Программы для распознавания текста
Зачем нужны программы распознавания текста.
Программы распознавания текста позволяют работать с отсканированными изображениями. С их помощью выполняется редактирование информации, исправление ошибок, сохранение данных в нужном формате и т.д.
Как работает сканер.
Чтобы лучше понять ценность упомянутых программ разберемся с тем, как работает сканер. Механизм устройства помещен в корпус, верхняя часть которого представлена стеклом. Внутри находится яркая лампа и зеркала. Именно они отвечают за «фотографирование» источника для сканирования. При этом шрифт и изображения считываются в виде цветных, серых или черно-белых точек (в зависимости от модели устройства). А за распознавание текста и картинок отвечает драйвер сканера.
Полученное изображение является своеобразной фотографией исходного источника, будь то разворот книги, лист формата A4 или справка. Программы для распознавания текста позволяют расширить возможности пользователя, редактировать текст, исправлять ошибки.
Для наглядности рассмотрим пример. Допустим, вам нужно вставить большой кусок текста из книги в дипломную работу. Чтобы не тратить время на перепечатывание с листа, страницы можно отсканировать. Однако этого недостаточно, поскольку вы получите файлы-картинки, которые не подойдут для использования в Microsoft Word. С помощью программ для распознавания текста пользователь отредактирует полученное изображение и сможет вставить информацию в текстовый редактор.
Возможности современных программ для распознавания текста.
Если предстоит сканирование листов с четко прописанными буквами, читабельным, ярким шрифтом, то с такой задачей справится любой сканер. Куда хуже обстоит дело, если речь идет о таких носителях информации, как старые, потрепанные листы бумаги или пожелтевшие газеты. Не каждый драйвер сможет идентифицировать подобный текст, а потому возможности специальной программы придутся как нельзя кстати. С их помощью утраченные области шрифта легко восстановить, дописав на клавиатуре в рамках редактора.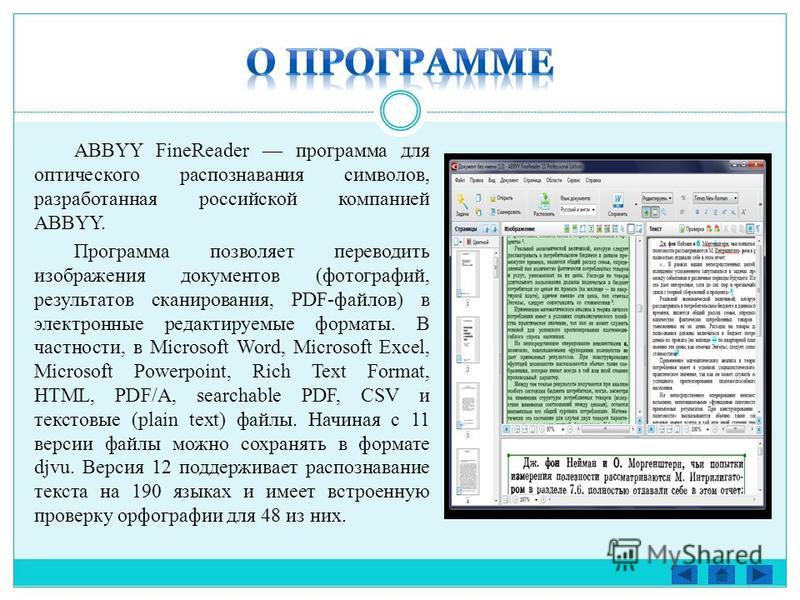
Отдельные программы предоставляют даже такие эксклюзивные возможности, как правка рукописного текста. Правда, для этого нужно, чтобы разрешение картинки было не меньше 300 точек на дюйм. Кроме того, буквы в строке должны быть примерно одной высоты, одного наклона и написаны как можно аккуратнее.
Функцию распознавания рукописного текста поддерживают такие программы, как ABBYY FineReader, CuneiForm (бесплатная утилита), MyScript Stylus, SimpleOCR и другие. Помимо русских символов они идентифицируют буквы, написанные на иностранном языке. Кроме того, программы распознают таблицы и рисунки, перенося их в компьютер для последующего редактирования.
Таким образом, ни один современный пользователь ПК, имеющий сканер, не обойдется без программы распознавания текста. Выбор платных и бесплатных утилит позволит выбрать то, что отвечает именно вашим запросам с точки зрения функциональности.
www.38i.ru
YAGF — программа для распознавания текста
2.
 8.2 YAGF — программа для распознавания текста
8.2 YAGF — программа для распознавания текстаСкачать документ
Окружение
- Версия РЕД ОС: 7.3.1
- Конфигурация: Рабочая станция
- Версия ПО: yagf-0.9.5-5
YAGF — графический интерфейс для консольных программ распознавания текстов: CuneiForm и Tesseract. YAGF позволяет управлять сканированием изображений, их предварительной обработкой и распознаванием. Программа поддерживает все основные растровые графические форматы (JPEG, PNG, BMP, TIFF, GIF, PNM, PPM, PBM и другие).
На нашем Youtube-канале вы можете подробнее ознакомиться с работой в программах для распознавания текста, просмотрев видео Распознавание текста, а также найти много другой полезной информации.
Для установки оболочки YAGF и дополнительных языковых пакетов словарей выполните команду с правами пользователя root:
- для РЕД ОС 7.
 1 или 7.2:
1 или 7.2:
 1 или 7.2:
1 или 7.2:yum install yagf aspell-ru aspell-en
- для РЕД ОС 7.3 и старше:
dnf install yagf aspell-ru aspell-en
В настройках программы выберите язык распознаваемого текста.
На вкладке «Обработка изображений» снимите галочку с пункта «Обрезать изображение при загрузке», чтобы не возникало проблем с отображением загруженного в программу документа.
Программа позволяет открыть для распознавания файлы, сохраненные на жестком диске, или сканировать новое изображение. Для того чтобы загрузить изображение, перейдите в меню Файл > Открыть и в диалоговом окне выберите один или несколько файлов. Кроме этого имеется возможность перетаскивать графические файлы мышью на темную полосу в левой части главного окна программы.
