Подключение и выполнение javascript
В этом разделе мы понемногу рассмотрим все основные элементы javascript. Это позволит тут же писать и тестировать простейшие скрипты.
Javascript подключается напрямую в HTML-файл. Самый простой способ — это написать javascript-команды внутрь тега <script> где-нибудь в теле страницы.
Когда браузер читает HTML-страничку, и видит <script> — он первым делом читает и выполняет код, а только потом продолжает читать страницу дальше.
Так, в следующем примере будет показано начало страницы, затем три раза выполнится функция alert, которая выводит окошко с информацией, а только потом появится остальная часть страницы.
<html>
<body>
<h2>Считаем кроликов</h2>
*!*
<script type="text/javascript">
for(var i=1; i<=3; i++) {
alert("Из шляпы достали "+i+" кролика!")
}
</script>
*/!*
<h2>.
..Посчитали</h2>
</body>
</html>

В этом примере использовались следующие элементы.
- <script type=»text/javascript»> … </script>
- Тег
<script>сообщает браузеру о том, что внутри находится исполняемый скрипт. Атрибутtypeговорит о том, что это javascript. Вообще говоря, атрибут может отсутствовать — разницы нет, но с точки зрения стандарта его следует указать. - Конструкция for
- Обычный цикл, по синтаксису аналогичный другим языкам программирования.
- Объявление var i
- Объявление переменной внутри цикла:
i— локальная переменная. - Функция alert
- Выводит сообщение на экран и ждет, пока посетитель не нажмет ОК
Обычно javascript стараются отделить от собственно документа.
Для этого его помещают внутрь тега HEAD, а в теле страницы по возможности оставляется чистая верстка.
В следующем примере javascript-код только описывает функцию count_rabbits, а ее вызов осуществляется по нажатию на кнопку input.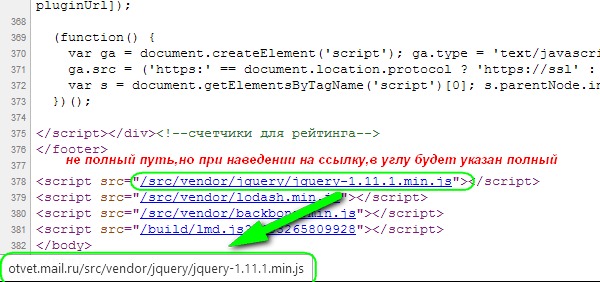
<html>
<head>
*!*
<script type="text/javascript">
function count_rabbits() {
for(var i=1; i<=3; i++) {
// оператор + соединяет строки
alert("Из шляпы достали "+i+" кролика!")
}
}
</script>
*/!*
</head>
<body>
*!*<input type="button" value="Считать кролей!"/>*/!*
</body>
</html>
Для указания запускаемой по клику функции в input был использован атрибут onclick. Это лишь вершина мощного айсберга javascript-событий.
Обычно javascript-код вообще не пишут в HTML, а подключают отдельный файл со скриптом, вот так:
<script src="/my/script.js"></script>
При этом файл /my/script.js содержит javascript-код, который иначе мог бы находиться внутри тега <script>.
Это очень удобно, потому что один и тот же файл со скриптами можно подключать на разных страницах. При правильных настройках сервера браузер закеширует его и не будет скачивать каждый раз заново.
При правильных настройках сервера браузер закеширует его и не будет скачивать каждый раз заново.
Чтобы подключить несколько скриптов — используйте несколько таких тегов:
<script src="/js/script1.js"></script> <script src="/js/script2.js"></script> ...
При указании атрибута src содержимое тега игнорируется.То есть одновременно подключить внешний файл и написать что-то внутри тега нельзя. Придется делать два разных тега <script>: первый с src, второй — с командами, которые будут выполнены после выполнения внешнего файла.
Современное оформление тэга <script>.
На плохое оформление сейчас ругается только валидатор. Поэтому эту заметку можно не читать.
Однако, знать это полезно хотя бы для того, чтобы сразу отличать современный и профессиональный скрипт от написанного эдак лет 5-6 назад.
- Атрибут
<script type=. ..> - По стандарту этот атрибут нужен для указания языка скрипта, но по умолчанию принят javascript, поэтому даже атрибута
typeнет — все работает ок. Но валидатор будет ругаться, т.к стандарт требует этот атрибут.<script type="text/html">как оригинальный способ добавить неотображаемые данные на страницу. Браузер не исполняет и не показывает<script>с неизвестным типом. В этом плане он ничем не отличается от обычного <div> с вечнымstyle="display:none". - Атрибут
<script language=...> - В старых скриптах нередко можно увидеть атрибут
language. Этот атрибут давно мертв и никому не нужен. Не используйте его для javascript. - Комментарии до и после скрипта
- В старых руководствах по javascript встречается указание «прятать» javascript-код от старых браузеров, заключая его в HTML-комментарии <!— … —>.
Браузер, от которого прятали код (старый Netscape), давно умер.
Современные браузеры комментарии просто игнорируют. Не ставьте их.
 ..>
..>Client-side storage — Изучение веб-разработки
Современные веб-браузеры поддерживают несколько способов хранения данных из веб-сайтов на компьютере пользователя — с разрешения пользователя — чтобы потом получать их, когда это необходимо. Это позволяет долгосрочно хранить данные, сохранять сайты или документы для использования без подключения к сети, сохранять пользовательские настройки для вашего сайта и многое другое. В этой статье объясняются основы того, как это все работает.
Ранее, мы говорили о разнице между статическими и динамическими сайтами. Большинство современных веб-сайтов являются динамическими — они хранят данные на сервере, используя какую-то базу данных (серверное хранилище), а затем запускают код на стороне сервера чтобы извлечь необходимые данные, вставить их в шаблоны статических страниц и передать полученный HTML-код клиенту для отображения в браузере пользователя.
Хранилище на стороне клиента работает по схожим принципам, но используется по-другому. Оно состоит из API-интерфейсов JavaScript, которые позволяют вам хранить данные на клиенте (то есть на компьютере пользователя), а затем извлекать их при необходимости. Это имеет много разных применений, таких как:
- Персонализация настроек сайта (например, отображение выбранных пользователем виджетов, цветовой схемы или размера шрифта).
- Сохранение предыдущей активности на сайте (например, сохранение содержимого корзины покупок из предыдущего сеанса, запоминание, был ли пользователь ранее авторизован в системе).
- Сохранение данных и ресурсов локально, так что сайт будет быстрее (и, возможно, экономичнее) загружаться или использоваться без подключения к сети.
- Сохранение созданных веб-приложением документов локально для использования в автономном режиме.
Часто, хранилища на сторонах клиента и сервера используются совместно. К примеру, вы должны загрузить из базы данных пакет музыкальных файлов для веб-игры, или музыкальный плеер хранит их в базе данных на стороне клиента, и воспроизводит по мере необходимости.
Пользователь должен будет загрузить музыкальные файлы только один раз — при последующих посещениях они будут извлечены из локальной базы данных.
Примечание. Существуют ограничения на объем данных, которые вы можете хранить с помощью API-интерфейсов на стороне клиента (возможно, как для отдельных API, так и в совокупности). Точный лимит варьируется в зависимости от браузера и, возможно, в зависимости от пользовательских настроек. Смотри Ограничения хранилища браузера и критерии переполнения для большей информации.
Старый подход: куки
Концепция хранения на стороне клиента существует уже давно. С первых дней Интернета, использовали cookies для хранения информации, чтобы персонализировать пользовательский опыт на веб-сайтах. Это самая ранняя форма хранилища на стороне клиента, обычно используемая в Интернете.
Из-за этого возраста существует ряд проблем — как технических, так и с точки зрения пользовательского опыта — связанных с файлами cookie. Эти проблемы настолько значительны, что при первом посещении сайта людям, живущим в Европе, показываются сообщения, информирующие их о том, будут ли они использовать файлы cookie для хранения данных о них. Это связано с частью законодательства Европейского Союза, известного как EU Cookie directive.
Эти проблемы настолько значительны, что при первом посещении сайта людям, живущим в Европе, показываются сообщения, информирующие их о том, будут ли они использовать файлы cookie для хранения данных о них. Это связано с частью законодательства Европейского Союза, известного как EU Cookie directive.
По этим причинам мы не будем учить вас, как использовать куки в этой статье. Они устарели, у них множество проблем с безопасностью, и неспособны хранить сложные данные. При этом существуют лучшие, более современные, способы хранения более широкого спектра данных на компьютере пользователя.
Единственным преимуществом файлов cookie является то, что они поддерживаются очень старыми браузерами, поэтому, если ваш проект требует, чтобы вы поддерживали устаревшие браузеры (например, Internet Explorer 8 или более ранние версии), файлы cookie могут по-прежнему быть полезными, но для большинства проектов вы не нужно больше прибегать к ним.
Почему по-прежнему создаются новые сайты с использованием файлов cookie? Это происходит главным образом из-за привычек разработчиков, использования старых библиотек, которые всё ещё используют куки-файлы, и наличия множества веб-сайтов, предоставляющих устаревшие справочные и учебные материалы для обучения хранению данных.
Новый подход: Web Storage и IndexedDB
Современные браузеры имеют гораздо более простые и эффективные API для хранения данных на стороне клиента, чем при использовании файлов cookie.
- The Web Storage API обеспечивает очень простой синтаксис для хранения и извлечения данных, состоящих из пар ‘ключ’ : ‘значение’. Это полезно, когда вам просто нужно сохранить некоторые простые данные, такие как имя пользователя, вошли ли они в систему, какой цвет использовать для фона экрана и т. д.
- The IndexedDB API обеспечивает браузер полной базой данных для хранения сложных данных. Это может быть использовано для хранения полных наборов записей клиентов и даже до сложных типов данных, таких как аудио или видео файлы.
Вы узнаете больше об этих API ниже.
Что нас ждёт в будущем: Cache API
Некоторые современные браузеры поддерживают новое Cache API. Этот API предназначен для хранения HTTP-ответов на конкретные запросы и очень полезен для таких вещей, как хранение ресурсов сайта в автономном режиме, чтобы впоследствии сайт можно было использовать без сетевого подключения. Cache обычно используется в сочетании с Service Worker API, однако это не обязательно.
Cache обычно используется в сочетании с Service Worker API, однако это не обязательно.
Использование Cache и Service Workers — сложная тема, и мы не будем подробно останавливаться на ней в этой статье, хотя приведём простой пример Offline asset storage в разделе ниже.
Web Storage API очень легко использовать — вы храните простые пары данных имя/значение (только строки, цифры и т.п.) и получаете их, когда необходимо.
Базовый синтаксис
Посмотрите:
Во-первых, посмотрите наши web storage шаблоны на GitHub (откройте в новой вкладке).
Откройте консоль инструментов JavaScript разработчика вашего браузера.
Все данные вашего веб-хранилища содержатся в двух объектоподобных структурах внутри браузера:
sessionStorageиlocalStorage. Первый сохраняет данные до тех пор, пока браузер открыт (данные теряются при закрытии браузера), а второй сохраняет данные даже после того, как браузер закрыт, а затем снова открыт. Мы будем использовать второй в этой статье, так как он, как правило, более полезен.Storage.setItem()метод позволяет сохранить элемент данных в хранилище — он принимает два параметра: имя элемента и его значение. Попробуйте ввести это в свою консоль JavaScript (измените значение на своё собственное имя, если хотите!):localStorage.setItem('name','Chris');Storage.getItem()метод принимает один параметр — имя элемента данных, который вы хотите получить — и возвращает значение элемента. Теперь введите эти строки в вашу консоль JavaScript:var myName = localStorage.getItem('name'); myNameПосле ввода во второй строке вы должны увидеть, что переменная
myNameтеперь содержит значение элемента данныхname.Storage.removeItem()метод принимает один параметр — имя элемента данных, который вы хотите удалить, — и удаляет этот элемент из веб-хранилища. Введите следующие строки в вашу консоль JavaScript:localStorage.removeItem('name'); var myName = localStorage.getItem('name'); myNameТретья строка должна теперь возвращать ноль — элемент
nameбольше не существует в веб-хранилище.
 Мы будем использовать второй в этой статье, так как он, как правило, более полезен.
Мы будем использовать второй в этой статье, так как он, как правило, более полезен. Введите следующие строки в вашу консоль JavaScript:
Введите следующие строки в вашу консоль JavaScript:Данные сохраняются!
Одной из ключевых особенностей веб-хранилища является то, что данные сохраняются между загрузками страниц (и даже в случае закрытия браузера, в случае localStorage). Давайте посмотрим на это в действии.
Снова откройте пустой шаблон нашего веб-хранилища, но на этот раз в другом браузере, отличном от того, в котором вы открыли этот учебник! Так будет удобнее.
Введите эти строки в консоль JavaScript браузера:
localStorage.setItem('name','Chris'); var myName = localStorage.getItem('name'); myNameВы должны увидеть возвращённое имя элемента.
Теперь закройте браузер и откройте его снова.
Введите следующий код:
var myName = localStorage.getItem('name'); myNameВы должны увидеть, что значение всё ещё доступно, даже после закрытия / открытия браузера.

Для каждого домена отдельное хранилище
Существуют отдельные хранилища данных для каждого домена (каждый отдельный веб-адрес загружается в браузер). Вы увидите, что если вы загрузите два веб-сайта (например, google.com и amazon.com) и попытаетесь сохранить элемент на одном веб-сайте, он не будет доступен для другого веб-сайта.
Это имеет смысл — вы можете представить себе проблемы безопасности, которые могут возникнуть, если веб-сайты смогут видеть данные друг друга!
Более развёрнутый пример
Давайте применим эти новые знания, написав простой рабочий пример, чтобы дать вам представление о том, как можно использовать веб-хранилище. Наш пример позволит вам ввести имя, после чего страница обновится, чтобы дать вам персональное приветствие. Это состояние также будет сохраняться при перезагрузке страницы / браузера, поскольку имя хранится в веб-хранилище.
Это состояние также будет сохраняться при перезагрузке страницы / браузера, поскольку имя хранится в веб-хранилище.
Вы можете найти пример HTML на personal-greeting.html — он содержит простой веб-сайт с заголовком, контентом и нижним колонтитулом, а также форму для ввода вашего имени.
Давайте создадим пример, чтобы вы могли понять, как он работает.
Во-первых, сделайте локальную копию нашего personal-greeting.html файла в новом каталоге на вашем компьютере.
Далее обратите внимание, как наш HTML ссылается на файл JavaScript с именем
index.js(см. строку 40). Нам нужно создать его, и записать в него наш код JavaScript. Создайте файлindex.jsв том же каталоге, что и ваш HTML-файл.Мы начнём с создания ссылок на все функции HTML, которыми мы должны манипулировать в этом примере — мы создадим их все как константы, поскольку эти ссылки не нужно изменять в жизненном цикле приложения.
Добавьте следующие строки в ваш файл JavaScript:const rememberDiv = document.querySelector('.remember'); const forgetDiv = document.querySelector('.forget'); const form = document.querySelector('form'); const nameInput = document.querySelector('#entername'); const submitBtn = document.querySelector('#submitname'); const forgetBtn = document.querySelector('#forgetname'); const h2 = document.querySelector('h2'); const personalGreeting = document.querySelector('.personal-greeting');Далее нам нужно включить небольшой обработчик событий, чтобы форма фактически не отправляла себя при нажатии кнопки отправки, так как это не то поведение, которое нам нужно. Добавьте этот фрагмент ниже вашего предыдущего кода:
form.addEventListener('submit', function(e) { e.preventDefault(); });Теперь нам нужно добавить обработчик событий, функция-обработчик которого будет запускаться при нажатии кнопки «Say hello».
В комментариях подробно объясняется, что делает каждый бит, но в сущности здесь мы берём имя, которое пользователь ввёл в поле ввода текста, и сохраняем его в веб-хранилище с помощью setItem(), затем запускаем функциюnameDisplayCheck(), которая будет обрабатывать обновление фактического текста сайта. Добавьте это в конец:submitBtn.addEventListener('click', function() { localStorage.setItem('name', nameInput.value); nameDisplayCheck(); });На этом этапе нам также необходим обработчик событий для запуска функции при нажатии кнопки «Forget» — она будет отображена только после того как кнопка «Say hello» будет нажата (две формы состояния для переключения между ними). В этой функции мы удаляем переменную
nameиз веб-хранилища используяremoveItem(), затем снова запускаемnameDisplayCheck()для обновления. Добавьте этот код в конец:forgetBtn.addEventListener('click', function() { localStorage. removeItem('name');
nameDisplayCheck();
});Самое время для определения самой функции
nameDisplayCheck(). Здесь мы проверяем была ли переменнаяnameсохранена в веб-хранилище с помощьюlocalStorage.getItem('name')в качестве условия. Если переменнаяnameбыла сохранена, то вызов вернёт —true; если же нет, то —false. Еслиtrue, мы показываем персональное приветствие, отображаем кнопку «Forget», и скрываем кнопку «Say hello». Если жеfalse, мы отображаем общее приветствие и делаем обратное. Опять же, добавьте следующий код в конец:function nameDisplayCheck() { if(localStorage.getItem('name')) { let name = localStorage.getItem('name'); h2.textContent = 'Welcome, ' + name; personalGreeting.textContent = 'Welcome to our website, ' + name + '! We hope you have fun while you are here.'; forgetDiv.style. display = 'block';
rememberDiv.style.display = 'none';
} else {
h2.textContent = 'Welcome to our website ';
personalGreeting.textContent = 'Welcome to our website. We hope you have fun while you are here.';
forgetDiv.style.display = 'none';
rememberDiv.style.display = 'block';
}
}Последнее но не менее важное, нам необходимо запускать функцию
nameDisplayCheck()при каждой загрузке страницы. Если мы не сделаем этого, персональное приветствие не будет сохранятся после перезагрузки страницы. Добавьте следующий фрагмент в конец вашего кода:document.body.onload = nameDisplayCheck;
 Добавьте следующие строки в ваш файл JavaScript:
Добавьте следующие строки в ваш файл JavaScript: В комментариях подробно объясняется, что делает каждый бит, но в сущности здесь мы берём имя, которое пользователь ввёл в поле ввода текста, и сохраняем его в веб-хранилище с помощью
В комментариях подробно объясняется, что делает каждый бит, но в сущности здесь мы берём имя, которое пользователь ввёл в поле ввода текста, и сохраняем его в веб-хранилище с помощью  removeItem('name');
nameDisplayCheck();
});
removeItem('name');
nameDisplayCheck();
}); display = 'block';
rememberDiv.style.display = 'none';
} else {
h2.textContent = 'Welcome to our website ';
personalGreeting.textContent = 'Welcome to our website. We hope you have fun while you are here.';
forgetDiv.style.display = 'none';
rememberDiv.style.display = 'block';
}
}
display = 'block';
rememberDiv.style.display = 'none';
} else {
h2.textContent = 'Welcome to our website ';
personalGreeting.textContent = 'Welcome to our website. We hope you have fun while you are here.';
forgetDiv.style.display = 'none';
rememberDiv.style.display = 'block';
}
}Ваш пример закончен — отличная работа! Всё что теперь осталось это сохранить ваш код и протестировать вашу HTML страницу в браузере. Вы можете посмотреть нашу завершённую версию работающую здесь.
Есть и другой, немного более комплексный пример описываемый в Using the Web Storage API.
IndexedDB API (иногда сокращают до IDB) это полная база данных, доступная в браузере, в которой вы можете хранить сложные связанные данные, типы которых не ограничиваются простыми значениями, такими как строки или числа.
Вы можете сохранить видео, фото, и почти все остальные файлы с IndexedDB.
Однако это обходится дорого: IndexedDB гораздо сложнее в использовании, чем Web Storage API.
В этом разделе мы действительно только коснёмся того, на что он способен, но мы дадим вам достаточно, чтобы начать.
Работа с примером хранения заметок
Here we’ll run you through an example that allows you to store notes in your browser and view and delete them whenever you like, getting you to build it up for yourself and explaining the most fundamental parts of IDB as we go along.
The app looks something like this:
Each note has a title and some body text, each individually editable. The JavaScript code we’ll go through below has detailed comments to help you understand what’s going on.
Предустановка
- First of all, make local copies of our
index.html,style.css, andindex-start.jsfiles into a new directory on your local machine. - Have a look at the files. You’ll see that the HTML is pretty simple: a web site with a header and footer, as well as a main content area that contains a place to display notes, and a form for entering new notes into the database. The CSS provides some simple styling to make it clearer what is going on. The JavaScript file contains five declared constants containing references to the
<ul>element the notes will be displayed in, the title and body<input>elements, the<form>itself, and the<button>. - Rename your JavaScript file to
index.js. You are now ready to start adding code to it.
Настраиваем базу данных
Now let’s look at what we have to do in the first place, to actually set up a database.
Below the constant declarations, add the following lines:
let db;Here we are declaring a variable called
db— this will later be used to store an object representing our database. We will use this in a few places, so we’ve declared it globally here to make things easier.Next, add the following to the bottom of your code:
window.onload = function() { };We will write all of our subsequent code inside this
window.onloadevent handler function, called when the window’sload (en-US)event fires, to make sure we don’t try to use IndexedDB functionality before the app has completely finished loading (it could fail if we don’t).Inside the
window.onloadhandler, add the following:let request = window.indexedDB.open('notes', 1);This line creates a
requestto open version1of a database callednotes. If this doesn’t already exist, it will be created for you by subsequent code. You will see this request pattern used very often throughout IndexedDB. Database operations take time. You don’t want to hang the browser while you wait for the results, so database operations are asynchronous, meaning that instead of happening immediately, they will happen at some point in the future, and you get notified when they’re done.To handle this in IndexedDB, you create a request object (which can be called anything you like — we called it
requestso it is obvious what it is for). You then use event handlers to run code when the request completes, fails, etc., which you’ll see in use below.Note: The version number is important. If you want to upgrade your database (for example, by changing the table structure), you have to run your code again with an increased version number, different schema specified inside the
onupgradeneededhandler (see below), etc. We won’t cover upgrading databases in this simple tutorial.Now add the following event handlers just below your previous addition — again inside the
window.onloadhandler:request.onerror = function() { console.log('Database failed to open'); }; request.onsuccess = function() { console.log('Database opened successfully'); db = request.result; displayData(); };The
request.onerror(en-US) handler will run if the system comes back saying that the request failed. This allows you to respond to this problem. In our simple example, we just print a message to the JavaScript console.The
request.onsuccess(en-US) handler on the other hand will run if the request returns successfully, meaning the database was successfully opened. If this is the case, an object representing the opened database becomes available in therequest.result(en-US) property, allowing us to manipulate the database. We store this in the dbvariable we created earlier for later use. We also run a custom function calleddisplayData(), which displays the data in the database inside the<ul>. We run it now so that the notes already in the database are displayed as soon as the page loads. You’ll see this defined later on.Finally for this section, we’ll add probably the most important event handler for setting up the database:
request.onupdateneeded(en-US). This handler runs if the database has not already been set up, or if the database is opened with a bigger version number than the existing stored database (when performing an upgrade). Add the following code, below your previous handler:request.onupgradeneeded = function(e) { let db = e.target.result; let objectStore = db.createObjectStore('notes', { keyPath: 'id', autoIncrement:true }); objectStore.createIndex('title', 'title', { unique: false }); objectStore. createIndex('body', 'body', { unique: false });
console.log('Database setup complete');
};This is where we define the schema (structure) of our database; that is, the set of columns (or fields) it contains. Here we first grab a reference to the existing database from
e.target.result(the event target’sresultproperty), which is therequestobject. This is equivalent to the linedb = request.result;inside theonsuccesshandler, but we need to do this separately here because theonupgradeneededhandler (if needed) will run before theonsuccesshandler, meaning that thedbvalue wouldn’t be available if we didn’t do this.We then use
IDBDatabase.createObjectStore()(en-US) to create a new object store inside our opened database. This is equivalent to a single table in a conventional database system. We’ve given it the name notes, and also specified anautoIncrementkey field calledid— in each new record this will automatically be given an incremented value — the developer doesn’t need to set this explicitly. Being the key, the idfield will be used to uniquely identify records, such as when deleting or displaying a record.We also create two other indexes (fields) using the
IDBObjectStore.createIndex()(en-US) method:title(which will contain a title for each note), andbody(which will contain the body text of the note).
 If this doesn’t already exist, it will be created for you by subsequent code. You will see this request pattern used very often throughout IndexedDB. Database operations take time. You don’t want to hang the browser while you wait for the results, so database operations are asynchronous, meaning that instead of happening immediately, they will happen at some point in the future, and you get notified when they’re done.
If this doesn’t already exist, it will be created for you by subsequent code. You will see this request pattern used very often throughout IndexedDB. Database operations take time. You don’t want to hang the browser while you wait for the results, so database operations are asynchronous, meaning that instead of happening immediately, they will happen at some point in the future, and you get notified when they’re done. We won’t cover upgrading databases in this simple tutorial.
We won’t cover upgrading databases in this simple tutorial.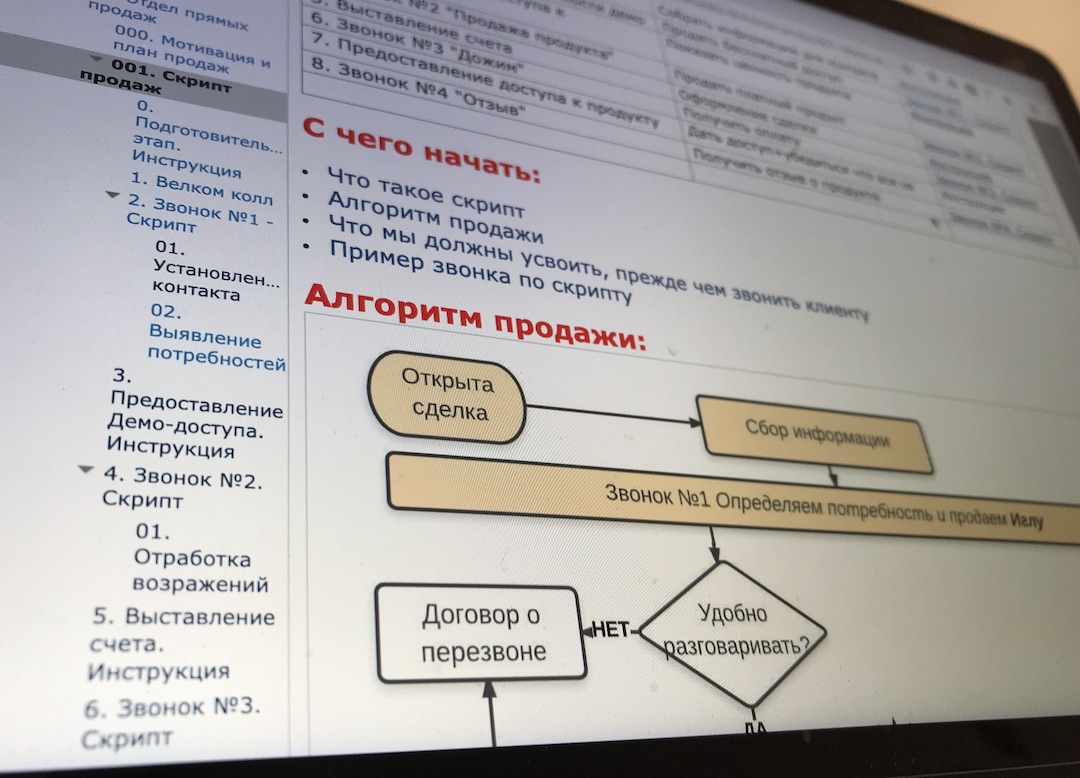 We store this in the
We store this in the  createIndex('body', 'body', { unique: false });
console.log('Database setup complete');
};
createIndex('body', 'body', { unique: false });
console.log('Database setup complete');
}; Being the key, the
Being the key, the So with this simple database schema set up, when we start adding records to the database each one will be represented as an object along these lines:
{
title: "Buy milk",
body: "Need both cows milk and soya.",
id: 8
}Добавляем данные в базу данных
Now let’s look at how we can add records to the database. This will be done using the form on our page.
