно было более эффективно сортировать корреспонденцию. Следующие три являются важными основными методами программы:
1. Предварительная обработка изображения
- На первом этапе технология преобразует физическую форму документа в изображение, например изображение записи. Цель этого этапа — сделать представление машины точным, а также устранить любые нежелательные аберрации.
- Концепт впоследствии преобразуется в черно-белое изображение, оцениваемое по сравнению с яркими и темными областями (символами).
- Затем изображение сегментируется на отдельные части, такие как электронные таблицы, текст или графические вставки, с помощью системы OCR.

2. Распознавание символов AI
Искусственный интеллект анализирует темные участки изображения, чтобы распознавать символы и цифры. Как правило, ИИ использует один из следующих подходов для нацеливания на одну букву, фразу или абзац за раз:
- Распознавание образов: технологии используют различные языки, текстовые форматы и почерк для обучения системы искусственного интеллекта. Программа сравнивает буквы на обнаруженном изображении букв с нотами, которые она уже научила находить совпадения.
- Распознавание признаков: Алгоритм использует правила, основанные на определенных свойствах символов, для распознавания новых символов. Количество угловых, пересекающихся или изогнутых линий в букве является одним из примеров функции.
Для идентификации исходных символов алгоритм использует правила, основанные на определенных атрибутах символов. Например, одна черта — это количество угловатых, пересекающихся или изогнутых линий в символе.
3. Постобработка
AI исправляет недостатки в финальном файле во время постобработки. Один из подходов состоит в том, чтобы обучить ИИ глоссарию терминов, которые появятся в статье. Затем ограничьте вывод ИИ этими словами/форматами, чтобы убедиться, что никакие интерпретации не выходят за рамки словаря.
Какая технология лежит в основе OCR?
Оптическое распознавание символов, или OCR, — это метод, который позволяет преобразовывать многие виды документов в настраиваемые и доступные данные, такие как оцифрованные бумажные документы, PDF-файлы или фотографии, полученные с помощью телефона с камерой.
Сканер может генерировать растровое изображение, которое представляет собой не что иное, как набор черно-белых или цветных точек, представляющих документ. Вам потребуется программное обеспечение OCR для извлечения и повторного использования данных из изображений документов, фотографий с камеры или PDF-файлов, содержащих только изображения. Эта программа будет выделять буквы на изображении, преобразовывать их в слова, а затем слова в фразы, позволяя вам извлекать и изменять исходную информацию о букве.
Приложения/программное обеспечение OCR
«Сканер PDF: сканирование документов + распознавание текста» — один из самых известных инструментов распознавания текста, который, как правило, получает положительные отзывы благодаря своим удобным функциям. Программа, совместимая с пользователями Android, позволяет вам добавлять свою подпись к документам, импортируя фотографии и PDF-файлы.
Онлайн-распознавание символов
Это OCR также очень простое и простое в использовании, и к нему можно получить доступ в Интернете. Кроме того, «Бесплатное онлайн-распознавание текста» выгодно тем, что оно поддерживает 46 языков, включая итальянский, португальский, испанский, японский и китайский.
Офисная линза
Office Lens — это мобильное OCR, разработанное Microsoft. Его основная функция заключается в преобразовании заметок, написанных на доске, в цифровой формат. Он также может редактировать цифровые версии печатных изданий, фирменных бланков и рекламных щитов. Его привлекательность проистекает из его способности улучшать и оптимизировать сделанные фотографии, динамически изменяя их размер в соответствии с масштабом.
Его привлекательность проистекает из его способности улучшать и оптимизировать сделанные фотографии, динамически изменяя их размер в соответствии с масштабом.
Преимущества оптического распознавания символов
Основными преимуществами технологии оптического распознавания текста являются экономия времени, уменьшение количества ошибок и снижение усилий. Сжатие в ZIP-файлы, выделение фраз, интеграция в веб-страницу и пересылка по электронной почте — это параметры, недоступные для печатных копий.
В то время как фотографирование документов позволяет сохранять их в цифровом виде, OCR добавляет возможность изменять и искать эти документы.
Применение OCR
OCR имеет широкий спектр применения, и любая компания, имеющая дело с физическими документами, может извлечь из этого выгоду. Вот несколько примеров известных вариантов использования:
Обработка текстов
Обработка текста, пожалуй, одно из первых и самых популярных приложений OCR. Печатные файлы можно сканировать и превращать в изменяемые и доступные версии — искусственный интеллект помогает обеспечить максимально точное преобразование этих документов.
Печатные файлы можно сканировать и превращать в изменяемые и доступные версии — искусственный интеллект помогает обеспечить максимально точное преобразование этих документов.
