Сканирование и распознавание текста. — SOS.MirTesen.ru
Оптическое распознавание текста англ. optical character recognition (сокр. OCR) — перевод последовательности изображений символа в последовательность кодов, использующихся для представления в текстовом редакторе. Перевод осуществляется с помощью различных алгоритмов, после преобразования изображения в набор элементарных точек.
В данный момент очень сложно найти бесплатную программу для распознавания текста. Но Вам повезло, здесь Вы можете скачать такую программу.
Бесплатная программа для автоматического распознавания отсканированного текста. Вид у программы не карамельный, но дело своё она знает.Компьютер уже уверенно вошел в жизнь рядового гражданина. Когда надо получить сравнительно небольшой объем печатной информации, проще всего набрать этот текст вручную при помощи текстового редактора.
Однако иногда надо «переписать» целую книгу. В таких случаях рациональнее всего использовать сканер.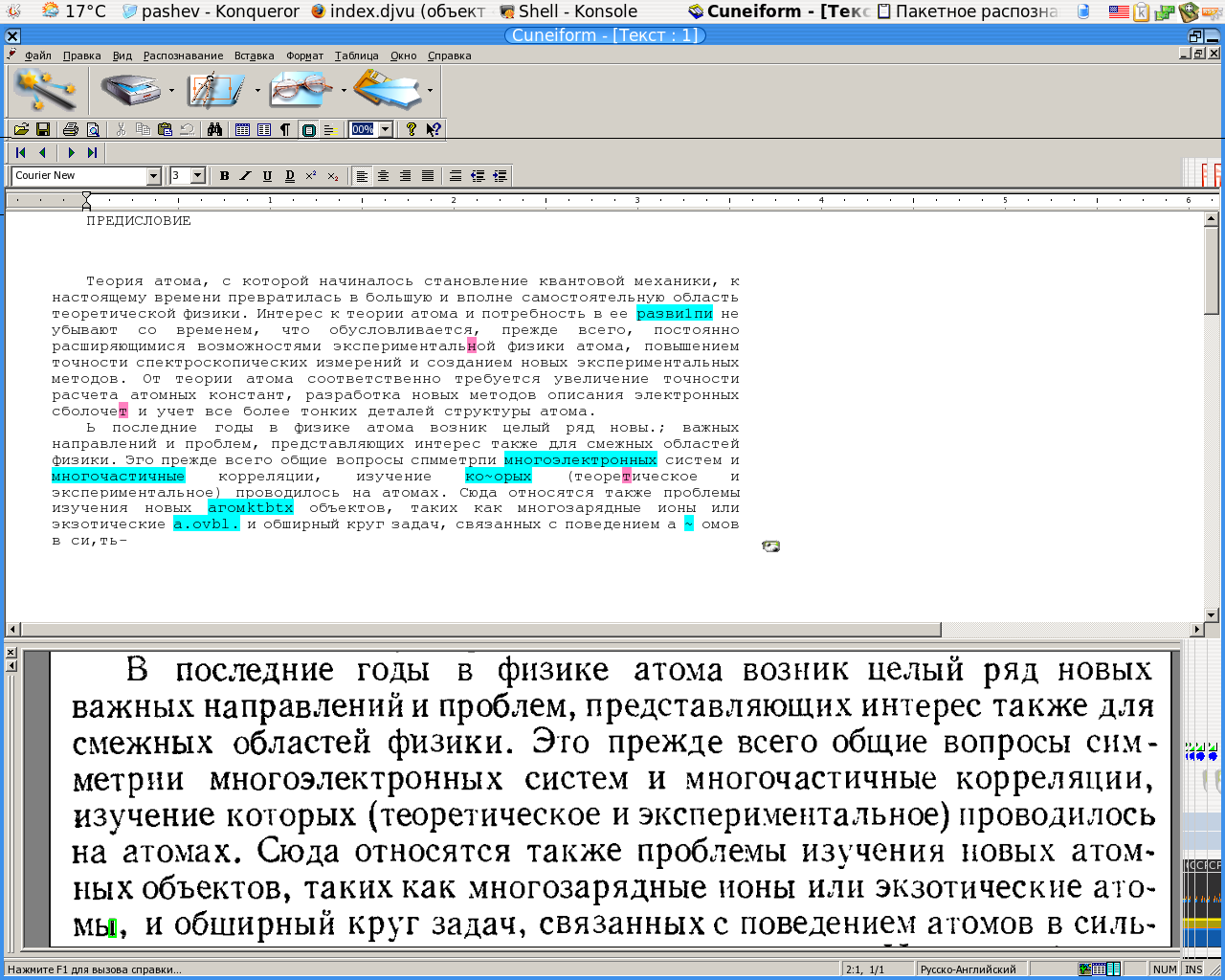 Но сам по себе сканер делает только фотокопию текста, которую никак нельзя редактировать. Для того, чтобы изменить информацию на полученном изображении следует провести распознавание документа.
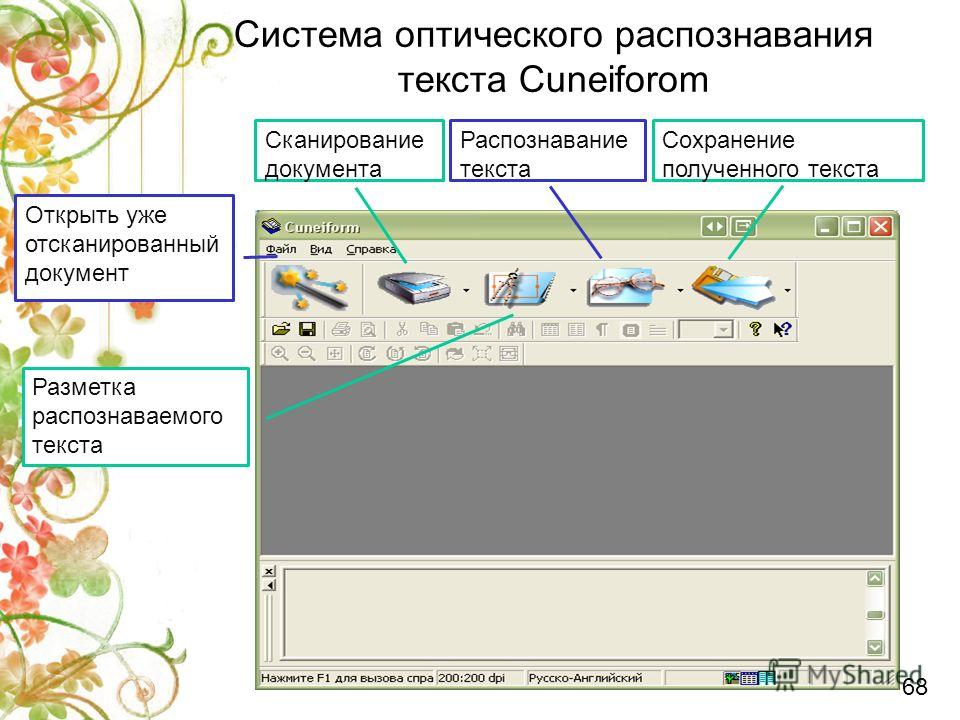
Но сам по себе сканер делает только фотокопию текста, которую никак нельзя редактировать. Для того, чтобы изменить информацию на полученном изображении следует провести распознавание документа.Бесспорным лидером в этом деле является система OCR (англ. optical character recognition — оптическое распознавание текста) от Abbyy — FineReader. Но стоит она довольно дорого и не каждый может позволить себе иметь в своем арсенале такой инструмент. Сегодня мы познакомимся с бесплатной альтернативой Файн Ридера — программой CuneiForm. Приведу сравнительную таблицу возможностей обеих пакетов:
Сравнение распознавалки текста CuneiForm с платным аналогом FineReader
| Особенности | CuneiForm | FineReader |
| Стоимость | бесплатно | от 1340 р. |
| Количество языков распознавания | 34 | 184 |
| Возможность комбинировать языки распознавания | — | + |
| Сохранение исходного форматирования текста | + | + |
| Пакетное распознавание текста | + | +/- |
| Ограничение по разрешению файла-скана | до 400 dpi | нет |
| Поддержка всех типов сканеров | только с TWAIN-интерфейсом | + |
Как видим, если хочется бесплатно распознавать текст, придется кое в чем уступить. Первое, с чем придется смириться — неумение CuneiForm работать с некоторыми сканерами (в особенности сканерами МФУ). Поэтому придется сканировать документ при помощи стандартных функций Windows. Второе — надо следить за разрешением сканирования. Это связано с тем, что CuneiForm не может обрабатывать большие файлы (свыше 100 Кбайт), а чем выше разрешение, тем больший размер файла-скана. Зато качество распознавания текста в программе намного выше, чем у платного конкурента, а поэтому оптимальным вариантом параметров скана будет 200 dpi (можно и больше, но тогда есть вероятность, что программа просто зависнет). Количество языков тоже невелико, но основные есть. Более того, хоть комбинировать языки и нельзя, зато в CuneiForm есть смешанный англо-русский режим распознавания! На этом минусы заканчиваются :). Можно начинать установку.
Первое, с чем придется смириться — неумение CuneiForm работать с некоторыми сканерами (в особенности сканерами МФУ). Поэтому придется сканировать документ при помощи стандартных функций Windows. Второе — надо следить за разрешением сканирования. Это связано с тем, что CuneiForm не может обрабатывать большие файлы (свыше 100 Кбайт), а чем выше разрешение, тем больший размер файла-скана. Зато качество распознавания текста в программе намного выше, чем у платного конкурента, а поэтому оптимальным вариантом параметров скана будет 200 dpi (можно и больше, но тогда есть вероятность, что программа просто зависнет). Количество языков тоже невелико, но основные есть. Более того, хоть комбинировать языки и нельзя, зато в CuneiForm есть смешанный англо-русский режим распознавания! На этом минусы заканчиваются :). Можно начинать установку.
Установка CuneiForm
Здесь сложностей нет, поскольку Вам поможет инсталлятор. Просто запускайте установочный файл и следуйте инструкциям. После установки в меню «Пуск» появится новый раздел. Открываем его и запускаем CuneiForm.
После установки в меню «Пуск» появится новый раздел. Открываем его и запускаем CuneiForm.
Интерфейс программы
Интерфейс CuneiForm намного проще, чем у Fine Reader, и почти не требует настройки. Программой можно полностью управлять благодаря кнопкам на панели инструментов. Рассмотрим их более детально:
Программа может работать в режиме мастера, который активируется первой кнопкой. Но если CuneiForm не поддерживает Ваш сканер, то от этого режима стоит отказаться. Следующая кнопка запускает процесс сканирования (опять же, если есть поддержка сканера). На этой и следующих кнопках Вы можете заметить небольшие стрелочки. Нажав на них, мы получим доступ к некоторым дополнительным функциям.