Below your previous event handler (but still inside the window.onload handler), add the following line, which sets up an onsubmit handler that runs a function called addData() when the form is submitted (when the submit <button> is pressed leading to a successful form submission):
form. onsubmit = addData;Now let’s define the addData() function. Add this below your previous line:
function addData(e) {
e.preventDefault();
let newItem = { title: titleInput.value, body: bodyInput.value };
let transaction = db.transaction(['notes'], 'readwrite');
let objectStore = transaction.objectStore('notes');
var request = objectStore.add(newItem);
request.onsuccess = function() {
titleInput.value = '';
bodyInput.value = '';
};
transaction.oncomplete = function() {
console.log('Transaction completed: database modification finished.');
displayData();
};
transaction.onerror = function() {
console.log('Transaction not opened due to error');
};
}This is quite complex; breaking it down, we:
- Run
Event.preventDefault()on the event object to stop the form actually submitting in the conventional manner (this would cause a page refresh and spoil the experience). - Create an object representing a record to enter into the database, populating it with values from the form inputs. note that we don’t have to explicitly include an
idvalue — as we expained early, this is auto-populated. - Open a
readwritetransaction against thenotesobject store using theIDBDatabase.transaction()(en-US) method. This transaction object allows us to access the object store so we can do something to it, e.g. add a new record. - Access the object store using the
IDBTransaction.objectStore(en-US) property, saving it in theobjectStorevariable. - Add the new record to the database using
IDBObjectStore.add()(en-US). This creates a request object, in the same fashion as we’ve seen before. - Add a bunch of event handlers to the
requestand thetransactionto run code at critical points in the lifecycle. Once the request has succeeded, we clear the form inputs ready for entering the next note. Once the transaction has completed, we run the displayData()function again to update the display of notes on the page.
 Once the transaction has completed, we run the
Once the transaction has completed, we run the Отображаем данные
We’ve referenced displayData() twice in our code already, so we’d probably better define it. Add this to your code, below the previous function definition:
function displayData() {
while (list.firstChild) {
list.removeChild(list.firstChild);
}
let objectStore = db.transaction('notes').objectStore('notes');
objectStore.openCursor().onsuccess = function(e) {
let cursor = e.target.result;
if(cursor) {
let listItem = document.createElement('li');
let h4 = document.createElement('h4');
let para = document.createElement('p');
listItem.appendChild(h4);
listItem.appendChild(para);
list.appendChild(listItem);
h4.textContent = cursor.value.title;
para.textContent = cursor.value.body;
listItem. setAttribute('data-note-id', cursor.value.id);
let deleteBtn = document.createElement('button');
listItem.appendChild(deleteBtn);
deleteBtn.textContent = 'Delete';
deleteBtn.onclick = function(e) {
deleteItem(e);
};
cursor.continue();
} else {
if(!list.firstChild) {
let listItem = document.createElement('li');
listItem.textContent = 'No notes stored.'
list.appendChild(listItem);
}
console.log('Notes all displayed');
}
};
} setAttribute('data-note-id', cursor.value.id);
let deleteBtn = document.createElement('button');
listItem.appendChild(deleteBtn);
deleteBtn.textContent = 'Delete';
deleteBtn.onclick = function(e) {
deleteItem(e);
};
cursor.continue();
} else {
if(!list.firstChild) {
let listItem = document.createElement('li');
listItem.textContent = 'No notes stored.'
list.appendChild(listItem);
}
console.log('Notes all displayed');
}
};
}
setAttribute('data-note-id', cursor.value.id);
let deleteBtn = document.createElement('button');
listItem.appendChild(deleteBtn);
deleteBtn.textContent = 'Delete';
deleteBtn.onclick = function(e) {
deleteItem(e);
};
cursor.continue();
} else {
if(!list.firstChild) {
let listItem = document.createElement('li');
listItem.textContent = 'No notes stored.'
list.appendChild(listItem);
}
console.log('Notes all displayed');
}
};
}Again, let’s break this down:
- First we empty out the
<ul>element’s content, before then filling it with the updated content. If you didn’t do this, you’d end up with a huge list of duplicated content being added to with each update. - Next, we get a reference to the
notesobject store usingIDBDatabase.transaction()(en-US) andIDBTransaction.(en-US) like we did in objectStoreaddData(), except here we are chaining them together in one line. - The next step is to use
IDBObjectStore.openCursor()(en-US) method to open a request for a cursor — this is a construct that can be used to iterate over the records in an object store. We chain anonsuccesshandler on to the end of this line to make the code more concise — when the cursor is successfully returned, the handler is run. - We get a reference to the cursor itself (an
IDBCursor(en-US) object) using letcursor = e.target.result. - Next, we check to see if the cursor contains a record from the datastore (
if(cursor){ ... }) — if so, we create a DOM fragment, populate it with the data from the record, and insert it into the page (inside the<ul>element). We also include a delete button that, when clicked, will delete that note by running thedeleteItem()function, which we will look at in the next section. - At the end of the
ifblock, we use theIDBCursor.continue()(en-US) method to advance the cursor to the next record in the datastore, and run the content of theifblock again. If there is another record to iterate to, this causes it to be inserted into the page, and thencontinue()is run again, and so on. - When there are no more records to iterate over,
cursorwill returnundefined, and therefore theelseblock will run instead of theifblock. This block checks whether any notes were inserted into the<ul>— if not, it inserts a message to say no note was stored.
 objectStore
objectStore
Удаляем данные
As stated above, when a note’s delete button is pressed, the note is deleted. This is achieved by the deleteItem() function, which looks like so:
function deleteItem(e) {
let noteId = Number(e.target.parentNode. getAttribute('data-note-id'));
let transaction = db.transaction(['notes'], 'readwrite');
let objectStore = transaction.objectStore('notes');
let request = objectStore.delete(noteId);
transaction.oncomplete = function() {
e.target.parentNode.parentNode.removeChild(e.target.parentNode);
console.log('Note ' + noteId + ' deleted.');
if(!list.firstChild) {
let listItem = document.createElement('li');
listItem.textContent = 'No notes stored.';
list.appendChild(listItem);
}
};
} getAttribute('data-note-id'));
let transaction = db.transaction(['notes'], 'readwrite');
let objectStore = transaction.objectStore('notes');
let request = objectStore.delete(noteId);
transaction.oncomplete = function() {
e.target.parentNode.parentNode.removeChild(e.target.parentNode);
console.log('Note ' + noteId + ' deleted.');
if(!list.firstChild) {
let listItem = document.createElement('li');
listItem.textContent = 'No notes stored.';
list.appendChild(listItem);
}
};
}
getAttribute('data-note-id'));
let transaction = db.transaction(['notes'], 'readwrite');
let objectStore = transaction.objectStore('notes');
let request = objectStore.delete(noteId);
transaction.oncomplete = function() {
e.target.parentNode.parentNode.removeChild(e.target.parentNode);
console.log('Note ' + noteId + ' deleted.');
if(!list.firstChild) {
let listItem = document.createElement('li');
listItem.textContent = 'No notes stored.';
list.appendChild(listItem);
}
};
}- The first part of this could use some explaining — we retrieve the ID of the record to be deleted using
Number(e.target.parentNode.getAttribute('data-note-id'))— recall that the ID of the record was saved in adata-note-idattribute on the<li>when it was first displayed. We do however need to pass the attribute through the global built-in Number() object, as it is currently a string, and otherwise won’t be recognized by the database. - We then get a reference to the object store using the same pattern we’ve seen previously, and use the
IDBObjectStore.delete()(en-US) method to delete the record from the database, passing it the ID. - When the database transaction is complete, we delete the note’s
<li>from the DOM, and again do the check to see if the<ul>is now empty, inserting a note as appropriate.

So that’s it! Your example should now work.
If you are having trouble with it, feel free to check it against our live example (see the source code also).
Храним сложные данные через IndexedDB
As we mentioned above, IndexedDB can be used to store more than just simple text strings. You can store just about anything you want, including complex objects such as video or image blobs. And it isn’t much more difficult to achieve than any other type of data.
To demonstrate how to do it, we’ve written another example called IndexedDB video store (see it running live here also). When you first run the example, it downloads all the videos from the network, stores them in an IndexedDB database, and then displays the videos in the UI inside
When you first run the example, it downloads all the videos from the network, stores them in an IndexedDB database, and then displays the videos in the UI inside <video> elements. The second time you run it, it finds the videos in the database and gets them from there instead befoire displaying them — this makes subsequent loads much quicker and less bandwidth-hungry.
Let’s walk through the most interesting parts of the example. We won’t look at it all — a lot of it is similar to the previous example, and the code is well-commented.
For this simple example, we’ve stored the names of the videos to fetch in an array of objects:
const videos = [ { 'name' : 'crystal' }, { 'name' : 'elf' }, { 'name' : 'frog' }, { 'name' : 'monster' }, { 'name' : 'pig' }, { 'name' : 'rabbit' } ];To start with, once the database is successfully opened we run an
init()function. This loops through the different video names, trying to load a record identified by each name from thevideosdatabase.If each video is found in the database (easily checked by seeing whether
request.resultevaluates totrue— if the record is not present, it will beundefined), its video files (stored as blobs) and the video name are passed straight to thedisplayVideo()function to place them in the UI. If not, the video name is passed to thefetchVideoFromNetwork()function to … you guessed it — fetch the video from the network.function init() { for(let i = 0; i < videos.length; i++) { let objectStore = db.transaction('videos').objectStore('videos'); let request = objectStore.get(videos[i].name); request.onsuccess = function() { if(request.result) { console.log('taking videos from IDB'); displayVideo(request.result.mp4, request.result.webm, request.result.name); } else { fetchVideoFromNetwork(videos[i]); } }; } }The following snippet is taken from inside
fetchVideoFromNetwork()— here we fetch MP4 and WebM versions of the video using two separateWindowOrWorkerGlobalScope.(en-US) requests. We then use the fetch()Body.blob()method to extract each response’s body as a blob, giving us an object representation of the videos that can be stored and displayed later on.We have a problem here though — these two requests are both asynchronous, but we only want to try to display or store the video when both promises have fulfilled. Fortunately there is a built-in method that handles such a problem —
Promise.all(). This takes one argument — references to all the individual promises you want to check for fulfillment placed in an array — and is itself promise-based.When all those promises have fulfilled, the
all()promise fulfills with an array containing all the individual fulfillment values. Inside theall()block, you can see that we then call thedisplayVideo()function like we did before to display the videos in the UI, then we also call thestoreVideo()function to store those videos inside the database.let mp4Blob = fetch('videos/' + video.name + '.mp4').then(response => response.blob() ); let webmBlob = fetch('videos/' + video.name + '.webm').then(response => response.blob() );; Promise.all([mp4Blob, webmBlob]).then(function(values) { displayVideo(values[0], values[1], video.name); storeVideo(values[0], values[1], video.name); });Let’s look at
storeVideo()first. This is very similar to the pattern you saw in the previous example for adding data to the database — we open areadwritetransaction and get an object store reference ourvideos, create an object representing the record to add to the database, then simply add it usingIDBObjectStore.add()(en-US).function storeVideo(mp4Blob, webmBlob, name) { let objectStore = db.transaction(['videos'], 'readwrite').objectStore('videos'); let record = { mp4 : mp4Blob, webm : webmBlob, name : name } let request = objectStore. add(record);
...
};Last but not least, we have
displayVideo(), which creates the DOM elements needed to insert the video in the UI and then appends them to the page. The most interesting parts of this are those shown below — to actually display our video blobs in a<video>element, we need to create object URLs (internal URLs that point to the video blobs stored in memory) using theURL.createObjectURL()method. Once that is done, we can set the object URLs to be the vaues of our<source>element’ssrcattributes, and it works fine.function displayVideo(mp4Blob, webmBlob, title) { let mp4URL = URL.createObjectURL(mp4Blob); let webmURL = URL.createObjectURL(webmBlob); ... let video = document.createElement('video'); video.controls = true; let source1 = document.createElement('source'); source1.src = mp4URL; source1.type = 'video/mp4'; let source2 = document. createElement('source');
source2.src = webmURL;
source2.type = 'video/webm';
...
}

 fetch()
fetch()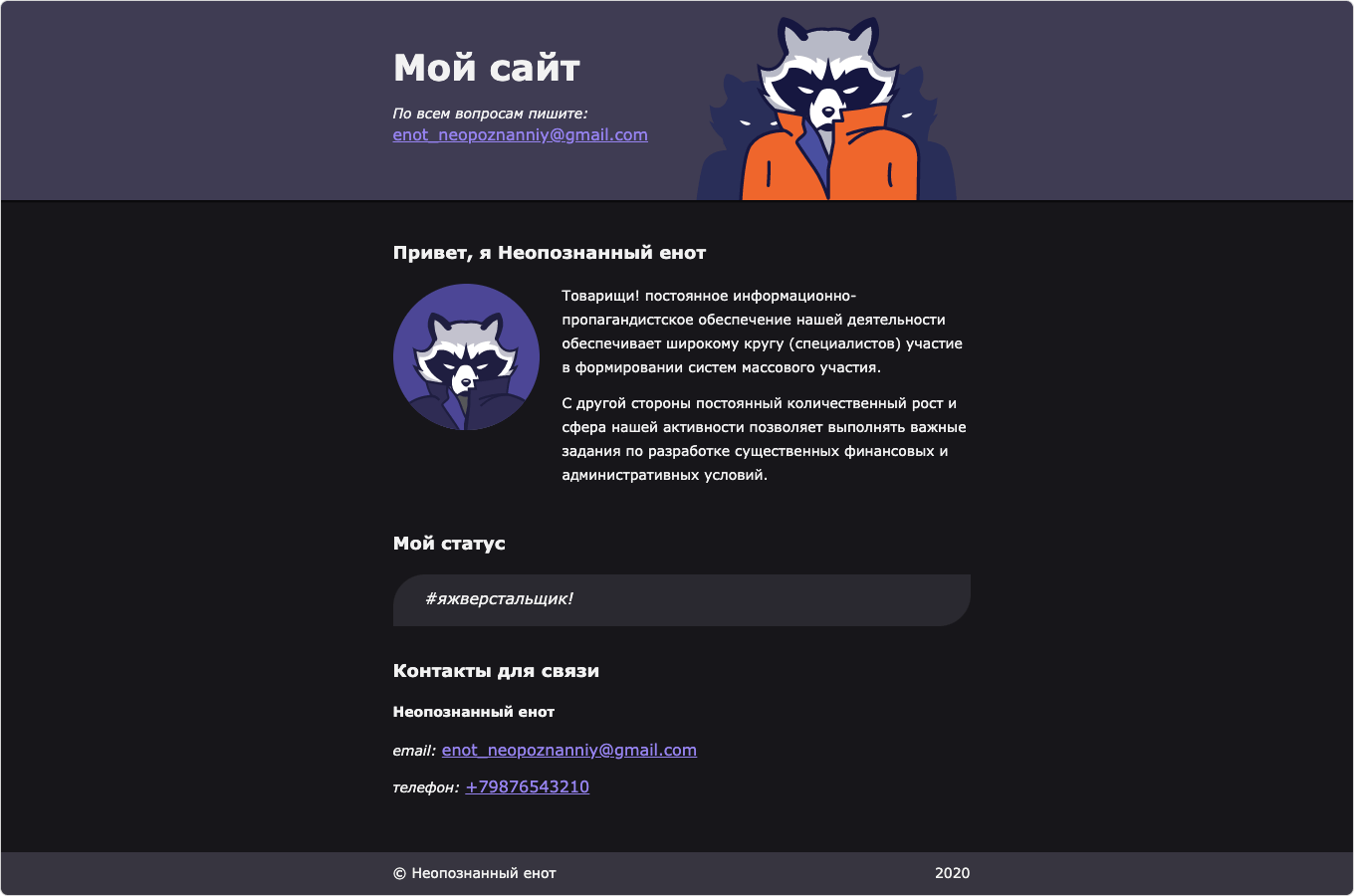
 add(record);
...
};
add(record);
...
}; createElement('source');
source2.src = webmURL;
source2.type = 'video/webm';
...
}
createElement('source');
source2.src = webmURL;
source2.type = 'video/webm';
...
}Пример ниже показывает, как создать приложение, которое будет хранить данные большого объёма в хранилище IndexedDB, избегая необходимости скачивать их повторно. Это важное улучшение пользовательского опыта, но есть одно замечание — основной HTML, CSS, и файлы JavaScript все ещё нужно загружать каждый раз при запросе сайта, это значит, что данный пример не будет работать при отсутствии сетевого соединения.
Это тот случай, когда Service workers и Cache API приходят на помощь.
Сервис-воркер это файл JavaScript, который регистрируется на конкретном источнике (веб-сайте или части сайта на конкретном домене) при обращении браузером. После регистрации, он может управлять страницами на этом источнике. Воркер находится между загруженной страницей и сетевым соединением, перехватывая сетевые запросы источника.
Когда worker перехватывает запрос, он может делать многие вещи (смотри идеи для использования сервис-воркеров), но классический пример это сохранение сетевых ответов и затем доступ к ним при запросе, вместо запросов по сети.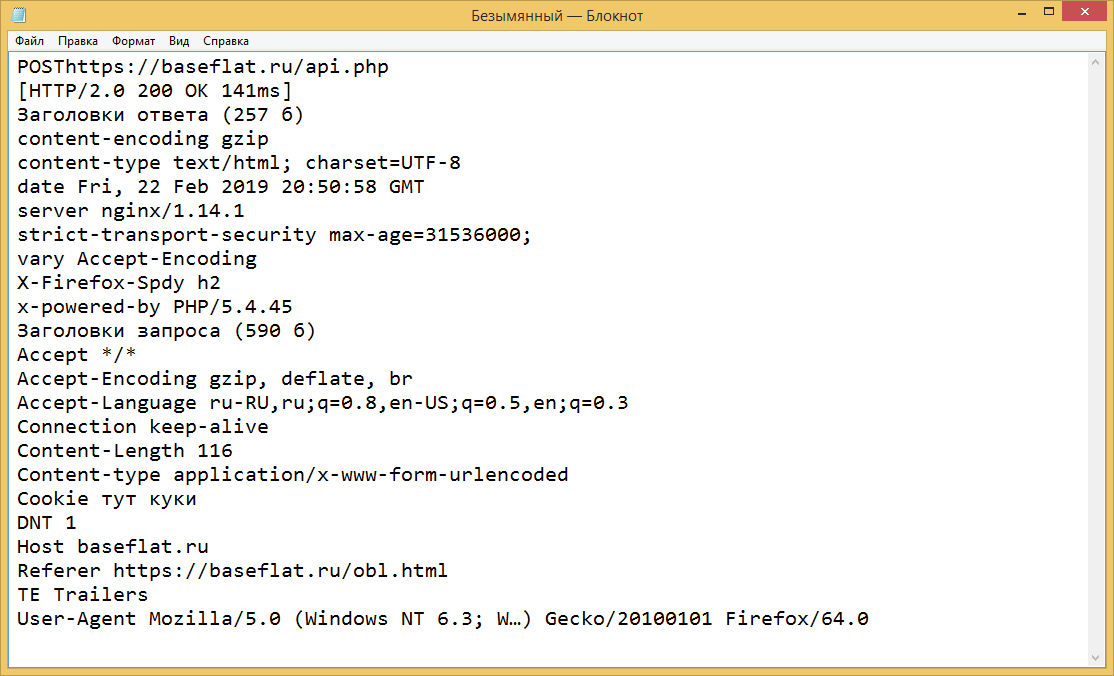 В результате, это позволяет сделать веб-сайт полностью работающим в офлайне.
В результате, это позволяет сделать веб-сайт полностью работающим в офлайне.
Cache API это ещё один механизм хранения данных на клиенте с небольшим отличием — он разработан для хранения HTTP ответов, и прекрасно работает с сервис-воркерами.
Note: Service workers и Cache доступны в большинстве современных браузеров. В момент написания статьи, Safari ещё не имел реализации, но скоро должна быть.
Пример сервис воркера
Давайте взглянем на пример, чтобы дать вам немного мыслей о том, что из этого может выйти. Мы создали другую версию примера хранения видео, который использовался в предыдущей секции — эта функциональность идентична, за исключением того, что этот пример также сохраняет HTML, CSS, и JavaScript в Cache API посредством сервис-воркеров, что позволяет приложению работать полностью в офлайне!
Смотри пример хранилище видео с IndexedDB и сервис-воркером, и его исходный код.
Регистрируем сервис воркер
Первое, что нужно заметить, это дополнительный кусок кода, расположенный в основном JavaScript файле (см. index.js). Первое,что мы делаем, это проверка на то, что
index.js). Первое,что мы делаем, это проверка на то, что serviceWorker доступен в объекте Navigator. Если этот так, тогда мы знаем, что как минимум, базовые функции сервис-воркера доступны. Внутри проверки мы используем метод ServiceWorkerContainer.register() для регистрации сервис-воркера, находящегося в файле sw.js на текущем источнике, таким образом, он может управлять страницами в текущей или внутренних директориях. Когда промис выполнится, сервис-воркер считается зарегистрированным.
if('serviceWorker' in navigator) {
navigator.serviceWorker
.register('/learning-area/javascript/apis/client-side-storage/cache-sw/video-store-offline/sw.js')
.then(function() { console.log('Service Worker зарегистрирован'); });
}Примечание: Путь к файлу sw.js указан относительно корня сайта, а не JavaScript файла, содержащего основной код. Полный путь — https://mdn.. Корень —  github.io/learning-area/javascript/apis/client-side-storage/cache-sw/video-store-offline/sw.js
github.io/learning-area/javascript/apis/client-side-storage/cache-sw/video-store-offline/sw.jshttps://mdn.github.io, и следовательно указываемый путь должен быть /learning-area/javascript/apis/client-side-storage/cache-sw/video-store-offline/sw.js. Если вы хотите использовать данный пример на своём сервере, вы также должны изменить путь к скрипту. Это довольно запутанно, но обязано так работать по причинам безопасности.
Устанавливаем сервис воркер
В следующий раз, когда страница с сервис-воркером будет запрошена (например когда страница будет перезагружена), сервис-воркер запустится на этой странице и начнёт контролировать её. Когда это произойдёт, событие install будет вызвано в сервис-воркере; вы можете написать код внутри сервис-воркера, который будет вызван в процессе установки.
Давайте взглянем на файл сервис-воркера sw.js. Вы можете видеть, что обработчик события install зарегистрирован на self. Ключевое слово
Ключевое слово self это способ ссылки на глобальную область видимости сервис-воркера из файла с сервис-воркером.
Внутри обработчика install мы используем метод ExtendableEvent.waitUntil(), доступном в объекте события, чтобы сигнализировать, что работа продолжается, и браузер не должен завершать установку, пока все задачи внутри блока не будут выполнены.
Здесь мы видим Cache API в действии. Мы используем метод CacheStorage.open() для открытия нового объекта кеша, в котором ответы могут быть сохранены (похоже на объект хранилища IndexedDB). Промис выполнится с объектом Cache, представляющим собой кеш video-store . Затем мы используем метод Cache.addAll() для получения ресурсов и добавления ответов в кеш.
self.addEventListener('install', function(e) {
e.waitUntil(
caches.open('video-store').then(function(cache) {
return cache.addAll([
'/learning-area/javascript/apis/client-side-storage/cache-sw/video-store-offline/',
'/learning-area/javascript/apis/client-side-storage/cache-sw/video-store-offline/index. html',
'/learning-area/javascript/apis/client-side-storage/cache-sw/video-store-offline/index.js',
'/learning-area/javascript/apis/client-side-storage/cache-sw/video-store-offline/style.css'
]);
})
);
}); html',
'/learning-area/javascript/apis/client-side-storage/cache-sw/video-store-offline/index.js',
'/learning-area/javascript/apis/client-side-storage/cache-sw/video-store-offline/style.css'
]);
})
);
});
html',
'/learning-area/javascript/apis/client-side-storage/cache-sw/video-store-offline/index.js',
'/learning-area/javascript/apis/client-side-storage/cache-sw/video-store-offline/style.css'
]);
})
);
});На этом установка завершена.
Отвечаем на последующие запросы
Когда сервис-воркер зарегистрирован и установлен на странице HTML и сопутствующие ресурсы добавлены в кеш, все практически готово. Нужно сделать ещё одну вещь — написать код для ответа на дальнейшие сетевые запросы.
Это то, что делает вторая часть кода файла sw.js. Мы добавили ещё один обработчик к сервис-воркеру в глобальной области видимости, который запускает функцию-обработчик при событии fetch. Это происходит всякий раз, когда браузер делает запрос ресурса в директорию, где зарегистрирован сервис-воркер.
Внутри обработчика, мы сначала выводим в консоль URL запрашиваемого ресурса. Затем отдаём особый ответ на запрос, используя метод FetchEvent. (en-US). respondWith()
respondWith()
Внутри блока мы используем CacheStorage.match() чтобы проверить, можно ли найти соответствующий запрос (т.е. совпадение по URL) в кеше. Промис возвращает найденный ответ или undefined, если ничего не нашлось.
Если совпадение нашлось, то просто возвращаем его как особый ответ. В противном случае, используем fetch() для запроса ресурса из сети.
self.addEventListener('fetch', function(e) {
console.log(e.request.url);
e.respondWith(
caches.match(e.request).then(function(response) {
return response || fetch(e.request);
})
);
});На этом все для нашего простого сервис-воркера. Используя подобный метод, вы можете сделать гораздо больше вещей — для получения доп. информации смотрите рецепты использования сервис-воркеров. Спасибо Paul Kinlan за его статью Adding a Service Worker and Offline into your Web App, которая вдохновила на написание данного примера.
