4 программы для распознавания текста
Знакомство с интерфейсом компьютерных игр и прикладного программного обеспечения может обернуться настоящей головной болью, если вы не знаете языка, который в этом самом интерфейсе используется. Нельзя вот так просто взять и скопировать текст меню в буфер обмена и вставить его в поле переводчика как это обычно мы делаем с текстом документов или веб-сайтов.
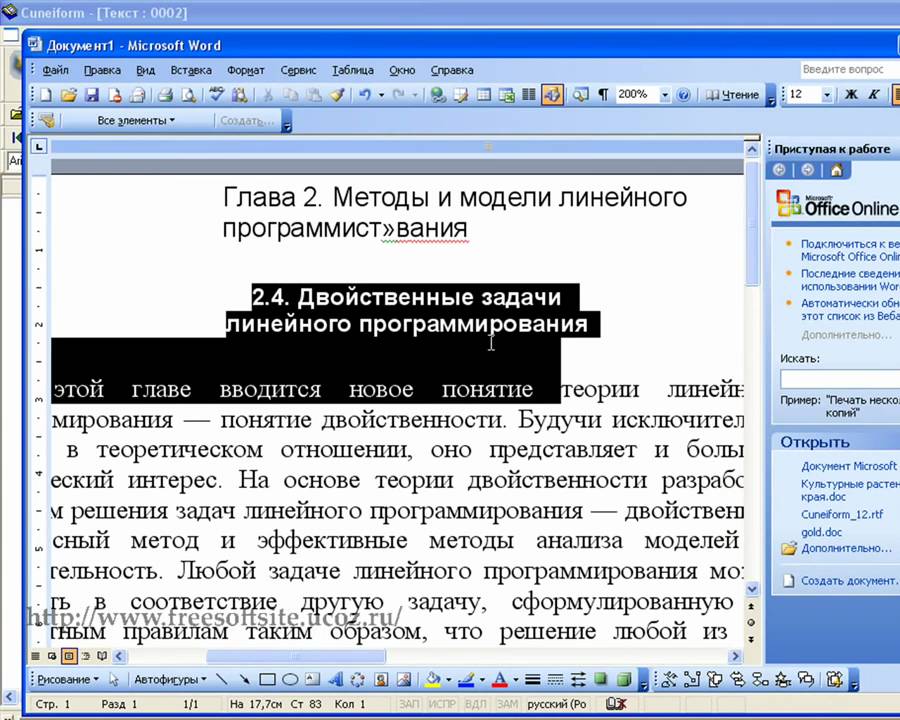
К счастью существуют утилиты позволяющие захватывать текст непосредственно с рабочего стола, то есть с изображений и элементов интерфейса. Как и ABBYY FineReader, являющейся одной из самых известных программ для распознания текста, эти утилиты используют технологию OCR. А вот и примеры.
Screenshot Reader
Замечательный коммерческий продукт от компании ABBYY. Утилита позволяет захватывать текст с изображений и преобразовывать его в редактируемый текст. Приложением поддерживается захват выделенной области, экрана, окна.
Извлекать можно не только текст, но и таблицы с последующим экспортом в файл, буфер обмена или Excel.
А еще Screenshot Reader умеет сохранять скриншоты и пересылать их по электронной почте. В общей сложности приложением поддерживается 179 языков. Утилита отличная, но использовать ее лучше вместе с родной ABBYY FineReader.
Capture2Text
Бесплатная портативная программка для распознавания текста. Работает программа с выделенной областью. Поддерживается более 30 языков, однако по умолчанию присутствуют только шесть языков, а именно английский, французский, немецкий, испанский, китайский и японский.
Файлы для русского и прочих языков нужно загружать отдельно с сайта разработчика.
Capture2Text также поддерживает распознание речи, правда особо высоким качеством распознания она похвастать не может. Из недостатков также можно отметить не очень удобный интерфейс.
SimpleOCR
Предназначается эта программа для работы с отсканированными документами, а вот с десктопа похоже захватывать текст она не умеет, по крайней мере, соответствующей опции мне так и не удалось найти.
