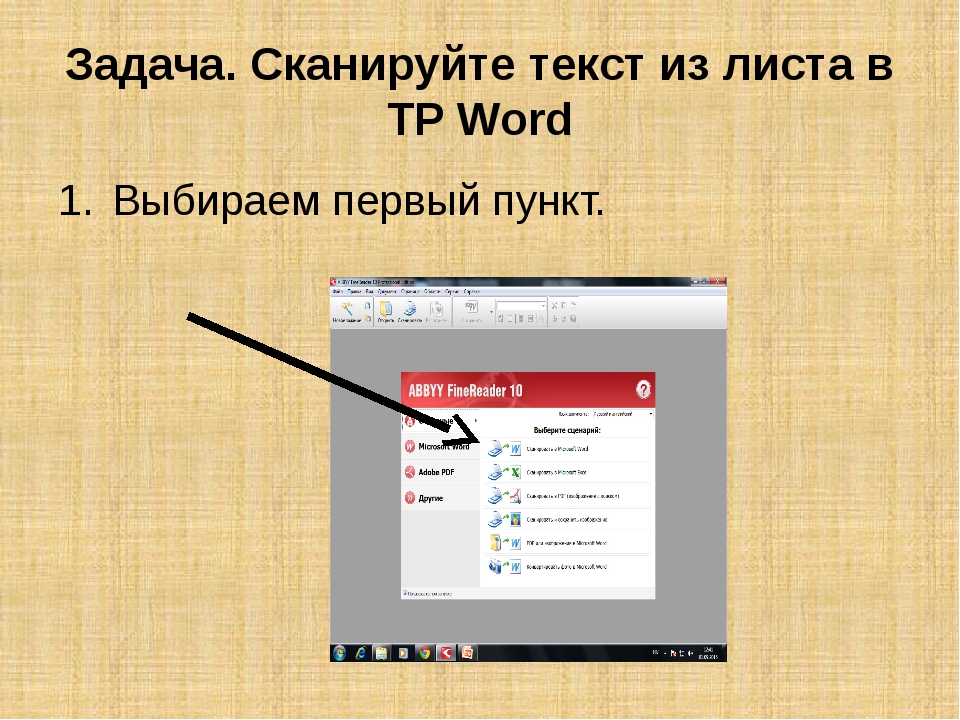
Программы для распознавания текста
Зачем нужны программы распознавания текста.
Программы распознавания текста позволяют работать с отсканированными изображениями. С их помощью выполняется редактирование информации, исправление ошибок, сохранение данных в нужном формате и т.д.
Как работает сканер.
Чтобы лучше понять ценность упомянутых программ разберемся с тем, как работает сканер. Механизм устройства помещен в корпус, верхняя часть которого представлена стеклом. Внутри находится яркая лампа и зеркала. Именно они отвечают за «фотографирование» источника для сканирования. При этом шрифт и изображения считываются в виде цветных, серых или черно-белых точек (в зависимости от модели устройства). А за распознавание текста и картинок отвечает драйвер сканера.
Полученное изображение является своеобразной фотографией исходного источника, будь то разворот книги, лист формата A4 или справка.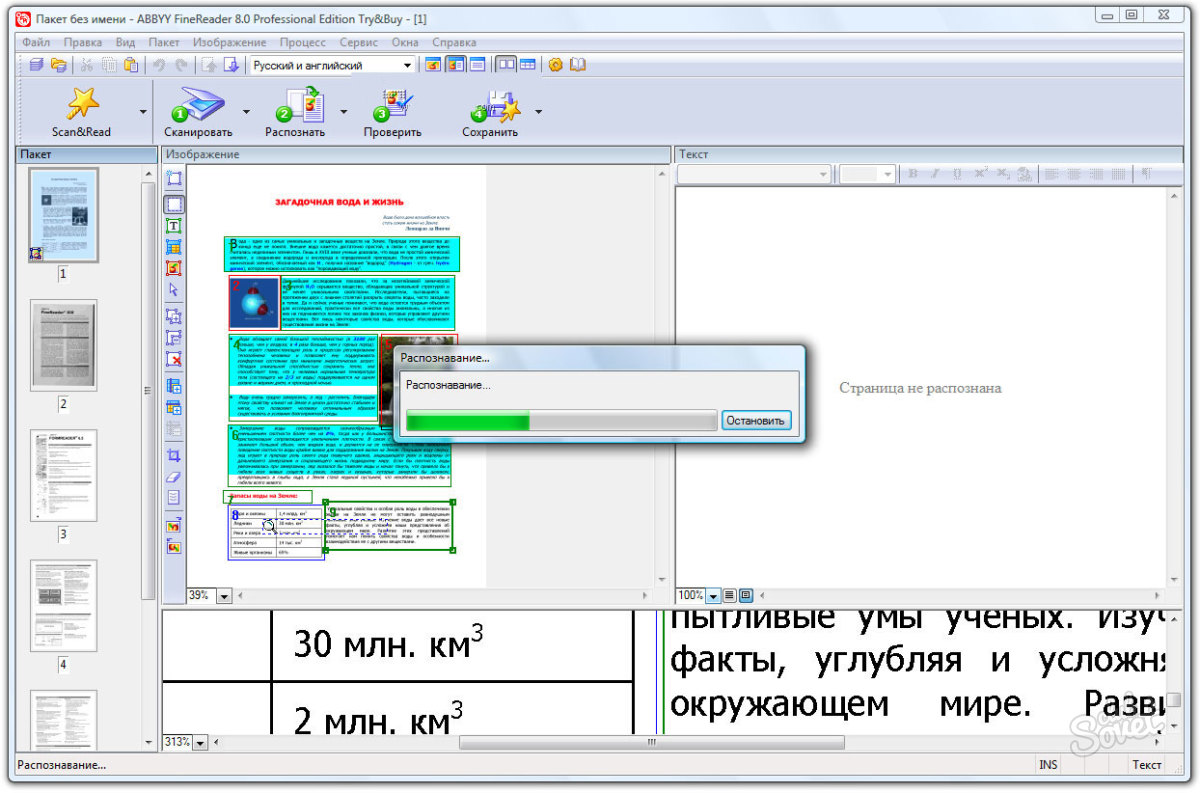
Для наглядности рассмотрим пример. Допустим, вам нужно вставить большой кусок текста из книги в дипломную работу. Чтобы не тратить время на перепечатывание с листа, страницы можно отсканировать. Однако этого недостаточно, поскольку вы получите файлы-картинки, которые не подойдут для использования в Microsoft Word. С помощью программ для распознавания текста пользователь отредактирует полученное изображение и сможет вставить информацию в текстовый редактор.
Возможности современных программ для распознавания текста.
Если предстоит сканирование листов с четко прописанными буквами, читабельным, ярким шрифтом, то с такой задачей справится любой сканер. Куда хуже обстоит дело, если речь идет о таких носителях информации, как старые, потрепанные листы бумаги или пожелтевшие газеты. Не каждый драйвер сможет идентифицировать подобный текст, а потому возможности специальной программы придутся как нельзя кстати.
Отдельные программы предоставляют даже такие эксклюзивные возможности, как правка рукописного текста. Правда, для этого нужно, чтобы разрешение картинки было не меньше 300 точек на дюйм. Кроме того, буквы в строке должны быть примерно одной высоты, одного наклона и написаны как можно аккуратнее.
Функцию распознавания рукописного текста поддерживают такие программы, как ABBYY FineReader, CuneiForm (бесплатная утилита), MyScript Stylus, SimpleOCR и другие. Помимо русских символов они идентифицируют буквы, написанные на иностранном языке. Кроме того, программы распознают таблицы и рисунки, перенося их в компьютер для последующего редактирования.
Таким образом, ни один современный пользователь ПК, имеющий сканер, не обойдется без программы распознавания текста. Выбор платных и бесплатных утилит позволит выбрать то, что отвечает именно вашим запросам с точки зрения функциональности.
Программы оптического распознавания документов — урок. Информатика, 7 класс.
Очень часто появляется необходимость перевести в электронный вид текст каких-то документов, или даже книг. Можно затратить определённое время и просто набрать этот текст с помощью клавиатуры. Но, чем больше исходный текст, тем больше времени будет затрачено на его ввод в память компьютера.
Поэтому для ввода текстов в память компьютера с бумажных носителей используют сканеры и программы распознавания символов.
После обработки документа сканером получается графическое изображение документа (графический образ). Но графический образ еще не является текстовым документом. Человеку достаточно взглянуть на лист бумаги с текстом, чтобы понять, что на нем написано. С точки зрения компьютера, документ после сканирования превращается в набор разноцветных точек, а вовсе не в текстовый документ.
Проблема распознавания текста в составе точечного графического изображения является весьма сложной. Подобные задачи решают с помощью специальных программных средств, называемых средствами распознавания образов.
Подобные задачи решают с помощью специальных программных средств, называемых средствами распознавания образов.
Наиболее широко известна и распространена такая программа отечественных производителей — ABBY FineReader.
Эта программа предназначена для распознавания текстов на русском, английском, немецком, украинском, французском и многих других языках (на 179 языках), а также для распознавания смешанных двуязычных текстов.
Возможности программы ABBY FineReader:
- Работает с разными моделями сканеров.
- Позволяет из бумажных документов, PDF-файлов и цифровых фото сделать редактируемый текст.
- Позволяет объединять сканирование и распознавание в одну операцию, работать с пакетами документов (многостраничными документами) и с бланками.
- Позволяет редактировать распознанный текст и проверять его орфографию.
- Сохраняет внешний вид документа, а также его структуру, то есть, расположение слов, абзацев, таблиц, изображений, заголовков и нумерация страниц останутся такими же, как и в оригинале.

- Экспортирует тексты в Word, Excel, PowerPoint или Outlook.

Преобразование бумажного документа в электронный вид происходит в пять этапов. Каждый из этих этапов программа FineReader может выполнять как автоматически, так и под контролем пользователя. Если все этапы проводятся автоматически, то преобразование документа происходит за один прием.
Пять этапов процесса обработки документа с помощью программы ABBY FineReader:
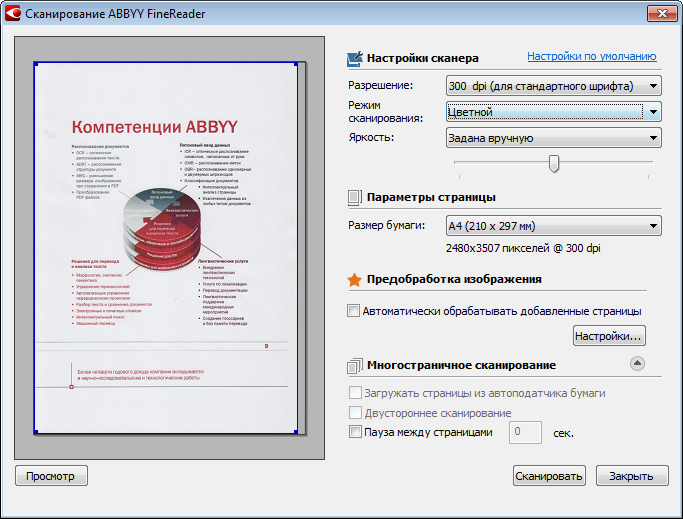
- Сканирование документа (кнопка Сканировать).
- Сегментация документа (кнопка Сегментировать).
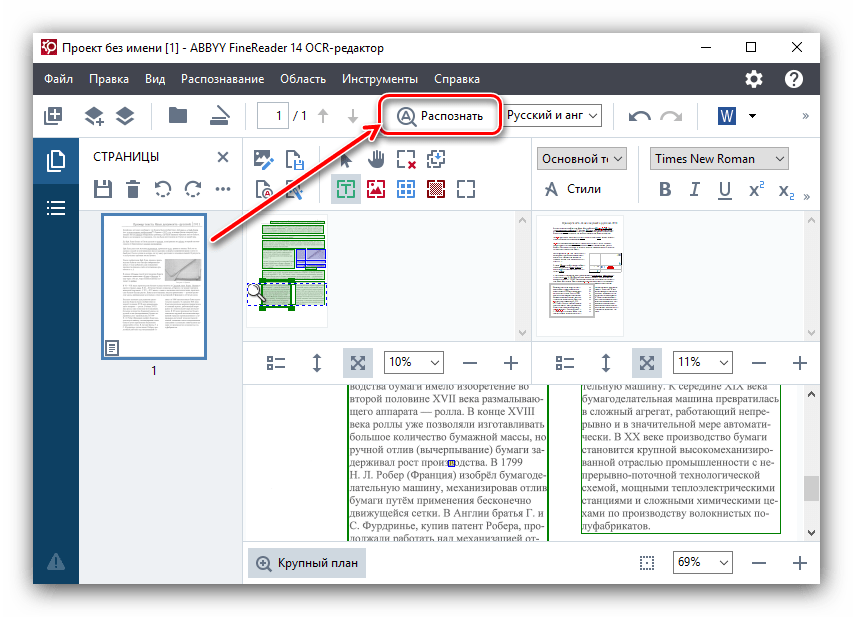
- Распознавание документа (кнопка Распознать).
- Редактирование и проверка результата (кнопка Проверить).
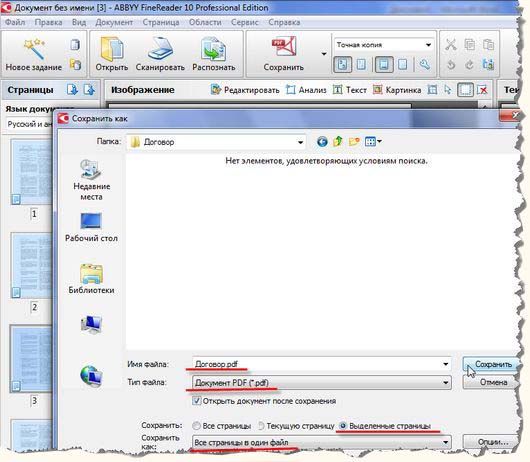
- Сохранение документа (кнопка Сохранить).
