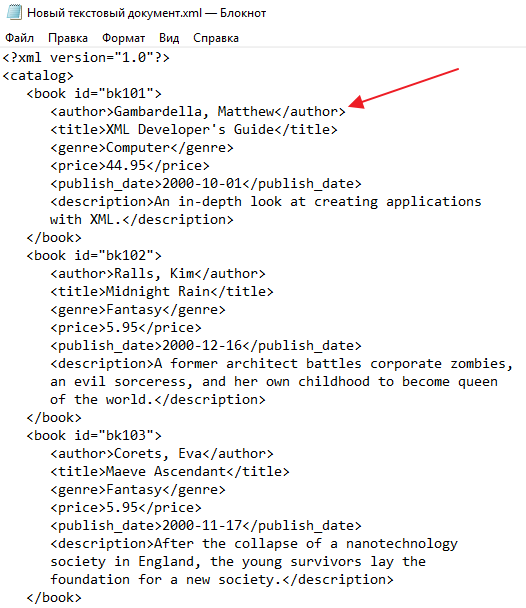
как прочитать документ — чтение, преобразование в структуру, записьxml 1C, примеры, как открыть файл
Работа с учетными программами представляет собой совокупность ежедневного выполняемых рутинных процессов. Использование сразу нескольких систем, отличающихся форматами хранения данных, обуславливает потребность в наличии универсального способа обработки. Подобным вариантом, оказывающим помощь в выгрузке, передаче и последующей загрузке информации в базу стал расширяемый язык разметки eXtensible Markup Language, рекомендованный к применению W3C (Консорциум Всемирной Паутины). Сегодня предприятия, пользующиеся стандартизированными библиотеками, имеют возможность в кратчайшие сроки реализовывать процесс обмена — создание, чтение и запись файлов XML, преобразуемых в структуру 1С, позволяет решить многие актуальные задачи.
Общее представление
Одним из главных преимуществ, отличающих рассматриваемую спецификацию, принято считать удобство и интуитивную понятность предлагаемого синтаксиса. Целью разработчиков являлось создание универсального языка разметки, одинаково комфортного для прочтения как машинными алгоритмами, так и непосредственными пользователями. Несмотря на внушительный по меркам индустрии возраст, релиз состоялся еще в 1998 году — стандарт по-прежнему остается одним из наиболее востребованных и популярных способов адаптации данных.
Целью разработчиков являлось создание универсального языка разметки, одинаково комфортного для прочтения как машинными алгоритмами, так и непосредственными пользователями. Несмотря на внушительный по меркам индустрии возраст, релиз состоялся еще в 1998 году — стандарт по-прежнему остается одним из наиболее востребованных и популярных способов адаптации данных.
Для прочтения написанной процедурой объектов достаточно передать путь к заданному документу, используя либо интерфейс, позволяющий вручную указывать место хранения, либо текст обработки, в котором точно прописывается актуальный маршрут. В рамках 1С работа с XML файлами зачастую реализуется с помощью объектной модели DOM — при условии, что размер элемента не превышает 100 МБ. Схема предусматривает последовательную проверку каждого представленного узла и на практике выглядит следующим образом:
- Объявление механизмов, применяемых для чтения.
- Определение цикла поочередного обхода.
- Считывание данных и их атрибутов.

- Представление информации, включая опцию записи в таблицы или переменные.
- Завершение процесса.
Результатом обработки, выполненной таким способом, становится вывод сообщений, содержащих импортированные сведения. При необходимости есть возможность заполнить заданную структуру и использовать ее для дальнейшей генерации документов и справочных записей. Стоит отметить, что функциональные возможности 1С позволяют быстро прочитать XML файл, что обуславливает популярность формата в тех случаях, когда требуется оперативный обмен данными со смежными источниками.
Механизм XDTO
В целях обеспечения доступности рассматриваемой методики разработчики учетной программы интегрировали собственную конфигурацию — Data Transfer Objects. В редакциях 8.1 и выше опция трансфера доступна по умолчанию, и позволяет пользователям не вдаваться в специфику формирования файловых объектов. За технические нюансы отвечает непосредственно платформа 1С, тогда как взаимодействующим с ней сотрудникам остается только указать информацию, требующую обработки.
Загрузка с помощью XDTO возможна после сообщения учетной программе его структуры, для передачи которой используется набор схем. Они создаются как с помощью специального приложения, так и в обычном текстовом редакторе. Итоговый документ должен описывать содержание и типы данных, которые будут использованы объектом. Перед тем как записать XML файл в 1С, схематическое описание загружается в общую конфигурацию, в раздел «Пакеты».
Самый простой вариант — создание вручную. Достаточно отразить наличие головного элемента и вложения с определенными атрибутами, экспортировать получившуюся в результате набора структуру в формат xsd, и передать ее второй стороне, исключая необходимость повторной генерации XDTO. Для сохранения новых версий на жестком диске применяется типовой серверный алгоритм, при этом следует учитывать, что сведения добавляются отдельно по каждой позиции, а при увеличении количества уровней вложения описывать придется все заголовки.
Готовые решения для всех направлений
Ускорьте работу сотрудников склада при помощи мобильной автоматизации. Навсегда устраните ошибки при приёмке, отгрузке, инвентаризации и перемещении товара.
Узнать большеМобильность, точность и скорость пересчёта товара в торговом зале и на складе, позволят вам не потерять дни продаж во время проведения инвентаризации и при приёмке товара.
Узнать большеОбязательная маркировка товаров — это возможность для каждой организации на 100% исключить приёмку на свой склад контрафактного товара и отследить цепочку поставок от производителя
Скорость, точность приёмки и отгрузки товаров на складе — краеугольный камень в E-commerce бизнесе. Начни использовать современные, более эффективные мобильные инструменты.
Узнать большеПовысьте точность учета имущества организации, уровень контроля сохранности и перемещения каждой единицы. Мобильный учет снизит вероятность краж и естественных потерь.
Повысьте эффективность деятельности производственного предприятия за счет внедрения мобильной автоматизации для учёта товарно-материальных ценностей.
Узнать большеПервое в России готовое решение для учёта товара по RFID-меткам на каждом из этапов цепочки поставок.
Узнать большеИсключи ошибки сопоставления и считывания акцизных марок алкогольной продукции при помощи мобильных инструментов учёта.
Узнать большеПолучение сертифицированного статуса партнёра «Клеверенс» позволит вашей компании выйти на новый уровень решения задач на предприятиях ваших клиентов..
Узнать большеИспользуй современные мобильные инструменты для проведения инвентаризации товара. Повысь скорость и точность бизнес-процесса.
Узнать большеПоказать все решения по автоматизацииСчитывание файла средствами внутреннего языка
Максимально простая процедура, для реализации которой создается объект ЧтениеXML — 1С, заранее получившая необходимую информацию, раскладывает содержание полученного документа по нужным разделам.
Особенности записи данных
В целях оперативного выполнения подобной операции платформой осуществляется отдельная обработка. Пользователь открывает учетную программу, авторизуется и последовательно выбирает разделы «Файл — выгрузка», указывая конкретную область сохранения документа — жесткий или съемный накопитель — а также требуемый формат. Стоит отметить, что скорость во многом зависит от размера объекта, так что перед запуском очередного цикла следует уточнить, какую именно информацию нужно выгрузить. Программа допускает слияние путем добавления новых позиций — в этом случае в качестве конечного указывается уже существующий элемент, либо используется буфер.
