Бэкап сайта: что такое и как грамотно его сделать
- Что такое Backup
- Зачем он нужен?
- Как его сделать?
Что это такое бэкап сайта?
Суть бэкапа сайта сводится к копированию баз данных, файлов сайта, почты, FTP-аккаунтов и множества других параметров хостинга. Проще говоря, мы сохраняем весь сайт и его настройки в отдельном месте и, при необходимости, можем вернуть сайт к той версии, которую сохранили. При этом может осуществляться копирование данных на текущий и бэкапный (дополнительный) сервер, располагающийся отдельно от серверов провайдера либо в другом дата-центре. Оно производится на случай, если что-то случится с сервером на котором хранится сайт.
Для чего нужно резервное копирование сайта?
Вы можете восстановить выполненный хостинг-провайдером бэкап, используя панель управления хостинг-аккаунтом, или обратившись к провайдеру, а затем начать работать над повышением уровня безопасности вашего сайта, а не заниматься восстановлением контента своего сайта по частям.
Однако может возникнуть и другая более сложная проблема – в результате какого-либо стихийного бедствия работоспособность сервера нарушается, и он, как и все сайты и бэкапы, содержащиеся на нем, также перестает работать. Для таких форс-мажорных случаев и предусмотрен сервис двойного резервного копирования.
У хостинг-провайдера имеется возможность оперативно восстановить работу своих сервисов и выполнить восстановление бэкапов данных пользователей, взяв их из другого бэкапного сервера, который расположен в другом дата-центре, и на который не повлияли форс-мажорные обстоятельства, нарушившие работу сайтов.
Поэтому перед приобретением хостинга обязательно поинтересуйтесь у провайдера предлагает ли он своим заказчикам сервис резервного копирования ваших данных и насколько регулярно он это выполняет и сколько времени хранит копии. Этот фактор существенно снизит риск потери данных.
Зачем сохранять к себе на компьютер?
Мы рекомендуем еженедельно сохранять к себе на компьютер резервную копию сайта.
Как сделать бэкап сайта?
Основная задача будет состоять в том, чтобы сохранить к себе на компьютер файлы сайта и базу данных, которые находятся на сервере хостера. Есть несколько вариантов того, как делать бэкап сайта. И сейчас мы их рассмотрим подробно.
С помощью хостинг-аккаунта
Заходите в панель управления хостингом и находите там раздел похожий на «Резервные копии», «Backup» или что-то подобное. Далее два пути:
- провайдер создаст копию (в одном архиве) и даст Вам ссылку чтобы скачать.
- провайдер сделает копию, и ее нужно будет скачать с сервера (на котором расположен Ваш сайт) с помощью FTP-клиента (обычно файл с копией находится в папке backup или подобной) или скачать через менеджер файлов в панели управления хостингом.
С помощью FTP-клиента и phpMyadmin
Начинаем с того, что устанавливаем и настраиваем FTP-клиент (это целесообразно делать в случае, если у хостинг-провайдера не реализована загрузка файлов через собственный файл-менеджер). После этого с его помощью скачиваем себе на компьютер абсолютно все файлы сайта, хранящиеся на сервере хостинг-провайдера. После этого с его помощью, скачиваем себе на компьютер абсолютно все файлы сайта, хранящиеся на сервере хостинг-провайдера.
После этого с его помощью скачиваем себе на компьютер абсолютно все файлы сайта, хранящиеся на сервере хостинг-провайдера. После этого с его помощью, скачиваем себе на компьютер абсолютно все файлы сайта, хранящиеся на сервере хостинг-провайдера.
Затем нужно скопировать базу данных на свой компьютер (еще называют создать дамп базы данных).
Как вернуть сайт к сохраненной версии?
Если в будущем вам понадобится вернуть сайт к той версии, которую вы сохранили на компьютер, то удалите полностью все файлы на сервере (не трогайте файлы настроек, удаляйте только из той папки, где хранятся файлы сайта, например public_html, www и т.д.). Сайт полностью перестанет работать (это не надолго). После этого очистите все таблицы в базе данных сайта (через phpMyadmin) и импортируйте в пустую БД ту базу данных, которая сохранена на Вашем компьютере. После этого загружайте файлы сайта на сервер и сайт должен заработать. Причем это будет та версия сайта, которую вы заранее сохраняли на свой компьютер.
На сколько часто нужно делать резервные копии сайта?
Желательно делать это несколько раз в месяц (речь о резервных копиях, которые вы делаете самостоятельно и загружаете к себе на компьютер). Обычно резервные копии создаются автоматически самим хостером и хранятся там около 2 недель. Мы рекомендуем загружать их себе на диск (или облачное хранилище типа Дропбокс) примерно 1-2 раза в месяц. Для большинства сайтов это будет хорошим соотношением усилий и эффективности.
Сколько бэкапов нужно постоянно хранить?
Это зависит от того, насколько часто обновляется ваш сайт. Оптимальным для большинства сайтов можно назвать количество бэкапов за год, если делать их 1-2 раза в месяц, то получается 12-25 копий.
Handy Backup — резервное копирование сайта на ПК в Windows Софт
Итак, в прошлой статье Handy Backup — cинхронизация сайта на ПК в Windows я рассказал про синхронизацию сайта на домашний локальный ПК, способ очень хорош, но имеет свои минусы, о которых я также упомянул, т. е. при синхронизации на компьютере хранится одна зеркальная копия сайта, очень удобно взять оттуда какой-нибудь файл или папку для восстановления на сайте, в случае утери, но если сайт будет заражен вирусами или успел синхронизироваться с нечаянно удаленными файлами или папками, то все пропало, на компьютере после синхронизации будет тоже самое и ничего уже не вернешь.
е. при синхронизации на компьютере хранится одна зеркальная копия сайта, очень удобно взять оттуда какой-нибудь файл или папку для восстановления на сайте, в случае утери, но если сайт будет заражен вирусами или успел синхронизироваться с нечаянно удаленными файлами или папками, то все пропало, на компьютере после синхронизации будет тоже самое и ничего уже не вернешь.
Это конечно в случае, если вы не настроили автоматическое регулярное резервное копирование сайта на сервере, если настроено, то на компьютер будут синхронизироваться резервные копии сайта и БД, тогда все впорядке, достаточно даже синхронизации, для восстановления сайта возьмете бэкап оттуда.
Итак, работать будем со стандартной версией программы Handy Backup Standard – резервное копирование файлов и папок в Windows.
Тут 64-разрядная версия Handy Backup.
Правда есть один нюанс, в стандартной версии программы резервное копирование по SFTP заблокировано, при попытке создать подключение по SFTP программа сообщит, что «эта опция недоступна в вашей версии программы».
Настройка создания резервной копии сайтов в Handy Backup
Установку программы я тут пропустил, она элементарна и есть в прошлой статье, перейдем сразу к настройкам.Шаг 2. Тут добавим подключение к сайту по FTP и выберем данные для резервного копирования.
Тут настроим FTP cоединение, достаточно логина и пароля и проверяем соединение по кнопке «Пробное соединение», если скажет «Успех!», выбираем удаленную директорию сайта, которую нужно бэкапить, я выбрал один сайт site1.ru, а путь к сайтам на Вашем хостинге/сервере может быть другой.
Тут Вы можете убрать галочки с ненужных папок, исключить их из резервной копии, например, папки с кешами Битрикс:
- /bitrix/cache/
- /bitrix/managed_cache
- /bitrix/stack_cache
А можно не выбирать вручную папки с кешем, можно прописать маски исключений по кнопке «Файловые фильтры», но тут может быть серьезная проблема, т.к. маски применяются ко всем файлам и папкам, отдельно для папки применить маску нет возможности в программе, и если на сайте в каком-нибудь модуле есть файл класса с названием «class_cache.php», то он тоже будет проигнорирован и при восстановлении сайта возникнут проблемы, так что, лучше вручную убрать галочки с ненужных папок, с масками будьте осторожны.
Шаг 3. Тут выбираем папку на компьютере, куда сохранять бэкапы сайта, у меня это всегда диск D:\BACKUP
Шаг 4. На этом шаге:
Тип копирования — полный (полностью сайт резервируем и сжимаем в архив).
Хранить несколько резервных копий
Работа с ошибками — не останавливаться при ошибках, скопировать все, что возможно.
Шаг 5. На этом шаге настраиваем сжатие бэкапа на компьютере, каждый день — это отдельная сжатая полная копия сайта на вашем ПК
Шаг 6. Настраиваем планировщик, расписание резервного копирования, но тут уже как удобно Вам.
Шаг 7. Тут можно запускать программы после завершения задачи и уведомлять на почту, но если для себя делаете, тогда тут ничего не надо настраивать.
Шаг 8. Задаем название задачи, с этим названием будет создана папка на компьютере.
После успешно проделанных операций сайт будет резервироваться на компьютере в таком виде, каждая папка соответствует дате создания бэкапа.
А если зайти в папку, то там мы увидим сжатую полную копию сайта «backup.zip», а «index.zip» — это список проиндексированнных программой папок.
При восстановлении сайта Вам понадобится только архив «backup.zip».
Все, резервное копирование сайта на локальный ПК в программе Handy Backup завершено!
Заключение
Это будет самый надежный способ резервирования сайта, если конечно настроено регулярное резервное копирование БД сайта на сервере, иначе будут резервироваться только файлы сайта.Если у кого-то возникнут трудности по настройке регулярного резервного копирования только БД сайта, сообщите, напишу мануал.
Как делать резервное копирование сайта Joomla 3
Вступление
Не всегда, и не все работы можно выполнить своими силами. Однако вам важно, что вы самостоятельно можете перестраховаться и делать резервные копии своих сайтов, чтобы их не потерять.
Вы не можете ремонтировать, не только удалённые сервера вашего хостинга, чаще вы не можете выполнять ремонтные работы в квартире и доме. Бич современного жителя — это поломки бытовой, офисной техники, ремонт компьютерной техники и компьютерная помощь.
Сообщаю, в Интернет есть специальные порталы называемые, агрегаторы сервис центров. На них в одном месте, у удобной навигацией собраны проверенные сайты и организации, оказывающие разнообразные услуги населению и организациям.
Например, сломался у вас компьютер. Открываете сайт агрегатора https://spb.service-scanner.ru/, и смотрите раздел «ремонт компьютеров». Там для Вас собрали 230+ сервисных центров по ремонту компьютерной техники, город Санкт-Петербург. Выбираете подходящий и сразу оставьте заявку.
От автора
Резервное копирование Joomla 3 можно делать несколькими способами, включая использование сторонних расширений. В этой статье я расскажу, как сделать самостоятельное резервное копирование сайта, без использования расширений. Это универсальный метод резервного копирования.
Joomla 3, как и любой другой Интернет ресурс, состоит из двух частей. Первая часть, это папки и файлы CMS Joomla, вторая часть это база данных вашего сайта. Полная резервная копия сайта, соответственно, включает копии двух этих частей.
Первая часть, это папки и файлы CMS Joomla, вторая часть это база данных вашего сайта. Полная резервная копия сайта, соответственно, включает копии двух этих частей.
Копия сайта
Чтобы сделать копию сайта, а более точно, копию CMS Joomla 3, нужно открыть каталог сайта по FTP и «тупо» скопировать все папки и файлы корневого каталога сайта себе на компьютер в отдельную папку. Все копия сайта готова. Переходим к копии базы данных сайта.
Копия базы данных
Для создания копии базы данных нужно войти в панель phpMyAdmin на вашем хостинге. Для авторизации в phpMyAdmin используется имя пользователя базы данных и пароль доступа к базе данных. Если вы их забыли, посмотрите эти данные в файле configuration.php.
Строки:
public $user = »; (пользователь базы данных).
public $password = »;( пароль доступа к базе данных).
После входа в phpMyAdmin кликните по названию базы данных. Откроется структура базы данных – список таблиц.
Копия базы данных делается очень просто. Ничего не выделяя, нажимаете кнопку «Экспорт». На следующей странице вы можете выбрать два варианта копирования. Быстрое копирование и Сжатое копирование.
Ничего не выделяя, нажимаете кнопку «Экспорт». На следующей странице вы можете выбрать два варианта копирования. Быстрое копирование и Сжатое копирование.
