Как извлечь графику из PDF? 2 простых способа
Знаете ли вы, что для извлечения графики из PDF все, что вам нужно, — это правильный инструмент для работы с PDF? С помощью правильного программного обеспечения для работы с PDF можно легко извлекать векторную графику из PDF-документов, оставляя исходный документ нетронутым. В этой статье мы расскажем вам, как использовать PDFelement для извлечения графики из PDF и выполнения многих других важных задач, которые сделают вас более продуктивным и эффективным на вашем рабочем месте. Процесс извлечения векторной графики из PDF освещается с помощью универсального инструмента под названием Wondershare PDFelement — Редактор PDF-файлов.
Скачать Бесплатно Скачать Бесплатно КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
Первый способ извлечения графики из PDF
Первый способ демонстрирует действие правой кнопки мыши для извлечения графического элемента из PDF, например, изображения. Шаги ниже подробно описывают этот процесс:
Шаг 1.
 Включите режим редактирования
Включите режим редактированияПосле открытия PDF-документа с помощью PDFelement, нажмите на опцию «Редактировать» в верхнем меню, а затем нажмите на значок «Правка» в правом верхнем подменю. Это приведет вас в режим редактирования, в котором вы можете извлекать графику из PDF.
Шаг 2. Выберите графику
Следующим шагом выберите графику, которую нужно извлечь, и щелкните по ней правой кнопкой мыши. В контекстном меню выберите опцию «Извлечь изображение».
Шаг 3. Извлеките графику из PDF
На последнем шаге выберите формат, в котором вы хотите извлечь изображение, и выберите местоположение выходной папки. Нажмите кнопку «Сохранить», и все готово.
Скачать Бесплатно Скачать Бесплатно КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
Второй способ извлечения графики из PDF
Этот подход использует функцию пакетного извлечения, чтобы получить все изображения в PDF-файле и извлечь их в отдельные файлы, как коллекцию изображений в PDF-файле или каждую страницу как отдельный файл изображения. Выбор за вами. Теперь о шагах процесса:
Выбор за вами. Теперь о шагах процесса:
Шаг 1: Щелкните опцию «В изображение»
Открыв PDF-файл в приложении, нажмите на опцию «В изображение» на вкладке «Конвертировать» вверху.
Шаг 2: Выберите выходной формат
На этом шаге вы можете выбрать целевой формат или формат вывода для извлеченной графики. Вы также можете переименовать файл.
Шаг 3: Извлеките все графические изображения
Скачать Бесплатно Скачать Бесплатно КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
Как видите, PDFelement достаточно гибок, чтобы предложить вам различные способы извлечения векторной графики из PDF-документов. Это особенно полезно, если вам не нужен текст или любое другое содержимое, а также если они нужны в виде файлов изображений для редактирования и других целей. Помимо извлечения изображений, программа также предлагает такие универсальные возможности:
Помимо извлечения изображений, программа также предлагает такие универсальные возможности:
1. Полный контроль над редактированием PDF
2. Простое преобразование других форматов в PDF
3. Точное преобразование PDF в другие форматы
4. Удобные инструменты навигации
5. Расширенные инструменты аннотирования и комментирования
6. Оптимизация размера файла
7. Шифрование файлов с помощью паролей для доступа и разрешения на изменение
8. Заполнение форм, создание форм и преобразование форм
9. Усовершенствованное распознавание текста (OCR) на более чем 20 языках
10. Пакетная обработка нескольких ключевых задач PDF, таких как извлечение данных, шифрование файлов, OCR и т.д.
11. Организация PDF-файлов путем слияния или разделения файлов, добавления или удаления страниц, изменения порядка, обрезки, поворота и т.д.
12. Обмен в облаке или по электронной почте из приложения.
13. Полный контроль над функциями печати
PDFelement — это не только надежный PDF-редактор с многофункциональной средой, но и средство управления другими документооборотами, которое поможет вам оцифровать весь офис.
