Как избежать блокировки сайта и что делать, если это произошло
В последнее время российское законодательство все активнее пополняется нормами, позволяющими блокировать интернет-сайты по самым разным причинам. Поэтому руководству компаний, в деятельности которых интернет занимает важное место, жизненно необходимо понимать, от чего может исходить угроза блокировки их ресурса, когда и как ее можно предотвратить.
В чем заключается блокировка сайта
Краткий ответ очевиден – сайт перестает работать. Но надо заметить, что технически блокируют не сайты, а домены и сетевые адреса, по которым они находятся. Поэтому блокировка означает прекращение работоспособности всех онлайн-ресурсов, которые приписаны к домену или сетевому адресу. В том числе это касается форумов, баз знаний и других совершенно некоммерческих ресурсов, которые непосредственно к причине блокировки, возможно, не имеют никакого отношения.
Кроме того, ценность любого онлайн-ресурса определяется прежде всего его известностью.
Убытки от вынужденного простоя онлайн-бизнеса не меньше, а зачастую и больше, чем у обычных офлайн-магазинов и офисов за аналогичный период времени. Поскольку время в случае блокировки сайта будет работать против вас, давайте разберемся в том, как именно это происходит и что можно сделать.
Процедура блокировки в определенных случаях различается, но зачастую выглядит примерно следующим образом:
- У Роскомнадзора появляется информация о незаконности содержимого сайта.
- Роскомнадзор определяет провайдера хостинга и направляет ему уведомление.

- Провайдер хостинга уведомляет владельца (администратора) сайта о необходимости в определенный срок удалить нелегальный контент.
- Если владелец сайта проигнорировал требование, то доступ к сайту ограничивает провайдер хостинга. Если он этого не делает, то блокировку проводят операторы связи (например, такие компании как «Ростелеком», SkyNet, «МегаФон» и т.п.) по требованию Роскомнадзора.

Может сложиться впечатление, что это длительная бюрократическая процедура. На самом деле иногда все происходит на удивление быстро. По закону у администратора сайта есть всего один рабочий (а иногда и календарный) день на удаление спорных материалов. Кроме того, даже моментальное устранение причины претензий Росмкомнадзора не поможет, если суд уже вынес решение о «вечной» блокировке.
Таким образом, два предварительных вывода:
1) Нужно приложить максимум усилий, чтобы не допустить «вечной» блокировки сайта, иначе ситуация может стать фатальной в рамках рассматриваемой проблемы и даже устранение причин блокировки не «оживит» ваш сайт (по крайней мере, по старому адресу).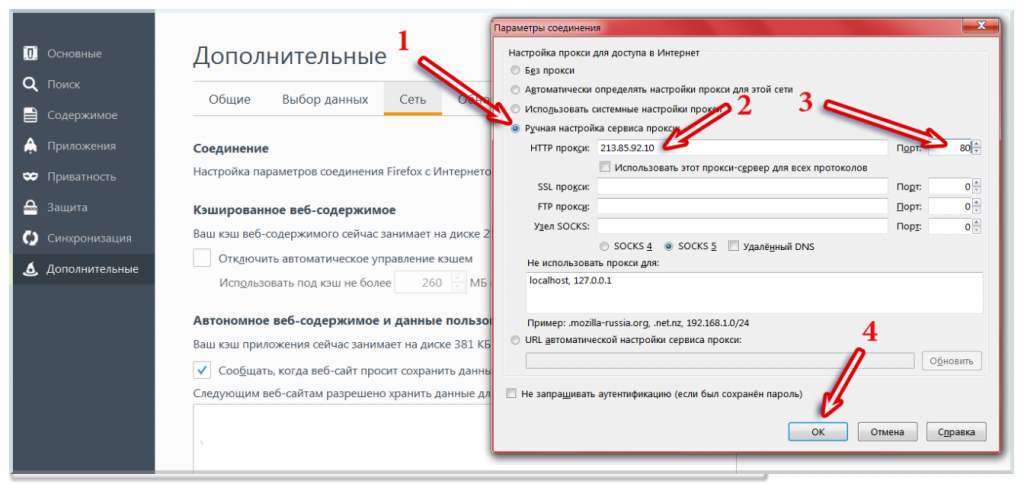
2) Поскольку времени на реакцию может оказаться очень мало, лучше вообще не доводить дело до блокировки, устранив все поводы для возможных претензий заранее.
Итак, профилактика. Любимый совет врачей, юристов, автомехаников и специалистов практически в любой сфере. Раз все так тепло отзываются о профилактике, возможно, это не такая глупая мысль. Но что конкретно можно сделать? Для ответа на этот вопрос важно понимать предпосылки блокировки.
За что могут заблокировать сайт
В самом общем виде основные причины блокировки можно разделить на два вида:
- когда информация на сайте нарушает права конкретных лиц,
- и когда она нарушает публичные интересы.
Как нетрудно догадаться, во втором случае владелец интернет-ресурса поставлен законом в более сложное положение. Но пойдем по порядку.
1. Незаконное использование чужих объектов авторских и смежных прав
Сайт может быть заблокирован по инициативе правообладателя, если на нем без соответствующего разрешения или с иными нарушениями закона используются объекты авторских и смежных прав (в том числе фильмы, музыка, тексты, изображения, программное обеспечение, но не фотография – это исключение). Например, если не получена лицензия на распространение или если незаконно удалена информация об авторстве. В таком случае сайт подпадает под пакет поправок, прозванный в СМИ «антипиратским законом». В последнее время он регулярно ужесточается по отношению к нарушителям, и применяется все чаще.
Например, если не получена лицензия на распространение или если незаконно удалена информация об авторстве. В таком случае сайт подпадает под пакет поправок, прозванный в СМИ «антипиратским законом». В последнее время он регулярно ужесточается по отношению к нарушителям, и применяется все чаще.
Здесь следует обратить внимание на следующее:
- Правообладатель вправе не только направить в адрес администратора сайта претензию о нарушении интеллектуальных прав, но и попросить суд принять обеспечительные меры. То есть можно подать в суд заявление с просьбой о блокировке сайта на период судебного разбирательства и даже на период до 15 дней до подачи официального иска с детализацией нарушений. Для удовлетворения такого заявления судом правообладателю не нужно доказывать незаконность использования его интеллектуальной собственности – достаточно подтвердить факт незаконного использования интеллектуальной собственности в интернете и наличие своих прав на эту собственность.
- Предписание о блокировании сайта может содержаться в решении суда по иску о нарушении исключительных прав. При этом такое решение в некоторых случаях предусматривает и другие меры ответственности к владельцу сайта – например, выплату компенсации за нарушение исключительного права.
- С недавнего времени закон предусматривает «пожизненную» блокировку сайта. Суд может вынести подобное решение, если на сайте неоднократно и неправомерно размещались объекты авторских и смежных прав (пример: блокировка Мосгорсудом сайта Rutracker.org).
 При этом такое решение в некоторых случаях предусматривает и другие меры ответственности к владельцу сайта – например, выплату компенсации за нарушение исключительного права.
При этом такое решение в некоторых случаях предусматривает и другие меры ответственности к владельцу сайта – например, выплату компенсации за нарушение исключительного права.2. Нарушение закона о персональных данных
Возможность блокировки сайта за нарушение порядка обработки персональных данных появилась в законодательстве одновременно с запретом хранить персональные данные россиян за рубежом, который вступил в силу 1 сентября 2015 года. По всей видимости, именно для сайтов, которые не успели локализовать сервера с персональными данными в РФ, и была введена эта процедура. Но в то же время, закон не ограничивается такого рода нарушениями и говорит о том, что поводом для блокировки может стать любое нарушение порядка обработки персональных данных.
Основанием для блокировки может стать решение суда, полученное по обращению субъекта персональных данных (то есть того гражданина, чьи данные обрабатываются). Яркий пример: решение Мещанского районного суда города Москвы о блокировке страницы сайта Lurkmore.to за использование изображения (фотографии) певца Валерия Сюткина в серии интернет-мемов. Но в этом деле речь шла не о нарушении авторских прав на фотографию, а о незаконном использовании изображения певца, которое тоже относится к персональным данным.
Порядок блокировки максимально похож на тот, который применяется при нарушении исключительных прав – владельцу сайта также предоставляется один рабочий день на устранение нарушений (чего, скорее всего, будет недостаточно в случае необходимости переноса данных в РФ).
