Зачем нужны программы распознавания текста OCR, самая известная из них / Справочник :: Бингоскул
Зачем нужны программы распознавания текста OCR, самая известная из них добавить в закладки удалить из закладокСодержание:
Мы разобрались с принципами работы систем оптического распознавания символов. Кратко ознакомились с историей развития технологий OCR. В публикации рассмотрим, зачем нужны программы для распознавания текста, назовём наиболее распространённые из них. Какие приложения для работы со сканами знаете вы? А кроме FineReader?
Цель применения приложений
При помощи сканера, камеры смартфона или фотоаппарата создаются цифровые копии бумажных документов. Воспринимать их содержимое на дисплее компьютера и ноутбука комфортно. На портативных устройствах просматривать страницу, содержимое которой не помещается на экран, неудобно. Придётся постоянно перетаскивать изображение по дисплею, масштабировать его.
Использовать скан книги, выдержки из периодического издания в качестве цитаты или исходника для работы (реферата, доклада, курсовой работы) можно после превращения картинки в текст. Для этого следует осуществить распознавание документа. Помогут в этом системы оптического распознавания информации – приложения, которые извлекают из графических файлов текстовую информацию, передают её в текстовый редактор или документ. Вследствие появляется возможность её редактирования, обработки.
Для этого следует осуществить распознавание документа. Помогут в этом системы оптического распознавания информации – приложения, которые извлекают из графических файлов текстовую информацию, передают её в текстовый редактор или документ. Вследствие появляется возможность её редактирования, обработки.
Часто поверх изображения накладывается текстовый слой, как на картинке выше. Так сохраняется внешний вид страниц книги и появляется возможность копирования, редактирования её содержимого.
Сканеры с программным обеспечением для распознавания символов широко применяются в библиотеках, архивных фондах для оцифровки бумажных книг, журналов, газет, брошюр, писем, прочих рукописей и бумажных документов с возможностью их дальнейшего редактирования или извлечения текстовой информации. Корпорация Google около 20 лет занимается оцифровкой архивов и книг, исторических источников.
Сколько времени займёт набор на клавиатуре пары цитат длиной в несколько абзацев? Считанные минуты. Если для выполнения курсовой или дипломной работы нужно набрать с десяток страниц, уйдут часы. Программы распознавания текста (OCR) решат проблему за десятки секунд, причём они справляются с сохранением структуры документа. Приложения определяют наличие таблиц, картинок, диаграмм, списков, справляются с текстом на нескольких языках, формулами. Они сохраняют тип и размер шрифта, способны очищать исходное изображение от дефектов: потёртости, желтизна бумаги, огрехи печати, перегибы страниц и прочее.
Если для выполнения курсовой или дипломной работы нужно набрать с десяток страниц, уйдут часы. Программы распознавания текста (OCR) решат проблему за десятки секунд, причём они справляются с сохранением структуры документа. Приложения определяют наличие таблиц, картинок, диаграмм, списков, справляются с текстом на нескольких языках, формулами. Они сохраняют тип и размер шрифта, способны очищать исходное изображение от дефектов: потёртости, желтизна бумаги, огрехи печати, перегибы страниц и прочее.
Примеры
Распространенные приложения для распознания документов:- CuneiForm;
- SimpleOCR;
- MyScript Stylus;
- Office Lens;
- Readiris 17;
- Readiris Pro;
- Freemore OCR;
- Scanitto Pro.
Самой известной программой оптического распознавания текстов является FineReader от компании ABBYY. Из инструмента для оцифровки файлов она превратилась в мощный инструмент для работы с цифровыми документами. Также разработаны десятки веб-сервисов для решения поставленной задачи.
Также разработаны десятки веб-сервисов для решения поставленной задачи.
Поделитесь в социальных сетях:
29 декабря 2021, 15:24
Информатика
Could not load xLike class!