Скачать Бесплатно Скачать Бесплатно КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
Как извлечь изображения из PDF на Mac
Margarete Cotty
2021-03-26 14:14:43 • Опубликовано : Советы по работе в PDFelement для Mac • Проверенные решения
Представьте, что вы получили электронное письмо с PDF-файлом, содержащим множество нужных вам изображений. Возможно, вы захотите сохранить эти изображения в виде отдельного файла JPEG. Итак, как вы можете извлечь изображения из PDF на Mac? Есть несколько доступных вариантов, и один из них-извлечь изображения из PDF-файла в JPEG-файл с помощью — PDFelement.
СКАЧАТЬ БЕСПЛАТНОСКАЧАТЬ БЕСПЛАТНО
СКАЧАТЬ БЕСПЛАТНО
Теперь, когда мы знаем, что извлечение изображений из PDF на Mac возможно благодаря программе PDFelement, давайте посмотрим, как именно получать изображения.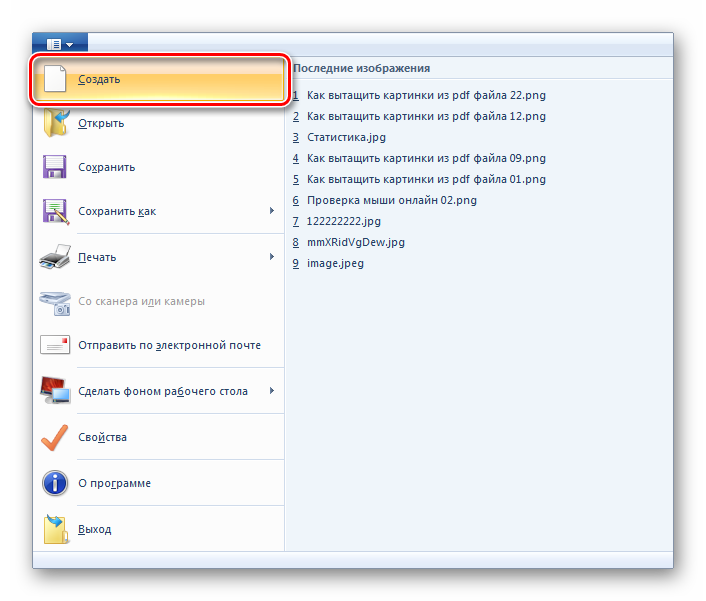 Как уже упоминалось выше, весь процесс довольно прост, даже для начинающих. В течение нескольких минут вы можете извлечь и сохранить изображение для дальнейшего использования. Вот шаги, которые вам нужно выполнить, чтобы сделать это:
Как уже упоминалось выше, весь процесс довольно прост, даже для начинающих. В течение нескольких минут вы можете извлечь и сохранить изображение для дальнейшего использования. Вот шаги, которые вам нужно выполнить, чтобы сделать это:
Шаг 1: Перейдите в режим редактирования
Откройте PDF-документ, из которого вы хотите извлечь изображение. Нажмите на вкладку «Изображение», чтобы перейти в режим редактирования.
Шаг 2: Выберите Изображения для Извлечения
Просмотрите документ, чтобы найти изображение/фотографию, которую вы хотите сохранить. Нажмите на изображение. Затем выберите опцию «Извлечь».
Шаг 3: Извлечение Изображений из PDF на Mac
Нажмите на кнопку «Извлечь», и появится всплывающее окно. Введите имя для изображения и выберите место для его сохранения. Наконец, нажмите на кнопку «Сохранить».
PDFelement успешно сохранит изображение в нужное вам место. Теперь вы можете открыть изображение и использовать его так, как вам захочется.