Выгрузка с помощью XDTO
Пакет представляет собой объект метаданных, предназначенный для обмена с использованием рассматриваемого формата. Его задача — создание понятной системе структуры, которая в дальнейшем будет использоваться ею в процессе выгрузки. Альтернативное решение — уже упомянутое применение файлового структурирования, при котором параметры задаются вручную.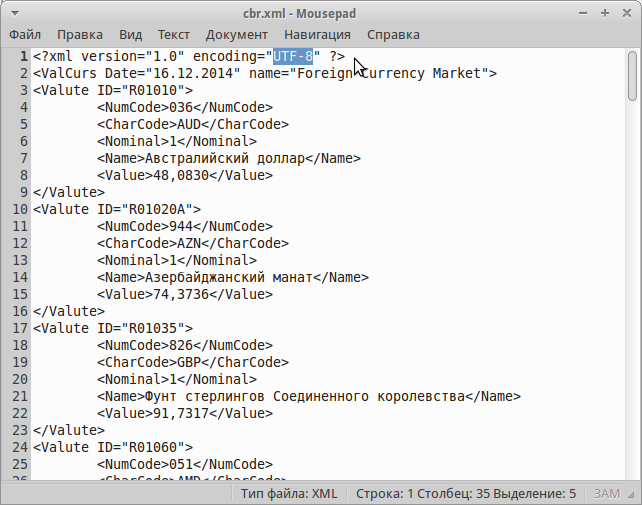 В обоих случаях завершение процедуры, означающее определение схемы, позволяет перейти к созданию документов любой сложности.
В обоих случаях завершение процедуры, означающее определение схемы, позволяет перейти к созданию документов любой сложности.
Как программно создать файл XML в 1С
Взаимодействие с документацией реализуется непосредственно через встроенный системный язык. Функционал, предлагаемый разработчиками начиная с версии 8.1, позволяет:
- Последовательно считывать и записывать информацию.
- Преобразовывать строки, выбранные из текстового содержания или значения атрибута, в заданный тип.
- Формировать строковое атрибутное представление для размещения в тексте.
- Получать формат, соответствующий переданному типовому параметру.
- Проверять возможность прочтения и соответствие структуре по умолчанию.
- Применять функцию «записатьXML» и возвращать тип данных.
- Использовать модель схемы и объектного доступа DOM, соответствующую стандартам Level 2, XPath и Load and Save, а также канонической версии 1.1 Canonical.
Используя внешнее соединение, механизмы работы и преобразования, можно организовывать интеграцию с прикладным обеспечением в соответствии с принятыми форматами.
Как осуществляется перенос между базами
Разработчики предлагают для решения подобной задачи форму 1С: Конвертация, основывающуюся на использовании стандартных файлов XML. Алгоритм процедуры предусматривает предварительное формирование пользователем документа, содержащего перечень последовательных правил, на основе которых и будет выполняться заданная операция. Программный продукт обеспечивает оперативный трансфер как между идентичными, так и между различными по типологии конфигурациями. В первом случае продолжительность процесса составляет не более часа, тогда как в остальных придется ждать чуть дольше.
Локализация баз данных в одном месте, равно как и наличие доступа сразу к нескольким хранилищам, обеспечивает возможность использования механизма OLE. Это достаточно удобная заготовка, в ходе которой реализуется прямая файловая транзакция, что не слишком сокращает время обработки, но при этом сводит к нулю вероятность возникновения ошибок. Нужно учитывать, что технология не подходит для применения в тех случаях, когда речь идет о распределенных областях хранения.![]()
Еще один, пожалуй, самый распространенный метод — файловый перенос. Простота и удобство обуславливаются возможностью использования любых форматов, включая doc, xls или dbf, однако на практике удобнее всего открыть в 1С файл XML, так как его структура позволяет сразу распределить информацию в соответствии с заданной схемой. Алгоритм укладывается в три последовательных операции: выгрузка, передача, загрузка. При этом фактическое местонахождение пользователей не имеет значения, что делает способ абсолютно универсальным. Небольшие размеры формируемых документов позволяют передавать их онлайн, через съемные носители или облачные сервисы хранения.
Из минусов, характерных для файлового метода, выделяют только два аспекта. Первый — необходимость наличия у юзера хотя бы начального уровня знаний и практических навыков работы с платформой. Второй — потребность в написании двух обработок, с помощью которых 1С и будет выгружать и загружать передаваемые данные.
Как правильно сформировать XML-документ произвольной структуры
Многие специалисты индустрии IT скрупулезно подходят к вопросу формирования файлов рассматриваемого стандарта, поскольку любые несоответствия, выявляемые программой в ходе прочтения, делают реализацию заданного процесса невозможной. В первую очередь это касается грамотного использования синтаксиса — так, например, несоблюдение порядка применения открывающих и закрывающих тегов приведет к появлению ошибки в тот момент, когда приложение получит команду его обработки.
В первую очередь это касается грамотного использования синтаксиса — так, например, несоблюдение порядка применения открывающих и закрывающих тегов приведет к появлению ошибки в тот момент, когда приложение получит команду его обработки.
На самом деле спецификация, определяющая правила корректного составления подобных схем и описаний, достаточно проста, и не требует особых пользовательских навыков. Можно сказать, что сегодня она даже не рассматривается в качестве обязательной для детального изучения, поскольку для создания нужных файлов всегда можно использовать встроенные программные механизмы или отдельные конфигураторы. В то же время нельзя не учитывать критичность ошибок, исключающих открытие документов другими приложениями и системными элементами.
Одно из преимуществ XML — отсутствие зависимости от конкретной платформы. Любая программа, предназначенная для обработки подобных объектов, способна считывать и использовать содержащуюся в них информацию, невзирая на то, какое оборудование или операционная система имеются в распоряжении пользователя.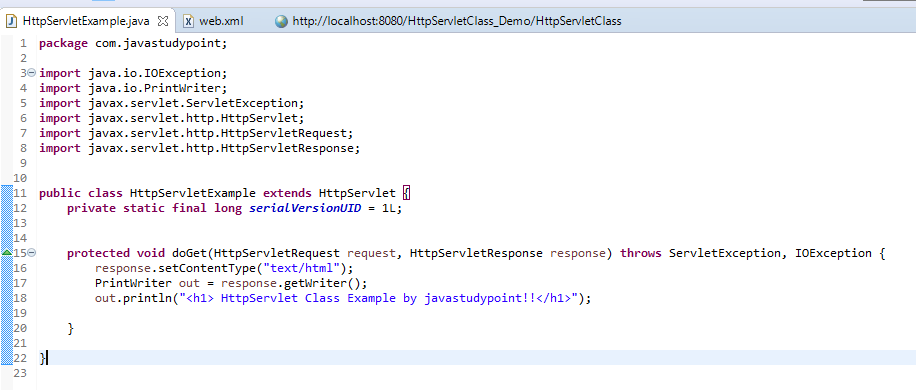 Так, например, грамотное применение структуры тегов позволяет открывать и обрабатывать данные, полученные с сервера, при помощи различных офисных приложений. Подобная совместимость во многом обуславливает популярность технологии в тех случаях, когда требуется быстрые трансферы между базами и компьютерами сети.
Так, например, грамотное применение структуры тегов позволяет открывать и обрабатывать данные, полученные с сервера, при помощи различных офисных приложений. Подобная совместимость во многом обуславливает популярность технологии в тех случаях, когда требуется быстрые трансферы между базами и компьютерами сети.
Стандартный алгоритм файловой генерации представляет собой следующую последовательность действий:
- Инициализация в 1С нового класса «ЗаписьXML», к примеру, с идентичным наименованием.
- Открытие временного файла и запись объявления.
- Заполнение содержания, с обязательным указанием начала и конца элемента.
- Запись и закрытие полученного объекта.
По умолчанию сгенерированный документ будет переведен в двоичные данные и вернется в место вызова функции создания, после чего может сохраняться в файловой структуре.
Преобразование объекта XDTO в текст
В ходе интеграции информационных систем, реализуемом с помощью вспомогательных сервисов, возможно появление необходимости в переводе пакета в текстовый вид — к примеру, с целью сохранения обменных логов. В подобной ситуации целесообразно придерживаться следующего алгоритма действий:
В подобной ситуации целесообразно придерживаться следующего алгоритма действий:
- Создать типовой файл записи.
- Отметить, что XML должно выводиться в строку 1С.
- Записать объект XDTO в элемент.
- Завершить процесс, получив результирующий вывод.
При этом нужно учитывать, что используемая пакетная переменная данных содержит информацию в формате, соответствующем одной из конфигураций, предложенных по умолчанию. В тех случаях, когда от платформы поступает запрос в сторону внешнего сервиса, предоставляющего динамическое описание, есть вероятность ошибки кода, обуславливаемой отсутствием в механизме сведений о структуре. Решение проблемы — замена в содержании элемента «ФабрикаXDTO» на «Прокси.ФабрикаXDTO», где последний является объектом типа WSПрокси, обеспечивающим обращение к ресурсу.