Лучшее бесплатное программное обеспечение для распознавания текста в Windows 10
Я по-прежнему предпочитаю записывать свою информацию и результаты на листе бумаги. Теперь к делу: эти бумажные документы продолжают накапливаться, и мне негде их хранить. Приложения OCR — хороший способ Чтобы избавиться от этих огромных стопок бумаги. Если вы не знаете, вы OCR. Приложения Преобразование Рукописные документы или отсканированные документы в текстовые файлы Редактируемый. Большинство приложений OCR хорошо работают со сканированными документами. Но их очень мало Приложения оптического распознавания символов Это безопасно обрабатывает рукописные тексты.
Теперь, если вы находитесь в том же сценарии, трудно решить, какой Приложение OCR — лучшее. Итак, вот список из 5 лучших бесплатных приложений OCR для Windows.
Как работают приложения OCR?
Приложения OCR (оптическое распознавание символов) работают с Отсканированные документы или распечатанные документы. Предположим, есть две линии, вертикальные и встречающиеся наверху. И между ними проходит еще одна горизонтальная линия. Приложению легко определить, что это алфавит «А». Он определяет угол линий, пересечений и объектов.
Теперь приложения применяют ту же логику к рукописному тексту. Но рукописные тексты сильно отличаются от машинных шрифтов, потому что у каждого свой стиль написания алфавита. В этой статье я использую стандартное изображение для рукописного текста плюс Скриншот протокола встречи Чтобы судить о результатах, получаю от приложений. Это будет тестовый образец для всех приложений OCR. Мы можем судить больше о Приложения по скорости и точности конвертации.
Лучшее бесплатное программное обеспечение для распознавания текста для Windows 10
1. Одно примечание
В Windows есть встроенное приложение для создания заметок One Note. Однако в One Note есть дополнительная функция, которая работает как OCR. Все, что вам нужно сделать, это скопировать и вставить отсканированное изображение или документы в One Note. Теперь дайте ему несколько минут, чтобы обработать изображение. В конце, когда вы щелкнете правой кнопкой мыши по изображению, вы получите опцию «Копировать текст из изображения».
Однако в One Note есть дополнительная функция, которая работает как OCR. Все, что вам нужно сделать, это скопировать и вставить отсканированное изображение или документы в One Note. Теперь дайте ему несколько минут, чтобы обработать изображение. В конце, когда вы щелкнете правой кнопкой мыши по изображению, вы получите опцию «Копировать текст из изображения».
Если у вас нет возможности «Копировать текст с изображения», подождите некоторое время. One Note все еще обрабатывает изображение и преобразует его в текст. Даже через некоторое время, если вы не получите эту возможность, знайте, что One Note не смог обработать фотографию. Вы можете немного подождать или попробовать вставить изображение еще раз. Это случилось со мной, когда я пытался преобразовать рукописные заметки в текст. Мне пришлось подождать около 10 минут, чтобы эта опция появилась.
Главный судья: One Note может легко конвертировать отсканированные или распечатанные документы, но не работает с рукописными текстами. Он не смог преобразовать образец рукописного изображения в текст. Появилась опция копирования текста там, где некоторые слова были нежелательными, которые я не мог понять. Скажем так, это было очень неточно. Но, с другой стороны, с протоколом встречи это было довольно точно.
Он не смог преобразовать образец рукописного изображения в текст. Появилась опция копирования текста там, где некоторые слова были нежелательными, которые я не мог понять. Скажем так, это было очень неточно. Но, с другой стороны, с протоколом встречи это было довольно точно.
Положительные:
- Бесплатно.
- Точно для файлов PDF.
Минус:
- расход времени.
- Не работает с рукописным текстом.
زيارة Одна нота
2. Гугл Диск
Google Диск предоставляет самый простой способ преобразовать ваши документы в редактируемый текст. Хотя в Google Keep также есть функция OCR, которая включает меню и визитки, вы не получаете поддержки Google Doc. Итак, мы будем придерживаться функции распознавания текста на Google Диске. Это будет наиболее удобный способ, все, что вам нужно сделать, это «Загрузить изображение на Google Диск». Затем щелкните его правой кнопкой мыши, перейдите в раздел «Открыть с помощью» и нажмите «Документы Google». Теперь, в зависимости от размера и сложности файла, приложение Google Doc преобразует изображение в текст.
