Редактирование PDF файлов • фриланс-работа для специалиста • категория Обработка данных ≡ Заказчик Дмитрий Р.
6 из 6
проект завершен
публикация
прием ставок
утверждение условий
резервирование
выполнение проекта
проект завершен
Доброе утро,
Вот тут есть ПДФ файлы
https://drive.google.com/open?id=1WeY2rApPN-_Bf749yUiYZm7wHTMA9f7d
нужно убрать все надписи РРЦ в рублях вообще, а там где целая колонка — убрать колонку.
https://i.imgur.com/VHXfvWo.png
https://i.imgur.com/eemDOma.jpg
https://i.imgur.com/f4SctWL.png
Создать аналогичную версию в редактируемом Павер поинте.
есть вопросы спрашивайте.
Отзыв заказчика о сотрудничестве с Максом Києвом
Редактирование PDF файловКачество
Профессионализм
Стоимость
Контактность
Сроки
Все сделано качественно, оперативно и как для себя. С меня премия
С меня премия
Отзыв фрилансера о сотрудничестве с Дмитрием Р.
Оплата
Постановка задачи
Четкость требований
Контактность
Дмитрий хороший и добросовестный заказчик. Сотрудничество прошло отлично. Рекомендую.
Макс Київ | Сейф
- Ставки 13
- Обсуждение 1
дата онлайн рейтинг стоимость время выполнения
ставка скрыта фрилансером
- 1 день900 UAH 1 день900 UAH
Доброго Дня! Готов обсудить детали проекта и выполнить сегодня.
https://www.facebook.com/maystrenko.kirill
Freelancehunt - Победившая ставка1 день200 UAH Победившая ставка1 день200 UAH
Дмитрий, добрый день!
Уберу надписи и колонку — быстро и недорого. Большой опыт редактирования PDF-файлов.
Большой опыт редактирования PDF-файлов.
Создать отдельную редактируемую версию — нужно обсуждать, и она точно будет не в PowerPoint.
Пожалуйста, обращайтесь. Буду рад сотрудничеству. - фрилансер больше не работает на сервисе
- 1 день500 UAH 1 день500 UAH
Сделаю. Нужно обсудить детали того как это должно выглядеть в Павер поинте.
И с Павер поинте и с редактированием PDF файлов работаю постоянно. Есть еще вариант сделать Google презентацию — тогда сможет любой по ссылке с любого устройства просматривать - 1 день450 UAH 1 день450 UAH
Посмотрел файлы.
Оценил объемы работ.
450 грн Срок 1 день.
Как вариант можем работать напрямую с поэтапной оплатой. - 1 день400 UAH 1 день400 UAH
Готова сделать все быстро и качественно) буду рада сотрудничеству!
- фрилансер больше не работает на сервисе
- фрилансер больше не работает на сервисе
- фрилансер больше не работает на сервисе
- 3 дня200 UAH 3 дня200 UAH
Дмитрий, добрый день.
Первый каталог уже готов (убрала все надписи РРЦ). Второй обработаю сегодня же. За эту часть работы цена 200 гривен.
По поводу переноса все в павер поинт: будут некоторые отличия, и есть еще что обсудить с Вами. Перенос каталога в Павер Поинт будет стоить еще +500 гривен Добрый день.
Опыт работы в дизайне и полиграфии более 10 лет + фриланс.
Работу делаю ответственно в оговоренный срок. Готов обсудить детали.
Портфолио Freelancehunt- 7 дней2670 UAH 7 дней2670 UAH
Здравствуйте. Готов работать над вашим проектом. Можем обсудить детали.
 Большой опыт редактирования PDF-файлов.
