как посмотреть кэшированную копию в Яндексе и Гугле
Сохраненная копия сайта (в Яндексе или другой поисковой системе) — это версия страницы, которая уже проиндексирована. Если при вводе поискового запроса посмотреть на сниппет нужного результата, там найдется блок с дополнительными данными. Там-то и лежит «Сохраненная копия».
Что это такое, зачем она нужна, как просмотреть и каковы последствия отсутствия копии — вопросы, на которые несложно найти простые ответы.
С помощью сохраненной копии можно просмотреть сайт, если к нему будет внезапно ограничен доступ по той или иной причине.
В Google происходит то же самое — найдя в cash копию и перейдя по ссылке, можно просмотреть, как выглядела страница, когда Гугл в последний раз ее скопировал.
Для чего нужны сохраненные страницы?
Кэш-страницы сайта в поисковых системах позволяют увидеть, какую версию документа уже успели проиндексировать роботы поисковых систем и участвует ли страница в ранжировании. Грубо говоря, если страница начала сохраняться — это главный фактор пройденной индексации.
Бесплатный бэкап
В работе с сайтами, может возникнуть масса непредвиденных ситуаций. Особенно на стадии запуска проекта, на сайте частенько ведутся технические работы, предполагающие корректировку дизайна и текстовых блоков. В такие моменты не исключены ошибки, которые могут «положить» сайт или нарушить его работу, также могут пропасть тексты, изображения и так далее.
Большинству разработчиков знакомы такие ситуации и если не был проведен бэкап, а дешевый хостинг не позволяет сделать «откат», то все печально. Вот тут-то и приходит на помощь кэш сайтов — копия позволяет сохраниться и проверить, какие ошибки нужно исправить.
Важно! Все же не стоит надеяться на Яндекс и Гугл, и хранить сайт только в копиях поисковиков. Если робот попал на нерабочую страницу или ее версию с ошибками, он будет копировать то, что «видел», и старая информация будет недоступна. Так что заранее продумывайте способы «отката» сайта.
SEO-продвижение
Еще один случай, когда кеш придет на помощь, связан с текстами. Например, вы откорректировали текст, чтобы повысить его релевантность. Чтобы проверить, обновилась и проиндексировалась ли нужная страница, достаточно взглянуть на копию.
Например, вы откорректировали текст, чтобы повысить его релевантность. Чтобы проверить, обновилась и проиндексировалась ли нужная страница, достаточно взглянуть на копию.
Технические проблемы, просрочка оплаты и так далее
Часто интернет-ресурсы бывают недоступны из-за технических проблем на сервере, истечения срока оплаты хостинга и т.п. В этом случае попасть на сайт можно также через копию, которая хранится в кэше.
Как посмотреть кэшированную копию в Яндексе: основные способы
Перед тем как открыть сохраненную копию сайта в Яндексе, выберите удобный способ — с помощью сервисов (Page Promoter в Firefox или RDS bar в Google Chrome) или вручную. Плагины — это удобно, но они могут давать сбой, поэтому стоит освоить и ручной метод просмотра.
Способ № 1 — плагины
Расширения для браузеров, плагины и различные онлайн-сервисы позволяют быстро открывать кэш сайтов. Один из самых популярных на сегодня сервисов — это RDS bar. Плагин отличается интуитивным пользовательским интерфейсом и позволяет посмотреть последние изменения страницы, отсканированной роботами. Но если нужная страница еще не проиндексировалась, то и плагин ничего не покажет.
Но если нужная страница еще не проиндексировалась, то и плагин ничего не покажет.
Способ № 2 — вручную
Самый простой и эффективный «механический» способ просмотра. Что нужно сделать:
- Найти в поисковике нужную страницу — по запросу или вбив в поисковую строку адрес сайта.
- В результате поиска в сниппете нажать на маленькую стрелочку.
- В выпавшем окошке нажать «Сохраненная копия».
