|
 FineReader Online спроектирован исключительно для выполнения основных сценариев. Если вы ищете профессиональное OCR-решение,
ABBYY FineReader подойдет для ваших целей лучше всего. ABBYY FineReader имеет следующие преимущества*:
FineReader Online спроектирован исключительно для выполнения основных сценариев. Если вы ищете профессиональное OCR-решение,
ABBYY FineReader подойдет для ваших целей лучше всего. ABBYY FineReader имеет следующие преимущества*: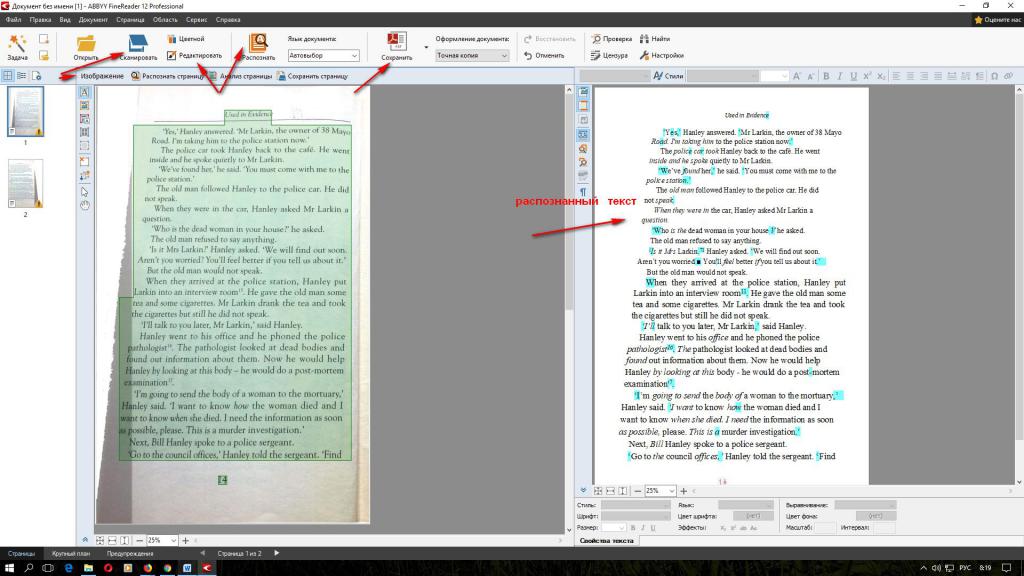 в App Store и Google Play.
в App Store и Google Play.
Как отсканировать документ и распознать его в MS Word
Если Вы выбрали быстрый путь написания теоретической главы, о котором мы говорили в параграфе 2.1., вероятней всего Вам не обойтись без сканирования документов. В ином случае, этот пункт можете пропустить и начинать конспектировать материалы найденные в библиотеке.
Перед началом сканирования нужно определиться, что именно Вы хотите использовать при написании работы. А для этого нужно сначала просмотреть имеющуюся литературу и выделить карандашом нужные моменты.
Когда я впервые сканировал статью из журнала для своей первой курсовой, для меня это занятие было невообразимо сложным. В результате нескольких часов работы со сканером и FineReader’ом у меня на выходе вышла бредятина, не поддающаяся редактированию. В итоге пришлось все набирать руками. Чтобы у Вас не случилось подобного, рассмотрим подробнее все технические моменты сканирования.
В результате нескольких часов работы со сканером и FineReader’ом у меня на выходе вышла бредятина, не поддающаяся редактированию. В итоге пришлось все набирать руками. Чтобы у Вас не случилось подобного, рассмотрим подробнее все технические моменты сканирования.
Для сканирования вам понадобится:
- Книга или журнал, который нужно отсканировать
- Компьютер с установленным FineReader’ом
- Качественный сканер
Сканер не обязательно покупать. Можно, например, взять на время у товарища. Я пользуюсь сканером CanoScan Lide 60. Это хоть и не самая новая модель, но мне очень нравится этот компактный, быстрый и удобный в работе “девайс”. Если Вы взяли на время сканер, для того чтобы он работал нужно сначала установить программу-драйвер. Драйвера и руководство по установке всегда можно найти на установочном диске, который прилагается к устройству или скачать на сайте у производителя. После установки драйвера, подключите сканер к компьютеру с помощью соединительного шнура. Теперь можно уже непосредственно приступить к сканированию.
Но сначала немного теории. Вы должны знать, что процесс сканирования состоит из двух этапов:
1. Непосредственно сканирование документа. На этом этапе сканнер как бы фотографирует поверхность сканируемого документа и сохраняет полученное изображение на компьютер в виде обычного файла .jpg .gif или в другом формате;
2. Распознавание документа. Это процесс преобразования текста из изображения сделанного сканером в обычный тест, который потом можно сохранить в Word и редактировать. Распознавание осуществляется без участия сканера, с помощью специальной программы (самая популярная Adobe FineReader). Таким образом, Вы можете сначала отсканировать несколько листов текста и сохранить их в виде изображения и только потом преобразовывать в текст.
Итак, начнем этап первый – сканирование:
Запускаем драйвер сканера:
Пуск – Все программы – Canon – ScanGear (название драйвера я указываю для своего сканера).
Открываем крышку сканера и кладем книгу. Книгу, журнал или что у вас там есть нужно класть текстом вниз, как можно ровнее по отношению к краям рабочей поверхности сканера:
Очень важно сделать так, чтобы крышка сканера как можно плотнее прижимала сканируемый документ, не допуская попадания внешнего освещения не рабочую поверхность сканера, которая соприкасается с документом.
Выполним необходимые установки в драйвере сканера.
Первым делом нужно установить разрешение, в котором будет отсканирован документ. Разрешение – это показатель, который определяет уровень детализации объекта при сканировании и определяется в точках на дюйм (dpi, или т/д). Чем больше разрешение, тем качественнее получается изображение. Но, при сканировании текстовых документов нет смысла устанавливать максимальное разрешение, поскольку толку от этого будет ноль. Кроме того, сканирование с большим разрешением занимает больше времени. Я рекомендую устанавливать разрешение в пределах 400-500 т/д (dpi). При такой настройке изображения получаются достаточно качественными для хорошего их распознания, а сам процесс сканирования не занимает много времени. Посмотрите скриншот установок моего сканера:
Для начала нужно перейти в “Расширенный режим”. Источником всегда будет “Планшет” (планшетный сканер). Цветной режим лучше установить “Черно-белый”, ведь для сканирования текста нам цвета не нужны, а это уменьшит размер изображений на выходе. Разрешение, как я уже сказал, следует установить 400 т/д. Выходной размер изображения – обязательно “А4”. Теперь можно смело жать на кнопку “Сканировать”. Мой сканер устроен таким образом, что сначала запоминает отсканированные изображения во внутренней памяти, и только при закрытии окна драйвера предлагает сохранить их на компьютер. Мне остается только указать место, куда будут сохранены результаты работы.
У вас должны получаться файлы такого типа:
При увеличении такого изображения должен быть отчетливо виден текст.
Распознавание
Второй этап – распознание полученных изображений и их преобразование в текст. Как я уже говорил, для этого понадобится специальная программа – FineReader. Скачайте программу по этой ссылке (72Мб). Чтобы скачать нажмите на стрелочку в правом верхнем углу окна. Распакуйте архив и в папке afr_lrp найдите файл – ABBYY FineReader 12.0.101.exe. Двойной клик на этом файле запустит установку программы на вашем компьютере. Эта версия программы достаточно новая. Все скриншоты ниже я делал используя более старую версию, поэтому интерфейс программы будет немного отличаться от скриншотов. Учтите это при изучении данной инструкции.
Окно FineReader имеет следующий вид:
После установки языка, на котором напечатаны отсканированные Вами ранее документы, можно начинать распознание. Если в тексте присутствует сразу два языка (например, русский и английский) установку сделайте соответственно.
Чтобы начать распознание нажмите на стрелку справа от первой кнопки Сканировать – а затем – Открыть изображение:
Откроется окно выбора изображений. Откройте папку в которую Вы сохранили отсканированные изображения, нажмите CTRL + A (английское) на клавиатуре и нажмите на кнопку Открыть.
После этого слева в окне FineReader’а появятся эскизы добавленных файлов, по центру – на данный момент выделенный эскиз в увеличенном виде, снизу – еще большее увеличение, а справа результат распознания:
Для примера я взял всего два изображения. На скриншоте выше выделено первое из них, его сейчас и распознаем. Как видите, изображение отсканировано вертикально, чтобы распознать текст снимок нужно сначала развернуть на 90 градусов.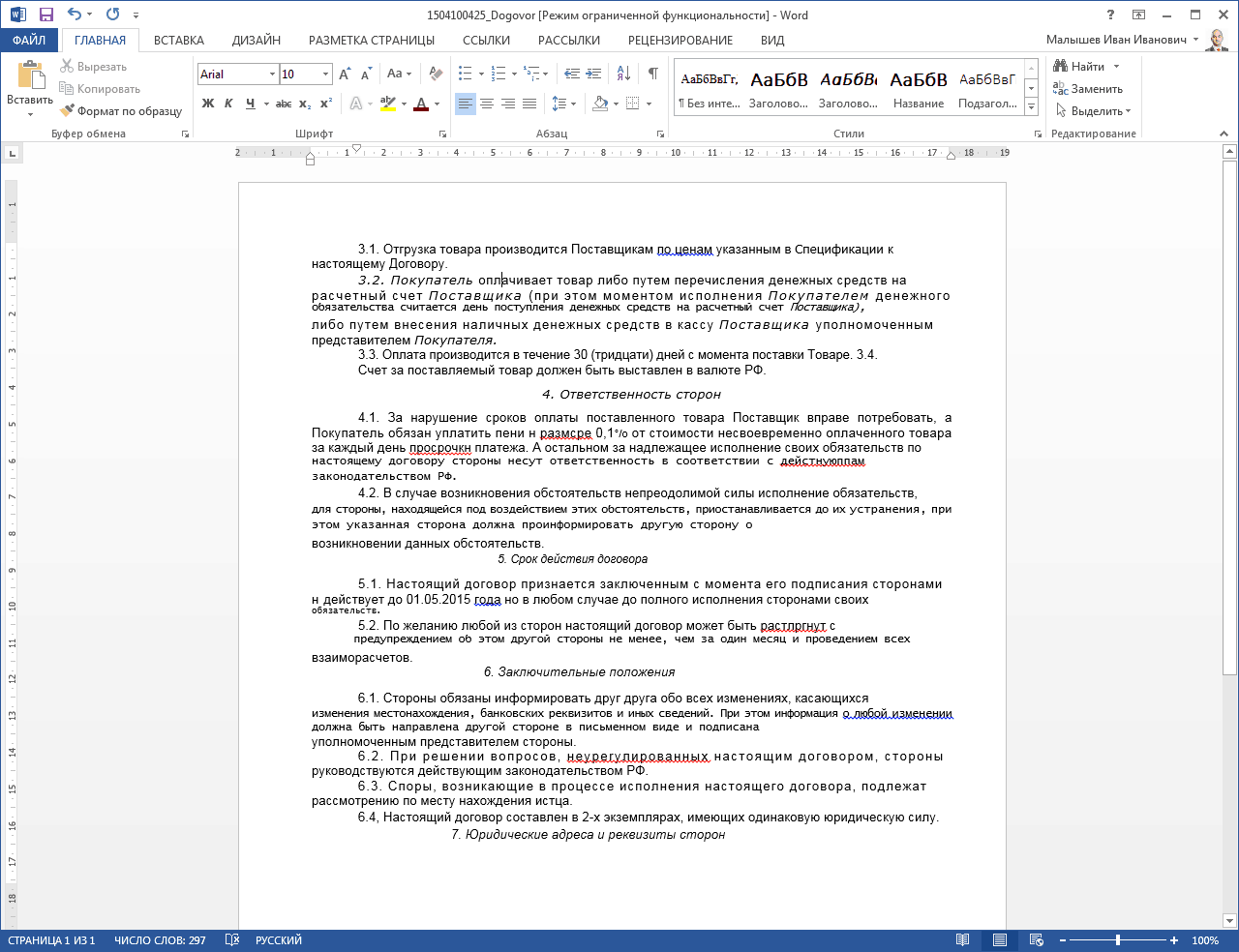 Для этого воспользуемся кнопками и . Следующим шагом нужно указать программе, какую именно часть изображения нужно распознать, а также задать тип данных, которые должны получиться на выходе текст, таблица или изображение. Для этого существуют кнопки, соответственно: . Например, если нужно отметить текстовый блок, нажимаем левой кнопкой на , после этого нажимаем левой кнопкой мышки в левом верхнем углу текстового блока и, удерживая левую кнопку, перетягиваем в правый нижний угол. Для примера я полностью подготовил к распознанию одно изображение:
Для этого воспользуемся кнопками и . Следующим шагом нужно указать программе, какую именно часть изображения нужно распознать, а также задать тип данных, которые должны получиться на выходе текст, таблица или изображение. Для этого существуют кнопки, соответственно: . Например, если нужно отметить текстовый блок, нажимаем левой кнопкой на , после этого нажимаем левой кнопкой мышки в левом верхнем углу текстового блока и, удерживая левую кнопку, перетягиваем в правый нижний угол. Для примера я полностью подготовил к распознанию одно изображение:
Как видите, все текстовые блоки в примере выше выделены зеленым, а рисунки – красным. Таблицы подготавливаются к распознанию аналогично. Для этого предназначена кнопка . Для того, чтобы перейти к следующему снимку, кликните левой кнопкой мыши на его эскизе слева. Таким образом подготавливаются к распознанию все полученные в результате сканирования изображения. После того, как подготовка изображений завершена, следует выделить их все. Для этого кликните левой кнопкой в пустом месте на панели эскизов (она называется Пакет) и нажмите Ctrl+A (английское) на клавиатуре. Далее кликните на кнопку и подождите пока FineReader преобразует изображения в текст. После этого можно сохранять полученный текст в Word с помощью кнопки , после нажатия на которую откроется окно Мастер сохранения результатов. В нем необходимо выбрать формат для сохранения – Microsoft Word, а также поставить отметку чтобы сохранились все страницы:
После нажатия кнопки ОК программа создаст документ Word и вставит в него текст из распознанных страниц в том порядке, в котором они находятся на панели эскизов (Пакет). Полученный документ сразу же сохраните в папку в файловой структуре дипломной работы и можете приступать к редактированию. Как это делается, описано в моем бесплатном курсе.