Работа с CuneiForm
Теперь давайте опробуем CuneiForm на практике. Если программа поддерживает Ваш сканер, то первой кнопкой, которую следует нажать, будет «Получить изображение». Если же такой возможности нет, то откроем уже готовый скан (поддерживаются форматы JPG, GIF, BMP, PNG (не всегда корректно), а также TIF (в полной мере)).
Если же такой возможности нет, то откроем уже готовый скан (поддерживаются форматы JPG, GIF, BMP, PNG (не всегда корректно), а также TIF (в полной мере)).
Теперь следует произвести разметку. Она помогает определить блоки, из которых состоит страница. Поддерживается распознавание блоков в виде текста (синяя рамка), рисунков (зеленая рамка) или таблиц (оранжевая рамка) (автоматическую разметку можно доработать вручную, используя контекстное меню блока).
Когда текст обозначен, самое время провести его распознавание. Для этого нажимаем следующую кнопку. По окончании процесса распознавания в рабочем окне отобразится текст, который можно редактировать в небольшом встроенном текстовом редакторе похожем на Microsoft Word. При этом Вы сразу сможете увидеть те слова, в которых программа «не уверена» (голубая подсветка) и в которых есть ошибка (сомнительная буква — розовая).
И, наконец, после успешного редактирования можно сохранить результат нашей работы. Кликаем последнюю кнопку на панели инструментов и сохраняем текст как RTF, HTML или TXT-файл.
Кликаем последнюю кнопку на панели инструментов и сохраняем текст как RTF, HTML или TXT-файл.
Если же Вы желаете большего, то, нажав на стрелочку сбоку, Вы сможете выбрать опции экспорта в одну из предложенных программ (Microsoft Word, Excel или Евфрат).
Посмотрите на предыдущий скриншот. Наверняка вы обратили внимание, что в дополнительных меню кнопок, начиная с «Разметки» и заканчивая «Сохранением», есть в конце пункт «Автомат». Активирование этой опции освобождает Вас от нажатия выбранной кнопки. То есть можно автоматизировать процесс обработки скана до того, что Вы будете лишь открывать новый документ. Все остальное CuneiForm сделает сама!
Общие настройки CuneiForm
Программа изначально настроена самым оптимальным образом, но если Вы что-то захотите изменить, просто зайдите в меню «Файл» и выберите опцию «Общие параметры». Это может пригодиться для смены языка и некоторых других параметров распознавания, форматирования и сканирования текстов.
Пакетное распознавание
На этом можно было бы и закончить, если бы в пакет CuneiForm не входила еще одна утилитка. Откройте «Пуск» снова и в папке с программой обнаружите еще одно приложение — «Пакетное распознавание». Представьте, что Вы отсканировали целую книгу! и теперь надо ее распознать!!! Если открывать каждый файл-скан по отдельности на это уйдет уйма времени, пакетный же режим представляет возможность указать нужные файлы, а об остальном программа позаботится сама.
Для начала нужно создать новый пакет файлов. Нажимаем соответствующую кнопку и следуем подсказкам запустившегося мастера:
На последнем этапе мы можем либо просто сохранить наш пакет, либо начать немедленное распознавание. В последнем случае запустится режим распознавания, который может затянуться на несколько минут (в зависимости от количества файлов-сканов).
По окончании распознавания Вы сможете увидеть в основном окне все распознанные документы. Если распознавание прошло успешно, то в левой боковой панели Вы обнаружите активными только два списка: «Исходные» и «Обработанные». Если же будут файлы, которые не удалось распознать, их мы найдем в разделе «Ошибки».
Если распознавание прошло успешно, то в левой боковой панели Вы обнаружите активными только два списка: «Исходные» и «Обработанные». Если же будут файлы, которые не удалось распознать, их мы найдем в разделе «Ошибки».
Теперь остается только сохранить полученные файлы и радоваться жизни :).
Потенциал у CuneiForm явно хороший, однако разработка ведется довольно медленно. Несмотря на открытый исходный код, компания Cognitive, видимо, очень требовательна к разработчикам, раз прогресс так долго не появляется. Остается только надеяться, что дело сдвинется с мертвой точки и программа станет еще лучшей, а пока довольствуемся малым. Но такое ли уж оно и малое… Выбор за Вами!
P.S. Данная статья предназначена для свободного распространения. Приветствуется её копирование с сохранением авторства Руслана Тертышного и всех P.S. и P.P.S.
P.P.S. Вам также может пригодится еще одна довольно занятная программа. Kleptomania, пусть и не полноценная система распознавания, но может помочь Вам захватить текст и графику с экрана для последующей обработки:
Kleptomania, пусть и не полноценная система распознавания, но может помочь Вам захватить текст и графику с экрана для последующей обработки:
http://www.bestfree.ru/soft/office/capture.php#Kleptomania
Ну что тут ещё добавить? Скажем дружно СПАСИБО Руслану (ну и меня похвалить не забудьте).
Онлайн-сервисы для распознавания текста / Программное обеспечение
Как только человек изобрел компьютер, он стал переносить в него свои знания. Поскольку главным носителем знаний до появления компьютерной техники были книги, возникла задача — каким образом накопленную информацию можно быстро перевести в «цифру»? Глупо было бы использовать для этого самый простой и очевидный способ перевода книг в цифровой формат — набор вручную. Человечество тысячелетиями накапливало различные тексты, поэтому процесс их повторного «написания» занял бы невероятно много времени. Для решения этой задачи необходимо было найти какой-то простой и эффективный способ автоматизации процесса повторного набора текста. Так возникли различные технологии оптического распознавания текста или сокращенно OCR (optical character recognition). В наши дни с процедурой перевода машинописного листа в текстовый документ знаком каждый студент и школьник. Печатный текст сканируется (или фотографируется), затем с помощью специального программного обеспечения компьютер анализирует снимок текста, выделяет на изображении отдельные элементы и создает новый документ, в который заносит все распознанные буквы и символы. Такой документ, как правило, является редактируемым, благодаря чему можно исправлять ошибки машинного распознавания и работать с ним как с набранным текстом. В зависимости от сложности исходного текста и качества отсканированного изображения, процесс обработки документа OCR-приложением занимает больше или меньше времени. К счастью, сегодня процедура перевода набранного текста в формат электронного документа занимает намного меньше времени, чем несколько лет назад — аппаратные возможности компьютеров за последние десять лет заметно увеличились, а благодаря постоянным усовершенствованиям алгоритмов анализа изображения процент ошибок стал намного меньше.
Так возникли различные технологии оптического распознавания текста или сокращенно OCR (optical character recognition). В наши дни с процедурой перевода машинописного листа в текстовый документ знаком каждый студент и школьник. Печатный текст сканируется (или фотографируется), затем с помощью специального программного обеспечения компьютер анализирует снимок текста, выделяет на изображении отдельные элементы и создает новый документ, в который заносит все распознанные буквы и символы. Такой документ, как правило, является редактируемым, благодаря чему можно исправлять ошибки машинного распознавания и работать с ним как с набранным текстом. В зависимости от сложности исходного текста и качества отсканированного изображения, процесс обработки документа OCR-приложением занимает больше или меньше времени. К счастью, сегодня процедура перевода набранного текста в формат электронного документа занимает намного меньше времени, чем несколько лет назад — аппаратные возможности компьютеров за последние десять лет заметно увеличились, а благодаря постоянным усовершенствованиям алгоритмов анализа изображения процент ошибок стал намного меньше.

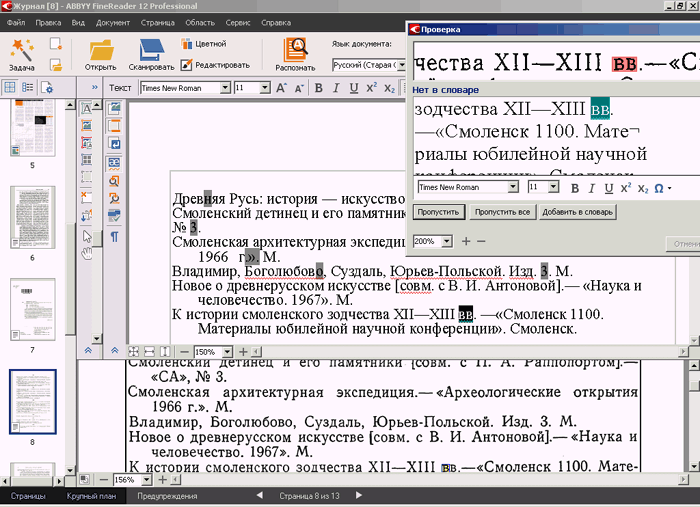
 Во-вторых, объем файла, загружаемого на сервер, не должен превышать 10 мегабайт. Но самое неприятное ограничение — небольшое количество документов, которое можно распознать. Зайдя под одной учетной записью, можно обработать не более десяти файлов. Однако и это, согласитесь, неплохо. FineReader Online может также обрабатывать тексты, содержащие любые комбинации поддерживаемых языков. При этом сервис не позволяет выбирать более трех языков распознавания для одного документа. Разработчики мотивируют это тем, что подобная функция существенно замедлила бы процесс распознавания текста. Готовый результат распознавания текста может быть сохранен в один из форматов — MS Word (.doc), MS Excel (.xls), PDF, PDF/A, RTF и TXT. В принципе, сервис справляется с поставленной задачей и определяет текст. Однако, справедливости ради, следует сказать, что даже очень хорошее качество исходного изображения не дает стопроцентной гарантии распознавания. Даже такое «идеальное» изображение, как скриншот всплывающей подсказки на странице сервиса, FineReader Online распознал с ошибками.