Тестируем наш пример офлайн
Для тестирования примера, вам нужно загрузить его несколько раз, чтобы быть уверенным, что сервис-воркер точно установлен. Когда это сделано, вы можете:
Когда это сделано, вы можете:
- отключиться от сетевого соединения.
- нажмите Файл > Перейти в офлайн, если вы используете Firefox.
- перейдите в инструменты разработчика, выберите Application > Service Workers, нажмите галочку Offline, если используете Chrome.
Если обновите страницу с примером снова, вы увидите, что все работает как обычно. Все данные хранятся в офлайн хранилище — ресурсы страницы в кеше, а видео в базе данных IndexedDB.
Это всё, пока что. Мы надеемся наш краткий обзор client-side storage окажется полезным для вас.
Проблемы безопасности сайтов «б/у» или как грамотно принять сайт на поддержку — CMS Magazine
Иногда сайты меняют своих «хозяев». Причины для этого могут быть разные: веб-студия получает клиента с его старыми сайтами на обслуживание (поддержку), компания или частное лицо приобретает новый проект с целью пополнения своих интернет-активов, веб-студия покупает «движок» с готовой базой данных для внутреннего использования и т.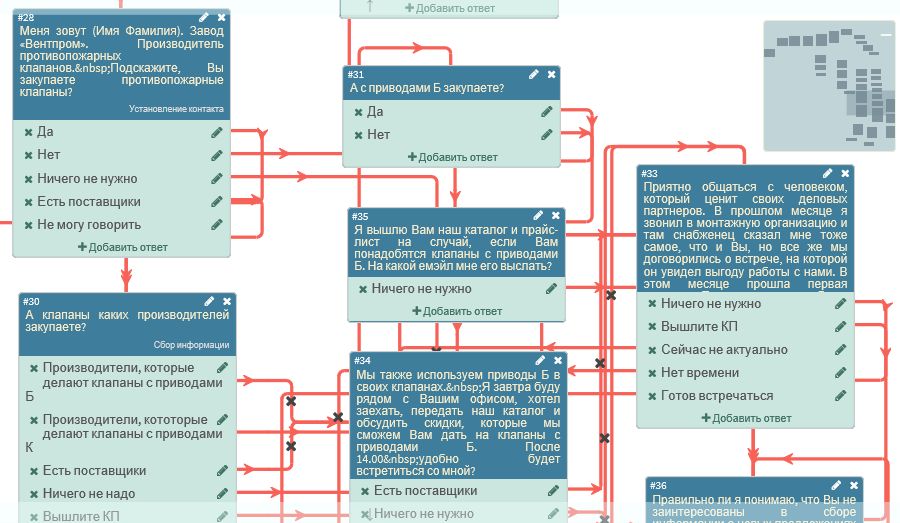 п. Во всех случаях скрипты сайта и база данных попадают в распоряжение новых администраторов и достаточно часто содержат ряд неприятных сюрпризов («пасхальных яиц» или «закладок»), которые случайно или намеренно оставил предыдущий хозяин или веб-мастер, ранее занимающийся разработкой и обслуживанием данного ресурса. Бэкдоры, веб-шеллы, дорвеи, black-hat seo ссылки, дополнительный административный аккаунт — это лишь небольшая часть проблем, с которыми может столкнуться новый хозяин или новоиспеченный администратор сайта. Но обо всем по порядку…
п. Во всех случаях скрипты сайта и база данных попадают в распоряжение новых администраторов и достаточно часто содержат ряд неприятных сюрпризов («пасхальных яиц» или «закладок»), которые случайно или намеренно оставил предыдущий хозяин или веб-мастер, ранее занимающийся разработкой и обслуживанием данного ресурса. Бэкдоры, веб-шеллы, дорвеи, black-hat seo ссылки, дополнительный административный аккаунт — это лишь небольшая часть проблем, с которыми может столкнуться новый хозяин или новоиспеченный администратор сайта. Но обо всем по порядку…
Рассмотрим типичную историю «брошенного» сайта.
Некая компания заказывает сайт в небольшой веб-студии (или у фрилансера). Исполнитель успешно разрабатывает ей сайт «под ключ» на какой-нибудь популярной или, что печальнее, самописной CMS, а по окончании работ передает сайт на администрирование компании-владельцу. Естественно, разрабочик объясняет владельцу ресурса, как загружать новые картинки, обновлять цены, менять текст на страницах, указывать новые контактные данные и пр. И даже все это оформляет в виде руководства пользователя. А спустя некоторое время, что называется «волею судеб», разработчик сайта исчезает и «корпоративное представительство» остается «брошенным».
И даже все это оформляет в виде руководства пользователя. А спустя некоторое время, что называется «волею судеб», разработчик сайта исчезает и «корпоративное представительство» остается «брошенным».
Вначале ситуация для компании не критичная, так как заказчик все еще может обновлять существующий контент на сайте, но вот спустя некоторое время, начинаются проблемы, так как масштабировать функционал сайта под новые бизнес-задачи своими силами он уже не может. А автор сайта пропал.
Что делает в подобном случае компания-владелец? Обычно она обращается к фрилансеру за доработками (кое-где освежить дизайн, заменить старые адреса и телефоны, добавить на сайте пару новых разделов и пр). С этого момента начинается самое интересное, так как не все фрилансеры одинаково «полезны». Если с исполнителем повезло, он выполнит свои обязательства, получит оплату и пожелает всего хорошего. Если же со стороны заказчика возникнут претензии к веб-разработчику или последний окажется недобросовестным исполнителем, велика вероятность хулиганства или мести.
Например, обиженный веб-мастер с целью дополнительного (фонового) заработка может незаметно разместить в шаблонах сайта код по продаже ссылок или мобильный редирект на WAP-партнерку. В первом случае владелец сайта через некоторое время увидит чужие ссылки в футере или сайдбаре страницы, а во втором — часть посетителей, открывающих сайт с мобильных устройств, будет перенаправляться на сайт, продающий медиа-контент за смс. Процент от продаж и доход от продажных ссылок будет составлять пассивный доход нечестному веб-мастеру, а владелец сайта какое-то время будет даже не подозревать о том, что у него на сайте паразитируют.
Особо коварные веб-мастера с замашками хакеров могут оставлять на сайте бэкдоры, загрузчики или веб-шеллы, а также создать дополнительные аккаунты на хостинге или в админке сайта, чтобы в нужный момент получить контроль над файлами и базой данных сайта. Имея в запасе механизмы для контроля и администрирования сайта, они могут шантажировать заказчика или полностью уничтожить сайт и резервные копии на хостинге.
Долго ли, коротко ли, но история с нерадивым веб-мастером заканчивается, с ним прощаются, и сайт снова остается «брошенным». Опираясь на прошлый негативный опыт работы с фрилансером, владелец сайта в следующий раз обращается уже в веб-студию, первоочередная задача которой — грамотно принять сайт на поддержку, выполнить аудит, убрать «закладки» непорядочных веб-мастеров и предотвратить их появление в дальнейшем.
Кроме «закладок» у сайтов, разработанных достаточно давно (назовем их для простоты «сайтами б/у»), есть еще одна серьезная проблема безопасности: уязвимости в скриптах и, как следствие, взлом и заражение вредоносным кодом. Поскольку «движок» сайта обновлять было некому, такие проекты работают на древних версиях CMS и скриптов с большим числом уязвимостей, которые успешно эксплуатируются хакерами.
Чтобы сайт взломали совсем не обязательно, чтобы сайт был популярным. Достаточно того, чтобы он по некоторым запросам появлялся в результатах поисковой выдачи. В ходе массовой атаки, нацеленной на определенную уязвимость, сайт появится в выборке и взламывается в автоматическом режиме вместе с несколькими сотнями других сайтов, работающих на той же уязвимой версии CMS (кстати, уязвимость может быть не только и не столько в ядре CMS, сколько в плагинах и расширениях).
Конечно, идеальный вариант на этапе приема сайта на обслуживание — привлечь для проведения аудита сайта специалистов-«безопасников», но при наличие в команде опытных веб-разработчиков большую часть работы можно выполнить и своими силами.
Итак, рассмотрим проблемы безопасности сайтов, с которыми может столкнуться новый саппорт сайта.
Проблемы безопасности сайтов «б/у»На что в первую очередь следует обратить внимание новому администратору ресурса, который получает сайт на поддержку?
Спам-ссылки (black-hat seo ссылки)На всех (или некоторых) страницах сайта встречаются ссылки на чужие ресурсы, которые владелец сайта не размещал. Ссылки могут располагаться в футере сайта, в сайдбаре или в коде страницы, но не видны посетителю сайта (потому что размещаются в невидимом слое).
Источником появления ссылок может быть код биржи ссылок, который внедрен в шаблоны или скрипты (код sape, trustlink, linkfeed и др). Кроме того при разработке сайта могли использоваться бесплатные шаблоны или нелицензионные плагины, в которых часто внедряют как статические ссылки, так и код загрузки блока ссылок с удаленного сервера. Если данная проблема обнаружена на сайте, необходимо найти код, который внедряет ссылки на страницы и удалить его. В большинстве случаев задача решаемая поиском по файлам. Кстати, код ссылок может быть не только в файлах, но и базе данных.
Кроме того при разработке сайта могли использоваться бесплатные шаблоны или нелицензионные плагины, в которых часто внедряют как статические ссылки, так и код загрузки блока ссылок с удаленного сервера. Если данная проблема обнаружена на сайте, необходимо найти код, который внедряет ссылки на страницы и удалить его. В большинстве случаев задача решаемая поиском по файлам. Кстати, код ссылок может быть не только в файлах, но и базе данных.
Искать внешние ссылки можно SEO-сервисами, которые показывают внешние ссылки на страницах, с помощью грабберов контента (Teleport, Xenu Link Sleuth), а также путем анализа исходного кода страниц. Кроме того, использование специализированного сканера вредоносного кода, например, AI-BOLIT, также ищут внедрения ссылок в код.
Для того чтобы управлять сайтом через веб, достаточно загрузить на хостинг так называемый веб-шелл — основной инструмент хакера.
Веб-шелл представляет собой скрипт с возможностями файлового менеджера (можно редактировать файлы на хостинге, загружать новые, удалять текущие, менять атрибуты, выполнять поиск), менеджера базы данных и туннелинга (читать содержимое БД, выполнять произвольные SQL команды, пробрасывать подключение к локальной БД с удаленного сервера). Веб-шелл отображает текущую конфигурацию сервера, имеет интерфейс для приема и автоматического выполнения команд, и многое другое. Это своего рода «кухонный комбайн», который предоставляет злоумышленнику полный контроль над сайтом, а порой и всем аккаунтом хостинга. В настоящий момент существует большое число веб-шеллов, отличающихся по функциональным возможностям и интерфейсу.
Веб-шелл отображает текущую конфигурацию сервера, имеет интерфейс для приема и автоматического выполнения команд, и многое другое. Это своего рода «кухонный комбайн», который предоставляет злоумышленнику полный контроль над сайтом, а порой и всем аккаунтом хостинга. В настоящий момент существует большое число веб-шеллов, отличающихся по функциональным возможностям и интерфейсу.
Бэкдор — это небольшой хакерский скрипт или фрагмент кода, инжектированный в один из скриптов CMS. Задача бэкдора — предоставить хакеру «черный ход», через который можно выполнить произвольный код или загрузить веб-шелл, а далее получить контроль над скомпрометированным сайтом или сервером.
Пример «загрузчика»:
«Загрузчик» (Uploader) — это еще один вариант бэкдора, позволяющий загрузить произвольный файл на сервер. Естественно, хакера в первую очередь интересует загрузка инструментов для взлома (веб-шеллы, туннеллеры, спам-рассыльщики, и пр). «Загрузчик» достаточно сложно обнаружить, так как он представляет собой небольшой скрипт с кодом, встречающимся и в легитимных скриптах загрузки файлов на сервер (например, в upload формах CMS). Поэтому даже обнаружив файл «загрузчика» неопытный веб-мастер может не придать ему значения. Пример «зарузчика»:
Поэтому даже обнаружив файл «загрузчика» неопытный веб-мастер может не придать ему значения. Пример «зарузчика»:
Пример «загрузчика»:
Для поиска хакерских скриптов эффективно воспользоваться сканером вредоносного кода AI-BOLIT (http://revisium.com/ai/), который «заточен» под детектирование вредоносного кода в PHP/Perl/шелл скриптах.
УязвимостиМожно с уверенностью утверждать, что в большинстве динамических сайтов, реализованных на PHP, ASP и скриптах с использованием CGI, есть уязвимости. Если сайт работает на популярной CMS, которая давно не обновлялась или написан неопытным веб-разработчиком, то данный сайт попадает в зону риска и уже скорее всего был (или в скором времени будет) взломан в ходе массовых атак через известные «дыры». При этом не важно, какая у сайта посещаемость и насколько он популярен. Чтобы снизить вероятность взлома, CMS сайта необходимо как можно быстрее обновить до последней доступной версии, на нее необходимо установить все существующие патчи безопасности, и, желательно, выполнить процедуру CMS hardening («цементирование» или «заморозку» сайта), которая запретит несанкционированные изменения на сайте. Кроме того, необходимо просканировать сайт на наличие хакерских скриптов, веб-шеллов и бэкдоров, чтобы проверить его на компрометацию и гарантировать безопасность сайта в будущем.
Кроме того, необходимо просканировать сайт на наличие хакерских скриптов, веб-шеллов и бэкдоров, чтобы проверить его на компрометацию и гарантировать безопасность сайта в будущем.
Для поиска уязвимостей на сайте можно специализированным программным обеспечением (Acunetix Web Vulnerability Scanner, XSpider, Nikto, Metasploit Framework, sqlmap и другими инструментами пентестера), а для популярных CMS и модулей — проверить уязвимости по базе http://www.cvedetails.com
Редирект — это несанкционированное перенаправление посетителя на сторонний ресурс. Пример: посетитель открывает зараженный сайт в мобильном браузере и перенаправляется на ресурс для взрослых или WAP-портал, где ему предлагают подписку на медиа-контент за смс.
Причиной мобильного редиректа может быть фрагмент кода, вставленный злоумышленником в шаблон, скрипт или базу данных сайта. Чтобы достоверно проверить свои сайты на наличие мобильного редиректа, в большинстве случаев достаточно подключить мобильное устройство к мобильному интернету через 3G/LTE сеть и открыть сайт в мобильном браузере.
Подробно вопрос обнаружения и удаления мобильных редиректов был рассмотрен в нашем докладе на конференции Яндекса: https://events.yandex.ru/lib/talks/2673/
Вирусный код, рекламаНа страницах сайта клиента недобросовестный веб-мастер может размесить код, который время от времени будет показывать всплывающие баннеры, открывать попандеры при клике по ссылками, вставлять тизерные блоки или контекстную рекламу. Из-за грамотного таргетирования, который настраивает хакер, владелец сайта может долго не замечать несанкционированную рекламу (например, она может показываться только западным посетителям или тем, кто открывает сайт с мобильного устройства). А недобросовестный веб-мастер будет продолжительное время зарабатывать за счет подобного паразитирования на чужом сайте.
Дополнительный (забытый) административный аккаунт, заброшенные FTP аккаунты и невежественность подрядчиковНаиболее типичная ошибка владельца сайта — доверить все доступы от сайта фрилансеру и забыть об этом.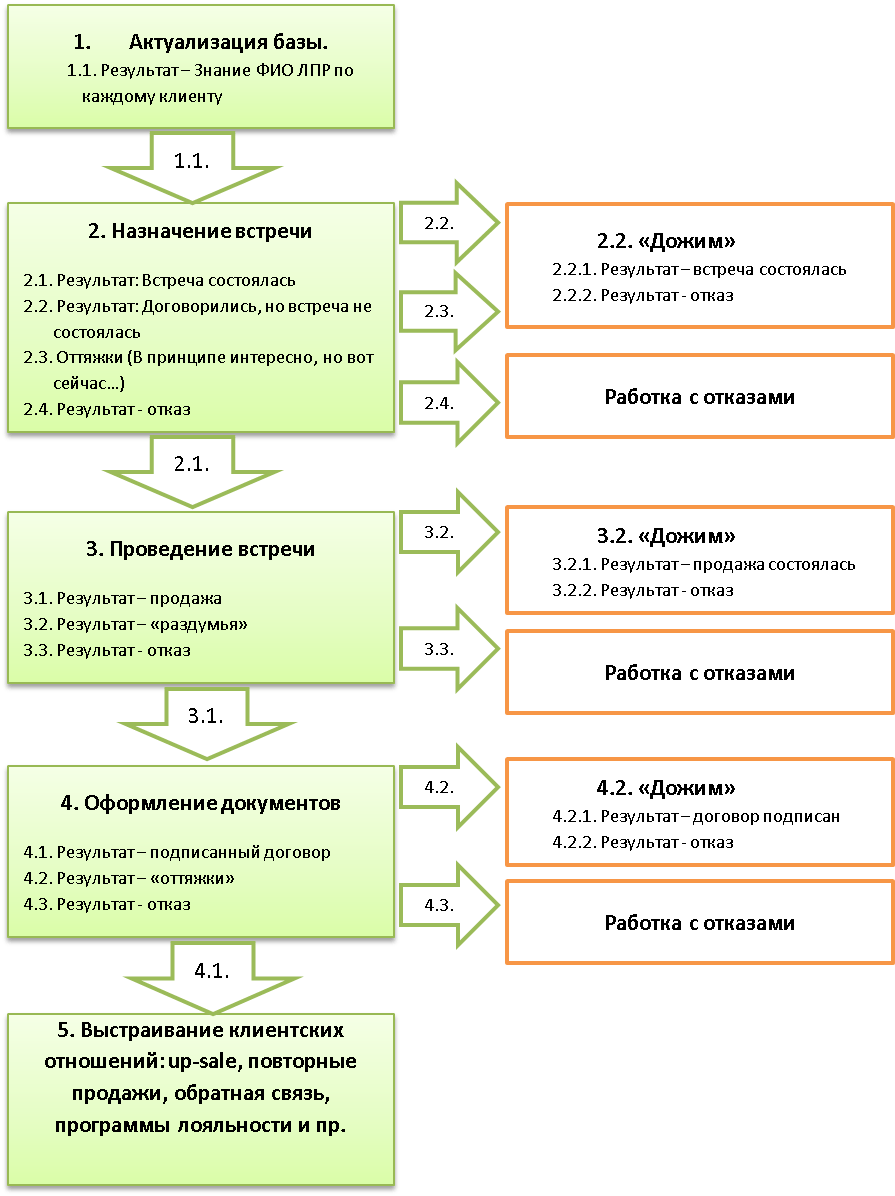 Среди рядовых контент-менеджеров и веб-разработчиков лишь малый процент осведомлен о технике безопасности или так называемой «гигиене безопасности» при работе с сайтом. Поэтому очень часто обслуживание сайта именно сторонними специалистами (контент-менеджерами, администраторами, веб-мастерами) является причиной взлома сайтов.
Среди рядовых контент-менеджеров и веб-разработчиков лишь малый процент осведомлен о технике безопасности или так называемой «гигиене безопасности» при работе с сайтом. Поэтому очень часто обслуживание сайта именно сторонними специалистами (контент-менеджерами, администраторами, веб-мастерами) является причиной взлома сайтов.
Почему это происходит? Все просто: в распоряжении наемных специалистов оказываются «ключи от квартиры, где деньги лежат», но из-за слабой осведомленности о безопасности и защите сайта эти ключи в буквальном смысле прячутся под коврик у парадной двери. А хакеры это знают и активно пользуются этим.
Перечислим наиболее типичные «проколы» специалистов и владельцев сайтов, приводящие к компрометации или заражению ресурсов:
-
Компьютер веб-мастера, работающего по FTP, может быть заражен троянской программой, перехватывающей FTP трафик и ворующей пароли, или шпионской программой, которая извлекает пароли из FTP-клиента. В результате пароль оказывается у хакера, а через некоторое время на хостинг проникает бот и заражает файлы вредоносным кодом.
-
Веб-разработчик может выходить в интернет через открытые сети (в кафе, в парке, в метро и через другие открытые WI-FI точки) без использования VPN, в результате чего доступы к хостингу и в административную панель сайта оказываются скомпрометированы, а переписка с владельцем сайта, содержащая конфиденциальную информацию, перехвачена злоумышленником (сейчас этим может заниматься любой школьник используя снифер трафика в promiscuous mode или специализированные приложения наподобие Intercepter-NG).
-
Владелец сайта создает один аккаунт для всех подрядчиков и часто с полными привилегиями (например, дает root доступ к серверу). При таком подходе в случае инцидентов или проблем с сайтом (взлом, заражение, уничтожение данных) практически невозможно найти виновного. Кроме того, доступы могут передаваться и дальше по цепочке субподрядчикам, не соблюдающим элементарную «гигиену безопасности», или по незащищенным информационным каналами (например, в открытом виде по ICQ, электронной почте и т.
п.), поэтому их могут легко (причем, случайно) перехватить или украсть злоумышленники и получить доступ к сайту или хостингу.
 п.), поэтому их могут легко (причем, случайно) перехватить или украсть злоумышленники и получить доступ к сайту или хостингу.
п.), поэтому их могут легко (причем, случайно) перехватить или украсть злоумышленники и получить доступ к сайту или хостингу.Теперь вы понимаете, почему не стоит доверять подрядчику (не имеет значения это веб-студия или фрилансер), и почему следует немедленно после окончания работ с сайтом менять все пароли.
Старые административные email’ыВ большинстве случаев тот, кто разрабатывает сайт, занимается его размещением на хостинге, а также создает первый административный аккаунт в CMS. Поэтому в регистрационных данных и аккаунтах остаются email’ы разработчика (иногда даже домен приобретается на автора сайта, а не компанию-владельца). Если разработчик ответственный и грамотный, перед сдачей проекта он заменит свои регистрационные данные на данные владельца сайта, а также проинформирует о необходимости смены паролей и научит, как это делать. Но иногда email’ы и пароли остаются неизменными много лет, а владелец сайта даже не подозревает, что все аккаунты зарегистрированы на чужие email’ы и, в случае необходимости, бывший разработчик сайта может получить несанкционированный доступ к сайту.
Например, если между заказчиком и исполнителем произойдет конфликт, исполнитель, пользуясь случаем, может поменять все доступы к хостингу и сайту, и начнет шантажировать владельца. Согласитесь, ситуация не самая приятная. Более того, если хостинг или домен зарегистрирован на исполнителя, заказчик может полностью потерять сайт. Такие случаи не редкость.
Подмена платежных реквизитов и контактных данныхЕсли на сайте есть страница с реквизитами для оплаты (банковские реквизиты, номера электронный кошельков), следует периодически проверять их корректность, так как в результате взлома сайта хакер может незаметно изменить их на свои и какое-то время получать переводы вместо владельца сайта. Иногда хакеры по заказу конкурентов могут взломать сайт компании и заменить контактный телефон или email адрес, на который отправляются заказы, на адрес или телефон конкурента (или установить дублирующую отправку заказов на сторонний email с целью шпионажа). Владельцу сайта не всегда удается своевременно обнаружить подмену.
Если сайт был разработан достаточно давно, то скорее всего часть функциональности перестанет работать. Причин может быть несколько: это и переход хостера на более новую версию PHP, с которой не совместима старая версия CMS, и возможный взлом/заражение сайта вредоносным кодом, и некорректные действия администратора сайта, приводящие к ошибкам в работе (например, повреждению шаблонов).
Поэтому при приеме сайта на сопровождение желательно провести функциональное тестирование и выявить все ошибки в работе, о которых сообщить владельцу сайта.
ЧеклистПрием сайта на сопровождение — процедура, требующая проведения детального анализа: необходимо проверить как безопасность, так и функциональность ресурса, в противном случае вместе с новым клиентом можно получить новые проблемы.
Для удобства приводим чеклист новоиспеченного администратора сайта. Вот что нужно сделать сразу после получения сайта на обслуживание (поддержку):
-
Проверить регистрационную информацию аккаунта хостинга и домена.
Убедиться, что все email’ы, контактные данные принадлежат владельцу сайта (включая домен, хостинг-аккаунт и административные аккаунты CMS). -
Удалить лишние аккаунты: FTP/SSH, администраторов CMS. Оставить только минимально необходимый набор.
-
Сменить пароли у оставшихся аккаунтов: от биллинг и хостинг панелей, FTP, SSH, административных аккаунтов CMS. А также проверить и скорректировать привилегии для аккаунтов (сделать минимально допустимые права для каждого пользователя).
-
Выполнить аудит безопасности сайта: просканировать сайт на наличие вредоносного кода, вирусов, фактов взлома. Вылечить сайт, если необходимо, и установить защиту от взлома.
-
Обновить CMS и скрипты до актуальных версий, установить все необходимые патчи безопасности.
-
Проверить все основные сценарии поведения пользователя, выполнить функциональное тестирование пользовательских и административных разделов.
-
Настроить систему мониторинга сайта для своевременного обнаружения проблем в работе или взлома
-
Настроить систему резервного копирования сайта
-
Настроить систему логирования (включить логи веб-сервера, FTP и почтового сервера с архивацией, установить максимально возможные периоды ротации)
-
Выработать правила безопасной работы с сайтом для персонала, обслуживающего ресурс и оформить ее в виде памятки.
 Убедиться, что все email’ы, контактные данные принадлежат владельцу сайта (включая домен, хостинг-аккаунт и административные аккаунты CMS).
Убедиться, что все email’ы, контактные данные принадлежат владельцу сайта (включая домен, хостинг-аккаунт и административные аккаунты CMS).
Как можно заметить, проблем у сайтов «б/у» достаточно. Тем не менее если знать, откуда ждать беду, аккуратно проверить все основные элементы, своевременно диагностировать и устранить проблемы, то дальнейшая поддержка ресурса будет простой и не потребует значительных ресурсов.
Из-за чего медленно работает сайт и как это исправить
Скорость загрузки сайта — критически важная характеристика. Как для разработчиков, так и для пользователей. Никто не захочет ждать загрузки страницы 5–10 секунд. Прождав хотя бы пару, клиент уйдет к конкурентам. А потерянные посетители — это потерянная прибыль. Поэтому так важно следить за производительностью своего ресурса и постоянно оптимизировать скорость загрузки страниц.
Далее рассмотрим распространенные причины медленной загрузки сайта и методы их решения.
JavaScript, блокирующий рендеринг страницы
Большая часть интерактива сайтов пишется на языке JavaScript. При отсутствии должной оптимизации скрипты, созданные с помощью JS, могут приводить к чересчур медленной работе сайта. Ведь браузер в первую очередь попытается подгрузить именно скрипт. От него зависит, как быстро посетитель увидит содержимое страницы. Поэтому стоит:
- Провести рефакторинг JS-кода. В нем не должно быть избыточных расчетов и действий, замедляющих работу всего ресурса.
- Использовать асинхронную загрузку скриптов, чтобы они подгружались независимо от прочих элементов страницы.
- Вывести тяжелые скрипты в конец разметки файла index.html. Пусть скрипты загружаются в последнюю очередь.