Большой опыт редактирования PDF-файлов. 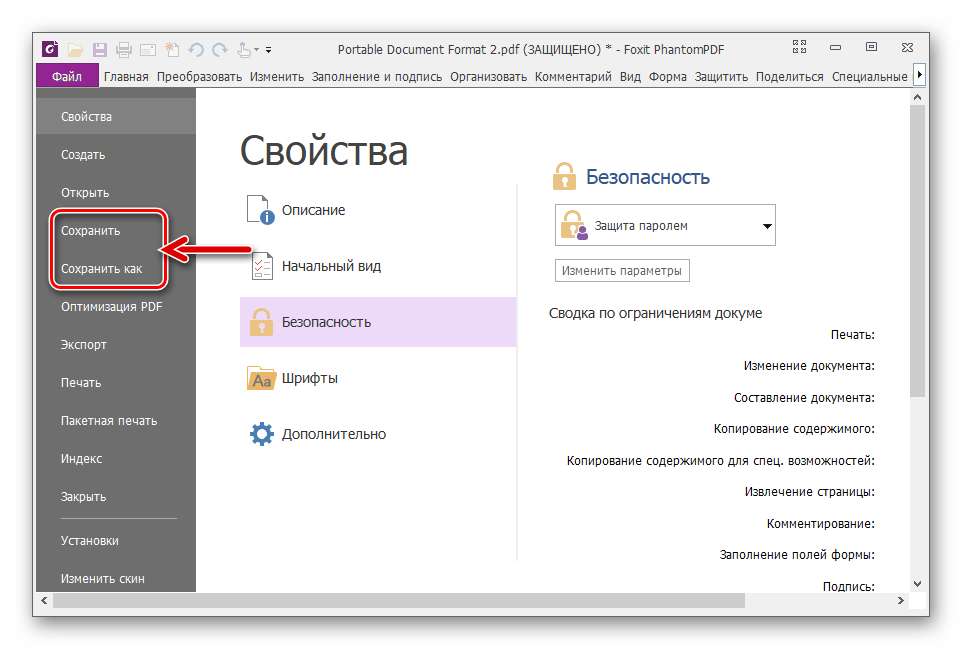
 Первый каталог уже готов (убрала все надписи РРЦ). Второй обработаю сегодня же. За эту часть работы цена 200 гривен.
Первый каталог уже готов (убрала все надписи РРЦ). Второй обработаю сегодня же. За эту часть работы цена 200 гривен. 3 года назад
195 просмотров
- распознать текст в PDF
Работа с PDF-файлами в Python: чтение и разбор
Сегодня формат переносимых документов (PDF) относится к наиболее часто используемым форматам данных. В 1990 году структура документа PDF была определена Adobe. Идея, лежащая в основе формата PDF, заключается в том, что передаваемые данные / документы выглядят одинаково для обеих сторон, участвующих в процессе коммуникации — для создателя, автора или отправителя и получателя. PDF является преемником формата PostScript и стандартизирован как ISO 32000-2: 2017 .
В 1990 году структура документа PDF была определена Adobe. Идея, лежащая в основе формата PDF, заключается в том, что передаваемые данные / документы выглядят одинаково для обеих сторон, участвующих в процессе коммуникации — для создателя, автора или отправителя и получателя. PDF является преемником формата PostScript и стандартизирован как ISO 32000-2: 2017 .
Обработка PDF документов
Для Linux существуют мощные инструменты командной строки, такие как pdftk и pdfgrep. Как разработчик, вы с огромным энтузиазмом создаете свое собственное программное обеспечение, основанное на Python и использующее свободно доступные библиотеки PDF.
Эта статья — начало небольшой серии, в которой будут рассмотрены эти полезные библиотеки Python. В первой части мы сосредоточимся на манипулировании существующими PDF-файлами. Вы узнаете, как читать и извлекать содержимое (как текст, так и изображения), вращать отдельные страницы и разбивать документы на отдельные страницы. Вторая часть будет посвящена добавлению водяных знаков на основе наложений. Третья часть будет посвящена исключительно написанию / созданию PDF-файлов, а также удалению и повторному объединению отдельных страниц в новый документ.
Третья часть будет посвящена исключительно написанию / созданию PDF-файлов, а также удалению и повторному объединению отдельных страниц в новый документ.
Инструменты и библиотеки
Спектр доступных решений для связанных с Python инструментов, модулей и библиотек PDF немного сбивает с толку, и требуется время, чтобы понять, что к чему и какие проекты поддерживаются постоянно. На основании нашего исследования это те кандидаты, которые соответствуют современным требованиям:
PyPDF2 : библиотека Python для извлечения информации и содержимого документов, постраничного разделения документов, объединения документов, обрезки страниц и добавления водяных знаков. PyPDF2 поддерживает как незашифрованные, так и зашифрованные документы.
PDFMiner : полностью написан на Python и хорошо работает для Python 2.4. Для Python 3 используйте клонированный пакет PDFMiner.six . Оба пакета позволяют анализировать и преобразовывать PDF-документы. Это включает в себя поддержку PDF 1.7, а также языков CJK (китайский, японский и корейский) и различные типы шрифтов (Type1, TrueType, Type3 и CID).
PDFQuery : он описывает себя как «быструю и удобную библиотеку очистки PDF», которая реализована как оболочка для PDFMiner, lxml и pyquery . Его цель состоит в том, чтобы «надежно извлекать данные из наборов PDF-файлов, используя как можно меньше кода».
tabula-py : Это простая оболочка Python для tabula-java , которая может читать таблицы из PDF-файлов и преобразовывать их в Pandas DataFrames. Это также позволяет вам конвертировать файл PDF в файл CSV / TSV / JSON.
pdflib для Python: расширение библиотеки Poppler, которое предлагает для него привязки Python. Это позволяет вам анализировать и конвертировать PDF документы. Не следует путать его коммерческий клон с таким же именем.