1) На этапе сканирования производится получение изображений при помощи сканера и сохранение их в виде, удобном для последующей обработки. Чтобы начать сканирование, надо включить сканер и щелкнуть на кнопке Сканировать.
Чтобы начать сканирование, надо включить сканер и щелкнуть на кнопке Сканировать.
2) Второй этап работы — сегментация, разбиение страницы на блоки текста. Если страница содержит колонки, иллюстрации, врезки, подрисуночные подписи или таблицы, то порядок распознавания требует коррекции. Содержимое страницы разбивается на блоки, внутри каждого из которых распознавание осуществляется в естественном порядке. Блоки нумеруются, исходя из порядка включения их в документ. При автоматической сегментации (кнопка Сегментировать) определение границ блоков осуществляется автоматически. При этом учитываются поля документа, просветы между колонками, рамки.
3) Процесс распознавания текста после сегментации начинается с щелчка на кнопке Распознать и полностью автоматизирован.
4) Когда распознавание данной страницы завершается, полученный текстовый документ отображается в окне Текст. Заключительные этапы работы позволяют отредактировать полученный текст с помощью средств, напоминающих текстовый редактор WordPad.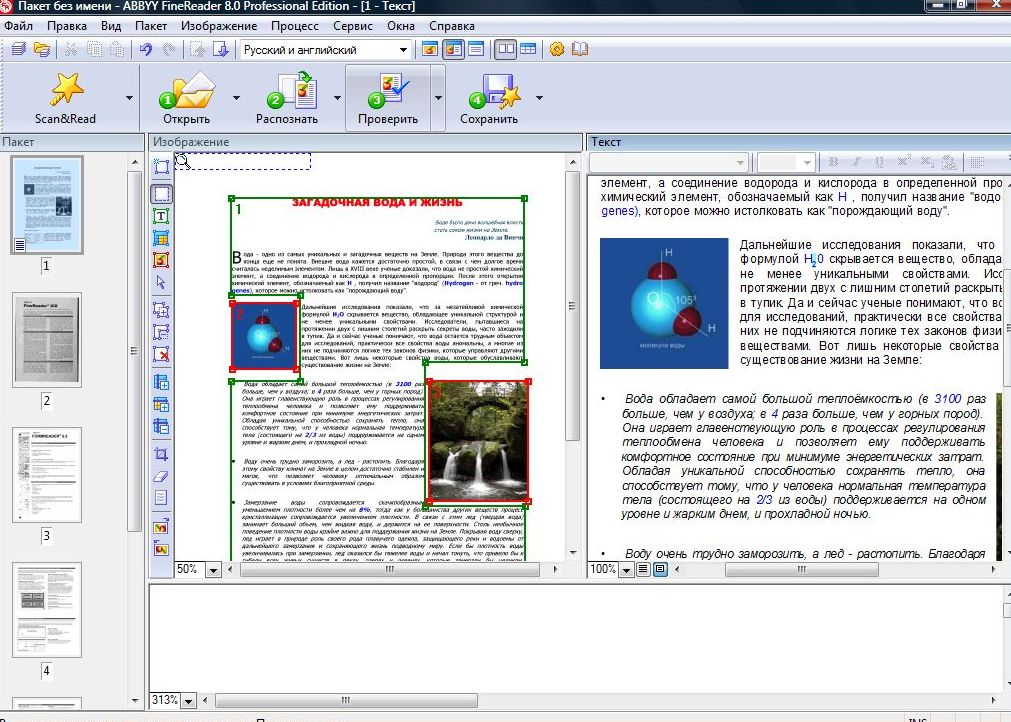 Провести проверку орфографии с учетом трудностей распознавания позволяет кнопка Проверить.
Провести проверку орфографии с учетом трудностей распознавания позволяет кнопка Проверить.
5) По щелчку на кнопке Сохранить запускается Мастер сохранения результатов. Он позволяет сохранить распознанный текст или передать его в другую программу (например, в Microsoft Word) для последующей обработки полученный текст можно сохранить в виде форматированного или неформатированного документа.
Глава 18 Система распознавания текста FineReader
Система
распознавания
одна из
наиболее
перспективных
областей
применения
искусственного
интеллекта.
Существует
решение,
максимально
приближенное
к
человеческой
способности
читать: оно
построено на
принципах,
сформулированных
в результате
наблюдений
за
поведением
животных и человека.
Это
технология
целостного,
целенаправленного
и
адаптивного
восприятия.
Процесс обработки FineReader осуществляется в несколько этапов:
1. Сканирование.
2. Выделение блоков на изображении.
3. Распознавание.
Затем нужно проверить ошибки и сохранить результат распознавания (передать его в другое приложение, например в текстовый редактор WORD, в Буфер и т.п.).
FineReader это система оптического распознавания текстов. Она преобразует полученное с помощью сканера графическое изображение (картинку) в текст (то есть в коды букв, «понятные» компьютеру). Основные модификации Standard, Professional, Рукопись.
Функции, обеспечиваемые модификациями FineReader
| Функции | Standard | Professional | Рукопись |
| Типы распознаваемых текстов | Печатные |
Печатные, рукописные |
|
| Распознавание штрих-кода | нет | да | да |
| Возможность обучения новым символам | да | да | да |
Распознавание
многоколоночного
текста с
картинками
и таблицами. Сохранение
оформления
в формате RTF
Сохранение
оформления
в формате RTF |
да | да | да |
| Интернет: сохранение документа в формате HTML | да | да | да |
| Поддержка языков | |||
| Встроенная программа проверки орфографии | да | да | да |
| Распознавание многоязычных документов | да | да | да |
| Создание новых языков |
нет |
да | да |
| Распознавание таблиц | |||
| Распознавание таблиц, сохранение результатов в форматах RTF, CSV, XLS, DBF | да | да | да |
| Ручная и автоматическая сегментация таблиц | да | да | да |
| Пост-редактор распознанных таблиц | да | да | да |
В
библиотеках
следует,
конечно,
применять
профессиональные
версии
программ (это
замечание
касается
любых
программ). Если есть
возможность,
а главное
уровень
решаемых
задач, то
необходимо
приобретать
модификацию
Рукопись.
Если есть
возможность,
а главное
уровень
решаемых
задач, то
необходимо
приобретать
модификацию
Рукопись.
Библиотекарям приходится сканировать именно тексты, которые должны быть потом распознаны и превращены в текстовый файл. Если же сканер используется для выполнения платных услуг по сканированию и распознавание не требуется, то можно использовать программы, предназначенные только для сканирования и сохранения картинки.
Для большего комфорта работы необходимо, чтобы программа была связана с подключенным к ней сканером: меню Сервис Выбор сканера.
О планшетных сканерахНаиболее
универсальный
и наиболее
распространенный
тип сканера. Как правило,
обеспечивает
высокое
разрешение
при средней и
высокой
скорости
сканирования.
Как правило,
обеспечивает
высокое
разрешение
при средней и
высокой
скорости
сканирования.
Планшетные сканеры делятся на две группы:
1. Для работы в офисе и дома.
Как правило, эти сканеры обладают максимальным оптическим разрешением 300 dpi, обычно достаточным для систем распознавания текстов и проведения простых работ по вводу фотографий для любительских фотоальбомов или дизайна страниц в Интернете. Они могут подключаться через параллельный порт, собственную ISA или PSI карту, или SCSI. Обычно имеют максимальную область сканирования A4.
2. Профессиональные сканеры.
Цветные.
Оптическое
разрешение 600 dpi
и выше. Имеют SCSI
интерфейс.
Зачастую
комплектуются
модулем для
сканирования
слайдов. Область
сканирования
от Legal до A3.
Область
сканирования
от Legal до A3.
Некоторые модели сканеров могут дополнительно комплектоваться устройством автоматической подачи бумаги (Automat Document Feeder ADF). Как правило, они производятся только для моделей, имеющих либо SCSI, либо другой достаточно быстрый интерфейс с компьютером.
При выборе модели сканера необходимо обращать внимание на следующие моменты:
1. Если предполагается сканировать толстые книги, желательно, чтобы крышка сканера это позволяла не была жестко закреплена, а могла выдвигаться.
2. Если
сканер
снабжен
автоподатчиком,
необходимо
проследить,
как сканер и
его драйвер
обрабатывают
ситуацию
перекоса
бумаги в
лотке
автоподатчика. Сканер
должен
позволять
легко
разрешать
эту проблему.
Сканер
должен
позволять
легко
разрешать
эту проблему.
3. Следует обращать внимание на шум, производимый при сканировании. Некоторые дешевые сканеры довольно шумные, что может доставить массу неудобств при работе в офисе или дома.
О листовых сканерахПрименяются обычно в офисе или дома для сканирования отдельных листов. Однако существуют модели, у которых снимается нижняя часть, что позволяет сканировать книги и журналы, но при этом качество изображения, как правило, резко снижается. Из-за невысокой скорости и среднего качества изображения применяются при эпизодической работе.
До
недавнего
времени
листовые
сканеры
служили
дешевой
альтернативой
планшетным. Дополнительным
стимулом при
покупке
может
служить
экономное
использование
рабочего
пространства.
Существуют
модели для
сканирования
как черно-белых,
так и цветных
изображений.
Обычно
максимальная
область
сканирования
A 4.
Дополнительным
стимулом при
покупке
может
служить
экономное
использование
рабочего
пространства.
Существуют
модели для
сканирования
как черно-белых,
так и цветных
изображений.
Обычно
максимальная
область
сканирования
A 4.
При выборе данной модели сканера необходимо обращать внимание на следующие моменты:
1. Сканер должен легко «захватывать» бумагу из лотка.
2. Как сканер и его драйвер обрабатывают ситуацию перекоса бумаги в лотке. Сканер должен позволять легко разрешать эту проблему.
3. Часто
бывает
полезной
способность
TWAIN-драйвера
сканера
сканировать
в
автоматическом
режиме всю
стопку
документов,
вставленную
в лоток, а не
ждать
команды
после
сканирования
каждого
листа. Как
правило, эта
способность
связана с
другой не
менее важной
автоматическое
определение
того,
кончилась ли
бумага в
лотке.
Как
правило, эта
способность
связана с
другой не
менее важной
автоматическое
определение
того,
кончилась ли
бумага в
лотке.
Из-за невысокого качества получаемого изображения ручные сканеры применяются обычно дома. В отличие от других типов сканеров, позволяют получать хорошее изображение области около корешка книг в жестком переплете.
До недавнего времени они служили дешевой альтернативой планшетным сканерам.
Модели с мотором иногда позволяют достигать лучшего качества сканирования за счет более равномерного перемещения сканера.
Дополнительным
стимулом при
покупке
может
служить
экономное
использование
рабочего
пространства. Существуют
модели,
предназначенные
для
сканирования
черно-белых и
модели для
сканирования
цветных
изображений.
Обычно
максимальная
ширина
сканируемой
области 10 см.
Существуют
модели,
предназначенные
для
сканирования
черно-белых и
модели для
сканирования
цветных
изображений.
Обычно
максимальная
ширина
сканируемой
области 10 см.
При выборе модели сканера необходимо обращать внимание на следующие моменты:
1. Качество
отсканированного
изображения (лучше
всего
текста).
Качество
изображения
не должно
страдать при
более или
менее
равномерном
перемещении
сканера.
Обычно
запоминается
скорость
сканирования
на разных
этапах и
происходит
программная
компенсация
неизбежных
вертикальных
искажений.
Если драйвер
сканера не
умеет
компенсировать
вертикальные
искажения, то
получить
качественное
изображение
текста
практически
невозможно.
2. Проверьте, позволяет ли сканер указывать направление сканирования: слева направо, сверху вниз, справа налево.
3. Часто бывает полезной способность TWAIN-драйвера склеивать куски изображений. К сожалению, ею не всегда можно реально воспользоваться.
Некоторые общие советы на применение сканеров при вводе документов:1. Документация сканера и сопровождающего программного обеспечения должна быть на русском языке.
2. В документации должны быть указаны адреса центров технического обслуживания.
3. Сканер
должен иметь
в комплекте TWAIN-драйвер
совместимый
с той
операционной
системой, в
которой вы
будете его
использовать. Обычно на коробке
сканера при
этом
присутствует
логотип Twain-compliant
или Twain-compatible. Как
правило, все
современные
сканеры
имеют TWAIN-драйвер,
совместимый
с MS Windows’95, 98. Кроме
того, все
сканеры
подключаемые
через SCSI,
одинаково
успешно
работают в MS Windows’95,
98 и Windows NT 4.0.
Проблему
могут
составить
только
сканеры,
подключаемые
через
параллельный
порт или
специальные
карты, при
работе в MS Windows NT 4.0.
Обычно на коробке
сканера при
этом
присутствует
логотип Twain-compliant
или Twain-compatible. Как
правило, все
современные
сканеры
имеют TWAIN-драйвер,
совместимый
с MS Windows’95, 98. Кроме
того, все
сканеры
подключаемые
через SCSI,
одинаково
успешно
работают в MS Windows’95,
98 и Windows NT 4.0.
Проблему
могут
составить
только
сканеры,
подключаемые
через
параллельный
порт или
специальные
карты, при
работе в MS Windows NT 4.0.
4. Обратите
внимание на
диалог с
опциями
сканера,
который
возникает
перед
сканированием.
