Как увеличить объем облака Майл.Ру бесплатно?
Главная » Mail диск
Как увеличить объем облака Майл бесплатно мучает многих пользователей. Особенно интересуются этим вопросом только что скачавшие и начавшие пользоваться услугами ресурса Облака Mail.Ru. Компания предлагает даром пользоваться объемом в 100 гб. Если этого места не хватит, есть платные решения.
Важно! Получить возможность сэкономить на аренде расширенного места на облаке можно только на официальном сайте cloud Mail.Ru
Содержание
- Возможно, ли бесплатно увеличение размера Облака?
- Вариант 1: Внесение промокала
- Вариант 2: Оплата расширенного доступа за 1 год
Такой функции на текущий год не предоставляется. При запуске проекта облачного архива данных были меньшие массивы от 25 гигов. Тогда Облако Майл РУ предлагало даром без выполнения условий акции увеличить размеры до 100 гб.
Тогда Облако Майл РУ предлагало даром без выполнения условий акции увеличить размеры до 100 гб.
Теперь компания решали отказать от таких способов, и сразу предоставляла всем пользователям возможность использовать облачное размещение на 100 гигабайт. Все остальные способы увеличения памяти стали платными. Есть 2 варианта, как получить расширенный размер онлайн ресурса по выгодной цене:
- Внести промокод;
- Оплатить тариф сразу за 1 год.
Чем больше используется размер, тем больше клиент может получить скидки .
Вариант 1: Внесение промокала
Облако Майл РУ часто проводит акции и конкурсы. Они разыгрывают ценные призы и промокоды. Это позволяет пользоваться электронными продуктами компании по выгодной цене. Получить промокод достаточно просто. В раздел официальной страницы Маил Ру «Акции» есть перечень заданий и условий. Выполняя их, клиент получает код, состоящий из цифр и букв.
Чтобы его ввести при покупке места на обычно размещение необходимо выполнить следующие действия:
- Перейти на страницу cloud Mail.
 Ru.
Ru. - Нажать на кнопку «Подключить тариф».
- В нижней части открывшегося окна нажать на надпись «У меня есть промокод».
- Ввести код и нажать по кнопке «Активировать».
 Ru.
Ru.Скидки автоматически будет рассчитана. После этого можно приобретать по сниженной цене нужный размер ресурса.
Вариант 2: Оплата расширенного доступа за 1 год
Второй способ позволяет оплачивать только 10 месяц из 12. При открытии тарифных планов следует выполнить следующие действия:
- Выбрать нужный объем ресурса.
- Нажать «Подключить».
- В новом окне выбрать оплату за год.
- Произвести расчёт.
Снижение цены уже вписывается автоматически. Люди оплачивают только 10 месяцев. Последние 2 идут в подарок
Как у уже было выяснено, на 2018 год компания Маил Ру решила ограничить бесплатную возможность расширения. Было решено увеличить безвозмездный объём до 100 гигабайт и убрать акции по увеличению.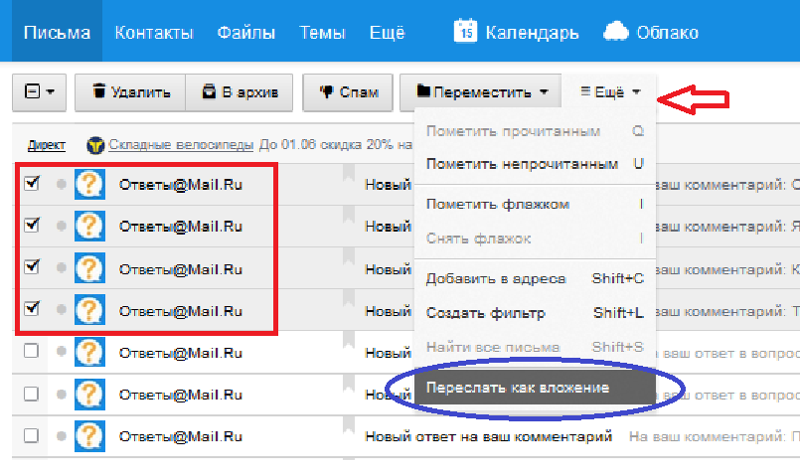
В результате cloud Mail.Ru стал одними крупных по СНГ облачных хранилищ, которые предлагают бесплатно место в размере 100 Гб. Если требуется размер данных увеличить, доступны выгодные решения по годовой оплате и промокоду. Они помогут значительно сэкономить при увеличении объёма сохраняемых данных на сервер до 4 терабайт.
Рейтинг
( Пока оценок нет )
10
Понравилась статья? Поделиться с друзьями:
Как увеличить размер хранилища в облаке Mail.Ru
3 мин.