И последний момент. Эсли Вы сканировали газету или журнал, текст там часто дается в виде колонок (как в рассматриваемом примере выше). Эти колонки в Ворде нужно преобразовать в одну. Выделите текст в виде колонок и выполните команду: Формат – Колонки – Одна – ОК. Только после этого можно ставить Книжную ориентацию в Параметрах страницы, отступы полей, шрифт и т.д.
Эти колонки в Ворде нужно преобразовать в одну. Выделите текст в виде колонок и выполните команду: Формат – Колонки – Одна – ОК. Только после этого можно ставить Книжную ориентацию в Параметрах страницы, отступы полей, шрифт и т.д.
Как распознать текст с картинки в Word
Представьте себе функцию, позволяющую извлечь текст из изображения и быстро вставить его в другой документ. На самом деле это возможно. Вам больше не нужно терять время, набирая все, потому что есть программы, которые используют оптическое распознавание символов (OCR) для анализа букв и слов в изображении, а затем конвертируют их в текст.
В наши дни существует так много бесплатных и эффективных опций, позволяющих извлечь текст из изображения, а не печатать его вручную. Ниже представлены самые удобные и эффективные программы и их сравнение.
Как распознать текст с картинки в Word
Видео — распознавание текста с картинки в WORD
Извлечение текста с помощью OneNote
OneNote OCR уже на протяжении нескольких лет остается одной из самых лучших программ для распознавания текста. Однако, распознавание это одна из тех менее известных функций, которые пользователи редко используют, но как только вы начнете ее использовать, вы будете удивлены тем, насколько быстрой и точной она может быть. Действительно, способность извлекать текст — одна из особенностей, которая делает OneNote лучше Evernote.
Это стандартная программа, скорее всего вам не придется устанавливать ее самостоятельно. Найдите ее на компьютере в папке Microsoft Office или же с помощью поиска на панели «Пуск». Запустите программу.
Инструкции по извлечению текста:
- Шаг 1. Откройте любую страницу в OneNote, желательно пустую.
Открываем любую страницу в OneNote
- Шаг 2.
 Перейдите в меню «Вставка»> «Изображения» и выберите файл изображения и настройте язык распознавания.
Перейдите в меню «Вставка»> «Изображения» и выберите файл изображения и настройте язык распознавания.Выберите файл изображения
- Шаг 3. Щелкните правой кнопкой мыши по вставленному изображению и выберите «Копировать текст с изображения». Он сохранится в буфере обмена.
 Перейдите в меню «Вставка»> «Изображения» и выберите файл изображения и настройте язык распознавания.
Перейдите в меню «Вставка»> «Изображения» и выберите файл изображения и настройте язык распознавания.Копируем текст с изображения
Теперь вы можете вставить его куда угодно. Удалите вставленное изображение, если оно вам больше не нужно.
Вставляем текст куда угодно
На заметку! Это быстрый и удобный способ извлечения текста из картинки, но есть одно «но» — One Note работает подобным образом лишь с латиницей. Он не распознает русский текст.
Использование онлайн-сервисов
Онлайн-сервисы по распознаванию текста с изображения работают примерно по одному и тому же принципу. В примере ниже использовался Free Online OCR. На этом сайте стоит ограничение. Регистрация даст вам доступ к дополнительным функциям, недоступным для гостей: конвертировать многостраничный PDF (более 15 страниц) в текст, большие изображения и ZIP-архивы, выбирать языки распознавания, конвертировать в редактируемые форматы и многое другое. Распознать короткий тест можно и без регистрации.
- Шаг 1. Откройте сайт бесплатного OCR. Выберите изображение посредством кнопки «Select File». Это может быть и PDF файл.
Открываем сайт бесплатного OCR
- Шаг 2. Выберите язык и нажмите на кнопку «CONVERT».
Выбираем язык и нажимаем на кнопку «CONVERT»
Текст появится в поле ниже. Вы также можете скачать в формате Microsoft Word.
Этот способ имеет ряд преимуществ:
- Вам не придется скачивать и устанавливать стороннее программное обеспечение.
- Итог можно скачать в виде текстового документа.
- Это быстро.
- Более того на сайте можно распознавать текст на одном из множества предложенных языков.
Видео — Как распознавать текст с картинки, фотографии или PDF файла
 youtube.com/embed/J1I_xEwR2fo?feature=oembed» frameborder=»0″ allow=»autoplay; encrypted-media» allowfullscreen=»»/>
youtube.com/embed/J1I_xEwR2fo?feature=oembed» frameborder=»0″ allow=»autoplay; encrypted-media» allowfullscreen=»»/>
Как извлечь текст из изображений с помощью ABBY FineReader
Существует две версии этой программы. Одна работает в автоматическом режиме онлайн, другая же — десктопная, ее придется скачать и установить на компьютер. Обе — платные. Однако в онлайн-версии можно бесплатно распознать текст с не более 5 страниц, а в установленной программе первое время действует пробный бесплатный период. На сегодня это один из лучших инструментов для распознавания текста с картинки.
Онлайн версия
- Шаг 1. Перейдите на сайт FineReader.
Открываем сайт FineReader
- Шаг 2. Загрузите изображение. Выберите нужный вам язык и нажмите на кнопку регистрации. Следуйте указаниям на сайте. Как только вы зарегистрируетесь, сайт перенаправит вас на другую страницу. Нажмите на кнопку «Распознать» и дождитесь окончания процесса.
Загружаем файл, выбираем язык, выбираем формат сохранения
Текст сохранится в формате docs. Скачайте его.
Десктопная версия
- Шаг 1. Запустите FreeReader и нажмите «Сканировать изображение», чтобы выбрать файл, содержащий текст. Он загрузится в программу, при необходимости их можно отредактировать, чтобы улучшить распознаваемость текста. Программа предложит вам выделить область, текст с которой нужно распознать.
- Шаг 2. Извлечение текста. Нажмите «Распознать», чтобы извлечь текст из выделения. Выбранный текст будет отображаться в текстовом окне через несколько секунд.
Извлекаем текст
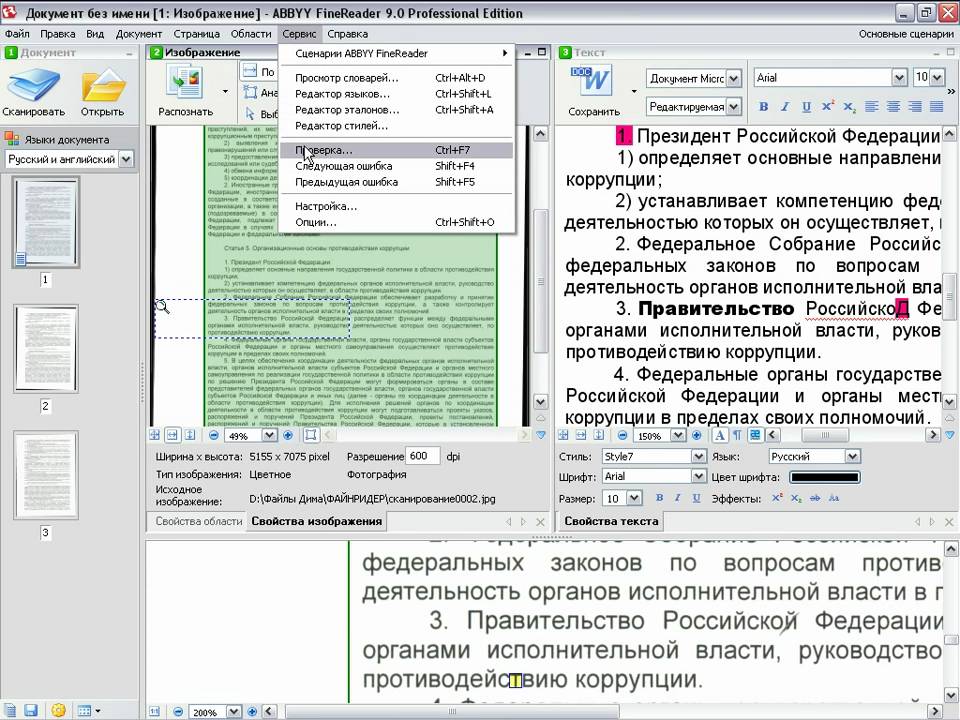
Шаг 3. Проверка. В этой программе есть функция проверки. Нажав на эту кнопку, пользователь на экране будет видеть некорректно распознанные слова и фрагмент оригинала. На этом этапе можно быстро исправить практически все ошибки программы.
Шаг 4. Сохраните текст любым из предложенных способов.
Сохраняем текст
Обратите внимание:
- Во-первых, вам нужно убедиться, что исходное изображение четкое, хорошего качества.
- Во-вторых, выбор правильного механизма OCR важен, и вам нужно учитывать их сильные и слабые стороны.
- В-третьих, убедитесь, что ваши изображения масштабированы до нужного размера (не менее 300 DPI).
- Низкая контрастность приведет к плохому OCR, поэтому вам необходимо исправить это до распознавания.
- Удалите шумы и дефекты.
- Если изображение перекошено, отредактируйте его.
Видео — Как распознать PDF в Word
Сравнение популярный инструментов распознавания текста
| Название программы | OneNote | FineReader OCR Online | Free Online OCR |
|---|---|---|---|
| Условия использования | Стандартная программа, входящая в пакет Microsoft Office. Как правило, присутствует на всех компьютерах ОС Windows | Онлайн версия программы. До 5 страниц бесплатно при регистрации | Бесплатный онлайн-сервис. Не требует регистрации |
| Скорость | Мгновенное распознавание | Процесс происходит на сервере. Время ожидания не больше 5 минут | Мгновенное распознавание |
| Особенности | Это не главная функция программы, а лишь побочная. Хоть она и достаточно хороша, не ждите от нее совершенства | Сокращенная версия основной программы. В полной компьютерной версии намного больше опций, повышающих качество распознавания. Доступно распознавание теста сразу на нескольких языках, если в тексте есть вставки на другом языке. Сохраняет форматирование | Скорость. Доступность |
| Число доступных языков | В русскоязычной версии программы доступно три языка: русский, английский, немецкий | Множество языков | Множество языков |
| Результат |
Хотя рынок заполнен программным обеспечением OCR, которое может извлекать текст из изображений, хорошая программа OCR должна делать больше, чем просто распознавание текста. Она должна поддерживать макет содержимого, текстовые шрифты и графику как в исходном документе.
Она должна поддерживать макет содержимого, текстовые шрифты и графику как в исходном документе.
Понравилась статья?
Сохраните, чтобы не потерять!
Как распознать текст в Word — Онлайн сервисы для бесплатного распознавания текста
Все мы уже привыкли фотографировать расписание, документы, страницы книг и многое другое, но по ряду причин «извлечь» текст со снимка или картинки, сделав его пригодным для редактирования, все же требуется.
