Как извлечь изображения из PDF
PDF-файлы сложно редактировать и извлекать из них информацию, но вы можете это сделать с помощью правильных инструментов. Вот как извлечь изображения из PDF-файла.
Файл PDF (portable document format) обеспечивает быстрый и удобный способ обмена и печати документов и файлов. Вы можете редактировать и создавать PDF-файлы, если у вас есть нужные приложения, но в основном это файлы, доступные только для чтения, которые вы можете открыть на любом устройстве. Из-за того, как работают PDF-файлы, извлечение текста и изображений из них сложная задача без правильных инструментов. Вот как извлечь изображения из PDF-файла.
Читайте также: Что такое файл RAR и как его открыть?
Как извлечь изображения из PDF-файла с помощью Adobe Reader DC
Вы можете извлекать изображения по одному с помощью бесплатной версии Adobe Reader DC. Щелкните правой кнопкой мыши на изображении, которое вы хотите извлечь, и нажмите на инструмент Выбора (значок курсора). Вы также можете нажать на значок курсора на верхней панели, если у вас уже настроен ярлык.
Щелкните правой кнопкой мыши на изображении, которое вы хотите извлечь, и нажмите на инструмент Выбора (значок курсора). Вы также можете нажать на значок курсора на верхней панели, если у вас уже настроен ярлык.
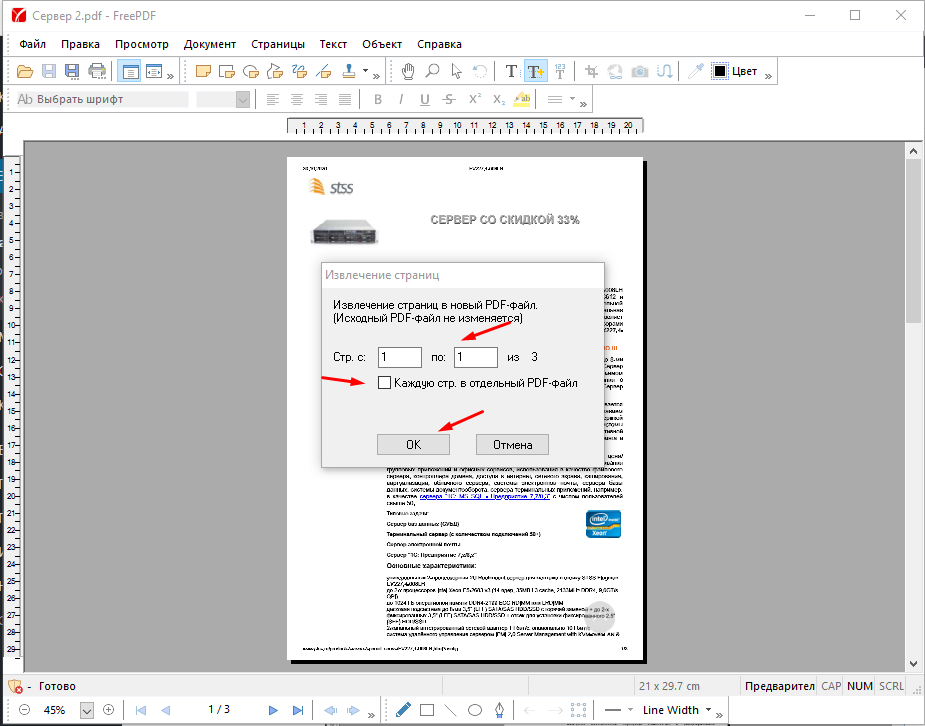
Щелкните по изображению, затем щелкните правой кнопкой мыши и выберите Сохранить изображение как. Вы можете извлечь и сохранить изображение в папку на компьютере.
Вам понадобится Adobe Acrobat Pro DC, если у вас большой файл с большим количеством изображений. Это дорогая подписка, но вы можете воспользоваться 7-дневной бесплатной пробной версией, чтобы убедиться, что она того стоит. Откройте PDF-файл, перейдите на вкладку Инструменты и выберите Экспортировать PDF.
Вы также можете перейти в раздел Просмотр > Инструменты > Экспорт PDF > Открыть, если вы не видите вкладку. Вы также можете увидеть опцию Экспортировать PDF в правом меню, в зависимости от настроек меню.
В разделе Параметры экспорта PDF выберите Изображение.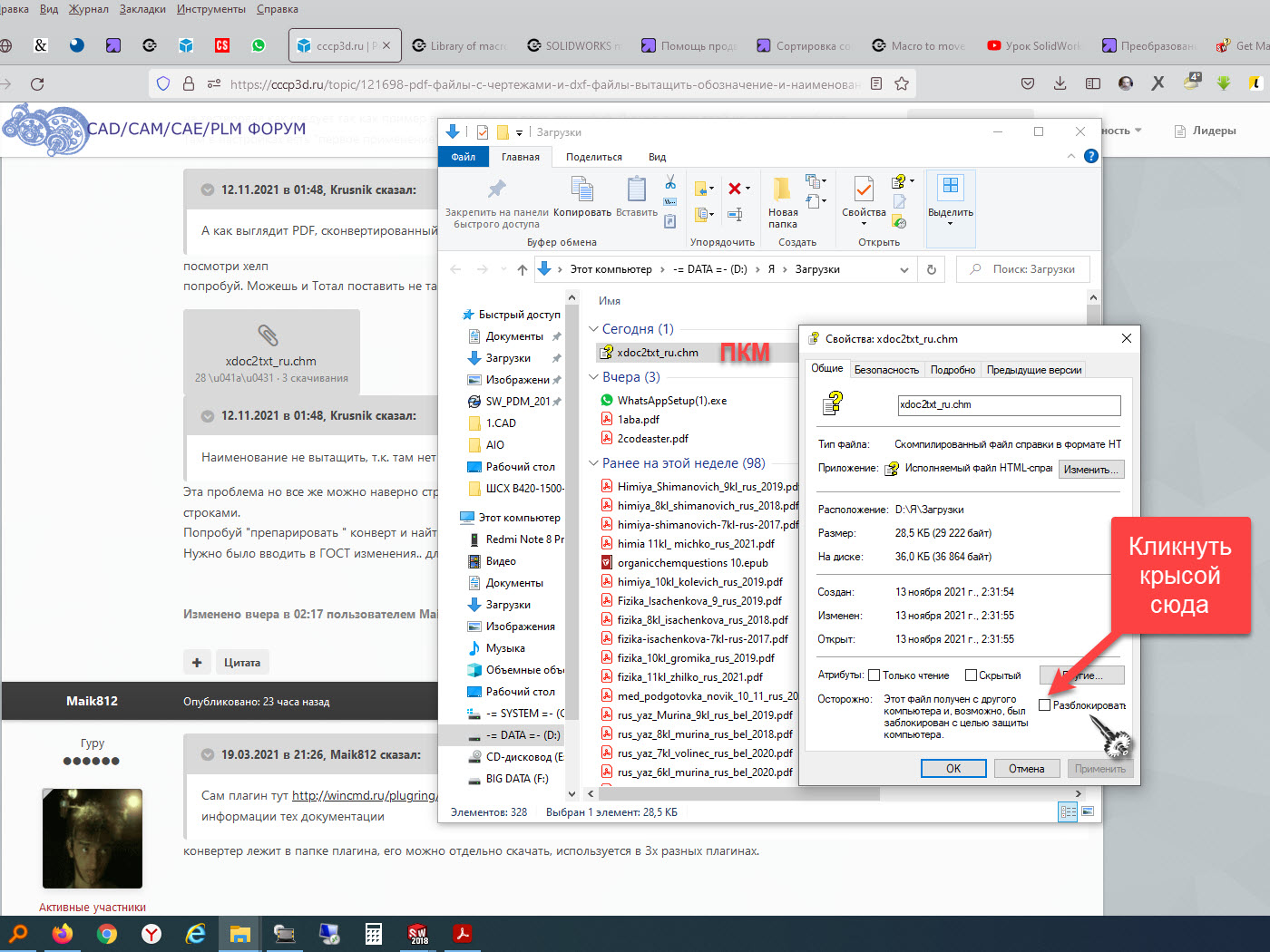 Выберите нужный формат и убедитесь, что вы установили флажок рядом с пунктом Экспортировать все изображения. Если вы этого не сделаете, он преобразует каждую страницу PDF-файла в формат JPEG вместо извлечения только изображений. Нажмите на Экспорт и выберите папку, в которую вы хотите сохранить все изображения.
