5 бесплатных программ для распознавания текста

 Windows
Windows  Android
Android- Back
- Антишпионы
- Бесплатные антивирусы
- Файрволы
- Шифрование
- Графика
- Back
- Графические редакторы
- Конвертеры
- Просмотр
- САПР и Чертеж
- Создание скриншотов
- Интернет
- Back
- Блокировка рекламы
- Браузеры
- ВКонтакте
- Загрузчики
- Интернет ТВ
- Контроль трафика
- Мессенджеры
- Облачные хранилища
- Почтовые клиенты
- Радио плееры
- Раздача Wi-Fi
- Социальные сети
- Торрент программы
- Удаленный доступ
- Медиа
- Back
- Аудио редакторы
- Видеоредакторы
- Запись CD
- Запись с экрана
- Изменение голоса
- Каталогизаторы
- Кодеки
- Конвертеры
- Проигрыватели
- Утилиты
- Офис
- Back
- Офисные пакеты
- PDF принтеры
- Переводчики
- Планировщики
- Просмотрщики
- Распознавание текста
- Сканирование
- Читалки
- Наука
- Back
- Астрономия и география
- Клавиатурные тренажеры
- Разработка
- Back
- Web редакторы WYSIWYG
- Редакторы кода
- Утилиты
- FTP клиенты
- Система
- Back
- Администрирование
- Архиваторы
- Бэкап данных
- Быстродействие
- Виртуальные диски
- Восстановление данных
- Данные о системе
- Дефрагментация
Программы для распознавания текста

Утомительное перепечатывание текста для приведения его в электронный вид давно уже отошло в прошлое, ведь сейчас существуют довольно продвинутые системы распознавания, работа с которыми требует минимального вмешательства пользователя. Программы для оцифровки текста востребованы как в офисе, так и дома. В настоящее время существует довольно большое разнообразие различных приложений для распознавания текста, но какие из них действительно лучшие? Попробуем разобраться в этом вопросе.
ABBYY FineReader
Эбби Файн Ридер – самая популярная программа для сканирования и распознавания текста в России, а, возможно, и в мире. Данное приложение имеет в своем арсенале все необходимые инструменты, что и позволило ему достичь такого успеха. Кроме сканирования и распознавания, ABBYY FineReader позволяет производить расширенное редактирование полученного текста, а также выполнять ряд других действий. Программа отличается очень качественным распознаванием текста и быстротой работы. Мировую популярность она заслужила также благодаря возможности оцифровки текстов на многих языках мира, а также мультиязычному интерфейсу. Среди немногих недостатков FineReader можно, разве что, выделить большой вес приложения и необходимость платить за пользование полноценной версией.
Скачать ABBYY FineReader
Урок: Как распознать текст в ABBYY FineReader
Readiris
Главным конкурентом Эбби Файн Ридер в сегменте оцифровки текста является приложение Readiris. Это функциональный инструмент для распознавания текста как со сканера, так и с сохраненных файлов различных форматов (PDF, PNG, JPG и др.). Хотя по функционалу данная программа несколько уступает ABBYY FineReader, она значительно превосходит большинство других конкурентов. Главной же фишкой Readiris является возможность интеграции с целым рядом облачных сервисов для хранения файлов. Недостатки у Readiris практически те же, что и у ABBYY FineReader: большой вес и необходимость платить немалые деньги за полноценную версию.

Скачать Readiris
VueScan
Разработчики VueScan главное внимание сконцентрировали все-таки не на процессе распознавания текста, а на механизме сканирования документов с бумажных носителей. Причем программа хороша именно тем, что работает с очень большим перечнем сканеров. Для ее взаимодействия с устройством не требуется установка драйверов. Более того, VueScan позволяет работать с дополнительными возможностями сканеров, которые даже родные приложения этих устройств не помогают раскрыть в полной мере. Также у программы есть инструмент распознавания сканируемого текста. Но данная функция пользуется популярностью только в связи с тем, что ВуеСкан – отличное приложение для сканирования. Собственно, функционал по оцифровке текста довольно слаб и неудобен, поэтому распознавание в VueScan используется для решения несложных задач.
