Программа оценки точности разметки коротких имён биологических объектов в неструктурированных текстах на английском языке (ЭНДПред / ANDPred)
Разработчик
ФГБНУ ФИЦ ИЦиГ СО РАН
Авторы
Иванисенко Т.В., Деменков П.С., Иванисенко В.А.
Краткая характеристика
Программа предназначена для автоматической оценки соответствия названий биологических объектов длинною 5 символов и менее, размеченных по словарю, их типам. Оценка осуществляется программой на основе использования трансформерных моделей глубокого машинного обучения, настроенных на классификацию имён биологических объектов по их типам, в соответствие с тем контекстом, в котором они упоминаются. Программа позволяет осуществлять анализ текстов с предварительно размеченными в них биологическими объектами одного из заданных типов, на основе словарей в любых текстах на английском языке, включая, научную литературу, патенты, электронные медицинские карточки, а также другие источники. Всего программой «ЭНДПред» поддерживается 12 типов молекулярно-генетических объектов: клетка, заболевание, ген, белок, лекарство, метаболит, молекулярная функция, микро-РНК, клеточный путь, клеточная компонента, а также побочный эффект. В качестве входных данных программа использует тексты на английском языке, в которых проверяемый объект заменяется на специальный тэг <andsystem-candidate>. Такой подход позволяет программе осуществлять оценку, руководствуясь исключительно информацией об окружении объекта (его контексте). В качестве выходных данных программа возвращает числовое значение, являющееся вероятностью соответствия рассматриваемого объекта заданному типу, или нескольким типам одновременно. Например, заболевание и побочный эффект.
Всего программой «ЭНДПред» поддерживается 12 типов молекулярно-генетических объектов: клетка, заболевание, ген, белок, лекарство, метаболит, молекулярная функция, микро-РНК, клеточный путь, клеточная компонента, а также побочный эффект. В качестве входных данных программа использует тексты на английском языке, в которых проверяемый объект заменяется на специальный тэг <andsystem-candidate>. Такой подход позволяет программе осуществлять оценку, руководствуясь исключительно информацией об окружении объекта (его контексте). В качестве выходных данных программа возвращает числовое значение, являющееся вероятностью соответствия рассматриваемого объекта заданному типу, или нескольким типам одновременно. Например, заболевание и побочный эффект.
Области возможного использования
Программа может быть применена в любых областях наук о жизни, связанных с задачами повышения точности распознавания поименованных биологических сущностей заданных типов, в предварительно размеченных текстах на естественном языке.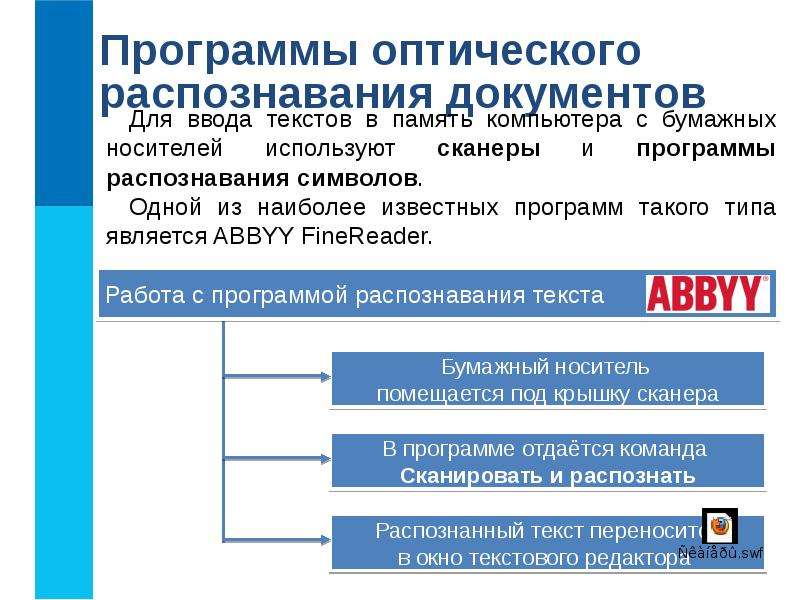
Степень готовности разработки к практическому применению
Программа готова к практическому применению.
Возможный технический и (или) экономический эффект
Основной экономический эффект от внедрения разработанной программы заключается в повышении точности распознавания молекулярно-биологических сущностей в текстах, и снижении ошибки, связанной с лингвистической неопределенностью, за счёт анализа только коротких имён объектов. В частности, повышение точности распознавания ведёт к более качественному установлению новых, ранее неизвестных взаимодействий, между молекулярно-генетическими объектами, посредствам оценки их со-встречаемости. Данный момент играет особое значение при решении задач связанных с поиском новых лекарственных мишеней, разработке новых способов терапии заболеваний, исследовании молекулярно-генетических механизмов, протекающих внутри организмов и т. д.