Содержание:
Как увеличить объем Mile Cloud бесплатно, сразу с момента регистрации, интересует всех новичков. Пользователь, который недавно начал использовать хранилище резервных копий, не знает всех сложностей, связанных с расширением лимитов свободного места. Поэтому рекомендуем изучить все нюансы, чтобы не тратить деньги без надобности.
Поэтому рекомендуем изучить все нюансы, чтобы не тратить деньги без надобности.
Когда предоставляется бесплатный объем?
Те, кто регистрируется в одноименной поисковой системе, открывают почтовый ящик электронной почты и получают в подарок определенный объем хранилища. В дальнейшем вы можете загружать сюда информацию в любом формате, включая фотографии, музыку и видео. Храните актуальные текстовые документы.
Поэтому бесплатное хранилище предоставляется только после регистрации. На сегодняшний день размер безлимитного пространства составляет 8 ГБ. Несколько лет назад новый пользователь получил 100 ГБ бесплатно. К сожалению, не существует равных условий для всех новичков: у некоторых доступно только 8 ГБ, а у некоторых 25 или 100 ГБ. Это зависит от периода регистрации.
Полезная информация! Для вновь зарегистрировавшихся действуют новые правила, которые предусматривают скидки и бонусы за использование бронирования в Интернете.
На каких основаниях допускается увеличить пространство на «облаке»
Если покупатель почтового ящика не изменяет традициям и много лет пользуется услугами поисковой системы, ему полагаются скидки. Ежегодно проводятся конкурсы с призами в виде полезных акций для постоянных пользователей.
Ежегодно проводятся конкурсы с призами в виде полезных акций для постоянных пользователей.
Предоставление промокода
Не все знают, как бесплатно увеличить почтовое облако разными тарифами. Фактически, эта функция доступна только тем, кто получил промокод. Вы можете получить существенную скидку на хранение данных на длительный срок. Он предоставляется по электронной почте по определенным вопросам, и для его использования мы действуем в соответствии с инструкциями.
- Открываем облачное хранилище, затем в левом верхнем углу находим блок с обозначением текущего тарифного плана, нажимаем кнопку «Увеличить громкость».
- В открывшемся меню подписки предлагают расширить облако, заплатив разными способами. Пропускаем этот момент и нажимаем ссылку «Еще».
- Откроется следующее окно со списком доступных ставок. Здесь внизу нажмите на ссылку «Применить промокод».
- В следующем окне диска введите полученный в подарок код (состоящий из цифр и букв) и нажмите кнопку «Применить код».
Кроме того, шифрование будет зарегистрировано в системе, поэтому пользователь сможет воспользоваться скидками на бесплатное пространство для работы с любым лимитом.
Экономия при годовой покупке
Учтите, что если вы планируете увеличить размер на купленную ставку, при оплате безлимитного срока в течение одного года есть хорошая акция. Вы можете существенно сэкономить свои финансовые ресурсы, а также получить бесплатное пользование помещением на два месяца в подарок.
Рассмотрим алгоритм такого приобретения:
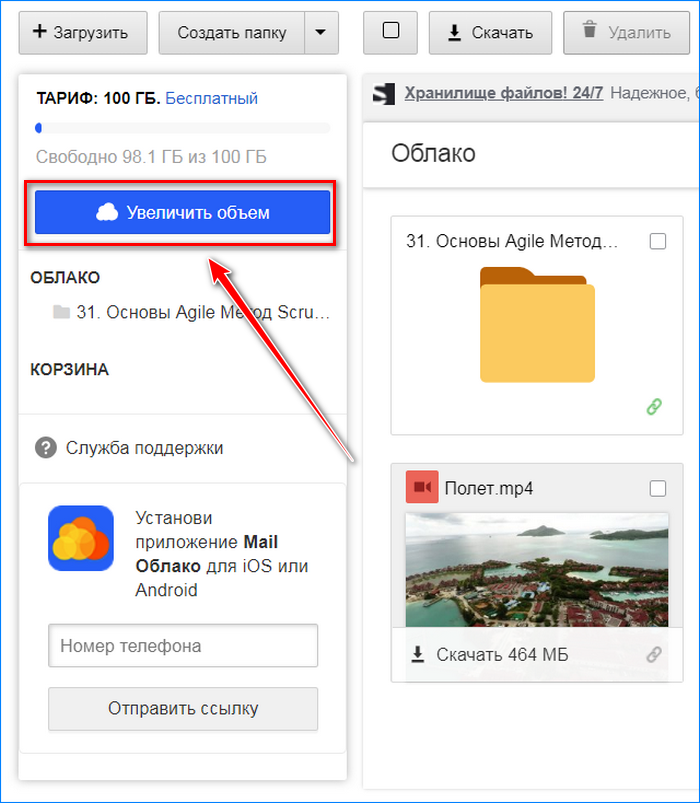
- Снова откройте облако и нажмите кнопку «Увеличить громкость», в появившемся окне с предложением совершить покупку выберите любой подходящий вариант. Если оплата картой вам не удобна, нажмите ссылку «Другие способы оплаты».