Все, что вам нужно, — это качественное программное обеспечение для работы с PDF, которое имеет множество функций, одной из которых является извлечение изображений и фотографий из PDF-документов.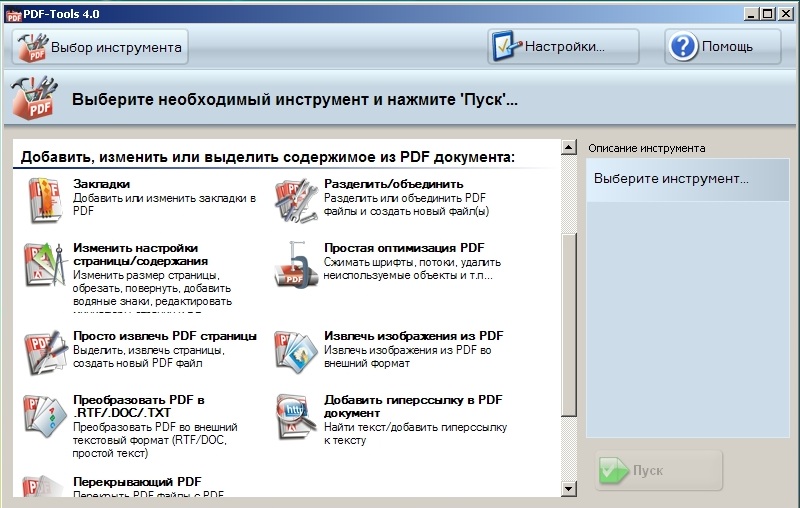
- Извлекает изображения из PDF-файла. Кроме того, позволяет добавлять изображения, копировать, вставлять и заменять изображения, поворачивать и обрезать изображения.
- Позволяет редактировать страницы с помощью таких функций, как обрезка, разделение, замена, вставка и многих других. Вы также можете добавить поля страниц и метки страниц.
- Позволяет использовать как обычные, так и расширенные функции редактирования текста, такие как интуитивно понятный абзацы, однострочный режим редактирования и т.д.
- Вы можете создавать профессиональные PDF-документы в течение нескольких минут. Также вы можете добавлять комментарии, текстовые поля, печати, стикеры и многое другое.

- Вы можете создавать персонализированные PDF-формы с помощью расширенных функций заполнения и создания форм.

СКАЧАТЬ БЕСПЛАТНОСКАЧАТЬ БЕСПЛАТНО
СКАЧАТЬ БЕСПЛАТНО
Скачать Бесплатно или Купить PDFelement прямо сейчас!
Скачать Бесплатно или Купить PDFelement прямо сейчас!
Купить PDFelement прямо сейчас!
Купить PDFelement прямо сейчас!
Извлечение изображений из PDF с помощью Python
В этом уроке мы рассмотрим, как извлекать изображения из файлов PDF с помощью Python.
Содержание
- Введение
- Образец PDF-файла
- Извлечение изображений из PDF с помощью Python
- Полный код
- Заключение
 youtube.com/embed/GkCd1TvvE68?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share» allowfullscreen=»»>
youtube.com/embed/GkCd1TvvE68?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share» allowfullscreen=»»> Введение
Извлечение изображений из файлов PDF — очень распространенная задача, которая часто выполняется при работе с различными отчетами.
Это утомительная задача, если вы делаете это вручную для каждого файла, используя доступное программное обеспечение и онлайн-инструменты.
В этом уроке мы рассмотрим, как извлекать изображения из файлов PDF с помощью Python.
Чтобы продолжить следовать этому руководству, нам потребуются следующие библиотеки Python:
Если они у вас не установлены, откройте «Командную строку» (в Windows) и установите их, используя следующий код:
pip установить PyMuPDF pip установить подушку
Образец файла PDF
Вот файл PDF, который мы будем использовать в этом руководстве:
sample_fileСкачать
Этот файл PDF будет находиться в той же папке, что и файл main. py с нашим кодом.
py с нашим кодом.
