Что можно узнать о квартире из открытых справочников / Хабр
Госструктуры выкладывают в интернет справочники с десятками гигабайтов информации. Если знать где искать, можно легально собрать данные о квартирах в промышленных масштабах.
Базы с индексами и районами городов тоже открыты. Бонусом я расскажу, как найти эти части адреса, если их не хватает.
Все справочники из этой статьи бесплатны и открыто лежат в интернете. Ни один не украли из ФСБ таинственные хакеры.
Существует ли жилье
Когда отправляешь клиенту письмо или пиццу, полезно проверить, если ли квартира. Обидно отдавать деньги за недошедшее письмо или впустую гонять курьера.База данных Центризбиркома — простой для понимания справочник, по которому можно проверить существование квартиры.
По задумке база ЦИК нужна, чтобы каждый гражданин мог узнать свой избирательный участок. Для нас же главное, что в ней есть адреса вплоть до квартир.
Онлайн-версия базы ЦИК похожа на «Проводник» в старых версиях Windows
У базы есть недостаток: в ней хранятся только квартиры, где прописаны граждане России с избирательным правом.
Еще один минус — скорость спайдеринга. База хостится на очень медленных серверах, поэтому качать данные придется неделями: крупный город без области загружается сутки. При этом можно запустить спайдер, прийти на следующий день и увидеть, что сбор прервался из-за изменений в структуре базы.
Вроде бы идеальная альтернатива — государственный адресный реестр ФИАС, о котором мы писали в других статьях. По документации в нем есть адреса до квартиры, а еще он доступен в .dbf. Проблема одна: таблица с квартирами в ФИАС почти пуста: согласно ФИАС, в Москве около 70 000 квартир. Жилых домов лишь немногим меньше.
Куда лучше ФИАС для проверки квартиры подойдут данные Фонда государственной кадастровой оценки. Об этом справочнике мы расскажем в разделе «Площадь».
Почтовый индекс
Индекс адресата нужно проверять перед любым отправлением, иначе посылка может уйти не туда. Замдиректора Тюменского филиала Почты сокрушается: «Почти 30% <…> отправлений, а это около 6 миллионов единиц, приходят с неверным индексом, и мы либо возвращаем обратно корреспонденцию, либо она уходит по другому адресу.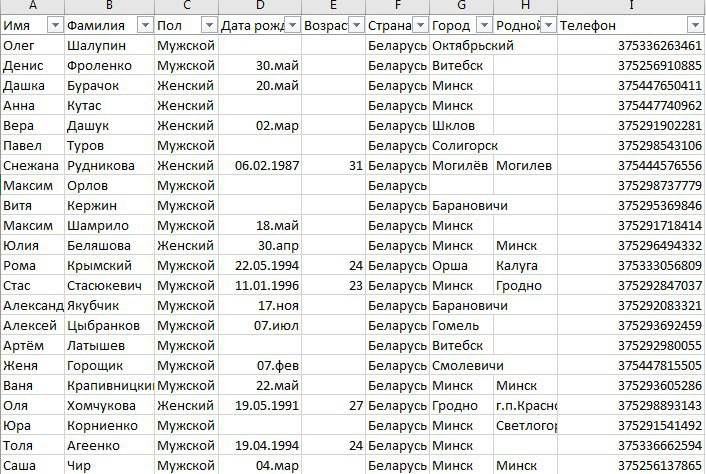 ..».
..».Найти или проверить индекс можно в базе Почты России, ее выкладывают на странице http://vinfo.russianpost.ru/database/ops.html в .dbf-формате. Данные обновляют дважды в месяц.
В базе Почты нет приближения до улицы или дома, только населенный пункт и список индексов. Для нас этого достаточно: если индекс до населенного пункта правильный, пересылка в нужное отделение отсрочит доставку всего на 2–3 дня.
Например, клиент оставил адрес «683000, г. Нижний Новгород, ул…». База Почты говорит, что такого индекса в Нижнем нет, а отделения 683xxx находятся в Петропавловске-Камчатском. Клиент ошибся скорее в цифрах, чем в названии города, поэтому хорошее решение — загрузить из базы Почты индексы Нижнего Новгорода и подставить в адрес минимальный 603000. Так посылка придет в нужный город, не путешествуя по стране месяцами.
Как подключить базу индексов Почты России, уже писал Envek, вы найдете подробности в его статье.
Район города
Районы нужны риелторам, чтобы группировать квартиры для продажи и аренды. К району удобно привязать стоимость доставки внутри города.
К району удобно привязать стоимость доставки внутри города.Городской район редко указывают в адресе: не прижилось. При этом знать, в каком районе находится дом, иногда полезно.