Особенно часто с необходимостью преобразовать фото в текст сталкиваются школьники и студенты. Это естественно, ведь никто не будет переписывать или набирать текст, зная, что есть более простые методы. Было бы прям идеально, если бы преобразовать картинку в текст можно было в Microsoft Word, вот только данная программа не умеет ни распознавать текст, ни конвертировать графические файлы в текстовые документы.
Единственная возможность «поместить» текст с JPEG-файла (джипег) в Ворд — это распознать его в сторонней программе, а затем уже оттуда скопировать его и вставить или же просто экспортировать в текстовый документ.
Содержание
Распознавание текста
ABBYY FineReader по праву является самой популярной программой для распознавания текста. Именно главную функцию этого продукта мы и будем использовать для наших целей — преобразования фото в текст. Из статьи на нашем сайте вы можете более подробно узнать о возможностях Эбби Файн Ридер, а также о том, где скачать эту программу, если она еще не установлена на у вас на ПК.
Распознавание текста с помощью ABBYY FineReader
Скачав программу, установите ее на компьютер и запустите. Добавьте в окно изображение, текст на котором необходимо распознать. Сделать это можно простым перетаскиванием, а можно нажать кнопку «Открыть», расположенную на панели инструментов, а затем выбрать необходимый графический файл.
Теперь нажмите на кнопку «Распознать» и дождитесь, пока Эбби Файн Ридер просканирует изображение и извлечет из него весь текст.
Вставка текста в документ и экспорт
Когда FineReader распознает текст, его можно будет выделить и скопировать. Для выделения текста используйте мышку, для его копирования нажмите «CTRL+С».
Теперь откройте документ Microsoft Word и вставьте в него текст, который сейчас содержится в буфере обмена. Для этого нажмите клавиши «CTRL+V» на клавиатуре.
Урок: Использование горячих клавиш в Ворде
Помимо просто копирования/вставки текста из одной программы в другую, Эбби Файн Ридер позволяет экспортировать распознанный им текст в файл формата DOCX, который для MS Word является основным. Что для этого требуется сделать? Все предельно просто:
- выберите необходимый формат (программу) в меню кнопки «Сохранить», расположенной на панели быстрого доступа;
- кликните по этому пункту и укажите место для сохранения;
- задайте имя для экспортируемого документа.
После того, как текст будет вставлен или экспортирован в Ворд, вы сможете его отредактировать, изменить стиль, шрифт и форматирование. Наш материал на данную тему вам в этом поможет.
Примечание: В экспортированном документе будет содержаться весь распознанный программой текст, даже тот, который вам, возможно, и не нужен, или тот, который распознан не совсем корректно.
Урок: Форматирование текста в MS Word
Видео-урок по переводу текста с фотографии в Word файл
Преобразование текста на фото в документ Ворд онлайн
Если вы не хотите скачивать и устанавливать на свой компьютер какие-либо сторонние программы, преобразовать изображение с текстом в текстовый документ можно онлайн. Для этого существует множество веб-сервисов, но лучший из них, как нам кажется, это FineReader Online, который использует в своей работе возможности того же программного сканера ABBY.
ABBY FineReader Online
Перейдите по вышеуказанной ссылке и выполните следующие действия:
1. Авторизуйтесь на сайте, используя профиль Facebook, Google или Microsoft и подтвердите свои данные.
Примечание: Если ни один из вариантов вас не устраивает, придется пройти полную процедуру регистрации. В любом случае, сделать это не сложнее, чем на любом другом сайте.
2. Выберите пункт «Распознать» на главной странице и загрузите на сайт изображение с текстом, который нужно извлечь.
3. Выберите язык документа.
4. Выберите формат, в котором требуется сохранить распознанный текст. В нашем случае это DOCX, программы Microsoft Word.
5. Нажмите кнопку «Распознать» и дождитесь, пока сервис просканирует файл и преобразует его в текстовый документ.
6. Сохраните, точнее, скачайте файл с текстом на компьютер.
Примечание: Онлайн-сервис ABBY FineReader позволяет не только сохранить текстовый документ на компьютер, но и экспортировать его в облачные хранилища и другие сервисы. В числе таковые BOX, Dropbox, Microsoft OneDrive, Google Drive и Evernote.
После того, как файл будет сохранен на компьютер, вы сможете его открыть и изменить, отредактировать.
На этом все, из данной статьи вы узнали, как перевести текст в Ворд. Несмотря на то, что данная программа не способна самостоятельно справиться с такой, казалось бы, простой задачей, сделать это можно с помощью стороннего софта — программы Эбби Файн Ридер, или же специализированных онлайн-сервисов.
FineReader – распознавание текста. Microsoft Office
FineReader – распознавание текста
Ввести со сканера текст в компьютер – задача не слишком трудная. Однако работать с таким текстом невозможно: как и любое сканированное изображение, страница с текстом представляет собой графический файл – обычную картинку. Отсюда возникают проблемы: во-первых, в графическом формате страница занимает слишком много места, и, скажем, отсканированная книга не на каждый жесткий диск поместится. И вторая, самая главная проблема: сканированный текст можно будет только читать, но не редактировать и не вставлять его фрагменты в создаваемый вами документ. Ведь сам сканер распознавать буквы именно как буквы не умеет: они для него – всего лишь пятна и точки черного цвета.
Отсюда возникают проблемы: во-первых, в графическом формате страница занимает слишком много места, и, скажем, отсканированная книга не на каждый жесткий диск поместится. И вторая, самая главная проблема: сканированный текст можно будет только читать, но не редактировать и не вставлять его фрагменты в создаваемый вами документ. Ведь сам сканер распознавать буквы именно как буквы не умеет: они для него – всего лишь пятна и точки черного цвета.
К счастью, на свете существуют программы, способные перевести сканированный текст из графического в текстовый формат – программы распознавания текста или OCR.
Современная OCR должна уметь многое: распознавать тексты, набранные не только определенными шрифтами (именно так работали распознавалки первого поколения), но и самыми экзотическими, вплоть до рукописных. Уметь корректно работать с текстами, содержащими слова на нескольких языках, корректно распознавать таблицы. И самое главное – корректно распознавать не только четко набранные тексты, но и такие, качество которых, мягко говоря, далеко от идеала. Например, текст с пожелтевшей газетной вырезки или третьей машинописной копии. Само собой, распознать текст – это еще полдела. Не менее важно обеспечить возможность сохранения результата в файле популярного текстового (или табличного) формата – скажем, формата Microsoft Word или Excel.
Как видим, для того чтобы получить электронную, готовую к редактированию копию любого печатного текста, программе OCR необходимо выполнить «цепочку» из множества отдельных операций:
Сканирование. За эту работу отвечает, собственно, не программа OCR, а встроенное в систему программное обеспечение вашего сканера. Именно с его помощью вы можете задать нужные вам параметры сканирования – например, разрешение (рекомендуется 300 dpi), цветовой режим (для простых текстов достаточно черно-белого или LineArt) – и выделить ту область документа, которую вам необходимо «скопировать» в компьютер.
Сегментация. Полученную со сканера «картинку» подхватывает OCR-программа. Но до распознавания еще далеко – сначала надо отделить текстовые элементы от графики, да и текст в ряде случаев разбить на отдельные куски (например, при многоколоночной верстке).
Полученную со сканера «картинку» подхватывает OCR-программа. Но до распознавания еще далеко – сначала надо отделить текстовые элементы от графики, да и текст в ряде случаев разбить на отдельные куски (например, при многоколоночной верстке).
Распознавание. На этом этапе текст переводится из графической формы в обычную текстовую.
Проверка орфографии и правка. Встроенная система проверки орфографии «проходится» по тексту, проверяя и корректируя последствия работы системы распознавания. Спорные слова и символы выделяются особым предупреждающим цветом. Потом наступает очередь пользователя, который также может внести свою лепту в этот ответственный процесс.
Сохранение. Для дальнейшей обработки документ должен быть передан «на поруки» соответствующей программе – как правило, одному из продуктов семейства Microsoft Office. Или сохранен в формате, соответствующем его содержанию: текст – в DOC или RTF, таблица – в XLS… Да и встроенную графику желательно в документе оставить…
Все эти операции в большинстве программ OCR могут выполняться как в автоматическом, с помощью программы-мастера, так и в ручном режиме, по отдельности. С двумя первыми и последней операциями с легкостью справится любая программа распознавания. А вот весь процесс целиком по зубам, увы, только нескольким продуктам, разработанным в нашей стране. Тут надо сделать небольшую поправку: на самом деле корректно работать с русским языком умеют практически все современные «распознавалки», вне зависимости от того, где они были разработаны. Более того, в состав Microsoft Office-2003 уже включена абсолютно бесплатная программа распознавания Microsoft Office Document Scanning! Однако для российских пользователей само понятие «программа распознавания текста» чаще всего неразрывно связано с программой FineReader. Ибо компания ABBYY смогла не просто создать удобный для пользователя и качественный продукт, но и, самое главное, удачно «раскрутить» его.
Одним из козырей FineReader является поддержка неимоверного количества языков распознавания – 176, в числе которых вы найдете экзотические и древние языки, и даже популярные языки программирования (Basic, С/C++, COBOL, Fortran, Java, Pascal)! Так что FineReader сможет без запинки справиться с древнегреческим свитком или с бледными распечатками исходных текстов программ, сделанных вашими предками лет 30 назад. Как ни странно, большинство пользователей на деле интересуется совсем другим. Офисных работников интересует распознавание типовых форм документов, студентов – возможность быстро «передрать» для реферата многостраничный текст из учебника, сканируя и распознавая книжный разворот целиком, бухгалтеров – возможность автоматического распознавания таблиц и документов на бланках… Все это и многое другое FineReader умеет… или не все, а только частично, в зависимости от модификации продукта. Далеко не все возможности из нашего перечня включены в самую простую модификацию программы, которую вы можете получить бесплатно вместе со сканером. Пакетное сканирование, грамотная обработка таблиц и изображений – для всего этого стоит приобрести профессиональную версию программы – FineReader Pro. Заодно она умеет безукоризненно читать штрихкоды, позволяет добавлять в базу данных новые языки. А самая мощная (и дорогостоящая) версия – FineReader Office – без труда справится и с распознаванием любых бланков и форм! Все версии FineReader, от самой простой до самой мощной, объединяет, на мой взгляд, главное достоинство программы – интерфейс. Для запуска процесса распознавания вам достаточно просто положить документ в сканер и нажать единственную кнопку (мастер Scan & Read) на панели инструментов программы. Все дальнейшие операции – сканирование, разбивку изображения на «блоки» и, наконец, собственно распознавание программа выполнит автоматически. Пользователю останется только установить нужные параметры сканирования – рекомендуется разрешение в 300 dpi и режим черно-белого изображения или LineArt.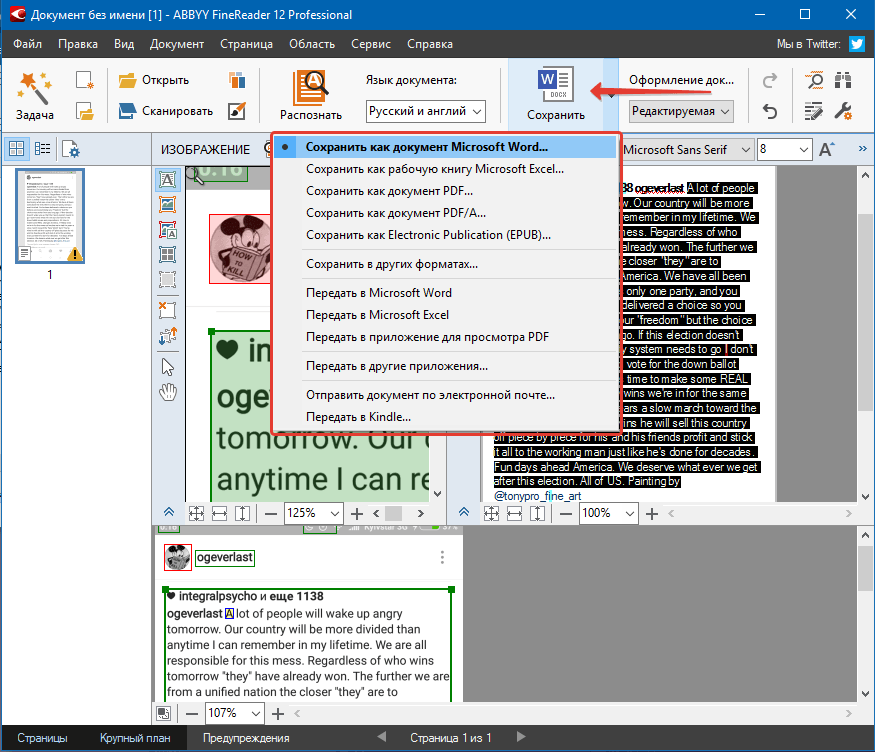 Впрочем, текст можно отсканировать и в цветном режиме: в этом случае FineReader сможет грамотно распознать цветовое выделение шрифтов и сохранить его в готовом документе.