- Нажать и посетить сайт с данными, сохраненными с последнего визита робота на страницу.
Как посмотреть сохраненную копию страницы в Google
Алгоритм просмотра кэшированных страниц в системе Гугл не отличается от ручного способа для Яндекса. Все просто:
- В браузере вбейте в поисковую строку адрес или название нужного сайта (или поисковый запрос).
- В выдаче справа от URL нажмите на стрелку.
- В выпавшем окошке кликните по разделу «Сохраненная копия».
- Чтобы перейти к текущей версии, просто нажмите на кнопку «Текущая страница».


Почему страницы может не быть?
Иногда во время поиска при нажатии на стрелочку сниппета нужного пункта может и не быть. Это происходит по ряду причин:
- Сбой в работе поисковика. В Яндексе даже не скрывают, что нет никаких гарантий на наличие и показ копий — система может просто не сохранять страницы по какой-либо причине.
- Второй вариант: html-кодировка документа содержит мета-тег «robots» со значением «noarchive», что означает запрет на кэширование. Чтобы не рисковать из-за этого трафиком, стоит внимательно настроить соответствующие блоки и очистить ненужные значения.
Нет копии: чем это грозит?
С точки зрения продвижения — опасность нулевая. А вот сами причины, из-за которых невозможно сохранение, могут быть вредны, нужно разбираться именно в них.
Эксперты уверены, что проблема с копиями может обернуться трудностями при работе с биржами ссылок. Так, на некоторых известных биржах строго контролируют, есть ли в Яндексе копия, проверяя параметр No Index Cache (NIC).
Другие способы
- Наберите в адресной строке http://webcache.googleusercontent.com/search?q=cache:https://www.google.ru/ — где https://www.google.ru поменяйте на адрес нужного вам сайта.
- http://cachedview.com/ — этот сервис ищет копии не только в Google, но и во Всемирном архиве интернета.
- http://www.thesearchenginelist.com/ — а этот ресурс поможет найти копии, если Гугл и Яндекс не сохранили документ. Поочередно перебираем поисковики, рассчитывая на то, что кто-то заглянул на ваш сайт и «заскринил» данные.
Заключение
Всем мы хорошо помним и знаем, что всё нужно бэкапить — от семейных фото с отпуска до страниц сайтов. Но настолько же хорошо мы об этом еще и забываем. В этом случае приходит на помощь сохраненная версия сайта, которую можно найти в Яндексе, Гуле и других поисковых системах и даже вытянуть из Всемирных архивов.
Главное, чтобы поисковые системы успели кэшировать ваши страницы, а от вас дело за малым — просто выбрать удобный способ просмотра копии.
8 способов найти удаленный сайт или страницу
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кеша Google надо в адресной строке набрать:
http://webcache. googleusercontent.com/search?q=cache:http://www.iphones.ru/
googleusercontent.com/search?q=cache:http://www.iphones.ru/
Где http://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета
Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет
К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт».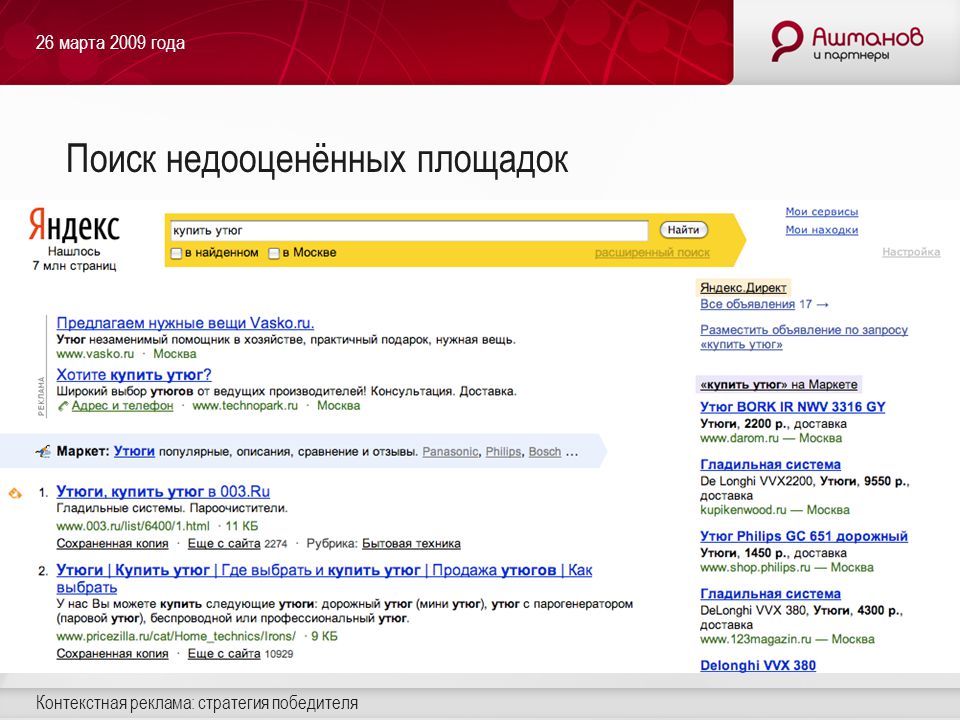 Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist. com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari.
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com.
Для начала можно пробить контакты, связанные с сайтом на emailhunter.com.
Источник: iphones.ru
Как загрузить весь веб-сайт для чтения в автономном режиме
Несмотря на то, что в наши дни Wi-Fi доступен повсюду, тем не менее время от времени вы можете оказаться без него. И когда вы это сделаете, могут быть веб-сайты, которые вы хотели бы сохранить, чтобы иметь к ним доступ в автономном режиме — возможно, для исследований, развлечения или даже просто для потомков.
Довольно просто сохранить отдельные веб-страницы для чтения в автономном режиме, но что, если вы хотите загрузить весь веб-сайт? Не волнуйтесь, это проще, чем вы думаете. Но не верьте нам на слово. Вот несколько отличных инструментов, которые вы можете использовать для загрузки любого веб-сайта для чтения в автономном режиме — без каких-либо проблем.
1. Веб-копия
WebCopy от Cyotek берет URL-адрес веб-сайта и сканирует его на наличие ссылок, страниц и мультимедиа.
Что интересно в WebCopy, так это то, что вы можете настроить несколько проектов, каждый из которых имеет свои собственные настройки и конфигурации. Это упрощает повторную загрузку многих сайтов в любое время; каждый, таким же образом каждый раз.
Один проект может копировать множество веб-сайтов, поэтому используйте их по организованному плану (например, проект «Технический» для копирования технических сайтов).
Как загрузить весь веб-сайт с помощью WebCopy
- Установите и запустите приложение.
- Перейдите к File > New , чтобы создать новый проект.
- Введите URL-адрес в поле Веб-сайт .
- Измените поле
- Поиграйте с Project > Rules… (подробнее о правилах WebCopy).
- Перейдите к Файл > Сохранить как… , чтобы сохранить проект.
- Нажмите Копировать на панели инструментов, чтобы начать процесс.

После завершения копирования вы можете использовать вкладку Результаты для просмотра состояния каждой отдельной страницы и/или медиафайла. На вкладке Errors показаны все проблемы, которые могли возникнуть, а на вкладке Skiped показаны файлы, которые не были загружены. Но самое главное Карта сайта , которая показывает полную структуру каталогов веб-сайта, обнаруженную WebCopy.
Чтобы просмотреть веб-сайт в автономном режиме, откройте проводник и перейдите к сохраненной папке, которую вы ранее указали. Откройте index.html (или иногда index.htm ) в выбранном вами браузере, чтобы начать просмотр. Как видите, это сильно отличается от сохранения отдельных веб-страниц через приложения, еще одна практика, которая также слишком распространена в наши дни.