Русского языка я тоже не нашел, попытка распознать кириллический текст также не увенчалась успехом. В общем SimpleOCR можно представить как некое подобие ABBYY FineReader или лучше сказать пародию на FineReader.
Из достоинств отметить можно разве что низкие требования к системе, малый вес и умение сохранять форматирование исходного файла.
FreeOCR
Еще один аналог FineReader (заметьте именно аналог, а не подобие), который мне так и не удалось установить. По какой-то причине мой Avast заблокировал загрузку файлов программы (устанавливается FreeOCR через веб-инсталлятор) и, в общем, на этом все и завершилось.
Судя по описаниям, работает FreeOCR с уже существующими файлами, то есть захватывать скриншоты как это умеет делать Screenshot Reader программа не может.
Русский язык по умолчанию отсутствуют, загружать и устанавливать языковой пакет нужно отдельно. Несомненным плюсом FreeOCR является бесплатность и простота использования.
Итог
Так что если вам нужна хорошая распознавалка, выбирайте Screenshot Reader, не пожалеете, а еще лучше установить полный пакет ABBYY FineReader.
Стоит этот продукт немало, с другой стороны найти «обработанную» рабочую версию не составит особого труда.
Программы для распознавания текста из изображений 2019
Автор Олег Донских На чтение 8 мин Просмотров 906 Опубликовано Обновлено
Несмотря на то, что в цифровую эпоху все идет в цифровую форму, вы возможно заметили, что бумага не исчезла. У нас все еще есть стопки распечаток, книг, счетов, листовок, журналов, выписок и других газет, с которыми нам приходится иметь дело ежедневно.
Содержание
- Как текстовые документы могут идти в ногу с текущими технологическими изменениями
- Программы для распознавания текста из изображений
- Программы для распознавания текста из изображений для Ubuntu
- Readiris 17
- ABBYY FineReader 14
- Microsoft OneNote (бесплатно)
- Simple OCR (Free)
- Free OCR
- Boxoft Free OCR (Бесплатно)
- Top OCR (Платный)
- ABBYY FineReader Online (бесплатно)
- Распознавание текста онлайн
Как текстовые документы могут идти в ногу с текущими технологическими изменениями
Вот тут-то и появляется оптическое распознавание символов (OCR). Программное обеспечение OCR позволяет оцифровывать печатные или рукописные документы, делая их редактируемыми с помощью программ обработки текста.
Программное обеспечение OCR позволяет оцифровывать печатные или рукописные документы, делая их редактируемыми с помощью программ обработки текста.
Оптическое распознавание символов (OCR) — это программа, которая может конвертировать отсканированные, распечатанные или рукописные файлы изображений в машиночитаемый текстовый формат. Или если говорить более просто это программы для распознавания текста из изображений.
Возможно, у вас есть книга или квитанция, которую вы напечатали или напечатали несколько лет назад, и вы хотите, чтобы она была в цифровом формате, но вы не хотите ее перепечатывать. OCR может быть очень полезным в таком случае.
В этой статье, мы поговорим про лучшие программы для распознавания текста из изображений. Это основной вопрос, который у вас может возникнуть перед загрузкой OCR. Мы поможем вам выбрать, ответив на более конкретные вопросы:
- Поддерживает ли программа несколько форматов файлов?
- Есть ли в программе OCR распознавание разных языков?
- Можете ли вы использовать инструмент OCR онлайн?
- Распознает ли текст из файлов изображений?
Программы для распознавания текста из изображений
Сразу стоит отметить, что в этом списке, присутствуют программы не только для Ubuntu но и с поддержкой Windows/macOS.
Программы для распознавания текста из изображений для Ubuntu
- GOCR.
- CLARA.
- OCRAD.
- KOOKA.
- OCRFeeder.
- Tesseract.
Чтобы запустить Tesseract Goto откройте Terminal и введите следующее
tesseract imagefile.tif outputfile.txt
Readiris 17
Readiris 17 — последняя версия этого высокопроизводительного программного обеспечения для распознавания текста. Он поставляется с новым интерфейсом, новым механизмом распознавания и более быстрым управлением документами. Вы можете легко конвертировать во многие различные форматы, в том числе в аудиофайлы благодаря его устному распознаванию.