В YAGF можно получать изображения со сканера с помощью программы XSane. Если XSane не установлена, то установите эту программу командой от пользователя root:
- для РЕД ОС 7. 1 или 7.2:
 1 или 7.2:
1 или 7.2:yum install xsane
- для РЕД ОС 7.3 и старше:
dnf install xsane
Чтобы получить изображение перейдите в меню Файл > Сканировать. Будет запущена программа XSane. При необходимости настройте параметры сканирования в XSane и нажмите кнопку «Сканировать». После завершения сканирования в окне просмотра изображений YAGF появится сканированное изображение.
YAGF предоставляет простые операции подготовки сканированного изображения, такие как выделение блока текста для распознавания и поворот. Если изображение ориентировано неправильно, его можно повернуть на 90 градусов по часовой или против часовой стрелки, а также на 180 градусов. Делается это с помощью кнопок на панели быстрого доступа в окне просмотра изображений.
Если необходимо распознать не весь текст на изображении, а отдельную его часть, то для этого выделите мышью один или несколько фрагментов в окне просмотра изображений.
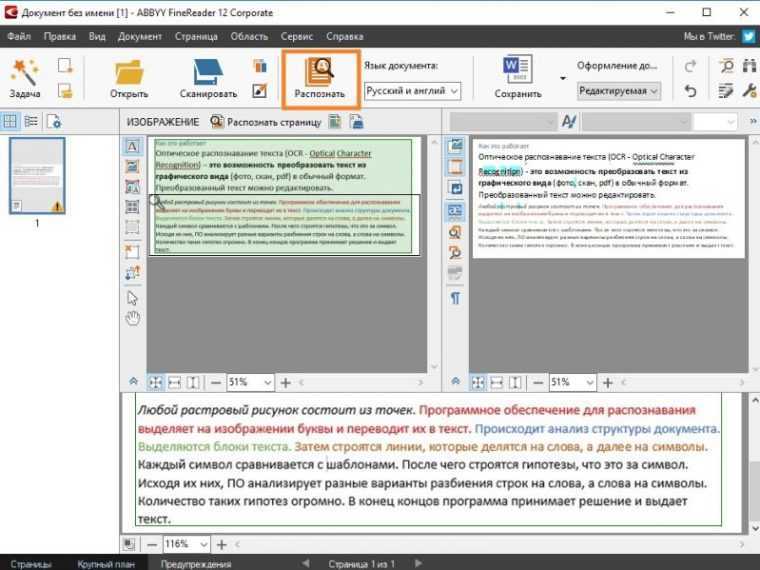
Для распознавания текста на изображении, перейдите в меню Файл > Распознать или воспользуйтесь комбинацией клавиш Ctrl+R.
Для сохранения текста в меню Файл и выберете пункт «Сохранить весь текст» или «Сохранить текст на текущей странице». Также можно скопировать текст в буфер обмена с помощью правой кнопки мыши.
Примечание!
Для распознавания текста на английском языке с помощью Tesseract в программе YAGF необходимо указать стандартный путь расположения файлов — «Настройки» — «Распознавание» — «Расположение данных Tesseract» — /usr/share/tesseract/tessdata/.
После сохранения пути выберите язык в настройках.
Если вы нашли ошибку, пожалуйста, выделите текст и нажмите Ctrl+Enter.
Создание скриншотов и запись видео с экрана
Программы для сканирования в РЕД ОС
Top 10 OCR software in 2023
OCR или Optical Character Recognition находит несколько применений — от оцифровки книг до автоматизации обработки счетов. Современное программное обеспечение OCR работает быстро и точно и может извлекать данные из плохо отформатированных сканов, изображений низкого качества и даже рукописных документов. Это то, что позволяет приложениям OCR выполнять широкий спектр функций, помимо простого извлечения данных, и открывает путь для интеллектуальной обработки документов . Однако на рынке доступно несколько программ для оптического распознавания символов, которые помогают преобразовывать документы в их цифровые копии, и вопрос заключается в том, как выбрать наиболее подходящее решение для оптического распознавания символов для вашего бизнеса.
Современное программное обеспечение OCR работает быстро и точно и может извлекать данные из плохо отформатированных сканов, изображений низкого качества и даже рукописных документов. Это то, что позволяет приложениям OCR выполнять широкий спектр функций, помимо простого извлечения данных, и открывает путь для интеллектуальной обработки документов . Однако на рынке доступно несколько программ для оптического распознавания символов, которые помогают преобразовывать документы в их цифровые копии, и вопрос заключается в том, как выбрать наиболее подходящее решение для оптического распознавания символов для вашего бизнеса.
Если вы планируете перейти на безбумажный путь в своих повседневных деловых операциях, вот десять лучших программных решений для оптического распознавания символов, которые вы можете рассмотреть.
Давайте сразу перейдем к делу: —
10 лучших программ оптического распознавания текста для вашего бизнеса в 2023 году Программное обеспечение OCR используется для преобразования символов из отсканированных изображений и бумажных документов в цифровой текст для более быстрой обработки и упрощенного хранения электронных документов.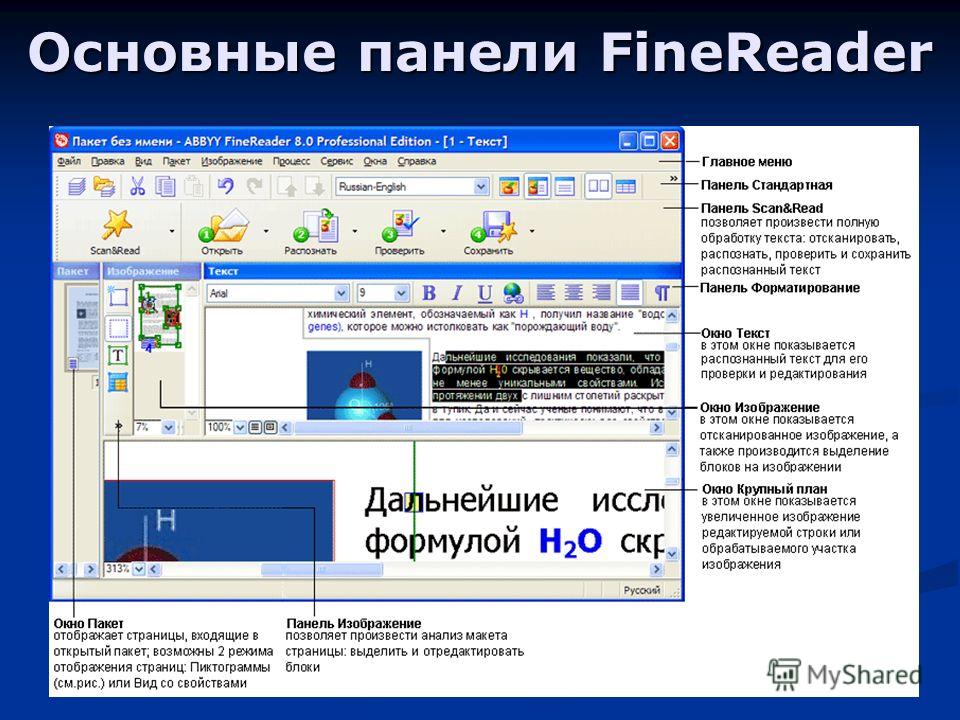 Сегодня современные решения OCR основаны на облаке и могут использоваться для оцифровки нескольких типов документов за считанные минуты.