Выберите нужный формат и убедитесь, что вы установили флажок рядом с пунктом Экспортировать все изображения. Если вы этого не сделаете, он преобразует каждую страницу PDF-файла в формат JPEG вместо извлечения только изображений. Нажмите на Экспорт и выберите папку, в которую вы хотите сохранить все изображения.
Как извлечь изображения из PDF-файла онлайн
Если на вашем компьютере нет программы для чтения PDF, такой как Adobe Acrobat, вы можете использовать такие инструменты, как Sejda, для извлечения изображений из PDF-файла онлайн.
Загрузите свой PDF-файл и выберите Extract single images.
Если в файле много изображений, Sejda сохранит их вместе в ZIP-файле. Загрузите ZIP-файл и распакуйте его, чтобы сохранить фотографии. Если в файле всего несколько изображений, вы можете сначала отредактировать и обрезать их перед загрузкой.
Как удалить изображения из PDF-файла с помощью инструмента обрезки
Если вам не нужны целые изображения из PDF-файла, самый простой способ получить их, не требуя дополнительного редактирования, — это использовать инструмент обрезки Windows. Используйте инструмент поиска Windows и введите Инструмент обрезки.
Используйте инструмент поиска Windows и введите Инструмент обрезки.
Выберите режим Прямоугольника в раскрывающемся списке Режимы обрезки. Затем одновременно нажмите клавишу с логотипом Windows, Shift и S.
Выберите изображение или часть изображения, которую вы хотите извлечь. Нажмите на всплывающее окно подтверждения, чтобы открыть параметры редактирования. Нажмите на кнопку Сохранить (значок гибкого диска в правом верхнем углу), чтобы сохранить извлеченное изображение.
Подробнее: Как создавать файлы PDF
Рекомендуемые статьи
Похожие посты
Не пропустите
Как извлечь изображения из PDF и использовать их где угодно
Способ 1: используйте специальную программу для чтения PDF
Способ 2: Запустите Adobe Photoshop
Способ 4: установка крошечного программного обеспеченияPkPdfConverter
PDF формирователь
Маленький PDF
PDFdu. com
com
Формат Portable Document Format (PDF) похож на ламинированную пластиком бумагу. Вы можете видеть, что внутри, но не можете извлечь изображения из PDF. Например, вы можете захотеть использовать графику или встроенную диаграмму из профессионального отчета в формате PDF в презентации.
Мы полагаемся на Portable Document Format, чтобы сохранить документ как есть. Но вы все равно можете повозиться с ним и извлечь изображения из файла PDF. Итак, давайте посмотрим, как получить изображения из файла PDF и использовать их в другом месте.
Способ 1: используйте специальную программу для чтения PDF
Извлечение изображения из PDF — это легкая прогулка, если у вас есть профессиональная версия Adobe Acrobat. Это позволяет вам извлечь одно изображение или несколько изображений за пару кликов. На официальной справочной странице Adobe Acrobat показано, как экспортировать PDF в другие форматы.
Некоторые альтернативные программы чтения PDF, такие как Nitro PDF Reader (Pro), также имеют эту функцию. Но кто платит деньги за программу для чтения PDF, верно? Давайте посмотрим, как мы можем бесплатно брать изображения из PDF.
Но кто платит деньги за программу для чтения PDF, верно? Давайте посмотрим, как мы можем бесплатно брать изображения из PDF.
Быстрый способ извлечения изображений с помощью бесплатной программы Adobe Reader DC. Если вам нужно извлечь только одно или несколько изображений, попробуйте этот ярлык в бесплатной версии Adobe Reader:
- Щелкните документ правой кнопкой мыши и выберите «Выбрать инструмент» во всплывающем меню.
- Перетащите, чтобы выделить текст, или нажмите, чтобы выбрать изображение.
- Щелкните правой кнопкой мыши выбранный элемент и выберите «Копировать ». Теперь изображение находится в вашем буфере обмена.
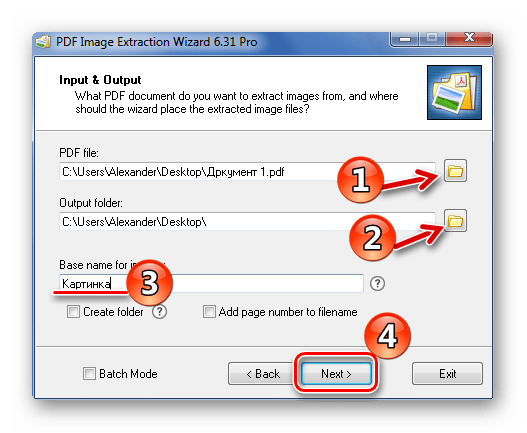
В качестве альтернативы: используйте инструмент «Снимок».