3. Распространение «запрещенной» информации
Под запрещенной к распространению информацией понимаются, прежде всего, конкретные категории информации, определенные в законе:
- порнография с участием несовершеннолетних;
- информация об изготовлении / использовании наркотиков;
- информация о способах суицида;
- данные о несовершеннолетних, пострадавших в результате противоправных действий;
- нелегальные интернет-казино.
Информацию, попадающую в этот перечень, признают запрещенной к распространению уполномоченные государственные органы, решения которых являются основанием для включения адреса сайта в реестр запрещенных онлайн-ресурсов.
Следует помнить, что запрещенными можно признать и любые другие сведения, но уже в судебном порядке. Суды, например, неоднократно выносили решения о блокировке в отношении сайтов, через которые дистанционно продавался алкоголь в нарушение закона.
Логично предположить, что суд, признавая информацию запрещенной, должен основываться на нормах закона, из которых следовала бы необходимость ограничения доступа к информации. Например, закон запрещает нарушение тайны переписки или распространение информации, составляющей коммерческую тайну – в таких случаях блокировка будет обоснованной. Однако, как показывает практика, существуют факторы, которые делают последствия регулирования в этой сфере достаточно непредсказуемыми и опасными для бизнеса. Например:
Например, закон запрещает нарушение тайны переписки или распространение информации, составляющей коммерческую тайну – в таких случаях блокировка будет обоснованной. Однако, как показывает практика, существуют факторы, которые делают последствия регулирования в этой сфере достаточно непредсказуемыми и опасными для бизнеса. Например:
- Широкое понимание судами своих полномочий по ограничению доступа к информации. Зачастую судебные акты, где та или иная информация признавалась запрещенной, мотивировались не только положениями законов, но и, помимо прочего, тем, что блокируемые сведения, по мнению судов, «подрывали принятые моральные устои общества». Иными словами, не выработан четкий и ограниченный круг критериев, позволяющих протестировать информацию на легальность.
- Владелец сайта может и не знать о судебном процессе по блокировке. Ответчиками нередко бывают операторы связи, а не администраторы сайтов. Кроме того, процесс может проходить в порядке так называемого «особого производства»: суд просто констатирует незаконность информации без участия какого-либо лица в качестве ответчика.
4. Призывы к экстремизму и беспорядкам, а также к участию в несанкционированных публичных мероприятиях
Такого рода информация блокируется по требованию Генпрокурора РФ или его заместителей, а владелец сайта уведомляется об ограничении доступа к ресурсу постфактум – одновременно с блокировкой сайта об этом информируется провайдер хостинга, а он, в свою очередь, должен в течение 24 часов известить администратора сайта. Последний имеет возможность удалить незаконную информацию, после чего уведомить об этом Роскомнадзор, с разрешения которого операторы возобновляют доступ к заблокированному ресурсу.
5. Нарушение «организатором распространения информации» своих обязанностей
Проблема в том, что понятие «организатора распространения информации» дано в законодательстве достаточно расплывчато. Статус организатора распространения информации связан с тем, что такое лицо вовлечено в передачу электронных сообщений. Очевидно, что законом подразумеваются социальные сети, почтовые сервисы, мессенджеры, форумы и тому подобные ресурсы.
На организаторов распространения информации возлагаются специфические обязанности, в частности: хранить в течение полугода сведения о пользователях и об обмене сообщениями между ними, а также предоставлять такие сведения органам, которые ведут оперативно-разыскную деятельность. Если обязанности, возложенные на организатора распространения информации, не исполняются, то ему может поступить уведомление Роскомнадзора с указанием срока на их исполнение (минимум 15 дней). Если уведомление будет проигнорировано, то Роскомнадзор направит операторам связи решение о блокировке ресурса, а его владельца проинформирует об этом через провайдера хостинга.
Что делать
Пока работоспособности сайта ничего не угрожает, можно методично минимизировать угрозы. «В зоне риска» находятся все онлайн-ресурсы, где контент генерируется и размещается самими пользователями, и при этом не проходит серьезной премодерации (если она вообще присутствует). Опасность существует и для тех сайтов, администраторы которых не проверяют законность публикации на них материалов: текстов, видеороликов, аудиозаписей и т. п. Вторая большая группа ресурсов, которые потенциально могут быть заблокированы – сайты, содержащие информацию, которая обрабатывается с нарушением законодательства о персональных данных. Это, по сути, означает, что в зоне риска находятся практически любые сайты, предусматривающие регистрацию (создание личных кабинетов или аккаунтов) пользователей.
п. Вторая большая группа ресурсов, которые потенциально могут быть заблокированы – сайты, содержащие информацию, которая обрабатывается с нарушением законодательства о персональных данных. Это, по сути, означает, что в зоне риска находятся практически любые сайты, предусматривающие регистрацию (создание личных кабинетов или аккаунтов) пользователей.
Можно сократить риски, отключив некоторые функции сайта. Например, новостные порталы часто закрывают комментарии к публикациям по особо острым темам, где логично ожидать повышенного накала страстей и эмоциональных обсуждений.
Сложно перестараться с получением согласий пользователей на передачу своих персональных данных для обработки и на безвозмездное использование интернет-ресурсом материалов, опубликованных пользователями. Такие оговорки часто встречаются на практике, в том числе в качестве подробных правовых документов, помещенных в разделе юридической информации. Ссылки на условия использования сайта нередко скрывают под собой развернутые, детально проработанные пользовательские соглашения, оферты, политики конфиденциальности, условия об использовании объектов авторских и смежных прав, а также другие положения, регламентирующие отношения сайта с посетителями.
Безусловно, стоит позаботиться о том, чтобы на корпоративном сайте не могло появиться сообщений, прямо противоречащих законодательству РФ – например, призывов к употреблению наркотиков, суицидам, экстремизму, беспорядкам и т.д. Но всего не предусмотреть. Поэтому главное, о чем следует позаботиться заблаговременно – отработать внутреннюю систему оповещений и назначить конкретных ответственных за немедленную реакцию на любые претензии регулирующих органов. Если проблема будет устранена в течение дня, шансы на сохранение работоспособности ресурса резко возрастут.
Кроме того, владелец сайта, наряду с хостинг-провайдером или оператором связи, могут в течение трех месяцев обжаловать решение Роскомнадзора о включении сайта в реестр запрещенных. Не исключено, что это потребуется сделать, даже если ваш сайт или конкретные страницы сайта не содержат нелегальный контент. Дело в том, что блокировки могут выполняться не совсем корректно технически (в особенности, если говорить о блокировке по сетевому адресу), и «заодно» с блокируемым ресурсом пропадает доступ к тем ресурсам, на которых размещен совершенно легальный контент. Из-за этих особенностей под угрозой, например, уже находилась «Википедия».
Из-за этих особенностей под угрозой, например, уже находилась «Википедия».
Есть и другие нюансы. Так, за пределами этой статьи остаются такие случаи, как запрет использования доменного имени из-за схожести с чужим товарным знаком или обязанность администратора удалить информацию, которая порочит честь или деловую репутацию другого лица. Дело в том, что такого рода нарушения, как правило, не могут быть поводом для блокировки сайта, тем более в административном порядке. Во всяком случае, не должны становиться таким поводом.
Задача владельца и администратора сайта – внимательно изучить законодательную базу и выполнять все, что может быть четко формализовано. А в остальном нужно быть готовым быстро реагировать, и знать, как именно бороться за свои права.
когда не допустить легче, чем обойти — Digital Rights Center на vc.ru
Блокировка сайтов — это реальность, которой, к сожалению, в России уже никого не удивить, особенно с момента начала событий на Украине. Ежедневно блокируются веб-страницы самой разной тематики, причем зачастую без каких-либо внятных объяснений, просто с мотивировкой “за размещение не соответствующей действительности информации”.
Ежедневно блокируются веб-страницы самой разной тематики, причем зачастую без каких-либо внятных объяснений, просто с мотивировкой “за размещение не соответствующей действительности информации”.
131 просмотров
По данным объединения «Роскомсвобода», количество заблокированных из соображений военной цензуры сайтов давно преодолело отметку в 3000. Например, одно из самых первых решений, вынесенное в самом начале «спецоперации», собрало уже больше 2700 сайтов и ссылок. Лидером по блокировкам в этом вопросе является Генпрокуратура, но региональные суды также весьма интенсивно ограничивают доступ к материалам, которые не укладываются в информационную повестку российских властей.