Желательно,
чтобы в этом
окне была
легко
доступна
опция выбора
типа
сканируемого
изображения (черно-белый,
серый,
цветной). В
идеале еще и
серый с 16
градациями (обычно
только с 256
градациями)
это позволит
включать
встроенный в
систему FineReader автоматический
подбор
яркости при
сканировании
в сером (обычно
серое
изображение
с 16 градациями
сканируется
быстрее за
счет
меньшего
объема
информации,
чем с 256
градациями). Возможность
работать с
серым
изображением
особенно
важна для
библиотек,
так как очень
часто
возникает
необходимость
сканирования
печатных
текстов
разного
качества (бумага,
шрифт и т.д.).
Возможность
работать с
серым
изображением
особенно
важна для
библиотек,
так как очень
часто
возникает
необходимость
сканирования
печатных
текстов
разного
качества (бумага,
шрифт и т.д.).
Окно программы
Окно программы FineReader имеет сложную структуру (оно разбито на несколько кадров, в которых отражаются результаты сканирования, страницы, которые необходимо распознать, результаты распознавания).
Нажмите кнопку с изображением сканера на панели инструментов (сканировать).
Вы
можете
добавлять
отсканированные
страницы в
пакет, по
умолчанию
создаваемый
при запуске
программы,
или открыть
другой пакет (нажмите
кнопку) и
записывать
отсканированные
страницы в
него.
Нажмите стрелку справа от кнопки и из локального меню выберите пункт Сканировать и распознать.
Система отсканирует изображение, выделит на нем блоки, а затем распознает его.
Если у Вас отмечен пункт Открывать последний пакет (меню Сервис, пункт Опции…, закладка Установки), то при загрузке программа будет открывать последний пакет, с которым вы работали в предыдущей сессии.
Параметры сканирования:
Яркость: для светлых документов необходимо уменьшить яркость (сделать их темнее), для темных увеличить (сделать их светлее).
Разрешение: 300 dpi для большинства документов; 400600 dpi для документов, набранных мелким шрифтом.
Выбор разрешения это регулировка яркости у всех типов изображения.
 Часто у черно-белых
изображений
регулировка
яркости
осуществляется
не выбором
яркости (brigthness), а
выбором
порога (threshold). Это
ничем не хуже,
однако, если
вы потом
отключите
опцию Показ
диалога TWAIN-драйвера, то
скорее всего
не сможете
регулировать
яркость.
Часто у черно-белых
изображений
регулировка
яркости
осуществляется
не выбором
яркости (brigthness), а
выбором
порога (threshold). Это
ничем не хуже,
однако, если
вы потом
отключите
опцию Показ
диалога TWAIN-драйвера, то
скорее всего
не сможете
регулировать
яркость.
| Особенности входного изображения | Что сделать |
| Светлые или тонкие буквы | Уменьшить яркость (сделать темнее) |
| Темные или толстые буквы | Увеличить яркость (сделать светлее) |
| Глянцевая бумага | Уменьшить яркость |
| Слипшиеся символы | Увеличить яркость |
| Разрывы | Уменьшить яркость |
| Смазанные или заполненные контуры букв | Увеличить яркость |
Обратите
внимание на
скорость
сканирования
в режиме
черно-белого
изображения
(300 dpi). Желательно,
чтобы это
время не
превышало 12
минуты.
Желательно,
чтобы это
время не
превышало 12
минуты.
Обратите внимание на скорость сканирования в режиме цветного изображения (300 dpi). Желательно, чтобы это время не превышало 56 минут. В некоторых дешевых моделях, подключаемых через параллельный порт, это время может достигать огромных значений.
Некоторые
TWAIN-драйверы
при запуске
сканирования
показывают
окно с
сообщением о
том, что идет
разогрев (Warming ) или
калибровка (Calibrating ). Как
правило, это
занимает
около минуты.
Иногда эта
операция
происходит
при каждом
запуске
сканирования,
даже если оно
идет
практически
непрерывно
или
сканируется
предварительное
изображение (Preview). Как
утверждают
разработчики
сканеров, это
необходимо
для более
корректной
цветопередачи. Желательно,
чтобы этого
режима не
было вообще
или чтобы он
был
отключаемым.
Желательно,
чтобы этого
режима не
было вообще
или чтобы он
был
отключаемым.
Повернуть изображение
Распознаваемое изображение должно иметь стандартную ориентацию: текст должен читаться сверху вниз и строки должны быть параллельны нижнему краю экрана.
Вы можете указать программе, чтобы она автоматически подбирала ориентацию страницы.
Если ориентация не подбирается автоматически, повернуть изображение можно вручную:
1. Выделите нужные изображения.
Выделить одну страницу Нажмите на нее мышью.
Выделить несколько страниц подряд Удерживая клавишу SHIFT, нажмите мышью на первую страницу выборки, а затем на последнюю.
2. Выделить
несколько
страниц не
подряд
Выделить
несколько
страниц не
подряд
Удерживая клавишу CTRL, последовательно нажимайте на интересующие страницы.
Нажмите кнопку, с изображением направления, чтобы повернуть изображение на 90.
Из меню Изображение выберите пункт Повернуть на 180, чтобы перевернуть изображение вверх ногами.
Таким же образом можно повернуть активное открытое изображение.
Распознавание
Установка языка распознавания и типа текста:
Язык распознавания и тип текста являются главными параметрами распознавания.
Языки,
которые
имеют
словарную
поддержку:
английский,
голландский,
датский,
испанский,
итальянский,
немецкий,
норвежский,
польский,
португальский,
русский,
украинский,
финский
французский,
шведский.
При распознавании текста на том или ином языке выберите нужный язык из списка на панели Распознавание.
Если нужного языка нет в списке, то выберите значение Другой… и в открывшемся списке найдите нужный язык или выберите несколько языков, слова которых встречаются в распознаваемом тексте.
Тип текста определяется в системе автоматически. Однако для распознавания текстов, напечатанных на пишущей машинке или матричном принтере в черновом режиме, чтобы повысить надежность и скорость распознавания, выберите соответствующее значение в списке на панели инструментов.
Если
вы
распознавали
тексты,
напечатанные
на пишущей
машинке или
матричном
принтере, то
при
возвращении
к
типографскому
тексту не
забудьте
снова
выбрать
значение Авто.
Открытие изображения:
-
Меню Файл Открыть.
-
Выберите диск и папку, где находятся нужные файлы.
-
Выберите нужные файлы и нажмите OK.
-
Выбранные файлы копируются в текущий пакет.
-
Вы можете указать, чтобы выбранные изображения не копировались, а перемещались в пакет (отметьте пункт Перемещать файлы в пакет).
Тогда при загрузке в текущий пакет выбранные файлы будут копироваться туда, где находится ваш пакет и удаляться оттуда.
Также можно добавлять изображения из буфера или через drag-&-drop.
Запуск распознавания:
-
Выделите нужные страницы в окне пакета.
Подведите
курсор и
щелкните 1 раз
левой
кнопкой мыши.
-
Нажмите кнопку Распознать открытую страницу. Активизируйте открытое изображение и нажмите кнопку Распознать.
 Подведите
курсор и
щелкните 1 раз
левой
кнопкой мыши.
Подведите
курсор и
щелкните 1 раз
левой
кнопкой мыши.
Распознать все нераспознанные страницы:
-
Нажмите стрелку справа от кнопки Распознать и из открывшегося меню выберите пункт Распознать все нераспознанные страницы.
-
Программа выделяет блоки (если они еще не выделены) и распознает изображения.
Установить расположение текста на странице:
Программа
FineReader
автоматически
определяет
раскладку
текста на
странице. Для
книг, газет,
факсов,
отчетов и т. п.
подходит
положение Автоматическое
определение.
И только в
редких
случаях,
например при
распознавании
оглавлений и
листингов
программ,
нужно
специально
указывать
программе,
что текст
напечатан в
одну колонку.
п.
подходит
положение Автоматическое
определение.
И только в
редких
случаях,
например при
распознавании
оглавлений и
листингов
программ,
нужно
специально
указывать
программе,
что текст
напечатан в
одну колонку.
1. Меню Сервис Опции
2. В диалоге Опции выберите закладку Сегментация.
3. В группе Число колонок выберите пункт Одна колонка (для текста, напечатанного в одну колонку с большими промежутками между словами) или Автоматическое определение.
Сохранить результаты распознавания в файл:
1. Если Вы хотите сохранить не все страницы пакета, то выделите нужные в окне Пакет.
2. Нажмите
стрелку
справа от
кнопки Сохранить
и в
открывшемся
меню
выберите
пункт Сохранить
в файл.
3. В открывшемся диалоговом окне выберите диск, каталог и укажите имя и расширение файла, в который хотите экспортировать распознанный текст.
4. Установите переключатель Какие страницы сохранять в положение Все распознанные или Только выделенные.
5. Чтобы записывать каждую страницу в отдельный файл, отметьте пункт Записывать каждую страницу в отдельный файл. Тогда имена, которые эти файлы получат, будут состоять из заданного имени и порядкового номера (1, 2, и т.д.).
6. Нажмите OK.
Вы можете передать результаты распознавания в одно из следующих приложений: MS Word, MS Excel, Corel WordPerfect, Lotus Word Pro или PROMT:
1. Активизируйте
окно пакета (нажмите
в нем мышью) и
нажмите
стрелку
справа от
кнопки Сохранить.
Активизируйте
окно пакета (нажмите
в нем мышью) и
нажмите
стрелку
справа от
кнопки Сохранить.
2. В открывшемся меню выберите пункт Передать в Word, Передать в Excel и т.п.
Для выделенных страниц:
1. Если вы хотите передать в другое приложение не все страницы, а только некоторые, то выделите нужные страницы в окне Пакет.
2. Нажмите на стрелку справа от кнопки Сохранить и выберите пункт Мастер сохранения результатов.
3. В
открывшемся
списке
выберите
нужное
приложение и
отметьте
пункт Сохранять
только
выделенные
страницы. По
нажатию Готово
в этом
диалоге
результаты
распознавания
передаются в
выбранное
приложение.
Назад
Проверьте свои знания
РАСПОЗНАВАНИЕ ТЕКСТА. ОБЗОР ПРОГРАММ ДЛЯСКАНИРОВАНИЯ И РАСПОЗНАВАНИЯ ТЕКСТА (OCR)
ABBYY Finereader – популярная программа распознавания текста российской компании ABBYY
Finereader обеспечивает качественное распознавание и сохранение оформления документов. Существуют три версии этого пакета распознавания: Home Edition, Professional Edition и Corporate Edition, которые отличаются своими возможностями, пользовательским интерфейсом, ценой и типом лицензии.
Версия Home Edition предназначена только для домашнего использования и пригодится тем, кому время от времени
требуется получить распознанную копию страниц книги, учебника, статьи из журнала
для последующего редактирования в распространенных офисных программах. Интерфейс программы упрощен, для работы
можно выбрать один из типовых способов обработки изображения и нажатием одной кнопки быстро получить результат.
Professional и Corporate Edition имеют профессиональный интерфейс, дополнительно содержат поддержку распознавания PDF файлов, встроенный редактор текста, проверку орфографии. Corporate версия ориентирована на использование в организациях, поддерживаются сетевые сканеры и многофункциональные устройства, добавлены возможности для совместной работы пользователей.
Программа производит распознавание текста с более 180 языков, для 38 из них предусмотрена встроенная проверка орфографии. Начиная с версии Professional, распознаются иврит, японский, тайский, китайский языки. Finereader открывает файлы графических форматов (TIFF, JPG, PFD, PNG и др.) в том числе DjVu – компактный формат для хранения отсканированных документов, книг.
В версии 9.0 также есть возможность распознавания изображений, полученных с цифровых фотоаппаратов.
Обработка таких изображений имеет свои особенности, нужно скорректировать неравномерное освещение страницы,
недостаточную резкозть, изгиб строчек текста.
Купить ABBYY Finereader в интернет-магазине Ozon.ru:
ABBYY FineReader 9.0 Home Edition
ABBYY FineReader 10 Professional Edition
ABBYY FineReader 9.0 Corporate Edition
Что почитать:
А. П. Корнеев, А. А. Иванова, Р. Г. Прокди. Программа FineReader. Серия: Компьютерная шпаргалка
Подробнее о программе распознавания текста Finereader (возможности, скриншоты)…
Сканирование и распознавание. 300 лучших программ на все случаи жизни
Сканирование и распознавание
Ввести со сканера текст в компьютер – задача не слишком трудная. Однако работать с таким текстом невозможно: как и любое сканированное изображение, страница с текстом представляет собой графический файл – обычную картинку. Отсюда возникают проблемы: во-первых, в графическом формате страница занимает слишком много места, и, скажем, отсканированная книга не на каждый жесткий диск поместится. И вторая, самая главная проблема: сканированный текст можно будет только читать, но не редактировать и не вставлять его фрагменты в создаваемый вами документ. Ведь сам сканер распознавать буквы именно как буквы не умеет: они для него – всего лишь пятна и точки черного цвета.
Ведь сам сканер распознавать буквы именно как буквы не умеет: они для него – всего лишь пятна и точки черного цвета.
К счастью, на свете существуют программы, способные перевести сканированный текст из графического в текстовый формат – программы распознавания текста или OCR (Optical Character Recognition).
Современная OCR должна уметь многое: распознавать тексты, набранные не только определенными шрифтами (именно так работали распознавалки первого поколения), но и самыми экзотическими, вплоть до рукописных. Уметь корректно работать с текстами, содержащими слова на нескольких языках, корректно распознавать таблицы. И самое главное – корректно распознавать не только четко набранные тексты, но и такие, качество которых, мягко говоря, далеко от идеала. Например, текст с пожелтевшей газетной вырезки или третьей машинописной копии. Само собой, распознать текст – это еще полдела. Не менее важно обеспечить возможность сохранения результата в файле популярного текстового (или табличного) формата – скажем, формата Microsoft Word или Excel.
