Как узнать вид сайта в прошлом через WebArchive
У 9 из 10 наших читателей есть свой сайт или интернет-магазин на 1C-UMI. Кто-то создал его недавно, а кому-то уже можно праздновать юбилей. За годы развития веб-ресурсы претерпевают множество изменений во внешнем виде и функционале. Иногда хочется вспомнить, каким же был ваш проект раньше, когда всё только начиналось. Или поднять какую-то утерянную информацию, которая была на сайте ранее. Сделать это легко при помощи чудо-сервиса Wayback Machine.
Как пользоваться веб-архивом
Откройте сервис, вбейте в строку поиска домен или полный адрес своего сайта. Сервис автоматически начнет поиск и через пару секунд покажет вам результаты в виде временной шкалы и календаря с датами, когда были сделаны снимки ресурса.
Чтобы перейти к конкретному году, кликните по соответствующему блоку на шкале. Затем в календаре ниже нажмите на одну из дат, выделенных голубым цветом. Если в тот день было сделано несколько снимков, при нажатии на дату вы увидите окно для выбора нужного вам времени.
Вот так выглядел наш сайт 1C-UMI летом 2012 года:
А вот так его видели наши пользователи осенью 2016 года:
Чем дольше ресурс работает, тем больше его снимков будет в WebArhive. Для путешествия в прошлое используйте временную шкалу и блок переключения месяцев и чисел справа от нее.
Самое классное — что данный сервис не делает скриншоты сайтов, а сохраняет их целиком. Таким образом, вы увидите версию 10-летней давности и, все разделы, формы, почитаете тексты, полистаете изображения и многое другое.
Какие сайты попадают в веб-архив
Оказаться в Wayback Machine может любой сайт. Особенно это касается тех веб-ресурсов, которые находятся в каталоге DMOZ. Но так как сейчас туда свое «детище» уже не добавить, будет достаточно того, что на вашу площадку ссылаются сайты, снимки которых уже присутствуют в веб-архиве. А даже если таких ссылок нет, ваш ресурс все равно может попасть в базу сервиса.
Как проверить? Для сайтов на 1С-UMI откройте раздел «Реклама/SEO → Управление robots.txt» в панели управления сайтом и проверьте, нет ли в нем следующей записи:
User-agent: ia_archiver
Disallow: /
Если такой записи (как выше) нет, все хорошо, ваш сайт имеет шанс на попадание в веб-архив. В противном случае, при поиске своего ресурса в сервисе вы увидите надпись, как на скриншоте ниже.
Если вы не хотите ждать, когда сервис соблаговолит сделать снимок вашего сайта, добавьте его в базу WebArchive вручную. Для этого найдите функцию «Save Page Now», которая находится в центральной части страницы справа.
Укажите ссылку на свой ресурс и нажмите на кнопку «SAVE PAGE». Сохранение начнется через несколько секунд и, спустя минуту или около того, будет закончено. За ходом выполнения вы можете наблюдать в небольшом окошке по центру экрана.
После сохранения снимка страницы начнет загружаться только что архивированная версия сайта.
По окончании процесса окно загрузки закроется, и вы сможете просмотреть сохраненный снимок, побродить по всем разделам сайта и т. д.
Чем будет полезен веб-архив для вас
Данный сервис годится не только для того, чтобы смотреть, в каком состоянии была ваша страничка или любой другой ресурс некоторое время назад. С его помощью вы можете восстановить свой сайт, его страницу, какой-то текст или элемент, если вдруг по какой-то причине данные были стерты. Чтобы этого не произошло, не забывайте почаще выполнять резервное копирование вашего сайта, ну, а на экстренный случай имейте в виду WebArchive. Но имейте в виду также, что WebArchive делает снимки по своему усмотрению с непредсказуемой частотой, поэтому нужной вам версии сайта в нем может и не оказаться.
Вручную восстанавливать ресурс из веб-архива очень долго и для этого нужно неплохо разбираться в сайтостроении и верстке. Однако при желании восстановление можно автоматизировать при помощи онлайн-инструмента ARCHIVARIX.
До 200 файлов сервис восстанавливает бесплатно, а при большем количестве взимает небольшую плату.
Веб-архив может быть вам полезен и тем, что он содержит колоссальное количество уникальных текстов, которые опубликованы на канувших в небытие ресурсах. Как это можно использовать с выгодой для своего бизнеса? Допустим, вы запускаете сайт. Сами писать тексты не можете из-за отсутствия времени, а на оплату услуг копирайтера денег нет. Чтобы не откладывать запуск проекта, попробуйте найти уникальный контент в Wayback Machine.
Найдите любой сайт, близкий вашему по тематике, откройте его содержимое, скопируйте тексты и прогоните их через софт или сервис проверки на плагиат. Статьи, которые окажутся уникальными (от 90% и выше), вы можете без зазрения совести опубликовать на своем сайте. Это не будет считаться хищением, так как тексты после удаления ресурсов стали ничейными.
Для поиска таких сайтов можно использовать базы хостинговых компаний. Обычно они публикуют список тех доменов, срок действия которых истек или вот-вот истечет. Существуют и специальные программы, которые ищут освободившиеся домены по нужным параметрам.
Существуют и специальные программы, которые ищут освободившиеся домены по нужным параметрам.
Несколько фактов о веб-архиве
Первый запуск сервиса WebArchive состоялся в 1996 году. С тех пор этот инструмент сумел накопить в своей базе более 338 миллиардов сайтов. Представьте, сколько это! А дисковое пространство, которое занято информацией в архиве, составляет 1015 Терабайт. Если перевести на математический язык, то это квадриллион.
На следующий год после основания сервиса WebArchive добавил в свою базу сам себя. Хотите посмотреть, как он выглядел на тот момент? Тогда взгляните на изображение ниже.
Это самый первый его снимок от 26 января 1997 года.
На данный момент веб-архив считается наилучшим способом из бесплатных для создания снимков интернет-ресурсов. Возьмите его на вооружение.
Заказать качественный сайт за любой бюджет, разработка сайтов в Москве, по всей России — Disprove
Создание сайтов
— важный шаг развития компаний, разработка качественного сайта залог хорошей прибыли и завлечение новый клиентов на сайт. Бренд компании должен быть известен, соответствовать 100% доверию среди покупателей. Заказать сайт лучше сейчас, не забывайте о конкурентах.
Бренд компании должен быть известен, соответствовать 100% доверию среди покупателей. Заказать сайт лучше сейчас, не забывайте о конкурентах.Интернет становится частичкой жизни, чаще люди интересуются новинками, используя мобильные системы, лежащих всегда под рукой. За небольшой скидкой готовы потратить не один день чтобы получить интересующую новинку. Поэтому важно, чтобы сайт решал основные задачи: безопасность, стабильность, быстрый отклик и дружелюбный интерфейс.
Компания «Disprove» представляет множество услуг по созданию, развитию, продвижению в поисковых системах сайта. Создать интересный дизайн сайта или оптимизировать сайт под мобильные устройства. У нас богатый опыт в разработке интернет магазинов, также крупных сервисов, поэтому мы понимаем важность и необходимость инструментов на сайте.
Вам остается только пользоваться сайтом. Не важно если вы находитесь в Москве или в другом городе, наши менеджеры позвонят и будут на связи для решения любых поставленных задач.
Хотите заказать качественный сайт? Вы пришли по адресу. Все работы делятся на несколько этапов — отрисовка дизайна сайта, создание веб-страниц сайта и программирование сайта. Минимальная стоимость разработки сайта рассчитана индивидуально для каждого проекта. Нам не нужно искать специалистов на стороне, сайт разрабатывается нами, что гарантирует не затягивание сроков, выполнения работы в срок.
Заказать
сайт просто, необходимо зайти в нужный раздел, чтобы сделать заказ, используйте форму обратной связи. Вы также можете обратиться к нашим менеджерам для озвучивания своих вопросов, заявка вас ничему не обязывает. Мы обязательно свяжемся и решим поставленные задачи.Разрабатывать сайты не единственная наша специальность — сайта в поисковых системах, техническая поддержка сайта. Ознакомиться с услугами вы можете, перейдя по ссылкам.
Вы можете познакомиться с ценами на системы управлением сайта перейдя по ссылке — Цены
Создание и продвижение сайтов WEB-35
В настоящее время разработка собственного сайта в Вологде является одним из главнейших атрибутов предприятий и организаций, которые желают работать и зарабатывать также и благодаря интернету. Большинство компаний, которые занимаются продажами товаров и услуг, стремятся к тому, чтобы потенциальный клиент смог с помощью поисковой выдачи найти сайт организации.
Большинство компаний, которые занимаются продажами товаров и услуг, стремятся к тому, чтобы потенциальный клиент смог с помощью поисковой выдачи найти сайт организации.
Грамотно разработанный веб-сайт станет отличным методом распространения информации об организации. На сайте предоставлена информация об организации, описание товаров и услуг, адрес, схема проезда, контактные данные Она необходима для того, чтобы у посетителя, который зашел на ваш сайт, сложилось полное впечатление о компании и о её возможностях.
В настоящее время большое количество людей пользуются Интернет-ресурсом. Исходя из этого, получается, что при помощи создания сайта о вашей организации узнает большее количество будущих клиентов.
Возможность создания для вашей организации сайта не ограничивается предоставлением только информации для интернет-пользователей, с помощью его можно хорошо отрекламировать товар или услугу, которые Вы предоставляете. Без помощи рекламы не было бы возможности узнать о существовании вашей организации, а с помощью интернета это стало намного легче и эффективнее.
Конечно, чтобы ваш веб-сайт оказался на приличном месте среди конкурентов, необходимо принять определенные меры например продвижение сайта или контекстная реклама, и в случае с продвижением сайта это займет некоторое время, но эти затраты достаточно быстро окупаются.
Еще одной важной причиной для создания сайта является то, что это современный способ для предоставления рекламной информации. Для современных компаний иметь собственный интернет-сайт считается достаточно хорошим тоном.

Имея свой сайт, Вы получаете отличную систему для рекламы ваших товаров или услуг всем заинтересованным людям. Тем самым Вы приобретёте огромные возможности для развития своего бизнеса.
Как парсить информацию с любого сайта при помощи Screaming Frog
Если вам нужно просто собрать с сайта мета-данные, можно воспользоваться бесплатным парсером системы Promopult. Но бывает, что надо копать гораздо глубже и добывать больше данных, и тут уже без сложных (и небесплатных) инструментов не обойтись.
Евгений Костин рассказал о том, как спарсить любой сайт, даже если вы совсем не дружите с программированием. Разбор сделан на примере Screaming Frog Seo Spider.
Что такое парсинг и зачем он нужен
ПО для парсинга
Пример 1. Как спарсить цену
Пример 2. Как спарсить фотографии
Пример 3. Как спарсить характеристики товаров
Пример 4. Как парсить отзывы (с рендерингом)
Как парсить отзывы (с рендерингом)
Пример 5. Как спарсить скрытые телефоны на сайте ЦИАН
Пример 6. Как парсить структуру сайта на примере DNS-Shop
Возможности парсинга на основе XPath
Ограничения при парсинге
Что такое парсинг и зачем он нужен
Парсинг нужен, чтобы получить с сайтов некую информацию. Например, собрать данные о ценах с сайтов конкурентов.