Примечание: База данных копируется текстовым файлом в формате sgl. Либо, в сжатых вариантах, zip, gzip. Для многих серверов предпочтительнее делать копию базы данных в сжатом формате gzip.
Выбираете сжатие gzip и нажимаете Ok. После сохранения файла на компьютере, копия базы данных готова.
Примечание: Если вы делаете копию всей базы данных, в соответствующем окне должны быть выделены все таблицы базы. По умолчанию они и выделены, поэтому менять ничего не нужно, просто проверьте.
Восстановление сайта
Резервное копирование Joomla 3 позволяет восстанавливать сайт при любых проблемах. Восстанавливается сайт зеркально копированию. А именно, очищаете корневую папку сайта и закачиваете резервную копию. В phpMyAdmin удаляете все таблицы базы данных и, используя кнопку «Импорт» заливаете копию базы данных. Все. Эти два простых шага помогут восстановить сайт при любых «авариях» на сайте.
Все. Эти два простых шага помогут восстановить сайт при любых «авариях» на сайте.
©Joomla3-x.ru
Другие статьи раздела: Администрирование Joomla 3
Бэкап сайта — что это, как выполнить правильно
Этим термином обозначают процесс резервного копирования всех файлов сайта, а также базы данных, аккаунтов FTP, параметров хостинга и даже сообщений почты. По сути, создается копия сайта, актуальная по состоянию на определенный момент. Все изменения, вносимые после создания бэкапа, в этой копии не отображаются, поэтому такая копия позволяет вернуть сайт к состоянию на момент его создания.
Копирование всей информации может производиться как на тот же сервер, так и на другой.
В последнем случае это может быть важным на случай форс-мажорных происшествий
с физическими носителями информации – жесткими дисками серверов. Например, на случай пожара, ограбления,
стихийных бедствий полезно, чтобы копии сайта хранились в другом дата-центре
(возможно, даже на другом континенте).
Например, на случай пожара, ограбления,
стихийных бедствий полезно, чтобы копии сайта хранились в другом дата-центре
(возможно, даже на другом континенте).
Для чего еще необходимо резервное копирование
Наиболее частой угрозой для сайтов является хакерская атака с целью повреждения или изменения его
файлов.
Без резервного копирования, то есть бэкапа, восстановление было бы весьма дорогостоящим и трудоемким,
что приводило бы к потерям времени и денег. Актуальный бэкап позволяет просто восстановить все данные,
за исключением тех, которые были внесены после его создания, что гораздо проще.
Произведенный провайдером хостинга бэкап можно восстановить через панель управления вашим аккаунтом.
Также вы можете обратиться в службу поддержки провайдера. Если же вам пришлось восстанавливать
работоспособность сайта из резервной копии после хакерской атаки, уделите внимание вопросам
безопасности сайта, поскольку бэкап – это крайний вариант.
На случай, если проблема возникла именно на физическом уровне – с оборудованием провайдера – предусмотрена услуга двойного бэкапа с сохранением резервной копии в другом дата-центре. Хостинг-провайдер может быстро восстановить все сервисы, используя оборудование резервных дата-центров, причем все функции будут доступны в полном объеме.
На выбор провайдера для хостинга сайта возможность создавать внешний бэкап должна оказывать немалое влияние. Задайте вопрос – насколько часто производится резервное копирование – обычное и двойное, а также какова глубина архива (срок хранения копий). В экстренных условиях от этого может зависеть ваш бизнес.
Создание бэкапа на компьютере
Резервную копию сайта стоит время от времени сохранять и на своем компьютере. Рекомендуем делать это хотя бы раз в неделю. Это поможет в случае, если глубина архива провайдера
не позволяет восстановить изменения, внесенные некоторое время назад. Например,
если сайт был заражен месяц назад, а провайдер сохраняет бэкапы лишь в течение недели.
Рекомендуем делать это хотя бы раз в неделю. Это поможет в случае, если глубина архива провайдера
не позволяет восстановить изменения, внесенные некоторое время назад. Например,
если сайт был заражен месяц назад, а провайдер сохраняет бэкапы лишь в течение недели.
Если вам нужно восстановить сайт из резервной копии на компьютере, сделать это несложно. Для начала удалите все файлы с сервера, кроме файлов, отвечающих за его настройки. Затем очищайте таблицы из базы данных. Это можно сделать с помощью инструмента phpMyadmin. Теперь нужно заполнить ее импортированными с вашего компьютера данными. И только после этого загрузите файлы резервной копии на сервер.
Желательно, чтобы бэкап сайта производился каждый день. Такие резервные копии чаще всего создаются
провайдером хостинга, срок их хранения в среднем равен двум неделям. Один-два раза в месяц их можно
выгружать на свой компьютер или выбранное вами облачное хранилище –
сейчас таких на рынке представлено множество.
Один-два раза в месяц их можно
выгружать на свой компьютер или выбранное вами облачное хранилище –
сейчас таких на рынке представлено множество.
Сколько резервных копий нужно
Если ваш сайт обновляется сравнительно редко, вам вполне хватит выгружать резервную копию раз в месяц,
таким образом, у вас будет до 12 бэкапов за год. Если обновления довольно часты,
необходимо сохранять до 25 копий за последний год. Все зависит от частоты и глубины обновлений на сайте.
Как сделать резервную копию вашего ПК Windows или Mac
Одна из наиболее распространенных ошибок, с которыми вы могли столкнуться, — это потеря содержимого вашего ПК из-за непредвиденных обстоятельств и невозможность восстановить какую-либо его часть, потому что вы не сделали его резервную копию. Если ваш жесткий диск выходит из строя или подвергается атаке вредоносного ПО, вы можете быть уверены, что все будет хорошо, если вы приняли необходимые меры предосторожности и выполнили резервную копию вашего компьютера.
Не уверены, что подлежит резервному копированию? Вы можете начать с личных файлов, таких как домашнее видео, фотографии, библиотека музыкальных файлов и важные документы, которые может быть трудно восстановить. Для личных файлов следует часто создавать резервные копии. Вы также можете создать резервную копию вашей операционной системы, программ и других параметров настроек, которые вы считаете необходимыми. Регулярное резервное копирование данных компьютера и обеспечение приоритетного порядка его выполнения сэкономит ваши деньги и время в случае чрезвычайной ситуации.
Существует несколько способов выполнения резервного копирования вашей системы, включая резервное копирование данных, размещенных в сети и локально. Рекомендуется иметь не менее трех копий всех важных файлов — оригинал, резервную копию и резервную копию резервной копии. Наличие резервных копий, размещенных в сети и локально, защитит вас от 99 процентов возможной потери данных.
Локальная или местная резервная копия — это копия, которая физически хранится в месте вашего нахождения, например, резервная копия, сделанная на внешний жесткий диск, что является более быстрым, простым и намного более безопасным способом. Windows предоставляет простое решение для резервного копирования ваших данных, которое называется Windows Backup (Резервное копирование Windows). Оно известно как функция Restore (Восстановление) в Windows 7 и File History (История файлов) в Windows 10. Прежде всего, убедитесь, что емкость вашего внешнего жесткого диска является такой же или превышающей емкость внутреннего диска, резервную копию которого вы собираетесь создать. Далее, введите слово «backup» (резервная копия) в строке поиска и выберите «Backup settings» (Настройки резервного копирования). В верхней части экрана вы увидите «Backup using File History» (Резервное копирование с использованием истории файлов) и можете использовать кнопку «плюс», чтобы указать компьютеру, на какие диски следует выполнить резервное копирование всего содержимого. Затем вы можете запланировать выполнение резервного копирования настолько часто, насколько захотите.
Windows предоставляет простое решение для резервного копирования ваших данных, которое называется Windows Backup (Резервное копирование Windows). Оно известно как функция Restore (Восстановление) в Windows 7 и File History (История файлов) в Windows 10. Прежде всего, убедитесь, что емкость вашего внешнего жесткого диска является такой же или превышающей емкость внутреннего диска, резервную копию которого вы собираетесь создать. Далее, введите слово «backup» (резервная копия) в строке поиска и выберите «Backup settings» (Настройки резервного копирования). В верхней части экрана вы увидите «Backup using File History» (Резервное копирование с использованием истории файлов) и можете использовать кнопку «плюс», чтобы указать компьютеру, на какие диски следует выполнить резервное копирование всего содержимого. Затем вы можете запланировать выполнение резервного копирования настолько часто, насколько захотите.
Если вы — пользователь Mac, вы можете перейти в раздел «System Preferences» (Настройки системы), «Time Machine» и выбрать диск для резервного копирования. Затем вы можете настроить эту программу для выполнения ежечасных обновлений и копирования любых изменений на выбранный вами жесткий диск. Это простой процесс, однако с его помощью резервные копии хранятся только до тех пор, пока на жестком диске не закончится место. Любые последующие данные будут перезаписаны на самые ранние данные, что может стать проблемой, если вам понадобится получить доступ к данным, записанным ранее по временной шкале.
Затем вы можете настроить эту программу для выполнения ежечасных обновлений и копирования любых изменений на выбранный вами жесткий диск. Это простой процесс, однако с его помощью резервные копии хранятся только до тех пор, пока на жестком диске не закончится место. Любые последующие данные будут перезаписаны на самые ранние данные, что может стать проблемой, если вам понадобится получить доступ к данным, записанным ранее по временной шкале.
Автономная (нелокальная) резервная копия делается всякий раз, когда ваши файлы хранятся где-либо, кроме текущего местоположения вашей системы. В техническом смысле это может быть жесткий диск, который вы храните в доме друга, но обычно это означает резервную копию вашей системы, хранящуюся в сети. Приложения Dropbox, Google Drive, iCloud и OneDrive — это удобные и низкозатратные варианты, которые позволяют автоматически синхронизировать наиболее важные для вас файлы. В зависимости от того, для какого объема данных вы планируете создать резервную копию, вам может потребоваться приобрести тарифный план. Вы можете использовать программное обеспечение выбранной вами платформы хранения данных, чтобы установить предпочитаемые вами параметры настроек. Резервная копия ваших данных будет выполнена в соответствии с вашими предпочтениями каждый раз, когда вы будете подключены к сети Интернет.
Вы можете использовать программное обеспечение выбранной вами платформы хранения данных, чтобы установить предпочитаемые вами параметры настроек. Резервная копия ваших данных будет выполнена в соответствии с вашими предпочтениями каждый раз, когда вы будете подключены к сети Интернет.
Более обстоятельным и безопасным способом создания резервных копий всей системы является использование образа диска или «образа-фантома». Для этого вам потребуется специальное программное обеспечение. Существуют бесплатные варианты, такие как программы Macrium Reflect и EaseUS для жестких дисков объемом 1ТБ или менее, а также платные варианты, такие как ПО Acronis True Image. Выберите подходящее для вас программное обеспечение для резервного копирования и восстановления, изучая имеющиеся варианты, например, читая обзоры и просматривая видео, чтобы посмотреть, соответствует ли оно вашим потребностям. Пользователи Mac могут использовать приложение Disk Utility для создания образа диска.
Суть в том, что резервное копирование вашего компьютера — это легкий и простой процесс, который сэкономит для вас много денег и времени на случай, если с вашим компьютером что-либо случится. Выделение времени для частого резервного копирования данных памяти и накопителя, а также выполнение этого в приоритетном порядке являются отличными мерами защиты от потери или кражи ваших данных. В целом, это представляет собой хороший навык, особенно если вы работаете с большим количеством конфиденциальной и персональной информации или информации, связанной с бизнесом.
Резервное копирование и восстановление файлов вашей системы с помощью компьютера
Вы можете создать на компьютере (Windows/Mac) резервную копию файлов из вашей системы.
Позднее вы всегда сможете восстановить эти данные в системе. Всегда делайте резервную копию данных системы перед тем как заменить карту памяти для системы PS Vita на карту большего объема, перед тем как сдать систему на ремонт или выбросить ее. Рекомендуется регулярно выполнять резервное копирование системы.
Рекомендуется регулярно выполнять резервное копирование системы.
- Перед тем как приступить к этой процедуре, вам необходимо сделать следующее:
- В систему серии PCH-1000 должна быть вставлена карта памяти для системы PS Vita.
