Пакетная работа с PDF-файлами — преобразование, сжатие, редактирование
Пакетная PDF-печать, конвертирование и редактирование поможет работать быстрее.
Пакетная конвертация в PDF и наоборот.
- Перетащите несколько файлов Word, PPT, изображений и других файлов, чтобы создать PDF.
- Поддержка пакетной конвертации PDF в JPG, PNG, Word, Excel, text, HTML и многое другое.
- Сэкономьте время на выполнение рутинных задач. Больше не нужно конвертировать несколько файлов по отдельности.
| Пакетная конвертация PDF | PDF в DOCX, PDF в DOC, PDF в XLSX, PDF в XLS, PDF в XML, PDF в PPTX, PDF в PPT, PDF в TXT, PDF в изображения |
| Пакетное создание PDF | Word в PDF, Excel в PDF, PPT в PDF, Изображения в PDF, HTML в PDF, XML в PDF, RTF в PDF |
Пакетная конвертация в PDF и наоборот.

Пакетная конвертация
Пакетное создание
Сжатие нескольких файлов PDF одновременно.
Сжатие нескольких больших файлов по отдельности — сложная задача, которая отнимает много времени. Пакетный PDF-компрессор упрощает одновременное сжатие больших PDF-файлов. Вы сможете выбрать подходящую степень: высокую, среднюю или низкую.
Compress multiple PDF files at once.
Создание доступных PDF-файлов с функцией пакетного распознания текста.
PDFelement позволяет вам одновременно конвертировать несколько PDF-файлов в текст с возможностью поиска или редактирования. Функция OCR позволяет распознавать 22 различных языка.
Скачать Бесплатно Скачать Бесплатно Скачать Бесплатно Скачать БесплатноСоздание доступных PDF-файлов с функцией пакетного распознания текста.
Быстрое и простое пакетное редактирование PDF.

Добавьте водяной знак, нумерацию Бейтса, фон, верхний и нижний колонтитулы в PDF в пакетном режиме.
Скачать Бесплатно Скачать Бесплатно Скачать Бесплатно Скачать БесплатноБыстрое и простое пакетное редактирование PDF.
Водяной знак
Нумерация Бейтса
Фон
Верхний & нижний колонтитулы
Пакетная защита PDF-файлов с помощью паролей.
Добавляйте пароли к нескольким PDF-файлам в пакетном режиме. Функция позволит за секунды добавлять, открывать, редактировать и устанавливать разрешения на печать для множества файлов.
Скачать Бесплатно Скачать Бесплатно Скачать Бесплатно Скачать БесплатноПакетная защита PDF-файлов с помощью паролей.
Дополнительные пакетные функции для PDF-файла
Извлечение данных в пакетном режиме
Извлечение данных из PDF в CSV.
Пакетная печать PDF
Печатайте несколько PDF-файлов одновременно.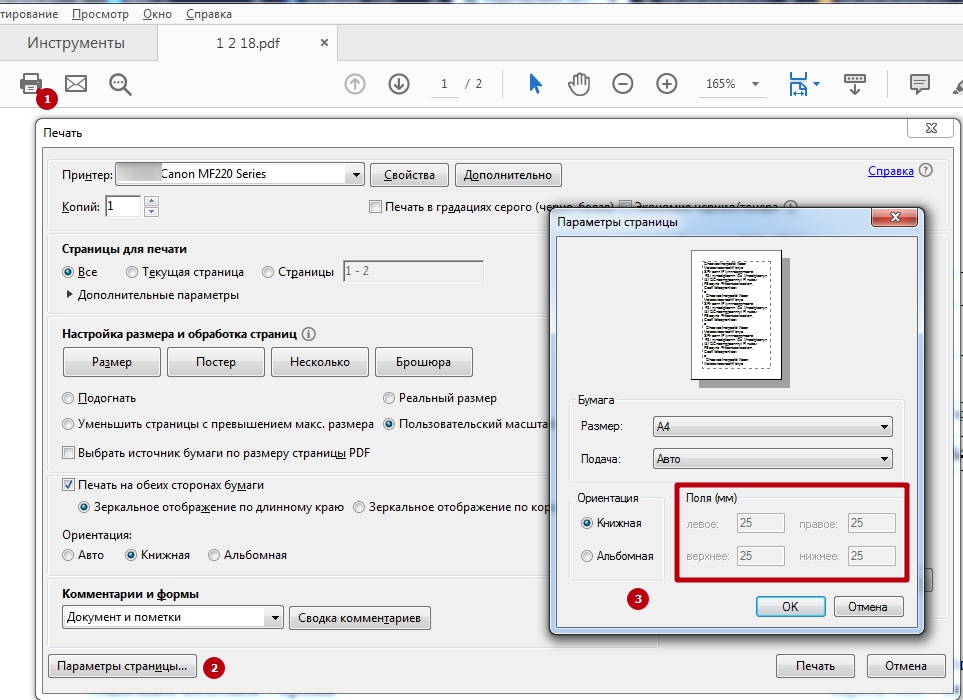
Удаление пустых страниц
Удалите все пустые страницы в PDF одним щелчком мыши.