Скачать VueScan
CuneiForm
Приложение CuneiForm – отличное решение для распознавания текста с фото, изображений, сканера. Популярность оно приобрело благодаря применению особой технологии оцифровки, совмещающей шрифтонезависимое и шрифтовое распознавание. Это позволяет максимально точно распознавать текст, учитывая даже элементы форматирования, но при этом сохранять высокую скорость работы. В отличии от большинства программ для распознавания текста, эта абсолютно бесплатна. Но у данного продукта имеется и целый ряд недостатков. Так, он не работает с одним из самых популярных форматов – PDF, — а также имеет плохую совместимость с некоторыми моделями сканеров. Кроме того, приложение на данный момент разработчиками официально не поддерживается.

Скачать CuneiForm
WinScan2PDF
В отличии от CuneiForm, единственной функцией WinScan2PDF является оцифровка полученного со сканера текста в формат PDF. Главное преимущество этой программы – простота использования. Она подойдет тем людям, которые очень часто сканируют бумажные документы и распознают текст в формате PDF. Главный недостаток ВинСкан2ПДФ связан с очень ограниченным функционалом. Собственно, больше ничего данный продукт не умеет делать, кроме указанной выше процедуры. Он не может сохранять результаты распознавания в другой формат, кроме PDF, а также не предоставляет возможности оцифровки файлов изображений, которые уже хранятся на компьютере.
Скачать WinScan2PDF
RiDoc
РиДок является универсальным офисным приложением для сканирования документов и распознавания текста. Его функционал все-таки немного уступает ABBYY FineReader или Readiris, но и стоимость заметно меньше. Поэтому по соотношению «цена – качество» RiDoc выглядит даже предпочтительнее. В то же время, существенных ограничений по функционалу программа не имеет, и одинаково хорошо выполняет как задачу сканирования, так и распознавания. Фишкой РиДок является возможность уменьшения изображений без потери качества. Единственный существенный недостаток – не совсем корректная работа по распознаванию мелкого текста.

Скачать RiDoc
Безусловно, среди перечисленных программ любой пользователь сможет отыскать ту, которая ему придется по душе. Выбор будет зависеть как от конкретных задач, которые приходится чаще всего решать, так и от финансового состояния.
 Мы рады, что смогли помочь Вам в решении проблемы. Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Мы рады, что смогли помочь Вам в решении проблемы. Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.Помогла ли вам эта статья?
ДА НЕТПредположим, вам нужно извлечь откуда-нибудь печатный текст. Из защищённого PDF, с изображения, со скриншота, с сайта, где копирование текста отключено — да откуда угодно. Вы можете, конечно, установить громоздкий и мощный ABBYY FineReader, но в большинстве случаев его возможности избыточны. Крошечная утилита Easy Screen OCR распознает любой текст быстрее, чем Fine Reader запустится.
Скачайте и установите Easy Screen OCR. Приложение имеет версии для Windows и macOS. После установки и запуска в трее вашей операционной системы появится значок программы. Щёлкните по нему правой кнопкой мыши и откройте настройки (Preferences).
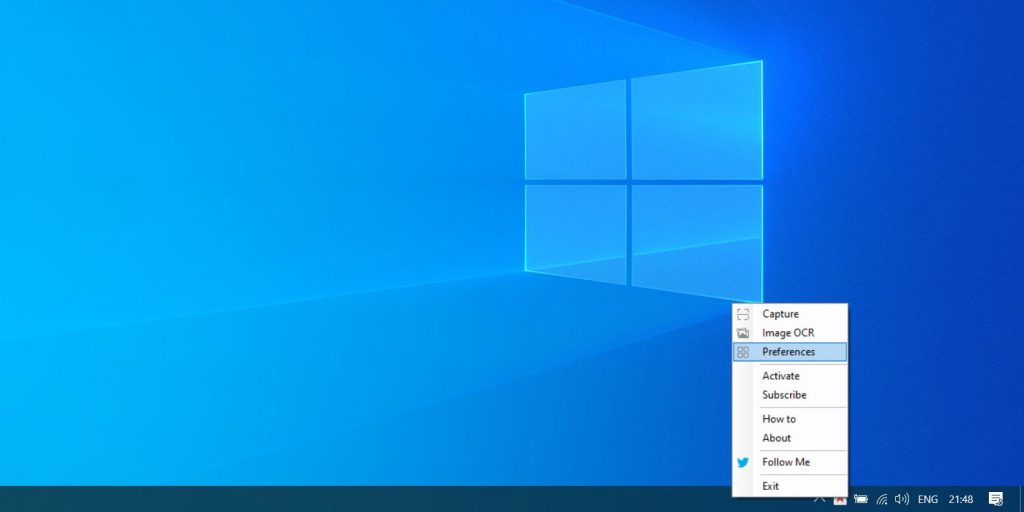
В настройках можно включить запуск программы вместе с системой. Кроме того, на вкладке «Язык» (Language) присутствует важная опция — язык распознаваемого текста.