Одно из применений парсинга — наполнение каталога новыми товарами на основе уже существующих сайтов в интернете.
Упрощенно, парсинг — это сбор информации. Есть более сложные определения, но так как мы говорим о парсинге «для чайников», то нет никакого смысла усложнять терминологию. Парсинг — это сбор, как правило, структурированной информации. Чаще всего — в виде таблицы с конкретным набором данных. Например, данных по характеристикам товаров.
Парсер — программа, которая осуществляет этот сбор. Она ходит по ссылкам на страницы, которые вы указали, и собирает нужную информацию в Excel-файл либо куда-то еще.
Парсинг работает на основе XPath-запросов. XPath — язык запросов, который обращается к определенному участку кода страницы и собирает из него заданную информацию.
ПО для парсинга
Здесь есть важный момент. Если вы введете в поисковике слово «парсинг» или «заказать парсинг», то, как правило, вам будут предлагаться услуги от компаний, которые создадут парсер под ваши задачи. Стоят такие услуги относительно дорого. В результате программисты под заказ напишут некую программу либо на Python, либо на каком-то еще языке, которая будет собирать информацию с нужного вам сайта. Эта программа нацелена только на сбор конкретных данных, она не гибкая и без знаний программирования вы не сможете ее самостоятельно перенастроить для других задач.
При этом есть готовые решения, которые можно под себя настраивать как угодно и собирать что угодно. Более того, если вы — SEO-специалист, возможно, одной из этих программ вы уже пользуетесь, но просто не знаете, что в ней есть такой функционал. Либо знаете, но никогда не применяли, либо применяли не в полной мере.
Либо знаете, но никогда не применяли, либо применяли не в полной мере.
Вот две программы, которые являются аналогами.
Эти программы занимаются сбором информации с сайта. То есть они анализируют, например, его заголовки, коды, теги и все остальное. Помимо прочего, они позволяют собрать те данные, которые вы им зададите.
Профессиональные инструменты PromoPult: быстрее, чем руками, дешевле, чем у других, бесплатные опции.
Съем позиций, кластеризация запросов, парсер Wordstat, сбор поисковых подсказок, сбор фраз ассоциаций, парсер мета-тегов и заголовков, анализ индексации страниц, чек-лист оптимизации видео, генератор из YML, парсер ИКС Яндекса, нормализатор и комбинатор фраз, парсер сообществ и пользователей ВКонтакте.
Давайте смотреть на реальных примерах.
Пример 1. Как спарсить цену
Предположим, вы хотите с некого сайта собрать все цены товаров. Это ваш конкурент, и вы хотите узнать, сколько у него стоят товары.
Возьмем для примера сайт mosdommebel. ru.
ru.
У нас есть страница карточки товара, есть название и есть цена этого товара. Как нам собрать эту цену и цены всех остальных товаров?
Мы видим, что цена отображается вверху справа, напротив заголовка h2. Теперь нам нужно посмотреть, как эта цена отображается в html-коде.
Нажимаем правой кнопкой мыши прямо на цену (не просто на какой-то фон или пустой участок). Затем выбираем пункт Inspect Element для того, чтобы в коде сразу его определить (Исследовать элемент или Просмотреть код элемента, в зависимости от браузера — прим. ред.).
Мы видим, что цена у нас помещается в тег с классом totalPrice2. Так разработчик обозначил в коде стоимость данного товара, которая отображается в карточке.
Фиксируем: есть некий элемент span с классом totalPrice2. Пока это держим в голове.
Есть два варианта работы с парсерами.
Первый способ. Вы можете прямо в коде (любой браузер) нажать правой кнопкой мыши на тег <span> и выбрать Скопировать > XPath. У вас таким образом скопируется строка, которая обращается к данному участку кода.
У вас таким образом скопируется строка, которая обращается к данному участку кода.
Выглядит она так:
/html/body/div[1]/div[2]/div[4]/table/tbody/tr/td/div[1]/div/table[2]/tbody/tr/td[2]/form/table/tbody/tr[1]/td/table/tbody/tr[1]/td/div[1]/span[1]Но этот вариант не очень надежен: если у вас в другой карточке товара верстка выглядит немного иначе (например, нет каких-то блоков или блоки расположены по-другому), то такой метод обращения может ни к чему не привести. И нужная информация не соберется.
Поэтому мы будем использовать второй способ. Есть специальные справки по языку XPath. Их очень много, можно просто загуглить «XPath примеры».
Например, такая справка:
Здесь указано как что-то получить. Например, если мы хотим получить содержимое заголовка h2, нам нужно написать вот так:
//h2/text()Если мы хотим получить текст заголовка с классом productName, мы должны написать вот так:
//h2[@class="productName"]/text()То есть поставить «//» как обращение к некому элементу на странице, написать тег h2 и указать в квадратных скобках через символ @ «класс равен такому-то».
То есть не копировать что-то, не собирать информацию откуда-то из кода. А написать строку запроса, который обращается к нужному элементу. Куда ее написать — сейчас мы разберемся.
Куда вписывать XPath-запрос
Мы идем в один из парсеров. В данном случае — Screaming Frog Seo Spider.
Эта программа бесплатна для анализа небольшого сайта — до 500 страниц.
Интерфейс Screaming Frog Seo Spider
Например, мы можем — бесплатно — посмотреть заголовки страниц, проверить нет ли у нас каких-нибудь пустых тайтлов или дубликатов тега h2, незаполненных метатегов или каких-нибудь битых ссылок.
Но за функционал для парсинга в любом случае придется платить, он доступен только в платной версии.
Предположим, вы оплатили годовую лицензию и получили доступ к полному набору функций сервиса. Если вы серьезно занимаетесь анализом данных и регулярно нуждаетесь в функционале сервиса — это разумная трата денег.
Во вкладке меню Configuration у нас есть подпункт Custom, и в нем есть еще один подпункт Extraction. Здесь мы можем дополнительно что-то поискать на тех страницах, которые мы укажем.
Здесь мы можем дополнительно что-то поискать на тех страницах, которые мы укажем.
Заходим в Extraction. Нам нужно с сайта Московского дома мебели собрать цены товаров.
Мы выяснили в коде, что у нас все цены на карточках товара обозначаются тегом <span> с классом totalPrice2. Формируем вот такой XPath запрос:
//span[@class="totalPrice2"]/spanИ указываем его в разделе Configuration > Custom > Extractions. Для удобства можем назвать как-нибудь колонку, которая у нас будет выгружаться. Например, «стоимость»:
Таким образом мы будем обращаться к коду страниц и из этого кода вытаскивать содержимое стоимости.
Также в настройках мы можем указать, что парсер будет собирать: весь html-код или только текст. Нам нужен только текст, без разметки, стилей и других элементов.
Нажимаем ОК. Мы задали кастомные параметры парсинга.
Как подобрать страницы для парсинга
Дальше есть еще один важный этап. Это, собственно, подбор страниц, по которым будет осуществляться парсинг.
Это, собственно, подбор страниц, по которым будет осуществляться парсинг.
Если мы просто укажем адрес сайта в Screaming Frog, парсер пойдет по всем страницам сайта. На инфостраницах и страницах категорий у нас нет цен, а нам нужны именно цены, которые указаны на карточках товара. Чтобы не тратить время, лучше загрузить в парсер конкретный список страниц, по которым мы будем ходить, — карточки товаров.
Откуда их взять? Как правило, на любом сайте есть карта сайта XML, и находится она чаще всего по адресу: «адрес сайта/sitemap.xml». В случае с сайтом из нашего примера — это адрес:
https://www.mosdommebel.ru/sitemap.xml.Либо вы можете зайти в robots.txt (site.ru/robots.txt) и посмотреть. Чаще всего в этом файле внизу содержится ссылка на карту сайта.
Ссылка на карту сайта в файле robots.txt
Даже если карта называется как-то странно, необычно, нестандартно, вы все равно увидите здесь ссылку.
Но если не увидите — если карты сайта нет — то нет никакого решения для отбора карточек товара.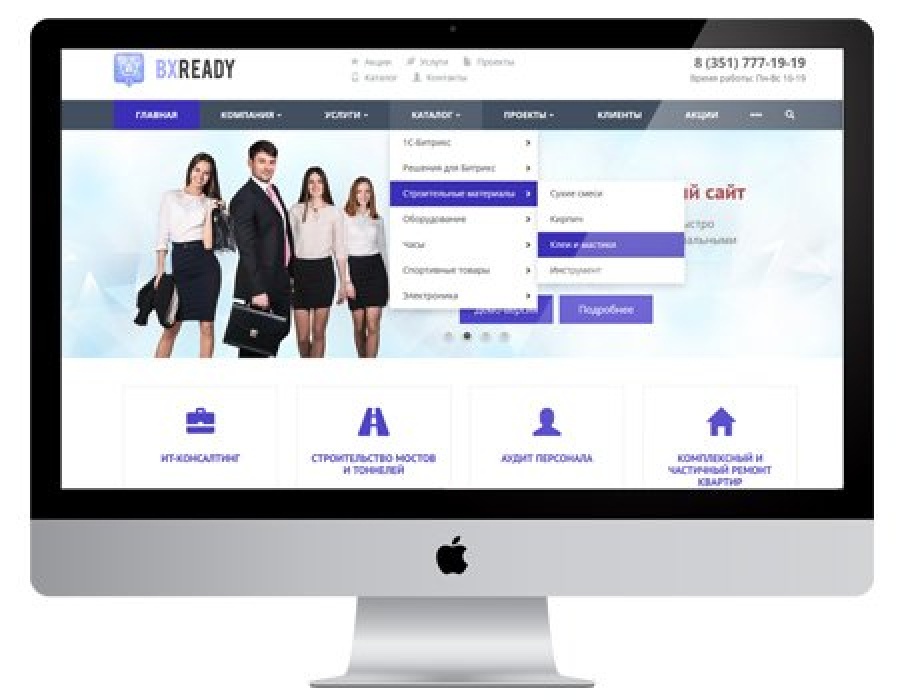 Тогда придется запускать стандартный режим в парсере — он будет ходить по всем разделам сайта. Но нужную вам информацию соберет только на карточках товара. Минус здесь в том, что вы потратите больше времени и дольше придется ждать нужных данных.
Тогда придется запускать стандартный режим в парсере — он будет ходить по всем разделам сайта. Но нужную вам информацию соберет только на карточках товара. Минус здесь в том, что вы потратите больше времени и дольше придется ждать нужных данных.
У нас карта сайта есть, поэтому мы переходим по ссылке https://www.mosdommebel.ru/sitemap.xml и видим, что сама карта разделяется на несколько карт. Отдельная карта по статичным страницам, по категориям, по продуктам (карточкам товаров), по статьям и новостям.
Ссылки на отдельные sitemap-файлы под все типы страниц
Нас интересует карта продуктов, то есть карточек товаров.
Ссылка на sitemap-файл для карточек товара
Возвращаемся в Screaming Frog Seo Spider. Сейчас он запущен в стандартном режиме, в режиме Spider (паук), который ходит по всему сайту и анализирует все страницы. Нам нужно его запустить в режиме List.
Мы загрузим ему конкретный список страниц, по которому он будет ходить. Нажимаем на вкладку Mode и выбираем List.
Жмем кнопку Upload и кликаем по Download Sitemap.
Указываем ссылку на Sitemap карточек товара, нажимаем ОК.