Readiris — это одно из самых мощных программ для распознавания текста, которое требует меньше усилий для начала работы. Хотя это платная программа, вы получаете то, за что платите. Readiris поддерживает большинство форматов файлов и поставляется с другими привлекательными функциями, которые упрощают процесс преобразования.
Например, изображения могут быть получены из подключенных устройств, таких как сканеры, и приложение также позволяет настраивать параметры обработки, такие как настройки DPI.
После завершения обработки Readiris определяет текстовые разделы или зоны и позволяет извлекать тексты либо из определенной зоны, либо из всего файла.
Readiris имеет редкую функцию сохранения в облаке, которая позволяет пользователям сохранять извлеченный текст в различные сервисы облачного хранения, такие как Google Drive, OneDrive, Dropbox и другие.
Он также имеет множество функций редактирования и обработки текста, что позволяет пользователям даже сканировать штрих-коды. Подписка начинается от 99 долларов, и предоставляется 10-дневная бесплатная пробная версия. Использование программы на Ubuntu возможно через Wine.
ABBYY FineReader 14
ABBYY FineReader 14 — это самое мощное программное обеспечение для распознавания текста на рынке и лучший инструмент для тех, кому нужно быстрое и точное распознавание текста.
Этот оптический распознаватель прекрасно справляется с работой с большими объемами и оснащен передовыми инструментами коррекции для сложных задач.
Превосходный инструмент проверки легко исправляет сомнительные показания, делая аккуратное сравнение между текстами OCR и оригиналом.
ABBYY Finereader 14 делает больше, чем вы ожидаете от распознавания текста. Вы хотите конвертировать старую книгу на 500 страниц в PDF с возможностью поиска? ABBYY справится с этим с максимальной точностью.
ABBYY извлечет самые точные тексты из изображений, найденных в Интернете.
Кроме того, он может конвертировать отсканированный документ в HTML или в формат ePub, используемый электронными читателями. Использование программы на Ubuntu возможно через Wine.
Microsoft OneNote (бесплатно)
Microsoft OneNote также можно использовать в качестве OCR, несмотря на его функциональность в качестве хранителя заметок. Существует опция «Копировать текст из изображения», которая позволяет извлекать текст из изображений.
Его простота — вот что делает его уникальным; просто вставьте картинку в OneNote, затем щелкните правой кнопкой мыши на картинке и выберите «Копировать текст из картинки», а OneNote сделает все остальное. Он сохраняет текст в буфер обмена, а затем вы можете вставить текст в Microsoft Word или любую другую программу по вашему выбору.
Тем не менее, он не поддерживает таблицы и столбцы. Использование программы на Ubuntu возможно через Wine.
Simple OCR (Free)
Если говорить про программы для распознавания текста из изображений, то это приложение является очень удобным. Simple OCR — это удобный инструмент, который вы можете использовать для преобразования распечаток в печатном виде в редактируемые текстовые файлы.
Если у вас много рукописных документов и вы хотите преобразовать их в редактируемые текстовые файлы, тогда Simple OCR будет вашим лучшим вариантом.
Тем не менее, рукописное извлечение имеет ограничения и предлагается только как 14-дневная бесплатная пробная версия. Машинная печать бесплатна и не имеет ограничений.
Машинная печать бесплатна и не имеет ограничений.
Существует встроенная проверка орфографии, которую вы можете использовать для проверки расхождений в преобразованном тексте. Вы также можете настроить программное обеспечение для чтения непосредственно со сканера.
Как и Microsoft OneNote, Simple OCR не поддерживает таблицы и столбцы. Использование программы на Ubuntu возможно через Wine.
Free OCR
Free OCR использует Tesseract Engine, который был создан HP и теперь поддерживается Google.
Tesseract — очень мощный движок, и сегодня он считается одним из самых точных механизмов распознавания текста в мире. Free OCR отлично справляется с форматами PDF и поддерживает устройства TWAIN, такие как цифровые камеры и сканеры изображений.