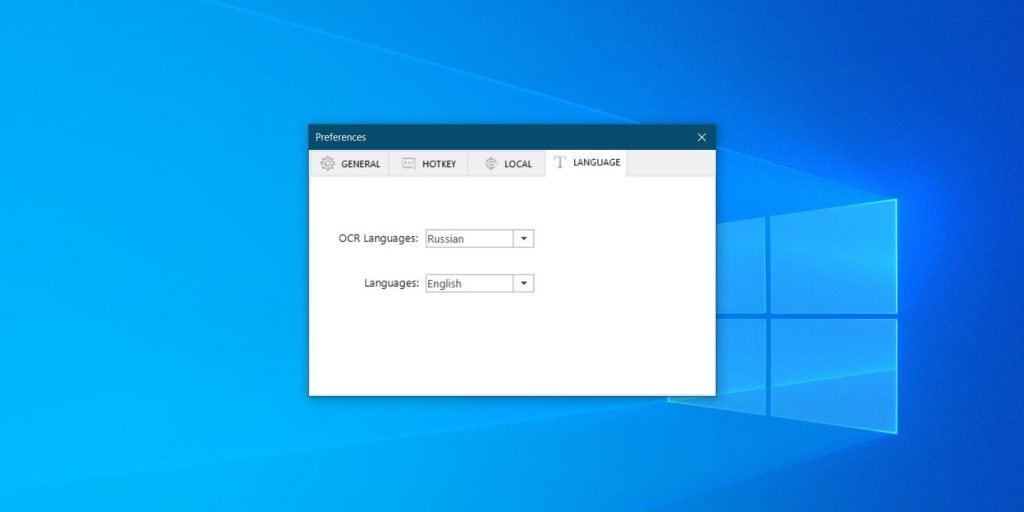
Переключившись на эту вкладку, выберите в выпадающем списке OCR Languages русский язык, а затем закройте настройки. Всего Easy Screen OCR поддерживает около сотни языков.
Теперь программа готова к работе. Чтобы распознать любой текст на экране, щелкните по значку Easy Screen OCR в трее правой кнопкой мыши и выберите пункт Capture. Вы сможете выбрать область экрана с некопируемым текстом.
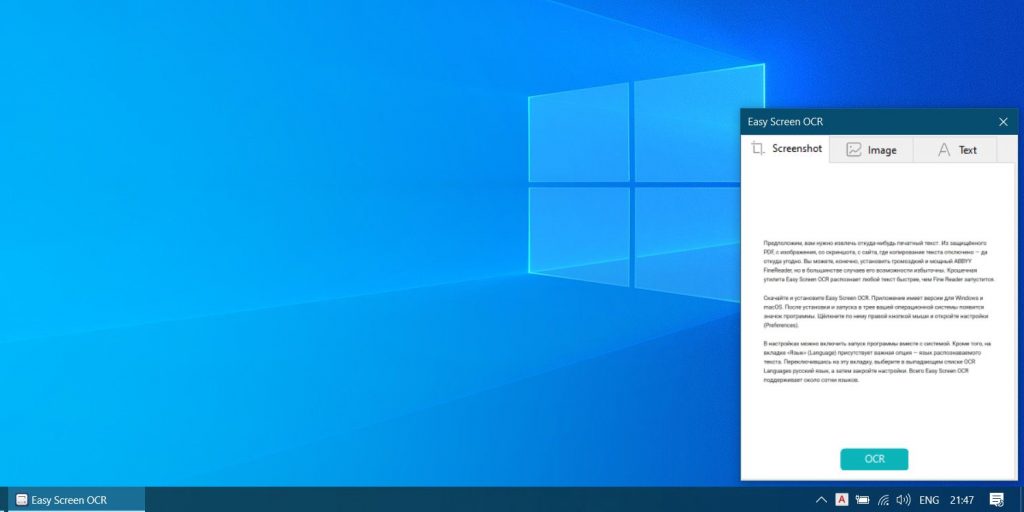
Затем внизу появится всплывающее окно с захваченной областью. Нажмите кнопку OCR, и программа покажет вам готовый текст. Его можно будет скопировать и отредактировать.