Программа скачает все ссылки, указанные в карте сайта. В нашем случае Screaming Frog обнаружил более 40 тысяч ссылок на карточки товаров:
Нажимаем ОК, и у нас начинается парсинг сайта.
После завершения парсинга на первой вкладке Internal мы можем посмотреть информацию по всем характеристикам: код ответа, индексируется/не индексируется, title страницы, description и все остальное.
Это все полезная информация, но мы шли за другим.
Вернемся к исходной задаче — посмотреть стоимость товаров. Для этого в интерфейсе Screaming Frog нам нужно перейти на вкладку Custom. Чтобы попасть на нее, нужно нажать на стрелочку, которая находится справа от всех вкладок. Из выпадающего списка выбрать пункт Custom.
И на этой вкладке из выпадающего списка фильтров (Filter) выберите Extraction.
Вы как раз и получите ту самую информацию, которую хотели собрать: список страниц и колонка «Стоимость 1» с ценами в рублях.
Задача выполнена, теперь все это можно выгрузить в xlsx или csv-файл.
После выгрузки стандартной заменой вы можете убрать букву «р», которая обозначает рубли. Просто, чтобы у вас были цены в чистом виде, без пробелов, буквы «р» и прочего.
Таким образом, вы получили информацию по стоимости товаров у сайта-конкурента.
Если бы мы хотели получить что-нибудь еще, например, дополнительно еще собрать названия этих товаров, то нам нужно было бы зайти снова в Configuration > Custom > Extraction. И выбрать после этого еще один XPath-запрос и указать, например, что мы хотим собрать тег <h2>.
Просто запустив еще раз парсинг, мы собираем уже не только стоимость, но и названия товаров.
В результате получаем такую связку: url товара, его стоимость и название этого товара.
Если мы хотим получить описание или что-то еще — продолжаем в том же духе.
Важный момент: h2 собрать легко. Это стандартный элемент html-кода и для его парсинга можно использовать стандартный XPath-запрос (посмотрите в справке).
В случае же с описанием или другими элементами нам нужно всегда возвращаться в код страницы и смотреть: как называется сам тег, какой у него класс/id либо какие-то другие атрибуты, к которым мы можем обратиться с помощью XPath-запроса.
 В случае же с описанием или другими элементами нам нужно всегда возвращаться в код страницы и смотреть: как называется сам тег, какой у него класс/id либо какие-то другие атрибуты, к которым мы можем обратиться с помощью XPath-запроса.
В случае же с описанием или другими элементами нам нужно всегда возвращаться в код страницы и смотреть: как называется сам тег, какой у него класс/id либо какие-то другие атрибуты, к которым мы можем обратиться с помощью XPath-запроса.Например, мы хотим собрать описание. Нужно снова идти в Inspect Element.
Оказывается, все описание товара лежит в теге <table> с классом product_description. Если мы его соберем, то у нас в таблицу выгрузится полное описание.
Здесь есть нюанс. Текст описания на странице сайта сделан с разметкой. Например, здесь есть переносы на новую строчку, что-то выделяется жирным.
Если вам нужно спарсить текст описания с уже готовой разметкой, то в настройках Extraction в парсере мы можем выбрать парсинг с html-кодом.
Если вы не хотите собирать весь html-код (потому что он может содержать какие-то классы, которые к вашему сайту никакого отношения не имеют), а нужен текст в чистом виде, выбираем только текст. Но помните, что тогда переносы строк и все остальное придется заполнять вручную.
Но помните, что тогда переносы строк и все остальное придется заполнять вручную.
Собрав все необходимые элементы и прогнав по ним парсинг, вы получите таблицу с исчерпывающей информацией по товарам у конкурента.
Такой парсинг можно запускать регулярно (например, раз в неделю) для отслеживания цен конкурентов. И сравнивать, у кого что стоит дороже/дешевле.
Пример 2. Как спарсить фотографии
Рассмотрим вариант решения другой прикладной задачи — парсинга фотографий.
На сайте Эльдорадо у каждого товара есть довольно-таки немало фотографий. Предположим, вы их хотите взять — это универсальные фото от производителя, которые можно использовать для демонстрации на своем сайте.
Задача: собрать в Excel адреса всех картинок, которые есть у разных карточек товара. Не в виде файлов, а в виде ссылок. Потом по ссылкам вы сможете их скачать либо напрямую загрузить на свой сайт. Большинство движков интернет-магазинов, таких как Битрикс и Shop-Script, поддерживают загрузку фотографий по ссылке. Если вы в CSV-файле, который используете для импорта-экспорта, укажете ссылки на фотографии, то по ним движок сможет загрузить эти фотографии.
Если вы в CSV-файле, который используете для импорта-экспорта, укажете ссылки на фотографии, то по ним движок сможет загрузить эти фотографии.
Ищем свойства картинок
Для начала нам нужно понять, где в коде указаны свойства, адрес фотографии на каждой карточке товара.
Нажимаем правой клавишей на фотографию, выбираем Inspect Element, начинаем исследовать.
Смотрим, в каком элементе и с каким классом у нас находится данное изображение, что оно из себя представляет, какая у него ссылка и т.д.
Изображения лежат в элементе <span>, у которого id — firstFotoForma. Чтобы спарсить нужные нам картинки, понадобится вот такой XPath-запрос:
//*[@id="firstFotoForma"]/*/img/@srcУ нас здесь обращение к элементам с идентификатором firstFotoForma, дальше есть какие-то вложенные элементы (поэтому прописана звездочка), дальше тег img, из которого нужно получить содержимое атрибута src. То есть строку, в которой и прописан URL-адрес фотографии. Попробуем это сделать.
Попробуем это сделать.
Берем XPath-запрос, в Screaming Frog переходим в Configuration > Custom > Extraction, вставляем и жмем ОК.
Для начала попробуем спарсить одну карточку. Нужно скопировать ее адрес и добавить в Screaming Frog таким образом: Upload > Paste
Нажимаем ОК. У нас начинается парсинг.
Screaming Frog спарсил одну карточку товара и у нас получилась такая табличка. Рассмотрим ее подробнее.
Мы загрузили один URL на входе, и у нас автоматически появилось сразу много столбцов «фото товара». Мы видим, что по этому товару собралось 9 фотографий.
Для проверки попробуем открыть одну из фотографий. Копируем адрес фотографии и вставляем в адресной строке браузера.
Фотография открылась, значит парсер сработал корректно и вытянул нужную нам информацию.
Теперь пройдемся по всему сайту в режиме Spider (для переключения в этот режим нужно нажать Mode > Spider). Укажем адрес https://www.eldorado.ru, нажимаем старт и запускаем парсинг.
Так как программа парсит весь сайт, то по страницам, которые не являются карточками товара, ничего не находится.
А с карточек товаров собираются ссылки на все фотографии.
Таким образом мы сможем собрать их и положить в Excel-таблицу, где будут указаны ссылки на все фотографии для каждого товара.
Если бы мы собирали артикулы, то еще раз зашли бы в Configuration > Custom > Extraction и добавили бы еще два XPath-запроса: для парсинга артикулов, а также тегов h2, чтобы собрать еще названия. Так мы бы убили сразу двух зайцев и собрали бы связку: название товара + артикул + фото.
Пример 3. Как спарсить характеристики товаров
Следующий пример — ситуация, когда нам нужно насытить карточки товаров характеристиками. Представьте, что вы продаете книжки. Для каждой книги у вас указано мало характеристик — всего лишь год выпуска и автор. А у Озона (сильный конкурент, сильный сайт) — характеристик много.
Вы хотите собрать в Excel все эти данные с Озона и использовать их для своего сайта. Это техническая информация, вопросов с авторским правом нет.
Это техническая информация, вопросов с авторским правом нет.
Изучаем характеристики
Нажимаете правой кнопкой по характеристике, выбираете Inspect Element и смотрите, как называется элемент, который содержит каждую характеристику.
У нас это элемент <div>, у которого в качестве класса указана строка eItemProperties_Line.
И дальше внутри каждого такого элемента <div> содержится название характеристики и ее значение.
Значит нам нужно собирать элементы <div> с классом eItemProperties_Line.
Для парсинга нам понадобится вот такой XPath-запрос:
//*[@class="eItemProperties_line"]Идем в Screaming Frog, Configuration > Custom > Extraction. Вставляем XPath-запрос, выбираем Extract Text (так как нам нужен только текст в чистом виде, без разметки), нажимаем ОК.
Переключаемся в режим Mode > List. Нажимаем Upload, указываем адрес страницы, с которой будем собирать характеристики, нажимаем ОК.
После завершения парсинга переключаемся на вкладку Custom, в списке фильтров выбираем Extraction.
И видим — парсер собрал нам все характеристики. В каждой ячейке находится название характеристики (например, «Автор») и ее значение («Игорь Ашманов»).
Пример 4. Как парсить отзывы (с рендерингом)
Следующий пример немного нестандартен — на грани «серого» SEO. Это парсинг отзывов с того же Озона. Допустим, мы хотим собрать и перенести на свой сайт тексты отзывов ко всем книгам.
Покажем процесс на примере одного URL. Начнем с того, что посмотрим, где отзывы лежат в коде.
Они находятся в элементе <div> с классом jsCommentContent:
Следовательно, нам нужен такой XPath-запрос:
//*[@class="jsCommentContents"]Добавляем его в Screaming Frog. Теперь копируем адрес страницы, которую будем анализировать, и загружаем в парсер.
Жмем ОК и видим, что никакие отзывы у нас не загрузились:
Почему так? Разработчики Озона сделали так, что текст отзывов грузится в момент, когда вы докручиваете до места, где отзывы появляются (чтобы не перегружать страницу). То есть они изначально в коде нигде не видны.
То есть они изначально в коде нигде не видны.
Чтобы с этим справиться, нам нужно зайти в Configuration > Spider, переключиться на вкладку Rendering и выбрать JavaScript. Так при обходе страниц парсером будет срабатывать JavaScript и страница будет отрисовываться полностью — так, как пользователь увидел бы ее в браузере. Screaming Frog также будет делать скриншот отрисованной страницы.
Мы выбираем устройство, с которого мы якобы заходим на сайт (десктоп). Настраиваем время задержки перед тем, как будет делаться скриншот, — одну секунду.
Нажимаем ОК. Введем вручную адрес страницы, включая #comments (якорная ссылка на раздел страницы, где отображаются отзывы).
Для этого жмем Upload > Enter Manually и вводим адрес:
Обратите внимание! При рендеринге (особенно, если страниц много) парсер может работать очень долго.
Итак, парсер собрал 20 отзывов. Внизу они показываются в качестве отрисованной страницы. А вверху в табличном варианте мы видим текст этих отзывов.
Пример 5. Как спарсить скрытые телефоны на сайте ЦИАН
Следующий пример — сбор телефонов с сайта cian.ru. Здесь есть предложения о продаже квартир. Допустим, стоит задача собрать телефоны с каких-то предложений или вообще со всех.
У этой задачи есть особенности. На странице объявления телефон скрыт кнопкой «Показать телефон».
После клика он виден. А до этого в коде видна только сама кнопка.
Но на сайте есть недоработка, которой мы воспользуемся. После нажатия на кнопку «Показать телефон» мы видим, что она начинается «+7 967…». Теперь обновим страницу, как будто мы не нажимали кнопку, посмотрим исходный код страницы и поищем в нем «967».