Третий метод в приоритете. Вывод скрипта в конец разметки безопасен для сайта и точно положительно повлияет на скорость загрузки страниц.
Отсутствие системы CDN
CDN расшифровывается как Content Delivery Network, что в переводе означает «сеть доставки контента». Это множество серверов по всей планете, на которых хранится один и тот же веб-сайт. И независимо от того, из какой части света посетитель заходит на ресурс, он получит данные с ближайшего сервера, что позитивно скажется на скорости загрузки.
Существует несколько провайдеров CDN-систем. Например, Cloudflare. Сервис дает возможность разместить свой сайт в нескольких частях планеты (конкретнее можно узнать на официальном сайте сервиса). Нередко вебмастера подгружают jQuery и другие компоненты с CDN-серверов, чтобы не тратить на их обработку ресурсы арендованного VDS.
Избыток информации в базе данных
Под избытком понимается не просто большой массив данных, а массив бесполезных данных. Это довольно часто встречающееся явление. К примеру, плагины для WordPress хранят внушительное количество информации в базе данных, и эта информация остается там даже после удаления дополнения. БД разрастается и начинает работать медленнее, влияя на производительность всего сайта.
Бывали случаи, когда базу данных на несколько гигабайт увеличивали параметры планировщика задач Сron. От этого время загрузки страницы увеличивалось до 10 секунд.
Необходимо провести чистку и оптимизацию БД. Нужно удалить лишние записи из таблиц options и postmeta. Если вы пользуетесь WordPress, то можно активировать плагины Clean Options или Plugin Garbage Collector.
Также рекомендуется следить за структурой базы данных и кэшировать популярные запросы.
Неправильно настроенные или неоптимизированные CSS-файлы
CSS, хоть и являясь языком разметки, а не полноценным языком программирования, может негативно повлиять на скорость работы сайта. Он тоже требует базовой оптимизации.
Он тоже требует базовой оптимизации.
- Прописывайте тег @media, чтобы ваш ресурс знал, какой CSS-файл нужно задействовать в конкретной ситуации (на мобильном устройстве, в полноэкранном режиме).
- Не создавайте слишком много внешних CSS-файлов. Старайтесь объединять их (лучше в один).
- Используйте CSS-код прямо в HTML (по возможности). Тогда сайту придется меньше обращаться к внешним файлам.
Лучше начать с первого метода. Потом попробовать второй. Внедрение Inline-CSS подойдет только для небольших порций кода и не окажет значительного влияния на скорость загрузки страницы.
Выключенный OPcache
Если вы используете на своем сайте динамические файлы PHP, то следовало бы использовать встроенный механизм кэширования OPcache. Этот движок поставляется вместе с PHP и значительно ускоряет загрузку всех элементов написанных на этом языке. А вместе с ними и загрузку всей страницы.
Система кэширования и акселерации PHP у Timeweb включена по умолчанию. У других провайдеров может потребоваться ручная настройка модуля.
У других провайдеров может потребоваться ручная настройка модуля.
Чтобы запустить OPcache вручную, надо:
- Создать на сайте файл PHP.ini.
- Ввести туда команду zend_extension=opcache.so.
- Сохранить внесенные изменения.
Теперь проверим, работает ли OPcache, создав файл phpinfo.php и отыскав там строчку Opcode Caching. Если напротив нее написано Up and Running, то дополнительные настройки не потребуются.
Настройка кэширования и устранения связанных неполадок
Кэширование — важная составляющая производительности любого сайта и веб-приложения. Тут можно работать сразу в двух направлениях: настроить кэширование данных на стороннем ресурсе (как в СDN-cистемах) и оптимизировать хранение кэша в браузере посетителей.
Можно подключиться к системе кэширования сайтов Cloudflare. Это стоит недорого и позволяет перенести всю нагрузку на их серверы. Они кэшируют даже скрипты и стили.
Во втором случае нужна настройка кэша на сервере и в браузере пользователя. Для сайтов, работающих на WordPress, есть плагины WP Super Cache и Proxy Cache Purge. С помощью них можно отправить запрос на удаление кэш-файлов с устройства пользователя. Таким образом, удастся избежать проблем, если вдруг скопившееся кэш-файлы повредятся и станут помехой при загрузке страницы.
Для сайтов, работающих на WordPress, есть плагины WP Super Cache и Proxy Cache Purge. С помощью них можно отправить запрос на удаление кэш-файлов с устройства пользователя. Таким образом, удастся избежать проблем, если вдруг скопившееся кэш-файлы повредятся и станут помехой при загрузке страницы.
Неоптимизированные изображения
Медиаконтент и картинки могут быть довольно тяжелыми. Это отнимает драгоценное пространство в хранилище сервера и замедляет загрузку сайта. В зависимости от скорости подключения посетителя влияние тяжелых изображений на время загрузки может быть весьма заметным. Следует заняться их оптимизацией.
Можно сделать это прямо на компьютере, уменьшив разрешение картинки или воспользовавшись утилитой в духе Squash. А можно подключить к своему сайту плагин-оптимизатор. Например Robin, Image Optimizer, WP Compress либо один из их аналогов.
Такие плагины автоматически сокращают размер загружаемых изображений на 40–80%, практически не влияя на их качество (удаляются EXIF-данные и некоторые цвета).
Скрипты конфликтуют с другими элементами страницы
При неправильной настройке или обращении к несуществующим элементам JavaScript-код может негативно повлиять на загрузку сайта. Вплоть до полного «зависания».
Зачастую такое происходит из-за ошибки в коде. Человек, который его писал, ошибся в значении, написал лишнюю цифру или некорректно указал класс. Сайт или веб-приложение, пытаясь выполнить запрос человека, попросту «застревает», столкнувшись с непредвиденной логической или синтаксической ошибкой.
В этом случае нужен грамотный анализ кода и рефакторинг. Такую ошибку сможет исправить только человек.
Можно воспользоваться сервисами Pingdom, Web Page Test или GTmetrix, чтобы проверить, влияют ли на скорость загрузки страницы подключенные к сайту скрипты.
Не загружаются файлы из внешних источников
Проблемы возникают, если сайт пытается использовать какой-то файл, но не может его найти. Если это условная картинка на стороннем сервере, то в статье просто будет отсутствовать одно изображение. Если же это скрипт, отвечающий за фундаментальную логику ресурса или ссылка на важный фреймворк в духе React, то сайт может не загрузиться или загружаться слишком медленно. В этом случае стоит перепроверить все ссылки на файлы, хранящиеся на сторонних ресурсах и исправить «битые».
Если же это скрипт, отвечающий за фундаментальную логику ресурса или ссылка на важный фреймворк в духе React, то сайт может не загрузиться или загружаться слишком медленно. В этом случае стоит перепроверить все ссылки на файлы, хранящиеся на сторонних ресурсах и исправить «битые».
Похожие проблемы возникают при удалении или повреждении файлов после установки обновлений или атаки вирусов. На такой случай следует всегда иметь под рукой резервную копию всего ресурса целиком.
Плагины в CMS слишком тяжелые
Внушительная часть ресурсов вашей VDS или виртуального хостинга могут уходить на поддержку CMS. То есть систему управления данными наподобие WordPress, Joomla или Drupal. А если установить в них увесистые плагины, то можно лишиться еще части ресурсов, выделенных на работу сайта.
Некоторые дополнения съедают слишком большое количество памяти, из-за чего резко падает скорость загрузки всего сайта. В этом случае не поможет кэширование и другие методы «ускорения» ресурса.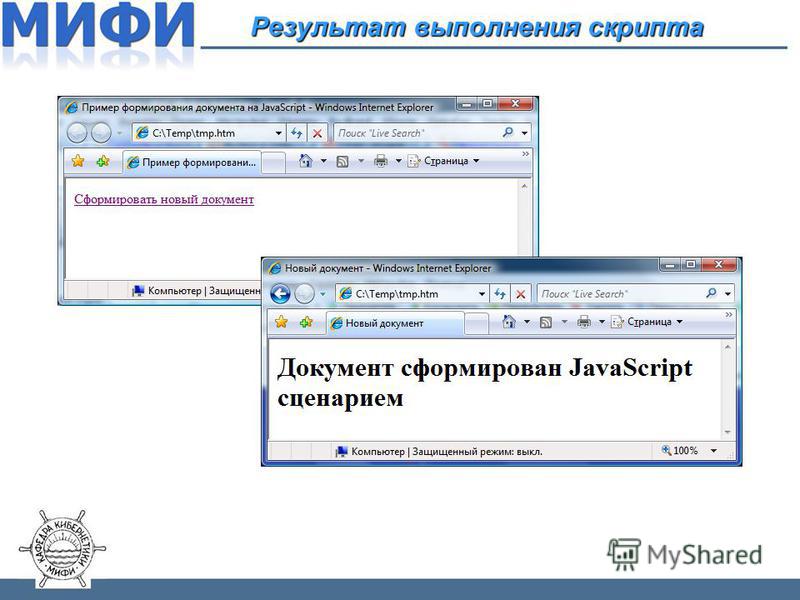 Придется избавляться от «прожорливых» расширений.
Придется избавляться от «прожорливых» расширений.
Некоторые дополнения могут работать некорректно из-за сбоя при установке или обновлении. Стоит их переустановить или обновить в надежде на автоматическое исправление проблемы.
Избыток рекламы
Без нее никуда, понятно. Реклама — отличный способ монетизировать сайт, но с ней лучше не перебарщивать. Избыток баннеров резко увеличит время загрузки вашего сайта.
В первую очередь проблема возникнет на стадии появления дополнительных HTTP-запросов. Потребуется гораздо больше времени на обработку каждого из них. Если у вас на странице есть поп-апы или автоматически воспроизводимые ролики, то из-за них могут создаваться сотни HTTP-запросов, которые без особых усилий заставят сайт «повиснуть».
Так что придется подсократить количество рекламы, чтобы не заставлять посетителей слишком долго ждать загрузки страницы.
К тому же это попросту выглядит убого в 2020 году. Всплывающие баннеры и автоматически воспроизводимый медиаконтент — моветон, и дело даже не в производительности.
Отсутствие gZip-компрессии
Избыточный размер компонентов сервера — основной ответ на вопрос «почему мой сайт работает медленно». К счастью, файлы сайта можно сжать. Если активировать gZip-компрессию, то сервер получит команду упаковать все веб-объекты (включая изображения, стили, JavaScript и т.п.) в один контейнер (архив), перед тем как отправить его в браузер, запросивший данные.
Компрессия сократит время ответа сервера за счет сокращения размера передаваемой информации между VDS и компьютером пользователя.
gZip-компрессия — бескомпромиссное решение без недостатков. Простой способ сделать весь ресурс шустрее, ничего не потеряв и не потратив время на выяснение других причин медленной загрузки контента.
Вирусы
Такое бывает редко, но бывает. На сервер тоже может проникнуть вирус, как и на локальный компьютер, особенно если ваш VDS работает на базе Windows. На этой ОС словить «заразу» куда проще. Но и Linux не защищен на 100%.
Вирусы на сервере, как и на обычном ПК, могут съедать часть ресурсов и заметно замедлять его работу. Решение — антивирус. Проверить сайт можно с помощью специального онлайн-сервиса. А вот чтобы провести комплексную чистку и удалить менее распространенные угрозы, придется установить профессиональное решение. Например Ai-Bolit. Он сможет найти подозрительные скрипты, незащищенные каталоги и странные переадресации.
Решение — антивирус. Проверить сайт можно с помощью специального онлайн-сервиса. А вот чтобы провести комплексную чистку и удалить менее распространенные угрозы, придется установить профессиональное решение. Например Ai-Bolit. Он сможет найти подозрительные скрипты, незащищенные каталоги и странные переадресации.
Чтобы подключить облачный антивирус, надо обратиться к своему хостинг-провайдеру.
Медленный хостинг
Возможно, дело вовсе не в сайте, а в сервере. Не все провайдеры предлагают одинаковую производительность. Не все серверы подходят под все типы сайтов и веб-приложений. Не всегда хостинг дает достаточно ресурсов для реализации проектов заказчика. Поэтому важно подобрать себе хорошего провайдера.
Выбрать Timeweb, к примеру, если еще не сделали этого. Одни из самых шустрых серверов в РФ. Есть специализированные решения с 5-герцовыми процессорами, адаптированные под CMS Битрикс. Есть серверы в Европе. Поэтому сомневаться в производительности или доступности VDS на базе Timeweb не придется.
Есть ненулевая вероятность, что дело не в хостинге, а выбранной конфигурации сервера (или виртуального хостинга). В этом случае надо заказать более дорогую опцию с необходимыми характеристиками.
Проблемы на стороне клиента
Последнее, на что стоит сетовать — браузер пользователя. Бывает и так, что страницы долго открываются не у всех сразу, а только у конкретных людей. Повлиять на такого рода проблемы зачастую невозможно.
Все, что вы можете сделать, удобно подать им инструкцию по устранению общих проблем. Например, рассказать им, как удалить из браузера кэш, как очистить историю, переустановить или сменить браузер, проверить ОС антивирусом и т.п.
Но это стоит делать только в том случае, если вы на 100% уверены в наличии проблем на стороне клиента.
Зачастую же решить проблемы с медленной работой сайта и сервера помогают описанные выше методы. Задействовав сразу несколько, можно добиться весомого прироста.
И не забывайте, что производительность ресурса напрямую связана с удовлетворенностью клиентов, а их удовлетворенность влияет на ваш доход и репутацию сайта.
Восстановление сайта на Joomla
В этой статье мы рассмотрим восстановление сайта под управлением Joomla 2.5 из резервной копии созданной, компонентом Akeeba Backup. Для восстановления сайта нам потребуются: последняя резервная копия и скрипт Akeeba Kickstart с сайта Akeeba Backup. Нам не нужно заново устанавливать Joomla, всё уже есть в резервной копии. О том, как настроить резервное копирование сайта на Joomla 2.5 можно узнать из предыдущей статьи «Резервное копирование Joomla 2.5».
Возможны три ситуации, требующие восстановления сайта: повреждены или отсутствуют только файлы сайта, повреждена только база данных сайта и повреждены и файлы и база данных.
Первый случай самый простой. Нужно распаковать архив резервной копии и заменить полученными файлами и папками, файлы и папки на сервере. Для распаковки архива понадобится архиватор eXtract Wizard. Это программа кроссплатформенная, есть версия для Windows, Linux, MacOS. С сайта Akeeba Backup скачиваем и устанавливаем версию для той операционной системы, в которой работаем. Версия для Windows — здесь. На момент написания статьи был доступен стабильный релиз eXtract Wizard 3.3. Распаковываем архив резервной копии в какую-нибудь локальную директорию. При этом в распакованном архиве будет дополнительная папка, которая называется «Installation». Это папка инсталлятора для восстановления из полной резервной копии. Внимание, не копируйте эту папку на сервер! Выбираем нужные нам файлы и папки и передаём их на сервер, используя протокол SFTP. Всё, файлы восстановлены!
Версия для Windows — здесь. На момент написания статьи был доступен стабильный релиз eXtract Wizard 3.3. Распаковываем архив резервной копии в какую-нибудь локальную директорию. При этом в распакованном архиве будет дополнительная папка, которая называется «Installation». Это папка инсталлятора для восстановления из полной резервной копии. Внимание, не копируйте эту папку на сервер! Выбираем нужные нам файлы и папки и передаём их на сервер, используя протокол SFTP. Всё, файлы восстановлены!
Теперь рассмотрим случай, когда повреждена только база данных сайта. Для восстановления базы данных лучше и проще воспользоваться её резервной копией. Т. е. если делалась отдельно резервная копия базы данных, то легче восстановить из неё. А если отдельно база данных не бэкапилась? Здесь нам опять пригодится распакованный архив резервной копии, а точнее вышеупомянутая папка «Installation». Нет, мы не будем её копировать, нам понадобится несколько файла, находящиеся в подпапке sql. У меня их три. Один файл с расширением .sql, другой с расширением .s01 и третий файл – databases.ini. Но прежде чем приступить к восстановлению базы данных из этих файлов, нужно эти файлы немного изменить. Открываем файл databases.ini и копируем значение prefix без кавычек. Обратите внимание на информацию, хранящуюся в этом файле! Далее, поочерёдно открываем файлы с расширением .sql и .s01 в текстовом редакторе и производим замену символов #__ (решётка и два подчёркивания) на скопированное нами значение. Если этого не сделать, то после восстановления мы получим не работающий сайт. Будет выдаваться примерно такая ошибка: «Table ‘_session’ doesn’t exist SQL=INSERT INTO». При восстановлении из отдельной копии базы данных такой ошибки не будет, потому что в ней (копии) сразу вписаны «правильные» префиксы таблиц.
Один файл с расширением .sql, другой с расширением .s01 и третий файл – databases.ini. Но прежде чем приступить к восстановлению базы данных из этих файлов, нужно эти файлы немного изменить. Открываем файл databases.ini и копируем значение prefix без кавычек. Обратите внимание на информацию, хранящуюся в этом файле! Далее, поочерёдно открываем файлы с расширением .sql и .s01 в текстовом редакторе и производим замену символов #__ (решётка и два подчёркивания) на скопированное нами значение. Если этого не сделать, то после восстановления мы получим не работающий сайт. Будет выдаваться примерно такая ошибка: «Table ‘_session’ doesn’t exist SQL=INSERT INTO». При восстановлении из отдельной копии базы данных такой ошибки не будет, потому что в ней (копии) сразу вписаны «правильные» префиксы таблиц.
Заходим в phpMyAdmin, переходим на вкладку «Базы данных», выделяем нашу повреждённую базу и нажимаем «Удалить».
Подтверждаем удаление и на этой же вкладке создаём новую базу данных с тем же именем и той же кодировкой.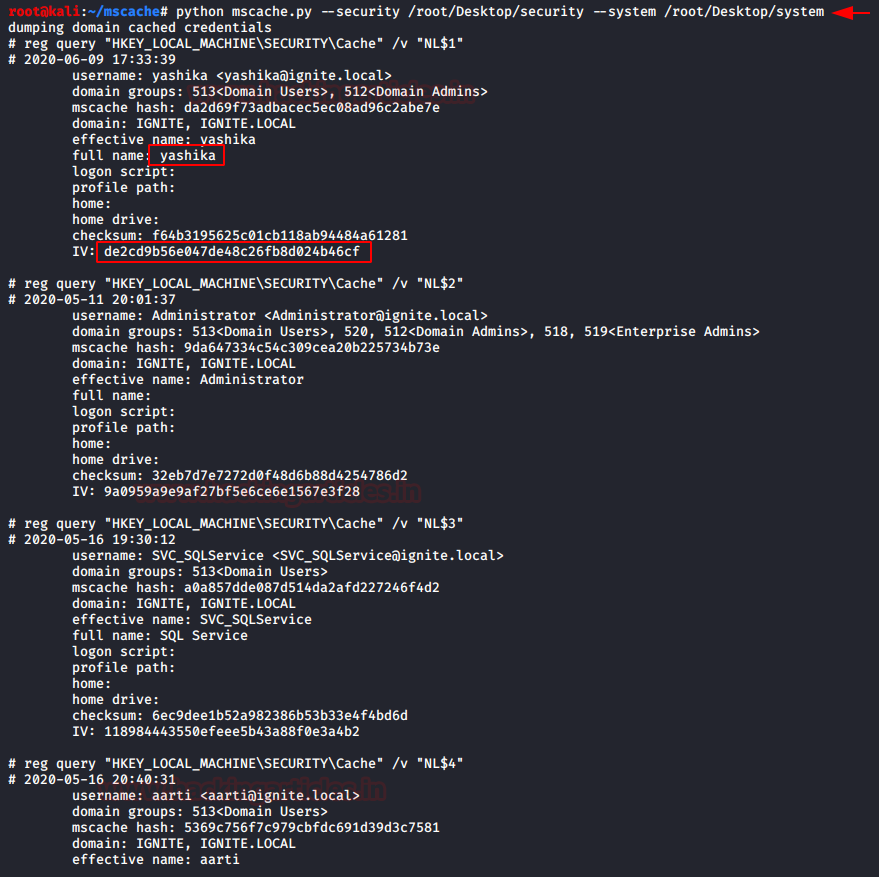
Переходим на вкладку «Импорт». Теперь, если есть отдельная резервная копия базы данных, тогда импортируем только её, а если есть два файла из полной резервной копии, то один за другим импортируем их.
Всё, база данных восстановлена!
Теперь рассмотрим восстановление сайта из полной резервной копии. Качаем Akeeba Kickstart. На момент написания статьи последняя стабильная версия скрипта была 3.3.2. Освобождаем корневую директорию сайта от файлов и папок, а затем любым доступным способом переносим в неё архив или все части архива (если резервная копия делилась) резервной копии. Туда же переносим распакованный архив Akeeba Kickstart или, если позволяет хостинг, то распаковываем архив со скриптом прямо на сервере.
Набираем в адресной строке http://yoursite/kickstart.php и читаем предупреждение о том, что:
- Kickstart не инсталлятор. Это средство для распаковки архива. Настоящий инсталлятор был вложен в архив во время резервного копирования.
- Kickstart не только распаковывает архив. Вы можете использовать Akeeba eXtract Wizard и загрузить распакованные файлы, используя FTP.
- Работа Kickstart зависит от конфигурации сервера. Так, он может не работать на некоторых серверах.
- Вы должны скачать и загрузить вашу архивную копию сайта с помощью FTP в двоичном режиме передачи. Любой другой метод может привести к повреждению резервной копии и ошибкам при восстановлении.
- Ошибки в работе сайта после восстановления, как правило, вызваны файлом .htaccess или директивами php.ini. Вы должны понимать, что пустые страницы, 404 и 500 ошибки обычно можно обойти путём редактирования вышеупомянутых файлов. Это не наша работа, чтобы возиться с файлами конфигурации, так как это может быть опасно для вашего сайта.
- Kickstart перезаписывает файлы без предупреждения. Если вы не уверены, что у вас всё в порядке с этим, не продолжайте.
- Попытка восстановить сайт по временному URL панели хостера (cPanel) (например, http://1. 2.3.4/~username) приведёт к провалу, и ваш сайт будет, по всей видимости, не работоспособным.
- Вы должны прочитать документацию перед использованием этого программного обеспечения. Большинство проблем можно избежать или легко обойти, имея представление, как это программа работает.
- Этот текст не означает, что уже обнаружена проблема. Это стандартный текст, который отображается при каждом запуске Kickstart.
 2.3.4/~username) приведёт к провалу, и ваш сайт будет, по всей видимости, не работоспособным.
2.3.4/~username) приведёт к провалу, и ваш сайт будет, по всей видимости, не работоспособным.Переходим по ссылке.
Выбираем файл архива или первую часть составного архива, с которого начнётся восстановление сайта. После нажатия на кнопку «Старт» начнётся распаковка архива. По окончании распаковки мы увидим следующее окно.
Нажимаем «Запустить инсталлятор». Откроется новое окно или вкладка в зависимости от браузера и его настроек, в котором запустится мастер установки, а язык диалога станет английским. Это окно/вкладка инсталлятора. На первой странице — «Check» будут отображены результаты проверки соответствия хостинга требованиям установки Joomla 2. 5.
5.
Так же как и при «чистой» установке Joomla 2.5 обязательные требования (верхняя таблица) должны быть выполнены. Если требования выполнены, а так же существуют директории для кэша, временных файлов и журналов, то нажимаем кнопку «Next» и переходим к странице «DB Restore».
В группе «Connection parameters» (параметры подключения) проверяем или заполняем следующие поля. В поле «Database type» устанавливаем тип базы данных – в нашем примере mysql. В поле «Database server host name» вписываем имя сервера с базой данных, в поле «User name» — имя пользователя (администратора) БД, а в следующем поле – его пароль. В поле «Database name» вводим имя базы данных. Все остальные параметры на этой странице можно оставить со значениями по умолчанию. Переходим к следующей странице, нажав кнопку «Next» и если всё заполнено правильно, то видим окно восстановления базы данных. Нажимаем «ОК» и переходим к странице «SiteInfo».
В группе «Site Parameters» (Параметры сайта) заполняем поля «Site Name» (Название сайта), «Site e-mail address» (Адрес эл. почты сайта), «Site e-mail sender name» (Имя отправителя эл. почты сайта). Обращаем внимание на опцию «Override tmp and log paths» (Переопределить пути к временным файлам и журналам). Галочку не ставим. В группе «Super Administrator settings» (Настройки Суперадминистратора) выбираем из списка пользователя с правами суперадминистратора, вводим его пароль с подтверждением, а точнее новый пароль. Т. е. если не заполнить поля для ввода пароля, то пароль останется прежним. А так же вводим адрес его электронной почты. Проверяем путь к директории для временных файлов и путь к файлам журналов. Нажимаем «Next», после чего начинается восстановление сайта. По окончании восстановления мы попадём на страницу «Finish».
почты сайта), «Site e-mail sender name» (Имя отправителя эл. почты сайта). Обращаем внимание на опцию «Override tmp and log paths» (Переопределить пути к временным файлам и журналам). Галочку не ставим. В группе «Super Administrator settings» (Настройки Суперадминистратора) выбираем из списка пользователя с правами суперадминистратора, вводим его пароль с подтверждением, а точнее новый пароль. Т. е. если не заполнить поля для ввода пароля, то пароль останется прежним. А так же вводим адрес его электронной почты. Проверяем путь к директории для временных файлов и путь к файлам журналов. Нажимаем «Next», после чего начинается восстановление сайта. По окончании восстановления мы попадём на страницу «Finish».
Теперь можно закрыть окно или вкладку инсталлятора и перейти к окну или вкладке Kickstart, которое теперь выглядит так.
Запускаем очистку и получаем следующее приглашение.
Об авторе:
Меня зовут Андрей Золкин. Из более, чем пятнадцати лет работы в сфере информационных технологий, десять лет работаю с системами, базирующимися на открытом исходном коде. На страницах сайта Aitishnik.Ru веду блоги по CMC Joomla и Debian GNU/Linux.
Из более, чем пятнадцати лет работы в сфере информационных технологий, десять лет работаю с системами, базирующимися на открытом исходном коде. На страницах сайта Aitishnik.Ru веду блоги по CMC Joomla и Debian GNU/Linux.
Ещё статьи о Joomla 2.5
-
Joomla авторизация через соц. сети
В последнее время стало «модно» предоставлять посетителям сайта возможность регистрации и авторизации, используя свои учетные записи в социальных сетях. В этом есть определенная логика — не каждый хочет проходить регистрацию на сайте. По…
Настройка Apache, MySQL, PHP
Открываем в текстовом редакторе конфигурационный файл вэб-сервера Apache.