- Выберите «Правка» > «Сделать снимок».
- Перетащите прямоугольник вокруг области, которую хотите скопировать, и отпустите кнопку мыши.
- Нажмите клавишу Esc, чтобы выйти из режима моментального снимка.
 Теперь изображение находится в вашем буфере обмена.
Теперь изображение находится в вашем буфере обмена.
 Теперь изображение находится в вашем буфере обмена.
Теперь изображение находится в вашем буфере обмена.Способ 2: Запустите Adobe Photoshop
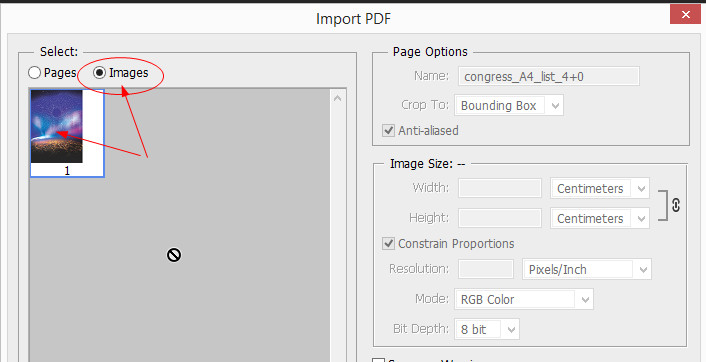
Adobe Photoshop может показаться излишним для получения изображений из PDF-файлов. Но процесс такой же простой — откройте PDF-документ в Adobe Photoshop. Появится диалоговое окно Импорт PDF .
Выберите изображения вместо страниц. Вы можете выбрать изображения, которые хотите извлечь. Нажмите OK, а затем сохраните (или отредактируйте) изображение, как обычно. Adobe Illustrator и CorelDraw также предлагают аналогичные функции. Используя этот подход, вы можете легко извлечь изображение и перенести его в другую программу настольной издательской системы.
Использование программы редактирования графики, такой как Photoshop, также позволяет экспортировать изображения из PDF в другие форматы, такие как PNG или GIF. Например, в Photoshop есть функция быстрого экспорта, которую вы можете настроить, если делаете это часто.
Использовать Inkscape? Inkscape — лучшая бесплатная альтернатива Photoshop, если у вас ограниченный бюджет. Он также имеет процесс импорта PDF, который позволяет вам выборочно сохранять нетекстовые части документа.
Он также имеет процесс импорта PDF, который позволяет вам выборочно сохранять нетекстовые части документа.
Теперь давайте рассмотрим некоторые из лучших бесплатных решений для бесплатного сохранения изображений из PDF.
Использование встроенного инструмента Snipping в Windows кажется очевидным. Но вы, как и многие люди, скучаете по встроенному инструменту для создания скриншотов, скрытому в Windows 10, Windows 8.1 и Windows 7.
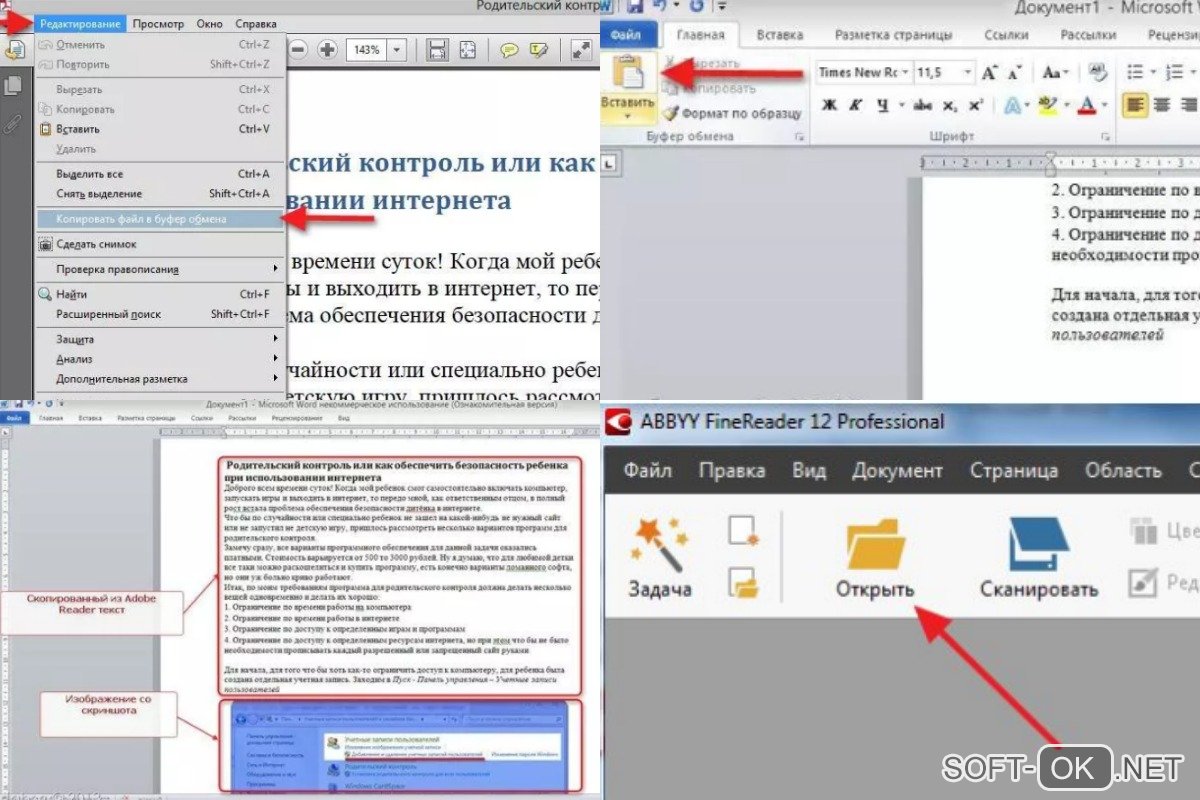
- Нажмите кнопку «Пуск ». Введите Snipping Tool в поле поиска на панели задач. Затем выберите Snipping Tool из списка результатов.
- Щелкните Режим. Выберите режим произвольной формы, прямоугольный, оконный или полноэкранный режим. Для произвольных или прямоугольных фрагментов используйте мышь, чтобы выбрать область, которую вы хотите захватить.
- Выберите «Создать» и перетащите на раздел, который вы хотите вырезать.
- Используйте кнопки «Сохранить как» и «Копировать », чтобы сохранить его на рабочий стол или отправить в буфер обмена. Кроме того, вы можете использовать значок «Поделиться» для экспорта изображений из PDF-файла на ближайшее устройство, электронную почту или любые другие приложения, которые вы настроили с помощью Snipping Tool.