Кроме того, он поддерживает практически все известные файлы изображений и многостраничные файлы TIFF. Вы можете использовать программное обеспечение для извлечения текста из картинок, и оно делает это с высокой степенью точности.
И, как и другое программное обеспечение Free OCR, Free OCR не поддерживает вывод таблиц и столбцов.
Boxoft Free OCR (Бесплатно)
Boxoft Free OCR — еще один удобный инструмент, который вы можете использовать для извлечения текста из всех видов изображений.
Эта бесплатная программа проста в использовании и способна анализировать многостолбцовый текст с высокой степенью точности.
Он поддерживает несколько языков, включая английский, испанский, итальянский, голландский, немецкий, французский, португальский, баскский и многие другие.
Это программное обеспечение OCR позволяет вам сканировать ваши бумажные документы и конвертировать их в редактируемые тексты в течение очень короткого времени.
Хотя существуют опасения, что это средство распознавания текста не справляется с извлечением текста из рукописных заметок, оно исключительно хорошо работает с печатными копиями.
Top OCR (Платный)
TopOCR отличается от типичного программного обеспечения OCR во многих аспектах, но выполняет работу точно. Лучше всего работает с цифровыми камерами и сканерами. Если говорить про лучшие программы для распознавания текста из изображений, то обязательно стоит и рассказать про эту программу более детально.
Лучше всего работает с цифровыми камерами и сканерами. Если говорить про лучшие программы для распознавания текста из изображений, то обязательно стоит и рассказать про эту программу более детально.
Его интерфейс также отличается, поскольку у него есть два окна — окно изображения (источника) и текстовое окно.
Как только изображение получено с камеры или сканера с левой стороны, извлеченный текст появляется с правой стороны, где находится текстовый редактор.
Программное обеспечение поддерживает форматы GIF, JPEG, BMP и TIFF. Вывод также может быть преобразован в несколько форматов, включая PDF, HTML, TXT и RTF.
Программное обеспечение также поставляется с настройками фильтра камеры, которые можно применять для улучшения изображения.
ABBYY FineReader Online (бесплатно)
Если вы хотите насладиться мощными функциями, которые ABBYY предлагает, но не хотите идти дорогим путем, то вы можете попробовать бесплатную онлайн-версию.
FineReader Online поддерживает множество входных файлов, таких как PDF, JPEG, JPG, PNG, DCX, PCX, TIFF, TIF и BMP. Поддерживаемые выходные файлы включают PDF, Word, Excel, e-Pub и Powerpoint.
Поддерживаемые выходные файлы включают PDF, Word, Excel, e-Pub и Powerpoint.
Бесплатная версия позволяет вам конвертировать до 10 страниц в месяц, и она требует сначала сделать регистрацию, которая также бесплатна.
Однако, если вы интенсивный пользователь и хотите конвертировать больше страниц в месяц, вам необходимо подписаться на платную версию.
Распознавание текста онлайн
Еще один отличный способ, это распознавать текст онлайн. Сайт img2txt предлагает очень удобный, легкий и быстрый для распознавания текста.
Готово! В этой статье, мы поговорили про лучшие программы для распознавания текста из изображений. Рынок наводнен программами OCR, которые могут извлекать текст из изображений и сэкономить вам много времени, которое вы могли бы потратить на перепечатывание документа.