- Среди перечисленных платежных систем мы находим наиболее удобные. При необходимости щелкните раскрывающееся меню под кнопкой «Еще». Затем подтвердите действие кнопкой «Оплатить».
- Когда счет будет сформирован, придет сообщение. В этой ситуации нажмите кнопку «Готово» и перейдите в выбранный кошелек для оплаты.
 В этой ситуации нажмите кнопку «Готово» и перейдите в выбранный кошелек для оплаты.
В этой ситуации нажмите кнопку «Готово» и перейдите в выбранный кошелек для оплаты.Если по какой-либо причине вы передумаете о пожертвовании, просто проигнорируйте полученное уведомление.
Популярные тарифы и степень экономии
Проект Mail.ru по использованию облачного хранилища дает своим клиентам возможность выбирать выгодные тарифы. Всего есть пакеты по 7 гигабайт. Чтобы сэкономить при покупке определенного лимита, пользователь должен заплатить за год. Обратите внимание на размер сбережений на фото.
Используя стрелку на фото, пользователь может ознакомиться с другими видами ставок и их ставкой на год.
Mile.ru — первое облачное хранилище, появившееся в сети. За время своего долгого существования он заслужил множество положительных отзывов. При этом услуга считается бюджетной по сравнению с аналогами.
Как включить режим инкогнито в Яндекс.Браузере
Что такое режим инкогнито и зачем он нужен Этот формат работы распространен среди всех популярных людей. В программе открывается история приватного…
В программе открывается история приватного…
Как открыть меню в Яндекс Браузере
Из меню в Яндекс браузере можно перейти в любой раздел сайта, который нужен пользователю. Но чтобы попасть в меню, нужно знать, где вы находитесь…
Менеджер паролей
Рано или поздно у большинства пользователей браузеров возникает идея аккуратного хранения паролей. Да, у кого-то есть для этого «волшебный&…
Как сделать скриншот в Яндекс Браузере
Функция скриншота популярна у всех пользователей, от новичков до профессионалов. Это позволяет сохранить важную информацию на ваш компьютер в вид…
Что такое адресная строка браузера
Каждый пользователь, ищущий информацию в Интернете, использует адресную строку браузера. Казалось бы, это банальный и привычный инструмент, котор…
Казалось бы, это банальный и привычный инструмент, котор…
Владельцы веб-сайтов и контент-менеджеры стараются сделать текст максимально читабельным, чтобы пользователи быстро и удобно получали нужную им и…
Сравнение Облака@Mail.Ru и Dropbox
Облако@Mail.Ru
—
Ненадежная служба хранения
Нравится
много места
варианты обмена
Не нравится
нет бэкапов
нет истории версий
синхронизация в 1 канал
отсутствуют файлы, все написано в отзыве
По поводу техподдержки сервиса cloud.mile.ru у меня постоянно возникают вопросы, уже накопилась приличная переписка. С другими сервисами (дропбокс и гугл диск) у меня вообще вопросов не возникло.
С Cloud. Mail.ru вы действительно чувствуете себя незащищенным, а точнее чувствуете, что ваши данные не защищены и что-то будет потеряно. в случае неудачной синхронизации.
Mail.ru вы действительно чувствуете себя незащищенным, а точнее чувствуете, что ваши данные не защищены и что-то будет потеряно. в случае неудачной синхронизации.
У меня занято около 400 Гб из 1000 Гб в облаке. Я понимаю, конечно, что этот 1 Тб был получен в ходе кампании mail.ru перед новым годом и теоретически саппорт mail.ru может отправить всех халявщиков нафиг. Но я в принципе готов платить за услугу, если бы она была надежной.
Вариант №1 для отсутствующих файлов
Суть в том, что сама синхронизация происходит, по моим предположениям, в один канал, т.е. программа может очень долго синхронизировать кучу мелких файлов. А пока идет синхронизация, наделав дел, вы выключаете компьютер, ничего не подозревая, а утром, уже на работе, включаете другой компьютер, который также подключен к облаку. Вы можете обнаружить, что некоторые из этих мелких файлов исчезли из-за того, что их не было на домашнем компьютере, ну просто они не загрузились и программа считает, что все должно синхронизироваться так, как было на домашнем компьютере.
В результате файлы то тут, то там пропадают — пздц как весело становится. Ладно, если речь идет о временных файлах, а если это снимки с родными, которых уже нет ни в телефоне, ни в фотоаппарате?
Вариант №2 для отсутствующих файлов
Далее. При переименовании файлов на одном компьютере в облаке пишется, что файл *** удален.
То есть программа тупо удаляет файлы из облака, чтобы потом залить их под новым именем.
И опять же, в тот момент, когда вы переименовали файлы, программа удалила их в облаке — выключаешь компьютер.
В результате файлы удаляются в облаке, удаляются на рабочем компе.