 Кроме того, вы можете использовать значок «Поделиться» для экспорта изображений из PDF-файла на ближайшее устройство, электронную почту или любые другие приложения, которые вы настроили с помощью Snipping Tool.
Кроме того, вы можете использовать значок «Поделиться» для экспорта изображений из PDF-файла на ближайшее устройство, электронную почту или любые другие приложения, которые вы настроили с помощью Snipping Tool.Snipping Tool — это быстрый удар. Для более серьезных проектов, требующих пакетного извлечения изображений из PDF-файлов, обратитесь к бесплатному специализированному ПО.
Способ 4: установка крошечного программного обеспечения
Вы найдете несколько программ, которые могут извлекать выбранные или все изображения из файла PDF. Вот два:
PkPdfConverter
Это небольшая бесплатная программа, которую вы можете установить с Sourceforge. Разархивируйте загрузку размером 5,6 МБ и запустите ее как портативную программу. Элементы управления в простом графическом пользовательском интерфейсе Windows говорят сами за себя.
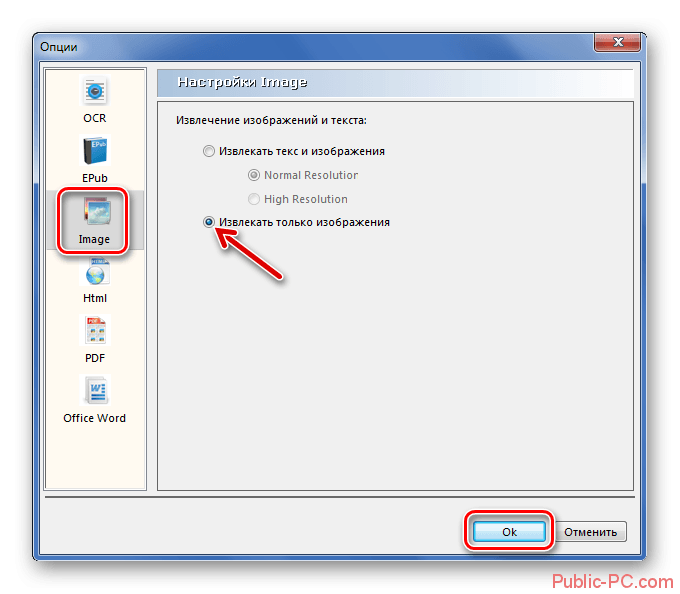
Откройте целевой файл. Введите диапазон номеров страниц, которые вы хотите включить. В раскрывающемся списке представлены четыре варианта вывода для извлечения PDF:
- PDF в текст.
- PDF в изображение.
- Извлечение изображений из PDF-страниц.
- PDF в HTML.

Нас интересует третий выход. Вы можете нажать «Дополнительные настройки» и установить пользовательское качество изображения. Или оставьте их по умолчанию. Затем нажмите «Преобразовать», и программа начнет сканирование всех страниц в файле.
Просмотрите результат в рамке справа. Вы также можете просмотреть определенный формат изображения с помощью средства просмотра изображений. Все извлеченные изображения могут быть сохранены в определенной папке автоматически.
PDF формирователь
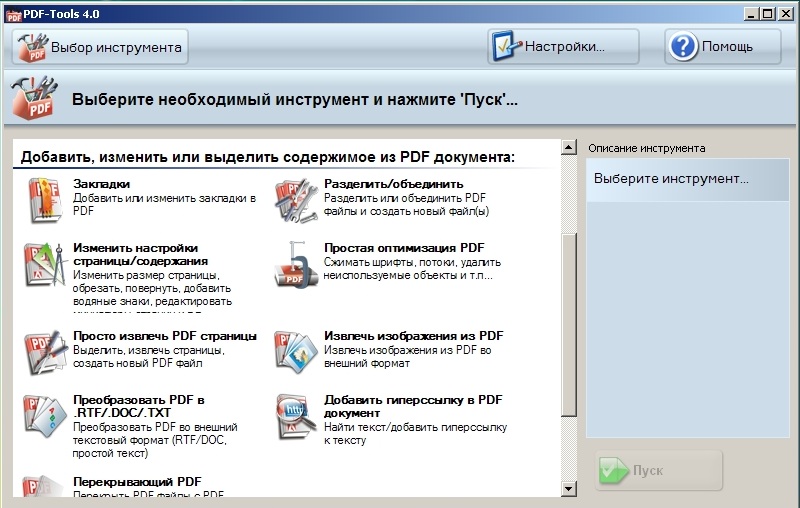
PDF Shaper Free — это полнофункциональное программное обеспечение, работающее в Windows 10. Программное обеспечение имеет простой интерфейс. Есть платная версия, но, к счастью, бесплатная версия сохранила функцию извлечения изображений.
PDF Shaper минимален, но некоторые полезные функции скрыты под капотом.
- Нажмите на символ «+», чтобы добавить свой файл.
- Прокрутите вниз, чтобы выбрать «Извлечь изображения» в группе «Извлечь ».
- Выберите папку или создайте новую папку, чтобы сохранить все извлеченные изображения из PDF.
- PDF Shaper автоматически получает все изображения из PDF.
Установленное программное обеспечение — лучшее решение, если вы беспокоитесь о конфиденциальности своего PDF-документа. Если нет, есть много хороших онлайн-решений на выбор. Далее мы идем за несколькими из них.
Если вам не нужно ничего устанавливать, не делайте этого, потому что эти онлайн-инструменты PDF могут справиться практически со всеми повседневными задачами.