Однако хорошие программы для распознавания текста из изображений должно делать больше, чем извлекать текст из печатных документов. Оно должно поддерживать макет, текстовые шрифты и текстовый формат в качестве исходного документа.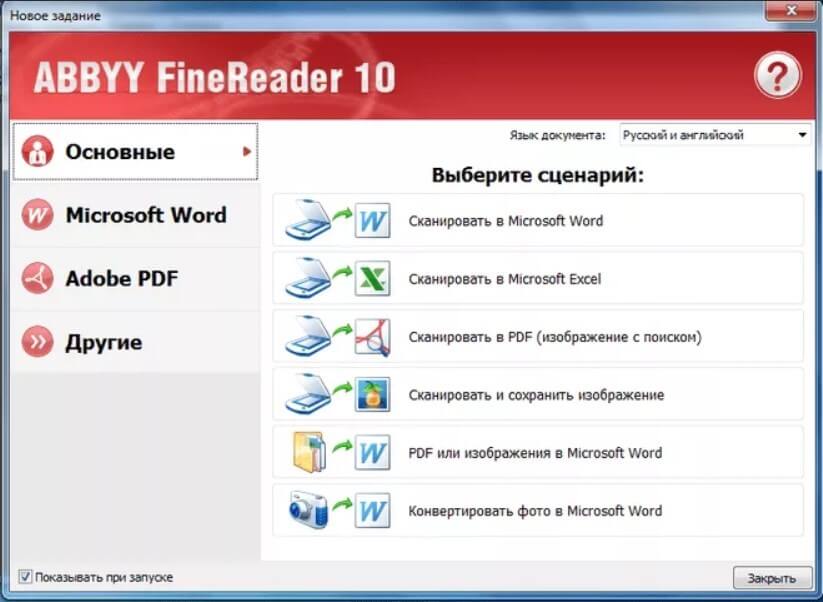
Мы надеемся, что эта статья поможет вам найти лучшее программное обеспечение для распознавания текста. Не стесняйтесь комментировать и делиться.
Бесплатный онлайн OCR — конвертер изображений в текст и PDF в Doc
Преобразователь изображений в текст позволяет извлекать текст из изображений или преобразовывать PDF в форматы Word, Excel или Text с помощью программного обеспечения для оптического распознавания символов онлайн
Реклама
1 ШАГ — Загрузить файл
ВЫБЕРИТЕ ФАЙЛ…| 2 ШАГ — Выберите язык и формат вывода |
| АНГЛИЙСКИЙФРИКАНСКИЙАНСАЛБАНСКИЙБАССКИЙБРАЗИЛЬСКИЙБОЛГАРСКИЙБЕЛОРУССКИЙКАТАЛАНСКИЙКИТАЙСКИЙУПРОЩЕННЫЙКИТАЙСКИЙТРАДИЦИОННЫЙХОРВАТСКИЙЧЕХДАНСКИЙГОЛЛАНДСКИЙСПЕРАНТОЭСТОНСКИЙФИНСКИЙФРАНЦУЗСКИЙГАЛИЙСКИЙГЕРМАНСКИЙГРЕЧЕСКИЙВЕНГЕРСКИЙИСЛАНДСКИЙИНДОНЕЗИЙСКИЙИТАЛЬЯНСКИЙЯПОНСКИЙКОРЕЙСКИЙЛАТИНСКИЙЛАТВИЙСКИЙЛИТВСКИЙ МАКЕДОНСКИЙМАЛАЙСКИЙМОЛДАВСКИЙНОРВЕЖСКИЙПОЛЬСКИЙПОРТУГИЙСКИЙРУМАНСКИЙРУССКИЙСЕРБСКИЙСЛОВАСКЛОВЕНСКИЙИСПАНСКИЙШВЕЦИОНСКИЙТАГАЛОГТУРКИШУКРАИНСКИЙMicrosoft Word (docx)Microsoft Excel (xlsx)Text Plain (txt) |
3 ШАГ — Конвертировать
Максимальный размер файла 15 мб.
Реклама
Использование OCR онлайн |
для извлечения текста и символов из отсканированных PDF-документов (включая многостраничные файлы), фотографий и изображений, снятых цифровой камерой
Изображение в текст |
Любые изображения JPG, BMP или PNG могут быть преобразованы в текстовые форматы вывода с тем же макетом, что и исходный файл
Преобразование PDF в DOC |
Конвертируйте PDF в WORD или EXCEL онлайн. Извлечение текста из отсканированных PDF-документов, фотографий и захваченных изображений без оплаты
Совместимость с iOS и Android |
Вы можете конвертировать файлы с мобильных устройств (iPhone или Android) или ПК (Windows\Linux\MacOS)
Безопасное преобразование |
Все документы, загруженные под бесплатной учетной записью «Гость», будут автоматически удалены после преобразования.