Он называется httpd.conf и находится в корневой папке сервера, в поддиректории conf. В нашем примере C:\www\conf\httpd.conf. Найдём и раскомментируем (удалим…Расширения Joomla! Общие сведения
В первой статье о Joomla говорилось о том, что с её помощью можно сделать: и простой сайт-визитку, и интернет-магазин, и блог, и сайт социальной сети. Это достигается за счет использования тысяч различных расширений: компонентов,…
Virtuemart — изменение цены в зависимости от свойства товара…
Многие владельцы интернет магазинов на Virtuemart 1.1.x сталкивались со следующей задачей: есть варианты одного и того же товара, которые отличаются друг от друга только каким-нибудь свойством, например, размером, фасовкой, массой,.
..Маленький шаг в безопасность Joomla 2.5
Как известно, всегда есть, мягко говоря, любопытные люди, так и мечтающие «поколдовать» в чужой админке. В Joomla админка, она же панель управления, располагается по адресу: http://наш_сайт/administrator/. Так вот в целях безопасности…
Карта сайта в Joomla 2.5
В этой статье мы поговорим о карте сайта, а точнее о том, как создать карту сайта на Joomla в форматах HTML и XML. Карта сайта в формате HTML представляет собой страницу со ссылками на материалы сайта. Она помогает посетителям…
 Он называется httpd.conf и находится в корневой папке сервера, в поддиректории conf. В нашем примере C:\www\conf\httpd.conf. Найдём и раскомментируем (удалим…
Он называется httpd.conf и находится в корневой папке сервера, в поддиректории conf. В нашем примере C:\www\conf\httpd.conf. Найдём и раскомментируем (удалим… ..
..«Я отключил Java Script на неделю, и это было прекрасно»
Оказывается, существует альтернативное, лучшее интернет-пространство. Оно скрывается за той сетью, в которую мы выходим каждый день с телефона, планшета или ноутбука. Интернет без рекламы, без необходимости бесконечно прокручивать страницы или закрывать всплывающие окна, предлагающие поделиться материалом в соцсети или подписаться на рассылку. И, что лучше всего, чтобы открыть для себя этот новый мир, не нужны особые расширения браузера или приложения с ограниченным доступом. Надо поменять всего один небольшой параметр в настройках. Просто передвиньте флажок, который активизирует «JavaScript» и все, добро пожаловать в более чистую и простую сеть.
Оно скрывается за той сетью, в которую мы выходим каждый день с телефона, планшета или ноутбука. Интернет без рекламы, без необходимости бесконечно прокручивать страницы или закрывать всплывающие окна, предлагающие поделиться материалом в соцсети или подписаться на рассылку. И, что лучше всего, чтобы открыть для себя этот новый мир, не нужны особые расширения браузера или приложения с ограниченным доступом. Надо поменять всего один небольшой параметр в настройках. Просто передвиньте флажок, который активизирует «JavaScript» и все, добро пожаловать в более чистую и простую сеть.
JavaScript — это язык программирования, который применяется практически для всех современных браузеров. Когда-то его использовали для создания простых скриптов, ответственных, например, за проверку заполнения всех полей до нажатия кнопки Submit. С тех пор интернет стал намного быстрее, браузеры — сложнее, и JavaScript превратился в инструмент для разработки сложных сетевых приложений. Некоторые из них, например Google Docs, в размерах и функциональности не уступают стандартным офисным. Но проблема в том, что при переходе на веб-сайт автоматически запускаются созданные для него программы JavaScript. Довольно сложно разобраться в назначении каждого скрипта, это делает пользователя уязвимым для интернет-мошенничества и вредоносного ПО.
Но проблема в том, что при переходе на веб-сайт автоматически запускаются созданные для него программы JavaScript. Довольно сложно разобраться в назначении каждого скрипта, это делает пользователя уязвимым для интернет-мошенничества и вредоносного ПО.
Многие вещи просто работали и, чаще всего, работали лучше
JavaScript — это еще и ключевой элемент большинства раздражающих рекламных объявлений — как видимых, так и скрытых. В последнее время многие пользователи устанавливают программы для блокировки рекламы: возможно оттого, что заботятся о приватности и безопасности, или им просто очень сильно она надоела. На прошлой неделе не кто иной, как Эдвард Сноуден, разоблачитель АНБ (Агентство национальной безопасности США), в своем интервью для Intercept заявил, что мы не просто имеем право, но обязаны блокировать все объявления в сети, по крайней мере до тех пор, пока системные администраторы и интернет-провайдеры не обеспечат защиту пользователя от вредоносной рекламы и зомби-cookies (способных «вытащить» личную информацию пользователя без его согласия).
Некоторые (сейчас их немного, но это пока) все же продвинулись немного дальше и попросту блокируют JavaScript. В этом месяце я решил стать одним из них хотя бы на неделю и посмотреть, что из себя представляет жизнь без JavaScript. К концу этого срока я потерял терпение и решил вернуться к обычной сети со всеми ее недостатками.
Это просто работает
Как вы понимаете, у меня возникли некоторые трудности. Netflix не работал. YouTube тоже, по крайней мере, без подключения Adobe Flash, — а это уже убедительный аргумент в пользу JavaScript. Естественно, о работе с Google Docs тоже можно было забыть. Facebook направил меня на версию без JavaScript для мобильных телефонов и я пытался зайти на сайт с ноутбука — на телефоне открывалась только пустая страница. С Twitter не было таких проблем, но очень не хватало счетчика символов, так что трудно было уловить момент, когда сообщение становилось слишком длинным. Я мог просматривать WIRED, но не мог оставлять комментарии. Некоторые страницы просто отказывались загружаться.
Некоторые страницы просто отказывались загружаться.
Что самое удивительное, многие вещи просто работали и, чаще всего, работали лучше. Страницы загружались почти мгновенно, батарея ноутбука держалась дольше, а отвлекающих моментов в сети стало меньше — при этом у вас нет чувства вины, которое возникает у тех, кто устанавливает блокировщик рекламы. В конце концов, я не пытался никого обмануть — реклама просто не может приспособиться к моим настройкам.
Разумеется, блокировка JavaScript не обеспечивает абсолютную анонимность. Cookies — самая большая угроза приватности для пользователей сети — никуда не денутся. Достаточно просто зайти на сайт, чтобы «поделиться» личной информацией, а если этот сайт извлекает какой-либо контент (например, шрифт или изображение) из внешних серверов, потенциально они тоже могут воспользоваться вашими данными. По мнению Дениэла Ведитца, главного специалиста по защите информации в компании Mozilla, основной причиной всех проблем с приватностью в последние годы является не JavaScript, а плагины, такие как Adobe Flash и Acrobat. Тем не менее, отключение JavaScript частично защищает приватность пользователя и уменьшает количество инструментов, с помощью которых посторонние могут заполучить его данные.
Тем не менее, отключение JavaScript частично защищает приватность пользователя и уменьшает количество инструментов, с помощью которых посторонние могут заполучить его данные.
В случаях, когда работа требовала использования JavaScript, я легко мог открыть другой браузер и активировать его там. Вдобавок, некоторые браузеры (Google Chrome) или плагины (NoScript) предоставляют возможность выборочно подключать JavaScript для проверенных сайтов. Но с точки зрения ярых защитников свободного интернета, ни в коем случае нельзя заходить на страницы, использующие неизвестный JavaScript. Это убеждение они настойчиво стараются распространить.
Освободите сеть
Фонд свободного ПО (организация, курирующая разработку, распространение и популяризацию бесплатного ПО — прим. Newочём) не собирается отказываться от JavaScript, а выступает скорее за предоставление пользователям большей прозрачности и контроля над кодами, от которых зависит работа компьютера. Организация, основанная Ричардом Столлманом (создателем GNU — одной из первых бесплатных операционных систем) придерживается мнения, что разработчики ПО должны открыть свободный доступ к кодам, отвечающим за их приложения, так, чтобы пользователи могли не только просмотреть их, но и внести свои изменения. По мнению Столлмана и его компании, возможность понимать и контролировать эти коды — не только вопрос практичности, но и моральный долг.
По мнению Столлмана и его компании, возможность понимать и контролировать эти коды — не только вопрос практичности, но и моральный долг.
Конечно же Фонд был против использования запатентованной платформы Adobe Flash, которая отвечает за анимированные и интерактивные элементы на веб-сайтах. После того, как Flash утратила былую популярность, организация переключилась на JavaScript. В 2013 г. была запущена кампания, основанная на идее, что создатели сайтов должны использовать коды JavaScript с бесплатным и свободным доступом или, в крайнем случае, обеспечить работу сайта без них. Чтобы помочь пользователям избежать проприетарного JavaScript, Фонд разработал LibreJS, плагин для браузера Firefox, который блокирует многие (но не все) коды JavaScript. Однако важнее, может быть, то, что организация сотрудничает с разработчиками таких сайтов, как Reddit или Greenpeace, помогая им стать менее зависимыми от патентованного JavaScript.
Одним из самых успешных начинаний в этом плане является CrowdSupply, что-то среднее между Etsy и Kickstarter, — сайт, работающий на основе краудфандинга.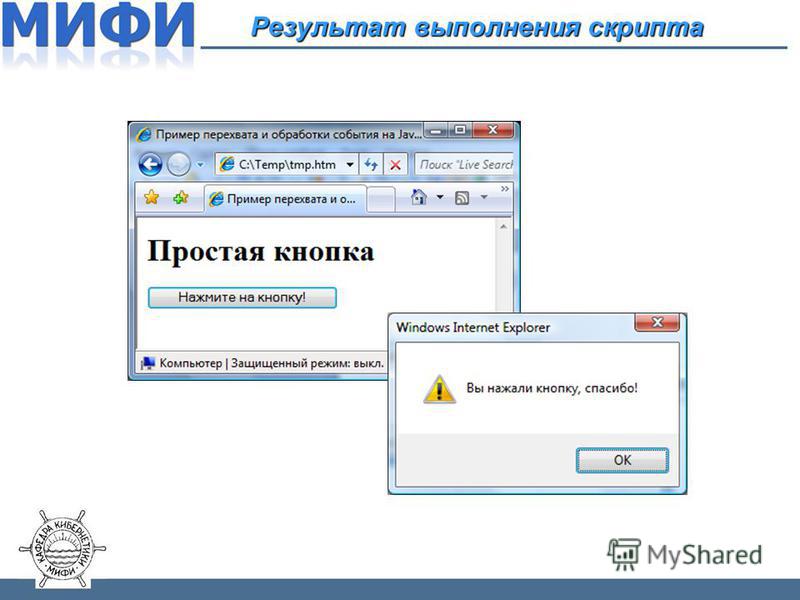
Соучредитель CrowdSupply, Джошуа Лифтон, уже проявлял интерес к JavaScript, когда Столлман написал ему о кампании Free JavaScript ранее в этом году. Из всех товаров, проданных через CrowdSupply, самые известные — ноутбуки с открытым исходным кодом от Novena и Purism. Многие покупатели, желающие их приобрести, отключают JavaScript на своих устройствах.
«Во время некоторых кампаний электронные письма приходили каждый день. Можно предположить, что на одного человека, отправившего письмо, приходится сотня тех, кто не отправил, — пояснил Лифтон. — Некоторые писали без каких-либо идеологических побуждений. Кто-то, как выяснилось, не знал, что JavaScript является причиной его проблем. В любом случае, приходило понимание того, что это действительно важная проблема; кампания убедила многих отказаться от патентованного JavaScript. Сейчас сайт CrowdSupply все еще использует Google Analytics, но пользователи могут заходить на сайт без JavaScript. В результате, сайт работает быстрее, он проще в использовании, что, по мнению Лифтона, только увеличит продажи. «Мы ставим акцент на идее, но не могу отрицать, что это полезно и для бизнеса», — комментирует Лифтон.
Я же к концу недели неохотно включил JavaScript. Главной причиной стали мои любимые расширения Google Chrome, которые не могут работать без него. Кроме того мне, как и всем, нравится потоковое видео и интерактивные изображения. Но, благодаря эксперименту, я теперь желаю в большей степени контролировать процессы в своем браузере. Я узнал о том, как много ненужных вещей встроено в сеть и о том, как легко можно от них избавиться.
Автор: Клинт Финли.Оригинал: WIRED.
Перевела: Наташа Живова.
Редактировала: Анна Небольсина.
2361 шт. НАПИШУ БОТ TELEGRAM СОЗДАМ СЛОЖНОСТИ ЛЮБОЙ СКРИПТ ИЛИ
Товары (2361 шт.) для сравнения из 1 магазинов: Kwork.
Сделаю форму обратной связи для сайта
Цена: 500 ₽ в Kwork
Подробнее Купить
Сделаю или отредактирую для вас удобную форму обратной связи для любой платформы сайта, с любым количеством полей, чекбоксов и так далее, с настройкой и установкой.
Разработаю бота для VK вконтакте и Telegram
Цена: 500 ₽ в Kwork
Подробнее Купить
Готов разработать чат-бота для таких платформ как: Telegram, vk . На языке программировании Python . С использованием популярных библиотек, а так же базой данных : MongoDb, sqlite3 и другие. Смогу разработать чат-ботов различной направленности : игровых ботов, ботов для коммерческого использования и. т. д. Цена исходя из конкретной задачи может меняться. Всё зависит от сложности чат-бота. В результате работы предоставлю: Исходные коды с объяснением как установить на сервер Файл запуска вашего бота в формате .exe (Для упрощения работы на системах windows)
Телеграм бот
Цена: 500 ₽ в Kwork
Подробнее Купить
Создадим телеграм бота любой сложности, в самые быстрые сроки ! Для создания нам необходимо полное описание бота которого вы хотите и все
Написание парсера сайтов на Python
Цена: 500 ₽ в Kwork
Подробнее Купить
Перед покупкой прочитайте пожалуйста описание до конца. Один кворк включает в себя парсинг одного сайта Перед парсингом мне нужно обязательно ознакомиться с сайтом. Только после ознакомления я смогу взяться за работу. С каждой страницы возможно сохранение до 5 полей. Каждое дополнительное поле можно заказать отдельно. Максимальный объём для одного кворка — 10 000 строк. Дополнительный объём можно заказать отдельно. Парсер пишу на Python 3 с использованием сторонних модулей (BeautifulSoup, Selenium) Внимание! Есть исключения с которыми я НЕ работаю: Соцсети Сайты, возвращающие капчу Сайты, блокирующие по IP (если у вас нет списка работающих proxy) Поисковики (Yandex, Google и т. д. )
Создание NodeJS-бэкенд системы
Цена: 2500 ₽ в Kwork
Подробнее Купить
Создание простой бэкенд системы или API на базе Node.js с использованием баз данных MySQL, SQLite, JSON на базе стандартных библиотек Node.js, без сторонних систем, API и других сервисов. До 10 команд (запросов) к системе.
Интерактивная карта для вашего сайта. До 20 меток
Цена: 500 ₽ в Kwork
Подробнее Купить
Подготовлю скрипты(js) интерактивной яндекс карты для вашего сайта с размещением до 20 меток на карте. Подготовлю и сформирую данные для карты из Ваших данных.
Discord Bot Чат бот или Музыкальный бот
Цена: 500 ₽ в Kwork
Подробнее Купить
Создам бота в дискорде, который будет реагировать на ваши команды, собирать и сохранять информацию, присылать картинки, мемы, могу сделать его музыкальным. Сможет стримить музыку с YouTube или Soundcloud (для других сервисов уточняйте).
Напишу скрипт на PHP любой сложности
Цена: 1500 ₽ в Kwork
Подробнее Купить
Напишу скрипт на PHP любой сложности . Не работаю с сайтами, сделанными на конструкторах типа adobe muse, wix и другие, также не работаю с CMS и с 1C Битрикс! Если не подходит кворк, создам для вас индивидуальный, под вашу задачу. Буду рад сотрудничать на продолжительной основе.
Telegram бот
Цена: 500 ₽ в Kwork
Подробнее Купить
Создам чат бота для Telegram. Быстро. Качественно. Надежно. Не дорого. Все по вашему желанию. Покупайте!
Бот для Тelegram
Цена: 500 ₽ в Kwork
Подробнее Купить
Создам бота для вашего канала или страницы в Телеграм. Основные функции — рассылка постов, простой диалог.
Discord Бот
Цена: 1500 ₽ в Kwork
Подробнее Купить
Данный кворк предоставляет вам возможность создать своего Discord бота с нужными для вас функциями. Отличие в том что в боте будут нужные для вас функции, вы сможете поменять его название/аватарку, в любой момент я могу дополнить бота и у вас будут его исходники!)
Создам чат бота для вконтакте
Цена: 1000 ₽ в Kwork
Подробнее Купить
Сделаю бота для группы вконтакте опыт пол года и есть примеры могу сделать бота квест и разговорного бота
Напишу парсер или соберу данные с сайта
Цена: 500 ₽ в Kwork
Подробнее Купить
Соберу товары с интернет-магазинов. Для точной оценки стоимости проекта и вообще его возможности необходимо показать донора с которого планируется сбор. Не работаю с серпом поисковых систем. Так же не работаю с агрегаторами вроде авито циан и т. п.
Скрипт для увеличения подписчиков вк
Цена: 500 ₽ в Kwork
Подробнее Купить
Доброго времени суток, хотелось бы вам много подписчиков? Тогда вы правильно пришли, скрипт работает автоматически, вы просто запускаете и всё. Гарантия возврата денег, при каких-то ошибках)
Быстрый скрипт магазина
Цена: 500 ₽ в Kwork
Подробнее Купить
Возможности магазина: Скорость загрузки и работы. Подробная документация. Быстрое оформление заказа. Адаптивный шаблон. Настраиваемые фильтры. SEO — оптимизация для поисковиков. Скидки, купоны, сертификаты. Поддержка виртуальных товаров. Популярные способы оплаты, доставки. Открытый исходный код. Поддержка пользователей. Поддержка приема платежей: Authorize.Net Кредитная карта Google Checkout Интеркасса Invoice Kvitancia Liqpay Money Order Check Paypal Prochange Киви Rbkmoney Робокасса SamplePayment In-store Pickup Stripe Вебмани Яндекс. Деньги YandexFizlico Zpayment
DLE Автоматически наполняемые коллекции — подборки по ключевым словам
Цена: 500 ₽ в Kwork
Подробнее Купить
Данный модуль DLE (DataLife Engine) используется для автоматической сортировки новостей сайта в подборки по ключевым словам или словосочетаниям из заголовков, краткого или полного описания, тегов или дополнительных полей. А так же с поиском только в определенной категории на сайте. К примеру, можно создать подборку “Фильмы про Зомби” и выставить в модуле условие, чтобы в эту категорию попадали все новости, где встречается в тексте слово “зомби” . Или собрать коллекцию всех фильмов с любимым актёром из доп поля «Актёр». Или сделать поиск франшиз. Или создать категорию “Топ фильмов IMDB (или Кинопоиск)” и выставить условие, чтобы парсить в нее все фильмы с оценкой не ниже 9.0 по оценке IMDB или Кинопоиска. Как используется: Указывается фраза, по которой нужно вести поиск новостей для подборки — и выбор, где производить поиск: в какой категории (во всех, если не указано), в кратком/полном описании, тегах, заголовке или в доп полях. То есть вы один раз задаете настройки для подборки — и новые подходящие новости будут отсортировываться в созданные подборки автоматически. Имеет функцию поиска со всеми склонениями слов, а так же по словосочетаниям
Получите 60 премиум плагинов для магазина на WooCommerce
Цена: 500 ₽ в Kwork
Подробнее Купить
Получите комплект лучших премиум плагинов дополнений для интернет-магазина на WooCommerce. Все плагины куплены с официального сайта разработчика и продаются по лицензии GNU General Public License (GNU GPL). Лицензия GNU GPL подразумевает свободное скачивание, использование, модификацию и распространение файлов. Обязательно прочтите подробнее условия лицензии в прикрепленном файле! Список всех премиум плагинов для интернет-магазина на движке WordPress для WooCommerce находится в прикрепленном файле.
Боты для платформы мета4
Цена: 3000 ₽ в Kwork
Подробнее Купить
Готовые боты для платформы мета4. Отличный помощник, работает когда Вас нет за ПК или срочно нужно отойти по срочным делам. Очень важно! ! Не работает на Демо-счетах! ! !
Создам чат-бота в вконтакте
Цена: 500 ₽ в Kwork
Подробнее Купить
Создам бота в вк, который сможет автоматически отвечать на частые вопросы, переводить в меню, общаться с клиентами и переводить на вас.
Чат-бот для сайта
Цена: 500 ₽ в Kwork
Подробнее Купить
Об этом кворке Увеличь продажи с сайта, раскрыв весь потенциал и мощь чат ботов для сайта! Чат бот продает, консультирует, собирает заявки 24 часа в сутки, 7 дней в неделю 365 дней. Продаёт строго по вашему сценарию продаж, без отклонений в сторону и непрофессиональных ошибок, которые делает человек. Дизайн настраивается под ваши пожелания. Мгновенная доставкадиалога чата на почту. Разве ни такой чат бот вы хотите установить на сайт? Тогда присылайте указанный в инструкции материал и увеличьте продажи, раскрыв весь потенциал и мощь чат ботов для сайта. внимание! Чат бот для сайта не использует никаких мессенджеров. . Чтобы вставить чат бот на ваш сайт вставьте ссылку из сервиса до закрывающегося тега . Примеры чат-ботов: https://botsrv.com/qb/pXNoar1xV2mlBOn4/5doqer3q0xbR6ZL0?mode=preview https://botsrv.com/qb/pXNoar1xV2mlBOn4/nj7qyrYqpwrkgxzB
Создаю, исправляю код в Html, Js, Php, JQuery, MySql подключение к БД
Цена: 500 ₽ в Kwork
Подробнее Купить
C WordPress, Bitrix и т. д. НЕ работаю!!! Напишу или отредактирую код на html, js, php, jquery. Это могут быть различные калькуляторы, виджеты и так далее. Про консультирую по установке или работе готового скрипта. Вид: Создание и доработка
Напишу Telegram, VK бота на заказ
Цена: 500 ₽ в Kwork
Подробнее Купить
Напишу Telegram, VK бота для канала, группы, либо самостоятельного бота. Гарантия работоспособности бота Публикация из Вконтакте Поддержка в течение дня Опыт работы с Telegram больше 5 лет. Разработка каждого бота проходить с нуля и вручную.
Напишу Бота телеграмм
Цена: 500 ₽ в Kwork
Подробнее Купить
Опыт разработки более 2х лет. Писал боты для лучших групп в телеграмме. Боты любой сложности и любого функционала. Чат-боты для телеграма. Всё быстро и удобно
Скрипт для просмотра 500-600K stories в instagram ежедневно 2020
Цена: 500 ₽ в Kwork
Подробнее Купить
Описание: Hyperloop Terminal — это скрипт консольный создан для masslooking (mecca просмотра) историй. Все, что вам нужно, это предоставить некоторые обязательные параметры, установить цели и запустить скрипт. Мы создали специальное подробное цифровое руководство по установке и настройке. Вам не будет сложно. На данный момент предполагаемая скорость может составлять около 500-600 тысяч просмотров в день. Каждый день мы прилагаем все усилия, чтобы улучшить наш алгоритм и увеличить скорость. Самое главное, что наш скрипт поддерживает двухфакторную аутентификацию‚ может обходить проверку проверки‚ использовать несколько целей, поддерживать прокси и настраивать задержки между запросами в Instagram. внимание: подходит для опытных пользователей php-скриптов. Требует настройки сервера.
Напишу и подключу Telegram бота любой сложности
Цена: 500 ₽ в Kwork
Подробнее Купить
Готов создать для вас бота на языке программирования Python. Опыт разработки более 4 лет Пишу ботов любой сложности и функционала, с возможность подключения любых сторонник API, баз данных, формы оплаты
показать еще …
Страницы: | 1 | … | 19 | 20 | 21 | … | 79 |
Веб-парсинг страницы JavaScript с помощью Python
Лично я предпочитаю использовать scrapy и selenium и докеризировать их в отдельных контейнерах. Таким образом, вы можете установить как с минимальными трудностями, так и сканировать современные веб-сайты, которые почти все содержат javascript в той или иной форме. Вот пример:
Используйте scrapy startproject , чтобы создать свой скребок и написать своего паука, скелет может быть таким простым, как этот:
импортный лом
класс MySpider (scrapy.Паук):
name = 'my_spider'
start_urls = ['https://somewhere.com']
def start_requests (самостоятельно):
yield scrapy.Request (url = self.start_urls [0])
def parse (self, response):
# обрабатывать результаты, очищать элементы и т. д.
# сейчас просто проверяли, все работает
печать (response.body)
Настоящее волшебство происходит в middlewares.py. Перезаписать два метода в промежуточном программном обеспечении загрузчика, __init__ и process_request , следующим образом:
# импортировать дополнительные модули, которые нам нужны
импорт ОС
из копирования импорт глубокой копии
от времени импортный сон
из сигналов импорта scrapy
из лома.http импорт HtmlResponse
из selenium import webdriver
класс SampleProjectDownloaderMiddleware (объект):
def __init __ (сам):
SELENIUM_LOCATION = os.environ.get ('SELENIUM_LOCATION', 'NOT_HERE')
SELENIUM_URL = f'http: // {SELENIUM_LOCATION}: 4444 / wd / hub '
chrome_options = webdriver.ChromeOptions ()
# chrome_options.add_experimental_option ("mobileEmulation", mobile_emulation)
self.driver = webdriver.Remote (command_executor = SELENIUM_URL,
желаемые_возможности = chrome_options.to_capabilities ())
def process_request (self, request, spider):
self.driver.get (request.url)
# немного спать, чтобы страница успела загрузиться
# или отслеживайте элементы на странице, чтобы продолжить, как только страница будет готова
сон (4)
# если вам нужно манипулировать содержимым страницы, например, щелкать и прокручивать, сделайте это здесь
# self.driver.find_element_by_css_selector ('. my-class'). click ()
# вам нужен только теперь правильно и полностью отрисованный html с вашей страницы, чтобы получить результаты
body = deepcopy (self.driver.page_source)
# копируем текущий url в случае редиректа
url = deepcopy (self.driver.current_url)
вернуть HtmlResponse (url, body = body, encoding = 'utf-8', request = request)
Не забудьте включить это промежуточное ПО, раскомментировав следующие строки в файле settings.py:
DOWNLOADER_MIDDLEWARES = {
'sample_project.middlewares.SampleProjectDownloaderMiddleware': 543,}
Next для докеризации. Создайте свой Dockerfile из легкого образа (здесь я использую python Alpine), скопируйте в него каталог вашего проекта, требования для установки:
# Использовать официальную среду выполнения Python в качестве родительского образа
ОТ python: 3.6-альпийский
# устанавливаем некоторые пакеты, необходимые для scrapy, а затем скручиваем, потому что это удобно для отладки
RUN apk --update добавить linux-headers libffi-dev openssl-dev build-base libxslt-dev libxml2-dev curl python-dev
WORKDIR / my_scraper
ДОБАВИТЬ requirements.txt / my_scraper /
RUN pip install -r requirements.txt
ДОБАВЛЯТЬ . / скребки
И, наконец, объедините все это в docker-compose.yaml :
версия: '2'
Сервисы:
селен:
изображение: селен / автономный хром
порты:
- «4444: 4444»
shm_size: 1 Гб
my_scraper:
строить: .зависит от:
- «селен»
среда:
- SELENIUM_LOCATION = samplecrawler_selenium_1
объемы:
-.: / my_scraper
# используйте эту команду, чтобы контейнер работал
команда: tail -f / dev / null
Запустите docker-compose up -d . Если вы делаете это в первый раз, ему потребуется некоторое время, чтобы получить последнюю версию selenium / standalone-chrome, а также создать образ скребка.