При этом эксперты не считают, что существует серьезная вероятность тотальной блокировки интернета в России или ее отключения от внешнего трафика.
«У нас сеть максимально интегрирована во Всемирную сеть, трансграничных каналов перехода интернет-трафика намного больше, чем, например, в Казахстане или Китае. Она более устойчива к внешним воздействиям, но тем не менее в нее можно внести ограничения, которые не позволят в полной мере использовать интернет широкой группой населения. <…> Но техническая мысль пойдет по пути разработки сети без возможности контроля государства. Это сейчас происходит: развиваются мэш-сети, децентрализованные платформы обмена информацией, децентрализованные мессенджеры, анонимные сети. Возможно, это будет следующий виток — Web3.0–4.0, и он пойдет по пути полной децентрализации, полного отсутствия контроля со стороны телекома, владельцев интернет-ресурсов, IT-компаний, корпораций, самих пользователей.
Она более устойчива к внешним воздействиям, но тем не менее в нее можно внести ограничения, которые не позволят в полной мере использовать интернет широкой группой населения. <…> Но техническая мысль пойдет по пути разработки сети без возможности контроля государства. Это сейчас происходит: развиваются мэш-сети, децентрализованные платформы обмена информацией, децентрализованные мессенджеры, анонимные сети. Возможно, это будет следующий виток — Web3.0–4.0, и он пойдет по пути полной децентрализации, полного отсутствия контроля со стороны телекома, владельцев интернет-ресурсов, IT-компаний, корпораций, самих пользователей.
Никто не сможет влиять на работу децентрализованных платформ. Они сейчас развиваются на уровне местных сообществ, но ничего не мешает их масштабировать. Чем больше государство будет подавлять интернет, тем больше будут развиваться децентрализованные платформы», — говорит Артем Козлюк, руководитель «Роскомсвободы».
Иначе говоря, способы обойти блокировку того или иного ресурса в России найдутся всегда. Но это решение постфактум. А какова возможность не допустить подобного развития событий и избежать блокировки в принципе?
Но это решение постфактум. А какова возможность не допустить подобного развития событий и избежать блокировки в принципе?
Конечно, за последние полгода ситуация со свободой информации и наступлением цензуры осложнилась настолько, что теперь говорить о том, что есть шанс даже при теоретически полном выполнении всех норм закона не допустить блокировок — попросту самонадеянно. Увы, власть и суды теперь вообще могут принимать соответствующие решения, не оглядываясь особо на какие-то там требования каких-то там законов. Но тем не менее, механизм уберечься от подобного развития есть, и именно его мы сейчас попробуем описать.
Разумеется, первоочередная задача — это не размещать на своем веб-ресурсе сведения, за которые блокировка следует автоматически в силу закона: экстремистские материалы, информацию о суициде или способах его совершения, детскую порнографию или сведения об изготовлении наркотических средств. Сюда же теперь относятся «фейковые” материалы, публикации или репосты СМИ-иноагентов и »дискредитирующие” сведения о российской армии и органах власти (такова новая реальность последних месяцев).
Однако это, что называется, очевидные вещи, за которые “прилетает” моментально. Но помимо них, есть несколько магистральных направлений, которые стоит укрепить всем держателям сайтов — это защита персональных данных, защита интеллектуальной собственности (читай: авторских прав) , а также защита прав потребителя.
1. Работайте с персональными данными согласно закону — и претензий к вам будет гораздо меньше.
Особо пристальное внимание государство уделяет нарушению сбора и обработки персональных данных как основанию для блокировки того или иного интернет-ресурса. По закону все владельцы сайтов, которые собирают сведения о своих посетителях, считаются операторами персональных данных и обязаны следовать ряду правил.
Для того, чтобы обезопасить себя от штрафов и блокировки ресурса, вам понадобится опубликовать в открытом доступе политику конфиденциальности (это основной документ, описывающий цель и порядок сбора персональных данных пользователей) , а также подготовить целый ряд локальных внутренних документов, описывающих алгоритм работы с такими данными внутри вашей компании. После этого необходимо уведомить о размещении всех этих сведений Роскомнадзор.
После этого необходимо уведомить о размещении всех этих сведений Роскомнадзор.
Важное уточнение — вся база персональных данных должна находиться на территории Российской Федерации! В противном случае ресурс могут внести в «Реестр нарушителей прав» и заблокировать – именно по этой причине, например, в 2016 году был заблокирован популярнейший ресурс LinkedIn
2. Защита авторских прав — одна из гарантий того, что ваш сайт останется в свободном доступе
Гражданский кодекс дает автору произведений, в том числе фотографий и текстов, исключительное право на них, включая право на опубликование (cт. 1255 ГК РФ) . В общем случае перепечатка текста целиком без согласия автора, даже с указанием имени, — уже нарушение закона.
Закон (ст. 1274 ГК РФ) позволяет публиковать произведения без разрешения автора в информационных, научных, учебных или культурных целях. В этом случае обязательно должны быть указаны имя автора и первоначальный источник. Этот пункт коммерческие порталы часто пытаются использовать для защиты. Но не все так просто: список вариантов такого использования четко прописан в гражданском кодексе — цитирование и использование отрывков, а не произведения целиком, в некоммерческих целях.
Но не все так просто: список вариантов такого использования четко прописан в гражданском кодексе — цитирование и использование отрывков, а не произведения целиком, в некоммерческих целях.
Отдельными нарушениями также являются некоторые манипуляции с текстами и фотографиями. Например, удаление водяного знака с фотографии — это нарушение права на неприкосновенность произведения. По закону вносить изменения в произведения нельзя (ст. 1266 ГК РФ) .
Публикация без имени или за подписью другого человека — тоже нарушение, даже если автор дал разрешение на перепечатку. Статья 1265 ГК РФ защищает право признаваться автором произведения и право публиковаться под своим именем, псевдонимом или анонимно.
Если вы размещаете чужой контент, соблюдая все вышеуказанные условия, то шанс на блокировку ресурса, учитывая сказанное нами в начале статьи, конечно, не сведется к нулю (ибо теперь нельзя быть уверенными, что тот или иной сайт не закроют просто потому что) , — но станет существенно меньшим.
3. Соблюдение правил публичной оферты в интернете — это тоже способ избежать блокировки вашего сайта
Для защиты от возможных исков покупателей или пользователей сайта необходимо обязательно создать особый вид договоров, который устанавливает «правила игры» на вашем ресурсе — публичную оферту. Строжайшее соблюдение ее правил поможет избежать блокировки вашей веб-страницы.
В соответствии со статьей 432 Гражданского кодекса договор заключается посредством направления оферты (предложения заключить договор) одной стороной и ее акцепта (принятия предложения) другой стороной. Размещение оферты в электронной форме на сайте компании равнозначно направлению оферты клиенту. А совершение клиентом действия, предусмотренного такой офертой, является ее акцептом.
Во-первых, четко обозначьте юридические понятия в тексте оферты — это поможет избежать последующих претензий со стороны пользователей и, как следствие, принятия решений о блокировке ресурса на основании их жалоб.
Во-вторых, в случае если на вашем сайте есть возможность размещения какого-либо пользовательского контента, обозначьте основные правила относительно его использования. Этот пункт публичной оферты будет носить характер лицензионного соглашения между вами и пользователями и обезопасит от возможных претензий.
Еще важный момент: если вы планируете в целях ведения бизнеса осуществлять какую-либо рекламную рассылку, то обязательно пропишите цели и характер возможных email или sms-рассылок. Укажите, что вы оставляете за собой право осуществлять рассылку в рекламных, ознакомительных и иных целях, уместных для вашего ресурса.
Кроме того, всегда помните о том, что избежать блокировки вашего сайта можно, если регулярно отслеживать актуальные изменения в законодательстве и информацию соответствующих госорганов на официальных сайтах и аккаунтах в социальных сетях.
Говоря “госорганов”, мы не ошибаемся. Очень многие думают, что инициатива решений о блокировке того или иного сайта исходить лишь от Роскомнадзора как уполномоченного органа — но это далеко не так. Подобными полномочиями обладает целый ряд федеральных органов исполнительной власти: МВД, ФНС, Генпрокуратура, Роспотребнадзор, Росалкогольрегулирование, Росздравнадзор и даже (в определенных случаях) Росмолодежь. РКН же осуществляет непосредственное внесение сайта в тот или иной реестр запрещенной информации. Именно поэтому и происходит столь частое упоминание его, как инициатора блокировки, но отнюдь не всегда это является корректным. Об этом тоже надо помнить и знать.