Как видим, для того, чтобы получить электронную, готовую к редактированию копию любого печатного текста, программе OCR необходимо выполнить «цепочку» из множества отдельных операций:
Сканирование. За эту работу отвечает, собственно, не программа OCR, а встроенное в систему программное обеспечение вашего сканера.
Сегментация. Полученную со сканера «картинку» подхватывает OCR-программа. Но до распознавания еще далеко – сначала надо отделить текстовые элементы от графики, да и текст в ряде случаев разбить на отдельные куски (например, при многоколонной верстке).
Распознавание. На этом этапе текст переводится из графической формы в текстовую.
Проверка орфографии и правка. Встроенная система проверки орфографии «проходится» по тексту, проверяя и корректируя последствия работы системы распознавания.
Сохранение. Для дальнейшей обработки документ должен быть передан «на поруки» соответствующей программе – как правило, одному из продуктов семейства Microsoft Office. Или сохранен в формате, соответствующем его содержанию: текст – в DOC или RTF, таблица – в XLS.
Или сохранен в формате, соответствующем его содержанию: текст – в DOC или RTF, таблица – в XLS.
Все эти операции в большинстве программ OCR могут выполняться как в автоматическом, с помощью программы-мастера, так и в ручном режиме, по отдельности.
С двумя первыми и последней операциями справится любая программа распознавания. А вот весь процесс целиком по зубам, увы, только нескольким продуктам, разработанным в нашей стране. Хотя в теории с русским текстом должны справляться еще несколько западных «распознавалок», качество их работы не может сравниться с CuneiForm от фирмы Cognitive и FineReader от ABBYY Software.
Обе программы вы можете приобрести отдельно или получить бесплатно вместе с купленным вами сканером. В частности, известная во всем мире компания HewlettPackard (на долю которой приходится значительная часть рынка сканеров в России) поставляет вместе со своей продукцией упрощенную версию CuneiForm.
FineReader
Сайт: http://www.abbyy. com
com
Размер: 35 140 Мб (Поставляется на CD)
Статус: Commercial
Цена: $130 (Professional), $260 (Corporate)
Именно эту программу чаще всего поминают, когда речь заходит о системах распознавания. И вполне заслуженно – компания ABBYY ( http://www.abbyy.com) смогла не просто создать удобный для пользователя и качественный продукт, но и, самое главное, удачно «раскрутить» его, обеспечив «Файнридеру» пламенную любовь всей компьютерной прессы. Одно это, согласитесь, многого стоит.
Другим удачным ходом разработчиков FineReader стало внедрение в продукт массы дополнительных функций, которые простому пользователю, возможно, и без надобности, но зато производят впечатление на определенные группы покупателей. Так, одним из козырей FineReader является поддержка неимоверного количества языков распознавания – почти 200, в числе которых вы найдете экзотические и древние языки, и даже популярные языки программирования (Basic, С/C++, COBOL, Fortran, Java, Pascal)! Так что FineReader сможет без запинки справиться с древнегреческим свитком или с бледными распечатками исходных текстов программ, сделанных вашими предками лет 30 назад.
Как ни странно, большинство пользователей на деле интересуются совсем другим. Офисных работников интересует распознавание типовых форм документов, студентов – возможность быстро «передрать» для реферата многостраничный текст из учебника, сканируя и распознавая книжный разворот целиком, бухгалтеров – возможность автоматического распознавания таблиц и документов на бланках. Все это и многое другое FineReader умеет… или не все, а только частично, в зависимости от модификации продукта. Далеко не все возможности из нашего перечня включены в самую простую модификацию программы, которую вы можете получить бесплатно вместе со сканером. Пакетное сканирование, грамотная обработка таблиц и изображений – для всего этого стоит приобрести профессиональную версию программы – FineReader Pro. Заодно она умеет безукоризненно читать штрихкоды, позволяет добавлять в базу данных новые языки. А самая мощная (и дорогостоящая) версия – FineReader Corporate без труда справится и с распознаванием любых бланков и форм! Эта версия отличается также поддержкой сетевого режима, возможностью удаленного администрирования и рядом других возможностей.
После завершения распознавания страницы FineReader предложит пользователю выбор: сканировать и распознавать дальше (для многостраничного документа) или сохранить полученный текст в одном из множества популярных форматов – от документов Microsoft Office до HTML или PDF. Можно, впрочем, сразу же перебросить документ в Word или Excel, и уже там исправить все огрехи распознавания (без них обойтись просто невозможно). При этом FineReader полностью сохраняет все особенности форматирования документов и его графическое оформление.
Данный текст является ознакомительным фрагментом.
Продолжение на ЛитРес
|
|
ABBYY FineReader: как работать
|
|
Как установить ABBYY FineReader 11
|
|
|
|
Как запустить ABBYY FineReader
|
Как настроить ABBYY FineReader 12 Professional
|
|
|
|
ABBYY FineReader — как переводить
|
<
ABBYY FineReader: как распознать текст
|
|
|
|
|
 Помимо сканирования документации программа может перевести текстовую информацию из формата Word, например, в файл PDF обратно.
Помимо сканирования документации программа может перевести текстовую информацию из формата Word, например, в файл PDF обратно.
 Инструмент для сканирования предельно точно распознает текст в выбранном печатном документе, не перенося постранично информацию. Кроме того, программа старается сохранить шрифты, колонтитулы и разметку текста на странице максимально близко к оригиналу.
Инструмент для сканирования предельно точно распознает текст в выбранном печатном документе, не перенося постранично информацию. Кроме того, программа старается сохранить шрифты, колонтитулы и разметку текста на странице максимально близко к оригиналу.
 exe и выбрать один из видов инсталляции. Обычный режим установит FineReader в стандартной конфигурации на компьютер. В процессе установки необходимо будет выбрать язык интерфейса, место размещения программы и другие стандартные пункты по установке.
exe и выбрать один из видов инсталляции. Обычный режим установит FineReader в стандартной конфигурации на компьютер. В процессе установки необходимо будет выбрать язык интерфейса, место размещения программы и другие стандартные пункты по установке.
 Настройка и запуск ABBYY FineReader 12 Professional функционально не отличается от установки других версий. Инструмент автоматически распознает языки, сложные таблицы и списки, так что практически не требуется дополнительного редактирования.
Настройка и запуск ABBYY FineReader 12 Professional функционально не отличается от установки других версий. Инструмент автоматически распознает языки, сложные таблицы и списки, так что практически не требуется дополнительного редактирования.
 Стандартные настройки предлагают перевести текстовый файл в документ Word, создать таблицу Exel, конвертировать в PDF-файл и другие нужные форматы. После выбора действия нужно будет указать язык распознавания, режим распознавания (цветной или черно-белый) и задать дополнительные пункты распознавания.
Стандартные настройки предлагают перевести текстовый файл в документ Word, создать таблицу Exel, конвертировать в PDF-файл и другие нужные форматы. После выбора действия нужно будет указать язык распознавания, режим распознавания (цветной или черно-белый) и задать дополнительные пункты распознавания.
 Тщательный режим будет удобен для работы с некачественными текстовыми файлами, текстами на цветном фоне или сложными таблицами. Быстрое распознавание рекомендовано для больших объемов файлов или когда ограничены временные рамки.
Тщательный режим будет удобен для работы с некачественными текстовыми файлами, текстами на цветном фоне или сложными таблицами. Быстрое распознавание рекомендовано для больших объемов файлов или когда ограничены временные рамки.

6 лучших приложений для Android OCR для извлечения текста из изображений
Вам нужно оцифровать какой-либо печатный текст, чтобы вы могли сохранить его в электронном виде? В конце концов, есть много преимуществ, чтобы стать безбумажным
, Если это так, все, что вам нужно, это инструмент оптического распознавания символов (OCR).
Мы рассмотрели несколько онлайн-инструментов OCR
в прошлом, но ничто не сравнится с удобством возможности оцифровывать документы прямо с вашего телефона Android. Прежде чем погрузиться в лучшие инструменты OCR для Android, давайте посмотрим, как мы их тестировали.
Наша методика тестирования
Мы отсканировали различные выдержки из биографии Стива Джобса Уолтера Айзексона. Сначала мы отсканировали отрывки с простым форматированием.
Затем мы отсканировали отрывки со страниц, которые были немного сложнее форматировать. Только горстка приложений поддерживает извлечение текста из рукописного текста, поэтому мы проверили рукописные заметки скорописью
, Сканирование проводилось в хорошо освещенных условиях окружающей среды.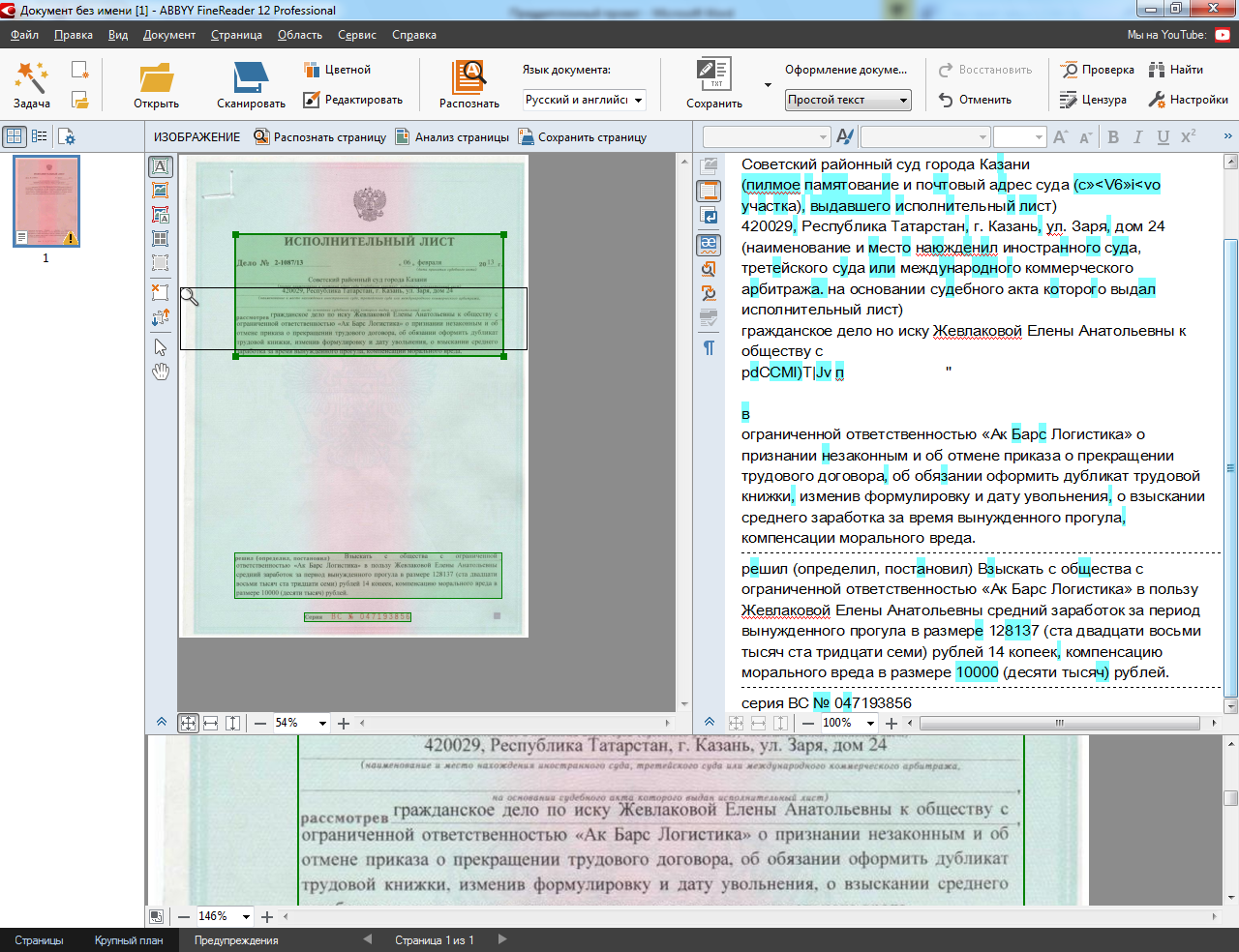 Наконец, эти документы были запущены под одними из лучших инструментов OCR для Android. Вот как они выполнили.
Наконец, эти документы были запущены под одними из лучших инструментов OCR для Android. Вот как они выполнили.
1. Google Keep
Отличное приложение для создания заметок от Google в нескольких хитрых уловках
и имеет много творческого использования.
Он также имеет встроенную поддержку OCR. В ходе нашего тестирования мы обнаружили, что извлечение текста в Google Keep работает довольно последовательно как в простом, так и в сложном форматировании текста. Это также сохраняет оригинальное форматирование текста в значительной степени.
Инструкция по извлечению текста:
- Добавьте новую заметку и нажмите на + значок.
- Выбрать Сфотографировать сканировать документ с камеры или выбрать Выберите изображение импортировать изображение из вашей галереи.
- Откройте картинку, нажмите на три точки переполнение меню и выберите Захватить текст изображения.

Текст должен быть извлечен за несколько секунд. Возможно, лучше всего то, что текстовая заметка будет синхронизироваться на всех ваших устройствах автоматически, поэтому вы можете отсканировать документ на своем телефоне Android и отредактировать его позже на своем компьютере.
Скачать: Google Keep (бесплатно)
2. Сканер текста [OCR]
В нашем тестировании текстовый сканер [OCR] занял второе место после Google Keep. Приложение поддерживает более 50 языков, включая китайский, японский, французский и другие. Он даже поддерживает извлечение текста из рукописного текста. Интерфейс приложения имеет важные функции сканирования, такие как увеличение и ползунок яркости, чтобы захватить текст максимально четким способом.