Как видите, это сильно отличается от сохранения отдельных веб-страниц через приложения, еще одна практика, которая также слишком распространена в наши дни.
Загрузка: WebCopy для Windows (бесплатно)
2. HTTrack
HTTrack более известен, чем WebCopy, и, возможно, лучше, поскольку он имеет открытый исходный код и доступен на платформах, отличных от Windows. Интерфейс немного неуклюжий и оставляет желать лучшего, однако он работает хорошо, так что пусть это вас не смущает.
Как и WebCopy, он использует подход, основанный на проектах, который позволяет копировать несколько веб-сайтов и упорядочивать их. Вы можете приостанавливать и возобновлять загрузку, а также обновлять скопированные веб-сайты, повторно загружая старые и новые файлы.
Как загрузить полный веб-сайт с помощью HTTrack
- Установите и запустите приложение.
- Нажмите Next , чтобы начать создание нового проекта.
- Дайте проекту имя, категорию, базовый путь, затем нажмите Next .
- Выберите Загрузить веб-сайт(ы) для действия, затем введите URL-адрес каждого веб-сайта в поле Веб-адреса , по одному URL-адресу в строке. Вы также можете сохранить URL-адреса в файле TXT и импортировать его, что удобно, когда вы хотите повторно загрузить те же сайты позже. Нажмите Следующий .
- Настройте параметры, если хотите, затем нажмите Готово .

После того, как все загружено, вы можете просматривать сайт в обычном режиме, просто перейдя туда, куда были загружены файлы, и открыв index.html или index.htm в браузере.
Как использовать HTTrack с Linux
Если вы являетесь пользователем Ubuntu, вот как вы можете использовать HTTrack для сохранения всего веб-сайта:
- Запуск терминала и введите следующую команду:
sudo apt-get install httrack
- Он запросит ваш пароль Ubuntu (если вы его установили). Введите его и нажмите Введите . Терминал загрузит инструмент через несколько минут.
- Наконец, введите эту команду и нажмите Введите . Для этого примера мы загрузили популярный веб-сайт Brain Pickings.
httrack https://www.brainpickings.org/
- Это загрузит весь веб-сайт для чтения в автономном режиме.
 Введите его и нажмите Введите . Терминал загрузит инструмент через несколько минут.
Введите его и нажмите Введите . Терминал загрузит инструмент через несколько минут.Здесь вы можете заменить URL-адрес веб-сайта на URL-адрес любого веб-сайта, который вы хотите загрузить. Например, если вы хотите загрузить всю Британскую энциклопедию, вам нужно настроить команду так:
httrack https://www.britannica.com/
Загрузить: HTTrack для Windows и Linux | Android (бесплатно)
3. СайтСакер
Если вы работаете на Mac, лучшим вариантом будет SiteSucker . Этот простой инструмент копирует целые веб-сайты, сохраняет ту же структуру и включает все соответствующие медиафайлы (например, изображения, PDF-файлы, таблицы стилей).
Он имеет чистый и простой в использовании интерфейс — вы буквально вставляете URL-адрес веб-сайта и нажимаете Enter .
Одной из его отличных функций является возможность сохранить текущую загрузку в файл, а затем использовать этот файл для повторной загрузки тех же файлов и структуры в будущем (или на другом компьютере). Эта функция также позволяет SiteSucker приостанавливать и возобновлять загрузку.
SiteSucker стоит около 5 долларов и не поставляется с бесплатной версией или бесплатной пробной версией, что является его самым большим недостатком. Для последней версии требуется macOS 11 Big Sur или выше. Старые версии SiteSucker доступны для старых систем Mac, но некоторые функции могут отсутствовать.
Загрузить : SiteSucker для iOS | Mac (4,99 доллара США)
4. Получить
Wget — это утилита командной строки, которая может извлекать все типы файлов по протоколам HTTP и FTP. Поскольку веб-сайты обслуживаются через HTTP, а большинство файлов веб-медиа доступны через HTTP или FTP, это делает Wget отличным инструментом для загрузки целых веб-сайтов.