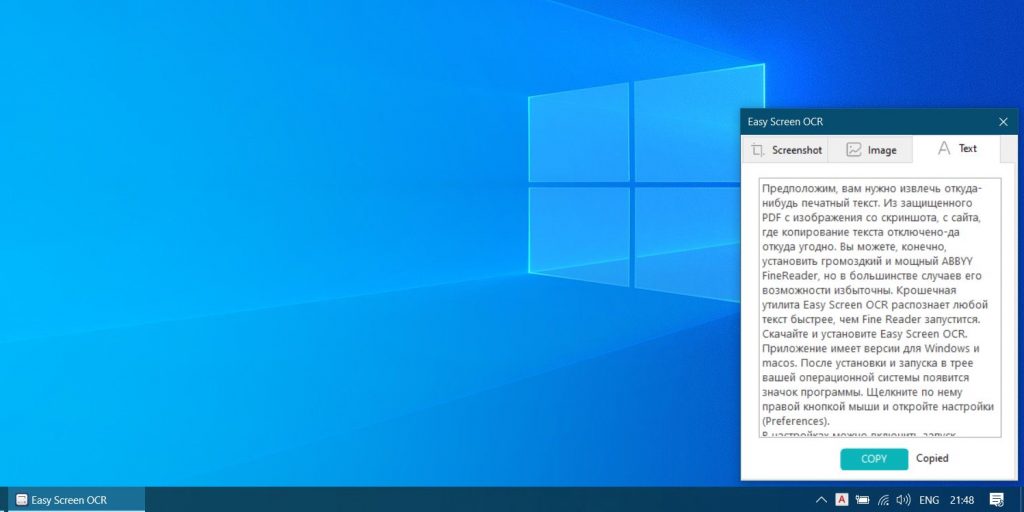
Кроме того, Easy Screen OCR способна копировать текст с картинок. Для этого выберите в меню пункт Image OCR и перетащите нужную картинку в появившееся окно. Программа умеет сканировать не только печатный текст, но даже рукописный.
Easy Screen OCR можно попробовать бесплатно в течение трёх дней, потом придётся оформить подписку за 9 долларов в месяц (или 49 в год). Если, узнав о таких условиях, вы решили, что не так уж оно вам и надо, то вот вам список бесплатных онлайн-инструментов для распознавания текста.
Загрузить Easy Onscreen OCR →

Цена: Бесплатно
|
RiDoc сканирует документы, делая отсканированный документ малого размера без потери качества изображения. Простая и удобная программа для ежедневного сканирования и распознавания текста. Используйте RiDoc для создания электронных документов (цифровой копии документа). Основные функции программы: Используйте RiDoc 30 дней БЕСПЛАТНО в режиме полного функционала (без ограничений) для ознакомления возможностей программы*. Программа RiDoc работает с TWAIN и WIA совместимыми сканерами (МФУ). Для успешного сканирования документов требуется, чтобы на компьютере, на котором установлена программа RiDoc, были установлены и настроены драйвера сканера TWAIN или WIA.
* триал-период программы RiDoc (период ознакомления с возможностями работы программы RiDoc) равен 30 дням. В триал-период установленная Вами программа RiDoc работает без ограничений (в полном объеме). По окончании триал-периода устанавливаются ограничения на результаты работы программы RiDoc. |
- Товары
- Клиенты
- Случаи использования
- Переполнение стека Публичные вопросы и ответы
- Команды Частные вопросы и ответы для вашей команды
- предприятие Частные вопросы и ответы для вашего предприятия
- работы Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимать технический талант
- реклама Связаться с разработчиками по всему миру
Как работает сканирование документов OCR?
Крис Вудфорд. Последнее обновление: 28 марта 2020 г.
Вы когда-нибудь пытались прочитать почерк друга? Считай, что тебе повезло, то, что вы не работаете на почтовую службу США, которая должна расшифровать и доставить около 30 миллионов рукописных конвертов каждый день! Так как большая часть нашей жизни компьютеризирована, это жизненно важно, чтобы машины и люди могли понимать друг друга и передавать информацию туда и обратно.В основном на компьютерах есть вещи их путь — мы должны «говорить» с ними через относительно грубые устройства, такие как клавиатуры и мыши, чтобы они могли понять, что мы хотим, чтобы они делали. Но когда речь идет об обработке более человеческих видов информации, таких как старомодная печатная книга или письмо, написанное Перьевая ручка, компьютеры должны работать намного тяжелее. Вот где оптический характер распознавание (OCR). Это тип программное обеспечение (программа), которая может автоматически анализировать печатный текст и превращать его в форма, которую компьютер может обрабатывать более легко.OCR в сердце всего, от программ анализа почерка на мобильных телефонах до гигантские машины для сортировки почты, которые обеспечивают все эти миллионы писем достигают своих назначений. Как именно это работает? Давайте присмотрись!