Сравнительные характеристики с известными разработками
Наиболее близким аналогом по функционалу с программой «ЭНДПред» является модуль классификации генов и белков в размеченных текстах веб-ориентированной системы «STRING» (https://string-db. org/). Реализованный в системе модуль выполняет аналогичную функцию, классифицируя имена генов и белков, в размеченных текстах, на правильные и ошибочные. Система распознавания имён заболеваний и лекарств, включая побочные эффекты от их применения (https://github.com/MaastrichtU-IDS/prodigy-drug-indication-annotation), является другим примеров системы, обладающей похожим функционалом. Онлайн ресурс «Polysearch 2.0» (http://polysearch.ca) позволяет осуществлять в текстах идентификацию биомедицинских сущностей, таких как заболевания человека, гены, белки, метаболиты, токсины, метаболические пути, лекарства и др. При этом, для разметки данный ресурс не использует контекстный анализ окружения сущности. Более того, ни один из вышеприведенных аналогов, не позволяет анализировать все те типы объекты, которые поддерживаются программой «ЭНДПред». Одновременно с этим, программа «ЭНДПред» проверяет только короткие имёна длинною 5 и менее символов. На данный диапазон приходится подавляющая часть ошибок, связанных с пересечением названий объектов с разного рода общеупотребительными словами, аббревиатурами и одноименными объектами других типов.
org/). Реализованный в системе модуль выполняет аналогичную функцию, классифицируя имена генов и белков, в размеченных текстах, на правильные и ошибочные. Система распознавания имён заболеваний и лекарств, включая побочные эффекты от их применения (https://github.com/MaastrichtU-IDS/prodigy-drug-indication-annotation), является другим примеров системы, обладающей похожим функционалом. Онлайн ресурс «Polysearch 2.0» (http://polysearch.ca) позволяет осуществлять в текстах идентификацию биомедицинских сущностей, таких как заболевания человека, гены, белки, метаболиты, токсины, метаболические пути, лекарства и др. При этом, для разметки данный ресурс не использует контекстный анализ окружения сущности. Более того, ни один из вышеприведенных аналогов, не позволяет анализировать все те типы объекты, которые поддерживаются программой «ЭНДПред». Одновременно с этим, программа «ЭНДПред» проверяет только короткие имёна длинною 5 и менее символов. На данный диапазон приходится подавляющая часть ошибок, связанных с пересечением названий объектов с разного рода общеупотребительными словами, аббревиатурами и одноименными объектами других типов. Это позволяет программе «ЭНДПред» обрабатывать большие объёмы текстов за значительно меньшее время и при меньших вычислительных ресурсах, чем это требуется существующим аналогам, практически без потери в точности.
Это позволяет программе «ЭНДПред» обрабатывать большие объёмы текстов за значительно меньшее время и при меньших вычислительных ресурсах, чем это требуется существующим аналогам, практически без потери в точности.
Защита разработки
Свидетельство о регистрации №2022668741, зарегистрирована в Реестре ПрЭВМ 11.10.2022, бюл. № 10. Номер и дата поступления заявки: 2022667645 от 28.09.2022.
Нейронная сеть считает лес кругляк и распознает автомобильные номера. Как это сделано? / Хабр
Полученный результатВ статье покажем, как алгоритмы компьютерного зрения помогают решить задачу автоматического определения объема круглого леса в лесовозе по фотографии. Пройдем путь от идеи до прототипа. Расскажем, какие были выбраны решения и почему.
Необходимая подготовка читателя — должно быть общее представление о компьютерном зрении (computer vision) и нейронных сетях. Здесь не будет описаний, что такое сверточная нейронная сеть и т.п., статей по таким основам найдете много на хабре (вот хорошая Глубокое обучение для новичков: распознаем изображения с помощью сверточных сетей). В то же время, совсем новички могут получить представление, какие знания и компетенции нужны для решения подобных задач.
В то же время, совсем новички могут получить представление, какие знания и компетенции нужны для решения подобных задач.
Применялись:
Keras/Tensorflow
OpenCV
YOLOv5
В статье ниже упоминаются еще всякие штуки.
По условию задачи требовалось определить объем бревен в лесовозе по фотографии с телефона. «Линейкой» будет автомобильный номер.
Размер автомобильного номерного знака определен в ГОСТ Р 50577-2018:
Для расчета объема нужна еще длина бревен — задается вручную.
Теперь по шагам, какие были выбраны решения и почему.
Алгоритм:
Обнаружить бревна
Обнаружить автомобильный номер, распознать и определить его размер на фото
Рассчитать диаметры бревен в см
С чего начать? Конечно посмотреть, какие уже есть решения и подходы. При этом не забыть заглянуть в ГОСТ 32594-2013 «Лесоматериалы круглые. Методы измерений».