В нашем тестировании у него не было проблем с извлечением текста, хотя извлечение текста из рукописных заметок казалось его ахиллесовой пятой. Но это не удивительно, так как почерк может сильно отличаться
от человека к человеку. Тем не менее, это по-прежнему одно из немногих приложений, которое на самом деле поддерживает извлечение текста из рукописных заметок, поэтому стоит попробовать.
Тем не менее, это по-прежнему одно из немногих приложений, которое на самом деле поддерживает извлечение текста из рукописных заметок, поэтому стоит попробовать.
Инструкция по извлечению текста:
- Нажмите на синяя кнопка спуска захватить и отсканировать документ. Кроме того, вы также можете импортировать существующее изображение, нажав на Значок галереи.
Извлеченный текст теперь должен отображаться. Отсюда вы можете вносить изменения в текст, копировать его или делиться им со сторонними приложениями.
Скачать: Сканер текста [OCR] (бесплатно с рекламой)
3. Текстовая Фея
Text Fairy — еще один достойный инструмент для извлечения изображений для Android, способный распознавать текст более чем на 50 языках, включая китайский, японский, голландский, французский и многие другие. Он поддерживает многие индийские языки, такие как хинди, бенгали, маратхи, телугу и т. Д. При первом запуске приложения вам будет предложено загрузить необходимые языки.
Он сканировал наш тестовый документ без каких-либо ошибок, но имел проблемы при распознавании текста со страницы, содержащей пару изображений. Это прямо упоминает, что у него есть некоторые проблемы с распознаванием разноцветных букв. Кроме того, стоит упомянуть, что перед сканированием документа необходимо выполнить много шагов вручную, что делает его непригодным для пакетного сканирования. Лучше всего ограничить его использование сканированием книг и журналов с простым макетом.
Инструкция по извлечению текста:
- Нажмите на Значок камеры захватить изображение. Или нажмите на Значок галереи импортировать картинку из галереи.
- Выберите раздел изображения, который вы хотите отсканировать. Нажмите на стрелка вперед продолжать.
- Выберите, будет ли макет документа одним или двумя столбцами.
- Выберите язык текста.
- Наконец, нажмите Начните.
Если все идет хорошо, текст должен быть извлечен, и теперь вы можете редактировать или копировать его в любое место.
Скачать: Текстовая Фея (Бесплатно)
4. Офисный объектив
Office Lens — это решение Microsoft о переносе портативного приложения для сканирования на устройства Android. Его особенностью заголовка является возможность сканировать и оцифровывать документы, но он также поставляется с удобной опцией OCR. Он включен в премиум-вариант, но вы можете получить его бесплатно, зарегистрировав бесплатную учетную запись Microsoft. Регистрация также открывает другие функции, такие как 5 ГБ бесплатного хранилища OneDrive и возможность сохранения в нескольких форматах.
В нашем тестировании Office Lens показалось одним из лучших приложений для распознавания текста с изображения. Кажется, что нет никаких проблем с распознаванием даже разноцветных шрифтов. Кроме того, это лучшее приложение Android OCR для распознавания текста из рукописных заметок. Он тесно интегрируется с другими продуктами Microsoft, такими как OneNote и Office 365. Если вы клянетесь экосистемой Microsoft
использовать линзу Office не составляет никакого труда.
Инструкция по извлечению текста:
- Откройте Объектив Office и наведите камеру на документ, который вы хотите отсканировать. Он автоматически обнаруживает участок изображения с текстом, но вы можете настроить его вручную. нажмите Кнопка спуска камеры.
- Нажмите Сохранить.
- В разделе «Сохранить в» выберите слово документ и нажмите Проверьте значок.
После открытия вы можете вносить любые необходимые изменения.
Скачать: Офисный объектив (бесплатно)
5. Сканер текста OCR
OCR Text Scanner отличается упрощенным интерфейсом и поддерживает более 55 языков, включая английский, французский, итальянский, шведский и другие. В нашем тестировании это, казалось, работало в основном хорошо на документах, хотя в разных местах пропускало слово или два. Он не может извлечь текст изображения из рукописных заметок. Он также изобилует рекламой, поэтому вам придется ждать около пяти секунд между каждым сканированием.
Инструкция по извлечению текста:
- Нажмите Значок камеры сканировать документ. Чтобы импортировать документ из галереи, коснитеськнопка переполнения а затем нажмите Импортировать.
- Выберите язык документа и нажмите Захватить текст изображения.
Должен отображаться извлеченный текст. Вы можете легко скопировать или поделиться текстом здесь.
Скачать: Сканер текста OCR (бесплатно с рекламой)
6. CamScanner
CamScanner был одним из наших любимых приложений для сканирования документов на вашем телефоне
какое-то время. Но, как ни странно, его функция OCR довольно проста. В нашем тестировании он часто пропускал определенные слова или писал их с ошибками. Это не так уж плохо, но приложения, упомянутые выше, обычно дают лучшие результаты. Отличительной особенностью является то, что он может обрабатывать документы в пакетном режиме. В отличие от некоторых других приложений, он не требует много ручной настройки перед сканированием документа.
Бесплатная версия CamScanner позволяет просматривать текст только для чтения, поэтому, конечно, вам придется перейти на премиум-версию, чтобы редактировать извлеченный текст.
Инструкция по извлечению текста:
- Нажмите Значок камеры сканировать документ с помощью камеры вашего устройства. Чтобы импортировать изображение из вашей галереи, нажмите на переполнение меню и выберите Импорт из галереи.
- Откройте изображение и нажмите на признать.
- Вы можете нажать Распознать всю страницу чтобы извлечь текст из всего изображения, или нажмите Выберите область извлечь текст из определенного раздела.
Скачать: CamScanner (бесплатно, полностью)
Как вы извлекаете текст?
Помните, что ни один инструмент OCR не является на 100% надежным, когда дело доходит до извлечения текста. Всегда рекомендуется редактировать и корректировать документы
прежде чем сохранить их. Google Keep работал довольно последовательно для оцифровки моих документов, а Office Lens отлично работал для оцифровки моих рукописных заметок.
Google Keep работал довольно последовательно для оцифровки моих документов, а Office Lens отлично работал для оцифровки моих рукописных заметок.
Тем не менее, ваш пробег может варьироваться в зависимости от стиля текста документа или его языка, поэтому лучше проверить все приложения и посмотреть, что работает лучше для вас.
Какое приложение вы предпочитаете извлекать текст из ваших документов? Если ваше любимое приложение отсутствует в списке, сообщите нам об этом в комментариях ниже.
Кредит изображения: guteksk7 / Depositphotos
10 лучших бесплатных программ для оптического распознавания текста для работы со сканированными файлами PDF
OCR — это технология, используемая для преобразования файлов изображений в редактируемый текст. Файлы на основе изображений относятся к документам, которые были отсканированы из учебников, журналов или любых текстовых источников и обычно сохраняются в формате PDF. OCR может извлекать текст из этих изображений и делать его редактируемым. В этой статье мы познакомим вас с 10 лучшими бесплатными программами чтения OCR , которые помогут вам легко редактировать отсканированные файлы PDF.
OCR может извлекать текст из этих изображений и делать его редактируемым. В этой статье мы познакомим вас с 10 лучшими бесплатными программами чтения OCR , которые помогут вам легко редактировать отсканированные файлы PDF.
10 лучших бесплатных программ для распознавания текста
1. PDFelement
PDFelement может легко помочь вам в работе с отсканированными документами PDF благодаря передовой технологии распознавания текста. Эта функция может распознавать текст в отсканированных PDF-файлах, чтобы сделать ваш файл и текст доступными для редактирования. Кроме того, он также может конвертировать ваши отсканированные PDF-файлы в другие редактируемые форматы документов, такие как Excel, Word, PPT, Text и другие. Качество вашего исходного документа также будет полностью сохранено.
PDFelement оснащен мощными инструментами редактирования, которые позволяют вставлять, удалять или изменять текст, изображения и страницы.Вы также можете заполнять как интерактивные, так и неинтерактивные формы и создавать новые формы с различными вариантами заполнения форм и создания форм.
2. FreeOCR
Этот онлайн-инструмент OCR полностью бесплатен и не требует регистрации или предоставления адреса электронной почты. Он поддерживает такие типы файлов изображений, как GIF, JPG, BMP, TIFF или PDF с текстом в несколько столбцов. И он распознает более 30 разных языков. Размер загрузки ограничен 2 МБ или 5000 пикселей, и вы можете загружать только 10 изображений в час.
3. i2OCR
i2OCR имеет возможность загружать типы файлов изображений, такие как JPEG, TIF, BMP, PNG, PBM, GIF, PPM, PGM или URL-адрес изображения. Эта программа позволяет конвертировать изображения с вашего локального диска или из Интернета. Регистрация не требуется. Он поддерживает документы PDF с текстом в несколько столбцов и распознает 33 языка. В отличие от FreeOCR, он позволяет пользователям загружать изображения без каких-либо ограничений по количеству.
4. Онлайн OCR
Online OCR может преобразовывать фотографии и цифровые изображения в текст. Он распознает 32 языка и конвертирует отсканированные PDF-файлы в форматы Text, Word и RTF. Он также извлекает текст из изображений JPG, JPEG, BMP, TIFF и GIF и преобразует его в редактируемые документы Word, Text, PDF, Excel или HTML. Вы можете конвертировать 15 изображений в час.
Он распознает 32 языка и конвертирует отсканированные PDF-файлы в форматы Text, Word и RTF. Он также извлекает текст из изображений JPG, JPEG, BMP, TIFF и GIF и преобразует его в редактируемые документы Word, Text, PDF, Excel или HTML. Вы можете конвертировать 15 изображений в час.
5. Бесплатное онлайн-распознавание текста
Free Online OCR может преобразовывать снимки экрана, отсканированные документы, факсы и фотографии в текст с возможностью поиска и редактирования, например TXT, DOC, RTF и PDF. Он поддерживает форматы BMP, PDF, PNG, TIFF, JPG (JPEG) и GIF.
6. Cvisiontech
Cvisiontech также поддерживает одновременную загрузку нескольких файлов TIFF, PDF, BMP и JPG. Вам необходимо убедиться, что размер любого загруженного файла не превышает 100 МБ. Эта программа позволит вам сжать целевой файл и оптимизировать его для веб-сайта.
7. SuperGeek Free Document OCR
SuperGeek Free Document OCR — это удобный и мощный конвертер изображений OCR, предназначенный как для профессиональных, так и для домашних пользователей. Он может читать текст из JPG, JPEG, TIF, TIFF, PNG, BMP, PSD, GIF, EMF, WMF, J2K, DCX, PCX, JP2 и т. Д.и конвертируйте файлы в редактируемые документы MSWord и TXT всего за несколько кликов.
Он может читать текст из JPG, JPEG, TIF, TIFF, PNG, BMP, PSD, GIF, EMF, WMF, J2K, DCX, PCX, JP2 и т. Д.и конвертируйте файлы в редактируемые документы MSWord и TXT всего за несколько кликов.
8. onOCR
Независимо от размера отсканированного PDF-файла или файла изображения onOCR справится с этим. Бесплатное распознавание текста может преобразовать нередактируемый документ в текст, который можно копировать и редактировать как угодно. Он также позволяет обрабатывать как большие, так и маленькие изображения и превращать их в редактируемый текст.
9. Инвестинтех
Able2Extract от Investintech — это мощный инструмент для управления PDF-файлами, который можно использовать для преобразования отсканированных PDF-файлов в более 10 различных редактируемых типов файлов.Вы также можете создавать защищенные PDF-файлы практически из любого типа файлов, просматривать и редактировать PDF-файлы, извлекать текст из отсканированного документа, а также изменять и предварительно просматривать преобразованный файл.
10. OCRGeek
OCRGeek.com позволяет выполнять онлайн-оптическое распознавание текста партиями. Это позволяет без проблем загружать несколько файлов одновременно. Весь процесс быстрый и легкий. Все ваши документы будут сразу организованы и преобразованы в формат TXT. OCRgeek поддерживает следующие форматы ввода: JPG, PNG, TIFF, PDF, DJVU, GIF и BMP.
Видео: 5 лучших программ для распознавания текста
Загрузите или купите PDFelement бесплатно прямо сейчас!
Загрузите или купите PDFelement бесплатно прямо сейчас!
Купите PDFelement прямо сейчас!
Купите PDFelement прямо сейчас!
Сканировать текст
Сканировать текст — techteach меню — главное меню — меню сканирования —Сканирование текста — детали
Опции:
Сканирование: Вы можете сканировать распечатанную страницу как 1) изображение или используйте 2) программное обеспечение OCR (Optical Character Reading), чтобы преобразовать его в текст.

Отдельный лист легко сканировать. Страница в тонком журнале или мягкую обложку довольно легко разместить правильно — сломайте корешок и держите крышку сканера так, чтобы страница касалась стекла сканера, равномерно, насколько это возможно. Страницу книги в твердом переплете трудно сканировать, потому что вы можете не захотеть повредить книгу — Сделайте это в копировальной мастерской, по листу за каждую страницу, которую затем можно будет успешно сканировать.
Отредактируйте изображения: они могут понадобиться
обрезка (чтобы избавиться от темных полей, где копия не касалась
сканер), выпрямление, резкость, лучший контраст, точечный
удаление…..
ИЛИ преобразовать каждую страницу в текст с помощью OCR
программное обеспечение, если в нем есть только текст. Полученный текст потребуется
тщательное редактирование, особенно если копия некачественная или очень
используется мелкий шрифт, курсив или ударение. Помните, для
Например, что 1 и! и я, и я очень похожи, как и g и q. И т.д. Используйте свое воображение или попробуйте расшифровать старинный рукописный
документ, чтобы узнать, насколько это может быть сложно.
И т.д. Используйте свое воображение или попробуйте расшифровать старинный рукописный
документ, чтобы узнать, насколько это может быть сложно.