приходишь домой а файлов там нет, потому что программа посчитала облако приоритетом и удалила файлы в синхпаке. p>
Короче говоря, очень осторожно пользоваться этим сервисом, даже если он стоит денег.
Еще раз повторяю — в дропбоксе и гуглдрайве такого еще не было. Но, увы, стоимость за 1 ТБ в год их услуг по-прежнему неподъемная.
242491
Отзыв
17 марта 2016 г.
Облако@Mail.Ru
—
Давно ли у вас есть почта от Mail.ru? Получите 100 ГБ бесплатно!
Понравилось
Отличное мобильное приложение.
Есть настольная версия.
Есть веб-редакторы типа слов и таблиц
100 гб бесплатно.
Не понравилось
Если вы новый пользователь то у вас будет 25 гб. Но есть акции — следите за новостями.
Полностью доволен!
238581
Отзыв
7 декабря 2016 г.
Облако@Mail.Ru
—
Отличный и, что удивительно для mail.ru, не навязчивый сервис.
Понравилось
— Просто
— Удобно
— Без лишних напоминаний о его существовании
Не понравилось
— Не заметил
На ноутбуке есть несколько папок с достаточно важной рабочей информацией, которая постоянно обновляется и модифицируется . Скачал приложение, установил и все. Теперь висит в трее и зеркалит все нужные папки в облаке, к тому же никак о себе не напоминает, при этом в самой папке видно какие файлы синхронизированы, а какие нет. Удобно и ненавязчиво.
Скачал приложение, установил и все. Теперь висит в трее и зеркалит все нужные папки в облаке, к тому же никак о себе не напоминает, при этом в самой папке видно какие файлы синхронизированы, а какие нет. Удобно и ненавязчиво.
234801
Отзыв
17 сентября 2015 г.
Облако@Mail.Ru
—
Большое и бесплатное облако
Понравилось
Один из крупнейших облачных дисков
Все сохранено и все хорошо
Не понравилось
Мобильное приложение
Не в срок 1 Тб, а в срок 100Гб. Однако этого вполне достаточно для размещения там материалов, которые некуда деть или они засоряют телефон.
В целом все удобно и хорошо работает.
В мобильном приложении есть недоработка, но это может быть не из-за самого приложения, а из-за каких-то проблем со связью. Иногда обрывается в загрузке мобильного приложения или все очень долго висит, т.к. много файлов.
Иногда обрывается в загрузке мобильного приложения или все очень долго висит, т.к. много файлов.
177342
Отзыв
10 мая 2018 г.
Облако@Mail.Ru
—
Как загрузить и скачать с сервиса «Облако Mail.ru»
Понравилось
внешний вид
Не понравилось
один недостаток, он же самый основной — очень низкая скорость скачивания и выгрузки, что является большой проблемой для больших файлов. Терпения просто не хватит! И если вам повезет и процесс не прервется, вы скачаете. НЕТ обновления! Что ж, похоже на простую и неподходящую услугу!
На сегодняшний день нет удобных решений для загрузки и скачивания больших файлов в Cloud Mail ru, кроме одного — Maxthon Nitro
184440
Отзыв
10 февраля 2018 г.
Базы данных платформы IIoT — Как Mail.ru Cloud Solutions работает …
Здравствуйте, меня зовут Андрей Сергеев, я работаю руководителем отдела разработки IoT-решений в Mail.ru Cloud Solutions. Все мы знаем, что универсальной базы данных не существует. Особенно, когда стоит задача построить IoT-платформу, способную обрабатывать миллионы событий с различных датчиков в режиме, близком к реальному времени.
Наш продукт Mail.ru IoT Platform начинался как прототип на базе Tarantool. Я собираюсь рассказать вам о нашем путешествии, проблемах, с которыми мы столкнулись, и решениях, которые мы нашли. Я также покажу вам текущую архитектуру современной платформы промышленного Интернета вещей. В этой статье мы рассмотрим:
- наши требования к базе данных, универсальные решения и теорему CAP
- является ли база данных + сервер приложений в одном подходе серебряной пулей
- эволюция платформы и используемых в ней баз данных
- количество используемых Tarantool’ов и как мы пришли к этому
Mail.
 ru IoT Platform сегодня
ru IoT Platform сегодняНаш продукт Mail.ru IoT Platform — независимая платформа для построения решений промышленного интернета вещей. Это позволяет нам собирать данные с сотен тысяч устройств и обрабатывать этот поток почти в режиме реального времени, используя определяемые пользователем правила (скрипты на Python и Lua) среди других инструментов.
Платформа может хранить неограниченное количество необработанных данных из источников. Он также имеет набор готовых компонентов для визуализации и анализа данных, а также встроенные инструменты для предиктивного анализа и разработки приложений на основе платформы. локальная установка на объектах заказчика. В 2020 году мы планируем его выпуск в виде общедоступного облачного сервиса.