Подобными полномочиями обладает целый ряд федеральных органов исполнительной власти: МВД, ФНС, Генпрокуратура, Роспотребнадзор, Росалкогольрегулирование, Росздравнадзор и даже (в определенных случаях) Росмолодежь. РКН же осуществляет непосредственное внесение сайта в тот или иной реестр запрещенной информации. Именно поэтому и происходит столь частое упоминание его, как инициатора блокировки, но отнюдь не всегда это является корректным. Об этом тоже надо помнить и знать.
Публикация подготовлена при поддержке юристов DRC.
Telegram-канал.
Как избежать блокировки веб-сайтов Защитой от угроз
Почему Защита от угроз блокирует веб-сайты?
Защита от угроз блокирует веб-сайты, чтобы защитить вас от потенциальных онлайн-угроз. В частности, если вы попытаетесь получить доступ к веб-сайту, который Threat Protection идентифицирует как потенциальный источник вредоносного ПО, страница будет заблокирована для вашей собственной защиты.
В большинстве случаев защита от угроз блокирует страницу в целях вашей безопасности. Однако иногда это может привести к ложному срабатыванию и помешать вам получить доступ к безопасному веб-сайту.
Однако иногда это может привести к ложному срабатыванию и помешать вам получить доступ к безопасному веб-сайту.
Если вы хотите обойти блокировку Защиты от угроз, отключать Защиту от угроз не нужно. Вместо этого просто нажмите кнопку «Разблокировать», которая должна быть видна при попытке доступа к заблокированному веб-сайту, или измените настройки защиты от угроз.
Связанные статьи
Как избежать блокировки веб-сайтов Защитой от угроз
Вы можете изменить настройки Защиты от угроз через приложение NordVPN. Это позволяет вам выбирать, какие функции защиты от угроз активны. У разных пользователей разные потребности, поэтому не все захотят оставить настройки по умолчанию.
Если вы не уверены, какая конфигурация настроек вам подходит, взгляните на приведенные ниже варианты использования и выберите наиболее подходящий для вас вариант.
Приоритет: Конфиденциальность
Если вашим главным приоритетом является сохранение конфиденциальности, а не безопасности, вы можете отключить «Блокировать вредоносные веб-сайты», оставив включенными «Блокировщик веб-трекеров», «Блокировщик рекламы» и «Обрезка URL». Вы будете подвергаться большему риску из-за веб-сайтов, которые могут заразить ваше устройство вредоносными программами, но вы все равно сможете наслаждаться повышенной конфиденциальностью в Интернете.
Вы будете подвергаться большему риску из-за веб-сайтов, которые могут заразить ваше устройство вредоносными программами, но вы все равно сможете наслаждаться повышенной конфиденциальностью в Интернете.
Конфиденциальность намного сложнее поддерживать, если ваши данные не защищены. Защита вашей онлайн-активности от корпораций и брокеров данных важна, но еще важнее защитить себя от хакеров и киберпреступников, которые могут использовать вредоносное ПО для слежки за вами.
Приоритет: безопасность
Если вашим приоритетом номер один является безопасность, и вы не беспокоитесь о том, что корпорации и мошенники собирают вашу личную информацию, основной функцией защиты от угроз, которую вы хотите включить, является «Блокировка вредоносных веб-сайтов». Оставляя эту систему включенной, вы позволяете защите от угроз блокировать потенциально опасные вредоносные веб-сайты. Вы также можете включить «Блокировщик рекламы», поскольку киберпреступники могут использовать онлайн-рекламу в качестве системы для доставки вредоносного ПО.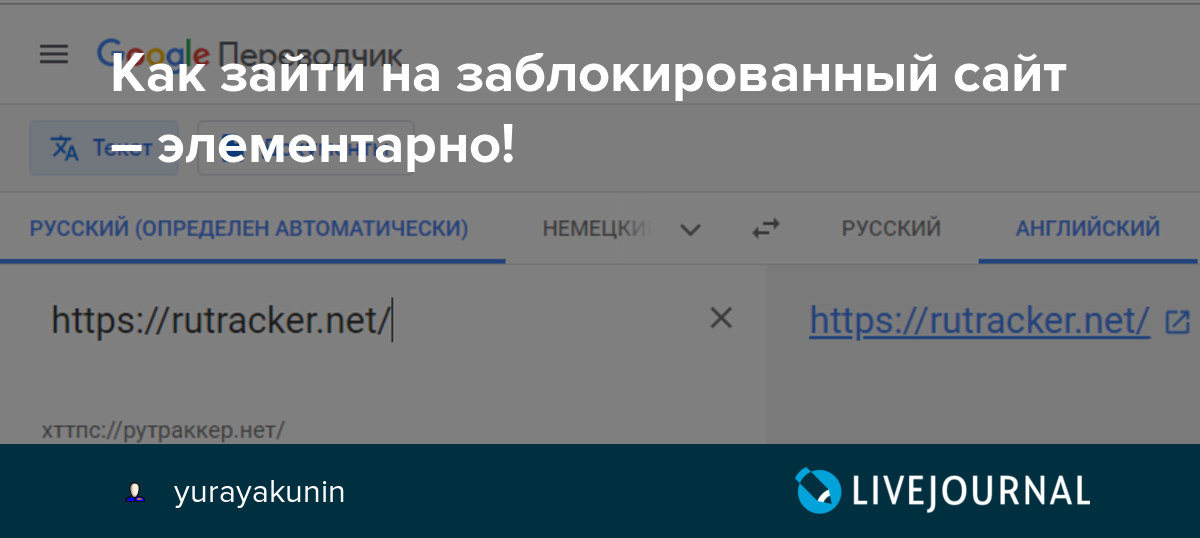
Приоритет: просмотр без рекламы
Если вы используете Защиту от угроз только потому, что хотите видеть меньше надоедливой рекламы и всплывающих окон, вам следует включить «Блокировщик рекламы» во время работы в Интернете. Это обеспечит более чистый пользовательский интерфейс на большинстве веб-сайтов и будет иметь дополнительный бонус в виде защиты от вредоносной рекламы (онлайн-рекламы, созданной для мошенничества и распространения вредоносных программ).
Хотя онлайн-реклама раздражает, заражение вашего устройства вредоносным ПО еще хуже, поэтому мы настоятельно рекомендуем вам воспользоваться другими функциями защиты от угроз, такими как «Блокировка вредоносных веб-сайтов».
Приоритет: более безопасная работа в сети
Наилучший вариант для большинства пользователей — использовать все функции защиты от угроз в сети. Полное включение Защиты от угроз еще больше повышает конфиденциальность и безопасность и обеспечивает наилучшие возможности работы в Интернете. Вы можете ограничить угрозу вредоносных программ, заблокировать раздражающую рекламу и защитить себя от агрессивных трекеров одним нажатием кнопки.
Вы можете ограничить угрозу вредоносных программ, заблокировать раздражающую рекламу и защитить себя от агрессивных трекеров одним нажатием кнопки.
Ложные срабатывания функции «Блокировать вредоносные веб-сайты» очень редки, но вы всегда можете отключить эту функцию в определенных случаях, когда точно знаете, что веб-сайт, к которому вы пытаетесь получить доступ, безопасен. Вы даже можете внести этот URL в белый список, не отключая полностью функцию блокировки.
Защита от угроз NordVPN — это мощный инструмент, повышающий безопасность и защищающий конфиденциальность. Получите его сегодня и просматривайте безопасно.
Интернет-безопасность начинается одним щелчком мыши.