Поскольку веб-сайты обслуживаются через HTTP, а большинство файлов веб-медиа доступны через HTTP или FTP, это делает Wget отличным инструментом для загрузки целых веб-сайтов.
Wget поставляется в комплекте с большинством систем на базе Unix. Хотя Wget обычно используется для загрузки отдельных файлов, его также можно использовать для рекурсивной загрузки всех страниц и файлов, найденных на начальной странице:
wget -r -p https://www.makeuseof.com
В зависимости от размера загрузка всего веб-сайта может занять некоторое время.
Однако некоторые сайты могут обнаруживать и предотвращать то, что вы пытаетесь сделать, потому что копирование веб-сайта может стоить им большой пропускной способности. Чтобы обойти это, вы можете замаскироваться под веб-браузер с помощью строки пользовательского агента:
.wget -r -p -U Mozilla https://www.thegeekstuff.com
Если вы хотите быть вежливым, вам также следует ограничить скорость загрузки (чтобы не перегружать полосу пропускания веб-сервера) и сделать паузу между каждой загрузкой (чтобы не перегружать веб-сервер слишком большим количеством запросов):
wget -r -p -U Mozilla --wait=10 --limit-rate=35K https://www.
 thegeekstuff.com
thegeekstuff.com Как использовать Wget на Mac
На Mac вы можете установить Wget с помощью одной команды Homebrew: brew install wget .
- Если у вас еще не установлен Homebrew, загрузите его с помощью этой команды:
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install )"
- Затем установите Wget с помощью этой команды:
brew install wget
- После завершения установки Wget вы можете загрузить веб-сайт с помощью этой команды: вместо этого нужно будет использовать эту портированную версию. Загрузите и установите приложение и следуйте инструкциям, чтобы завершить загрузку с сайта.
5. Телепорт Про
Получите Телепорт Про. Серьезно. Хотя последняя версия приложения была выпущена еще в 2015 году, оно работает так же хорошо, как и тогда.
Помимо простой загрузки всего веб-сайта, приложение также содержит множество других функций и хитростей.
. Например, когда вы загружаете и устанавливаете приложение, в главном меню приложения вы увидите следующие параметры на выбор:- Создать копию веб-сайта на жестком диске.
- Дублировать весь веб-сайт вместе со структурой каталогов.
- Поиск на сайте определенных типов файлов.
- Поиск веб-сайта по заданным ключевым словам.
- Навигация по всем сайтам, связанным с центральным сайтом.
Эти и множество других подобных функций делают это приложение удобной программой для вашего инструментария. Единственным недостатком, который мы обнаружили, было ограничение на бесплатную версию. Используя незарегистрированную версию, вы можете скопировать только 500 страниц в одном проекте. Более того, вы можете использовать его всего 40 раз, после чего вам придется приобрести премиум-версию.
Скачать: Teleport Pro для Windows (бесплатная пробная версия, доступна платная версия)
Простая загрузка веб-сайтов целиком
Теперь, когда вы знаете, как загрузить весь веб-сайт, вы никогда не останетесь без чтения, даже если у вас нет доступа в Интернет.
Но помните: чем больше сайт, тем больше загрузка. Поэтому мы не рекомендуем загружать большие сайты, такие как MUO, потому что вам потребуются тысячи МБ для хранения всех медиафайлов, которые используют такие сайты.
Как клонировать веб-сайт
Если вы когда-либо создавали веб-сайт с нуля, вы знаете, что это может быть сложный и трудоемкий проект. Нужно учитывать так много элементов, от цветовой палитры до навигации и оптимизации скорости загрузки — и это только начало.