Готовые решения для всех направлений
Ускорьте работу сотрудников склада при помощи мобильной автоматизации. Навсегда устраните ошибки при приёмке, отгрузке, инвентаризации и перемещении товара.
Мобильность, точность и скорость пересчёта товара в торговом зале и на складе, позволят вам не потерять дни продаж во время проведения инвентаризации и при приёмке товара.
Узнать большеОбязательная маркировка товаров — это возможность для каждой организации на 100% исключить приёмку на свой склад контрафактного товара и отследить цепочку поставок от производителя
Узнать большеСкорость, точность приёмки и отгрузки товаров на складе — краеугольный камень в E-commerce бизнесе. Начни использовать современные, более эффективные мобильные инструменты.
Узнать большеПовысьте точность учета имущества организации, уровень контроля сохранности и перемещения каждой единицы. Мобильный учет снизит вероятность краж и естественных потерь.
Узнать большеПовысьте эффективность деятельности производственного предприятия за счет внедрения мобильной автоматизации для учёта товарно-материальных ценностей.
Узнать большеПервое в России готовое решение для учёта товара по RFID-меткам на каждом из этапов цепочки поставок.
Исключи ошибки сопоставления и считывания акцизных марок алкогольной продукции при помощи мобильных инструментов учёта.
Узнать большеПолучение сертифицированного статуса партнёра «Клеверенс» позволит вашей компании выйти на новый уровень решения задач на предприятиях ваших клиентов..
Узнать большеИспользуй современные мобильные инструменты для проведения инвентаризации товара. Повысь скорость и точность бизнес-процесса.
Узнать большеПоказать все решения по автоматизацииКак обмениваться данными, используя файлы других форматов
Последовательный процесс преобразования информации, реализуемый в ходе использования учетной платформы, называется сериализация. Рассматриваемый алгоритм реализуется автоматически, в тех случаях, когда от пользователя поступает запрос на импорт или экспорт. При этом целесообразно провести предварительную настройку, в рамках которой допускается выбор конкретных файловых типов, разрядности, а также иных технических параметров — таким образом вероятность ошибки при работе с разными программами будет ниже.
Очевидно, что при использовании условных офисных приложений обычная процедура копирования будет малоэффективна. В этом случае создается отдельная конфигурация — загрузчик, подключаемый к системе, и контролирующий общий цикл преобразования. Подобные системы обычно разрабатываются под предприятие, с учетом специфических особенностей и нюансов, характерных для повседневной деятельности. Инвестиции окупаются за счет сокращения временных издержек, а также минимизации технических проблем, вызванных расхождением в форматах.
Как загрузить XML документ произвольной структуры
Для решения этой задачи необходимо написание стандартной обработки, при создании которой следует учитывать следующие аспекты:
- Путь к загружаемому объекту указывается в переменной.
- Используется модель последовательного доступа.
- Проверяется, текущая часть элемента — чтение атрибутов возможно только в том случае, если она является начальной.
После завершения цикла в информационное окно выводится текстовое уведомление либо признак конца элемента.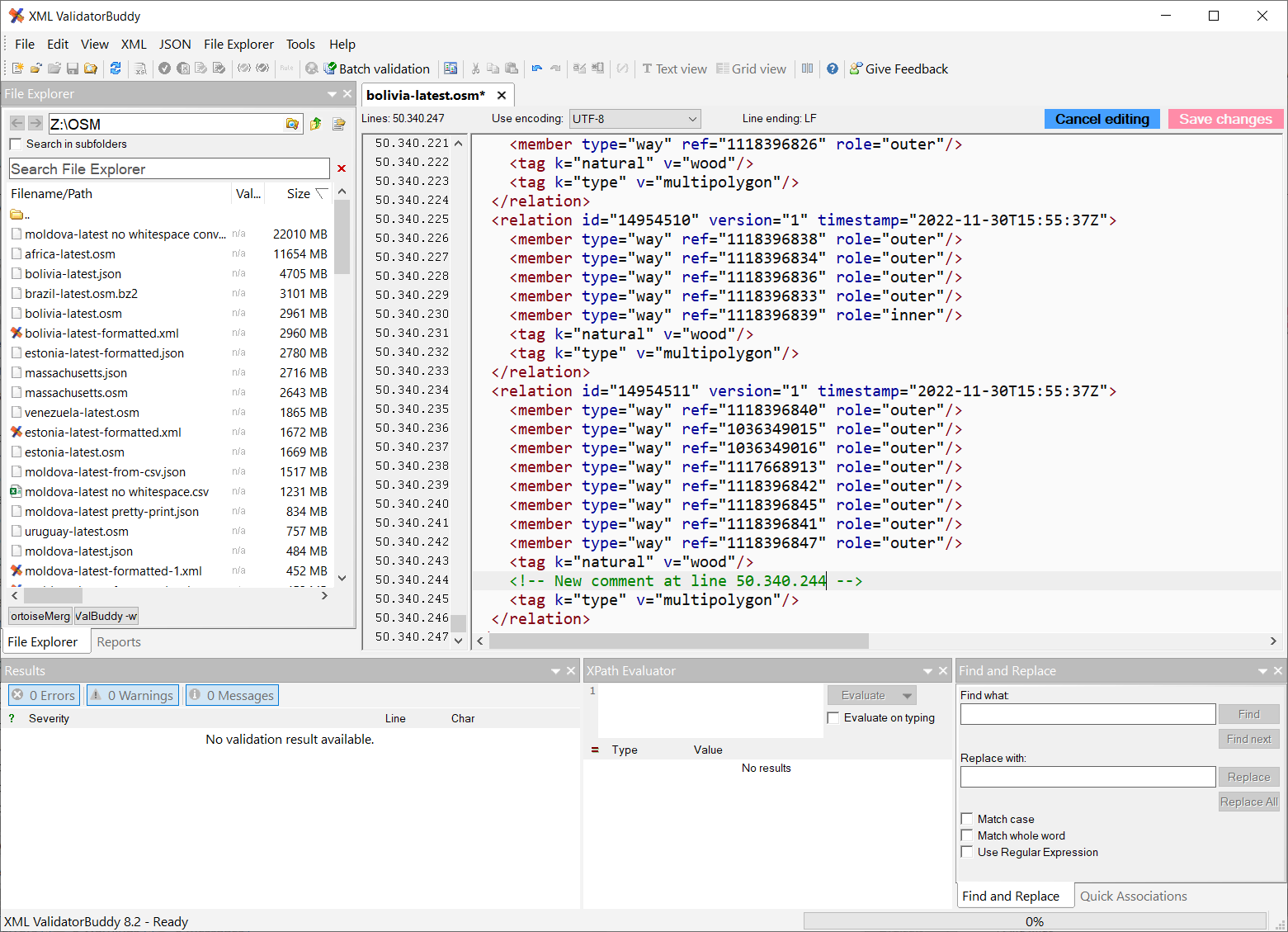 Если тестовая проверка не показала наличия ошибок в чтении — алгоритм может использоваться для дальнейшего решения производственных задач.
Если тестовая проверка не показала наличия ошибок в чтении — алгоритм может использоваться для дальнейшего решения производственных задач.
Заключение
Специфика взаимодействия с учетными платформами обуславливает необходимость наличия у сотрудников базовых знаний и определенного уровня квалификации, позволяющего свободно работать с документами и отчетностью. С учетом того, что большинство отечественных компаний используют 1С, грамотная работа с XML становится немаловажным аспектом. Быстрый обмен данными и оперативная обработка информации способствуют принятию правильных решений, и, как следствие, приносят выгоду бизнесу. Добиться желаемого эффекта — повышения эффективности — также помогает оптимизация рутинных процессов, для реализации которой достаточно интегрировать продукты мобильной автоматизации, предлагаемые компанией «Клеверенс».