Оставайтесь в безопасности с ведущим в мире VPN
Получите NordVPN
Узнайте больше
Парсинг веб-страниц в Python: избегайте обнаружения, как ниндзя
Парсинг должен извлекать контент из HTML. Звучит просто, но есть много препятствий.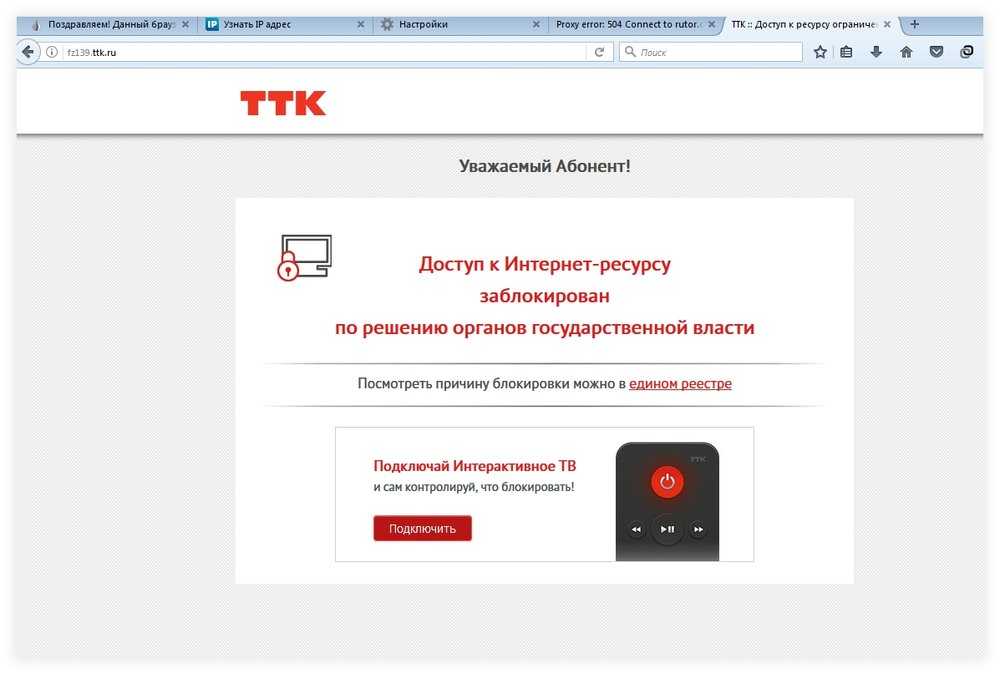 Первый — получить указанный HTML. Для этого мы будем использовать Python, чтобы избежать обнаружения .
Первый — получить указанный HTML. Для этого мы будем использовать Python, чтобы избежать обнаружения .
Если вы были там, то знаете, что это может потребовать обхода систем защиты от ботов. Веб-скрапинг без блокировки с помощью Python или любого другого инструмента — это не прогулка в парке.
Веб-сайты стремятся защитить свои данные и доступ. Существует много возможных действий, которые может предпринять защитная система. Оставайтесь с нами, чтобы узнать, как смягчить их воздействие. Или напрямую обойти обнаружение ботов с помощью Python Requests или Playwright .
Примечание. При масштабном тестировании никогда не используйте свой домашний IP-адрес напрямую. Небольшая ошибка или оплошность, и вы получите бан.
Предварительные требования
Чтобы код работал, вам необходимо установить python3. В некоторых системах он предустановлен. После этого установите все необходимые библиотеки, запустив pip install .
pip запрашивает установку драматурга npx playwright install
Скопировано!
Ограничение скорости IP-адреса
Наиболее простой системой безопасности является запрет или ограничение запросов с одного и того же IP-адреса. Это означает, что обычный пользователь не будет запрашивать сотню страниц за несколько секунд, поэтому он продолжает помечать это соединение как опасное.
запросы на импорт
ответ = запросы.получить('http://httpbin.org/ip')
печать (ответ.json () ['происхождение'])
# xyz.84.7.83 Скопировано!
Ограничения скорости IP работают аналогично ограничениям скорости API, но общедоступной информации о них обычно нет. Мы не можем знать наверняка, сколько запросов мы можем безопасно выполнить.
Наш интернет-провайдер присваивает нам наш IP-адрес, на который мы не можем повлиять или скрыть. Решение состоит в том, чтобы изменить его. Мы не можем изменить IP-адрес машины, но мы можем использовать разные машины. Центры обработки данных могут иметь разные IP-адреса, хотя это не является реальным решением.
Центры обработки данных могут иметь разные IP-адреса, хотя это не является реальным решением.
Прокси есть. Они принимают входящий запрос и передают его конечному получателю. Никакой обработки там нет. Но этого достаточно, чтобы замаскировать наш IP и обойти блокировку, так как целевой сайт увидит IP прокси.
Ротация прокси
Существуют бесплатные прокси, хотя мы их не рекомендуем. Они могут работать для тестирования, но ненадежны. Мы можем использовать некоторые из них для тестирования, как мы увидим в некоторых примерах.
Теперь у нас другой IP, и наше домашнее подключение в целости и сохранности. Хороший. Но что, если они заблокируют IP-адрес прокси? Мы вернулись в исходное положение.
Разочарованы тем, что ваши парсеры снова и снова блокируются?
API ZenRows обрабатывает для вас вращающиеся прокси-серверы и автономные браузеры.
Попробуйте БЕСПЛАТНО
Мы не будем подробно останавливаться на бесплатных прокси. Просто используйте следующий в списке. Часто меняйте их, так как срок их службы обычно невелик.
Просто используйте следующий в списке. Часто меняйте их, так как срок их службы обычно невелик.
Платные прокси-сервисы, с другой стороны, предлагают ротацию IP . Наш сервис будет работать так же, но сайт будет видеть другой IP. В некоторых случаях они ротация для каждого запроса или каждые несколько минут . В любом случае их гораздо сложнее запретить. И когда это произойдет, через короткое время мы получим новый IP.
запросов на импорт
прокси = {'http': 'http://190.64.18.177:80'}
ответ = запросы.получить('http://httpbin.org/ip', прокси=прокси)
print(response.json()['origin']) # 190.64.18.162 Скопировано!
Мы знаем о них; это означает, что службы обнаружения ботов также знают о них. Некоторые крупные компании блокируют трафик с известных IP-адресов прокси-серверов или центров обработки данных. Для этих случаев существует более высокий уровень прокси: Жилой .
Более дорогие и иногда ограниченные по пропускной способности, резидентные прокси предлагают нам IP-адреса, используемые обычными людьми. Это означает, что наш мобильный провайдер может назначить нам этот IP-адрес завтра. Или у друга вчера было. Они неотличимы от реальных конечных пользователей.
Это означает, что наш мобильный провайдер может назначить нам этот IP-адрес завтра. Или у друга вчера было. Они неотличимы от реальных конечных пользователей.
Мы можем очистить все, что захотим, верно? Самые дешевые по умолчанию, дорогие по необходимости. Нет, еще не там. Мы преодолели только первое препятствие, впереди еще несколько. Мы должны выглядеть как законные пользователи, чтобы нас не пометили как бот или парсер.
Следующим шагом будет проверка наших заголовков запроса . Самый известный из них — User-Agent (сокращенно UA), но их гораздо больше. UA следует формату, который мы увидим позже, и у многих программных инструментов есть свои собственные, например, у GoogleBot. Вот что получит целевой веб-сайт, если мы напрямую используем Python Requests или cURL.
запросов на импорт
ответ = запросы.получить('http://httpbin.org/headers')
print(response.json()['заголовки']['User-Agent'])
# python-запросы/2.25.1 Скопировано!
curl http://httpbin.
 org/headers # { ... "User-Agent": "curl/7.74.0" ... }
org/headers # { ... "User-Agent": "curl/7.74.0" ... } Скопировано!
Многие сайты не проверяют UA, но это огромный красный флаг для тех, кто это делает. Нам придется подделать его. К счастью, большинство библиотек допускают пользовательские заголовки. Следуя примеру с использованием запросов:
импортных запросов
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/88.0.4324.96 Safari/537.36"}
ответ = запросы.получить('http://httpbin.org/headers', заголовки=заголовки)
print(response.json()['headers']['User-Agent']) # Mozilla/5.0 ... Скопировано!
Чтобы получить текущий пользовательский агент, зайдите на httpbin — так же, как это делает фрагмент кода — и скопируйте его. Запрос всех URL-адресов с одним и тем же UA также может вызвать некоторые предупреждения , что немного усложняет решение.
В идеале у нас должны быть все текущие возможные пользовательские агенты, и мы должны чередовать их, как мы это делали с IP-адресами. Поскольку это почти невозможно, мы можем иметь хотя бы несколько. Есть списки пользовательских агентов, доступных для выбора.
Поскольку это почти невозможно, мы можем иметь хотя бы несколько. Есть списки пользовательских агентов, доступных для выбора.