Тогда: Для использования на Bb или в другом месте на
в сети у вас есть альтернативы:
Вы можете использовать каждую страницу как изображение, ИЛИ вы можете использовать преобразованный в текст
и отредактированная версия.
В любом случае добавьте изображения или текст в документ Word или, желательно, в
HTML-документ, который автоматически откроется в Интернете.
Необходимо:
Вам нужен сканер — очень недорогой.
Программное обеспечение OCR — необходимо для преобразования
печатного текста в оцифрованный текст:
Большинство сканеров включают базовое программное обеспечение для редактирования изображений и текста.
конверсия. Профессиональное распознавание символов (оптический символ
Распознавание): рекомендуется TextBridge или OmniPage,
особенно для текста на иностранном языке.Последняя версия OmniPage
Включает более 100 языков и словарей.
Сканер делает изображение страницы. Тогда программное обеспечение
пытается распознать текст на изображении.
Это сложно для программного обеспечения и приводит к ошибкам. Пока мы «читаем»
слова в контексте, бедные глупые
программного обеспечения
должен распознавать комбинации точек индивидуально.
Представьте себе написанные от руки или напечатанные 1 и l и i а я и! и | — или подумайте о g, p, q и j.Они очень похожи, особенно когда отпечаток крошечный или копия плохой.
Или выделите текст курсивом: 1liI! | — особенно gpqj когда отпечаток очень мелкий или подчеркнут: — 1liI! | — gpqjБудьте готовы проверить весь отсканированный текст очень осторожно!
Убедитесь, что публикуемые вами сообщения с легкостью разборчиво!
Советы по OCR:
- Короткий текст набирать быстрее, чем отсканировать и вычитать его.
- Важно хорошо чистить
страницы для сканирования.
- Компьютерные страницы сканируют очень точно.
- Для сканирования страниц или статей из книги или журнала, нужно иметь хорошую копию каждой страницы, сделанной в копии магазин, чтобы они были прямыми и не имели очень темных теней там, где страница не трогает из-за корешка книги или журнала.
- На странице с иллюстрацией или при печати в несколько столбцов выберите области текста перед сканированием.
- Обычно текст сканируется на 100%, но вы должен увеличивать страницу или часть страницы, скажем, на 200%, когда очень мелкий шрифт, чтобы улучшить результаты распознавания символов.
- Если ваша копия темная или кривая, отсканируйте это как изображение, а затем отредактируйте изображение, прежде чем использовать символ признание.
Наконец:
Если вы хотите использовать иллюстрированную страницу как есть, отсканируйте
целый
страницу как изображение. Если он есть в книге, получите профессиональный экземпляр каждого
страница из копировального магазина — чтобы она была прямой и без темных
тени. Отсканируйте, а затем обрежьте изображение, чтобы
избавиться от теней и, при необходимости, отредактировать для контраста и резкости.
Отсканируйте, а затем обрежьте изображение, чтобы
избавиться от теней и, при необходимости, отредактировать для контраста и резкости.
Если вы хотите сканировать рукописный текст, например
письмо или
свидетельство о рождении предка, отсканируйте его как изображение.
Если вы хотите отсканировать только изображение с иллюстрированной страницы, выберите его,
отсканируйте его, затем обрежьте и отредактируйте с помощью программного обеспечения для обработки изображений.
Я предпочитаю размещать страницы в виде изображений в
Формат Acrobat .pdf.
Hoffmann, ноябрь.2006
8 лучших программ оптического распознавания текста на 2020 год [Бесплатная и платная]
В наши дни почти все (например, фотографии, музыка, видео) стало цифровым, и это имеет смысл, поскольку цифровым контентом можно удобно управлять. Так как же текстовые документы могут оставаться позади? Благодаря достижениям в технологиях оптического распознавания символов (OCR) оцифровка печатных или рукописных текстов стала проще, чем когда-либо.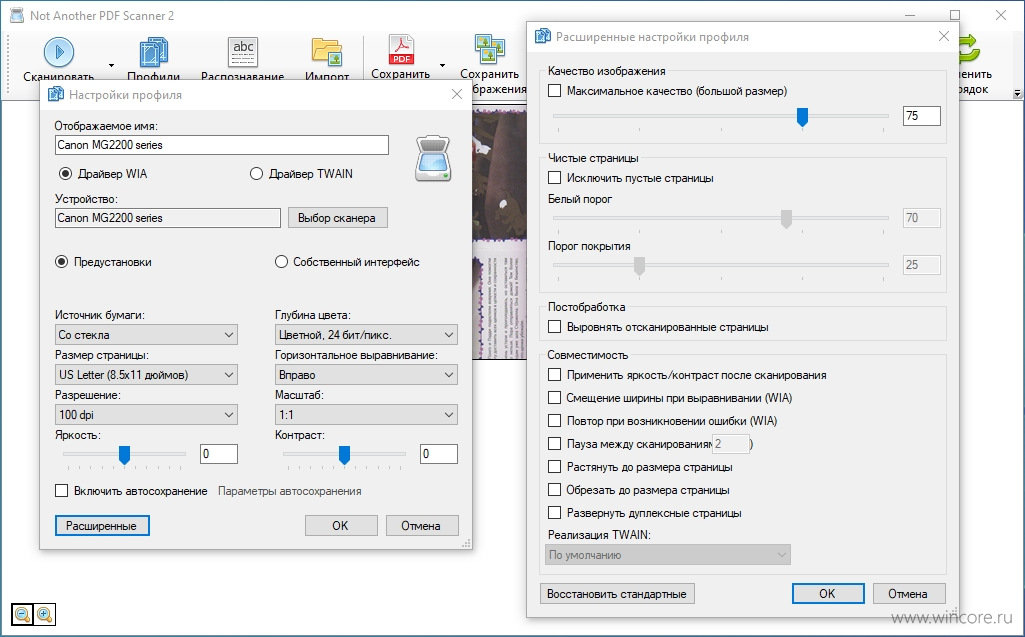 Для этого вам понадобится несколько действительно хороших программ для оптического распознавания текста, и именно об этом и идет эта статья.Это программное обеспечение может либо получать исходный текст со сканирующих устройств, либо вы можете вводить собственные изображения или файлы PDF для преобразования в редактируемый текст. Заинтригованы? Что ж, давайте не будем ходить вокруг да около и перейдем к 8 лучшим программам распознавания текста, которые вы должны использовать в 2020 году.
Для этого вам понадобится несколько действительно хороших программ для оптического распознавания текста, и именно об этом и идет эта статья.Это программное обеспечение может либо получать исходный текст со сканирующих устройств, либо вы можете вводить собственные изображения или файлы PDF для преобразования в редактируемый текст. Заинтригованы? Что ж, давайте не будем ходить вокруг да около и перейдем к 8 лучшим программам распознавания текста, которые вы должны использовать в 2020 году.
Лучшее программное обеспечение для распознавания текста для Windows, macOS и Linux
1. ABBYY FineReader
Когда дело доходит до оптического распознавания символов, мало что может сравниться с ABBYY FineReader. Наполненный до краев безумным количеством мощных функций, ABBYY FineReader позволяет легко извлекать текст из любых изображений.
Несмотря на объем и обширный список функций, ABBYY FineReader очень проста в использовании. Он может извлекать текст практически из всех популярных форматов изображений , таких как PNG, JPG, BMP и TIFF. И это еще не все. ABBYY FineReader также может извлекать текст из файлов PDF и DJVU. После загрузки исходного файла или изображения (которое предпочтительно должно иметь разрешение не менее 300 точек на дюйм для оптимального сканирования) программа анализирует его и автоматически определяет различные разделы файла, содержащие извлекаемый текст.Вы можете извлечь весь текст или выбрать только определенные разделы. После этого все, что вам нужно сделать, это использовать опцию Сохранить, чтобы выбрать выходной формат, а ABBYY FineReader позаботится обо всем остальном. Поддерживаются многочисленные форматы вывода, такие как TXT, PDF, RTF и даже EPUB.
И это еще не все. ABBYY FineReader также может извлекать текст из файлов PDF и DJVU. После загрузки исходного файла или изображения (которое предпочтительно должно иметь разрешение не менее 300 точек на дюйм для оптимального сканирования) программа анализирует его и автоматически определяет различные разделы файла, содержащие извлекаемый текст.Вы можете извлечь весь текст или выбрать только определенные разделы. После этого все, что вам нужно сделать, это использовать опцию Сохранить, чтобы выбрать выходной формат, а ABBYY FineReader позаботится обо всем остальном. Поддерживаются многочисленные форматы вывода, такие как TXT, PDF, RTF и даже EPUB.
Выходной текст прекрасно редактируется, и текст даже из документов с наиболее интенсивным содержанием (например, имеющих несколько столбцов и сложные макеты) извлекается безупречно.Другие функции включают расширенную языковую поддержку , множество стилей / размеров шрифтов и инструменты коррекции изображений для файлов, полученных со сканеров и камер.
При всем этом, что отличает ABBYY FineReader от остальных программ, так это почти идеальная точность. С новым обновлением Finereader 15 теперь программное обеспечение использует AI для улучшения распознавания символов . ИИ особенно используется при извлечении текстов из документов, написанных на японском, корейском и китайском языках.Короче говоря, если вам нужно самое лучшее программное обеспечение для оптического распознавания текста с расширенными функциями, расширенным форматом ввода / вывода и поддержкой обработки, выбирайте ABBYY FineReader.
Доступность платформы: Windows и macOS
Цена: Платные версии начинаются от 199 долларов США, доступна 30-дневная бесплатная пробная версия
Загрузить
2. Тессеракт
Tesseract, пожалуй, самое мощное и продвинутое программное обеспечение для распознавания текста в этом списке, и я расскажу вам, почему. Прежде всего, немного истории. Он был разработан HP в 1994 году, но вскоре компания выпустила его под лицензией Apache для разработки с открытым исходным кодом. В 2006 году проект взял на себя Google и спонсировал разработчиков для работы над Tesseract. Перенесемся вперед, и Tesseract стал самым мощным движком OCR, который использует Deep Learning для извлечения текстов из изображений (BMP, PNG, JPEG, TIFF и т. Д.) И файлов PDF . Существует множество онлайн-сервисов, которые используют Tesseract OCR API для распознавания и преобразования больших массивов изображений и файлов PDF.И что самое приятное, он доступен для всех основных операционных систем, включая Windows, macOS и Linux. Не говоря уже о том, что в отличие от ABBYY и Adobe, Tesseract полностью бесплатен , и вы можете использовать его для преобразования тысяч изображений в текст, не платя ни копейки.
Прежде всего, немного истории. Он был разработан HP в 1994 году, но вскоре компания выпустила его под лицензией Apache для разработки с открытым исходным кодом. В 2006 году проект взял на себя Google и спонсировал разработчиков для работы над Tesseract. Перенесемся вперед, и Tesseract стал самым мощным движком OCR, который использует Deep Learning для извлечения текстов из изображений (BMP, PNG, JPEG, TIFF и т. Д.) И файлов PDF . Существует множество онлайн-сервисов, которые используют Tesseract OCR API для распознавания и преобразования больших массивов изображений и файлов PDF.И что самое приятное, он доступен для всех основных операционных систем, включая Windows, macOS и Linux. Не говоря уже о том, что в отличие от ABBYY и Adobe, Tesseract полностью бесплатен , и вы можете использовать его для преобразования тысяч изображений в текст, не платя ни копейки.
Однако есть одна небольшая проблема. Tesseract не предлагает графический интерфейс. Вам придется использовать механизм OCR в командной строке, что не всем нравится. Поэтому для решения этой проблемы разработчики создали клиентов с графическим интерфейсом пользователя, используя исходный код Tesseract для различных операционных систем.Я протестировал несколько из них и отсортировал лучшие клиенты Tesseract GUI для различных операционных систем. Если вы хотите быстро преобразовать изображения или PDF-файлы в редактируемый текст, используйте OCR Space (ссылка ниже) в веб-браузере. Он очень быстрый и отлично справляется со своей задачей. Если вы используете Windows , используйте gImageReader ; для Linux используйте OCRFeeder, а для macOS используйте PDF OCR X. Вот и все, но если вы хотите самостоятельно протестировать больше клиентов с графическим интерфейсом, перейдите по этой ссылке. Кроме того, если у вас есть опыт, вы, конечно, можете использовать Tesseract в командной строке.
Вам придется использовать механизм OCR в командной строке, что не всем нравится. Поэтому для решения этой проблемы разработчики создали клиентов с графическим интерфейсом пользователя, используя исходный код Tesseract для различных операционных систем.Я протестировал несколько из них и отсортировал лучшие клиенты Tesseract GUI для различных операционных систем. Если вы хотите быстро преобразовать изображения или PDF-файлы в редактируемый текст, используйте OCR Space (ссылка ниже) в веб-браузере. Он очень быстрый и отлично справляется со своей задачей. Если вы используете Windows , используйте gImageReader ; для Linux используйте OCRFeeder, а для macOS используйте PDF OCR X. Вот и все, но если вы хотите самостоятельно протестировать больше клиентов с графическим интерфейсом, перейдите по этой ссылке. Кроме того, если у вас есть опыт, вы, конечно, можете использовать Tesseract в командной строке.
Доступность платформы: Web, Windows, macOS и Linux
Цена: Бесплатно
Загрузить: Веб-браузер, Windows, macOS, Linux, командная строка
3.
 OmniPage Ultimate от Kofax
OmniPage Ultimate от KofaxOmniPage Ultimate — это программное обеспечение профессионального уровня для преобразования изображений (JPG и PNG), документов и PDF-файлов в цифровые файлы. Если у вас большая компания и вам нужно надежное программное обеспечение для оптического распознавания текста, я настоятельно рекомендую OmniPage Ultimate от Kofax.Однако для частных лиц это программное обеспечение было бы слишком дорогим. Что касается функций, OmniPage может точно оцифровывать изображения и документы, делая их доступными для редактирования и поиска. Он также поддерживает длинный список форматов изображений, поэтому независимо от расширения файла вы можете легко преобразовать его в любой формат файла, который вам нужен. По функциям, я бы сказал, он очень близок к ABBYY FineReader.