И вот, мы видим, что этот телефон уже есть в коде. Он находится у ссылки, с классом a10a3f92e9—phone—3XYRR. Чтобы собрать все телефоны, нам нужно спарсить содержимое всех элементов с таким классом.
Используем этот класс в XPath-запросе:
//*[@class="a10a3f92e9--phone--3XYRR"]Идем в Screaming Frog, Custom > Extraction. Указываем XPath-запрос и даем название колонке, в которую будут собираться телефоны:
Указываем XPath-запрос и даем название колонке, в которую будут собираться телефоны:
Берем список ссылок (для примера я отобрал несколько ссылок на страницы объявлений) и добавляем их в парсер.
В итоге мы видим связку: адрес страницы — номер телефона.
Также мы можем собрать в дополнение к телефонам еще что-то. Например, этаж.
Алгоритм такой же:
- Кликаем по этажу, Inspect Element.
- Смотрим, где в коде расположена информация об этажах и как обозначается.
- Используем класс или идентификатор этого элемента в XPath-запросе.
- Добавляем запрос и список страниц, запускаем парсер и собираем информацию.
Пример 6. Как парсить структуру сайта на примере DNS-Shop
И последний пример — сбор структуры сайта. С помощью парсинга можно собрать структуру какого-то большого каталога или интернет-магазина.
Рассмотрим, как собрать структуру dns-shop.ru. Для этого нам нужно понять, как строятся хлебные крошки.
Нажимаем на любую ссылку в хлебных крошках, выбираем Inspect Element.
Эта ссылка в коде находится в элементе <span>, у которого атрибут itemprop (атрибут микроразметки) использует значение «name».
Используем элемент span со значением микроразметки в XPath-запросе:
//span[@itemprop="name"]Указываем XPath-запрос в парсере:
Пробуем спарсить одну страницу и получаем результат:
Таким образом мы можем пройтись по всем страницам сайта и собрать полную структуру.
Возможности парсинга на основе XPath
Что можно спарсить:
1. Любую информацию с почти любого сайта.
Нужно понимать, что есть сайты с защитой от парсинга. Например, если вы захотите спарсить любой проект Яндекса — у вас ничего не получится. Авито — тоже довольно-таки сложно. Но большинство сайтов можно спарсить.
2. Цены, наличие товаров, любые характеристики, фото, 3D-фото.
3. Описание, отзывы, структуру сайта.
4. Контакты, неочевидные свойства и т.д.
Любой элемент на странице, который есть в коде, вы можете вытянуть в Excel.
Ограничения при парсинге
- Бан по user-agent. При обращении к сайту парсер отсылает запрос user-agent, в котором сообщает сайту информацию о себе. Некоторые сайты сразу блокируют доступ парсеров, которые в user-agent представляются как приложения. Это ограничение можно легко обойти. В Screaming Frog нужно зайти в Configuration > User-Agent и выбрать YandexBot или Googlebot.
Подмена юзер-агента вполне себе решает данное ограничение. К большинству сайтов мы получим доступ таким образом.
- Запрет в robots.txt. Например, в robots.txt может быть прописан запрет индексирования каких-то разделов для Google-бота. Если мы user-agent настроили как Googlebot, то спарсить информацию с этого раздела не сможем.
Чтобы обойти ограничение, заходим в Screaming Frog в Configuration > Robots.txt > Settings
И выбираем игнорировать robots.txt
- Бан по IP. Если вы долгое время парсите какой-то сайт, то вас могут заблокировать на определенное или неопределенное время. Здесь два варианта решения: использовать VPN или в настройках парсера снизить скорость, чтобы не делать лишнюю нагрузку на сайт и уменьшить вероятность бана.
 Здесь два варианта решения: использовать VPN или в настройках парсера снизить скорость, чтобы не делать лишнюю нагрузку на сайт и уменьшить вероятность бана.
Здесь два варианта решения: использовать VPN или в настройках парсера снизить скорость, чтобы не делать лишнюю нагрузку на сайт и уменьшить вероятность бана.- Анализатор активности / капча. Некоторые сайты защищаются от парсинга с помощью умного анализатора активности. Если ваши действия похожи на роботизированные (когда обращаетесь к странице, у вас нет курсора, который двигается, или браузер не похож на стандартный), то анализатор показывает капчу, которую парсер не может обойти. Такое ограничение можно обойти, но это долго и дорого.
Теперь вы знаете, как собрать любую нужную информацию с сайтов конкурентов. Пользуйтесь приведенными примерами и помните — почти все можно спарсить. А если нельзя — то, возможно, вы просто не знаете как.
3 способа превратить любой сайт в приложение для Android • Оки Доки
Установка слишком большого количества приложений на телефон не только замедляет его работу, но и снижает расход заряда аккумулятора. Многие приложения также запрашивают инвазивные разрешения, что делает их кошмаром конфиденциальности.
Многие приложения также запрашивают инвазивные разрешения, что делает их кошмаром конфиденциальности.
Один из способов избежать всего этого — запустить браузер и использовать веб-сайты вместо приложений, но это не всегда очень эффективное решение.
Итак, сегодня мы покажем вам, как вы можете превратить практически любой веб-сайт в собственное приложение для Android с полной функциональностью, включая темный режим, полноэкранный интерфейс и многое другое.
В магазине Google Play есть несколько приложений, которые позволяют превращать сторонние веб-сайты в собственные приложения для Android. Сегодня мы будем использовать три из них для нашей демонстрации.
Первое, названное Hermit, вероятно, является самым известным приложением в своем сегменте, а также на сегодняшний день наиболее многофункциональным. Кроме того, мы также будем использовать приложение с открытым исходным кодом под названием Native Alpha, которое необходимо загрузить с Github.
Наконец, мы также покажем вам, как использовать старый добрый Google Chrome, чтобы создавать приложения для Android из веб-сайтов. Итак, без лишних слов, приступим.
Итак, без лишних слов, приступим.
Примечание. Службы, у которых нет полнофункциональных веб-сайтов, не смогут волшебным образом получить функциональность собственных приложений с помощью методов, описанных ниже.
Например, Instagram не позволяет загружать изображения на свой веб-сайт, а это означает, что созданное вами приложение также будет затруднено.
Приложение 1: Hermit; Developer: Chimbori
На данный момент лучший способ превратить сайт в мобильное приложение — это приложение под названием Hermit (Бесплатно). Его можно бесплатно загрузить в магазине Google Play.
Почти все соответствующие функции, включая создание приложений, темный режим, блокировку рекламы, полноэкранный интерфейс и т. д.
Доступны в бесплатной версии. Однако некоторые расширенные функции, такие как скриптлеты, теги, блокировщик контента и настраиваемый пользовательский агент, находятся за платным доступом.
- Hermit позволяет создавать приложение двумя способами — либо выбирая «готовое» легкое приложение из существующего инвентаря приложения, либо вручную вводя URL-адрес.

- Нажмите на знак «+» на верхней панели, чтобы увидеть всю библиотеку легких приложений.
- Теперь прокрутите вниз, чтобы проверить все доступные приложения, и выберите то, которое вам нужно. Я использую Википедию в демонстрационных целях.
- Как только вы создадите приложение Wikipedia lite, оно появится на главной странице Hermit (левый снимок экрана ниже), а также будет ярлык на домашней странице телефона (правый снимок экрана ниже). Вы можете нажать на любой ярлык, чтобы запустить свое облегченное приложение.
- Чтобы использовать темный режим для недавно созданного облегченного приложения, запустите его и нажмите значок шестеренки (меню настроек) в правом верхнем углу.
- Теперь нажмите на опцию Dark Mode в правом нижнем углу выдвижной панели. Приложение перезагрузится во всей своей темной красоте.
Примечание. Не забудьте изменить системную тему на темную («Настройки»> «Дополнительные настройки»> «Тема»> «Темная»), чтобы все страницы настроек и меню отображались в темном режиме.
Не забудьте изменить системную тему на темную («Настройки»> «Дополнительные настройки»> «Тема»> «Темная»), чтобы все страницы настроек и меню отображались в темном режиме.
Вы также можете превратить любой сайт в облегченное приложение для Android с помощью Hermit. Мы используем Beebom в качестве примера, и вот как это сделать:
- Введите целевой URL-адрес в строку поиска внизу и нажмите Enter. Как только сайт загрузится, нажмите значок шестеренки в правом верхнем углу.
- В выдвигающемся меню нажмите «Создать облегченное приложение». Вы получите возможность выбрать имя приложения и отредактировать его URL-адрес, прежде чем сделать окончательный выбор. Вы также можете добавить ярлык на главный экран, установив флажок [1]. Наконец, нажмите «Создать» [2].
- Веб-приложение Beebom будет добавлено на главный экран Hermit, а также на главный экран вашего устройства, если вы выберете этот вариант на последнем шаге. Вы сможете запустить приложение с любого ярлыка.
 Вы сможете запустить приложение с любого ярлыка.
Вы сможете запустить приложение с любого ярлыка.Hermit — это многофункциональное приложение, которое по большей части отлично работает. Он предлагает вариант темного режима, полноэкранный пользовательский интерфейс без полей и даже встроенный блокировщик рекламы, которые можно настроить для каждого облегченного приложения отдельно.
Однако он немного глючит, и, по моему опыту, вам, возможно, придется дважды или трижды попробовать определенные варианты, прежде чем заставить их работать так, как рекламируется.
Приложение 2: Native Alpha; Developer: Cyclonid
Native Alpha — это приложение для Android с открытым исходным кодом, которое может превратить любой веб-сайт в приложение для Android за секунды. Созданный разработчиком Cyclonid, он использует встроенный Android WebView для отображения веб-сайта.
По соображениям конфиденциальности вы можете использовать альтернативные веб-просмотры, такие как Bromite, на устройствах с root-доступом. Native Alpha все еще находится на стадии предварительного выпуска и еще не размещена в Play Store. Вы можете скачать его с Github (Бесплатно) и загрузите его на свой телефон Android.
Native Alpha все еще находится на стадии предварительного выпуска и еще не размещена в Play Store. Вы можете скачать его с Github (Бесплатно) и загрузите его на свой телефон Android.
Примечание. Native Alpha совместим только с Android Oreo и более новыми версиями. Разработчик говорит, что поддержка более старых версий находится в разработке, но для этого еще нет ETA.
- При первом запуске Native Alpha вам будет предложено добавить URL-адрес для создания вашего первого веб-приложения. Введите URL-адрес целевого сайта. Чтобы ярлык для облегченного приложения был на главном экране, удерживайте переключатель « Вкл. » [1] и нажмите ОК [2].
Примечание. Вы можете создавать упрощенные веб-приложения в любое время, нажав красную кнопку «+» в правом нижнем углу на главной странице приложения.
- Приложение автоматически загрузит значок в высоком разрешении, если он есть на веб-сайте. Если нет, нажмите кнопку «Установить пользовательский значок», чтобы добавить значок по вашему выбору из вашей галереи или установленного пакета значков. Нажмите OK> Добавить, когда закончите.
 Нажмите OK> Добавить, когда закончите.
Нажмите OK> Добавить, когда закончите.- Теперь вы увидите свой новый ярлык приложения Beebom Lite на главном экране вашего телефона, а также на домашней странице Native Alpha.