Количество показов: 5237
Как открыть файл XML в Человекочитаемом формате
Статьи › Портал Госуслуг › Как открыть файл XML с госуслуг на телефоне
Нажимаем на ссылку «Открыть мой документ», выбираем файл XML и получаем выписку в человекочитаемом формате! Его можно тут же распечатать или сохранить в формате pdf. Правда для того, чтобы все получилось, на каком-то этапе нужно будет установить плагин СБИС, но с этим проблем обычно не бывает.
Правда для того, чтобы все получилось, на каком-то этапе нужно будет установить плагин СБИС, но с этим проблем обычно не бывает.
- Чем открывать файл формата XML
- Как открыть XML файл Росреестра в читаемом виде
- Как открывать файлы в формате XML
- Как прочитать документ в формате XML
- Чем открывать файлы XML
- Как открыть XML файл в читаемом виде
- Как открыть файл XML в читаемом формате
- Как открыть XML в нормальном виде
Чем открывать файл формата XML
Как и чем открыть XML‑файл на компьютере:
1. Браузер Если вам нужно только просмотреть содержимое файла, проще всего воспользоваться этим способом.
2. Встроенный текстовый редактор Подойдёт, если нужно не только просмотреть, но и отредактировать какие‑либо данные внутри XML.
3. Microsoft Word.
4. Microsoft Excel.
5. На iPhone.
Как открыть XML файл Росреестра в читаемом виде
Нажать на «Проверка электронного документа»:
1. Кликнуть на «Выберите файл».
Кликнуть на «Выберите файл».
2. Указать путь к выписке из Росреестра в формате xml, которую необходимо открыть.
3. Выбрать функцию «Показать в человеко-читаемом формате».
Как открывать файлы в формате XML
Если вы используете Excel 2016 или более раннюю версию, на вкладке Данные нажмите кнопку Из других источников, а затем щелкните Из импорта данных XML. Выберите диск, папку или расположение в Интернете, где находится файл данных XML (XML-файл), который вы хотите импортировать. Выберите файл и нажмите кнопку Открыть.
Как прочитать документ в формате XML
Открыть xml в блокноте или WordPad:
Простой блокнот Windows способен мгновенно открывать файлы XML. Как это сделать? Просто щелкните правой кнопкой мыши по рассматриваемому файлу и в контекстном меню, которое будет показано, выберите пункты Открыть с помощью → Блокнот. И, вуаля!
Чем открывать файлы XML
Как открыть файл XML:
1. Если нужно просмотреть содержимое, используйте браузер.
2. Если нужно открыть таблицу, лучше всего подойдет Excel: откройте программу, кликните CTRL+O, а затем укажите путь, по которому расположен файл на вашем компьютере.
Как открыть XML файл в читаемом виде
Microsoft Word:
Вариант для случаев, когда вам интересна сама информация внутри XML, а не его структура. В отличие от обычных текстовых редакторов Word умеет отображать данные в форматированном и более читаемом виде. Найдите файл на диске и так же сделайте правый клик, после чего выберите «Открыть с помощью» → Word.
Как открыть файл XML в читаемом формате
Если вы хотите открыть файл XML и отредактировать его, вы можете использовать текстовый редактор. Вы можете использовать текстовые редакторы по умолчанию, которые поставляются с вашим компьютером, например Блокнот в Windows или TextEdit на Mac. Все, что вам нужно сделать, это найти файл XML, щелкнуть файл XML правой кнопкой мыши и выбрать параметр «Открыть с помощью».
Как открыть XML в нормальном виде
Вариант для случаев, когда вам интересна сама информация внутри XML, а не его структура. В отличие от обычных текстовых редакторов Word умеет отображать данные в форматированном и более читаемом виде. Найдите файл на диске и так же сделайте правый клик, после чего выберите «Открыть с помощью» → Word.
В отличие от обычных текстовых редакторов Word умеет отображать данные в форматированном и более читаемом виде. Найдите файл на диске и так же сделайте правый клик, после чего выберите «Открыть с помощью» → Word.
Как разобрать файлы XML с помощью python? [Код включен]
От заказа продуктов через Instamart и покупки гардероба в Myntra до бронирования отпуска на MakemyTrip — в этом десятилетии веб-сайты стали незаменимыми! Вы когда-нибудь задумывались, как эти веб-сайты отображают информацию для клиентов в легко интерпретируемом виде, а также обрабатывают и взаимодействуют с данными в бэкэнде?
Существуют определенные форматы файлов, которые восполняют этот пробел, будучи интерпретируемыми как для машинного языка, так и для человека. Одним из таких широко используемых форматов является XML, сокращение от Extensible Markup Language.
Что такое файлы XML и как их использовать?
Файлы XML используются для хранения и передачи данных между клиентами и серверами. Это позволяет нам определять данные в структурированном формате с помощью тегов, атрибутов и значений. Одним из основных преимуществ XML является его гибкость. Его можно использовать для представления данных во многих форматах и легко адаптировать для новых целей. Это делает его популярным выбором для таких приложений, как веб-службы, обмен данными и файлы конфигурации. В этой статье я познакомлю вас с различными методами Python для анализа XML-файла на практическом примере.
Это позволяет нам определять данные в структурированном формате с помощью тегов, атрибутов и значений. Одним из основных преимуществ XML является его гибкость. Его можно использовать для представления данных во многих форматах и легко адаптировать для новых целей. Это делает его популярным выбором для таких приложений, как веб-службы, обмен данными и файлы конфигурации. В этой статье я познакомлю вас с различными методами Python для анализа XML-файла на практическом примере.
Вы ищете автоматизированный анализ XML? Попробуйте автоматизированные рабочие процессы Nanonets. Начните бесплатную пробную версию прямо сейчас.
Понимание структуры XML-файлов
Прежде чем мы углубимся в детали анализа XML-файлов, давайте сначала разберемся с различными частями XML-документа. В XML элемент является фундаментальным строительным блоком документа, который представляет собой структурированную часть информации. Содержимое элемента всегда должно быть заключено между открывающим и закрывающим тегами, как показано ниже.
Содержимое элемента всегда должно быть заключено между открывающим и закрывающим тегами, как показано ниже.
Я буду использовать пример файла «travel_pckgs.xml», который содержит сведения о различных турпакетах, предлагаемых компанией. Я буду продолжать использовать один и тот же файл в блоге для ясности.
<турпакеты> <пакет>Ощутите великолепную красоту Парижа и французскую культуру. Париж, Франция <цена>3000 <длительность>7 <платеж>да <возврат>да <пакет>Отправляйтесь в захватывающее приключение на гавайских пляжах! Гавайи, США <цена>4000 <длительность>10 <платеж>нет <возврат>нет <пакет>Побалуйте себя красотой и очарованием Италии и получите все- инклюзивный тур по настоящей итальянской кухне! Италия <цена>2000 <длительность>8 <платеж>да <возврат>нет <пакет>Ощутите красоту пляжей острова, включая подводное плавание. Андаманские и Никобарские острова <цена>800 <длительность>8 <платеж>нет <возврат>да
 дайвинг и ночное плавание на байдарках по мангровым зарослям.
дайвинг и ночное плавание на байдарках по мангровым зарослям.В файле содержатся данные о 4 турпакетах с подробной информацией о пункте назначения, описании, цене и способах оплаты, предоставленных агентством. Давайте посмотрим на разбивку различных частей приведенного выше XML:
- Корневой элемент: Элемент самого верхнего уровня называется корневым, который в нашем файле равен
- Атрибут: «id» — это атрибут каждого элемента
в нашем файле. Обратите внимание, что атрибут должен иметь уникальные значения («Отпуск в Париже», «Приключение на Гавайях» и т. д.) для каждого элемента. Как видите, атрибут и его значение обычно упоминаются внутри начального тега. - Дочерние элементы : Элементы, завернутые в корень, являются дочерними элементами. В нашем случае все теги
- Подэлементы: Дочерний элемент может иметь больше подэлементов внутри своей структуры. Дочерний элемент
имеет подэлементы , и, , дополнительно имеет подэлементы и , которые обозначают, есть ли у конкретного пакета варианты оплаты через EMI и возврата или нет.
 Как видите, атрибут и его значение обычно упоминаются внутри начального тега.