Сегодня современные решения OCR основаны на облаке и могут использоваться для оцифровки нескольких типов документов за считанные минуты.
Вот список 10 лучших решений OCR для вашего бизнеса:
Мощная платформа на основе искусственного интеллекта для автоматизации сбора, извлечения и обработки данных для различных типов документов. Docsumo использует комбинацию интеллектуальных алгоритмов распознавания текста, искусственного интеллекта и машинного обучения для оцифровки документов и их преобразования в различные форматы. Модели API обучены распознавать различные макеты документов и извлекать из них данные. Пользователи могут загружать файлы массово, и им не нужно просматривать их вручную, как только API-интерфейсы научатся читать предпочитаемые ими типы документов.
Верхние функции- Интеллектуальные (AI-энергетические) OCR
- Изображение или передача данных
- Правила проверки данных
- Документ Извлечение данных
- Правила детекции
- Automatic Document Document Document. время
- Несколько форматов вывода
 время
времяЗапросите цену.
Pros- Возможность настройки и возможность автоматизации.
- Отличная поддержка клиентов.
- Полная интеграция с популярными бизнес-системами.
- Документация API требует более подробной информации.
- Он все еще находится в стадии роста.
Adobe Acrobat Pro DC — это сквозной процессор документов с мощными функциями распознавания текста. Он использует оптическое распознавание символов (OCR) для преобразования отсканированных документов, PDF-файлов и других изображений в оцифрованные документы, которые легко доступны для поиска и редактирования пользователями. Программное обеспечение специально разработано для профессионалов бизнеса и совместимо с операционными системами Windows и Mac.
- Индексация
- Многоязычная поддержка
- Извлечение данных
- Текстовые редактирование
, в то время как бесплатная версия, доступная для приложения, это доступно. Доступ к дополнительным функциям, включая функции OCR, стоит от 1,95 доллара в месяц.
Плюсы- Надежная ценность бренда.
- Полная интеграция с другими решениями пакета Adobe.
- Специальные мобильные приложения.
- Дополнительные функции доступны за дополнительную плату.
- Периодический пакет подписки.
Rossum помогает пользователям организовывать, управлять и обрабатывать все входящие документы. Это особенно полезно для обработки счетов-фактур. Он использует искусственный интеллект для сканирования и интерпретации различных типов файлов, независимо от макетов и форматов документов. Rossum также позволяет своим пользователям добавлять углубленную интеграцию, семантику кодирования и получать автоматические подтверждения, запросы на редактирование или исправление, а также предупреждения о преобразованиях документов, которые настроены в соответствии с бизнес-требованиями.
Rossum также позволяет своим пользователям добавлять углубленную интеграцию, семантику кодирования и получать автоматические подтверждения, запросы на редактирование или исправление, а также предупреждения о преобразованиях документов, которые настроены в соответствии с бизнес-требованиями.
- Zone selection tools
- Indexing
- Multi-language support
- Multiple output formats
- Metadata extraction
- Text editing
- Image pre-processing
Rossum offers как бесплатная пробная версия, так и бесплатная версия. Вы можете связаться с ними, чтобы узнать больше об их индивидуальной структуре ценообразования.
Плюсы- Извлечение данных с помощью ИИ.
- Отличная поддержка клиентов.
- Удобный интерфейс.
- Интеграция через API может быть затруднена.
- Некоторые функции требуют ручного вмешательства.
- Нишевое приложение в основном для выставления счетов.

Readiris автоматически преобразует изображения, бумажные документы и файлы PDF в текст с возможностью поиска и редактирования. Readiris использует всего несколько щелчков мыши для преобразования документов и управления ими в одном месте. Он может подписывать документы, редактировать, объединять, и скорость преобразования очень хорошая, когда речь идет о преобразовании документов в различные форматы файлов. Пользователи могут дополнительно извлекать тексты, встроенные в изображения, с помощью интеллектуальной технологии захвата данных OCR.
Top Features- Batch processing
- Indexing
- Text editing
- Multi-language support
- Multiple output formats
Readiris does not offer a free trial or a free version.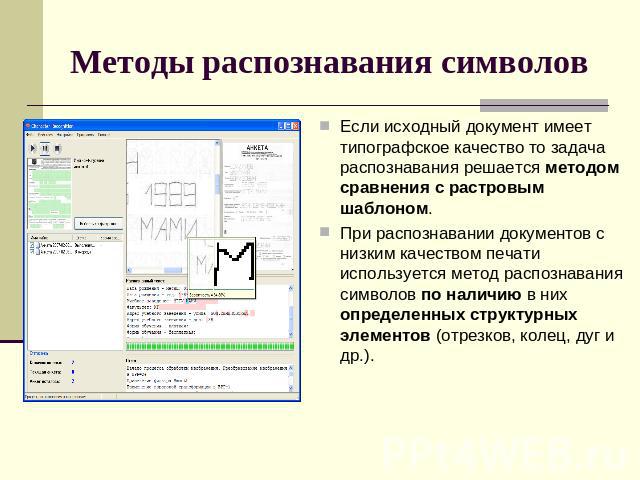 Программное обеспечение доступно при единовременной оплате в размере 33,56 долларов США за функцию.