Пакетная конвертация в PDF и наоборот.
- Перетащите несколько файлов Word, PPT, изображений и других файлов, чтобы создать PDF.
- Поддержка пакетной конвертации PDF в JPG, PNG, Word, Excel, text, HTML и многое другое.
- Сэкономьте время на выполнение рутинных задач. Больше не нужно конвертировать несколько файлов по отдельности.
| Пакетная конвертация PDF | PDF в DOCX, PDF в DOC, PDF в XLSX, PDF в XLS, PDF в XML, PDF в PPTX, PDF в PPT, PDF в TXT, PDF в изображения |
| Пакетное создание PDF | Word в PDF, Excel в PDF, PPT в PDF, Изображения в PDF, HTML в PDF, XML в PDF, RTF в PDF |
Пакетная конвертация в PDF и наоборот.
Пакетная конвертация в PDF и наоборот.

- Перетащите несколько файлов Word, PPT, изображений и других файлов, чтобы создать PDF.
- Поддержка пакетной конвертации PDF в JPG, PNG, Word, Excel, text, HTML и многое другое.
- Сэкономьте время на выполнение рутинных задач. Больше не нужно конвертировать несколько файлов по отдельности.
| Пакетная конвертация PDF | PDF в DOCX, PDF в DOC, PDF в XLSX, PDF в XLS, PDF в XML, PDF в PPTX, PDF в PPT, PDF в TXT, PDF в изображения |
| Пакетное создание PDF | Word в PDF, Excel в PDF, PPT в PDF, Изображения в PDF, HTML в PDF, XML в PDF, RTF в PDF |
Пакетная конвертация в PDF и наоборот.
Пакетная конвертация
Пакетное создание
Сжатие нескольких файлов PDF одновременно.
Сжатие нескольких больших файлов по отдельности — сложная задача, которая отнимает много времени. Пакетный PDF-компрессор упрощает одновременное сжатие больших PDF-файлов. Вы сможете выбрать подходящую степень: высокую, среднюю или низкую.
Пакетный PDF-компрессор упрощает одновременное сжатие больших PDF-файлов. Вы сможете выбрать подходящую степень: высокую, среднюю или низкую.
Сжатие нескольких файлов PDF одновременно.
Создание доступных PDF-файлов с функцией пакетного распознания текста.
PDFelement позволяет вам одновременно конвертировать несколько PDF-файлов в текст с возможностью поиска или редактирования. Функция OCR позволяет распознавать 22 различных языка.
Скачать Бесплатно Скачать Бесплатно Скачать Бесплатно Скачать БесплатноСоздание доступных PDF-файлов с функцией пакетного распознания текста.
Быстрое и простое пакетное редактирование PDF.
Добавьте водяной знак, нумерацию Бейтса, фон, верхний и нижний колонтитулы в PDF в пакетном режиме.
Скачать Бесплатно Скачать Бесплатно Скачать Бесплатно Скачать БесплатноБыстрое и простое пакетное редактирование PDF.

Водяной знак
Нумерация Бейтса
Фон
Верхний & нижний колонтитулы
Пакетная защита PDF-файлов с помощью паролей.
Добавляйте пароли к нескольким PDF-файлам в пакетном режиме. Функция позволит за секунды добавлять, открывать, редактировать и устанавливать разрешения на печать для множества файлов.
Пакетная защита PDF-файлов с помощью паролей.
Дополнительные пакетные функции для PDF-файла
Извлечение данных в пакетном режиме
Извлечение данных из PDF в CSV.
Пакетная печать PDF
Печатайте несколько PDF-файлов одновременно.
Удаление пустых страниц
Удалите все пустые страницы в PDF одним щелчком мыши.
Функция пакетной обработки ускоряет любую работу с PDF.
Образование
«PDF-файлы можно создать легко и быстро, перетаскивая скриншоты слайдов курса в окно «Пакетное создание. »
»
—— Мисс Грин, Учительница
Маркетинг
«PDFelement помогает мне легко конвертировать старые PDF-листовки в документы Word для обновления информации. Приложение — настоящая палочка-выручалочка!»
—— Ричард, маркетолог
ИТ-обучение
«Добавление водяных знаков ко всем учебным материалам одним щелчком мыши упрощает работу в 100 раз! Функция помогает быстрее выполнять поставленные задачи.»
—— Дэниел, ИТ-разработчик
Скачать Бесплатно Скачать Бесплатно Скачать Бесплатно Скачать БесплатноКак конвертировать PDF за 3 простых шага.
Шаг 1. Нажмите на кнопку «Пакетная обработка».
Перейдите в раздел «Инструмент» и выберите «Пакетная обработка».
Шаг 2. Выберите опцию
Выберите вариант пакетной обработки из 11 функций: конвертация, редактирование и многое другое.
Шаг 3. Пакетная обработка PDF
Добавьте все PDF-файлы, которые вы хотите обработать в пакетном режиме, во всплывающее окно. Нажмите «Применить», чтобы начать работу.