PyFPDF : библиотека для создания документов PDF под Python. Портировано из библиотеки FPDF PHP, известной замены PDFlib-расширения со множеством примеров, сценариев и производных.
PDFTables : коммерческий сервис, предлагающий извлечение из таблиц в виде документа PDF. Предлагает API, позволяющий использовать PDFTables в качестве SAAS.
PyX — графический пакет Python: PyX — это пакет Python для создания файлов PostScript, PDF и SVG. Он сочетает в себе абстракцию модели чертежа PostScript с интерфейсом TeX / LaTeX. Сложные задачи, такие как создание 2D и 3D графиков в готовом для публикации качестве, построены из этих примитивов.
ReportLab : амбициозная промышленная библиотека, в основном ориентированная на точное создание PDF-документов. Доступна свободно как версия с открытым исходным кодом, так и коммерческая улучшенная версия с именем ReportLab PLUS.
PyMuPDF (он же «fitz»): привязки Python для MuPDF, который является облегченным средством просмотра PDF и XPS. Библиотека может получать доступ к файлам в форматах PDF, XPS, OpenXPS, epub, комиксах и художественных книгах, а также известна своей высокой производительностью и высоким качеством рендеринга.
pdfrw : чистый анализатор PDF на основе Python для чтения и записи PDF. Он точно воспроизводит векторные форматы без растеризации. Вместе с ReportLab он помогает повторно использовать части существующих PDF-файлов в новых PDF-файлах, созданных с помощью ReportLab.
| Библиотека | Используется для |
|---|---|
| PyPDF2 | чтение |
| PyMuPDF | чтение |
| PDFlib | чтение |
| PDFTables | чтение |
| Табула-ру | чтение |
| PDFMiner.six | чтение |
| PDFQuery | чтение |
| pdfrw | Чтение, Запись / Создание |
| ReportLab | Запись / Создание |
| дарохранительница | Запись / Создание |
| PyFPDF | Запись / Создание |
Ниже мы сосредоточимся на PyPDF2 и PyMuPDF и объясним, как извлечь текст и изображения самым простым способом. Чтобы понять использование PyPDF2, помогло сочетание официальной документации и множества примеров, доступных на других ресурсах. Напротив, официальная документация PyMuPDF намного понятнее и значительно быстрее при использовании библиотеки.
Извлечение текста с помощью PyPDF2
PyPDF2 может быть установлен как обычный программный пакет, так и с использованием pip3 (для Python3). Тесты здесь основаны на пакете для предстоящего выпуска Debian GNU / Linux 10 «Buster». Имя пакета Debian является
Тесты здесь основаны на пакете для предстоящего выпуска Debian GNU / Linux 10 «Buster». Имя пакета Debian является python3-pypdf2.
В листинге 1 PdfFileReader сначала импортируется класс. Затем, используя этот класс, он открывает документ и извлекает информацию о документе, используя метод getDocumentInfo(), количество используемых страниц getDocumentInfo() и содержимое первой страницы.
Обратите внимание, что PyPDF2 начинает считать страницы с 0, и поэтому вызов pdf.getPage(0)извлекает первую страницу документа. В конце концов, извлеченная информация печатается в stdout.
Листинг 1: Извлечение информации и содержимого документа.
#!/usr/bin/python from PyPDF2 import PdfFileReader pdf_document = "example.pdf" with open(pdf_document, "rb") as filehandle: pdf = PdfFileReader(filehandle) info = pdf.getDocumentInfo() pages = pdf.Рис. 1: Извлеченный текст из файла PDF с использованием PyPDF2getNumPages() print (info) print ("number of pages: %i" % pages) page1 = pdf.getPage(0) print(page1) print(page1.extractText())

Как показано на рисунке 1 выше, извлеченный текст печатается на постоянной основе. Здесь нет ни абзацев, ни разделений предложений. Как указано в документации по PyPDF2, все текстовые данные возвращаются в том порядке, в котором они представлены в потоке содержимого страницы, и их использование может привести к неожиданностям. Это в основном зависит от внутренней структуры документа PDF и от того, как поток инструкций PDF был создан процессом записи PDF.