Во-вторых, объем файла, загружаемого на сервер, не должен превышать 10 мегабайт. Но самое неприятное ограничение — небольшое количество документов, которое можно распознать. Зайдя под одной учетной записью, можно обработать не более десяти файлов. Однако и это, согласитесь, неплохо. FineReader Online может также обрабатывать тексты, содержащие любые комбинации поддерживаемых языков. При этом сервис не позволяет выбирать более трех языков распознавания для одного документа. Разработчики мотивируют это тем, что подобная функция существенно замедлила бы процесс распознавания текста. Готовый результат распознавания текста может быть сохранен в один из форматов — MS Word (.doc), MS Excel (.xls), PDF, PDF/A, RTF и TXT. В принципе, сервис справляется с поставленной задачей и определяет текст. Однако, справедливости ради, следует сказать, что даже очень хорошее качество исходного изображения не дает стопроцентной гарантии распознавания. Даже такое «идеальное» изображение, как скриншот всплывающей подсказки на странице сервиса, FineReader Online распознал с ошибками.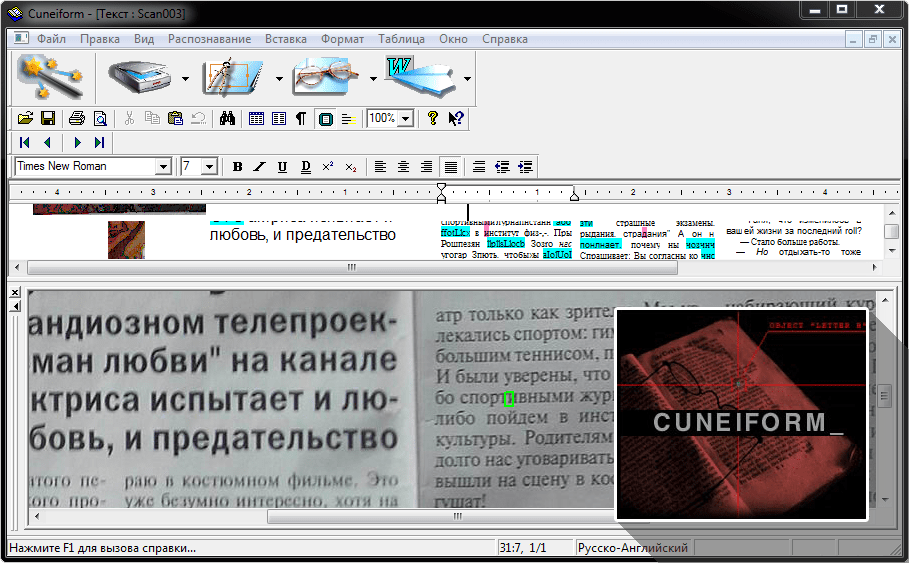
 Выбор языка осуществляется при загрузке файла. Даже если не указать язык, сервис попытается определить его автоматически, правда, не исключено, что он ошибется, поэтому лучше все же выбрать язык вручную. Стоит заметить, что выбрать можно лишь один язык. Каждому зарегистрированному пользователю предоставляется два бесплатных кредита, которые можно использовать для распознавания двух страниц формата A4. Если необходимо работать с б
Выбор языка осуществляется при загрузке файла. Даже если не указать язык, сервис попытается определить его автоматически, правда, не исключено, что он ошибется, поэтому лучше все же выбрать язык вручную. Стоит заметить, что выбрать можно лишь один язык. Каждому зарегистрированному пользователю предоставляется два бесплатных кредита, которые можно использовать для распознавания двух страниц формата A4. Если необходимо работать с б Бесплатная версия этой программы дает возможность обработать десять фотографий, а коммерческий вариант, снимающий это ограничение, обойдется в 14 долл. Пользователям, которые часто обращаются к услугам сервиса со своего настольного компьютера, предлагается скачать утилиту Unimessage Solo, предназначенную для сканирования файлов. Особенность этой программы в том, что в ней реализована интеграция с сервисом ocrNow! Кроме этого, созданные с ее помощью файлы можно загрузить на Facebook. Данный сервис является коммерческим. Для работы с ним необходимо приобретать кредиты, каждый кредит — возможность распознавания одной страницы документа. Однако даже в демонстрационном режиме с его помощью можно переводить небольшие фрагменты текста. Сервис предлагает очень удобную загрузку файлов — на сервер можно загружать одновременно несколько изображений, упаковав их в ZIP-архив. Максимальный размер файла — 20 мегабайт, но можно использовать и файлы большего размера, однако для получения такой возможности необходимо связаться с администрацией сервиса.
Бесплатная версия этой программы дает возможность обработать десять фотографий, а коммерческий вариант, снимающий это ограничение, обойдется в 14 долл. Пользователям, которые часто обращаются к услугам сервиса со своего настольного компьютера, предлагается скачать утилиту Unimessage Solo, предназначенную для сканирования файлов. Особенность этой программы в том, что в ней реализована интеграция с сервисом ocrNow! Кроме этого, созданные с ее помощью файлы можно загрузить на Facebook. Данный сервис является коммерческим. Для работы с ним необходимо приобретать кредиты, каждый кредит — возможность распознавания одной страницы документа. Однако даже в демонстрационном режиме с его помощью можно переводить небольшие фрагменты текста. Сервис предлагает очень удобную загрузку файлов — на сервер можно загружать одновременно несколько изображений, упаковав их в ZIP-архив. Максимальный размер файла — 20 мегабайт, но можно использовать и файлы большего размера, однако для получения такой возможности необходимо связаться с администрацией сервиса. В качестве исходного формата графического файла можно использовать TIFF (поддерживаются в том числе и многостраничные документы), JPEG/JPG, BMP, PCX, PNG, GIF, PDF. Если с помощью данного сервиса распознается многостраничный документ, например, PDF, можно указать только отдельные страницы для распознавания. Для этого в настройках распознавания необходимо установить флажок напротив «Многостраничный документ» и в поле для диапазона страниц указать необходимые страницы через запятую (или диапазон страниц через дефис). Если указать, скажем «4,13», сервис распознает только четвертую и тринадцатую страницы. В демонстрационном режиме сервис OnlineOCR.ru распознаёт не весь текст, а только его часть. Всего сервис поддерживает 28 языков, включая русский, английский, белорусский, венгерский, голландский, греческий, датский, испанский, латвийский, латинский, немецкий, польский, шведский, финский, французский, украинский и др. Сервис позволяет хранить файлы с результатом распознавания в виртуальном рабочем кабинете online, редактировать, отправлять их по почте и выводить на печать.
В качестве исходного формата графического файла можно использовать TIFF (поддерживаются в том числе и многостраничные документы), JPEG/JPG, BMP, PCX, PNG, GIF, PDF. Если с помощью данного сервиса распознается многостраничный документ, например, PDF, можно указать только отдельные страницы для распознавания. Для этого в настройках распознавания необходимо установить флажок напротив «Многостраничный документ» и в поле для диапазона страниц указать необходимые страницы через запятую (или диапазон страниц через дефис). Если указать, скажем «4,13», сервис распознает только четвертую и тринадцатую страницы. В демонстрационном режиме сервис OnlineOCR.ru распознаёт не весь текст, а только его часть. Всего сервис поддерживает 28 языков, включая русский, английский, белорусский, венгерский, голландский, греческий, датский, испанский, латвийский, латинский, немецкий, польский, шведский, финский, французский, украинский и др. Сервис позволяет хранить файлы с результатом распознавания в виртуальном рабочем кабинете online, редактировать, отправлять их по почте и выводить на печать.
 Общее количество поддерживаемых языков, которые можно выбирать для распознавания, довольно много — двадцать девять, в том числе и русский. Качество распознавания документов удовлетворительное.
Общее количество поддерживаемых языков, которые можно выбирать для распознавания, довольно много — двадцать девять, в том числе и русский. Качество распознавания документов удовлетворительное.⇡#Заключение
Далеко не все услуги онлайновых сервисов для распознавания текста предоставляются бесплатно. Однако цена, которую просят их создатели, заметно ниже стоимости специализированного ПО. Естественно, если вам необходимо распознавать десятки документов ежедневно, то платить создателям онлайнового сервиса для вас вряд ли будет выгодно — гораздо дешевле будет один раз заплатить за лицензию программы. Но если вы пользуетесь подобными средствами лишь время от времени, то проще заплатить за распознавание необходимого числа страниц или попытаться обойтись полностью бесплатными сервисами.Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Программное обеспечение для онлайн-распознавания текста
Он-лайн конвертер
Ниже указан список конвертеров, специализирующихся на оптическом распознавании символов (OCR). Извлекайте текст из отсканированных страниц, изображений и т.д.!
Извлекайте текст из отсканированных страниц, изображений и т.д.!
 д. Наш конвертер OCR позволяет бесплатно конвертировать изображения в текст.
Читать далее…
Конвертируйте из PDF в Word с помощью этого бесплатного онлайн-конвертера Word.
д. Наш конвертер OCR позволяет бесплатно конвертировать изображения в текст.
Читать далее…
Конвертируйте из PDF в Word с помощью этого бесплатного онлайн-конвертера Word. Извлекайте текст из отсканированных изображений и делайте PDF-документы редактируемыми всего в несколько кликов!
Читать далее…
Извлекайте текст из сканированных изображений с помощью этого бесплатного конвертера OCR.
Извлекайте текст из отсканированных изображений и делайте PDF-документы редактируемыми всего в несколько кликов!
Читать далее…
Извлекайте текст из сканированных изображений с помощью этого бесплатного конвертера OCR. Отсканированный документ или отсканированное изображение — без проблем! Получите текст со своих отсканированных изображений.
Читать далее…
Отсканированный документ или отсканированное изображение — без проблем! Получите текст со своих отсканированных изображений.
Читать далее…Распознавание для Windows XP, 7, 8, 10
Freemore OCR
7 февраля, 2017Freemore OCR – бесплатная и простая в использовании программа для компьютера, которая позволяет быстро и легко извлекать текст из изображений и PDF-документов, с последующим их… Скачать
Графика и дизайн, Другое, Конвертеры графики, Распознавание, Текст
WinScan2PDF
29 апреля, 2016WinScan2PDF – небольшая, бесплатная и портативная (не требующая инсталляции) программа для сканирования различных документов с помощью любого установленного сканера, и дальнейшего их сохранения на компьютер в… Скачать
PDF, Конвертеры текста, Распознавание, Текст
HippoScan
18 апреля, 2016HippoScan (ранее ScanTool) – бесплатная программа для компьютера, которая пригодится тем пользователям, кто часто делает электронные копии бумажных документов. Работает под управлением операционных систем Microsoft Windows XP,… Скачать
Работает под управлением операционных систем Microsoft Windows XP,… Скачать
Распознавание, Текст
NAPS2
11 марта, 2016NAPS2 (Not Another PDF Scanner 2) – очень удобная оболочка для сканирования документов и сохранения их в формат PDF или в виде графического изображения (BMP,… Скачать
PDF, Распознавание, Текст
Hunspell
18 апреля, 2015Hunspell – свободная версия компьютерной программы для проверки орфографии в операционных системах семейства Microsoft Windows. Программа Hunspell предназначена для языков со сложной системой словообразования и обширной… Скачать
Распознавание, Текст
Tesseract-OCR
14 апреля, 2014Tesseract-OCR (англ. тессеракт) – свободная компьютерная программа для распознавания текстов, разрабатывавшаяся Hewlett-Packard с середины 1980-х по середину 1990-х, а затем 10 лет «пролежавшая на полке»…. Скачать
тессеракт) – свободная компьютерная программа для распознавания текстов, разрабатывавшаяся Hewlett-Packard с середины 1980-х по середину 1990-х, а затем 10 лет «пролежавшая на полке»…. Скачать
Распознавание, Текст
CuneiForm
19 января, 2014CuneiForm (англ. cuneiform кьюниформ – клинопись), Cognitive OpenOCR – свободно распространяемая открытая система оптического распознавания текстов российской компании Cognitive Technologies. Первоначально система CuneiForm была разработана… Скачать
Распознавание, Текст
GNU Aspell
10 января, 2014GNU Aspell (или Aspell) — свободная компьютерная программа для проверки орфографии, разработанная для замены Ispell. Это стандартная программа проверки орфографии для системы GNU. Она также компилируется под другие UNIX-подобные операционные системы и Microsoft Windows…. Скачать
Скачать
Распознавание, Текст
Polyglot 3000
3 января, 2013Полиглот 3000 – автоматический определитель языка, который предназначен для быстрого и корректного определения того на каком языке написан введённый вами текст. Программа работает в операционных… Скачать
Другое, Распознавание, Текст
Microsoft OneNote и Nuance OmniPage в сравнении
Инструменты оптического распознавания символов (OCR) позволяют быстро преобразовывать печатный или рукописный текст в цифровой текст. Допустим, вы хотите быстро скопировать и отредактировать текст с изображения в Instagram или отсканированной фотографии. Вы можете сделать это в кратчайшие сроки с помощью инструмента распознавания текста!