Прототип на базе Tarantool: как мы начинали
Наша платформа начиналась как пилотный проект — прототип с одним экземпляром Tarantool. Его основными функциями были получение потока данных от OPC-сервера, обработка событий Lua-скриптами в режиме реального времени, мониторинг ключевых показателей на его основе, генерация событий и оповещений для вышестоящих систем.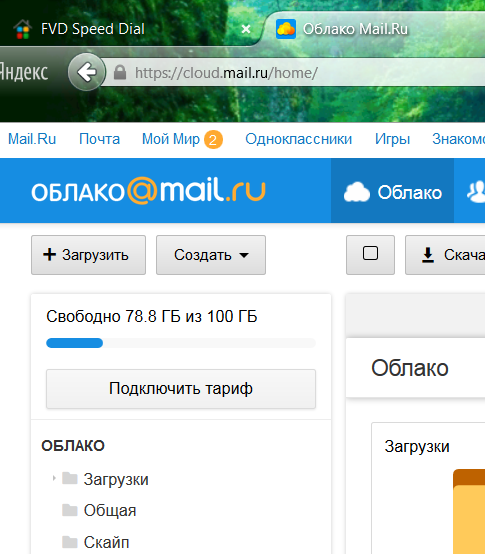
Блок-схема прототипа на базе Tarantool[/caption] Этот прототип даже показал себя в полевых условиях многоскважинной площадки в Ираке. Он работал на нефтяной платформе в Персидском заливе, отслеживая ключевые показатели и отправляя данные в систему визуализации и журнал событий. Пилот был признан успешным, но затем, как это часто бывает с прототипами, его отправили в холодное хранилище, пока мы не получили его в свои руки.
Наши цели в разработке платформы IoT
Вместе с прототипом мы поставили перед собой задачу создать полнофункциональную, масштабируемую и отказоустойчивую платформу IoT, которую затем можно было бы выпустить в качестве общедоступной облачной службы.
Нам нужно было построить платформу со следующими характеристиками:
- Одновременное подключение сотен тысяч устройств
- Прием миллионов событий каждую секунду
- Обработка потока данных практически в реальном времени
- Хранение необработанных данных за несколько лет
- Инструменты аналитики как для потоковых, так и для исторических данных
- Поддержка развертывания в нескольких центрах обработки данных для обеспечения максимальной устойчивости к стихийным бедствиям
Плюсы и минусы прототипа платформы
В начале активной разработки прототип имел следующую структуру:
- Tarantool, который использовался как база данных + Application Server
- все данные хранились в памяти Tarantool
- в этом Tarantool было Lua-приложение, которое выполняло прием и обработку данных и вызывало пользовательские скрипты с поступающими данными
Такой тип структуры приложения имеет свои преимущества:
- Код и данные хранятся в одном месте — что позволяет манипулировать данными прямо в памяти приложения и избавиться от лишних сетевых манипуляций, характерных для традиционных приложений
- Tarantool использует JIT (Just in Time Compiler) для Lua. Он компилирует код Lua в машинный код, позволяя выполнять простые скрипты Lua со скоростью, подобной C (40 000 RPS на ядро и даже выше!)
- Tarantool основан на совместной многозадачности. Это означает, что каждый вызов хранимой процедуры выполняется в собственном волокне, похожем на сопрограмму. Это дает дополнительный прирост производительности для задач с операциями ввода-вывода, например. сетевые манипуляции
- Эффективное использование ресурсов: инструменты, способные обрабатывать 40 000 RPS на ядро, довольно редки
 Он компилирует код Lua в машинный код, позволяя выполнять простые скрипты Lua со скоростью, подобной C (40 000 RPS на ядро и даже выше!)
Он компилирует код Lua в машинный код, позволяя выполнять простые скрипты Lua со скоростью, подобной C (40 000 RPS на ядро и даже выше!)Есть и существенные недостатки:
- у меня есть сотни петабайт для Tarantool
- Этот пункт является прямым следствием преимущества №1. Весь код платформы состоит из процедур, хранящихся в базе данных, а это означает, что любое обновление кодовой базы — это, по сути, обновление базы данных, и это отстой
- Динамическое масштабирование усложняется, поскольку производительность всей системы зависит от используемой памяти. Короче говоря, вы не можете просто добавить еще один Tarantool для увеличения пропускной способности, не теряя при этом 24–32 Гб памяти (при запуске Tarantool выделяет всю память под данные) и не перераспределяя существующие данные. Кроме того, при шардинге мы теряем преимущество №1 — данные и код могут храниться не в одном Tarantool 9.0170
- Производительность снижается по мере усложнения кода по мере развития платформы. Это происходит не только потому, что Tarantool выполняет весь код Lua в одном системном потоке, но и потому, что LuaJIT переходит в режим интерпретации вместо компиляции при работе со сложным кодом
 Короче говоря, вы не можете просто добавить еще один Tarantool для увеличения пропускной способности, не теряя при этом 24–32 Гб памяти (при запуске Tarantool выделяет всю память под данные) и не перераспределяя существующие данные. Кроме того, при шардинге мы теряем преимущество №1 — данные и код могут храниться не в одном Tarantool 9.0170
Короче говоря, вы не можете просто добавить еще один Tarantool для увеличения пропускной способности, не теряя при этом 24–32 Гб памяти (при запуске Tarantool выделяет всю память под данные) и не перераспределяя существующие данные. Кроме того, при шардинге мы теряем преимущество №1 — данные и код могут храниться не в одном Tarantool 9.0170Вывод: Tarantool — хороший выбор для создания MVP , но он не подходит для полнофункциональной, простой в обслуживании и отказоустойчивой платформы IoT, способной получать, обрабатывать и хранить данные с сотен тысяч устройств.