Нажмите «Применить», чтобы начать работу.
Часто задаваемые вопросы о пакетной обработке PDF.
Как конвертировать несколько PDF-файлов в Word?
Откройте «Пакетная обработка» на вкладке «Инструмент». Нажмите кнопку «Создать» и добавьте несколько JPG-файлов в PDFelement. Нажмите на кнопку «Применить», чтобы конвертировать изображения в формат PDF.
-
Как лучше всего сохранить несколько изображений в один PDF-файл?
Лучший способ — использовать опцию «Объединение» в PDFelement. Добавьте несколько изображений и нажмите кнопку «Применить», чтобы перенести изображения в PDF-файл.

-
Можно ли вы поставить водяные знаки на несколько PDF-файлов одновременно?
Да. С помощью PDFelement вы можете легко поставить водяные знаки на несколько PDF-файлов в пакетном режиме. Просто перейдите в меню Инструмент > Пакетная обработка > Водяной знак в PDFelement.
Делайте больше с помощью PDFelement.
Выберите подписку PDFelement, которая подойдет именно вам
Редактируйте, печатайте, создавайте и защищайте документы. Облачное хранилище объемом 100 ГБ для совместной работы.
Годовая подписка Бессрочная лицензия
$55,99 $79,99
$55,99 $79,99
$75,99 $99,99
$75,99 $99,99
Скачать Бесплатно
Купить СейчасСкачать Бесплатно
Купить СейчасСкачать Бесплатно
Купить СейчасСкачать Бесплатно
Версия для Mac >>Версия для Windows >>Редактируйте, печатайте, создавайте и защищайте документы.
Годовая подписка Бессрочная лицензия
$65,99 $99,99
$65,99 $99,99
$95,99 $159,99
$95,99 $159,99
Скачать Бесплатно
Купить СейчасСкачать Бесплатно
Купить СейчасСкачать Бесплатно
Купить СейчасСкачать Бесплатно
Версия для Mac >> Версия для Windows >>
Редактируйте, печатайте, подписывайте и защищайте документы. Облачное хранилище объемом 100 ГБ для совместной работы.
Годовая подписка
$79,99 $129,99
$79,99 $129,99
Скачать Бесплатно
Купить СейчасСкачать Бесплатно
Версия для Mac >> Версия для Windows >>
Доступны командные лицензии. Подробнее>>
Присоединяйтесь к нашему социальному сообществу, чтобы получать больше новостей, тенденций и обновлений!
Простые инструменты PDF для всех пользователей и любого места работы.

Выход новой версии ContentReader PDF 15 : от 03.05.2023 — 1С‑Рарус: Дистрибьюция ПО
Компания Content AI сообщила о выходе новой улучшенной версии ContentReader PDF 15.
О продукте
ContentReader PDF для Linux — интеллектуальный редактор PDF, разработанный отечественной компанией Content AI. Это качественная альтернатива зарубежному ПО FineReader PDF и Adobe Acrobat.
Продукт поддерживает операционные системы на базе Linux, совместим с наиболее распространенными российскими ОС, такими как Astra Linux, Alt Linux, РЕД ОС, ОС Атлант и др. Программа содержит все необходимые инструменты для работы с PDF и бумажными документами.
Благодаря AI‑технологии, программа обеспечивает высокую точность и скорость работы. ContentReader PDF помогает пользователям сократить время на рутинных задачах в работе с электронными документами. А бизнесу помогает оптимизировать затраты на закупку и поддержку различного ПО.
О новой версии
Функциональность ContentReader PDF 15 включает все необходимые инструменты для работы с PDF‑документами, в том числе редактирование, защита, создание, конвертирование и распознавание текста в отсканированных документах.
Основные возможности новой версии:
- Работа с PDF‑документами: просмотр, изменение ориентации страниц и кадрирование, объединение нескольких PDF‑документов в один файл или его разделение, копирование информации из других файлов с сохранением форматирования, заполнение интерактивных полей в документе и другие манипуляции.
- Редактирование PDF‑документов: отредактировать готовый PDF‑документ или создать на его основе новый, добавить или изменить колонтитулы, гиперссылки, водяные знаки и штампы, нумерацию страниц, добавить или удалить изображения, найти необходимый текст.
- Защита PDF‑документов: установка пароля на документ, цифровая подпись, а также функции автоматического удаления конфиденциальных и скрытых данных.
- Создание PDF‑документов: создание PDF‑файла в программе ContentReader PDF 15, через проводник Windows или непосредственно в программах Microsoft Office.
- OCR‑редактор: распознавание текста в отсканированных документах и конвертация PDF‑документов в редактируемые форматы (Word, Excel, PowerPoint и т. д.).
- Совместная работа: функции совместного просмотра, редактирования и комментирования PDF‑документов.