Интернет благословил нас множеством бесплатных опций оптического распознавания текста, но есть и платные.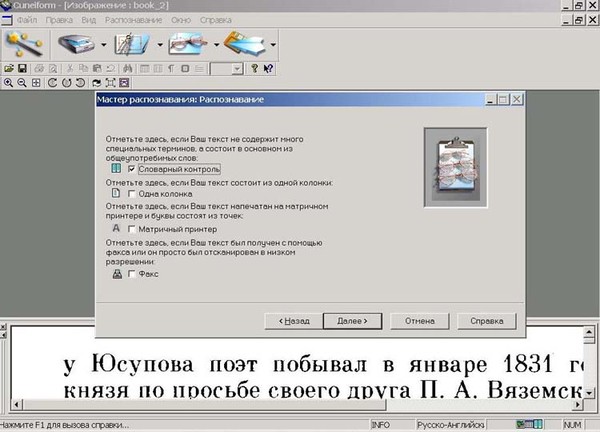 Итак, вот что я хочу знать: стоит ли платить за инструмент OCR, если вы можете просто использовать его бесплатно?
Итак, вот что я хочу знать: стоит ли платить за инструмент OCR, если вы можете просто использовать его бесплатно?
В этом посте я протестирую один из лучших бесплатных инструментов распознавания текста в сравнении с одним из лучших платных вариантов распознавания текста.
Приготовьтесь к Microsoft OneNote (бесплатно) по сравнению с Nuance OmniPage 18 (60 долларов).
В целом, большинство инструментов OCR работают примерно одинаково:
- Вы импортируете файл на основе изображения, такой как изображение JPG или PDF.

- Вы указываете инструменту OCR преобразовать изображение в текстовый документ.
- Инструмент начинает работать и создает версию текста, которую вы можете редактировать.

Эта же общая процедура применима как к OneNote, так и к OmniPage.
Чтобы оценить, какой инструмент (если какой из них) действительно лучше, я оцениваю каждый из них в нескольких тестах. И, прежде чем мы продолжим, позвольте мне пояснить:
И, прежде чем мы продолжим, позвольте мне пояснить:
Если вы собираетесь использовать OneNote для распознавания текста, используйте только настольную версию программы OneNote 2016.
Веб-приложение, которое у вас, вероятно, есть на вашем компьютере, если вы используете Windows 10, не имеет тех же возможностей, что и настольное программное обеспечение 2016 года.
Если вы попытаетесь использовать OCR в любом приложении OneNote, кроме настольного программного обеспечения 2016 года, это не сработает.Поверьте, я пробовал.
Перейдите сюда, чтобы бесплатно загрузить OneNote 2016. Убедитесь, что вы нажали ссылку «Рабочий стол Windows»!
Убедитесь, что вы нажали ссылку «Рабочий стол Windows»!
Рейтинг процесса
Чтобы измерить, насколько хорошо каждый инструмент выполняет определенные функции, я решил оценить точность каждого инструмента по шкале от 1 до 5. Оценка 5 означает, что инструмент транскрибирует текст точно, без орфографических или синтаксических ошибок.
Оценка 5 означает, что инструмент транскрибирует текст точно, без орфографических или синтаксических ошибок.
Чтобы четко определить, какой инструмент был наиболее полезным, я решил попытаться преобразовать следующие файлы в текст:
- PDF-файл
- Загруженная фотография в формате JPG с текстом
- Фотография смартфона с текстом
- Отсканированная записка, напечатанная от руки
- Отсканированная рукописная заметка
Что касается ожиданий, я ожидаю, что оба этих инструмента будут одинаково хорошо сочетаться друг с другом.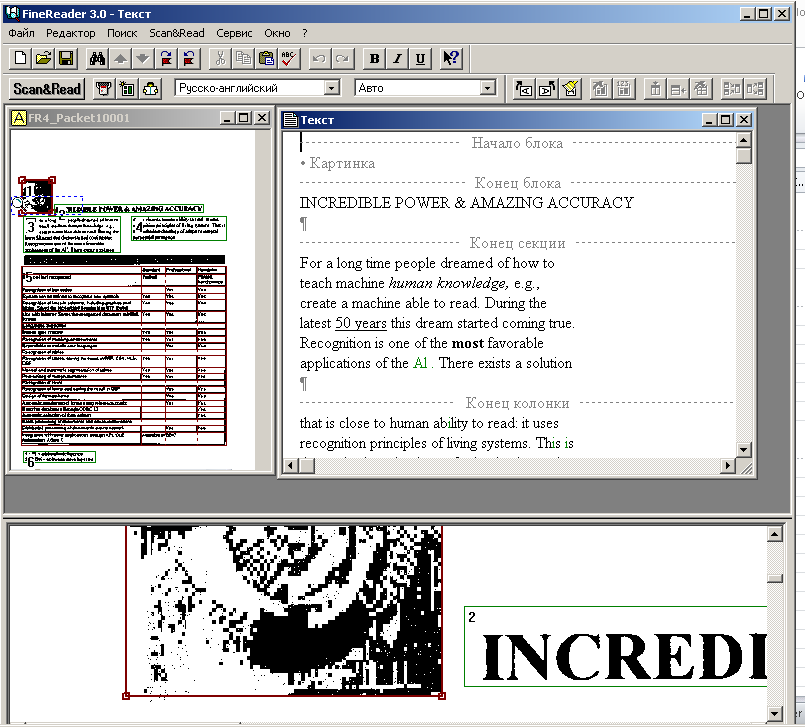 По моему опыту, платные и бесплатные инструменты часто относительно равны, за исключением, может быть, нескольких ярких функций со стороны платного инструмента. (Просто посмотрите Google Docs и Microsoft Word.)
По моему опыту, платные и бесплатные инструменты часто относительно равны, за исключением, может быть, нескольких ярких функций со стороны платного инструмента. (Просто посмотрите Google Docs и Microsoft Word.)
Я не часто использую OneNote и, конечно же, никогда не использовал его ни для чего, кроме набора простых заметок.Итак, я думаю, что эти тесты будут точным отображением не только функций распознавания текста обоих инструментов, но и того, насколько они интуитивно понятны.
Ниже вы можете увидеть, насколько хорошо каждый из этих тестов работал в OneNote и OmniPage.
PDF в текст
Чтобы протестировать эту функцию с помощью обоих инструментов OCR, я загрузил этот PDF-файл из Lakeshore Learning.
Вот как работает каждый инструмент:
OneNote
Чтобы загрузить PDF-файл в OneNote, я использовал опцию File Printout , чтобы добавить PDF-файл на одну из страниц моей записной книжки:
Следуя инструкциям в этой статье Microsoft, я щелкнул правой кнопкой мыши изображение PDF и выбрал Копировать текст с этой страницы распечатки .
Мне пришлось потратить некоторое время на поиски в Google, чтобы понять, как это сделать, но после небольшого исследования процесс оказался относительно простым.
На новую страницу я вставил текст. OneNote успешно скопировал текст с первой страницы PDF-документа. Он не очень хорошо справлялся с сохранением форматирования из PDF, но текст был редактируемым и доступным для поиска, и казалось, что ничего не написано неправильно.
OneNote успешно скопировал текст с первой страницы PDF-документа. Он не очень хорошо справлялся с сохранением форматирования из PDF, но текст был редактируемым и доступным для поиска, и казалось, что ничего не написано неправильно.
Оценка OneNote: 5
OmniPage
В OmniPage есть пошаговое меню кнопок в верхней части главного экрана, в котором указывается, что делать.Используя это, я загрузил PDF-файл в программу.
Затем я нажал кнопку Next , чтобы выполнить распознавание текста.
Затем я щелкнул Сохранить в файлы и назвал свой новый документ.
И когда я открыл файл, текст был аккуратно преобразован в документ Microsoft Word со всеми исходными изображениями PDF и полностью редактируемым текстом.Форматирование оставалось неизменным, и я не заметил ни слова с ошибками, ни прерывистых строк текста.
Единственная странность OmniPage OCR заключалась в том, что при загрузке и преобразовании файла PDF не открывались изображения.
Вы могли подумать, что увидите предварительный просмотр документа или что-то в этом роде, но этого не произошло.Мне это вроде как понравилось, потому что вы можете просто переходить от одного шага к другому и быстро завершить OCR.
Оценка OmniPage: 5
Загрузил JPG в текст
Что может быть лучше для тестирования этих инструментов OCR, чем опробовать их на цитатах Pinterest?
Для этого теста я загрузил фотографию в формате JPG из аккаунта Pinterest Down To Health.[Больше недоступно]
Вот как складываются результаты этого теста:
OneNote
С новой страницы в OneNote я вставил картинку.(Вы делаете это аналогично тому, как вы вставляете изображение в Microsoft Word или любую другую программу Office.)
Как и в случае с примером PDF, я щелкнул изображение правой кнопкой мыши и выбрал Копировать текст с изображения .
Однако когда я попытался вставить скопированный текст под изображением, OneNote ничего не смог вставить.
Я попытался вставить его как обычный текст, сохранить исходное форматирование и форматирование слияния, но ничего не помогло.
Возможно, OneNote не удалось скопировать текст из-за текстурированного фона изображения.Однако текст на этом изображении довольно темный по контрасту, и я думаю, что хороший инструмент OCR должен уметь его извлечь.
Оценка OneNote: 1
OmniPage
Следуя тем же шагам, что и в предыдущем тесте, я загрузил фотографию в OmniPage.Однако на этот раз программа была немного не уверена в текстуре фона на фотографии.
Он был довольно близок к распознаванию слов «GO DO», но был далек от попытки расшифровать «WHAT».