запросы на импорт
импортировать случайный
пользовательские_агенты = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/92.0.4515.107 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/90.0.4430.212 Safari/537.36',
'Mozilla/5.0 (iPhone; ЦП iPhone OS 12_2, например Mac OS X) AppleWebKit/605.1.15 (KHTML, например Gecko) Mobile/15E148',
'Mozilla/5.0 (Linux; Android 11; SM-G960U) AppleWebKit/537.36 (KHTML, как Gecko) Chrome/89.0.4389.72 Mobile Safari/537,36'
]
user_agent = random.choice(user_agents)
заголовки = {'Агент пользователя': user_agent}
ответ = запросы.получить('https://httpbin.org/headers', заголовки=заголовки)
print(response.json()['заголовки']['User-Agent'])
# Mozilla/5. 0 (iPhone; процессор iPhone OS 12_2, как Mac OS X) ... 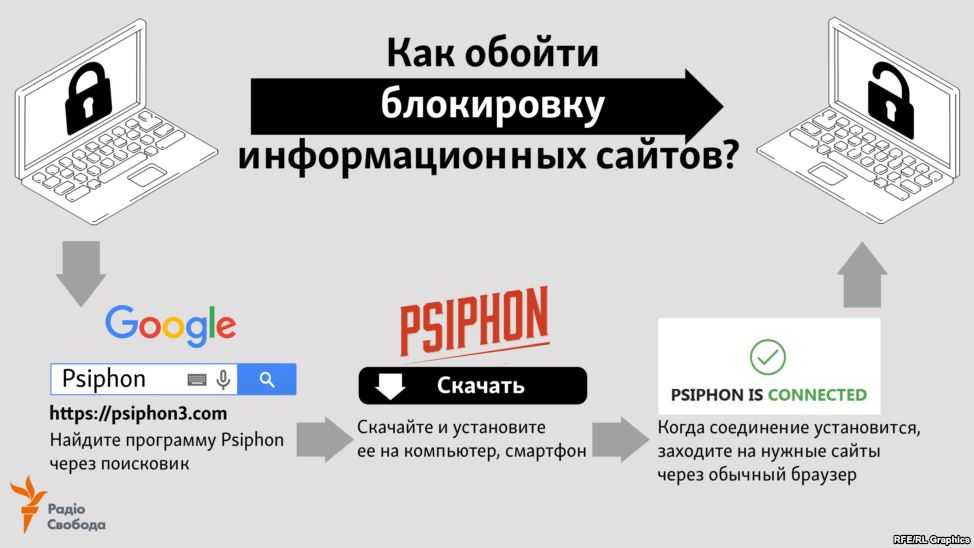 0 (iPhone; процессор iPhone OS 12_2, как Mac OS X) ...
0 (iPhone; процессор iPhone OS 12_2, как Mac OS X) ... Скопировано!
Имейте в виду, что браузеры довольно часто меняют версии, и этот список может устареть через несколько месяцев. Если мы собираемся использовать ротацию User-Agent, нам необходим надежный источник. Мы можем сделать это вручную или воспользоваться услугами поставщика услуг.
Мы на шаг ближе, но в заголовках все же есть один изъян: антибот-системы тоже знают этот трюк и проверяют другие заголовки вместе с User-Agent.
Каждый браузер или даже версия отправляет разные заголовки . Проверьте Chrome и Firefox в действии:
{
«Принять»: «text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v =b3;q=0,9",
"Accept-Encoding": "gzip, deflate, br",
«Принять язык»: «en-US, en; q = 0,9",
«Хост»: «httpbin.org»,
"Sec-Ch-Ua": "\"Chromium\";v=\"92\", \" Not A;Brand\";v=\"99\", \"Google Chrome\";v=\ "92\"",
"Сек-Ч-Уа-Мобайл": "?0",
"Sec-Fetch-Dest": "документ",
"Sec-Fetch-Mode": "навигация",
"Sec-Fetch-Site": "нет",
"Sec-Fetch-User": "?1",
«Обновление-небезопасные-запросы»: «1»,
«User-Agent»: «Mozilla/5. 0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/92.0.4515.107 Safari/537.36»
}  0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/92.0.4515.107 Safari/537.36»
}
0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/92.0.4515.107 Safari/537.36»
} Скопировано!
{
«Принять»: «текст/html, приложение/xhtml+xml, приложение/xml; q=0,9,изображение/webp,*/*;q=0,8",
"Accept-Encoding": "gzip, deflate, br",
«Принять язык»: «en-US, en; q = 0,5»,
«Хост»: «httpbin.org»,
"Sec-Fetch-Dest": "документ",
"Sec-Fetch-Mode": "навигация",
"Sec-Fetch-Site": "нет",
"Sec-Fetch-User": "?1",
«Обновление-небезопасные-запросы»: «1»,
«User-Agent»: «Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:90.0) Gecko/20100101 Firefox/90.0»
} Скопировано!
Это означает то, что вы думаете. Предыдущий массив с 5 пользовательскими агентами неполный. Нам нужен массив с полным набором заголовков для каждого User-Agent. Для краткости покажем список с одним пунктом. Это уже достаточно давно.
В этом случае недостаточно скопировать результат из httpbin. В идеале было бы скопировать его прямо из источника. Проще всего это сделать с помощью Firefox или Chrome DevTools или эквивалента в вашем браузере. Перейдите на вкладку «Сеть», посетите целевой веб-сайт, щелкните правой кнопкой мыши запрос и скопируйте его как cURL. Затем преобразуйте синтаксис curl в Python и вставьте заголовки в список.
Проще всего это сделать с помощью Firefox или Chrome DevTools или эквивалента в вашем браузере. Перейдите на вкладку «Сеть», посетите целевой веб-сайт, щелкните правой кнопкой мыши запрос и скопируйте его как cURL. Затем преобразуйте синтаксис curl в Python и вставьте заголовки в список.
запросов на импорт
импортировать случайный
список_заголовков = [{
«авторитет»: «httpbin.org»,
'управление кешем': 'max-age=0',
'сек-ч-уа': '"Хром";v="92", "Не бренд";v="99", "Google Chrome";v="92"',
'sec-ch-ua-mobile': '?0',
'небезопасные запросы на обновление': '1',
'агент пользователя': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/92.0.4515.107 Safari/537.36',
'принять': 'текст/html,приложение/xhtml+xml,приложение/xml;q=0.9,изображение/avif,изображение/webp,изображение/apng,*/*;q=0.8,приложение/signed-exchange;v =b3;q=0,9',
'sec-fetch-site': 'нет',
'sec-fetch-mode': 'навигация',
'sec-fetch-user': '?1',
'sec-fetch-dest': 'документ',
'принять-язык': 'en-US,en;q=0. 9',
} # , {...}
]
заголовки = random.choice(headers_list)
ответ = запросы.получить('https://httpbin.org/headers', заголовки=заголовки)
print(response.json()['headers']) 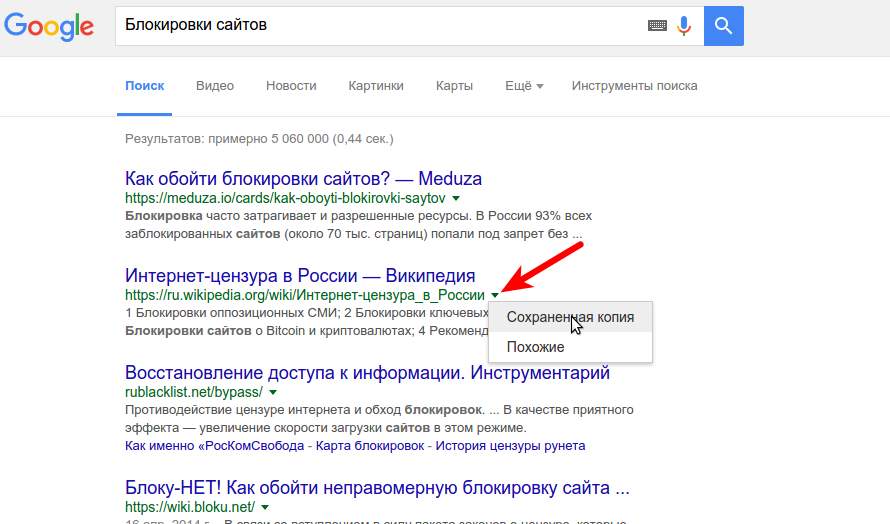 9',
} # , {...}
]
заголовки = random.choice(headers_list)
ответ = запросы.получить('https://httpbin.org/headers', заголовки=заголовки)
print(response.json()['headers'])
9',
} # , {...}
]
заголовки = random.choice(headers_list)
ответ = запросы.получить('https://httpbin.org/headers', заголовки=заголовки)
print(response.json()['headers']) Скопировано!