Кроме того, OmniPage Ultimate использует собственную технологию для определения расположения изображений и автоматического поворота документа в правильной ориентации.Кроме того, вы можете запланировать большие объемы файлов PDF для пакетной обработки, используя его инструмент автоматизации. Не говоря уже о том, что может определять более 120 языков и соответственно обрабатывать изображения и документы. Что касается форматов выходных файлов, он поддерживает PDF, DOC, EXCL, PPT, CDR, HTML, ePUB и другие. Учитывая все аспекты, OmniPage Ultimate кажется надежным решением для оптического распознавания текста для корпоративных пользователей.
Доступность платформы: Windows
Цена: Бесплатная пробная версия на 15 дней, платная версия за 183 доллара США
Загрузить
4.Readiris
Вы ищете чрезвычайно мощное программное обеспечение для оптического распознавания текста с большим количеством функций, но для начала работы с ним не требуется много усилий? Взгляните на Readiris, возможно, это именно то, что вам нужно.
Приложение профессионального уровня Readiris обладает обширным набором функций, во многом идентичным ранее рассмотренному ABBYY FineReader. Readiris поддерживает множество форматов изображений, от BMP до PNG и от PCX до TIFF. Кроме того, можно обрабатывать файлов PDF и DJVU. Изображения могут быть получены со сканеров, и приложение также позволяет вам устанавливать пользовательские параметры обработки для исходных файлов / изображений, такие как сглаживание и регулировка DPI, перед их анализом. Хотя Readiris отлично обрабатывает изображения с низким разрешением, оптимальное разрешение должно быть не менее 300 dpi.
После завершения анализа Readiris определяет текстовые разделы (или зоны), и текст может быть извлечен либо из определенных зон, либо из всего файла . Извлеченный текст доступен для редактирования и поиска и может быть сохранен во многих форматах, таких как PDF, DOCX, TXT, CSV и HTM.
Более того, функция сохранения в облаке Readiris Pro позволяет напрямую сохранять извлеченный текст в различных облачных хранилищах, таких как Dropbox, OneDrive, Google Drive и др. Также имеется большое количество функций редактирования / обработки текста, и даже штрих-коды можно сканировать.
В общем, вы должны использовать Readiris, если вам нужны надежные функции извлечения / редактирования текста в простом в использовании пакете с расширенной поддержкой форматов ввода / вывода.Однако Readiris немного не работает, когда дело доходит до обработки документов со сложными макетами, такими как несколько столбцов, таблиц и т. Д.
Доступность платформы: Windows и macOS
Цена: Платные версии начинаются от 49 долларов США, доступна 10-дневная бесплатная пробная версия
Загрузить
5. Adobe Acrobat Pro DC
Если вы ищете мощное программное обеспечение для оптического распознавания текста для профессионального использования, я не могу рекомендовать Adobe Acrobat Pro DC.Поскольку это Adobe — создатель PDF и различных стандартов документов, компания разработала мощный механизм распознавания текста для точного извлечения текстов из файлов PDF со сканированными изображениями. Хотя Adobe Acrobat не так функционально, как ABBYY FineReader, он, несомненно, превосходит уровень извлечения. Например, вы можете легко импортировать текстовые PDF-файлы в Adobe Acrobat, а затем использовать его технологию OCR для преобразования файла в редактируемый текст. Однако, если вы хотите выбрать изображение, сначала вам нужно будет создать PDF-файл с изображением, а затем только вы сможете его импортировать.В этом отношении есть некоторые ограничения, но в остальном Adobe Acrobat — гораздо более способное программное обеспечение для распознавания текста.
С учетом всего вышесказанного, лучшая часть этого программного обеспечения заключается в том, что оно сохраняет шрифт исходного документа, используя свой метод создания пользовательского шрифта. Поскольку у Adobe есть огромный репозиторий собственных обычных и дизайнерских шрифтов, он автоматически сопоставляет стиль шрифта исходного документа, а затем преобразует PDF в этот конкретный шрифт. А в случае, если шрифт недоступен, генерирует собственный шрифт, используя аналогичную типографику .Это та функция, которую может использовать только Adobe. Итак, если вы хотите преобразовать тысячи страниц отсканированных изображений в файлы PDF (например, книги), то Adobe Acrobat Pro DC — лучшее программное обеспечение для оптического распознавания текста, которое вы можете выбрать.
Доступность платформы: Windows и macOS
Цена: Бесплатная пробная версия на 7 дней, платная версия начинается от 12,99 долларов США в месяц
Загрузить
6.Microsoft OneNote
OneNote — это впечатляюще многофункциональное приложение для создания заметок, с которым также легко начать работу. Однако делать заметки — не единственное, в чем он хорош. Если вы используете OneNote как часть своего рабочего процесса, вы можете использовать его для выполнения базового извлечения текста благодаря встроенным в него функциям распознавания текста.
Использовать OneNote для извлечения текста из изображений до смешного просто. Если вы используете настольное приложение, все, что вам нужно сделать, это использовать опцию Insert , чтобы добавить изображение в любой из блокнотов или разделов.Как только это будет сделано, просто щелкните изображение правой кнопкой мыши и выберите вариант Копировать текст с изображения . Все текстовое содержимое изображения будет скопировано в буфер обмена и может быть вставлено (и, следовательно, отредактировано) в любом месте в соответствии с требованиями. Будь то PNG, JPG, BMP или TIFF, OneNote поддерживает почти все основные форматы изображений.
Однако возможности извлечения текста в OneNote весьма ограничены, и он не может работать с изображениями со сложными макетами текстового содержимого, такими как таблицы и подразделы.Так что об этом вам следует помнить.
Доступность платформы: Windows и macOS
Цена: Бесплатно
Загрузить
7. Amazon Textract
В 2019 году Amazon запустила свое программное обеспечение OCR под названием Textract, которое имеет модель машинного обучения и было обучено с использованием миллионов документов. Он может автоматически обнаруживать печатный текст из изображений (JPG и PNG) и файлов PDF и отображать его в цифровом виде с почти идеальной точностью.Хотя Textract в основном доступен в веб-браузере, вы также можете загрузить его и использовать службу через командную строку. Кроме того, Textract кажется довольно мощным программным обеспечением OCR, поскольку может не только извлекать тексты, но также таблицы, поля, числа и ключевые значения. Мне особенно нравится извлечение таблицы из отсканированных изображений, так как оно может значительно упростить редактирование текста. Textract хранит данные таблицы, используя предопределенную схему, в которой он извлекает все данные в виде строк и столбцов.
Тем не менее, Amazon Textract предлагает свои услуги как для частных лиц, так и для предприятий. Как домашний пользователь, вы можете зарегистрировать аккаунт AWS уровня бесплатного пользования и использовать сервис, но имейте в виду, что вы можете конвертировать только 1000 страниц в месяц. В целом Amazon Textract представляет собой отличное программное обеспечение для оптического распознавания текста, которое может использоваться как обычными пользователями, так и предприятиями.
Доступность платформы: Web, Windows, macOS, Linux
Цена: Бесплатно первые 3 месяца, тариф Premium начинается с 1 доллара.50 на 1000 страниц
Загрузить
8. Google Документы
Не многие знают, что в Документах Google есть скрытая функция распознавания текста. Да, вы все правильно прочитали, и для использования этой функции вам не нужен аккаунт G Suite. Конечно, это не самый простой подход, но для обычных пользователей, которые хотят бесплатно конвертировать PDF-файлы в редактируемый текст. , тогда Документы Google — лучший вариант, без исключений. Все, что вам нужно сделать, это загрузить файл PDF на Google Диск.После этого щелкните его правой кнопкой мыши и перейдите к опции «Открыть с помощью». Наконец, нажмите Google Docs, и все готово. Теперь PDF-файл откроется в Google Docs и автоматически преобразует его в редактируемый текст в течение нескольких секунд. Как это круто?
Теперь вы можете редактировать весь текст, искать в нем, редактировать и, наконец, сохранять файл в нескольких форматах файлов, которые изначально поддерживаются Документами Google. В моем тестировании он довольно хорошо работал с файлами PDF , которые были созданы с помощью текстовых редакторов.Однако имейте в виду, что он не может преобразовывать изображения или отсканированные изображения в виде файлов PDF. Итак, если вам нужен бесплатный и простой инструмент OCR для преобразования файлов PDF в редактируемый текст, тогда Google Docs поможет вам.
Доступность платформы: Web, Windows, macOS, Linux
Цена: Бесплатно
Посетите: Google Диск / Google Docs
Все готово для преобразования изображений и PDF-файлов в текст?
Оцифровка печатного и рукописного текстового контента чрезвычайно полезна, так как значительно упрощает хранение, редактирование и совместное использование.И описанное выше программное обеспечение OCR быстро справляется с этим, независимо от того, насколько простыми или расширенными являются ваши потребности в извлечении текста. Нужны функции извлечения текста профессионального уровня с лучшими инструментами постобработки? Выберите ABBYY FineReader, Tesseract или OmniPage. Вы бы предпочли более простое программное обеспечение для оптического распознавания текста, которое позволяет выполнять базовые операции? Используйте OneNote или Google Docs. Попробуйте их и посмотрите, как они работают для вас. Знаете ли вы о каком-либо другом программном обеспечении для распознавания текста, которое могло быть включено в список выше? Выкрикивайте в комментариях ниже.
Что такое программа OCR и как ее использовать с PDF
25 Янв in Работа с PDF, Бизнес-тренды Обзор оптического распознавания символов: как работает OCRОптическое распознавание символов (OCR) — это расширенная функция, которая позволяет пользователям преобразовывать бумажные документы и изображения в редактируемые PDF-файлы. Это можно сделать с помощью сканера и функций распознавания текста, которые можно активировать после успешного сканирования документа с помощью приложения PDF, такого как Soda PDF .
Цель состоит в том, чтобы превратить изображение текста в сам текст. Что это значит? Представьте, что у вас есть изображение, содержащее слова (например, JPEG меню ресторана). С помощью программного обеспечения OCR вы можете сканировать изображение меню ресторана и преобразовывать его в редактируемый документ PDF. Другими словами, вы сможете изменить текст, который ранее был статическим изображением.
Преимущества использования программы OCRПреимущества использования программного обеспечения OCR многочисленны, главное из которых — это время, которое оно сэкономит вам в долгосрочной перспективе.Вместо того чтобы переписывать весь документ , чтобы иметь его цифровую и редактируемую копию на вашем компьютере, вы можете просто отсканировать бумажный документ и активировать функцию распознавания текста.
Это также сэкономит ваше время , потому что вам не придется вручную искать в стопке бумаг, если вы ищете конкретный документ. После того, как ваши файлы оцифрованы, вы можете просто выполнить поиск по определенным ключевым словам на своем компьютере. Вы даже можете выполнять поиск в каждом PDF-документе, если просто хотите найти слово в этом конкретном документе.
Функция OCRSoda PDF также позволяет пользователям выбирать между ручным и автоматическим распознаванием текста . Ручная функция дает вам свободу решать, как механизм OCR будет взаимодействовать с вашими изображениями (т. Е. Настраивая поля для распознавания текста в изображении).
Этот продвинутый инструмент распознает текст в документах, изображениях и даже рукописных заметках. Это может быть очень удобно для профессионалов отрасли, таких как юристы, врачи и учителя.
Использование программного обеспечения OCR Soda PDF в ИнтернетеЧто замечательно в Soda PDF, так это то, что он также предлагает онлайн-решение PDF для ваших нужд OCR.Вы можете легко распознать текст в своих документах и изображениях прямо на ходу через веб-браузер. Просто посетите Soda PDF Online и получите OCR-ing.
Поиск OCR Функция OCR Search вSoda PDF предназначена для пользователей, которые хотят искать и распознавать текст в изображениях или отсканированных документах. Мы рекомендуем этот инструмент тем, кому нужно искать в документах сходства, например, при сравнении контрактов или счетов-фактур.
Редактировать OCRНаша функция OCR Edit предназначена для тех, кому нужно простое решение для преобразования отсканированных документов в редактируемые PDF-файлы. С помощью OCR Edit вы можете не только сканировать и распознавать текст на изображениях или отсканированных документах, но и редактировать идентифицируемые слова, что позволяет легко создавать редактируемые PDF-файлы из любого напечатанного документа!
Автоматический или ручной: Какая у вас передача текста?Soda PDF даже позволяет выбирать между автоматическим или ручным распознаванием текста.
Выберите, хотите ли вы, чтобы наша функция OCR автоматически сканировала ваше изображение или изображения в вашем PDF-файле для распознавания текста. Или, если вы предпочитаете вручную выделять текст в изображении для распознавания, вы можете выбрать оптическое распознавание текста вручную.
Обратите внимание, что в зависимости от того, какой инструмент OCR вы выберете, OCR Auto или OCR Manual смогут распознавать и идентифицировать текст только в этих изображениях вашего PDF-документа.Если вы хотите иметь возможность изменять текст, а не просто идентифицировать текст, мы рекомендуем использовать наш инструмент редактирования OCR, который позволяет вам изменять текст в любом файле изображения или отсканированном документе.
Мы настоятельно рекомендуем OCR Edit для тех, кто хочет изменить отсканированные документы. Наше программное обеспечение OCR поможет вам повысить вашу производительность и легко поможет вам управлять печатными документами, с легкостью превращая их в оцифрованные файлы.