Две основные проблемы, которые мы хотели решить
Прежде всего, мы хотели решить две основные проблемы:
- Отказ от концепции базы данных + сервера приложений. Мы хотели обновить код приложения независимо от базы данных.
- Упрощение динамического масштабирования в условиях стресса. Мы хотели иметь легкое независимое горизонтальное масштабирование максимально возможного количества функций
 Мы хотели обновить код приложения независимо от базы данных.
Мы хотели обновить код приложения независимо от базы данных.Для решения этих проблем мы применили инновационный подход, который не был хорошо протестирован — микросервисную архитектуру, разделенную на Stateless (приложения) и Stateful (база данных). ).
Чтобы сделать обслуживание и масштабирование сервисов без сохранения состояния еще проще, мы контейнеризировали их и внедрили Kubernetes.
Теперь, когда мы разобрались со службами без сохранения состояния, нам нужно решить, что делать с данными.
Основные требования к базе данных IoT-платформы
Сначала мы старались не усложнять — мы хотели хранить все данные платформы в одной универсальной базе данных. Проанализировав наши цели, мы пришли к следующему списку требований к универсальной базе данных:
- ACID-транзакции — клиенты будут вести реестр своих устройств на платформе, поэтому мы не хотим потерять некоторые из них при модификации данных
- Строгая согласованность — мы должны получить одинаковые ответы все узлы базы данных
- Горизонтальное масштабирование для записи и чтения — устройства отправляют огромный поток данных, которые необходимо обрабатывать и сохранять практически в режиме реального времени
- Отказоустойчивость — платформа должна быть способна управление данными из нескольких центров обработки данных для обеспечения максимальной отказоустойчивости
- Доступность — никто не будет использовать облачную платформу, которая отключается при отказе одного из узлов
- Объем хранилища и хорошее сжатие — нам нужно хранить несколько лет (петабайты!) необработанных данных, которые также необходимо сжатый.
- Производительность — быстрый доступ к необработанным данным и инструментам для потоковой аналитики, включая доступ из пользовательских скриптов (десятки тысяч запросов на чтение в секунду!)
- SQL — мы хотим, чтобы наши клиенты знакомый язык
Проверка наших требований с помощью САР-теоремы
Прежде чем мы начали изучать все доступные базы данных, чтобы увидеть, соответствуют ли они нашим требованиям, мы решили проверить, адекватны ли наши требования, используя известный инструмент — САР-теорему.
Теорема CAP утверждает, что распределенная система не может одновременно обладать более чем двумя из следующих качеств:
- Непротиворечивость – данные во всех узлах не имеют противоречий в любой момент времени
- Доступность – любой запрос к распределенной системе приводит к правильному ответу, однако без гарантии совпадения ответов всех узлов системы
- Допуск на разделение – даже когда узлы не связаны, они продолжают работать независимо
Например, кластер Master-Slave PostgreSQL с синхронной репликацией является классическим примером системы CA, а Cassandra — классической системой AP.
Вернемся к нашим требованиям и классифицируем их с помощью CAP-теоремы:
- ACID-транзакции и строгая (или, по крайней мере, невозможная) согласованность — это C.
- Горизонтальное масштабирование для записи и чтения + доступность — это A (multi-master) .
- Отказоустойчивость P: если один центр обработки данных отключается, система должна работать.
Вывод: универсальная база данных, которая нам нужна, должна предлагать все качества теоремы CAP, а это означает, что ни одна из существующих баз данных не может удовлетворить все наши потребности.
Выбор базы данных на основе данных, с которыми работает платформа IoT
Не имея возможности выбрать универсальную базу данных, мы решили разделить данные на два типа и выбрать базу данных для каждого типа, с которым будет работать база данных.