Искать район по адресу удобно в базе ЦИК, о которой мы говорили в первом разделе. В ней есть дома и квартиры, поэтому вы получите точный результат. Проблемы тоже никуда не делись: в базе не хватает квартир и домов, а на спайдеринг уходят недели.
Быстрое решение для поиска района — ОКАТО (Общероссийский классификатор объектов административно-территориального деления). В этом колоссальном документе расписана структура административного деления России от субъекта федерации до улицы. Домов в справочнике нет.
ОКАТО лежит в виде готовой базы данных на сайте ГНИВЦ ФНС. Для любителей поспайдерить есть еще текстовый вариант в «КонсультантПлюсе». Там же подробно описана структура справочника.
Так, начиная с районов Алтайского края, ОКАТО описывает всю структуру административного подчинения страны
Парсинг справочника даст базу внутригородских районов с подчиненными улицами.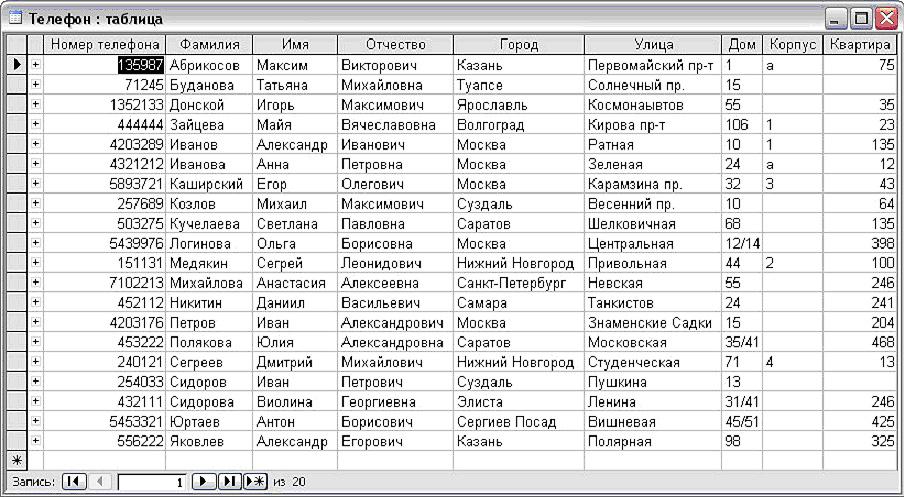
Минус ОКАТО — запрос невозможно уточнить с помощью дома. Если улица раскинулась на несколько районов, однозначный результат не получить. В таких случаях база ЦИК сработает лучше.
ФИАС же, главный адресный справочник страны, для наших целей вовсе не подойдет: там не заполнили районы даже для Москвы.
Площадь
По площади считают цену квартиры, фильтруют предложения в базе данных риелторов.Площадь жилья есть в открытых данных Фонда государственной кадастровой оценки. Кроме площади в базе кадастровой оценки много интересного: по правилам любое здание и помещение в России должно быть оценено по кадастровой стоимости, материалам, этажности и т. д. Также данные кадастровой оценки используют, чтобы проверить существование квартиры.
Базы данных кадастровой оценки скачивают на сайте Росреестра.
Нас интересует пункт «Отчеты об определении кадастровой стоимости»
Отчеты разделены по регионам и загружать их придется отдельно. Для каждого региона доступно несколько отчетов.
Площади квартир хранятся в отчете с помещениями, сооружениями, объектами незавершенного строительства и зданиями
Большинство отчетов датировано 2011–2014 годом, но других других данных у государства для нас нет. Спасибо и на том.
Скачивать отчеты — отдельное «удовольствие»: архив с файлами по республике Марий Эл «весит» всего 1,5 гигабайта, но с сайта Росреестра скачивался пять часов.
Внутри архива Росреестра сотни xml-файлов с параметрами квартир и домов: площадями, кадастровыми номерами, идентификаторами КЛАДР, кодами ОКАТО, материалами, из которых построены дома
Парсинг кадастрового отчета — особая тема, которая заслуживает большой статьи. Когда-нибудь мы ее напишем, а пока — описание XML-схемы отчетов на сайте Росреестра.
Примерная стоимость
Стоимость жилья используют банки, чтобы оценивать достаток заемщиков.Когда есть площадь, для подсчета стоимости жилья не хватает только цены квадратного метра. Цену «квадрата» в доме ищут на сайтах объявлений: irr.ru, avito.ru, cian.ru. Объявление подходит, если в нем есть адрес дома, стоимость и площадь.
Цену «квадрата» в доме ищут на сайтах объявлений: irr.ru, avito.ru, cian.ru. Объявление подходит, если в нем есть адрес дома, стоимость и площадь.