Теперь, в зависимости от размера и сложности файла, приложение Google Doc преобразует изображение в текст.
Преобразование печатных документов работает лучше, чем рукописный текст. По какой-то причине рукописный текст имеет странное форматирование и другой размер текста. Вы можете изменить это, очистив форматирование всего текста после преобразования.
Единственная загвоздка с Google Drive OCR Conversion заключается в том, что она имеет множество ограничений. Загруженная фотография или документ не может быть больше 2 МБ. Документ должен быть расположен лицевой стороной вверх, и вам нужно изменить ориентацию, если это не так. Это явно означает, что вы не можете конвертировать огромные файлы PDF или всю свою рукописную библиотеку.
Вердикт: Используя мой образец изображения, Google смог точно преобразовать образец в редактируемый текст. При этом тексты имели плохое форматирование и не соответствовали размеру текста. Итак, пришлось проверять формат вручную.
Положительные:
- скорость.
- Точность для файлов PDF, а также рукописных заметок.
минусы:
- Нет возможности обработать файл.
- Максимум 2 МБ.
визит Google Drive
3. Бесплатное распознавание текста
FreeOCR — очень популярное приложение OCR для Windows. Приложение OCR по своей сути использует движок визуального распознавания Google под названием Tesseract. Пользовательский интерфейс приложения FreeOCR является ортодоксальным, что имеет смысл с момента его последнего обновления в 2015 году. Вы получаете две части, разделенные на входное изображение и выходной текст. Вверху есть панель инструментов, где вы можете иметь две отдельные кнопки для загрузки PDF-файла или изображения. После того, как вы загрузите форму, вам просто нужно нажать кнопку OCR на верхней панели инструментов. В развернутом меню нажмите «OCR для текущей страницы».
У вас также есть возможность активировать процесс распознавания текста для нескольких документов. Итак, вам нужно загрузить все страницы и выбрать «OCR для всех страниц». После нескольких секунд обработки приложение отображает извлеченный текст на правой панели. Вы можете скопировать этот текст или преобразовать его в файл MS Word или RTF. Элементы управления для этого доступны в левой части панели вывода.
Итак, вам нужно загрузить все страницы и выбрать «OCR для всех страниц». После нескольких секунд обработки приложение отображает извлеченный текст на правой панели. Вы можете скопировать этот текст или преобразовать его в файл MS Word или RTF. Элементы управления для этого доступны в левой части панели вывода.
Вердикт: FreeOCR поддерживает несколько языков, таких как французский, немецкий, итальянский и т. Д. Это кажется изящной функцией, хотя я не могу ее протестировать. Что я могу проверить, так это свой почерк на листе бумаги. Поэтому FreeOCR с треском провалился. Типичный тестовый документ был преобразован в несколько несущественных алфавитов, таких как One Note, и был очень неточным. Что касается протокола встречи, FreeOCR был полностью точен. Хотя он не конвертирует таблицы.
Положительные:
- Хорошая обработка файлов
- السرعة
- Точно для PDF-файлов или отсканированного документа
- Многоязычная поддержка
Минус:
- Плохое управление файлами
- Не работает для рукописных заметок
Скачать FreeOCR
4.
 Простое распознавание текста
Простое распознавание текстаSimpleOCR — это простой OCR и менеджер документов. Он имеет полный набор программного обеспечения для управления файлами, сканирования файлов и индексации файлов. Я просто пройдусь через SimpleOCR, который предназначен для распознавания символов рукописного текста и отсканированных документов. Специальный SimpleOCR использует Fine Reader OCR для обработки документов и идентификации текста.
Первоначально вам необходимо обучить программное обеспечение, используя рукописный текст или сканированные документы определенного шрифта. Приложению будет легче понять, если вы используете один и тот же шрифт для большинства своих документов. Вы можете конвертировать бесчисленное количество документов и изображений, но для рукописных документов вы получаете 14-дневную пробную версию. При этом преобразование файлов PDF и отсканированных документов выполняется быстро и точно. Управление файлами отличное, а пакетная обработка файлов работает безупречно.