В первом приближении мы разделили данные на два типа:
- Метаданные – модель мира, устройства, правила, настройки. Практически все данные кроме данных с конечных устройств
- Исходные данные с устройств – показания датчиков, телеметрия и техническая информация с устройств. Это временные ряды сообщений, содержащие значение и метку времени
 Практически все данные кроме данных с конечных устройств
Практически все данные кроме данных с конечных устройствВыбор базы данных для метаданных
Наши требования
Метаданные по своей сути являются реляционными. Обычно эти данные имеют небольшой объем и редко изменяются, но метаданные весьма важны. Мы не можем его потерять, поэтому важна согласованность — по крайней мере, с точки зрения асинхронной репликации, а также ACID-транзакций и горизонтального масштабирования чтения.
Этих данных сравнительно немного и они будут меняться довольно редко, поэтому можно обойтись без горизонтального масштабирования чтения, а также возможной недоступности читаемой базы в случае сбоя. Вот почему, говоря языком теоремы CAP, нам нужна система CA.
Что обычно работает. Если мы зададим такой вопрос, нам подойдет любая классическая реляционная база данных с поддержкой кластера асинхронной репликации, т. е. PostgreSQL или MySQL.
е. PostgreSQL или MySQL.
Аспекты нашей платформы. Нам также требовалась поддержка деревьев с особыми требованиями. В прототипе была фича, взятая из систем класса RTDB (базы данных реального времени) — моделирование мира с помощью дерева тегов. Они позволяют нам объединить все клиентские устройства в одну древовидную структуру, что значительно упрощает управление и отображение большого количества устройств.
Так выглядит дерево устройств
Это дерево позволяет связать конечные устройства со средой. Например, мы можем поместить устройства, физически находящиеся в одной комнате, в одно поддерево, что облегчит работу с ними в дальнейшем. Эта функция очень удобна, к тому же мы хотели работать с RTDB в будущем, и этот функционал там в основном является отраслевым стандартом.
Для полной реализации деревьев тегов потенциальная база данных должна соответствовать следующим требованиям:
- Поддержка деревьев произвольной ширины и глубины.
- Модификация элементов дерева в транзакциях ACID.
- Высокая производительность при обходе дерева.
Классические реляционные базы данных могут довольно хорошо работать с небольшими деревьями, но они хуже справляются с произвольными деревьями.
Возможное решение. Использование двух баз данных: графовой для дерева и реляционной для всех остальных метаданных.
Этот подход имеет серьезные недостатки:
- Чтобы обеспечить согласованность между двумя базами данных, вам необходимо добавить внешний координатор транзакций.
- Эта конструкция сложна в обслуживании и не так надежна.
- В результате мы получаем две базы данных вместо одной, а графовая база данных нужна только для поддержки ограниченного функционала.
Возможное, но не идеальное решение с двумя базами данных
Наше решение для хранения метаданных. Мы немного подумали и вспомнили, что этот функционал изначально был реализован в прототипе на базе Tarantool и получилось очень хорошо.
Прежде чем продолжить, я хотел бы дать неортодоксальное определение Tarantool: Tarantool — это не база данных, а набор примитивов для построения базы данных для вашего конкретного случая.
Доступные примитивы из коробки:
- Пробелы — аналог таблиц для хранения данных в базах данных.
- Полноценные транзакции ACID.
- Асинхронная репликация с использованием журналов WAL.
- Инструмент сегментирования, поддерживающий автоматическое повторное разделение.
- Сверхбыстрый LuaJIT для хранимых процедур.
- Большая стандартная библиотека.
- Менеджер пакетов LuaRocks с еще большим количеством пакетов.
Наше решение CA представляло собой реляционную + графовую базу данных на базе Tarantool. С помощью примитивов Tarantool мы собрали идеальное хранилище метаданных:
- Пространства для хранения.
- Транзакции ACID – уже на месте.
- Асинхронная репликация — уже на месте.
- Отношения — мы построили их на хранимых процедурах.
- Деревья — тоже построены на хранимых процедурах.
Наша кластерная установка является классической для подобных систем — один Master для записи и несколько Slave с асинхронными репликациями для масштабирования чтения.
В результате мы имеем быстрый масштабируемый гибрид реляционной и графовой баз данных.
Один экземпляр Tarantool способен обработать тысячи запросов на чтение, в том числе с активным обходом дерева.
Выбор базы данных для хранения данных с устройств
Наши требования
Этот тип данных характеризуется частой записью и большим объемом данных: миллионы устройств, несколько лет хранения, петабайты обоих входящих сообщений и сохраненные данные. Его высокая доступность очень важна, поскольку показания датчиков важны для пользовательских правил и наших внутренних служб.
Важно, чтобы база данных предлагала горизонтальное масштабирование на чтение и запись, доступность и отказоустойчивость, а также готовые аналитические инструменты для работы с этим массивом данных, желательно на базе SQL. Мы можем пожертвовать согласованностью и ACID-транзакциями, поэтому с точки зрения теоремы CAP нам нужна система AP.
Мы можем пожертвовать согласованностью и ACID-транзакциями, поэтому с точки зрения теоремы CAP нам нужна система AP.