Впрочем, текст можно отсканировать и в цветном режиме: в этом случае FineReader сможет грамотно распознать цветовое выделение шрифтов и сохранить его в готовом документе.
После завершения распознавания страницы FineReader предложит пользователю выбор: сканировать и распознавать дальше (для многостраничного документа) или сохранить полученный текст в одном из множества популярных форматов – от документов Microsoft Office до HTML или PDF. Можно, впрочем, сразу же перебросить документ в Word или Excel и уже там исправить все огрехи распознавания (без них обойтись просто невозможно). При этом FineReader полностью сохраняет все особенности форматирования документов и графическое оформление.
Данный текст является ознакомительным фрагментом.
Продолжение на ЛитРесКак распознать текст с картинки в Word
Эти сайты и программы помогут извлечь текстовое содержимое изображений и бумаг, чтобы вам было удобнее с ним работать.
1. Office Lens
- Платформы: Android, iOS, Windows.
- Распознаёт: снимки камеры.
- Сохраняет: DOCX, PPTX, PDF.
Этот сервис от компании Microsoft превращает камеру смартфона или ПК в бесплатный сканер документов. С помощью Office Lens вы можете распознать текст на любом физическом носителе и сохранить его в одном из «офисных» форматов или в PDF. Итоговые текстовые файлы доступны для редактирования в Word, OneNote и других сервисах Microsoft, интегрированных с Office Lens. К сожалению, с русским языком программа справляется не так хорошо, как с английским.
2. Adobe Scan
- Платформы: Android, iOS.
- Распознаёт: снимки камеры.
- Сохраняет: PDF.
Adobe Scan тоже использует камеру смартфона, чтобы сканировать бумажные документы, но сохраняет их копии только в формате PDF. Приложение полностью бесплатно. Результаты удобно экспортировать в кросс‑платформенный сервис Adobe Acrobat, который позволяет редактировать PDF‑файлы: выделять, подчёркивать и зачёркивать слова, выполнять поиск по тексту и добавлять комментарии.
3. FineReader
- Платформы: веб, Android, iOS, Windows.
- Распознаёт: JPG, TIF, BMP, PNG, PDF, снимки камеры.
- Сохраняет: DOC, DOCX, XLS, XLSX, ODT, TXT, RTF, PDF, PDF/A, PPTX, EPUB, FB2.
FineReader славится высокой точностью распознавания. Увы, бесплатные возможности инструмента ограниченны: после регистрации вам позволят отсканировать всего 10 страниц. Зато каждый месяц будут начислять ещё по пять страниц в качестве бонуса. Подписка стоимостью 129 евро позволяет сканировать до 5 000 страниц в год, а также открывает доступ к десктопному редактору PDF‑файлов.
4. Online OCR
- Платформы: веб.
- Распознаёт: JPG, GIF, TIFF, BMP, PNG, PCX, PDF.
- Сохраняет: TXT, DOC, DOCX, XLSX, PDF.
Веб‑сервис для распознавания текстов и таблиц. Без регистрации Online OCR позволяет конвертировать до 15 документов в час — бесплатно. Создав аккаунт, вы сможете отсканировать 50 страниц без ограничений по времени и разблокируете все выходные форматы. За каждую дополнительную страницу сервис просит от 0,8 цента: чем больше покупаете, тем ниже стоимость.
5. img2txt
- Платформы: веб.
- Распознаёт: JPEG, PNG, PDF.
- Сохраняет: PDF, TXT, DOCX, ODF.
Бесплатный онлайн‑конвертер, существующий за счёт рекламы. img2txt быстро обрабатывает файлы, но точность распознавания не всегда можно назвать удовлетворительной. Сервис допускает меньше ошибок, если текст на загруженных снимках написан на одном языке, расположен горизонтально и не прерывается картинками.
Сервис допускает меньше ошибок, если текст на загруженных снимках написан на одном языке, расположен горизонтально и не прерывается картинками.
6. Microsoft OneNote
- Платформы: Windows, macOS.
- Распознаёт: популярные форматы изображений.
- Сохраняет: DOC, PDF.
В настольной версии популярного блокнота OneNote тоже есть функция распознавания текста, которая работает с загруженными в заметки изображениями. Если кликнуть правой кнопкой мыши по снимку документа и выбрать в появившемся меню «Копировать текст из рисунка», то всё текстовое содержимое окажется в буфере обмена. Программа доступна бесплатно.
7. Readiris 17
- Платформы: Windows, macOS.
- Распознаёт: JPEG, PNG, PDF и другие.
- Сохраняет: PDF, TXT, PPTX, DOCX, XLSX и другие.
Мощная профессиональная программа для работы с PDF и распознавания текста. С высокой точностью конвертирует документы на разных языках, включая русский. Но и стоит Readiris 17 соответственно — от 49 до 199 евро в зависимости от количества функций. Вы можете установить пробную версию, которая будет работать бесплатно 10 дней. Для этого нужно зарегистрироваться на сайте Readiris, скачать программу на компьютер и ввести в ней данные от своей учётной записи.
OCR РАСПОЗНАВАНИЕ ТЕКСТА ИЗ PDF И ИЗОБРАЖЕНИЙ
Как работает наш OCR сервис
Что такое OCR
Вы когда-нибудь хотели иметь возможность найти в печатном цифровом материале или отсканированном документе конкретный текст? Или возникла ли у вас необходимость отредактировать содержимое журнала или отсканированного PDF-документа, не перепечатывая весь документ? Классическим решением во всех этих случаях было бы перенабрать весь контент и его отредактировать. Это все еще нормальная практика, когда дело доходит до редактирования печатных контрактов, брошюр или страниц журнала. Но мы все знаем, насколько трудоемким и беспокойным может стать это решение, если источник представляет собой обыкновенное изображение. Бесплатный OCR сервис — это то, что может решить вашу проблему, сэкономить деньги, сэкономить ваше драгоценное время и обеспечить быстрые и эффективные результаты всего за несколько шагов.
Но мы все знаем, насколько трудоемким и беспокойным может стать это решение, если источник представляет собой обыкновенное изображение. Бесплатный OCR сервис — это то, что может решить вашу проблему, сэкономить деньги, сэкономить ваше драгоценное время и обеспечить быстрые и эффективные результаты всего за несколько шагов.
Оптическое распознавание символов или OCR — это технология, позволяющая преобразовывать печатные или рукописные документы в редактируемые текстовый материал. Просто отсканировав напечатанные документы с помощью программного обеспечения для распознавания текста OCR, вы можете легко конвертировать файлы в печатные копии, которые можно редактировать, копировать или распространять согласно вашим требованиям. Сканеры текста OCR очень универсальны и могут сканировать текст из изображений, печатных документов и файлов PDF. Программное обеспечение OCR можно загрузить или использовать в качестве онлайн-сервисов.
Как работает OCR
Хотя понятие «машинного распознавания текста» не ново и появилось еще в 1960-х годах, в то время компьютер мог считать единственный вариант шрифта, называемый OCR-A. С развитием технологии сканеры текста OCR стали более продвинутыми и позволили пользователям использовать эту технологию для более широкого спектра приложений. В настоящее время текстовые сканеры OCR в основном используют два различных метода для преобразования печатного текста в редактируемый.
Метод сопоставления матриц
Первый метод — это метод сопоставления матриц. Этот метод работает по принципу сопоставления печатного текста с базой данных шаблонов символов и шрифтов. Сканер текста OCR сканирует напечатанный текст, сравнивает его с существующей библиотекой шаблонов и, когда совпадение найдено, преобразует данные в соответствующий код ASCII. Затем вы можете манипулировать этими данными в соответствии с вашими требованиями. Этот метод быстро возвращает результаты, но из-за ограниченной базы данных символов метод сопоставления матриц имеет свои ограничения.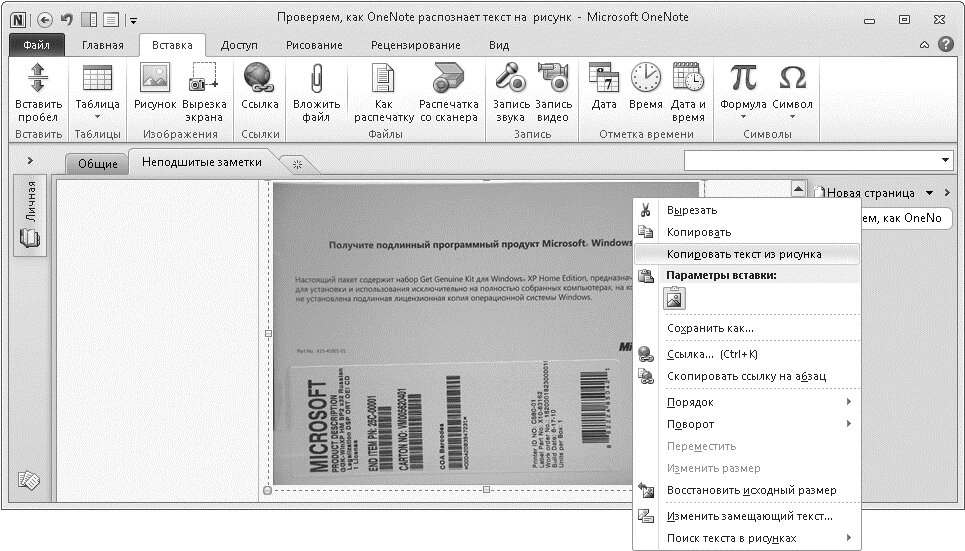 Алгоритм завершается ошибкой, когда он пытается распознать текст, которого нет в его базе данных, и выводит неверный текст. Следовательно, пользователи должны сохранять бдительность при использовании этого метода, поскольку он может генерировать ошибки, которые необходимо будет впоследствии исправить вручную.
Алгоритм завершается ошибкой, когда он пытается распознать текст, которого нет в его базе данных, и выводит неверный текст. Следовательно, пользователи должны сохранять бдительность при использовании этого метода, поскольку он может генерировать ошибки, которые необходимо будет впоследствии исправить вручную.
Метод извлечения особенностей
Другой метод, используемый программным обеспечением OCR, — это метод извлечения признаков текста. Этот метод основан на искусственном интеллекте, где онлайн программное обеспечение OCR предназначено для определения общих точек в форме букв, таких как искривления, наклоны и пробелы в алфавите. Сканеры текста OCR ищут эти общие точки в тексте и возвращают результаты в коде символов ASCII после того, как найден определенный процент «совпадения». Следовательно, этот метод ищет повторяющиеся шаблоны или правила, которые представляют букву, и программное обеспечение может предсказать букву, просто просматривая общие точки, найденные в шаблоне. Метод является более гибким и может работать с большим количеством печатных или рукописных документов.
Кроме того, искусственный интеллект постоянно обновляет свои знания о различных почерках и шрифтах, что делает его более универсальным в использовании и оставляет возможности дальнейших улучшений и модернизаций алгоритма.
OCR онлайн сервисы
Самый простой способ сконвертировать распечатанные файлы в редактируемую версию — использование онлайн-сервисов OCR, в том числе нашим сервисом. Использовать онлайн-сервисы OCR чрезвычайно просто, поскольку вам нужно только отсканировать документ, загрузить его, и файл будет преобразован в редактируемую версию. Бесплатный сервис OCR — это отличная возможность для бизнеса сэкономить своё драгоценное время и деньги.
Есть несколько преимуществ использования бесплатных услуг OCR онлайн сервисов. Эти преимущества включают в себя:
- Время, затрачиваемое на весь процесс, значительно сокращается, и большие документы можно подготовить всего за несколько минут. Редактировать контракты, страницы журналов и брошюры теперь стало очень просто.
- Упрощение процесса извлечения данных из сложных документов.
- Снижение вероятности человеческой ошибки, связанной с методом чтения и перепечатывания.
- Устранение трудозатрат в часах, необходимых для затратного процесса ввода данных.
- Сканеры текста OCR являются сложными и могут также распознавать сложные почерки, которые могут занять время, чтобы человеческий глаз мог их прочитать и обработать.
 Редактировать контракты, страницы журналов и брошюры теперь стало очень просто.
Редактировать контракты, страницы журналов и брошюры теперь стало очень просто.Благодаря более быстрому циклу обработки и современным сканерам распознавания текста, эта технология может сэкономить достаточно значительное количество времени и средств для пользователей, которые смогут распорядиться своим временем более эффективно.