- Свяжите учетную запись Sony Entertainment Network со своей системой.
- Подключите компьютер к Интернету.
- Загрузите и установите на компьютер программу «Помощник по управлению данными для PlayStation®».
Загрузите программу «Помощник по управлению данными» с этого сайта:
http://cma.dl.playstation.net/cma/
- Чтобы провести резервное копирование данных или восстановление системы, закройте все используемые приложения.
Примечание
Вы не сможете таким образом создать резервную копию информации о призах. Нужно синхронизировать информацию о призах с PlayStation™Network, чтобы данные о призах сохранились на серверах PlayStation™Network. Войдя в PlayStation™Network, выберите (Призы), чтобы синхронизировать информацию о призах.
Войдя в PlayStation™Network, выберите (Призы), чтобы синхронизировать информацию о призах.
- 1.
- На компьютере запустите программу «Помощник по управлению данными».
- Windows:
Найдите в области уведомлений на панели задач значок программы «Помощник по управлению данными», чтобы убедиться, что приложение работает. - Mac:
Найдите на панели меню значок программы «Помощник по управлению данными», чтобы убедиться, что приложение работает. - 2.
- Выберите на системе (Управление данными) > [Скопировать контент].
- 3.
- Выберите (Компьютер), затем выберите (кабель USB) или (Wi-Fi).
Для подключения по Wi-Fi поставьте отметку в поле [Подключиться к системе PS Vita или системе PS TV по сети] в меню [Настройки сетевого подключения] программы «Помощник по управлению данными» и зарегистрируйте систему на компьютере. Подробнее см. в разделе «Передача данных на компьютер и с компьютера по Wi-Fi».
- 4.
- Выберите [Создать резервную копию] или [Восстановить].
- Для завершения процесса следуйте инструкциям на экране.

- Для всех учетных записей можно создать не более 10 резервных копий.
- На жестком диске, использующем файловую систему FAT32, невозможно создать файл размером больше 4 Гб.
- Если вы измените имя резервной копии или имя папки, в которой она сохранена, возможно, вы не сможете восстановить данные системы с помощью этой копии.
- Восстановить данные из резервной копии можно только в системе PS Vita, связанной с той же учетной записью, с которой система PS Vita была связана на момент создания этой резервной копии. Резервную копию можно использовать для восстановления данных и на другой системе PS Vita, если эта система PS Vita связана с той же самой учетной записью.
- На резервное копирование и восстановление видеофайлов, взятых напрокат в PlayStation®Store, распространяются следующие ограничения:
- Восстанавливать взятые напрокат видеофайлы можно только на той же системе PS Vita, на которой была сделана резервная копия.
- Если после резервного копирования вы скопируете (переместите) взятый напрокат видеофайл на систему PS3™, видеофайл нельзя будет восстановить.
- Восстанавливать взятые напрокат видеофайлы можно только на той же системе PS Vita, на которой была сделана резервная копия.
- Пока производится резервное копирование данных или восстановление системы, кнопка питания, кнопка PS и все сетевые функции недоступны.
- В некоторых случаях вы не сможете создать резервную копию видеофайла и восстановить его.
Удаление резервной копии
На 4-м шаге инструкции «Создание резервных копий и восстановление файлов системы PS Vita с помощью компьютера» выберите [Удалить файлы резервных копий]. Для удаления файла следуйте инструкциям на экране.
Вы также можете удалить резервные копии файлов с компьютера вручную. Резервные копии файлов хранятся в папке, выделенной под [Файлы приложений/резервных копий] в приложении «Помощник по управлению данными».
Как сделать бэкап сайта на WordPress: 2 способа резервного копирования
Для резервного копирования можно использовать стандартный инструмент cPanel, или же использовать специальные плагины.
О резервном копировании встроенными средствами cPanel можно прочесть в разделе «Мастер резервного копирования» статьи «Раздел Файлы в cPanel».
В данной статье мы рассмотрим детальнее резервное копирование с помощью плагина All-in-One WP Migration.
Как восстановить сайт из резервной копии WordPress с помощью плагина All-in-One WP Migration
Существует огромное количество плагинов для создания резервных копий сайта.
Мы рассмотрим один из самых популярных плагинов — All-in-One WP Migration. Он очень удобен для переноса сайта, создания регулярных резервных копий и изменения доменного имени сайта.
Сначала нужно установить плагин All-in-One WP Migration в консоли сайта:
1. Для этого перейдите в Плагины – Добавить новый и введите название плагина в поиске.
2. Нажмите Установить и Активировать:
После активации плагин появится в меню административной панели.
У плагина есть три функции:
Рассмотрим каждую отдельно по порядку.
Экспорт
Перед экспортом сайта желательно отключить все плагины. Чтобы создать резервную копию текущего состояния сайта, перейдите в функцию Экспорт:
Эта функция позволяет создать бекап сайта и экспортировать его в различные локации. В бесплатной версии плагина единственная возможность для загрузки копии — сохранить ее на компьютере в виде файла. Для этого выберите Экспортировать в файл:
Вам предложат сохранить файл с расширением .wpress в одной из директорий вашего компьютера:
Резервные копии
Все созданные резервные копии плагина находятся в разделе Резервные копии. Здесь же нужную копию можно скачать на компьютер, либо сразу восстановить вместо текущей:
Импорт
Если вы переносите сайт с другого хостинга или меняете домен, используйте функцию Импорт. С ее помощью можно восстановить резервную копию из файла с расширением .wpress:
1. После запуска импорта отобразится предупреждение о замене всех текущих медиафайлов, плагинов, тем и базы данных.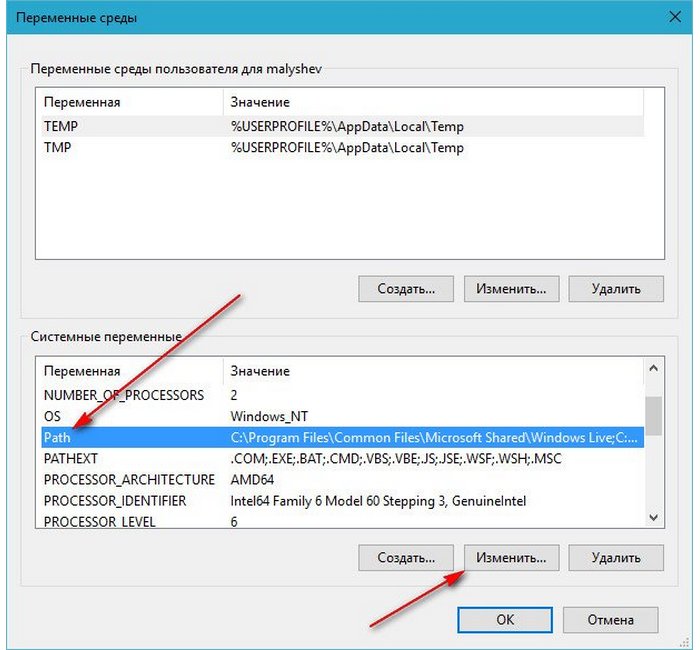 После завершения импорта нажмите на Permalinks Settings, чтобы обновить постоянные ссылки:
После завершения импорта нажмите на Permalinks Settings, чтобы обновить постоянные ссылки:
2. Вас перенаправит на страницу входа в консоль сайта. Авторизуйтесь, используя данные для входа на импортированный сайт.
3. Перейдите в раздел Настройки – Постоянные ссылки административной панели WordPress и сохраните изменения.
Так вы можете переносить копию сайта с компьютера на хостинг или изменять домен сайта без дополнительных изменений в базе данных и настройках сайта.
Если нужно изменить домен сайта, создайте резервную копию сайта на старом домене и импортируйте ее с помощью плагина на сайт с новым доменом. Обратите внимание: если вы таким образом переносите сайт на новый хостинг, предварительно установите WordPress.
Помогла ли эта статья решить вашу проблему?
Ваш ответ поможет улучшить статьи в будущем.
Как скопировать ссылку или URL-адрес веб-страницы
Обновлено: 01.02.2021, Computer Hope
В Windows и macOS URL (адрес) веб-страницы можно выбрать, выделить и скопировать в буфер обмена из адресной строки. После копирования вы можете вставить его в другую программу или документ (например, в электронное письмо). Чтобы узнать о дополнительных методах копирования или обмена URL-адресом, продолжайте читать.
После копирования вы можете вставить его в другую программу или документ (например, в электронное письмо). Чтобы узнать о дополнительных методах копирования или обмена URL-адресом, продолжайте читать.
Скопируйте URL (адрес) на настольный компьютер или ноутбук
- Выделите адрес, наведя курсор мыши на адресную строку и щелкнув левую кнопку мыши один раз или нажав сочетание клавиш F6 , чтобы попасть в адресную строку.
- После выделения адреса нажмите Ctrl + C или Command + C на клавиатуре, чтобы скопировать его. Вы также можете щелкнуть правой кнопкой мыши любой выделенный раздел и выбрать Копировать из раскрывающегося меню.
- После копирования адреса вставьте этот адрес в другую программу, щелкнув пустое поле и нажав Ctrl + V или Command + V . Вы также можете щелкнуть правой кнопкой мыши любой выделенный раздел и выбрать Вставить из раскрывающегося меню.

Многие веб-страницы, включая Computer Hope, имеют ссылку Share или E-Mail , по которой вы можете поделиться ею с друзьями.
Практика вставки URL
Вы можете попрактиковаться в копировании и вставке URL-адреса этой страницы, выполнив указанные выше действия, а затем вставив URL-адрес в текстовое поле ниже.
Если все сделано правильно, в поле выше будет «https://www.computerhope.com/issues/ch000867.htm».
Скопируйте адресную ссылку на смартфон или планшет
- Откройте предпочтительный мобильный Интернет-браузер.
- Найдите адресную ссылку, которую вы хотите скопировать.
Если адресная строка не отображается, попробуйте прокрутить вверх пальцем. Также имейте в виду, что адресная строка будет видна только в приложении браузера. Если вы просматриваете веб-страницу через другое приложение, она может быть недоступна.
- Коснитесь адресной строки один раз, чтобы выделить весь текст, содержащийся в ней.
- Нажмите и удерживайте выделенный текст и выберите Копировать .
- На устройствах меньшего размера символ копирования текста выглядит как два одинаковых листа бумаги.
- Откройте приложение, в которое вы хотите вставить адрес.
- Снова нажмите и удерживайте и выберите Вставить .
.jpg)
Практика вставки URL
Вы можете попрактиковаться в копировании и вставке URL-адреса этой страницы в поле ниже, выполнив указанные выше действия.
Если все сделано правильно, «https://www.computerhope.com/issues/ch000867.htm «должно быть в поле выше.
Копирование ссылки на видео YouTube на веб-сайте и в приложении
КончикВы также можете использовать шаги, описанные выше, как скопировать URL-адрес, чтобы скопировать ссылку на видео YouTube. Мы включаем следующие шаги в качестве альтернативного метода копирования ссылки на видео.
На настольном компьютере и мобильном устройстве вы можете щелкнуть значок общего доступа, который должен напоминать значок общего доступа, показанный на рисунке ниже.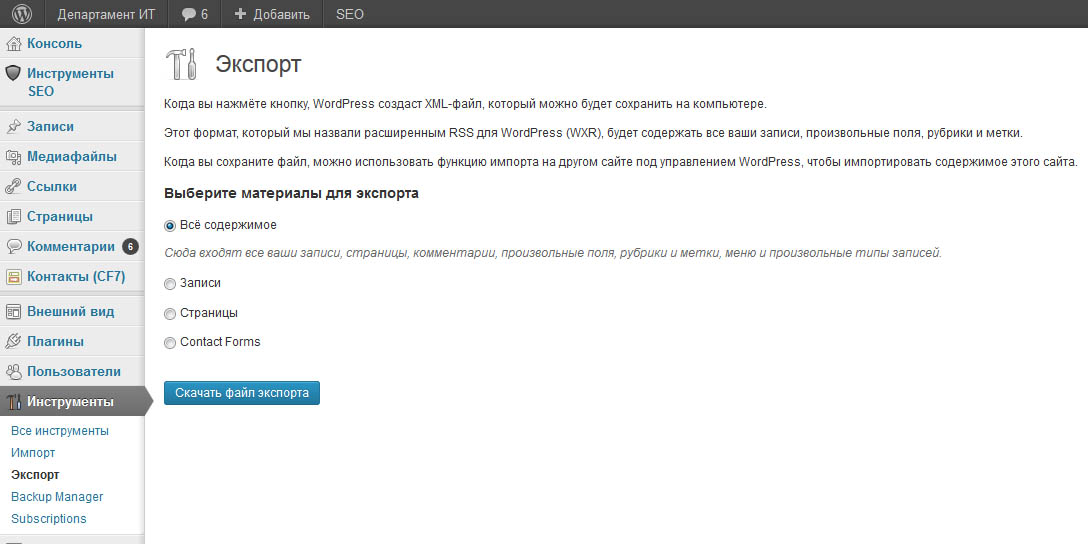 После того, как вы нажмете ссылку «Поделиться», в дополнение к службам социальных сетей появится URL-адрес видео, которое можно скопировать и вставить куда угодно.