Подробнее о лицензировании
| Название продукта | Тип лицензии | Срок лицензии | Артикулы | Цена без НДС |
|---|---|---|---|---|
| ContentReader PDF 15 Standard | Standalone | 1 год | CR15‑1S1W01 | 6 466 |
| ContentReader PDF 15 Business | Standalone | 1 год | CR15‑2S1W01 | 11 736 |
| ContentReader PDF 15 Corporate | Standalone | 1 год | CR15‑3S1W01 | 27 346 |
РазвернутьСвернуть
Если вы в поисках качественной замены к привычному FineReader PDF или только выбираете редактор электронных документов — присмотритесь к ContentReader PDF. Он станет надежным помощником для ваших клиентов!
Он станет надежным помощником для ваших клиентов!
Желаем успешных продаж!
По вопросам приобретения продуктов обращайтесь в отдел продаж системного программного обеспечения:
- эл. почта: [email protected];
- тел.: +7 (495) 642-78-78;
- или в ваше региональное представительство компании «1С‑Рарус».
Похожие новости
- Партнер «1С-Рарус» – СофтСервис автоматизировала учет в ООО «Кросс-Моторс».
6 Марта 2023
График работы «1С‑Рарус» в марте 2023 года7 Апреля 2023
Продукт «Альфа-Авто: Автосалон+Автосервис+Автозапчасти КОРП, редакция 6» получил сертификат «Совместимо!»27 Апреля 2023
График работы «1С‑Рарус» в мае 2023 года
PdfProcessing — Обзор — Telerik Document Processing
Доступно для: Пользовательский интерфейс для ASP. NET MVC | Пользовательский интерфейс для ASP.NET AJAX | Пользовательский интерфейс для Blazor | Пользовательский интерфейс для WPF | Пользовательский интерфейс для WinForms | Пользовательский интерфейс для Silverlight | Пользовательский интерфейс для Xamarin | Пользовательский интерфейс для WinUI | Пользовательский интерфейс для ASP.NET Core | Пользовательский интерфейс для .NET MAUI
NET MVC | Пользовательский интерфейс для ASP.NET AJAX | Пользовательский интерфейс для Blazor | Пользовательский интерфейс для WPF | Пользовательский интерфейс для WinForms | Пользовательский интерфейс для Silverlight | Пользовательский интерфейс для Xamarin | Пользовательский интерфейс для WinUI | Пользовательский интерфейс для ASP.NET Core | Пользовательский интерфейс для .NET MAUI
RadPdfProcessing — это библиотека обработки, позволяющая создавать, импортировать и экспортировать PDF-документы из вашего кода. Вы можете использовать его в любом веб-приложении или настольном приложении .NET, не полагаясь на стороннее программное обеспечение, такое как Adobe Acrobat.
В этой статье мы перечислим самые популярные функции библиотеки. Если вы хотите узнать, как использовать библиотеку, перейдите прямо к статье Начало работы с RadPdfProcessing .
RadPdfProcessing является частью Telerik Document Processing,
Библиотека . NET профессионального уровня для создания файлов PDF, Word, XLSX и HTML и управления ими. Чтобы попробовать его, подпишитесь на бесплатную 30-дневную пробную версию.
NET профессионального уровня для создания файлов PDF, Word, XLSX и HTML и управления ими. Чтобы попробовать его, подпишитесь на бесплатную 30-дневную пробную версию.
Скачать бесплатную пробную версию
Если у вас еще не установлена программа Telerik Document Processing , ознакомьтесь с разделом Первые шаги , чтобы узнать, как получить пакеты с помощью различных пакетов с элементами управления Telerik.
API RadPdfProcessing содержит два разных редактора, позволяющих выбирать между редактированием в потоковом режиме или использованием гораздо более мощной и гибкой фиксированной структуры документа, позволяющей рисовать на странице.