В интернете нашлось несколько готовых решений для автоматического расчета количества и размеров бревен. Это дало понимание, что задача точно решаемая. Но готовых opensource по распознаванию кругляка не попалось.
Для обнаружения бревен предпочтение сразу отдали нейронным сетям. Алгоритмы классического машинного обучения не рассматривали, в computer vision задачах они проигрывают нейронным сетям с большим отрывом. Ниже есть пример, где это наглядно видно.
Обнаруживаем на изображении бревна
Если задуматься, то чем обнаружение отдельного бревна на изображении отличается от задачи обнаружения лица человека? Гипотеза, что решение, которое хорошо обнаруживает лица при соответствующем обучении справится и с бревнами, оказалась верной.
Остановились в итоге на решении YOLOv5. Оно не специализируется прям на лицах/бревнах, но выбрано т.к.:
найдены примеры, подтверждающие качественное обнаружение лиц с помощью YOLOv5
впечатляющая производительность (может работать с видеопотоком в режиме реального времени).

решение достаточно популярное и простое для внедрения

И не прогадали. Для тестирования было выбрано несколько фото, где бревен поменьше. Лучше разметить несколько разных фото с малым количеством бревен, чем много бревен на одном фото. Уже на трех(!) размеченных фото с лесовозами, на изображениях 320х320, yolo показала свой потенциал. То что yolo прекрасно справится с задачей, сомнений не осталось.
Для тренировки YOLOv5 необходимо для каждого изображения создать текстовый файл с тем же именем, но расширением .txt. В файл записывается номер класса объекта и координаты рамки (bounding box):
<object-class> <x_center> <y_center> <width> <height>
Класс один — кругляк. Обнаружение номера не стали мешать с бревнами, чтобы избежать сильной разбалансировки классов.
Пример содержимого файла разметки:
0 0.263172 0.139302 0.093695 0.
 09838
0 0.310295 0.219907 0.095899 0.094797
0 0.40275 0.224041 0.083499 0.090939
0 0.53971 0.11891 0.104993 0.116567
0 0.502508 0.211089 0.097828 0.093144
09838
0 0.310295 0.219907 0.095899 0.094797
0 0.40275 0.224041 0.083499 0.090939
0 0.53971 0.11891 0.104993 0.116567
0 0.502508 0.211089 0.097828 0.093144Обратите внимание, что координаты относительные, в интервале от 0 до 1.
Для расширения тренировочной базы применена аугментация (получение новых изображений с помощью случайного сдвига, масштабирования, растягивания исходных изображений). С этой задачей отлично справилась библиотека Albumentations — простая в использовании и функциональная.
Важно учитывать, что не все варианты аугментации одинаково полезны. Например в нашей задаче поворот изображения на случайный угол собьет координаты рамки относительно контура бревна и ухудшит точность определения размеров. Такие нюансы надо учитывать.
Новое положение рамки относительно бревна после поворота. Так делать не надо!От качества разметки зависит многое. А в задаче с определением точных размеров тем более. Поэтому к разметке подошли серьезно, подготовили ТЗ.
Тестовые изображения были размечены в бесплатном labelme. Но у этого инструмента два существенных недостатка:
Для конвертации в формат YOLO пришлось использовать дополнительную библиотеку Labelme2YOLO.
Из-за отсутствия направляющих линий у курсора, неудобно делать ограничивающие рамки для круглых объектов.
Есть бесплатный онлайн инструмент https://www.makesense.ai/, который умеет сохранять сразу в формате YOLO.
Сейчас, все чаще используем для разметки решение Superannotate.
Обнаруживаем и распознаем автомобильный номер
К этой задаче подступались с мыслями: «Здесь точно проблем не будет. Решений, статей, описаний найдется миллион. Самое трудное будет выбрать лучшее из хороших«. И ошиблись. Самым трудным оказалось найти нормально работающее. Казалось бы, распознавание автомобильных номеров в computer vision, это как создание калькулятора в традиционном программировании.
После изучения темы сложилось впечатление, что решений по распознаванию номеров очень много, но бОльшая часть построена на алгоритмах классического машинного обучения и годится для решения задач со строгими условиями, например: номер чистый, положение номера +/- фиксированное (перед шлагбаумом или на расстоянии 20-30 метров от камеры), яркое освещение.
Хорошее решение на нейронных сетях сделали и развивают ребята nomeroff.net. Его использовали в первом прототипе. Плюс этого решения — сразу умеет возвращать координаты углов номера, которые как раз нужны для определения размеров. Nomeroff.net показал себя лучше классического ML.