Вердикт: SimpleOCR не может точно идентифицировать образец рукописного текста. Тем не менее, некоторые детали получились очень хорошо. Главное в SimpleOCR — это то, что вам нужно предоставить программе много написанных примеров. В идеале, это требует, чтобы вы предоставили ему образцы из 300-500 слов, чтобы он соответствующим образом попрактиковался. Поскольку он не перелистал протокол встречи, что было удивительно, он не смог найти текст. Во всем списке OCR SimpleOCR — единственное приложение, которое не может автоматически определять набранный текст.
Тем не менее, некоторые детали получились очень хорошо. Главное в SimpleOCR — это то, что вам нужно предоставить программе много написанных примеров. В идеале, это требует, чтобы вы предоставили ему образцы из 300-500 слов, чтобы он соответствующим образом попрактиковался. Поскольку он не перелистал протокол встречи, что было удивительно, он не смог найти текст. Во всем списке OCR SimpleOCR — единственное приложение, которое не может автоматически определять набранный текст.
Положительные:
- Управление файлами
- Встроенный словарь и автозамена
минусы:
- Процесс конвертации медленный и долгий
- Неточно для рукописных заметок
Скачать Простое распознавание символов
5. Интернет-магазин Abby Fine Reader
Подобно SimpleOCR, Abby Fine Reader также представляет собой полный набор программного обеспечения для управления файлами. Однако есть веб-версия, которая выполняет распознавание текста для документов. Вам необходимо зарегистрироваться на сайте и вы получите всего 10 конверсий бесплатно. Abby Fine Reader использует тот же подход FineReader Engines, что и SimpleOCR. Это делает результаты очень предсказуемыми.
Abby Fine Reader использует тот же подход FineReader Engines, что и SimpleOCR. Это делает результаты очень предсказуемыми.
Вы должны загрузить файл в веб-приложение или подключить к нему свою учетную запись Google Диска. Abby Fine также поддерживает некоторые другие облачные сервисы, такие как DropBox и OneDrive. После того, как вы загрузили документы, вы можете продолжить знакомство с ними, нажав кнопку «Распознать».
Вердикт: С моим образцом документа Эбби Файн Ридер не смогла его распознать. Для тестирования попробовал скриншоты для мобильных устройств и PDF-документы. Приложение смогло точно преобразовать их в текст. Веб-приложение не предоставляет вам тексты напрямую, и вам необходимо преобразовать их в другой тип документа и экспортировать в облачную службу. Это действительно делает веб-приложение зависимым от облачных сервисов.
Положительные:
- Интуитивно понятный процесс и быстрое преобразование
- Множественные варианты экспорта и облачные сервисы
- многопроцессорность
Минус:
- Не работает для рукописных заметок
زيارة Abby Fine Reader онлайн
Лучшее программное обеспечение для оптического распознавания текста для Windows
Если вам нужно иметь дело с преобразованием отсканированных PDF-файлов, Одна нота Хорошее простое решение. Однако процесс преобразования с помощью приложения One Note занимает много времени. Для обработки нескольких документов из PDF файлы Для сканирования и больших документов вы можете попробовать FreeOCR или Abby Fine Reader. Для рукописных текстов я предпочитаю использовать Google Drive В любой день. Он работает хорошо и оказался наиболее точным в нашем тестировании.
Однако процесс преобразования с помощью приложения One Note занимает много времени. Для обработки нескольких документов из PDF файлы Для сканирования и больших документов вы можете попробовать FreeOCR или Abby Fine Reader. Для рукописных текстов я предпочитаю использовать Google Drive В любой день. Он работает хорошо и оказался наиболее точным в нашем тестировании.
Если у вас возникнут дополнительные вопросы или проблемы, дайте мне знать в комментариях ниже.
Источник
Какое лучшее программное обеспечение для распознавания текста на основе OCR для PDF-файлов?