Программное обеспечение доступно при единовременной оплате в размере 33,56 долларов США за функцию.
- Высокая скорость чтения и анализа.
- Аккуратный интерфейс.
- Высокая точность.
- Ограниченные сочетания клавиш.
- Ограниченные возможности для простых текстовых файлов.
- Отсутствует опция «сохранить в буфер обмена».
- Дорого для ограниченной функциональности.
Docparser помогает идентифицировать данные и извлекать их из документов на основе изображений с помощью технологии Zonal OCR. Docparser может извлекать табличные данные, устанавливать пользовательские правила анализа, интеллектуальные фильтры и обладает мощными возможностями предварительной обработки изображений. Пользователи могут воспользоваться преимуществами технологии сканирования штрих-кодов и QR-кодов при чтении документов и пересылать проанализированные документы в различные облачные приложения прямо с платформы.
- Извлечение данных
- Агрегация данных
- Публикация данных
- Контакт (Телефон или электронная почта). Извлечение
- Axtraction
- Независимый от платформы облачный сервис.
- Доступная цена за страницу.
- Готовые шаблоны для нескольких категорий.
- Отсутствует функция автозарядки.
- Сложные правила синтаксического анализа могут значительно увеличить время синтаксического анализа.
ABBYY Flexicapture поставляется с расширенными функциями для сканирования фотографий/документов в формате PDF и преобразования их в текст, таблицу и другие форматы. ABBYY Flexicapture помогает предприятиям отказаться от ручного ввода данных, сосредоточиться на более продуктивных задачах и автоматизировать различные административные процессы. Программное обеспечение позволяет пользователям сканировать, оцифровывать, извлекать, редактировать, защищать, совместно и обмениваться всеми видами документов и максимально эффективно использовать цифровые рабочие места.
Top Features- AI-powered OCR technology
- Batch processing
- Text editing
- Multi-language support
- Multiple output formats
- Image pre-processing
- Metadata extraction
Узнать цену
Pros- Простота в использовании благодаря интуитивно понятному пользовательскому интерфейсу и обширным функциям.
- Может легко воспроизводить таблицы и их содержимое.
- Мощная многоязычная поддержка.
- Высокая степень точности.

- Многопользовательский доступ требует многократного лицензирования.
- Нет инструмента для объединения нескольких файлов в один документ.
OmniPage Ultimate упрощает преобразование документов в редактируемые, доступные для поиска и совместно используемые аналоги. OmniPage оптимизирует рабочие процессы документов для предприятий и позволяет владельцам бизнеса легко оцифровывать файлы с высокой точностью. Он может преобразовывать критически важные для бизнеса документы в редактируемые форматы и отправлять их в предварительно запрограммированные бизнес-процессы. Кроме того, решение OCR может направлять несколько файлов в любую корпоративную сеть, будь то общедоступная или частная.
Top включает- Индексация
- Переработка партии
- РЕДАЛИРОВАНИЕ ТЕКСТРА
- Предварительная обработка изображения
- FUNCALE 9002SINTION 9002SIMILINTION 9002SIMILINTION 9002SIMILINTION 9002SLINTIAL 9002SINTION 9002. доступна по цене 499 долларов США за одну лицензию, которую можно установить не более чем на 2 компьютера с ОС Windows. Плюсы
- Удобный пользовательский интерфейс.
- Обучаемый двигатель.
- Делает возможной автоматизацию.
- Склонен к зависанию и отставанию из-за низкой скорости обработки.
- Точность снижается при вводе данных с низким разрешением.
Google Doc AI позволяет пользователям обрабатывать различные документы, включая PDF-файлы, счета-фактуры, платежные формы и другие типы файлов. Он использует алгоритмы искусственного интеллекта для достижения более высокой точности данных и сокращения количества ручных проверок человеком. Вы можете сократить расходы на обработку, обеспечить соблюдение законодательства и извлечь ценную информацию из нескольких документов, чтобы повысить качество обслуживания клиентов всего за несколько кликов.
Основные функции Программное обеспечение может обрабатывать до миллиардов документов ежедневно, а технология компьютерного зрения, встроенная в платформу, позволяет пользователям читать и сканировать информацию из отсканированных изображений и неструктурированных текстов. Пользователи могут добавлять отзывы людей, чтобы повысить точность извлечения данных для моделей ИИ, применять проверку данных и пользовательские функции синтаксического анализа.- Интеграция проанализированных данных с Google Graph
- Многоязычная поддержка
- Обогащение данных в документах с помощью интеллектуального анализа
- Преобразование в PDF и работа с различными облачными продуктами разделитель документов
- Обратная связь Human in the Loop (HITL)
- Цены начинаются с 65 долларов США за 1000 страниц
- Простота использования благодаря поддержке масштабирования и высококачественному анализу данных
- Устранение человеческих ошибок и автоматизация ручных процессов документирования
- Обеспечивает многоязычную поддержку и использует глубокое обучение для распознавания более 200 языков.
- Быстрая и простая интеграция с облачной экосистемой.
- Настройка существующих API может занять много времени и усилий
- Постоянная потребность во вмешательстве человека для обучения модели ИИ
9. ТессерактТессеракт был разработан HP и поддерживается Google. Этот инструмент OCR на основе Python обещает высокую точность текста. Tesseract также является механизмом OCR с открытым исходным кодом, который использует обученные модели LSTM для точного извлечения и интерпретации информации из различных документов. Он предлагает поддержку устаревших приложений и имеет основной репозиторий, расположенный на Github. Его более поздние версии включают специальные функции, такие как анализ макета, ввод изображений, многоколоночный текст, уравнения и т. д.
Основные характеристики- Оптическое распознавание символов с открытым исходным кодом
- Извлечение данных
Tesseract — это инструмент с открытым исходным кодом, который абсолютно бесплатный.
Профи- Бесплатное распознавание символов с открытым исходным кодом.
- Превосходное распознавание алфавита даже рукописного содержимого.