Фото: распознавание персонажей. Для нас с вами это слово «an», но для компьютера это просто бессмысленный черно-белый узор. И обратите внимание, как волокна бумаги вносят некоторую путаницу в изображение. Если бы чернила были немного более блеклыми, серо-белый узор волокон начал бы мешать и затруднять распознавание букв.
Что такое OCR?
Фото: когда дело доходит до оптического распознавания символов, наши глаза и мозг намного превосходят любой компьютер.
Когда вы читаете эти слова на экране компьютера, ваши глаза и мозг оптическое распознавание символов, даже если вы этого не заметили! Ваши глаза распознают узоры света и тьмы, которые составляют символы (буквы, цифры и такие вещи, как пунктуация метки) напечатаны на экране, и ваш мозг использует эти цифры что я пытаюсь сказать (иногда читая символы, но в основном путем сканирования целых слов и целых групп слова сразу).
Компьютеры тоже могут это делать, но для них это действительно тяжелая работа. Первый Проблема в том, что у компьютера нет глаз, поэтому, если вы хотите, чтобы он читал что-то вроде страницы старой книги, вы должны представить ее изображение этой страницы, созданное с помощью оптического сканер или цифровая камера. Страница, которую вы создаете таким образом, является графический файл (часто в виде JPG) и, насколько это возможно, компьютер обеспокоены тем, что нет никакой разницы между ним и фотографией Тадж Махал или любой другой рисунок: это совершенно бессмысленный образец пикселей (цветные точки или квадраты, которые составляют компьютерная графика).Другими словами, компьютер имеет изображение страница, а не сам текст — он не может прочитать слова на страница, как мы можем, просто так. OCR — это процесс превращения изображение текста в самом тексте — другими словами, производя что-то как файл TXT или DOC из отсканированного JPG печатного или рукописного стр.
В чем преимущество распознавания текста?
После того, как напечатанная страница находится в этой машиночитаемой текстовой форме, вы можете сделать все виды вещей, которые вы не могли сделать раньше.Вы можете искать через это по ключевому слову (удобно, если его огромное количество), отредактируйте его с помощью текстовый процессор, включить его в веб-страницу, сжать в ZIP-файл и хранить его в гораздо меньшем объеме, отправить его по электронной почте — и все виды других изящных вещей. Машиночитаемый текст также может быть декодирован средства чтения с экрана, инструменты, использующие синтезаторы речи (компьютеризированные голоса, как тот, который использовал Стивен Хокинг), чтобы прочитать слова на экране так слепые и слабовидящие люди могут понять их. (Назад в В 1970-х годах одним из первых основных применений оптического распознавания текста стал копировальный аппарат. устройство под названием Kurzweil Reading Machine, которое может читать печатные книги вслух слепым людям.)
Фото: сканирование в вашем кармане: приложения для оптического распознавания текста на смартфоне — быстрые, точные и удобные. Слева: здесь я сканирую текст статьи, которую вы сейчас читаете, прямо с экрана моего компьютера, с помощью своего смартфона и текстового сканера (Android-приложение от Peace). Справа: несколько секунд спустя на экране моего телефона появляется очень точная версия отсканированного текста.
Как работает OCR?
Давайте предположим, что жизнь была действительно простой, и в алфавит: А.Даже тогда вы, вероятно, можете видеть, что OCR будет довольно сложная проблема — потому что каждый человек пишет букву А в немного по-другому. Даже с печатным текстом, есть проблема, потому что книги и другие документы печатаются во многих гарнитуры (шрифты) и буква А могут быть напечатаны во многих тонких разные формы.
Фото: между этими разными версиями заглавной буквы А есть немало различий, напечатаны разными компьютерными шрифтами, но есть и основное сходство: вы можете видеть, что почти все они сделаны из двух угловых линий, которые встречаются посередине сверху, с горизонтальной линией между ними.
Вообще говоря, есть два разных способа решить эту проблему, либо распознавая символы в их совокупности (распознавание образов) или путем обнаружения отдельных линий и штриховые символы сделаны из (функция обнаружения) и идентификации их таким образом. Давайте посмотрим на это по очереди.