Малый бизнес сталкивается с постоянными проблемами с документооборотом. Те, которые работают в течение длительного времени, часто имеют обширные системы бумажной документации, которые являются громоздкими и устаревшими. Новые компании по-прежнему должны подавать документы в государственные органы, которые контролируют их отрасли и работают с поставщиками и клиентами, сканируя и отправляя по электронной почте бумажные документы. Бремя отслеживания доходов, расходов и различных финансовых операций часто означает поспешное отправление бухгалтерам бумажных документов, которые лучше всего сохранить в цифровом формате.
Бремя отслеживания доходов, расходов и различных финансовых операций часто означает поспешное отправление бухгалтерам бумажных документов, которые лучше всего сохранить в цифровом формате.Малые предприятия хотят и должны оцифровывать свои документы, но для такого обновления требуется исключительное программное обеспечение. Хорошая новость: есть явный победитель среди лучших программ для распознавания текста, которые можно использовать для управления процессом оцифровки физических документов в формат PDF.
Четыре основные функции OCR для оцифровки ваших документов
Существует множество программ, которые могут выполнять эту функцию, поэтому, чтобы найти наилучший вариант для малого бизнеса, рассмотрите четыре ключевые функции, которые должны включать эти программы:
- High-Tech OCR. Оптическое распознавание символов прошло долгий путь с момента его появления несколько десятилетий назад. На сегодняшний день лучшее программное обеспечение для оцифровки включает ведущую в отрасли технологию OCR для точного распознавания текста, напечатанного практически любым шрифтом или почерком.
 Он может понять, какие части документа являются текстом, и даже сохранить исходное форматирование, а это означает, что вы потратите меньше времени на повторную проверку оцифрованных документов и столкнетесь с меньшим количеством ошибок транскрипции.
Он может понять, какие части документа являются текстом, и даже сохранить исходное форматирование, а это означает, что вы потратите меньше времени на повторную проверку оцифрованных документов и столкнетесь с меньшим количеством ошибок транскрипции. - Распознавание языка. В зависимости от вашего бизнеса вы можете работать с клиентами или поставщиками в разных частях мира. Одно дело, когда OCR распознает английский язык, но лучшее программное обеспечение распознает более 120 языков, что позволяет точно оцифровывать документы практически из любого источника.
- Автоматизация. Вы можете сэкономить значительное количество времени, автоматизировав части процесса оцифровки. Один из способов сделать это — автоматически отправить отсканированный PDF-файл на выбранный адрес электронной почты. Скорее всего, в вашем бизнесе есть уникальные процессы, поэтому вы можете выбрать встроенный рабочий процесс или разработать собственный, чтобы упростить повторяющиеся задания по конверсии.
- Интуитивно понятный пользовательский интерфейс. Независимо от того, насколько мощным является программное обеспечение, оно бесполезно, если пользовательский интерфейс представляет собой кошмар. Лучшее программное обеспечение для оцифровки включает в себя эти сильные стороны, оставаясь при этом простым для изучения новыми пользователями. По мере того, как вы станете более опытным в программном обеспечении, вы сможете разблокировать более мощные функции.
 Он может понять, какие части документа являются текстом, и даже сохранить исходное форматирование, а это означает, что вы потратите меньше времени на повторную проверку оцифрованных документов и столкнетесь с меньшим количеством ошибок транскрипции.
Он может понять, какие части документа являются текстом, и даже сохранить исходное форматирование, а это означает, что вы потратите меньше времени на повторную проверку оцифрованных документов и столкнетесь с меньшим количеством ошибок транскрипции.
Почему Kofax OmniPage превосходно распознает текст
Единственным программным обеспечением, обладающим всеми этими и другими преимуществами, является Kofax OmniPage. Это программное обеспечение включает в себя передовые технологии распознавания текста, невероятную точность, интеграцию с другим программным обеспечением и устройствами, варианты рабочего процесса одним щелчком мыши и интуитивно понятный пользовательский интерфейс. Что отличает его от сопоставимого программного обеспечения, так это то, что вы можете защитить доступ к все его функции при единовременной покупке вместо продления годовой лицензии.