 Выходные файлы для зарегистрированных пользователей хранятся один месяц
Выходные файлы для зарегистрированных пользователей хранятся один месяцБесплатная услуга |
Услуга OCR бесплатна для пользователей «Гость» (без регистрации) и позволяет конвертировать 15 файлов в час
Реклама
О КОМПАНИИ
ОСНОВНЫЕ ХАРАКТЕРИСТИКИ
ЦЕНЫ
ЭЛЕКТРОННАЯ ПОЧТА OCR
FAQ
УСЛОВИЯ ОБСЛУЖИВАНИЯ
КОНФИДЕНЦИАЛЬНОСТЬ PO ЛИСИ
СВЯЖИТЕСЬ С НАМИ
Авторские права © 2009-2023 Интернет OCR
ENGLISHDEUTSCHESPAÑOLFRANÇAISITALIANO日本語PORTUGUÊSPOLSKI한국어РУССКИЙ中文 (简体)中文 (繁體)
4 Лучшее распознавание текста в Linux, которое вы можете использовать в 2023 году
Использование оптического Linux программное обеспечение для распознавания символов (OCR) — разумный шаг для людей и компаний, которым необходимо кодировать огромное количество отсканированные или PDF-документы.
Программное обеспечение упрощает жизнь, если вы хотите отказаться от бумаги. Это позволяет вам сделать ваши нередактируемые файлы «читаемыми» вашим устройством. Более того, это дает вам возможность быстро извлекать текст из ваших изображений.
Существует множество приложений такого типа. Эта статья для вас, если вам трудно выбрать, что лучше всего подходит для извлечения текста из ваших изображений или PDF-файлов.
В этой статье
Часть 1 Список лучших программ для распознавания текста uzzyOCR
Часть 2 Преимущества и ограничения Linux OCR
Часть 3 Лучшее средство распознавания текста для Windows , Mac и iOS
Список лучших программ для оптического распознавания символов
Поиск программного обеспечения для оптического распознавания символов для Linux может быть сложной задачей. В отличие от Mac или Windows, эта операционная система имеет ограниченное число пользователей, часто в сфере высоких технологий. Из-за их небольшого количества вы можете найти меньше приложений такого рода, разработанных для этой системы. Вот некоторые из них.
Из-за их небольшого количества вы можете найти меньше приложений такого рода, разработанных для этой системы. Вот некоторые из них.
Tesseract
Если вам нравится бесплатное программное обеспечение с открытым исходным кодом, Tesseract должен быть одним из ваших лучших вариантов. Даже если вам не нужно ни копейки, чтобы установить это приложение на свой Linux, оно может дать вам отличные результаты. Это потому, что Google разработал и предоставил движок для этого приложения. Это программное обеспечение может значительно улучшить возможности и ресурсы технологического гиганта.
Tesseract — мощный инструмент распознавания символов. Он может легко конвертировать разделы ваших книг, PDF-файлы, архивы и другие типы текстов. Он также может обнаруживать символы в документах с крошечным размером шрифта и в тех случаях, когда текст трудно прочитать.
Tesseract может даже восстановить типы и размеры шрифтов в соответствии с оригиналом с минимальной ошибкой. Кроме того, он поддерживает более 100 глобальных языков, таких как китайский, испанский, арабский и региональные языки, такие как гуджарати, немецкий фрактур и кебуано.
Чтобы использовать это программное обеспечение для распознавания PDF в Ubuntu, выберите файл, который вы хотите обработать.
Затем в командной строке tesseract введите информацию о файле, включая:
- Имя файла, который вы хотите обработать.
- Имя файла, который будет создан вашей системой для хранения извлеченного текста. Он всегда будет сохраняться как .txt, поэтому нет необходимости указывать расширение файла.
- Вы также можете использовать параметр —dpi для уведомления Tesseract о разрешении изображения в точках на дюйм (dpi). Если вы не укажете значение dpi, Tesseract его вычислит.
Например, если файл img.png, команда может выглядеть так:
По умолчанию вывод будет img.txt.
gImageReader
Другим популярным программным обеспечением для распознавания текста в Linux является gImageReader. Это приложение может выполнять множество функций, включая извлечение текста из нескольких файлов и проверку орфографии. Он также может выполнять постобработку машиночитаемого текста.