Извлечение текста с помощью PyMuPDF
PyMuPDF доступен на веб-сайте PyPi, и вы устанавливаете пакет с помощью следующей команды в терминале:
$ pip3 install PyMuPDF
Отображение информации о документе, печать количества страниц и извлечение текста из документа PDF выполняется аналогично PyPDF2 (см.
fitz и возвращается к предыдущему имени PyMuPDF.Листинг 2: Извлечение содержимого из документа PDF с использованием PyMuPDF.
#!/usr/bin/python
import fitz
pdf_document = "example.pdf"
doc = fitz.open(pdf_document):
print ("number of pages: %i" % doc.pageCount)
print(doc.metadata)page1 = doc.loadPage(0)
page1text = page1.getText("text")
print(page1text) Приятной особенностью PyMuPDF является то, что он сохраняет исходную структуру документа без изменений — целые абзацы с разрывами строк сохраняются такими же, как в PDF-документе (см. Рисунок 2 ).
Рис. 2: извлеченные текстовые данныеИзвлечение изображений из PDF с помощью PyMuPDF
PyMuPDF упрощает извлечение изображений из документов PDF с использованием метода  Если изображение имеет цветовое пространство CMYK, оно будет сначала преобразовано в RGB.
Если изображение имеет цветовое пространство CMYK, оно будет сначала преобразовано в RGB.
Листинг 3: Извлечение изображений.
#!/usr/bin/python
import fitz
pdf_document = fitz.open("file.pdf")
for current_page in range(len(pdf_document)):
for image in pdf_document.getPageImageList(current_page):
xref = image[0]
pix = fitz.Pixmap(pdf_document, xref)
if pix.n Запустив этот скрипт Python на 400-страничном PDF, он извлек 117 изображений менее чем за 3 секунды, что удивительно. Отдельные изображения хранятся в формате PNG. Чтобы сохранить исходный формат и размер изображения вместо преобразования в PNG, взгляните на расширенные версии сценариев в вики PyMuPDF .
Рис. 3: Извлеченные изображения Разделение PDF-файлов на страницы с помощью PyPDF2
Для этого примера, в первую очередь необходимо импортировать классы PdfFileReader и PdfFileWriter. Затем мы открываем файл PDF, создаем объект для чтения и перебираем все страницы, используя метод объекта для чтения getNumPages.
Внутри цикла for мы создаем новый экземпляр PdfFileWriter, который еще не содержит страниц. Затем мы добавляем текущую страницу к нашему объекту записи, используя метод pdfWriter.addPage(). Этот метод принимает объект страницы, который мы получаем, используя метод PdfFileReader.getPage().
Следующим шагом является создание уникального имени файла, что мы делаем, используя исходное имя файла плюс слово «page» плюс номер страницы. Мы добавляем 1 к текущему номеру страницы, потому что PyPDF2 считает номера страниц, начиная с нуля.
Наконец, мы открываем новое имя файла в режиме (режиме wb) записи двоичного файла и используем метод write() класса pdfWriter для сохранения извлеченной страницы на диск.
Листинг 4: Разделение PDF на отдельные страницы.
#!/usr/bin/python
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_document = "example.pdf"
pdf = PdfFileReader(pdf_document)
for page in range(pdf. getNumPages()):
pdf_writer = PdfFileWriter
current_page = pdf.getPage(page)
pdf_writer.addPage(current_page)
outputFilename = "example-page-{}.pdf".format(page + 1)
with open(outputFilename, "wb") as out:
pdf_writer.write(out)
print("created", outputFilename)
Рис. 4: Разделение PDFНайти все страницы, содержащие текст
Этот вариант использования довольно практичен и работает аналогично pdfgrep. Используя PyMuPDF, скрипт возвращает все номера страниц, которые содержат данную строку поиска. Страницы загружаются одна за другой, и с помощью метода searchFor() обнаруживаются все вхождения строки поиска. В случае совпадения соответствующее сообщение печатается на stdout.
Листинг 5: Поиск заданного текста.
#!/usr/bin/python
import fitz
filename = "example.pdf"
search_term = "invoice"
pdf_document = fitz.open(filename):
for current_page in range(len(pdf_document)):
page = pdf_document. loadPage(current_page)
if page.searchFor(search_term):
print("%s found on page %i" % (search_term, current_page))
На рисунке 5 ниже показан результат поиска для термина «Debian GNU / Linux» в книге на 400 страниц.
Рис. 5: Поиск документа PDFЗаключение
Методы, показанные здесь, довольно мощные. Сравнительно небольшое количество строк кода позволяет легко получить результат. Другие варианты использования рассматриваются во второй части (скоро!), Посвященной добавлению водяного знака в PDF.