Как только это будет сделано, вы можете проверить, что ваши контейнеры работают с docker ps , а также убедиться, что имя контейнера селена совпадает с именем переменной среды, которую мы передали нашему контейнеру-скребку (здесь это было SELENIUM_LOCATION = samplecrawler_selenium_1 ).
Введите свой контейнер скребка с docker exec -ti YOUR_CONTAINER_NAME sh , команда для меня была docker exec -ti samplecrawler_my_scraper_1 sh , cd в правильный каталог и запустите парсер с scrapy crawl my_spider .
Все это есть на моей странице github, и вы можете получить это отсюда
Учебное пособие по парсингу веб-страниц — эпизод # 1 — Очистка веб-страницы (с помощью Bash)
Выполнение хобби-проектов — лучший способ попрактиковаться в науке о данных перед тем, как получить первую работу.И один из лучших способов получить реальные данные для хобби-проекта — это парсинг веб-страниц .
Я долгое время обещал это участникам курса — вот и она: серия моих руководств по парсингу для начинающих специалистов по данным!
Я покажу вам шаг за шагом, как вы можете:
- очистить общедоступную веб-страницу html
- извлечь из нее данные
- написать сценарий, который автоматически очистит тысяч общедоступных веб-страниц html на веб-сайте
- создать полезный (и увлекательный) анализ из полученных данных
- проанализировать огромный объем текста
- анализировать метаданные веб-сайта
Это эпизод №1, в котором мы сосредоточимся на шаге №1 (очистка общедоступной веб-страницы html).И в следующих выпусках мы продолжим шаги 2, 3, 4, 5 и 6 (масштабирование до тысяч веб-страниц, извлечение из них данных и анализ полученных данных).
Более того, я покажу вам весь процесс на двух разных языках данных, так что вы увидите полный объем. В этой статье я начну с более простого: bash . И в следующих статьях я покажу вам, как делать аналогичные вещи и в Python .
Так что пристегнитесь! Учебник по парсингу, эпизод №1 — поехали!
Прежде чем мы начнем…Это практическое руководство.Я настоятельно рекомендую вместе со мной заняться кодированием (и выполнять упражнения в конце статей).
Я предполагаю, что у вас уже есть некоторые знания о программировании на bash — и что у вас уже есть собственный сервер данных. Если нет, то сначала просмотрите эти руководства:
- Как установить Python, R, SQL и bash, чтобы практиковать науку о данных!
- Введение в эпизод № 1 Bash
- Введение в эпизод № 2 Bash
- Введение в эпизод № 6 Bash
Когда вы запускаете хобби-проект по науке о данных, вы всегда должны выбирать тему, которая вам нравится.
Что касается меня: я люблю публичные выступления.
Я люблю практиковать это сам и люблю слушать других… Так что просмотр презентаций TED для меня тоже хобби. Поэтому в этом уроке я проанализирую презентации TED.
К счастью, почти все презентации TED уже доступны в Интернете.
…
Более того, доступны их расшифровки!
…
(Спасибо, TED!)
Итак, нам «просто» нужно написать сценарий bash, который собирает для нас все эти расшифровки, и мы сможем начать углубленный анализ текста.
Примечание 1: Я выбрал очистку TED.com просто для примера. Если вы увлечены чем-то другим, после прочтения этих обучающих статей попробуйте найти проект по парсингу, который вам понравится! Вы занимаетесь финансами? Попробуйте почистить новости фондового рынка! Вы занимаетесь недвижимостью? Тогда почистите сайты недвижимости! Вы любитель кино? Вашей целью может быть imdb.com (или что-то подобное)!
Войдите на удаленный сервер!Хорошо, еще раз: для этого урока вам понадобится удаленный сервер.Если вы еще не настроили его, сейчас самое время! 🙂
Примечание. Если по какой-то причине вам не нравится мой сервер, вы можете использовать другую среду. Но я категорически против этого не рекомендую. Использование тех же инструментов, которые я использую, гарантирует, что все, что вы здесь прочитаете, будет работать и на вашей стороне. Итак, в последний раз: используйте эту настройку удаленного сервера для этого руководства.
Хорошо, допустим, у вас есть сервер. Большой!
Теперь откройте Терминал (или Putty) и войдите в систему со своим именем пользователя и IP-адресом.
Если все в порядке, вы должны увидеть командную строку… Примерно так:
Представляем вам новый любимый инструмент командной строки: curl Интересно, что во всем этом руководстве по парсингу веб-страниц вам нужно будет выучить только и новую команду bash. И это curl .
curl — отличный инструмент для доступа ко всему HTML-коду веб-сайта из командной строки. (Это хорошо для многих других процессов передачи данных с сервера на сервер, но мы пока не будем туда заходить.)
Давай попробуем прямо сейчас!
завиток https://www.ted.com/
Результат:
Ой, мальчик … Что это за бардак ??
Это полный HTML-код TED.com, и вскоре я объясню, как превратить его во что-то более значимое. Но перед этим кое-что важное.
Как видите, чтобы получить нужные данные, вам нужно будет использовать именно тот URL, по которому находится контент веб-сайта, и его полную версию.Так, например, эта короткая форма не подойдет:
curl ted.com
Просто ничего не возвращает:
И вы получите аналогичные пустые результаты для этих:
локон www.ted.com
локон http://www.ted.com
Даже если вы правильно определите протокол https , но пропустите часть www , вы получите короткое сообщение об ошибке, что контент вашего веб-сайта «был перемещен» :
Поэтому убедитесь, что вы вводите полный URL-адрес и используете тот, на котором фактически расположен веб-сайт.Это, конечно, отличается от веб-сайта к веб-сайту. Некоторые используют префикс www , некоторые нет. Некоторые до сих пор работают по протоколу http — большинство (к счастью) используют https .
Хороший трюк для поиска нужного URL-адреса — это открыть веб-сайт в браузере, а затем просто скопировать и вставить оттуда полный URL-адрес в окно терминала:
Итак, в случае TED это будет так:
завиток https://www.ted.com
Но, как я уже сказал, я не хочу царапать TED.com домашняя страница.
Я хочу почистить стенограммы переговоров. Итак, давайте посмотрим, как это сделать!
curl в действии: загрузка стенограммы одного выступления на TEDОчевидно, что первым шагом в проекте парсинга веб-страниц всегда является поиск правильного URL-адреса веб-страницы, которую вы хотите загрузить, извлечь и проанализировать.
А пока давайте начнем с одного выступления на TED. (Затем в следующем эпизоде этого руководства мы увеличим это количество до 3 300 выступлений.)
Для создания прототипа своего сценария я выбрал наиболее просматриваемую речь — это фраза сэра Кена Робинсона «Убивают ли школы творчество». (Отличный разговор, кстати, очень рекомендую посмотреть!)
Сама стенограмма находится по этому URL:
https://www.ted.com/talks/sir_ken_robinson_do_schools_kill_creativity/transcript
Итак, вам нужно скопировать и вставить это в командную строку — сразу после команды curl :
curl https: // www.ted.com/talks/sir_ken_robinson_do_schools_kill_creativity/transcript
Отлично!
Мы снова получили наш запутанный html-код, но на самом деле это означает, что мы на шаг ближе.
Если вы немного прокрутите вверх в окне Терминала, вы узнаете там части речи:
Это (пока) не самый удобный формат для анализа данных, но мы исправим его очень быстро.
Другой ваш любимый инструмент командной строки для очистки веб-страниц: html2textПомните, я сказал, что вам нужно выучить только одну новую команду bash в этом руководстве по парсингу? Ну, строго говоря, это было правдой, потому что эта другая команда не обязательна … Но она сделает вашу жизнь намного проще.Так что давайте разберемся и с этим!
Он называется html2text и предназначен для очистки ваших данных от кодов HTML и возврата на ваш экран только полезного содержания (текста, который мы хотим проанализировать).
К сожалению, html2text не является частью вашей текущей настройки сервера (это не встроенный инструмент), поэтому перед первым использованием вам необходимо установить его. (Впрочем, ничего страшного. Это занимает примерно 10 секунд.)
Введите в командную строку:
sudo apt-get install html2text
Он запросит ваш пароль (введите его!), А затем быстро установит инструмент html2text на ваш сервер.
Отлично! Давайте посмотрим на это в действии!
Очистка данных файла .html Повторите предыдущую команду curl , но на этот раз давайте также поместим команду html2text с вертикальной чертой ( | ) после нее.
Введите это:
curl https://www.ted.com/talks/sir_ken_robinson_do_schools_kill_creativity/transcript | html2text
Результат возвращается на экран.
Прокрутите немного вверх, и вы увидите это:
Разве это не мило?
Полный текст выступления сэра Кена на TED — только в окне вашего терминала, готовый для анализа! (Вы можете перепроверить его и сопоставить с тем, что вы видите на исходном веб-сайте.)
Ну почти готов к разбору.
На самом деле, если вы прокрутите все данные, которые вы скачали, вы все равно увидите некоторые текстовые фрагменты, которые вам не понадобятся.
Например, перед расшифровкой вы увидите:
И после расшифровки вы увидите это:
Видите ли, когда вы очищаете веб-сайт, вы очищаете его все содержимое.На этот раз были добавлены тексты верхнего меню, нижнего колонтитула и бокового меню. Они вам не понадобятся, поэтому следующим шагом будет избавление от них.
Удаление ненужных частей данных (с помощью команды sed)Мы постараемся найти шаблон, похожий на каждую веб-страницу с расшифровкой стенограммы на TED.com и четко ограничивающий начало и конец полезной части нашего контента (фактическая стенограмма выступления).
Пришло время для открытия данных!
Давайте скачаем еще несколько выступлений, сравним их и выясним, что это за шаблоны:
curl https: // www.ted.com/talks/sir_ken_robinson_do_schools_kill_creativity/transcript | html2text
curl https://www.ted.com/talks/amy_cuddy_your_body_language_may_shape_who_you_are/transcript | html2text
curl https://www.ted.com/talks/james_veitch_this_is_what_happens_when_you_reply_to_spam_email/transcript | html2text
К счастью для нас, он довольно ясен и понятен:
Нам придется удалить все до Подробности о строке , потому что там начинаются расшифровки стенограмм.
И нам придется удалить все после **** Programs & amp. инициатива **** (включая эту строку), где расшифровка стенограммы заканчивается.
В одном из моих предыдущих руководств по bash я уже писал об отличном инструменте командной строки: sed .
Для этих задач нам снова пригодится sed !
Чтобы удалить все строки с до данной строки в файле, вам нужно будет использовать этот код:
sed -n '/ [сам шаблон] /, $ p'
И чтобы удалить все строки после данной строки в файле, это код:
sed -n '/ [сам шаблон] / q; p'
Примечание: этот тоже удалит линию с рисунком!
Примечание:
Теперь, конечно, если вы не знаете sed наизнанку, вы не сможете разобраться в этих фрагментах кода самостоятельно.Но вот в чем дело: и вам не обязательно!
Если вы накапливаете свои знания в области науки о данных на практике, вы можете использовать Google и Stackoverflow и найти ответы на свои вопросы в Интернете. Что ж, это не просто нормально, это нужно делать!
Например, если вы не знаете, как удалять строки после данной строки в bash, введите в Google следующее:
Первый результат приводит вас к Stackoverflow — где прямо в первом ответе есть три (!) Альтернативных решения проблемы:
Кто сказал, что изучать науку о данных путем самообучения сейчас сложно?
Хорошо, болтовня окончена, давайте вернемся к нашему руководству по парсингу!
Давайте заменим части [сам шаблон] в ваших командах sed шаблонами, которые мы нашли выше, а затем добавим их в вашу команду с помощью каналов.
Примерно так:
curl https://www.ted.com/talks/sir_ken_robinson_do_schools_kill_creativity/transcript | html2text | sed -n '/ Подробности о разговоре /, $ p' | sed -n '/ Программы и amp. инициатив / кв; p '
Примечание 1. Я использовал разрывы строк в своей команде… но только для того, чтобы сделать мой код лучше. В этом случае использование разрывов строк не является обязательным.
Примечание 2: В Programs & amp. инициативы , я не добавил символы * к шаблону в sed , потому что строка (и шаблон) уже довольно уникальны без них.Если вы хотите их добавить, вы можете. Но вы должны знать, что * — это специальный символ в sed , поэтому, чтобы называть его символом в вашем тексте, вам придется «экранировать» его с помощью сначала обратная косая черта. Код будет выглядеть так: sed -n '/ \ * \ * \ * \ * Programs & amp. инициативы \ * \ * \ * \ * / q; p '
Опять же, это все равно не понадобится.
Давайте запустим команду и проверим результат!
Если вы прокрутите вверх, вы увидите это в начале возвращенного текста (конечно, без аннотаций):
Прежде, чем вы начнете беспокоиться обо всем хаосе в первых нескольких строках…
- Часть, которую я пометил желтой рамкой : это ваш код.(И, конечно же, это не часть возвращенных результатов.)
- Часть с синей рамкой : это всего лишь «строка состояния», которая показывает, насколько быстрым был процесс парсинга — он на вашем экране, но выиграл также не может быть частью загруженного содержимого веб-страницы. (Вы скоро это ясно увидите, когда мы сохраним наши результаты в файл!)
Однако тот, у кого есть красная рамка ( Подробная информация о выступлении ), является частью загруженного содержимого веб-страницы. … И вам это не понадобится.Он просто остался там, поэтому мы скоро удалим его.
Но сначала прокрутите вниз!
В конце файла ситуация чище:
У нас осталась только одна ненужная строка с надписью TED .
Итак, вы почти у цели …
Удаление первой и последней строк командами head и tail И в качестве последнего шага удалите первую ( Details About the talk ) и последнюю ( TED ) строки контента, который вы сейчас видите в Терминале! Эти две строчки не являются частью первоначального выступления … и вы не хотите, чтобы они использовались в вашем анализе.
Для этой небольшой модификации воспользуемся командами head и tail (я писал о них здесь).
Чтобы удалить последнюю строку, добавьте этот код: head -n-1
И чтобы удалить первую строку, добавьте этот код: tail -n + 2
И это будет ваш последний код:
.curl https://www.ted.com/talks/sir_ken_robinson_do_schools_kill_creativity/transcript | html2text | sed -n '/ Подробности о разговоре /, $ p' | sed -n '/ Программы и amp.инициатив / кв; p ' | голова -н-1 | хвост -n + 2
Можете попробовать…
Но я рекомендую сначала сохранить это в файл, чтобы вы могли повторно использовать полученные данные в будущем.
curl https://www.ted.com/talks/sir_ken_robinson_do_schools_kill_creativity/transcript | html2text | sed -n '/ Подробности о разговоре /, $ p' | sed -n '/ Программы и amp. инициативы / q; p '| голова -н-1 | хвост -n + 2 > proto_text.csv
Если вы распечатаете только что созданный proto_text.csv на свой экран, вы увидите, что вы прекрасно скачали, очистили и сохранили стенограмму выступления сэра Кена Робинсона на TED:
кот proto_text.csv
На этом вы закончили первый выпуск этого руководства по парсингу!
Отлично!
Упражнение — ваш собственный мини-проект по парсингуТеперь, когда вы увидели, как выполняется простая задача парсинга веб-страниц, я рекомендую вам попробовать это самостоятельно.
Выберите простую общедоступную веб-страницу в формате .html из Интернета — все, что вас интересует — и выполните те же действия, которые мы сделали выше:
- Загрузите сайт .html с
curl! - Извлеките текст с
html2text! - Очистите данные с помощью
sed,голова,хвост,grepили что-нибудь еще, что вам нужно!
Третий шаг может оказаться особенно сложным.Существует много-много типов проблем с очисткой данных … Но, в конце концов, это то, для чего нужен хобби-проект по науке о данных: решение проблем и задач! Так что дерзайте, выберите веб-страницу и очистите ее! 😉 И если вы застряли, не бойтесь обращаться за помощью в Google или Stackoverflow!
Примечание 1. Некоторые большие (или часто очищаемые) веб-страницы блокируют скрипты очистки веб-страниц. В этом случае на команду curl будет возвращено сообщение «403 запрещено». Пожалуйста, расценивайте это как «вежливый» запрос от этих веб-сайтов и постарайтесь все равно не найти способ очистить их веб-сайт.Им это не нужно — так что просто найдите другой проект.
Примечание 2: Также обратите внимание на правовой аспект парсинга веб-страниц. Вообще говоря, если вы используете свой сценарий исключительно для хобби-проекта, это, вероятно, вообще не будет проблемой. (Это не официальная юридическая консультация.) Но если ситуация станет более серьезной, на всякий случай, на всякий случай, проконсультируйтесь также с юристом!
Учебное пособие по веб-парсингу — краткое изложение и следующие шагиОчистить одну веб-страницу (или выступление на TED) — это хорошо…
Но скучно! 😉
Итак, в следующем выпуске этой серии руководств по веб-парсингу я покажу вам, как это масштабировать! Вы напишете сценарий bash, который — вместо одного выступления — очистит все 3000+ выступлений на TED.com. Давайте продолжим: руководство по веб-парсингу, выпуск 2.
И в следующих выпусках мы сосредоточимся на анализе огромного количества собранных текстов. Будет весело! Так что оставайся со мной!
Ура,
Томи Местер
Advanced Python Web Scraping: передовой опыт и обходные пути
Scraping — это простая концепция по своей сути, но в то же время она сложна. Это похоже на игру в кошки-мышки между владельцем веб-сайта и разработчиком, работающей в серой зоне закона.Эта статья проливает свет на некоторые препятствия, с которыми может столкнуться программист при сканировании веб-страниц, и различные способы их обхода.
Пожалуйста, помните о важности соскабливания.
Что такое парсинг веб-страниц?
Проще говоря, парсинг веб-сайтов — это процесс извлечения данных с веб-сайтов. Это может быть ручной или автоматизированный процесс. Однако извлечение данных с веб-страниц вручную может быть утомительным и избыточным процессом, который оправдывает целую экосистему из множества инструментов и библиотек, созданных для автоматизации процесса извлечения данных.При автоматическом парсинге веб-страниц вместо того, чтобы позволять браузеру отображать страницы для нас, мы используем самописные сценарии для анализа необработанного ответа от сервера. С этого момента в этой публикации мы будем просто использовать термин «веб-скрапинг», чтобы обозначать «автоматический веб-скрапинг».
Как выполняется парсинг веб-страниц?
Прежде чем мы перейдем к вещам, которые могут усложнить парсинг, давайте разберем процесс парсинга на общие этапы:
- Визуальный осмотр: выяснить, что извлечь
- Сделать HTTP-запрос к веб-странице
- Разобрать ответ HTTP
- Сохранение / использование соответствующих данных
Первый шаг включает использование встроенных инструментов браузера (таких как Chrome DevTools и Firefox Developer Tools) для поиска необходимой нам информации на веб-странице и определения структур / шаблонов для ее программного извлечения.
Следующие шаги включают методическое выполнение запросов к веб-странице и реализацию логики для извлечения информации с использованием выявленных нами шаблонов. Наконец, мы используем информацию для тех целей, для которых намеревались.
Например, допустим, мы хотим извлечь количество подписчиков PewDiePie и сравнить его с T-серией. Простой поиск в Google приводит меня к странице подсчета подписчиков Youtube в реальном времени Socialblade.
При визуальном осмотре мы обнаружили, что количество подписчиков находится внутри тега rawCount .
Давайте напишем простую функцию Python, чтобы получить это значение. Мы будем использовать BeautifulSoup для анализа HTML.
запросов на импорт
из bs4 импорт BeautifulSoup
def get_subscribers (url):
html = requests.get (url) .content
soup = BeautifulSoup (HTML)
return soup.select ('# rawCount') [0]. текст
Теперь посмотрим на подсчеты:
>>> get_subscribers ('https://socialblade.com/youtube/user/pewdiepie/realtime')
'80520035'
>>> get_subscribers ('https: // socialblade.com / youtube / user / tseries / realtime ')
"79965479"
Кажется, простой процесс, не так ли? Что может пойти не так?
Ответ на этот вопрос в основном зависит от способа программирования сайта и намерений владельца сайта. Они могут намеренно усложнить процесс очистки. С некоторыми сложностями легко справиться, а с некоторыми — нет.
Давайте перечислим эти сложности одну за другой и посмотрим решения для них в следующем разделе.
Сложности парсинга веб-страниц
Асинхронная загрузка и рендеринг на стороне клиента
Вы видите , а не .
Это одна из наиболее распространенных проблем, с которыми сталкиваются разработчики при парсинге веб-сайта с большим количеством Javascript. Первоначальный ответ, который мы получаем от сервера, может не содержать той информации, которую мы ожидали при визуальном осмотре.
Это происходит потому, что информация, которую мы на самом деле ищем, либо отображается на стороне браузера такими библиотеками, как Handlebars или React, либо извлекается путем выполнения будущих вызовов AJAX на сервер, а затем отображается браузером.
Вот несколько примеров:
- Веб-страницы с бесконечной прокруткой (Twitter, Facebook и т. Д.)
- Веб-страницы с предварительной загрузкой, такой как процентные полосы или загрузочные счетчики
Аутентификация
Многие веб-сайты имеют своего рода аутентификацию, о которой нам придется позаботиться в нашей программе парсинга. Для более простых веб-сайтов аутентификация может быть такой же простой, как запрос POST с именем пользователя и паролем или сохранение файла cookie.Однако могут быть и некоторые тонкости вроде:
- Скрытые значения : Наряду с именем пользователя и паролем вам может потребоваться добавить другие поля в полезную нагрузку POST (обычно CSRF_TOKEN, но также могут быть некоторые странные данные).
- Установка заголовков : могут быть определенные заголовки, которые нам нужно установить (реферер, авторизация и т. Д.)
Если мы получим от сервера следующие коды ответов, это, вероятно, указывает на то, что нам нужно получить право аутентификации, чтобы иметь возможность очистить.
| Код состояния HTTP | Что это значит |
|---|---|
| 401 | Неавторизованный |
| 403 | Запрещено |
| 407 | Требуется авторизация прокси-сервера |
Черный список на стороне сервера
Как мы упоминали ранее, ответ на вопрос «Что может пойти не так при соскабливании?» также зависит от намерений владельцев веб-сайтов.
На стороне сервера могут быть настроены механизмы защиты от соскабливания для анализа входящего трафика и шаблонов просмотра, а также блокировки автоматизированных программ от просмотра их сайта.
Простые идеи для такого анализа включают:
Анализ скорости запросов
Если сервер получает слишком много запросов в течение определенного периода времени от клиента, это красный флаг, указывающий на то, что на другом конце сайта просматривается человек. Еще хуже получение параллельных запросов с одного IP.
Еще один красный флаг — это повторение (клиент делает X запросов каждые Y секунд). Серверы могут измерять такие показатели и определять пороговые значения, превышающие которые они могут занести клиента в черный список.Механизмы могут быть намного сложнее, но идею вы поняли. Блокировка клиента обычно носит временный характер (в пользу бесплатного и открытого Интернета для всех), но в некоторых случаях может быть даже навсегда.
Проверка заголовков запросов также используется некоторыми веб-сайтами для обнаружения пользователей, не являющихся людьми. Идея состоит в том, чтобы сравнить поля входящего заголовка с теми, которые, как ожидается, будут отправлены реальными пользователями.
Например, некоторые инструменты и библиотеки отправляют очень отличный пользовательский агент при выполнении запросов к серверу, поэтому серверы могут выборочно разрешать только несколько пользовательских агентов и фильтровать остальные.Кроме того, некоторые веб-сайты могут предоставлять разный контент разным пользовательским агентам, что нарушает вашу логику парсинга.
Приманки
Владельцы сайта могут устанавливать ловушки в виде ссылок в HTML, которые не видны пользователю в браузере — самый простой способ сделать это — установить CSS как display: none — и если веб-скребок когда-либо при запросе этих ссылок сервер может узнать, что это автоматизированная программа, а не человек, просматривающий сайт, в конечном итоге он заблокирует парсер.
Обнаружение образов
Это включает в себя четко определенные шаблоны в способе просмотра веб-сайта (время в пределах кликов, местоположение кликов и т. Д.). Эти шаблоны могут быть обнаружены механизмами защиты от сканирования на стороне сервера, что приведет к занесению в черный список.
Коды состояния ответа, которые могут сигнализировать о внесении в черный список на стороне сервера, включают:
| Код статуса HTTP | Что это значит |
|---|---|
| 503 | Сервис недоступен |
| 429 | Слишком много запросов |
| 403 | Запрещено |
Перенаправления и капчи
Некоторые сайты просто перенаправляют свои старые сопоставления ссылок на новые (например, перенаправляют ссылки HTTP на ссылки https ), возвращая код ответа 3xx .
Кроме того, для фильтрации подозрительных клиентов серверы могут перенаправлять запросы на страницы, содержащие причудливые капчи, которые наш веб-парсер должен решить, чтобы доказать, что «это человек».
Такие компании, как Cloudflare, которые предоставляют услуги защиты от ботов или DDoS-атак, еще больше усложняют ботам доступ к фактическому контенту.
Конструкционные сложности
Сложная навигация
Иногда бывает сложно просмотреть все веб-страницы и собрать информацию.Например, разбиение на страницы может быть сложно обойти, если каждая страница в разбивке на страницы не имеет уникального URL-адреса или если он существует, но нет шаблона, который можно наблюдать для вычисления этих URL-адресов.
Неструктурированный HTML
Это когда сервер отправляет HTML, но не всегда предоставляет шаблон. Например, классы и атрибуты CSS динамически генерируются на стороне сервера и каждый раз уникальны. Иногда неструктурированный HTML также является следствием плохого программирования.
iframe тегиИногда контент, который мы видим на веб-сайте, представляет собой тег iframe, отображаемый из другого внешнего источника.
Хорошо! Мы перечислили сложности; теперь пришло время найти для них обходные пути.
Устранение сложностей парсинга веб-страниц с помощью Python
Выбор правильных инструментов, библиотек и фреймворков
Прежде всего, я не могу не подчеркнуть полезность инструментов браузера для визуального контроля.Эффективное планирование нашего подхода к веб-парсингу заранее, вероятно, поможет нам заранее сэкономить часы на головокружении. В большинстве случаев существующие (собственные) инструменты браузера — единственные инструменты, которые нам понадобятся для поиска контента, определения шаблонов в контенте, выявления сложностей и планирования подхода.