Распознавание образов
Если бы все писали букву А точно так же, получая компьютер признать это было бы легко. Вы бы просто сравнили отсканированное изображение с сохраненной версией буквы А и, если они совпадают, было бы это.Вроде как Золушка: «Если туфелька подходит …»
Так как же заставить всех писать одинаково? Еще в 1960-х, был разработан специальный шрифт OCR-A, который можно использовать на такие вещи, как банковские чеки и так далее. Каждое письмо было точно таким же ширина (так что это был пример того, что называется моноширинный шрифт) и штрихи были тщательно разработаны, чтобы каждая буква могла быть легко отличается от всех остальных. Чек-принтеры были спроектированы так все они использовали этот шрифт, и оборудование OCR было разработано для распознавания это тоже.Стандартизировав один простой шрифт, OCR стал относительно легко решить проблему. Единственная проблема в том, что большая часть мира печатные издания не написаны в OCR-A — и никто не использует этот шрифт для своих почерк! Поэтому следующим шагом было научить программы распознавания текста распознавать письма, написанные несколькими очень распространенными шрифтами (например, Times, Гельветика, Курьер и тд). Это означало, что они могли распознать много печатного текста, но не было никакой гарантии, что они смогут узнайте любой шрифт, который вы можете отправить им.
Фото: шрифт OCR-A: предназначен для чтения как компьютерами, так и людьми. Вы можете не распознавать стиль текста, но цифры, вероятно, выглядят знакомыми по чекам и компьютерным распечаткам. Обратите внимание, что похожие символы (например, строчная буква «l» в «Объяснении» и цифра «1» внизу) были разработаны таким образом, чтобы компьютеры могли легко различать их.
Обнаружение признаков
Также известен как извлечение признаков или интеллектуальное распознавание символов. (ICR), это гораздо более сложный способ определения персонажей.Предположим, что вы компьютерная программа OCR, представленная разные буквы, написанные множеством разных шрифтов; как ты выбираешь все буквы, как будто они все выглядят немного по-другому? Ты мог используйте правило, подобное этому: Если вы видите две наклонные линии, которые встречаются в вверху, в центре, и есть горизонтальная линия между ними примерно на полпути, это буква А. Применить это правило и вы узнаете большинство заглавных букв как, независимо от того, какой шрифт они написаны в. Вместо того, чтобы признать полный образец А, вы обнаруживаете отдельные компоненты компонента (угловые линии, перекрещенные линии или что-то еще) из чего сделан персонаж.Наиболее современные Omnifont OCR-программы (те, которые могут распознавать печатный текст любой шрифт признание. Некоторые используют нейронные сети (компьютерные программы который автоматически извлекает образцы мозговым способом).
Фото: обнаружение элементов: вы можете быть уверены, что смотрите на заглавную букву А, если сможете правильно определить эти три составные части.
Как работает распознавание рукописного ввода?
Распознавание символов, составляющих аккуратно напечатанный на компьютере компьютерный текст, сравнительно легко по сравнению с расшифровкой чьих-то писанок почерк.Это такая простая, но сложная, повседневная проблема где человеческий мозг бьется с умными компьютерами: мы все можем сделать грубая попытка угадать сообщение, скрытое даже в худшем человеке письмо. Как? Мы используем комбинацию автоматического распознавания образов, извлечение функций, и, что очень важно, знания об авторе и смысл написанного («Это письмо от моего друга Гарриет о классическом концерте, на котором мы ходили вместе, так что слово она написанное здесь, скорее всего, будет «тромбон», чем «трамвайная линия».«)
Фото: Распознавание рукописного текста: рукописному рукописному вводу (с соединением и слиянием букв) гораздо сложнее распознать компьютер, чем печатным шрифтом, потому что трудно понять, где заканчивается одна буква и начинается другая. Многие люди пишут так поспешно, что не удосуживаются полностью сформировать свои буквы, что делает распознавание по шаблону или функции чрезвычайно сложным. Другая проблема заключается в том, что почерк является выражением индивидуальности, поэтому люди могут изо всех сил отличать свое письмо от нормы.Когда речь заходит о чтении таких слов, мы в большой степени полагаемся на смысл написанного, наши знания писателя и слова, которые мы уже прочитали, — то, что компьютеры не могут так легко управлять.