Дополнительные требования. У нас было несколько дополнительных требований к решению для хранения гигантских объемов данных:
- Time Series — данные датчиков, которые мы хотели сохранить в специализированной базе.
- Открытый исходный код – преимущества открытого исходного кода очевидны.
- Бесплатный кластер — распространенная проблема среди современных баз данных.
- Хорошее сжатие — учитывая объем данных и их однородность, мы хотели эффективно сжать сохраненные данные.
- Успешное обслуживание — чтобы минимизировать риски, мы хотели начать с базы данных, которую кто-то уже активно эксплуатировал при нагрузках, подобных нашим.
Наше решение. Единственной базой данных, удовлетворяющей нашим требованиям, была ClickHouse — столбцовая база данных временных рядов с репликацией, мультимастером, шардингом, поддержкой SQL и бесплатным кластером. Более того, Mail.ru имеет многолетний успешный опыт эксплуатации одного из крупнейших кластеров ClickHouse.
Более того, Mail.ru имеет многолетний успешный опыт эксплуатации одного из крупнейших кластеров ClickHouse.
Но ClickHouse, каким бы хорошим он ни был, у нас не сработал.
Проблемы с базой данных устройства и их решение
Проблема с производительностью записи. У нас сразу возникла проблема с производительностью записи большого потока данных. Его нужно как можно быстрее доставить в аналитическую базу, чтобы правила, анализирующие поток событий в режиме реального времени, могли посмотреть историю конкретного устройства и решить, поднимать оповещение или нет.
Раствор. ClickHouse плохо работает с несколькими одиночными вставками, но хорошо работает с большими пакетами данных, легко справляясь с пакетной записью миллионов строк. Мы решили буферизовать входящий поток данных, а затем вставлять эти данные пачками.
Вот как мы справились с плохой производительностью записи
Проблемы с записью были решены, но это стоило нам нескольких секунд задержки между поступлением данных в систему и их появлением в нашей базе данных.
Критично для различных алгоритмов, реагирующих на показания датчиков в режиме реального времени.
Проблема с производительностью чтения. Stream Analytics для обработки данных в режиме реального времени постоянно нуждается в информации из базы данных — десятки тысяч мелких запросов. В среднем одна нода ClickHouse одновременно обрабатывает около сотни аналитических запросов. Он был создан для нечастой обработки тяжелых аналитических запросов с большими объемами данных. Конечно, это не подходит для расчета трендов в потоке данных от сотен тысяч датчиков.
ClickHouse плохо обрабатывает большое количество запросов
Решение. Мы решили разместить тайник перед Clickhouse. Кэш предназначался для хранения горячих данных, которые чаще всего запрашивались за последние 24 часа.
24 часа данных — это не год, но все же достаточно много — поэтому нам нужна система AP с горизонтальным масштабированием для чтения и записи и акцентом на производительность при записи одиночных событий и многочисленных чтений.
Нам также нужна высокая доступность, аналитические инструменты для временных рядов, постоянство и встроенный TTL. Итак, нам нужен был быстрый ClickHouse, который мог хранить все в памяти. Не найдя подходящих решений, мы решили построить его на основе примитивов Tarantool:
- Постоянство – проверить (WAL-логи + снимки).
- Производительность – проверка; все данные в памяти.
- Масштабирование – проверка; репликация + шардинг.
- Высокая доступность — проверить.
- Аналитические инструменты для временных рядов (группировка, агрегация и т. д.) — мы построили их на хранимых процедурах.
- TTL — построен на хранимых процедурах с одним фоновым файбером (сопрограммой).
Решение оказалось мощным и простым в использовании. Один экземпляр обрабатывал 10 000 считывающих RPC, включая аналитические.
Вот такая архитектура у нас получилась:
Окончательная архитектура: ClickHouse в качестве аналитической базы данных и кеш Tarantool, хранящий данные за 24 часа.
Для каждого типа данных мы нашли свою базу данных, но по мере развития платформы появилась еще одна — статус. Статус состоит из текущих статусов датчиков и устройств, а также некоторых глобальных переменных для правил потоковой аналитики.
Допустим, у нас есть лампочка. Свет может быть как включен, так и выключен, и нам всегда нужно иметь доступ к его текущему состоянию, в том числе и в правилах. Другой пример — переменная в правилах потока — например, какой-то счетчик.
Этот тип данных требует частой записи и быстрого доступа, но не занимает много места.
Хранилище метаданных плохо подходит для такого типа данных, так как статус может меняться довольно часто и у нас есть только один Мастер для записи. Долговечное и оперативное хранилище тоже не работает, потому что последний раз статус менялся три года назад, и нам нужен доступ для быстрого чтения.
Это означает, что база данных состояния должна иметь горизонтальное масштабирование для чтения и записи, высокую доступность, отказоустойчивость и согласованность на уровне значений/документов.
Ваш комментарий будет первым