- Использует технологии глубокого обучения для извлечения данных.
- Цифры могут быть искажены.
- Требуются технические знания высокого уровня.
- Поскольку это оптическое распознавание командной строки, в нем отсутствует графический интерфейс.
Полностью управляемый сервис машинного обучения Amazon автоматически извлекает полезные данные из массива входных данных. В Amazon Textract есть специальная функция, известная как Selective Context Attentional Scene Text Recognizer (SCATTER), которая использует технологию компьютерного зрения для распознавания текста на фоне сложных отсканированных изображений. Он может обнаруживать различные символы валюты, символы, строки и столбцы в больших таблицах, а также считывать данные из различных форм в высоком разрешении.
Top Features- Cloud-based application
- Form extraction
- Table extraction
- Handwriting recognition
- Bound boxes
- Workflow management
The company also offers 1000 free pages per month за первые три месяца.
Комплекты Textract OCR стоят от 0,60 до 1,50 долларов за 1000 страниц. Эта цена зависит от потребления и географического положения.
Pros- Отлично подходит для автоматизации процессов.
- Сочетает OCR с искусственным интеллектом.
- Гибкая модель выставления счетов.
- Необходимо повысить точность.
- Он может работать не так, как ожидалось, для разных типов данных.
OCR-решения для бизнеса способны просматривать огромные объемы данных и извлекать из них ключевую информацию.
1. Повышенная производительность OCR для предприятий используется для автоматизации основных бизнес-процессов, когда речь идет об управлении документооборотом, и предлагает следующие преимущества:
Программное обеспечение OCR может извлекать данные из нескольких источников, сортировать и систематизировать их. Сотрудники могут сэкономить время и усилия, затрачиваемые на ручную обработку, за счет автоматизации ввода данных с помощью этих инструментов.
2. Сокращение эксплуатационных расходов
Предприятиям не нужно оплачивать дополнительные расходы при внесении исправлений или беспокоиться о человеческих ошибках при обработке документов с помощью решений OCR. Решения OCR заменяют бумажные документы электронными версиями, что означает, что пользователи экономят место в физическом хранилище и надежно резервируют данные в облаке. Сокращение затрат на физическое хранение документов приводит к снижению затрат на доставку и большей экономии на печати, логистике цепочки поставок, этикетках и т.
3. Превосходное соответствие данных и безопасность д.
Бумажные документы могут быть легко украдены, потеряны или повреждены в процессе их совместного использования и транспортировки. Кроме того, они страдают от проблем с соблюдением правовых и нормативных требований, что является еще одним аспектом решений OCR, таким образом заботясь о конфиденциальности и безопасности данных пользователей.
Какое место занимает Docsumo среди всего программного обеспечения OCR?Docsumo — это конкурентоспособное решение для сбора данных, которое считается одним из ключевых игроков в индустрии интеллектуального распознавания текста. Ниже приведен список причин, по которым Docsumo отличается от других решений OCR:
1. Обнаружение мошенничества с документами в режиме реального времени
Будь то отсканированное изображение, фотография на фотографии, PDF-файл или обработанный фотошопом документ, Docsumo может обнаруживать схемы мошенничества в различных документах в режиме реального времени и обеспечивать достоверность данных.
2. Простота настройки взято из подлинных источников.
Для настройки и запуска Docsumo не требуются месяцы. Docsumo не заставляет пользователей придерживаться конкретных моделей ценообразования и использует подход с оплатой по факту использования, когда речь идет о подписках. Вы извлекаете столько документов, сколько хотите, обрабатываете их, а платформа взимает плату в зависимости от потребления пользователем.
3. Проверка документов и аналитика
Пользователи могут настраивать собственные правила синтаксического анализа с помощью Docsumo и пользоваться дополнительными преимуществами прогнозной аналитики, извлекая информацию из данных. Платформа может классифицировать элементы построчно и предоставляет более 100 различных показателей, которые бизнес может использовать для анализа извлеченных данных.
4. Обучение и адаптация клиентов
Docsumo предлагает новым пользователям бесплатную демоверсию на официальном сайте и помогает компаниям пройти адаптацию всего за 2–3 сеанса.
5. STP в обработке документов Платформа очень интуитивно понятна, удобна для начинающих, и клиентам легко ориентироваться в пользовательском интерфейсе.
Для страхования, юридических услуг, недвижимости, логистики и других отраслей промышленности Docsumo позволяет предприятиям достичь более 90% автоматизации STP и использовать настраиваемые правила для своих рабочих процессов управления документами. .
6. Отличная поддержка клиентов
Служба поддержки клиентов Docsumo очень надежна и доступна круглосуточно. В отличие от других платформ OCR, пользователи могут задавать свои вопросы через чат и быстро получать ответы на свои вопросы.
Есть ли бесплатные альтернативы?Для тех, кто ищет бесплатные решения для сканирования и сбора данных, Docsumo предлагает расширение Google Chrome и бесплатный инструмент OCR , который позволяет пользователям сканировать и оцифровывать документы с веб-сайтов, блогов и различных онлайн-источников.
Заключительные мысли . Другие отраслевые альтернативы включают SimpleOCR, VueScan, Boxoft Free OCR и Microsoft OneNote. С помощью высококлассного OCR-инструмента вы можете извлекать важную информацию даже из документов, которые плохо читаются компьютером. Эти программные приложения делают хранение, совместное использование и редактирование данных чрезвычайно простыми.
Для базового использования вы можете выбрать такие инструменты, как Microsoft Lens и SimpleOCR, однако, если у вас есть нишевые и профессиональные требования, для этой работы больше подходят специализированные решения, такие как ABBY Flexicapture, Docsumo или Docparser.
Приятного изучения!
Что такое OCR? — Объяснение оптического распознавания символов
Что такое OCR (оптическое распознавание символов)?
Оптическое распознавание символов (OCR) — это процесс преобразования изображения текста в машиночитаемый формат текста. Например, если вы сканируете форму или квитанцию, ваш компьютер сохраняет отсканированное изображение в виде файла изображения.
Вы не можете использовать текстовый редактор для редактирования, поиска или подсчета слов в файле изображения. Однако вы можете использовать OCR для преобразования изображения в текстовый документ с его содержимым, сохраненным в виде текстовых данных.Почему оптическое распознавание символов важно?