Перевод статьи: Working with PDFs in Python: Reading and Splitting

 getNumPages()):
pdf_writer = PdfFileWriter
current_page = pdf.getPage(page)
pdf_writer.addPage(current_page)
outputFilename = "example-page-{}.pdf".format(page + 1)
with open(outputFilename, "wb") as out:
pdf_writer.write(out)
print("created", outputFilename)
getNumPages()):
pdf_writer = PdfFileWriter
current_page = pdf.getPage(page)
pdf_writer.addPage(current_page)
outputFilename = "example-page-{}.pdf".format(page + 1)
with open(outputFilename, "wb") as out:
pdf_writer.write(out)
print("created", outputFilename) loadPage(current_page)
if page.searchFor(search_term):
print("%s found on page %i" % (search_term, current_page))
loadPage(current_page)
if page.searchFor(search_term):
print("%s found on page %i" % (search_term, current_page))
5 Методы извлечения данных PDF
Формат переносимых документов (PDF) — это формат файлов для совместного использования и обмена бизнес-данными. Вы можете легко просматривать, сохранять и распечатывать PDF-файлы.
Но редактирование, очистка/анализ или извлечение данных из PDF-файлов может быть большой проблемой.
Например, вы когда-нибудь пытались извлечь текст из PDF-файлов , извлечь таблицы из PDF-файлов или сделать простой PDF-файл доступным для поиска?
GiphyИзвлечение данных из PDF-файлов имеет решающее значение для реорганизации данных в соответствии с вашими требованиями.
В других форматах документов, таких как DOC, XLS или CSV, извлечь часть информации довольно просто. Просто отредактируйте данные или скопируйте и вставьте.
Но это довольно сложно сделать в случае PDF-файлов.
Редактирование невозможно, а копирование и вставка просто не сохраняет исходное форматирование и порядок — попробуйте извлечь таблицы из PDF!
При массовом извлечении данных PDF эти проблемы могут привести к ошибкам, задержкам или перерасходу средств, что может серьезно повлиять на вашу прибыль!
К счастью, существуют такие решения, как Nanonets , которые могут эффективно извлекать данные из PDF-документов.
Давайте рассмотрим 5 самых популярных способов, которыми компании извлекают данные из PDF-файлов.
Вот 5 различных способов извлечения данных из PDF в порядке возрастания эффективности и точности:
- Копировать и вставить
- Ручной ввод данных аутсорсинга
- PDF-конвертеры
- Инструменты для извлечения таблиц PDF
- Извлечение данных из PDF в Excel
- Автоматическое извлечение данных PDF
Требуется интеллектуальное решение для преобразования изображения в текст , PDF в таблицу , PDF в текст или извлечения данных PDF ? Проверьте предварительно обученный ИИ Nanonets для извлечения данных для банковских выписок, счетов, квитанций, паспортов, водительских прав и любых табличных данных!
Автоматизированное извлечение данных с использованием NanonetsКопирование и вставка
Giphy Метод копирования и вставки является наиболее практичным вариантом при работе с небольшим количеством простых документов PDF.
- Открытие каждого файла PDF
- Выбор части данных или текста на определенной странице или наборе страниц
- Копирование выбранной информации
- Вставка скопированной информации в файл DOC, XLS или CSV
💡 9000 3
Этот простой подход часто приводит к неустойчивому и подверженному ошибкам извлечению данных. Вам придется потратить значительное количество времени, чтобы осмысленно реорганизовать извлеченную информацию.
Аутсорсинг ручного ввода данных
GiphyРучное извлечение данных из PDF-файлов собственными силами для большого количества документов может стать неустойчивым и непомерно дорогим в долгосрочной перспективе.
Аутсорсинг ручного ввода данных является очевидной альтернативой, которая является одновременно дешевой и быстрой.
Онлайн-сервисы, такие как Upwork, Freelancer, Hubstaff Talent, Fiverr и другие подобные компании, имеют целую армию специалистов по вводу данных из стран со средним уровнем дохода в Южной Азии, Юго-Восточной Азии и Африке.
💡
Хотя этот подход может сократить затраты и задержки на извлечение данных, контроль качества и безопасность данных вызывают серьезную озабоченность! Поэтому решения для автоматизации ввода и автоматического извлечения данных становятся все более популярными.
GiphyХотите захватить данные из документов PDF или преобразовать PDF в Excel? Отъезд Nanonets PDF-скребок или PDF-парсер до очищать PDF-данные или разобрать PDF-файлы в масштабе!
Супер-счастливый пользователь NanonetsПреобразователи PDF
Преобразователи PDF — очевидный выбор для тех, кто заботится о качестве и безопасности данных.