Юридическая документация
Важнейшие утвержденные юридические документы, такие как кредитная документация, могут быть отсканированы и сохранены в электронной базе данных для удобного поиска. Документы также могут быть просмотрены и распространены многими людьми.
Банковское дело
Вы можете сфотографировать лицевую и оборотную сторону чека, который хотите внести на свой телефон. Чек может быть автоматически проверен с помощью технологии оптического распознавания символов на основе искусственного интеллекта, чтобы убедиться, что он является законным, и проверяет наличные деньги, которые вы хотите внести.
OCR и AI: преимущества для бизнеса
Преобразование физического письма в цифровое требует человеческого труда; каждую страницу придется перепечатывать, а это трудоемкая и подверженная ошибкам работа. Преобразование занимает меньше времени с использованием системы OCR и является более точным, чем исходный материал. Пользователи могут изменять, стилизовать и искать страницу после того, как OCR преобразует ее в формат PDF. Они также могут быстро поделиться им по электронной почте, встроить в веб-страницу и сохранить в виде zip-файлов.
Преобразование занимает меньше времени с использованием системы OCR и является более точным, чем исходный материал. Пользователи могут изменять, стилизовать и искать страницу после того, как OCR преобразует ее в формат PDF. Они также могут быстро поделиться им по электронной почте, встроить в веб-страницу и сохранить в виде zip-файлов.
Эта возможность интерпретации документов позволяет фирмам изучать многие документы без необходимости использования человеческого труда. Таким образом, сокращение трудоемких административных обязанностей имеет важное значение для повышения вовлеченности в работу и снижения убыли.
Изучите OCR сегодня
По мнению исследователей, ожидается, что спрос на оптическое распознавание текста на основе ИИ будет расти по мере того, как эти технологии станут более продуктивными и экономичными. Ознакомьтесь с уроками Simplilearn по искусственному интеллекту и машинному обучению, а также вариантами обучения, если вы хотите узнать больше об OCR. Курс № 1 по искусственному интеллекту и машинному обучению от TechGig в партнерстве с Purdue и IBM. Этот курс поможет вам освоить машинное обучение, глубокое обучение, статистику, обучение с подкреплением и НЛП.
Курс № 1 по искусственному интеллекту и машинному обучению от TechGig в партнерстве с Purdue и IBM. Этот курс поможет вам освоить машинное обучение, глубокое обучение, статистику, обучение с подкреплением и НЛП.
Что такое OCR и для чего оно используется?
Если вы работаете в офисе, оборудованном сканером документов, вы обязательно использовали PDF. И, возможно, вы знакомы с лучшим другом PDF, его акронимическим родственником, OCR или оптическим распознаванием символов.
Но что такое OCR? Почему это выгодно для PDF-файлов? В этой статье рассматривается, что такое OCR, и раскрываются наиболее популярные варианты использования.
Программное обеспечение OCR стало проще
Быстрое преобразование старых печатных документов в машиночитаемые данные.
Попробуйте Docparser бесплатно. Кредитная карта не требуется.
Содержание
- Введение
- История технологии распознавания текста
- Что такое OCR?
- Чем отличается полное распознавание символов от зонального распознавания?
История технологии OCR
Из мозга Эмануэля Голдберга
Самое раннее использование оптического распознавания символов можно проследить до телеграфной технологии и устройств чтения для слепых.
Эмануэль Голдберг изобрел машину, похожую на OCR. Он считывал символы и преобразовывал их в стандартный телеграфный код.
Примерно в то же время Эдмунд Фурнье д’Альбе изобрел оптофон. Как и изобретение Голдберга, это был портативный сканер, который производил тона, соответствующие определенным буквам или символам, при перемещении по странице.
В конце 1920-х — начале 1930-х годов Голдберг разработал машину для поиска в архивах микрофильмов с использованием оптического распознавания кода. Он назвал это своей «Статистической машиной». В 1931 года он запатентовал это изобретение, которое позже приобрела IBM.
Адаптация Курцвейла
Рэй Курцвейл основал компанию Kurzweil Computer Products Inc. в 1974 году, продолжая развивать технологию Omni-font OCR, позволяющую распознавать текст, напечатанный большинством шрифтов. Хотя Omni-font OCR часто приписывают Kurzweil, компании использовали его задолго до этого.
Курцвейл считал, что лучшее применение технологии оптического распознавания символов было для слепых — компьютер для чтения текста вслух. Устройство требовало двух вспомогательных технологий: планшетного ПЗС-сканера и синтезатора речи. Курцвейл представил готовый продукт 13 января 19 года.76, во время пресс-конференции. В 1978 году Kurzweil Computer Products выпустила коммерческую версию компьютерной программы OCR. Один из ее первых клиентов, LexisNexis, купил программу для загрузки юридических документов и новостных документов в свои онлайновые базы данных. На волне успеха Курцвейл продал свою компанию Xerox. В конце концов, компания выделилась как Scansoft, а затем объединилась с Nuance Communications.