Большинство бизнес-процессов связаны с получением информации из печатных СМИ. Бумажные формы, счета-фактуры, отсканированные юридические документы и распечатанные контракты — все это часть бизнес-процессов. Эти большие объемы документов требуют много времени и места для хранения и управления. Хотя безбумажное управление документами — это путь, сканирование документа в изображение создает проблемы. Процесс требует ручного вмешательства и может быть утомительным и медленным.
Кроме того, при оцифровке содержимого этого документа создаются файлы изображений со скрытым в них текстом. Текст в изображениях не может обрабатываться программным обеспечением для обработки текстов так же, как текстовые документы.
Технология оптического распознавания символов решает проблему путем преобразования текстовых изображений в текстовые данные, которые можно анализировать с помощью другого программного обеспечения для бизнеса. Затем вы можете использовать данные для проведения аналитики, оптимизации операций, автоматизации процессов и повышения производительности.Как работает OCR?
Механизм OCR или программное обеспечение OCR работают, используя следующие шаги:
Получение изображения
Сканер считывает документы и преобразует их в двоичные данные. Программное обеспечение OCR анализирует отсканированное изображение и классифицирует светлые области как фон, а темные области — как текст.
Предварительная обработка
Программа OCR сначала очищает изображение и удаляет ошибки, чтобы подготовить его к чтению. Вот некоторые из его методов очистки:
- Слегка выравнивание или наклон отсканированного документа для устранения проблем с выравниванием во время сканирования.
- Очистка или удаление пятен цифрового изображения или сглаживание краев текстовых изображений.
- Очистка прямоугольников и линий на изображении.
- Распознавание сценариев для многоязычной технологии OCR
Распознавание текста
Два основных типа алгоритмов оптического распознавания символов или программных процессов, используемых программным обеспечением оптического распознавания символов для распознавания текста, называются сопоставлением с образцом и извлечением признаков.
Сопоставление с образцом
Сопоставление с образцом работает путем выделения изображения символа, называемого глифом, и сравнения его с аналогичным сохраненным глифом. Распознавание образов работает, только если сохраненный глиф имеет тот же шрифт и масштаб, что и входной глиф. Этот метод хорошо работает с отсканированными изображениями документов, напечатанных известным шрифтом.
Извлечение признаков
Извлечение признаков разбивает или разлагает глифы на элементы, такие как линии, замкнутые контуры, направление линий и пересечения линий.
Затем он использует эти функции для поиска наилучшего совпадения или ближайшего соседа среди различных сохраненных глифов.Постобработка
После анализа система преобразует извлеченные текстовые данные в компьютеризированный файл. Некоторые системы OCR могут создавать аннотированные PDF-файлы, включающие как предыдущую, так и последующую версии отсканированного документа.
Какие существуют типы OCR?
Исследователи данных классифицируют различные типы технологий оптического распознавания символов в зависимости от их использования и применения. Ниже приведены несколько примеров:
Простое программное обеспечение для оптического распознавания символов
Простое средство оптического распознавания символов работает, сохраняя множество различных шрифтов и шаблонов текстовых изображений в качестве шаблонов. Программное обеспечение OCR использует алгоритмы сопоставления с образцом для сравнения текстовых изображений посимвольно со своей внутренней базой данных.
Если система сопоставляет текст слово за словом, это называется оптическим распознаванием слов. У этого решения есть ограничения, поскольку существует практически неограниченное количество шрифтов и стилей рукописного ввода, и каждый отдельный тип не может быть захвачен и сохранен в базе данных.Программное обеспечение для интеллектуального распознавания символов
Современные системы распознавания текста используют технологию интеллектуального распознавания символов (ICR) для чтения текста так же, как это делают люди. Они используют передовые методы, которые обучают машины вести себя как люди с помощью программного обеспечения для машинного обучения. Система машинного обучения, называемая нейронной сетью, анализирует текст на многих уровнях, многократно обрабатывая изображение. Он ищет различные атрибуты изображения, такие как кривые, линии, пересечения и петли, и объединяет результаты всех этих различных уровней анализа для получения окончательного результата. Несмотря на то, что ICR обычно обрабатывает изображения по одному символу за раз, процесс выполняется быстро, а результаты получаются за секунды.
Интеллектуальное распознавание слов
Интеллектуальные системы распознавания слов работают по тем же принципам, что и ICR, но обрабатывают изображения целых слов вместо предварительной обработки изображений в символы.
Оптическое распознавание меток
Оптическое распознавание меток идентифицирует логотипы, водяные знаки и другие текстовые символы в документе.
Каковы преимущества OCR?
Исследователи данных классифицируют различные типы технологий оптического распознавания символов в зависимости от их использования и применения. Вот несколько примеров:
Простое программное обеспечение для оптического распознавания символов
Простой механизм оптического распознавания символов работает, сохраняя множество различных шрифтов и шаблонов текстовых изображений в качестве шаблонов. Программное обеспечение OCR использует алгоритмы сопоставления с образцом для сравнения текстовых изображений посимвольно со своей внутренней базой данных.
Если система сопоставляет текст слово за словом, это называется оптическим распознаванием слов. У этого решения есть ограничения, поскольку существует практически неограниченное количество шрифтов и стилей рукописного ввода, и каждый отдельный тип не может быть захвачен и сохранен в базе данных.Программное обеспечение для интеллектуального распознавания символов
Современные системы распознавания текста используют технологию интеллектуального распознавания символов (ICR) для чтения текста так же, как это делают люди. Они используют передовые методы, которые обучают машины вести себя как люди с помощью программного обеспечения для машинного обучения. Система машинного обучения, называемая нейронной сетью, анализирует текст на многих уровнях, многократно обрабатывая изображение. Он ищет различные атрибуты изображения, такие как кривые, линии, пересечения и петли, и объединяет результаты всех этих различных уровней анализа для получения окончательного результата. Несмотря на то, что ICR обычно обрабатывает изображения по одному символу за раз, процесс выполняется быстро, а результаты получаются за секунды.