Как распознать текст с картинки в Word: лучшие способы и ресурсы
Бывало ли у вас такое, что, например, партнеры по бизнесу прислали какую-то документацию или проект договора о сотрудничестве в виде файла графического формата (обычной картинки или документа PDF)? По всей видимости, с этим сталкивались, если не все, то очень многие. А ведь документ вам бывает нужно срочно изменить, а чаще всего это касается редактирования текстовой части, которая может содержаться в исходном файле. Как распознать текст с картинки, чтобы затратить на это минимум времени и избежать возможного появления всевозможных ошибок и опечаток? Об этом и многом другом далее и пойдет речь. Способов «вытаскивания» текста из файлов графических типов или универсального формата PDF на сегодняшний день существует много, однако при рассмотрении некоторых из них будем отталкиваться от наиболее интересных, простых и понятных любому пользователю методов.
Как распознать текст с картинки в Word?
Начать стоит с одного из самых простых методов, который подойдет всем без исключения пользователям. Если речь идет о том, чтобы «вытащить» текст из PDF-документа, а затем отредактировать его и сохранить в «родном» формате текстового редактора Word, далеко ходить не нужно, поскольку все последние версии этого приложения, начиная с «Офиса» 2010 года выпуска, поддерживают работу с файлами PDF и позволяют их редактировать точно так же просто, как если бы это был самый обычный документ Word.
Чтобы в «Ворде» распознать текст с картинки формата PDF, который, если кто не знает, относится именно к графическим типам файлов, достаточно задать открытие документа, а в типе файла выбрать именно формат PDF. После этого текст можно будет и отредактировать, и сохранить повторно в виде «родного» формата редактора, выбрав в том же поле нужный тип (например, DOC или DOCX).
Дополнительные инструменты для Office 2003
Если же проблема состоит в том, как распознать текст с картинки в редакторе, входящем в состав офисного пакета, скажем, 2003 года, в котором формат PDF не поддерживается, то и в этом случае ничего сложного нет.
В довесок к самому текстовому редактору дополнительно можно установить инструмент в виде интегрируемого в Word расширения под названием File Format Converters, который добавит возможностей редактору в том плане, что он сможет работать и с файлами PDF, и с документами обновленных форматов вроде DOCX.
Как распознать текст с картинки в PDF?
Еще один способ извлечения текста непосредственно из графического объекта в PDF-формате состоит в том, чтобы воспользоваться любым из известных редакторов, рассчитанных на работу с такими документами. Одним из наиболее универсальных и практичных приложений можно назвать небезызвестную программу Reader от Adobe. Обратите внимание, что в данном случае речь идет именно о приложении «Ридер», а не об аналогичном просмотрщике «Акробат», который поддерживает только чтение документов (просмотр без возможности редактирования).
В самой программе вам нужно будет просто выделить нужный фрагмент текста, скопировать его в буфер обмена, а затем вставить в документ Word и сохранить в нужном конечном формате.
Использование приложения OneNote
Если разбираться в тонкостях того, как распознать текст с картинки без использования вышеописанных приложений, можно посоветовать воспользоваться еще одним уникальным апплетом, входящим в состав последних модификаций и сборок самих офисных пакетов, под названием OneNote, о возможностях которого многие пользователи в большинстве своем или забывают, или не знают вовсе.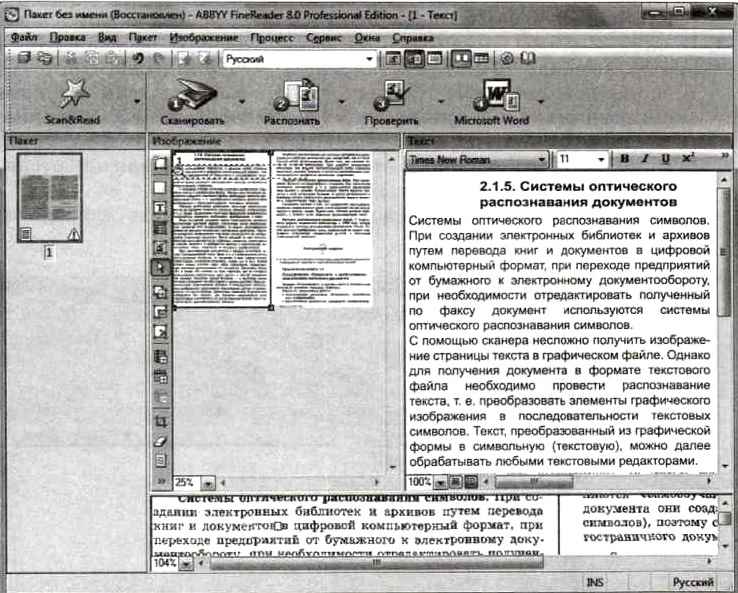 В программе потребуется для удобства работы всего лишь создать пустой документ, используя меню вставки поместить в него изображение с текстом из графического файла (любого формата), а затем настроить язык распознавания.
В программе потребуется для удобства работы всего лишь создать пустой документ, используя меню вставки поместить в него изображение с текстом из графического файла (любого формата), а затем настроить язык распознавания.
После этого останется только скопировать текст в буфер обмена, для чего используется специальный пункт «Копировать текст с картинки», после чего его можно будет вставить из буфера в любую другую программу.
Примечание: если вопросы касаются того, как с картинки распознать китайский текст или содержимое, представленное на любом другом неподдерживаемом для отображения языке, вам потребуется установить дополнительный языковой пакет, загрузив его, например, из официального источника Microsoft и интернете.
Система распознавания ABBYY Finereader
Естественно, если речь идет исключительно о том, как распознать текст с картинки в графических форматах, лучше всего применять для этого специализированные OCR-системы. Одной из самых мощных и популярных является программа ABBYY Finereader, а также ее онлайн-аналог в виде официального интернет-портала.
Это приложение работает по типу виртуального сканера, в котором нужно всего лишь задать направление распознавания, а иногда может потребоваться указать язык исходного документа (это относится к устаревшим версиям пакета). Когда сканирование текста на том же печатном листе или в графическом файле будет закончено, он будет автоматически перенаправлен, например, в Word или в любой другой офисный редактор.
Конвертеры форматов
Пока это были самые простые приложения, позволяющие распознать текст с картинки. Программы для выполнения таких действий включают в себя и еще одну категорию ПО, называемого конвертерами. Они интересны тем, что выполнять именно распознавание текстового содержимого графического файла в них не нужно. Суть состоит в том, чтобы переконвертировать исходный графический формат в выбранный текстовый, после чего преобразованный файл и можно будет открыть в нужном редакторе. Кроме того, очень часто именно такие приложения оказываются максимально эффективными, когда вам требуется обработать несколько десятков однотипных документов. Это называется пакетным режимом. Что же до самих программ, их в том же интернете можно найти огромное количество.
Кроме того, очень часто именно такие приложения оказываются максимально эффективными, когда вам требуется обработать несколько десятков однотипных документов. Это называется пакетным режимом. Что же до самих программ, их в том же интернете можно найти огромное количество.
Среди наиболее востребованных приложений можно отметить утилиты для преобразования PDF-файлов в любые другие форматы, конвертеры PDF или JPG в Word, универсальные преобразователи любого типа графики в текстовые файлы и т. д.
Онлайн-сервисы: нюансы использования и возможные ограничения
Наконец, если ни одно из предложенных решений вам не подходит, заниматься преобразованиями вручную просто лень или нет времени, пожалуйста, в интернете представлено огромное количество ресурсов, на которых все эти операции будут выполнены без вашего прямого участия. От вас потребуется только загрузить исходный графический файл, дождаться окончания извлечения текста и скачать готовый текстовый файл на собственный компьютер (или даже просто скопировать текст из окна с результатом). Правда, неудобство некоторых таких сервисов состоит только в том, что зачастую могут устанавливаться ограничения по количеству одновременно загружаемых для обработки файлов и лимиты, касающиеся их размера, не говоря уже и о том, что некоторые сервисы являются отнюдь не бесплатными. Зато многие из таких ресурсов определяют используемый в тексте язык автоматически, что избавляет вас от дополнительных ненужных действий по переводу.
Преобразование изображения JPEG в текст в MS Word
Все мы уже привыкли фотографировать расписание, документы, страницы книг и многое другое, но по ряду причин «извлечь» текст со снимка или картинки, сделав его пригодным для редактирования, все же требуется.
Особенно часто с необходимостью преобразовать фото в текст сталкиваются школьники и студенты. Это естественно, ведь никто не будет переписывать или набирать текст, зная, что есть более простые методы. Было бы прям идеально, если бы преобразовать картинку в текст можно было в Microsoft Word, вот только данная программа не умеет ни распознавать текст, ни конвертировать графические файлы в текстовые документы.
Единственная возможность «поместить» текст с JPEG-файла (джипег) в Ворд — это распознать его в сторонней программе, а затем уже оттуда скопировать его и вставить или же просто экспортировать в текстовый документ.
Распознавание текста
ABBYY FineReader по праву является самой популярной программой для распознавания текста. Именно главную функцию этого продукта мы и будем использовать для наших целей — преобразования фото в текст. Из статьи на нашем сайте вы можете более подробно узнать о возможностях Эбби Файн Ридер, а также о том, где скачать эту программу, если она еще не установлена на у вас на ПК.
Скачав программу, установите ее на компьютер и запустите. Добавьте в окно изображение, текст на котором необходимо распознать. Сделать это можно простым перетаскиванием, а можно нажать кнопку «Открыть», расположенную на панели инструментов, а затем выбрать необходимый графический файл.
Теперь нажмите на кнопку «Распознать» и дождитесь, пока Эбби Файн Ридер просканирует изображение и извлечет из него весь текст.
Вставка текста в документ и экспорт
Когда FineReader распознает текст, его можно будет выделить и скопировать. Для выделения текста используйте мышку, для его копирования нажмите «CTRL+С».
Теперь откройте документ Microsoft Word и вставьте в него текст, который сейчас содержится в буфере обмена. Для этого нажмите клавиши «CTRL+V» на клавиатуре.
Помимо просто копирования/вставки текста из одной программы в другую, Эбби Файн Ридер позволяет экспортировать распознанный им текст в файл формата DOCX, который для MS Word является основным. Что для этого требуется сделать? Все предельно просто:
- выберите необходимый формат (программу) в меню кнопки «Сохранить», расположенной на панели быстрого доступа;
кликните по этому пункту и укажите место для сохранения;
После того, как текст будет вставлен или экспортирован в Ворд, вы сможете его отредактировать, изменить стиль, шрифт и форматирование. Наш материал на данную тему вам в этом поможет.
Наш материал на данную тему вам в этом поможет.
Примечание: В экспортированном документе будет содержаться весь распознанный программой текст, даже тот, который вам, возможно, и не нужен, или тот, который распознан не совсем корректно.
Видео-урок по переводу текста с фотографии в Word файл
Преобразование текста на фото в документ Ворд онлайн
Если вы не хотите скачивать и устанавливать на свой компьютер какие-либо сторонние программы, преобразовать изображение с текстом в текстовый документ можно онлайн. Для этого существует множество веб-сервисов, но лучший из них, как нам кажется, это FineReader Online, который использует в своей работе возможности того же программного сканера ABBY.
Перейдите по вышеуказанной ссылке и выполните следующие действия:
1. Авторизуйтесь на сайте, используя профиль Facebook, Google или Microsoft и подтвердите свои данные.
Примечание: Если ни один из вариантов вас не устраивает, придется пройти полную процедуру регистрации. В любом случае, сделать это не сложнее, чем на любом другом сайте.
2. Выберите пункт «Распознать» на главной странице и загрузите на сайт изображение с текстом, который нужно извлечь.
3. Выберите язык документа.
4. Выберите формат, в котором требуется сохранить распознанный текст. В нашем случае это DOCX, программы Microsoft Word.
5. Нажмите кнопку «Распознать» и дождитесь, пока сервис просканирует файл и преобразует его в текстовый документ.
6. Сохраните, точнее, скачайте файл с текстом на компьютер.
Примечание: Онлайн-сервис ABBY FineReader позволяет не только сохранить текстовый документ на компьютер, но и экспортировать его в облачные хранилища и другие сервисы.
 В числе таковые BOX, Dropbox, Microsoft OneDrive, Google Drive и Evernote.
В числе таковые BOX, Dropbox, Microsoft OneDrive, Google Drive и Evernote.После того, как файл будет сохранен на компьютер, вы сможете его открыть и изменить, отредактировать.
На этом все, из данной статьи вы узнали, как перевести текст в Ворд. Несмотря на то, что данная программа не способна самостоятельно справиться с такой, казалось бы, простой задачей, сделать это можно с помощью стороннего софта — программы Эбби Файн Ридер, или же специализированных онлайн-сервисов.