Рецепта для быстрого накопления базы нет: объявления нужно собирать регулярно и чем дольше, тем лучше. Только так можно добиться сколько-нибудь хорошего покрытия по адресам. Правда, и через несколько лет в маленьких городах, поселках, деревнях будут белые пятна.
Чтобы регулярно получать объявления, лучше договориться с площадкой: написать владельцам и предложить сотрудничество.
Если площадка отказала, остается спайдерить. Нужно морально подготовиться к тому, что сайты объявлений постоянно меняют верстку и спайдер придется переписывать перед каждым запуском.
Что нельзя узнать легально
Некоторые данные можно получить только нарушив закон. Обычно продавцы нелегальной информации просто врут, предлагая набор несвязанных таблиц под видом секретной базы МВД.В открытом доступе нет и быть не может:
- списка людей, прописанных в квартире или доме;
- паспортных данных жильцов;
- но́мера домашнего телефона.

Проблемы открытых источников
В каждом пункте про каждый справочник я писал «есть проблема», «то еще удовольствие», «нужно перепроверить». Все это потому, что официальные государственные реестры составлены криво.Например, так наш разработчик оценил базу кадастровой оценки по Краснодарскому краю: «Номер квартиры не в поле apartments, а в поле name. В поле city много сельских округов, которые не парсятся (около 40%). Из 55885 домов с квартирами в итоговую выборку попали 25483».
Привести к продакшн-виду хоть ФИАС, хоть базу ЦИК, хоть отчет кадастровой оценки — задача для располагающего свободным временем человека с крепкими нервами. Мы ели эту соленую кашу килограммами, когда делали «Дадату». Чтобы не биться с кривыми справочниками, попробуйте наше API.
Один запрос к API «Дадаты» стоит 10 копеек, зато мы уже прошли семь кругов парсинга справочников и следим за всем, что государство выкладывает в открытый доступ
Индексы баз данных – проще некуда
14 Мая 2021 Базы данных
Самый простой способ сохранять данные в большой массив – добавлять их в самый конец данных.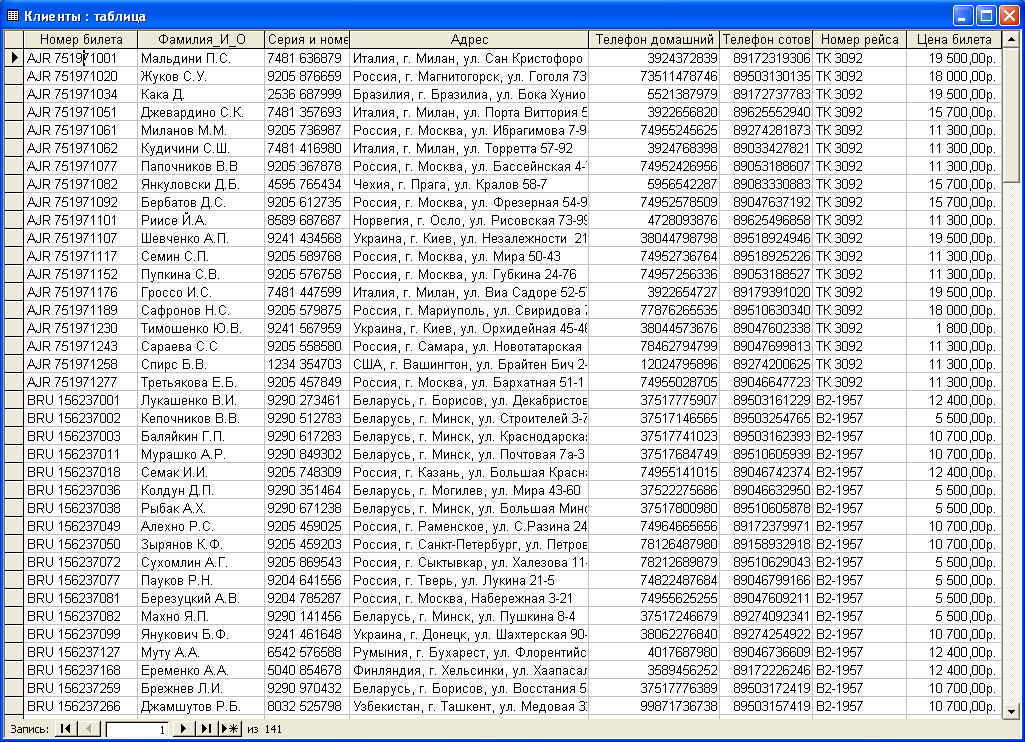 Рассмотрим телефонный справочник. Мне как-то говорили в комментариях, что на телефонном справочнике проще воспринимается информация, потому что эта проблема понятна всем.