Он также может выполнять постобработку машиночитаемого текста.
Позвольте gImageReader выполнить задачу OCR, выполнив следующие шаги:
Шаг 1 Нажмите Добавить изображения в левой части панели инструментов и выберите изображение или PDF-файл, который вы хотите обработать.
Шаг 2 Нажмите «ОК», чтобы импортировать изображение или файл PDF в программу.
Шаг 3 Вы также можете извлечь текст из файла, отображаемого на экране. Нажмите раскрывающийся список рядом с «Добавить изображения» и выберите «Сделать снимок экрана». gImageReader сделает скриншот содержимого на экране.
Шаг 4 После загрузки изображения в gImageReader щелкните панель вывода Toggle (одна со значком блокнота), чтобы открыть панель вывода. Это позволит отображать текст, который вы извлекаете из изображений или PDF-файлов.
Шаг 5 Теперь у вас есть возможность определить текст в файле автоматически или вручную.
Шаг 6 Если вы выбрали автоматическую идентификацию, нажмите кнопку «Автоопределение макета», выделив все текстовые блоки в выбранном документе.
Шаг 7 Выберите Распознать выделение > Текущая страница, чтобы начать извлечение текста.
Шаг 8 Если вы предпочитаете выделение текста вручную, наведите указатель мыши на текст, который хотите извлечь. Затем нажмите кнопку Распознать выбор, чтобы начать процесс.
OCRFeeder
Еще один бесплатный OCR с открытым исходным кодом для Linux — OCRFeeder. Разработчики предполагали, что это приложение будет эксклюзивным для пользователей Linux. В настоящее время команда GNOME поддерживает это программное обеспечение.
OCRFeeder ищет области содержимого и выделяет их для определения типа содержимого, будь то текст или изображение. Затем он обрабатывает текстовые области, используя серверную часть OCR.
Это приложение может использовать для выполнения почти все механизмы оптического распознавания символов командной строки, включая Tesseract. Он также имеет функции автоматического обнаружения и автоматической настройки для всех известных бесплатных движков. Следуйте этой процедуре, чтобы использовать OCRFeeder:
Следуйте этой процедуре, чтобы использовать OCRFeeder:
Шаг 1 Откройте программное обеспечение.
Шаг 2 Импортируйте изображение, из которого вы хотите извлечь текст. Вы также можете импортировать папку, содержащую файлы, которые вы собираетесь обрабатывать.
Шаг 3 Нажмите «Определить документ». После того, как вы идентифицировали документ, вы можете вручную выбрать части, которые хотите извлечь.
Шаг 4 Перед экспортом документа выберите «Правка» > «Редактировать страницу», чтобы выбрать нужную страницу.
Шаг 5 Экспортируйте документ, выбрав «Файл» > «Экспорт». Затем выберите желаемый выходной формат, предпочтительно формат .txt.
FuzzyOCR
FuzzyOCR — это плагин для SpamAssassin, антиспамовой платформы, которая проверяет различные файлы изображений, найденные в электронных письмах, чтобы определить, являются ли они спамом. Это приложение читает изображения, прикрепленные к электронной почте. Затем он решает, являются ли они спамом или нет, на основе списка слов.
После установки и настройки этого программного обеспечения OCR оно может выполнять обнаружение изображений. Узнайте, как заставить это приложение работать:
Шаг 1 После загрузки распакуйте FuzzyOCR и переместите все файлы FuzzyOCR* и каталог FuzzyOCR.
Шаг 2 Настройте его, чтобы он работал с помощью SpamAssassin, открыв имя файла /etc/mail/spamassassin/FuzzyOCR.cf, затем внесите некоторые изменения:
Шаг 3 После того, как FuzzyOCR настроен, вы можете отправлять каждое электронное письмо в SpamAssassin чтобы убедиться, что плагин правильно связан с программным обеспечением. Вот пример:
SpamAssassin теперь может распознавать спам-изображения с помощью FuzzyOCR
Преимущества и ограничения Linux OCR
Любое программное обеспечение Linux OCR дает много преимуществ. Благодаря развитию технологий эти приложения становятся все более и более надежными. Они незаменимы для людей и предприятий, которым необходимо быстрое и точное извлечение текста для безбумажной жизни.