Устройство требовало двух вспомогательных технологий: планшетного ПЗС-сканера и синтезатора речи. Курцвейл представил готовый продукт 13 января 19 года.76, во время пресс-конференции. В 1978 году Kurzweil Computer Products выпустила коммерческую версию компьютерной программы OCR. Один из ее первых клиентов, LexisNexis, купил программу для загрузки юридических документов и новостных документов в свои онлайновые базы данных. На волне успеха Курцвейл продал свою компанию Xerox. В конце концов, компания выделилась как Scansoft, а затем объединилась с Nuance Communications.
Перенесемся в 2000-е, распознавание текста стало доступно онлайн как услуга, в облачной среде и в мобильных приложениях (вспомните онлайн-переводы на иностранные языки).
В связи с изобретением смартфонов и смарт-очков OCR можно использовать для различных приложений, которые извлекают текст, снятый с помощью камеры устройства. Устройства без возможностей OCR используют API OCR для извлечения текста из файла изображения, захваченного и предоставленного устройством. API возвращает извлеченный текст в приложение устройства для дальнейшей обработки.
API возвращает извлеченный текст в приложение устройства для дальнейшей обработки.
Что такое OCR?
OCR означает оптическое распознавание символов. Это широко распространенная технология распознавания текста внутри изображений, таких как отсканированные документы и фотографии. Технология оптического распознавания символов используется для преобразования практически любых изображений, содержащих письменный текст (печатный, рукописный или печатный), в машиночитаемые текстовые данные.
Технология OCR стала популярной в начале 1990-х годов при оцифровке исторических газет. С тех пор технология претерпела ряд усовершенствований. В настоящее время решения обеспечивают почти идеальную точность распознавания текста. Кроме того, расширенные методы, такие как Zonel OCR, используются для автоматизации сложных рабочих процессов на основе документов.
Что такое полное распознавание символов по сравнению с зональным распознаванием символов?
При зональном распознавании символов в документах создаются зоны или области, чтобы установить определенные поля для целых страниц. Затем данные извлекаются из обозначенных областей. Все, что вырезано, вырезается, и любые символы, частично введенные в зональные поля, не могут быть прочитаны. «Умные зоны» оптимизируют извлечение данных, точность и позволяют пользователю устанавливать правила форматирования для расширенной обработки документов.
Затем данные извлекаются из обозначенных областей. Все, что вырезано, вырезается, и любые символы, частично введенные в зональные поля, не могут быть прочитаны. «Умные зоны» оптимизируют извлечение данных, точность и позволяют пользователю устанавливать правила форматирования для расширенной обработки документов.
OCR или полное OCR считывает весь документ. Затем он помещает текстовый слой поверх документа PDF. Текстовые слои позволяют выполнять поиск по всему содержимому документа. Это лучше всего подходит для отчетов, контрактов или любого документа с важными словами или фразами, которые можно найти.
Легко оцифровывайте бумажные документы
Быстро преобразуйте старые печатные документы в машиночитаемые данные!
Попробуйте Docparser бесплатно. Кредитная карта не требуется.
Для чего используется OCR?
Популярные варианты использования
Наиболее известный вариант использования OCR — преобразование печатных бумажных документов в машиночитаемые текстовые документы. После того, как отсканированный бумажный документ проходит обработку OCR, текст документа можно редактировать с помощью таких текстовых процессоров, как:
После того, как отсканированный бумажный документ проходит обработку OCR, текст документа можно редактировать с помощью таких текстовых процессоров, как:
- Microsoft Word
- Google Docs
До появления технологии OCR единственным способом оцифровки печатных бумажных документов был вручную перепечатать текст. Это не только отнимало много времени, но и сопровождалось неточностями и опечатками.
OCR часто используется как «скрытая» технология, поддерживающая многие известные системы и службы в нашей повседневной жизни. Менее известные, но не менее важные варианты использования технологии OCR включают:
- Распознавание паспортов для аэропортов
- Распознавание дорожных знаков
- Извлечение контактной информации из документов или визитных карточек
- Преобразование рукописных заметок в машиночитаемый текст
- Обход CAPTCHA системы защиты от ботов
- Предоставление возможности поиска в электронных документах, таких как Google Books или PDF-файлы
- Ввод данных для деловых документов (банковские выписки, счета-фактуры, квитанции)
- Вспомогательные средства для слепых
Технология оптического распознавания символов оказалась чрезвычайно полезной при оцифровке исторических газет и текстов, более ранние тексты проще и быстрее.
Ваш комментарий будет первым