Рассмотрим телефонный справочник. Мне как-то говорили в комментариях, что на телефонном справочнике проще воспринимается информация, потому что эта проблема понятна всем.
Итак, у нас есть таблица:
Как нам найти телефонный номер для Михаила Фленова? Берем первую запись здесь и тут же натыкаемся на мою фамилию и о чудо, с первого раза мы нашли нужную информацию. Но это идеальный случай, а если нам нужно найти телефон Баранова Алексея? Вот тут мы уже вынуждены будем идти по каждой строчке, сравнивать каждую из них и в результате будет 8 проверок. Это уже не весело.
Как можно ускорить поиск? Вариант есть, но для этого данные должны быть отсортированы и тогда мы сможем использовать классическое решение задачи поиска – бинарный поиск. Можем ли мы хранить в базе данных данные в отсортированном виде? Без проблем, давайте так и сделаем:
Смысл бинарного поиска – делить данные пополам и смотреть – текущее значение больше или меньше нужного. Допустим, что мы снова ищем мой телефон.
Значит нужная нам фамилия во второй половине списка:
Берем опять элемент в центре, это Валентина Сергеева и проверяем – нужная нам фамилия больше, или меньше? Она больше, значит снова берем вторую половину, где как раз и осталась нужная нам фамилия.
Всего три сравнения и мы попали на нужную нам запись.
Значит, чтобы мы могли быстро находить записи по фамилии мы должны хранить в базе данных информацию в отсортированном виде по фамилии.
Проблема решена? В принципе да, но. . . Телефоны ищут не только по фамилии, достаточно часто искать приходится и владельца по номеру телефона. Но так как у нас данные отсортированы по фамилии, в случае поиска по номеру мы вынуждены будем сканировать все записи.
Вернемся обратно к не отсортированным данным и вместо сортировки добавим новую колонку и назовем ее Key. Можете воспринимать это как первичный ключ, но для нас это будет как бы адрес, где находиться запись. То есть по адресу 1 находиться мой телефон, по адресу 2 это телефон Ивана Иванова и так далее.
dbtable4.png
Теперь вместо сортировки самих данных можно создать два индекса:
Слева индекс по фамилии, справа индекс по телефону. Оба отсортированы, а значит мы можем использовать бинарный поиск для того, чтобы найти нужные нам записи. Нужно искать по фамилии, мы берем левую таблицу, находим нужную фамилию и тут же видим Key – адрес, где находятся сами данные телефонной записи.
Проблема такого плоского индекса в том, что он плоский и нам постоянно нужно искать середину. Поддержка даже плоского индекса потребует затрат, ведь каждый раз, когда мы добавляем запись в базу данных нам нужно пересчитать два индекса и вставить новую запись в нужную позицию.
Допустим, что мы добавляем новый телефон для Киркорова. В случае с основной таблицей мы просто добавляем его в конец и даем новый номер 9:
Добавлять данные в конец очень просто и легко, много затрат не нужно. А вот в случае с индексом, нам нужно вставить данные в середину и подвинуть остальные данные в конец.
У вас есть десять кубиков, которые стоят в ряд. Чтобы поместить один в середину, нужно сначала подвинуть кубики, которые мешают в сторону, раздвинуть себе немного места и туда мы уже сможем вставить кубик.
Точно так же и с данными. И поддержка такого индекса может оправдать себя в огромном количестве случаев. Как часто мы добавляем телефоны? Уверен, что на много реже, чем мы ищем. Лучше затормозить одну операцию вставки новых данных и ускорить поиск, который может происходить сотни раз в секунду.
Раз уж мы так заморачиваемся и создаем плоский индекс, так может сделать что-то, чтобы нам не приходилось каждый раз искать середину? Может просто взять и расположить данные как-то в таком порядке, чтобы не приходилось постоянно искать эту середину?
Без проблем. Берем середину и ставим ее во главу нашей структуры данных. Теперь это Киркоров, он как раз удобно расположился в центре. Слева располагаются все имена, которые идут по алфавиту раньше Киркорова, а справа будут те, чьи фамилии после Киркорова.
Берем середину и ставим ее во главу нашей структуры данных. Теперь это Киркоров, он как раз удобно расположился в центре. Слева располагаются все имена, которые идут по алфавиту раньше Киркорова, а справа будут те, чьи фамилии после Киркорова.
Искать теперь будем начинать с центрального главного блока, то есть с Киркорова. Если мы снова ищем мой телефон, то теперь вместо поиска середины, мы начинаем с середины и сравниваем, — Фленов больше Киркорова? По росту точно нет, а вот фамилия по алфавиту расположена позже, значит мы должны двигаться на правый блок, где отсортированы данные, но нам нужно искать середину. Вместо поиска это середины, может разделить и этот блок? Это можно:
Опа, у нас получилось дерево! На третьем уровне в двух блоках по две фамилии и их можно разбить на два отдельных блока:
Вот теперь точно дерево и у каждого элемента только два подчиненных, причем слева всегда элемент меньше или в данном случае по алфавиту стоит выше, а справа больше, или по алфавиту стоит позже.