Native Alpha все еще находится на стадии предварительной версии, но в ней нет некоторых функций Hermit, включая темный режим и полноэкранный интерфейс. Однако существует экспериментальный блокировщик рекламы, который по умолчанию отключен, но его можно включить в настройках.
Native Alpha менее глючит, чем Hermit, а функции, которые он предлагает, более отполированы. Приложение находится в стадии активной разработки, и версия, которую я использовал, v0.85.1, была выпущена 30 января 2021 года. Так что будем надеяться, что разработчик добавит другие интересные функции раньше, чем позже.
Приложение 3: Google Chrome; Developer: Google
Знаете ли вы, что даже Google Chrome для Android позволяет (отчасти) создавать облегченные приложения для многих веб-сайтов?
Совершенно верно, универсальный браузер Google может создавать упрощенные приложения для сайтов, которые имеют встроенный манифест Progressive Web App (PWA). Вот как это сделать:
Вот как это сделать:
- Откройте Chrome и перейдите на веб-сайт, для которого вы хотите создать ярлык (облегченное приложение). Затем нажмите кнопку меню (три точки) в верхнем левом углу. Наконец, на выдвижной панели выберите «Добавить на главный экран».
Примечание. Это будет работать только в обычных вкладках, но не в режиме инкогнито.
- Вы получите возможность ввести имя для ярлыка, прежде чем Chrome добавит его на главный экран.
Примечание. Вы можете создавать ярлыки веб-сайтов на устройствах Android точно так же, как и в других популярных веб-браузерах, включая Firefox.
Обратите внимание, что в то время как облегченные приложения, созданные Native Alpha и Hermit, функционируют как автономные приложения (больше похожие на оболочки веб-сайтов), ярлыки, созданные Chrome, работают как вкладка браузера, а не как отдельное приложение.
В любом случае, это по-прежнему отличный вариант, особенно если вам не нужно устанавливать еще одно приложение на свой телефон.
Превращение веб-сайтов в приложения означает, что вам больше не нужно будет предоставлять какие-либо инвазивные разрешения для запуска этих служб на вашем телефоне. Они также не будут работать в фоновом режиме, отправляя ваши личные данные на свои серверы и потребляя при этом аккумулятор.
Поэтому используйте наше руководство выше, чтобы превратить веб-сайты в приложения на вашем телефоне Android, и сообщите нам, какой метод вы выбрали и для каких веб-сайтов.
Загородный отель «Царьград» — официальный сайт в Подмосковье
Царьград — курорт мирового уровня в ближайшем Подмосковье
Загородный отель Царьград расположен в уединенном месте на живописном берегу Оки. Отель находится в окружении тенистых деревьев и в достаточном удалении от мегаполиса, поэтому на территории такой чистый и пьянящий воздух.
Проживание в загородном отеле с открытым бассейном в Подмосковье возможно как в отдельных номерах, так и в коттеджах. Номерной фонд отвечает мировым стандартам и пропитан элементами русской архитектуры. Красивые интерьеры, необычные дизайнерские детали, живописный вид из окон дополнят положительными эмоциями насыщенный событиями и впечатлениями отдых.
Номерной фонд отвечает мировым стандартам и пропитан элементами русской архитектуры. Красивые интерьеры, необычные дизайнерские детали, живописный вид из окон дополнят положительными эмоциями насыщенный событиями и впечатлениями отдых.
Загородный отель Царьград предлагает Вам:
-
оборудованный частный пляж, где есть все условия для приятного досуга: можно прокатиться на гидроцикле, поиграть в волейбол, посетить Баккарди-бар — выбор только за Вами;
-
посещение бассейна с аквапарком — в то время, как дети учатся плавать или катаются на водных горках, взрослые расслабляются в джакузи или активно отдыхают на занятиях по аквааэробике;
-
полное расслабление и восстановление организма в Здравнице отеля — Вам доступен любой массаж мира, широкий перечень спа-процедур, индивидуальные косметологические и детокс-программы и многое другое;
-
множество вариантов загородного активного отдыха: возможность покататься на горных лыжах или сноуборде, взять на прокат велосипед или арендовать теннисный корт, провести время на стрельбище или на катке.

Отдых в загородном отеле с открытым бассейном в Подмосковье понравится не только взрослым, но и малышам. Дети смогут от души порезвиться на просторной территории отеля, поплескаться в бассейне, познакомиться с милыми жителями зоопарка и конного клуба, поучаствовать в мастер-классах и играх с аниматорами.
Мы позаботились о безопасности детей: территория загородного отеля находится под видеонаблюдением, в бассейне есть специальные неглубокие детские зоны, персонал отеля крайне внимателен к маленьким гостям. Поэтому родители могут наслаждаться каждой проводимой в отеле минутой и ни о чем не беспокоиться.
Царьград регулярно входит в рейтинги лучших загородных отелей Подмосковья с бассейном. И это мотивирует нас становиться еще лучше, предлагая новые интересные решения.
Веб-страницы, веб-сайты, веб серверы и поисковики — Изучение веб-разработки
В этой статье мы расскажем о различных понятиях связанных с Веб: о веб-страницах, веб-сайтах, веб-серверах и о поисковых системах.![]() Эти термины часто ставят в тупик как начинающих работу с Веб, так и людей, редко пользующихся сетью. Давайте же разберёмся, что именно эти понятия означают!
Эти термины часто ставят в тупик как начинающих работу с Веб, так и людей, редко пользующихся сетью. Давайте же разберёмся, что именно эти понятия означают!
| Необходимые знания: | Вы должны знать, как работает Интернет. |
|---|---|
| Цель: | Изучить различия между веб-страницами, веб-сайтами, веб-серверами и поисковыми системами. |
Как и любая другая область знаний, Веб полон специфичных терминов. Но не волнуйтесь, мы не хотим перегружать вас в самом начале вашего пути (а если любопытство всё же берёт верх, то у нас есть глоссарий). Однако, для начала несколько базовых терминов всё же придётся усвоить, так как вы будете встречать их в наших статьях довольно часто. Иногда эти термины легко перепутать, так как они связаны между собой, но имеют разные функции. Вы, наверное, не раз замечали их неправильное употребление в новостях или где-либо ещё.
Мы разберём эти понятия и технологии чуть позже, а сейчас краткие определения ниже станут для вас очень хорошим началом:
- Веб-страница
- Документ, который может быть отображён веб-браузерами, такими как: Firefox, Google Chrome, Microsoft Internet Explorer / Edge или Safari от Apple. Само понятие «веб-страница» для краткости будем называть просто «страница».
- Веб-сайт
- Коллекция веб-страниц, связанных между собой какими-либо способами. Употребление в лексике: «веб-сайт» или просто «сайт».
- Веб-сервер
- Компьютер, предоставляющий компьютерное и программное обеспечение, необходимое для функционирования веб-сайта.
- Поисковая система
- Веб-сайт, помогающий в поиске других веб-страниц, например такие как: Google, Bing или Yahoo.
 Само понятие «веб-страница» для краткости будем называть просто «страница».
Само понятие «веб-страница» для краткости будем называть просто «страница».Итак, давайте копнём чуть глубже и узнаем, как эти 4 термина связаны между собой, и почему данные понятия зачастую путают друг с другом.
Веб-страница
Веб-страница — простой документ, отображаемый на экране компьютера посредством браузера. Такой документ написан языком HTML (который мы рассмотрим более детально в других статьях). Веб-страница может содержать множество различных материалов, таких как:
- стилевая информация — контролирование страницы по восприятию и ощущению
- скрипты — которые делают страницу более динамичной и удобной в использовании для пользователей
- медиа — изображения, музыка и видео.

Примечание: браузеры зачастую могут отображать некоторые документы в формате PDF файла или изображения, но термин веб-страница больше относится непосредственно к HTML-документам. До конца статьи, в данном случае, мы будем использовать понятие документ.
Все веб-страницы в сети имеют свой уникальный адрес. Чтобы получить доступ к нужной странице просто наберите её адрес в адресной строке вашего браузера:
Веб-сайт — это коллекция страниц, связанных между собой какими-либо способами (включая их связи с иными ресурсами), которые доступны под единым доменным именем. Каждая страница сайта содержит прямые ссылки (практически всегда выделенные части текста, по которым можно кликнуть мышью), что позволяет пользователю быстро переходить от одной страницы веб-сайта к другой.
Чтобы получить доступ к веб-сайту, наберите его доменное имя в адресной строке браузера, и ваш браузер отобразит главную страницу сайта или, по-другому, домашнюю страницу:
Веб-страницу и веб-сайт особенно легко спутать между собой, когда сайт содержит всего одну страницу. Такой сайт иногда называют одностраничным веб-сайтом.
Веб-сервер
Веб-сервер — это компьютер, предоставляющий в сеть один или множество веб-сайтов (хостинг). Понятие «хостинг» — означает, что все страницы и прикреплённые к ним файлы содержатся на данном компьютере. Т.е. Веб-сервер будет отправлять любую страницу с сайта по запросу любого пользователя, что и будет хостингом для браузера пользователя.
Не путайте понятия веб-сайта и веб-сервера. Например, если вы слышите, что кто-либо говорит: «Мой веб-сайт не отвечает», на самом деле это означает, что это веб-сервер не отвечает на запрос, и поэтому недоступен и сам сайт. Более того, так как веб-сервер может разместить несколько сайтов, термин веб-сервер никогда не используется для обозначения веб-сайта, так как это могло бы привести к большой путанице. Вернёмся к предыдущему примеру: если бы мы сказали: «Мой веб-сервер не отвечает», это значило бы, что на этом сервере нет доступных сайтов в данный момент.
Поисковая система
Поисковые системы являются распространённой причиной путаницы в сети. Поисковая система — это специальный вид веб-сайта, который помогает пользователям найти нужные страницы других сайтов.
Наиболее популярные поисковые системы: Google, Bing, Yandex, DuckDuckGo, и многие другие. Некоторые из них универсальны, а какие-то ориентированы на определённую область. Используйте тот поисковик, который удобен вам.
Многие начинающие пользователи сети путают между собой поисковую систему и браузер. Давайте поясним: браузер — это программное обеспечение, которое находит и отображает веб-страницы; поисковая система — это специальный вид сайта, который помогает пользователям найти нужные страницы других сайтов. Путаница возникает из-за того, что когда кто-либо впервые запускает браузер, тот отображает домашнюю страницу поисковой системы. Это именно так, ведь первое, что вы делаете, запуская браузер, это находите веб-страницу и открываете её. Но не путайте инфраструктуру (т.е. браузер) с сервисом (т.е. поисковой системой). Это отличие несколько поможет вам, но даже некоторые специалисты произвольно употребляют данные понятия, так что из-за этого не следует особо переживать.
Ниже пример того, как браузер Firerox по умолчанию отображает окно поиска Google на стартовой (домашней) странице:
AnySite
AnySite — это настольный геодемографический инструмент поддержки принятия решений, идеально подходящий для предприятий розничной торговли, ресторанов, недвижимости и финансовых услуг.
AnySite — это незаменимое решение для поддержки принятия решений для аналитиков и руководителей, стремящихся выявить взаимосвязь между геодемографическими данными в сфере торговли и потенциалом или производительностью сайта.
Используйте AnySite для выбора оптимальных местоположений и анализа текущих местоположений на основе самых актуальных демографических характеристик торговых площадей.