Преобразователи PDF позволяют управлять извлечением данных самостоятельно, будучи быстрыми и эффективными. Конвертеры PDF доступны в виде программного обеспечения, веб-решений и даже мобильных приложений.
PDF-файлы чаще всего конвертируются в Excel (XLS или XLSX) или конвертируются в форматы CSV, поскольку они представляют таблицы в аккуратном виде; Конвертеры PDF в XML также популярны.
Просто загрузите PDF-документ и преобразуйте его в нужный формат.
Вот некоторые лучшие инструменты и программное обеспечение для преобразования PDF:
- Adobe
- Simply PDF
- SmallPDF
- PDF2Go
- PDFtoExcel
- Выписка из PDF-банка в Excel 9 0036
- PDFelement
- Nitro Pro
- Cometdocs
- iSkysoft PDF Converter Pro
💡
PDF-конвертеры не приспособлены для обработки документов большого размера. Массовое извлечение данных просто невозможно, и нужно повторять процесс извлечения данных для каждого документа, по одному!
Очень часто PDF-документы содержат таблицы, а также текст, изображения и рисунки. Во многих случаях интересующие данные обычно содержатся в таблицах.
Преобразователи PDF обрабатывают весь документ PDF, не предоставляя возможность ограничить извлечение данных определенным разделом в PDF (например, определенными ячейками, строками, столбцами или даже таблицами).
Инструменты извлечения PDF в таблицу делают именно это.
Инструменты/технологии извлечения таблиц PDF, такие как Tabula и Excalibur, позволяют выбирать разделы в PDF, рисуя рамку вокруг таблицы и затем извлекая данные в файл Excel (XLS или XLSX) или CSV.
💡
Хотя инструменты преобразования PDF в таблицы дают достаточно эффективные результаты, вам могут потребоваться усилия разработчиков или штатные специалисты, чтобы использовать базовые технологии, лежащие в основе этих инструментов, в соответствии с вашими собственными вариантами использования. Кроме того, такие инструменты извлечения данных PDF работают только с исходными файлами PDF, а не с отсканированными документами (которые используются чаще)!
Если ваши PDF-файлы связаны со счетами, квитанциями, паспортами или водительскими правами, ознакомьтесь с Nanonets’ Скребок PDF или Средство извлечения данных PDF для извлечения данных из документов PDF.
Интеллектуальные решения для обработки документов или программное обеспечение OCR на основе ИИ, такое как Nanonets, обеспечивают наиболее комплексное решение проблемы извлечения данных из PDF-файлов или извлечения текста из изображений.
Надежные, эффективные, чрезвычайно быстрые, конкурентоспособные по цене, безопасные и масштабируемые. Они также могут обрабатывать отсканированные документы, а также собственные файлы PDF.
Такие автоматические средства извлечения данных PDF используют комбинацию AI, ML/DL, OCR, RPA, распознавания образов, распознавания текста и других методов для точного извлечения данных в масштабе.
Автоматизированные инструменты извлечения данных PDF, такие как Nanonets, используют машинное обучение для предоставления предварительно обученных экстракторов, которые могут обрабатывать определенные типы документов.
Вот краткая демонстрация предварительно обученного экстрактора таблиц Nanonets:
 youtube.com/embed/u_8P6oUBgVI?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/> Предварительно обученная модель экстрактора таблиц Nanonets
youtube.com/embed/u_8P6oUBgVI?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/> Предварительно обученная модель экстрактора таблиц NanonetsПомимо использования предварительно обученных моделей извлечения, вы также можете создать свой собственный ИИ для извлечения данных из различных документов. . Вот как:
- Собрать пакет образцов документов для использования в качестве обучающего набора
- Обучить автоматизированное программное обеспечение для извлечения данных в соответствии с вашими потребностями
- Тестировать и проверить
- Запустить обученное программное обеспечение на реальных документах
- Обработать извлеченные данные
У Nanonets есть много интересных вариантов использования, которые могут оптимизировать эффективность вашего бизнеса, сократить расходы и ускорить рост. Узнайте, как варианты использования Nanonets могут применяться к вашему продукту.
Узнайте, как варианты использования Nanonets могут применяться к вашему продукту.
Обновление Декабрь 202 2 : этот пост был первоначально опубликован в Октябрь 2020 и с тех пор обновлялся много раз .
На слайде представлены результаты этой статьи. Вот альтернативная версия этого поста.
Полное руководство по автоматизированной обработке документов PDF
Спасибо! Ваша заявка принята!
Ой! Что-то пошло не так при отправке формы.