Используя предоставленное поле, я вручную исправил несколько ошибок и сказал программе завершить оптическое распознавание текста.Это произошло, и я сохранил получившийся документ так же, как и в предыдущем тесте.
Однако этот тест был в значительной степени провальным, поскольку программа могла действительно распознавать только те слова, которые я исправил вручную.
Я попытался щелкнуть и протестировать другие варианты, такие как Camera Image to Word , но и там не повезло.
Оценка OmniPage: 2
Смартфон фото в текст
Я очень люблю пить чай.Итак, для этого следующего текста я быстро сфотографировал коробку с чаем в пределах досягаемости моего компьютера.
Посмотрим, справились ли наши инструменты распознавания текста лучше с этим форматом файла.
OneNote
Снова используя опцию вставки фотографии, я добавил фотографию на новую страницу OneNote.
Я щелкнул изображение правой кнопкой мыши и выбрал Копировать текст с изображения .
Затем я щелкнул под изображением и вставил текст, который OneNote записал на удивление точно!
OneNote немного изменил некоторые строки текста, но я был приятно удивлен тем, насколько успешным оказался этот тест.
Текст был полностью редактируемым, и этот тест не занял много времени.
Оценка OneNote: 5
OmniPage
Мои надежды на этот тест были невысокими после серьезной неудачи с загруженным изображением JPG.Однако OmniPage также проделала действительно точную работу с этим тестом!
Перейдя к функции Workflow Assistant , я выбрал опцию Load Digital Camera Files и загрузил фотографию со своего смартфона.
Программа увеличила часть того, что, как мне кажется, было логотипом бренда на моей коробке для чая.Я просто проигнорировал возможность внести изменения.
Удивительно, но созданный OmniPage файл Word был на 100 процентов точным и редактируемым с несколькими странными кляксами дополнительного текста.
Оценка OmniPage: 4
Печатная запись в текст
Для следующего теста я написал небольшую заметку и отсканировал ее в облако.
Как вы могли догадаться, у меня дома не только сканер.Для сканирования этого изображения я использовал CamScanner, бесплатное приложение, доступное как для iOS, так и для Android, которое позволяет сканировать документы с помощью телефона.
Поскольку CamScanner дает вам возможность загружать отсканированные файлы в формате PDF или JPG, я решил попробовать оба.
OneNote
В обоих форматах файлов у меня все еще была возможность скопировать текст с этого изображения, когда я вставил его в OneNote.
Однако программное обеспечение не смогло использовать OCR для успешного копирования текста из изображения JPG.
Удалось скопировать немного текста из PDF-версии заметки, но не очень успешно.
Оценка OneNote: 1
OmniPage
Для изображения JPG напечатанного текста OmniPage не так хорошо справился с расшифровкой текста.
Когда я попробовал этот тест с форматом файла PDF, результат был примерно таким же.
Оценка OmniPage: 2
Рукописный ввод текста
Как и в случае с распечатанной заметкой, я отсканировал рукописную заметку с помощью CamScanner.
OneNote
Несмотря на то, что мне не удалось обнаружить какие-либо буквы из моей распечатанной заметки, OneNote смог скопировать какой-то текст из рукописной заметки.Однако это было крайне неточно.
С файлом PDF результат был еще хуже.
Оценка OneNote: 1
OmniPage
Поскольку OmniPage не мог даже распознать мой напечатанный текст, я не ожидал более сложного почерка.
Каким-то образом программа смогла импортировать мой почерк.Однако, похоже, он не мог сделать его редактируемым, даже когда я пытался импортировать его как обычный текст. То же самое было и при загрузке PDF-версии моего почерка.
Оценка OmniPage: 1
С невероятно близким счетом от 13 до 14 OmniPage едва ли обогнал OneNote.OmniPage смог распознать больше символов, чем OneNote, но, в конце концов, оба были одинаково полезны (или бесполезны). Тесты рукописного ввода, печатного письма и загруженного JPG поставили обе программы в тупик, но каждая из них хорошо справилась с PDF-файлом в текст и изображением смартфона для распознавания текста.
Но стоит ли вкладываться в платный инструмент распознавания текста? На мой взгляд, нет.Если OneNote может преуспевать и терпеть неудачу в тех же областях, что и OmniPage, зачем тратить 60 долларов?
Если вы не хотите устанавливать какое-либо программное обеспечение, вам следует попробовать один из этих бесплатных онлайн-инструментов распознавания текста.
Как вы думаете? Есть ли какая-то основная функция, которую мы упустили в OmniPage? Знаете ли вы какие-нибудь более платные или бесплатные инструменты распознавания текста? Расскажите нам в комментариях ниже!
Samsung наконец-то анонсирует серию телефонов Galaxy S21После нескольких недель утечек Samsung раскрыла все о своих будущих флагманах.
Об авторе Кайла Мэтьюз (136 опубликованных статей)Кайла Мэтьюз — старший писатель MakeUseOf, освещающий технологии потоковой передачи, подкасты, приложения для повышения производительности и многое другое.
Больше От Кайлы МэтьюзПодпишитесь на нашу рассылку новостей
Подпишитесь на нашу рассылку, чтобы получать технические советы, обзоры, бесплатные электронные книги и эксклюзивные предложения!
Еще один шаг…!
Подтвердите свой адрес электронной почты в только что отправленном вам электронном письме.
Лучшие приложения для сканирования, отслеживания и управления счетами
Будь то в целях налогообложения, управления бизнес-расходами или личных интересов бюджета, хранение физических квитанций — это немного хлопотно и утомительно. Но, к счастью, с достижениями в области распознавания изображений и финансовых приложений теперь вы можете отслеживать свои чеки с помощью смартфона.
Вот шесть лучших приложений для сканирования, отслеживания и управления бумажными счетами — от общих приложений для ведения заметок с функциями сканирования квитанций до специальных приложений для отслеживания расходов.
1.Expensify
ЗакрытьИзображение 1 из 3
Изображение 2 из 3
Изображение 3 из 3
Expensify — одно из самых популярных приложений для управления квитанциями благодаря функциям представления финансовых отчетов и расходов.Вы можете получать чеки через приложение, а также импортировать данные кредитной карты и создавать отчеты о пробегах. Вы можете отправить эти отчеты через приложение, просто введя адрес электронной почты получателя.
Один из недостатков приложения — время, необходимое для извлечения информации из изображений после того, как они были захвачены.Такое сканирование может иногда занимать несколько часов, что в первую очередь снижает удобство сканирования с распознаванием текста. Компания утверждает, что это происходит потому, что точность важнее скорости, но другие приложения могут сканировать точно и занимать гораздо меньше времени.
Элементы, которые работают в пользу приложения, — это его профессиональный внешний вид и возможность отслеживать расходы на конкретные поездки.
Хотя базовое приложение является бесплатным, этот план ограничен пятью сканированиями в месяц.Вы можете перейти на платный план через приложение, если хотите неограниченное сканирование и некоторые дополнительные функции.
Скачать: Expensify для Android | iOS (бесплатно, доступна подписка)
2.Зохо расход
ЗакрытьИзображение 1 из 3
Изображение 2 из 3
Изображение 3 из 3
Zoho Expense является частью более обширного набора приложений и программного обеспечения для отслеживания расходов Zoho, но в него встроено управление квитанциями и распознавание текста.Это делает его полезным для управления квитанциями, а также позволяет отслеживать такие расходы, как пробег.
Бесплатный план дает вам 100 бесплатных сканирований в месяц, что является огромным преимуществом по сравнению со многими другими приложениями для квитанций, которые ограничивают сканирование OCR. Его сканирование также является точным и быстрым, обычно правильная информация генерируется из чека менее чем за минуту.Хотя функция создания отчетов немного привередлива, в целом это приложение для сканирования квитанций является эффективным и действенным.
Скачать: Zoho Expense для Android | iOS (бесплатно, доступна подписка)
3.Evernote
ЗакрытьИзображение 1 из 3
Изображение 2 из 3
Изображение 3 из 3
Evernote — это обычное приложение для создания заметок, но тот факт, что оно может распознавать изображения с текстом, также делает его полезным приложением для хранения квитанций.Это особенно верно, если вы хотите вести учет квитанций, но не должны создавать отчеты о расходах.
Приложение не только позволяет делать изображения чеков для хранения, но также может сканировать вашу галерею на предмет изображений с текстом.После того, как вы включите эту функцию, Evernote даже уведомит вас, когда вы сделаете снимок квитанции с помощью приложения основной камеры, и спросит, хотите ли вы сохранить его. Лучший способ отсортировать квитанции, чтобы вы могли легко фильтровать их на более позднем этапе, — это добавить ярлык специально для них.
Если вам нужны более мощные инструменты управления квитанциями, вы можете вместо этого выбрать специальное приложение.Но если вы просто хотите вести учет квитанций, которые можно легко отсортировать, Evernote — полезный инструмент, который имеет другие организационные функции, которые вы можете использовать в повседневной жизни. Прочтите наше руководство по Evernote, чтобы узнать больше.
Скачать: Evernote для Android | iOS (бесплатно, доступна подписка)
4.Google Lens / Google Фото
ЗакрытьИзображение 1 из 3
Изображение 2 из 3
Изображение 3 из 3
Есть два способа организовать ваши чеки с помощью Google Lens — либо через его интеграцию с Google Assistant, либо через приложение Google Фото.Вы также можете получить к нему доступ как отдельное приложение на Android, но оно уже доступно через другие приложения, что более удобно.
При использовании с Ассистентом вы можете использовать команду Показать мои квитанции для создания списка ваших последних квитанций.В Android Oreo эта функция довольно упрощена. Но Android Pie лучше распознает и сортирует эти квитанции.
Вы также можете сортировать чеки с помощью Google Фото.Просто введите квитанций в строке поиска, и Фото откроет любые изображения квитанций.
Эти приложения не могут создавать отчеты для вас, но они по-прежнему полезны, если вам нужно хранить фотографии ваших чеков.Главное удобство заключается в том, что Google Assistant и Фотографии уже предустановлены на многих устройствах Android. Это означает, что вам не нужно загружать дополнительные приложения, и вместо этого вы можете интегрировать управление квитанциями в приложение, которое также управляет вашими фотографиями.
Если вы ищете способ отсканировать свои старые фотографии, у Google также есть варианты.
Загрузить: Google Lens для Android (бесплатно)
Скачать: Google Фото для Android | iOS (бесплатно)
Скачать: Google Ассистент для Android | iOS (бесплатно)
5.Смарт-квитанции
ЗакрытьИзображение 1 из 3
Изображение 2 из 3
Изображение 3 из 3
Smart Receipts — еще одно специальное приложение для управления квитанциями, которое может создавать отчеты и визуализации.Он также имеет множество специальных настроек, которые помогут вам организовать чеки в соответствии с вашими предпочтениями.