В программировании обычно балансируют такие деревья по-другому, но для нашего случая это не важно, мы сейчас не деревья проходим, а смотрим на принцип в целом.
Раз уж заморачиваться с индексом, так уж лучше построить такую систему, потому что теперь нам не нужно искать середину. Мы начинаем с середины. Если мы ищем Фленова, то мы двигаемся вправо и оказываемся в середине второй половины списка. В принципе, мы все еще ищем практически бинарным поиском, идея все еще та же, просто мы не рассчитываем больше середину, она уже рассчитана. Мы построили дерево из всех возможных вариантов.
Глядя на дерево мы можем сказать, что максимальная сложность поиска по всем элементам – 4 проверки. 9 элементов в списке простым перебором потребует 9 проверок, а в случае дерева/бинарного поиска только четыре. Скажу больше, если элементов будет 15, то сканирование всех займет 16 проверок, а по дереву только 4, потому что у нас еще место в дереве для еще 6 элементов.
Список из 31 элемента можно будет просмотреть максимум из 5 проверок, список из 63 элементов максимум за 6 проверок и так далее.
Но с точки зрения компьютера такое дерево не совсем эффективно. Дело в том, что компьютер не так эффективно читает по небольшому блоку информации. Да и постоянно перестраивать это дерево тоже будет не очень выгодно после каждой вставки данных.
Я сейчас гугланул и мне умный интернет сказал, что в случае с SSD дисками минимальная единица чтения или записи составляет 4 килобайта. Даже если нам нужен 1 байт с диска, он все равно прочитает физически 4 килобайта, и мы из них возьмем только 1 байт.
Если мы храним данные в Unicode, каждый символ может занимать от 1 до 4 байт. Допустим, что все символы 4 байта, а значит в одном блоке может поместиться 1024 символа. Если фамилия в базе данных занимает 20 символов, то мы только что прочитали с диска 4kb только для того, чтобы реально использовать 20 * 4 или 80 байт. Ужас. Может все же хранить данные плотнее в нашем дереве и пусть каждый блок дерева будет занимать 4 килобайта? В этом случае мы за раз прочитаем больше данных и потом в памяти просто пробежимся сразу же по всему содержимому блока.
MS Sql Server использует в качестве размера блока 8 килобайт, по крайней мере в документации все еще такая цифра.
Помимо уплотнения данных нам нужно подумать еще и про эффективность добавления и обновления данных. Давайте каждый блок данных заполнять не полностью и оставлять место для новых данных. Отлично, базы данных позволяют это делать и размер пустого пространства в блоке настраивается.
Итак, мы сохраняем ту же самую идею, но только в каждый блок дерева должны записать чуть больше данных и еще и оставить пустое пространства:
В корень дерева я взял каждый четвертый элемент, то есть 4-ю и 8-ю запись нашей таблицы. Теперь когда мы ищем Баранова, мы читаем корневой блок и проверяем первый элемент в блоке – он Иванова больше Баранова – Да, значит мы должны взять блок, ссылка на который расположена слева и мы попадем в левый нижний блок.
Если мы ищем Киркорова. Опять читаем корневой блок и проверяем Иванова больше Киркорова? Нет, проверяем Сергеева больше Киркорова? Да, значит читаем блок, ссылка на который находиться слева от Сергеевой.
Отлично, за два чтения с диска мы смогли найти нужную фамилию.
Так как в блоках есть пустое пространство, то мы можем без проблем добавлять данные. Допустим, что мы хотим добавить фамилию Бережной. Уже визуально мы видим, что эта фамилия принадлежит левому нижнему блоку. Мы читаем этот блок, вставляем в памяти новую фамилию и записываем обратно 4 килобайта. Одно чтение, одна запись и мы обновили индекс.
Базы данных немного варьируются в том, как они хранят индексы, но в целом идея такая. Просто бывают разные типы деревьев B-Tree и B+Tree.
Если говорить о таблице пользователей на сайте, то сколько записей мы можем вставить в день? Сколько пользователей регистрируется в день? Даже если будет 24 тысячи в сутки (это достаточно много) это будет 1 тысяча в час или чуть менее 17 в минуту или целых 3.5 секунды на одну вставку. Базе данных понадобиться миллисекунды на то, чтобы прочитать и обновить блок индекса, так что не бойтесь индексов, главное правильно их настраивать.