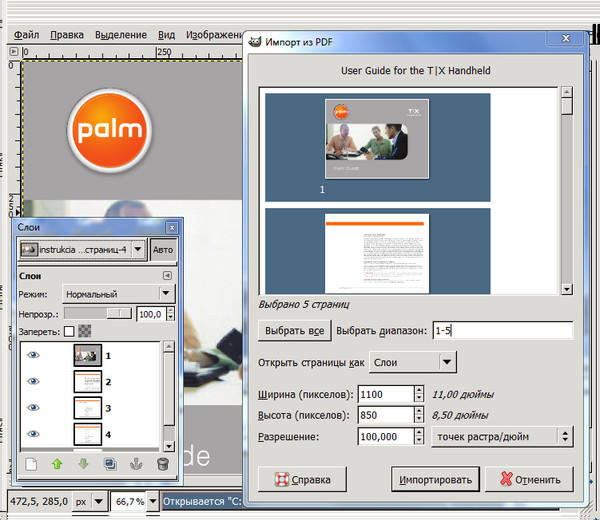
Маленький PDF
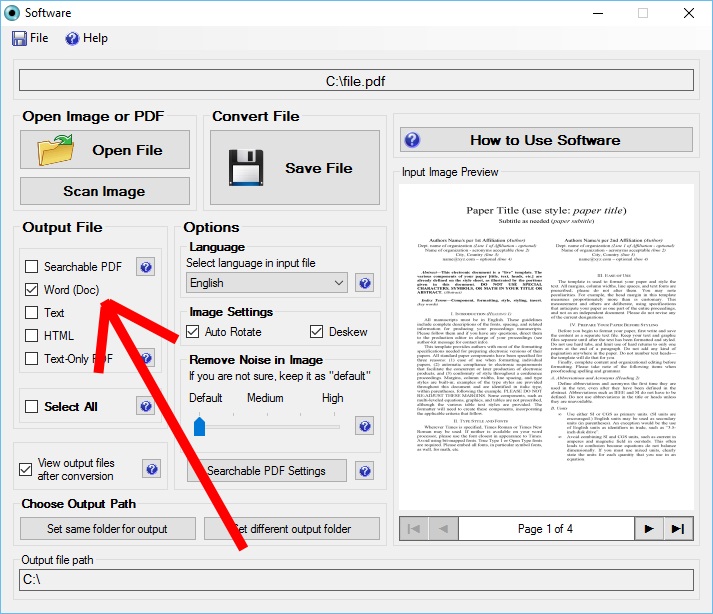
Малый PDF — умный, чистый и быстрый. У него есть модель ценообразования, но бесплатный план позволяет бесплатно загружать два PDF-файла каждый день. Есть 16 инструментов на выбор. Выберите плитку с надписью PDF to JPG.
- Перетащите файл PDF или загрузите его со своего рабочего стола. Вы также можете загрузить с Google Диска или Dropbox.
- Выберите «Извлечь одно изображение» или «Преобразовать целые страницы».
- Малый PDF сканирует файл и извлекает все изображения на следующем шаге. Вы можете выбрать изображение по отдельности, загрузить группу из них в виде ZIP-файла или сохранить его в Dropbox или Google Drive.
 Вы также можете загрузить с Google Диска или Dropbox.
Вы также можете загрузить с Google Диска или Dropbox.Маленький PDF — это чистое и элегантное решение. Вам даже не нужно входить в систему для случайного использования. Этот онлайн-инструмент PDF может сэкономить вам много работы.
PDFdu.com
Этот сайт представляет собой универсальный PDF-конвертер для самых разных нужд. У них также есть платные загружаемые инструменты, но вы можете избежать разорения с онлайн-версиями. PDFdu Free Online PDF Image Extractor выполняет эту задачу за четыре шага.
- Нажмите кнопку Обзор, чтобы выбрать и загрузить файл PDF.
- Выберите формат изображения.
- Нажмите Извлечь изображения и подождите.

Загрузите извлеченные изображения на свой компьютер в виде ZIP-файла или откройте их по одному в браузере. Вы можете экспортировать изображения из PDF в различные форматы изображений, включая JPG, BMP, GIF, PNG и Tiff. На сайте написано, что изображения извлекаются с высочайшим качеством. После завершения процесса нажмите синюю кнопку удаления, чтобы удалить PDF-документ с их сервера.
Это не единственные два доступных инструмента. Оставьте эти веб-приложения в качестве запасных вариантов:
- PDF24.org
- PDFaid.com
- PDFOnline.com
- Sciweavers.org
- ExtractPDF.com
Есть достаточно онлайн-конвертеров и экстракторов, чтобы сделать эту работу. Поскольку это самый популярный формат документа, существует множество способов оформления PDF-файла и манипулирования содержимым для нашего использования. Более интересный вопрос заключается в следующем: какая ситуация вынуждает вас извлекать изображения из PDF?
Кредит изображения: RTimages/Shutterstock
Источник записи: www. makeuseof.com
makeuseof.com
5 способов извлечения или копирования текста из изображения PDF (включено бесплатно онлайн)
Обычный PDF-файл содержит текст, изображения, ссылки, мультимедиа и различные интерактивные элементы. Но изображение PDF содержит только изображение, весь исходный текст становится изображением, оно может быть создано из файлов изображений или отсканировано в формат PDF, пользователям не разрешается извлекать или копировать любой текст из такого изображения PDF без OCR. На самом деле, извлечь или скопировать текст из изображения PDF сегодня не проблема, здесь у нас есть 6 решений в следующих 2 частях для вас, включая бесплатные онлайн-варианты.
- #1 Cisdem PDF Converter OCR (MacOS)
- #2 Adobe Acrobat (MacOS и Windows)
- #3 Документы Google (онлайн бесплатно)
- #4 Онлайн OCR (онлайн бесплатно)
- #5 Convertio (онлайн бесплатно)
Высокоточные решения
Мы уже много лет предлагаем PDF-решения и хорошо понимаем наших пользователей.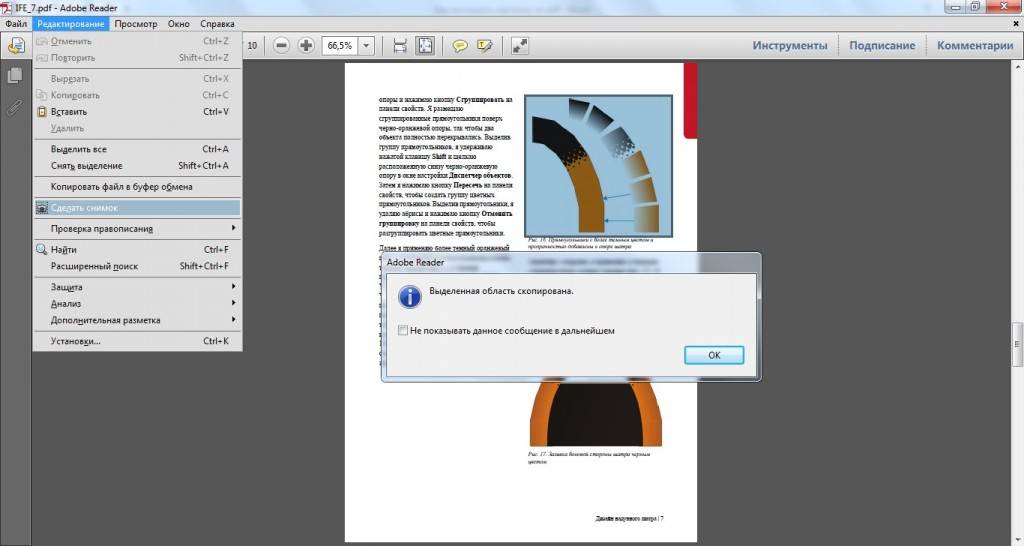 Большинство из них сначала хотят попробовать бесплатные онлайн-решения, но в конце выбирают специальную программу для своей работы, потому что экономия времени и эффективность всегда важнее затрат. Поэтому мы поставили эти высокоточные решения для извлечения текста из изображения PDF в начало нашего списка. Вы можете проверить детали и загрузить бесплатную пробную версию.