Основным недостатком является то, что бесплатный план требует, чтобы вы купили сканирование OCR, если вы не хотите вводить значения вручную.Вы получаете только два бесплатных сканирования OCR, а остальные необходимо приобрести в приложении. Это было бы хорошо для тех, кто готов платить за сканирование, но сканирование OCR не совсем точно при определении цен чеков. Это означает, что вам в конечном итоге придется отредактировать общее значение, что противоречит тому, почему вы заплатили за сканирование OCR.
Тем не менее, создание графиков и отчетов — полезная функция приложения.Тот факт, что графики создаются автоматически, особенно удобен и означает, что вы можете легко быть в курсе последних расходов. Вы также можете перейти на премиум-версию приложения, совершив покупку в приложении, что дешевле, чем покупка Smart Receipts Plus отдельно в Play Store.
Скачать: Smart Receipts для Android | iOS (доступна бесплатная, премиум-версия)
6.Квитанции Wave For Business
Распознавание текстаOCR | Продукты
Automotive
Идентификационные номера автомобилей (VIN) можно сканировать с помощью знакомого интеллектуального устройства на высокой скорости и даже с поврежденными или плохо освещенными кодами VIN в широком диапазоне расстояний и углов.
Узнать больше
Healthcare
Фармацевтическая продукция, данные которой не закодированы в штрих-коде, например, коды LOT или REF, сканируются с помощью OCR (оптического распознавания символов). Там, где есть штрих-код и текст, программное обеспечение Scandit обрабатывает и то, и другое одновременно.
Узнать больше
Post, Parcel & Express
Если этикетка на посылке или пакете настолько повреждена при транспортировке, что штрих-код не поддается сканированию, программа OCR (оптическое распознавание символов) может вместо этого прочитать сопроводительный текст.Программное обеспечение OCR интегрировано с SDK сканера штрих-кода для одновременного сканирования штрих-кодов и текста. Наше программное обеспечение сканирует несколько строк текста на многих этикетках за одно сканирование со смарт-устройства.
Узнать больше
Банковское дело
Сотрудники банка, используя знакомые интеллектуальные устройства, оснащенные программным обеспечением Scandit OCR, могут быстро сканировать любой буквенно-цифровой текст, например номера международных банковских счетов (IBAN) или номера документов / форм, в рабочие процессы. Клиенты мобильного банкинга могут использовать OCR для сканирования деталей платежа в мобильное приложение, избегая подверженного ошибкам ручного ввода важных чисел.
Узнать больше
Air Travel
Сотрудники авиакомпаний и аэропортов могут быстро сканировать машиночитаемые паспорта и удостоверения личности с помощью интеллектуального устройства, оснащенного программным обеспечением Scandit OCR. Например, сотрудники, обслуживающие пассажиров у выхода на посадку, не должны быть привязаны к дорогостоящим подиумам, а вместо этого могут использовать простые смартфоны или планшеты. А авиакомпании могут предложить пассажирам возможность сканировать собственные паспорта дома во время онлайн-регистрации.
Узнать больше
Розничная торговля
Как и в любой цепочке поставок, этикетки на упаковке в розничной торговле повреждаются при транспортировке, поэтому использование программного обеспечения OCR (оптического распознавания символов) для чтения сопроводительного текста вместо штрих-кодов может предотвратить дорогостоящие задержки доставки и отслеживания.Наше программное обеспечение сканирует несколько строк текста на многих этикетках за одно сканирование со смарт-устройства. OCR также используется для проверки личности лиц в цепочке поставок или клиентов, собирающих коллекции без правильного оформления документов.
Узнать больше
Лучшее программное обеспечение для преобразования речи в текст в 2021 году: бесплатные, платные и онлайн-приложения и услуги для распознавания голоса
Лучшее программное обеспечение для преобразования речи в текст позволяет легко и просто преобразовывать произнесенное слово в цифровой текст, который можно использовать или копировать в различных документах.
Лучшее программное обеспечение преобразования речи в текст
В то время как лучшее программное обеспечение преобразования речи в текст раньше предназначалось только для настольных компьютеров, разработка мобильных устройств и рост числа легкодоступных приложений означает, что транскрипция теперь также может выполняться на смартфоне или планшете .
Это сделало лучшие приложения для передачи голоса в текст все более ценными для пользователей в самых разных средах, от образования до бизнеса. Это не в последнюю очередь потому, что технология достигла уровня, на котором ошибки в транскрипции встречаются относительно редко, а некоторые сервисы по праву могут похвастаться 99.9% успеха от чистого звука.
Тем не менее, это применимо в основном к обычным ситуациям и обстоятельствам и исключает использование технической терминологии, необходимой в юридических или медицинских профессиях. Несмотря на это, цифровая транскрипция по-прежнему может обслуживать такие потребности, как создание заметок, которые по-прежнему можно легко сделать с помощью приложения для телефона, что упрощает процесс диктовки.
Однако разные программы преобразования речи в текст имеют разный уровень возможностей и сложности, при этом в некоторых из них используется расширенное машинное обучение для постоянного исправления ошибок, отмеченных пользователями, чтобы они не повторялись.Другие — это загружаемое программное обеспечение, качество которого зависит от его последнего обновления.
Вот лучшие программы распознавания речи в текст, которые должны быть более чем пригодными для большинства ситуаций и обстоятельств.
Лучшая плата за преобразование речи в текстовые приложения
- Dragon Anywhere
- Dragon Professional
- Otter
- Verbit
- Speechmatics
- Braina Pro
- Amazon Transcribe
- Microsoft Azure Speech to Text
- Watson Speech to Text
1.Dragon Anywhere
Лучшее мобильное приложение для преобразования речи в текст
Причины для покупки
+ Высокое качество распознавания речи + Синхронизация с настольным программным обеспечением Dragon + Отличное распознавание + Полнофункциональное приложение
Причины, по которым следует избегать
-Диктовка ограничена в приложении
Dragon Anywhere — это мобильный продукт Nuance для устройств Android и iOS, однако это не «облегченное» приложение, а предлагает полностью сформированные возможности диктовки, работающие через облако.
Таким образом, вы получаете такое же превосходное распознавание речи, как и в программном обеспечении для настольных ПК — единственное существенное различие, которое мы заметили, — это очень небольшая задержка в отображении наших произносимых слов на экране (несомненно, из-за обработки в облаке). Тем не менее, обратите внимание, что приложение в целом по-прежнему достаточно отзывчиво.
Он также может похвастаться поддержкой шаблонных фрагментов текста, которые можно настроить и вставить в документ с помощью простой команды, и они, вместе с настраиваемыми словарями, синхронизируются через мобильное приложение и настольное программное обеспечение Dragon.Кроме того, вы можете обмениваться документами на разных устройствах через Evernote или облачные сервисы (например, Dropbox).
Это не так гибко, как настольное приложение, однако, поскольку диктовка ограничена внутри Dragon Anywhere — вы не можете диктовать прямо в другом приложении (хотя вы можете скопировать текст с клавиатуры для диктовки Dragon Anywhere на третье место). вечеринка). Другими предостережениями являются необходимость подключения к Интернету для работы приложения (из-за его облачной природы) и тот факт, что это предложение по подписке без единовременной покупки, что может не понравиться всем.
Даже с учетом этих ограничений, это определенное благо иметь полноценное, мощное распознавание голоса того же безупречного качества, что и программное обеспечение для настольных ПК, которое можно использовать на телефоне или планшете, когда вы находитесь вдали от офиса.
Nuance Communications предлагает 7-дневную бесплатную пробную версию, чтобы испытать приложение перед тем, как оформить подписку.
(Изображение предоставлено Nuance)2. Dragon Professional
Решения для преобразования речи в текст бизнес-класса
Причины для покупки
+ Мощные функции + Разработано для профессионалов +160 слов в минуту
Следует Если вы ищете приложение для диктовки бизнес-класса, лучше всего будет Dragon Professional.Программа, предназначенная для профессиональных пользователей, предоставляет вам инструменты для диктовки и редактирования документов, создания электронных таблиц и просмотра веб-страниц с помощью голоса.
Согласно Nuance, это решение способно выполнять диктовку с эквивалентной скоростью набора 160 слов в минуту и с точностью 99% — и это готово, прежде чем будет выполнено какое-либо обучение (при этом приложение адаптируется к вашему голосу и словам, которые вы обычно используете).
Помимо создания документов с помощью голоса, вы также можете импортировать собственные списки слов.Существует также дополнительное мобильное приложение, которое позволяет вам расшифровывать аудиофайлы и отправлять их обратно на ваш компьютер.
Это мощный, гибкий и чрезвычайно полезный инструмент, который особенно хорош для отдельных лиц, таких как профессионалы и фрилансеры, позволяя гораздо более гибко и легко осуществлять набор текста и управление документами.
В целом интерфейс прост в использовании, и если вы вообще застряли, вы можете получить доступ к серии справочных руководств. И хотя программное обеспечение может показаться дорогим, это всего лишь единовременная плата, которая выгодно отличается от платных услуг транскрипции по подписке.
(Изображение предоставлено: Otter)3. Otter
Большое маленькое приложение для речи в текст
Причины для покупки
+ Уровень бесплатного пользования + Сотрудничество в команде + Параметры экспорта + Живые субтитры
Otter — это облачная программа преобразования речи в текст, специально предназначенная для мобильного использования, например, на ноутбуке или смартфоне. Приложение обеспечивает транскрипцию в реальном времени, позволяя вам искать, редактировать, воспроизводить и систематизировать по мере необходимости.
Otter продается как приложение специально для встреч, собеседований и лекций, чтобы было проще делать подробные заметки.Однако он также предназначен для совместной работы между командами, и разным докладчикам назначаются разные идентификаторы докладчиков, чтобы облегчить понимание транскрипции.
Существует три различных плана оплаты, основной из которых является бесплатным, и помимо упомянутых выше функций также включает в себя резюме ключевых слов и облако слов, чтобы упростить поиск упоминаний определенной темы. Вы также можете организовывать и публиковать, импортировать аудио и видео для транскрипции и предоставлять 600 минут бесплатного обслуживания.
Тариф Premium также включает расширенные параметры и параметры массового экспорта, возможность синхронизации звука из Dropbox, дополнительные скорости воспроизведения, включая возможность пропускать паузы без звука. Тариф Premium также позволяет преобразовывать речь в текст до 6000 минут.
План Teams также добавляет двухфакторную аутентификацию, управление пользователями и централизованное выставление счетов, а также статистику пользователей, голосовые отпечатки и субтитры в реальном времени.
TextGrabber сканирование и перевод в App Store
ABBYY TextGrabber легко и быстро оцифровывает фрагменты печатного текста, считывает QR-коды и превращает распознанный результат в действия: звоните, пишите, переводите на 100+ языков онлайн и на 10 языков офлайн, ищите в Интернете или на картах, создавайте события на календарь, редактировать, озвучивать и делиться любым удобным способом.