Распознавание текста онлайн — ТОП-9 сервисов
Распознавание текста с картинки, OCR (optical character recognition), то есть превращение картинки в текст доступно бесплатно на многих сайтах в режиме онлайн. Но везде свое качество и свои ограничения на количество распознаваемых картинок.
Я проверила с десяток онлайн-сервисов и составила рейтинг лучших.
Для примера распознавала фотографию документа, который есть у каждого – свидетельство ИНН физического лица (разрешением 1275×1750 пикселей).
| Сервис | Нужна регистрация | Рейтинг | Адрес |
|---|---|---|---|
| да | 3 | https://drive.google.com/drive | |
| Abbyy Finereader | да | 5 | https://finereaderonline.com/ru-ru |
| Online OCR2 | — | 5 | http://www.onlineocr.net |
| Free Online OCR | — | 2 | https://www.newocr.com |
| OCR Convert | — | 4 | http://www.ocrconvert.com |
| Free OCR | — | 1 | www.free-ocr.com |
| I2OCR | — | 4 | http://www.i2ocr.com |
| Яндекс ОCR | Распознает и переводит. | 5 | https://translate.yandex.ru/ocr |
| Convertio | Работает своеобразно | 3 | https://convertio.co/ru/ocr/ |
В Google можно распознавать неограниченное количество картинок, лишь бы они поместились на Google Drive. Нужно просто открыть картинку с Google диска с помощью Google Документов, и она автоматически распознается.
Нужно просто открыть картинку с Google диска с помощью Google Документов, и она автоматически распознается.
| Входные форматы | PDF , JPEG, PNG, GIF |
| Выходные форматы | Word, Open Document, RTF, Adobe PDF, HTML, Text Plain, Epub (но форматирование исчезает – нарушается компоновка картинок с текстом) |
| Размер файла | До 2 Мб |
| Ограничения | Ограничено только размером хранилищ Google. Качество исходника рекоменовано не меньше 10 пикселей по высоте для строки. |
| Качество | Так себе – качество распознавания свидетельства инн хуже, чем с Finereader. И ФИО, и номер инн полностью потеряны. |
Как пользоваться
- Загрузите файл на страницу drive.google.com или выберите там уже загруженную картинку
- Нажмите правой кнопкой мыши на нужный файл.
- Выберите “Открыть с помощью” –> “Google Документы”.
- Картинка преобразуется в документ Google и откроется на вкладке https://docs.google.com
Abbyy Finereader
В Abbyy Finereader Online самый удобный интерфейс, хорошее качество, но доступна только ознакомительная версия – можно распознать не более 10 страниц за две недели. (200 страниц в месяц стоят 299р). Для использования сервиса нужно зарегистрироваться (можно войти через аккаунты социальных сетей). Кроме того, полученный текст можно там же перевести на другой язык с помощью машинного перевода.
| Входные форматы | PDF, TIF, JPEG, BMP, PCX, PNG |
| Выходные форматы | Word, Excel, Power Point, Open Document, RTF, Adobe PDF, Text Plain, Fb2, Epub |
| Размер файла | До 100Мб |
| Ограничения | 10 картинок на две недели |
| Качество | Качество распознавания свидетельства инн оказалось хорошее. Примерно как у Online OCR – какие-то части документа лучше распознались тем сервисом, а какие-то – этим. |
Результат распознавания Finereader. (ФИО и город распознаны, но стерты вручную)
Как пользоваться- Загрузите файлы
- Выберите язык
- Выберите выходной формат
- Щелкните кнопку «Распознать»
Распознавание текста онлайн без регистрации
Online OCR
Online OCR http://www.onlineocr.net/ – единственный наряду с Abbyy Finereader сервис, который позволяет сохранять в выходном формате картинки вместе с текстом. Вот как выглядит распознанный вариант с выходным форматом Word:
Результат распознавания в Online OCR (ФИО и дата распознаны, но стерты вручную)
| Входные форматы | PDF, TIF, JPEG, BMP, PCX, PNG, GIF |
| Выходные форматы | Word, Excel, Adobe PDF, Text Plain |
| Размер файла | До 5Мб без регистрации и до 100Мб с ней |
| Ограничения | Распознает не более 15 картинок в час без регистрации |
| Качество | Качество распознавания свидетельства инн оказалось хорошее. Примерно как у Abbyy Finereader – какие-то части документа лучше распознались тем сервисом, а какие-то – этим. |
- Загрузите файл (щелкните «Select File»)
- Выберите язык и выходной формат
- Введите капчу и щелкните «Convert»
Внизу появится ссылка на выходной файл (текст с картинками) и окно с текстовым содержимым
Free Online OCR
Free Online OCR https://www.newocr.com/ позволяет выделить часть изображения. Выдает результат в текстовом формате (картинки не сохраняются).
| Входные форматы | PDF, DjVu JPEG, PNG, GIF, BMP, TIFF |
| Выходные форматы | Text Plain (PDF и Word тоже можно загрузить, но внутри них все равно текст без форматирования и картинок). |
| Размер файла | До 5Мб без регистрации и до 100Мб с ней |
| Ограничения | Ограничения на количество нет |
| Качество | Качество распознавания свидетельства инн плохое. |
Как пользоватьсяМожно распознавать как все целиком, так и выделить часть изображения для распознавания.
- Выберите файл или вставьте url файла и щелкните «Preview» – картинка загрузится и появится в окне браузера Не забудьте правильно указать язык.
- Выберите область сканирования (можно оставить целиком как есть)
- Выберите языки, на которых написан текст на картинке и щелкните кнопку «OCR»
- Внизу появится окно с текстом
OCR Convert
OCR Convert http://www.ocrconvert.com/ txt
| Входные форматы | Многостраничные PDF, JPG, PNG, BMP, GIF, TIFF |
| Выходные форматы | Text Plain |
| Размер файла | До 5Мб общий размер файлов за один раз. |
| Ограничения | Одновременно до 5 файлов. Сколько угодно раз. |
| Качество | Качество распознавания свидетельства инн среднее. (ФИО распознано частично). Лучше, чем Google, хуже, чем Finereader |
- Загрузите файл, выберите язык и щелкните кнопку «Process»
- Появится ссылка на файл с распознанным текстом
Free OCR
Free OCR www.free-ocr.com распознал документ хуже всех.
| Входные форматы | PDF, JPG, PNG, BMP, GIF, TIFF |
| Выходные форматы | Text Plain |
| Размер файла | До 6Мб |
| Ограничения | У PDF-файла распознается только первая страница |
| Качество | Качество распознавания свидетельства инн низкое – правильно распознано только три слова. |
- Выберите файл
- Выберите языки на картинке
- Щелкните кнопку “Start”
I2OCR
I2OCR http://www. i2ocr.com/ неплохой сервис со средним качеством выходного файла. Отличается приятным дизайном, отсутствием ограничений на количество распознаваемых картинок. Но временами зависает.
i2ocr.com/ неплохой сервис со средним качеством выходного файла. Отличается приятным дизайном, отсутствием ограничений на количество распознаваемых картинок. Но временами зависает.
| Входные форматы | JPG, PNG, BMP, TIF, PBM, PGM, PPM |
| Выходные форматы | Text Plain (PDF и Word тоже можно загрузить, но внутри них все равно текст без форматирования и картинок). |
| Размер файла | До 10Мб |
| Ограничения | нет |
| Качество | Качество распознавания свидетельства инн среднее – сравнимо с OCR Convert. Замечено, что сервис временами не работает. |
- Выберите язык
- Загрузите файл
- Введите капчу
- Щелкните кнопку «Extract text»
- По кнопке «Download» можно загрузить выходной файл в нужном формате
Яндекс OCR
Недавно обнаружила этот сервис, и он мне очень понравился качеством и простотой использования. Вообще то он предназначен для перевода загруженной картинки, но его можно использоваться и для распознавания текста с картинки. Регистрации не требует, ограничений на количество изображений нет. В данный момент находится в стадии бета-тестирования.
Просто перейдите на https://translate.yandex.ru/ocr, загрузите картинку (можно перетащить) и щелкните “Открыть в Переводчике”. Откроется как текст с картинки, так и перевод в правом поле.
Перетащите картинку Результат распознавания
Convertio
Convertio hhttps://convertio.co/ru/ocr/ работает своеобразно, поэтому сравнивать его тяжело. В целом не понравился. Свидетельство ИНН, загруженное целиком, он не распознал совсем, так как плохо выделяет текст среди картинок. Не распозналось ни одного слова! Для его проверки я вырезала текстовый кусочек из ИНН и распознала его – это удалось сделать.
К тому же временами он зависает в попытках что-либо распознать.
| Входные форматы | pdf, jpg, bmp, gif, jp2, jpeg, pbm, pcx, pgm, png, ppm, tga, tiff, wbmp, webp |
| Выходные форматы | Text Plain, PDF, Word , Excel, Pptx, Djvu, Epub, Fb2, Csv |
| Размер файла | ?, зависит от тарифа |
| Ограничения | 10 страниц бесплатно, дальше тарифы от 7 долларов. |
| Качество | Сложно оценить – файл с картинками (ИНН) не распознал совсем, отдельно вырезанный кусок текста распознал. Замечено, что при распознавании сервис временами зависает, возможно ваши картинки ставятся в большую очередь на бесплатном тарифе. |
- Загрузите файл
- Выберите язык
- Выберите выходной формат
- Введите капчу
- Щелкните “Преобразовать”
- Чтобы увидеть результат, промотайте наверх к форме загрузки файлов. Там же можно будет и скачать результат.
Интерфейс Convertio
Вырезанный и распознанный кусок (целиком не распознается):
Результат работы Convertio
Заключение
Лучше всего документ распознал Abbyy Finereader и Online OCR. Кроме того, эти сервисы сохраняют форматирование файла: где нет текста, оставляют картинки и компонуют их с распознанным текстом. Из новых сервисов хорош Яндекс OCR.
Хуже всего сработал Free OCR – он распознал всего три слова.
Распознавание текста онлайн — ТОП-9 сервисов: 4 комментария
СПАСИБО! И меня очень выручили… по поиску в яндексе мои попытки тоже были безуспешные, а статья помогла и выбрала отличный ресурс, который преобразовал все 30 страниц) к слову, нужно было очень быстро и срочно!)))
если есть такая возможность то напишите пожалуйста
есть страничка
на ней картинки с текстом
конкретно адреса электронной почты
https://www.math.fsu.edu/People/faculty.php
вопрос можно ли вытащить каким то средствами текст этих адресов
согласен что это не хорошо но увы нужно
сделайте скриншот, да распознайте картинку. Правда, качество там не очень
Правда, качество там не очень
спасибо admin за относительно свежую статью и рейтинг про
«OCR сервис онлайн»
мне для научной статьи на англ. только изображения бесплатно нашлись. pdf/doc нет.
Как распознать текст? Программа для распознавания текста
Функция распознавания текста может понадобиться в тех случаях, когда нужно перевести текст из книжного формата, в физическом варианте, в электронный. Ну, представим такую ситуацию: у нас есть книга на руках, которую нужно перенести на компьютер в файл Ворд, как будто мы её перепечатали сами с клавиатуры.
Здесь есть два варианта, либо сделать все как нужно, перепечатав текст из книги руками самому, и потратив на это уйму времени, либо второй вариант — это воспользоваться специальной программой для распознавания текста. Одна из таких называется ABBYY FineReader. О ней то мы сегодня и будем говорить.
Программа ABBYY FineReader была разработана специально для осуществления возможности распознавания текста, который отсканирован из книги, журнала, газеты и прочих печатных изданий.
Давайте я на реальном примере покажу Вам, как распознать текст после сканирования или после скачивания уже отсканированной книги, в программе ABBYY FineReader.
Подготовьте программу: найдите её, скачайте, установите, запустите. Подготовьте текст, который вам нужно распознать. Отсканируйте его, если нужно.
А теперь давайте запустим программу ABBYY FineReader. Процесс распознавания текста я буду показывать на примере последней, 11-ой, на данный момент версии.
Распознавание текста в программе ABBYY FineReader
Например, нам нужно книгу в PDF формате конвертировать в обычный текст в страницы Word. Для этого в открывшемся окне программы выбираем задачу «Файл (PDF/изображение) в Microsoft Word».
Нам сразу же предлагают указать на компьютере PDF файл для распознавания текста, который в нём имеется.
В течение нескольких минут выбранный файл будет открываться. Мы можем наблюдать за процессом.
Затем произойдет распознавание текста и по окончанию весь текст программа FineReader переместит в Word файл и откроет его.
Нам остается только исправить некоторые ошибки, если они будут, и сохранить файл в любое место на своем компьютере.
Кроме этого мы можем сами в программе распознанный текст передать или даже сразу сохранить в Ворд файл.