Для парсинга веб-страниц в Python доступно множество инструментов. Мы рассмотрим несколько популярных (и проверенных самостоятельно) вариантов, и когда их использовать. Для быстрой очистки простых веб-сайтов я обнаружил, что комбинация запросов Python (для обработки сеансов и выполнения HTTP-запросов) и Beautiful Soup (для анализа ответа и навигации по нему для извлечения информации) является идеальной парой.
Для более крупных проектов парсинга (где мне нужно собирать и обрабатывать большое количество данных и иметь дело со сложностями, не связанными с JS) Scrapy был весьма полезен.
Scrapy — это фреймворк (а не библиотека), который абстрагирует множество тонкостей для эффективного парсинга (одновременные запросы, использование памяти и т. Д.), А также позволяет подключать кучу промежуточного программного обеспечения (для файлов cookie, перенаправления, сеансов, кеширования, и т. д.) для решения различных задач. Scrapy также предоставляет оболочку, которая может помочь в быстром создании прототипа и проверке вашего подхода к очистке (селекторы, ответы и т. Д.)). Эта структура достаточно зрелая, расширяемая и пользуется хорошей поддержкой сообщества.
Для сайтов с большим количеством JavaScript (или сайтов, которые кажутся слишком сложными) обычно подходит Selenium. Хотя очистка с помощью Selenium не так эффективна по сравнению с Scrapy или Beautiful Soup, она почти всегда дает вам желаемые данные (что единственное, что имеет значение в большинстве случаев).
Обработка аутентификации
Для аутентификации, поскольку нам придется поддерживать файлы cookie и сохранять наш логин, лучше создать сеанс, который позаботится обо всем этом.Для скрытых полей мы можем вручную попробовать войти в систему и проверить отправляемую на сервер полезную нагрузку, используя сетевые инструменты, предоставляемые браузером, для определения отправляемой скрытой информации (если таковая имеется).
Мы также можем проверить, какие заголовки отправляются на сервер с помощью инструментов браузера, чтобы мы могли воспроизвести это поведение в коде, например, если аутентификация зависит от таких заголовков, как Authorization и Authentication ). Если сайт использует простую аутентификацию на основе файлов cookie (что в наши дни маловероятно), мы также можем скопировать содержимое файла cookie и добавить его в код вашего парсера (опять же, мы можем использовать для этого встроенные инструменты браузера).
Обработка асинхронной загрузки
Обнаружение асинхронной загрузки
Мы можем обнаружить асинхронную загрузку на самом этапе визуальной проверки, просмотрев источник страницы (параметр «Просмотреть исходный код» в браузере при щелчке правой кнопкой мыши) и затем выполнив поиск содержимого, которое мы ищем. Если вы не нашли текст в источнике, но все равно можете увидеть его в браузере, то, вероятно, он отображается с помощью JavaScript. Дальнейшая проверка может быть выполнена с помощью сетевого инструмента браузера, чтобы проверить, есть ли какие-либо запросы XHR, сделанные сайтом.
Обход асинхронной загрузки
Использование веб-драйвера
Веб-драйвер похож на симуляцию браузера с интерфейсом, которым можно управлять с помощью сценариев. Он может выполнять функции браузера, такие как рендеринг JavaScript, управление файлами cookie и сеансами и т. Д. Selenium Web Driver — это среда веб-автоматизации, разработанная для тестирования UI / UX веб-сайтов, но он также стал популярным вариантом для очистки динамически отображаемых сайтов с течением времени.
Излишне говорить, что, поскольку веб-драйверы являются имитацией браузеров, они потребляют много ресурсов и сравнительно медленнее по сравнению с такими библиотеками, как beautifulsoup и scrapy .
Selenium поддерживает несколько языков для написания сценариев, включая Python. Обычно он запускает экземпляр браузера, и мы можем видеть такие вещи, как нажатие и ввод данных на экране, что полезно во время тестирования. Но если нас интересует только парсинг, мы можем использовать «безголовые браузеры», у которых нет пользовательского интерфейса и которые работают быстрее с точки зрения производительности.
Chrome Headless — популярный выбор для веб-драйвера без головы, а другие варианты включают Headless Firefox, PhantomJS, spynner и HtmlUnit.Для некоторых из них может потребоваться установка xvfb и его оболочки Python (xvfbwrapper или pyvirtualdisplay) для имитации отображения экрана в виртуальной памяти без реального вывода на экран.
Проверка вызовов AJAX
Этот метод работает по идее « Если он отображается в браузере, он должен быть откуда-то ». Мы можем использовать инструменты разработчика браузера для проверки вызовов AJAX и попытаться выяснить, какие запросы отвечают за получение данных, которые мы ищем.Возможно, нам потребуется установить заголовок X-Requested-With для имитации запросов AJAX в вашем скрипте.
Решение проблемы бесконечной прокрутки
Мы можем справиться с бесконечной прокруткой, внедрив некоторую логику javascript в селен (см. Эту тему SO). Кроме того, обычно бесконечная прокрутка включает в себя дальнейшие вызовы AJAX на сервер, которые мы можем проверить с помощью инструментов браузера и воспроизвести в нашей программе очистки.
В поисках правильных селекторов
После того, как мы обнаруживаем элемент, который хотим извлечь визуально, следующим шагом для нас является поиск шаблона селектора для всех таких элементов, который мы можем использовать для извлечения их из HTML.Мы можем фильтровать элементы на основе их классов и атрибутов CSS с помощью селекторов CSS. Вы можете обратиться к этой быстрой шпаргалке, чтобы узнать о различных возможных способах выбора элементов на основе CSS.
Селекторы CSS— это обычный выбор для очистки. Однако другой метод выбора элементов, называемый XPath (язык запросов для выбора узлов в XML-документах), может быть полезен в определенных сценариях. Он предоставляет более универсальные возможности, например:
- Выбор элементов по их содержанию .Это не рекомендуемая практика, но она удобна для плохо структурированных страниц.
- Искать в любом направлении . Мы можем создавать запросы, которые ищут бабушек и дедушек, а затем искать их ребенка с определенными атрибутами / текстом. Это невозможно с селекторами CSS.
Некоторые люди утверждают, что XPath медленнее, чем селекторы CSS, но по моему личному опыту, оба работают одинаково хорошо. Хотя иногда один быстрее другого, разница в миллисекундах.Кроме того, при парсинге не очень сложных и хорошо структурированных веб-страниц я просто использую инструмент выбора Chrome / Firefox, чтобы получить XPath целевого элемента, вставить его в свой скрипт, и я готов работать в течение нескольких секунд. Сказав это, есть несколько проверок, которые могут пригодиться при выборе селекторов:
- Согласованность между браузерами. В разных браузерах по-разному реализованы механизмы оценки селекторов CSS и XPath. Таким образом, в очень немногих случаях используемые вами селекторы могут работать для определенных браузеров / версий, но не для других.К счастью, большинство браузеров в настоящее время поддерживают оценку этих запросов в самих инструментах браузера, чтобы мы могли быстро проверить.
Нажав Ctrl + F в инспекторе DOM, мы можем использовать выражение CSS (или XPath) в качестве поискового запроса. Браузер будет циклически повторяться, и мы увидим все совпадения. Это быстрый способ проверить, работает ли выражение.
- Выбор элементов по идентификаторам выполняется быстрее, поэтому мы должны предпочесть идентификаторы везде, где они доступны.
- XPpath более тесно связаны со структурой HTML, чем селекторы CSS, т.е.е. XPath с большей вероятностью сломается, если произойдут некоторые изменения в способе структурирования HTML на странице.
Устранение «черного списка» на стороне сервера
В последнем разделе мы обсудили некоторые методы, которые серверы используют для обнаружения автоматических ботов и их ограничения. Есть несколько вещей, которые мы можем сделать, чтобы предотвратить обнаружение нашего скребка:
Использование прокси-серверов и ротации IP . Для сервера это будет выглядеть так, как будто сайт просматривают несколько пользователей.Есть несколько сайтов, где вы можете найти список бесплатных прокси для использования (например, этот). Оба запроса
scrapyимеют функции для использования вращающихся прокси. При использовании прокси-серверов следует учитывать следующие моменты:- Бесплатные прокси-адреса обычно временны; через некоторое время они начнут выдавать ошибки подключения. Так что лучше предоставлять прокси динамически. Мы можем либо очистить список активных прокси (да, очистить для дальнейшей очистки) с сайтов со списком прокси, либо использовать какой-то API (несколько прокси-сервисов премиум-класса имеют эту функцию).
- Некоторые прокси устанавливают и отправляют заголовок
HTTP_X_FORWARDED_FORилиHTTP_VIA(или оба), который сервер может использовать для определения того, что мы используем прокси (и даже реальный IP-адрес). Поэтому рекомендуется использовать элитные прокси (прокси, которые отправляют оба эти поля заголовка как пустые).
Подмена и ротация пользовательского агента . Идея состоит в том, чтобы передать поле заголовка другого пользовательского агента (или нескольких разных пользовательских агентов по очереди), чтобы обмануть сервер.Список различных возможных пользовательских агентов доступен здесь. Подмена пользовательского агента может не всегда работать, потому что веб-сайты могут предлагать клиентские JS-методы, чтобы определить, является ли агент тем, о чем он заявляет. Мы также должны иметь в виду, что ротация пользовательских агентов без ротации IP-адресов в тандеме может сигнализировать серверу красный флаг.
Снижение скорости сканирования за счет добавления случайного времени ожидания между действиями (такими как выполнение запросов, ввод данных, щелчки по элементам и т. Д.). Это приведет к рандомизации шаблона просмотра и усложнит серверу различение между нашим парсером и реальным пользователем.
Scrapy имеет удлинитель автоматической дроссельной заслонки, позволяющий обходиться без дросселирования. Он имеет множество настраиваемых параметров для имитации реальных шаблонов просмотра.
Обработка перенаправлений и капч
Современные библиотеки, такие как запросов , уже заботятся о перенаправлениях HTTP, отслеживая их (сохраняя историю) и возвращая последнюю страницу.Scrapy также имеет промежуточное программное обеспечение перенаправления для обработки перенаправлений. Перенаправления не представляют особой проблемы, если мы в конечном итоге перенаправляемся на страницу, которую ищем. Но если нас перенаправляют на капчу, это становится непросто.
Очень простые текстовые капчи могут быть решены с помощью OCR (для этого есть библиотека Python под названием pytesseract). Текстовые капчи — это скользкая дорожка для внедрения в наши дни с появлением передовых методов распознавания текста (основанных на глубоком обучении, подобных этому), поэтому становится все труднее создавать изображения, которые могут превзойти машины, но не людей.
Кроме того, на случай, если мы не хотим нести накладные расходы на решение капчи, есть несколько доступных сервисов, которые предоставляют API для тех же, в том числе смерть от капчи, антигейт и антикапча. В некоторых из этих сервисов работают настоящие люди, которым платят за решение кода для вас. Тем не менее, вы можете в некоторой степени избежать использования капчи, используя прокси и ротацию IP-адресов.
Обработка
тегов iframe и неструктурированных ответов Для тегов iframe достаточно просто запросить правильный URL, чтобы вернуть нужные данные.Нам нужно запросить внешнюю страницу, затем найти iframe, а затем сделать еще один HTTP-запрос к атрибуту iframe src . Кроме того, мы ничего не можем поделать с неструктурированными HTML или URL-шаблонами, кроме как придумывать хаки (придумывать сложные запросы XPath, использовать регулярные выражения и т. Д.).
Другие полезные инструменты и библиотеки для парсинга
В некоторых особых случаях вам могут пригодиться следующие инструменты.
- Newspaper: Newspaper3k — это библиотека для парсинга статей.Он поддерживает несколько языков, предоставляет API для получения метаинформации, такой как сведения об авторе и дате публикации, а также функции NLP, такие как извлечение резюме и ключевых слов, извлечение авторов.
- PyAutoGUI: PyAutoGUI — это модуль автоматизации графического интерфейса пользователя, который позволяет программно управлять клавиатурой и мышью. Приятная функция PyAutoGUI — это поиск изображения на экране. Я наблюдал, как несколько человек использовали PyAutoGUI для навигации по сайту.
- EditThisCookie расширение браузера очень полезно, когда вы играете с файлами cookie и их содержимым.
- cloudflare-scrape: Я использовал этот модуль в прошлом, чтобы обойти проверки антиботов Cloudflare. В экосистеме парсинга в Python хорошо то, что есть много функций, которые вы найдете в открытом исходном коде или в виде фрагментов на Stack Overflow.
- tcpdump: вы можете использовать tcpdump для сравнения заголовков двух запросов (тот, который отправляет ваш парсер, а другой, который ваш браузер отправляет во время просмотра сайта)
- Burp Suite: Burp Suite полезен для перехвата запросов, которые браузер делает на сайте, и их анализа.
- Stem: на всякий случай, если вы хотите делать запросы с использованием python поверх TOR.
- Сервисы визуального парсинга, такие как Octoparse, Portia (с открытым исходным кодом и созданная командой scrapy), ParseHub, Dext и FMiner.
- Расширения браузера, такие как Web Scraper, Data Scraper и Agenty (для Chrome).
Соскоб с уважением
В этом посте мы рассмотрели типичные сложности, связанные с парсингом веб-сайтов, их возможные обходные пути, а также инструменты и библиотеки, которые мы можем использовать с Python.
Как упоминалось в начале, очистка похожа на игру в кошки-мышки, действующую в серой зоне законодательства, и может вызвать проблемы для обеих сторон, если не будет сделано с уважением. Нарушение авторских прав и злоупотребление информацией может повлечь за собой юридические последствия. Пара примеров, вызвавших разногласия, — это публикация данных OK Cupid исследователями и лабораториями HIQ, использующими данные Linkedin для продуктов HR.
Стандарт исключения роботов был разработан, чтобы сообщить о намерении владельцев сайтов индексироваться / сканироваться.В идеале наш парсер должен подчиняться инструкциям в файле robots.txt . Даже если robots.txt разрешает очистку, агрессивное выполнение этого может привести к перегрузке сервера, вызывая проблемы с производительностью или нехватку ресурсов на стороне сервера (даже сбои).
Хорошо включить время задержки, если сервер начинает дольше отвечать. Кроме того, менее популярное мнение заключается в том, чтобы связываться с владельцами сайтов напрямую для получения API и дампа данных перед очисткой, чтобы обе стороны были довольны.
Пропустили ли мы какие-нибудь советы по парсингу для разработчиков Python? Если да, дайте нам знать в разделе комментариев ниже!
Изучите Python, создавая проекты с DevProjects
Выбор динамически загружаемого контента — документация Scrapy 2.5.0
Некоторые веб-страницы показывают нужные данные, когда вы загружаете их в веб-браузер. Однако, когда вы загружаете их с помощью Scrapy, вы не можете получить желаемые данные. с помощью селекторов.
Когда это происходит, рекомендуется найти источник данных и извлечь данные от него.
Если вы этого не сделаете, но, тем не менее, можете получить доступ к нужным данным через модель DOM из вашего веб-браузера, см. Предварительный рендеринг JavaScript.
Поиск источника данных
Чтобы извлечь нужные данные, вы должны сначала найти их исходное местоположение.
Если данные представлены в нетекстовом формате, таком как изображение или документ PDF, используйте сетевой инструмент своего веб-браузера, чтобы найти соответствующий запрос и воспроизведите его.
Если ваш веб-браузер позволяет выбрать желаемые данные в виде текста, данные могут быть определены во встроенном коде JavaScript или загружены из внешнего ресурса в текстовый формат.
В этом случае вы можете использовать такой инструмент, как wgrep, чтобы найти URL-адрес этого ресурса.
Если оказывается, что данные поступают с исходного URL-адреса, вы должны проверить исходный код веб-страницы, чтобы определить, где находятся данные.
Если данные поступают с другого URL-адреса, вам нужно будет воспроизвести соответствующий запрос.
Проверка исходного кода веб-страницы
Иногда вам нужно проверить исходный код веб-страницы (не DOM), чтобы определить, где находятся нужные данные.
Используйте команду Scrapy fetch , чтобы загрузить содержимое веб-страницы, как показано
по Scrapy:
scrapy fetch --nolog https://example.com> response.html
Если нужные данные находятся во встроенном коде JavaScript внутри элемент,см.Анализ кода JavaScript.
Если вы не можете найти нужные данные,сначала убедитесь,что это не только Scrapy:загрузите веб-страницу с помощью HTTP-клиента,такого как curl или wget,и посмотрите,информацию можно найти в полученных ими ответах.
Если они получат ответ с желаемыми данными,измените свой ScrapyЗапросите,чтобы он соответствовал таковому у другого HTTP-клиента.Для
Например,попробуйте использовать ту же строку пользовательского агента(USER_AGENT)или
те жезаголовки.
Если они также получат ответ без требуемых данных,вам нужно будет принять шаги,чтобы сделать ваш запрос более похожим на запрос веб-браузера.Видеть Воспроизведение запросов.
Воспроизведение запросов
Иногда нам нужно воспроизвести запрос так,как его выполняет наш веб-браузер.
Используйте сетевой инструмент своего веб-браузера,чтобы увидеть как ваш веб-браузер выполняет желаемый запрос,и попытайтесь воспроизвести это запрос с помощью Scrapy.
Этого может быть достаточно,чтобы получитьRequestс тем же HTTP
метод и URL.Однако вам также может потребоваться воспроизвести тело,заголовки и
параметры формы(см.FormRequest)этого запроса.
Поскольку все основные браузеры позволяют экспортировать запросы в формате cURL,Scrapy включает методfrom_curl()для создания эквивалентаЗапроситьиз команды cURL.Чтобы получить больше информации
запрос на посещение от curl внутри сети
раздел инструмента.
Как только вы получите ожидаемый ответ,вы можете извлечь нужные данные из Это.
Вы можете воспроизвести любой запрос с помощью Scrapy.Однако иногда воспроизводя все необходимые запросы могут показаться неэффективными во время разработчика.Если это твой случае,и скорость сканирования не является для вас серьезной проблемой,в качестве альтернативы вы можете рассмотрите предварительный рендеринг JavaScript.
Если вы получаете ожидаемый ответиногда,но не всегда,проблема в возможно не ваш запрос,а целевой сервер.Целевой сервер может быть глючит,перегружен или блокирует некоторые из ваших запросов.
Обратите внимание,что для преобразования команды cURL в запрос Scrapy,вы можете использовать curl2scrapy.
Обработка различных форматов ответов
Когда у вас есть ответ с желаемыми данными,как вы извлекаете желаемые данные от него зависят от типа ответа:
Если ответ-HTML или XML,используйте селекторы как обычно.
Если ответ-JSON,используйте
json.load()для загрузки желаемых данных изresponse.text:данные=json.loads(response.text)
Если желаемые данные находятся внутри кода HTML или XML,встроенного в данные JSON,вы можете загрузить этот HTML-или XML-код в
Селектор,а затем используйте как обычно:selector=Селектор(данные['html'])
Если ответ-JavaScript или HTML с элементом
содержащие желаемые данные,см.Анализ кода JavaScript.Если ответ-CSS,используйте регулярное выражение для извлечь желаемые данные из
response.text.
Если ответ представляет собой изображение или другой формат на основе изображений(например,PDF),прочитать ответ как байты из
response.bodyи используйте OCR решение для извлечения желаемых данных в виде текста.Например,вы можете использовать pytesseract.Чтобы прочитать таблицу из PDF,tabula-py может быть лучшим выбором.
Если ответ-SVG,или HTML со встроенным SVG,содержащим желаемый data,вы можете извлечь нужные данные,используя селекторы,поскольку SVG основан на XML.
В противном случае вам может потребоваться преобразовать код SVG в растровое изображение,и обработать это растровое изображение.
Разбор кода JavaScript
Если желаемые данные жестко запрограммированы в JavaScript,вам сначала нужно получить Код JavaScript:
Если код JavaScript находится в файле JavaScript,просто прочтите
response.text.Если код JavaScript находится внутри элемента
страницы HTML,используйте селекторы для извлечения текста внутри этогоэлемент.
Если у вас есть строка с кодом JavaScript,вы можете извлечь желаемый данные с него:
Вы можете использовать регулярное выражение для извлеките желаемые данные в формате JSON,которые затем можно проанализировать с помощью
json.loads().Например,если код JavaScript содержит отдельную строку типа
var data={"поле":"значение"};,вы можете извлечь эти данные следующим образом:>>>pattern=r'\ bvar \ s + data \ s * = \ s * (\ {.*? \}) \ s *; \ s * \ n '>>>json_data=response.css('скрипт :: текст').re_first(шаблон)>>>json.loads(json_data) {'поле':'значение'}chompjs предоставляет API для синтаксического анализа объектов JavaScript в
dict.Например,если код JavaScript содержит
var data={поле:"значение",secondField:"второе значение"};вы можете извлечь эти данные следующим образом:>>>импортировать chompjs>>>javascript=response.css('сценарий :: текст').получать()>>>data=chompjs.parse_js_object(javascript)>>>данные {'поле':'значение','второе поле':'второе значение'}В противном случае используйте js2xml для преобразования кода JavaScript в документ XML.которые вы можете анализировать с помощью селекторов.
Например,если код JavaScript содержит
var data={field:"значение"};,вы можете извлечь эти данные следующим образом:>>>импорт js2xml>>>импортировать lxml.etree>>>из селектора импорта парселей>>>javascript=ответ.css('сценарий :: текст').get()>>>xml=lxml.etree.tostring(js2xml.parse(javascript),encoding='unicode')>>>селектор=Селектор(текст=xml)>>>selector.css('var [name = "data"]').get()' '
Предварительный рендеринг JavaScript
На веб-страницах,которые получают данные из дополнительных запросов,воспроизводя те запросы,содержащие желаемые данные,являются предпочтительным подходом.Усилия результат часто стоит:структурированные,полные данные с минимальным временем анализа и сетевая передача.
Однако иногда бывает очень сложно воспроизвести определенные запросы.Или ты может потребоваться что-то,чего вам не может дать ни один запрос,например,снимок экрана с веб-страница,отображаемая в веб-браузере.
В этих случаях используйте службу JavaScript-рендеринга Splash вместе с scrapy-splash для бесшовной интеграции.
Splash возвращает как HTML DOM веб-страницы,так что вы можете разобрать его с помощью селекторов.Он обеспечивает отличное гибкость за счет конфигурации или сценариев.
Если вам нужно что-то помимо того,что предлагает Splash,например,взаимодействие с DOM на лету из кода Python вместо использования ранее написанного скрипта,или обработки нескольких окон веб-браузера,вам может потребоваться вместо этого используйте безголовый браузер.
Использование автономного браузера
Headless browser-это специальный веб-браузер,который предоставляет API для автоматизация.
Самый простой способ использовать безголовый браузер с Scrapy-использовать Selenium,вместе с scrapy-selenium для бесшовной интеграции.
Учебное пособие по веб-парсингу на Python-Как очистить данные с веб-сайта
Python-прекрасный язык для программирования.У него отличная экосистема пакетов,гораздо меньше шума,чем на других языках,и он очень прост в использовании.
Python используется для множества вещей,от анализа данных до серверного программирования.И один из интересных вариантов использования Python-это веб-скрапинг.
В этой статье мы расскажем,как использовать Python для парсинга веб-страниц.По мере продвижения мы также проработаем полное практическое руководство в классе.
Примечание.Мы будем очищать веб-страницу,которую я размещаю,чтобы мы могли безопасно изучить ее.Многие компании не разрешают парсинг на своих веб-сайтах,так что это хороший способ научиться.Просто убедитесь,что проверили,прежде чем царапать.
Введение в класс веб-скрапинга
Предварительный просмотр класса codedamnЕсли вы хотите писать код,вы можете использовать этот бесплатный класс codedamn,который состоит из нескольких лабораторий,которые помогут вам изучить веб-скрейпинг.Это будет практическое упражнение по изучению codedamn,подобное тому,как вы изучаете на freeCodeCamp.
В этом классе вы будете использовать эту страницу для тестирования веб-скрапинга:https:res=requests.get('https://codedamn.com') печать(рез.текст) print(res.status_code)
Требования для прохождения:
- Получите содержимое следующего URL-адреса,используя
запросовmodule:https:#Сделайте запрос на https:#Сохраняем результат в переменной'res' res=requests.get('https://codedamn-classrooms.github.io/webscraper-python-codedamn-classroom-website/') txt=res.text status=res.status_code печать(текст,статус) #распечатать результатДавайте теперь перейдем к части 2,где вы создадите больше на основе существующего кода.
Это ссылка на эту лабораторную работу.
В этом классе вы будете использовать библиотеку под названием
BeautifulSoupна Python для выполнения парсинга веб-страниц.Вот некоторые особенности,которые делают BeautifulSoup мощным решением:- Он предоставляет множество простых методов и идиом Pythonic для навигации,поиска и изменения дерева DOM.Для написания приложения не требуется много кода.
- Beautiful Soup находится поверх популярных парсеров Python,таких как lxml и html5lib,что позволяет вам опробовать различные стратегии синтаксического анализа или торговать скоростью для гибкости.
По сути,BeautifulSoup может анализировать все,что вы ему предоставляете.
Вот простой пример BeautifulSoup:
из bs4 import BeautifulSoup page=requests.get("https://codedamn.com") soup=BeautifulSoup(page.content,'html.parser') title=soup.title.text#дает вам текст(...) Требования для прохождения:
- Используйте пакет
запросов,чтобы получить заголовок URL:https:из bs4 импорт BeautifulSoup #Сделайте запрос на https:page=requests.get("https://codedamn-classrooms.github.io/webscraper-python-codedamn-classroom-website/") soup=BeautifulSoup(page.content,'html.parser') #Извлечь заголовок страницы page_title=суп.title.text #распечатать результат print(page_title)Это тоже была простая лабораторная работа,где нам нужно было изменить URL-адрес и распечатать заголовок страницы.Этот код пройдет лабораторию.
Часть 3:Тело и голова в супе
Это ссылка на эту лабораторную работу.
В последней лабораторной работе вы видели,как можно извлечь
заголовоксо страницы.Также легко извлечь определенные разделы.Вы также видели,что для получения строки вам нужно позвонить по номеру
.text,но вы можете распечатать их,не вызывая.тексттоже,и он даст вам полную разметку.Попробуйте запустить пример ниже:запросов на импорт из bs4 импорт BeautifulSoup #Сделать запрос page=requests.get("https://codedamn.com") soup=BeautifulSoup(page.content,'html.parser') #Извлечь заголовок страницы page_title=soup.title.text #Извлечь тело страницы page_body=soup.body #Извлечь заголовок страницы page_head=soup.head #распечатать результат print(page_body,page_head)Давайте посмотрим,как вы можете извлечь разделы
bodyиheadсо своих страниц.Требования для прохождения:
- Повторите эксперимент с URL:
https:из bs4 импорт BeautifulSoup #Сделать запрос page=requests.get("https://codedamn-classrooms.github.io/webscraper-python-codedamn-classroom-website/") soup=BeautifulSoup(page.content,'html.parser') #Извлечь заголовок страницы page_title=soup.title #Извлечь тело страницы page_body=суп.тело #Извлечь заголовок страницы page_head=soup.head #распечатать результат print(page_title,page_head)Часть 4:выберите с помощью BeautifulSoup
Это ссылка на эту лабораторную работу.