Когда вы наводите камеру на печатный текст, TextGrabber мгновенно захватывает информацию и распознает ее без подключения к Интернету. Уникальный режим распознавания в реальном времени извлекает информацию на 60+ языках не только из документов, но и с любых поверхностей.
Победитель премии SUPERSTAR в категориях «Мобильное приложение для повышения производительности», «Мобильное приложение для захвата изображений» и «Ввод текста» в конкурсе Mobile Star Awards
——————- ——
«TextGrabber, вероятно, лучшее приложение, которое добавляет еще одну функцию вашему iPhone: сканер» — The Irish Times
«Результаты выдаются относительно быстро, и это здорово.Обязательно для студентов »- appadvice.com
« Лучшее приложение для преобразования изображений в текст для iPhone »- lifehacker.com
——————— —
ОСНОВНЫЕ ХАРАКТЕРИСТИКИ:
• Перевод в реальном времени прямо на экране камеры без фотографирования на 100+ языков онлайн (полнотекстовый перевод) и 10 языков офлайн (пословный перевод).
• Инновационный режим распознавания в реальном времени, основанный на технологии ABBYY RTR SDK, позволяет оцифровывать печатный текст прямо на экране камеры без фотографирования.
• Распознавание текста на 60+ языках, включая русский, английский, немецкий, испанский, греческий, турецкий, китайский и корейский, без подключения к Интернету.
• Все ссылки, номера телефонов, адреса электронной почты, почтовые адреса и даты после оцифровки становятся интерактивными: вы можете щелкнуть ссылку, позвонить, написать электронное письмо, найти адрес на картах или добавить событие в календарь.
• Ярлыки Siri. Чтобы распознать последнюю фотографию с помощью Siri, создайте ярлык Siri в настройках iPhone.
• Считыватель QR-кода.
• Мощные возможности преобразования текста в речь с помощью функции системы VoiceOver.
• Регулируемые размеры шрифта и звуковые подсказки для людей с ослабленным зрением: вы можете увеличить размер шрифта и использовать звуковые подсказки для элементов интерфейса.
• Отправьте результаты в любое приложение, установленное на устройстве, через системное меню.
• Весь извлеченный текст автоматически копируется, и его можно легко найти в папке «История».
————————
Бесплатная версия с рекламой и обеспечивает распознавание и перевод 3 текстов.
С помощью ABBYY TextGrabber вы можете сохранить и перевести любой печатный текст, который вам нужен, одним касанием экрана:
• Тексты с экрана телевизора или смартфона
• Квитанции
• Этикетки и счетчики
• Путевые документы
• Журнальные статьи и фрагменты книг
• Руководства и инструкции
• Ингредиенты рецептов и т. Д.
————————
СОВЕТ OCR: выберите соответствующий язык (до трех в раз) до распознавания
————————
Twitter @abbyy_mobile_ww
FB.com / AbbyyMobile
VK.com/abbyylingvo
YouTube.com/AbbyyMobile
————————
Автоматически продлеваемая подписка на Премиум-аккаунт позволяет использовать все функции этого приложения. Срок действия подписки: 1 месяц и 1 год. Подписка автоматически продлевается в конце периода, если вы не решите отменить подписку по крайней мере за 24 часа до окончания текущего периода. Оплата будет снята с вашей учетной записи iTunes при подтверждении покупки. Вы можете управлять своей подпиской и отключить автоматическое продление в настройках своей учетной записи после покупки.Любая неиспользованная часть бесплатного пробного периода, если таковая предлагается, будет аннулирована, если вы приобретете подписку на эту публикацию.
Конфиденциальность: https://www.abbyy.com/privacy/
Условия использования: http://www.textgrabber.pro/en/eula/
————— ———
ABBYY TEXTGRABBER — САМЫЙ БЫСТРЫЙ СПОСОБ ОЦИФРОВКИ, ПЕРЕВОДА И ДЕЙСТВИЯ ЛЮБОЙ ПЕЧАТНОЙ ИНФОРМАЦИИ!
Пожалуйста, оставьте отзыв, если вам нравится ABBYY TextGrabber. Спасибо!
Capture2Text
Capture2TextСодержание
Что такое Capture2Text?
Capture2Text позволяет пользователям быстро распознавать текст на части экрана с помощью Сочетание клавиш.Полученный текст по умолчанию будет сохранен в буфер обмена.
Концептуальная иллюстрация:
Capture2Text распространяется бесплатно и под лицензией GNU General Public License.
Скачать
Последнюю версию можно найти на странице загрузки Capture2Text, размещенной на SourceForge.
Системные требования
Поддерживаемые операционные системы:
- Окна 7
- Windows 8/8.1
- Windows 10
Примечание. Поддержка Windows XP была прекращена с версии Capture2Text v4.0.
Как запустить Capture2Text (установка не требуется)
- Распакуйте содержимое ZIP-файла.
- Дважды щелкните файл Capture2Text.exe. Вы должны увидеть значок Capture2Text на в правом нижнем углу экрана (хотя он может быть скрыт, и в этом случае вы придется нажать на стрелку «Показать скрытые значки»).
Установка дополнительных языков OCR
По умолчанию Capture2Text поставляется со следующими языками: английский, французский, немецкий, японский, корейский, русский и испанский.
Выполните следующие действия, если вы хотите установить дополнительные языки OCR:
- Загрузите словарь соответствующего языка OCR.
- Откройте файл .zip, который вы только что загрузили, с помощью 7-Zip или аналогичной программы для распаковки.
- Перетащите все файлы, содержащиеся в zip-файле, в папку tessdata:
- Перезапустите Capture2Text.
Поддерживаются следующие языки OCR:
| африкаанс (африкаанс) | греческий (эл. | гаитянский (шляпа) | персидский (fas) |
| древнегреческий (grc) | иврит (heb) | польский (pol) | |
| арабский (ара) | хинди (хин португальский) | por) | |
| Ассамский (asm) | Венгерский (hun) | Пушту (pus) | |
| Азербайджанский (aze) | Исландский (isl) | Румынский (ron) | |
| Баскский (eus) | Индийский (inc) | Русский (rus) | |
| Белорусский (bel) | Индонезийский (ind) | Санскрит (san) | |
| Бенгальский (ben) | Бенгальский (ben) (iku)сербский (srp) | ||
| боснийский (bos) | ирландский (gle) | сингальский (sin) | |
| болгарский (bul) | итальянский (ita) | kсловацкий (sl) | |
| бирманский (mya) | японский (jpn) | словенский (slv) | |
| каталонский (cat) | яванский (jav) | испанский (спа) | |
| Себуано (ceb) | Каннада (кан) | Суахили (swa) | |
| Центральный кхмерский (khm) | Казахский (kaz) | Шведский (swe) | |
| Чероки ( | ) Чероки ( | ) kir)Сирийский (syr) | |
| Китайский — упрощенный (chi_sim) | Корейский (kor) | Тагальский (tgl) | |
| Китайский — традиционный (chi_tra) | ( | Курух) tgk) | |
| Хорватский (hrv) | Лаосский (lao) | Тамильский (tam) | |
| Чешский (ces) | Latin (lat) | Telugu (tel) | латышский (lav) | тайский (tha) |
| голландский (nld) | литовский (lit) | тибетский (bod) | |
| дзонгха (dzo) | македонский | Тигринья (tir) | |
| Английский (eng) | Малайский (msa) | Турецкий (tur) | |
| Эсперанто (epo) | Малаялам (mal) | ||
| Эстонский (est) | Мальтийский (mlt) | Украинский (ukr) | |
| Финский (fin) | Marathi (mar) | Urdu (urd) | |
| Frankish (frk) | Математика / уравнения (equ) | Узбекский (uzb) | |
| Французский (fra) | Среднеанглийский (1100-1500) (enm) | Вьетнамский (vie) | |
| Галисийский (glg) | Среднефранцузский (1400-1600) (frm) | Валлийский (cym) | |
| Грузинский (kat) | Непальский (nep) | Идиш (yid) | |
| Немецкий (deu) | Норвежский (норвежский) |
Как выполнить стандартное распознавание текста
Выполните следующие действия, чтобы выполнить стандартный захват OCR с помощью окна захвата:
- Поместите указатель мыши в верхний левый угол текста, который нужно распознать.
- Нажмите горячую клавишу OCR (Windows Key + Q), чтобы начать захват OCR.
- Переместите указатель мыши, чтобы изменить размер синего поля захвата над текстом, который нужно OCR. Вы можете удерживать правую кнопку мыши и перетаскивать, чтобы переместить весь блок захвата.
- Снова нажмите горячую клавишу OCR (или щелкните левой кнопкой мыши или нажмите ENTER), чтобы завершить захват OCR. Текст OCR будет помещен в буфер обмена, и появится всплывающее окно, показывающее захваченный текст (всплывающее окно может быть отключено в настройках).
Как и для всех снимков OCR, вы должны вручную выбрать язык, который вы хотите OCR, в настройках.
Чтобы изменить язык оптического распознавания текста, щелкните правой кнопкой мыши значок Capture2Text на панели задач, выберите параметр «Язык оптического распознавания текста», а затем выберите нужный язык.
Для быстрого переключения между 3 языками используйте клавиши быстрого доступа к языку OCR: Клавиша Windows + 1, Клавиша Windows + 2 и Клавиша Windows + 3. Языки быстрого доступа можно указать в настройках.
Если выбран китайский или японский язык, необходимо указать текст направление (вертикальное / горизонтальное / авто) с использованием направления текста горячая клавиша: Windows Key + O. Если выбрано авто, то при ширина захвата более чем в два раза превышает высоту, в противном случае будет вертикальное используемый. Направление текста также влияет на то, как фуригана удаляется из японского текста.
(для японского) Capture2Text попытается автоматически удалить фуригану.
Как выполнить оптическое распознавание текста строки
Capture2Text может автоматически захватывать строку текста, ближайшую к указателю мыши.
Выполните следующие действия, чтобы выполнить оптическое распознавание текста строки:
- Наведите указатель мыши на строку текста, которую нужно захватить, или рядом с ней.
- Нажмите горячую клавишу Text Line OCR Capture (Windows Key + E).
- Capture2Text выделит захваченный текст и сохранит результат распознавания текста в буфер обмена.
Пример:
Как выполнить захват OCR прямой текстовой строки
Capture2Text может автоматически захватывать строку текста, начиная с символа, ближайшего к указателю мыши, и продвигаясь вперед.
Выполните следующие действия, чтобы выполнить захват OCR прямой текстовой строки:
- Наведите указатель мыши на символ, с которого нужно начать, или рядом с ним.
- Нажмите горячую клавишу прямого ввода текста строки OCR Capture (Windows + W).
- Capture2Text выделит захваченный текст и сохранит результат распознавания текста в буфер обмена.