Но, к счастью, начинать с нуля обычно не требуется. Вместо этого вы можете клонировать существующий веб-сайт или части веб-сайта, а затем настроить клонированный код в соответствии со своими потребностями и создать совершенно новый сайт. Этот процесс может быть гораздо более эффективным способом создания веб-сайта. Итак, клонируете ли вы веб-сайт для клиента или для своего личного портфолио, вот шаги, которые необходимо выполнить, а также некоторые вещи, о которых следует помнить при работе с клонированным веб-сайтом.
Во-первых, некоторые основные правилаПроцесс клонирования веб-сайта распространен в веб-разработке. Но вы, очевидно, не хотите просто копировать чужой сайт — вы хотите в конечном итоге сделать свой собственный уникальный сайт. К счастью, есть простые шаги, которые вы можете предпринять, чтобы избежать прямого копирования чьей-либо внешней работы.
Во-первых, подумайте о клонировании веб-сайта как о отправной точке — подобно шаблону — который вы сможете настроить и персонализировать. Затем вы сможете добавлять в этот шаблон свои собственные идеи и дизайны. Идея состоит в том, чтобы сделать веб-сайт полностью вашим, чтобы у вас не было юридических проблем, о которых нужно беспокоиться.
С этой целью остерегайтесь контента, который копируется при клонировании сайта.
Как клонировать веб-сайт с помощью Google Chrome Вам нужно будет заменить любой письменный или визуальный контент.Одним из способов клонирования веб-сайта является использование инструментов разработчика Google Chrome (DevTools), набора инструментов для разработчиков, который удобно встроен непосредственно в браузер Chrome.
Выполните следующие действия, чтобы клонировать веб-сайт с помощью Google Chrome:
- Выберите элемент на странице
- Щелкните правой кнопкой мыши на выбранном элементе и выберите «Проверить». Когда вы выбираете элементы, вы можете увидеть CSS, который показывает такие детали, как максимальная ширина и поля
- Нажмите на три точки в правом верхнем углу страницы и выберите «Открыть файл», который показывает вам все файлы, связанные с эта страница
- Введите нужный файл, например styles.css или index.html, затем выберите код и скопируйте его в текстовый редактор или в рабочее пространство Codecademy, если вы подписаны на Codecademy Pro 9. 0018
Этот метод также работает с JavaScript. Вы щелкаете правой кнопкой мыши элемент, выбираете «Проверить» и прокручиваете элементы на странице. Когда вы найдете файлы JavaScript, вы можете открыть и скопировать их в текстовый редактор.
Клонирование сложного веб-сайтаПростые веб-сайты, скорее всего, имеют только один файл CSS и HTML, но более сложные сайты, такие как Twitter, могут иметь несколько. Если вы хотите клонировать такой сайт, выполните следующие действия.
Чтобы скопировать HTML, выберите элемент и нажмите «Проверить», чтобы открыть DevTools. Затем нажмите «Источники» вверху. Вы увидите HTML-код, появившийся на этой вкладке, и вы можете выбрать его, скопировать, а затем вставить в текстовый редактор. Сохраните файл с расширением .html (myfilename.html).
Чтобы скопировать CSS, нажмите «Элементы» на верхней панели навигации DevTools. Вы увидите CSS в середине страницы. Щелкните main.CSS, чтобы открыть код. Выберите и скопируйте код, затем откройте новый лист в текстовом редакторе и вставьте CSS.
Сохраните файл с расширением .css.Работа с клонированным веб-сайтом
После того как вы скопировали код в текстовый редактор, вы можете отредактировать его и сделать его своим. Работа с клонированным веб-сайтом также является отличным способом научиться кодировать, поскольку позволяет взглянуть на внутреннюю работу живого веб-сайта. Вот языки программирования, с которыми вы будете работать при редактировании клонированного веб-сайта.
HTMLHTML означает язык гипертекстовой разметки. Он используется для создания структуры веб-страницы, включая абзацы, изображения и маркированные списки. HTML использует элементы, чтобы компоненты страницы действовали определенным образом. Например, чтобы обозначить текст как абзац, вы должны использовать тег
перед абзацем и
в конце абзаца. Элементы в скобках называются тегами. CSSВ то время как HTML придает веб-сайтам их базовую структуру, такую как заголовки и абзацы, каскадные таблицы стилей или CSS придают этим элементам стиль.