Модель документа библиотеки поддерживает:
| Функция | Описание |
|---|---|
| Страницы | Добавление, изменение или удаление страниц в документе. Свойства позволяют изменить размер страницы, ее поворот и многое другое. Свойства позволяют изменить размер страницы, ее поворот и многое другое. |
| Автоматическая компоновка | Несмотря на то, что формат PDF является фиксированным, иногда вам нужно будет вставить содержимое таким образом, чтобы оно размещалось на странице. RadPdfProcessing позволяет легко добиться этого с помощью блоков, таблиц и списков. |
| Изображения | Декодируется по запросу для повышения производительности. API позволяет получить закодированные данные изображения. Вы также можете контролировать качество изображения при сохранении документа. |
| Геометрия | Позволяет описать геометрию 2D-формы. |
| Форма XObjects | Form XObjects позволяет описывать составные объекты (состоящие из текста, изображений, векторных элементов и т. д.) в файле PDF и повторно использовать это содержимое в документе для уменьшения размера документа и повышения производительности рендеринга. |
| Интерактивные формы | Создание и изменение PDF-файлов, содержащих текстовые поля, кнопки, списки и другие интерактивные элементы управления, предоставляющие пользователю PDF-файла возможность интерактивного заполнения некоторых данных в PDF-документе и/или цифровой подписи заполненного документа. Вы также можете сгладить поля. |
| Цифровая подпись | Функция цифровой подписи позволяет подписывать и проверять документ PDF (ограниченно поддерживается в .NET Standard). |
| Отсечение | Вы можете определить контур других элементов содержимого, таких как изображения и контуры. |
| Закладки (контуры) | Добавление, удаление или изменение закладок в документе PDF. |
| Аннотации | Свяжите объект с местоположением на странице документа PDF. |
| Направления | Определяет конкретное представление документа. |
| Цвета и цветовые пространства | Поддержка разных типов обоих. |
| Шрифты | Поддержка стандартных шрифтов PDF, Type0, Type1, Type 3, CIDFontType2, TrueType и других. |
| Текстовые и графические свойства | Предоставьте параметры для изменения свойств различных элементов в элементах документа, чтобы вы могли добиться уникального внешнего вида. |
| Защита паролем | Поддержка документов, зашифрованных с помощью алгоритма шифрования 4 (RC4/AES-128) и алгоритма шифрования 5 с помощью AES 256 |
| Объединить документы и страниц документа | Вы можете объединить страницы из нескольких документов в один документ. |
| PdfStreamWriter | API предоставляет функцию, позволяющую экспортировать PDF-файлы с непревзойденной производительностью и минимальным объемом памяти. Чрезвычайно полезно, когда вам нужно добавить некоторый контент в существующий документ, объединить или разделить документы. Чрезвычайно полезно, когда вам нужно добавить некоторый контент в существующий документ, объединить или разделить документы. |
| Импорт PDF и экспорт в PDF или обычный текст | Вы можете импортировать или экспортировать файлы PDF и преобразовывать файлы PDF в обычный текст. |
Обработка PDF с помощью Python. Как извлечь текст из pdf… | Ахмед Хемири
Опубликовано в·
Чтение: 10 мин.·
2 июля 2019 г. Фото Джеймса Харрисона на Unsplash высокоуровневый интерпретируемый язык с относительно простым синтаксисом, Python идеально подходит даже для тех, у кого нет опыта программирования. Популярные библиотеки Python хорошо интегрированы и предоставляют решение для обработки неструктурированных источников данных, таких как Pdf, и могут быть использованы для того, чтобы сделать его более разумным и полезным. PDF — один из самых важных и широко используемых цифровых носителей. используется для предъявления и обмена документами. PDF-файлы содержат полезную информацию, ссылки и кнопки, поля форм, аудио, видео и бизнес-логику.
используется для предъявления и обмена документами. PDF-файлы содержат полезную информацию, ссылки и кнопки, поля форм, аудио, видео и бизнес-логику.
1- Почему Python для обработки PDF
Как вы знаете, обработка PDF относится к текстовой аналитике.
Большинство библиотек или фреймворков Text Analytics разработаны только на Python. Это дает рычаги для текстовой аналитики. Еще одна вещь, которую вы никогда не сможете обработать в формате PDF напрямую в существующих рамках машинного обучения или обработки естественного языка. Если они не доказывают явный интерфейс для этого, мы должны сначала преобразовать pdf в текст.
2- Библиотеки Python для обработки PDF
Как специалист по данным, вы можете не придерживаться формата данных.
Обработка PDF-файлов относится к области анализа текста, области, в которой используются программные инструменты для анализа больших объемов текстовых данных.
Python — популярный язык для разработки библиотек и фреймворков текстовой аналитики, обеспечивающий значительное преимущество в этой области.
Однако стоит отметить, что существующие платформы машинного обучения и обработки естественного языка обычно не включают прямой интерфейс для обработки PDF-файлов. Чтобы работать с PDF-файлами с помощью этих фреймворков, мы должны сначала преобразовать их в текстовый формат.
В этом разделе мы познакомимся с Top Python PDF Library:
PDFMiner
PDFMiner — это инструмент для извлечения информации из PDF-документов. В отличие от других инструментов, связанных с PDF, он полностью ориентирован на получение и анализ текстовых данных. PDFMiner позволяет получить точное расположение текста на странице, а также другую информацию, такую как шрифты или линии. Он включает конвертер PDF, который может преобразовывать файлы PDF в другие текстовые форматы (например, HTML). Он имеет расширяемый парсер PDF, который можно использовать не только для анализа текста, но и для других целей.
PyPDF2
PyPDF2 — это библиотека PDF на чистом языке Python, способная разделять, объединять, обрезать и преобразовывать страницы файлов PDF. Он также может добавлять пользовательские данные, параметры просмотра и пароли в файлы PDF. Он может извлекать текст и метаданные из PDF-файлов, а также объединять целые файлы вместе.
Он также может добавлять пользовательские данные, параметры просмотра и пароли в файлы PDF. Он может извлекать текст и метаданные из PDF-файлов, а также объединять целые файлы вместе.
pdf rw
pdfrw — это библиотека и утилита Python, которая читает и записывает PDF-файлы:
- Версия 0.4 протестирована и работает на Python 2.6, 2.7, 3.3, 3.4, 3.5 и 3.6
- Операции включают подмножество, слияние, вращение, изменение метаданных и т. д.