После того, как вы нажмете ссылку «Поделиться», в дополнение к службам социальных сетей появится URL-адрес видео, которое можно скопировать и вставить куда угодно.
Сокращение длинного адреса или URL
Некоторые веб-страницы могут иметь длинный URL-адрес, который может вызвать проблемы при вставке в другую программу, особенно в электронную почту. Если интересующая вас ссылка длинная (более 60 символов), скопируйте и вставьте URL-адрес на веб-страницу, которая создает короткую ссылку. Наш любимый сервис коротких ссылок — Tiny URL.
КончикСуществует также множество надстроек и расширений браузера, которые можно использовать, чтобы упростить копирование длинных адресов.
Копирование ссылки или изображения на странице
Чтобы скопировать адрес ссылки или изображения, щелкните объект правой кнопкой мыши и выберите в раскрывающемся меню Копировать адрес ссылки или Копировать изображение . Кроме того, пользователи могут просматривать свойства ссылки и копировать URL-адрес из этого меню.
| F A Q
Очень Часто задаваемые вопросы: Общие вопросы:Устранение неисправностей:Вопросы по зеркалу: Другие проблемы:Очень часто задаваемые вопросы: Q: HTTrack не захватывает все файлы, которые я хочу захватить! Хорошо, позвольте мне объяснить, как точно контролировать процесс захвата. Возьмем пример: Представьте, что вы хотите захватить следующий сайт: HTTrack по умолчанию захватит все ссылки, встречающиеся в www.someweb.com/gallery/ цветы / или в нижних каталогах, например
www.someweb.com/gallery/flowers/roses/. Это поведение по умолчанию HTTrack, НО, конечно, если вы хотите, вы можете указать HTTrack захватить другие каталоги, веб-сайты! .. Это легко сделать с помощью фильтров: перейдите на панель параметров , выберите вкладку «Правила проверки» и введите следующую строку:
(вы можете оставить пробел между каждым правилом, вместо того, чтобы вводить возврат каретки) Это означает «принимать все ссылки, начинающиеся с www.someweb.com/gallery/trees/ и www.someweb.com/photos/» — + означает «принять», а последний * означает «любой символ будет соответствовать после предыдущих». Помните, что * .doc или * .zip встречаются, когда вы хотите выбрать все файлы определенного типа на вашем компьютере: здесь почти то же самое, за исключением начала «+» Теперь мы можем захотеть исключить все ссылки в www.someweb.com / gallery / trees / hugetrees /, потому что с предыдущим фильтром
мы приняли слишком много файлов. Здесь снова вы можете добавить правило фильтрации, чтобы отклонять эти ссылки. Вы заметили — в начале третьего правила: это означает «отклонить ссылки, соответствующие правилу»
; и правило: «любые файлы, начинающиеся с www.someweb.com/gallery/trees/hugetrees/ Более сложный пример? Представьте, что вы хотите принимать все файлы jpg (файлы с типом .jpg), в названии которых есть слово «синий» и которые находятся на www.someweb.com Подробнее подробную информацию можно найти здесь! Q: Это программное обеспечение «бесплатное», но я купил его у авторизованного реселлера. В чем дело? Q: Есть ли риск заражения вирусами с этим программным обеспечением? Q: Установка не работает в Windows без прав администратора! Q: Где найти документацию на французском / других языках? Q: Работает ли HTTrack в Windows Vista / Windows Seven / Windows 8? Q: Работает ли HTTrack в Windows 95/98? Q: В чем разница между HTTrack, WinHTTrack и WebHTTrack? Q: Совместима ли HTTrack с Mac? Q: Можно ли компилировать HTTrack на всех Un * x? Q: Я использую HTTrack в профессиональных целях. А как насчет ограничений / лицензионных сборов? Q: Есть ли лицензионные отчисления за распространение зеркала, сделанного с использованием HTTrack? Q: Доступна ли версия DLL / библиотеки? Q: Доступна ли версия с графическим интерфейсом для Linux и Un * x? Устранение неполадок: Q: Захватывается только первая страница. Что случилось? A: Сначала проверьте файл hts-log.txt (и / или файл журнала ошибок hts-err.txt) — он может дать вам ценную информацию. Q: С WinHTTrack иногда сворачивание в системном трее вызывает сбой! A: Эта ошибка иногда появляется в оболочке некоторых систем. Q: Работает ли https URL? A: Да, HTTrack поддерживает (начиная с 3.20 выпуск) https (протокол уровня защищенных сокетов) сайты Q: Работает ли URL ipv6? A: Да, HTTrack поддерживает (начиная с версии 3.20) сайты ipv6, используя записи A / AAAA или прямые адреса v6 (например, http: // [3ffe: b80: 12: 34: 56 :: 78] /) Q: Файлы создаются со странными именами, например ‘-1.html’! A: Проверьте параметры сборки (возможно, вы выбрали определенную пользователем структуру с неправильными параметрами!) Q: При захвате реальных аудио / видео ссылок (.баран), у меня только ярлык! A: Да, но файл, связанный с .ra / .rm, должен быть записан вместе — кроме случаев, когда используется протокол rtsp: // (пока не поддерживается HTTrack) или если требуются соответствующие фильтры Q: Использование user: password @ address не работает! A: Опять же, сначала проверьте файлы журнала ошибок hts-log. Q: Когда я использую HTTrack, ничего не зеркалируется (нет файлов) Что
происходит? Q: Отсутствуют файлы! Что происходит?
Q: Есть поврежденные изображения / файлы! Как их исправить? A: Сначала проверьте файлы журнала, чтобы убедиться, что изображения действительно существуют удаленно и не являются поддельными страницами ошибок html, переименованными в.jpg (например, ошибка «Не найдено»). Повторно просканируйте веб-сайт с помощью «Продолжить прерванную загрузку», чтобы найти изображения, которые могут быть повреждены из-за различных ошибок (например, тайм-аут передачи). Затем проверьте, присутствует ли поврежденное изображение / имя файла в журнале (hts-log.txt) — в этом случае вы найдете там причину, по которой файл не был правильно пойман.  Если это не сработает, удалите поврежденные файлы (Примечание: для обнаружения поврежденных изображений вы можете просмотреть каталоги с помощью такого инструмента, как ACDSee, а затем удалить их) и повторно просканируйте веб-сайт, как описано ранее.HTTrack будет обязан повторно привязать удаленные файлы, и на этот раз он должен работать, если они действительно существуют удаленно !. Q: FTP ссылки не ловятся! Что происходит? В: У меня есть повторяющиеся файлы! В чем дело? Примечание. В некоторых редких случаях дубликаты файлов данных могут быть обнаружены при перенаправлении веб-сайта на другой файл.Эта проблема должна возникать редко, и ее можно избежать с помощью фильтров. Q: Я скачиваю слишком много файлов! Что я могу сделать? Q: Движок сходит с ума, получая тысячи файлов! В чем дело? Q: Файл иногда переименовывают (меняется тип)! Почему? Q: Как мне переименовать все файлы «.dat» в файлы «.zip»? Q: Я не могу получить доступ к нескольким страницам (доступ запрещен или перенаправление в другое место), но я могу с помощью своего браузера, что происходит? A: Некоторые страницы могут содержать файлы javascript или java, которые не распознаются.За например, сгенерированные имена файлов. Также могут быть проблемы с передачей (поломка трубы и т. Д.). Но большинство зеркал действительно работают. Мы все еще работаем над улучшением зеркального качества HTTrack. Q: Некоторые Java-апплеты работают некорректно! A: Java-апплеты могут не работать в некоторых случаях, например, если HTTrack не смог обнаружить все включенные классы или файлы, вызываемые в файле класса.  Иногда Java-апплеты должны быть в сети, потому что удаленные файлы
прямо поймал. Наконец, структура сайта может быть несовместима с классом (всегда старайтесь сохранить исходную структуру сайта.
когда вы хотите получить классы Java) Иногда Java-апплеты должны быть в сети, потому что удаленные файлы
прямо поймал. Наконец, структура сайта может быть несовместима с классом (всегда старайтесь сохранить исходную структуру сайта.
когда вы хотите получить классы Java) Если нет возможности заставить некоторые классы работать должным образом, вы можете исключить их с помощью фильтров.Они будут доступны, но только онлайн. Вопрос: HTTrack занимает слишком много времени на разбор, он очень медленный. Что случилось? A: В предыдущих (до 3.04) выпусках HTTrack были проблемы с синтаксическим анализом. Это было очень медленно, и выступления — особенно с огромными файлами HTML — было не очень хорошо. Движок теперь оптимизирован и должен очень быстро анализировать все HTML-файлы. Например, HTML-файл размером 10 МБ должен быть просканирован менее чем за 3–4 секунды. Следовательно, более высокие значения означают, что движку пришлось немного подождать для тестирования нескольких ссылок.
A: Возможно, вы пытаетесь подключиться к очень медленным сайтам. Попробуйте уменьшить значение TimeOut (см. параметры или параметр -Txx в программе командной строки). Обратите внимание, что вы откажетесь весь сайт (кроме случаев, когда опция не отмечена) в случае тайм-аута. Вы можете Версия оболочки, пропускайте также некоторые медленные файлы. Q: Я хочу обновить сайт, но это занимает слишком много времени! Что происходит? A: Во-первых, HTTrack всегда пытается минимизировать поток загрузки, опрашивая сервер о файл изменяется.Но поскольку HTTrack должен повторно сканировать все файлы с самого начала, чтобы восстановить структуру локального сайта, это может занять некоторое время. Кроме того, некоторые серверы не очень умны и всегда считают, что получают более новые файлы, заставляя HTTrack перезагружать их, даже если не было внесено никаких изменений! Q: Я хотел обновить сайт, но после обновления сайт пропал !! В чем дело? A: Возможно, вы сделали что-то не так, но не всегда
Q: Я нахожусь за брандмауэром. Что я могу сделать? A: Вам тоже нужно использовать прокси. Попросите администратора узнать прокси-сервер имя / порт. Затем используйте поле прокси в HTTrack или используйте параметр -P прокси: порт. в программе командной строки. Q: HTTrack вылетел во время зеркала, что происходит? Q: Я хочу обновить зеркальный проект, но HTTrack повторно переносит все страницы. В чем дело? Q: Я хочу продолжить зеркальный проект, но HTTrack повторно сканирует все страницы. Q: Окно HTTrack иногда «исчезает» в конце зеркального проекта. В чем дело? Вопросы по зеркалу: Q: Я хочу создать зеркало веб-сайта, но есть файлы вне
домен тоже. Как их получить? Q: Я забыл некоторые URL-адреса файлов в течение долгого времени.