Большинство из них сначала хотят попробовать бесплатные онлайн-решения, но в конце выбирают специальную программу для своей работы, потому что экономия времени и эффективность всегда важнее затрат. Поэтому мы поставили эти высокоточные решения для извлечения текста из изображения PDF в начало нашего списка. Вы можете проверить детали и загрузить бесплатную пробную версию.
#1 Cisdem PDF Converter OCR (Windows и macOS)
Cisdem PDF Converter OCR — это программа для повышения производительности, помогающая вам работать с файлами PDF. Она преобразует файлы PDF практически во все популярные форматы файлов, включая Word, Excel, PowerPoint, ePub, Keynote, Pages, Text, более 15 форматов. Таким образом, даже без дорогостоящего редактора PDF вы можете экспортировать PDF как другой редактируемый формат и редактировать в существующих файловых редакторах. Кроме того, он позволяет создавать PDF-файлы из Word, PowerPoint и других файлов, поэтому вы можете легко делиться своими файлами или распечатывать их в формате PDF.
Что касается функции оптического распознавания символов, то она не только преобразует изображение или файлы изображений в формате PDF в формат PDF с возможностью поиска для удобного извлечения или копирования текста, но также экспортирует их в хорошо отформатированные форматы Word, Excel, PowerPoint, Keynote, Pages, ePub. Тем не менее, вы можете конвертировать несколько изображений PDF одновременно. Его функция OCR также отлично справляется с распознаванием изображений PDF на английском, арабском, французском, испанском, японском, китайском, русском и т. д.
Основные характеристики Cisdem PDF Converter OCR
- Извлечение текста из изображения PDF и изображения
- OCR PDF и изображения в хорошо отформатированные PDF, Word, Excel, PowerPoint, Keynote, Pages и т. д.
- Пакетная обработка PDF-изображений
- Преобразование исходного PDF в более 15 форматов
- Распознавание более 200 языков из изображения PDF
- Создание PDF из других документов (Word, PowerPoint и т. д.)
 д.)
д.)Как извлечь текст из изображения PDF на Windows или Mac?
- Загрузите и установите Cisdem PDF Converter OCR на Windows или Mac.
Скачать бесплатно Скачать бесплатно - Импорт одного или нескольких изображений PDF в интерфейс Converter.
- Выберите вывод в виде PDF или текста.
- Щелкните значок настроек и выберите язык файла, затем нажмите OK.
- Нажмите «Преобразовать», чтобы сохранить изображение PDF в формате PDF с возможностью поиска или в редактируемом текстовом формате.
- Откройте выходной файл, извлеките текст или скопируйте текст из изображения PDF.
Кроме того, вы можете обратиться к этому обучающему видео на YouTube, чтобы извлечь тексты:
#2 Adobe Acrobat (MacOS и Windows)
Если вы ежедневно работаете с PDF-файлами, возможно, у вас установлен Adobe Acrobat, в этом случае извлечение или копирование текста из PDF-изображения станет для вас чрезвычайно простым . Но для пользователей, которые установили только Adobe Acrobat Reader, вы не можете извлечь или скопировать текст изображения PDF, поскольку в Adobe Reader нет функции OCR.
Но для пользователей, которые установили только Adobe Acrobat Reader, вы не можете извлечь или скопировать текст изображения PDF, поскольку в Adobe Reader нет функции OCR.
Как извлечь текст из изображения PDF в Acrobat?
- Откройте изображение PDF с помощью Adobe Acrobat.
- Перейдите в «Инструменты»> «Улучшение сканирования».
- Выберите «Распознать текст»> «В этом файле» и выберите язык файла, чтобы запустить Adobe OCR для изображения PDF.
- Теперь вы можете извлекать текст или копировать текст из файла изображения PDF в Acrobat.
- (Необязательно) Если вы хотите сохранить текст изображения в формате PDF, выберите «Инструменты»> «Экспорт PDF» и выберите выходной формат.
Бесплатные онлайн-решения
Для пользователей, которые хотят бесплатно извлечь текст из PDF-изображения онлайн, здесь мы также перечисляем 3 лучших и удобных онлайн-инструмента. Но перед руководством нам лучше иметь представление об ограничениях бесплатных онлайн-инструментов.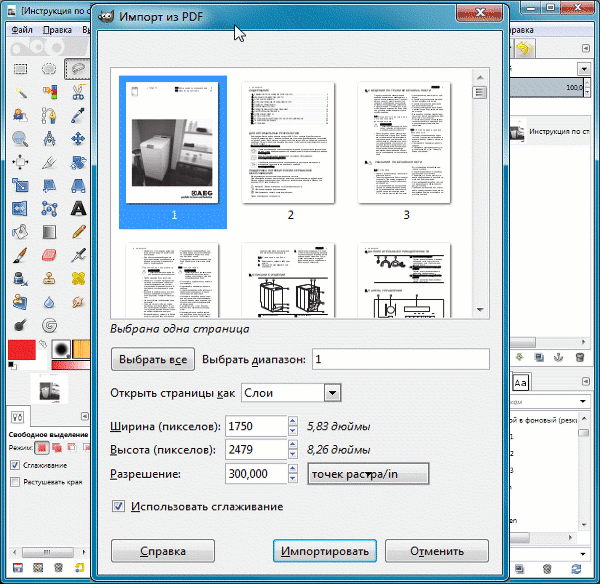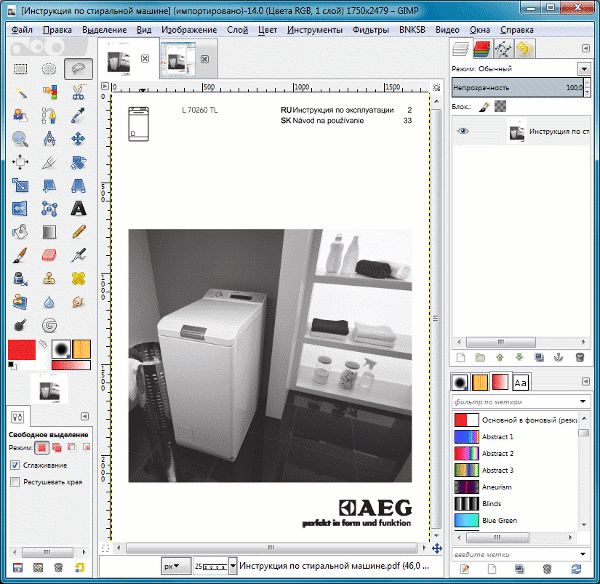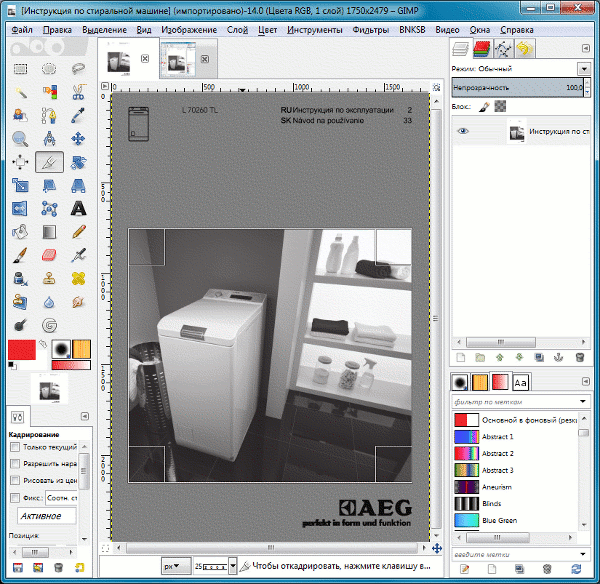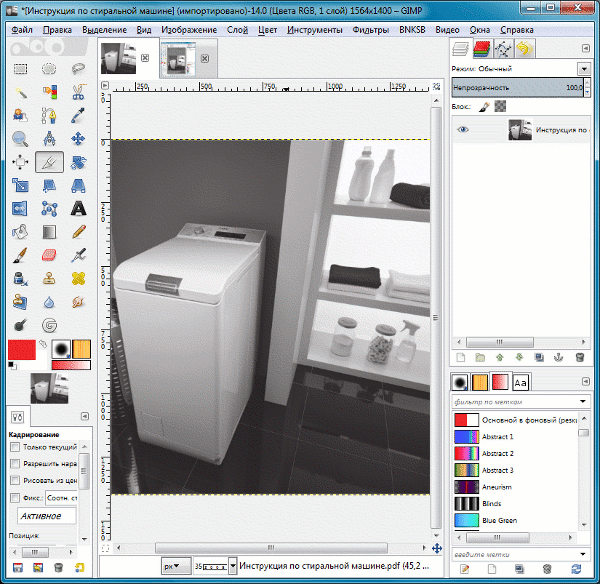