Интеллектуальное распознавание слов
Интеллектуальные системы распознавания слов работают по тем же принципам, что и ICR, но обрабатывают изображения целых слов вместо предварительной обработки изображений в символы.
Оптическое распознавание меток
Оптическое распознавание меток идентифицирует логотипы, водяные знаки и другие текстовые символы в документе.
Каковы преимущества OCR?
Ниже перечислены основные преимущества технологии OCR:
Текст с возможностью поиска
Предприятия могут преобразовать свои существующие и новые документы в полностью доступный для поиска архив знаний. Они также могут автоматически обрабатывать текстовую базу данных с помощью программного обеспечения для анализа данных для дальнейшей обработки знаний.
Операционная эффективность
Вы можете повысить эффективность, используя программное обеспечение OCR для автоматической интеграции рабочих процессов документов и цифровых рабочих процессов в вашем бизнесе.
Вот несколько примеров возможностей программного обеспечения OCR:- Сканирование заполненных вручную форм для автоматической проверки, просмотра, редактирования и анализа. Это экономит время, необходимое для ручной обработки документов и ввода данных.
- Найдите нужные документы, быстро выполнив поиск термина в базе данных, чтобы вам не приходилось вручную сортировать файлы в ящике.
- Преобразование рукописных заметок в редактируемые тексты и документы.
Решения искусственного интеллекта
OCR часто является частью других решений искусственного интеллекта, которые могут внедрять предприятия. Например, он сканирует и считывает номерные знаки и дорожные знаки в беспилотных автомобилях, обнаруживает логотипы брендов в сообщениях в социальных сетях или идентифицирует упаковки продуктов на рекламных изображениях. Такая технология искусственного интеллекта помогает предприятиям принимать более эффективные маркетинговые и операционные решения, которые сокращают расходы и улучшают качество обслуживания клиентов.
Для чего используется OCR?
Ниже приведены некоторые распространенные варианты использования OCR в различных отраслях:
Банковское дело
В банковской сфере OCR используется для обработки и проверки документов по кредитным документам, депозитным чекам и другим финансовым транзакциям. Эта проверка улучшила предотвращение мошенничества и повысила безопасность транзакций. Например, BlueVine — компания, занимающаяся финансовыми технологиями, которая предоставляет финансирование малому и среднему бизнесу. Компания использовала Amazon Textract, облачный сервис OCR, для разработки продукта для малого бизнеса в США, позволяющего быстро получать кредиты по программе защиты зарплаты (PPP) в рамках борьбы с COVID-19.пакет стимулирующих мер. Amazon Textract автоматически обрабатывал и анализировал десятки тысяч форм PPP в день, чтобы BlueVine могла помочь нескольким тысячам предприятий получить средства, сократив при этом более 400 000 рабочих мест.
Здравоохранение
Отрасль здравоохранения использует OCR для обработки записей пациентов, включая лечение, анализы, больничные записи и страховые выплаты.
OCR помогает оптимизировать рабочий процесс и сократить объем ручной работы в больницах, сохраняя записи в актуальном состоянии. Например, группа nib предоставляет медицинскую страховку более чем 1 миллиону австралийцев и получает тысячи медицинских заявлений в день. Его клиенты могут сфотографировать свой медицинский счет и отправить их через мобильное приложение nib. Amazon Textract автоматически обрабатывает эти изображения, чтобы компания могла утверждать заявки гораздо быстрее.Логистика
Логистические компании используют OCR для более эффективного отслеживания этикеток на упаковках, счетов-фактур, квитанций и других документов. Например, Foresight Group использует Amazon Textract для автоматизации обработки счетов в SAP. Ввод этих бизнес-документов вручную отнимал много времени и приводил к ошибкам, поскольку сотрудникам Foresight приходилось вводить данные в несколько учетных систем. Благодаря Amazon Textract программное обеспечение Foresight может более точно считывать символы в различных макетах, что повышает эффективность бизнеса.
 доступна по цене 499 долларов США за одну лицензию, которую можно установить не более чем на 2 компьютера с ОС Windows. Плюсы
доступна по цене 499 долларов США за одну лицензию, которую можно установить не более чем на 2 компьютера с ОС Windows. Плюсы  Программное обеспечение может обрабатывать до миллиардов документов ежедневно, а технология компьютерного зрения, встроенная в платформу, позволяет пользователям читать и сканировать информацию из отсканированных изображений и неструктурированных текстов. Пользователи могут добавлять отзывы людей, чтобы повысить точность извлечения данных для моделей ИИ, применять проверку данных и пользовательские функции синтаксического анализа.
Программное обеспечение может обрабатывать до миллиардов документов ежедневно, а технология компьютерного зрения, встроенная в платформу, позволяет пользователям читать и сканировать информацию из отсканированных изображений и неструктурированных текстов. Пользователи могут добавлять отзывы людей, чтобы повысить точность извлечения данных для моделей ИИ, применять проверку данных и пользовательские функции синтаксического анализа.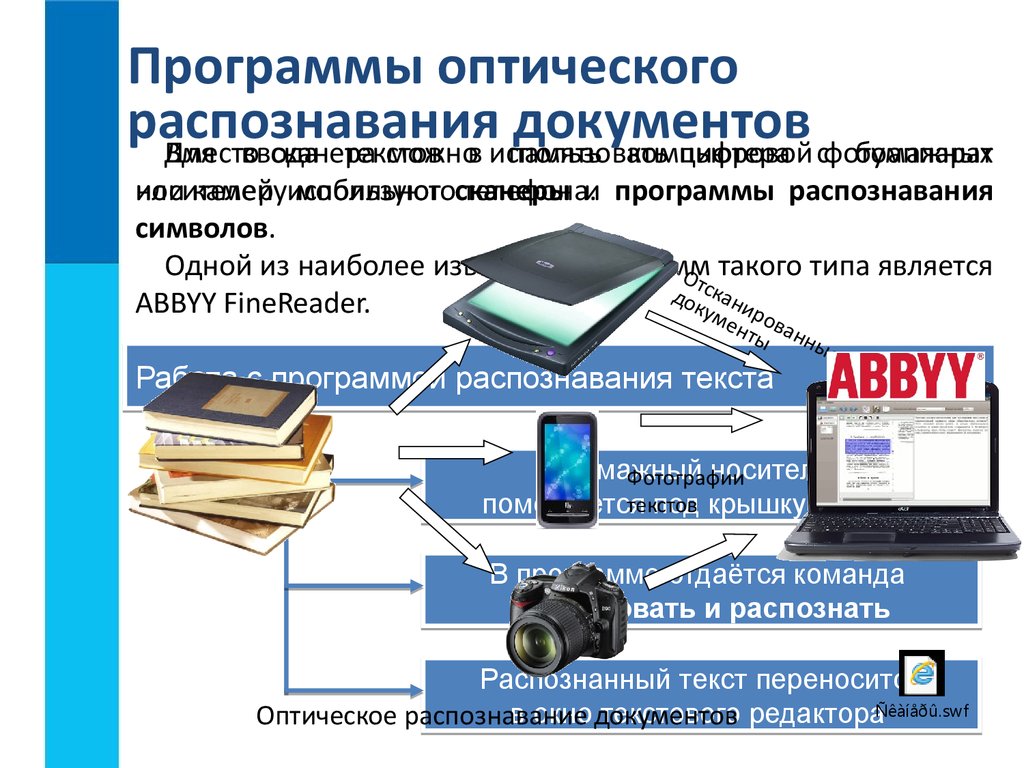


 OCR для предприятий используется для автоматизации основных бизнес-процессов, когда речь идет об управлении документооборотом, и предлагает следующие преимущества:
OCR для предприятий используется для автоматизации основных бизнес-процессов, когда речь идет об управлении документооборотом, и предлагает следующие преимущества:  д.