Как видите, атрибут и его значение обычно упоминаются внутри начального тега. Совет: Вы можете создать древовидное представление XML-файла, чтобы получить четкое представление об этом инструменте.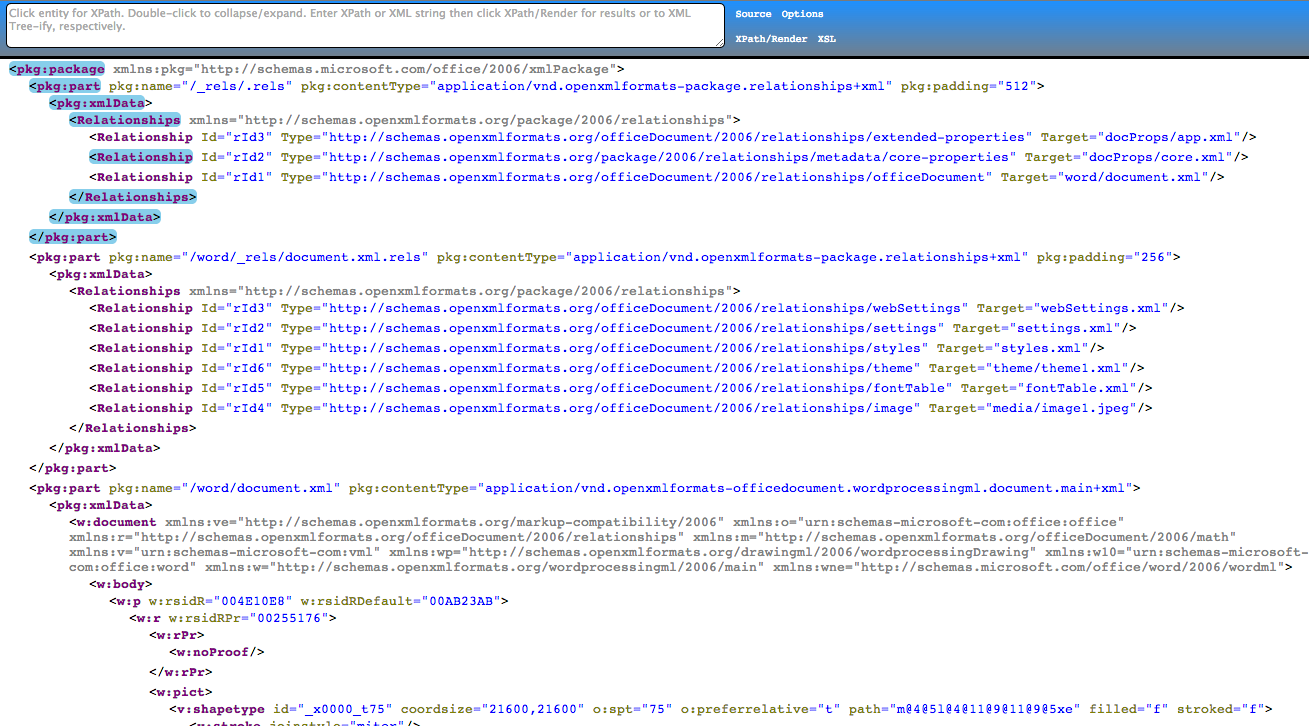 Посмотрите на иерархическое древовидное представление нашего XML-файла!
Посмотрите на иерархическое древовидное представление нашего XML-файла!
Отлично! Мы хотим читать данные, хранящиеся в этих полях, искать, обновлять и вносить изменения по мере необходимости для веб-сайта, верно? Это называется синтаксическим анализом, при котором XML-данные разбиваются на части и идентифицируются разные части.
Существует несколько способов анализа XML-файла в Python с помощью разных библиотек. Давайте погрузимся в первый метод!
Попробуйте Nanonets анализировать файлы XML. Начните бесплатную пробную версию без данных кредитной карты.
Использование Mini DOM для анализа XML-файлов
Я уверен, что вы сталкивались с DOM (Document Object Model), стандартным API для представления XML-файлов. Mini DOM — это встроенный модуль Python, который минимально реализует DOM.
Как работает мини-ДОМ?
Загружает входной XML-файл в память, создавая древовидную структуру «Дерево DOM» для хранения элементов, атрибутов и текстового содержимого. Поскольку XML-файлы также по своей природе имеют иерархическую древовидную структуру, этот метод удобен для навигации и извлечения информации.
Поскольку XML-файлы также по своей природе имеют иерархическую древовидную структуру, этот метод удобен для навигации и извлечения информации.
Давайте посмотрим, как импортировать пакет с помощью приведенного ниже кода. Вы можете проанализировать файл XML, используя функцию xml.dom.minidom.parse() , а также получить корневой элемент.
импорт xml.dom.minidom
# разбираем XML-файл
xml_doc = xml.dom.minidom.parse('travel_pckgs.xml')
# получить корневой элемент
корень = xml_doc.documentElement
print('Root is',root) Вывод, который я получил для приведенного выше кода:
>> Корень
Допустим, я хочу распечатать место, продолжительность и цена.
Функцию getAttribute() можно использовать для получения значения атрибута элемента.
Если вы хотите получить доступ ко всем элементам под определенным тегом, используйте метод getElementsByTagName() и укажите тег в качестве входных данных. Самое приятное то, что getElementsByTagName() можно использовать рекурсивно для извлечения вложенных элементов.
Самое приятное то, что getElementsByTagName() можно использовать рекурсивно для извлечения вложенных элементов.
# получить все элементы пакета
пакеты = xml_doc.getElementsByTagName («пакет»)
# перебираем пакеты и извлекаем данные
для пакета в пакетах:
package_id = package.getAttribute('id')
описание = package.getElementsByTagName('описание')[0].childNodes[0].data
цена = package.getElementsByTagName('price')[0].childNodes[0].data
продолжительность = package.getElementsByTagName('длительность')[0].childNodes[0].data
print('Идентификатор пакета:', package_id)
print('Описание:', описание)
print('Цена:', цена) Здесь показан вывод приведенного выше кода с извлеченными и напечатанными идентификатором, текстом описания и ценой каждого пакета.
Код пакета: Парижские каникулы Описание: Испытайте великолепную красоту Парижа и французскую культуру. Цена: 3000 ID пакета: Приключения на Гавайях Описание: Отправляйтесь в захватывающее приключение на гавайских пляжах! Цена: 4000 ID пакета: Бегство по-итальянски Описание: Насладитесь красотой и очарованием Италии и получите тур по итальянской кухне по системе «все включено»! Цена: 2000 ID пакета: Ретрит на Андаманских островах Описание: Испытайте красоту пляжей острова, включая подводное плавание.
 дайвинг и ночной каякинг через мангровые заросли.
Цена: 800
дайвинг и ночной каякинг через мангровые заросли.
Цена: 800 Анализатор Minidom также позволяет нам перемещаться по дереву DOM от одного элемента к его родительскому элементу, его первому дочернему элементу, последнему дочернему элементу и так далее. Вы можете получить доступ к первому потомку элемента
# получить первый элемент пакета
paris_package = xml_doc.getElementsByTagName('пакет')[0]
# получить первый дочерний элемент пакета
first_child = париж_пакет.firstChild
#print(first_child)
>>
<Элемент DOM: описание по адресу 0x7f2e4800d9д0>
Имя узла: описание
Node Value: None Вы можете убедиться, что «описание» является первым дочерним элементом  Проверьте приведенный ниже пример и его вывод.
Проверьте приведенный ниже пример и его вывод.
child_elements=paris_package.childNodes печать (дочерние_элементы) >> [<Элемент DOM: описание по адресу 0x7f057938e940>, <Элемент DOM: пункт назначения по адресу 0x7f057938e9d0>, <Элемент DOM: цена по адресу 0x7f057938ea60>, <Элемент DOM: продолжительность по адресу 0x7f057938eaf0>, <Элемент DOM: оплата по адресу 0x7f057938eb80>]
Подобно этому, minidom предоставляет больше способов обхода, таких как parentNode, lastChild nextSibling и т. д. Вы можете проверить все доступные функции библиотека здесь.