- Самый быстрый доступный анализатор PDF на чистом Python
- Много лет использовался типографией в допечатной подготовке
- Может использоваться с rst2pdf для точного воспроизведения вектора images
- Может использоваться как отдельно, так и в сочетании с лабораторией отчетов для повторного использования существующих PDF-файлов в новых. Это зависит от пакета PDFMiner.
3- Настройка среды
Шаг 1: Выберите версию Python для установки с Python.
org .Шаг 2: Загрузите исполняемый установщик Python.
Шаг 3: Запустите исполняемый установщик.
Шаг 4: Убедитесь, что Python установлен в Windows.
Шаг 5: Проверка установки Pip.
Шаг 6: Добавьте путь Python к переменным среды (необязательно).
Шаг 7 : Установите расширение Python для вашей IDE.
Я работаю с Python 3.7 в коде Visual Studio. Для получения дополнительной информации о том, как настроить среду и выбрать перехватчик Python для начала написания кода с помощью VS Code, см. Начало работы с Python в документации по VS Code.
Шаг 7: Теперь вы сможете выполнять скрипты Python в своей среде IDE.
Шаг 8 : Установите pdfminer.six
pip install pdfminer.six
Шаг 9 : Установить PyPDF2
pip install PyPDF2
Готово! Теперь вы можете начать обрабатывать PDF-документы с помощью Python.
4- Решение для извлечения текста из нескольких и больших PDF-документов Решение для извлечения текста из PDF-файлов основано на трех основных шагах:
- Разделение PDF-документов на набор документов (постраничное разделение)
- Обработка разделенных документов и извлечение текста.
Шаг 1: Настройка порта и префикса приложения Flask:
.datetime):
возврат о .__str__()
if isinstance(o, np.bool_):
return o.__str__()def writeToJSONFile(filepath, data):
с open(filepath, 'w') как файл:
json.dump( данные, файл, по умолчанию=myconverter, отступ=4)ports = {
"data_extraction": 5000
}PREFIX = "/api"
Фрагмент кода написан на Python и настраивает приложение Flask, определяя номер порта для конкретной службы и префикс для конечная точка API. Словарь
portsсодержит номер порта для службы под названием «data_extraction», для которой установлено значение 5000.Для переменной
PREFIXустановлено значение «/api», что означает, что все конечные точки API для приложения Flask будут этот префикс, например «/api/get_data» или «/api/analyze_text». Этот префикс помогает организовать маршруты API и упрощает управление различными конечными точками.Код также включает функцию с именем
writeToJSONFile, которая используется для записи данных в файл JSON, и функцию с именемmyconverter, которая используется для преобразования объектов datetime и логических значений numpy в строки при записи в JSON. файл.Шаг 2: Разделение PDF-документов :
import os
from PyPDF2 import PdfFileReader, PdfFileWriterdef splitting(upload_folder, split_folder):
'''Собирайте файлы PDF, разделяйте страницы и сохраняйте их
'''записей = os.listdir(upload_folder)
path = os.path.abspath(split_folder)для записи в записях:
uploaded_file = os.
path.join(upload_folder, entry)
output_file_folder = ОС .path.join(путь, запись)если не os.path.isdir(папка_файла_вывода):
os.mkdir(папка_файла_выхода)pdf = PdfFileReader(файл_загрузки, strict=False)
для страницы в диапазоне(pdf.getNumPages ()):
pdf_writer = PdfFileWriter()
pdf_writer.addPage(pdf.getPage(страница))
output_filename = \
os.path.join(output_file_folder, f'{page+1}.pdf')
с open(output_filename, 'wb') as out:
pdf_writer.write(out)Фрагмент кода написан на Python и определяет функцию с именем
, разделяющую, которая принимает два аргумента:upload_folderиsplit_folder. Эта функция используется для разделения PDF-документов постранично и сохранения полученных страниц в указаннуюsplit_folder.Функция сначала собирает все файлы PDF из
каталог upload_folderс использованием методаos.listdir(). Затем он создает новый каталог для каждого файла PDF в каталоге split_folder, используя метод os.mkdir() .Для каждого файла PDF функция использует класс
PdfFileReaderиз библиотеки PyPDF2 для чтения файла PDF и извлечения количества страниц. Затем он перебирает каждую страницу в документе PDF, используя циклдля, и создает новыйPdfFileWriter 9.0375 объект для каждой страницы. Страница добавляется в объектPdfFileWriterс помощью методаaddPage().Наконец, функция сохраняет выходной файл для каждой страницы в соответствующую папку с помощью метода
write() объектаPdfFileWriter. Имя выходного файла создается путем добавления номера страницы к исходному имени файла PDF.В целом, эта функция обеспечивает простой и эффективный способ разделения PDF-документов постранично и сохранения полученных страниц в указанной папке.