Классический ML (слева) безнадежно проигрывает нейронным сетям (справа).Но именно для российских номеров работа nomeroff.net оказалась недостаточно качественной. Может быть дело в базе российских номеров, на которой обучали, нужна больше. Возможно причина еще в том, что у прицепов другая комбинация символов на номере, а в базе был другой, более распространенный тип номеров.
Здесь важно отметить, что нам нужно не просто решение обнаруживающее номера. Оно должно возвращать координаты углов номера и быть обучено на базе, которую размечали с целью использовать автомобильный номер как эталон размера. Нельзя просто обвести номер рамкой, как при разметке бревен.
Нельзя просто обвести номер рамкой, как при разметке бревен.
Таких готовых решений не нашлось. Задачу поиска углов ставили перед собой далеко не все авторы. Вот пример, который справляется с распознаванием бельгийских номеров без поиска углов, с использованием YOLOv4 и сверточной сети https://medium.com/@theophilebuyssens/license-plate-recognition-using-opencv-yolo-and-keras-f5bfe03afc65 (eng)
Попадались также решения, которые потенциально можно адаптировать. Вот пример made in chine (ch):
Отмечу, что годных статей по ИИ на китайском языке, или английском, но с китайскими авторами, попадалось очень много. Вывод здесь делайте сами. PS: славянские фамилии тоже встречаются часто, в т.ч. в признанных сообществом решениях (тот же yolo, albumentation и др.), что лично нас радует.
Готового и полностью устраивающего решения не нашлось, поэтому стали делать свое. Тут пришлось окунуться в удивительный мир разных подходов. Только основная задача у них — распознать номер. А нам надо еще точные координаты рамки.
А нам надо еще точные координаты рамки.
Как распознавать номерные знаки
Сначала про распознавание номерного знака. У этой задачи больше практической ценности, чем у определения точных координат углов. Оговорюсь, что не считаю себя экспертом в ANPR. Если среди читателей найдутся специалисты, которые съели на этом собаку, и поправят/дополнят меня, буду только благодарен.
Современные подходы распознавания номеров сводятся к следующему алгоритму:
Найти на изображении автомобильный номер (сегментация или object detection с помощью нейронной сети)
Выделить на номере отдельные буквы/цифры. Перед этим можно сделать геометрические преобразования, чтобы убрать искажения перспективы и упростить дальнейшее OCR.
Распознать буквы и цифры с помощью нейронной сети или решений типа Tesseract. Но опять же, нейронные сети обогнали классический ML в таких задачах, поэтому на Tesseract я бы время не стал тратить.

Если нужен OCR, посмотрите в сторону решений Распознавание изогнутого текста (рус). В нашем случае текст не изогнутый, но статью рекомендую, если планируете заниматься темой распознавания текста. Читать было очень интересно.
Мы поставили перед собой цель не просто распознавать номер, а делать это не хуже человека. Даже если номер грязный или размытый. Для такого обучения нужна внушительная база. Мысль о необходимости размечать отдельные символы на нескольких тысячах фотографий номеров приводила в уныние.
Поэтому решено проверить сначала две гипотезы:
Обучать на сгенерированных изображениях номеров.
Номер распознавать целиком, без разметки отдельных символов.
Обе гипотезы подтвердились. Тестовый результат даже превзошел ожидания:
Предсказание после обучения на 5 тыс. сгенерированных номерахРаспознавание реальных номеров сетью обученной на «синтетических» данныхАрхитектура сети, на которой проверялась гипотезаПроверили также распознавание на изображении из примера выше. Правда нейронная сеть здесь после дополнительной доработки:
Правда нейронная сеть здесь после дополнительной доработки:
Как сгенерировать базу номеров
Можно взять готовый SVG файл и менять в нем знаки номера (https://github.com/ulex/generate_license_plates).
Купить скрипт (например здесь avto-nomer.ru).
Сделать свой генератор.
Чтобы быть уверенным, что все по ГОСТу, выбрали третий путь (свой генератор).
Раньше Вы возможно не обращали внимание, что автомобильные номера бывают разных типов. Конечно, возможно, знали, что у полиции номера синие, на маршрутках бывают желтые, а у мотоцикла квадратные. Но то что у них еще и разная комбинация букв-цифр обращают внимание не все.