зеркало .. Стоит ли все переделывать? Q: Я просто хочу получить все файлы ZIP или другие файлы в Интернете
сайт / на странице. Как мне это сделать? Q: На странице есть ZIP-файлы, но я не хочу передавать
их. Как мне это сделать? Q: Я не хочу загружать файлы ZIP размером более 1 МБ и файлы MPG размером менее 100 КБ.Является ли это возможным? Q: Я не хочу загружать файлы gif .. но что может произойти, если я
смотреть страницу? Q: Я не хочу загружать миниатюры .. возможно ли? Q: Я получаю все типы файлов на веб-сайте, но не выбрал
их на фильтрах! Q: Когда я использую фильтры, я получаю слишком много файлов! Q: Когда я использую фильтры, я не могу получить доступ к другому домену, но
отфильтровали это! Q: Должен ли я добавлять «+» или «-» в список фильтров, когда я хочу
использовать фильтры? Q: Я хочу найти файл (ы) на веб-сайте. Как мне это сделать? Q: Я хочу скачать ftp файлы / ftp сайт. Как мне это сделать? Q: Как мне получить исходные файлы .asp или .cgi вместо результата .html? Q: Как мне удалить эти раздражающие Q: Нужно ли мне выбирать между режимом передачи ascii / двоичным? Q: Может ли HTTrack выполнять аутентификацию на основе формы? Q: Могу ли я перенаправить загрузки в архив tar / zip? Q: Могу ли я использовать аутентификацию по имени пользователя и паролю на сайте? Q: Могу ли я использовать аутентификацию по имени пользователя и паролю для прокси? Q: Может ли HTTrack генерировать файлы, совместимые с HP-UX или ISO9660? Q: Есть ли поддержка SOCKS? Q: Что это за каталог hts-cache? Могу я его удалить? Q: Что означает строка «Отсканированные ссылки: 12/34 (+5)» в WinHTTrack / WebHTTrack? Q: Можно ли запустить зеркало из моих закладок? Q: Могу ли я преобразовать локальный веб-сайт (ссылки file: //) в стандартный веб-сайт? Q: Могу ли я скопировать проект в другую папку — Будет ли работать зеркало? Q: Могу ли я скопировать проект на другой компьютер / систему? Могу я тогда его обновить? Примечание. Примечание. Затем вы можете безопасно заменить существующую папку (под Windows) этой, потому что
версия для Linux / Unix не изменяла никаких параметров. Q: Как я могу получить адреса электронной почты на веб-страницах? Другие проблемы: Q: Моей проблемы нет в списке! |
 В чем дело?
В чем дело?  Почему?
Почему?  html»!
html»!  В чем дело?
В чем дело?  Как мне это сделать?
Как мне это сделать?  НО сначала проверьте, не связана ли ваша проблема с правилами сайта robots.txt.
НО сначала проверьте, не связана ли ваша проблема с правилами сайта robots.txt.  someweb.com/gallery/trees/ и на www.someweb.com/photos/
someweb.com/gallery/trees/ и на www.someweb.com/photos/ Измените предыдущие фильтры на:
Измените предыдущие фильтры на: 
 Вы можете бесплатно загрузить его, не платя никаких комиссий, скопировать его своим друзьям и изменить, если вы соблюдаете лицензию.
Нет официальных / авторизованных реселлеров, потому что HTTrack — это НЕ как коммерческий продукт.
Но с вас может взиматься плата за копирование или любые другие услуги (например, компакт-диски с программным обеспечением или коллекции условно-бесплатного программного обеспечения, или плата за обслуживание),
но вы должны были быть проинформированы о том, что это программное обеспечение является свободным программным обеспечением / GPL, и вы ДОЛЖНЫ получить копию стандартной общественной лицензии GNU.В противном случае это нечестно и несправедливо (например, продавать httrack на ebay, не сообщая, что это бесплатное программное обеспечение, — это афера).
Вы можете бесплатно загрузить его, не платя никаких комиссий, скопировать его своим друзьям и изменить, если вы соблюдаете лицензию.
Нет официальных / авторизованных реселлеров, потому что HTTrack — это НЕ как коммерческий продукт.
Но с вас может взиматься плата за копирование или любые другие услуги (например, компакт-диски с программным обеспечением или коллекции условно-бесплатного программного обеспечения, или плата за обслуживание),
но вы должны были быть проинформированы о том, что это программное обеспечение является свободным программным обеспечением / GPL, и вы ДОЛЖНЫ получить копию стандартной общественной лицензии GNU.В противном случае это нечестно и несправедливо (например, продавать httrack на ebay, не сообщая, что это бесплатное программное обеспечение, — это афера).  Архивы хранятся на серверах Un * x, не особо подверженных вирусам. Однако сообщалось, что некоторые мошеннические сайты бесплатных программ встраивают бесплатные программы и бесплатные программы в установщики вредоносных программ.Всегда загружайте httrack с основного сайта (www.httrack.com), а не из ненадежных источников!
Архивы хранятся на серверах Un * x, не особо подверженных вирусам. Однако сообщалось, что некоторые мошеннические сайты бесплатных программ встраивают бесплатные программы и бесплатные программы в установщики вредоносных программ.Всегда загружайте httrack с основного сайта (www.httrack.com), а не из ненадежных источников!  Вы можете загрузить версию, не являющуюся установщиком, и распаковать ее в любой каталог (или на USB-накопитель).
Вы можете загрузить версию, не являющуюся установщиком, и распаковать ее в любой каталог (или на USB-накопитель). 
 Всегда запрашивайте разрешение перед созданием зеркала сайта, даже если кажется, что сайт не требует лицензионных отчислений и / или без уведомления об авторских правах.
Всегда запрашивайте разрешение перед созданием зеркала сайта, даже если кажется, что сайт не требует лицензионных отчислений и / или без уведомления об авторских правах.  См. Вопросы / ответы выше .
См. Вопросы / ответы выше . Редкие случаи, но могут произойти.
В этом случае отчет об ошибке — это вообще хорошо!
Редкие случаи, но могут произойти.
В этом случае отчет об ошибке — это вообще хорошо! Если вы столкнулись с этой проблемой, не сворачивайте окно!
Если вы столкнулись с этой проблемой, не сворачивайте окно!  txt и hts-err.txt — это может дать вам ценную информацию.
txt и hts-err.txt — это может дать вам ценную информацию.  Ты
Вы можете изменить свой «идентификатор браузера» с помощью параметра Browser ID в поле OPTION.
Наконец, вы можете взглянуть на файл hts-log.txt (и hts-err.txt), чтобы узнать, что
получилось.
Ты
Вы можете изменить свой «идентификатор браузера» с помощью параметра Browser ID в поле OPTION.
Наконец, вы можете взглянуть на файл hts-log.txt (и hts-err.txt), чтобы узнать, что
получилось.  someweb.com / bar / *. html и т. д. по ..
someweb.com / bar / *. html и т. д. по .. txt не позволяет захватывать несколько файлов. В чем дело?
txt не позволяет захватывать несколько файлов. В чем дело?  html и index-2.html), не так ли?
html и index-2.html), не так ли?  (некоторые веб-мастера действительно сумасшедшие)
(некоторые веб-мастера действительно сумасшедшие)  com/big/index.html — это уловить все, что есть на http://www.someweb.com/big/. Фильтры — твои друзья,
используй их!
com/big/index.html — это уловить все, что есть на http://www.someweb.com/big/. Фильтры — твои друзья,
используй их!  cgi не будет распознаваться вашим браузером как html-страница или как изображение. HTTrack должен переименовать файл
как foo.html или foo.gif, чтобы его можно было просмотреть.
cgi не будет распознаваться вашим браузером как html-страница или как изображение. HTTrack должен переименовать файл
как foo.html или foo.gif, чтобы его можно было просмотреть.  вы вошли на определенные сайты, так что вам нужно войти в систему только один раз.Например, после ввода имени пользователя на веб-сайте вы можете
просматривать страницы и статьи, и в следующий раз, когда вы перейдете на этот сайт, вам не придется повторно вводить свое имя пользователя / пароль.
вы вошли на определенные сайты, так что вам нужно войти в систему только один раз.Например, после ввода имени пользователя на веб-сайте вы можете
просматривать страницы и статьи, и в следующий раз, когда вы перейдете на этот сайт, вам не придется повторно вводить свое имя пользователя / пароль.  Например, «a href =» / foo «» вместо «a href =» / foo / «» является распространенной ошибкой. Это заставит двигатель
сделайте дополнительный запрос и найдите реальное / foo / location.
Например, «a href =» / foo «» вместо «a href =» / foo / «» является распространенной ошибкой. Это заставит двигатель
сделайте дополнительный запрос и найдите реальное / foo / location. Следовательно,
Следовательно,  Поэтому все остальные файлы были удалены, чтобы показать текущее состояние сайта!
Поэтому все остальные файлы были удалены, чтобы показать текущее состояние сайта! Но мы не можем быть непогрешимыми. Если вы обнаружите ошибку, проверьте, есть ли у вас
последней версии HTTrack, и отправьте нам электронное письмо с подробным описанием вашего
проблема (тип ОС, соответствующие адреса, описание сбоя и все, что вы считаете
необходимо). Это может помочь и другим пользователям.
Но мы не можем быть непогрешимыми. Если вы обнаружите ошибку, проверьте, есть ли у вас
последней версии HTTrack, и отправьте нам электронное письмо с подробным описанием вашего
проблема (тип ОС, соответствующие адреса, описание сбоя и все, что вы считаете
необходимо). Это может помочь и другим пользователям.  В чем дело?
В чем дело?  someweb.com.
someweb.com.  zip в список фильтров.
zip в список фильтров. Избежать
которые определяют фильтры, такие как — * +
Избежать
которые определяют фильтры, такие как — * +  someweb.com / *
— * someweb * не будет работать, потому что — * someweb * имеет более высокий приоритет (потому что у него
были объявлены после + www.someweb.com)
someweb.com / *
— * someweb * не будет работать, потому что — * someweb * имеет более высокий приоритет (потому что у него
были объявлены после + www.someweb.com) .. -> из html файлов?
.. -> из html файлов?  Используйте user: password @ your_proxy_name в качестве имени вашего прокси (пример: smith:
Используйте user: password @ your_proxy_name в качестве имени вашего прокси (пример: smith: 
 Экспорт (Windows Linux)
Экспорт (Windows Linux)  Затем выберите этот проект, И повторно введите ВСЕ URL-адреса И переопределите все параметры, как если бы вы
создание нового проекта.
Это необходимо, поскольку профиль (winprofile.ini) не был создан с версией Linux / Unix.
Но не бойтесь, WinHTTrack будет использовать кешированные файлы для обновления проекта!
Затем выберите этот проект, И повторно введите ВСЕ URL-адреса И переопределите все параметры, как если бы вы
создание нового проекта.
Это необходимо, поскольку профиль (winprofile.ini) не был создан с версией Linux / Unix.
Но не бойтесь, WinHTTrack будет использовать кешированные файлы для обновления проекта!Передача информации на веб-сайт и с веб-сайта — Обзор авторских прав Rich Stim
Нарушение авторских прав происходит всякий раз, когда защищенный авторским правом материал копируется или размещается на веб-сайте без разрешения правообладателя. В этом разделе обсуждаются различные способы передачи информации между вашим сайтом и его пользователями, а также споры об авторских правах, которые могут возникнуть с каждым из них.
В этом разделе обсуждаются различные способы передачи информации между вашим сайтом и его пользователями, а также споры об авторских правах, которые могут возникнуть с каждым из них.
Размещение информации на веб-сайте
Игнорировать заголовок — содержимое подтаблицы
Публикация предполагает отправку пользователем информации с компьютера пользователя на веб-сайт («загрузка»). После публикации другие пользователи могут просматривать или копировать материал. Если ваш сайт не предлагает пользователям возможность публиковать материалы, вы можете пропустить этот раздел.
ПРИМЕР
Член дискуссионной группы размещает главу из книги Джона Гришема в чате группы в Интернете, делая ее доступной для копирования другими.
Хотя лицо, загрузившее материал, является фактическим нарушителем, лицо, обслуживающее сайт, может быть привлечено к ответственности за разрешение на размещение материала на сайте. Как и в случае с любым неавторизованным материалом, самый разумный подход к борьбе с несанкционированной загрузкой — это быстро удалить его или заблокировать доступ к нему до разрешения спора.
Сайт, разрешающий загрузку материалов, может размещать уведомление, запрещающее любую несанкционированную деятельность, и требовать, чтобы виновные оплатили любой ущерб, причиненный такой деятельностью.Уведомление должно быть размещено на видном месте, чтобы его видели лица, выполняющие загрузку. В качестве альтернативы, сайт может включать в себя соглашение «Нажмите, чтобы принять» (часто называемое соглашением о переносе по клику), устанавливающее аналогичные условия. Соглашение с переносом по клику — это страница или окно, которое появляется перед тем, как пользователю будет разрешено выполнить определенную функцию (в данном случае, загрузку), в которой изложены условия соглашения. Пользователю не будет разрешено продолжить, пока он или она не щелкнет поле, указывающее, что пользователь прочитал и принял соглашение.