Шаг 3: Извлечение текста из PDF-документов :
53 из pdfminer.
layout импортировать LAParams
из pdfminer.pdfpage import PDFPagedef pdf_to_text(path):
'''Извлечь текст из pdf-документов
'''manager = PDFResourceManager()
retstr = StringIO()
layout = LAParams(all_texts=False,Detect_vertical=True )
устройство = TextConverter(manager, retstr, laparams=layout)
интерпретатор = PDFPageInterpreter(manager, device)
с open(path, 'rb') в качестве пути к файлу:
для страницы в PDFPage.get_pages(filepath, check_extractable=True):
интерпретатор.процесс_страница(страница)
текст = retstr.getvalue()
device.close()
retstr.close()
возвращаемый текст output dir
'''# имена записей
записи = os.listdir(split_path)# повторить процесс для каждой записи
для записи в записях:# определить пользовательский список содержит пути к файлам записей
custom_list = os.listdir(os.path.join(split_path, entry))# список должен быть отсортирован
custom_list. sort(key=lambda f: int(re.sub(r'\D', '', f))) # повторить процесс для каждого пути к файлу
для file_path в custom_list:text_output = pdf_to_text(
os.path.join(split_path, entry, file_path))# сохранить текстовый файл каждой записи
с помощью open(os.path.join(text_path, f"{entry}.txt"),
"a",
encoding="utf-8") как text_file:
text_file .write(text_output)Этот фрагмент кода написан на Python и определяет две функции,
pdf_to_textиизвлечение, для извлечения текста из документов PDF и сохранения полученных текстовых файлов в выходной каталог.Функция
pdf_to_textпринимает путь к файлу PDF в качестве входных данных и возвращает извлеченный текст в виде строки. Это достигается с помощьюPDFResourceManager,TextConverterиPDFPageInterpreterиз библиотеки pdfminer. Функция перебирает каждую страницу документа PDF и обрабатывает ее с помощью методаprocess_pageобъектаPDFPageInterpreter. Результирующий текст затем возвращается в виде строки.Функция извлечения
split_pathиtext_path. Аргументsplit_path— это путь к каталогу, содержащему ранее разделенные страницы PDF, а аргументtext_pathаргумент — это путь к каталогу, в котором должны быть сохранены полученные текстовые файлы.Функция сначала собирает все записи (каталоги) в каталоге
split_pathс помощью методаos.listdir(). Затем он перебирает каждую запись и создает собственный список путей к файлам для каждой записи, снова используя метод os.listdir() . Этот список сортируется с использованием методаsort()и лямбда-функции, чтобы гарантировать, что страницы обрабатываются в правильном порядке.Для каждого пути к файлу в пользовательском списке функция извлекает текст с помощью функции
pdf_to_textи сохраняет полученный текстовый файл в каталогtext_pathс помощью функцииopen()и методаwrite().В целом, этот сценарий обеспечивает простой и эффективный способ извлечения текста из PDF-документов, разбитых на отдельные страницы, и сохранения полученных текстовых файлов в указанном каталоге.
Шаг 4: Оболочка утилит, связанных с извлечением: (API разделения и извлечения FLask)
'''Обертка утилит, связанных с извлечением,
'''import os
from flask import Flask, request, jsonify
из werkzeug.utils импортировать secure_filenameиз global_common импортировать порты
из global_common импортировать ПРЕФИКС
из извлечения импортировать извлечение
из разделения импортировать разделениеapp = Flask(__name__)
port = int(os.environ.get("ПОРТ", порты["извлечение_данных"]))path = os.getcwd()
# Каталоги проекта определены следующим образом:
# -data_dir-: data .
data = os.path.join(path, 'data')
если не os.path.isdir(data):
os.mkdir(data)# -upload_dir-: содержит загруженные файлы.
uploads = os.path.join(data, 'uploads')
если не os.path.isdir(uploads):
os.mkdir(uploads)# -preparation_dir-: содержит обработанные и подготовленные файлы.
подготовка = os.path.join(данные, 'files_preparation')
если не os.path.isdir(prepare):
os.mkdir(prepare)# -output_dir-: содержит сгенерированные текстовые файлы.
outputs = os.path.join(data, 'outputs')
if not os.path.isdir(outputs):
os.mkdir(outputs)# Проверить и проверить расширения файлов...
ALLOWED_EXTENSIONS = set( ['.pdf'])def allow_file(filename):
'''Оценить, входит ли расширение файла в список разрешенных каталогов
'''
lowercase_extension = os.path.splitext(filename)[1].lower( )
вернуть строчное_расширение в ALLOWED_EXTENSIONS@app.route(PREFIX + '/upload', методы = ['POST'])
def upload():
'''Загрузить файлы в процесс
'''
if request.method != 'POST':
resp = jsonify({'message': 'Операция не поддерживается'})
resp. status_code = 500
return resp# проверьте, есть ли в почтовом запросе файловая часть
if 'files[] ' нет в request.files:
resp = jsonify({'message': 'Нет части файла в запросе'})
resp.status_code = 500
return respfiles = request.files.getlist('files[]')
errors = {}
success = False# проверить, разрешен файл или нет.