Работаете ли вы в бизнесе с большим количеством файлов PDF?
Вам необходимо собирать данные из pdf-форм, гарантируя, что все данные будут сохранены в базе данных в неизменном виде?
Еще вопрос — вручную делаете?
Если да, то только вы можете себе представить, насколько трудоемким и подверженным ошибкам может быть весь процесс!
Ручной ввод данных, если он используется в среде высокоскоростного процессора данных, делает систему неэффективной, а встроенная очередь разрушает всю суть управления процессами для повышения производительности и системы. производительность. Вот как ручная обработка PDF позволяет вашему бизнесу полностью раскрыть свой потенциал:
производительность. Вот как ручная обработка PDF позволяет вашему бизнесу полностью раскрыть свой потенциал:
Ручная процедура выполняется людьми, которые не могут безошибочно выполнять рутинные действия. Скорее всего, человек может совершить ошибку. Эти ошибки толстых пальцев в основном можно разделить на две категории: —
i) Ошибки транскрипции — Эти ошибки обычно связаны с транскрибированием слов, которые включают опечатки, удаление, повторение или орфографические ошибки
ii) Ошибки транспонирования — Эти ошибки обычно связаны с цифрами, когда вы вводите цифры в неправильном порядке. Например, вместо 567 вы по ошибке ввели 576.
При отсутствии уровня проверки вероятность ошибок при ручном вводе данных может достигать 4 %. Это означает 400 ошибок на каждые 10 000 слов. Когда вы работаете с большим набором данных, эта частота ошибок может возрасти до 5% и более.
Человек не может конкурировать с компьютером, когда речь идет о времени обработки и точности. Что касается извлечения данных из PDF-файлов, включающих миллионы объектов, низкоскоростная конструкция ручной обработки проверяется на целостность и проверку данных, чтобы элемент данных, поступающий в систему, был точным.
При ручной обработке каждого документа может потребоваться до 10-15 минут для точного извлечения данных, просмотра и сохранения в структурированной базе данных. Для больших pdf-файлов время обработки легко может увеличиться до 45-60 минут.
Медленная ручная обработка делает весь процесс слишком дорогостоящим для поддержания. Допустим, вы вкладываете 20 долларов в час на человека в ручную обработку документов. Если человеку требуется 10 минут для обработки одного документа, стоимость обработки одного документа составит 3,33 доллара.
Добавьте стоимость дополнительного уровня проверки ко всему процессу, и стоимость станет еще выше.
4. Безопасность данных В системе, где защита данных является проблемой, ручной ввод данных может серьезно повлиять на нее. Чувствительные документы могут отрастить ноги и двигаться, тем самым ставя под угрозу всю схему. Для бизнеса конфиденциальность является первостепенной задачей. До 75,33 % данных могут быть потеряны/утекли во время ручной обработки PDF-документов, что может подвергнуть компанию риску.
Обработка документов является важным аспектом многих предприятий. Давайте посмотрим на эти предприятия и список документов, которые им необходимо обрабатывать на регулярной основе:
- BFSI: Счета, банковские выписки, контракты, отчеты, документы KYC
- Здравоохранение: Прайс-листы, отчеты , Медицинские формы.
- Образование: Платежные квитанции, Цифровые учебные материалы.
- Правительство и BPO: Контракты, банковские выписки, счета.
- Транспорт и логистика: Транспортные этикетки, контракты, счета-фактуры, заказы на поставку.

Эти документы часто отправляются по электронной почте в формате PDF или отсканированного изображения. В качестве следующего шага извлечение данных может быть выполнено либо вручную, либо с использованием автоматизированных методов обработки. Все больше и больше предприятий постепенно внедряют автоматизацию в свои процедуры ввода данных, причем сектор BFSI является лидером. Сектор BFSI доминировал на рынке роботизированной автоматизации процессов с более чем 29% мирового дохода от RPA в 2019 году согласно отчету, опубликованному Grand View Research.
За сектором BFSI внимательно следят Pharma и Healthcare. Если 2020 год является каким-либо признаком, отрасли здравоохранения и логистики собираются внедрить автоматизацию в гораздо более широком масштабе.
Принимая во внимание ограничения ручного извлечения данных, предприятия в настоящее время стремятся использовать автоматизированное программное обеспечение для извлечения данных PDF для обработки и анализа данных из документов PDF/отсканированных изображений с минимальным вмешательством человека.
- Для автоматического извлечения данных из полей форм PDF в Excel можно создавать и настраивать правила и формулы. Это сокращает затраты времени на поиск и извлечение данных. Кроме того, автоматический ввод данных обеспечивает точность данных на уровне 99,98 % и может помочь вам сосредоточиться на других секторах вашей компании.