Ограничения бесплатных онлайн-решений
- Ошибки OCR для распознавания текста из изображения PDF
- Ограничение размера файла
- Максимальное количество страниц файла
- Требуется много времени для загрузки файла или обработки OCR
- Потенциальные риски утечки информации
- Без пакетной обработки
#3 Google Docs (онлайн бесплатно)
Google Docs — это бесплатная онлайн-служба, предлагаемая Google для работы с PDF, Word, изображениями и другими документами. Пользователи могут открывать, просматривать, редактировать и экспортировать файлы. Кроме того, он способен обрабатывать OCR на отсканированных PDF-файлах и файлах изображений. Но самая большая проблема использования Google Docs для извлечения текста из PDF-изображения заключается в том, что есть ошибки OCR, и в выходном файле не будет сохранено форматирование.
Как скопировать текст из изображения PDF онлайн бесплатно с помощью Google Docs?
- Войдите в свою учетную запись Google.
- Перейдите в Google Диск>Создать>Загрузить файл, чтобы импортировать файл изображения PDF.
- Щелкните правой кнопкой мыши импортированное изображение PDF и выберите «Открыть с помощью»> «Документы Google».
- Затем текст PDF-изображения появляется в Google Docs, OCR завершается, теперь вы можете скопировать текст из PDF-изображения или отредактировать его при необходимости.
- (Необязательно) Если вы хотите извлечь текст из изображения PDF и сохранить его в отдельный файл, выберите «Файл» > «Загрузить как» > «Txt».

#4 OnlineOCR (Online Free)
OnlineOCR (onlineocr.net) — это простой онлайн-инструмент OCR для прямого извлечения или копирования текста из изображений PDF или файлов изображений. Распознанный текст будет отображаться на веб-странице для простой и быстрой проверки. . Кроме того, он поддерживает экспорт PDF-изображений в формате Word или Excel. Но вам придется вручную пересматривать ошибки OCR.
Как скопировать текст из изображения PDF онлайн бесплатно с помощью OnlineOCR?
- Перейти на Onlineocr. net.
- Щелкните Выбрать файл, чтобы загрузить изображение в формате PDF.
- Выберите язык файла из списка.
- Выберите вывод как текст или другие.
- Нажмите «Преобразовать», чтобы начать распознавание PDF-изображения в текст.
- Извлеките или скопируйте распознанный текст из изображения PDF или загрузите выходной файл.
 net.
net.#5 Convertio (бесплатно онлайн)
По сравнению с двумя вышеупомянутыми бесплатными онлайн-инструментами для извлечения текста из изображений PDF, Convertio поддерживает больше языков файлов и больше выходных форматов. Но основная причина, по которой я рекомендую Convertio OCR, заключается в том, что он помогает выполнять распознавание файлов, состоящих из двух языков, что значительно повышает точность распознавания при работе с двуязычными файлами. Однако вам разрешено конвертировать только 10 страниц бесплатно.
Как скопировать текст из изображения PDF онлайн бесплатно с помощью Convertio?
- Перейдите к Convertio OCR.
- Загрузите в программу одно или несколько изображений PDF.
- Выберите 1 или 2 языка файла, выберите выходной формат как Текст и введите номера страниц, из которых вы хотите извлечь текст.
- Затем нажмите Распознать, чтобы запустить OCR.
- Загрузите текстовый файл, и вы сможете извлечь или скопировать текст из изображения PDF.
Заключение
6 способов извлечения или копирования текста из PDF-изображения будет вполне достаточно для вас, и многие пользователи, ищущие решение по этому поводу, отдают больше внимания профессиональной автономной программе OCR, которая безопаснее в использовании и быстрее в использовании. процесс OCR, более точный результат, даже есть расширенные функции, предлагающие повысить вашу производительность при работе с файлами PDF. А вы? У вас есть лучший совет по этому поводу? Вы можете поделиться нами в комментарии.