Посмотрите это обучающее видео, чтобы узнать, как использовать OCR в Soda PDFСканирование и индексирование с оптическим распознаванием символов
Оптическое распознавание символов (OCR) преобразует изображения машинописного или четко напечатанного текста в машинно-кодированный текст, который можно редактировать и искать.Это позволяет быстро индексировать и выполнять поиск в любом формате электронного документа.
При сканировании бумажных документов в формат PDF или TIFF функция распознавания текста на стороне сервера в FileHold может автоматически распознавать эти документы для создания документа PDF с текстовым слоем, который можно индексировать для полнотекстового поиска. . Когда документы находятся в полном формате OCR, система управления документами позволяет автоматизировать полнотекстовое индексирование и поиск документов.Полнотекстовая индексация позволяет пользователям искать слово или фразу в теле документа, когда он хранится в библиотеке.
Безбумажный офис зависит от сканирования документов и создания изображений для создания хранилища электронного управления записями . Источником отсканированных документов могут быть специализированные сканеры, факсы или многофункциональные центры (MFC). Во всех случаях программное обеспечение позволяет пользователям легко импортировать документы в системы и правильно фиксировать типы документов и связанные с ними метаданные.
Программное обеспечение для сканирования документов с оптическим распознаванием текста
Каждая продажа программного обеспечения FileHold поставляется с программным обеспечением для сканирования документов на базе рабочей станции, которое поддерживает все сканеры TWAIN. Это позволяет пользователям вносить существующие бумажные документы, такие как контракты, почта, счета-фактуры и юридические документы, в систему программного обеспечения для управления документами. Программное обеспечение OCR, входящее в состав программного обеспечения для сканирования, преобразует эти отсканированные изображения в редактируемые и доступные для поиска форматы, такие как PDF или Microsoft Word.
Помимо программного обеспечения для сканирования, которое поставляется с каждой серверной лицензией, программное обеспечение для управления записями FileHold поддерживает все основные программные решения для сканирования, представленные на рынке (ABBY, Kofax, EMC, Kodak).
Для клиентов, все еще использующих EMC Quick Scan Pro, список поддерживаемых сканеров составляет: более 400 типов сканеров.
Вы можете сканировать документ и преобразовывать текст в данные, которые можно редактировать с помощью текстового редактора.Этот процесс называется OCR (оптическое распознавание символов). Чтобы сканировать и использовать OCR, вам необходимо использовать программу OCR, например, ABBYY FineReader. Программное обеспечениеOCR не может распознавать рукописные символы, а некоторые типы документов или текста трудно распознать программное обеспечение OCR, например: Элементы, скопированные с других копий Факсы Текст с короткими интервалами или межстрочным интервалом Табличный или подчеркнутый текст Курсивный или курсивный шрифт, размер шрифта менее 8 пунктов Для сканирования и преобразования текста с помощью ABBYY FineReader выполните следующие действия.
Mac OS X : откройте папки Приложения> ABBYY FineReader 5 Sprint Plus и дважды щелкните значок Запустить FineReader 5 Sprint . Перед вами откроется окно ABBYY FineReader.
В полностью автоматическом режиме щелкните Сканировать . Epson Scan выполняет предварительное сканирование, сканирование и преобразование текста в редактируемый формат, а затем отображает его в окне FineReader. В простом режиме выберите Magazine , Newspaper или Text / Line Art в качестве типа документа. Затем выберите Черно-белый или Цветной в качестве типа изображения и выберите Принтер или Другой в качестве настройки места назначения.Просмотрите и выберите область сканирования, как описано в разделе «Предварительный просмотр и настройка области сканирования». Затем нажмите Сканировать . Ваш документ будет отсканирован, преобразован в редактируемый текст и открыт в окне FineReader.В офисном режиме выберите Color , Grayscale или Black & White в качестве типа изображения и Document Table в качестве источника документа. Выберите размер исходного документа в качестве настройки размера и 300 dpi в качестве разрешения.Просмотрите и выберите область сканирования (для получения инструкций нажмите кнопку Help в окне Epson Scan). Затем нажмите Сканировать . Ваш документ будет отсканирован, преобразован в редактируемый текст и открыт в окне FineReader. В профессиональном режиме выберите Reflective в качестве типа документа, Document Table в качестве источника документа и Document в качестве типа автоматической экспозиции. Затем выберите Черно-белый или 24-битный цвет в качестве типа изображения и 300 dpi в качестве разрешения.Просмотрите и выберите область сканирования, как описано в разделе «Предварительный просмотр и настройка области сканирования». Затем нажмите Сканировать . Ваш документ будет отсканирован, преобразован в редактируемый текст и открыт в окне FineReader. Заметка:
|
Как собирать важные данные с помощью приложений для сканирования и оптического распознавания символов
Приложение для сканирования с оптическим распознаванием символов (OCR) незаменимо для организации работы.Лучшие приложения для сканирования помогут вам захватить любую информацию, такую как слайды презентации с собрания, заметки на доске, визитные карточки, не говоря уже о важных документах. Они пригодятся и для других целей, от оцифровки бумажных рецептов до сохранения гарантий.
Несколько лет назад мне пришлось получить новый паспорт и в тот же день сдать его на визу. Сразу после того, как я взял паспорт, я подумал: «Мне, наверное, нужно иметь его копию, прежде чем я его передам.»Я достал свой телефон и отсканировал его. Разумеется, на получение визы ушло больше двух недель, а тем временем мне понадобились данные моего паспорта для кучи документов. Хорошо, что у меня была четкая копия!
Как работают приложения для сканирования?
Когда вы используете мобильное приложение для сканирования, это не сильно отличается от фотографирования. В идеальной обстановке вы воспроизводите документ на контрастном фоне и наводите на него камеру телефона.
Затем приложение для сканирования проведет вас через весь процесс.Обычно вам предлагается выровнять края документа с метками обрезки на экране телефона. Держитесь крепче, но не волнуйтесь. Приложение подстраивается под легкие движения. Сканирование занимает секунду или две. Когда это будет сделано, вы обычно видите предварительный просмотр вашего документа. Затем приложение обычно спрашивает, хотите ли вы добавить дополнительные страницы или начать новое сканирование.
Возможно, вы думаете, что можете вообще пропустить приложение для сканирования и вместо этого сфотографировать любые документы, которые вы хотите сохранить в цифровом виде.Можно, но есть два недостатка. Во-первых, изображение вряд ли будет столь же четким, как сканированное изображение, поэтому вы рискуете получить нечитаемый текст. Во-вторых, вы не можете искать по тексту, что может сильно затруднить поиск того, что вам нужно позже.
Что следует сканировать с помощью приложения для сканирования?
Давайте рассмотрим примеры того, как вы можете использовать приложение для сканирования, чтобы оставаться организованным. После этого я объясню, какие функции вам следует искать в лучших приложениях для сканирования, и назову несколько приложений, в которых они есть.
Визитки
В следующий раз, когда кто-то вручит вам визитную карточку, воспользуйтесь приложением для сканирования, чтобы захватить контактную информацию этого человека, а затем верните карточку. Вы покажете, как легко быть безбумажным, а также собирать информацию о них в цифровом формате, чтобы вам не пришлось ничего вводить позже. Некоторые приложения для сканирования могут обнаруживать визитные карточки и создавать новую запись в приложении для контактов. Другие ищут в LinkedIn и предлагают подключиться там.
Доски и презентационные материалы
На собраниях большинство из нас хочет уделять каждому выступающему все свое внимание.Это сложно сделать, если мы смотрим на презентацию или доску, надеясь не пропустить важную деталь. Отличное решение — быстро сканировать слайды или другие материалы по мере их появления, зная, что вы сможете просмотреть их более подробно позже.
документов для электронной почты или резервного копирования
Несмотря на то, что многие люди и организации с удовольствием отправляют вам цифровые документы, все еще есть много случаев, когда мы сталкиваемся с бумажными документами. Предположим, ваш банк дает вам важный бумажный документ для подписи, но вы хотите, чтобы ваш юрист сначала его проверил.Это прекрасное время для использования вашего приложения для сканирования. Отсканируйте несколько страниц, чтобы отправить их по электронной почте. Некоторые приложения для сканирования включают в себя инструмент, который также позволяет вам подписывать их цифровой подписью.
Другие важные документы, которые вы, возможно, захотите отсканировать и сделать резервную копию, включают записи о прививках, налоговые документы и юридические свидетельства (о рождении, браке, иммиграции и т. Д.).
На что обращать внимание в приложении для сканирования
Лучшие приложения для сканирования четко фиксируют ваши документы, обеспечивают возможность поиска по тексту и помогают сохранять готовые файлы в нужных местах.Вот что нужно искать:
Автоматическое определение края
Отличное приложение для сканирования и оптического распознавания текста автоматически находит края документов. Когда вы наводите камеру на бумагу, метки обрезки, которые вы видите на экране, должны самостоятельно искать край документа и подстраиваться под другие размеры. Итак, сканируете ли вы лист бумаги формата А4 или визитку, приложение определит это автоматически.
Параметры сохранения и экспорта
Лучшие приложения для сканирования предоставляют вам варианты того, где вы можете сохранить или экспортировать недавно отсканированные тексты, например, Google Drive, Dropbox или другой сервис хранения.Вам не нужно приложение, которое заставляет вас хранить документы в новом месте.
OCR
Я упомянул оптическое распознавание символов в начале статьи. Когда у вас есть OCR, любые слова, которые вы сканируете, становятся текстом. Вы также можете скопировать и вставить текст или отредактировать его. Допустим, вы просматриваете рецепт и видите опечатку. С действительно хорошим приложением для сканирования и распознавания текста вы сможете исправить опечатку. Некоторые приложения могут преобразовать окончательный текст в знакомый формат обработки текста, например .docx. Другие позволяют изменять текст прямо в приложении, не открывая предварительно документ в текстовом редакторе.
OCR также позволяет выполнять поиск по тексту документов. Это означает, что если вы хотите найти свои записи о прививках, вы можете попробовать поискать по имени своего врача, чтобы найти файл. Вам не нужно помнить, как вы назвали файл. Если вы часто пользуетесь поиском для поиска файлов, то вам обязательно понадобится OCR.
Функция поиска
Может быть, вы не очень организованы, когда дело доходит до экспорта и сохранения файлов в другом месте. В этом случае вы захотите иметь возможность искать в содержимом приложения для сканирования все, что вы когда-то сканировали и теперь вам нужно.В отличном приложении для сканирования будет собственная функция поиска.
Поддержка нескольких страниц
Действительно хорошие приложения для сканирования могут сканировать несколько страниц подряд. Затем они должны с легкостью сопоставить все страницы в один PDF-файл. Самые современные приложения для сканирования также корректируют искажение страницы, например, когда вы сканируете страницы из книги и не можете заставить ее лежать ровно.
Цена
Многие из лучших приложений для сканирования и распознавания текста имеют бесплатный уровень обслуживания и платный уровень премиум-класса.OCR иногда считается премиальной функцией. Цены на приложения для сканирования и распознавания текста немного сумасшедшие. Какое-то время вы могли рассчитывать заплатить от 4 до 7 долларов за достойное приложение. Теперь единовременные сборы в десять раз выше. Хотя цены на подписку более разумные, некоторым людям требуется приложение для сканирования всего несколько раз в год.
Лучшие приложения для сканирования
Теперь, когда вы понимаете, что могут делать приложения для сканирования и почему они могут вам понадобиться, вот некоторые из лучших, которые вы можете найти. Я сосредоточился на приложениях, которые предлагают сканирование, а OCR и делают ваш текст редактируемым.Есть множество приложений, которые просто сканируют. Evernote Scannable и мобильное приложение Dropbox — два примера. Но они не дают вам окончательного текста, который вы можете скопировать, вставить или отредактировать. Эти приложения делают.
Независимо от того, какое приложение вы выберете, вы обнаружите, что наличие под рукой приложения для сканирования, которому вы доверяете, помогает вам оцифровывать ваши документы и оставаться организованным.
ABBYY FineScanner
Бесплатно; Pro за 4,99 доллара США в месяц, 19,99 доллара США в год или единовременную плату в размере 59,99 доллара США
ABBYY FineScanner, пожалуй, лучший и самый мощный сканер и приложение OCR для мобильных устройств.Он экспортирует файлы в различные форматы, позволяет сохранять файлы в большинстве основных служб хранения и даже выполняет распознавание текста на более чем 40 языках. Чтобы получить OCR, вам понадобится премиум-аккаунт, который стоит 4,99 доллара в месяц, 19,99 доллара в год или 59,99 доллара за разовую плату.
Доступно на Android, iOS
Microsoft Office Lens (бесплатно в Apple App Store)
Бесплатно
Microsoft Office Lens — одно из немногих совершенно бесплатных приложений для сканирования. Он немного медленнее и неуклюже, чем другие приложения с обнаружением краев и обрезкой, но выполняет свою работу.В приложении есть специальные режимы для сканирования визиток и доски. Чтобы отредактировать отсканированный текст, вы должны экспортировать текст через Microsoft OneDrive, а затем открыть его в Word.
Доступно для Android, iOS, Windows
Scanbot 9 (7,99 доллара США в Scanbot)
Бесплатно; Pro за 4,49 доллара в первый год, затем за 22,49 доллара в год; или 69,99 долларов США единовременно на iOS
Scanbot — отличное приложение для сканирования и распознавания текста. При этом компания недавно изменила свою модель ценообразования с недорогой единовременной платы на годовую подписку или более дорогую единовременную плату (69 долларов.99). Кроме того, очень сложно отследить цены. В любом случае стоит подумать о версии Pro Scanbot, если вам нужно быстрое и точное приложение для сканирования практически любого типа документа. Он имеет хорошие инструменты цветокоррекции и оптимизации, а также другие функции сканирования, такие как считыватель QR-кода и сканер штрих-кода.
Ваш комментарий будет первым