Например, с помощью CSS вы можете изменить размер и цвет текста и ссылок. Вы также можете создавать интересные макеты с боковыми панелями и создавать эффекты с помощью CSS.CSS начинается с селектора, который выбирает элемент HTML, который вы хотите изменить. Например, для заголовка h2 вы должны использовать h2 в качестве селектора. Затем следуют скобки {}. Внутри скобок у вас есть свойство и значение. Вот как это будет выглядеть для заголовка:
h2 { цвет синий; размер шрифта: 5em; }JavaScriptJavaScript — это язык программирования, позволяющий усложнять веб-сайты. Он используется вместе с HTML и CSS для таких действий, как увеличение или уменьшение изображения, отображение обновлений в реальном времени, воспроизведение аудио или видео, анимация 3D-графики и изменение цвета кнопки при наведении на нее курсора. JavaScript также можно использовать для создания мобильных приложений, создания веб-серверов, а также разработки и создания браузерных игр.
Как видите, шаги по клонированию веб-сайта довольно просты. Настоящая работа начинается, когда вы готовы приступить к изменению клонированного веб-сайта; и для этого вам нужно хорошо разбираться в HTML, CSS и JavaScript.
Новичок в программировании? HTML — хорошая отправная точка для изучения веб-дизайна и получения максимальной отдачи от клонированных веб-сайтов. Наш курс «Изучение HTML» знакомит вас с основами, включая таблицы и формы.
Learn CSS — это курс, основанный на ваших знаниях HTML и рассказывающий о цветах, размере текста, шрифте, выравнивании и расположении элементов. После этого вы можете посмотреть Learn Intermediate CSS, который научит вас создавать более продвинутые визуальные эффекты и макеты.
Если вы уже знаете HTML и CSS, наш курс «Изучение JavaScript» поможет вам создавать более продвинутые веб-сайты с основами JavaScript. Когда вы освоите основы, наш курс «Создание интерактивных веб-сайтов на JavaScript» поможет вам применить все, что вы узнали, на практике.
 Например, когда вы загружаете и устанавливаете приложение, в главном меню приложения вы увидите следующие параметры на выбор:
Например, когда вы загружаете и устанавливаете приложение, в главном меню приложения вы увидите следующие параметры на выбор:
 Вам нужно будет заменить любой письменный или визуальный контент.
Вам нужно будет заменить любой письменный или визуальный контент. 0018
0018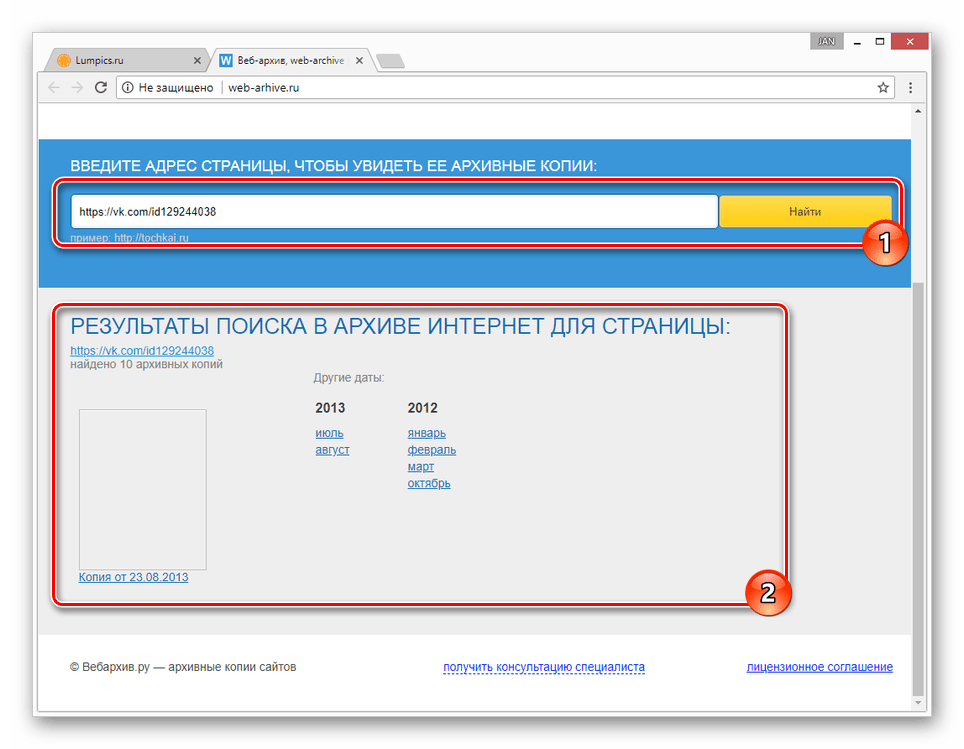 Сохраните файл с расширением .css.