Изучите функции, которые OmniPage предлагает малым предприятиям, и вскоре вы на собственном опыте убедитесь, как эта мощная опция позволяет вам работать сегодня, как завтра.
Объяснение оптического распознавания символов (OCR): все, что вам нужно знать . В то время как большинство предположило бы, что способность распознавать и переводить изображение в текст будет современным изобретением, основанным на каком-то современном алгоритме, правда в том, что программное обеспечение OCR и технология преобразования изображения в текст существуют по крайней мере с конца 19 века.20 с. Человек, ответственный за одну из первых инноваций OCR? Австрийский инженер по имени Густав Таушек. Именно он запатентовал устройство оптического распознавания символов в Германии в 1929 году и еще раз в США в 1935 году.
Но как Густаву Таушеку пришла в голову такая новая идея для программного обеспечения? И как это работало с таким архаичным ПО в то время? Не говоря уже о том, каково историческое значение программного обеспечения для распознавания текста Таушека? К счастью, на каждый из этих вопросов есть ответ. Читайте дальше, чтобы узнать больше о Густаве Таушеке и его изобретении OCR.
Читайте дальше, чтобы узнать больше о Густаве Таушеке и его изобретении OCR.
Краткие сведения
- Создан
- 1929
- Создатель
- Густав Таушек
- Исходное использование
- Распознавание текста 9003 7 Стоимость
- Н/Д
- Самые ранние формы OCR для текстовых устройств были разработаны в конце 1800-х годов для использования слепыми. Изобретатели надеялись, что их примитивное программное обеспечение для преобразования изображений в текст поможет слепым читать.
- В 1970-х годах американский изобретатель Рэй Курцвейл создал Kurzweil Computer Products Inc. — компанию, которая серьезно вдохновилась устройством Густава Таушека при создании своего программного обеспечения для оптического распознавания символов. Примечательно, что алгоритм Рэя Курцвейла был способен распознавать практически любой текстовый шрифт.
- В дополнение к своему новаторскому изобретению изображения для текста Густав Таушек разработал 169 патентов и продал их все IBM. Получив пятилетний контракт с софтверным гигантом, Таушек использовал технологию OCR для разработки системы учета на основе перфокарт и нескольких других устройств на основе перфокарт, зависящих от OCR.

Венский инженер Густав Таушек в начале 20 века был чем-то вроде гения-самоучки. С более чем 200 патентами на его имя, включая вышеупомянутые 169 проданных IBM, Таушек, несомненно, был гением программного обеспечения, способным творить далеко впереди того, что было изобретено его современниками в то время. На протяжении всей своей карьеры он работал как в IBM, так и в немецкой компании по производству оружия и автомобилей Rheinische Metallwaren- und Maschinenfabrik (известной сегодня как Rheinmetall).
Работа Таушека с оптическим распознаванием символов началась с создания программного обеспечения, способного точно и эффективно преобразовывать изображения в текст. Он в основном использовал эту запатентованную технологию в своих вычислительных машинах на основе перфокарт. Оттуда Таушек изобрел Читающую машину Таушека: механическое устройство, которое могло читать символы и цифры на изображении и преобразовывать их в печатные символы и цифры на листе бумаги.
Он в основном использовал эту запатентованную технологию в своих вычислительных машинах на основе перфокарт. Оттуда Таушек изобрел Читающую машину Таушека: механическое устройство, которое могло читать символы и цифры на изображении и преобразовывать их в печатные символы и цифры на листе бумаги.
Многие до Таушека, такие как американский изобретатель Чарльз Р. Кэри, придумали аналогичные, более ранние формы OCR, но Таушек был первым, кто убрал его со страницы и превратил в реальное устройство с помощью своего Читающая машина.
Патентный чертеж читающей машины Таушека . Оптическое распознавание символов (OCR): как это работало Считывающая машина Густава Таушека представляла собой механическое устройство, в котором использовался шаблон, соответствующий фотоэлектрическому фотодетектору. Пока картинка с текстом проходила перед глазоподобным окном читающей машины, устройство сравнения — диск с отверстиями в форме букв и цифр — вращалось перед окном в поисках подгонки. Когда текст на изображении совпадал с одним из отверстий в форме буквы на устройстве сравнения, машина поворачивала печатный барабан в соответствии с соответствующей буквой. Затем письмо было напечатано на листе бумаги.