Нам также потребуется создать пустую папку images для сохранения извлеченных изображений, поэтому структура каталогов проекта должна выглядеть так:
Начнем с импорта необходимых зависимостей:
#Импорт необходимых зависимостей импортировать фитц импорт ОС из изображения импорта PIL
Укажите путь к файлу PDF:
#Определяем путь к файлу PDF file_path = 'sample_file.pdf'
Откройте файл с помощью модуля fitz и извлеките всю информацию об изображениях:
#Открыть файл PDF
pdf_file = fitz.open(file_path)
# Подсчитать количество страниц в файле PDF
page_nums = длина (pdf_файл)
#Создать пустой список для хранения информации об изображениях
images_list = []
# Извлечь всю информацию об изображениях с каждой страницы
для page_num в диапазоне (page_nums):
page_content = pdf_file [номер_страницы]
images_list.extend(page_content.get_images())
Теперь давайте посмотрим на информацию об изображениях, которую мы извлекли:
печать (список_изображений)
И вы должны получить:
[(9, 0, 640, 491, 8, 'DeviceRGB', '', 'Image9', 'DCTDecode'), (10, 0, 640, 427, 8, 'DeviceRGB', '', 'Image10', 'DCTDecode'), (13, 0, 640, 427, 8, 'DeviceRGB', '', 'Image13', 'DCTDecode')]
, где каждый кортеж представляет следующее:
(внешняя ссылка, smask, ширина, высота, bpc, цветовое пространство , альтернативное цветовое пространство, имя, фильтр)
Теперь давайте добавим код обработки ошибок, если в файле PDF, с которым мы работаем, нет изображений:
# Выдавать ошибку, если в PDF нет изображений
если len(images_list)==0:
поднять ValueError (f 'Нет изображений в {file_path}')
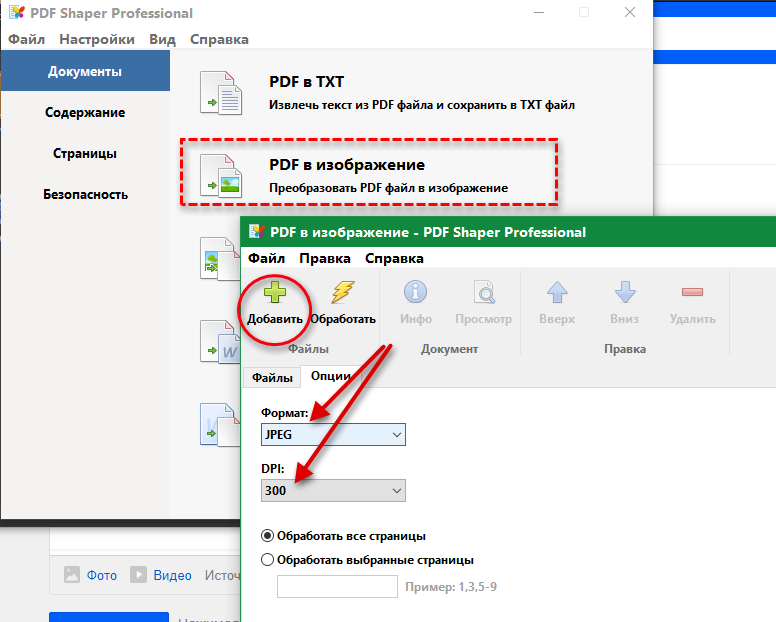
После того, как мы извлекли информацию об изображениях из файла PDF, мы можем извлечь фактические изображения и сохранить их на компьютере:
# Сохраняем все извлеченные изображения
для i изображение в перечислении (images_list, start = 1):
# Извлечь номер объекта изображения
Внешняя ссылка = изображение [0]
#Извлечь изображение
base_image = pdf_file. extract_image(внешняя ссылка)
# Хранить байты изображения
image_bytes = базовое_изображение['изображение']
#Сохранить расширение изображения
image_ext = базовое_изображение['ext']
#Сгенерировать имя файла изображения
image_name = str(i) + '.' + image_ext
#Сохранить изображение
с open(os.path.join(images_path, image_name) , 'wb') as image_file:
image_file.write(image_bytes)
image_file.close()
 extract_image(внешняя ссылка)
# Хранить байты изображения
image_bytes = базовое_изображение['изображение']
#Сохранить расширение изображения
image_ext = базовое_изображение['ext']
#Сгенерировать имя файла изображения
image_name = str(i) + '.' + image_ext
#Сохранить изображение
с open(os.path.join(images_path, image_name) , 'wb') as image_file:
image_file.write(image_bytes)
image_file.close()
extract_image(внешняя ссылка)
# Хранить байты изображения
image_bytes = базовое_изображение['изображение']
#Сохранить расширение изображения
image_ext = базовое_изображение['ext']
#Сгенерировать имя файла изображения
image_name = str(i) + '.' + image_ext
#Сохранить изображение
с open(os.path.join(images_path, image_name) , 'wb') as image_file:
image_file.write(image_bytes)
image_file.close()
После запуска кода вы должны увидеть извлеченные изображения в папке images :