А что если мы заполним блок до предела, а предел у нас будет 6 фамилий:
Теперь мы хотим вставить новую фамилию – Андреев. Без проблем, нужно просто разбить один блок на несколько, точно также, как у нас разбит корневой:
Если мы продолжим вставлять записи на буквы А и Б, то наше дерево будет дробиться и смещаться влево. Количество уровней слева может оказаться на много больше количества уровней справа и тогда поиск данных слева будет медленнее. Для того, чтобы решить эту проблему нужно хотя бы иногда делать реорганизацию индекса, чтобы база сбалансировала дерево.
Базы могут запрещать создавать индексы на колонки, размер которых не помещается в страницу, для SQL Server это 8 килобайт. В этом также есть свой смысл, потому что если одна колонка индекса не помещается в минимальную единицу чтения, то какой смысл от такого индекса? Он будет очень медленным.
Вообще эффективность индекса зависит еще и от размера данных в нем. Если индекс построен на числовую колонку для 4 байтовых чисел, то прочитав одну страницу мы получаем 8096 байт данных или 2024 числа.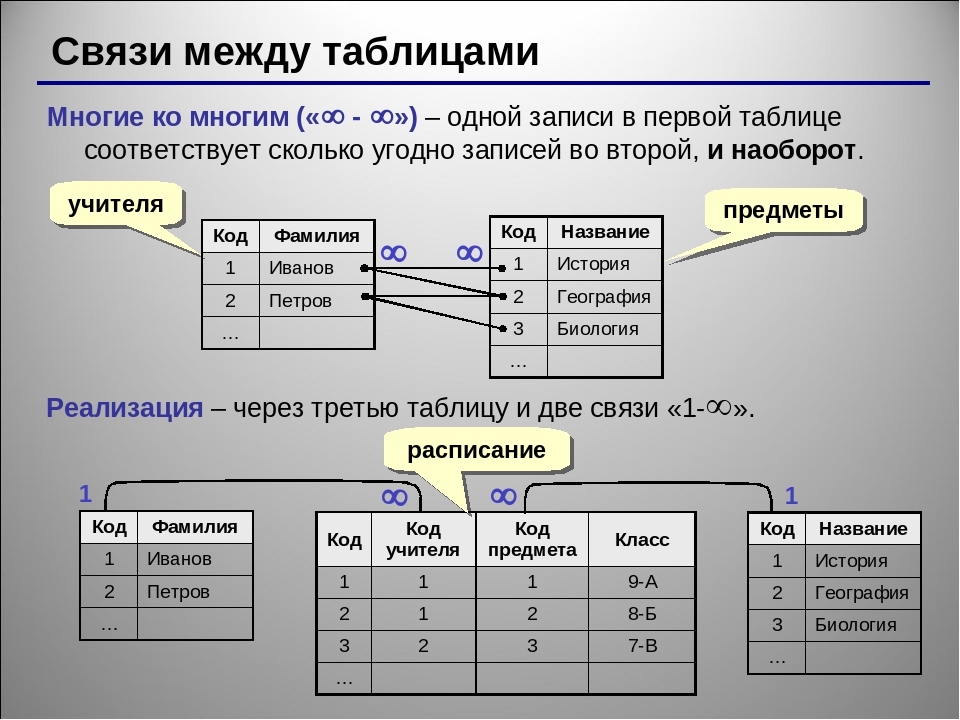 Это конечно не совсем правда, потому что там еще будет служебная информация, но все равно, даже если мы получим за раз 1 тысячу чисел, это уже круто. Поэтому индексация по числовым колонкам дает максимальную эффективность.
Это конечно не совсем правда, потому что там еще будет служебная информация, но все равно, даже если мы получим за раз 1 тысячу чисел, это уже круто. Поэтому индексация по числовым колонкам дает максимальную эффективность.
Индексы могут создаваться по нескольким колонкам, можно создать индекс по Фамилии и Имени, но добавлять имя в индекс может быть не эффективным, потому что это раздует дерево индекса и затормозит его. Очень часто проще найти всех Фленовых по индексу и потом уже отфильтровать результат по имени без индекса.