Ниже приведен пример соглашения «Нажмите, чтобы принять», предназначенного для запрещения несанкционированной публикации.
Ограничения загрузки
Пользователь соглашается не размещать:
- любые материалы, защищенные законами об авторском праве, товарных знаках или коммерческой тайне, если только с явного разрешения владельца; или
- любой материал, который может опорочить или посягнуть на частную жизнь любого человека.

Пользователь соглашается освободить владельцев сайта и их аффилированных лиц и сотрудников от любой ответственности (включая гонорары адвокатам), связанной с нарушением Пользователем данного соглашения.Если вы согласны с вышеуказанными условиями, нажмите кнопку принятия.
НАЖМИТЕ ДЛЯ ПРИНЯТИЯ
К сожалению, уведомления и соглашения «Нажмите, чтобы принять» не применяются во всех штатах единообразно. И, с практической точки зрения, уведомление или соглашение, требующее от лица, совершающего незаконную деятельность, уплаты ваших гонораров адвокату, ничего не стоит, если у этого человека нет денег. Тем не менее, стоит разместить на своем веб-сайте уведомление или соглашение «Нажмите, чтобы принять». Это может удержать некоторых пользователей от незаконных загрузок и может помочь продемонстрировать ваше усердие в попытках предотвратить их.
Уважаемый Рич: Несанкционированная публикация магистерской диссертации
Уважаемый Рич: Уважаемый Рич! Моя магистерская диссертация была размещена в Интернете (в виде PDF-документа) без моего разрешения. Тезис включает в себя значок авторского права, но не был зарегистрирован в Бюро регистрации авторских прав США. Публикация моей диссертации в Интернете является нарушением авторских прав? Если да, то как я могу его удалить?
Тезис включает в себя значок авторского права, но не был зарегистрирован в Бюро регистрации авторских прав США. Публикация моей диссертации в Интернете является нарушением авторских прав? Если да, то как я могу его удалить? Короткий ответ на ваш вопрос: да, несанкционированное воспроизведение вашей диссертации является нарушением, и да, вы имеете право на ее удаление (независимо от того, зарегистрировали ли вы работу).Однако то, будет ли он удален, зависит от нескольких факторов, в первую очередь от сайта, на котором он размещен.
Ключ к успеху
Обычно наиболее важным элементом в достижении удаления является поиск агента для обслуживания уведомления DMCA. Выполните поиск в Интернете по запросу «Агент DMCA для обслуживания». Помимо назначенного агента (или если вы не можете его найти) проверьте сайт на наличие других форм электронной почты (или других адресов) для владельца сайта. Иногда вы можете найти его по ссылке «Связаться с нами», и часто это просто «info @ nameofsite. com. » Многие сайты, которые публикуют файлы или публикуют документы, имеют специальный почтовый ящик для работы с нарушениями, часто это «[email protected]» или «[email protected]». Если на сайте нет назначенного агента и нет адреса электронной почты для связи с владельцами (плохой знак), найдите владельца, используя базу данных на Whois.net. Если ваш поиск приводит к «прокси-администратору» — компании, которая выступает в качестве администратора и скрывает имя и контактную информацию владельца, это тоже нехороший знак.После того как вы найдете агента, адрес электронной почты или почтовый адрес администратора сайта, вам следует подготовить и отправить уведомление о нарушении закона США «Об авторском праве в цифровую эпоху».
com. » Многие сайты, которые публикуют файлы или публикуют документы, имеют специальный почтовый ящик для работы с нарушениями, часто это «[email protected]» или «[email protected]». Если на сайте нет назначенного агента и нет адреса электронной почты для связи с владельцами (плохой знак), найдите владельца, используя базу данных на Whois.net. Если ваш поиск приводит к «прокси-администратору» — компании, которая выступает в качестве администратора и скрывает имя и контактную информацию владельца, это тоже нехороший знак.После того как вы найдете агента, адрес электронной почты или почтовый адрес администратора сайта, вам следует подготовить и отправить уведомление о нарушении закона США «Об авторском праве в цифровую эпоху».
Что делать, если сайт отказывается его закрывать?
Описанный выше подход обычно эффективен — по крайней мере, он часто работает для Уважаемых богатых сотрудников. Однако, если человек, опубликовавший тезис, отказывается удалить его (или он отвечает контрмерами), вам нужно будет продолжить регистрацию авторских прав (вы можете ускорить ее) и подать иск. Если вы сами не богаты, это может быть слишком дорого. Если у владельца веб-сайта большие карманы, и вы можете продемонстрировать финансовый ущерб, возможно, вы найдете юриста, который справится с этим на случай непредвиденных обстоятельств.
Если вы сами не богаты, это может быть слишком дорого. Если у владельца веб-сайта большие карманы, и вы можете продемонстрировать финансовый ущерб, возможно, вы найдете юриста, который справится с этим на случай непредвиденных обстоятельств.
Игнорировать заголовок — содержимое подтаблицы
Игнорировать заголовок — содержимое подтаблицы
Получение информации с веб-сайта
Так же, как пользователи иногда могут размещать информацию на веб-сайте, пользователь может — в обратном процессе — брать материал с веб-сайта и переносить его на компьютер пользователя.Обычно это делается либо путем загрузки, либо путем копирования и вставки. Многие сайты созданы для загрузки материалов пользователями. Сайты с условно-бесплатным ПО, например, позволяют пользователям загружать нужное программное обеспечение, щелкая загружаемый файл, который затем переносится на компьютер пользователя. Другой способ получения материалов с веб-сайтов — выделить текст, скопировать и вставить его в текстовый редактор на компьютере пользователя. Строго говоря, это не загрузка, но эффект тот же.Пользователь получил материал с веб-сайта и скопировал его на свой компьютер.
Строго говоря, это не загрузка, но эффект тот же.Пользователь получил материал с веб-сайта и скопировал его на свой компьютер.
Игнорировать заголовок — содержимое подтаблицы
Уважаемые богатые: агрегатор блогов
Уважаемый Рич: Уважаемый Рич! Я создал агрегатор блогов. У меня нет рекламы или чего-то еще, это только для меня и нескольких друзей. Я включаю отрывки из статей, ссылки на оригинальные статьи и некоторые из полных сообщений оригинальных статей. Кто-то заявил, что я нарушил их авторские права, отправил жалобу DMCA своему веб-хосту, который затем отключил мой сайт без какого-либо уведомления или возможности для меня внести исправления.Мой хозяин теперь утверждает, что они должны немедленно отключить весь веб-сайт без уведомления из-за DMCA 1998 года. Я прочитал о DMCA на сайте Бюро регистрации авторских прав. Это не говорит о том, что веб-сайт должен немедленно прекратить работу (или даже, кажется, очень ясно, насколько письменный материал представляет собой «нарушение»). Я немного запутался, так как большая часть этого для меня нова. Не могли бы вы подсказать?
Я немного запутался, так как большая часть этого для меня нова. Не могли бы вы подсказать? По содержанию на вашем сайте:
Нет проблем со ссылками в гипертекстовой форме.Воспроизведение полных статей, вероятно, является нарушением; предоставление выдержки спорно. Мы предполагаем, что владелец авторских прав отправил уведомление об удалении вашему провайдеру онлайн-услуг (OSP), который действовал «оперативно» и удалил контент, нарушающий авторские права. Удалив материал, OSP получает право на «безопасную гавань» от любой ответственности. Если вы оспариваете уведомление — многие из них являются оскорбительными — и готовы рискнуть судебным разбирательством, рассмотрите возможность встречного уведомления. (Вы можете найти образцы и дополнительную информацию в Интернете.) Если владелец авторских прав, подавший жалобу, не ответит на ваше встречное уведомление, подав судебный иск (э-э-э!), OSP может повторно опубликовать ваш контент.Эти правила и процедуры являются частью Закона о защите авторских прав в цифровую эпоху.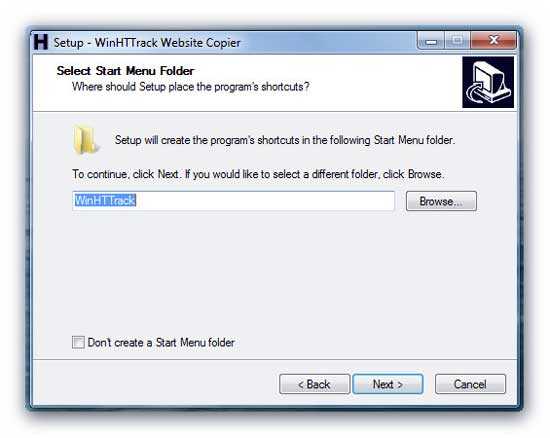
Несанкционированное копирование
Если вы не предлагаете материалы для загрузки на своем сайте, вас больше всего беспокоит не то, не нарушите ли вы чьи-то авторские права, а то, будут ли пользователи копировать ваш материал без вашего разрешения. В частности, если ваш сайт содержит охраняемые авторским правом работы сторонних авторов — например, если вы публикуете онлайн-журнал, — вам нужно будет сделать все возможное, чтобы предотвратить несанкционированное копирование материалов пользователями.Одна из попыток сдерживания (хотя и не обязательно эффективная) — это разместить заметку об авторских правах на видном месте на некоторых или всех страницах вашего сайта, четко указав, что материал защищен авторским правом.
Чтобы избежать того факта, что многие пользователи могут копировать информацию в любом случае, вы можете включить запрет на любое коммерческое использование материала в свое уведомление об авторских правах. Кроме того, вы можете потребовать, чтобы уведомление об авторских правах было включено в материал, чтобы любой, кто его прочитает, знал, кто его создал. Многие веб-мастера готовы согласиться на ограниченное копирование пользователями для личного использования, особенно если копии показывают, кто изначально создал материал.
Многие веб-мастера готовы согласиться на ограниченное копирование пользователями для личного использования, особенно если копии показывают, кто изначально создал материал.
ПРИМЕР
Nolo поддерживает веб-сайт с обширной правовой информацией для самопомощи. Поскольку цель Nolo состоит в том, чтобы дать людям возможность заниматься своими собственными юридическими делами, она готова принять некоторое копирование материалов на своем сайте с некоторыми ограничениями. Его политика в отношении авторских прав, доступ к которой можно получить почти с каждой страницы, частично гласит:
Ноло.com Политика авторских прав
Ваша ответственность при использовании сайта Nolo
Мы прилагаем все усилия, чтобы предоставлять полезную и точную информацию, чтобы помочь пользователям справиться с их собственными юридическими потребностями. Но законы и процедуры часто меняются и могут по-разному интерпретироваться. Nolo не утверждает, что вся информация на этом сайте актуальна.
Если вы используете информацию на этом сайте, прежде чем полагаться на нее, было бы разумно проверить информацию в авторитетном источнике, например, у юриста или юридических книг из юридических библиотек вашего штата. Отличный способ сделать это — провести собственное юридическое исследование. Чтобы узнать, как это сделать, см. Раздел «Правовые исследования».
Политика Nolo в отношении авторских прав в отношении содержания сайта
Nolo.com предоставляет информацию на этом сайте для чтения любым, но сохраняет за собой авторские права на весь текст и графику.Чтобы использовать эту информацию любым другим способом, вы должны строго следовать этим правилам.
Физические лица
Если это предназначено только для вашего личного использования, вы можете распечатывать копии этой информации, хранить файлы на своем компьютере и использовать гипертекстовые ссылки для ссылки на информацию.
Товарный знак
«Nolo» — зарегистрированная на федеральном уровне торговая марка. Все товарные знаки, представленные на nolo.com, являются собственностью их владельцев.
 Вы обязаны следить за тем, чтобы все, что вы здесь читаете, было точным, актуальным и соответствовало вашей ситуации. Кроме того, имейте в виду, что если вам нужна юридическая консультация, подкрепленная гарантией, вам необходимо обратиться к юристу.