Полный код
#Импорт необходимых зависимостей
импортировать фитц
импорт ОС
из изображения импорта PIL
#Определяем путь к файлу PDF
file_path = 'sample_file.pdf'
#Определить путь для сохраненных изображений
images_path = 'изображения/'
#Открыть файл PDF
pdf_file = fitz.open(file_path)
#Получить количество страниц в файле PDF
page_nums = длина (pdf_файл)
#Создать пустой список для хранения информации об изображениях
images_list = []
# Извлечь всю информацию об изображениях с каждой страницы
для page_num в диапазоне (page_nums):
page_content = pdf_file [номер_страницы]
images_list. extend(page_content.get_images())
# Выдавать ошибку, если в PDF нет изображений
если len(images_list)==0:
поднять ValueError (f 'Нет изображений в {file_path}')
# Сохраняем все извлеченные изображения
для i img в перечислении (images_list, start = 1):
# Извлечь номер объекта изображения
внешняя ссылка = изображение [0]
#Извлечь изображение
base_image = pdf_file.extract_image(внешняя ссылка)
# Хранить байты изображения
image_bytes = базовое_изображение['изображение']
#Сохранить расширение изображения
image_ext = базовое_изображение['ext']
#Сгенерировать имя файла изображения
image_name = str(i) + '.' + image_ext
#Сохранить изображение
с open(os.path.join(images_path, image_name) , 'wb') as image_file:
image_file.write(image_bytes)
image_file.close()

Заключение
В этой статье мы рассмотрели, как извлекать изображения из файлов PDF с помощью Python и PyMuPDF.
Не стесняйтесь оставлять комментарии ниже, если у вас есть какие-либо вопросы или предложения по некоторым изменениям, и ознакомьтесь с другими моими руководствами по программированию на Python.
Как извлечь изображение из PDF на Mac (включая ОС Big Sur)
Вопрос от читателя:
Я получил документ в формате PDF по электронной почте. Он содержит много красивых фотографий, которые я хотел бы сохранить. Есть ли способ сохранить все изображения сразу, а не по одному?
Это распространенная проблема, с которой сталкиваются многие люди при работе с PDF-файлами, полученными по электронной почте или загруженными из Интернета. К счастью, есть несколько хороших решений этой проблемы. Давайте рассмотрим 2 простых способа извлечения изображений из PDF на Mac.
1. Извлечение изображения из PDF на Mac с помощью PDF-редактора
Cisdem PDFMaster — универсальный инструмент PDF для просмотра, создания, редактирования, аннотирования, выделения, защиты и разблокировки, разделения и объединения, сжатия и даже для преобразования исходного файла в редактируемый форматы, он также поддерживает извлечение изображения из PDF на Mac. Это не повредит разрешению изображения.
Это не повредит разрешению изображения.
Основные функции Cisdem PDFMaster
- Базовые функции редактирования PDF: обрезка, аннотирование, добавление текста/формы, комментарий, выделение, подчеркивание и т. д.;
- Преобразование исходного PDF в 13 форматов: Word, PowerPoint, Keynote, Pages, ePub, изображения и т. д.;
- Создание PDF из Word, PowerPoint, ePub, CHM, HTML, изображения и т. д.;
- Объединение и разделение страниц PDF;
- Сжать PDF;
- Шифровать и расшифровывать PDF;
- Извлечь изображение из PDF;
Как извлечь изображение из PDF на Mac?