Типы российских номеров (взято здесь https://49.img.avito.st/640×480/3328866249.jpg)Изображение номеров в формате SVG создавалось с помощью библиотеки drawSvg. Пример кода, генерирующего номер:
import drawSvg as draw
plate_text = 'K627PO790'
plate_w = 520 # width
plate_h = 112 # height
th = 8 # thickness
plate_pos, plate_reg_w = ([59, 88, 142, 196, 275, 329, 372, 2], 160)
k_offset = {'K':36, 'P':252, 'O':302}
d = draw. Drawing(plate_w, plate_h, displayInline=False)
# Draw rectangle
r = draw.Rectangle(0,0,plate_w,plate_h, fill='#000000', rx=14, ry=14)
d.append(r)
base_colour = '#ffffff'
reg_colour = '#ffffff'
r = draw.Rectangle(th,th,plate_w-th,plate_h-th, fill=base_colour, rx=10, ry=10)
d.append(r)
# Draw region part
r = draw.Rectangle(plate_w-plate_reg_w,0,plate_reg_w,plate_h, fill='#000000', rx=9, ry=9)
d.append(r)
r = draw.Rectangle(plate_w-plate_reg_w+th,th,plate_reg_w-th,plate_h-th, fill=reg_colour, rx=5, ry=5)
d.append(r)
r = draw.Rectangle(0,0,plate_w-plate_reg_w+th//4,plate_h, fill='#000000', rx=9, ry=9)
d.append(r)
r = draw.Rectangle(th,th,plate_w-plate_reg_w-th//4,plate_h-th, fill=base_colour, rx=5, ry=5)
d.append(r)
# How many simbols
plate_len = 6
# Draw text
font_style = 'font-family:RoadNumbers'
for i, s in enumerate(plate_text[:plate_len]):
if s.isdigit():
d.append(draw.Text(s, 118, plate_pos[i], 16, fill='black', style=font_style)) # Text
else:
d.append(draw. Text(s, 118, k_offset[s], 16, fill='black', style=font_style)) # Text
# Text region
font_style = f'letter-spacing:{plate_pos[plate_len+1]}px;font-family:RoadNumbers'
d.append(draw.Text(plate_text[plate_len:], 94, plate_pos[plate_len], 36, fill='black', style=font_style)) Text
# Draw flag
flag_style="stroke-width:0.4;stroke:rgb(0,0,0)"
r = draw.Rectangle(465,12,38,21, fill='#ffffff', style=flag_style)
d.append(r)
flag_style="stroke-width:0.4;stroke:rgb(0,0,0)"
r = draw.Rectangle(465,19,38,7, fill='#00f')
d.append(r)
flag_style="stroke-width:0.4;stroke:rgb(0,0,0)"
r = draw.Rectangle(465,12,38,7, fill='#f00')
d.append(r)
# draw RUS
font_style = 'font-style:normal;letter-spacing:2px;font-stretch:normal;font-family:Arial'
d.append(draw.Text('RUS', 28, 400, 12, fill='black', style=font_style))
# Draw circle
d.append(draw.Circle(20, 56, 4,
fill='gray', stroke_width=1, stroke='black'))
d.append(draw.Circle(500, 56, 4,
fill='gray', stroke_width=1, stroke='black'))
d Результат работы скрипта Drawing(plate_w, plate_h, displayInline=False)
# Draw rectangle
r = draw.Rectangle(0,0,plate_w,plate_h, fill='#000000', rx=14, ry=14)
d.append(r)
base_colour = '#ffffff'
reg_colour = '#ffffff'
r = draw.Rectangle(th,th,plate_w-th,plate_h-th, fill=base_colour, rx=10, ry=10)
d.append(r)
# Draw region part
r = draw.Rectangle(plate_w-plate_reg_w,0,plate_reg_w,plate_h, fill='#000000', rx=9, ry=9)
d.append(r)
r = draw.Rectangle(plate_w-plate_reg_w+th,th,plate_reg_w-th,plate_h-th, fill=reg_colour, rx=5, ry=5)
d.append(r)
r = draw.Rectangle(0,0,plate_w-plate_reg_w+th//4,plate_h, fill='#000000', rx=9, ry=9)
d.append(r)
r = draw.Rectangle(th,th,plate_w-plate_reg_w-th//4,plate_h-th, fill=base_colour, rx=5, ry=5)
d.append(r)
# How many simbols
plate_len = 6
# Draw text
font_style = 'font-family:RoadNumbers'
for i, s in enumerate(plate_text[:plate_len]):
if s.isdigit():
d.append(draw.Text(s, 118, plate_pos[i], 16, fill='black', style=font_style)) # Text
else:
d.append(draw.
Drawing(plate_w, plate_h, displayInline=False)
# Draw rectangle
r = draw.Rectangle(0,0,plate_w,plate_h, fill='#000000', rx=14, ry=14)
d.append(r)
base_colour = '#ffffff'
reg_colour = '#ffffff'
r = draw.Rectangle(th,th,plate_w-th,plate_h-th, fill=base_colour, rx=10, ry=10)
d.append(r)
# Draw region part
r = draw.Rectangle(plate_w-plate_reg_w,0,plate_reg_w,plate_h, fill='#000000', rx=9, ry=9)
d.append(r)
r = draw.Rectangle(plate_w-plate_reg_w+th,th,plate_reg_w-th,plate_h-th, fill=reg_colour, rx=5, ry=5)
d.append(r)
r = draw.Rectangle(0,0,plate_w-plate_reg_w+th//4,plate_h, fill='#000000', rx=9, ry=9)
d.append(r)
r = draw.Rectangle(th,th,plate_w-plate_reg_w-th//4,plate_h-th, fill=base_colour, rx=5, ry=5)
d.append(r)
# How many simbols
plate_len = 6
# Draw text
font_style = 'font-family:RoadNumbers'
for i, s in enumerate(plate_text[:plate_len]):
if s.isdigit():
d.append(draw.Text(s, 118, plate_pos[i], 16, fill='black', style=font_style)) # Text
else:
d.append(draw.