Когда текст на изображении совпадал с одним из отверстий в форме буквы на устройстве сравнения, машина поворачивала печатный барабан в соответствии с соответствующей буквой. Затем письмо было напечатано на листе бумаги.
С этого времени в 1929 году и до наших дней устройство OCR претерпело множество различных изменений, чтобы удовлетворить самые разные потребности (которые будут затронуты ниже). В конце концов, однако, та же основная концепция остается неотъемлемой частью разработки устройств OCR: преобразование текста на изображении в машинно-кодированный текст.
После нового изобретения Таушека многие другие изобретатели и инженеры взяли его идеи и экстраполировали их во всевозможных различных заметных направлениях. Это, без сомнения, наиболее исторически значимая вещь в OCR: огромное количество различных применений творения Таушека, появившихся спустя десятилетия.
В 1931 году технология OCR была использована при создании устройства преобразования текста в телеграф. Оттуда, в 1951 году, эта технология превратилась в устройство для преобразования текста в азбуку Морзе. Затем, в 1966 году, технология стала способна читать рукописный текст и преобразовывать его в текст. В 1978 году появилась OCR Omni-font Рэя Курцвейла. Затем, в 80-х, технология OCR стала неотъемлемой частью сканеров штрих-кодов в розничных магазинах и аппаратов Xerox в офисах и школах. Сегодня Google Drive и Adobe Acrobat предлагают бесплатные онлайн-версии программного обеспечения для оптического распознавания текста, способные точно и четко работать на более чем 200 различных языках.
Оттуда, в 1951 году, эта технология превратилась в устройство для преобразования текста в азбуку Морзе. Затем, в 1966 году, технология стала способна читать рукописный текст и преобразовывать его в текст. В 1978 году появилась OCR Omni-font Рэя Курцвейла. Затем, в 80-х, технология OCR стала неотъемлемой частью сканеров штрих-кодов в розничных магазинах и аппаратов Xerox в офисах и школах. Сегодня Google Drive и Adobe Acrobat предлагают бесплатные онлайн-версии программного обеспечения для оптического распознавания текста, способные точно и четко работать на более чем 200 различных языках.
Очевидно, что от Густава Таушека до Рэя Курцвейла, Google Диска и всех, кто находится между ними, алгоритм OCR имеет большое историческое значение, и его продолжают обновлять и совершенствовать до сих пор.
Google Диск — это служба хранения и синхронизации файлов, созданная Google.©dennizn/Shutterstock.com
Далее…
Продолжайте читать похожие темы в этих статьях!
- Вот как работает распознавание лиц на вашем iPhone. Как-то жутко, но как-то круто!
- Исследуйте историю гипертекста: полное руководство. Вы буквально смотрите на какой-то гипертекст на этой странице, и если вы нажмете на эту статью!
- Dropbox против Google Диска: что лучше? Часто хорошие дебаты, но мы дадим вам детали, чтобы вы могли принять решение.
 Как-то жутко, но как-то круто!
Как-то жутко, но как-то круто!Объяснение оптического распознавания символов (OCR) — все, что вам нужно знать Часто задаваемые вопросы (часто задаваемые вопросы)
Что такое оптическое распознавание символов (OCR)?
Оптическое распознавание символов, часто сокращенно просто OCR, представляет собой преобразование текста на изображении в машинно-кодированный текст.
Как работает оптическое распознавание символов (OCR)?