Вы обязаны следить за тем, чтобы все, что вы здесь читаете, было точным, актуальным и соответствовало вашей ситуации. Кроме того, имейте в виду, что если вам нужна юридическая консультация, подкрепленная гарантией, вам необходимо обратиться к юристу. Любое другое использование или распространение строго запрещено.
Любое другое использование или распространение строго запрещено.Если вы выберете этот более либеральный подход, убедитесь, что все участники вашего сайта, которые могут сохранять авторские права на свою работу, понимают и принимают вашу политику. В противном случае, если они позже обнаружат, что их статья была скопирована, они могут подать на вас в суд за нарушение авторских прав на их работу.
Дорогие богатые: публикация сообщений электронной почты
Уважаемый Рич: Уважаемый Рич! Я разрешил кому-то опубликовать одно из моих писем. Другой человек попросил разрешения опубликовать его. Он сказал, что не изменит слов.Я просто сказал: «Да, но сделайте это анонимным». Он опубликовал электронное письмо по сегментам и ответил на каждый сегмент. Позже он перестал защищать ее анонимность. Я попросил его удалить мою электронную почту, но он утверждает, что, поскольку я дал ему разрешение, он имеет полное право сохранить его на своем веб-сайте.
Я попросил его удалить мою электронную почту, но он утверждает, что, поскольку я дал ему разрешение, он имеет полное право сохранить его на своем веб-сайте. Когда вы даете кому-либо разрешение на публикацию вашей защищенной авторским правом работы (ваш адрес электронной почты), вы даете лицензию. Мы предполагаем, что лицензия была получена путем обмена электронными письмами, и эти электронные письма образуют условия вашей лицензии.
Условия вашей лицензии. Похоже, у вашей лицензии было только одно условие: анонимность. Поскольку постер нарушил это условие, вы имеете право отозвать вашу лицензию, то есть удалить письмо. Если плакат игнорирует ваш запрос, вам нужно попробовать более действенную стратегию. Один из способов — связаться с поставщиком услуг другой стороны и отправить уведомление DMCA. Еще одна возможность — нанять адвоката, который будет угрожать плакату судебным иском о нарушении авторских прав и вторжении в частную жизнь.
Стоит ли усилий? Имейте в виду, что наем юриста или отправка уведомления DMCA следует использовать только в том случае, если опубликованное электронное письмо причиняет вам некоторый вред. Это не безошибочные стратегии — например, плакат может отстаивать действительную защиту авторских прав — и они обходятся дорого.
Это не безошибочные стратегии — например, плакат может отстаивать действительную защиту авторских прав — и они обходятся дорого.
Несанкционированная загрузка
Концепция несанкционированной загрузки может показаться странной, учитывая, что большинство сайтов, предлагающих файлы для загрузки, явно соглашаются с такой практикой.Однако даже если загрузка с вашего сайта специально разрешена, у вас все равно могут возникнуть опасения по поводу несанкционированного использования загруженных материалов. Например, если вы предлагаете бесплатные картинки для загрузки на своем сайте, вы можете запретить пользователям продавать картинки и ограничить их использование в личных целях. Если пользователь нарушает ограничение, вы можете подать в суд за нарушение контракта. Такой подход оказался успешным в спорах, основанных на картинках и стоковых фотографиях. Даже если соглашение не подлежит исполнению, его наличие может опровергнуть иск о невиновном нарушении со стороны пользователя.
Пример ограничения загрузки показан ниже. Вы можете опубликовать его как уведомление, отображаемое там, где его увидит загрузчик, или реализовать его как соглашение «Нажмите, чтобы принять».
Ограничения на скачивание
Пользователь соглашается с тем, что материалы, предоставленные для загрузки, должны использоваться исключительно в личных целях и не могут быть воспроизведены, отображены или распространены в каких-либо коммерческих целях.
Нажмите, чтобы принять
Ответственность за другие проблемы на веб-сайте
На веб-сайтах могут возникать споры из-за доменных имен, непристойности и мошенничества.Проблемы могут также возникнуть из-за содержания веб-сайта. Например, владельцам сайтов откровенно сексуального характера может потребоваться публиковать предупреждения; коммерческие сайты должны соответствовать торговым требованиям, таким как правила возврата и возврата; а сайты, предлагающие торговлю акциями, должны предоставлять заявления об отказе от ответственности по ценным бумагам. Сайты, предоставляющие загрузки, могут захотеть снять с себя ответственность за любые потенциальные вирусы. Эти проблемы с веб-сайтом выходят за рамки книги разрешений.
Копировальный аппарат веб-сайта | Сайты загрузки | Веб-потрошитель
Узнайте, как загрузить веб-сайт
Рекомендуемая литература: https: // prowebscraper.ru / blog / top-website-ripper-or-website-downloader-compare /
It’s Best Website Copier — бесплатный онлайн-инструмент, позволяющий бесплатно скачивать сайты со всем исходным кодом. Введите URL-адрес веб-сайта, и этот инструмент Site Downloader начнет сканирование веб-сайта и загрузит все ресурсы веб-сайта, включая изображения, файлы Javascript, файлы CSS и изображения Favicon. Как только он скопирует все активы веб-сайта, он предоставит вам ZIP-файл с исходным кодом. Этот загрузчик веб-сайтов представляет собой онлайн-поисковый робот, который позволяет вам загружать целые веб-сайты без установки программного обеспечения на свой компьютер.
Примечание. Скопируйте точный и правильный URL-адрес веб-сайта. Откройте целевой веб-сайт и скопируйте ссылку из адресной строки, а затем вставьте ее сюда, вместо того, чтобы вводить URL-адрес самостоятельно. Если у вас возникнут проблемы, позвоните по номеру и свяжитесь со мной . Я сделаю процесс вручную и отправлю вам файлы
Обновлено 15 АПРЕЛЯ 2020 г. [Улучшено]
Выпущено новое обновление Website Copier. Ниже приведены изменения, которые я внес в этом обновлении
.- Просмотр процента завершения вашего любимого веб-сайта с помощью ProgressBar
- Проверить статус процесса загрузки
Обновлено 8 ЯНВАРЯ 2020 г. [Исправлена и улучшена ошибка]
Выпущено новое обновление копира веб-сайта.Ниже приведены изменения, которые я внес в этом обновлении
.- Исправлена проблема с заменой ссылок на ресурсы и файлы HTML
- Загрузки шрифтов CSS
- Загрузки изображений (включены в таблицы стилей)
- Более эффективные и точные результаты
- Исправлены мелкие ошибки
Обновлено 28 ИЮЛЯ 2019 г. [Загрузить веб-сайт полностью]
Теперь он загружает весь веб-сайт со своими активами. Если вы обнаружите какую-либо ошибку, не стесняйтесь обращаться ко мне
Почему это БЕСПЛАТНЫЙ копировальный аппарат?
Как вы знаете, все остальные загрузчики веб-сайтов являются премиальными, но совершенно бесплатными.Вам не кажется, что почему? Вот и ответ. Как программист, мой главный приоритет — автоматизировать вещи для меня и других людей БЕСПЛАТНО от до ПОМОЧЬ людям и сэкономить их драгоценное время.
Почему это лучший копировальный аппарат для веб-сайтов?
Существуют десятки других онлайн-инструментов, которые позволяют загружать сайт онлайн, но почти эти офлайн-загрузчики веб-страниц не являются полностью бесплатными. Некоторые из них дают вам попробовать скачать сайт. Некоторые из них не предоставляют вам точный клон веб-сайта из-за своего премиум-членства.Если мы говорим об этом риппере веб-сайтов, то вы можете совершенно бесплатно загрузить любой веб-сайт, не открывая новую вкладку.
Интернет-возможности Website Ripper
Этот копировальный аппарат не требует времени, чтобы загрузить или сделать копию любого сайта. Если вы ищете копировальное устройство для веб-сайтов, которое не занимает слишком много времени для регистрации / входа в систему и чего-то еще, то вам обязательно понравится этот инструмент.
Веб-сайт содержит JS / CSS и изображения как их активы веб-сайта, и они называют свои активы.Некоторые другие инструменты для копирования веб-сайтов переименовывают свои активы, когда предоставляют вам zip-файл, но в этом инструменте вы получите исходное имя активов.
Вам не нужно ничего устанавливать, чтобы просто скопировать веб-сайт, например, процесс регистрации, решение Recaptcha. Вам просто нужно скопировать ссылку на сайт для скачивания в буфер обмена, вставить ее в раздел веб-сайта и нажать кнопку «Копировать». Это все
Как я уже говорил об активах, он загружает все ресурсы веб-сайта, включая изображения (jpg, jpeg, png), файлы CSS, файлы Javascript.
Почему для загрузки сайта следует использовать онлайн-копировальный аппарат?
Давайте немного поговорим о причинах использования загрузчика сайтов. Если у вас есть веб-сайт конкурента, и вы хотите следить за его дизайном и не хотите посещать его веб-сайт снова и снова, этот инструмент лучше всего подходит для вас. Он предоставит вам автономный HTML-сайт вашего конкурента, и вы сможете легко следить за его дизайном со своего компьютера, не посещая их веб-сайт. Другая причина: допустим, вы хотите сделать резервную копию своего сайта, чтобы сохранить контент для использования в автономном режиме, и вы не хотите загружать свой сайт, копируя каждый файл, тогда этот инструмент очень поможет вам и сэкономит ваше время.
, если вы веб-разработчик или веб-дизайнер, и ваш клиент попросил вас следовать конкретному дизайну, вам нужно только скопировать ссылку веб-сайта и загрузить весь веб-сайт по ссылке
Загрузить изображения с веб-сайта
С любого сайта можно скачивать только изображения. Если вы хотите это сделать, просто воспользуйтесь моим инструментом Images Downloader Online.
7 способов загрузки полных веб-сайтов для автономного доступа
Иногда вам требуется доступ к данным веб-сайта в автономном режиме.Может быть, вам нужна резервная копия вашего собственного веб-сайта, но у вашей службы хостинга нет возможности сделать это. Возможно, вы хотите имитировать структуру популярного веб-сайта или то, как выглядят его файлы CSS / HTML. В любом случае есть несколько способов загрузить часть или весь веб-сайт для автономного доступа.
Некоторые веб-сайты слишком хороши, чтобы просто оставаться в сети, поэтому мы собрали 8 потрясающих инструментов, которые вы можете использовать, чтобы легко загрузить любой веб-сайт прямо на свой локальный компьютер.Это что-то похожее на наше руководство по резервному копированию вашей учетной записи Twitter.
Программы, упомянутые ниже, могут очень хорошо служить этой цели для загрузки всего веб-сайта для автономного использования. Эти приложения предоставляют простые варианты, и вы можете начать загрузку всего веб-сайта всего за пару минут.
Загрузить веб-сайт частично или полностью для автономного доступа
1. HTTrack
HTTrack — чрезвычайно популярная программа для загрузки веб-сайтов.Хотя интерфейс не совсем современный, он отлично работает по своему прямому назначению. Мастер прост в использовании и будет сопровождать вас через настройки, которые определяют, где должен быть сохранен веб-сайт, и некоторые особенности, например, какие файлы следует избегать при загрузке.
Например, исключите с сайта целые ссылки, если у вас нет причин извлекать эти части.
Также укажите, сколько одновременных подключений должно быть открыто для загрузки страниц. Все они доступны с помощью кнопки «Установить параметры» во время работы мастера:
Если загрузка определенного файла занимает слишком много времени, вы можете легко пропустить его или отменить процесс на полпути.
Когда файлы будут загружены, вы можете открыть веб-сайт в его корне, используя файл, похожий на этот здесь, а именно «index.html».
Загрузить HTTrack
2. Getleft
УGetleft новый, современный интерфейс. После запуска нажмите «Ctrl + U» , чтобы быстро начать работу, введя URL-адрес и сохранив каталог. Перед началом загрузки вас спросят, какие файлы следует загрузить.
Мы используем Google в качестве нашего примера, поэтому эти страницы должны показаться вам знакомыми. Каждая страница, включенная в загрузку, будет извлечена, а это означает, что будет загружен каждый файл с этих страниц.
После запуска все файлы будут загружены в локальную систему следующим образом:
По завершении вы можете просматривать веб-сайт в автономном режиме, открыв основной файл индекса.