Как найти углы номера
Попытка научить yolo искать углы номера ни к чему не привела. Поиск углов в итоге сделан на обученной с нуля Resnet-50 (предобученная давала хуже результат). После обучения на 103 изображениях (на некоторых изображениях было больше одного номера) результат уже приемлемый:
Поиск углов в итоге сделан на обученной с нуля Resnet-50 (предобученная давала хуже результат). После обучения на 103 изображениях (на некоторых изображениях было больше одного номера) результат уже приемлемый:
Сеть ищет отдельно углы «левый верхний», «левый нижний», «правый верхний», «правый нижний».
Результат и выводы
Следующим шагом подбираются гиперпараметры, делается «тюнинг» архитектур и проводится обучение нейронных сетей на расширенной базе. Потом все модули объединяются в единое решение.
Иллюстрация разработки нашего AI-решенияФинальное решение работает следующим образом:
Первая YOLOv5 обнаруживает бревна.
Вторая YOLOv5 обнаруживает автомобильный номер. Фрагмент с номером (размером 128х128) передается для точного определения углов и распознавания.
Сеть на базе InceptionResNetV2 распознает номерной знак.
Сеть на базе ResNet50 определяет углы номерного знака.
Вычисляется диаметр бревен, площадь и объем, опираясь на координаты углов номера.

Описан пилотный проект, с большим потенциалом для оптимизаций.
В следующей части есть планы рассказать про интеграцию в телеграмм бот.
И у нас осталась задача определения сортности и сравнения лесовозов.
Группа авторов: Дмитрий Мокачев и Георгий Брегман
Программное обеспечение Google для оптического распознавания символов (OCR) поддерживает более 248 языков
Изображение:Изображение Кейт Тер Хаар. Изменено Opensource.com. СС BY-SA 2.0.
Программное обеспечение Google для оптического распознавания символов (OCR) теперь работает более чем с 248 языками мира (включая все основные языки Южной Азии). Он довольно прост и удобен в использовании и может определять большинство языков с точностью более 90%.
Технология извлекает текст из изображений, сканов печатного текста и даже рукописного текста, что означает, что текст можно извлечь практически из любых старых книг, рукописей или изображений.
OCR Google, вероятно, использует зависимости от Tesseract, механизма OCR, выпущенного как бесплатное программное обеспечение, или OCRopus, бесплатной системы анализа документов и оптического распознавания символов (OCR), которая в основном используется в Google Книгах. Разработанный как проект сообщества в 1995–2006 годах, а затем переданный Google, Tesseract считается одним из самых точных механизмов распознавания текста и работает более чем с 60 языками. Исходный код доступен на GitHub.
Страница поддержки проекта OCR предлагает дополнительные сведения о сохранении форматирования символов для таких вещей, как жирный шрифт и курсив после OCR в выходном тексте:
При обработке вашего документа мы пытаемся сохранить базовое форматирование текста, такое как полужирный и курсивный текст, размер и тип шрифта, а также разрывы строк. Однако обнаружить эти элементы сложно, и нам не всегда это удается. Другие элементы форматирования и структурирования текста, такие как маркированные и нумерованные списки, таблицы, текстовые столбцы, сноски или концевые сноски, скорее всего, будут потеряны.

На тамильском языке Программный директор Wikimedian и Wikimedia India Равишанкар Айякканну сообщил в Facebook после тестирования: «Для некоторых языков, таких как малаялам и тамильский, OCR работает почти со 100% точностью, наряду с поддержкой форматирования, например автоматической обрезки, разделения текста путем отбрасывания изображений и игнорирования цветного фона». Носители следующих индийских языков — бангла, малаялам, каннада, одия, тамильский и телугу — также прокомментировали пост в Facebook с отзывами после тестирования OCR.
Однако для некоторых шрифтов, таких как Gurmukhi (используется для написания пенджаби), вывод после OCR довольно плохой и приводит к тарабарщине текста в разных сценариях.
В целом, это довольно большой скачок для языков со старыми текстами, еще не оцифрованными.