Оптическое распознавание символов работает путем сопоставления текста на изображении с цифровой базой данных соответствующих букв и цифр, а затем его перепечатки или архивирования с точностью в более четкой и лаконичной форме.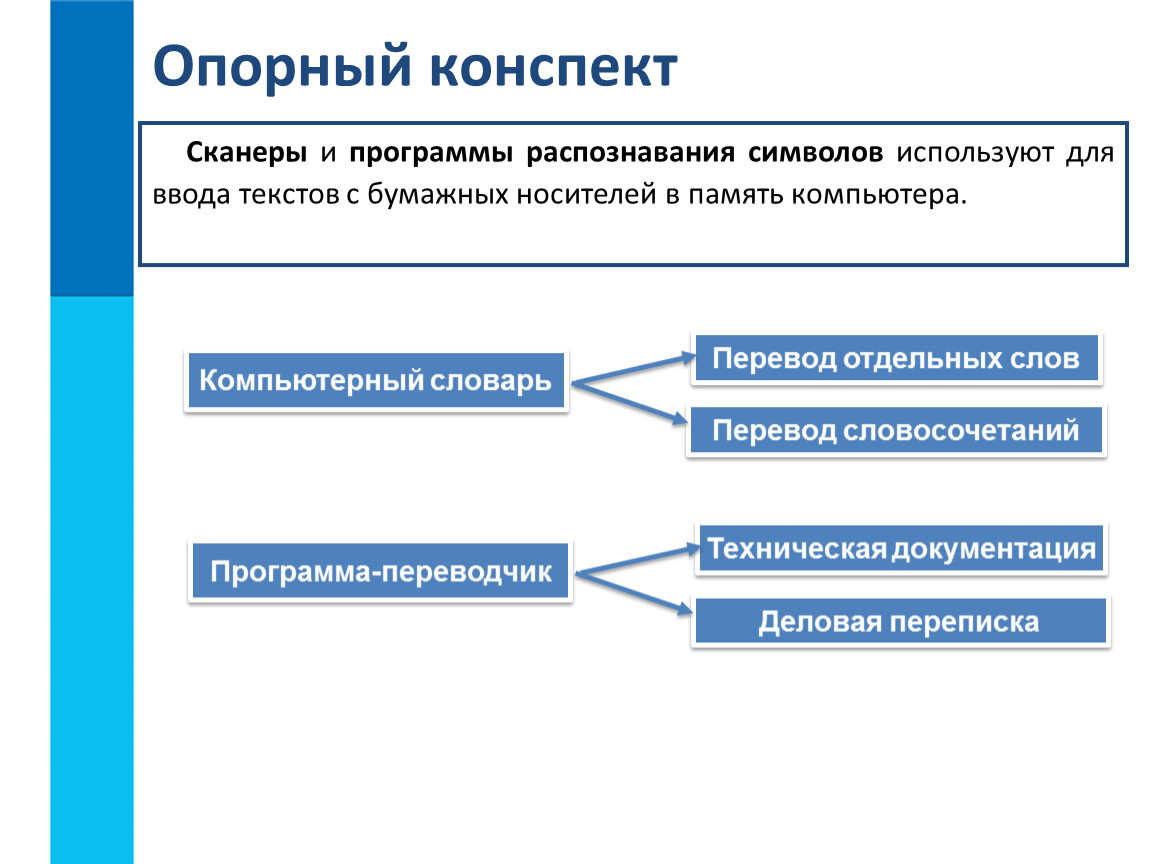
Кто изобрел оптическое распознавание символов (OCR)?
Оптическое распознавание символов было изобретено Густавом Таушеком, австрийским инженером-самоучкой, на счету которого более 200 патентов и изобретений.
Когда было изобретено оптическое распознавание символов (OCR)?
Оптическое распознавание символов было запатентовано Таушеком в Германии в 1929 году, затем снова запатентовано Паулем Генделем в США в 1933 году, а затем снова Таушеком в США в 1935 году. использовал?
Оптическое распознавание символов до сих пор используется самыми разными способами — будь то версия элементарного OCR Таушека, OCR Omni-font Рэя Курцвейла или функции OCR, предоставляемые Adobe и Google.
об авторе
Хизер
Хизер — учительница среднего образования, хорошо разбирающаяся в мире технологий. В свободное время она любит слушать исторические подкасты, играть в игры и публиковать сообщения в социальных сетях.
Ваш комментарий будет первым