Сохраните файл с расширением .css.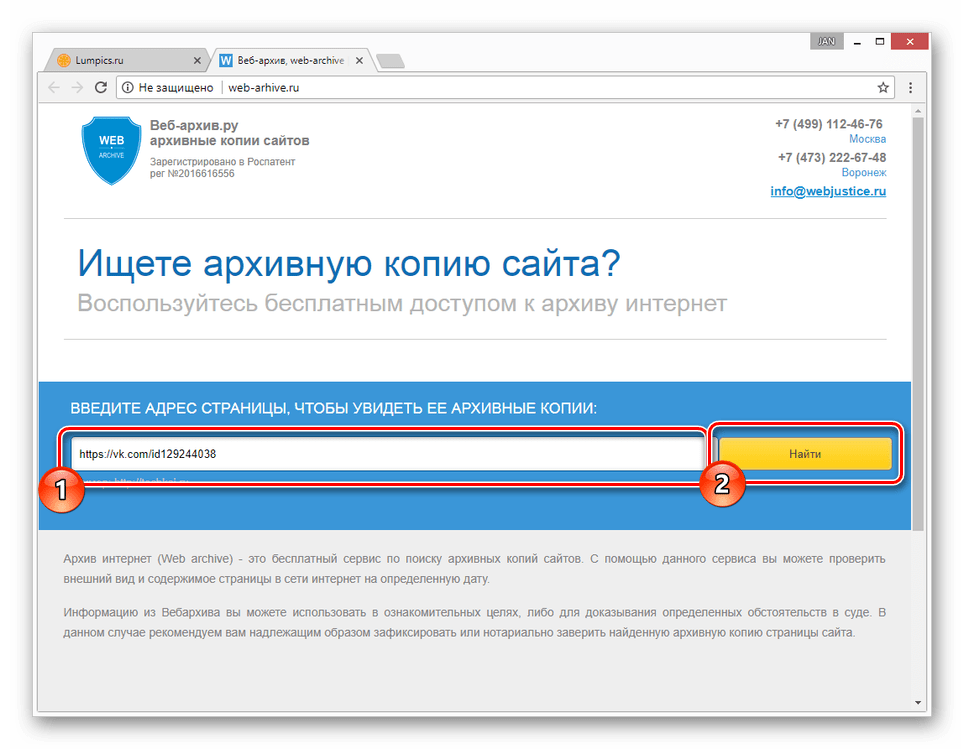 Например, с помощью CSS вы можете изменить размер и цвет текста и ссылок. Вы также можете создавать интересные макеты с боковыми панелями и создавать эффекты с помощью CSS.
Например, с помощью CSS вы можете изменить размер и цвет текста и ссылок. Вы также можете создавать интересные макеты с боковыми панелями и создавать эффекты с помощью CSS.

Ваш комментарий будет первым