Но основным недостатком этого метода является дорогое использование памяти, так как весь файл загружается в память. Нецелесообразно использовать минидом для больших файлов.
Автоматизировать синтаксический анализ XML Nanonets. Начните бесплатную пробную версию сегодня. Кредитная карта не требуется.
Использование библиотеки ElementTree для анализа XML-файлов
ElementTree — это широко используемый встроенный анализатор Python, который предоставляет множество функций для чтения, обработки и изменения XML-файлов. Этот синтаксический анализатор создает древовидную структуру для хранения данных в иерархическом формате.
Этот синтаксический анализатор создает древовидную структуру для хранения данных в иерархическом формате.
Начнем с импорта библиотеки и вызова функции parse() нашего файла XML. Вы также можете предоставить входной файл в строковом формате и использовать функцию fromstring() . После того, как мы инициализируем проанализированное дерево, мы можем использовать получить root () функция для получения корневого тега, как показано ниже.
импортировать xml.etree.ElementTree как ET
дерево = ET.parse('travel_pkgs.xml')
#вызов корневого элемента
корень = дерево.getroot()
print("Корень есть",корень)
Выход:
>>
Корневой элемент Извлечен корневой тег ‘travelPackages’!
Допустим, теперь мы хотим получить доступ ко всем первым дочерним тегам корня. Мы можем использовать простой цикл for и перебирать его, печатая дочерние теги, такие как пункт назначения, цена и т. д. Обратите внимание, что если бы мы указали значение атрибута внутри открывающего тега описания, круглые скобки не были бы пустыми. Посмотрите приведенный ниже фрагмент!
д. Обратите внимание, что если бы мы указали значение атрибута внутри открывающего тега описания, круглые скобки не были бы пустыми. Посмотрите приведенный ниже фрагмент!
для x в корне[0]:
печать (x.tag, x.attrib)
Выход:
>>
описание {}
место назначения {}
цена {}
продолжительность {}
payment {} Кроме того, функция iter() может помочь вам найти любой интересующий элемент во всем дереве. Давайте используем это для извлечения описаний каждого пакета туров в нашем файле. Не забудьте использовать атрибут text для извлечения текста элемента.
Для x в root.iter('описание'):
печать (x.текст)
Выход:
>>
«Ощутите великолепную красоту Парижа и французскую культуру».
«Отправляйтесь в захватывающее приключение на пляжах Гавайев!»
"Побалуйте себя красотой и очарованием Италии и получите тур по итальянской кухне по системе "все включено"!"
«Насладитесь красотой пляжей острова, подводным плаванием с аквалангом и ночным каякингом через мангровые заросли. 
При использовании ElementTree базовый цикл for достаточно эффективен для доступа к дочерним элементам. Посмотрим, как.
Анализ XML-файлов с помощью цикла for
Вы можете просто перебирать дочерние элементы с помощью цикла for, извлекая атрибуты, как показано ниже.
для тура в корень:
распечатать(тур.атриб)
Выход:
>>
{'id': 'Отпуск в Париже'}
{'id': 'Гавайские приключения'}
{'id': 'Побег из Италии'}
{'id': 'Andaman Island Retreat'} Для обработки сложных запросов и фильтрации ElementTee имеет метод findall() . Этот метод позволяет получить доступ ко всем дочерним элементам тега, переданным в качестве параметров. Допустим, вы хотите узнать о турпакетах стоимостью менее 4000 долларов, а также иметь EMIoption как «да». Проверьте фрагмент.
для пакета в root.findall('package'):
цена = int(package.find('price').text)
возврат = package.find('платеж/возврат').text.strip("'")
если цена < 4000 и возврат == 'да':
print(package. attrib['id'])  attrib['id'])
attrib['id']) Мы в основном перебираем пакеты через root.findall(‘package’), а затем извлекаем цену и возмещение с помощью метод find() . После этого мы проверяем ограничения и отфильтровываем подходящие пакеты, которые напечатаны ниже.
Вывод:
>>
Отпуск в Париже
Отдых на Андаманских островах
Используя ElementTree, вы можете легко изменять и обновлять элементы и значения XML-файла, в отличие от miniDOM и SAX. Давайте проверим, как в следующем разделе.
Как изменить файлы XML с помощью ElementTree?
Допустим, пришло время рождественских каникул и агентство хочет удвоить стоимость пакета. ElementTree предоставляет set() функция, которую мы можем использовать для обновления значений элементов. В приведенном ниже коде я получил доступ к цене каждого пакета через функцию iter() и манипулировал ценами. Вы можете использовать функцию write() для записи нового XML-файла с обновленными элементами.
для цены в root.iter('price'):
новая_цена = интервал (цена.текст)*2
цена.текст = ул(новая_цена)
price.set('обновлено', 'да')
tree.write('christmas_packages.xml') Вы сможете найти выходной файл, подобный тому, что показан на изображении ниже. Если вы помните, цены на «Отпуск в Париже» и «Приключения на Гавайях» в исходном файле составляют 3000 и 4000 долларов.
Но что, если мы захотим добавить новый тег
ET.SubElement(корень[3], 'остаться')
для x в root.iter('оставаться'):
курорт = 'Частная вилла Премиум'
x.text = ул(курорт) Надеюсь, вы тоже получили результаты! Пакет также предоставляет функцию pop() , с помощью которой можно удалить атрибуты и подэлементы, если они не нужны.
Простой API для XML (SAX)
SAX — еще один синтаксический анализатор Python, который устраняет недостаток miniDOM за счет последовательного чтения документа. Он не загружает все дерево в свою память, а также позволяет отбрасывать элементы, уменьшая использование памяти.
Во-первых, давайте создадим объект парсера SAX и зарегистрируем функции обратного вызова для различных событий, которые вы хотите обрабатывать в XML-документе. Для этого я определяю собственный класс TravelPackageHandler, как показано ниже, путем подкласса ContentHandler SAX.
импорт xml.sax
# Определите собственный класс SAX ContentHandler для обработки событий
класс TravelPackageHandler (xml.sax.ContentHandler):
защита __init__(сам):
self.packages = []
self.current_package = {}
self.current_element = ""
self.current_payment = {}
def startElement (я, имя, атрибуты):
self.current_element = имя
если имя == "пакет":
self.current_package = {"id": attrs.getValue("id")}
символы определения (я, содержание):
если self. current_element в ["описание", "назначение", "цена", "продолжительность", "вариант EMI", "возврат"]:
self.current_package[self.current_element] = content.strip()
если self.current_element == "оплата":
self.current_payment = {}
def endElement(я, имя):
если имя == "пакет":
self.current_package["платеж"] = self.current_payment
self.packages.append (self.current_package)
если имя == "оплата":
self.current_package["платеж"] = self.current_payment
def startElementNS(self, name, qname, attrs):
проходить
def endElementNS (я, имя, qname):
пройти  current_element в ["описание", "назначение", "цена", "продолжительность", "вариант EMI", "возврат"]:
self.current_package[self.current_element] = content.strip()
если self.current_element == "оплата":
self.current_payment = {}
def endElement(я, имя):
если имя == "пакет":
self.current_package["платеж"] = self.current_payment
self.packages.append (self.current_package)
если имя == "оплата":
self.current_package["платеж"] = self.current_payment
def startElementNS(self, name, qname, attrs):
проходить
def endElementNS (я, имя, qname):
пройти
current_element в ["описание", "назначение", "цена", "продолжительность", "вариант EMI", "возврат"]:
self.current_package[self.current_element] = content.strip()
если self.current_element == "оплата":
self.current_payment = {}
def endElement(я, имя):
если имя == "пакет":
self.current_package["платеж"] = self.current_payment
self.packages.append (self.current_package)
если имя == "оплата":
self.current_package["платеж"] = self.current_payment
def startElementNS(self, name, qname, attrs):
проходить
def endElementNS (я, имя, qname):
пройти В приведенном выше фрагменте используются методы startElement(), character(), и endElement() для извлечения данных из элементов и атрибутов XML. Когда синтаксический анализатор SAX читает документ, он запускает зарегистрированные функции обратного вызова для каждого встречающегося события. Например, если он встречает начало нового элемента, он вызывает функцию startElement(). Теперь давайте воспользуемся нашим настраиваемым обработчиком, чтобы получить различные идентификаторы пакетов, проанализировав XML-файл нашего примера.