Преимущества
Более высокая производительность. Вместо кодирования самостоятельно или делегирования его кому-либо, вы можете запустить это программное обеспечение и позволить ему делать свое дело. Вы можете начать преобразование текста, одновременно выполняя обычную работу.
Низкая стоимость. Эта технология дешевле, чем платить кому-то за ввод большого количества текстовых данных вручную. Преобразование текста и изображений PDF в машиночитаемые требует меньше энергии и ресурсов.
Высокая точность. Эти приложения позволяют читать захваченную информацию. Планшетные сканеры и новейшие цифровые камеры создают изображения с высоким разрешением, что позволяет этим приложениям обнаруживать текст.
Увеличенный объем памяти. Для хранения файлов отсканированных изображений, особенно с высоким разрешением, требуется много места на жестком диске. Превращение их в редактируемые компьютером документы даст вашему диску достаточно места для хранения других, более важных файлов.
Превосходная защита данных. Утерянные или отсканированные бумажные документы могут стать кошмаром для безопасности. Неправильное обращение с файлом может сделать его подверженным фальсификации. Хранить документы без подписей и печатей можно, если уметь их конвертировать и хранить в редактируемом файле.
Ограничения
Сложность распознавания рукописного текста. Эти приложения эффективно работают с печатным текстом, но имеют проблемы с чтением рукописного. Как и в случае с людьми, некоторые почерки трудно читать.
Для установки могут потребоваться технические специалисты. Вам может понадобиться несколько человек с продвинутыми техническими навыками для установки программного обеспечения Linux OCR для PDF-файлов и других файлов. В отличие от Windows или Mac, только небольшая часть людей знает, как использовать эту операционную систему.
По-прежнему требуется много редактирования. Хотя современное программное обеспечение для оптического распознавания символов обладает высокой точностью, оно по-прежнему подвержено ошибкам. Вам по-прежнему необходимо тщательно проверять документы и вручную исправлять их, чтобы убедиться в отсутствии ошибок.
Вам по-прежнему необходимо тщательно проверять документы и вручную исправлять их, чтобы убедиться в отсутствии ошибок.
Точность распознавания зависит от качества изображения.
Лучшее средство OCR для Windows, Mac и iOS
Приложения для распознавания символов доступны не только пользователям Linux. Пользователи Windows и Mac также могут выбирать из широкого спектра программного обеспечения для извлечения текста. Среди доступного программного обеспечения PDFelement — ваш разумный выбор с его передовыми функциями.
Wondershare PDFelement — Редактор PDF имеет полный набор функций, которые делают извлечение текста удобным для пользователя. Программное обеспечение точно выполнит свою задачу, загрузив PDF или другие форматы изображений.
Помимо оптического распознавания символов, он имеет множество функций, которые могут упростить вашу работу. Сделав текст редактируемым, вы можете вносить изменения и преобразовывать файлы в форматы PDF, Word, Excel и PowerPoint.
Попробуйте бесплатно Попробуйте бесплатно КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
Ниже описано, как установить это программное обеспечение и использовать его в качестве инструмента распознавания текста в Windows:
Шаг 1 Загрузите и установите PDFelement с веб-сайта.
Шаг 2 Откройте файл PDF и нажмите OCR на дополнительной навигационной кнопке, чтобы использовать функцию OCR. Появится всплывающее окно с вопросом, хотите ли вы загрузить дополнительную функцию. Нажмите «Загрузить» и завершите установку.
Шаг 3 После завершения установки документ можно преобразовать в текстовый файл. Нажмите на кнопку OCR, которая приведет вас к этому выбору:
Шаг 4 После завершения извлечения документа PDF выберите формат, в который вы хотите преобразовать документ.
Попробуйте бесплатно Попробуйте бесплатно КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
Если вы используете бесплатную пробную версию, вы можете использовать функцию OCR для ограниченного числа преобразований и функций.
Ваш комментарий будет первым