Он разработан, чтобы предоставить аналитикам и маркетологам новое местоположение, торговую площадку с несколькими площадками для клиентов и понимание рынка.
AnySite обеспечивает интуитивно понятное использование самых подробных собственных и сторонних источников данных, доступных на рынке.
А с подключаемым модулем AnySite Segmentation Plug-In, использующим данные сегментации домашних хозяйств MicroBuildHS®, вы можете глубже понять, кто ваши лучшие клиенты, где они находятся в ваших торговых областях, и использовать профили этих лучших клиентских сегментов для привлечения новых клиентов.
AnySite доступен для США и Канады.
РАСШИРЕНИЕ ВАШЕГО БИЗНЕСА С ДЕМОГРАФИЧЕСКИМИ ОТЧЕТАМИ И КАЧЕСТВЕННЫМИ КАРТАМИ ПРЕЗЕНТАЦИЙ
- Доступ к важной демографической информации для анализа сайта. Идеально подходит для нетехнических пользователей в сфере коммерческой недвижимости, розничных финансовых услуг и экономического развития.
- Quick-view Reporting упрощает создание отчетов на сайтах. Отчеты можно доставлять с помощью Excel.
- Создавайте собственные тематические карты оттенков на основе стандартных переменных или пользовательских переменных.
- Быстрое и удобное выполнение анализа рынка для внутренних встреч или встреч с клиентами
- Развивайте детальное понимание ключевых клиентских сегментов в ваших текущих и потенциальных областях торговли
- Проста в использовании, требует очень небольшого знания приложений ГИС.
ПОЛЬЗУЙТЕСЬ ЛУЧШИМИ ВОЗМОЖНОСТЯМИ РАСПОЛОЖЕНИЯ
- Принимайте лучшие решения с помощью мощных возможностей выбора места
- Получите ценную информацию о демографической и конкурентной среде
- Выделение информации с помощью тематического сопоставления и управления слоями
- Ориентируйте маркетинг на поведение и образ жизни потребителей с помощью демографических данных Groundview® и данных сегментации MicroBuild® по этапам жизни домохозяйства, доступных через подключаемый модуль сегментации.Также можно добавить подсчет трафика, аэрофотоснимки и данные о потребительских расходах.
БЕСПЛАТНАЯ ИНТЕГРАЦИЯ МЕСТОПОЛОЖЕНИЯ В СУЩЕСТВУЮЩИЕ БИЗНЕС-ПРОЦЕССЫ
- Принимайте более обоснованные решения на основе визуализации ключевых данных и информации о местоположении
- Легко импортировать большинство собственных или сторонних баз данных
ОСОБЕННОСТИ
- Интеграция данных позволяет подключать, извлекать, составлять отчеты и отображать информацию из собственных или сторонних источников данных.
- Создание и интеграция рабочих пространств MapInfo Professional
- AnySite может быть предварительно упакован в соответствии с вашими потребностями без наборов данных, чтобы вы могли быстро приступить к работе.
- С легкостью экспортируйте отчеты в файлы различных форматов (например, dbf, tab, Excel).
- Простота развертывания с различными конфигурациями.
- Предлагает возможности пакетной обработки
- Используя AnySite, профессионалы отрасли могут анализировать взаимосвязь между производительностью сайта и геодемографическими характеристиками рынка.Демографические переменные, извлеченные из AnySite Data Engine (ASDE), можно агрегировать на уровне группы блоков, переписного участка, почтового индекса, округа или штата.
Green Any Site — Делайте что-нибудь хорошее для планеты, каждый раз делая покупки в Интернете
С Green Any Site вы можете легко пожертвовать часть любой покупки в Интернете на благо окружающей среды. Это бесплатно, ничего не нужно устанавливать, и каждый раз, когда вы что-то покупаете, требуется всего лишь один клик.
Вот как это работает. Интернет-магазины платят другим сайтам процент от каждой покупки за рефералов.Когда вы используете GAS, мы следим за тем, чтобы все эти деньги шли на поддержку экологических целей, а не попадали в чужой карман.
- Добавьте в закладки нашу специальную ссылку
. - В следующий раз, когда вы будете делать покупки,
нажмите «Green This!» - Завершите покупку
как обычно. - Часть вашей покупки
будет пожертвовать
на экологические цели.
Покупки в Интернете удобно, легко и часто дешевле, чем посещение розничных магазинов, но все же это оказывает значительное воздействие на окружающую среду.Все, что вы покупаете, нужно производить, упаковывать и отправлять, создавая отходы и загрязнение на каждом этапе.
С Green Any Site вы можете компенсировать это влияние и многое другое. Все, что вам нужно сделать, это прямо сейчас перейти на нашу страницу установки и добавить в закладки специальную ссылку. Это самая короткая «установка» за всю историю…
Затем в следующий раз, когда вы будете делать покупки в Интернете, прежде чем добавить что-нибудь в корзину, щелкните закладку … И вуаля: вы только что сделали что-то великое для всей планеты.
Вы никогда не заплатите ни цента. Достаточно быстро щелкнуть мышью, и мы автоматически пожертвуем часть вашей покупки Зеленому, потому что наши пользователи выбрали этот месяц.
Приступая к работе — Использование ГАЗА и изменение ситуации Как это работает? или … Откуда деньги?Мы поддерживаем: Conservation International
Каждый месяц мы жертвуем 100% нашего дохода от озеленения ваших покупок другой экологической организации.
В настоящее время мы поддерживаем Conservation International, названную Charity Navigatior в числе «10 лучших благотворительных организаций, о которых все слышали».
Основанная в 1987 году, Conservation International стремится защитить жизнь на Земле и продемонстрировать, что человеческое общество будет процветать, когда оно находится в равновесии с природой.
Green Any Site — Делайте что-нибудь хорошее для планеты каждый раз, когда делаете покупки в Интернете
Как нажатие кнопки может помочь окружающей среде?
Нажимая кнопку «зеленая эта» перед совершением покупки в Интернете, вы гарантируете, что часть потраченных вами денег будет передана в пользу зеленой благотворительной организации.
Нужно ли мне доплачивать при покупках?
Конечно, нет! Ваш опыт покупок не изменится вообще, кроме того, что вы нажмете «зеленый это!» кнопка. Вы по-прежнему можете получать любые обычные скидки, которые может предложить сайт, или использовать любые купоны, которые у вас есть.
Откуда деньги?
Нажав «зеленый это!» кнопка, вы сообщаете магазину, что мы вам отправили. Затем этот магазин дает нам процент от суммы вашей покупки, которую мы затем жертвуем на экологическое предприятие по вашему выбору.
Куда уходят деньги?
Ищете альтернативные источники энергии? Углеродная компенсация? Сажать деревья? Тебе решать! Каждый зарегистрированный пользователь голосует за то, кому мы ежемесячно жертвуем деньги.
В период бета-тестирования «зеленые» организации будут выбраны группой из нескольких известных экологических блоггеров и лидеров. Вскоре будет введена полная система выдвижения и голосования за зеленые организации.
Разве вам не нужно подписывать соглашения с каждым интернет-магазином, чтобы это работало?
Вместо того, чтобы убеждать всех розничных продавцов «идти на экологию», мы выбрали путь наименьшего сопротивления и просто использовали устоявшиеся методы ведения бизнеса — аффилированный маркетинг.
Нам не нужно убеждать и заключать новые соглашения с розничными продавцами, потому что мы работаем в соответствии с теми же соглашениями и условиями, что и партнерские маркетологи. Единственная разница … Мы жертвуем 100% денег, которые получаем.
Кто стоит за этой инициативой?
Green Any Site был разработан, профинансирован и создан этим парнем:
Я веб-разработчик из Израиля, и я трачу слишком много времени, беспокоясь о потере энергии из-за бездействующей электроники в моем доме, и раздражаю продавцов замечаниями типа «нет, мне не нужен пластиковый пакет с этим.«
Это мой маленький вклад в развитие планеты… пожалуйста.
Если вы хотите связаться со мной с любыми отзывами, вопросами, идеями или просто рассказать о своем дне, вы можете связаться со мной по электронной почте или в Твиттере.
Если вы отправите мне сообщение в твиттере, я обещаю ответить и подписаться на вас.
Могу ли я доверять тебе, что ты не оставишь часть денег себе?
Не верь мне! Вы можете проверить меня … Я буду использовать наш блог, чтобы раскрывать информацию обо всех доходах, которые мы получаем от использования GAS пользователями (совокупные данные, не идентифицирующие личность данные о наших пользователях), и, когда это возможно по закону, размещать отсканированные материалы всех полученных чеков и счетов.Я также опубликую полную информацию обо всех сделанных пожертвованиях вместе с квитанциями / сертификатами. Наши пользователи будут выбирать организации, которые будут получать пожертвования, и голосовать за них каждый месяц.
Как проверить посещаемость любого сайта (7 лучших инструментов)
Хотите проверить посещаемость любого сайта, в том числе вашего?
Проверка посещаемости веб-сайта позволяет вам увидеть, насколько хорошо ваш сайт работает и как он сравнивается с вашими конкурентами.
В этой статье мы покажем вам, как проверить посещаемость любого веб-сайта с помощью различных онлайн-инструментов.
Почему вы должны проверять посещаемость вашего веб-сайта?
Проверяя статистику своего веб-сайта, вы можете легко увидеть, как он работает.
Данные о посещаемости вашего веб-сайта покажут вам, откуда идет ваш трафик, как посетители взаимодействуют с вашим сайтом и какие стратегии цифрового маркетинга работают.
Если вы хотите получить больше подписчиков по электронной почте, увеличить продажи своего интернет-магазина или просто увеличить общий трафик, то вам необходимо регулярно проверять аналитику своего веб-сайта.
Отслеживая посещаемость своего сайта, вы будете знать, на каком уровне находится ваш сайт в настоящее время и что вы можете сделать для его улучшения.
Почему вам следует проверять посещаемость веб-сайта конкурентов?
Анализ статистики посещаемости сайта конкурента может выявить много полезной информации, например:
- Страницы и посты, приносящие вашим конкурентам наибольший трафик
- По каким ключевым словам ваши конкуренты ранжируются
- Каналы, по которым у них больше всего трафика
Всю эту информацию можно использовать для улучшения вашей стратегии контент-маркетинга, построения ссылок, процесса исследования ключевых слов и многого другого.
Понимая, что приносит вашим конкурентам больше всего трафика, вы сможете настроить таргетинг на те же ключевые слова и темы, чтобы привлечь больше трафика для своего веб-сайта.
Лучшие инструменты для проверки любого трафика веб-сайта (включая конкурентов)
Существует множество бесплатных и платных инструментов для проверки трафика, которые вы можете использовать. У каждого из них есть уникальные особенности, которые отличают их.
Большинство экспертов используют несколько инструментов для проверки оценок посещаемости веб-сайтов своих конкурентов. Мы всегда рекомендуем читателям попробовать как минимум два разных инструмента для анализа статистики веб-трафика.
Используя различные инструменты, вы сможете заполнить пробелы и получить более точную статистику посещаемости любого веб-сайта.
По мере роста вашего сайта WordPress и роста бюджета вы можете вкладывать средства в несколько инструментов, чтобы получить больше информации и доминировать на своем рынке.
Сказав это, давайте взглянем на лучшие инструменты, чтобы проверить, сколько трафика получает веб-сайт.