Мы могли бы добавить заголовок Referer для дополнительной безопасности — например, Google или внутреннюю страницу того же веб-сайта. Это маскировало бы тот факт, что мы всегда запрашиваем URL-адреса напрямую, без взаимодействия. Но будьте осторожны, так как добавление реферера изменит больше заголовков. Вы не хотите, чтобы ваш скрипт запроса Python был заблокирован такими ошибками.
Файлы cookie
Мы проигнорировали указанные выше файлы cookie, поскольку они заслуживают отдельного раздела. Файлы cookie могут помочь вам обойти некоторые антиботы или заблокировать ваши запросы . Они являются мощным инструментом, который нам нужно правильно понять.
Файлы cookie могут отслеживать сеанс пользователя и запоминать этого пользователя после входа в систему , например. Веб-сайты назначают каждому новому пользователю сеанс cookie. Есть много способов сделать это, но мы постараемся упростить. Затем браузер пользователя будет отправлять этот файл cookie в каждом запросе, отслеживая активность пользователя.
Веб-сайты назначают каждому новому пользователю сеанс cookie. Есть много способов сделать это, но мы постараемся упростить. Затем браузер пользователя будет отправлять этот файл cookie в каждом запросе, отслеживая активность пользователя.
В чем проблема? Мы используем чередующиеся прокси, поэтому каждый запрос может иметь разные IP-адреса из разных регионов или стран. Антиботы могут увидеть этот шаблон и заблокировать его, так как это не естественный способ просмотра для пользователей.
С другой стороны, после обхода решения для защиты от ботов оно будет отправлять ценные файлы cookie. Защитные системы не будут проверять дважды, если сессия выглядит законной. Узнайте, как обойти Cloudflare для получения дополнительной информации.
Помогут ли файлы cookie нашим сценариям Python Requests избежать обнаружения ботов? Или они причинят нам вред и заблокируют нас? Ответ кроется в нашей реализации.
В простых случаях лучше всего не отправлять файлы cookie. Сеанс поддерживать не нужно.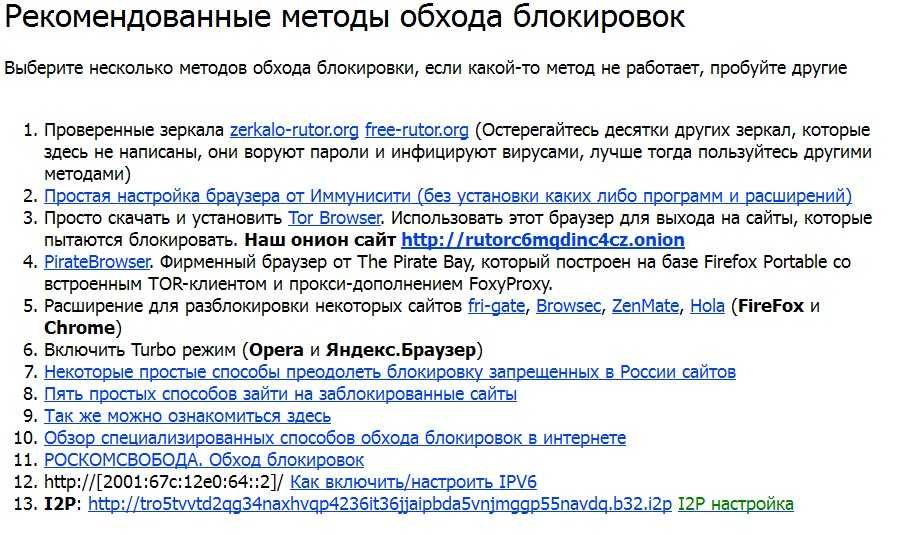
Для более сложных случаев и программного обеспечения для защиты от ботов сеансовые файлы cookie могут быть единственным способом получить и очистить окончательный контент. Всегда принимая во внимание, что запросы сеанса и IP должны совпадать.
То же самое происходит, если мы хотим, чтобы контент генерировался в браузере после вызовов XHR. Нам нужно будет использовать безголовый браузер. После первоначальной загрузки Javascript попытается получить некоторый контент с помощью вызова XHR. Мы не можем сделать этот вызов без файлов cookie на защищенном сайте.
Как мы будем использовать безголовые браузеры, в частности Playwright, чтобы избежать обнаружения? Продолжайте читать!
Безголовые браузеры
Некоторые системы защиты от ботов будут отображать содержимое только после того, как браузер решит вызов Javascript. И мы не можем использовать запросы Python для имитации подобного поведения браузера. Нам нужен браузер с выполнением Javascript, чтобы запустить и пройти вызов.
Наиболее часто используемыми и известными библиотеками являются Selenium, Puppeteer и Playwright. Избегать их — из соображений производительности — было бы предпочтительнее, и они сделают очистку медленнее. Но иногда альтернативы нет.
Посмотрим, как запустить Драматурга. Фрагмент ниже показывает простой скрипт, посещающий страницу, который печатает отправленные заголовки. Вывод показывает только User-Agent, но, поскольку это настоящий браузер, заголовки будут включать весь набор (Accept, Accept-Encoding и т. д.).
импорт json
из playwright.sync_api импортировать sync_playwright
с sync_playwright() как p:
для browser_type в [p.chromium, p.firefox, p.webkit]:
браузер = тип_браузера.запуск()
страница = браузер.new_page()
page.goto('https://httpbin.org/headers')
jsonContent = json.loads(page.inner_text('pre'))
print(jsonContent['заголовки']['User-Agent'])
браузер.закрыть()
# Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, как Gecko) HeadlessChrome/93. 0.4576.0 Сафари/537.36
# Mozilla/5.0 (X11; Linux x86_64; rv:90.0) Gecko/20100101 Firefox/90.0
# Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, как Gecko) Version/15.0 Safari/605.1.15  0.4576.0 Сафари/537.36
# Mozilla/5.0 (X11; Linux x86_64; rv:90.0) Gecko/20100101 Firefox/90.0
# Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, как Gecko) Version/15.0 Safari/605.1.15
0.4576.0 Сафари/537.36
# Mozilla/5.0 (X11; Linux x86_64; rv:90.0) Gecko/20100101 Firefox/90.0
# Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, как Gecko) Version/15.0 Safari/605.1.15 Скопировано!
У этого подхода есть своя проблема: взгляните на пользовательские агенты. Chromium включает HeadlessChrome , который сообщит целевому веб-сайту, что это безголовый браузер. Они могут действовать в соответствии с этим.
Вернемся к разделу заголовков: мы можем добавить собственные заголовки, которые перезапишут заголовки по умолчанию. Замените строку в предыдущем фрагменте на эту и вставьте действительный User-Agent:
browser.new_page(extra_http_headers={'User-Agent': '...'}) Скопировано!
Это просто начальный уровень с безголовыми браузерами. Безголовое обнаружение — это самостоятельная область, и многие люди работают над ней. Некоторые, чтобы обнаружить это, некоторые, чтобы избежать блокировки. Например, вы можете посетить pixelcan с реальным браузером и безголовым. Чтобы считаться «последовательным», вам нужно много работать.
Например, вы можете посетить pixelcan с реальным браузером и безголовым. Чтобы считаться «последовательным», вам нужно много работать.
Посмотрите на снимок экрана ниже, сделанный при посещении пиксельного сканера с Playwright. Видишь УА? С тем, что мы подделываем, все в порядке, но они могут определить, что мы лжем, проверив Javascript API навигатора.
Мы можем передать user_agent , и драматург установит для нас пользовательский агент в javascript и заголовок. Хороший!
page = browser.new_page(user_agent='...')
Скопировано!
В более сложных случаях вы можете легко добавить скрытность Драматурга в свои сценарии и усложнить обнаружение. Помимо прочего, он обрабатывает несоответствия между заголовками и API-интерфейсами Javascript браузера.
Таким образом, обеспечить 100% покрытие сложно, но в большинстве случаев оно вам не понадобится. Сайты всегда могут выполнять более сложные проверки: WebGL, сенсорные события или состояние батареи.
Вам не понадобятся эти дополнительные функции, если только вы не пытаетесь очистить веб-сайт, требующий обхода решения для защиты от ботов, такого как Akamai. И для этих случаев эти дополнительные усилия будут обязательными. И требовательный, если честно.
Географические ограничения или геоблокировка
Пробовали ли вы когда-нибудь смотреть CNN за пределами США?