Облегчение
Когда компьютеры должны распознавать почерк, проблема часто упрощенный для них. Например, компьютеры сортировки почты вообще узнавать только почтовый индекс на конверте, а не весь адрес. Таким образом, они просто должны определить относительно небольшой объем текста сделан только из основных букв и цифр.Люди рекомендуется писать коды разборчиво (оставляя пробелы между символы, используя все заглавные буквы), а иногда и конверты предварительно напечатаны с небольшими квадратами для вас, чтобы написать символы в помочь вам держать их отдельно.
Формы, предназначенные для обработки OCR, иногда имеют отдельные поля, в которые люди могут писать каждое письмо или слабые руководящие принципы, известные как поля гребня, которые побуждают людей держать буквы отдельно и пиши разборчиво (Как правило, поля гребенки печатаются в специальном цвет, например розовый, называется выпадающим цветом, который можно легко отделить от текст, который люди пишут, обычно черными или синими чернилами.)
Планшетные компьютеры и мобильные телефоны с распознаванием почерка часто используют функцию выделения для распознавания письма, как вы их пишете. Если вы пишете письмо А, например, сенсорный экран может чувствовать, что вы пишете сначала одну угловую линию, затем другой, а затем горизонтальная линия, соединяющая их. Другими словами, компьютер получает преимущество в распознавании функций, потому что вы формируя их по отдельности, один за другим, и это делает выделение объектов очень проще, чем выбирать черты из почерка на бумаге.
Кто изобрел OCR?
Большинство людей считают, что заставить машины читать человеческий текст относительно недавнее новшество, но оно старше, чем вы могли предположить. Вот Экскурсия по истории OCR:
- 1928/9: Густав Таушек из Вены, Австрия запатентовал базовый OCR «читающий аппарат». Пол Хендель из General Electric подает патент на подобную систему в Соединенных Штатах в апреле 1931 года. Оба основаны на идее использования светочувствительных фотоэлементов для распознавания узоров. на бумаге или карточке.
- 1949: Л.Е. Флори и В.С. Пайк из RCA Laboratories разрабатывает аппарат на основе фотоэлементов, который может читать текст слепым людям на скорость 60 слов в минуту. (Читайте все об этом в февральском выпуске журнала Popular Science за 1949 год.)
- 1950: Дэвид Х. Шепард разрабатывает машины, которые могут превращать печатную информацию в машиночитаемую форму для военных США и позже основывает новаторскую компанию OCR под названием Intelligent Machines Исследования (IMR). Shepherd также разрабатывает машиночитаемый шрифт под названием Farrington B (также называемый OCR-7B и 7B-OCR), который теперь широко используется для печати тисненных чисел на кредитных картах.
- 1960: Лоуренс (Ларри) Робертс, исследователь компьютерной графики, работающий в MIT, развивает раннее распознавание текста, используя специально упрощенные шрифты, такие как OCR-A. Позже он становится одним из отцы-основатели интернета.
- 1950-х / 1960-х годов: Reader’s Digest и RCA работают вместе над разработкой некоторых из первых коммерческих систем оптического распознавания текста.
- 1960-е годы: почтовые службы по всему миру начинают использовать технологию распознавания текста для сортировки почты. К ним относятся Почтовая служба США, Главное почтовое отделение Великобритании (GPO, теперь называется Royal Mail), Canada Post и Немецкая Немецкая Почта.При поддержке таких компаний, как Lockheed Martin, почтовые службы и по сей день остаются в авангарде исследований OCR.
- 1974: Раймонд Курцвейл разрабатывает считывающую машину Kurzweil (KRM), которая объединяет планшетный сканер и синтезатор речи в машине, которая может читать печатные страницы вслух для слепых людей. Программное обеспечение Kurzweil для оптического распознавания символов приобретается Xerox и продается под названиями ScanSoft и (позже) Nuance Communications.
- 1993: Apple Newton MessagePad (PDA) — один из первых портативных компьютеров с функцией распознавания рукописного ввода на сенсорном экране.В течение 1990-х годов распознавание рукописного ввода становится все более популярной функцией на мобильных телефонах, КПК (особенно новаторских Palm и PalmPilot) и другие наладонники.
- 2000: Исследователи из Университета Карнеги-Меллона решают проблему разработки хорошего распознавания текста система с ног на голову — и разработать систему уничтожения спама под названием CAPTCHA (см. подпись ниже).
- 2007: Выпуск iPhone побуждает к разработке удобных приложений для смартфонов «укажи и нажми», которые могут сканировать и конвертировать текст с помощью камеры телефона.