Примечание редактора: статья была обновлена на основе отзывов сообщества. Мы изменили «OCR Google частично использует Tesseract, механизм OCR, выпущенный как бесплатное программное обеспечение» на «OCR Google, вероятно, использует зависимости от Tesseract, механизма OCR, выпущенного как бесплатное программное обеспечение, или OCRopus, бесплатную систему анализа документов и оптического распознавания символов (OCR), которая в основном используется в Google Книгах». Если у вас есть дополнительные отзывы о статье или технологии, сообщите нам об этом в комментариях. -Рикки Эндсли
Эта работа находится под лицензией Creative Commons Attribution-Share Alike 4.0 International License.Программное обеспечение для распознавания текста | Технология Capture
Результаты решения
Типы OCR
Истории клиентов
Дополнительная информация
Что такое OCR?
 youtube.com/embed/0Q-TSHZLwsA» allowfullscreen=»1″>
youtube.com/embed/0Q-TSHZLwsA» allowfullscreen=»1″> Оптическое распознавание символов (OCR) — важный инструмент для любого бизнеса, связанного с ручным вводом данных. Представьте, что вы принимаете решения на основе данных, застрявших в горах бумаги. Или необходимость вводить информацию из электронного файла, потому что это плоское изображение (недоступный для поиска текст). Программное решение для распознавания текста автоматически извлекает данные из изображения электронного документа и оживляет его. Больше не нужно тратить время на ввод данных вручную. У вас есть реальные оперативные данные, с которыми вы можете работать и интегрировать их в существующие системы.
Общие термины технологии захвата
Чтобы помочь вам лучше понять сложный мир захвата, давайте начнем с некоторых основ. В зависимости от типа данных, которые необходимо извлечь, доступны различные технологии. Например, OCR, ICR, OMR и Intelligent Capture являются наиболее распространенными.
Оптическое распознавание символов (OCR)
Распространенное заблуждение, что программное обеспечение OCR может извлекать все типы данных. На самом деле OCR используется исключительно для извлечения машинопечатного текста. Эти решения могут быть основаны на шаблонах или в паре с искусственным интеллектом. С добавлением искусственного интеллекта ваша система может считывать и извлекать данные без шаблонов (как человек).
На самом деле OCR используется исключительно для извлечения машинопечатного текста. Эти решения могут быть основаны на шаблонах или в паре с искусственным интеллектом. С добавлением искусственного интеллекта ваша система может считывать и извлекать данные без шаблонов (как человек).
Интеллектуальное распознавание символов (ICR)
Программное обеспечение ICR считывает рукописные символы с помощью искусственного интеллекта. В зависимости от типа документа это может быть сделано с помощью полей или сотовых полей.
Оптическое распознавание меток (OMR)
Программное обеспечение оптического распознавания меток можно использовать для выбора варианта из списка вариантов. Этот список может включать флажки и закрашенные кружки.
Программное обеспечение Intelligent Capture
Эта новая категория программного обеспечения для ввода объединяет все технологические возможности OCR, ICR и OMR в одном решении. Решения Intelligent Capture могут обрабатывать множество типов данных. Например, интеллектуальный захват может считывать машинопечатный текст, рукописный текст, флажки, переключатели и штрих-коды.
Например, интеллектуальный захват может считывать машинопечатный текст, рукописный текст, флажки, переключатели и штрих-коды.
Где использовать программное обеспечение OCR
Запись OCR может быть полезна практически везде в вашей организации. Хотя это популярное процессное решение в отделах кредиторской задолженности, OCR помогает и другим отделам. Начните задавать вопросы об этих процессах владельцам бизнеса, например:
- Существуют ли отделы, которые регулярно обрабатывают большие объемы бумажных или электронных документов?
- Сколько точек соприкосновения с людьми происходит в этом процессе?
- Какие области вручную вводят данные в системы?
- Куда должна идти информация, когда она входит в процесс?
- Должна ли информация направляться через определенную систему или человека? Как он туда попадает?
Результаты решения OCR
Экономьте время
Освободите себя от ручного ввода данных и получите больше свободного времени. Интеллектуальные и передовые решения OCR могут мгновенно проверять и передавать извлеченную информацию в систему управления контентом, ERP и другие бизнес-системы. В ваших обычных бизнес-системах вы можете легко искать, анализировать, обрабатывать и синхронизировать данные с существующими элементами данных. В результате оптимизации этих процессов вы и ваши сотрудники сможете выполнять более важные задачи.
Интеллектуальные и передовые решения OCR могут мгновенно проверять и передавать извлеченную информацию в систему управления контентом, ERP и другие бизнес-системы. В ваших обычных бизнес-системах вы можете легко искать, анализировать, обрабатывать и синхронизировать данные с существующими элементами данных. В результате оптимизации этих процессов вы и ваши сотрудники сможете выполнять более важные задачи.