Также в программе ABBYY FineReader можно распознать текст сразу со сканера, то есть кладем печатный вариант в сканер и в программе выбираем чтобы она сразу распознавала текст.
Есть и другие варианты.
Надеюсь эти примеры по распознаванию текста в программе ABBYY FineReader вам понятны и с другими способами вы уже разберетесь сами.
Ранее я уже писал урок про то, как распознать текст, но там мы использовали не программу FineReader, а онлайн сервис. Впрочем, если вам эта тема интересна, то рекомендую почитать этот урок: Как распознать текст онлайн.
Удачи!
Интересные статьи по теме:
Как сканировать в Word? — Бесплатное распознавание текста в Word
Скачать бесплатно OCR в Word
Введение
Бесплатное распознавание текста в Word упрощает сканирование изображения и преобразование сканированного изображения в слово, чтобы вы могли соответствующим образом изменять свои данные. Например, у вас есть скан-книга и вы хотите отредактировать некоторые части книги; вы не можете выполнить задание в файле изображения. Чтобы решить эту проблему, вы можете попробовать бесплатное распознавание текста в Word, которое основано на технологии оптического распознавания символов и предназначено для чтения содержимого отсканированных изображений и преобразования их в Word. Этот пост будет посвящен Как сканировать в Word с помощью нашего бесплатного программного обеспечения для сканирования в Word.
Этот пост будет посвящен Как сканировать в Word с помощью нашего бесплатного программного обеспечения для сканирования в Word.
Шаг 1. Отсканируйте изображение
Запустите Free OCR to Word и нажмите «Сканировать…» , чтобы выбрать сканер, подключенный к вашему компьютеру, и активировать программу сканера вашей системы.
Вы можете нажать «Предварительный просмотр» , чтобы увидеть файл для сканирования. Затем щелкните «Сканировать» , чтобы выполнить сканирование.
Через несколько секунд изображение сканируется в окно изображения.Щелкните «По размеру изображения», «По ширине», «Увеличить» и «Уменьшить» , чтобы настроить изображение до нужного размера. При необходимости щелкните «Повернуть по ACW» или «Повернуть по часовой стрелке» , чтобы исправить положение в правом верхнем углу. Перетащите указатель мыши на и выберите часть изображения , содержащую текст, который вы хотите извлечь. Если вы хотите извлечь весь текст, просто увеличьте как можно больше.
Шаг 2. Извлеките текст
Щелкните «OCR» , чтобы извлечь текст из выделения.Извлеченный текст отобразится в текстовом окне через несколько секунд. Щелкните текстовое окно , и вы можете найти некоторые инструменты для работы с документами вверху. «Очистить текстовое окно» предназначено для удаления всего текста, а есть кнопка «Удалить разрывы строк» для упрощения редактирования. Вы также можете нажать «Копировать все тексты в буфер обмена» , чтобы скопировать текст и поместить его в приложение по вашему выбору.
Шаг 3. Вывод в Word
Щелкните «Экспорт текста в Microsoft Word» , чтобы вывести извлеченный текст в Word, затем вы можете сохранить его как документ Word. (Чтобы сохранить извлеченный текст как * .txt, щелкните «Сохранить текст» .)
(Чтобы сохранить извлеченный текст как * .txt, щелкните «Сохранить текст» .)
Следите за нами и ставьте лайки:
Posted in TutorialTagged Как сканировать в Word, сканировать в WordИзображение в текст в App Store
Сканируйте, распознавайте текст (OCR), печатайте и управляйте документами с помощью устройства iOS!
Word Scanner превращает ваше мобильное устройство в мощный универсальный мобильный сканер для быстрого сканирования документов и книг, создания электронных копий в форматах PDF, PDF с возможностью поиска, JPEG и TXT.Создавайте бесплатные высококачественные отсканированные изображения одним касанием.
Молниеносное автоматическое обнаружение и сканирование кромок. Используйте свой iPhone / iPad со сканером Word для сканирования бумажных документов, книг, соглашений, квитанций, журналов, статей, заметок, рецептов, изображений, диаграмм, слайдов таблиц, досок и получения идеальных цифровых копий.
КЛЮЧЕВЫЕ ХАРАКТЕРИСТИКИ:
* Сканирование с помощью камеры или выбор фотографий из Camera Roll
* Преобразование отсканированных изображений в редактируемый текст с помощью технологии OCR
* Печать отсканированных документов
* Редактирование перспективы и границ сканирования, исправление или изменение ориентации
сканирование в приложении
* Совместное использование сканированных изображений по отдельности или отправка нескольких файлов в одном PDF-файле Почта, iMessage или сохранение в фотопленке
* Электронная почта и печать в одно касание
* Красивый дизайн и простота использования
Получить полную версию чтобы получить доступ ко всем функциям Premium!
* Выберите один из вариантов подписки:
— годовая подписка с 3-дневным бесплатным пробным периодом.
* Ваша бесплатная пробная подписка будет автоматически заменена на платную, если автоматическое продление не будет отключено по крайней мере за 24 часа до окончания бесплатного пробного периода.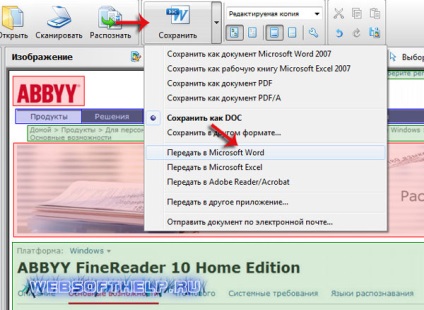 Вы можете отменить подписку в настройках iTunes как минимум за 24 часа до окончания бесплатного пробного периода. Плата за подписку будет снята с вашей учетной записи iTunes при подтверждении вашей покупки и в начале каждого срока продления.
Вы можете отменить подписку в настройках iTunes как минимум за 24 часа до окончания бесплатного пробного периода. Плата за подписку будет снята с вашей учетной записи iTunes при подтверждении вашей покупки и в начале каждого срока продления.
* Обратите внимание: любая неиспользованная часть бесплатного пробного периода (если предлагается) будет аннулирована при покупке премиальной подписки в течение бесплатного пробного периода.
* Вы можете отменить бесплатную пробную версию или подписку в любое время, отключив автоматическое продление в настройках своей учетной записи iTunes. Это необходимо сделать за 24 часа до окончания бесплатного пробного периода или периода подписки, чтобы избежать списания средств. Отмена вступит в силу на следующий день после последнего дня текущего периода подписки, и вы будете переведены на бесплатную услугу.
Политика конфиденциальности: https://wordscanner.app/privacypolicy.html
EULA: https://wordscanner.app/eula.html
Есть вопросы или предложения? Не стесняйтесь, напишите нам по адресу support @ wordscanner.приложение
Сканирование в Microsoft Word
Задача Сканировать в Microsoft Word в окне Новая задача позволяет создавать документы Microsoft Word из изображений, полученных со сканера или цифровой камеры.
- Откройте окно Новая задача , щелкните вкладку Сканировать , а затем щелкните задачу Сканировать в Microsoft Word .
- Выберите устройство и укажите настройки сканирования.
- Нажмите кнопку Preview или щелкните в любом месте изображения.
- Просмотрите изображение. Если вас не устраивает качество изображения, измените настройки сканирования и снова нажмите кнопку Preview .
- Укажите настройки преобразования. Эти параметры определяют внешний вид и свойства выходного документа.
- Сохранить форматирование
Выберите соответствующий параметр в зависимости от того, как вы планируете использовать выходной документ.

- Точная копия
Выходной документ будет выглядеть почти так же, как оригинал, но с ограниченными возможностями редактирования.. - Редактируемая копия
Внешний вид выходного документа может немного отличаться от оригинала, но документ можно легко редактировать. - Форматированный текст
Типы шрифтов, размеры шрифтов и форматирование абзацев будут сохранены. Выходной текст будет помещен в один столбец. - Обычный текст
Будет сохранено только форматирование абзаца. Выходной текст будет помещен в один столбец, и везде будет использоваться один шрифт.
Выберите язык (и) вашего документа. См. Также: Языки OCR .
Выберите этот параметр, если вы хотите сохранить изображения в выходном документе.
Выберите этот параметр, чтобы сохранить верхние, нижние колонтитулы и номера страниц.
Задайте настройки предварительной обработки изображений, такие как определение ориентации страницы и настройки автоматической предварительной обработки. Эти настройки могут значительно улучшить исходные изображения, что приведет к повышению точности распознавания текста. См. Также: Параметры обработки изображений .
Открывает раздел DOC (X) / RTF / ODT на вкладке Параметры формата диалогового окна Параметры , где можно указать дополнительные параметры (вы также можете открыть это диалоговое окно поле, щелкнув Параметры… в меню Инструменты ).

Нажмите Сканировать снова , чтобы сканировать другие страницы с текущими настройками, или нажмите Завершить сканирование , чтобы закрыть диалоговое окно.
По завершении задачи в указанной вами папке будет создан документ Microsoft Word. Все страницы документа также будут открыты в редакторе OCR.
Программное обеспечениеOCR — конвертируйте отсканированные изображения в Word, Excel, PDF с возможностью поиска, HTML или другие текстовые форматы без повторного ввода
Во время своего набега на мир сканирования документов вы, вероятно, встречали термин « OCR ». Возможно, вы даже знаете, что это означает « Optical Character Recognition ».Но что такое OCR на самом деле и что вам нужно знать о нем, чтобы наилучшим образом использовать этот сложный и ценный инструмент?
Мы здесь, чтобы дать вам краткий обзор оптического распознавания символов, ответить на любые ваши вопросы и порекомендовать лучшее программное обеспечение для оптического распознавания текста для вашего проекта сканирования. Давай начнем!
Что такое OCR?
Основной целью оптического распознавания символов является быстрое и автоматическое преобразование отсканированных изображений машинно-напечатанного (печатного) текста, который для компьютера представляет собой не более значимый набор пикселей, чем любое другое изображение, такое как альбомная фотография, в реальное изображение. текстовые данные, которые можно просматривать и изменять.Точная механика этого процесса сложна, но достаточно сказать, что движок OCR будет смотреть на данные пикселей и искать шаблоны, похожие на буквы, числа и другие символы, и создавать оцифрованную запись этих символов.
Типы OCR
Существует два основных типа оптического распознавания символов:
Full Page OCR — Преобразует всю страницу в один из следующих форматов:
- Обычный текст — На странице сохраняется только основная текстовая информация в последовательном порядке.
- Форматированный текст — Текстовая информация сохраняется в последовательных абзацах с сохранением размера и стиля шрифта. Это также может сохранить таблицы в табличном формате, например электронные таблицы.
- Exact Copy — Вся информация на странице сохраняется, включая графику, и размещается на странице таким образом, чтобы максимально точно воссоздать исходный документ.
- Файл с возможностью поиска — Текстовая информация сохраняется на скрытом слое за отсканированным изображением, что позволяет выполнять поиск по файлу, сохраняя внешний вид оригинала.

Zone OCR — Распознает строки текста, расположенные в определенных областях страницы. Обычно это делается для индексирования и управления документами. Информацию можно использовать для присвоения имени файлу, сохранения его в определенном месте или архивации определенных фрагментов данных в организованном формате, таком как база данных.
Уровни программного обеспечения OCR
Программное обеспечениеOCR бывает разных типов, которые различаются по цене в зависимости от их функций, скорости и точности.Например, вы можете получить бесплатное программное обеспечение, такое как SimpleOCR, которое будет работать в крайнем случае, но оно сможет конвертировать только изображения BMP , JPG и TIF английского или французского текста в простые текстовые документы Формат TXT или DOC , по одной странице за раз.
С другой стороны, вы можете вложить несколько сотен долларов в корпоративную версию высококлассного программного обеспечения, которое сможет отслеживать определенные папки для входящих документов в различных форматах изображений и на разных языках, а затем автоматически воссоздавать точные копии всех страницы в выбранном формате.
Вы также можете найти профессиональные версии этого программного обеспечения, которые позволят сократить разрыв в цене и включают многие функции корпоративных выпусков, но при этом все же требуют некоторого участия пользователя во время преобразования.
Повышение точности
Хотя некоторые механизмы распознавания текста лучше других, ни одно программное обеспечение не может гарантировать 100% точность. Это связано с тем, что есть и другие факторы, в том числе качество сканирования. Программа распознавания не сможет выполнять свою работу, если сканер неправильно оцифровывает страницу.
Для получения наилучших результатов рекомендуется сканировать с разрешением 300 точек на дюйм. Черно-белый (битональный) режим предпочтительнее, чем режимы «Оттенки серого» или «Цвет», и, хотя большинство современных сканеров довольно хорошо настроены «из коробки», вы можете настроить параметры яркости и контрастности для конкретных документов.