Индексы бывают кластерными и не кластерные. Кластерные – это когда сама строка с данными будет находиться в индексе, обычно для этого выделяют самые последние блоки (самые нижние), их называют листьями дерева. Может быть только один кластерный индекс, потому что в нем хранятся уже сами данные – вся строка телефонной записи – имя, фамилия, номер телефона. Хранить все эти данные в двух разных индексах – теоретически возможно, но это бред, потому что это только раздует базу.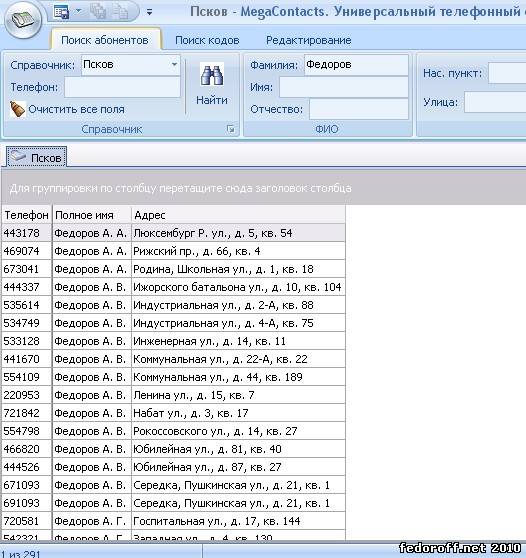
Проще создать остальные индексы не кластерными, где на листьях дерева находится только информация о том, где найти данные, обычно в листьях дерева хранится просто первичный ключ. То есть по не кластерному индексу, который создан для колонки Фамилия мы находим первичный ключ, а потом по первичному ключу ищем по кластерному индексу сами данные.
Внимание!!! Если ты копируешь эту статью себе на сайт, то оставляй ссылку непосредственно на эту страницу. Спасибо за понимание
Национальная база данных адресов | Министерство транспорта США
Министерство транспорта США (USDOT) и его партнеры на всех уровнях правительства признают необходимость национальной базы данных адресов (NAD). Точные и актуальные адреса имеют решающее значение для безопасности транспортировки и являются жизненно важной частью Next Generation 9-1-1. Они также необходимы для широкого спектра государственных услуг, включая доставку почты, выдачу разрешений и размещение школ. Чтобы удовлетворить эту потребность, USDOT сотрудничает с адресными программами правительств штатов, местных властей и племен для сбора их официальных данных в NAD.
Чтобы удовлетворить эту потребность, USDOT сотрудничает с адресными программами правительств штатов, местных властей и племен для сбора их официальных данных в NAD.
Чтобы узнать больше об адресах и Национальной базе данных адресов, посетите эту StoryMap.
Версия 14 NAD, содержащая 75,9 миллиона записей, теперь доступна для загрузки по ссылке в верхнем левом углу этой страницы.
NAD работает по одной и той же схеме с 2017 года. Эта схема была основана на стандарте адресов следующего поколения 9-1-1 Национальной ассоциации номеров экстренных служб (NENA) и стандарте содержания адресных данных Федерального комитета по географическим данным (FGDC). С тех пор подгруппа адресного контента подкомитета по адресам FGDC собрала требования к контенту для NAD, и NAD находится в процессе миграции и перехода на новую схему для согласования с этими требованиями к контенту. Руководство по последней схеме будет представлено здесь в ближайшем будущем.
Если вы представляете правительство штата или местного самоуправления и хотели бы включить свои адреса в NAD, свяжитесь с нами по адресу nad@dot. gov.
gov.
Просмотрите подробную информацию об участии по штатам под картами.
Карта национальной базы данных адресов (NAD) USDOT, статус обработки по округам (по состоянию на июль 2023 г.)Просмотрите подробную информацию о статусе обработки по округам под картами.
Карта национальной базы данных адресов (NAD) USDOT, срок предоставления данных по штатам (по состоянию на июль 2023 г.)Просмотрите подробную информацию о сроках предоставления данных по штатам под картами.
Карта национальной базы данных адресов (NAD) USDOT, участие партнеров по штатам (по состоянию на июль 2023 г.)Ключ с цветовой кодировкой описывается следующим образом:
Тридцать шесть (36) темно-зеленых штатов предоставили адресные данные, включая: Аризона, Арканзас, Калифорния, Колорадо, Коннектикут, Делавэр, Округ Колумбия, Флорида, Иллинойс, Индиана, Айова, Канзас, Кентукки, Мэн, Мэриленд, Массачусетс, Монтана, Небраска, Нью-Джерси, Нью-Мексико, Нью-Йорк, Северная Каролина, Северная Дакота, Огайо, Оклахома, Пенсильвания, Род-Айленд, Теннесси, Техас, Юта, Вермонт, Вирджиния, Вашингтон, Вай Сконсин и Вайоминг.
Три (3) желтых штата еще не представили данные для обработки, включая: Миссисипи, Пуэрто-Рико и Западная Вирджиния.
Шесть (6) светло-фиолетовых штатов не имеют данных для предоставления, включая: Алабама, Джорджия, Айдахо, Луизиана, Миссури и Невада.
Семь (7) темно-фиолетовых штатов могут иметь данные, которые не находятся в открытом доступе, включая: Гавайи, Мичиган, Миннесота, Нью-Гемпшир, Орегон, Южная Каролина и Южная Дакота.