# Создать объект парсера SAX
парсер = xml.sax.make_parser()
обработчик = TravelPackageHandler()
parser.setContentHandler(обработчик)
parser.parse ("путешествие_pckgs.xml")
для пакета в handler.packages:
print(f'Package: {package["id"]}') Output >>
Package: Paris Vacation
Package: Hawaii Adventure
Package: Italian Getaway
Package: Andaman Island Retreat
SAX can использоваться для больших файлов и потоковой передачи из-за его эффективности. Но это неудобно при работе с глубоко вложенными элементами. Что делать, если вы хотите получить доступ к любому произвольному узлу дерева? Поскольку он не поддерживает произвольный доступ, синтаксическому анализатору придется последовательно читать весь документ, чтобы получить доступ к определенному элементу.
Синхронизируйте все ваши двойные записи с Nanonets. Держите все свои счета сбалансированными, 24×7. Настройте процессы учета менее чем за 15 минут. Смотри как.
Потоковый синтаксический анализатор для XML
Это библиотека Python pulldom , которая предоставляет API потокового синтаксического анализатора с DOM-подобным интерфейсом.
Как это работает?
Обрабатывает XML-данные по принципу «вытягивания». То есть вы явно запрашиваете у синтаксического анализатора следующее событие (например, начальный элемент, конечный элемент, текст и т. д.) в данных XML.
Синтаксис знаком тому, что мы видели в предыдущих библиотеках. В приведенном ниже коде я демонстрирую, как импортировать библиотеку и использовать ее для печати туров продолжительностью 4 дня и более, а также обеспечить возврат средств при отмене.
из синтаксического анализа импорта xml.dom.pulldom
события = разбор ("travel_pkgs.xml")
для события, узел в событиях:
если событие == pulldom.START_ELEMENT и node.tagName == 'package':
продолжительность = int(node.getElementsByTagName('длительность')[0]. firstChild.data)
возврат = node.getElementsByTagName('refund')[0].firstChild.data.strip("'")
если продолжительность > 4 и возврат == 'да':
print(f"Пакет: {node.getAttribute('id')}")
print(f"Продолжительность: {длительность}")
print(f"Возврат: {возврат}")  firstChild.data)
возврат = node.getElementsByTagName('refund')[0].firstChild.data.strip("'")
если продолжительность > 4 и возврат == 'да':
print(f"Пакет: {node.getAttribute('id')}")
print(f"Продолжительность: {длительность}")
print(f"Возврат: {возврат}")
firstChild.data)
возврат = node.getElementsByTagName('refund')[0].firstChild.data.strip("'")
если продолжительность > 4 и возврат == 'да':
print(f"Пакет: {node.getAttribute('id')}")
print(f"Продолжительность: {длительность}")
print(f"Возврат: {возврат}") Вы должны получить результат вида:
Пакет: Парижские каникулы
Продолжительность: 7
Возврат: да
Пакет: Ретрит на Андаманских островах
Продолжительность: 8
Возврат: да 90 003
Проверьте результаты! Парсер pull сочетает в себе несколько функций miniDOM и SAX, что делает его относительно эффективным.
Резюме
Я уверен, что вы уже хорошо разбираетесь в различных парсерах, доступных в Python. Не менее важно знать, когда выбрать парсер, чтобы сэкономить время и ресурсы. Среди всех парсеров, которые мы видели, ElementTree обеспечивает максимальную совместимость с выражениями XPath, помогающими выполнять сложные запросы. Minidom имеет простой в использовании интерфейс и может быть выбран для работы с небольшими файлами, но он слишком медленный в случае больших файлов. В то же время SAX используется в ситуациях, когда файл XML постоянно обновляется, как в случае машинного обучения в реальном времени.
В то же время SAX используется в ситуациях, когда файл XML постоянно обновляется, как в случае машинного обучения в реальном времени.
Одной из альтернатив для анализа ваших файлов является использование инструментов автоматического анализа, таких как Nanonets. Наносети могут помочь вам извлечь данные из любого документа за считанные секунды, не написав ни одной строки кода.
O Оптимизируйте эффективность своего бизнеса, сократите расходы и ускорьте рост. Узнайте , как варианты использования Nanonets могут применяться к вашему продукту.
pandas.read_xml — документация pandas 2.0.1
- pandas.read_xml( path_or_buffer , * , xpath=’./*’ , namespaces=None , elems_only=False , attrs_only = Ложь , имен = Нет , dtype = Нет , конвертеры=Нет , parse_dates=Нет , encoding=’utf-8′ , парсер=’lxml’ , таблица стилей=Нет , iterparse = Нет , сжатие = ‘infer’ , storage_options=Нет , dtype_backend=_NoDefault. no_default )[источник]
Чтение XML-документа в объект
DataFrame.Новое в версии 1.3.0.
- Параметры
- path_or_buffer str, объект пути или файлоподобный объект
String, объект пути (реализующий
os.PathLike[str]) или файлоподобный объект, реализующий функциюread(). Строка может быть любым допустимым XML строка или путь. Строка также может быть URL-адресом. Действительные схемы URL включают http, ftp, s3 и файл.- xpath str, необязательный, по умолчанию ‘./*’
XPath для анализа необходимого набора узлов для миграции на DataFrame. XPath должен возвращать набор элементов, а не один элемент. Примечание. Парсер
etreeподдерживает ограниченный XPath. выражения. Для более сложного XPath используйтеlxml, который требует монтаж.- пространства имен dict, необязательный
Пространства имен, определенные в XML-документе как словари с ключом префикс пространства имен и значение URI.
Нет необходимости включать все
пространства имен в XML, только те, которые используются в xpathвыражение. Примечание: если документ XML использует пространство имен по умолчанию, обозначенное как xmlns=’’ без префикса, вы должны назначить любой временный префикс пространства имен, такой как «doc», к URI для анализа базовые узлы и/или атрибуты. Например,пространств имен = {"doc": "https://example.com"}- elems_only bool, необязательный, по умолчанию False
Анализировать только дочерние элементы по указанному
xpath. По умолчанию, возвращаются все дочерние элементы и непустые текстовые узлы.- attrs_only bool, необязательный, по умолчанию False
Анализировать только атрибуты по указанному
xpath. По умолчанию возвращаются все атрибуты.- имена в виде списка, необязательно
Имена столбцов для DataFrame проанализированных XML-данных.
Используйте этот параметр, чтобы
переименовать исходные имена элементов и различать элементы с одинаковыми именами и
атрибуты.- dtype Введите имя или словарь столбца -> тип, необязательно
Тип данных для данных или столбцов. Например. {‘a’: np.float64, ‘b’: np.int32, ‘с’: ‘Int64’} Используйте str или объект вместе с подходящими настройками na_values чтобы сохранить и не интерпретировать dtype. Если указаны преобразователи, они будут применены ВМЕСТО. преобразования dtype.
Новое в версии 1.5.0.
- преобразователи dict, опционально
Dict функций для преобразования значений в определенных столбцах. Ключи могут либо быть целыми числами или метками столбцов.
Новое в версии 1.5.0.
- parse_dates bool или список int или имена или список списков или dict, по умолчанию False
Идентификаторы для анализа индекса или столбцов на дату и время.
Поведение следующее:логическое значение. Если True -> попробуйте проанализировать индекс.
список целых или имен. например Если [1, 2, 3] -> попробуйте проанализировать столбцы 1, 2, 3 каждый как отдельный столбец даты.
список списков. например Если [[1, 3]] -> объединить столбцы 1 и 3 и проанализировать как один столбец даты.
дикт, напр. {‘foo’ : [1, 3]} -> анализировать столбцы 1, 3 как дату и вызывать результат ‘foo’
Новое в версии 1.5.0.
- encoding str, необязательный, по умолчанию ‘utf-8’
Кодировка XML-документа.
- парсер {‘lxml’,’etree’}, по умолчанию ‘lxml’
Модуль парсера для извлечения данных. Только «lxml» и «etree» поддерживаются. С «lxml» более сложные поиски XPath и возможность использовать таблицу стилей XSLT поддерживаются.