1. SEMRush
SEMRush — это универсальный инструмент для анализа трафика и исследования конкуренции. Это лучший инструмент для анализа и мониторинга трафика любого веб-сайта.
Мы используем этот инструмент на WPBeginner для исследования ключевых слов, отслеживания рейтинга ключевых слов и многого другого.
После ввода URL-адреса конкурента вы получите подробную разбивку по общему трафику конкурента.
Вы сможете увидеть важные показатели веб-сайта, такие как объем ежемесячного трафика с течением времени, распределение трафика по странам, ключевые слова, которые приносят им наибольший трафик, и многое другое.
На вкладке «Аналитика трафика» отображается количество уникальных посетителей, общее количество посещений, средняя продолжительность посещения, количество просмотров страниц и показатель отказов, который получает сайт.
Эта функция похожа на просмотр аккаунта Google Analytics вашего конкурента.
Еще одна отличная функция, называемая массовым анализом трафика, позволяет анализировать уровни трафика для нескольких конкурентов одновременно.
В зависимости от вашего тарифного плана вы можете сравнить до 200 сайтов. Это дает вам полное представление о вашей нише, веб-сайтах, получающих наибольший трафик, и любых возможностях трафика, которые вы можете использовать.
Вы также найдете подробные аналитические отчеты по трафику, которые предоставят вам информацию, например, какие сайты отправляют больше всего реферального трафика, какие страницы на их сайтах являются наиболее ценными и какие места приносят им наибольший трафик.
Вы можете воспользоваться 14-дневной пробной версией или ограниченным бесплатным планом, который дает вам доступ к основным данным веб-сайта.
Если вам нужны полные отчеты, тогда премиальные планы начинаются с 119,95 долларов в месяц, что дает вам полный доступ к источникам трафика конкурентов, рейтингам, социальным сетям и многому другому.
2. SimilarWeb
SimilarWeb — это онлайн-средство проверки посещаемости веб-сайтов, которое дает вам представление о трафике вашего конкурента и о том, какие каналы являются наиболее ценными.
Вместо того, чтобы просто предоставлять трафик из поиска, вы будете получать подробные отчеты обо всей стратегии движения веб-сайта.
Запустив веб-сайт с помощью инструмента, вы получите разбивку по общему трафику, включая отчет по странам.
Вы получите такие показатели взаимодействия, как показатель отказов, количество страниц, просмотренных за посещение, средняя продолжительность посещения и основные источники трафика для этого веб-сайта.
Помимо обычного поискового трафика, вы узнаете, какие оплачиваемые ключевые слова приносят посещаемость веб-сайта, какие социальные каналы являются наиболее ценными, а также сети контекстно-медийной сети, которые сайт использует для монетизации.
Наконец, вы получите подробную разбивку по аудитории сайта, какие еще сайты они интересуют, сайты с наибольшим количеством переходов и список сайтов-конкурентов для дальнейшего изучения.
Бесплатная версия инструмента предоставляет вам полезные данные о трафике. Если вам требуются более подробные отчеты, вы можете создать корпоративную учетную запись с индивидуальной ценой.
3. Консоль поиска Google
Google Search Console — это бесплатный инструмент от Google, который позволяет анализировать трафик из поисковых систем.
Этот инструмент дает вам полное представление о том, как ваш сайт просматривается поисковыми системами.
Показывает количество показов, кликов, рейтинг кликов (CTR) и среднюю позицию ваших ключевых слов в поисковых системах.
Это поможет вам понять, по каким ключевым словам вы ранжируете и какой объем поиска они приносят. Эта информация может помочь вам увеличить посещаемость.
Например, если вы обнаружите, что занимаете 11-ю позицию в рейтинге, вы можете оптимизировать сообщение в блоге, чтобы попытаться переместить его на первую страницу результатов поиска.
Вы также можете увидеть, какие страницы проиндексированы, есть ли ошибки и многое другое.
После добавления вашего сайта в Google Search Console вы можете начать просмотр данных вашего сайта.
Самый простой способ — подключить свою учетную запись Google Search Console к All in One SEO. Для получения дополнительной информации см. Наше руководство о том, как добавить свой сайт WordPress в Google Search Console.
Вы также можете использовать инструмент MonsterInsights, упомянутый ниже, для просмотра рейтинга ваших ключевых слов в административной области WordPress с использованием данных Google Search Console.
Подробнее см. В нашем руководстве о том, как увидеть ключевые слова, которые люди используют для поиска вашего сайта WordPress.
4. Убер-совет
Ubersuggest — это бесплатный и премиальный инструмент от Нила Пателя, который предлагает массу полезных данных о посещаемости веб-сайтов.
Он прост в использовании, а интерфейс создан для начинающих. Если вы никогда раньше не занимались поиском ключевых слов или анализом трафика, этот инструмент сделает это невероятно простым.
Функция анализатора трафика дает вам подробную разбивку трафика вашего конкурента с течением времени, ключевые слова, по которым они получают наибольший трафик, и самые популярные страницы на сайте.
Все, что вам нужно сделать, это ввести URL-адрес веб-сайта, который вы хотите проанализировать, и нажать «Поиск».
На странице «Обзор трафика» показано общее количество органических ключевых слов, по которым ранжируется сайт, ежемесячный органический трафик, авторитет домена и общее количество обратных ссылок.
Вы также можете глубже изучить каждый раздел отчета о трафике. Например, вы можете развернуть результаты «Самые популярные страницы», чтобы получить разбивку по каждой опубликованной странице на сайте и предполагаемый объем трафика, который она приносит каждый месяц.
Результаты также дают вам приблизительное количество обратных ссылок, а также количество репостов Facebook и Pinterest. Эти данные дают вам общее представление о том, что вам нужно сделать, чтобы превзойти эту страницу в результатах поиска.
Бесплатная версия инструмента дает вам доступ к данным за последние 3 месяца. Премиум-планы начинаются с 29 долларов в месяц, что делает его одним из самых дешевых инструментов в этом списке.
5. Serpstat
Serpstat предлагает широкий спектр различных инструментов SEO.То, что начиналось как простой инструмент исследования ключевых слов, превратилось в универсальный инструмент анализа веб-сайтов.
Несмотря на то, что он обладает множеством функций, им все равно очень легко пользоваться. Просто введите URL-адрес, и инструмент сгенерирует отчет о трафике.
Есть функции проверки трафика, а также инструменты анализа обратных ссылок, аудита сайта и отслеживания рейтинга.
Функции анализа трафика предоставляют вам всевозможные полезные данные о веб-сайте, включая обычные и оплачиваемые ключевые слова, которые привлекают трафик, среднее количество посетителей, которые сайт получает в месяц, и страницы, которые получают наибольший трафик.
Вы также найдете информацию о тенденциях, чтобы увидеть, как рейтинг сайта, трафик и ключевые слова меняются с течением времени.
Бесплатная версия инструмента дает вам доступ к части общих данных, доступных для доменного имени. Премиум-планы начинаются с 69 долларов в месяц и дают вам доступ ко всем данным, которые предоставляет инструмент.
6. Ahrefs
Ahrefs — один из самых популярных инструментов SEO на рынке, которому доверяют такие бренды, как Netflix, Uber и Facebook.Это поможет вам увидеть, сколько трафика получают ваши конкуренты и почему они занимают такое высокое место.
Ahrefs сканирует более 6 миллиардов веб-страниц каждый день, при этом более 200 миллионов веб-сайтов находятся в их индексе. Это много данных, но это дает вам полезную информацию, которая поможет вам превзойти своих конкурентов и получить больше трафика.
Интерфейс очень простой и удобный. Просто введите URL-адрес веб-сайта в поле поиска, и инструмент извлечет всю доступную информацию о веб-сайте.
Обзорный отчет поиска дает вам обзор органического поискового трафика, который получает сайт, авторитет домена, крупнейших конкурентов и многое другое.
Вы можете отфильтровать отчет, чтобы просмотреть статистику трафика за год, последние 30 дней или за все время.
Несмотря на то, что данных много, их легко отфильтровать и найти нужные показатели веб-сайта.
Имейте в виду, что данные о трафике показывают только данные обычного поиска, а не другие источники, такие как социальные сети.
Существует 7-дневная пробная версия за 7 долларов США, после чего тарифы начинаются с 99 долларов в месяц. Учитывая объем данных, к которым у вас есть доступ, это удивительно доступно.
7. MonsterInsights
Если вы хотите анализировать собственный трафик, то единственный инструмент, который вам следует использовать, — это Google Analytics. Однако настроить Google Analytics самостоятельно и анализировать собственные данные может быть сложно.
Мы рекомендуем использовать MonsterInsights — лучший плагин Google Analytics для WordPress, который используют более 3 миллионов сайтов, включая Microsoft, Yelp, PlayStation и другие.
Он позволяет легко настроить Google Analytics в WordPress и просматривать данные о трафике прямо в панели управления WordPress.
Вы сможете увидеть свои самые популярные сообщения, страницы, целевые страницы, посещаемость главной страницы и многое другое. Это поможет вам понять поведение пользователей и значительно упростит развитие вашего блога WordPress.
Последние мысли о том, как проверить трафик на вашем веб-сайте
Существуют всевозможные инструменты, которые вы можете использовать для проверки посещаемости вашего веб-сайта и трафика веб-сайтов конкурентов.
Проверка трафика конкурентов даст вам представление о вашем рынке и о том, что вы можете сделать, чтобы получить больше трафика. В то время как мониторинг вашего собственного трафика веб-сайта покажет вам, работают ли ваши SEO, социальные сети и другие стратегии генерации трафика.
Лучший способ проверить посещаемость вашего веб-сайта — это MonsterInsights. За пару кликов вы можете просмотреть данные о посещаемости вашего сайта прямо в панели управления WordPress.
Если вашей целью является тщательное исследование конкурентов и вы хотите проверять посещаемость любого веб-сайта, то SEMRush — наш лучший выбор.Он не только предоставит вам точные данные о трафике, но и станет одним из лучших инструментов SEO на рынке.
Мы надеялись, что эта статья помогла вам узнать, как проверять посещаемость любого сайта. Вы также можете взглянуть на наше полное руководство по WordPress SEO, и в нашем экспертном списке из 24 обязательных плагинов WordPress для бизнес-сайтов.
Если вам понравилась эта статья, то подпишитесь на наш канал YouTube для видеоуроков по WordPress. Вы также можете найти нас в Twitter и Facebook.
Как найти URL-адрес RSS-канала почти для любого сайта
RSS не мертв, но теперь найти RSS-каналы труднее, чем раньше. Браузеры больше не указывают на них, а веб-сайты редко ссылаются на них.
И все же большинство сайтов действительно предлагают RSS-каналы. Вот несколько способов быстро найти эти каналы, когда поиск в Google не помогает. Мы также покажем вам, как создавать собственные RSS-каналы для приложений, которые их не предлагают.
Как найти URL-адрес RSS-канала для большинства веб-сайтов
Шокирующее количество веб-сайтов создано с использованием WordPress — около 30 процентов из 10 миллионов самых популярных веб-сайтов.Это означает, что есть большая вероятность, что любой посещаемый вами веб-сайт является сайтом WordPress, и все эти сайты предлагают RSS-каналы, которые легко найти.