- Благодаря интегрированным механизмам распознавания текста вы можете удалять данные с фотографий без повторного ввода их вручную. Это снижает вероятность опечаток и других ошибок при удалении. Ручное извлечение данных снижает количество ошибок на 95% и снижает риск потери данных.
- Весь конвейер извлечения может быть автоматизирован и запущен с многочисленными файлами PDF для извлечения необходимых деталей. Это повышает производительность компании и гарантирует доступность данных при необходимости. Сотрудник выполняет в среднем 250 поисковых запросов информации для поиска записей вручную, когда он может сделать это за гораздо меньшее время с помощью автоматических экстракторов.
 Это повышает производительность компании и гарантирует доступность данных при необходимости. Сотрудник выполняет в среднем 250 поисковых запросов информации для поиска записей вручную, когда он может сделать это за гораздо меньшее время с помощью автоматических экстракторов.
Это повышает производительность компании и гарантирует доступность данных при необходимости. Сотрудник выполняет в среднем 250 поисковых запросов информации для поиска записей вручную, когда он может сделать это за гораздо меньшее время с помощью автоматических экстракторов. - Автоматическое извлечение также обеспечивает отслеживаемость. Они отслеживают ваши данные и помогают вам во время проверок. Компании, использующие автоматическое извлечение данных, имеют показатель успеха 7%, чем те, которые используют ручное извлечение.
Основным недостатком автоматического извлечения является невозможность чтения и сбора данных из растровых PDF-файлов. Например, вам нужно максимально увеличить размер изображений выше 1000 для сканирования с высоким разрешением. Следовательно, для извлечения необходимы векторные PDF-файлы. Это требует большего участия оператора и ручной очистки. Мало того, когда растровый PDF-файл обрабатывается с помощью программного обеспечения, плоское изображение будет преобразовано в слой трассировки для ручной работы.
Следовательно, для извлечения необходимы векторные PDF-файлы. Это требует большего участия оператора и ручной очистки. Мало того, когда растровый PDF-файл обрабатывается с помощью программного обеспечения, плоское изображение будет преобразовано в слой трассировки для ручной работы.
Аналитика и таблицы помогают компаниям, предоставляя обзор их производительности. Информация, представленная в таблицах, помогает компаниям оптимизировать свой бизнес и находить эффективные способы принятия более эффективных решений в будущем. К сожалению, автоматические PDF-файлы показывают, что данные в таблице недействительны, и для их исправления требуются ручные предложения.
Docsumo предоставляет дружественный и простой для понимания интерфейс для извлечения данных PDF.
 youtube.com/embed/XpYDhmyo2yc»>
youtube.com/embed/XpYDhmyo2yc»> Вот шаги, которые необходимо выполнить для успешного извлечения данных из PDF.
- Загрузить PDF-документ: Войдите на домашнюю страницу Docsumo, выберите параметр преобразования PDF и перетащите или загрузите документ в указанное место, где вы хотите его преобразовать. Если у вас есть файл Microsoft, документ Google или файл, хранящийся в облаке, Docsumo читает его и выполняет необходимые действия.
- Подтверждение поля: После загрузки документа вам будет предложено подождать 30 секунд, максимальное время, необходимое для преобразования документа.
- Поля редактирования: С помощью панели просмотра проверьте извлеченные детали. Если требуются какие-либо изменения, вы можете редактировать и вносить изменения до преобразования.
- Проверка и утверждение: Если после вашего выбора в программном обеспечении появятся какие-либо предложения, примите решение, выбрав или отклонив его.

- Загрузите файл: После завершения всей процедуры вам будет предложено выбрать формат файла, в котором вы хотите загрузить выходной файл. Выберите один из следующих 4 вариантов: —
i) Загрузить JSON
ii) Загрузить Excel
iii) Загрузить CSV
iv) Загрузить текст
Final Words Предприятия должны обрабатывать несколько файлов PDF в день. Но иногда случаются сбои, особенно при переводе отсканированных PDF-документов в Excel. С этими ограничениями сталкиваются различные приложения.
Для этого компания Docsumo разработала средство извлечения данных, которое помогает пользователю извлекать данные из pdf-форм, включая отсканированные и неотсканированные pdf-файлы, путем преобразования их в Excel и другие форматы.
С помощью нашего бесплатного инструмента для извлечения данных PDF вы можете преобразовать указанные данные за считанные секунды. Он удобен в использовании, а беспроблемный опыт привлек множество клиентов по всему миру..png)
Ваш комментарий будет первым