Это называется геоблокировка. Только связи внутри США могут смотреть CNN в прямом эфире. Чтобы обойти это, мы могли бы использовать виртуальную частную сеть (VPN). Затем мы можем просматривать как обычно, но веб-сайт будет видеть локальный IP-адрес благодаря VPN.
То же самое может произойти при парсинге сайтов с геоблокировкой. Для прокси есть аналог: геолоцированных прокси . Некоторые провайдеры прокси позволяют нам выбирать из списка стран. С этой активацией мы будем получать только локальные IP-адреса, например, из США.
Шаблоны поведения
В наши дни блокировки IP-адресов и пользовательских агентов недостаточно. Они становятся неуправляемыми и несвежими за часы, если не за минуты. Пока мы выполняем запросы с чистыми IP-адресами и реальными пользовательскими агентами, мы в основном в безопасности. Здесь задействовано больше факторов, но большинство запросов должны быть действительными.
Они становятся неуправляемыми и несвежими за часы, если не за минуты. Пока мы выполняем запросы с чистыми IP-адресами и реальными пользовательскими агентами, мы в основном в безопасности. Здесь задействовано больше факторов, но большинство запросов должны быть действительными.
Однако большинство современных программ для защиты от ботов используют машинное обучение и модели поведения, а не только статические маркеры (IP, UA, геолокацию). Это означает, что нас бы обнаружили, если бы мы всегда выполняли одни и те же действия в одном и том же порядке .
- Перейти на главную страницу
- Нажмите кнопку «Магазин»
- Прокрутите вниз
- Перейти на страницу 2
- …
Через несколько дней запуск одного и того же скрипта мог привести к блокировке всех запросов . Многие люди могут выполнять одни и те же действия, но у ботов есть кое-что, что делает их очевидными: скорость. С программным обеспечением мы будем выполнять каждый шаг последовательно, в то время как фактический пользователь займет секунду, затем щелкнет, медленно прокрутит вниз с помощью колесика мыши, переместит мышь на ссылку и щелкнет.
С программным обеспечением мы будем выполнять каждый шаг последовательно, в то время как фактический пользователь займет секунду, затем щелкнет, медленно прокрутит вниз с помощью колесика мыши, переместит мышь на ссылку и щелкнет.
Может, и не нужно все это притворяться, но знайте о возможных проблемах и знайте, как с ними справляться.
Мы должны думать, чего мы хотим. Возможно, нам не нужен этот первый запрос, так как нам нужна только вторая страница. Мы могли бы использовать это как точку входа, а не домашнюю страницу. И сохраните один запрос. Он может масштабироваться до сотен URL-адресов на домен. Не нужно посещать каждую страницу по порядку, прокручивать вниз, нажимать на следующую страницу и начинать заново.
Чтобы очистить результаты поиска, как только мы распознаем шаблон URL для разбиения на страницы, нам нужны только две точки данных: количество элементов и элементов на странице. И в большинстве случаев эта информация присутствует на первой странице или запросе.
запросы на импорт
из bs4 импортировать BeautifulSoup
ответ = запросы.получить('https://scrapeme.live/shop/')
суп = BeautifulSoup(response.content, 'html.parser')
страницы = суп.выбрать('.woocommerce-pagination a.page-numbers:not(.next)')
print(pages[0].get('href')) # https://scrapeme.live/shop/page/2/
print(pages[-1].get('href')) # https://scrapeme.live/shop/page/48/ Скопировано!
Один запрос показывает нам, что есть 48 страниц. Теперь мы можем поставить их в очередь. Смешивая с другими методами, мы собирали контент с этой страницы и добавляли оставшиеся 47. Чтобы очистить их в обход систем защиты от ботов, мы могли бы:
- Перетасуйте порядок страниц, чтобы избежать обнаружения шаблонов
- Используйте разные IP-адреса и User-Agent, чтобы каждый запрос выглядел как новый
- Добавьте задержки между некоторыми вызовами можно было бы написать какой-нибудь фрагмент, смешав все это, но в реальной жизни лучший вариант — использовать инструмент со всем этим, например, Scrapy, pyspider, node-crawler (Node. js) или Colly (Go). Идея фрагментов состоит в том, чтобы понять каждую проблему отдельно. Но для масштабных реальных проектов справиться со всем самостоятельно было бы слишком сложно.
Капча
Даже самый хорошо подготовленный запрос может быть пойман и показан капча. В настоящее время разгадывание капчи достижимо — Anti-Captcha и 2Captcha — но пустая трата времени и денег. Лучшее решение — избегать их . Второй вариант — забыть об этом запросе и повторить попытку.
Исключение очевидно: сайты, которые всегда показывают капчу при первом посещении. Мы должны решить это, если нет способа обойти это. А затем использовать файлы cookie сеанса, чтобы избежать повторного вызова .
Это может показаться нелогичным, но подождать секунду и повторить тот же запрос с другим IP и набором заголовков будет быстрее, чем разгадывать капчу. Попробуйте сами и расскажите о своих впечатлениях 😉.
Будьте хорошим гражданином Интернета
Мы можем использовать несколько веб-сайтов для тестирования, но будьте осторожны, делая то же самое в больших масштабах.
Старайтесь быть хорошим интернет-гражданином и не создавайте небольшие DDoS-атаки. Ограничьте количество взаимодействий для каждого домена. Amazon может обрабатывать тысячи запросов в секунду. Но не все целевые сайты будут.Мы всегда говорим о режиме просмотра «только для чтения». Откройте страницу и прочитайте ее содержимое. Никогда не отправляйте форму и не выполняйте активные действия со злым умыслом.
Если мы выберем более активный подход, несколько других факторов будут иметь значение: скорость письма, движение мыши, навигация без щелчков, одновременный просмотр многих страниц и так далее. Программное обеспечение для предотвращения ботов особенно агрессивно с активными действиями. Как и положено из соображений безопасности.
Мы не будем обсуждать эту часть, но эти действия дадут им новые причины блокировать запросы. Опять же, добропорядочные граждане не пробуют массовые входы в систему. Мы говорим о парсинге, а не о вредоносных действиях.
Иногда веб-сайты усложняют сбор данных, возможно, не специально.
Но с современными интерфейсными инструментами классы CSS могут меняться ежедневно, разрушая тщательно подготовленные сценарии. Для получения дополнительной информации прочитайте нашу предыдущую запись о том, как очищать данные в Python.Заключение
Хотим, чтобы вы помнили о непростых вещах:
- IP ротационные прокси
- Резидентные прокси для сложных целей
- Полный набор заголовков, включая User-Agent
- Обход обнаружения ботов с помощью Playwright, когда требуется вызов Javascript — возможно, добавление скрытого модуля
- Избегайте шаблонов, которые могут пометить вас как бота
Есть много других, и, вероятно, больше мы не рассмотрели. Но с помощью этих методов вы должны иметь возможность сканировать и очищать в масштабе. В конце концов, веб-скрапинг без блокировки с помощью Python возможен, если вы знаете, как это сделать.
Свяжитесь с нами, если вы знаете больше приемов парсинга веб-сайтов или сомневаетесь в их применении.
 js) или Colly (Go). Идея фрагментов состоит в том, чтобы понять каждую проблему отдельно. Но для масштабных реальных проектов справиться со всем самостоятельно было бы слишком сложно.
js) или Colly (Go). Идея фрагментов состоит в том, чтобы понять каждую проблему отдельно. Но для масштабных реальных проектов справиться со всем самостоятельно было бы слишком сложно. Старайтесь быть хорошим интернет-гражданином и не создавайте небольшие DDoS-атаки. Ограничьте количество взаимодействий для каждого домена. Amazon может обрабатывать тысячи запросов в секунду. Но не все целевые сайты будут.
Старайтесь быть хорошим интернет-гражданином и не создавайте небольшие DDoS-атаки. Ограничьте количество взаимодействий для каждого домена. Amazon может обрабатывать тысячи запросов в секунду. Но не все целевые сайты будут. Но с современными интерфейсными инструментами классы CSS могут меняться ежедневно, разрушая тщательно подготовленные сценарии. Для получения дополнительной информации прочитайте нашу предыдущую запись о том, как очищать данные в Python.
Но с современными интерфейсными инструментами классы CSS могут меняться ежедневно, разрушая тщательно подготовленные сценарии. Для получения дополнительной информации прочитайте нашу предыдущую запись о том, как очищать данные в Python.
Ваш комментарий будет первым