д.  взято из подлинных источников.
взято из подлинных источников.  Платформа очень интуитивно понятна, удобна для начинающих, и клиентам легко ориентироваться в пользовательском интерфейсе.
Платформа очень интуитивно понятна, удобна для начинающих, и клиентам легко ориентироваться в пользовательском интерфейсе.  . Другие отраслевые альтернативы включают SimpleOCR, VueScan, Boxoft Free OCR и Microsoft OneNote.
. Другие отраслевые альтернативы включают SimpleOCR, VueScan, Boxoft Free OCR и Microsoft OneNote.  Вы не можете использовать текстовый редактор для редактирования, поиска или подсчета слов в файле изображения. Однако вы можете использовать OCR для преобразования изображения в текстовый документ с его содержимым, сохраненным в виде текстовых данных.
Вы не можете использовать текстовый редактор для редактирования, поиска или подсчета слов в файле изображения. Однако вы можете использовать OCR для преобразования изображения в текстовый документ с его содержимым, сохраненным в виде текстовых данных. Технология оптического распознавания символов решает проблему путем преобразования текстовых изображений в текстовые данные, которые можно анализировать с помощью другого программного обеспечения для бизнеса. Затем вы можете использовать данные для проведения аналитики, оптимизации операций, автоматизации процессов и повышения производительности.
Технология оптического распознавания символов решает проблему путем преобразования текстовых изображений в текстовые данные, которые можно анализировать с помощью другого программного обеспечения для бизнеса. Затем вы можете использовать данные для проведения аналитики, оптимизации операций, автоматизации процессов и повышения производительности.
 Затем он использует эти функции для поиска наилучшего совпадения или ближайшего соседа среди различных сохраненных глифов.
Затем он использует эти функции для поиска наилучшего совпадения или ближайшего соседа среди различных сохраненных глифов. Если система сопоставляет текст слово за словом, это называется оптическим распознаванием слов. У этого решения есть ограничения, поскольку существует практически неограниченное количество шрифтов и стилей рукописного ввода, и каждый отдельный тип не может быть захвачен и сохранен в базе данных.
Если система сопоставляет текст слово за словом, это называется оптическим распознаванием слов. У этого решения есть ограничения, поскольку существует практически неограниченное количество шрифтов и стилей рукописного ввода, и каждый отдельный тип не может быть захвачен и сохранен в базе данных.
 Если система сопоставляет текст слово за словом, это называется оптическим распознаванием слов. У этого решения есть ограничения, поскольку существует практически неограниченное количество шрифтов и стилей рукописного ввода, и каждый отдельный тип не может быть захвачен и сохранен в базе данных.
Если система сопоставляет текст слово за словом, это называется оптическим распознаванием слов. У этого решения есть ограничения, поскольку существует практически неограниченное количество шрифтов и стилей рукописного ввода, и каждый отдельный тип не может быть захвачен и сохранен в базе данных.
 Вот несколько примеров возможностей программного обеспечения OCR:
Вот несколько примеров возможностей программного обеспечения OCR:
 OCR помогает оптимизировать рабочий процесс и сократить объем ручной работы в больницах, сохраняя записи в актуальном состоянии. Например, группа nib предоставляет медицинскую страховку более чем 1 миллиону австралийцев и получает тысячи медицинских заявлений в день. Его клиенты могут сфотографировать свой медицинский счет и отправить их через мобильное приложение nib. Amazon Textract автоматически обрабатывает эти изображения, чтобы компания могла утверждать заявки гораздо быстрее.
OCR помогает оптимизировать рабочий процесс и сократить объем ручной работы в больницах, сохраняя записи в актуальном состоянии. Например, группа nib предоставляет медицинскую страховку более чем 1 миллиону австралийцев и получает тысячи медицинских заявлений в день. Его клиенты могут сфотографировать свой медицинский счет и отправить их через мобильное приложение nib. Amazon Textract автоматически обрабатывает эти изображения, чтобы компания могла утверждать заявки гораздо быстрее.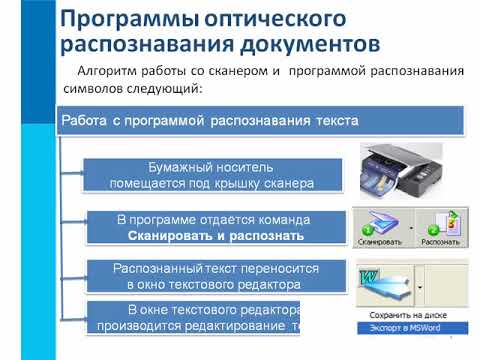
Ваш комментарий будет первым