Фото: из исследования OCR мы знаем, что компьютерам трудно распознать плохо напечатанные слова, которые люди могут читать относительно легко. Вот почему подобные загадки CAPTCHA используются, чтобы не дать спамерам атаковать почтовые системы, доски объявлений и другие веб-сайты. Этот был разработан Университетом Карнеги-Меллона, а затем приобретен Google как часть своей оригинальной системы reCAPTCHA. У оригинальной reCAPTCHA было дополнительное преимущество: когда вы печатали искаженные слова, вы помогали Google распознать часть отсканированного текста из старой книги, которую она хотела преобразовать в машиночитаемую форму.По сути, вы делали небольшое OCR от имени Google. Большинство веб-сайтов теперь переключились на другой, более безопасный тест CAPTCHA, который включает в себя идентификацию фотографий автомобилей, гор и других повседневных вещей.
,
| ||||||||||||||||||||||||||
Сканирование
Подкаст загружается. Проблемы? Слишком медленно? Вы также можете получить доступ к подкасту по нажав здесь.
Это сообщение исчезнет после полной загрузки подкаста.
В академическом контексте вам придется много читать, и вам нужно будет использовать различные навыки чтения, чтобы помочь вам читать быстрее. Сканирование текста является еще одним примером такого навыка (Скимминг и обзор текста два других). Эта страница объясняет что такое сканирование и как сканировать текст.
Что такое сканирование?
Сканирование текста означает быстрый просмотр его для поиска конкретной информации. Сканирование обычно используется в повседневной жизни, например, при поиске слова в словаре или поиске слова вашего друга. имя в каталоге контактов вашего телефона. Сканирование и другой навык быстрого чтения, Скимминга, часто путают, хотя они совсем разные. В то время как скимминг связан с Поиск общей информации , а именно основных идей, сканирование включает поиск конкретной информации .
Как сканировать текст
Прежде чем начать сканирование для получения информации, вы должны попытаться понять, как устроен текст. Это поможет вам найти информация быстрее. Например, при поиске слова в словаре или имени друга в списке контактов вы Уже известно, что информация расположена в алфавитном порядке. Это означает, что вы можете быстрее перейти к той части, которую хотите, без необходимости просматривать все. По этой причине, Скимминг может быть полезным навыком в сочетании со сканированием, чтобы дать вам общее представление о структуре текста.Заголовки разделов, если они есть, могут быть особенно полезны.
При сканировании вы будете искать ключевые слова или фразы. Их будет особенно легко найти, если они являются именами, потому что они начнется с заглавной буквы или цифр / дат. После того, как вы определились с областью текста, которую нужно сканировать, вы должны провести глаза вниз по странице, в зигзагообразным узором, чтобы взять как можно больше текста. Этот подход делает сканирование более случайным, чем другие навыки быстрого чтения Такие как скимминг и геодезия.Также рекомендуется использовать палец при перемещении вниз (или назад) по странице, чтобы сосредоточить свое внимание и сохранить отслеживать, где вы находитесь.
Поиск против сканирования
Иногда вы можете искать идею, а не искать фактическое слово или фразу. В этом случае вы будете искать , а не сканировать. Сканирование текста, чтобы помочь понять организацию, особенно важно при поиске для идеи. Также полезно угадать или предсказать тип ответа, который вы найдете, или какой-либо язык, связанный с ним.В этом случае, у вас все еще есть слова или фразы, которые вы можете использовать для сканирования текста. Таким образом, поиск — это частично скимминг, частичное сканирование. Например, если вы читаете текст о раке кожи и хотите найти причины, вы должны просмотреть текст, чтобы понять структуру, который может быть структура решения проблемы; Вы, возможно, уже знаете, что воздействие солнечного света является одной из причин, поэтому вы можете сканируйте на предмет «солнечного света» или «солнца», и потому, что вы ищете причины, которые вы могли бы искать переходные слова, такие как «потому что» или «причина» или «причина».
Понравился сайт? Попробуйте книги. Введите адрес электронной почты, чтобы получить бесплатный образец от жанров академического письма , часть книги EAP серии книг.
Контрольный список
Ниже приведен контрольный список для сканирования текста. Используйте это, чтобы проверить свое понимание.
Рекомендации
Макговерн Д., Мэтьюз М. и Маккей С.Е. (1994) Чтение . Харлоу: Pearson Education Limited.
Slaght, J. and Harben, P. (2009) Reading . Чтение: Garnet Publishing Ltd.
Wallace, M.J. (2004) Изучение навыков на английском языке . Кембридж: издательство Кембриджского университета.
,
Ваш комментарий будет первым