- Шаг 1: Загрузите и установите Cisdem PDFMaster на свой Mac;
Скачать бесплатно - Шаг 2: Запустите программу и нажмите PDF Convert;
- Шаг 3: Затем перетащите файл PDF, из которого вы хотите извлечь изображение;
- Шаг 4: Выберите «Извлечь изображение» и выберите формат изображения, которое вы хотите извлечь из PDF-файла;
- Шаг 5: Нажмите «Преобразовать», чтобы начать извлечение изображений из PDF на Mac;
2.
 Извлечение изображения из PDF на Mac Online
Извлечение изображения из PDF на Mac OnlineЕсли вам нужно извлечь изображение только из небольшого PDF-файла или оно вам нужно только на какое-то время, лучшим бесплатным вариантом является использование онлайн-сервиса преобразования. С помощью этих услуг вы загружаете файл PDF, а затем загружаете извлеченный файл изображения.
ИзвлечьPDF | С помощью этого бесплатного онлайн-инструмента вы можете извлекать изображения, текст или шрифты из файла PDF. Нет необходимости в установке или регистрации. вы также можете указать URL-адрес PDF-файлов. Максимальный размер файла составляет 10 МБ.
Smallpdf | Конвертируйте PDF в JPG онлайн. После преобразования изображения представляются вам в виде загружаемых отдельных файлов изображений. Вы также можете загрузить все изображения одним пакетом в виде zip-файла.
Примечание: Обратите внимание, что, загружая PDF-файл в Интернет, вы должны согласиться с некоторыми условиями, которые полностью перечислены на этих веб-сайтах.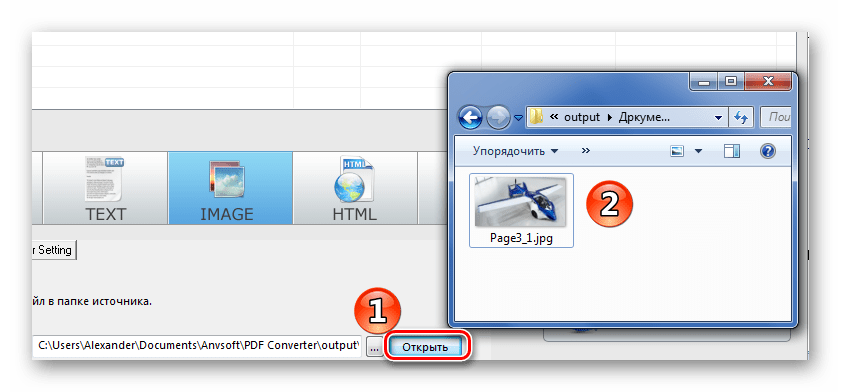 Поэтому не загружайте для обработки большие или строго конфиденциальные PDF-файлы.
Поэтому не загружайте для обработки большие или строго конфиденциальные PDF-файлы.
3. Извлечение изображения из PDF на Mac с помощью PDF Converter
Cisdem PDF Converter OCR Mac — это больше, чем программа распознавания PDF для Mac. Он позволяет пользователям конвертировать все PDF-файлы, включая исходные и отсканированные, в 16 часто используемых форматов: Word, Excel, PowerPoint, Keynote, Pages, ePub, HTML, текст, изображение и т. д. Благодаря быстрой и простой обработке вы получите результат. файлы с тем же качеством, что и оригинал. Кроме того, вы можете извлекать изображения из PDF на Mac напрямую с помощью этого инструмента.
- Загрузите бесплатную пробную версию Cisdem PDF Converter OCR, установите и запустите на своем Mac.
Скачать бесплатно - Импорт одного или нескольких PDF-файлов в программу для извлечения изображений. Перетащите файлы или нажмите «+», чтобы добавить файлы.
- Извлечь изображение из PDF. Программа автоматически обнаружит, есть ли изображения в файле PDF.

Ваш комментарий будет первым