Загрузить Getleft
По завершении вы можете открыть загрузку и просмотреть ее в автономном режиме, например:
3.Cyotek WebCopy
Используйте предопределенные пароли для аутентификации и создавайте правила с помощью Cyotek WebCopy, чтобы загрузить полный сайт для просмотра в автономном режиме. Запустите копию ключа «F5» и наблюдайте, как файлы загружаются.
Общий размер загруженных в настоящее время файлов отображается в правом нижнем углу окна.
Вы даже можете создать веб-диаграмму для визуального представления файлов.
Загрузить Cyotek WebCopy
4.Википедия Свалки
Википедия не рекомендует пользователям использовать программы, подобные указанным выше, для загрузки со своих сайтов. Вместо них у них Дампы можно скачать здесь. Например, вот дампы за 28 октября 2013 г .:
Загрузите эти куски данных в формате XML, извлекая их с помощью чего-то вроде 7-Zip.
Скачать Дампы Википедии
5. SiteSucker
Если вы пользователь Mac, это может быть хорошим вариантом для загрузки всего веб-сайта для просмотра в автономном режиме.Он делает все, асинхронно копируя веб-страницы сайта, PDF-файлы, изображения, таблицы стилей и другие файлы на ваш локальный диск.
Процесс загрузки полного веб-сайта не может быть проще, чем этот, когда вам просто нужно ввести URL-адрес и нажать клавишу возврата, и вы получите все содержимое веб-сайта прямо на свой компьютер.
Вы также можете использовать SiteSucker для создания локальных копий веб-сайтов. У него есть онлайн-руководство, в котором объясняются все функции. SiteSucker локализует загружаемые файлы, что позволяет просматривать сайт в автономном режиме.
Загрузить SiteSucker
Как использовать SiteSucker для загрузки всего веб-сайта для просмотра в автономном режиме
- Введите название сайта
- При необходимости выберите папку для загрузки.
- Нажмите «Загрузить», и он начнет свое волшебство.
6. Загрузчик Web2Disk
Web2Disk Downloader — это ответ на вопрос: как быстро и легко загрузить весь веб-сайт на свой компьютер? Он поставляется со всеми изящными функциями для выполнения вашей задачи.Он поставляется с мощным механизмом, который позволяет ему изменять веб-сайты по мере их загрузки, что в конечном итоге заставляет все ссылки работать непосредственно с жесткого диска компьютера.
Вы можете просматривать загруженные веб-сайты в любом браузере. Он не имеет ограничений по количеству страниц и сайтов, поэтому вы можете загружать столько сайтов, сколько захотите. Вам просто нужно купить его один раз и использовать вечно. Он также имеет функцию «Планировщик», которая автоматически загружает и архивирует сайты ежедневно, еженедельно или ежемесячно.
Скачать Web2Disk
Как использовать Web2Disk для загрузки всего веб-сайта
Установите программу и запустите ее.Теперь введите URL-адрес веб-сайта, который вы хотите загрузить, и имя нового проекта.
Вы можете сохранить весь контент в любом месте вашего ПК. Просмотрите путь к файлу, чтобы указать предпочтительное расположение. Теперь нажмите Go .
Пусть процесс завершится.
После этого вы увидите сообщение слева внизу: Загрузка завершена .
7. Автономный загрузчик
Offline Downloader позволяет загружать n количество веб-сайтов, на которых вам не нужно сотни раз щелкать мышью при сохранении файлов в каталоге.Загруженные веб-ссылки можно переименовать в относительные локальные файлы, что позволяет легко перемещать информацию на компакт-диск или любой другой привод.
Позволяет сделать точную копию любого сайта на вашем жестком диске. Просматривать сайты с фотоальбомами или галереями очень просто, а различные типы графических файлов доступны для чтения, например файлы JPG и GIF.
Возможно, вы не сможете открыть его из панели поиска Windows, пока не войдете в систему как администратор. В противном случае второй вариант заключается в том, что вы создаете ярлык на рабочем столе, перейдя в расположение файла Offline Downloader.
Скачать автономный загрузчик
Иногда вам нужно не все содержимое веб-сайта, а только некоторые конкретные данные. В таких случаях лучше использовать веб-скребок. Такой инструмент, как ProWebScraper, может помочь вам очистить цены, контактные данные или другие данные с ваших целевых веб-страниц.
Заключение
Среди перечисленных программ с уверенностью скажу, вы сможете скачать любой веб-сайт, какой захотите. Независимо от того, требуется ли аутентификация или вы хотите, чтобы извлекались только избранные страницы, одна из вышеперечисленных бесплатных программ наверняка подойдет.
Википедия — отличный ресурс для автономного доступа. Изучаете какую-то тему или просто хотите прочитать информацию по определенной теме? Загрузите данные из дампов Википедии и обращайтесь к ним в автономном режиме в любое время.
Бонусный совет: Если вам нравится идея доступа к веб-сайтам в автономном режиме, вы можете прочитать об использовании Gmail без подключения к Интернету с расширением Gmail Offline.
Как скопировать полный веб-сайт с содержанием базы данных и другими статическими и динамическими данными? Лучший ответ — использовать специальное программное обеспечение, позволяющее делать это автоматически.Handy Backup — хороший пример такого решения для резервного копирования всего веб-сайта. Вы можете скопировать весь веб-сайт с базой данных только с внутренней резервной копией веб-сайта, когда у вас есть доступ к содержимому сайта, например через протокол FTP. Резервное копирование веб-сайта включает два шага: 1 Во-первых, создайте резервную копию всего сайта со всем его содержимым, графикой и другими данными. Это можно сделать, просто скопировав файлы с веб-сервера через FTP. 2 Во-вторых, создайте резервную копию базы данных на жестком диске.Просто скопировать файлы базы данных недостаточно; Для этого вам понадобится специальная программа для резервного копирования баз данных, например Handy Backup. Копирование полной базы данных веб-сайтов любого типаНезависимо от того, какая СУБД используется для вашего веб-сайта (например, PostgreSQL, MySQL или MS SQL Server), в Handy Backup всегда есть подключаемый модуль для копирования всего веб-сайта с базой данных. . Это также верно и для статических данных, поскольку Handy Backup допускает соединения SFTP и FTPS, а также прямые сетевые ссылки. Автозапуск по расписаниюВы можете установить время начала для создания резервных копий базы данных веб-сайта и статических данных, а также интервал от минут до месяцев для повторения действий резервного копирования. Кроме того, вы можете использовать расширенный параметр запуска задачи по некоторому системному событию (например, при подключении USB-накопителя к серверу). Большой выбор типов хранилищС Handy Backup вы можете использовать как локальные, так и онлайн-хранилища резервных копий, включая локальные и сетевые диски, FTP-серверы, облака, подключенные к S3 и WebDAV, коммерческие облачные сервисы, такие как Amazon S3 , Dropbox, OneDrive (OneDrive для бизнеса) или Box или даже другие сетевые машины! Рекомендуемое решение Версия 8.2.1, построен 15 января 2021 года. 112 МБ Окончательное решение для одного сервера, Small Business edition позволяет копировать весь веб-сайт с базой данных прямо из коробки! Это просто. Создайте новую задачу резервного копирования. Затем выберите подключаемый модуль статических данных (FTP или другой) для подключения к серверу веб-сайта и добавьте статические данные в список резервных копий. Чтобы скопировать полную базу данных веб-сайта, выберите также соответствующий плагин базы данных, подключитесь к динамической базе веб-сайта и сохраните ее таблицы в той же задаче. Чтобы узнать больше об использовании Handy Backup в качестве программного обеспечения для резервного копирования веб-сайтов, прочтите специальную статью, в которой представлена вся важная и необходимая информация об автоматическом резервном копировании веб-сайтов. Вы всегда можете найти дополнительную информацию в Руководстве пользователя. В следующем коротком видео вы узнаете, как создавать резервные копии веб-сайтов с помощью Handy Backup. Здесь вы можете увидеть, насколько просто создать задачу для копирования как статического, так и динамического контента веб-сайта в выбранное хранилище.
Внимание! Обратите внимание: в этом видео предполагается, что вы уже установили Handy Backup на свой локальный компьютер. Если вы еще этого не сделали, скачайте его копию. Почувствуйте, как легко скопировать весь веб-сайт с базой данных с помощью Handy Backup! См. Также: |
Загрузчик веб-сайтов | Интернет-копировальный аппарат | Загрузчик сайта
Хотите, чтобы на ваш компьютер была загружена полная копия сайта? Тогда вам стоит взглянуть на загрузчик веб-сайтов.
Копирование содержимого URL-адреса вручную — огромная работа. Вы никогда не будете готовы к таким неприятностям. Однако вам не придется испытывать такие хлопоты, если вы можете использовать Site Downloader. Он может предоставить вам автономную копию веб-сайта всего за несколько кликов.
Зачем скачивать сайт?
К скачиванию вас будут подталкивать разные причины. Прежде чем использовать наш копировальный аппарат в Интернете, важно четко понимать все причины, по которым вам следует загрузить веб-сайт.
— Сделайте резервную копию
Если вы являетесь владельцем веб-сайта, вы четко понимаете важность регулярного резервного копирования. Веб-загрузчик сможет вам в этом помочь. Это будет самый простой доступный способ сделать резервную копию ваших веб-файлов. Это потому, что вы можете просто загрузить весь веб-сайт, ничего не упуская.
— Доступ к веб-сайту в автономном режиме
Если вы загрузите веб-сайт с помощью загрузчика сайта, вы сможете без проблем получить к нему доступ в автономном режиме.Это также может обеспечить вам удобную и беспроблемную работу. Вам не придется полагаться на подключение к Интернету для доступа к тем же веб-страницам на более позднем этапе. Это потому, что на ваш компьютер загружена вся копия сайта.
— Перенос сайта.
-Миграция сайта Если ваш хостинг-провайдер не предлагает качественные услуги, вы столкнетесь с необходимостью перенести его на другой хост. Онлайн-загрузчик также сможет вам в этом помочь.Некоторые хостинг-провайдеры стремятся заблокировать людей. В результате вы не сможете получить доступ к своим исходным файлам в Интернете. Это еще одна причина, по которой вам следует воспользоваться копировальным аппаратом. С его помощью вы сможете скопировать весь контент на новый хост.
— Узнайте, как разрабатывается веб-сайт
Люди, которые хотят стать веб-дизайнерами или веб-разработчиками, также могут подумать об использовании онлайн-загрузчиков веб-сайтов. В конце дня вы сможете получить отличные впечатления от этого инструмента.Это потому, что вы можете иметь автономный доступ ко всем исходным файлам с помощью онлайн-копира веб-сайта. Тогда вы сможете понять, как создавался сайт. Наряду с этим вы также сможете спроектировать или разработать такую страницу самостоятельно.
— Скребок экрана.
Инструмент, который вы используете для клонирования веб-сайта в Интернете, также поможет вам с очисткой экрана. С его помощью вы можете легко извлечь полезные данные из Интернета. Вы обнаружите, что запустить s.алгоритмы сканирования в автономном Интернете по сравнению с онлайн-сайтом. Вы также заметите, что алгоритм очистки работает плавнее и быстрее.
— Возвращение веб-файлов после истечения срока действия хостинга
Мы часто забываем платить за хостинг. В результате наши сайты будут удалены. Если у вас нет доступа к резервной копии, вам придется пережить трудный период. Это потому, что вам придется столкнуться с множеством проблем, чтобы получить доступ к веб-страницам и их содержанию.Здесь вам следует обратиться за помощью в интернет-архив. Вы можете использовать интернет-архив, а затем использовать копировальное устройство для загрузки контента и снова запустить свой сайт.
«SitePuller удобен. Так же просто, как разжевывать клонировать сайт с помощью их сервиса. Хорошая работа. — Саймон из TrustPilot »
Преимущества использования качественного загрузчика веб-сайтов
Вы рассчитываете получить беспроблемный опыт использования загрузчика, который вы используете.Тогда вы сможете сохранять душевное спокойствие и получить доступ ко всем функциям, которые вы получаете.
Если вы можете использовать хороший клонер, такой как SitePuller, вы сможете получить копию сайта на любом устройстве или в любой операционной системе.
Ваш комментарий будет первым