Штриховые линии над шестью (6) штатами представляют участие племен или на местном уровне, а не участие в масштабах штата, включая: Алабама, Луизиана, Миннесота, Миссури, Южная Каролина и Южная Дакота.
Обратите внимание, что не все штаты имеют 100% покрытие.
Карта национальной базы данных адресов (NAD) USDOT, статус обработки по округам (по состоянию на июль 2023 г.)
Карта содержит ключ с цветовой кодировкой, который определяет уровень статуса NAD по округам.
Клавиша с цветовой кодировкой описывается следующим образом:
Темно-зеленый цвет означает, что отправленные адресные данные были обработаны для следующих девятнадцати (19) целых штатов: Аризона, Коннектикут, Делавэр, округ Колумбия, Иллинойс, Индиана, Мэн, Массачусетс, Монтана, Нью-Джерси, Нью-Мексико, Нью-Йорк, Северная Каролина, Огайо, Род-Айленд, Теннесси, Юта, Вермонт и Вирджиния; и Двадцать три (23) частичных штата, включая части: Алабама, Аляска, Арканзас, Калифорния, Колорадо, Флорида, Айова, Канзас, Кентукки, Луизиана, Мэриленд, Миннесота, Миссури, Небраска, Северная Дакота, Оклахома, Пенсильвания, Южная Каролина, Южная Дакота, Техас, Вашингтон, Висконсин и Вайоминг.
Светло-желтый цвет указывает на то, что данные еще не предоставлены для обработки и остаются в состоянии «В очереди» для следующих трех (3) штатов: Миссисипи, Пуэрто-Рико и Западная Вирджиния; и Девять (9) частичных штатов, включая части: Аляски, Калифорнии, Флориды, Кентукки, Небраски, Оклахомы, Пенсильвании, Техаса и Вашингтона.
Светло-фиолетовый цвет указывает на то, что данные не существуют или не являются частью общегосударственной программы для следующих трех (3) целых штатов: Джорджия, Айдахо и Невада; и Восемь (8) частичных штатов, включая части: Алабама, Арканзас, Колорадо, Айова, Луизиана, Миссури, Висконсин и Вайоминг.
Темно-фиолетовый цвет указывает на то, что данные могут не находиться в открытом доступе для следующих четырех (4) целых штатов: Гавайи, Мичиган, Нью-Гемпшир и Орегон; и Семь (7) частичных штатов, включая части: Колорадо, Канзас, Мэриленд, Миннесота, Северная Дакота, Южная Каролина и Южная Дакота.
Обратите внимание, что не все штаты имеют 100% покрытие.
Карта включает ключ с цветовой кодировкой, который определяет период предоставления данных NAD по штатам.
Ключ с цветовой кодировкой описывается следующим образом:
Темно-зеленый цвет означает, что самым последним данным не более шести (6) месяцев для следующих Тринадцати (13) штатов: Алабама, Аризона, Иллинойс, Индиана, Кентукки, Миннесота, Монтана, Небраска, Нью-Йорк, Северная Каролина, Огайо, Вашингтон и Вайоминг.
Светло-зеленый цвет указывает на то, что самым последним данным меньше одного (1) года для следующих двадцати двух (22) штатов: Аляска, Арканзас, Калифорния, Колорадо, Коннектикут, Делавэр, округ Колумбия, Флорида, Канзас, Мэн, Мэриленд, Массачусетс, Нью-Мексико, Оклахома, Пенсильвания, Южная Каролина, Южная Дакота, Теннесс ee, Техас, Юта, Вермонт и Вирджиния.
Желтый цвет означает, что самым последним данным не более двух (2) лет для следующих шести (6) состояний: Айова, Луизиана, Миссури, Нью-Джерси, Северная Дакота и Род-Айленд.
Красный цвет означает, что самым последним данным не менее трех (3) лет для штата: Висконсин.
Темно-серый цвет означает, что данные в настоящее время не предоставляются для следующих десяти (10) штатов: Джорджия, Гавайи, Айдахо, Мичиган, Миссисипи, Невада, Нью-Гемпшир, Орегон, Пуэрто-Рико и Западная Вирджиния.
Обратите внимание, что не все штаты имеют 100% покрытие.
php — Поиск полного имени или имени или фамилии в базе данных MySQL с именем и фамилией в отдельных столбцах
спросил
Изменено 1 год, 5 месяцев назад
Просмотрено 42к раз
Часть коллектива PHP Я работаю с существующей базой данных, в которой имя и фамилия разделены в базе данных. Мне нужно создать функцию, которая будет принимать один поисковый запрос и возвращать результаты.
Ваш комментарий будет первым