Чтобы найти RSS-канал WordPress, просто добавьте / feed в конец URL-адреса; например, https://justinpot.com/feed . Я делаю это каждый раз, когда посещаю веб-сайт, для которого мне нужен RSS-канал — это почти всегда работает.
Если это не сработает, вот несколько уловок для поиска RSS-каналов на других сайтах.
Если сайт размещен на Tumblr , добавьте
/ rssв конец URL-адреса.Примерно так:https://example.tumblr.com/rssЕсли сайт размещен на Blogger , добавьте
каналов / сообщений /по умолчанию в конец URL. Примерно так:example.blogspot.com/feeds/posts/defaultЕсли публикация размещена на носителе Medium , добавьте
/ feed /перед названием публикации. Таким образом,medium.com/example-siteстановитсяmedium.com/feed/example-siteСтраницы каналов YouTube дублируются как RSS-каналы.Просто скопируйте и вставьте URL-адрес канала в программу чтения RSS. Вы также можете найти здесь OPML-файл для всех ваших подписок.
Найдите RSS-канал для любого сайта, проверив исходный код
Неужели ни один из вышеперечисленных приемов не сработал? Вы можете попробовать найти RSS-канал, проверив исходный код веб-страницы. Не паникуйте! Это проще, чем кажется.
Щелкните правой кнопкой мыши пустое место на веб-сайте, для которого требуется RSS-канал, затем щелкните Просмотреть источник страницы (точная формулировка может отличаться в зависимости от вашего браузера).
Теперь найдите код, нажав Ctrl + F (Windows, Linux) или команду + F (Mac). Начните с поиска rss , например:
Если поиск rss не работает, попробуйте вместо него atom . Найдите URL-адрес RSS, как вы можете видеть выше, затем скопируйте его в программу чтения каналов.
Создание собственных RSS-каналов с помощью Zapier
Некоторые сайты просто не предлагают RSS-каналы, что разочаровывает, но вы можете использовать RSS от Zapier для создания RSS-каналов с данными из тысяч приложений.
Например, вы можете создать RSS-каналы для Twitter:
или Instagram:
Или даже для различных сервисов Google:
Это всего лишь несколько примеров. Вы можете создать свой собственный RSS-канал, который будет извлекать практически любую информацию, которую вы можете себе представить. Начни здесь.
Хотите узнать больше о RSS? Ознакомьтесь с нашим списком лучших бесплатных приложений для чтения RSS или прочитайте о способах использования RSS для повышения вашей производительности.
Просмотр и удаление истории просмотров в Internet Explorer
Используйте последнюю версию браузера, рекомендованную Microsoft
Получите скорость, безопасность и конфиденциальность с Microsoft Edge.
Попробуй это сейчас
История просмотров — это информация, которую Internet Explorer сохраняет на ПК во время просмотра веб-страниц. Чтобы помочь вам улучшить ваш опыт, сюда входит информация, которую вы вводили в формы, пароли и сайты, которые вы посещали. Однако, если вы используете общий или общедоступный компьютер, возможно, вы не захотите, чтобы Internet Explorer сохранял вашу историю.
Просмотр истории просмотров и удаление определенных сайтов
Просматривая историю просмотров, вы можете удалить определенные сайты или вернуться на уже посещенную веб-страницу.
В Internet Explorer нажмите кнопку Избранное .
Выберите вкладку История и выберите способ просмотра истории, выбрав фильтр в меню. Чтобы удалить определенные сайты, щелкните правой кнопкой мыши сайт в любом из этих списков и выберите Удалить . Или вернитесь на страницу, выбрав любой сайт в списке.
Удалить историю просмотров
Регулярное удаление истории просмотров помогает защитить вашу конфиденциальность, особенно если вы используете общий или общедоступный компьютер.
В Internet Explorer нажмите кнопку Инструменты , укажите на Безопасность , а затем выберите Удалить историю просмотров .
Выберите типы данных или файлов, которые вы хотите удалить с вашего ПК, а затем выберите Удалить .
Что удаляется при удалении истории просмотров
Типы информации | Что удаляется | Internet Explorer версии |
|---|---|---|
История просмотров | Список посещенных вами сайтов. | Все |
Кэшированные изображения временных файлов Интернета | Копии страниц, изображений и другого мультимедийного содержимого, хранящегося на вашем ПК. Браузер использует эти копии, чтобы быстрее загружать контент при следующем посещении этих сайтов. | Все |
Файлы cookie | Информация, которую сайты хранят на вашем компьютере, чтобы запомнить ваши предпочтения, такие как ваш вход в систему или ваше местоположение. | Все |
История загрузок | Список файлов, загруженных из Интернета. При этом удаляется только список, а не сами файлы, которые вы скачали. | Только Internet Explorer 11 и Internet Explorer 10 |
Данные формы | Информация, которую вы ввели в формы, например ваш адрес электронной почты или адрес доставки. | Все |
Пароли | Пароли, которые вы сохранили для сайтов. | Все |
Защита от отслеживания, фильтрация ActiveX и данные «Не отслеживать» | Веб-сайты, которые вы исключили из фильтрации ActiveX, и данные, которые браузер использует для обнаружения активности отслеживания. | Все |
Избранное | Список сайтов, которые вы сохранили как избранные. Не удаляйте избранное, если вы хотите удалить только отдельные сайты — это удалит все ваши сохраненные сайты. | Все |
Данные фильтрации InPrivate | Сохраненные данные, используемые InPrivate Filtering для определения сайтов, которые могут автоматически передавать сведения о вашем посещении. | Только для Internet Explorer 9 и Internet Explorer 8 |
Semrush — Платформа управления видимостью в Интернете
«Я использую Semrush уже более 7 лет и очень полагаюсь на него, чтобы помочь мне переместить любой сайт, над которым я работаю, в топ Google».
Кейси Камиллери Маркс Директор по цифровому маркетингу, Nlyte Software«Что мне больше всего нравится в Semrush, так это то, что он охватывает все области поиска с помощью своих инструментов, так что я могу иметь полный обзор моих проектов.”
Эстер Хименес Старший консультант по SEO и UX, Annalect, Omnicom Media Group«Если вы попросите агентство обеспечить 10-кратный органический рост поиска за счет контента, они назначат большую команду для вашего проекта. Наша команда по контенту, напротив, работает с Semrush, не имея армии людей, специализирующихся на SEO ».
Фабрицио Балларини Отвечает за SEO, TransferWise«Когда дело доходит до чистой стоимости, Semrush выигрывает.Это в основном потому, что вы получаете полнофункциональный программный пакет для SEO И ПО Google Рекламы по той же ежемесячной цене ».
Брайан Дин Основатель Backlinko«Мы выбрали Semrush, потому что отслеживание ключевых слов было намного более точным, чем наши предыдущие инструменты, а интерфейс был очень интуитивно понятным».
Фредди Хант Директор по SEO и контент-маркетингу, Oneupweb«Существует прямая корреляция между использованием Semrush, ориентацией на SEO и тем огромным ростом, который у нас был.В 2019 году наш органический трафик вырос на 230%. Буквально каждый день мы получаем самый высокий трафик на нашем сайте ».
Эрик Богард Вице-президент по маркетингу, Arkadium«С помощью Semrush мы уполномочили каждую маркетинговую команду в университете удвоить свой трафик, как мы это сделали для центральных сайтов».
Шефали Джоши Аналитик по оптимизации маркетинга, Университет Монаш«Я никогда не видел, чтобы местная стоматологическая клиника занимала такое место в мировом рейтинге, как сейчас.Мы занимаем место в национальном рейтинге. Из-за инструмента. Просто как тот. И я до сих пор не использую даже 50% от этого ».
Эд Чаллинор Соучредитель и генеральный директор Smileworks«Наш общий органический трафик увеличился в семь раз, при этом трафик блогов составил более 75% посещений! Semrush позволил нам оптимизировать и запустить нашу контент-стратегию, не нуждаясь в армии экспертов по SEO.”
Барбора Ясова Контент-стратег, Landbot«Помощник по написанию SEO-оптимизации Семруша — единственный в своем роде. Я был поражен отзывами и рекомендациями, которые он предоставил мне для улучшения моего SEO, читаемости текста, оригинальности и тона голоса ».
Месмер Дуэ Консультант по цифровому маркетингу, Blue Lance«Используя Semrush, моя команда экономит много времени, работая над правильным контентом и более ориентированным на данные способом.Семруш — моя правая рука в решении многих задач, он помогает мне и моей команде разрабатывать стратегию ».
Идан Сегал Ведущий специалист по органическому росту, Wix«Мы создали комплексную контентную стратегию, чтобы увеличить потенциальный органический трафик на 123%. Мы активно использовали инструменты Semrush для достижения наших целей ».
Ильяс Текер Основатель, консультант по SEO, Mosanta«Когда вы сидите за столом с генеральным менеджером, они просто хотят знать долю рынка.Market Explorer — идеальный инструмент, чтобы быстро показать, какова роль и классификация нашего бренда на рынке ».
Эмануэле Арозио Руководитель глобального SEO, Triboo Group«Моя любимая часть Semrush — это сила, которую он имеет для конкурентной разведки. Когда у вас больше данных, это упрощает принятие разумных рекламных решений.”
Дигнора Альтамиранда Руководитель группы маркетинга, Avature«Мне нравится функция, которая позволяет вам анализировать разрыв ключевых слов и обратных ссылок с вашими конкурентами. Это очень полезно для определения того, по каким ключевым словам вы не ранжируетесь, что вы могли бы получить ».
Пол Мелуццо Креативный директор, Omnislash Visual«Semrush сыграл ключевую роль в том, чтобы помочь мне лучше понять конкурентную среду моих рекламных кампаний.Мне удалось сократить разрыв между моими органическими и оплачиваемыми усилиями, тем самым распределяя свой бюджет и тактику комплексным образом ».
Андреа Круз Менеджер по цифровому маркетингу, KoMarketing«Моя любимая функция — это инструмент анализа контекстной рекламы. Он сообщает мне, какие виды PPC-рекламы запускаются в конкретном домене. Хорошо оптимизировать мою собственную стратегию PPC! »
Вашиштха Капур Соучредитель affNext«С Semrush я обнаружил слабые места в PPC для презентаций, где я только освещал SEO.Я нашел новых конкурентов клиентов, о которых они не подозревали, и ключевые слова, на которые они могут ориентироваться ».
Джудит Льюис Основатель, deCabbit Consultancy«Я использовал инструмент подсказки ключевых слов PPC для создания рекламы для моих клиентов. И эти объявления не только соответствуют задачам клиента, но и дают отличные результаты ».
Анкитаа Гохайн Далмия Основатель, специалист по стратегии цифрового контента, AnksImage«Набор инструментов для социальных сетей от Semrush — лучший в своем деле.Я использую этот инструмент с большим успехом, и он помог мне повысить узнаваемость в социальных сетях ».
Джигар Агравал SEO-специалист, внештатный сотрудник«Я использую Semrush последние 5 лет, особенно для SEO, написания контента, а теперь даже для маркетинга в социальных сетях. ”
Химани Канкария Консультант по электронной коммерции и SEO-стратег, eComKeeda«Хотя это не основная функция Semrush, мне очень нравится их инструмент для публикации сообщений в социальных сетях — я бы попробовал.”
Тревор Столбер Основатель Агентства цифрового маркетинга STOLBER .
Ваш комментарий будет первым