Пример:
Как выполнить захват OCR пузырьков
Capture2Text может автоматически захватывать текст, содержащийся в пузыре речи / мысли комиксов, если пузырек полностью закрыт.
Выполните следующие действия, чтобы выполнить захват OCR в виде пузырьков:
- Поместите указатель мыши в пустую часть пузыря (не на текст).
- Нажмите горячую клавишу «Захват OCR» (Клавиша Windows + S).
- Capture2Text выделит захваченный текст и сохранит результат распознавания текста в буфер обмена.
Пример:
Как указать активный язык OCR
Чтобы указать активный язык OCR, щелкните правой кнопкой мыши значок в области уведомлений, выберите Язык OCR и выберите языки OCR из списка:
Перевод
Чтобы включить функцию перевода, сначала откройте диалоговое окно настроек (щелкните правой кнопкой мыши значок в области уведомлений и выберите «Настройки… «) и щелкнув вкладку» Перевести «.
Установите флажок «Добавить перевод в буфер обмена», чтобы добавить переведенный текст в буфер обмена с помощью предоставленного разделителя. Установите флажок «Показать перевод во всплывающем окне», чтобы отображать переведенный текст рядом с текстом OCR во всплывающем окне. Например:.Каждый установленный язык OCR может быть переведен на другой язык.
Примечание 1: Некоторые языки OCR не поддерживают перевод.Неподдерживаемые языки отображаться не будут.
Примечание 2: Для перевода требуется доступ в Интернет.
Настройки
Щелкните правой кнопкой мыши значок Capture2Text на панели задач в правом нижнем углу экрана, а затем выберите параметр «Настройки …», чтобы открыть диалоговое окно «Настройки». Вы можете навести указатель мыши на многие метки параметров, чтобы отобразить полезную подсказку, объясняющую этот параметр.
На вкладке «Горячие клавиши» можно указать, какие клавиши и модификаторы использовать для каждой горячей клавиши.Чтобы отключить горячую клавишу, выберите «
Текущий язык OCR: укажите используемый активный язык OCR. Вы также можете указать активный язык OCR в меню значка на панели задач.
Quick-Access Languages: языки, используемые для каждой из горячих клавиш быстрого доступа.
Белый список. Сообщите механизму распознавания текста, что захваченный текст будет содержать только указанные символы.
Черный список: Сообщите механизму OCR, что захваченный текст никогда не будет содержать указанные символы.
Ориентация текста: ориентация текста, который будет захвачен. Этот параметр используется только в том случае, если в качестве активного языка распознавания выбран китайский или японский. Если выбран параметр «Авто», будет использоваться горизонтальное положение, когда ширина захвата более чем в два раза превышает высоту, в противном случае будет использоваться вертикальное. Направление текста также влияет на то, как фуригана удаляется из японского текста. Вы также можете указать ориентацию текста в меню значка на панели задач или с помощью горячей клавиши «Ориентация текста».
Файл конфигурации Tesseract: расширенная функция, позволяющая указать файл конфигурации Tesseract.
Trim Capture: во время предварительной обработки OCR обрезайте захваченное изображение до пикселей переднего плана и добавьте тонкую границу. Точность распознавания текста будет более стабильной и даже может быть улучшена.
Deskew Capture: во время предварительной обработки OCR попытайтесь компенсировать наклон текста, обнаруженный при захвате OCR.
Содержит параметры для настройки автоматических захватов. Для получения дополнительной информации наведите указатель мыши на метки параметров.
Позволяет указать цвета окна захвата OCR.Прозрачность можно изменить, настроив значение «Альфа-канал» в диалоговом окне выбора цвета.
Позволяет указать положение, цвет и шрифт предварительного просмотра. Вы можете отключить предварительный просмотр, сняв флажок «Показать окно предварительного просмотра».
Сохранить в буфер обмена: сохранить захваченный текст OCR в буфер обмена.
Показать всплывающее окно: показать захваченный текст OCR во всплывающем окне:
Сохранять разрывы строк: Установите этот флажок, если вы не хотите, чтобы символы возврата каретки и перевода строки удалялись из захваченного текста.
Logging: позволяет сохранять все записи в указанный файл в указанном формате. В формате могут использоваться следующие токены: $ {capture}, $ {translation}, $ {timestamp}, $ {linebreak}, $ {tab}. Формат по умолчанию: «$ {capture} $ {linebreak}».
Вызов исполняемого файла: расширенная функция, позволяющая вызывать исполняемый файл после завершения распознавания текста. Могут использоваться следующие токены: $ {capture}, $ {translation}, $ {timestamp}. Пример:
C: \ Anaconda3 \ python.exe "C: \ Scripts \ test.py" "$ {capture}" "$ {translation}"
Позволяет выполнять замену текста. Поддерживает регулярные выражения. Текст слева будет заменен текстом справа. Для каждого языка OCR могут быть указаны разные замены.
См. Раздел перевода.
На этой странице можно включить функцию преобразования текста в речь, установить громкость и выбрать параметры (голос, скорость, высота тона) для использования для каждого языка OCR.
Включить преобразование текста в речь: включить преобразование текста в речь при захвате текста.
Если этот параметр отмечен и голос не установлен на «
Громкость: основная громкость функции преобразования текста в речь. Применимо ко всем языкам.
Язык распознавания: укажите параметры речи для выбранного языка распознавания текста.
- Скорость: Скорость преобразования текста в речь.
- Pitch: Высота голоса для преобразования текста в речь.
- Голос: Голос для преобразования текста в речь. Установите значение «
», чтобы отключить функцию преобразования текста в речь только для выбранного языка OCR.
Предварительный просмотр: предварительный просмотр текущей скорости, высоты тона и голоса.
Параметры командной строки
Использование: Capture2Text_CLI.exe [параметры]
Capture2Text может использоваться для распознавания файлов изображений или части экрана.Примеры:
Capture2Text_CLI.exe --screen-rect "400 200 600 300"
Capture2Text_CLI.exe --vertical -l "Китайский - упрощенный" -i img1.png
Capture2Text_CLI.exe -i img1.png -i img2.jpg -o result.txt
Capture2Text_CLI.exe -l японский -f "C: \ Temp \ image_files.txt"
Capture2Text_CLI.exe --show-languages
Параметры:
- ?, -h, --help Отображает эту справку.
-v, --version Отображает информацию о версии.
-b, --line-breaks Не удалять разрывы строк из текста OCR.-d, --debug Выводить захваченное изображение и предварительно обработанное
изображение для отладки.
--debug-timestamp Добавить метку времени для отладки изображений, когда
используя опцию -d.
-f, --images-file <файл> Файл, содержащий пути файлов изображений к
OCR. Один путь на строку.
-i, --image <файл> Файл изображения для OCR.Вы можете OCR несколько
файлы изображений, например: "-i -i
-i "
-l, --language <язык> используемый язык распознавания текста. Чувствительный к регистру.
По умолчанию "английский". Использовать
--show-languages для вывода списка установленных
Языки OCR.
-o, --output-file <файл> Выводить текст OCR в этот файл.Если не
указано, будет использоваться стандартный вывод.
--output-file-append Добавить в файл при использовании опции -o.
-s, --screen-rect <"x1 y1 x2 y2"> Координаты прямоугольника, определяющего область
экрана в OCR.
-t, --vertical OCR вертикальный текст. Если не указано,
предполагается горизонтальный текст.
-w, --show-languages Показать установленные языки, которые можно использовать
с опцией "--language".--output-format Формат для использования при выводе текста OCR.
Вы можете использовать эти токены:
$ {capture}: текст OCR.
$ {linebreak}: разрыв строки (\ r \ n).
$ {tab}: символ табуляции.
$ {timestamp}: время этого экрана или каждого
файл был обработан.$ {file}: файл, который был обработан или
экран прямоугольник.
Формат по умолчанию - "$ {capture} $ {linebreak}".
--whitelist <символы> Распознавать только указанные символы.
Пример: «0123456789».
--blacklist <символы> Не распознавать указанные символы.
Пример: «0123456789».--clipboard Выводить текст OCR в буфер обмена.
--trim-capture Во время предварительной обработки OCR выполняется обрезка
изображение в пиксели переднего плана и добавьте тонкий
граница.
--deskew Во время предварительной обработки OCR попытаться
компенсировать наклон текста.
--scale-factor Коэффициент масштабирования для использования во время предварительной обработки.Диапазон: [0,71, 5,0]. По умолчанию - 3,5.
--tess-config-file <файл> (Дополнительно) Путь к конфигурации Tesseract
файл.
------
Для Capture2Text.exe (в отличие от Capture2Text_CLI.exe) вы можете указать дополнительную опцию:
--portable Хранить файл настроек .ini в том же каталоге
как.EXE файл.
Устранение неполадок и часто задаваемые вопросы
- Когда я дважды щелкаю Capture2Text.exe, я получаю сообщение об отсутствии файла DLL.
Решение: установите распространяемый пакет Visual Studio 2015.
- Capture2Text вообще не работает. Что я могу сделать?
Возможные решения:
Убедитесь, что вы разархивировали Capture2Text.Поищите в Google, если не знаете, как разархивировать файл.
Убедитесь, что ваше антивирусное программное обеспечение не блокирует Capture2Text. Обратитесь к документации, прилагаемой к вашему антивирусному программному обеспечению.
Убедитесь, что вы скачали последнюю версию с SourceForge.
Перезагрузите компьютер.
Попросите внука помочь вам 🙂
- Я нашел ошибку!
Отлично! Создайте заявку и опишите ошибку.
- Я хочу сделать предложение.
Отлично! Создайте заявку и опишите свое предложение.
- Capture2Text выводит символы мусора.
Решение: укажите правильный язык распознавания текста.
- Интересующий меня язык не отображается в меню языка распознавания текста.
Прочтите Установка дополнительных языков распознавания текста.
- Я не вижу значок Capture2Text на панели задач.персонаж).
- Я щелкнул значок Capture2Text в трее, но он ничего не сделал.
Вместо этого щелкните его правой кнопкой мыши.
- Capture2Text не работает на моем Mac.
Capture2Text — это программное обеспечение только для Windows. Если у вас есть технический опыт, не стесняйтесь портировать его (но не просите меня помочь).
- Где деинсталлятор?
Нет ни одного. Capture2Text также не имеет установщика.Удалять Capture2Text со своего компьютера, просто удалите каталог Capture2Text.
- Где находится файл настроек .ini?
Введите «% appdata% \ Capture2Text» в проводнике Windows.
Вы можете удалить его, чтобы восстановить настройки по умолчанию.
- Как сделать Capture2Text портативным?
Вызовите Capture2Text.exe с параметром —portable. Вы можете создать для этого ярлык.Установка этого параметра заставит Capture2Text хранить файл настроек .
Ваш комментарий будет первым