Если у вас нет сканера с необходимой скоростью, качеством или другими функциями, необходимыми для сканирования ваших документов, вы всегда можете найти большой выбор сканеров прямо здесь, в ScanStore!
У нас даже есть удобное руководство по сканерам, которое поможет вам найти идеальный сканер для ваших конкретных требований и ценового диапазона.
Ограничения OCR
Программное обеспечениеOCR также ограничено в том, что оно может распознать. Большинство программ оптического распознавания текста предназначены только для распознавания машинно-напечатанного текста, а не рукописного ввода. Хотя есть программное обеспечение ICR, которое может распознавать рукописную информацию, они, как правило, представляют собой решения корпоративного уровня для работы по обработке форм, а не для распознавания всей страницы.
Аналогичным образом, большинство программ оптического распознавания текста могут преобразовывать только традиционные машинные шрифты, но не рукописные шрифты или каллиграфию.Существует множество шрифтов, и механизмы распознавания текста зависят от общих форм разделенных букв для распознавания текста, поэтому шрифты, которые необычны или сливаются вместе, не будут распознаны.
Подробнее
Заинтересованы? Вот как узнать больше.
Сначала посетите страницу оптического распознавания символов в ScanStore и просмотрите различные доступные варианты программного обеспечения. Во-вторых, обратитесь к представителю ScanStore, который поможет ответить на все оставшиеся вопросы, которые могут у вас возникнуть.В-третьих, загрузите одну из наших доступных 30-дневных демонстраций, чтобы вы могли увидеть программное обеспечение в действии на своем компьютере.
|
|


 Чтобы узнать, предлагает ли ваш продукт HP программное обеспечение Readiris Pro OCR, ознакомьтесь с разделом «Доступность» ниже.
Чтобы узнать, предлагает ли ваш продукт HP программное обеспечение Readiris Pro OCR, ознакомьтесь с разделом «Доступность» ниже. Просто введите слово или фразу для поиска в окно поиска Readiris на рабочем столе, и программа найдет все подходящие файлы. Вы даже можете уточнить свой поиск с помощью таких категорий, как размер файла, папка и дата.
Просто введите слово или фразу для поиска в окно поиска Readiris на рабочем столе, и программа найдет все подходящие файлы. Вы даже можете уточнить свой поиск с помощью таких категорий, как размер файла, папка и дата.Изображение в текст: как извлечь текст из изображения
Представьте, что существует простой способ получить или извлечь текст из изображения, отсканированного документа или файла PDF и быстро вставить его в другой документ.
Хорошая новость заключается в том, что вам больше не нужно тратить время на ввод всего текста, потому что есть программы, использующие оптическое распознавание символов (OCR) для анализа букв и слов на изображении, а затем их преобразования в текст.
Существует ряд причин, по которым вы можете захотеть использовать функцию OCR для копирования текста из изображения или PDF.
- Вставьте текст с изображения или снимка экрана в Microsoft Office или другой документ.
- Сохранение текста в сообщении об ошибке, всплывающем окне или меню, где текст не может быть выделен.
- Захватить текст в каталоге файлов (имя файла, размер файла, дата изменения).
Независимо от вашей ситуации, этот тип функциональности может быть полезен, особенно когда вам нужно скопировать информацию из папки с файлами или снимка экрана веб-сайта, что обычно требует от вас значительного количества времени для повторного ввода всего текста.
К счастью, есть чрезвычайно простой способ захвата текста или преобразования изображения текста в редактируемый текст.С Snagit достаточно всего нескольких шагов, чтобы быстро извлечь текст с изображения.
Извлеките текст сегодня!
Загрузите бесплатную пробную версию Snagit, чтобы быстро и легко извлекать текст из изображений.
Скачать бесплатную пробную версию
Вот все, что вам нужно знать о том, как снимать текст с экрана компьютера или извлекать текст из изображения.
Как записывать текст в Windows или Mac
Шаг 1. Настройте параметры захвата
Чтобы захватить текст, откройте окно захвата, выберите вкладку «Изображение» и установите для выбора значение «Захватить текст».
Вы также можете ускорить процесс с помощью предустановки «Захват текста».
Шаг 2. Сделайте снимок экрана
Начните захват, затем с помощью перекрестия выберите область экрана с нужным текстом.
Snagit анализирует выбранный вами текст и отображает отформатированный текст.
Если указанный шрифт не установлен на вашем компьютере, Snagit заменит его системным шрифтом аналогичного стиля.
Выделите текст, который хотите скопировать, или нажмите «Копировать все…», чтобы скопировать весь текст в буфер обмена.
Шаг 3. Вставьте текст
Наконец, вы можете вставить текст в документ, презентацию или любое другое место назначения.
Изображение в текст: как извлечь текст из изображения с помощью OCR
Шаг 1. Найдите свое изображение
Вы можете захватить текст из отсканированного изображения, загрузить файл изображения со своего компьютера или сделать снимок экрана на рабочем столе.
Шаг 2. Откройте текст для захвата в Snagit
Открыв изображение в редакторе Snagit, перейдите в меню «Правка» и выберите «Захватить текст».
Или просто щелкните изображение правой кнопкой мыши или щелкните изображение и выберите «Захватить текст».
Шаг 3. Скопируйте текст
Затем скопируйте текст и вставьте его в другие программы и приложения.
И все. Извлечение текста из изображений, PDF-файлов или отсканированных документов не требует особых усилий.
Извлеките текст сегодня!
Загрузите бесплатную пробную версию Snagit, чтобы быстро и легко извлекать текст из изображений.
Скачать бесплатную пробную версию
Часто задаваемые вопросы
Как преобразовать изображение в текст?Загрузите ваше изображение в Snagit.Затем щелкните правой кнопкой мыши в любом месте изображения и выберите «Захватить текст». Это сканирует ваше изображение и преобразует его в текст.
Как извлечь текст из изображения в Windows?Сначала используйте Snagit, чтобы сделать снимок экрана с изображением или загрузить его в редактор.
Snagit использует программное обеспечение оптического распознавания символов, или OCR, для распознавания и извлечения текста из изображения на компьютере с Windows.
Как извлечь текст из отсканированного PDF-файла?Вы можете захватить текст из отсканированного изображения, загрузить файл изображения со своего компьютера или сделать снимок экрана на рабочем столе.Затем просто щелкните изображение правой кнопкой мыши и выберите «Захватить текст».
Текст из отсканированного PDF-файла можно затем скопировать и вставить в другие программы и приложения.
Как скопировать текст с изображения?Воспользуйтесь окном захвата изображений Snagit. Затем в раскрывающемся списке выберите «Захватить текст». По завершении появится окно со всем текстом, готовым для копирования и вставки.
Примечание редактора. Этот пост был первоначально опубликован в 2017 году и был обновлен для обеспечения точности и полноты.
3 шага для сканирования слов с изображения
2020-12-21 15:26:49 • Отправлено по адресу: OCR Solution • Проверенные решения
При работе с электронными документами, такими как романы, мотивационные книги, налоговые формы, отчеты и т. Д., Вы можете найти уместным скопировать определенную информацию и вставить ее в новый документ, чтобы сохранить в качестве справочного материала для дальнейшего использования.Как и в ряде ситуаций, такая информация может содержать изображения; это означает, что функция копирования и вставки, которая есть во всех операционных системах, не очень поможет в таком сценарии, когда вам нужно будет извлекать текст из изображений. Лучшее решение здесь — использовать программу для сканирования картинки в текст . А PDFelement, один из самых популярных менеджеров PDF, идеально подходит для сканирования слов с изображения.
Сканирование слов с изображения с помощью PDFelement
Чтобы выполнить эту операцию с PDFelement, вы можете отсканировать изображение и преобразовать его в текст за 3 быстрых шага.Эти шаги расширяются следующим образом:
Шаг 1. Подключите сканер
Сначала подключите сканер к компьютеру, если изображение сохранено в вашем мобильном телефоне, вы можете подключиться к своему мобильному телефону. Затем откройте PDFelement, нажмите кнопку «Стрелка» в верхнем левом углу, чтобы попасть в главное окно. Щелкните «Главная»> «Со сканера», чтобы подключить сканер.
Шаг 2. Сканирование изображений
Во всплывающем окне вы получите дополнительные настройки сканирования, выберите нужный вариант, а также параметр «Распознать текст (OCR)», чтобы начать сканирование.
Шаг 3. Преобразовать в текст
После сканирования он автоматически создаст PDF-документ, открытый в программе. Вы можете нажать кнопку «Другим»> «Преобразовать в текст», чтобы начать преобразование.
Вы можете нажать кнопку «Другим»> «Преобразовать в текст», чтобы начать преобразование.
Как сканировать изображение в текст с помощью Google Drive
Google Диск включает мощный и простой в использовании инструмент распознавания текста, который может помочь вам сканировать изображение в текст, давайте проверим шаги.
Шаг 1.Создайте отсканированный PDF-файл или PDF-файл на основе изображений
Используйте камеру или мобильное устройство, чтобы сфотографировать текст, и используйте PDFelement для преобразования изображения в PDF. Или вы можете создать PDF напрямую со сканера с помощью PDFelement.
Шаг 2. Откройте отсканированный PDF-файл на Google Диске.
Сначала войдите в свою учетную запись Google Диска, нажмите кнопку «Мой диск», чтобы выбрать «Загрузить файлы».
Шаг 3. Преобразование в текст с помощью Google Drive OCR
Теперь ваш отсканированный PDF-файл в вашей учетной записи, щелкните файл правой кнопкой мыши и выберите «Открыть с помощью Google Docs».Когда появляется значок листа, это означает, что файл загружается.
Шаг 4. Преобразование изображения в текст на Google Диске
Файл откроется в Документах Google, и его содержимое будет преобразовано в редактируемый текст, однако, возможно, возникнет небольшая проблема с форматированием, вы можете редактировать его напрямую. Или вы можете использовать PDFelement для редактирования файлов PDF. Нажмите кнопку «Файл»> «Загрузить», чтобы сохранить редактируемый файл напрямую в файл формата .txt.
Лучший инструмент для сканирования слов с изображения
PDFelement — это первоклассная программа для управления файлами для создания, открытия, аннотирования, редактирования и сохранения PDF-файлов.Это один из самых мощных конвертеров, позволяющий преобразовывать документы PDF в различные форматы, включая Word, PowerPoint, Excel, HTML, JPG, JPEG, PNG, BMP и т. Д. , И т.д. Универсальное программное обеспечение PDFelement поставляется с удобный интерфейс. Его технология OCR не только выдающаяся, но и очень точная, поскольку позволяет преобразовывать отсканированные документы в полностью редактируемый формат. Кроме того, его инструмент OCR позволяет искать, редактировать, изменять размер, а также форматировать текст. Он также многоязычный и поддерживает английский, французский, немецкий, испанский и многие другие языки.
, И т.д. Универсальное программное обеспечение PDFelement поставляется с удобный интерфейс. Его технология OCR не только выдающаяся, но и очень точная, поскольку позволяет преобразовывать отсканированные документы в полностью редактируемый формат. Кроме того, его инструмент OCR позволяет искать, редактировать, изменять размер, а также форматировать текст. Он также многоязычный и поддерживает английский, французский, немецкий, испанский и многие другие языки.
- Используется для заполнения PDF-форм.
- Позволяет импортировать файлы из облака, Wi-Fi, камеры или фото библиотеки.
- Помогает вам организовать — повернуть, переупорядочить или удалить — страницы PDF.
- Отлично подходит для сканирования и преобразования изображений.
- Используется для создания электронных подписей, штампов, а также добавления их в документы.
Сравнение двух вышеуказанных методов сканирования изображения в текст
Выше мы предоставили вам два метода сканирования изображения в текст, и каждый из них имеет свои преимущества, вы можете выбрать любой из них по своему усмотрению.PDFelement предоставляет более специализированное решение PDF со многими профессиональными функциями, связанными с PDF, фактически оно может удовлетворить все ваши потребности, связанные с документами PDF, такими как редактирование, комментирование, преобразование, создание, совместное использование, защита и многое другое. Google Диск намного проще в использовании, и без установки какой-либо программы вы можете выполнить задачу онлайн напрямую. Однако Google Диск предоставляет только ограниченные функции, связанные с документами PDF. Если вам нужен комплексный и универсальный инструмент для работы с PDF, PDFelement — лучший выбор.
Загрузите или купите PDFelement бесплатно прямо сейчас!
Загрузите или купите PDFelement бесплатно прямо сейчас!
Купите PDFelement прямо сейчас!
Купите PDFelement прямо сейчас!
.

Ваш комментарий будет первым