для файла в файлах:
если файл и разрешенный_файл(имя_файла):
имя_файла = имя_безопасного_файла(имя_файла)
файл.сохранить(os.path.join(загрузки, имя файла))
успех = True
иначе:
errors[file.filename] = 'Тип файла не разрешен'если успех и ошибки:
errors['message'] = 'Файл(ы) успешно загружены'
resp = jsonify(ошибки)
resp.status_code = 404
return respв случае успеха:
9 0002 соответственно = jsonify(errors)
resp = jsonify({'message': 'Файлы успешно загружены'})
resp.status_code = 200
return resp
resp. status_code = 404
return resp@app.route(PREFIX + '/extraction', method=['POST'])
def extract_function():
'''Извлечь данные из files
'''
if request.method == 'POST': # проверьте метод запроса
если не os.listdir(uploads): # если папка для загрузки пуста return -> error
resp = jsonify({'message': 'Файлы не найдены'})
resp.status_code = 500
return resptry:
# разделение : разделить документы на отдельные страницы.
разделение(загрузка, подготовка)# извлечение: извлечение текста из страниц.
извлечение (подготовка, вывод)resp = jsonify({'message': 'Файлы успешно извлечены'})
resp.status_code = 200
return respкроме:
resp = jsonify({'message': ' ошибка при извлечении'})
resp.status_code = 404
return resp
else:resp = jsonify({'message': 'Операция не поддерживается'})
resp.status_code = 500
return respif __name__ == '__ главная__':
app. run(debug=True, host='0.0.0.0', port=port) Это приложение Flask, которое включает в себя утилиты разделения и извлечения, разработанные на предыдущих шагах. Он предоставляет две конечные точки:
-
/upload: принимает файлы для обработки и сохраняет их взагружает каталог. -
/extraction: запускает процесс разделения и извлечения файлов в каталоге, загружаети сохраняет полученные текстовые файлы в выходной каталог
Сценарий определяет несколько каталогов, которые будут использоваться на протяжении всего процесса:
-
data: основной каталог данных, который будет содержать все остальные каталоги. -
загрузки: каталог, в котором будут сохранены загруженные файлы. -
files_preparation: каталог, в котором будут сохранены разделенные файлы. -
выводит: каталог, в котором будут сохранены извлеченные текстовые файлы.
Функция
allow_fileпроверяет, имеет ли данный файл разрешенное расширение (в данном случаеpdf).Функция загрузки
files[]. Он сохраняет загруженные файлы взагружает каталоги возвращает соответствующий ответ.Функция
extract_functionпринимает запросы POST и запускает процесс разделения и извлечения загруженных файлов. Он сохраняет полученные текстовые файлы в каталогoutputsи возвращает соответствующий ответ.В случае сбоя процесса разделения или извлечения возвращается сообщение об ошибке.
Шаг 5: Запись Dockerfile
ИЗ python:3.7
КОПИРОВАТЬ . /app/
WORKDIR /app
RUN pip install -r requirements.txt
ENTRYPOINT ["python3"]
CMD ["app.py"]Шаг 6: Компоновка приложения (запись файла Docker-Compose )
версия: '3'
сервисы:
веб:
сборка: '. '
порты:
- '5000:5000'Шаг 7: Тестирование приложения Flask (загрузка и извлечение)
Кроме того, я прикрепил коллекцию почтальона в проекте PDFs-TextExtract GitHub.
curl -X POST http://127.0.0.1:5000/api/upload
curl -X POST http://127.0.0.1:5000/api/upload --form 'files[]=@"toto.pdf "' --form 'files[]=@"test.pdf"'
curl -X POST http://127.0.0.1:5000/api/extraction
Полная версия Extraction доступна на GitHub.
Пожалуйста, проверьте это через:
Разветвление и Репозиторий Starring — лучший способ поддержать проект.
ahmedkhemiri95/PDFs-TextExtract
Python Извлечение текста из нескольких PDF-документов — Python 3.7 Как специалист по данным, вы можете не придерживаться формата данных. PDF-файлы…
github.com
Если у вас есть какие-либо отзывы, комментарии или интересные идеи, чтобы поделиться о моей статье, не стесняйтесь обращаться ко мне на моем канале социальных сетей LinkedIn
Вы можете подписаться на меня на Github: https://github.
 org .
org .

 path.join(upload_folder, entry)
path.join(upload_folder, entry)  Затем он создает новый каталог для каждого файла PDF в каталоге
Затем он создает новый каталог для каждого файла PDF в каталоге .png) layout импортировать LAParams
layout импортировать LAParams  sort(key=lambda f: int(re.sub(r'\D', '', f)))
sort(key=lambda f: int(re.sub(r'\D', '', f)))  Результирующий текст затем возвращается в виде строки.
Результирующий текст затем возвращается в виде строки.

 status_code = 500
status_code = 500  status_code = 404
status_code = 404  run(debug=True, host='0.0.0.0', port=port)
run(debug=True, host='0.0.0.0', port=port) 
 '
' 
Ваш комментарий будет первым