Теперь,когда вы изучили некоторые части BeautifulSoup,давайте посмотрим,как можно выбирать элементы DOM с помощью методов BeautifulSoup.
Когда у вас есть переменная
soup(как и в предыдущих лабораторных работах),вы можете работать с ней.Выберите,который является селектором CSS внутри BeautifulSoup.То есть вы можете добраться до дерева DOM так же,как вы выбираете элементы с помощью CSS.Давайте посмотрим на пример:запросов на импорт из bs4 импорт BeautifulSoup #Сделать запрос page=requests.get("https://codedamn-classrooms.github.io/webscraper-python-codedamn-classroom-website/") soup=BeautifulSoup(page.content,'html.parser') #Извлечь первый текст(...)
first_h2=soup.select('h2')[0].text.selectвозвращает список всех элементов Python.Вот почему вы выбрали здесь только первый элемент с индексом[0].Соответствующие требования:
- Создайте переменную
all_h2_tags.Установите пустой список. - Используйте
.select,чтобы выбрать все тегии сохранить текст этих тегов h2 в спискеall_h2_tags. - Создайте переменную
sevenh_p_textи сохраните внутри нее текст 7-го элементаp(индекс 6).
Решение для этой лабораторной работы:
запросов на импорт из bs4 импорт BeautifulSoup #Сделать запрос страница=запросы.получать("https://codedamn-classrooms.github.io/webscraper-python-codedamn-classroom-website/") soup=BeautifulSoup(page.content,'html.parser') #Создать all_h2_tags как пустой список all_h2_tags=[] #Установите all_h2_tags для всех тегов h2 супа для элемента в soup.select('h2'):all_h2_tags.append(element.text) #Создаем седьмой_п_текст и устанавливаем его как седьмой элемент текста p страницы sevenh_p_text=soup.select('p')[6].текст print(all_h2_tags,седьмой_p_text)Продолжаем.
Часть 5:Самые популярные предметы,которые собираются прямо сейчас
Это ссылка на эту лабораторную работу.
Давайте продолжим и извлечем самые популярные элементы,извлеченные из URL:https:"title":'Asus AsusPro Adv... '.полоска(),"review":'2 отзыва \ n \ n \ n'.strip()}
- Обратите внимание,что вы используете метод
stripдля удаления любых лишних символов новой строки/пробелов,которые могут быть в выводе.Этоважно,,чтобы пройти эту лабораторную работу. - Добавьте этот словарь в список с названием
top_items - Распечатайте этот список в конце
В этой задаче нужно выполнить довольно много задач.Давайте сначала посмотрим на решение и разберемся,что происходит:
запросов на импорт из bs4 импорт BeautifulSoup #Сделать запрос страница=запросы.получать("https://codedamn-classrooms.github.io/webscraper-python-codedamn-classroom-website/") soup=BeautifulSoup(page.content,'html.parser') #Создать top_items как пустой список top_items=[] #Извлечь и сохранить в top_items согласно инструкциям слева products=soup.select('div.thumbnail') для элемента в продуктах:title=elem.select('h5> a.title')[0].text review_label=elem.select('div.ratings')[0].текст info={"title":title.strip(),"обзор":review_label.полоска()} top_items.append(информация) print(top_items)Обратите внимание,что это только одно из решений.Вы можете попробовать это и другим способом.В этом решении:
- Прежде всего вы выбираете все элементы
div.thumbnail,которые дают вам список отдельных продуктов - Затем вы перебираете их
- Поскольку
selectпозволяет вам объединить себя в цепочку,вы можете используйте select еще раз,чтобы получить заголовок. - Обратите внимание:поскольку вы работаете внутри цикла для
div.thumbnailуже,селекторh5>a.titleдаст вам только один результат внутри списка.Вы выбираете 0-й элемент этого списка и извлекаете текст. - Наконец,вы удаляете лишние пробелы и добавляете их в свой список.
Понятно,верно?
Это ссылка на эту лабораторную работу.
До сих пор вы видели,как можно извлекать текст,или,скорее,innerText элементов.Давайте теперь посмотрим,как можно извлекать атрибуты,извлекая ссылки со страницы.
Вот пример того,как извлечь всю информацию об изображении со страницы:
запросов на импорт из bs4 импорт BeautifulSoup #Сделать запрос page=requests.get("https://codedamn-classrooms.github.io/webscraper-python-codedamn-classroom-website/") soup=BeautifulSoup(page.content,'html.parser') #Создать top_items как пустой список image_data=[] #Извлечь и сохранить в top_items согласно инструкциям слева images=soup.select('img') для изображения в изображениях:src=изображение.получить('src') alt=image.get('alt') image_data.append({"src":src,"alt":alt}) print(image_data)В этой лабораторной работе ваша задача состоит в том,чтобы извлечь атрибут
hrefссылок с их текстом.Убедитесь в следующем:- Вы должны создать список с именем
all_links - В этом списке храните всю информацию о ссылках.Он должен быть в следующем формате:
info={"href":"<ссылка здесь>","текст":"<текст ссылки здесь>"}- Убедитесь,что в вашем
текстенет пробелов - Убедитесь,что вы проверили ваш
.текстравен None,прежде чем вы позвоните по нему.strip(). - Сохраните все эти dicts в
all_links - Распечатайте этот список в конце
Вы извлекаете значения атрибутов точно так же,как вы извлекаете значения из dict,используя функцию
get.Давайте посмотрим на решение для этой лабораторной работы:запросов на импорт из bs4 импорт BeautifulSoup #Сделать запрос page=requests.get("https: //codedamn-classrooms.github.io / webscraper-python-codedamn-classroom-website / ") soup=BeautifulSoup(page.content,'html.parser') #Создать top_items как пустой список all_links=[] #Извлечь и сохранить в top_items согласно инструкциям слева ссылки=soup.select('а') для ahref в ссылках:text=ahref.text text=text.strip(),если текст не больше None'' href=ahref.get('href') href=href.strip(),если href не равно None else'' all_links.append({"href":href,"текст":текст}) печать(все_ссылки)Здесь вы извлекаете атрибут
href,как и в случае с изображением.Единственное,что вы делаете,это также проверяете,нет ли.Мы хотим установить для него пустую строку,иначе мы хотим удалить пробелы.Часть 7:Создание CSV из данных
Это ссылка на эту лабораторную работу.
Наконец,давайте разберемся,как можно сгенерировать CSV из набора данных.Вы создадите CSV со следующими заголовками:
- Название продукта
- Цена
- Описание
- Обзоры
- Изображение продукта
Эти продукты расположены в
div.эскиз.Шаблон CSV приведен ниже:запросов на импорт из bs4 импорт BeautifulSoup импорт csv #Сделать запрос page=requests.get("https://codedamn-classrooms.github.io/webscraper-python-codedamn-classroom-website/") soup=BeautifulSoup(page.content,'html.parser') all_products=[] products=soup.select('div.thumbnail') для продукта в продуктах:#TODO:Работа print(«Работайте над продуктом здесь») keys=all_products[0].keys() с open('products.csv','w',newline='')в качестве output_file:dict_writer=csv.DictWriter(выходной_файл,ключи) dict_writer.writeheader() dict_writer.writerows(all_products)Вам необходимо извлечь данные с веб-сайта и создать этот CSV-файл для трех продуктов.
Соответствующие требования:
- Название продукта-это версия названия товара с обрезанными пробелами(пример-Asus AsusPro Adv..)
- Цена-это обрезанные пробелы,но полная ценовая этикетка продукта(пример-1101,83 доллара США)
- Описание представляет собой версию описания продукта,обрезанную пробелами(пример-Asus AsusPro Advanced BU401LA-FA271G,темно-серый,14 дюймов,Core i5-4210U,4 ГБ,128 ГБ SSD,Win7 Pro).
- Обзоры представляют собой версию описания продукта с обрезкой пробелов.продукт(пример-7 отзывов)
- Изображение продукта-это URL-адрес(атрибут src)изображения продукта(пример-/ webscraper-python-codedamn-classroom-website /cart2.png)
- Имя CSV-файла должно бытьproducts.csvи должно храниться в том же каталоге,что и ваш файлscript.py
Давайте посмотрим на решение этой лабораторной работы:
запросов на импорт из bs4 импорт BeautifulSoup импорт csv #Сделать запрос page=requests.get("https://codedamn-classrooms.github.io/webscraper-python-codedamn-classroom-website/") soup=BeautifulSoup(page.content,'html.parser') #Создать top_items как пустой список all_products=[] #Извлечь и сохранить в top_items согласно инструкциям слева продукты=суп.выберите('div.thumbnail') для продукта в продуктах:name=product.select('h5> a')[0].text.strip() description=product.select('p.description')[0].text.strip() price=product.select('h5.price')[0].text.strip() reviews=product.select('div.ratings')[0].text.strip() image=product.select('img')[0].get('src') all_products.append({"name":имя,"description":описание,"цена":цена,"reviews":отзывы,"image":изображение}) ключи=все_продукты[0].ключи() с open('products.csv','w',newline='')в качестве output_file:dict_writer=csv.DictWriter(выходной_файл,ключи) dict_writer.writeheader() dict_writer.writerows(all_products)Здесь наиболее интересен блок
для.Вы извлекаете все элементы и атрибуты из того,что вы уже изучили во всех лабораториях.Когда вы запустите этот код,вы получите хороший CSV-файл.И это все основы веб-парсинга с BeautifulSoup!
Заключение
Я надеюсь,что этот интерактивный класс от codedamn помог вам понять основы парсинга веб-страниц с помощью Python.
Если вам понравился этот класс и этот блог,расскажите мне об этом в моем твиттере и Instagram.Хотелось бы услышать отзывы!
19 полезных скриптов Google Apps для автоматизации Google Диска
Google Drive предлагает отличные функции для хранения и работы с различными типами файлов,но в нем отсутствуют некоторые функции,которые имеют решающее значение для вашей работы.Скрипты Google Apps-это простой в использовании язык сценариев,на которомвыполняет задачи,которые в противном случае недоступны на Диске.
Существуют сценарии,позволяющие читать/извлекать текст из изображений,конвертировать файлы,автоматически создавать резервные копии социальных фотографий или сохранять вложения Gmail.Большинство скриптов также позволяют автоматизировать эти службы.
Давайте посмотрим,как использовать скрипты Google Apps,чтобызаполнить недостающие дырына Google Диске и сделать многое другое без сторонних инструментов.
5 лучших бесплатных приложений для Android,помогающих автоматизировать задачи5 лучших бесплатных приложений для Android,помогающих автоматизировать задачи
Большинство людей любит Android за свободу творчества,которую предоставляет идентичность с открытым исходным кодом...Читать далее
Как запускать скрипты Google Apps
Чтобы создать и запустить сценарий на Диске,выполните следующие действия:
- Создайте/откройте документ или таблицу Google.В менюИнструментывыберитеРедактор сценариев.
- Удалите существующий код и добавьте свой код.Перейдите вFile>Save>добавьте имя скрипта>нажмитеOK.
- Для выполнения щелкните ► или в менюВыполнитьвыберите функцию.Если скрипт запускается впервые,он запросит вашу аутентификацию.Проверьте необходимые разрешения и нажмитеРазрешить.
- Желтая полоса появится в центре вверху,чтобы указать,что скрипт запущен.
Обратите внимание,что эти шаги предназначены для общих сценариев,и для выполнения некоторых сценариев могут потребоваться определенные дополнительные инструкции.
1.Преобразование и отправка Google Таблиц по электронной почте
Что делает:
- ПреобразуетGoogle Таблиц вPDF иотправляет их по почте,используя вашу учетную запись Gmail
- Позволяет преобразоватьи отправить только один лист,используя его идентификатор листа.
- Отправьте PDF-файлнескольким лицам,добавив их адреса,разделенные запятыми.
Сценарий использования:
Это полезно в сценариях,например,когда вы хотите отправить маркетинговые данные третьему лицу,но не хотите передавать всю таблицу целиком.Вы можете использовать этот скрипт для отправки PDF-версии.Таким образом,необходимые данные передаются без ущерба для всей информации вашей таблицы.
2.Преобразование изображений в текст с помощью OCR
Что делает:
- Преобразует изображения в текстдокументов с помощью технологии OCR;сохраняет их на вашем диске.
Сценарий использования:
Этот скрипт оказывается полезным в ситуациях,когда вам нужно отредактировать текст в imges или провести исследование большого количества изображений.Это делает преобразованные изображения доступными для редактирования и поиска.Это экономит ваше время и усилия и обеспечивает надежный вывод текста,поскольку использует встроенную технологию распознавания текста Google.
3.Редакторы файлов треков на Google Диске
Что делает:
- Узнает,какой пользователь внес изменения в исходные файлы вашего Google Диска.
- Отображает дату и время,когда файл был изменен.вместе с именами и адресами электронной почтыпользователей,которые внесли изменения в ваши общие документы/файлы.
Сценарий использования:
Этот скрипт полезен для отслеживания изменений,сделанных на вашем диске,включая Таблицы,Документы,Презентации и другие форматы Google Диска.
4.Сохранение веб-страницы на Google Диске
Что делает:
- Сохраняет или создает резервную копию веб-страницыпо любому URL-адресу на Google Диске.
- Выбирает веб-страницу,асохраняет то же,что и файл HTML(по умолчанию)или настроенное вами расширение.
- Поддерживает красивую структуру папокдля хранения нескольких веб-страниц или их копий.
Сценарий использования:
Этот скрипт особенно полезен для исследователей,ученых,блоггеров и тому подобное,которым нужно исследовать множество веб-сайтов и,возможно,потребуется сохранить их для использования в будущем.Не забудьте изменитьRESOURCE_URLво фрагменте на ссылку,которую вы хотите загрузить.
5.Отправьте документ Google по электронной почте
Что делает:
- Отправляет документ Google по электронной почте кому угодно и размещает содержание документакак тело сообщения электронной почты(а не вложение).
- Преобразует документв HTMLи отправляет его по электронной почте
Сценарий использования:
Если вы хотите отправить что-то не как вложение,а как часть электронного письма,это то,что выполняет свою работу.Обратите внимание,что вы должны изменитьdocumentId,recipient,subjectна их фактические значения в 4-й строке.
6.Разместите веб-сайт на Google Диске
Что делает:
- Размещайте любой статический веб-сайт,включая такие файлы,как HTML,CSS,JS,изображения,подкасты и т.Д.На Google Диске.(Диск нельзя использовать для обслуживания динамических сайтов,например сайтов,использующих серверную часть PHP или Java.)
Сценарий использования:
Этот скрипт полезен,если вы не хотите покупать план хостинга или домен для своего сайта.Это совершенно бесплатно,а серверы Google намного быстрее,чем у многих хостинг-провайдеров в мире.
7.Загрузите фотографии из Instagram на Диск
Что делает:
- Загрузкинесколько фотографий из Instagramи автоматически сохраните их на свой диск.
- Загрузите фотографии с помощью определенных теговили с любого определенного URL-адреса Instagram.
- Изображения хранятся в отдельной папке на Диске для упрощения обслуживания.
Сценарий использования:
Это полезно для поклонников Instagram,коллекционеров и исследователей,которые хранят резервные копии данных на Диске.
8.Преобразуйте документ Google в Markdown
Что делает:
- Преобразует документ Google в формат уценки(.md).
- Он автоматически отправляет вам преобразованный документ вместе с изображениями.(Обратите внимание,что могут возникнуть проблемы с данными,использующими сложное форматирование.)
Сценарий использования:
Это полезно для блоггеров и издателей,которые регулярно используют формат уценки для публикации в Интернете.Используя это,они могут избежать ручной работы по преобразованию своего контента для каждого черновика.
9.Установите автоматическое истечение срока для общих данных
Что делает:
- Задает интервал автоматического истечениядля общих файлов и папок на Диске
- Автоматическиудаляет доступ другим пользователямпо истечении определенного периода(авто-истечения срока действия).
Сценарий использования:
Этот сценарий полезен для предоставления ограниченного доступа к данным вашего диска и избавляет вас от беспокойства о том,что вы забыли скрыть данные.Эта функция уже доступна дляпользователей Google Apps for Work,но если вы бесплатный пользователь,то это для вас.
10.Сохраните вложения Gmail на диске
Что делает:
- Извлекает исохраняет все вложения Gmail в определенную папкуна вашем диске.
- Уведомлять о ходеизвлеченных вложений по электронной почте,но требует настройки параметров уведомлений.
Сценарий использования:
Если вы предпочитаете хранить вложения в облачных хранилищах,таких как Диск,то вам нужен этот скрипт.
11.Искать все файлы на Google Диске
Что делает:
- Ищет все ваши файлына диске и отображает результаты в удобном для восприятия стиле в таблице Google.
- Поддерживает документы,листы,презентации и некоторые другие текстовые форматы.
Сценарий использования:
С его помощью можно быстро просматривать файлы и груды данных.
12.Список каталогов на Google Диске
Что делает:
- Перечисляет всефайлов и папокиз каталогаGoogle Дискарекурсивно
- Запишите эти данные в удобном для просмотра формате в электронной таблице.
Сценарий использования:
Подходит для анализа всех данных на вашем Диске и для управления файлами.Обратите внимание,что для того,чтобы этот сценарий работал,вы должны сначала установитьfolderIdв коде.Идентификатор папки-это все,что находится после части адреса папки «папок/».
13.Преобразование документов Google в HTML
Что делает:
- ПреобразуетGoogle Docs в формат HTMLдля удобного обмена или использования на веб-страницах или в редакторах исходного кода.
- Поддерживает различные базовые HTML-теги или параметры форматирования,но понимает,что они не очень хорошо подходят для сложного форматирования текста.
Сценарий использования:
Полезен в основном для писателей,блоггеров и издателей,которые ищут публикации для инструментов,готовых к работе с HTML.Не забудьте установить в коде переменныеKEY и FILE_ID.
14.Объединение данных из нескольких листов
Что делает:
- Объединяет данные из нескольких листовопределенной электронной таблицыв один лист текущей электронной таблицы.
Сценарий использования:
Этот сценарий полезен в ситуациях,когда у вас есть несколько листов общих данных(включая общие заголовки и структуру),и вы хотите объединить их в один большой лист данных.
15.Экспорт таблиц Google в файлы CSV
Что делает:
- Экспортирует листы текущей электронной таблицы какотдельных файлов CSVна Диске.
Сценарий использования:
Это полезно для людей,которые регулярно используют Таблицы для управления и хранения данных и которым требуются данные в формате CSV для совместного использования или использования в других приложениях.Без этого Google Таблицы конвертируют и загружают только один лист за раз.
После копирования кода в редактор сценариев снова откройте эту электронную таблицу и проверьте менюAdd-ons.
16.Преобразование таблицы Google в счет-фактуру в формате PDF
Что делает:
- Преобразует любой конкретный лист вPDF-счет-фактуруи сохраняет на свой Диск.
Сценарий использования:
Подходит для пользователей,которые регулярно используют экосистему Google Apps в качестве рабочего инструмента и имеют дело со счетами на продукты и т.Д.
17.Загрузите URL-адрес прямо на Google Диск
Что делает:
- Автоматически загружает любой отдельный файл(или несколько файлов)с определенного URL-адресана ваш диск.
- Файлы сохраняются в определенной папкена диске,и он может легко загружать несколько файлов по нескольким ссылкам при условии,что они предоставляются по одному.
Сценарий использования:
Для людей,которым нравится хранить данные из Интернета на Диске.Все,что для этого нужно,-это ссылка на нужную страницу.Чтобы использовать,скопируйте код в редактор сценариев и перейдите кОпубликовать>Развернуть как веб-приложение…
18.Загрузите профили Google+в Google Таблицы
Что делает:
- Извлекает данные из общедоступных профилей Google+в таблицу Google.Полученные данные включают имя,информацию о работе,изображение профиляи многое другое.
- Единственный требуемый ввод-это идентификатор профиля человека,о котором вы хотите получить данные,и это работает для нескольких профилей.
Сценарий использования:
Это чрезвычайно полезно для ввода данных и аналитиков социальных сетей для сбора данных.
19.Преобразование вложений PDF в обычный текст
Что делает:
- Преобразует все вложенияPDFиз Gmail в формат обычного текстадля удобного обмена/хранения
- Вы можетеуказать исходный язык PDF-файла(для извлечения текста)исохранить выходные текстовые файлывместе с исходнымифайлами PDFна Google Диске.
Сценарий использования:
Вы регулярно получаете PDF-файлы по электронной почте и хотите сохранить их на Диске в исходной или текстовой форме.Он выполняет свою работу партиями.
Как вы нашли этот список?Знаете ли вы еще какие-нибудь скрипты Google Apps,которые помогут облегчить жизнь пользователю Диска?Пожалуйста,дайте нам знать,используя раздел комментариев ниже.
Как очистить Интернет с помощью Playwright
Драматург-восходящая звезда в области парсинга веб-страниц и автоматизации.Если вы думали,что Кукловод могущественен,Драматург поразит вас.
Логотип PlaywrightPlaywright-это библиотека автоматизации браузера,очень похожая на Puppeteer.Оба позволяют управлять веб-браузером с помощью всего нескольких строк кода.Возможности безграничны.От автоматизации рутинных задач и тестирования веб-приложений до интеллектуального анализа данных.
С Playwright вы можете запускать Firefox и Safari(WebKit),а не только браузеры на основе Chromium.Это также сэкономит ваше время,потому что Playwright автоматизирует повторяющийся код,такой как ожидание появления кнопок на странице.
Вам не нужно быть знакомым с Драматургом,Кукольником или веб-парсингом,чтобы пользоваться этим руководством,но знание HTML,CSS и JavaScript является обязательным.
В этом руководстве вы узнаете,как:
- Запустить браузер с Playwright
- Нажимать кнопки и ждать действий
- Извлекать данные с веб-сайта
Проект
Для демонстрации Основы Playwright,мы создадим простой парсер,который извлекает данные о темах GitHub.Вы сможете выбрать тему,и парсер вернет информацию о репозиториях,помеченных этой темой.
Страница для JavaScript GitHub TopicМы будем использовать Playwright,чтобы запустить браузер,открыть страницу темы GitHub,нажать кнопкуЗагрузить еще,чтобы отобразить больше репозиториев,а затем извлечь следующую информацию:
- Владелец
- Имя
- URL
- Количество звездочек
- Описание
- Список тем репозитория
Установка
Для использования Playwright вам понадобится Node.js версии выше 10 и менеджер пакетов.Мы будем использовать
npm,который предустановлен с Node.js.Вы можете подтвердить их наличие на своем компьютере,запустив:node-v&&npm-vЕсли вам не хватает Node.js или NPM,посетите руководство по установке,чтобы начать работу.
Теперь,когда мы знаем,что наша среда работает,давайте создадим новый проект и установим Playwright.
мкдир драматург-скрепер&&компакт-диск драматург-скрепер npm init-y npm i playwrightПри первой установке Playwright загружаются двоичные файлы браузера,поэтому установка может занять немного больше времени.
Создание скребка
Создание скребка с помощью Playwright на удивление легко,даже если у вас нет опыта скребка.Если вы разбираетесь в JavaScript и CSS,это будет совсем несложно.
В папке проекта создайте файл с именем
scraper.js(или выберите любое другое имя)и откройте его в своем любимом редакторе кода.Сначала мы убедимся,что Playwright правильно установлен и работает,запустив простой скрипт.Теперь запустите его с помощью редактора кода или выполнив следующую команду в папке проекта.
node scraper.jsЕсли вы видели открытое окно Chromium и успешную загрузку страницы GitHub Topics,поздравляем,вы только что роботизировали свой веб-браузер с помощью Playwright!
Тема JavaScript GitHubЗагрузка дополнительных репозиториев
Когда вы впервые открываете страницу темы,количество отображаемых репозиториев ограничено 30.Вы можете загрузить больше,нажав кнопкуЗагрузить еще…внизу страницы.
Нам нужно сообщить Playwright о двух вещах,чтобы он загрузил больше репозиториев:
- Нажмите,Загрузить еще…кнопку.
- Подождите,пока загрузятся репозитории.
Нажимать кнопки с Playwright очень просто.Приставив к искомой строке префикс
Нажатие кнопкиtext=,Playwright найдет элемент,содержащий эту строку,и щелкнет по нему.Он также будет ждать появления элемента,если он еще не отображен на странице.Это огромное улучшение по сравнению с Puppeteer,и с ним приятно работать с Playwright.
После нажатия нужно дождаться загрузки репозиториев.Если бы мы этого не сделали,парсер мог завершить работу до того,как новые репозитории появятся на странице,и мы пропустили бы эти данные.
Ожиданиеpage.waitForFunction()позволяет выполнять функцию внутри браузера и ждать,пока функция не вернетtrue.Чтобы найти этот селектор
Chrome Dev Toolsarticle.border,мы использовали инструменты разработчика браузера,которые можно открыть в большинстве браузеров,щелкнув правой кнопкой мыши в любом месте страницы и выбравInspect.Это означает:Выберите тегс границейclass.Давайте вставим это в наш код и проведем тестовый запуск.
Если вы посмотрите запуск,вы увидите,что браузер сначала прокручивает страницу вниз и нажимает кнопкуЗагрузить еще…,которая меняет текст наЗагрузка еще.Через секунду или две вы увидите следующую партию из 30 репозиториев.Прекрасная работа!
Теперь,когда мы знаем,как загрузить больше репозиториев,мы извлечем нужные данные.Для этого воспользуемся функцией
Извлечение данных со страницыpage.$$ eval.Он сообщает браузеру найти определенные элементы,а затем выполнить функцию JavaScript с этими элементами.Это работает так:Страница
$$ evalнаходит наши репозитории и выполняет предоставленную функцию в браузере.Мы получаемrepoCards,который представляет собой массиввсех элементов репо.Возвращаемое значение функции становится возвращаемым значением страницы.$$ eval.Благодаря Playwright вы можете извлекать данные из браузера и сохранять их в переменной в Node.js.Магия!Если вам сложно понять сам код извлечения,обязательно ознакомьтесь с этим руководством по работе с селекторами CSS и этим руководством по использованию этих селекторов для поиска элементов HTML.
А вот и код с извлечением.Когда вы запустите его,вы увидите 60 репозиториев,информация о которых выводится на консоль.
Заключение
В этом руководстве мы узнали,как запустить браузер с помощью Playwright и управлять его действиями с помощью некоторых из самых полезных функций Playwright:страницы
.click()для имитации щелчков мыши,page.waitForFunction(),чтобы ждать,пока что-то произойдет,иpage.$$ eval()для извлечения данных со страницы браузера. - Создайте переменную
- Повторите эксперимент с URL:
Ваш комментарий будет первым
[an error occurred while processing the directive]