- таблица стилей str, объект пути или файловый объект
URL-адрес, файловый объект или необработанная строка, содержащая сценарий XSLT.
Эта таблица стилей должна сглаживать сложные, глубоко вложенные XML-документы.
для облегчения разбора. Чтобы использовать эту функцию, у вас должен быть модуль lxml. установлен и укажите «lxml» как парсерxpathдолжен ссылочные узлы преобразованного XML-документа, сгенерированного после XSLT преобразование, а не исходный XML-документ. Только XSLT 1.0 скрипты, а не более поздние версии в настоящее время поддерживаются.- iterparse dict, необязательный
Узлы или атрибуты для извлечения при итеранализе XML-документа как dict с ключом, являющимся именем повторяющегося элемента, и значением, являющимся список элементов или имен атрибутов, которые являются потомками повторяющегося элемент. Примечание. Если этот параметр используется, он заменит синтаксический анализ
xpath. и в отличие от xpath, потомки не должны быть связаны друг с другом, но могут существовать в любом месте документа под повторяющимся элементом. Эта память-
Эффективный метод следует использовать для очень больших файлов XML (500 МБ, 1 ГБ или 5 ГБ+).
Например,iterparse = {"row_element": ["child_elem", "attr", "grandchild_elem"]}Новое в версии 1.5.0.
- сжатие str или dict, по умолчанию ‘infer’
Для распаковки данных на лету на диске. Если «infer» и «path_or_buffer» пути, а затем определить сжатие из следующих расширений: ‘.gz’, ‘.bz2’, ‘.zip’, ‘.xz’, ‘.zst’, ‘.tar’, ‘.tar.gz’, ‘.tar.xz’ или ‘.tar.bz2’ (иначе без сжатия). При использовании «zip» или «tar» ZIP-файл должен содержать только один файл данных для чтения. Установите на
Нетбез декомпрессии. Также может быть dict с набором ключей'method'на один из {'zip','gzip','bz2','zstd','tar'} и другие пары ключ-значение пересылаются наzipfile.ZipFile,gzip.GzipFile,bz2., BZ2File zstandard.ZstdDecompressorилиtarfile.TarFileсоответственно. Например, следующее может быть передано для декомпрессии Zstandard с использованием пользовательский словарь сжатия:сжатие={'метод': 'zstd', 'dict_data': my_compression_dict}.Новое в версии 1.5.0: добавлена поддержка файлов .tar .
Изменено в версии 1.4.0: поддержка Zstandard.
- storage_options dict, необязательный
Дополнительные параметры, которые имеют смысл для конкретного подключения к хранилищу, например. хост, порт, имя пользователя, пароль и т. д. Для URL-адресов HTTP(S) пары ключ-значение пересылаются на
urllib.request.Requestв качестве параметров заголовка. Для других URL-адреса (например, начинающиеся с «s3://» и «gcs://») пары «ключ-значение» переадресовано наfsspec.open. Дополнительные сведения см. вfsspecиurllib. подробности и дополнительные примеры вариантов хранения см. здесь.- dtype_backend {«numpy_nullable», «pyarrow»}, по умолчанию используются DataFrames с поддержкой NumPy
Какой dtype_backend использовать, например. должен ли DataFrame иметь NumPy массивы, обнуляемые dtypes используются для всех dtypes, которые имеют обнуляемый реализация, когда установлено «numpy_nullable», pyarrow используется для всех dtypes, если установлено «pyarrow».
dtype_backends все еще экспериментальны.
Новое в версии 2.0.
- Возвращает
- df
Кадр данных.
См. также
-
read_json Преобразование строки JSON в объект pandas.
-
read_html Чтение таблиц HTML в список объектов DataFrame.
Примечания
Этот метод лучше всего подходит для импорта неглубоких XML-документов в следующий формат, который идеально подходит для двухмерного
DataFrame(строка за столбцом).<корень> <строка>данные данные данные ... <строка> ... ...В качестве формата файла XML-документы могут быть разработаны любым способом, включая расположение элементов и атрибутов, если оно соответствует W3C Характеристики. Таким образом, этот метод является удобным обработчиком для конкретный более плоский дизайн и не все возможные XML-структуры.
Однако для более сложных XML-документов таблица стилей
Эта функция будет всегда возвращать один
DataFrameили увеличивать исключения из-за проблем с документом XML,xpathили другими параметры.См. документацию read_xml в разделе IO документов для получения дополнительной информации об использовании этого метода для анализа XML.
файлы в DataFrames.Примеры
>>> xml = ''' ... <данные xmlns="http://example.com"> ... <строка> ...
квадрат ... <градусы>360 ... <стороны>4.0 ... ... <строка> ...круг ... <градусы>360 ... <стороны/> ... ... <строка> ...треугольник ... <градусы>180 ... <стороны>3.0 ... ... '''>>> df = pd.read_xml(xml) >>> дф стороны формы градусов 0 квадрат 360 4,0 1 круг 360 NaN 2 треугольник 180 3,0>>> xml = ''' ... <данные> ... <строка форма="квадрат" градусов="360" сторон="4.0"/> ... <строка shape="круг" градусов="360"/> ... <строка shape="треугольник" градусов="180" стороны="3.0"/> ... '''
>>> df = pd.read_xml(xml, xpath=".//строка") >>> дф стороны формы градусов 0 квадрат 360 4,0 1 круг 360 NaN 2 треугольник 180 3,0>>> xml = '''

 no_default )[источник]
no_default )[источник] Нет необходимости включать все
пространства имен в XML, только те, которые используются в
Нет необходимости включать все
пространства имен в XML, только те, которые используются в  Используйте этот параметр, чтобы
переименовать исходные имена элементов и различать элементы с одинаковыми именами и
атрибуты.
Используйте этот параметр, чтобы
переименовать исходные имена элементов и различать элементы с одинаковыми именами и
атрибуты. Поведение следующее:
Поведение следующее: Эта таблица стилей должна сглаживать сложные, глубоко вложенные XML-документы.
для облегчения разбора. Чтобы использовать эту функцию, у вас должен быть модуль
Эта таблица стилей должна сглаживать сложные, глубоко вложенные XML-документы.
для облегчения разбора. Чтобы использовать эту функцию, у вас должен быть модуль  Эта память-
Эффективный метод следует использовать для очень больших файлов XML (500 МБ, 1 ГБ или 5 ГБ+).
Например,
Эта память-
Эффективный метод следует использовать для очень больших файлов XML (500 МБ, 1 ГБ или 5 ГБ+).
Например,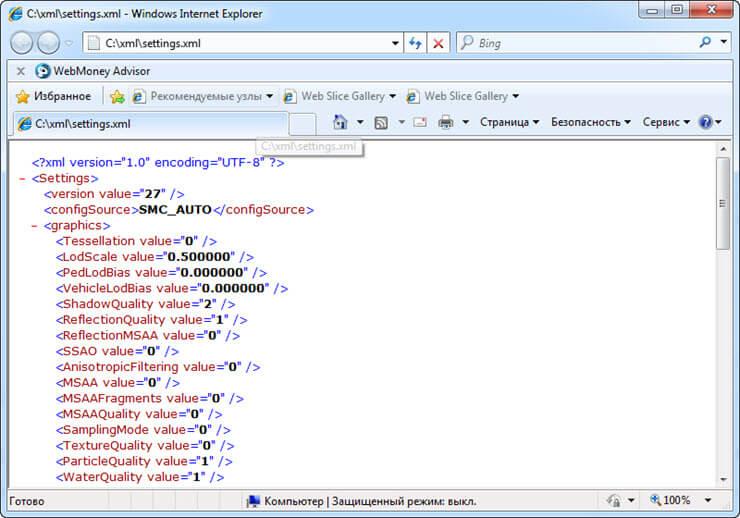 BZ2File
BZ2File  подробности и дополнительные примеры вариантов хранения см. здесь.
подробности и дополнительные примеры вариантов хранения см. здесь.
 файлы в DataFrames.
файлы в DataFrames.
Ваш комментарий будет первым