Конни Уизли Конни пишет приложения для повышения производительности и утилит для Mac с 2009 года.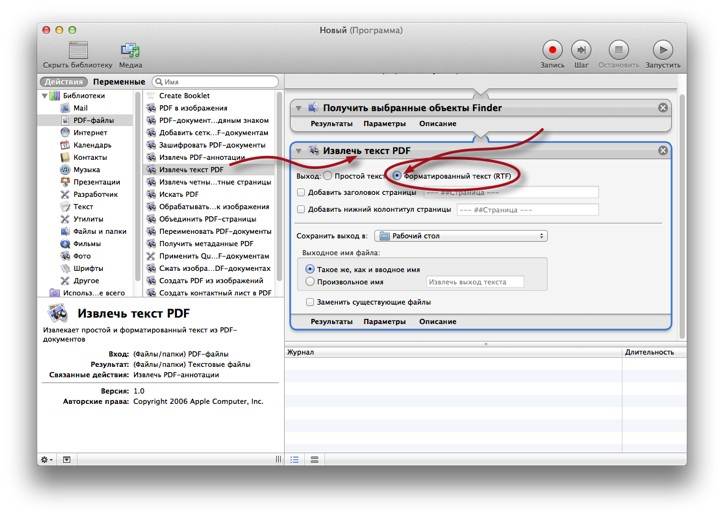
Популярные статьи
4 лучших веб-сайта для загрузки бесплатного шаблона плана урока в формате PDF 6 лучших способов конвертировать PDF в слайды Google, которые вы должны попробовать Cisdem PDF Converter OCR 5.1.0 выпущен с улучшенным качеством преобразованияИзвлекать изображения из PDF без повторной выборки в python?
В Python с PyPDF2 для фильтра CCITTFaxDecode:
импортировать PyPDF2 импортировать структуру """ Ссылки: Формат PDF: http://www.adobe.com/content/dam/Adobe/en/devnet/acrobat/pdfs/pdf_reference_1-7.pdf. CCITT Group 4: https://www.itu.int/rec/dologin_pub.asp?lang=e&id=T-REC-T.6-198811-I!!PDF-E&type=items Извлечение изображений из pdf: http://stackoverflow.com/questions/2693820/extract-images-from-pdf-without-resampling-in-python Извлечение изображений, закодированных с помощью CCITTFaxDecode в .net: http://stackoverflow.com/questions/2641770/extracting-image-from-pdf-with-ccittfaxdecode-filter Формат TIFF и теги: http://www.awaresystems.be/imaging/tiff/faq.html """ def tiff_header_for_CCITT (ширина, высота, img_size, CCITT_group = 4): tiff_header_struct = '<' + '2s' + 'h' + 'l' + 'h' + 'hhll' * 8 + 'h' вернуть struct.pack (tiff_header_struct, b'II', # Индикация порядка байтов: Маленький индеец 42, # Номер версии (всегда 42) 8, # Смещение до первого IFD 8, # Количество тегов в IFD 256, 4, 1, ширина, # ImageWidth, LONG, 1, ширина 257, 4, 1, высота, # ImageLength, LONG, 1, длина 258, 3, 1, 1, # BitsPerSample, SHORT, 1, 1 259, 3, 1, CCITT_group, # Compression, SHORT, 1, 4 = кодирование факса CCITT Group 4 262, 3, 1, 0, # Пороговое значение, SHORT, 1, 0 = WhiteIsZero 273, 4, 1, struct. K < 0 --- Чистое двумерное кодирование (Группа 4) K = 0 --- Чистое одномерное кодирование (Группа 3, 1-D) K > 0 --- Смешанное одно- и двумерное кодирование (Группа 3, 2-D) """ если xObject[obj]['/Filter'] == '/CCITTFaxDecode': если xObject[obj]['/DecodeParms']['/K'] == -1: CCITT_группа = 4 еще: CCITT_группа = 3 ширина = xObject[obj]['/Width'] высота = xObject[obj]['/Height'] data = xObject[obj]._data # извините, getData() не работает для CCITTFaxDecode img_size = длина (данные) tiff_header = tiff_header_for_CCITT (ширина, высота, img_size, CCITT_group) img_name = obj[1:] + '.tiff' с открытым (img_name, 'wb') как img_file: img_file.write(tiff_header + данные) # # импорт ио # из изображения импорта PIL # im = Image.
 calcsize(tiff_header_struct), # StripOffsets, LONG, 1, длина заголовка
278, 4, 1, высота, # RowsPerStrip, LONG, 1, длина
279, 4, 1, img_size, # StripByteCounts, LONG, 1, размер изображения
0 # последний ИФД
)
pdf_filename = 'скан.pdf'
pdf_file = открыть (pdf_filename, 'rb')
cond_scan_reader = PyPDF2.PdfFileReader(pdf_file)
для i в диапазоне (0, cond_scan_reader.getNumPages()):
страница = cond_scan_reader.getPage(i)
xObject = страница['/Ресурсы']['/XObject'].getObject()
для объекта в xObject:
если xObject[obj]['/Subtype'] == '/Image':
"""
Фильтр CCITTFaxDecode декодирует данные изображения, закодированные с использованием
Факсимильное (факсовое) кодирование CCITT Группы 3 или Группы 4. Кодировка CCITT
предназначен для достижения эффективного сжатия монохромного (1 бит на пиксель) изображения
данных в относительно низком разрешении, и поэтому полезен только для данных растрового изображения, а не
для цветных изображений, изображений в оттенках серого или общих данных.
calcsize(tiff_header_struct), # StripOffsets, LONG, 1, длина заголовка
278, 4, 1, высота, # RowsPerStrip, LONG, 1, длина
279, 4, 1, img_size, # StripByteCounts, LONG, 1, размер изображения
0 # последний ИФД
)
pdf_filename = 'скан.pdf'
pdf_file = открыть (pdf_filename, 'rb')
cond_scan_reader = PyPDF2.PdfFileReader(pdf_file)
для i в диапазоне (0, cond_scan_reader.getNumPages()):
страница = cond_scan_reader.getPage(i)
xObject = страница['/Ресурсы']['/XObject'].getObject()
для объекта в xObject:
если xObject[obj]['/Subtype'] == '/Image':
"""
Фильтр CCITTFaxDecode декодирует данные изображения, закодированные с использованием
Факсимильное (факсовое) кодирование CCITT Группы 3 или Группы 4. Кодировка CCITT
предназначен для достижения эффективного сжатия монохромного (1 бит на пиксель) изображения
данных в относительно низком разрешении, и поэтому полезен только для данных растрового изображения, а не
для цветных изображений, изображений в оттенках серого или общих данных.
Ваш комментарий будет первым