Повышение соответствия и безопасности
Отслеживание бумажных документов и передача их между работниками по своей сути рискованны. Особенно, когда вы имеете дело с конфиденциальной информацией. Эта технология может интегрироваться с вашей системой управления контентом или системами ERP/HRIS. Вы дополнительно повышаете безопасность, автоматизируя управление важными и конфиденциальными документами. Интеллектуальное распознавание текста также включает журнал действий и утверждений пользователей. Этот журнал является удобной функцией для обеспечения подотчетности работников и предоставления вам контрольного журнала.
Этот журнал является удобной функцией для обеспечения подотчетности работников и предоставления вам контрольного журнала.
Снижение риска человеческой ошибки
Какими бы талантливыми ни были ваши сотрудники, они всего лишь люди. Из-за этого может произойти дорогостоящая человеческая ошибка. Захват OCR снижает риск для вашего бизнеса. Вы можете доверять этой технологии в правильном выполнении работы, поскольку она может идентифицировать и точно обрабатывать широкий спектр документов.
Растет вместе с вами
Хранение кучи бумажных документов помешает вашей компании добиться успеха. Так почему бы не избавить свой бизнес от этого бремени с помощью масштабируемого решения, такого как распознавание текста? Вы обнаружите, что OCR может идти в ногу с меняющимися потребностями вашей организации. Эти решения могут применять полученные знания для документирования изменений и расширения в новых областях вашей организации по мере необходимости.
Эти решения могут применять полученные знания для документирования изменений и расширения в новых областях вашей организации по мере необходимости.
Решение для распознавания текста также может помочь вашей организации в развитии. Благодаря искусственному интеллекту и машинному обучению интеллектуальное распознавание текста может выявлять шаблоны и выявлять важную информацию и идеи. Через образование система может улучшить себя и применить знания в новых ситуациях. Кроме того, он может обнаруживать недостатки и адаптироваться к немного другим документам. Все эти возможности позволяют технологии активно думать о будущем. В результате ваша компания процветает и может справляться с трудностями.
Отличная окупаемость инвестиций
Окупаемость интеллектуальных технологий распознавания текста обычно составляет 12–18 месяцев, но некоторые компании получают результаты даже быстрее.
Сокращение затрат на оплату труда при расширении возможностей сотрудников
Ваши сотрудники могут многое предложить. Какая трата времени для них, чтобы посвящать часы утомительным и утомительным задачам, таким как ввод данных каждую неделю. К счастью, OCR ускоряет выполнение ручных задач. Ваши сотрудники могут добиться большего за меньшее время. Теперь у них будет время направить свои таланты и уникальный опыт на более важные дела.
Типы OCR
01.
Интеллектуальное распознавание текста
02.
Расширенный захват
03.
Полнотекстовый поиск
01.
Intelligent OCR Capture
Intelligent OCR Capture — наиболее распространенный тип решения для ввода, которое развертывают клиенты Naviant. Более 80 процентов важной информации содержится в неструктурированных и неуправляемых документах. Разблокируйте его с помощью интеллектуальных платформ ввода данных OCR, таких как Brainware и ABBYY.
Интеллектуальное распознавание текста точно извлекает и сортирует важную информацию из входящих бумажных и электронных документов. Затем он передает содержимое в ваши основные бизнес-приложения без использования шаблонов или подробных инструкций со стороны пользователя. Неважно, есть ли у вас разные типы файлов, на разных языках, в разных отделах. И без шаблонов, которые нужно создавать, это самый быстрый и самый точный способ захвата контента во внешнем интерфейсе и доставки его туда, где он вам нужен.
Объедините его с программным обеспечением для управления контентом OnBase, чтобы получить мощное решение для автоматизации точек доступа.
Далее: Advanced Capture
02.
Advanced Capture
Advanced Capture — это менее сложная форма сбора, для которой требуются предварительно определенные формы (шаблоны) и правила для извлечения и обработки данных.
При использовании шаблонов OCR с предсказуемыми зонами классификация и индексация автоматизированы. Он поддерживает OCR, OMR, сопоставление логотипа или изображения, ICR, распознавание штрих-кода и даже обнаружение подписи.
Это решение для ввода данных повышает точность и скорость процессов индексации документов, освобождая сотрудников для выполнения более важных задач. Извлечение данных также упрощается за счет устранения нагрузки, связанной с наличием множества различных приложений, баз данных и дублирования конфигурации.
Далее: Полнотекстовый поиск
03.
Полнотекстовый поиск
Полнотекстовый поиск — это простейшая версия OCR Capture. Хотя он не обеспечивает возможности извлечения, классификации или индексирования, он предоставляет ценные возможности поиска в стиле Google для поиска содержимого, скрытого в ваших документах.
Ваш комментарий будет первым